1. Introduction
The automated extraction and localisation of urban objects is an active field of research in photogrammetry with the focus on detailed representations. Building being a key urban object is indispensable to diverse applications in cartographic mapping, urban planning, civilian and military emergency responses, and the crisis management [
1,
2]. Accurate and updated information of the buildings is quite imperative to keep these applications operational. At a first glance, a building may appear to be a simple object that can be easily classified and extracted. However, in reality, automatic building extraction is quite challenging due to the differences in viewpoint, surrounding environment, and complex shape and size of the buildings. There have been several attempts to develop a fully autonomous system that can not only deal with occlusion, shadow, and vegetation but also identify objects with different geometric and radiometric characteristics from diverse and complex scenes.
In the past, some promising solutions used the interactive initialisation setup, followed by an automatic extraction procedure [
3]. However, this approach stood practical only if a trained human operator would make the initialisation and supervise the extraction process. Beginning with a single data type, either image [
4] or height data [
5], automatic building extraction has proven to be a non-trivial task [
6]. It can be considered as two interdependent tasks, detection and reconstruction [
7], where, arguably, the accuracy of later is subject to a reliable detection. However, both the tasks are challenging especially on complex scenes. Since today, the rule-based procedures have shown a success in achieving a certain level of automaticity [
8]. These rules are based on the expert knowledge and describe the appearance, dimension, and constraints on different features to distinguish urban objects. The methods in [
2,
9,
10,
11] are the few examples.
This paper concentrates on building detection and boundary regularisation using multisource data. We first discuss the related works in building detection paradigm and then cover the relevant literature on boundary regularisation. The development of very high resolution spaceborne images makes it possible to sense individual buildings in an urban scenario [
12], which is imperative in various reconstruction, cartographic, and crisis management applications. However, an increasing spectral and textural information in high-resolution imagery does not warrant a proportional increase in building detection accuracy [
9,
13], rather add to the spectral ambiguities [
14]. Consequently, objects of the same type may appear with different spectral signatures whereas different objects may appear to have similar spectral signatures under various background conditions [
15]. These factors together with the sensory noises reduce the building detection rate. Therefore, using the spectral information alone to differentiate these objects will eventually result in poor performance [
12].
On the other hand, Airborne Laser Scanning (ALS) data provide a height information of salient ground features, such as buildings, trees, bushes, terrain, and other 3D objects. Therefore, adopting height variation to distinguish these urban objects is a more suitable cue than the spectral and texture changes. However, the accuracy of the detected boundaries is often compromised due to the point cloud sparsity and hence, reduces the planimetric accuracy [
9,
15]. In addition, the appearance of trees and buildings sometimes appear similar under complex urban scenes [
10], where height information alone is hardly perceived to produce a finer classification [
13]. Therefore, several researchers have developed a consensus to use multisource data in designing better detection strategies to increase the building detection rate [
2,
9,
10,
15,
16].
Based on the processing strategy, building extraction methods are broadly divided into three categories [
2,
9,
17,
18]. The model-driven approaches estimate a building boundary by fitting input data to the adopted model from a predefined catalogue (e.g., flat, saddle,
etc.). Therefore, the final boundary is always topologically correct. However, the boundary of a complex building cannot be determined if the respective model is not present in the catalogue. For example, Zhou
et al. [
13] interpolated the Light Detection And Ranging (LiDAR) data and used image knowledge to extract urban houses and generated 3D building models while considering the steep discontinuities of the buildings. Similarly, another example is a geometric information-driven method [
19] that used aspect graphs containing features such as geometry, structures, and shapes for building identification and 3D representation. In contrast, the data-driven approaches pose no constraint on the building appearance and can approximate a building of any shape. A disadvantage of these methods is their susceptibility to the incompleteness and inaccuracy of the input data [
2], such as Awrangjeb and Fraser [
11], that clustered the similar surfaces based on the coplanarity feature using the non-ground LiDAR points and extracted the buildings. However, it suffers from under-segmentation issue because of the incompleteness of 3D points. The hybrid approaches, however, exhibit the characteristics of both model- and data-driven approaches, for example, Habib
et al. [
18] proposed a pipeline framework for automatic building identification and reconstruction using LiDAR data and aerial imagery. The segmentation of the buildings and the boundary generation were achieved through a data-driven approach using LiDAR point cloud, while rectangular primitives were fitted to reconstruct the object.
Despite the agreement to use multisource data, how to optimally combine the distinct features so that their weaknesses can be compensated effectively is a hot area of investigation. Haala [
20] classified the integrated data-driven methods into two categories. The methods reported in [
2,
9,
15,
21] used both ALS data and airborne imagery primarily for building extraction. The spatial features like Normalised Difference Vegetation Index (NDVI), entropy, and illumination were used to eliminate vegetation and overcome shadows and occlusion issues. Thus, detection rate and planimetric accuracy of the detected buildings were fairly high. Our proposed building detection method falls under this category. The method in [
2] primarily separated the LiDAR data to generate a building mask and later, used image features like NDVI and entropy for building extraction. Due to large height threshold of 2.5 m to avoid roadside furniture, bushes, and several low height objects, many small buildings (with area < 10 m
) were also missed. On the other hand, the methods in [
15,
22] generated a DSM from the first and last pulse return of the LiDAR data, which was used along with NDVI and spatial relationship between buildings and trees to complement the detection process.
The techniques in the second group use LiDAR as the primary cue for building detection and employ spatial features only to remove vegetation [
10,
23]. Consequently, such approaches undergo a poor horizontal accuracy of the detected buildings due to LiDAR point discontinuity. A method based on the Dempster–Shafer theory in [
10], classified LiDAR data into several groups representing buildings, trees, grassland, and bare soil. Finally, a morphology operation was performed to eliminate small segments requiring parameter tuning based on the estimation of wooded areas. This results in poor detection rate for the small buildings because of large area threshold (30 m
) and untrained Dempster–Shafer model [
24]. Xiao
et al. [
6] used edge, height information and a dense image matching technique to detect the façades in oblique images, which were represented as vertical planes to define the building hypotheses. The main disadvantage is that it fails to extract small buildings and simply ignores the building attachments and small structures in the backyards and in open areas. Rottensteiner [
10], after carrying out a comparative study, argues that a building extraction method generally fails to detect partially occluded buildings and often merges a tree standing close to them.
