
Effect of Label Noise on the Machine-Learned Classification of Earthquake Damage



Abstract
:
1. Introduction
2. Related Work
2.1. Pixel- vs. Object-Based Classifiers
2.2. Label Noise
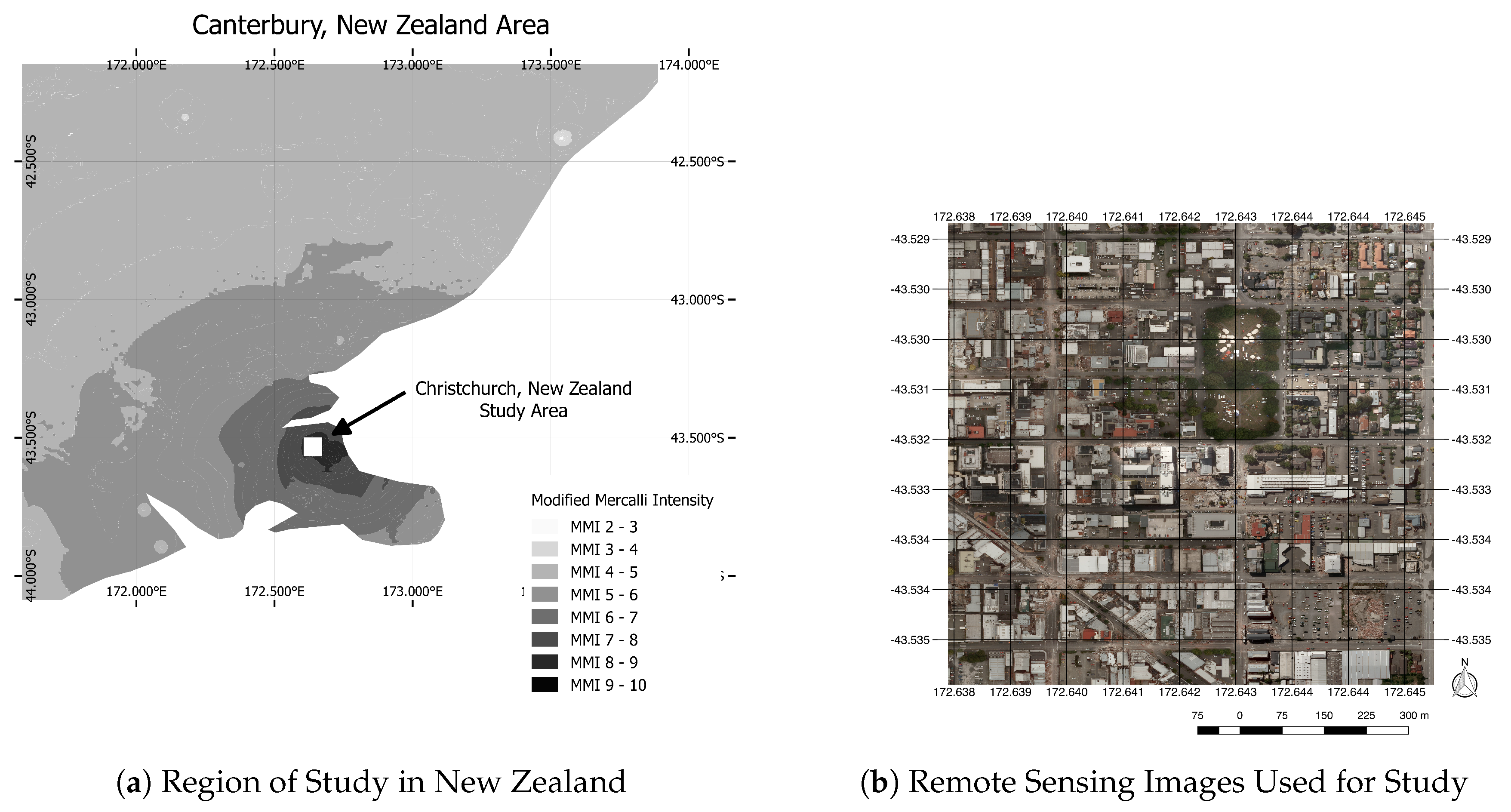
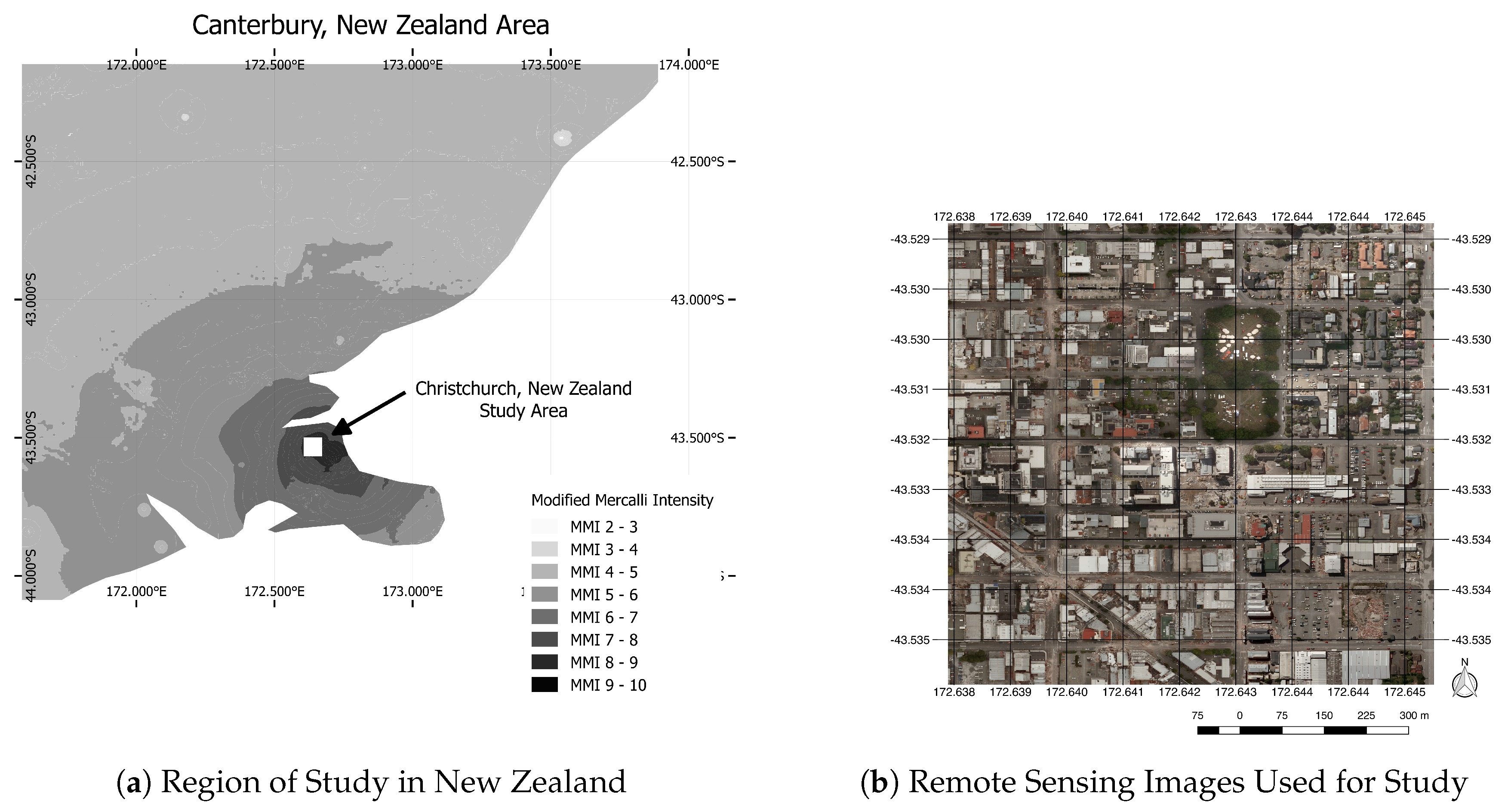
3. Study Area and Data
Study Site
4. Experiments
4.1. Experimental Setup
4.1.1. Classification
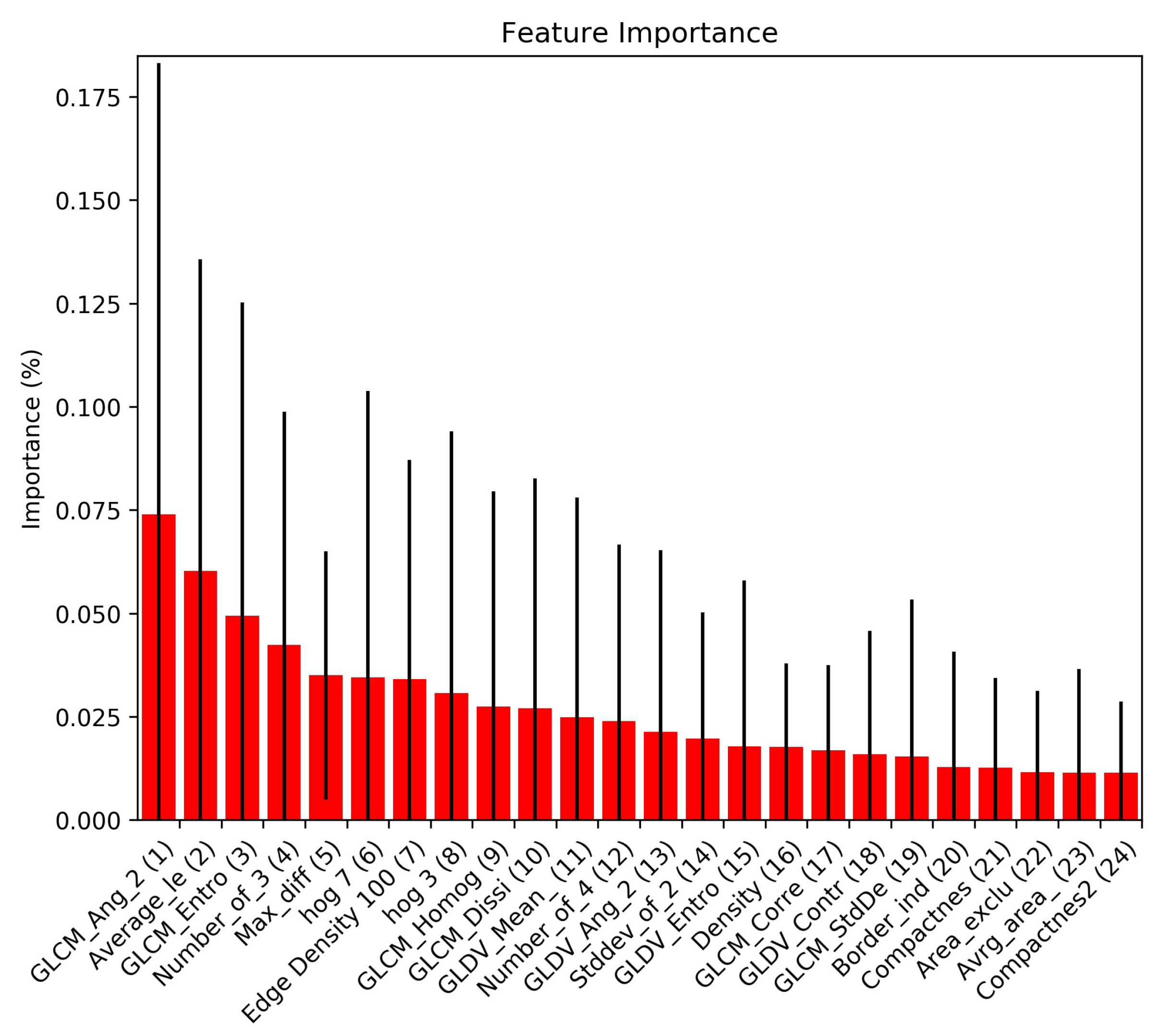
