
Dimensionality Reduction of Hyperspectral Image with Graph-Based Discriminant Analysis Considering Spectral Similarity



Abstract
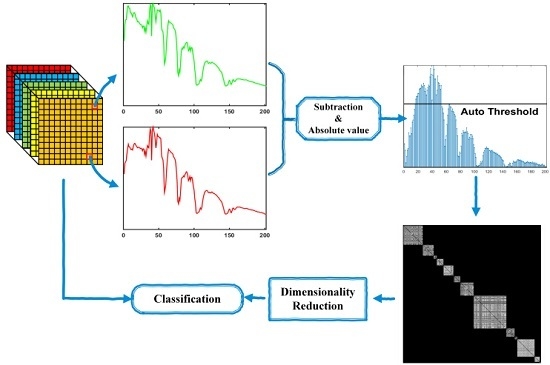
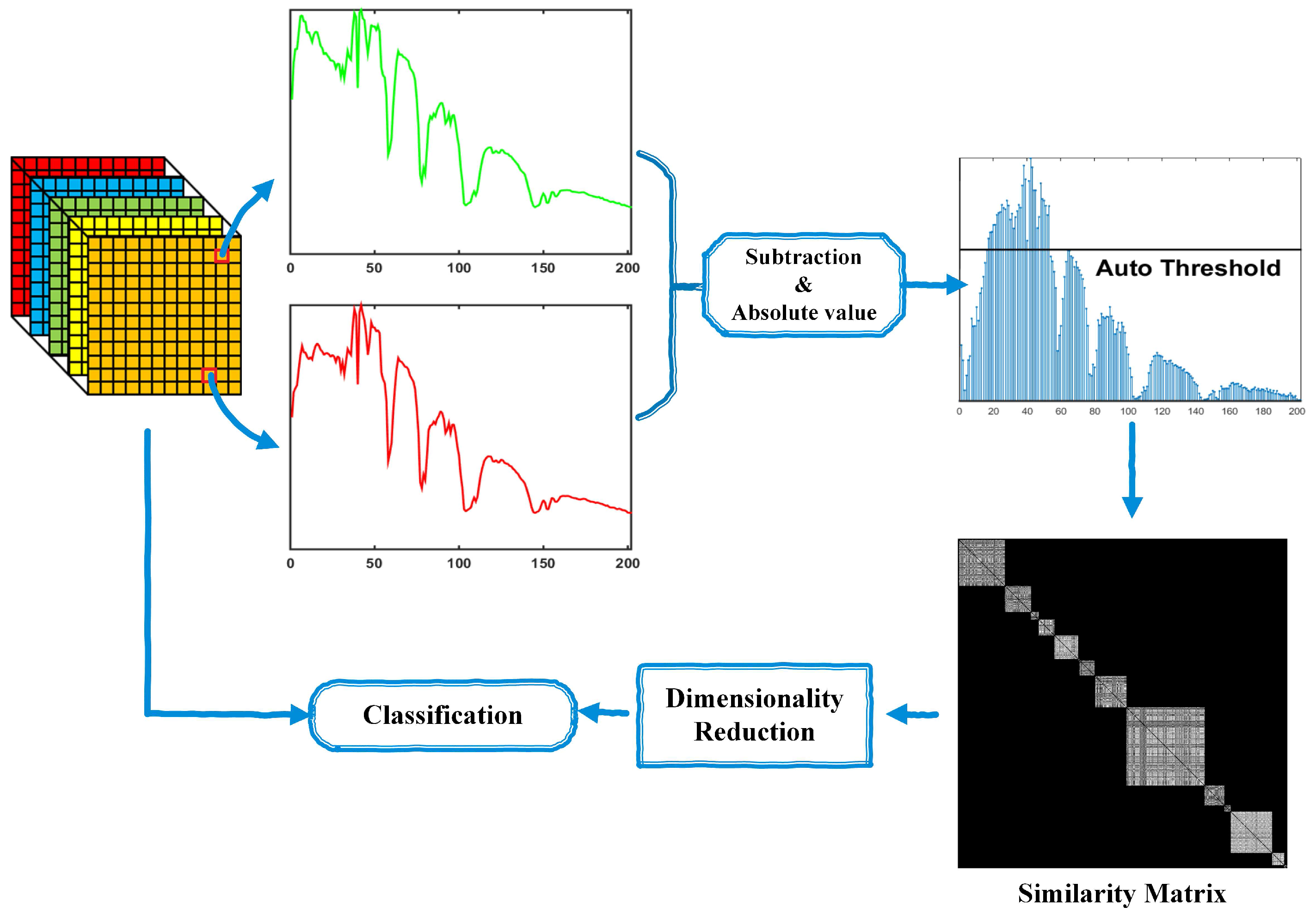
:
1. Introduction
2. Related Work
2.1. Graph-Embedding Dimensionality Reduction Framework
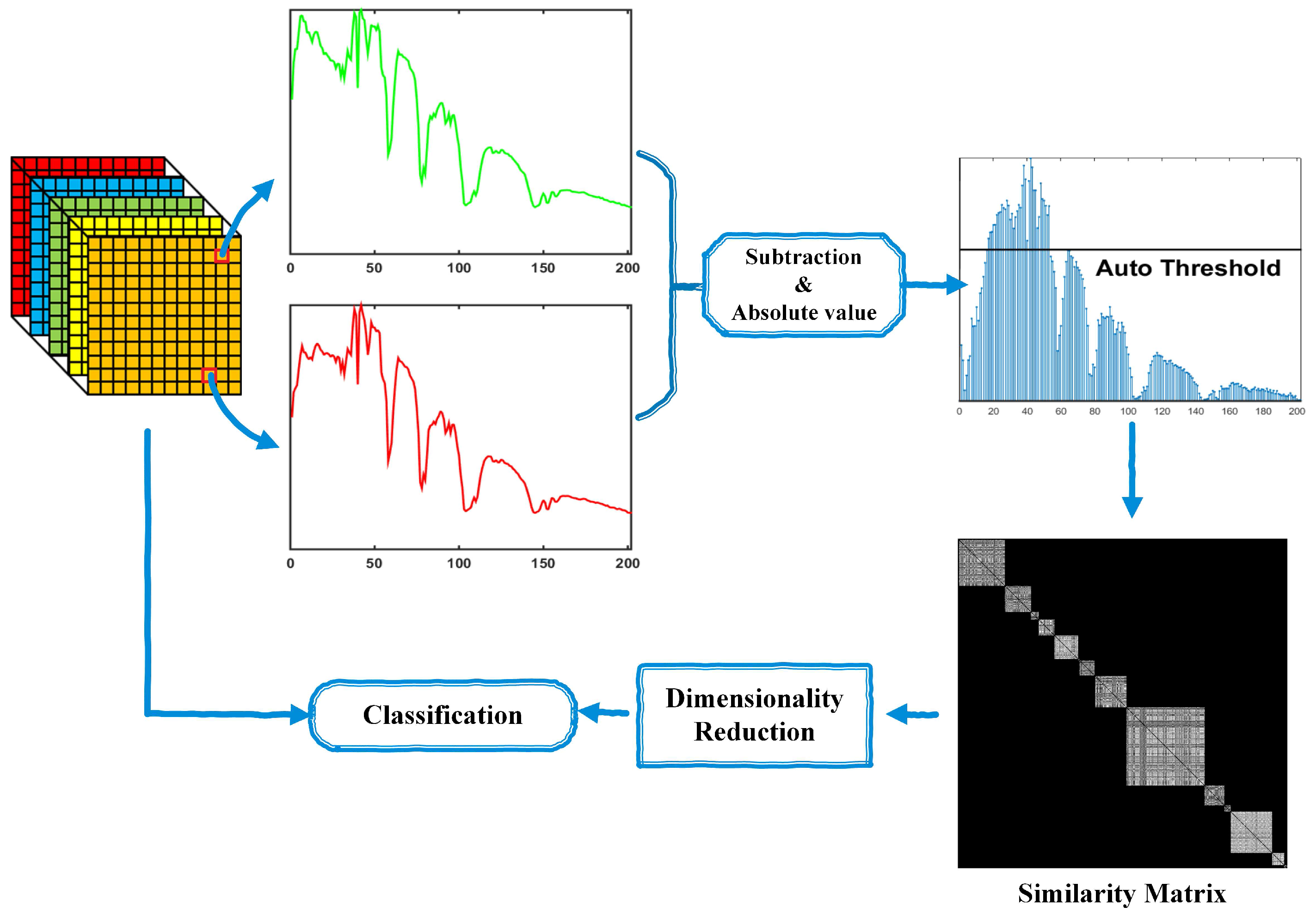
2.2. Similarity Graph in LPP and SGDA
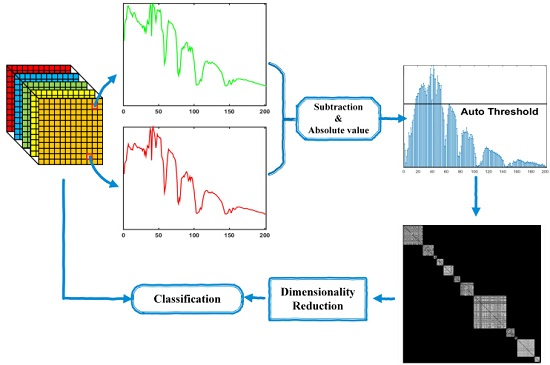
3. Proposed GDA-SS
3.1. GDA-SS
3.2. Analysis on GDA-SS
4. Experimental Results
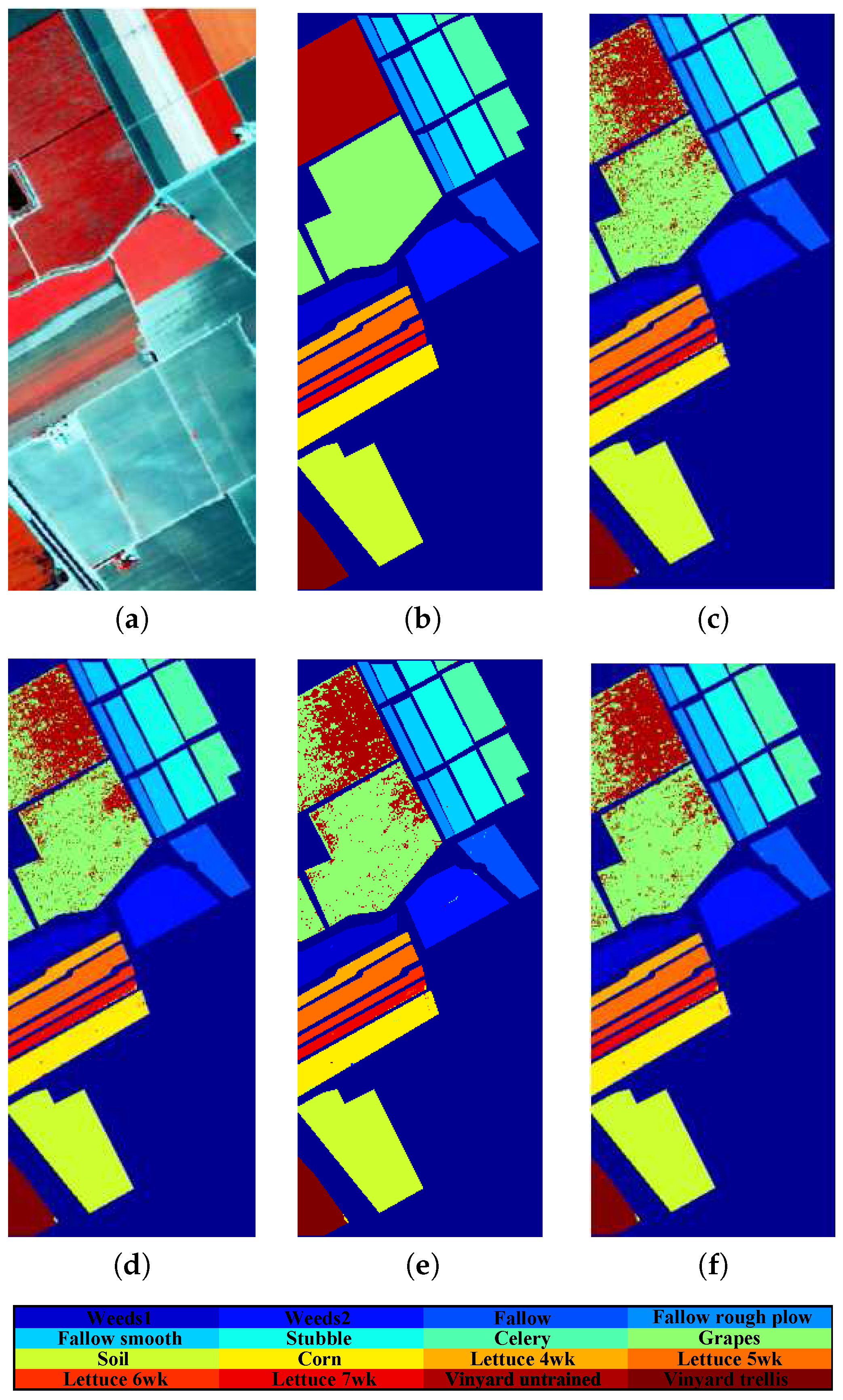
4.1. Hyperspectral Data
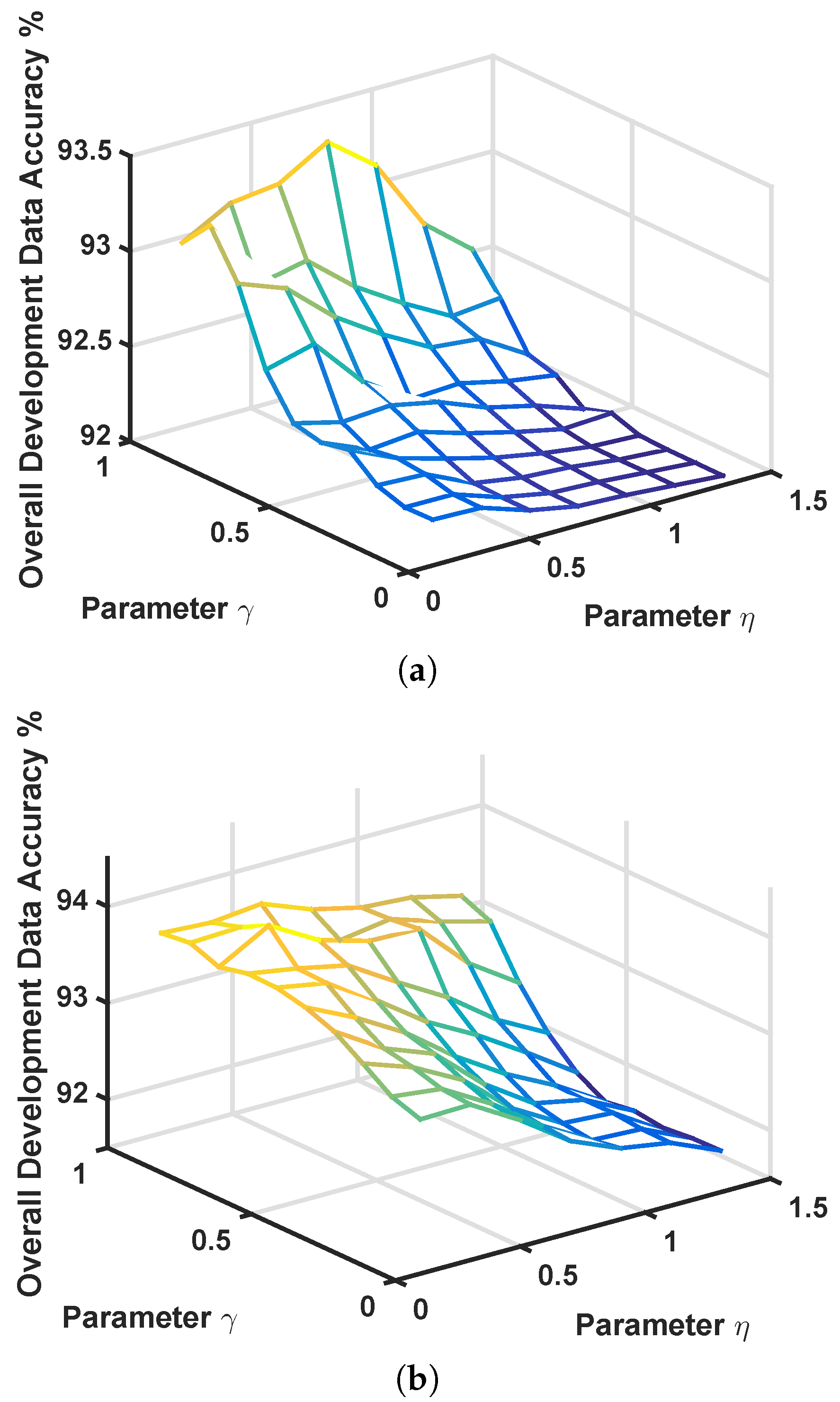
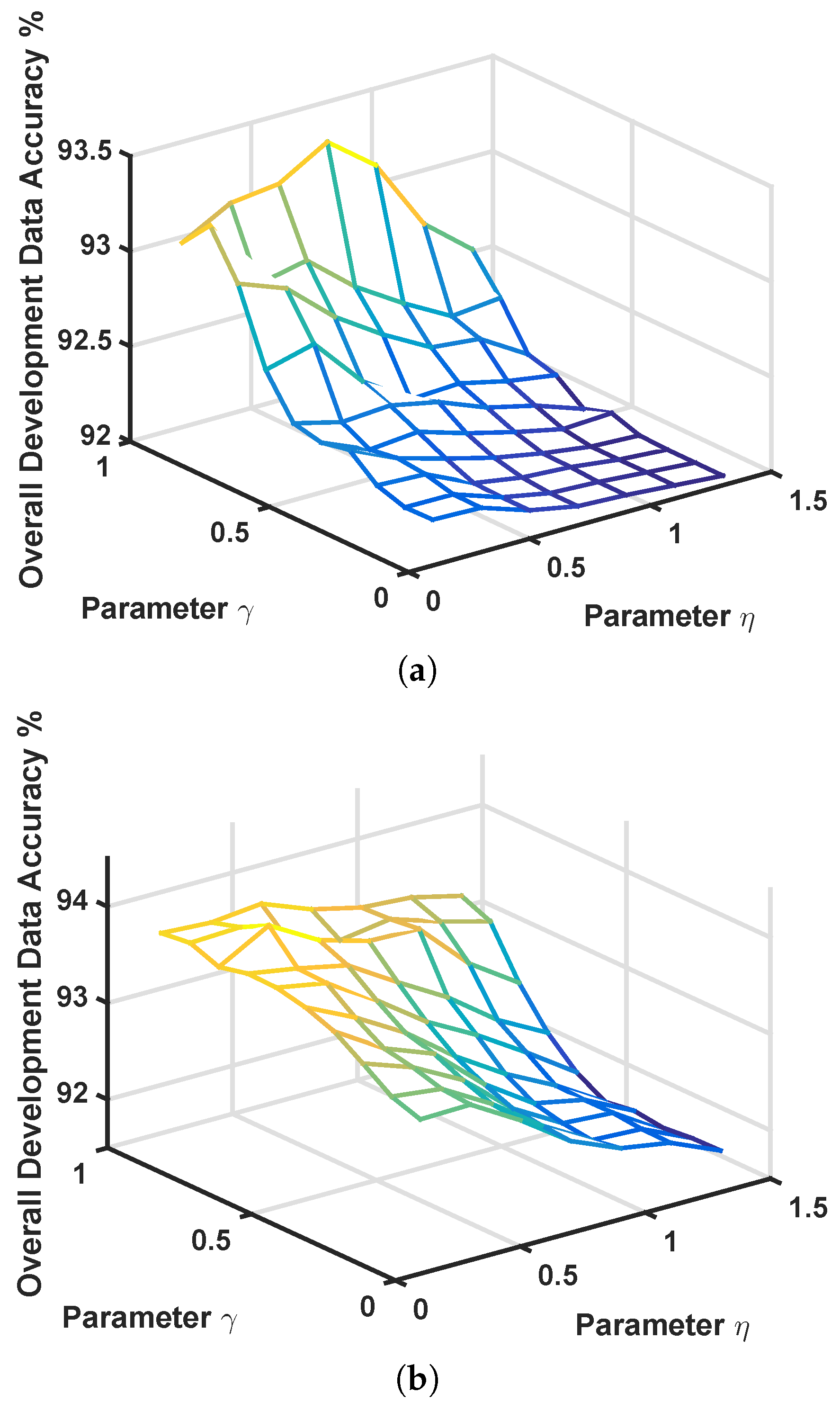
4.2. Parameter Tuning
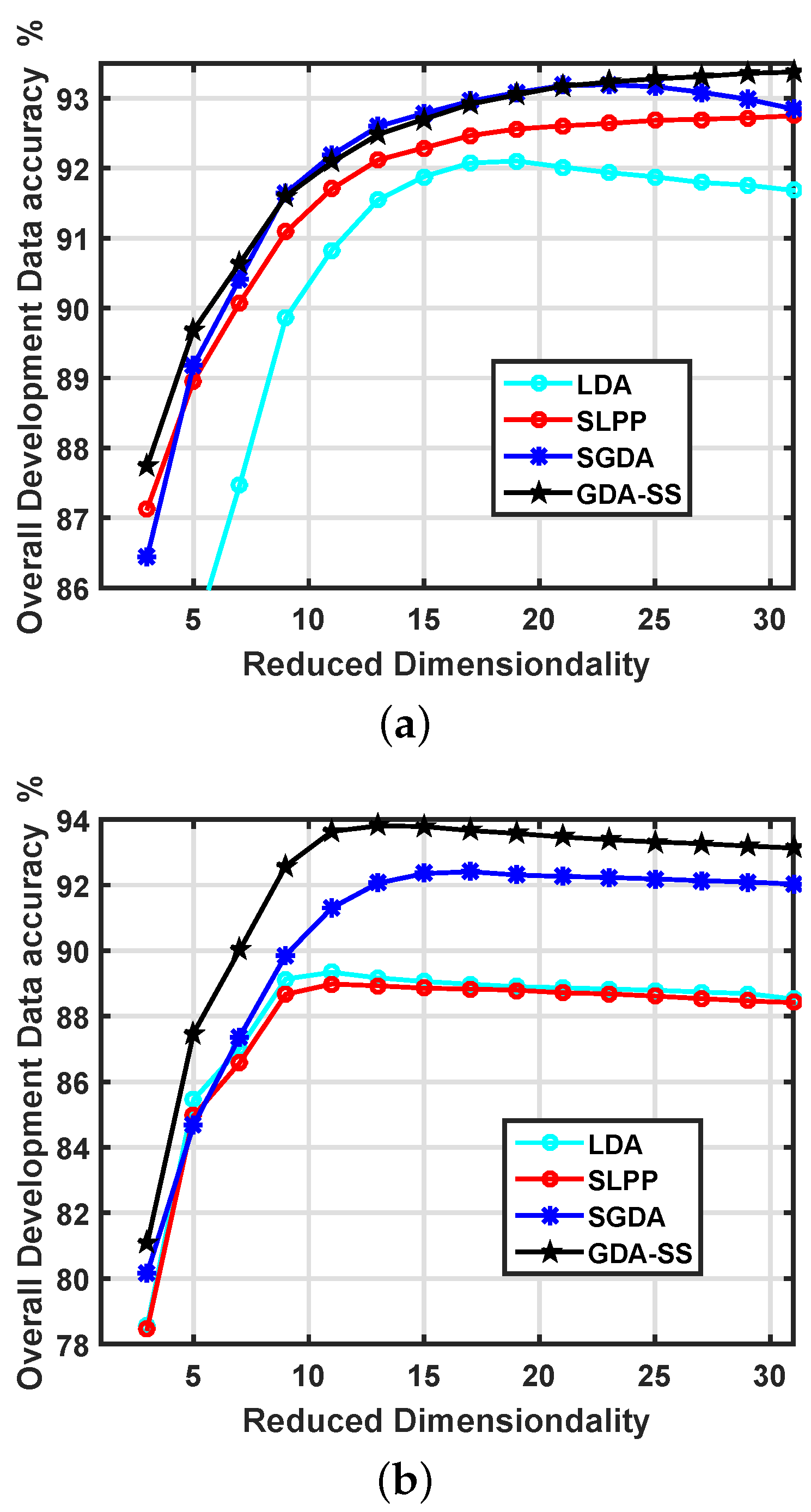
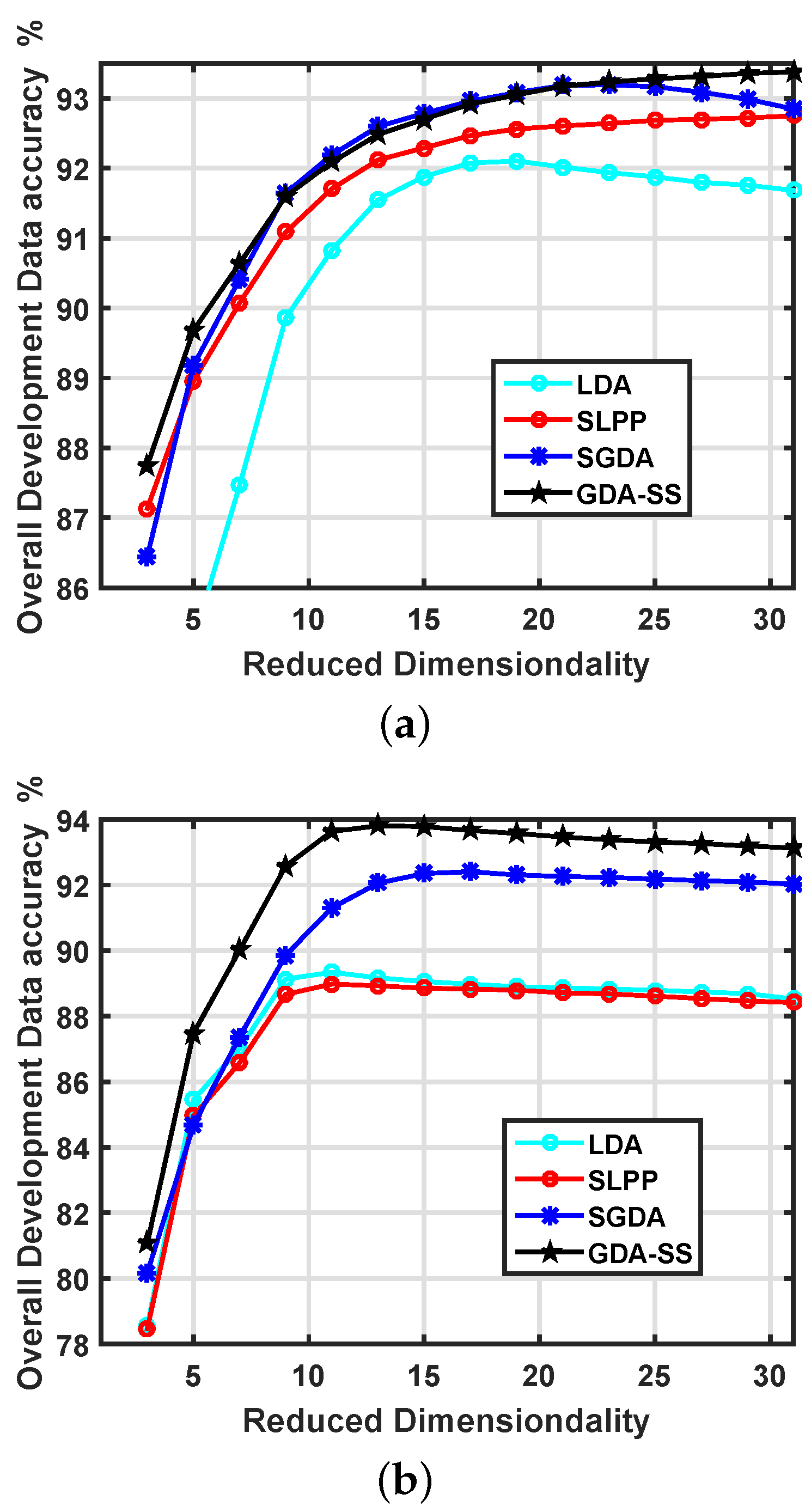
4.3. Classification Performance
4.4. More Robustness Test of GDA-SS
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Prasad, S.; Li, W.; Fowler, J.E.; Bruce, L.M. Information Fusion in the Redundant-Wavelet-Transform Domain for Noise-Robust Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3474–3486. [Google Scholar]
- Du, B.; Zhang, L.; Zhang, L.; Chen, T.; Wu, K. A Discriminative Manifold Learning Based Dimension Reduction Method for Hyperspectral Classification. Int. J. Fuzzy Syst. 2012, 14, 272–277. [Google Scholar]
- Gao, L.; Li, J.; Khodadadzadeha, M.; Plaza, A.; Zhang, B.; He, Z.; Yan, H. Subspace-Based Support Vector Machines for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 349–353. [Google Scholar]
