1. Introduction
Terrestrial laser scanners were first introduced about 15 years ago. Since then, they have been exploited in increasing numbers for a wide variety of research and mapping solutions, both in terrestrial (TLS) and mobile (MLS) laser scanning configurations. They are regularly applied in archaeology [
1], geology [
2], building modelling and reconstruction [
3,
4], outdoor object determination [
5], and outdoor mapping [
6]. TLS has also made a breakthrough in a wide variety of forestry applications, including both forest inventory and ecology applications (e.g., Dassot
et al.[
7] and references therein). More recently, MLS data combined with RGB information have also been utilized in individual tree species classification on ground level [
8].
At present, the properties of both laser ranging units and their supporting instrumentation have grown significantly from their earlier versions.
Table 1 illustrates the development of different contemporary laser scanning systems and also gives an overview of their general properties. More extensive scanner comparisons and descriptions can be found in detailed product surveys (e.g., by Lemmens [
9,
10]) and in laser scanning text books (e.g., Shan & Toth or Vosselman & Maas [
11,
12]). The table shows how laser scanner measurement frequencies and maximum ranges have increased steadily. Improved measurement capability also means that the dataset sizes have grown correspondingly as a result of higher number of points, better accuracy, and additional point information such as individual point intensities or their return numbers. Nevertheless, the raw computing power and data storage sizes have also increased along with the growing dataset sizes, thus compensating for the burden.
However, in cases where a scanner is on ground level and it scans over a wide solid angle around it, it is possible that the number of laser points may become locally higher than needed for analysis. Furthermore, the scanning geometry causes a large variance within the point cloud and makes algorithm parametrization difficult. For example, such scanning scenes are often located in forest environments where a scanner is surrounded with vegetation and other natural targets with irregular shapes. Local point densities can also be considered higher than required in the built environment if measurements are carried out to capture the general properties of the area, e.g., to determine object locations and their rough outlines, and when accurate object modelling is not the main priority. As point cloud processing performance is directly dependant on the available number of points, this means that a higher than required number of points is disadvantageous for data processing and therefore slows it down. The same holds for data storage: once the local point density reaches its application-specific limit, additional points will still require storage space without adding significant information to the analysis.
High number of points is mainly a problem with close-to-medium range TLS and MLS systems with wide scanning angles.
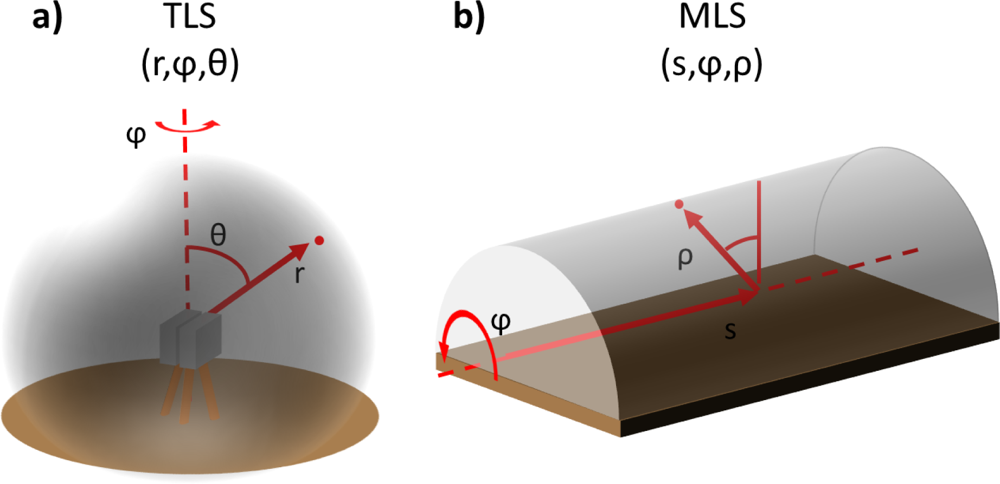
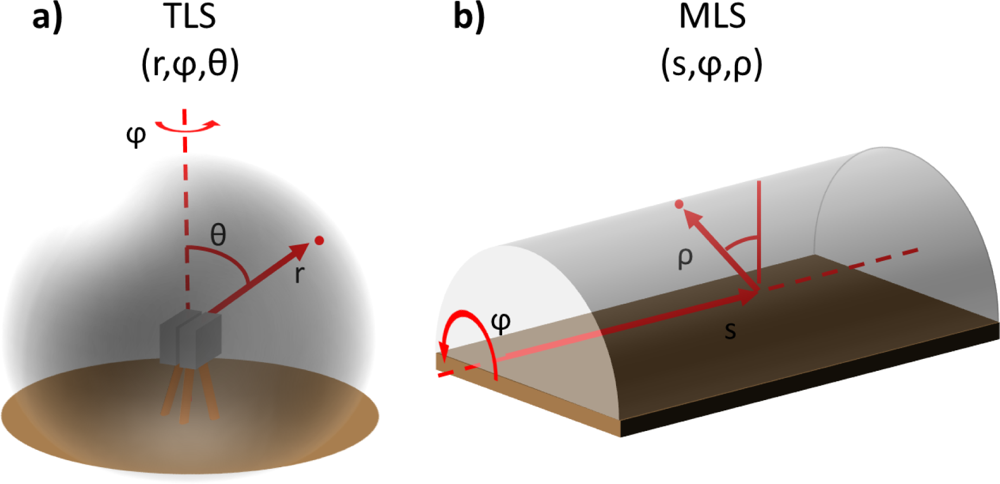
Figure 1 illustrates typical scanning geometries of a stationary terrestrial and a mobile laser scanning system. The terrestrial scanning geometry illustrated in
Figure 1(a) is a spherical one and it is collected with scanners that have two freely rotating axes. The mobile case in
Figure 1(b) demonstrates the scanning geometry of a fully rotating single laser scanner mounted on a moving vehicle. The scanning plane is typically circular or elliptical depending on the tilt of the scanner with respect to the axis of the trajectory. When the platform moves, the formed point cloud can be described as a helix or a cylinder depending on the platform direction and velocity. In both geometries, the structural properties of the scanner or the platform often limit available scanning angles to some extent.
Local point densities in the vicinity of both scanner types might rise over hundreds of thousands of points per square meter (e.g., see Litkey
et al.[
25]). This is because they both usually collect data with evenly spaced angular steps, resulting in a uniformly distributed point cloud representation with respect to scanning angles. However, since the scanners are located
within the study scene in both geometries, the ground and nearby objects cover a significant portion of the solid angle around the scanner. This leads to a significant variance in point density on target surfaces. The extent of the variance depends on the surface distance from the scanner.