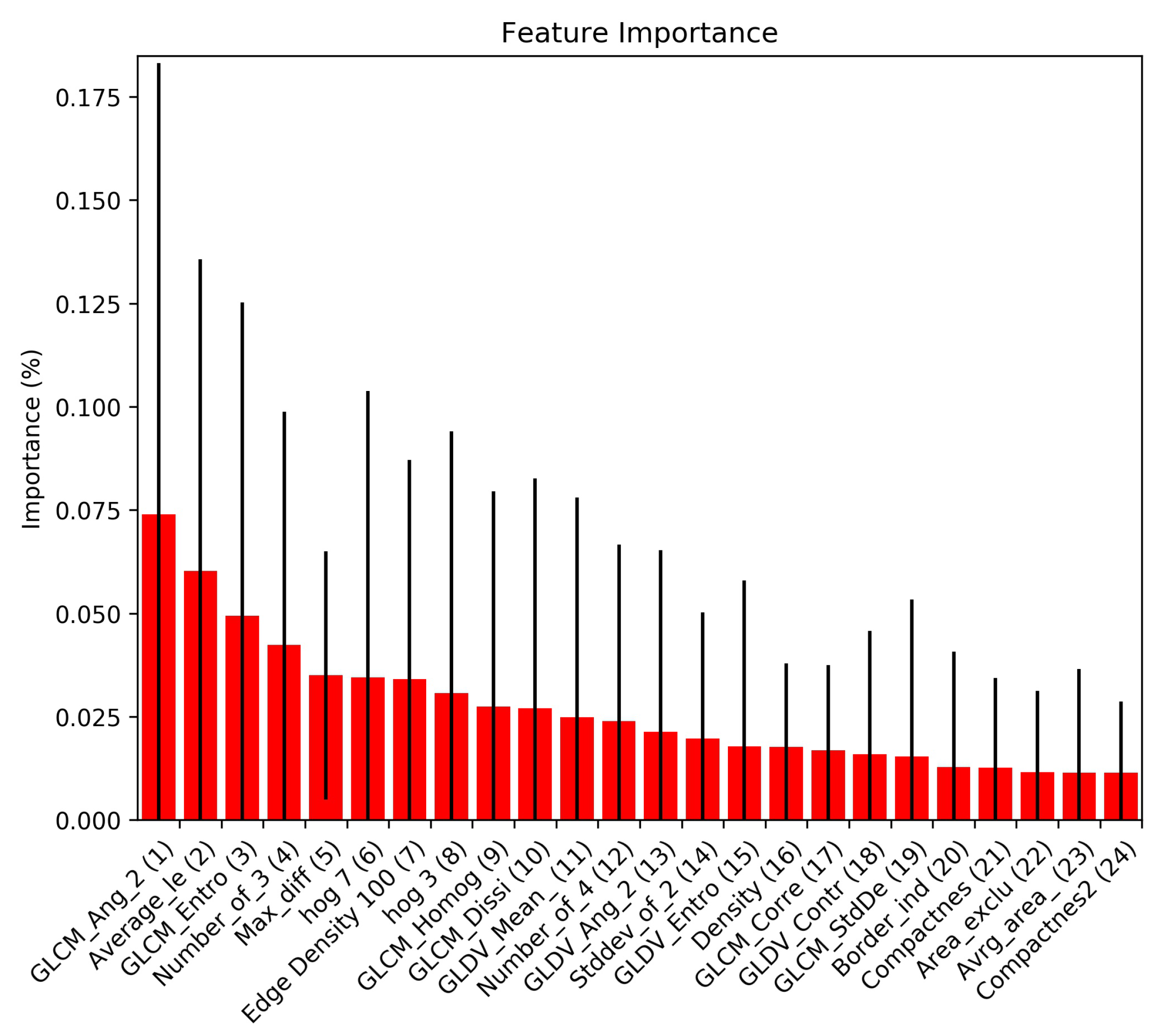
4.1.2. Feature Extraction
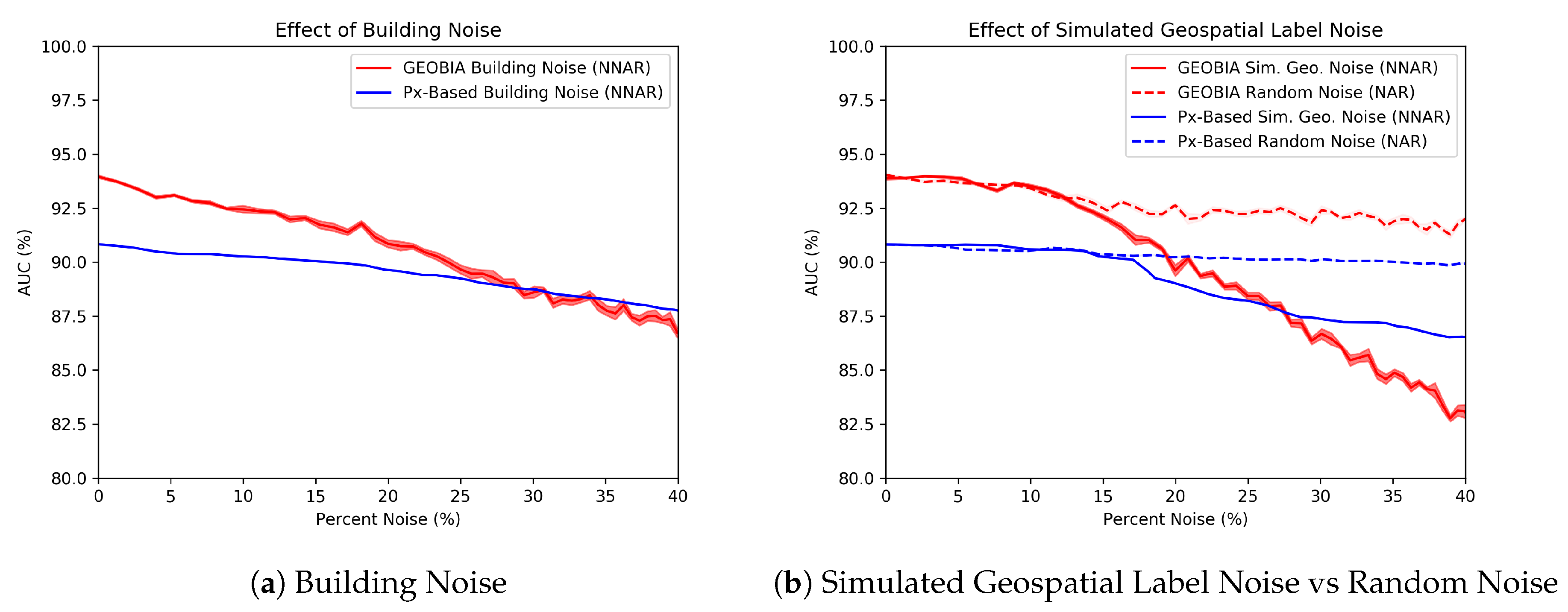
4.1.3. Label Noise Simulation
- NAR: NAR or random noise is simulated such that our labeled rubble class is flipped with probability zero while non-rubble is flipped with probability , where is the number of non-rubble segments in an image. At the start of the experiment, 19,024 of the 19,745 segments are non-rubble, so the probability that a non-rubble segment is flipped is .