- Li, W.; Tramel, E.W.; Prasad, S.; Fowler, J.E. Nearest Regularized Subspace for Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 477–489. [Google Scholar] [CrossRef]
- Li, W.; Chen, C.; Su, H.; Du, Q. Local Binary Patterns and Extreme Learning Machine for Hyperspectral Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3681–3693. [Google Scholar] [CrossRef]
- Gu, Y.; Liu, T.; Jia, X.; Benediktsson, J.A.; Chanussot, J. Nonlinear Multiple Kernel Learning with Multiple-Structure-Element Extended Morphological Profiles for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3235–3247. [Google Scholar] [CrossRef]
- Prasad, S.; Bruce, L.M. Limitations of Principal Component Analysis for Hyperspectral Target Recognition. IEEE Geosci. Remote Sens. Lett. 2008, 5, 625–629. [Google Scholar] [CrossRef]
- Li, W.; Prasad, S.; Fowler, J.E.; Bruce, L.M. Locality-Preserving Dimensionality Reduction and Classification for Hyperspectral Image Analysis. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1185–1198. [Google Scholar] [CrossRef]
- Li, W.; Prasad, S.; Fowler, J.E. Hyperspectral Image Classification Using Gaussian Mixture Model and Markov Random Field. IEEE Geosci. Remote Sens. Lett. 2014, 11, 153–157. [Google Scholar] [CrossRef]
- Yan, S.; Xu, D.; Zhang, B.; Zhang, H.J.; Yang, Q.; Lin, S. Graph Embedding and Extensions: A General Framework for Dimensionality Reduction. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 40–51. [Google Scholar] [CrossRef] [PubMed]
