Evaluation of Reliability of the Recomputed Nutrient Intake Data in the National Heart, Lung, and Blood Institute Twin Study



Abstract
1. Introduction
2. Subjects and Methods
2.1. Study Population
2.2. Baseline Food Consumption Data and the NHLBI Nutrient Dataset
2.3. Recalculation of Nutrients Intakes
2.4. Statistical Analyses
3. Results
3.1. Univariate Analyses
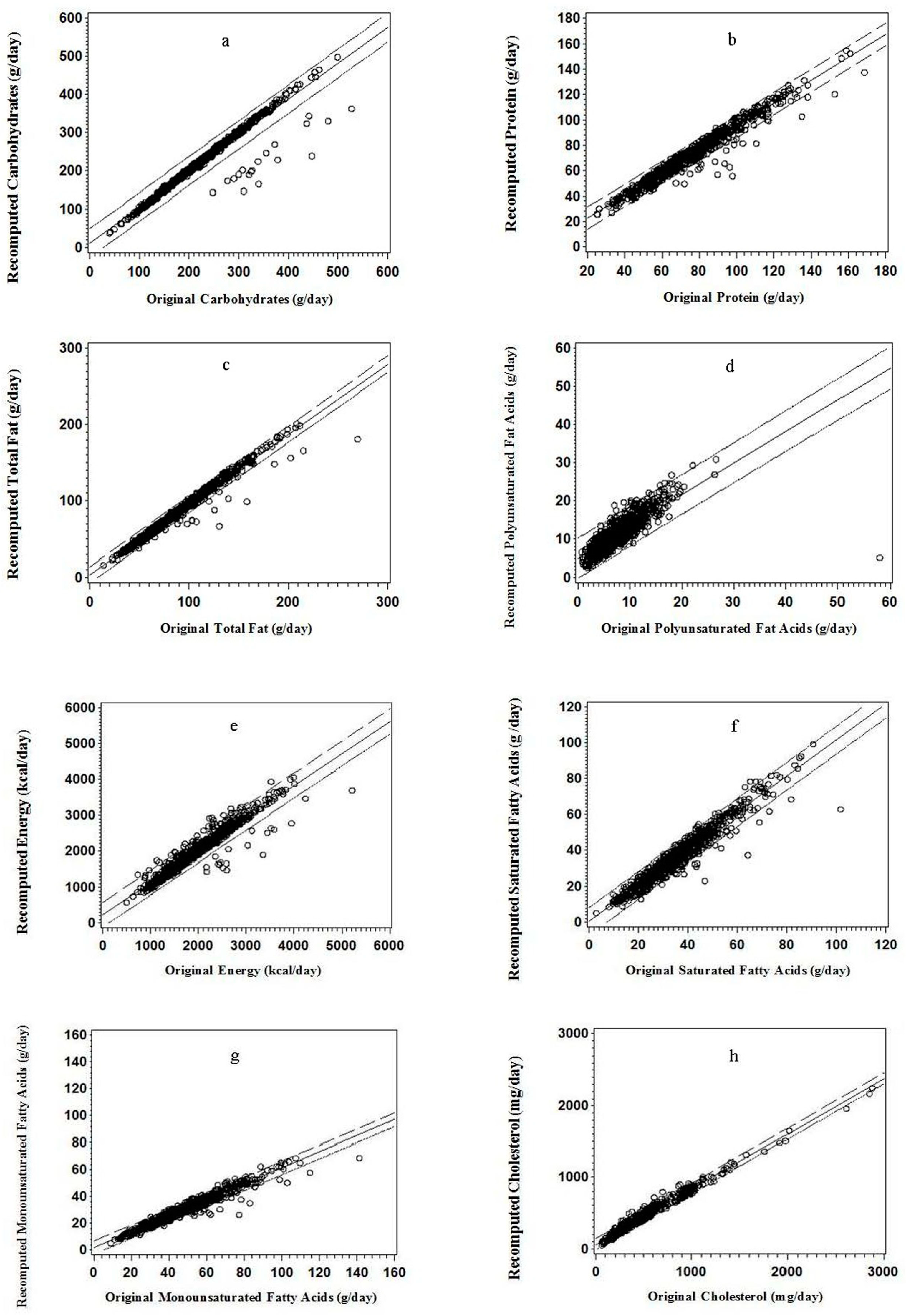
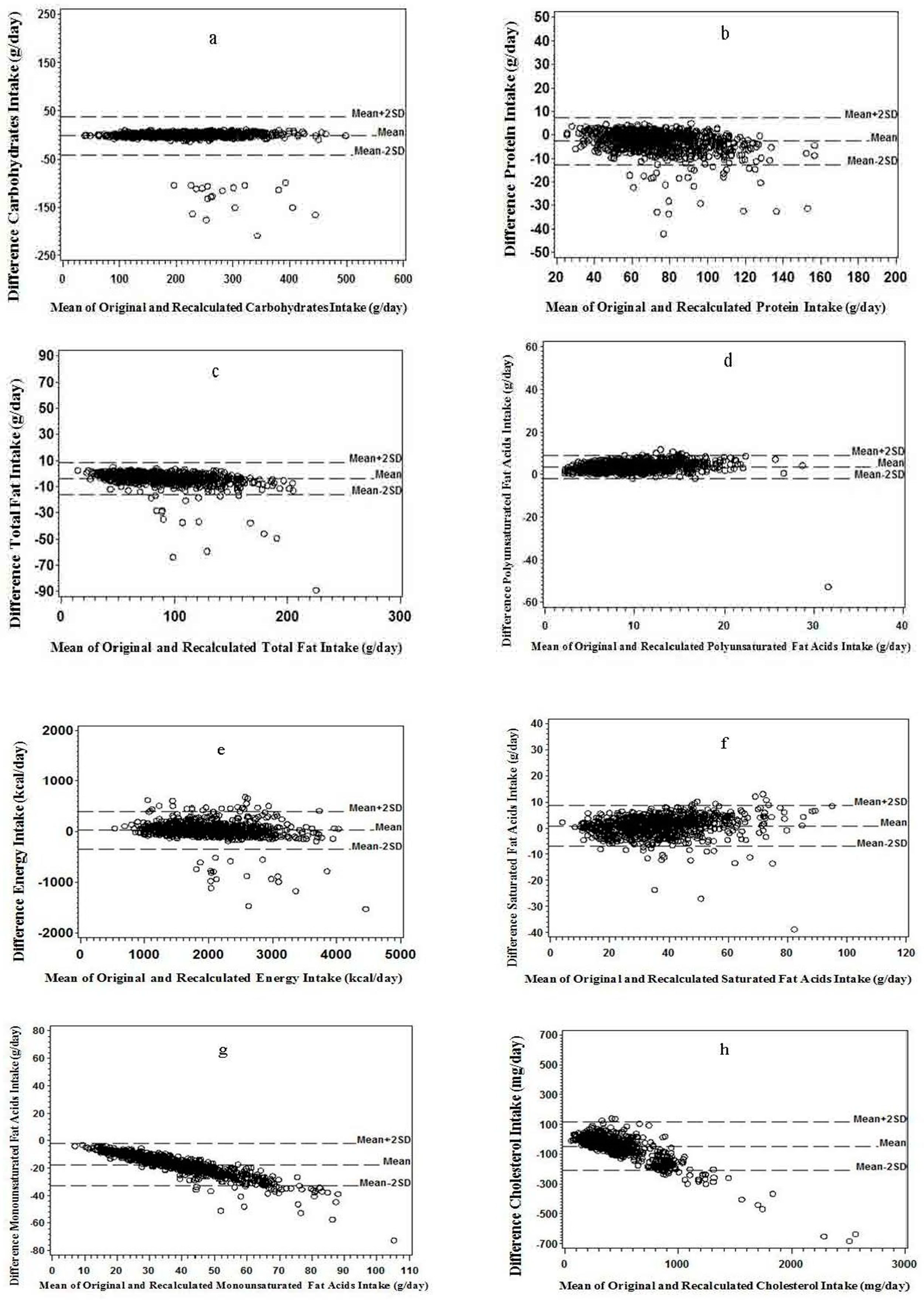
3.2. Correlation and Regression Analyses
3.3. Graphic Analyses
3.4. Quintile Agreement and Extreme Quintile Disagreement
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CI | confidence intervals |
| MUFA | monounsaturated fatty acids |
| NHLBI | National Heart, Lung, and Blood Institute |
| PUFA | polyunsaturated fatty acids |
| R2 | R-square |
| SD | standard deviations |
| SFA | saturated fatty acids |
| SR21 | Standard Reference 21 |
| USDA | United States Department of Agriculture |
References
- Coulston, A.M.; Boushey, C.; Ferruzzi, M.G.; Delahanty, L.M. Nutrition in the Prevention and Treatment of Disease, 4th ed.; Academic Press: London, UK; San Diego, CA, USA, 2017. [Google Scholar]
- Shim, J.S.; Oh, K.; Kim, H.C. Dietary assessment methods in epidemiologic studies. Epidemiol. Health 2014, 36, e2014009. [Google Scholar] [CrossRef] [PubMed]
- Greenfield, H.; Southgate, D.A.T. Food Composition Data: Production, Management and Use; FAO: Rome, Italy, 2003. [Google Scholar]
- Bazzano, L.A.; He, J.; Ogden, L.G.; Loria, C.M.; Vupputuri, S.; Myers, L.; Whelton, P.K. Agreement on nutrient intake between the databases of the first national health and nutrition examination survey and the ESHA food processor. Am. J. Epidemiol. 2002, 156, 78–85. [Google Scholar] [CrossRef] [PubMed]
- Hjortland, M. The effects of heredity and environment on nutrient intake of adult monozygotic and dizygotic twins. Ph.D. Thesis, University of Minnesota, Minneapolis, MN, USA, 1972. [Google Scholar]