Qin and Fang [
14] first obtained an initial building mask hierarchically by considering the shadow and off-terrain objects. Later, a graph cut optimisation technique based on spectral and height similarity was used to refine the mask by exploring the connectivity between the building and non-building pixels. This method can handle shadows and small buildings to a good extent, but the building patches on steep slopes, roof parts under shadows and the roofs with vegetation cannot be extracted. Zhang
et al. [
12] proposed a dual morphology top-hat profile to overcome the spectral ambiguity using DSM and ultra-high-resolution image for feature classification. However, the accuracy of the DSM remains a critical factor in building extraction, particularly for small objects.
Chen
et al. [
15] proposed a hierarchical approach for building detection using normalised DSM (nDSM) and QuickBird imagery. The initial building segments were estimated by truncating both nDSM and NDVI, and final buildings were determined using region size and spatial relation between trees and buildings. Nevertheless, the success of this method is completely dependent on the quality of the nDSM, which is generally not available for many areas. Following the mask generation process in [
15], Grigillo
et al. [
25] eliminated the vegetation under shadows by truncating areas with low homogeneity. However, this method fails to address occlusion and works well when trees are isolated and produces inaccurate building boundary when surrounded by trees.
The following works give an outlook on boundary regularisation, which is a process outlining a building periphery with minimum possible lines. A polygon extraction method in [
