1. Introduction
Type 1 diabetes mellitus (T1DM) is a chronic autoimmune disease characterized by the destruction of pancreatic β-cells, responsible for insulin production. T1DM typically develops in childhood or early adolescence but can occur at any age. Unlike Type 2 diabetes, T1DM is not associated with lifestyle factors. While the pathogenesis of T1DM is not fully understood, it is believed to involve a combination of genetic and environmental factors. In T1DM, the immune system mistakenly targets and destroys the β-cells which leads to dysglycemia and makes the patients insulin-dependent [
1,
2]. Dysglycemia refers to fluctuations in blood glucose (BG) outside the safe range, considered between 70 and 180 mg/dL by the American Diabetes Association (ADA) and the European Association for the Study of Diabetes (EASD) [
3]. Hypoglycemia occurs when BG levels are below the safe range, causing acute complications such as confusion, tachycardia, shakiness, and irritability [
3]. Moreover, severe hypoglycemia may lead to behavioral changes, visual disturbances, seizures, a loss of consciousness, coma, or even death. Hypoglycemic events involving loss of consciousness or requiring the assistance of another person may be frightening and have a substantial negative effect on the quality of life of patients and their families [
4]. On the other hand, BG levels above the safe range, hyperglycemia, lead to long-term complications such as retinopathy, nephropathy, and cardiovascular disease [
5]. Severe hyperglycemia symptoms include polyuria, polydipsia, and weight loss, but unlike hypoglycemia, life-threatening complications associated with hyperglycemia events are not imminent but long-term, so patients fear more hypoglycemia [
4,
6]. Although, most of the morbidity and mortality associated with diabetes are related to complications derived from chronic hyperglycemia.
To avoid such complications, patients with T1DM are treated using insulin replacement regimens, requiring basal insulin and mealtime insulin to compensate for the meals’ carbohydrates (CHO) content [
7]. Carbohydrate counting (CC) is widely recommended as a meal-planning tool for T1DM patients. Using this approach, patients need to dose prandial insulin according to Equation (1) [
8].
where B is the bolus insulin in units (U), CHO is the quantity of carbohydrates to be consumed in g, ICR is the insulin-to-carbohydrate ratio in g/U, G is the preprandial BG and G
T is the target BG in mg/dL, ISF is the Insulin Sensitivity Factor in mg/dL/U, and IOB (Insulin on Board) is the insulin remaining active from the previous bolus administrations in U. In CHO, the patient introduces the carbohydrate intake planned for each meal resulting from their estimation by performing CC.
Thus, accurately performing CC is paramount to dose the insulin bolus and, consequently, to achieve proper BG regulation [
9,
10]. Indeed, CHO over- and underestimations introduce errors in the bolus insulin that may lead to hypoglycemic and hyperglycemic episodes, respectively. Therefore, CC demands nutritional education and training, which can be challenging for most individuals [
11]. Several studies corroborate that T1DM patients frequently commit errors in CC [
9,
12,
13,
14,
15,
16]. In addition, CC errors proportionally relate to the size of meals, with underestimations being more common in large meals, which can result from fearing hypoglycemic events once the consequences could be immediate [
12,
15,
16,
17]. Smart, in [
18,
19], assessed the impact of different CHO estimation errors on postprandial glycemia, concluding that errors around 20 g in meals containing 60 g of CHO may lead to undesirable BG excursions, while variations around 10 g result in acceptable BG fluctuations.
Nevertheless, each individual has their own characteristics, such as ICR and ISF, so these generalized limits provide orientation but can be improved. For that purpose, Abreu et al., in [
20], presented an analytic method to determine the safe limit to CC error using personalized data. The authors used Equation (2) to calculate the maximum admissible absolute error while counting carbohydrates to ensure the postprandial BG level was on target.
where ∆CHO
max is the maximum absolute error allowed when performing CC; G
H and G
L are the high and low BG thresholds, respectively, for maintaining BG levels within range.
Based on patient-specific CC maximum errors, personalized CC educational programs can be tailored to address the needs of each patient rather than following a one-size-fits-all approach. In this way, a patient with a maximum allowable error of less than the general recommendation of 10 g should be made aware and trained more rigorously, while patients with a higher margin of error can feel more confident in performing CC and improving their treatment adherence. Indeed, knowing patients’ specific limits to CC error is crucial to improve their motivation and engagement.
To the best of our knowledge, apart from the one proposed by Abreu et al. [
20], no other method allows computing patient-specific limits for the CC error. Therefore, it is crucial to assess its effectiveness. The main goal of this work was to study if the upper limit obtained from Equation (2) could be taken as a boundary value to preserve on-target postprandial BG. We aimed to understand the impact of different CC errors within and outside the safe limits in patients’ glycemic behavior. Additionally, we intended to analyze the differences between distinct profiles—patients with a tendency to overestimate CHO, patients who underestimate, and patients who used to perform both over- and underestimations of CHO. To achieve this goal, an in silico trial was designed using the University of Virginia (UVA)/Padova Type 1 Diabetes Mellitus Simulator (T1DMS).