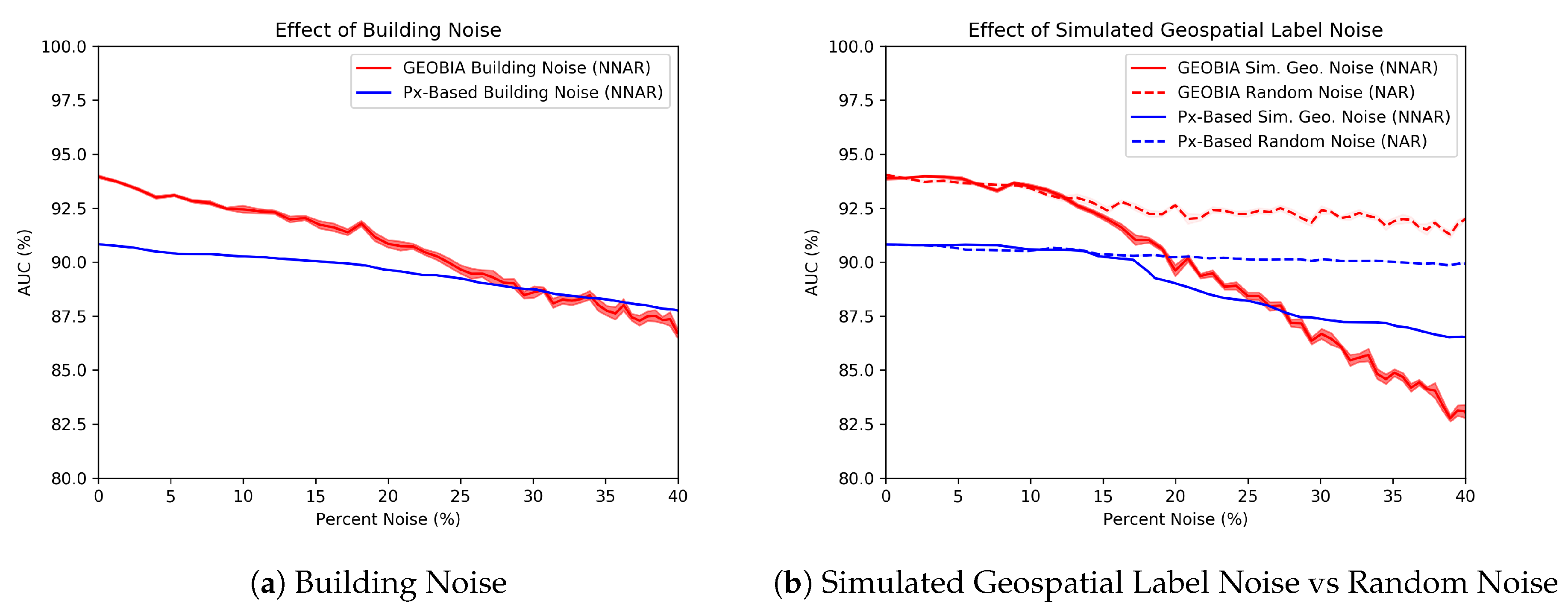
- Building noise: This type of NNAR represents the scenario in which a labeler misinterprets the task and includes parts of the buildings adjacent to the rubble. For this class-specific contamination, rather than flipping all non-rubble labels with equal likelihood, we flip only the labels of non-rubble segments containing buildings.