26] determined a dominant direction of the building using the cross correlation mapping and later, used a rotating template and angle histogram to obtain a regularised boundary. Fu and Shan [
27] used three primitive models based on locating 2D rectangles to construct 3D polyhedral primitives followed by assembling the final buildings with right-angled corners. Ma [
28] categorised the lines into two perpendicular classes and carried out a weighted adjustment to calculate the azimuth of these classes using the Gauss-Markov model. Finally, the adjacent parallel lines were combined together to construct a regularised boundary. Sampath and Shan [
17] utilised a conditional hierarchical least squares method ensuring the lines participating in regularisation had the slopes of parallel lines equal or a product of the slopes of perpendicular lines was
(orthogonal). Similarly, the technique in [
29] forced boundary line segments to be either parallel or perpendicular to the dominant building orientation when appropriate and fitted the data without a constraint elsewhere. A compass line filter [
30], on the other hand, extracted straight lines from irregularly distributed 3D LiDAR points and constructed a boundary by topological relations between adjacent planar and local edge orientation. For building boundary extraction, Wei [
31] used the alpha-shape algorithm and applied a circumcircle regularisation approach to outline the rectangular buildings.
The literature on building extraction methodologies accentuate that success of the most existing detection methods relies on the quality of DEM and the accuracy of co-registration between the multisource data. They often impose constraints on several features such as height, area, and orientation to distinguish different urban objects and remove vegetation. These