2. Methods
To evaluate the effectiveness of Equation (2), we conducted a series of in silico trials using the T1DMS approved by the Food and Drug Administration, which allows the evaluation of 33 virtual patients under multiple scenarios. Our study involved several experiments with different CHO estimation errors, both within and outside the calculated safe range for each patient. Subsequently, we compared the glycemic data obtained from these scenarios with the data collected in a control scenario, where there was no discrepancy between the actual CHO content and the patients’ estimations.
2.1. Subjects
This study encompassed all the subjects available on the T1DMS, which includes 11 adults, 11 adolescents, and 11 children. The different age groups presented considerable differences in the ICR and the ISF. The adult population had a mean ICR of 15.9 ± 4.5 g/U and an ISF of 42.2 ± 8.0 mg/dL/U, whereas the adolescents exhibited an ICR of 17.6 ± 7.0 g/U and an ISF of 57.1 ± 13.8 mg/dL/U. The children displayed an even more significant difference, with an ICR of 26.5 ± 5.3 g/U and an ISF of 117.8 ± 27.7 mg/dL/U. The ICR and ISF values of each patient were used in Equation (2), along with the glucose parameters G
L, G
T, and G
H defined as 70, 100, and 180 mg/dL, respectively, following the ADA and EASD guidelines [
3]. By carrying this out, per-subject safe limits for the error on the CHO estimations were computed, as presented in
Table 1. The ∆CHO
max values for all subjects had a mean value of 9.13 ± 2.99 g, with a maximum of 16.55 g and a minimum of 5.37 g.
2.2. Simulation Scenarios
All the simulations conducted were open-loop, covering 90 days, with patients undergoing intensive insulin therapy using multiple daily injections following a basal-bolus scheme. The T1DMS automatically determined the basal rate based on the subject-specific optimal rate. The bolus insulin for each meal was calculated using Equation (1), with the ICR and ISF of each patient set as previously mentioned, the GT established at 100 mg/dL, and the IOB assumed to be negligible, as the meal plan presented in
Table 2 was designed to ensure proper time intervals between meals [
8]. Equation (3) provides the CHO values used in Equation (1), representing the estimated amount of CHO in each meal while accounting for potential CC errors.
where CHO
True is the real quantity of CHO in the meal, according to the meal scheme presented in
Table 2, and ∆CHO∼N (µ, σ
2) is a uniformly distributed random variable representing the CHO estimation error.
From the meal plan in
Table 2 and using different ∆CHO distributions, nine scenarios were designed with different error ranges. These errors will affect the amount of bolus insulin administered in all 450 meals. An error-free scenario was developed as the control experiment (E
0), where patients eat and dose the bolus insulin according to the nutritional plan without estimation errors. All other experiments aimed to observe the impact in the postprandial BG of different CC errors, i.e., near, below, and above the maximum allowed for each patient. Moreover, to better represent real possible error trends in patients when estimating the amount of CHO, the experiments encompassed symmetric and polarized error intervals. In this way, we could analyze the impact of errors on various patient profiles, including those who consistently overestimate CHO content, those who consistently underestimate it, as well as those who make mistakes above and below the correct CHO content. To evaluate the impact of CC errors in patients with the same tendency to CHO underestimation and overestimation, we designed experiment E
1, whose ∆CHO distribution was centered on zero and generated errors within ±∆CHO
max with a confidence interval (CI) of 95%.
The remaining experiments aimed to evaluate the effect of CC errors in patients with a propensity to CHO overestimation (i.e., E
3, E
5, E
7 and E
9) or underestimation (i.e., E
2, E
4, E
6 and E
8).
Table 3 shows the CC error intervals used in each experiment, obtained by adjusting the ∆CHO distribution with a CI of 95%.
E3 and E5 allowed us to assess the impact of CHO overestimations when the patient performed CC errors within the safe interval with a mean value of −0.5∆CHOmax and −0.75∆CHOmax, respectively. In its turn, E7 and E9 were used to evaluate the effect of CHO overestimations on the limit and outside the safe interval. Therefore, the ∆CHO distribution used in E7 generated a narrow interval of CC errors, centered on −∆CHOmax, while E9 used an interval where 97.5% of the CC errors were outside the safe interval, up to −1.5∆CHOmax.
Similarly, E2 and E4 let us evaluate the consequences of CHO underestimations within the safe interval with a mean value of 0.5∆CHOmax and 0.75∆CHOmax, respectively. Finally, E6 allowed us to assess the impact of CHO underestimations on the limit and E8 outside the safe interval.