- Roweis, S.T.; Saul, L.K. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps and spectral techniques for embedding and clustering. In Proceedings of the Neural Information Processing Systems: Natural and Synthetic, Vancouver, BC, Canada, 3–8 December 2001; Volume 14, pp. 585–591. [Google Scholar]
- He, X.; Niyogi, P. Locality Preserving Projections. In Advances in Neural Information Processing System; Thrun, S., Saul, L., Schölkopf, B., Eds.; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Zhai, Y.; Zhang, L.; Wang, N.; Guo, Y.; Cen, Y.; Wu, T.; Tong, Q. A Modified Locality Preserving Projection Approach for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1059–1063. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, D.; Yang, J.; Niu, B. Globally maximizing, locally minimizing: unsupervised discriminant projection with applications to face and palm biometrics. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 650–664. [Google Scholar] [CrossRef] [PubMed]
- Cai, H.; Mikolajczyk, K.; Matas, J. Learning linear discriminant projections for dimensionality reduction of image descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 338–352. [Google Scholar] [PubMed]
- Qiao, L.; Chen, S.; Tan, X. Sparsity Preserving Projections with Applications to Face Recognition. Pattern Recognit. 2010, 43, 331–341. [Google Scholar]
- Kokiopoulou, E.; Saad, Y. Enhanced graph-based dimensionality reduction with repulsion Laplaceans. Pattern Recognit. 2009, 42, 2392–2402. [Google Scholar] [CrossRef]