methods have been observed devoid of addressing the buildings which are small in size, under shadows or especially partly occluded. Furthermore, the building outlines produced by these data-driven approaches are generally ragged. Therefore, the set research objective of this study is to develop a method equally capable enough to (1) deal with a moderate misregistration between LiDAR point cloud data and orthoimagery; (2) identify the buildings which are partially occluded or under shadows; (3) extract the buildings as small as possible without affecting the larger ones; and finally (4) generate the regularised and well-delineated building boundaries.
The initial version of the proposed building detection approach is published in [
32]. Here, it is presented in more detail and extends the initial version in the following aspects. A comprehensive evaluation and analysis of a wide range of test data sets have been included. These data sets differ in scene complexity, vegetation, topography, building sizes, and LiDAR resolution (1 to 29 points/m
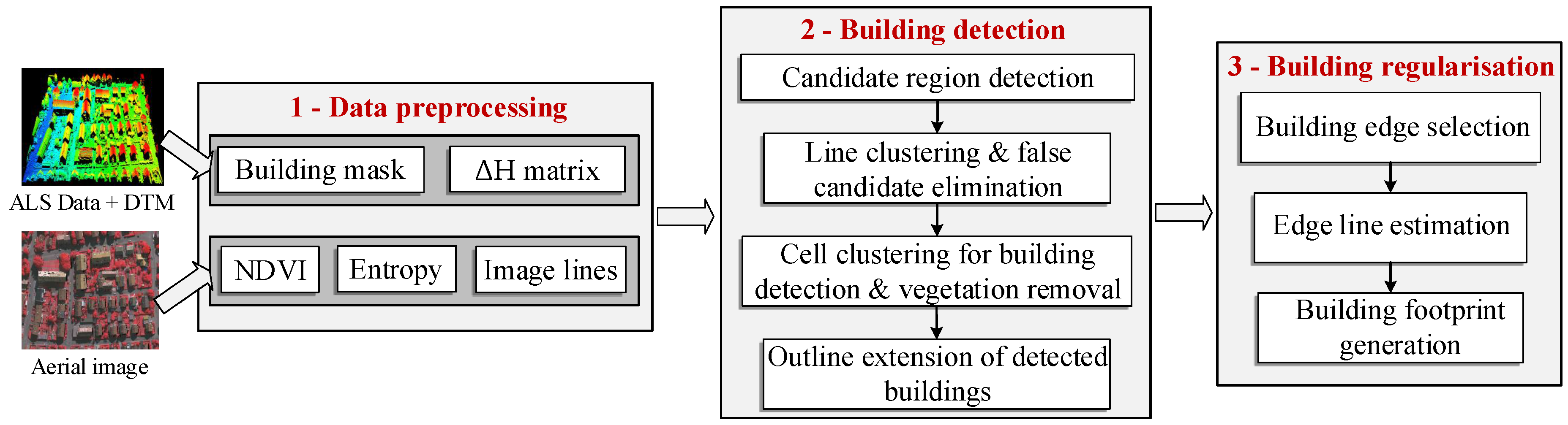
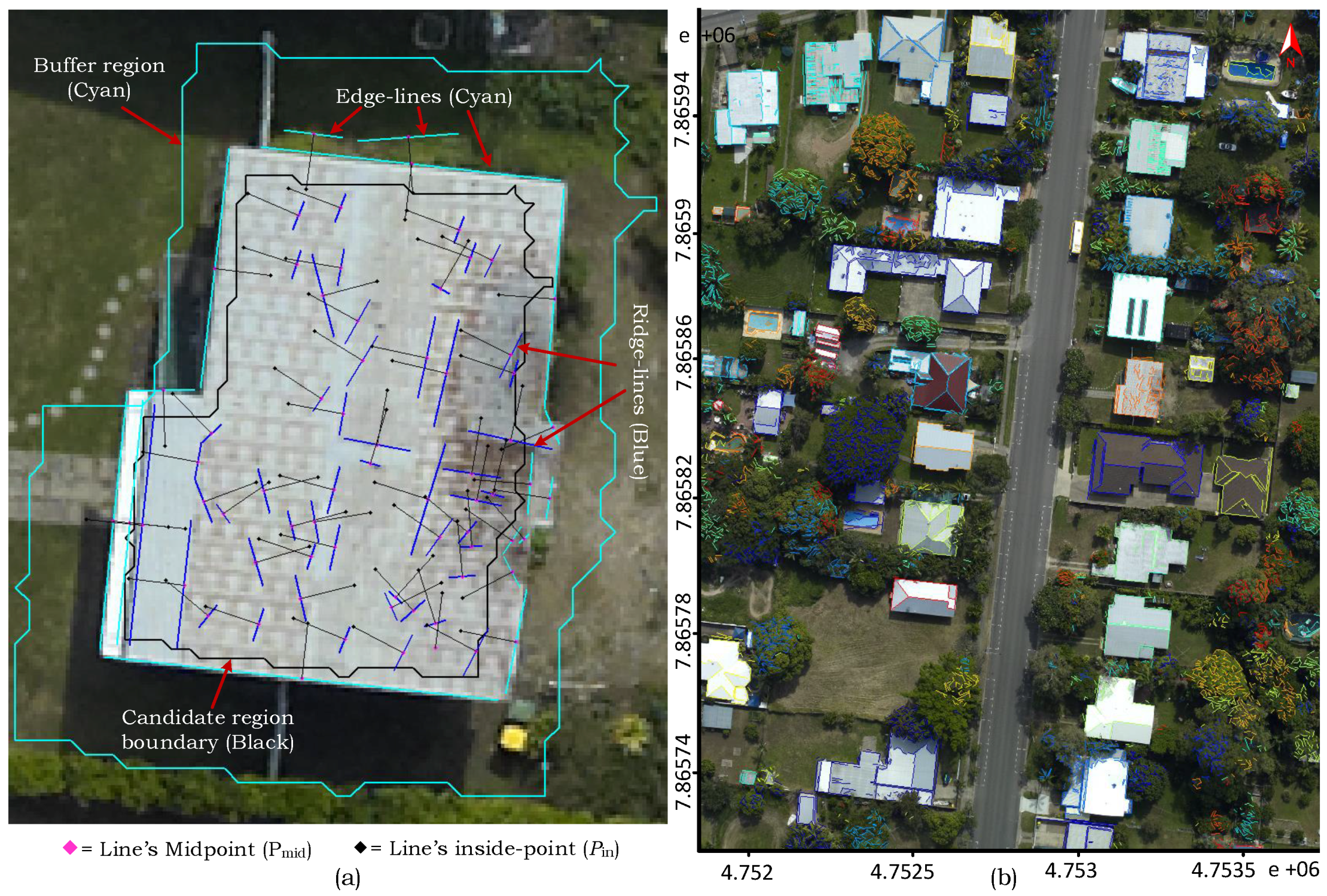
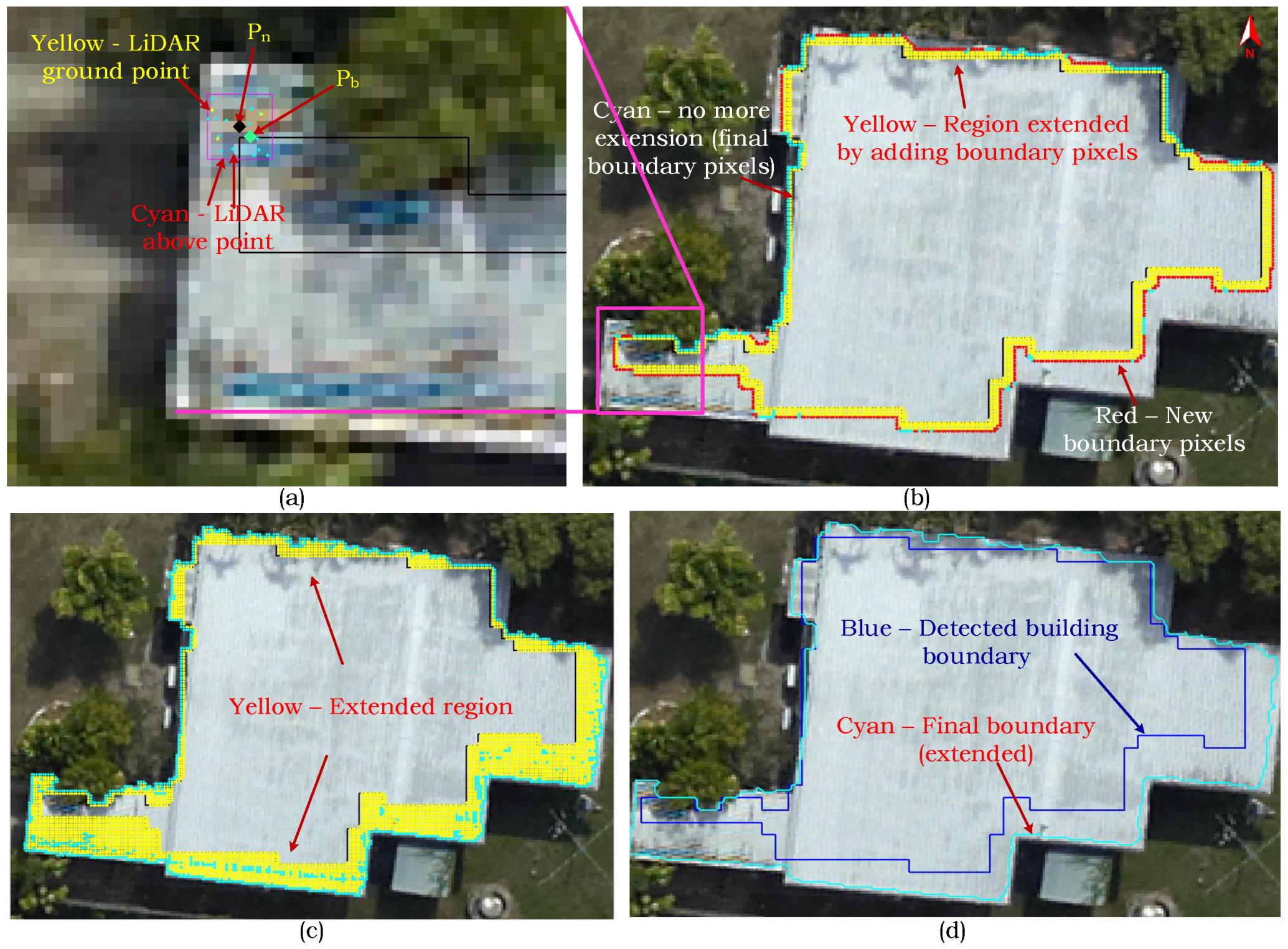
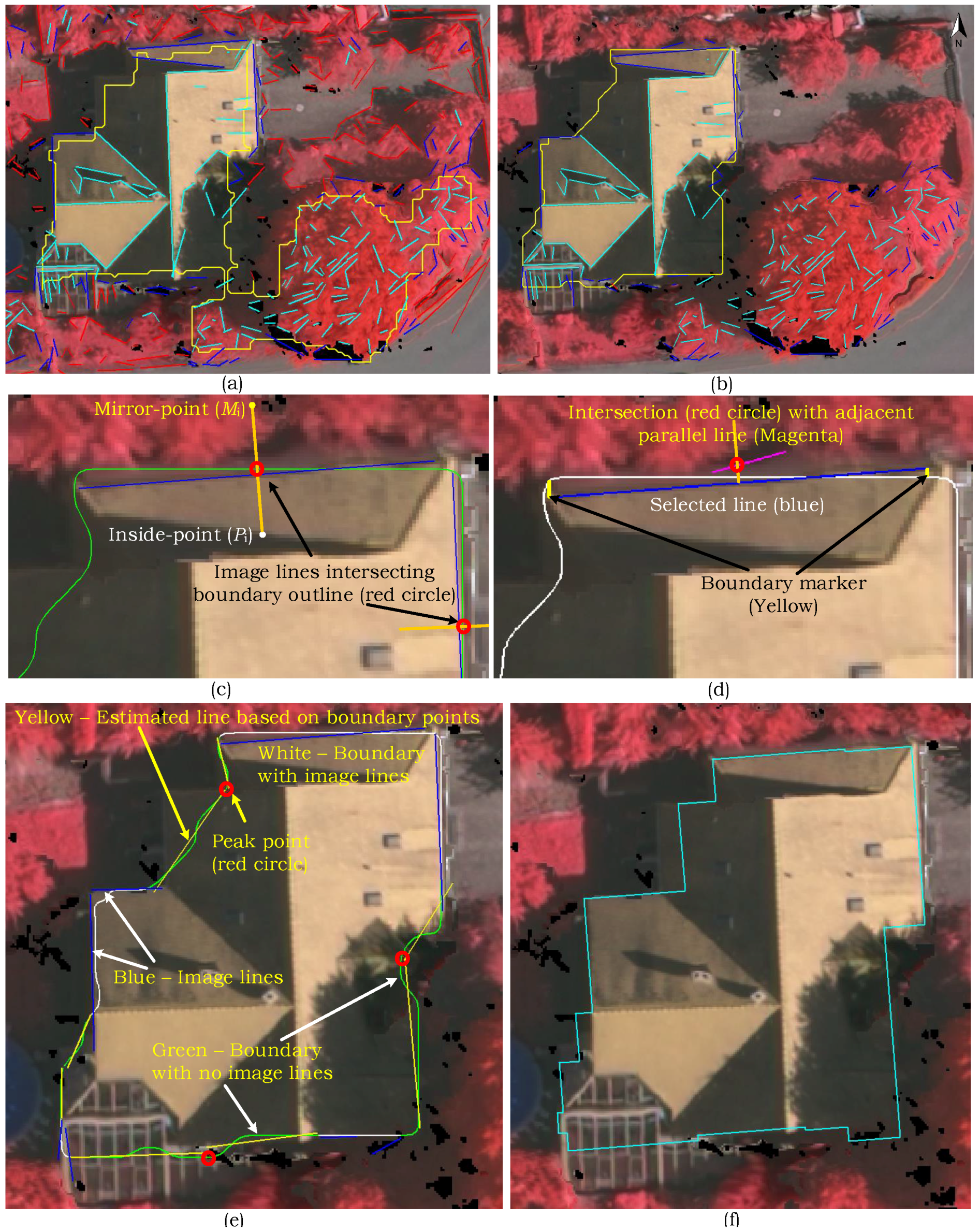
). We further incorporate LiDAR’s point density feature in different processes to make the proposed approach flexible and robust towards multiple data acquisition sources, e.g., airborne and mobile laser scanning systems. An adaptive local rather a global height threshold is utilised in one of the detection steps for fine delineation of the building boundaries. Moreover, a new boundary regularisation technique is also introduced which generates 2D building footprints using the spectral information (image lines) assuming buildings are rectilinear.