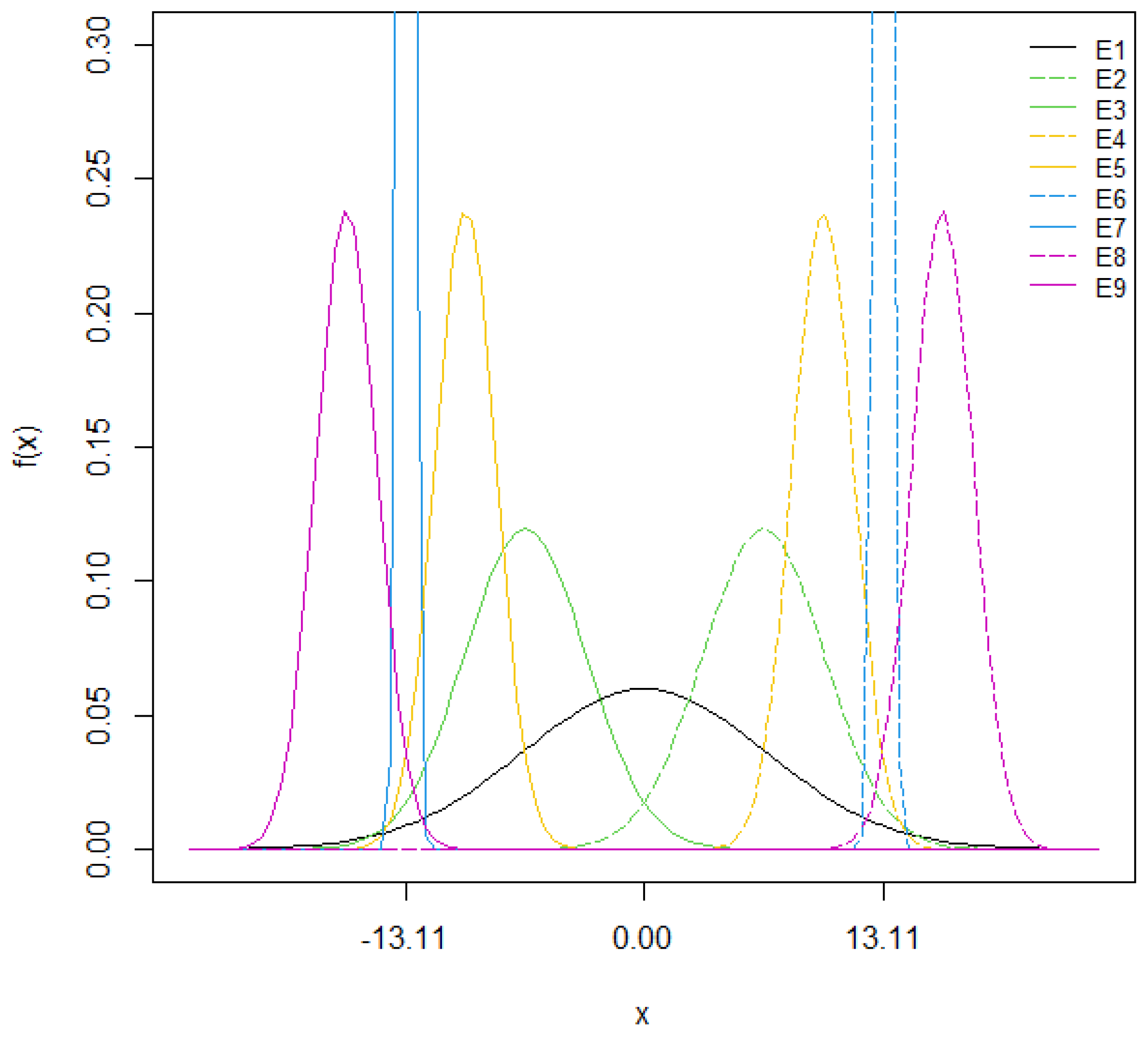
As an example,
Figure 1 illustrates the ∆CHO distributions applied to create the experiments used to assess the impact of different CC errors on the postprandial BG of the virtual subject Adult#1, whose ∆CHO
max = 13.11 g.
2.3. Statistical Method
The metrics selected to assess the glycemic outcome after applying the proposed method were as follows: (1) time in range (TIR), defined as the percentage of time spent within the range of 70–180 mg/dL; (2) time above range (TAR), i.e., hyperglycemia, defined as the percentage of time spent above 180 mg/dL; (3) time below range (TBR), i.e., hypoglycemia, defined as the percentage of time spent below 70 mg/dL; (4) the percentage of time spent below 50 mg/dL; and (5) the percentage of time spent above 300 mg/dL.
A normal Q-Q plot and Shapiro–Wilk tests were applied to verify if the percentage values obtained in the experiments followed the normal distribution. As the data did not follow the normal distribution, we decided to use the bootstrap method instead of the central limit theorem because of the small number of patients in the study. Moreover, CIs and hypothesis tests for the difference between the means, using the nonparametric bootstrap method, were used to compare the results of each experiment (E1, En, …, E9) with the results of the error-free scenario (i.e., E0) obtained in each metric. We also define as subjects’ exclusion criteria a TIR < 90% in E0 to avoid effects on glucose regulation unrelated to the CHO estimate.