In cases where all the measured data needs to be saved, one of the best approaches is to use memory efficient data formats. These take into account the special characteristics of the data and can thus save each point in a small space. Both commercial and openly accessible formats have been developed for this purpose. One of the most popular open formats for saving laser point data is the binary LAS [
26]. Furthermore, laser point clouds saved in LAS format can be packed further with proper encoding as Isenburg, and Mongus and Žalik have demonstrated [
27,
28]. The LAS format is mainly developed and used for saving airborne data, but it can be also utilized for the storage of TLS data. Recently, another data format, ASTM E57, has been introduced [
29]. The main aim of ASTM E57 is to store 3D imaging system data on a more general level. For this purpose, the format is designed to provide a flexible means for storing both laser point cloud and imagery data regardless of the scanner system.
Another space-saving approach is to compress 3D point cloud information using octrees [
30–
32]. Octrees divide the point cloud area into equally sized cubes, which are further divided into eight child cubes. The branching is continued until the maximum branching level, controlled by cube size and number of points within a cube, is reached. Octrees have been used in computer graphics for a long time to present volumetric data (
cf. [
30,
33] and their references). The branching structure and inherent neighbourhood information of octrees also allow fast access to data on point level.
If point removal is allowed, dataset sizes can be reduced in several ways, either during measurements or during data processing. During measurements, it is possible to limit scanning angles so that hits from the immediate vicinity of the scanner are excluded. However, hard thresholds remove all points from the excluded area, which may leave out important data. Hard thresholding also causes discontinuities, which may cause additional problems if data are used for interpolation, fitting, or when the dataset is georeferenced with other datasets.
Another method for reducing data during measurements is to set a suitable scanning resolution. When the targets of interest are scanned from a distance, the possible overlap between neighbouring laser points increases. This happens because the laser footprint increases as a function of distance due to laser beam divergence, but the sampling interval remains constant. This effect becomes important and should be tested for if the scanning is performed from a distance, and especially with limited fields of view. Detailed discussion of laser footprint sizes and test cases can be found in articles by Lichti and Jamtsho and by Pesci
et al.[
34,
35]. In this paper, possible point overlap effects were not accounted for in data analysis as all range distances were relatively short,
i.e., within 30 m, to the scanners.
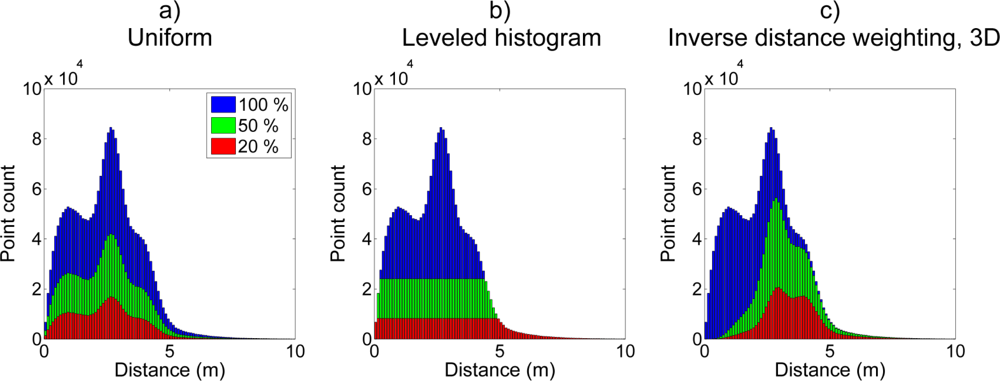
During processing, dataset size reduction can be achieved by sampling the point cloud with a suitable filtering algorithm. A straightforward way to perform this is to take a uniform sample of the data. However, point densities in the previously mentioned TLS and MLS scanning geometries have strong distance dependency and they drop rapidly when the distance to the scanner increases. In other terms, if one creates a distance distribution of all point distances to the scanner, it will have a dominant peak at close range. When the point cloud is sampled uniformly, then the distance distribution of the sampled point cloud resembles the shape of the full data distribution.
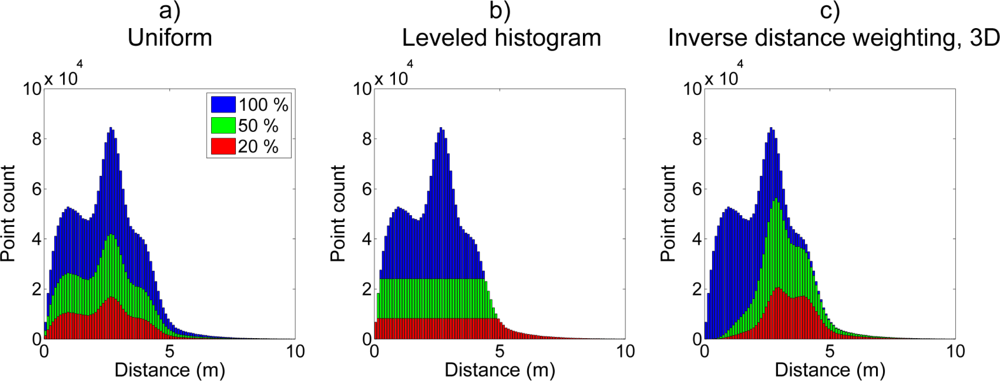
Figure 2(a) illustrates this with a synthetic example. As the distance distribution shape is retained, it means that point densities drop by the same amount in all distances. Therefore, the high density parts of the point cloud will still have the most points. However, lower point densities, in general, mean that the effective range for detecting objects of interest decreases. This decreases the usability of uniform sampling as the loss of effective scanning range requires that additional measurements and data registrations have to be carried out.
In addition to the straightforward hard thresholding and uniform point sampling, various other computational techniques have been developed to reduce point cloud sizes. These include: utilization of local geometry representations to search for and remove redundant points from object surfaces [
36]; projections of rigid and adaptive grids on object surfaces [
37]; point cloud measure-direction equalization with the use of sensor characteristics [
38]; and range-dependent median filtering along 2D scan lines [
39]. The first two techniques utilize point-to-point or neighbouring point distances in analysis, which allows high quality object sampling but is computationally heavy. The third technique samples the whole point cloud. The fourth technique uses the median values of consecutively measured points along each scan line, making it very fast.
In this paper, the main aims are to present two sampling methods and to test their efficiency for improving data utilization. The sampling methods use point cloud distance distributions of the whole point cloud to reduce data size. The methods are quick to perform and they require only a little prior knowledge of the scanned area and the scanning configuration. Method efficiency is evaluated in three separate case studies in which data were collected with a different laser scanning system in each case. The paper focuses on the sampling methods and how they affect data processing. Therefore, the case studies were selected from earlier experiments to utilize known processing algorithms and their results. This approach also allows us to inspect how the processing algorithms are affected by different sampling methods. In addition, the paper also aims to: (i) discuss the differences detected between the results in the case studies; and (ii) suggest possible improvements for future research.
The rest of the paper is structured as follows: first, the sampling methods and their references are described; second, results from three separate case studies are presented and reviewed; and third, the studies and their results are summarized.