- Fabsitz, R.R.; Garrison, R.J.; Feinleib, M.; Hjortland, M. A twin analysis of dietary intake: Evidence for a need to control for possible environmental differences in MZ and DZ twins. Behav. Genet. 1978, 8, 15–25. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Krasnow, R.E.; Reed, T. Midlife moderation-quantified healthy diet and 40-year mortality risk from CHD: The prospective National Heart, Lung, and Blood Institute Twin Study. Br. J. Nutr. 2016, 116, 326–334. [Google Scholar] [CrossRef] [PubMed]
- Kandula, N.R.; Puri-Taneja, A.; Victorson, D.E.; Dave, S.S.; Kanaya, A.M.; Huffman, M.D. Mediators of Atherosclerosis in South Asians Living in America: Use of Web-Based Methods for Follow-Up and Collection of Patient-Reported Outcome Measures. JMIR Res. Protoc. 2016, 5, e95. [Google Scholar] [CrossRef] [PubMed]
- Woynaroski, T.; Oller, D.K.; Keceli-Kaysili, B.; Xu, D.; Richards, J.A.; Gilkerson, J.; Gray, S.; Yoder, P. The stability and validity of automated vocal analysis in preverbal preschoolers with autism spectrum disorder. Autism Res. Off. J. Int. Soc. Autism Res. 2017, 10, 508–519. [Google Scholar] [CrossRef]
- Elmadfa, I.; Meyer, A.L. Importance of food composition data to nutrition and public health. Eur. J. Clin. Nutr. 2010, 64 (Suppl. 3), S4–S7. [Google Scholar] [CrossRef] [PubMed]
- Wolmarans, P.; Kunneke, E.; Laubscher, R. The use of the South African Food Composition Database System (SAFOODS) and its products in assessing dietary intake data. Part II. S. Afr. J. Clin. Nutr. 2009, 22, 59–67. [Google Scholar] [CrossRef]
- Dresser, C.M. From nutrient data to a data base for a health and nutrition examination survey. Organization, coding and values-real or imputed. In Proceedings of the 8th National Nutrient Data Base Conference, Minneapolis, MN, USA, 25–27 July 1983. [Google Scholar]
- Dawber, T.R.; Pearson, G.; Mann, G.V.; Kannel, W.B.; Shurtleff, D.; McNamara, P. Dietary assessment in the epidemiologic study of coronary heart disease: The Framingham study. II. Reliability of measurement. Am. J. Clin. Nutr. 1962, 11, 226–234. [Google Scholar] [CrossRef]
- Moghames, P.; Hammami, N.; Hwalla, N.; Yazbeck, N.; Shoaib, H.; Nasreddine, L.; Naja, F. Validity and reliability of a food frequency questionnaire to estimate dietary intake among Lebanese children. Nutr. J. 2016, 15, 4. [Google Scholar] [CrossRef]