3. Results
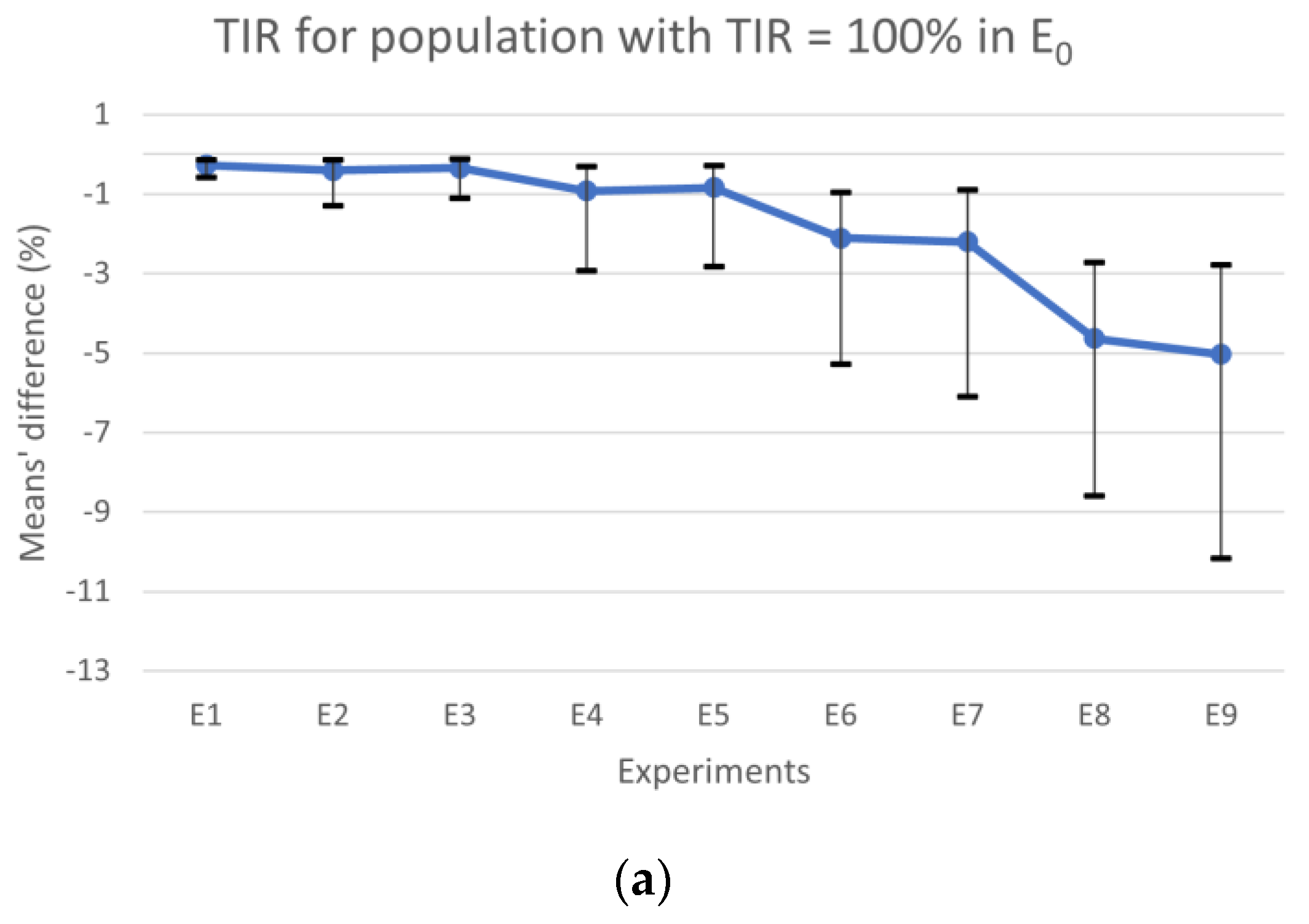
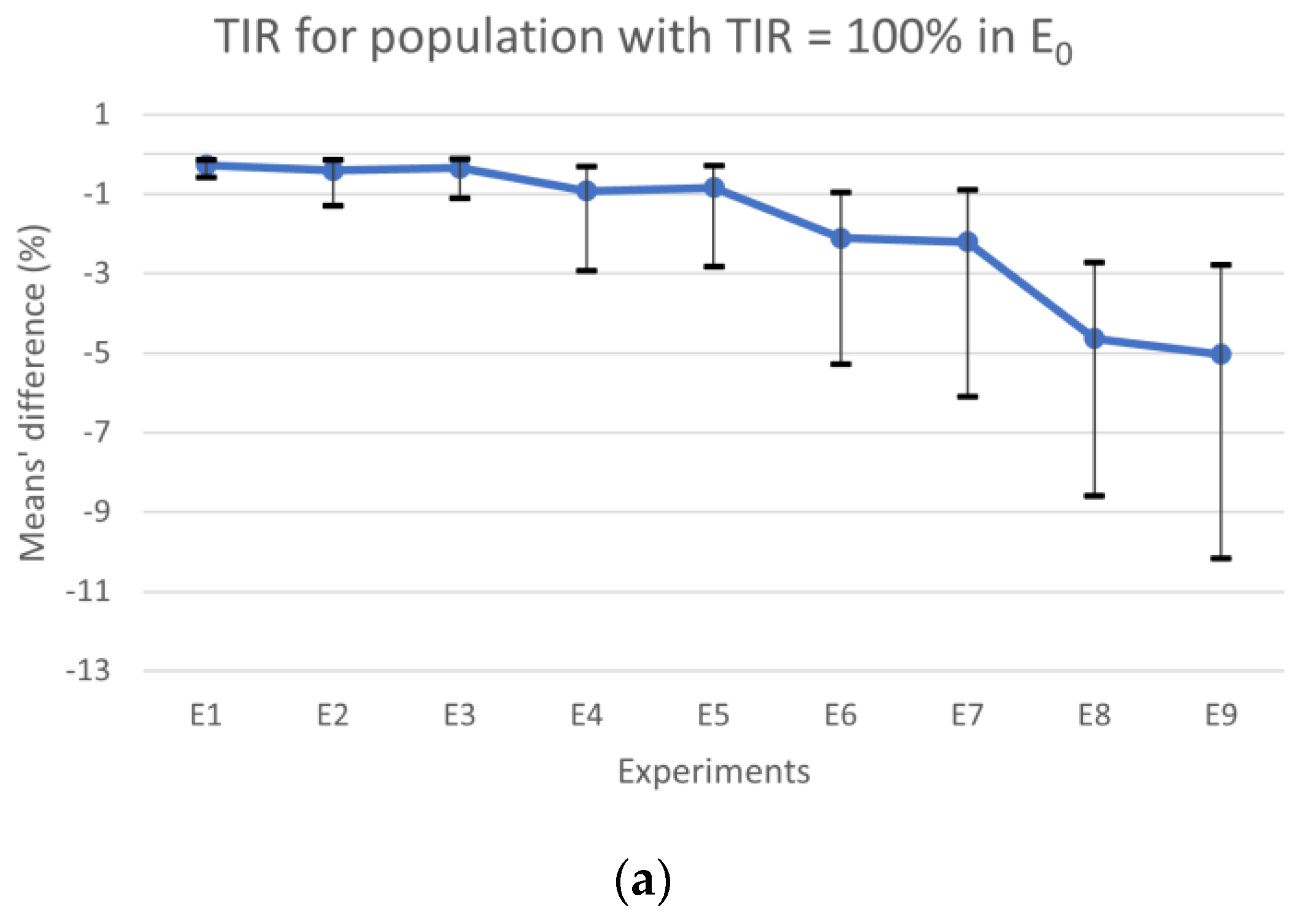
After conducting the E
0 scenario, we found that five patients had a TIR below 90%, so we excluded them from the statistical analysis to avoid potential bias. To further explore the results, we analyzed the data separately for patients who maintained their glucose levels within range throughout the study, i.e., TIR = 100%, and those with a TIR above 90%. We used paired samples to compare the means of these two populations with the means obtained from E
0 and applied confidence intervals and hypothesis tests. The results for the population with a TIR = 100% and TIR ≥ 90% are summarized in