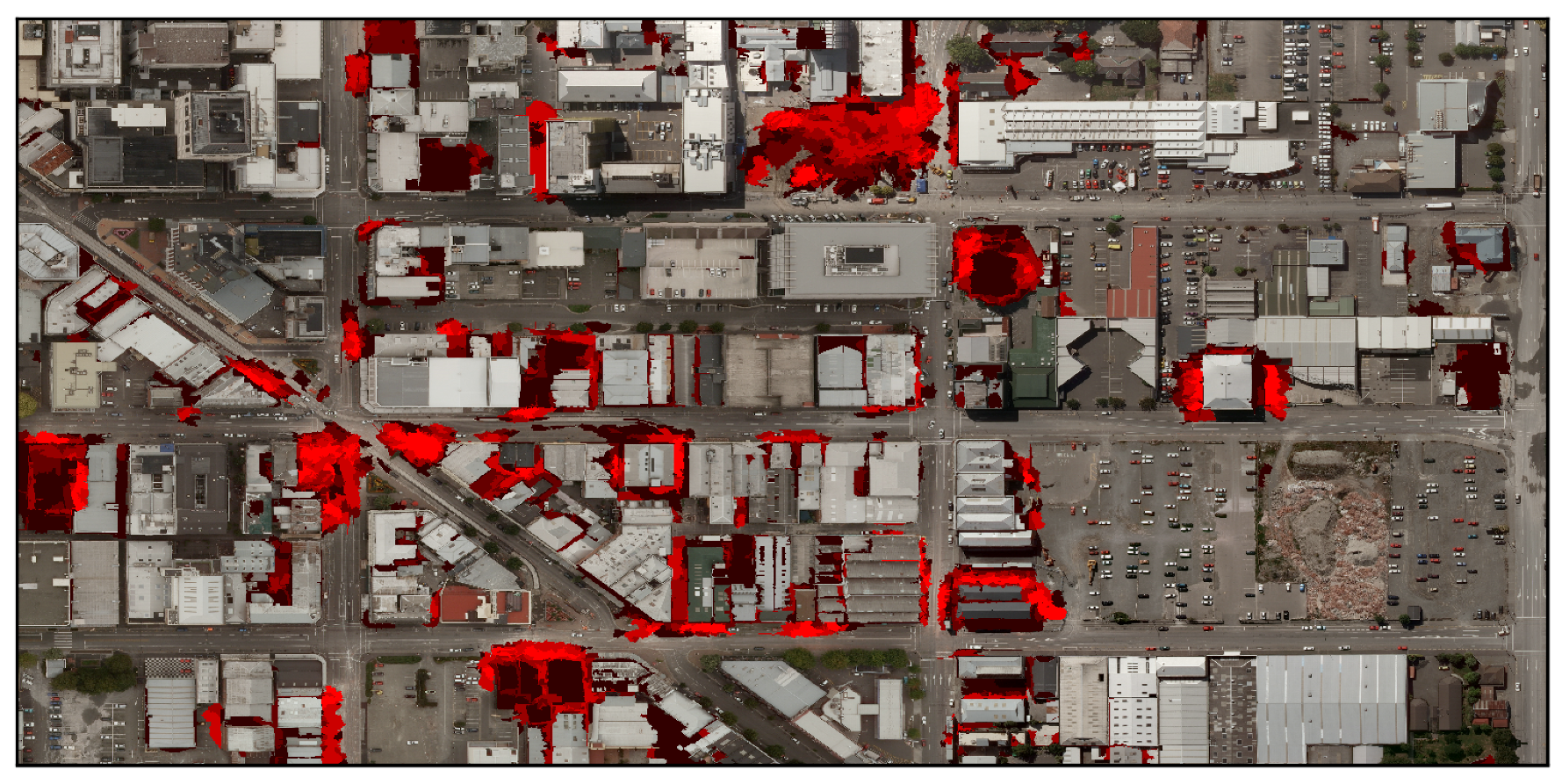
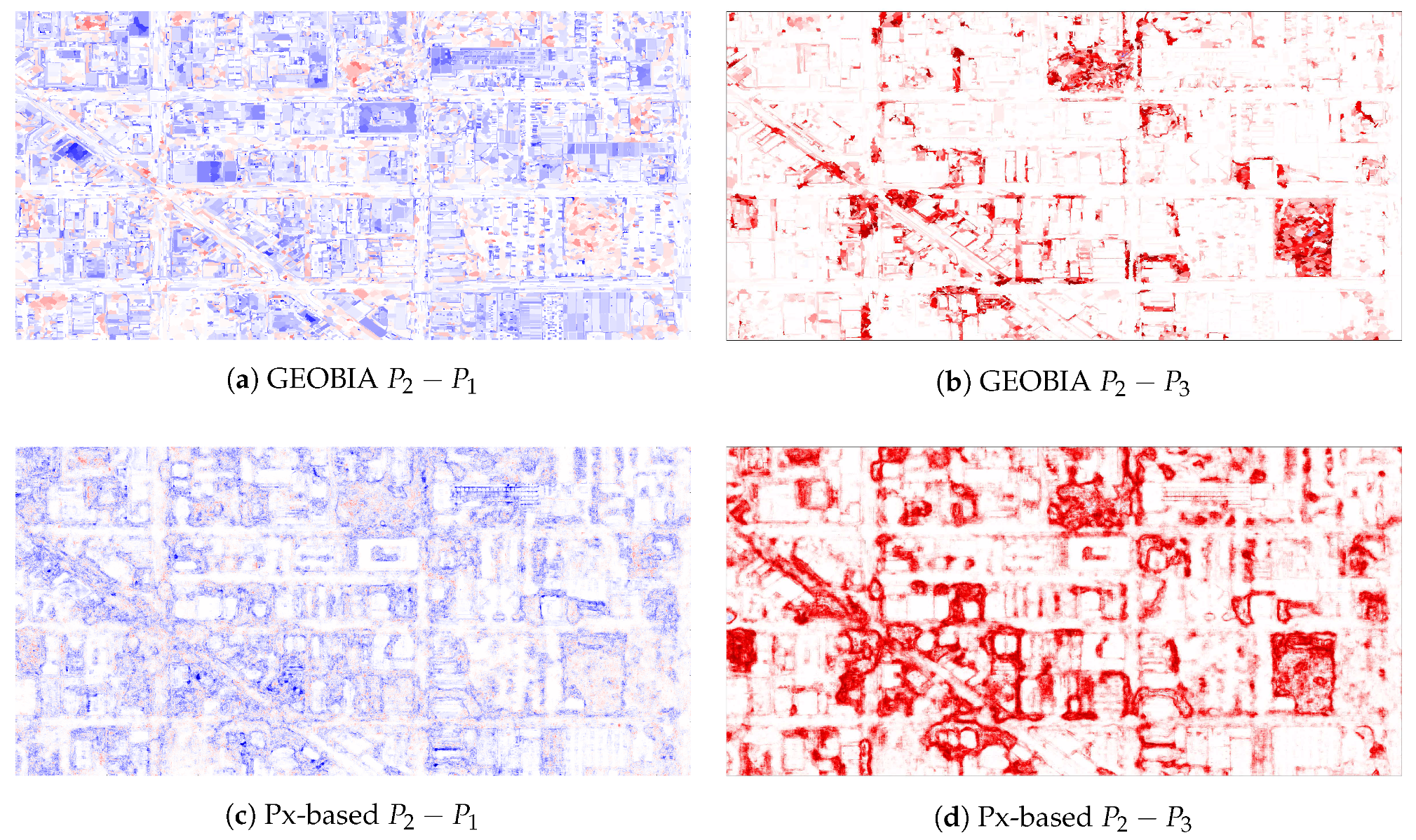
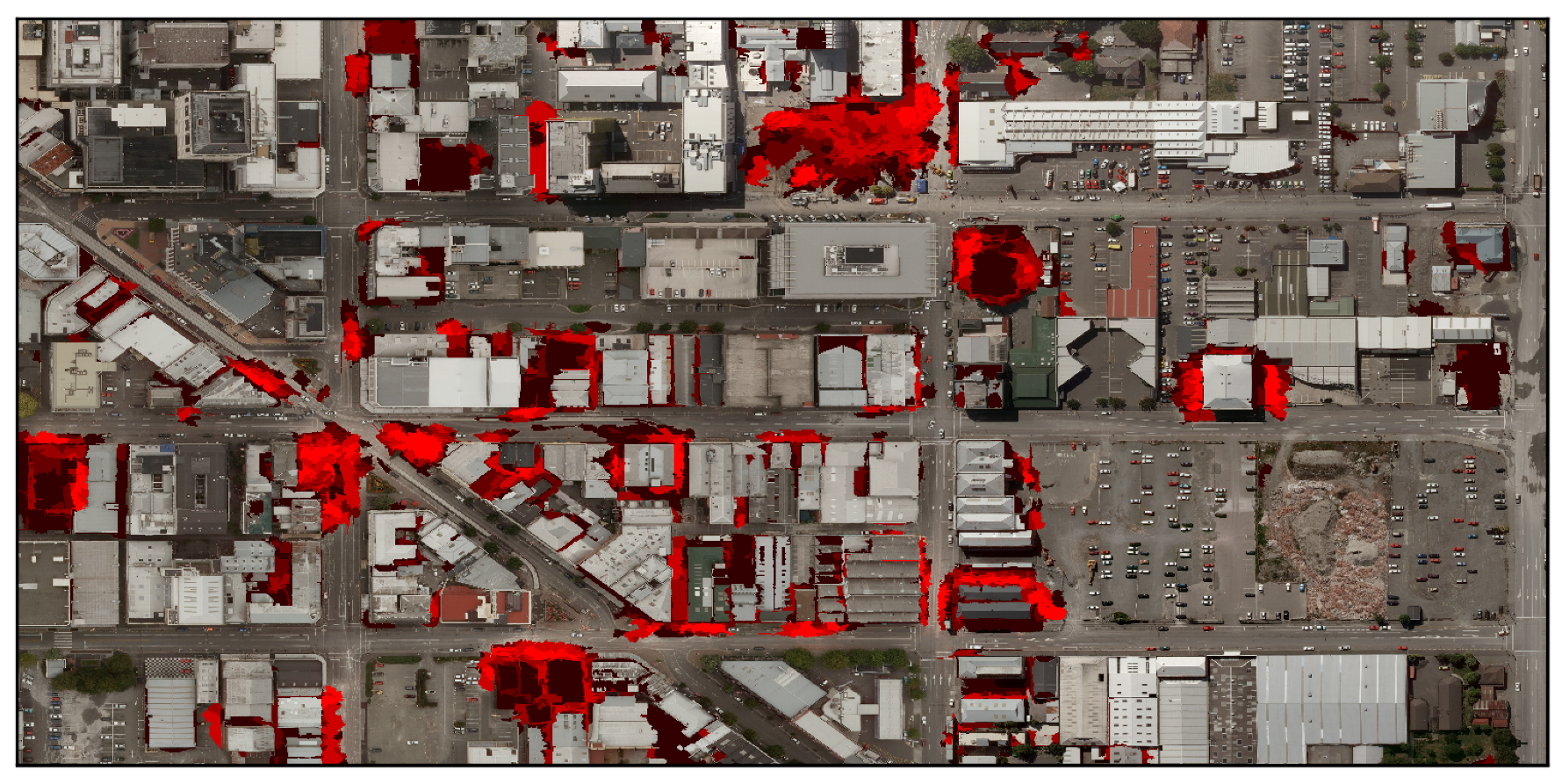
- Geospatial noise: This type of noise is simulated by applying a morphological dilation to the areas correctly labeled as rubble. Non-rubble data that are geospatially closer to rubble are therefore more likely to be corrupted. This emulates imprecise labeling tools because the regions of interest have not changed, only the width of the label. An example of this process’s appearance can be seen in Figure 5.
4.1.4. Performance Evaluation and Metrics
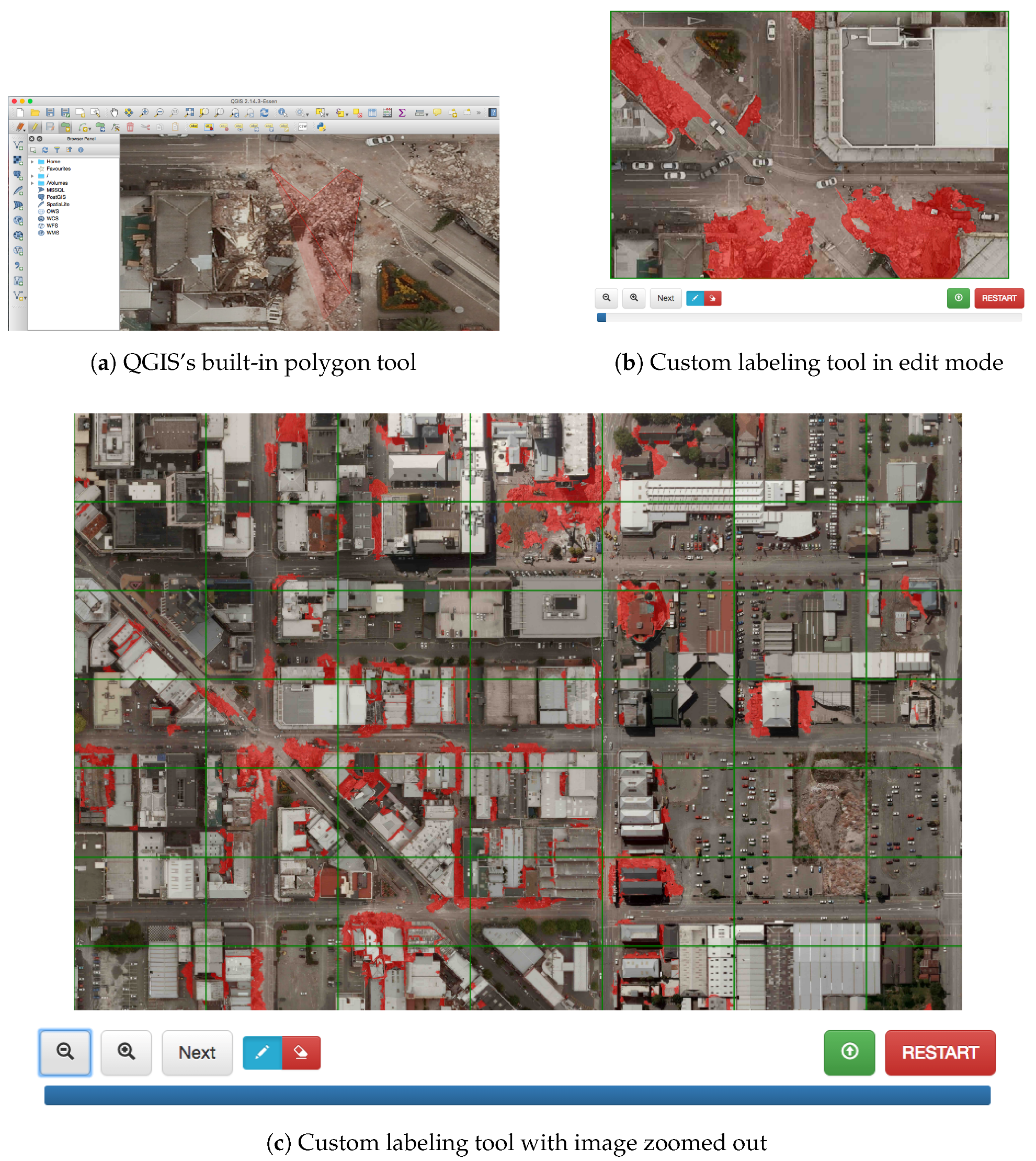
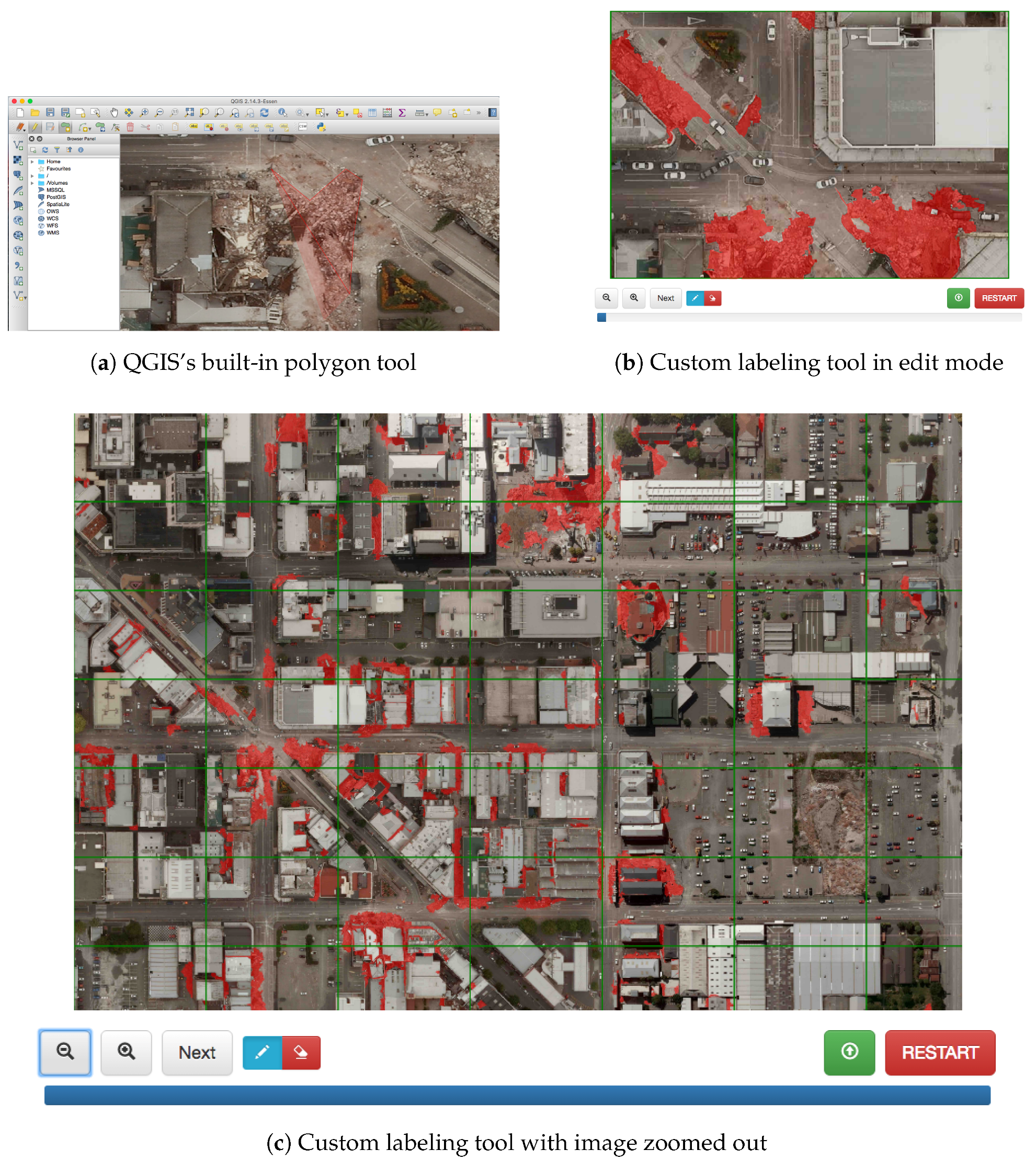