2. Sampling Method Descriptions
This section presents the algorithms of the two reference and the two range-based sampling methods. To guarantee result comparability between the methods in each case study, the following laser point selection rules were applied in all cases. The first rule was that a single laser point could be picked only once in each subsample. The second rule was that the size of each subsample, within rounding limits, had to be preserved. This meant that if the wanted number of laser points were not available in a selected part of a distance distribution, the remaining points were picked from other parts of the distribution.
2.2. Leveled Histogram Sampling
The leveled histogram sampling, referred as “lh” in the text, aims to collect scanned points evenly from all distances. Resulting histogram shapes with 20% and 50% sampling ratios are illustrated in the center of
Figure 2. As
Figure 2(b) shows, the resulting sampling distribution is artificially flat. This sampling method is based on the assumption that all parts of a point cloud distribution are likely to carry information in them even if their total number of points is low. On the other hand, distribution parts with a very high point count are likely to have excessive points that do not add to the information content. Therefore, part of them can be removed with no significant effect on the analysis result. The point selection in high density parts of the distribution is performed uniformly as individual points are not assumed to have critical information in them.
The algorithm requires two control parameters, the sample size and histogram bin width. The sampling algorithm is as follows:
Calculate a histogram with even-width bins from point cloud data with Nb bins and calculate the number of the sample points Snb in each bin so that
.
Select all points located in bins with less than Snb points in them and deduct their number from the Sn. Calculate the number of possible excess points, Nex, so that
, where Sbin;i is the number of points in a bin with less than Snb points and the l is the index of all such bins.
Divide the excess number of points evenly into the remaining bins so that Snb(2) = Snb(1) + Nex(1), where the number in parenthesis is the iteration step count.
Repeat steps 2 and 3 until all remaining bins have more than Snb(m) points, where m is the total number of iterations.
Select Snb(m) random points from each remaining bin so that the sum of all selected points totals Sn.
2.3. Inversely Weighted Distance Sampling, Two and Three Dimensional Cases
Inversely weighted distance sampling draws its idea from spherical volume point picking (e.g., in [
40]), but uses it in an inverted way. Instead of generating uniformly distributed random points within a space, random numbers are generated and range-weighted inversely to pick individual points randomly from the point cloud. Inverse weights are set for points based on the assumed point cloud distribution. Here, uniform point cloud distributions within a disk and within a sphere were assumed corresponding to a two- and three-dimensional case, respectively. The cases are labeled as “s2d” and “s3d” in the text. The point weighting was carried out by determining a point rank number as:
Pr = ⌊
Stot ×
U1/d⌋ + 1, where
Stot is the total number of points,
U is a uniformly distributed random number (0 <
U ≤ 1),
d is the selected dimension, and the brackets mark the floor function. The selection algorithm is as follows:
Sort every point in the point cloud according to their distance (2D or 3D) from the scanner.
Generate a uniformly distributed random number (U) and weight it inversely to calculate a weighted random point rank number (Pr).
Select the point with the corresponding rank number, move it to a selected point list, and update the remaining point list.
Repeat steps 2 and 3 until Sn points are picked.
Figure 2(c) shows how the resulting distribution of the sampled (a 3D case) point cloud is heavily weighted on the distant side of the distribution, while the number of points close to the scanner is reduced significantly.
3. Evaluation of Sampling Methods in Three Case Studies
To evaluate the performances of the different sampling methods, they were tested in three separate case studies. The case studies were reference target detection from a TLS dataset, pole-like object detection from an MLS dataset, and wall detection from another MLS dataset. The case studies were selected to represent a variety of different laser scanning applications and configurations as this allowed to study how the sampling methods, different scanning geometries, environments, and data collection techniques affect together the full data processing chain.
In each case study, a dataset was first collected with a different TLS or MLS platform. After possible pre-processing steps, new datasets were created by sampling the full dataset with each sampling method and with several sampling ratios each. Then, the new datasets were processed with a case study specific algorithm. The algorithm parametrization was kept constant in each run. This approach was chosen to limit changes in results and processing times only on the effects depending on sampling ratios and point cloud selection methods. Finally, the results and processing times obtained with different sampling methods and ratios were compared against those obtained with the full point cloud. All sampling and analysis were carried out with MATLAB (MathWorks Inc., Natick, MA, USA).
The method performance was evaluated with two main criteria. The first evaluation criterion was the preservation of the full-data result obtained with a case study specific algorithm. Ideally, a good sampling method would result in data subsamples whose properties remain close to those of the full data as long as possible when the sampling ratio is lowered. This would imply that the sampling method is successfully reducing points from high density areas while preserving the information content of the others. The second criterion was the change in the total processing time, including the time spent in sampling. The results for both criteria are reported with respect to the full data results in each case study.
3.1. Case Study I: Spherical Reference Target Detection in a Forest Environment from TLS Data
3.1.1. Study Object and Reference Target Detection Description
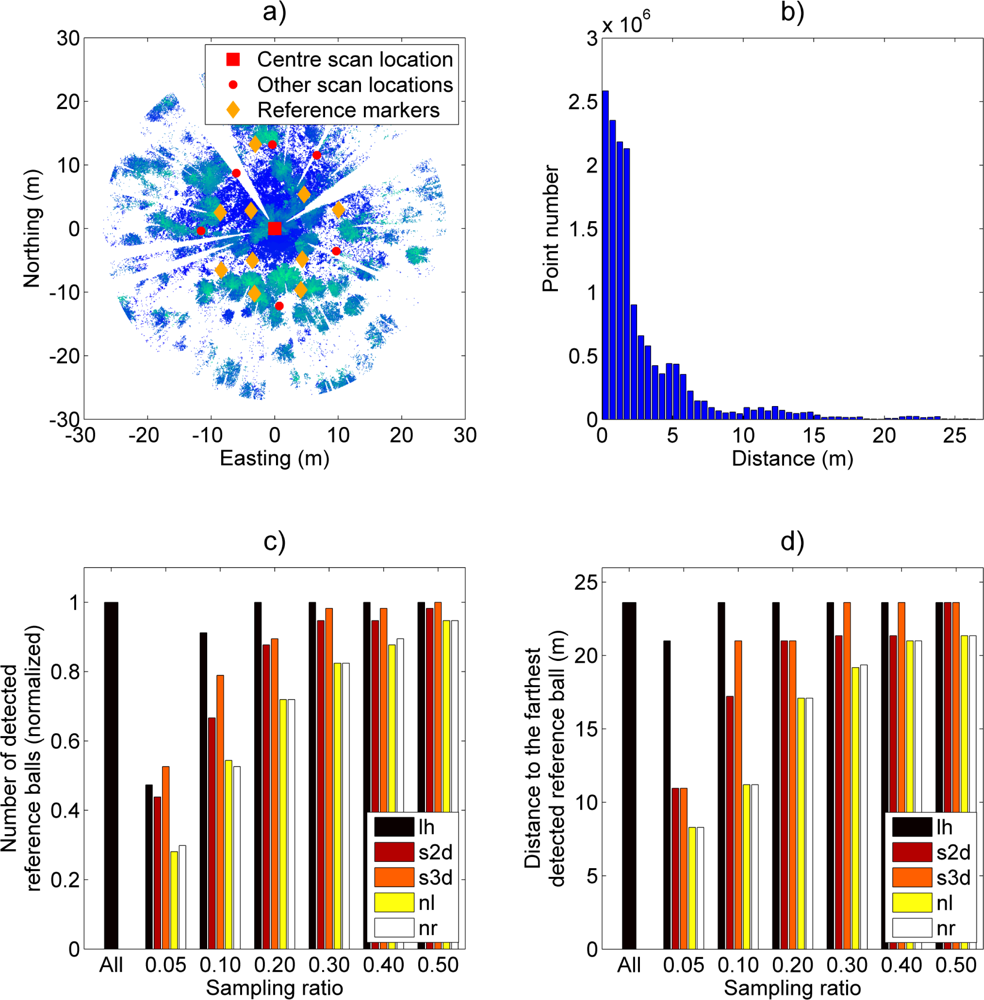
The objective of Case Study I was to determine the maximum range in which a spherical reference target could be detected and how sampling with different methods affects the maximum detection range. The study was carried out by planting 10 high reflectance reference spheres in a forest plot area. The diameter of a single reference sphere was 145 mm. Reference targets are used in terrestrial scanning to register different scans (i.e., to align them) with the reference coordinate frame and with each other.