Figure 2 and
Figure 3, respectively. Additionally, the tables in
Appendix A provide more detailed information on the results in
Figure 2 and
Figure 3.
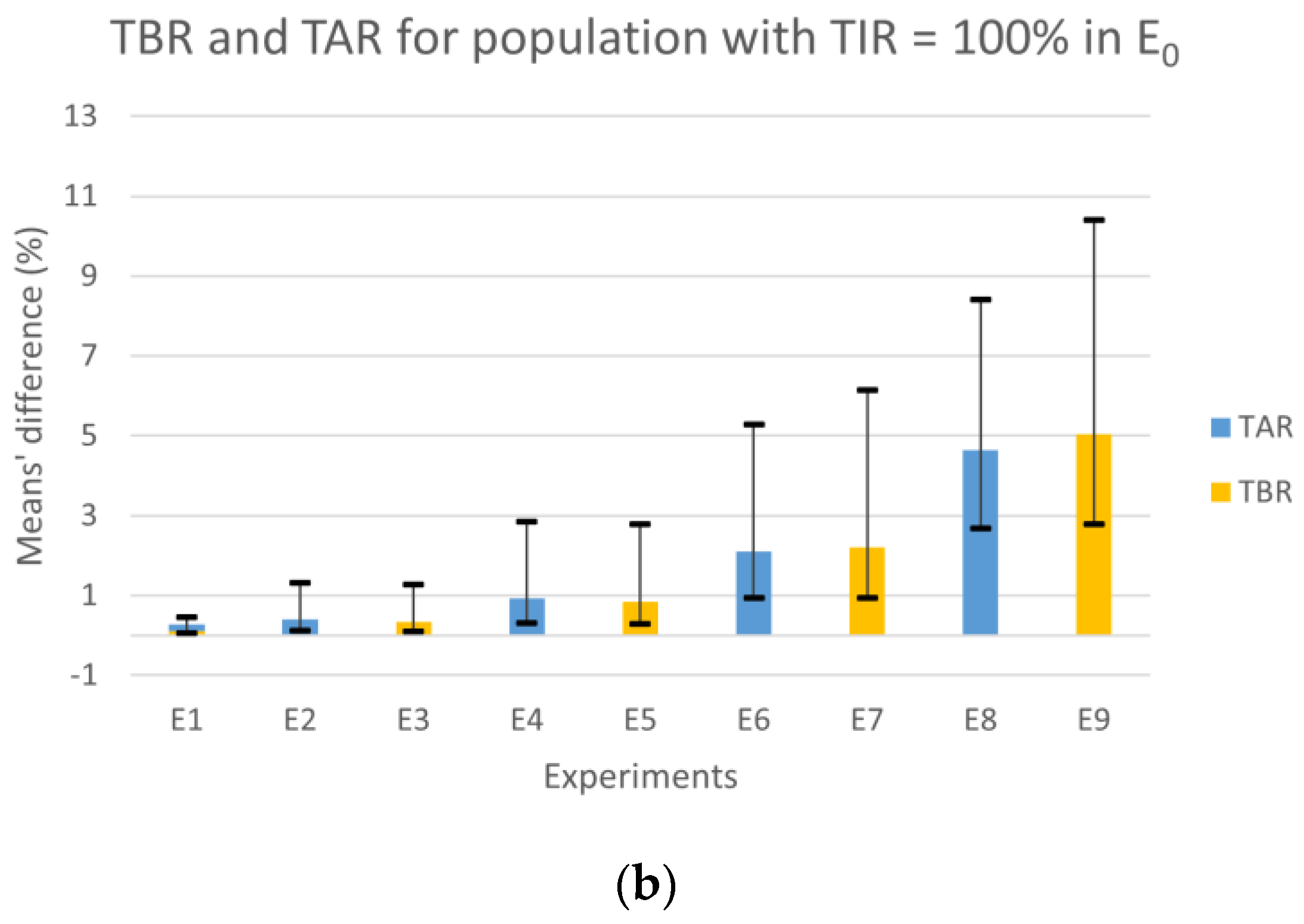
Figure 2a shows the results for TIR, the horizontal line represents the experiments’ mean values, and the vertical lines are the CIs. The results obtained for TBR and TAR means’ differences are plotted in
Figure 2b with colored bars, whereas the CIs for the most expressive condition (TBR or TAR) in each experiment are represented by vertical lines. When comparing the results obtained from E
0 with those obtained from experiments where the CC error falls within the range of [−∆CHO
max, ∆CHO
max] (i.e., E