- Dai, J.; Krasnow, R.E.; Liu, L.; Sawada, S.G.; Reed, T. The association between postload plasma glucose levels and 38-year mortality risk of coronary heart disease: The prospective NHLBI twin study. PLoS ONE 2013, 8, e69332. [Google Scholar] [CrossRef]
- Reed, T.; Carmelli, D.; Christian, J.C.; Selby, J.V.; Fabsitz, R.R. The NHLBI male veteran twin study data. Genet. Epidemiol. 1993, 10, 513–517. [Google Scholar] [CrossRef] [PubMed]
- Carmelli, D.; Swan, G.E.; Robinette, D.; Fabsitz, R. Genetic influence on smoking—A study of male twins. N. Engl. J. Med. 1992, 327, 829–833. [Google Scholar] [CrossRef] [PubMed]
- Feinleib, M.; Christian, J.C.; Borhani, N.O.; Rosenman, R.; Garrison, R.J.; Wagner, J.; Kannel, W.B.; Hrubec, Z.; Schwartz, J.T. National heart and lung institute twin study of cardiovascular disease risk factors—Organization and methodology. Acta Genet. Med. Gemellol. 1976, 25, 125–128. [Google Scholar] [CrossRef]
- Burke, B. The dietary history as a tool in research. J. Am. Diet. Assoc. 1947, 23, 1041–1046. [Google Scholar]
- Mann, G.V.; Pearson, G.; Gordon, T.; Dawber, T.R.; Lyell, L.; Shurtleff, D. Diet and cardiovascular disease in the Framingham study. Am. J. Clin. Nutr. 1962, 11, 200–225. [Google Scholar] [CrossRef] [PubMed]
- U.S. Department of Agriculture, Agricultural Research Service. USDA National Nutrient Database for Standard Reference, Release 21. Nutrient Data Laboratory Home Page. 2008. Available online: https://www.ars.usda.gov/northeast-area/beltsville-md-bhnrc/beltsville-human-nutrition-research-center/nutrient-data-laboratory/docs/sr21-home-page/ (accessed on 20 December 2018).
- Bukenya, R.; Ahmed, A.; Andrade, J.M.; Grigsby-Toussaint, D.S.; Muyonga, J.; Andrade, J.E. Validity and Reliability of General Nutrition Knowledge Questionnaire for Adults in Uganda. Nutrients 2017, 9, 172. [Google Scholar] [CrossRef]
- Yuan, Y.Q.; Li, F.; Wu, H.; Wang, Y.C.; Chen, J.S.; He, G.S.; Li, S.G.; Chen, B. Evaluation of the Validity and Reliability of the Chinese Healthy Eating Index. Nutrients 2018, 10, 114. [Google Scholar] [CrossRef]