Reference target detection was determined by counting the number of hits on them. Outlines of the targets were manually set using full point cloud. At least 30 hits were required to guarantee a reliable detection of a reference sphere with low spatial uncertainty. The farthest sphere-scanner distance was 25.8 m, which was within the theoretical detection range of 43.7 m. To guarantee possible detection of all reference spheres, a 27.0 m horizontal threshold range was set around each scanner. As all spheres were within the theoretical detection distance, the maximum number of visible reference spheres was 70 if each sphere would have been visible to every scanning location. However, all spheres were not visible to every scanner location due to occlusions within the plot.
3.1.2. Data and Measurement Descriptions
Data for Case Study I consisted of seven TLS point clouds. Scans were taken from a single forest plot in May 2010 in Evo, Finland. One scan was performed in the middle of the plot and the other six scans were measured from the edges of the plot, between 10 and 14 m from the plot center, with 60 degree spacing. A Leica HDS6100 (Leica Geosystems AG, Switzerland) terrestrial laser scanner was used for the measurements. The scanner transmits a continuous laser beam (wavelength 650–690 nm) and determines distance based on the detected phase difference. The maximum measurement range of the scanner was 79 m. The distance measurement accuracy is 2–3 mm up to 25 m. The field-of-view (FOV) of the scanner is 360° × 310°. The transmitted beam is circular and it has a 3 mm diameter at the exit. The beam divergence is 0.22 mrad. The used measurement resolution produces 43.6 M (million) laser points in the FOV, and the point spacing is 6.3 mm at a distance of 10 m. Each scan consisted of approximately 31.5 M points after pre-filtering. All scans were pre-filtered with a default filter included in the scanner import software, Leica Cyclone, before sampling. The filter removes points with low intensity, downward angle, and range, as well as points that are near an object egde (mixed) or isolated.
3.1.3. Sampling Results
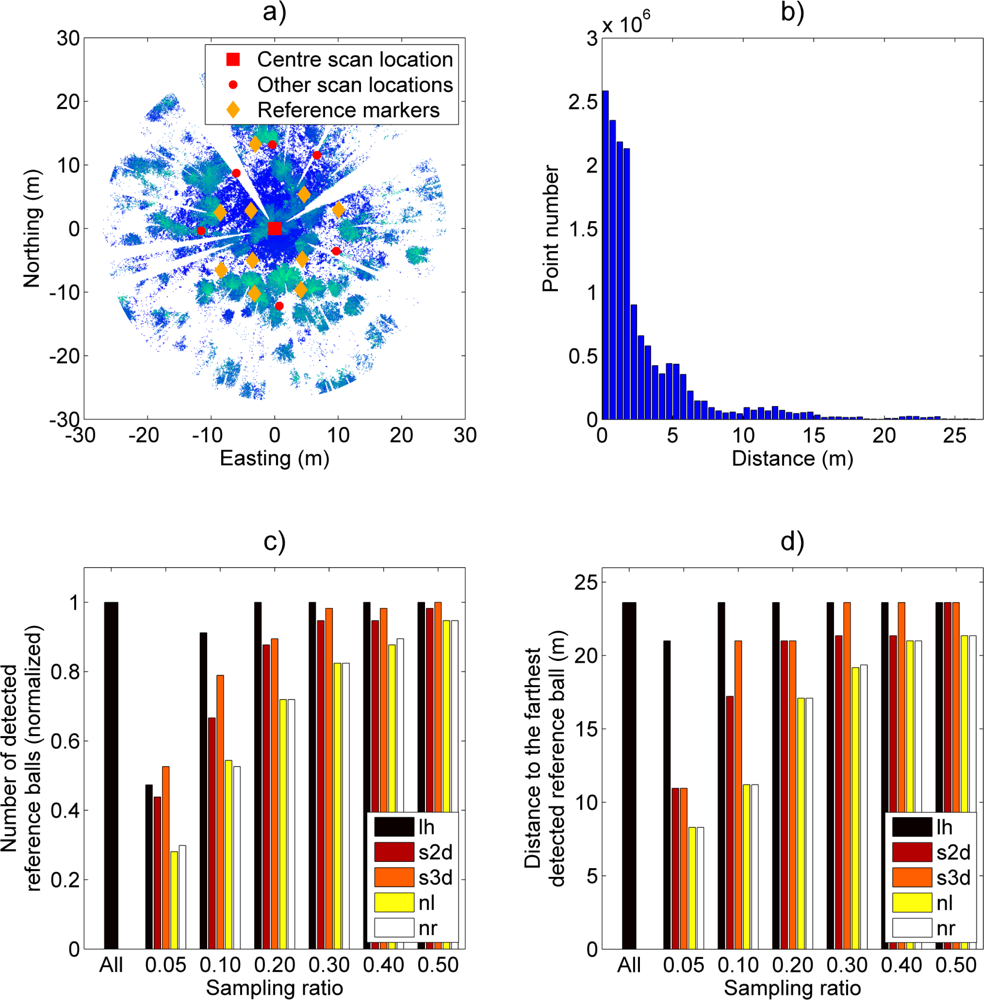
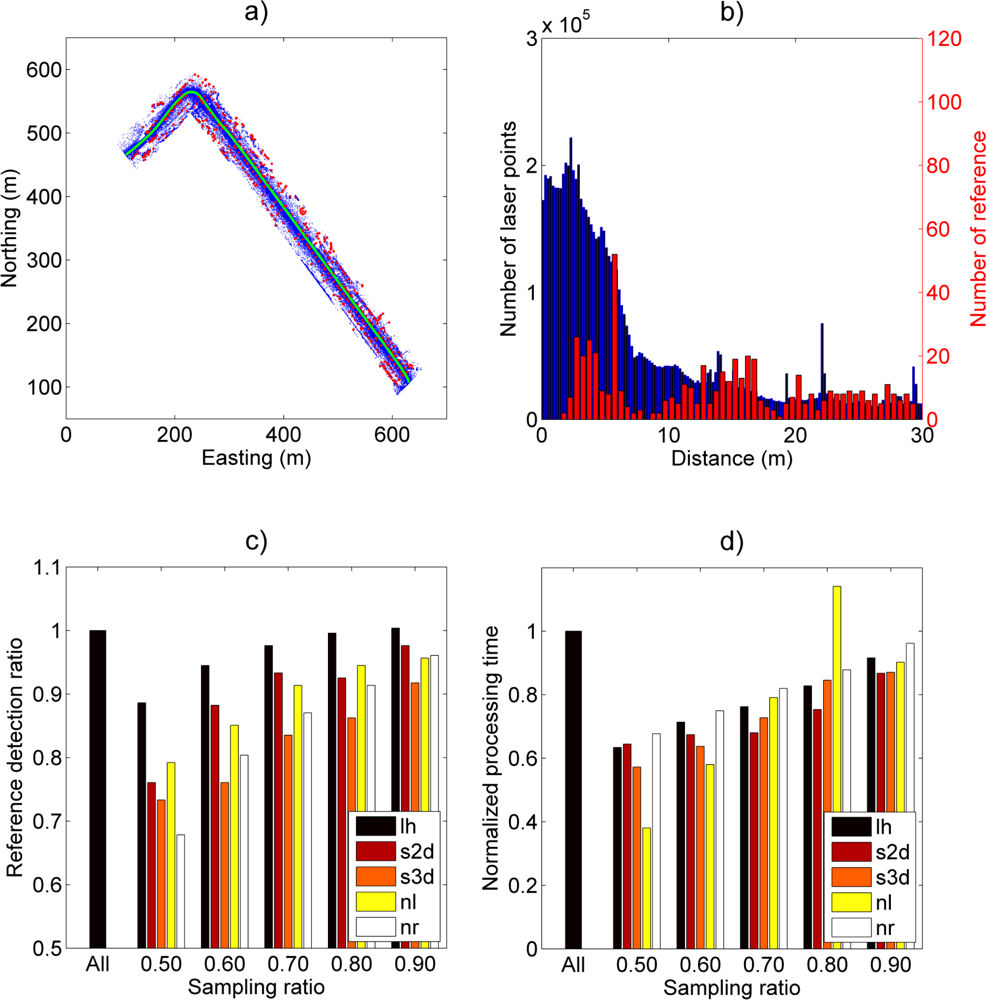
The results of Case Study I are illustrated in
Figure 3. A total of 57 reference spheres were visible to all scanners out of a possible 70 in the full data. The farthest detected sphere was located 23.6 m away from a scanner.
Figure 3(a,b) illustrates a point cloud of a single scan and its distance distribution. Point clouds of other scans had similar distribution shapes. As
Figure 3(b) shows, the distance distribution is mainly concentrated near the scanner. The shape of the distribution implies that sampling techniques sensitive to point distances should obtain similar results to those with the full data when using a low number of sampled points.
Figure 3(c,d) shows that all reference spheres were already detected with a sampling ratio of 20% with the “lh” method and that all different sampling methods detected over 90% of the possible targets with the 50% sampling ratio. The best performing sampling method, “lh”, detected 50 out of 57 targets already at a sampling ratio of 10%. With uniform (nr) and linear (nl) sampling, a 40% sampling ratio was required to reach the same detection level. The performance of distance-weighting sampling methods (s2d and s3d) was between those of the uniform and the leveled histogram methods.
Additionally, the distance of the farthest detected target was tested using each sampling method and ratio (
