Hidden Markov Models for Real-Time Estimation of Corn Progress Stages Using MODIS and Meteorological Data

Abstract
:1. Introduction
2. Study Area and Data Sets
- (1)
- Daily NDVI time series, which is derived from the atmospherically corrected MODIS MOD09GQ (MODIS Surface Reflectance Daily L2G Global 250 m) dataset with 250 m spatial resolution. This data set is publicly available through the “Vegetation Condition Explorer” ( http://dss.csiss.gmu.edu/NDVIDownload/), maintained by the Center for Spatial Information Science and Systems (CSISS), George Mason University.
- (2)
- NASS’s Cropland Data Layer (CDL), which is a raster, geo-referenced crop-specific land use data layer. The spatial resolution of years 2006–2009 is 56 m, and the rest is 30 m. The data set is publicly available via “CropScape” ( http://nassgeodata.gmu.edu/), produced operationally by USDA/NASS.
- (3)
- NASS’s CPRs, which record the percent complete (area ratio) of crop fields that has either reached or completed a specific progress stage over a specific administrative unit. It is publicly available via NASS’s “Quick Stats 2.0” service ( http://www.nass.usda.gov/Quick_Stats/). More details of the first three data sets can refer to [19].
- (4)
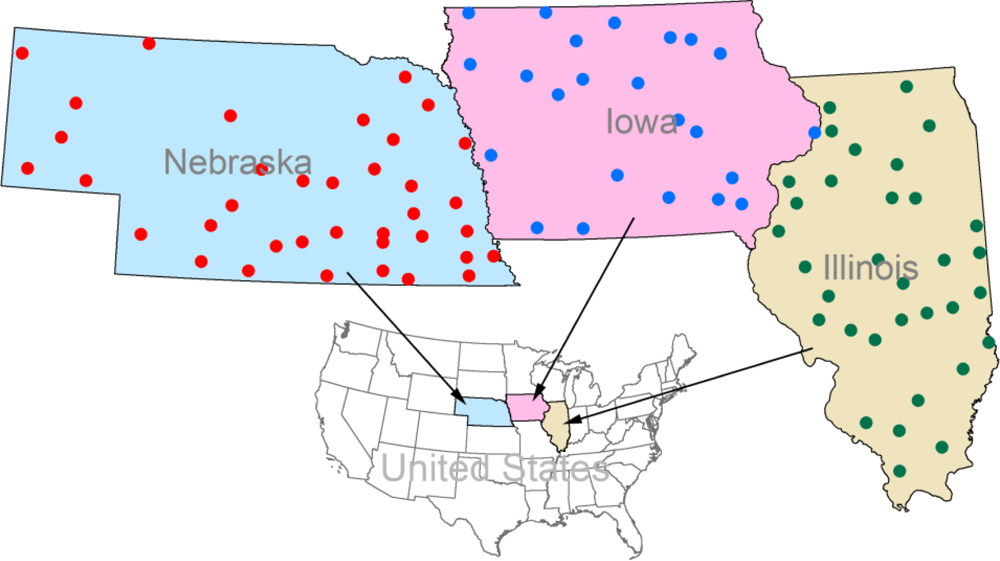
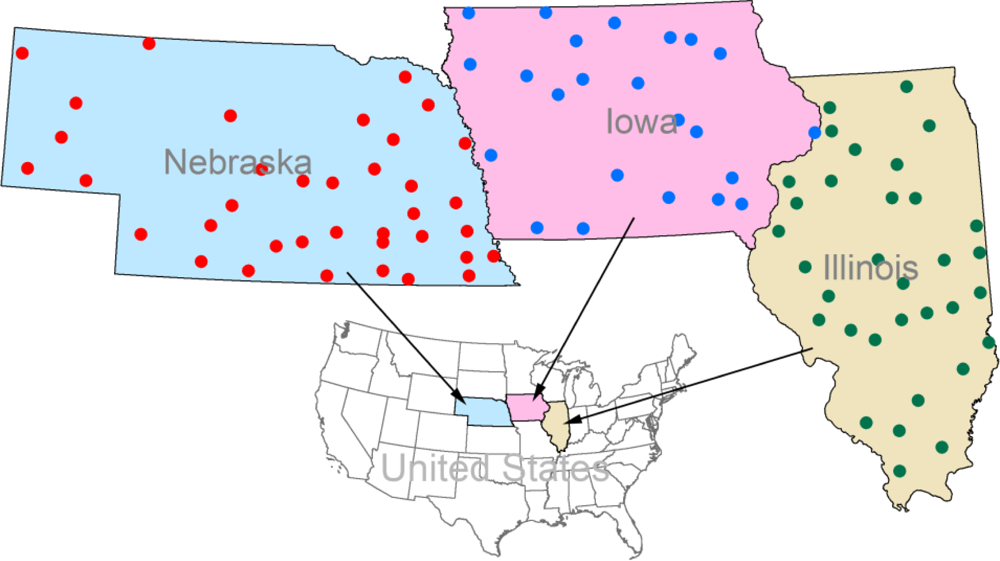
- Daily minimum and maximum temperatures, which are derived from the United States Historical Climatology Network (USHCN) [27]. USHCN is a high-quality network of US Cooperative Observer Network stations, specially selected for analyzing long-term variability and change in the whole contiguous United States [27]. In this study, 23, 33, and 37 meteorological stations are chosen for the states of Iowa, Illinois, and Nebraska, respectively (Figure 1 and Appendix: Table A1). The meteorological stations were selected with a number of criteria including length of period of record, and spatial coverage.