- Daniel, W. Biostatistics: A Foundation for Analysis in the Health Sciences, 7th ed.; Wiley: New York, NY, USA, 1999. [Google Scholar]
- Bland, J.M.; Altman, D.G. Statistical methods for assessing agreement between two methods of clinical measurement. Int. J. Nurs. Stud. 2010, 47, 931–936. [Google Scholar] [CrossRef]
- Carithers, T.; Talegawkar, S.; Rowser, M.; Henry, O.; Dubbert, P.; Bogle, M.; Taylor, H.J.; Tucker, K. Validity and Calibration of Food Frequency Questionnaires Used with African-American Adults in the Jackson Heart Study. J. Am. Diet. Assoc. 2009, 109, 1184–1193. [Google Scholar] [CrossRef]
- Chiu, S.; Bergeron, N.; Williams, P.T.; Bray, G.A.; Sutherland, B.; Krauss, R.M. Comparison of the DASH (Dietary Approaches to Stop Hypertension) diet and a higher-fat DASH diet on blood pressure and lipids and lipoproteins: A randomized controlled trial. Am. J. Clin. Nutr. 2016, 103, 341–347. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Tuvblad, C.; Raine, A.; Baker, L. Genetic and environmental influences on nutrient intake. Genes Nutr. 2013, 8, 241–252. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Zhang, J.; Fu, B.; Xie, H.; Wang, Y.; Qian, X. Evaluation of empirical rule of linearly correlated peptide selection (ERLPS) for proteotypic peptide-based quantitative proteomics. Proteomics 2014, 14, 1593–1603. [Google Scholar] [CrossRef] [PubMed]
- Grafarend, E.W.; Awange, J.L. Applications of Linear and Nonlinear Models: Fixed Effects, Random Effects, and Total Least Squares; Springer: Heidelberg, NY, USA, 2012. [Google Scholar]
- Giavarina, D. Understanding Bland Altman analysis. Biochem. Med. 2015, 25, 141–151. [Google Scholar] [CrossRef] [PubMed]
- Fairweather-Tait, S.J. Bioavailability of dietary minerals. Biochem. Soc. Trans. 1996, 24, 775–780. [Google Scholar] [CrossRef] [PubMed]
- Sugiura, S.H.; Dong, F.M.; Rathbone, C.K.; Hardy, R.W. Apparent protein digestibility and mineral availabilities in various feed ingredients for salmonid feeds. Aquaculture 1998, 159, 177–202. [Google Scholar] [CrossRef]