- Zhang, L.; Qiao, L.; Chen, S. Graph-optimized locality preserving projections. Pattern Recognit. 2010, 43, 1993–2002. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, S.; Qiao, L. Graph optimization for dimensionality reduction with sparsity constraints. Pattern Recognit. 2012, 45, 1205–1210. [Google Scholar] [CrossRef]
- Peng, X.; Zhang, L.; Yi, Z.; Tan, K.K. Learning Locality-Constrained Collaborative Representation for Robust Face Recognition. Pattern Recognit. 2014, 47, 2794–2806. [Google Scholar] [CrossRef]
- Ly, N.; Du, Q.; Fowler, J.E. Sparse Graph-Based Discriminant Analysis for Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3872–3884. [Google Scholar]
- Ly, N.; Du, Q.; Fowler, J.E. Collaborative Graph-Based Discriminant Analysis for Hyperspectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2688–2696. [Google Scholar]
- Chen, P.; Jiao, L.; Liu, F.; Zhao, J.; Zhao, Z.; Liu, S. Semi-supervised double sparse graphs based discriminant analysis for dimensionality reduction. Pattern Recognit. 2017, 61, 361–378. [Google Scholar] [CrossRef]
- Cheng, B.; Yang, J.; Yan, S.; Fu, Y.; Huang, T.S. Learning With ℓ1-Graph for Image Analysis. IEEE Trans. Image Process. 2010, 19, 858–866. [Google Scholar] [CrossRef] [PubMed]
- He, W.; Zhang, H.; Zhang, L.; Philips, W.; Liao, W. Weighted Sparse Graph Based Dimensionality Reduction for Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 686–690. [Google Scholar] [CrossRef]