3. Feature Extraction
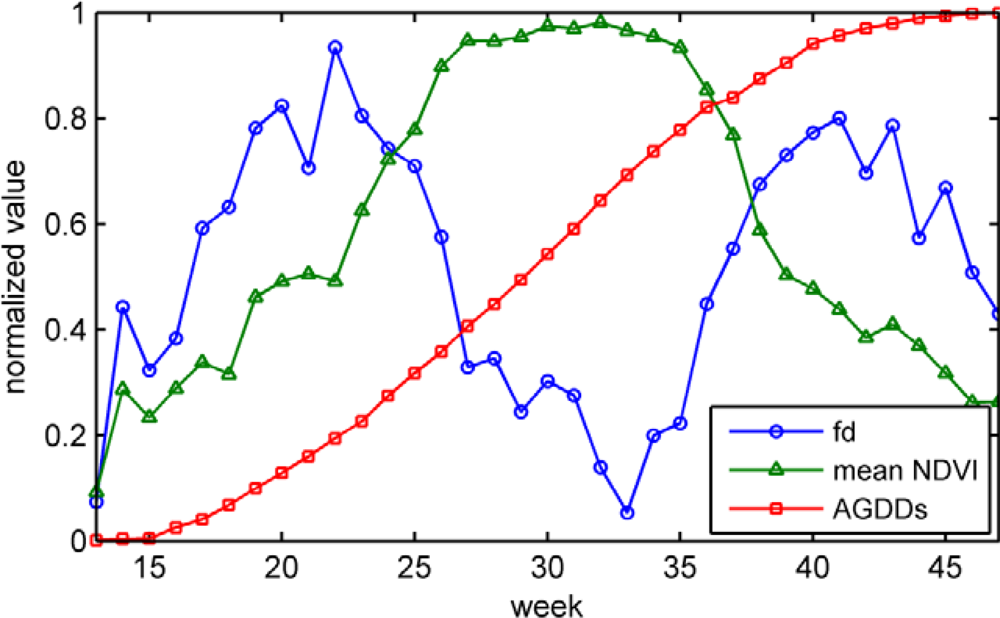
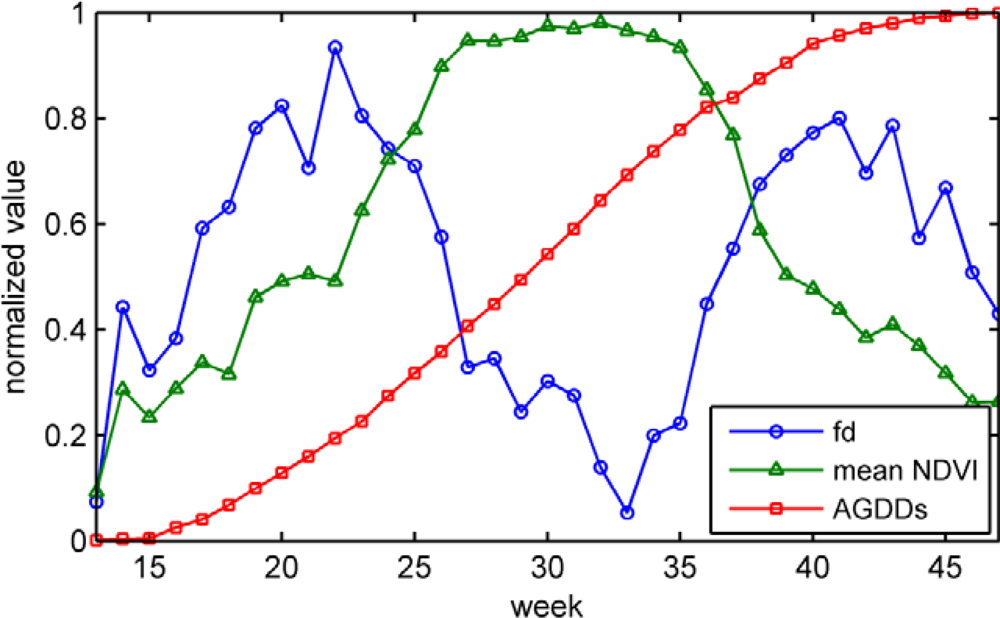
3.1. Mean NDVI
3.2. Fractal Dimension