- Holden, J.M.; Eldridge, A.L.; Beecher, G.R.; Buzzard, I.M.; Bhagwat, S.; Davis, C.S.; Douglass, L.W.; Gebhardt, S.; Haytowitz, D.; Schakel, S. Carotenoid content of U.S. foods: An update of the database. J. Food Comp. Anal. 1999, 12, 169–196. [Google Scholar] [CrossRef]
- Willett, W. Nutritional Epidemiology, 2nd ed.; Oxford University Press: New York, NY, USA, 1998. [Google Scholar]



{kind=link}
{kind=link}
| whole milk, skim milk, tea, coke/soft drink, coffee, cheese other than cottage cheese, ice cream, sweet rolls, cake/pie, eggs, salads, potatoes, cooked vegetables, spaghetti, rice, cereals, fruit juice, fruit, gravy, jam, peanut butter, beer, wine, alcohol (distilled), pork, beef, hamburger, hot dog/luncheon meats, chicken/turkey, lamb, liver, shellfish, other fishes, oil for fried food, chocolate, candy (hard), nuts, potato chips, bread, butter, sugar added in coffee, cream added in coffee, milk added in coffee, cream and sugar added in coffee, milk and sugar added in coffee, sugar added in tea, cream added in tea, milk added in tea, cream and sugar added in tea, milk and sugar added in tea, oil and vinegar type salad dressing, mayonnaise, cheese-type salad dressing |
| Nutrient | Estimated Intake Per Day | Paired Difference 1 | Percent Mean Difference 2 (%) | |
|---|---|---|---|---|
| Recalculated | Original | |||
| Mean ± SD 3 | Mean ± SD | Mean ± SD | ||
| Energy (kcal/day) | 2051 ± 589 | 2022 ± 626 | 28.5 ± 187 | 2.5 |
| Total carbohydrates (g/day) | 224 ± 73.4 | 225 ± 75.5 | −1.6 ± 19.6 | −0.3 |
| Protein (g/day) | 72.3 ± 20.3 | 75.1 ± 21.9 | −2.7 ± 4.9 | −3.1 |
| Fat (g/day) | 87.5 ± 32.2 | 91.2 ± 34.5 | −3.7 ± 6.1 | −3.7 |
| Saturated fat (g/day) | 36.6 ± 14.8 | 35.7 ± 14.2 | 0.9 ± 3.9 | 2.7 |
| Polyunsaturated fat (g/day) | 11.7 ± 4.4 | 8.0 ± 4.2 | 3.7 ± 2.7 | 62.6 |
| Monounsaturated fat (g/day) | 30.1 ± 11.1 | 47.5 ± 18.2 | −17.5 ± 7.8 | −36.3 |
| Cholesterol (mg/day) | 436 ± 246 | 484 ± 314 | −47.2 ± 80.5 | −5.9 |
| Nutrient | Correlation Coefficients | Regression Analysis | |||
|---|---|---|---|---|---|
| Intra-Class | Pearson’s | R-Square | β Coefficient (95% CI) | ||