- Li, W.; Du, Q. Laplacian Regularized Collaborative Graph for Discriminant Analysis of Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7066–7076. [Google Scholar] [CrossRef]
- Tan, K.; Zhou, S.; Du, Q. Semi-supervised Discriminant Analysis for Hyperspectral Imagery with Block-Sparse Graph. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1765–1769. [Google Scholar] [CrossRef]
- Li, W.; Liu, J.; Du, Q. Sparse and Low-Rank Graph for Discriminant analysis of Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4094–4105. [Google Scholar] [CrossRef]
- He, X.; Yan, S.; Hu, Y.; Niyogi, P.; Zhang, H.J. Face recognition using Laplacianfaces. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 328–340. [Google Scholar] [PubMed]
- Zhao, R.; Du, B.; Zhang, L. A robust nonlinear hyperspectral anomaly detection approach. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1227–1234. [Google Scholar] [CrossRef]
- Platt, J. Advances in Large Margin Classifiers. In Probabilistic Outputs for Support Vector Machines and Comparison to Regularized Likelihood Methods; Smola, A., Ed.; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Li, C.H.; Kuo, B.C.; Lin, C.T.; Huang, C.S. A Spatial-Contextual Support Vector Machine for Remotely Sensed Image Classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 784–799. [Google Scholar] [CrossRef]