4.2. Human-Labeled Training Data and Labeling Tools
5. Results and Discussion
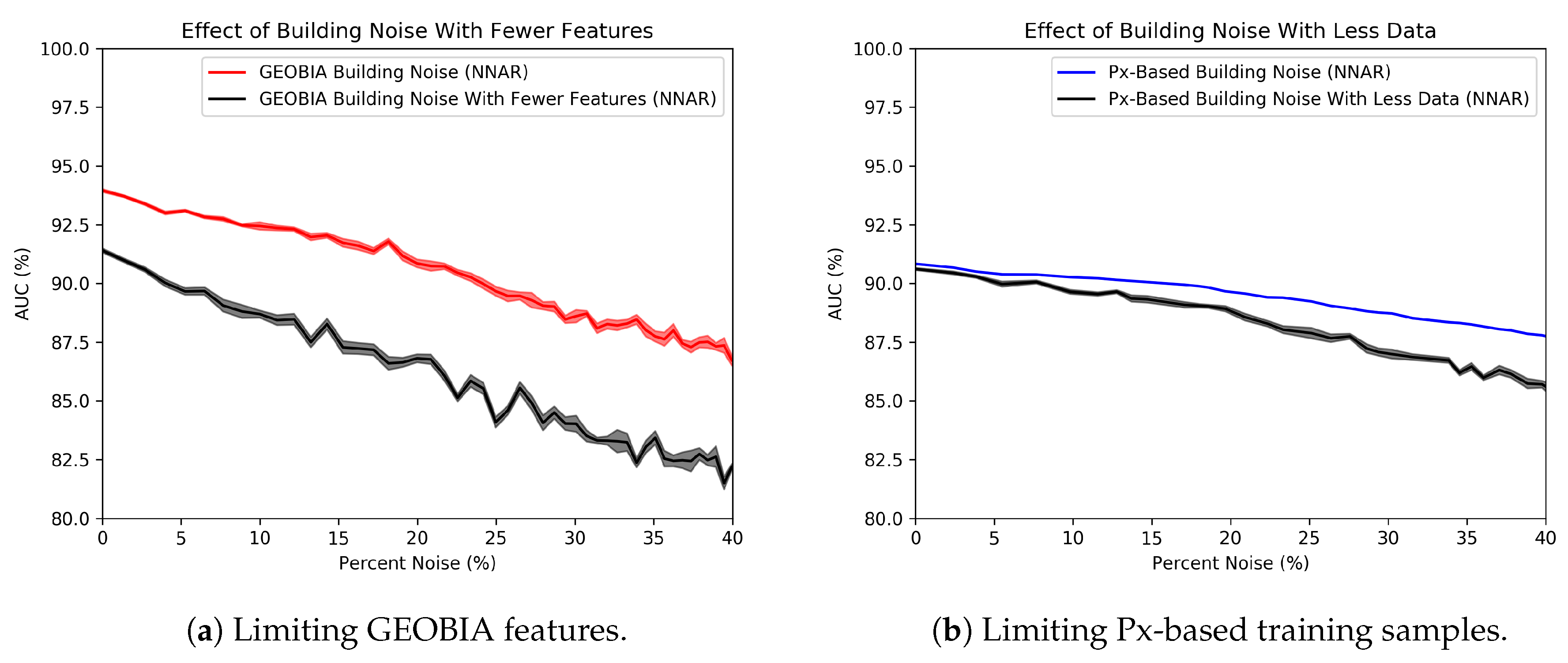
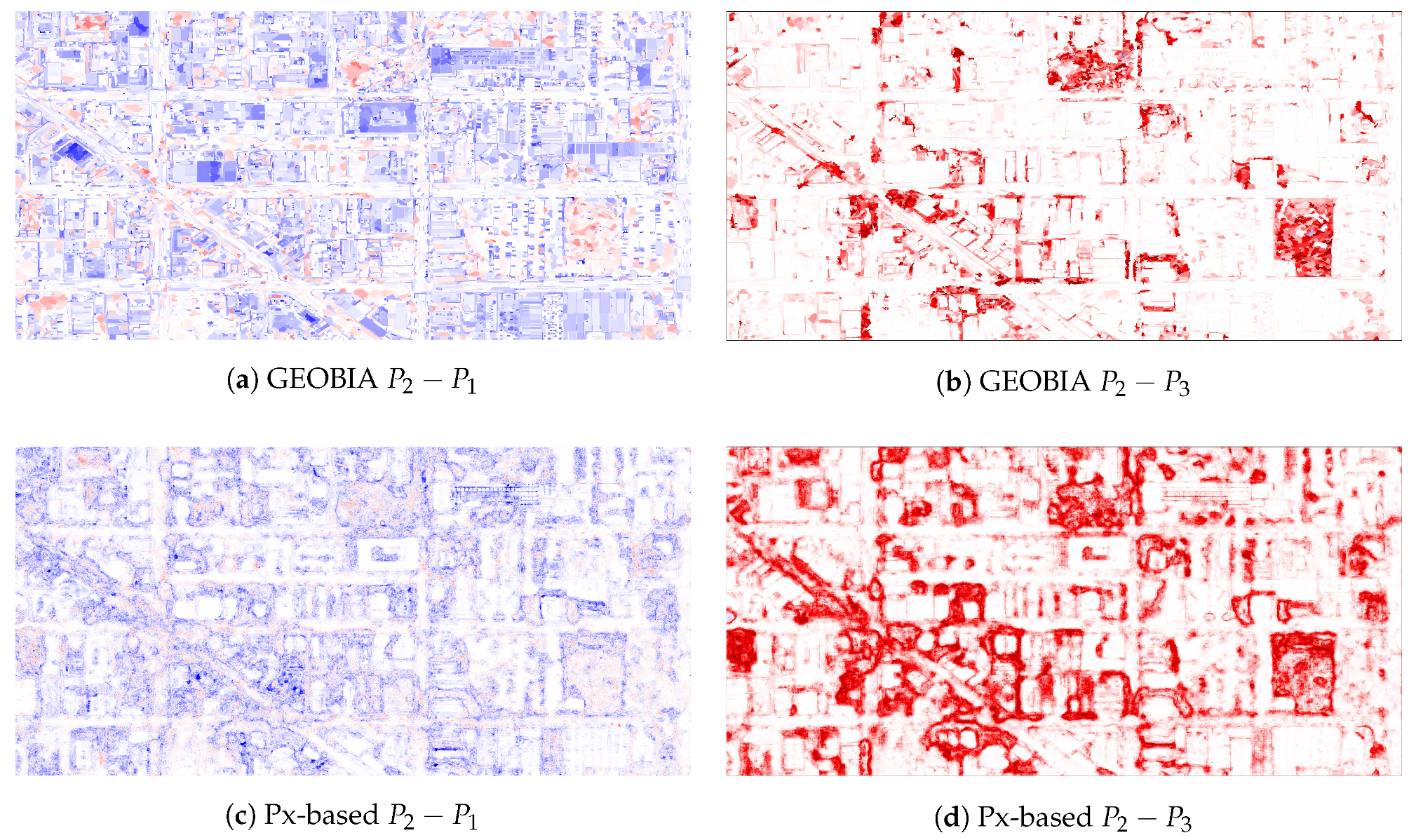
5.1. Experiments with Simulated Noise
Explaining the Noise Resilience of the Px-Based Classifier
5.2. Experiments with Human-Labeled Training Sets
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kaya, G.; Taski, K.; Musaoglu, N.; Ersoy, O. Damage assessment of 2010 Haiti earthquake with post-earthquake satellite image by support vector selection and adaptation. Photogramm. Eng. Remote Sens. 2011, 77, 1025–1035. [Google Scholar] [CrossRef]