1, E
2, E
3, E
4, and E
5) for the population with TIR = 100%, we observed that the absolute maximum of the differences between means for TBR, TIR, and TAR were 0.84%, 0.92%, and 0.92%, respectively. Additionally, the differences’ absolute maximum in the CIs for TBR, TIR, and TAR were 2.79%, 2.93%, and 2.85%, respectively. However, for experiments falling outside this interval (i.e., E
6, E
7, E
8 and E
9), we observed a larger absolute maximum for differences in TBR, which was 5.04%, in TIR was 5.03%, and 4.64% in TAR. In this case, the absolute maximum in the CIs for TBR, TIR, and TAR was 10.40%, 10.17%, and 8.41%, respectively, when compared to E
0. According to the guidelines, the maximum time spent in hypoglycemia < 50 mg/dL should be less than 1% and generally, for TBR, it should be less than 4% [
3]. Therefore, when comparing E
9 with E
0, we found that the mean difference for time spent in hypoglycemia < 50 mg/dL was 0.95%, which is close to the limit. Additionally, the TBR was 5.04%, which exceeds the recommended limit.
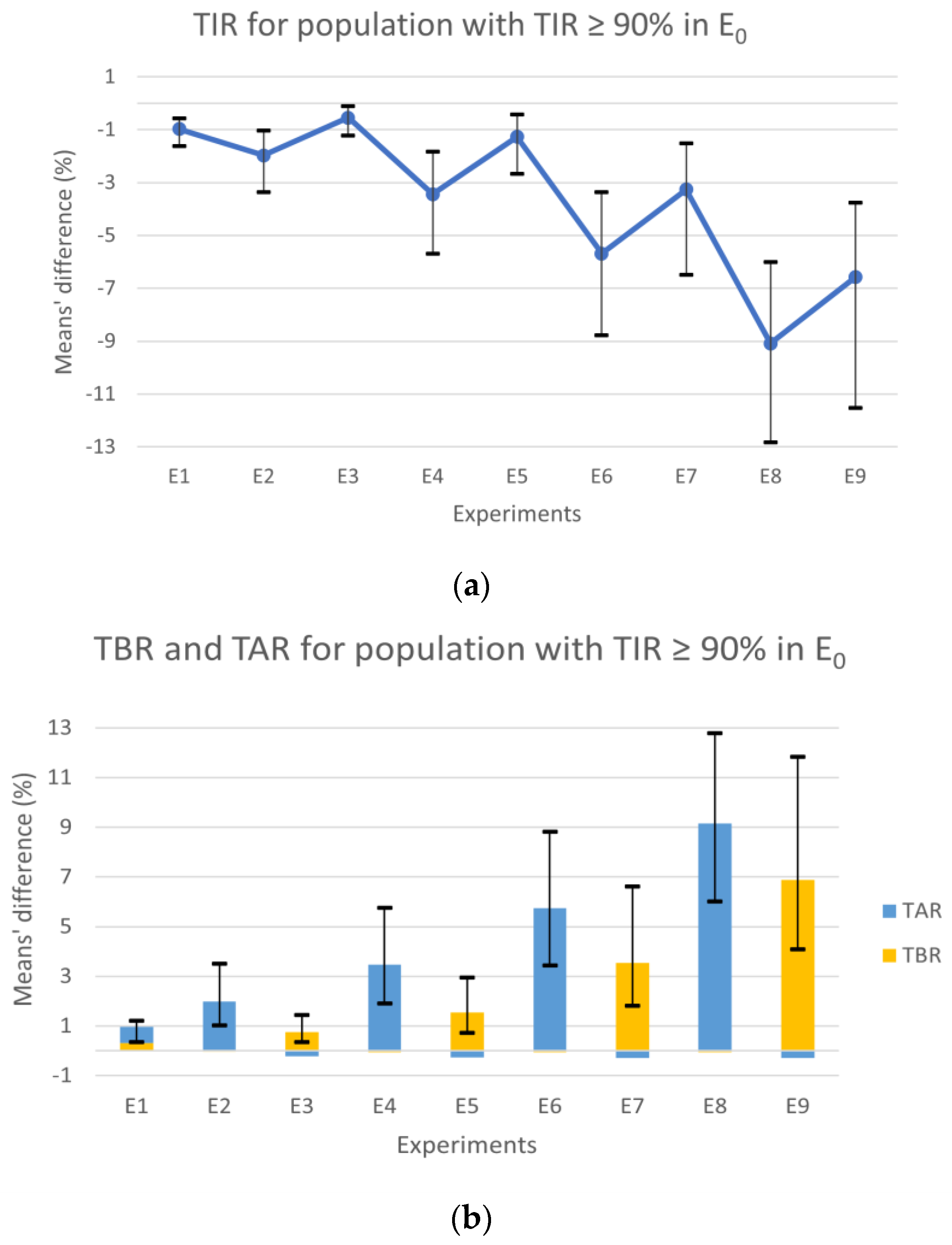
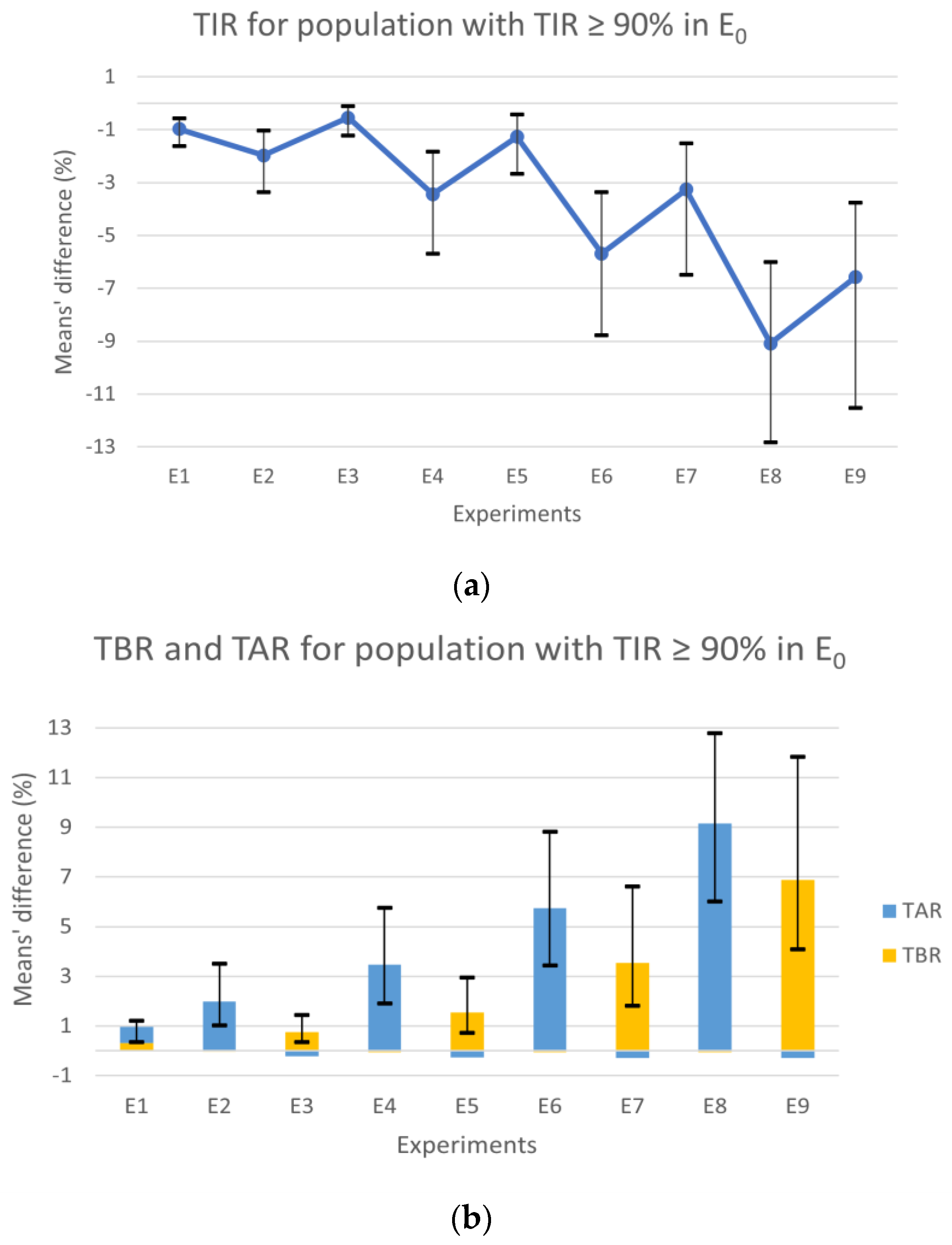
After analyzing the results of the population with a TIR of 100%, a second analysis was conducted that included patients with a TIR ≥ 90% (
Figure 3), attempting to recreate a more realistic scenario with subjects that can still be considered controlled.