- Chen, G.; Qian, S.E. Denoising of Hyperspectral Imagery Using Principal Component Analysis and Wavelet Shrinkage. IEEE Trans. Geosci. Remote Sens. 2011, 49, 973–980. [Google Scholar] [CrossRef]
- Villa, A.; Benediktsson, J.A.; Chanussot, J.; Jutten, C. Hyperspectral image classification with independent component discriminant analysis. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4865–4876. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
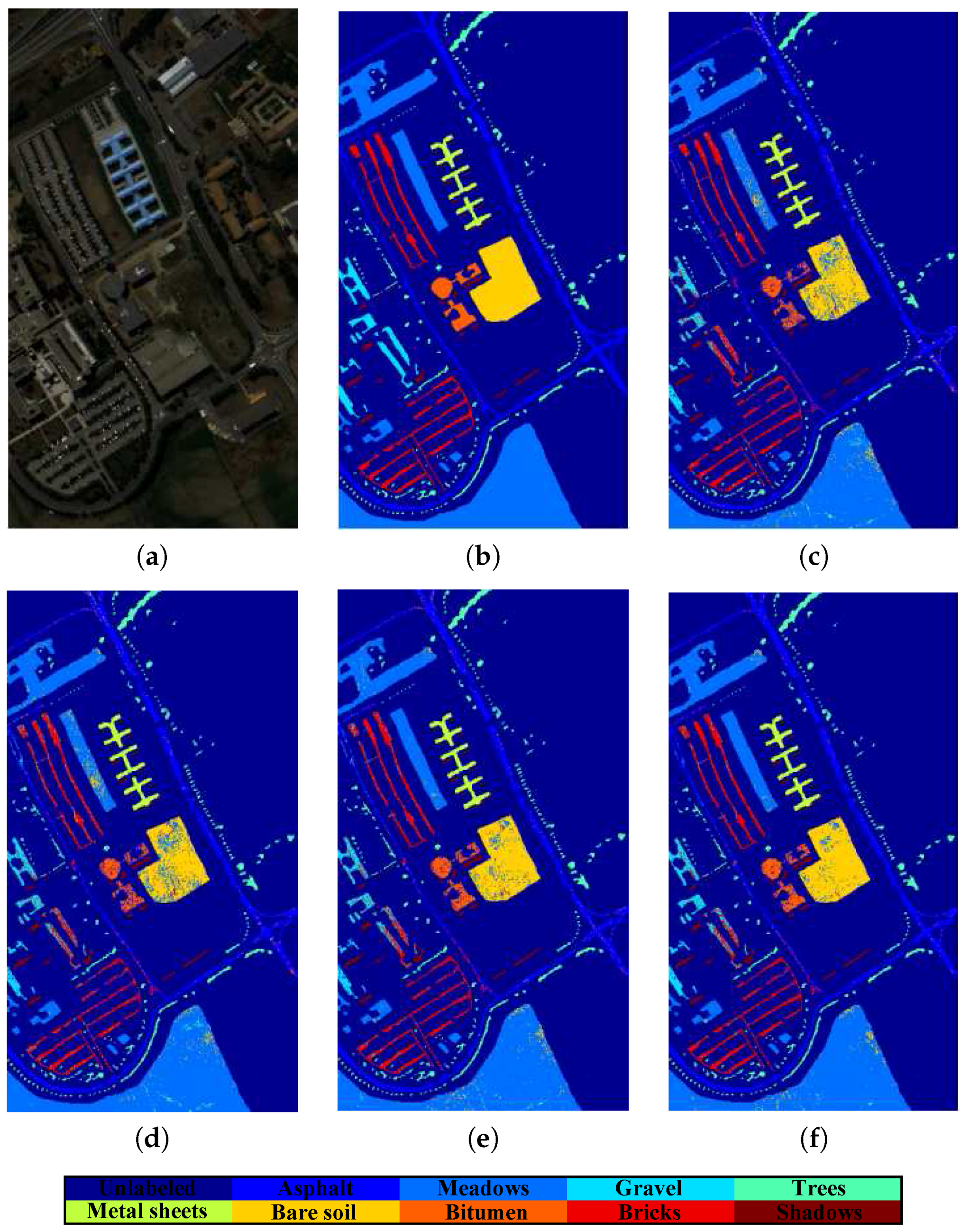{kind=link}
{kind=link}
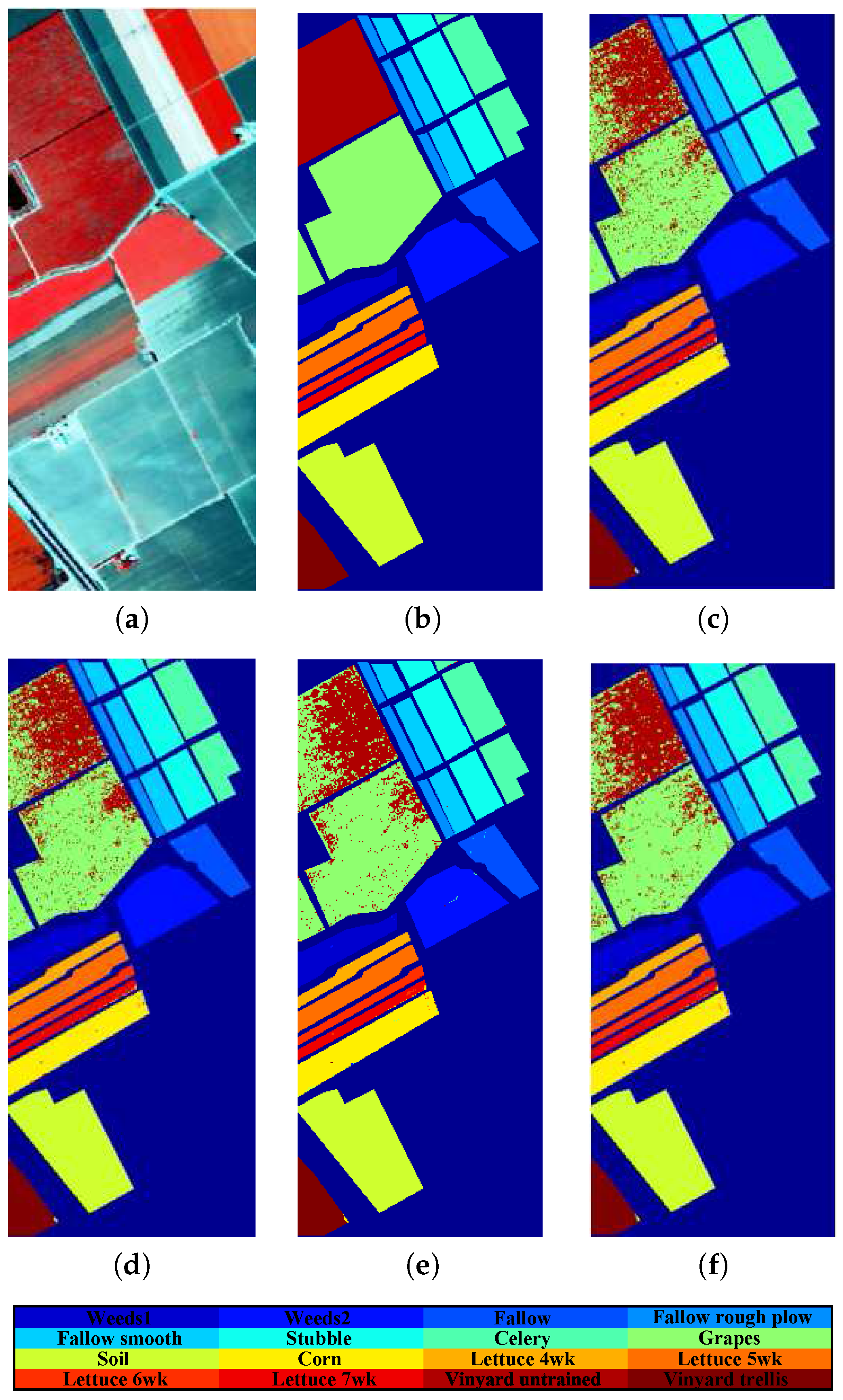
| Class | Train | Test | LDA | SLPP | SGDA | GDA-SS | |
|---|---|---|---|---|---|---|---|
| 1 | Brocoli-green-weeds-1 | 100 | 1909 | 99.75 | 100 | 99.63 | 99.90 |
| 2 | Brocoli-green-weeds-2 | 186 | 3540 | 99.79 | 99.97 | 99.97 | 99.97 |
| 3 | Fallow | 99 | 1877 | 99.75 | 99.68 | 99.84 | 99.79 |
| 4 | Fallow-rough-plow | 70 | 1324 | 99.64 | 99.32 | 99.09 | 98.94 |
| 5 | Fallow-smooth | 134 | 2544 | 98.54 | 98.47 | 98.43 | 98.43 |
| 6 | Stubble | 198 | 3761 | 99.77 | 99.28 | 99.31 | 99.34 |
| 7 | Celery | 179 | 3400 | 99.80 | 99.82 | 99.71 | 99.74 |
| 8 | Grapes-untrained | 564 | 10,707 | 84.38 | 86.79 | 89.33 | 89.93 |
| 9 | Soil-vinyard-develop | 310 | 5893 | 98.19 | 99.64 | 99.63 | 99.78 |
| 10 | Corn-senesced-green-weeds | 164 | 3114 | 97.99 | 96.82 | 97.11 | 97.69 |
| 11 | Lettuce-romaine-4wk | 53 | 1015 | 98.31 | 97.04 | 99.21 | 98.72 |
| 12 | Lettuce-romaine-5wk | 96 | 1831 | 99.74 | 99.73 | 99.89 | 99.89 |
| 13 | Lettuce-romaine-6wk | 46 | 870 | 98.69 | 98.74 | 98.16 | 98.51 |