Figure 3(d)). Here, the leveled histogram (lh) method is clearly the best-performing. It can detect the farthest target already at a 10% sampling ratio and a target over 20 m away already at the 5% sampling ratio. The second-best performing sampling method is the distance-weighting method (s3d) that obtains respective results at sampling ratios of 30% and 10%. The reference methods obtained over a 20-meter detection distance at a sampling ratio of 40%.
The time required for point sampling varied from under one second with the linear point selection (nl) to close to 30 seconds with the 3D distance-weighting method (s3d). When compared against the processing times of other processing steps, such as data loading times and point delineation from the point cloud, the sampling times were below 10% of the whole processing time in all cases.
3.2. Case Study II: Pole and Tree Trunk Detection in an Urban Environment from MLS Data (FGI Roamer)
3.2.1. Study Object and the Algorithm Description
The objective of the second case study was to compare the number of pole shaped objects detected from an urban street environment. False detections were not of interest in this study as it was assumed that point cloud subsampling would not have increased the false positive ratio.
The pole detection algorithm applied in Case Study II detects first individual segments from data to find candidate clusters whose shape resembles poles and trunks [
41]. The candidates were then classified either into “pole-like” or “other” object classes based on five attributes. The algorithm requires that the scanning plane is tilted with respect to both vertical and driving directions. With this configuration, several short sweeps were measured from each vertical pole-like object that was longer than a preset length threshold. First, the algorithm segments the data along scan lines (each scan line individually) to find short point groups that resembled sweeps reflecting from poles. Then, point groups were clustered and groups on top of each other were searched for from adjacent scan lines. Before classification, the clusters were merged if needed. Clusters were then classified as “pole-like” and “others” classes using a five-step decision tree. Classification attributes included the cluster shape, cluster orientation, cluster length, number of sweeps in the cluster, and local point distribution around the cluster [
41].
3.2.2. The Data Description and Reference Results
The data were collected with an FGI Roamer mobile mapping system. It contains a Faro Photon
™ 80 phase-based laser scanner and a NovAtel SPAN
™ navigation system that are fitted to a rigid platform, which can be mounted on a car. Faro scans 2D profiles with a field of view of 320
° in a scanning plane and the motion of the vehicle provides the third dimension. Comprehensive measurement system specifications are described in detail in earlier studies by Kukko
et al. and Lehtomäki
et al.[
42,
43]. The test area was a location in the city of Espoo, southern Finland, and it is one of the EuroSDR test fields [
44].
The dataset was collected with a 48 Hz scanning frequency and it consisted of 8.2 M laser points. The reference contained 538 tree trunks, traffic signs, traffic lights, lamp posts, parking meters, and other poles. Object locations were picked manually from dense terrestrial reference scans. The reference was limited to closer than 30 m from the trajectory and to objects taller than one meter. Earlier studies in the EuroSDR test field had shown that the detection rate of the algorithm was 51.8% for all targets [
43].