To meet the set objectives and evaluate rigorously, the proposed approach is tested using the ISPRS (German) and the Australian benchmark data sets. Compared to the ISPRS benchmark, the Australian data sets are found far complex and challenging due to hilly terrain (Eltham and Hobart), dense vegetation, shadows, occlusion, and low point density (1 point/m
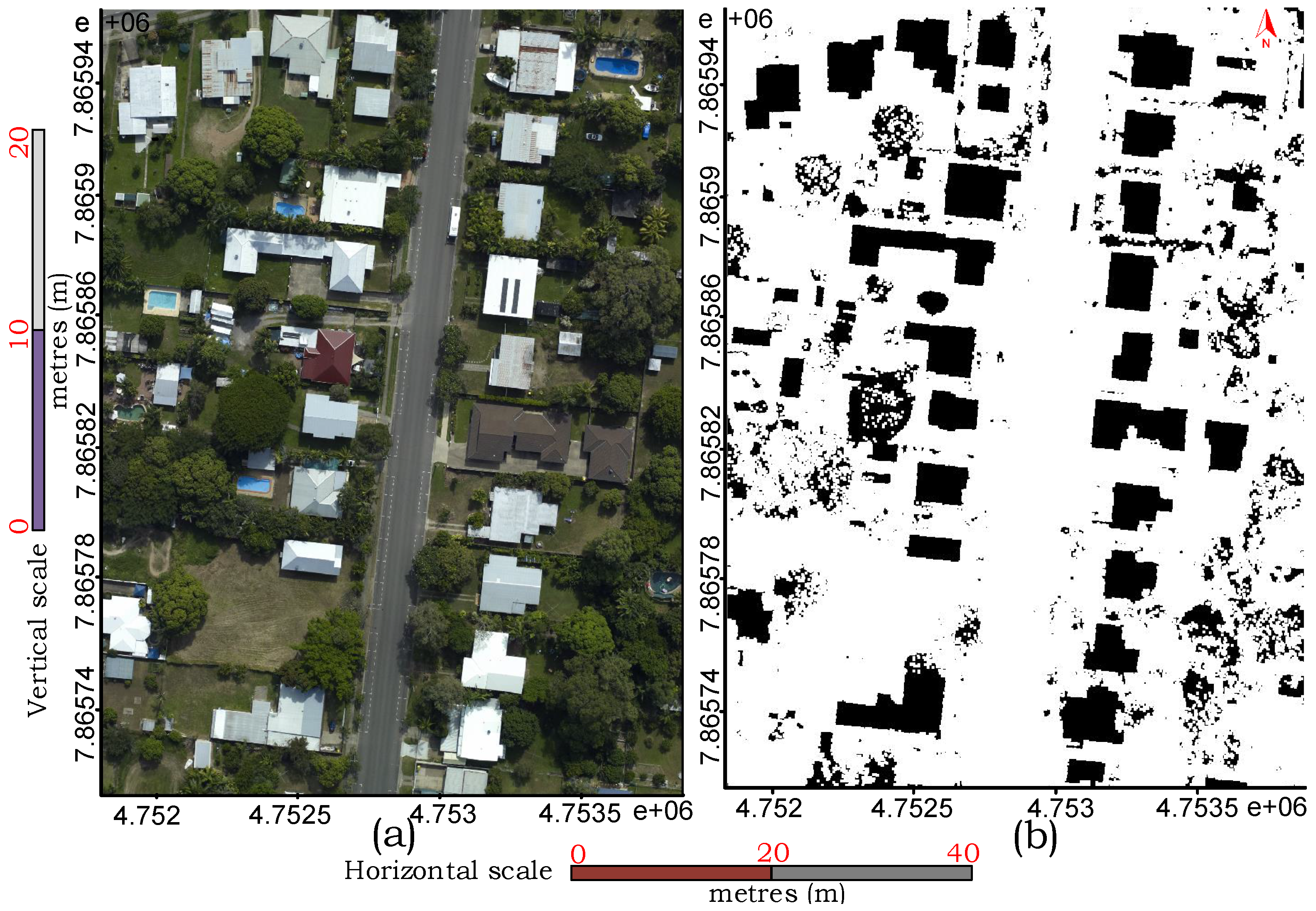
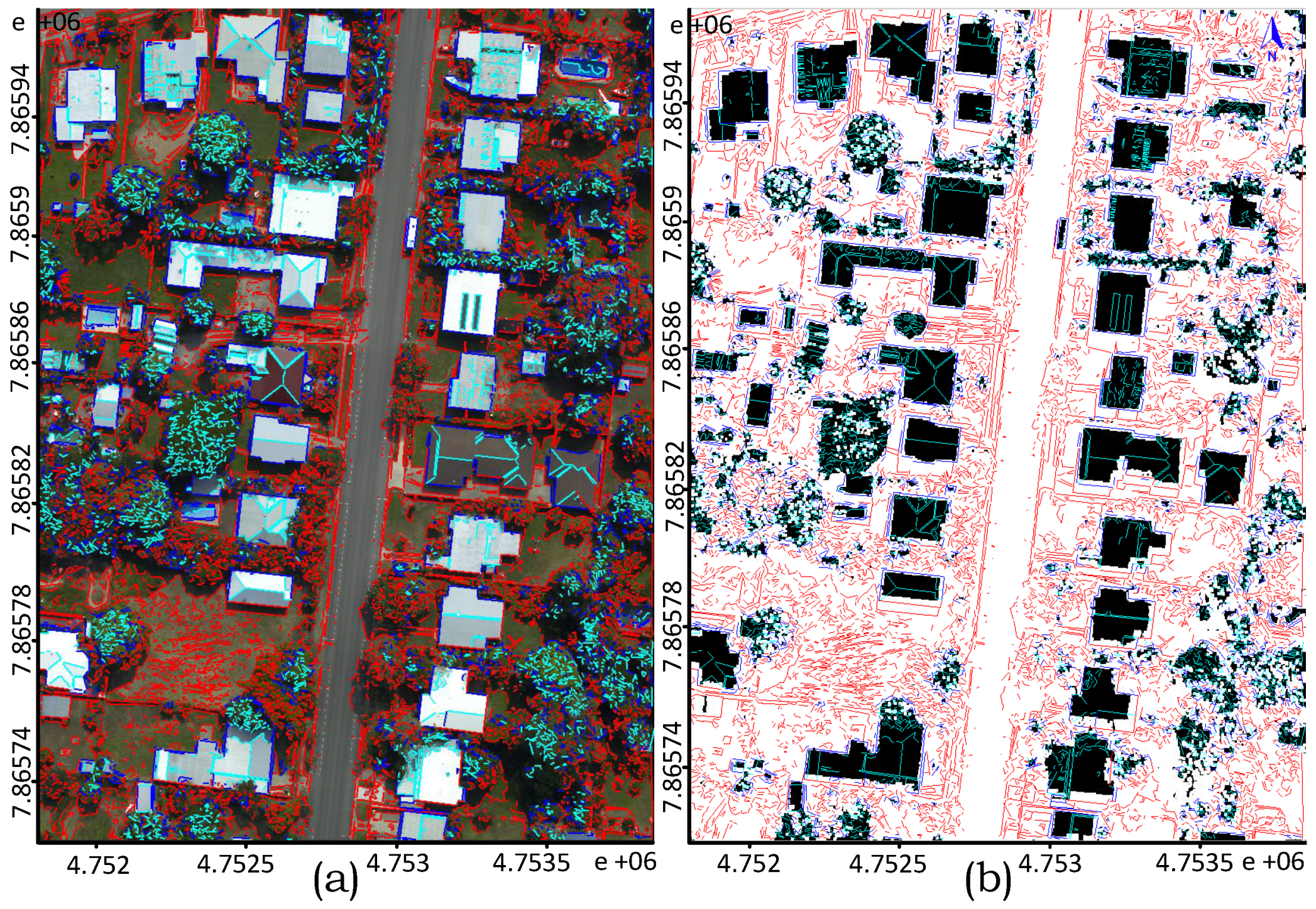
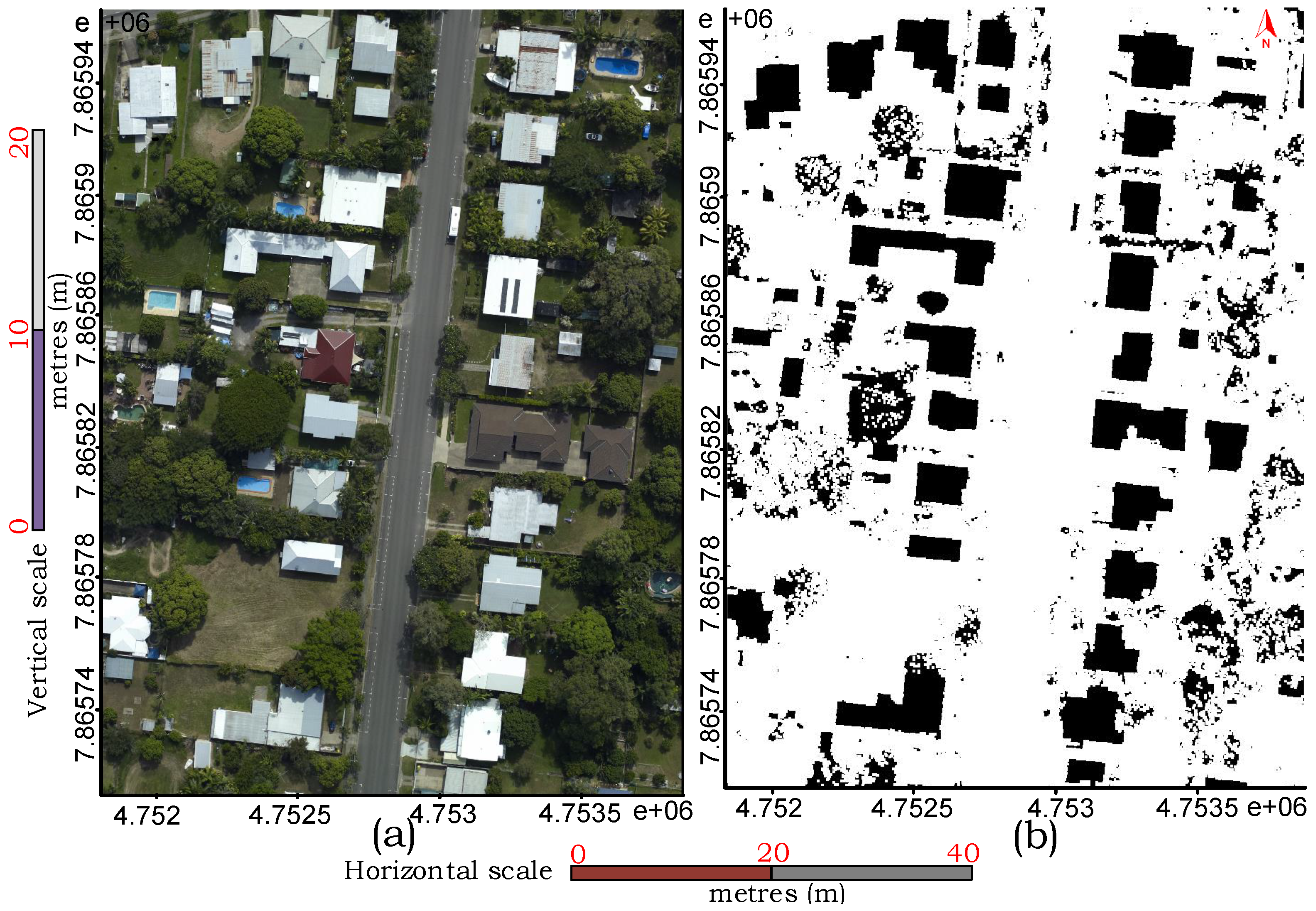
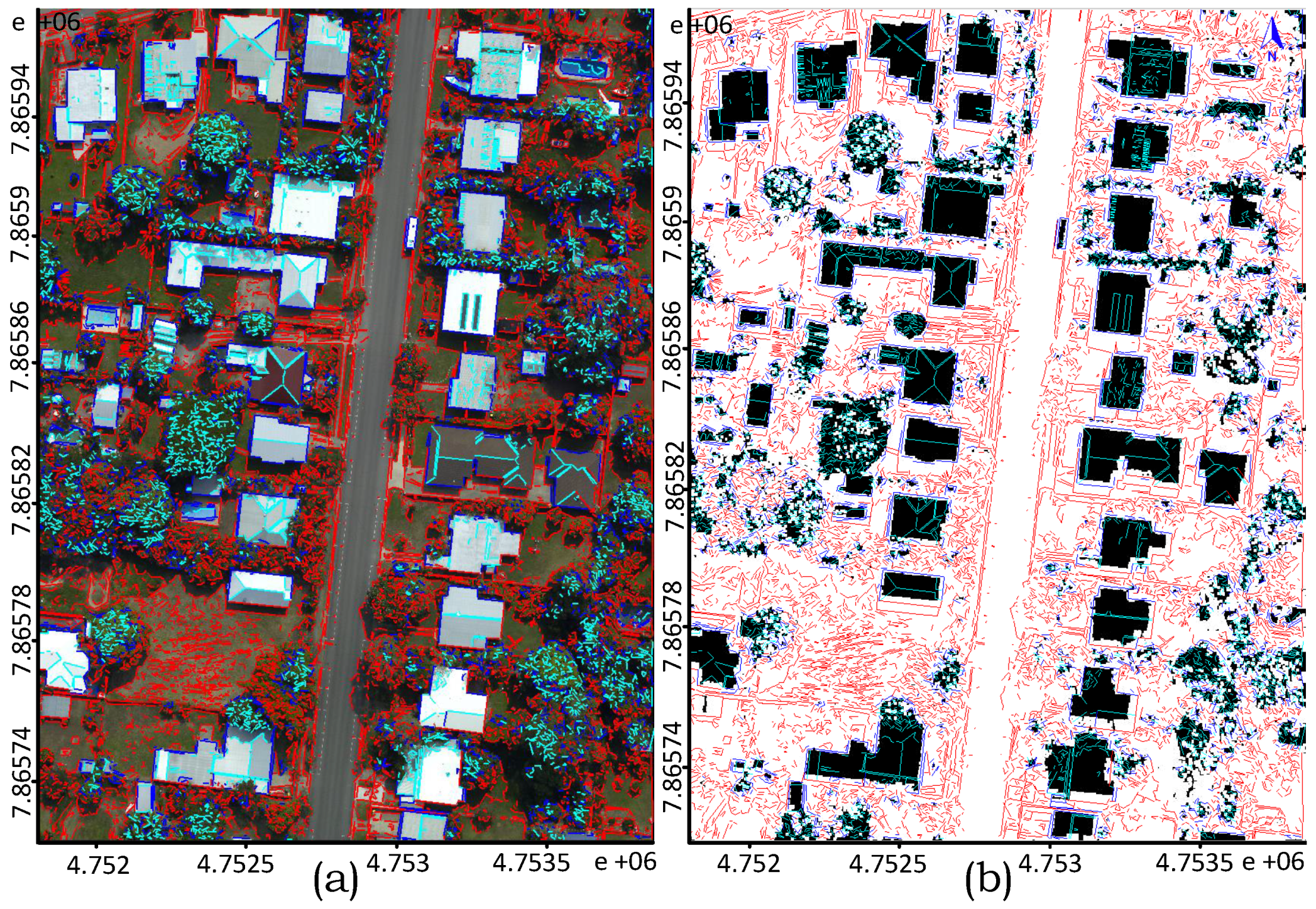
). Often, the buildings are covered with close by trees or shadows as described by real examples in
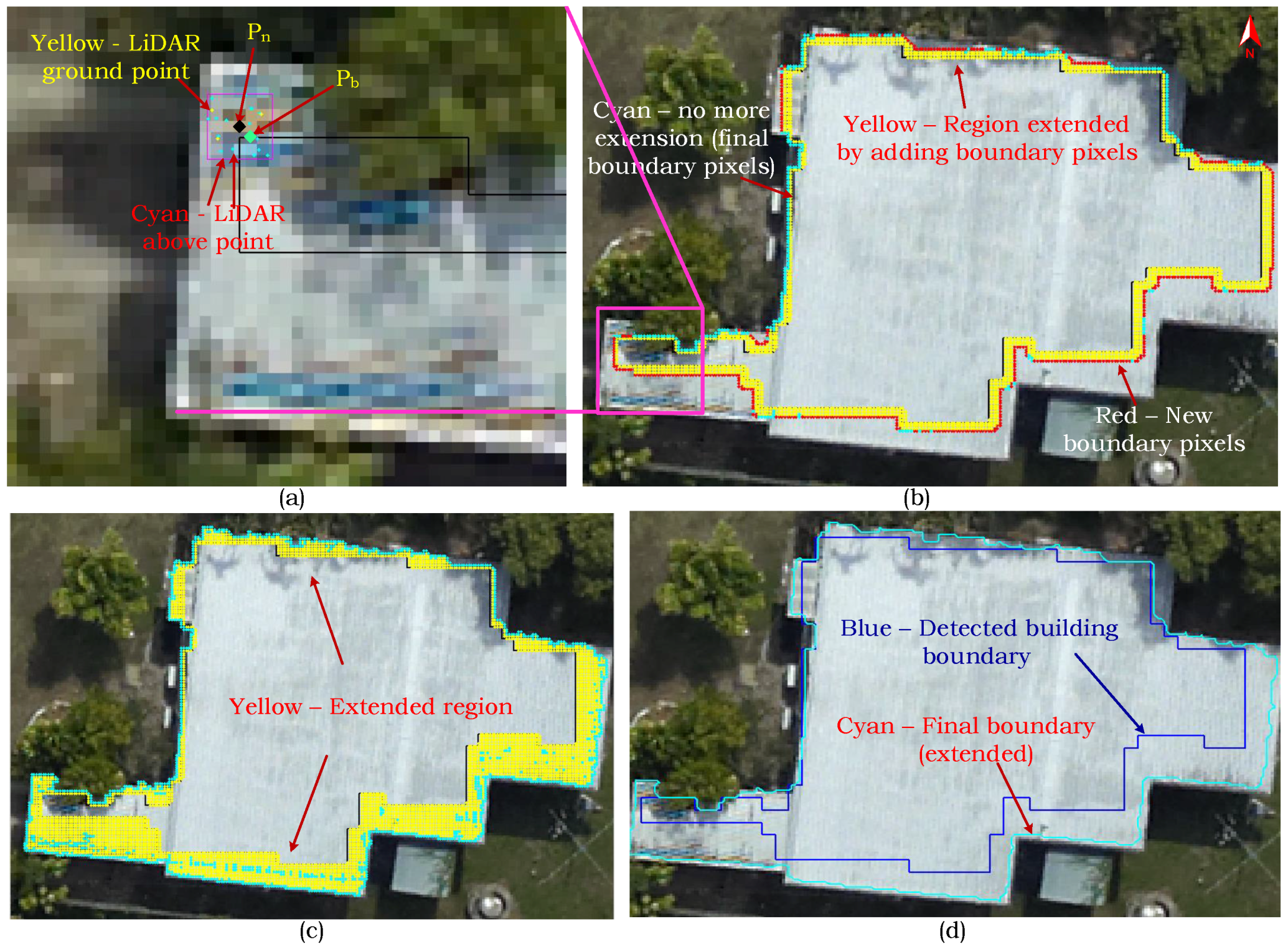
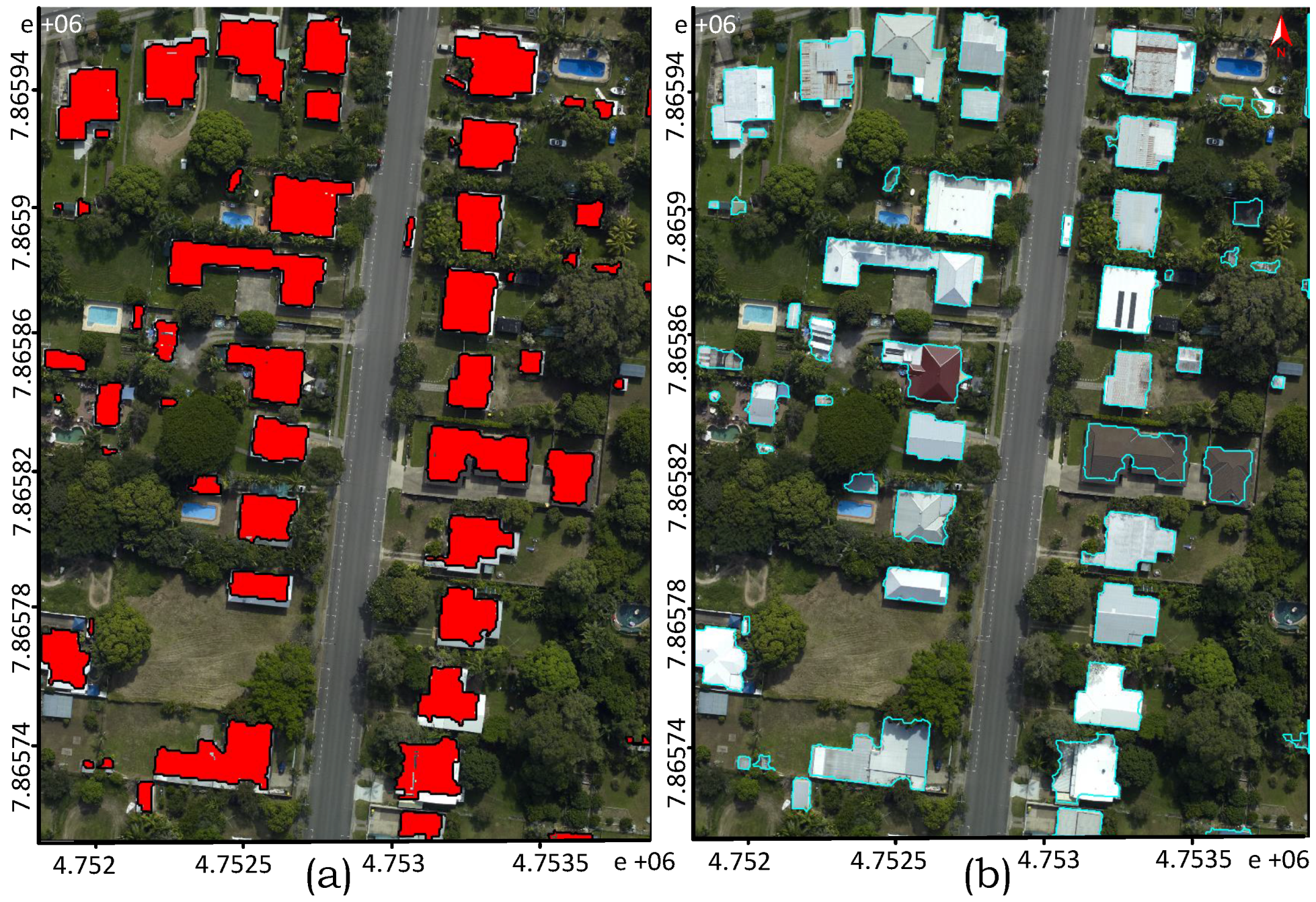