- Li, P.; Xu, H.; Liu, S.; Guo, J. Urban building damage detection from very high resolution imagery using one-class SVM and spatial relations. In Proceedings of the IEEE International, Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; pp. V-112–V-114m. [Google Scholar]
- McMurren, J.; Verhults, S.; Young, A. New Zealand’s Christchurch Earthquake Clusters. Open Data’s Impac. 2016. Available online: http://odimpact.org/case-new-zealands-christchurch-earthquake-clusters.html (accessed on 20 July 2016).
- Huynh, A.; Eguchi, M.; Lin, A.Y.-M.; Eguchi, R. Limitations of crowdsourcing using the EMS-98 scale in remote disaster sensing. In Proceedings of the 2014 IEEE Aerospace Conference, Big Sky, MT, USA, 1–8 March 2014; pp. 1–8. [Google Scholar]
- Corbane, C.; Saito, K.; Dell’Oro, L.; Bjorgo, E.; Gill, S.P.D.; Piard, B.E.; Huyck, C.K.; Kemper, T.; Lemoine, G.; Spence, R.J.S.; et al. A comprehensive analysis of building damage in the January 12, 2010 Mw7 Haiti earthquake using high-resolution satellite and aerial imagery. Photogramm. Eng. Remote Sens. 2011, 77, 997–1009. [Google Scholar] [CrossRef]
- Clark, L. How Nepal’s Earthquake Was Mapped in 48 hours. Wired. 28 April 2015. Available online: http://www.wired.co.uk/article/mapping-nepal-after-the-earthquake (accessed on 29 July 2016).