3.2.3. Sampling Results
The results of Case Study II are illustrated in
Figure 4.
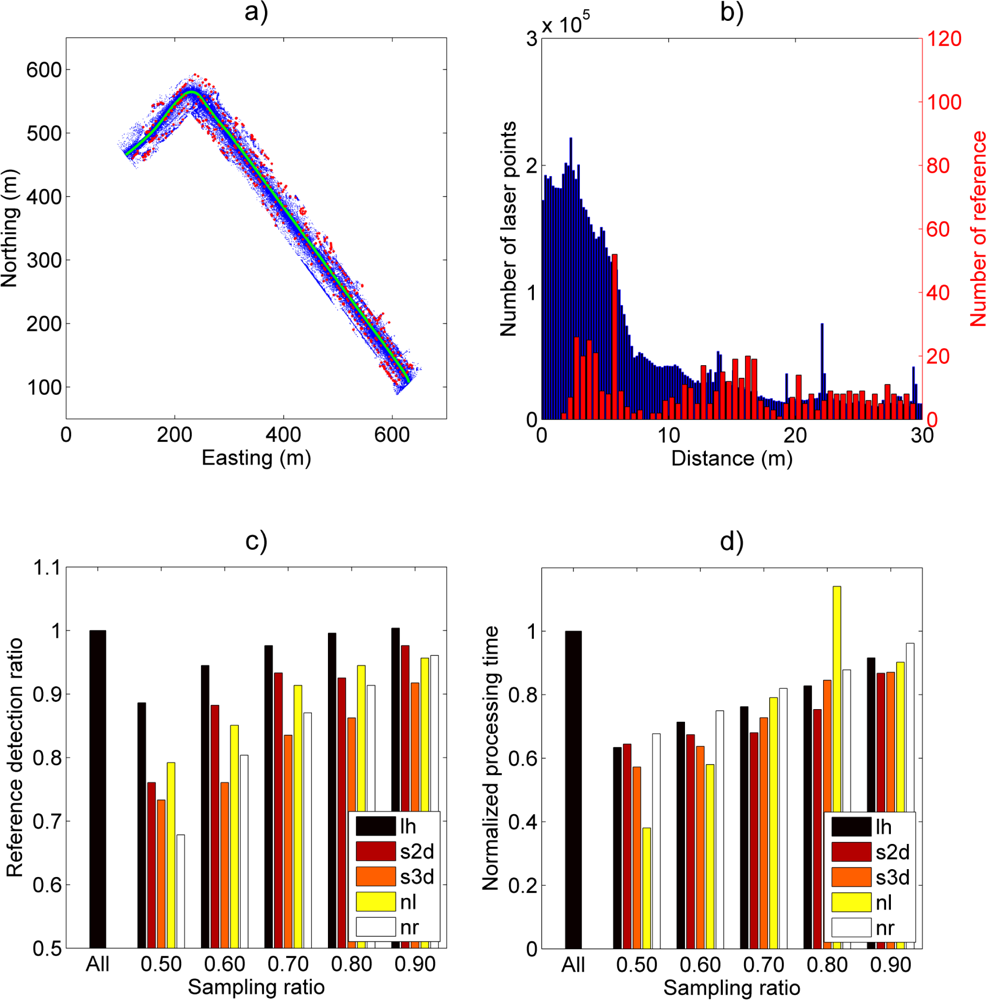
Figure 4(a) illustrates the point cloud with pole-like objects marked with red, and the scanner trajectory marked with green. The point cloud distance and the target distance distributions are shown in
Figure 4(b). The target distance distribution shows how around one third of the poles are located within a 10 m horizontal distance from the scanner trajectory. The point cloud distribution is again concentrated close to the scanner, but not as pronouncedly as in Case Study I in which a stationary scanner was used.
Figure 4(c) shows the effect of a sampling ratio in the pole detection against the case with the full data. Changes in pole detection performance resemble each other more than in Case Study I as the pole detection rate remains higher than the sampling ratio for all sampling methods. Overall, the leveled histogram (lh) performs the best among all methods when the sampling ratio was 50% or above. The best individual performance/sampling ratio for the leveled histogram (lh) method is around 60% sampling ratio where it still achieves 94.5% performance compared with the full data result. Below a 50% sampling ratio, the performance of all sampling methods deteriorates so low that utilizing their results would not be feasible in practical analysis.
The total processing time results, normalized against the full data result, are shown in
Figure 4(d). The processing times drop in a relatively linear fashion for all methods. However, the linear point selection method (nl) showed a clear deviation from this trend at an 80% sampling ratio. This effect was most likely caused by the pole detection algorithm after it encountered complicated point configurations in the sampled point data. This conclusion was based on a comparison made between the sampling and the pole-searching times.
When inspecting the results, it must be kept in mind that they have been normalized against the results obtained with the full data. This means that the absolute values of pole detection ratios are lower than presented in
Figure 4(c). Therefore, determining a suitable sampling ratio for a practical application has to be resolved case-by-case.