Figure 1. The evaluation study, particularly on the Australian data sets, demonstrates the robustness of the proposed technique in regularising boundary and separating partly occluded buildings from connected vegetation and detecting small buildings apart from the larger ones.
The rest of the paper is organised as follows:
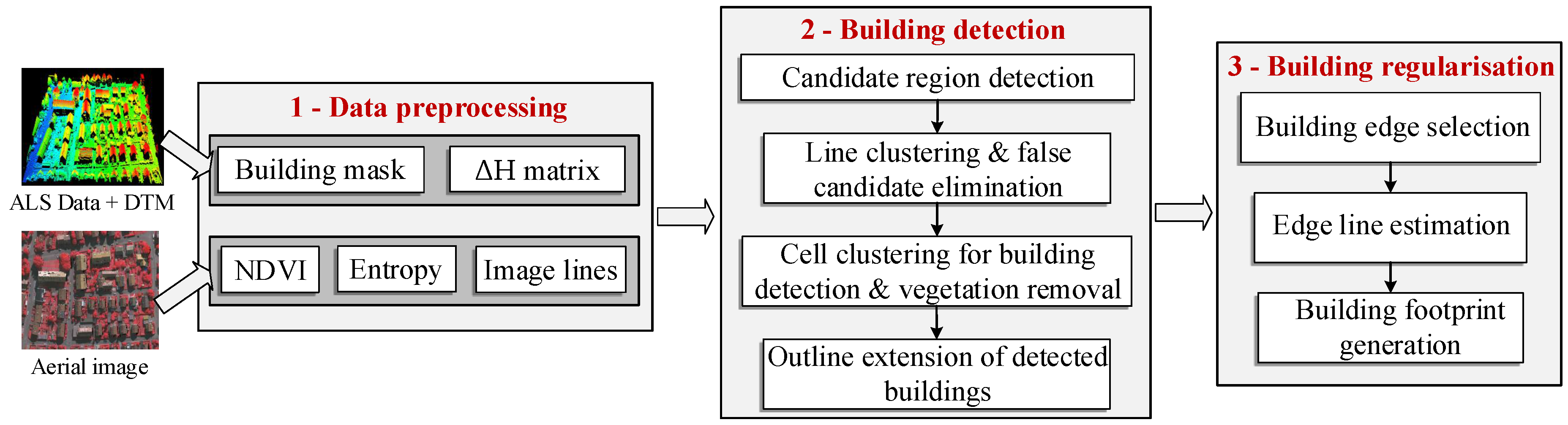
Section 2 details the proposed building detection and the boundary regularisation techniques.
Section 3 presents the performance study and discusses the experimental results using five test data sets followed by a comparative analysis. Finally,
Section 4 concludes the paper.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}