| 14 | Lettuce-romaine-7wk | 54 | 1016 | 96.45 | 95.18 | 92.52 | 95.28 |
| 15 | Vinyard-untrained | 363 | 6905 | 60.66 | 63.50 | 71.06 | 70.33 |
| 16 | Vinyard-vertical-trellis | 90 | 1717 | 99.39 | 99.20 | 99.30 | 99.30 |
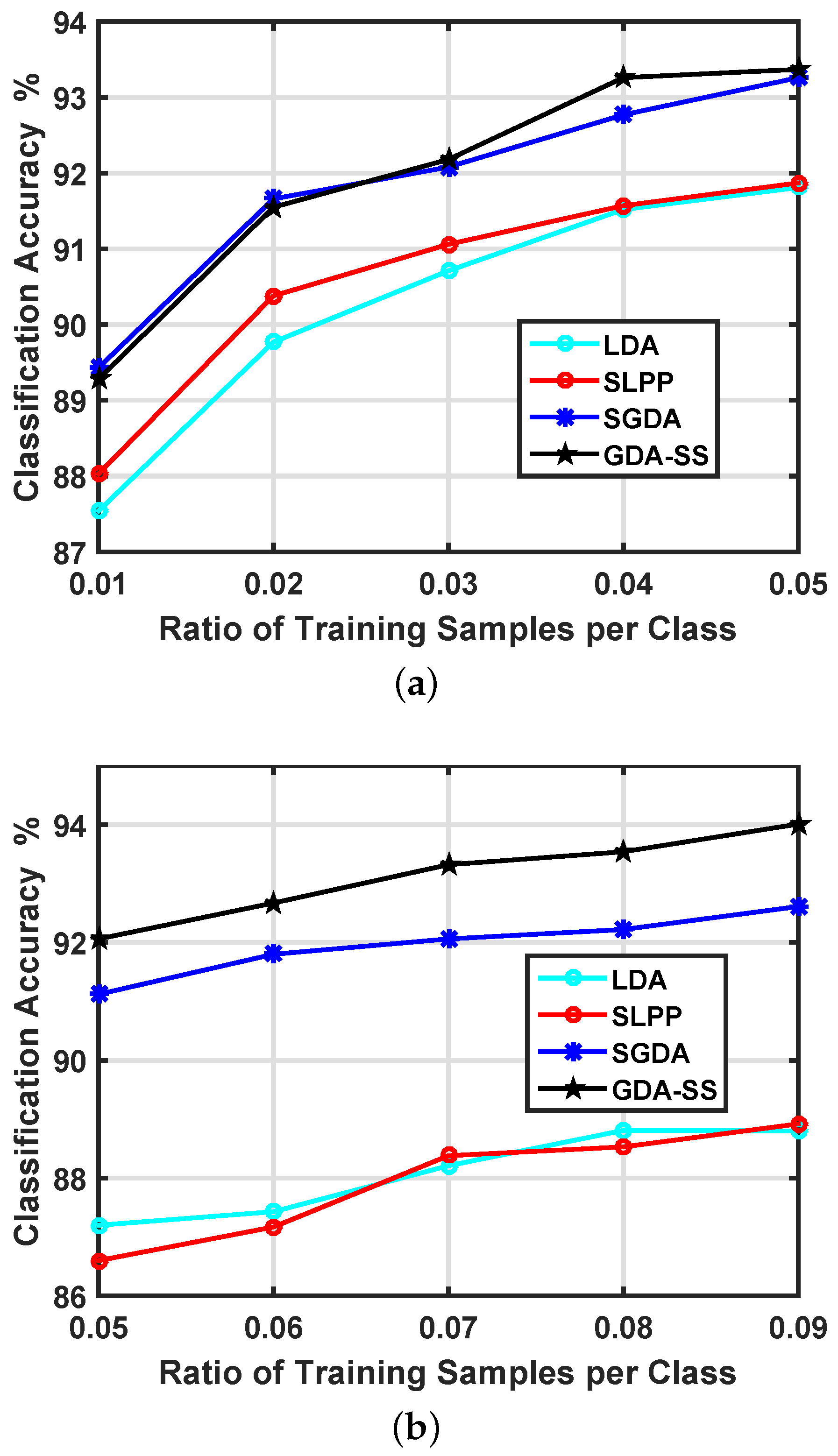
| OA | 90.85 | 91.94 | 93.26 | 93.40 | |||
| AA | 95.68 | 95.83 | 96.39 | 96.59 | |||
| Class | Train | Test | LDA | SLPP | SGDA | GDA-SS | |
|---|---|---|---|---|---|---|---|
| 1 | Asphalt | 530 | 6101 | 93.39 | 91.51 | 92.17 | 95.33 |
| 2 | Meadows | 1492 | 17,157 | 96.36 | 95.68 | 96.96 | 97.65 |
| 3 | Gravel | 168 | 1931 | 58.74 | 64.16 | 62.40 | 70.53 |
| 4 | Trees | 245 | 2819 | 90.86 | 90.49 | 94.08 | 93.33 |
| 5 | Painted Metal Sheets | 108 | 1237 | 99.48 | 99.60 | 99.76 | 99.84 |
| 6 | Bare Soil | 402 | 4627 | 78.99 | 76.92 | 88.48 | 92.33 |
| 7 | Bitumen | 106 | 1224 | 75.41 | 66.26 | 76.88 | 79.33 |
| 8 | Self-Blocking Bricks | 295 | 3387 | 86.11 | 82.70 | 87.95 | 91.23 |
| 9 | Shadows | 76 | 871 | 99.37 | 99.77 | 95.14 | 99.89 |
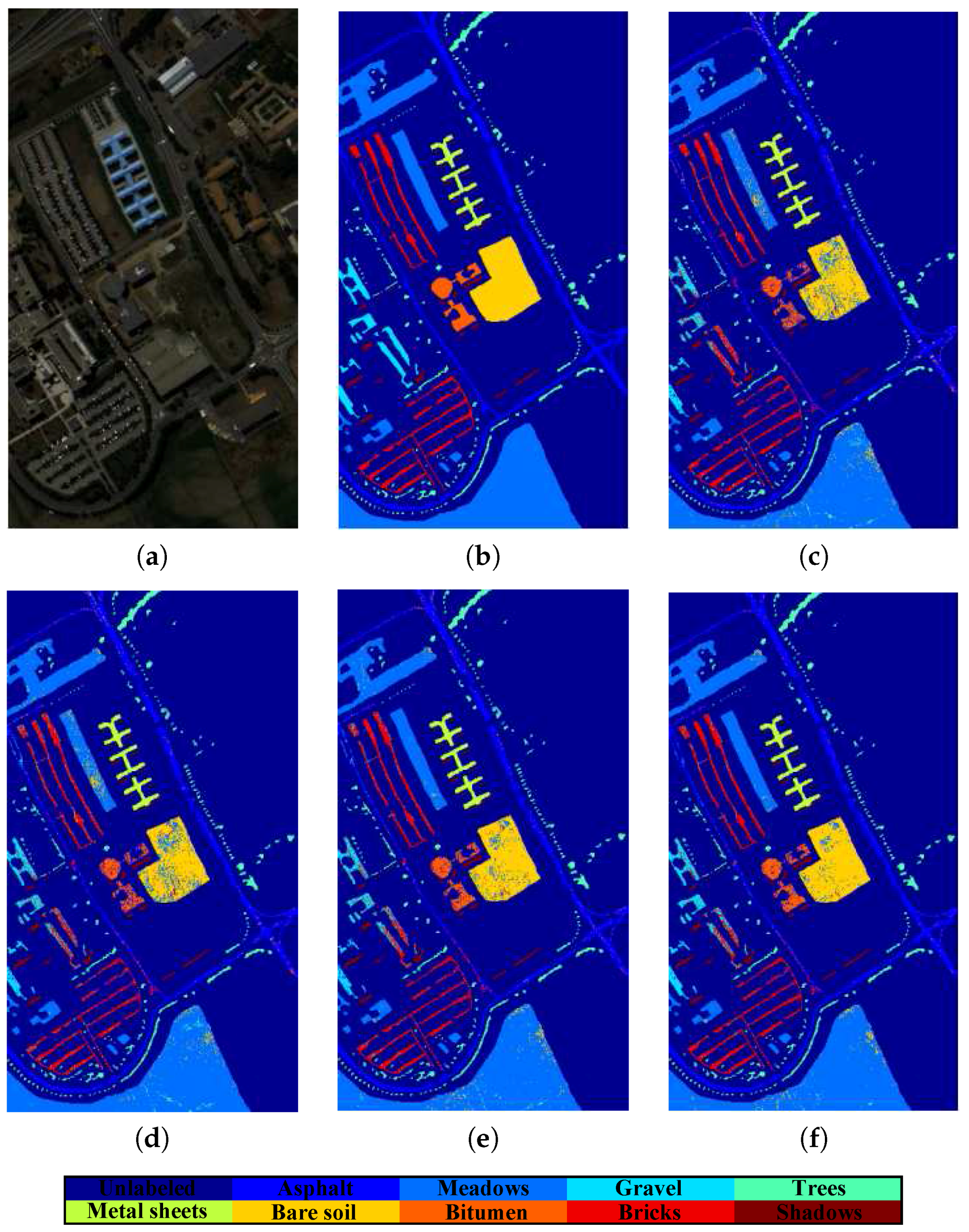
| OA | 90.51 | 89.09 | 92.56 | 94.02 | |||
| AA | 86.52 | 85.23 | 88.73 | 91.05 | |||
| Salinas Z/Significant? | University of Pavia Z/Significant? |
|---|---|
| GDA-SS vs. SGDA | |
| 4.91/yes | 12.33/yes |
| GDA-SS vs. SLPP | |
| 16.87/yes | 35.17/yes |
| GDA-SS vs. LDA | |
| 18.56/yes | 33.55/yes |
| Distance Datasets | Salinas | Univesity of Pavia |
|---|---|---|
| Proposed | 93.40 | 94.02 |