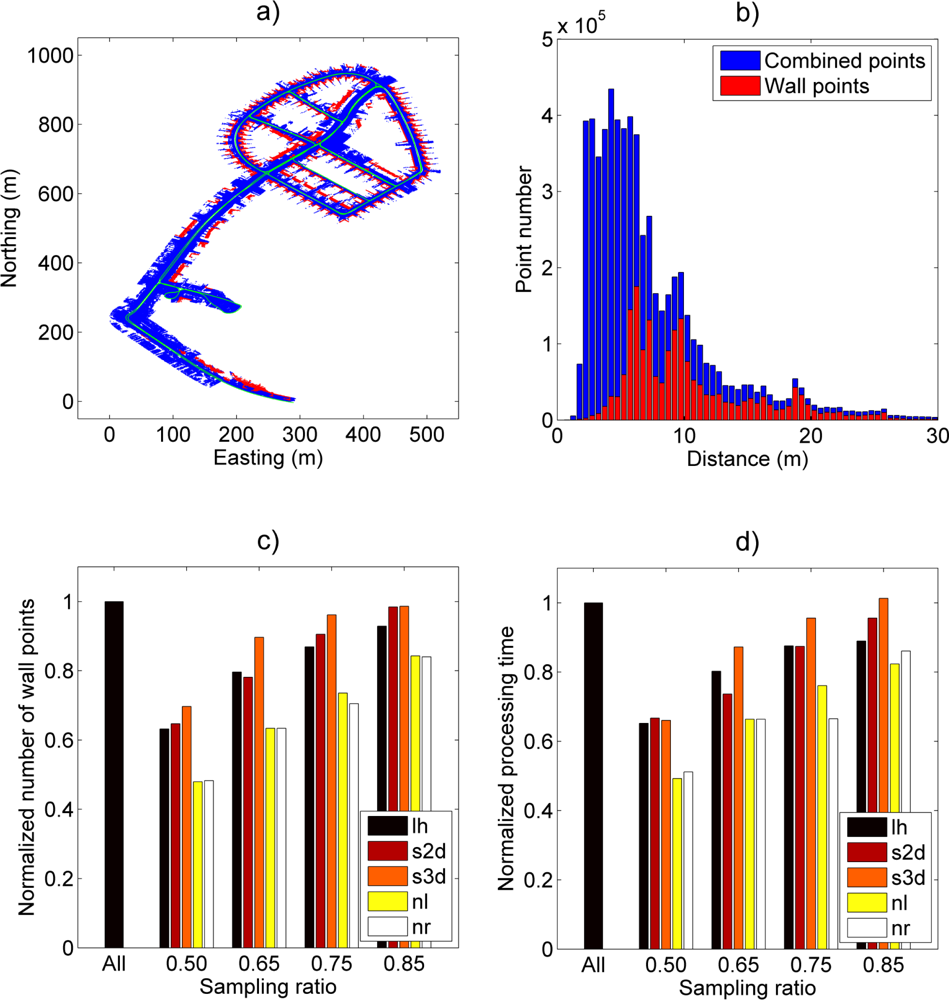
3.3. Case Study III: Wall Detection in an Urban Environment from MLS Data (FGI Sensei)
3.3.1. Study Object and the Algorithm Description
The third case study tested the effects of different sampling techniques on a wall detection algorithm developed for mobile laser scanner data by Zhu
et al. [
4]. The algorithm filters first for noise points using returning pulse widths and isolated points with height statistics. Then, it searches for ground points within the data. The ground points are classified with a grid search that uses height minima of local bins and point cloud height statistics. After ground level determination, walls and buildings are extracted from the data using a two-pass wall detection algorithm: The algorithm creates a binary image of the area using the overlap between two grid layers taken from different heights and then searches for lines within the image. Tall buildings are detected during the first pass and low buildings during the second pass. Laser points located within the line pixels of the binary image are labeled as wall points.
3.3.2. The Data Description and Reference Results
The dataset was collected with a low-cost mobile mapping system, Sensei. The Sensei system is built at the Finnish Geodetic Institute and it has been utilised in road-side mapping studies [
8,
45]. The measurement configuration consisted of an Ibeo Lux laser scanner (Ibeo Automotive Systems GmbH, Hamburg, Germany), a Novatel 702 GG GPS receiver (NovAtel Inc., Calgary, AB, Canada), and a Novatel SPAN-CPT inertial navigation system. The Sensei system can also carry an imaging system, but this was not utilised in the current case study. The laser scanner is capable of collecting 38,000 pts/s over a 110
° opening angle.
The dataset was collected from a residential area located in Kirkkonummi, southern Finland. The area consists of one- and two-story houses. The dataset covered about 6,900 m of roadside environment with partial overlap. The dataset contained about 9.0 M points after noise point filtration. Out of these points, 4.4 M were classified as ground points and 1.9 M points were classified as wall points. The rest of the above-ground points were not used in analysis.
3.3.3. Sampling Results
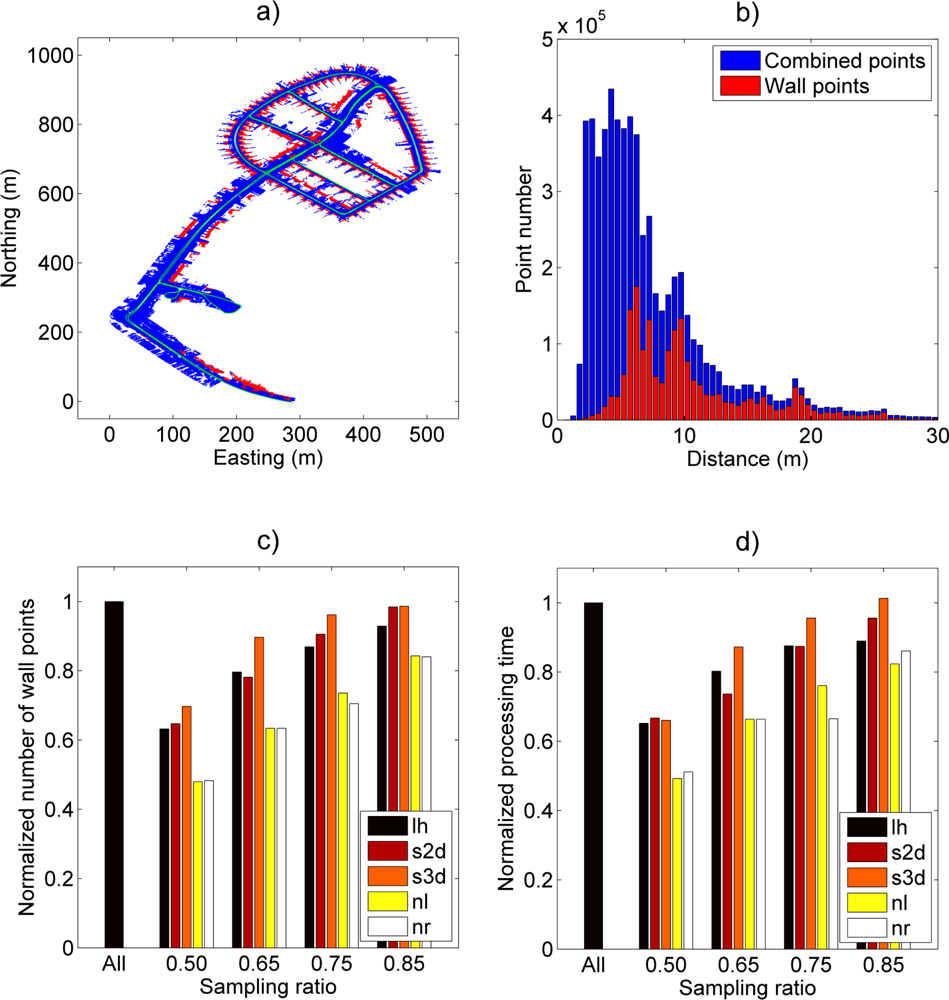
An illustration of Case Study III and its results are presented in
Figure 5.
Figure 5(a,b) shows the study area and the point distance distribution of the wall points and the combined wall and ground points. The blue color represents the combined points and the red color represents the wall points as detected by the algorithm. The laser scanner trajectory is colored with green in
Figure 5(a). Inspection of the distance distributions shows that the analyzed point cloud consists mainly of wall points as the distance to the scanner increases. This was expected as the scanner trajectory was located in a densely built area with low vegetation. However, points close to the scanner were mainly ground hits.