- See, L.; Mooney, P.; Foody, G.; Bastin, L.; Comber, A.; Jacinto, E.; Steffen, F.; Kerle, N.; Jiang, B.; Laakso, M.; et al. Crowdsourcing, Citizen Science or Volunteered Geographic Information? The Current State of Crowdsourced Geographic Information. ISPRS Int. J. Geo-Inf. 2016, 5, 55. [Google Scholar] [CrossRef]
- Bialas, J.; Oommen, T.; Rebbapragada, U.; Levin, E. Object-based classification of earthquake damage from high-resolution optical imagery using machine learning. J. Appl. Remote Sens. 2016, 10, 036025. [Google Scholar] [CrossRef]
- Ghimire, B. An Evaluation of Bagging, Boosting, and Random Forests for Land-Cover Classification in Cape Cod, Massachusetts, USA. GISci. Remote Sens. 2012, 49, 623–643. [Google Scholar] [CrossRef]
- Gislason, P. Random Forests for land cover classification. Patter Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.; van der Meer, F.; van der Werff, H.; van Coillie, G.; et al. Geographic Object-Based Image Analysis-Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Blaschke, T.; Lang, S.; Lorup, E.; Zeil, P. Object-oriented image processing in an integrated GIS/remote sensing environment and perspectives for environmental applications. Environ. Inf. Plan. Politics 2000, 2, 555–570. [Google Scholar]
- Rodriguesz-Galiano, V.; Ghimire, B.; Rogan, J.; Rigol-Sanchez, J. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Simard, M.; Saatchi, S.S.; De Grandi, G. The use of decision tree and multiscale texture for classification of JERS-1 SAR data over tropical forest. IEEE Trans. Geosci. Remote Sens. 2000, 38, 2310–2321. [Google Scholar] [CrossRef]
- Marpu, P.R. Geographic Object-Based Image Analysis. Ph.D. Thesis, The Faculty of Geosciences, Geo-Engineering and Mining of the Technische Universitat Bergakademie, Freiberg, Germany, 2009. [Google Scholar]
- Frénay, B.; Verleysen, M. Classification in the presence of label noise: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 845–869. [Google Scholar] [CrossRef] [PubMed]
- Chhikara, R.; McKeon, J. Linear Discriminant Analysis with Misallocation in Training Samples. J. Am. Stat. Assoc. 1984, 79, 899–906. [Google Scholar] [CrossRef]
- Foody, G.M.; Pal, M.; Rocchini, D.; Garzon-Lopez, C.X.; Bastin, L. The Sensitivity of Mapping Methods to Reference Data Quality: Training Supervised Image Classifications with Imperfect Reference Data. ISPRS Int. J. Geo-Inf. 2016, 5, 199. [Google Scholar] [CrossRef]
- Foody, G.M. The impact of imperfect ground reference data on the accuracy of land cover change estimation. Int. J. Remote Sens. 2009, 30, 3275–3281. [Google Scholar] [CrossRef]
- Foody, G.M. Assessing the accuracy of the land cover change with imperfect ground reference data. Remote Sens. Environ. 2010, 114, 2271–2285. [Google Scholar] [CrossRef]
- Land Information New Zealand. Christchurch Earthquake Imagery. Available online: http://www.linz.govt.nz/land/maps/linz-topographic-maps/imagery-orthophotos/christchurch-earthquake-imagery (accessed on 3 September 2013).
- Breiman, L. Random Forests. Mach. Learn. 2001. [Google Scholar] [CrossRef]
- Baatz, M.; Schäpe, A. Multiresolution segmentation: An optimization approach for high quality multi-scale image segmentation. XII Angew. Geogr. Informationsverarbeitung 2000, XII, 12–23. [Google Scholar]
- Lowe, G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV Library. Dr. Dobb’s. Available online: http://www.drdobbs.com/open-source/the-opencv-library/184404319 (accessed on 27 April 2017).
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. Scikit-image: Image processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef] [PubMed]
- Definiens Developer Reference Book XD 2.0.4. Definiens AG, 2012. Available online: http://www.imperial.ac.uk/media/imperial-college/medicine/facilities/film/Definiens-Developer-Reference-Book-XD-2.0.4.pdf (accessed on 1 August 2017).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Features |
|---|---|
| Spectral | Brightness, Mean Value, Standard Deviation, Max. Diff., Hue, Saturation, Intensity |
| Texture | GLCM Homogeneity, GLCM Contrast, GLCM Dissimilarity, GLCM Entropy, GLCM Angular 2nd Momentum, GLCM Mean, GLCM Std. Dev., GLCM Correlation, GLDV Angular 2nd Momentum, GLDVEntropy |
| Shape | Extent Area, Border Length, Length, Length/Thickness, Length/Width, Number of Pixels, Thickness, Volume, Width |
| Shape Asymmetry, Border Index, Compactness, Density, Elliptic Fit, Main Direction, Radius of Largest Enclosed Ellipse, Radius of Smallest Enclosed Ellipse, Rectangular Fit, Roundness, Shape Index | |
| Based on Polygons Area (excluding inner polygons), Area (including inner polygons), Average Length of Edges (Polygon), Compactness (Polygon), Length of Longest Edge (Polygon), Number of Edges (Polygon), Number of Inner Objects (Polygon), Perimeter (Polygon), Polygon Self-Intersection (Polygon), Std. Dev. Of Length of Edges | |
| Based on Skeletons Average Branch Length, Average Area Represented by Segments, Curvature/Length (Only Main Line), Degree of Skeleton Branching, Length of Main Line (No Cycles), Length of Main Line (Regarding Cycles), Length/Width (Only Main Line), Maximum Branch Length, Number of Segments, Std. Dev. Curvature (Only Main Line), Std. Dev. of Area Represented by Segments, Width (Only Main Line) |
| Dataset | Labeling Tool | Methodology |
|---|---|---|
| QGIS Polygon Drawing | Full image labeled. Tendency toward over-labeling rubble. | |
| Web-based Segment Labeling (scale = 50) | Full image labeled by segment. Considered the cleanest of three. | |
| eCognition Segment Labeling (scale = 25) | Partial image labeled. Some rubble areas omitted from training. |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frank, J.; Rebbapragada, U.; Bialas, J.; Oommen, T.; Havens, T.C. Effect of Label Noise on the Machine-Learned Classification of Earthquake Damage. Remote Sens. 2017, 9, 803. https://doi.org/10.3390/rs9080803
Frank J, Rebbapragada U, Bialas J, Oommen T, Havens TC. Effect of Label Noise on the Machine-Learned Classification of Earthquake Damage. Remote Sensing. 2017; 9(8):803. https://doi.org/10.3390/rs9080803
Chicago/Turabian StyleFrank, Jared, Umaa Rebbapragada, James Bialas, Thomas Oommen, and Timothy C. Havens. 2017. "Effect of Label Noise on the Machine-Learned Classification of Earthquake Damage" Remote Sensing 9, no. 8: 803. https://doi.org/10.3390/rs9080803
APA StyleFrank, J., Rebbapragada, U., Bialas, J., Oommen, T., & Havens, T. C. (2017). Effect of Label Noise on the Machine-Learned Classification of Earthquake Damage. Remote Sensing, 9(8), 803. https://doi.org/10.3390/rs9080803