| Cosine | 91.92 | 91.13 |
| Jaccard | 92.01 | 90.83 |
| Correlation | 91.91 | 91.18 |
| Salinas | University of Pavia | |||||
|---|---|---|---|---|---|---|
| No Filter | Average Filter | Wavelet De-Noising | No Filter | Average Filter | Wavelet De-Noising | |
| GDA-SS | 93.40 | 93.41 | 93.40 | 94.02 | 94.08 | 94.05 |
| SGDA | 93.26 | 93.46 | 93.41 | 92.56 | 92.93 | 92.76 |
| SLPP | 91.94 | 91.95 | 91.74 | 89.09 | 89.08 | 89.02 |
| LDA | 90.85 | 92.24 | 92.24 | 90.51 | 89.51 | 89.59 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, F.; Li, W.; Du, Q.; Zhang, B. Dimensionality Reduction of Hyperspectral Image with Graph-Based Discriminant Analysis Considering Spectral Similarity. Remote Sens. 2017, 9, 323. https://doi.org/10.3390/rs9040323
Feng F, Li W, Du Q, Zhang B. Dimensionality Reduction of Hyperspectral Image with Graph-Based Discriminant Analysis Considering Spectral Similarity. Remote Sensing. 2017; 9(4):323. https://doi.org/10.3390/rs9040323
Chicago/Turabian StyleFeng, Fubiao, Wei Li, Qian Du, and Bing Zhang. 2017. "Dimensionality Reduction of Hyperspectral Image with Graph-Based Discriminant Analysis Considering Spectral Similarity" Remote Sensing 9, no. 4: 323. https://doi.org/10.3390/rs9040323
APA StyleFeng, F., Li, W., Du, Q., & Zhang, B. (2017). Dimensionality Reduction of Hyperspectral Image with Graph-Based Discriminant Analysis Considering Spectral Similarity. Remote Sensing, 9(4), 323. https://doi.org/10.3390/rs9040323