The normalized wall point ratio in
Figure 5(c) shows that sampling methods utilising inverse distance weighting have the best performance for this kind of distance distribution. The inverse three-dimensional distance weighting (s3d) performed the best among all methods by including 90% of the wall points detected from the full dataset with a 65% sampling ratio. This was expected as the method puts most weight on the most distant points. A corresponding two-dimensional method (s2d) and leveled histogram sampling (lh) had similar performance when compared against each other, but their performance was clearly below that of the inverse 3D distance weighting (s3d). Uniform (nr) and linear (nl) point selection methods resulted in a close to linear response in wall point detection and their performances were clearly lower than with other techniques.
The processing times measured during wall determination were longer with the new sampling methods than with the reference methods. The main reason for this was most likely within the wall point search routine. This estimation is based on comparing the ratio of found wall points against the total processing time (
Figure 5(c,d)). The figures show that there was a close resemblance between the wall point ratio and total processing time. This would imply that the total processing time depends heavily on the final number of found wall points regardless of the sampling ratio (e.g., compare method “s3d” wall point ratios and processing times at sampling ratios from 65% to 85%).
4. Discussion
The results of Case Studies I–III demonstrate that the implementation of straightforward sampling methods retains most of the required information content of data while saving both processing time and data storage space. This is important as it means that a point cloud can be sampled efficiently by knowing only its general distance characteristics. Furthermore, unsupervised sampling methods can be integrated tightly into data processing chains. This should give significant benefits when data are collected operatively on a large scale. The results also imply that the best sampling method and ratio are dependent on the application requirements, so case-by-case testing for the best sampling method is recommended.
Moreover, it is possible to lower the effective sampling ratios as low as 10% of the full data size in a good case as Case Study I demonstrates. However, in Case Studies II and III, where scanners were mounted on mobile mapping systems and the objects of interest consisted of more points and more complex shapes, the most effective sampling ratios—in terms of overall point count and processing time speed-up—were found already at around 60% of the full data. Below that ratio, the sampled point clouds lost so much information content that it was no longer feasible to use those clouds for target detection. This highlights the need to consider carefully which type of sampling method would save the information content best, and what would be the minimal level of the needed information content, i.e., the sampling ratio, before processing large areas.
It was also shown that the efficiency of a particular sampling method depends on the shape of the point cloud distance distribution of the targets of interest. For example, in Case Studies I and II, the targets of interest were located evenly along the distance axis. In these cases, the leveled histogram (lh) approach had the best performance. On the other hand, when the object points were located away from the scanner, as in Case Study III, the inverse distance weighting methods retained most of the object information. In general, both proposed sampling methods retained information better than the two reference methods, namely uniform point sampling (nr) and linear point selection (nl).
While the new sampling methods are able to save the information content of data better than uniform and linear sampling, the gains in total processing times were not that clear. The sampling processes took only a small percentage of the total processing time in each case study, which implied that the processing algorithms themselves were sensitive to the spatial distribution of point clouds. A possible explanation for this is that the new sampling methods were designed to preserve distant points. Thus, the processing algorithms had to analyse larger areas, which in turn slowed them down. This conclusion was further backed up by the fact that the processing times in both uniformly and linearly sampled point clouds, which reduce effective scanning range, scaled nearly linearly with the number of points in all case studies.
It was also observed that processing algorithms might have occasional sensitivity to individual sampling method and point ratio combinations, i.e., in Case Study II. In such a case, the total processing times might be significantly longer than would be otherwise expected.
Overall, when changes in both analysis performance and in total processing times are taken into account in all case studies, the results show that distance distribution-based sampling methods retain information content better than uniform or linear sampling. However, the sampling method, analysis algorithm, and its parametrization all have a cumulative effect on the final result. Therefore, prior testing is still required before processing large datasets. Nevertheless, it is possible to reduce point cloud sizes quite safely by tens of percents with a properly selected and parametrized sampling method, and still retain most of the target information. We also assume that more specialized distribution-based sampling approaches could allow even higher point reductions.
To sum up the results, the leveled histogram (lh) sampling gave the best general performance in the case studies. If most of the objects are known to be distributed away from a scanner, then sampling with inversely weighted distance sampling is likely to yield the best results. The strength of the range-based sampling methods is that they can be applied quickly and in principle to most types of TLS and MLS data. However, since the methods are based on point cloud statistics
i.e., they treat the point cloud as a whole, there are limitations that need to be considered. First, the methods do not account for the neighbourhood information of individual points. While this saves processing time, it reduces the method suitability for studies where high point densities are required to preserve detail, e.g., in accurate building facade extraction and modeling [
46–
48], or in road marker detection and mapping [
49,
50]. Reviews by Rottensteiner (2012) and by Wang and Jie (2009) give comprehensive overviews about the common techniques used in solving these problems [
51,
52]. Second, the point cloud should be such that it can be described with a relatively smooth distance distribution,
i.e., the point cloud spatial dimensions should be large compared with object sizes. These limitations mean that the presented methods are the best suited for scanning configurations where short-to-medium scanning ranges and a wide solid angle are used, and where the main goal is in locating and extracting the general shape of objects of interest.
5. Conclusions
In this paper, we propose two sampling approaches to reduce point cloud data while retaining most of the information content of the full dataset. The data reduction is achieved with efficient point cloud sampling methods that use the information about the data collection geometry i.e., point cloud distance distributions. The sampling methods were tested in three separate case studies in which data were collected with a different sensor system in each case. Multiple case studies allowed the study of the combined effects of the sapling methods, different scanning geometries, environments, and data collection techniques on study outcomes.
In conclusion, the results obtained with the new sampling methods were promising. The leveled histogram (lh) and inverted distance weighting (s2d, s3d) performed better than their references in all three case studies. Moreover, none of the new sampling method implementations was particularly optimized for any of the case studies. Because of this, we expect that the implementation of more advanced sampling techniques is possible and that they are likely to yield even better data processing performance and allow high-level integration in data processing chains. The new sampling methods demonstrated in this article were carried out using only point cloud distance distributions. It would be of interest to test if there are other point cloud statistics that could be sampled with a similar approach. Additionally, if such statistics are found, it would be of interest to test the effect of combining or using different sampling methods consecutively. This would possibly allow even further dataset size reductions while preserving most of the required information content.
At present, the demand for accurate geoinformation data continues to increase rapidly with growing commercial and social interest. This means that larger areas will be scanned with high resolution on an operative scale, both outdoors and indoors. Additionally, laser scanning techniques continue to improve all the time and the new scanner systems are faster and have a longer range than their predecessors. Furthermore, new types of scanners are also emerging: multiple wavelength and hyperspectral laser scanners that are able to collect both spatial and spectral information simultaneously [
53–
55]. Moreover, some of these systems collect spectral data with full waveform. All these improvements and new properties mean that dataset sizes are likely to grow significantly when compared with the present situation. As a result, new sampling methods that improve the processing efficiency of continually growing point clouds will be of interest in the coming years as their demand will grow in both TLS and MLS. Therefore, it is imperative that efficient and information-preserving data sampling methods are already being developed to guarantee efficient exploitation of these novel laser scanning systems when they reach operative capability.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}