Observing the population with TIR above 90% in E
0, the experiments’ results for the TIR (
Figure 3a) showed a consistent degradation through the experiments with the increase in the error, similar to the results for the population always in range. However, contrary to the results from the first analysis (
Figure 2a), the symmetric experiments revealed notable differences, with the scenarios in the underestimation zone showing worse results. The observed decrease in TIR is directly related to the TAR and TBR variations with slight differences. Analyzing
Figure 3b, the different deterioration proportions of TAR and TBR in the experiments in under- and overestimation zones, respectively, are also evident. The experiments in the overestimation zone also show a small improvement in TAR, expressed through the short blue bars under zero. The experiments in the underestimation zone showed minor improvements in TBR with values up to one-hundredth.
The experiments E
1, E
2, E
3, and E
4 continued to show results similar to the error-free scenario, with mean values under 4%. Although, the difference absolute maximum for the CI of E
4 was 5.76% in the TAR, which is further within the goals of 25% for TAR [
3]. In E
6 and E
8, a significant deterioration in the TAR compared to the control scenario was observed, reaching a difference of 12.78% in E
8. Similarly, the symmetrical experiments E
7 and E
9 showed an increase in TBR, though it was considerably less. Globally, we found that the results of the experiments where the tendency was to underestimate CHO, that is, where hyperglycemia was more likely to occur, showed less favorable results (
Figure 3b blue bars). This fact can be explained by postprandial glycemic peaks that typically happen 1–2 h after a meal [
21] since Equation (2) was obtained with the condition that the BG will be close to the target 2–3 h after a meal and not before.
All the results showed an increase in the CIs as the scenarios included a bigger error. Generally, we could observe a pronounced deterioration in the results in the last four experiments (E6–9), where 50 and 97.5% of the meals had a CC error outside the range of [−∆CHOmax, ∆CHOmax].
4. Discussion
After calculating the maximum allowable error in CHO counting for each patient, such that it did not lead to undesirable postprandial BG fluctuations, we determined that the average value among the 33 subjects in the sample was 9.13 g. This value is in line with the findings of Smart [
18], which concluded that errors up to 10 g were considered safe. However, using the ICR and ISF values of each subject to compute the error threshold showed that it could vary greatly. For example, Adolescent#5 presented a maximum error of 5.50 g, while Adolescent#7 showed a much higher maximum value of 16.55 g.
The experiments conducted included a control scenario and nine scenarios introducing different CC errors. A scenario was created in which patients made errors up to the maximum error of both underestimating and overestimating the amount of CHO in the meal, and the remaining scenarios were created to represent situations in which the patient’s tendency was always to underestimate or overestimate. We considered it relevant to perform polarized experiments, as some aforementioned studies [
11,
14,
16,
17] demonstrate how the most common tendency is to underestimate larger meals, in contrast to snacks, which are typically overestimated.
It is also important to note that CHO is not the only factor that influences postprandial glycemia, other nutrients present in the meal, such as fats and proteins, as well as previous physical activity, can affect postprandial BG. Thus, two groups of patients were defined for the analysis of results, one with TIR of 100% in the error-free experiment and another for subjects with TIR above 90%. For the group of patients always in range, we could better isolate the impact of incorrect CHO estimations. Nevertheless, having BG always in range is not the most common glycemic profile for patients with T1DM; for that reason, we analyzed the second group with TIR above 90%. This way, we intended to reproduce a more realistic scenario.
The data from the two groups showed some differences. As expected, the glycemic control of the group with TIR greater than 90% deteriorated more sharply, especially in the underestimation zone experiments. This may be due to the postprandial peaks, once the calculation of the maximum error was developed to make BG on target 2–3 h after the meal and not before. In this trial, the patients used continuous glucose monitors to collect BG levels every 5 min, including the peaks logs. It is noteworthy that the goals for T1DM are far more permissive for TAR (<25% of the time) than for TBR (<4%) [
3].
To the best of our knowledge, this was the first study to utilize a patient-specific calculation to compute the maximum error in CC. The results demonstrated how the TIR, TAR, and TBR values deteriorated as the error introduced approached the limit, highlighting the last experiments (E6–9), where the maximum error was exceeded in 50 and 97.5% of the meals. This shows that the proposed method for defining personalized limits for CC error could be suitable for setting up a new approach to train and evaluate patients’ CC abilities. This method has the potential to personalize treatment and empower the patient by providing them with an understanding of their true limits.
However, it is necessary to note the limitations of this study. The sample used was small, with fewer than 30 subjects remaining for statistical analysis. To overcome this, the nonparametric bootstrap method was implemented. Furthermore, as mentioned in the previous section, the method used to calculate the safe interval was designed to make the postprandial glycemic on target 2–3 h after the meal, leading to an increase in the TAR and, consequently, to the worst TIR values in the scenarios where the patients underestimated CHO. To overcome this, the mathematical model could be adjusted by applying correction factors to the safe interval to compensate for the postmeal peak effect. Although the simulator is an excellent tool for an initial phase of preclinical testing, the study must be repeated in a sample of patients in a real-world context to validate the method. It may also be pertinent to carry out a differentiated analysis for the different age groups.





{kind=link}
{kind=link}
{kind=link}
{kind=link}