| ICC | (95% CI) | ||||
| Energy (kcal/day) | 1.00 | (1.00, 1.00) | 0.95 1 | 0.91 | 1.01 (0.99, 1.04) |
| Total carbohydrates (g/day) | 1.00 | (1.00, 1.00) | 0.97 1 | 0.93 | 0.99 (0.98, 1.01) |
| Protein (g/day) | 1.00 | (1.00, 1.00) | 0.98 1 | 0.95 | 1.05 (1.04, 1.07) |
| Fat (g/day) | 1.00 | (1.00, 1.00) | 0.99 1 | 0.97 | 1.06 (1.04, 1.07) |
| Saturated fat (g/day) | 1.00 | (1.00, 1.00) | 0.96 1 | 0.93 | 0.92 (0.90, 0.94) |
| Polyunsaturated fat (g/day) | 1.00 | (1.00, 1.00) | 0.80 1 | 0.63 | 0.76 (0.73, 0.80) |
| Monounsaturated fat (g/day) | 1.00 | (1.00, 1.00) | 0.97 1 | 0.95 | 1.59 (1.57, 1.62) |
| Cholesterol (mg/day) | 1.00 | (1.00, 1.00) | 0.99 1 | 0.98 | 1.26 (1.25, 1.27) |
| Nutrient | Same Quintile (%) | Opposite Extreme Quintile (%) |
|---|---|---|
| Energy (kcal/day) | 78.6 | 0.1 |
| Total carbohydrates (g/day) | 92.0 | 0.1 |
| Protein (g/day) | 80.2 | 0 |
| Fat (g/day) | 90.7 | 0 |
| Saturated fat (g/day) | 75.4 | 0.1 |
| Polyunsaturated fat (g/day) | 51.2 | 0.1 |
| Monounsaturated fat (g/day) | 80.3 | 0 |
| Cholesterol (mg/day) | 79.7 | 0 |
| Mean of percentage | 78.5 | 0.1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, Y.; Chen, S.-B.; Ding, G.; Dai, J. Evaluation of Reliability of the Recomputed Nutrient Intake Data in the National Heart, Lung, and Blood Institute Twin Study. Nutrients 2019, 11, 109. https://doi.org/10.3390/nu11010109
Yao Y, Chen S-B, Ding G, Dai J. Evaluation of Reliability of the Recomputed Nutrient Intake Data in the National Heart, Lung, and Blood Institute Twin Study. Nutrients. 2019; 11(1):109. https://doi.org/10.3390/nu11010109
Chicago/Turabian StyleYao, Yecheng, Sheng-Bo Chen, Gangqiang Ding, and Jun Dai. 2019. "Evaluation of Reliability of the Recomputed Nutrient Intake Data in the National Heart, Lung, and Blood Institute Twin Study" Nutrients 11, no. 1: 109. https://doi.org/10.3390/nu11010109
APA StyleYao, Y., Chen, S.-B., Ding, G., & Dai, J. (2019). Evaluation of Reliability of the Recomputed Nutrient Intake Data in the National Heart, Lung, and Blood Institute Twin Study. Nutrients, 11(1), 109. https://doi.org/10.3390/nu11010109