3.3. AGDDs
4. Corn Progress Percentages Estimation
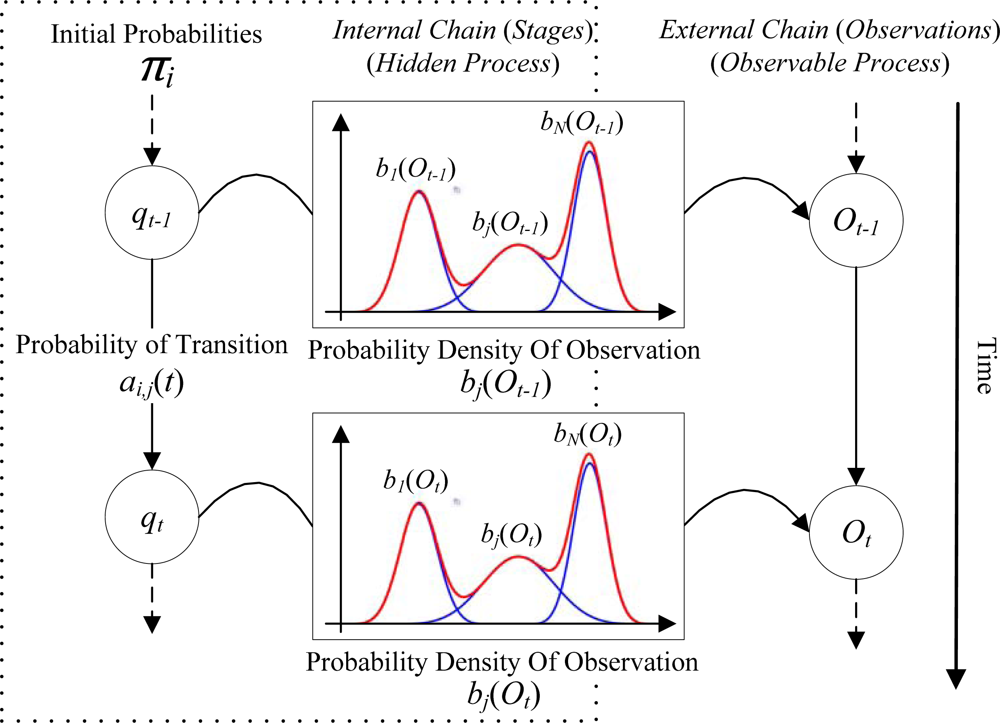
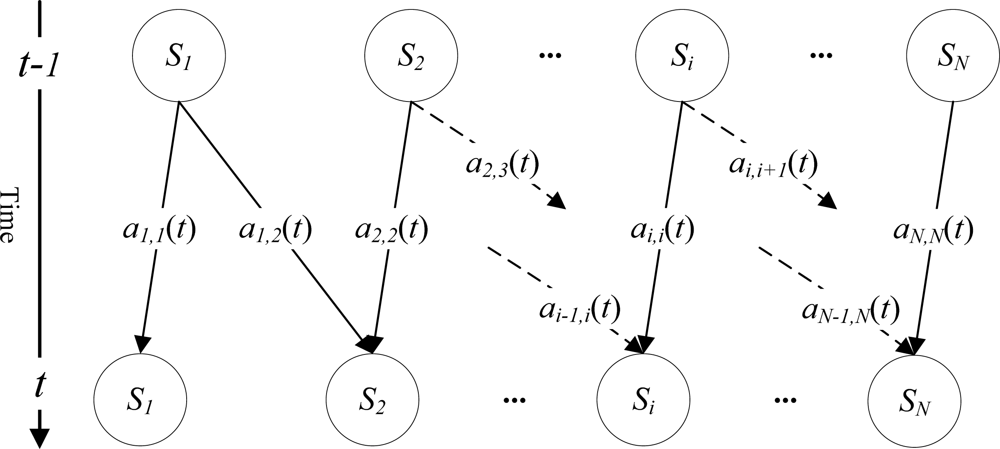
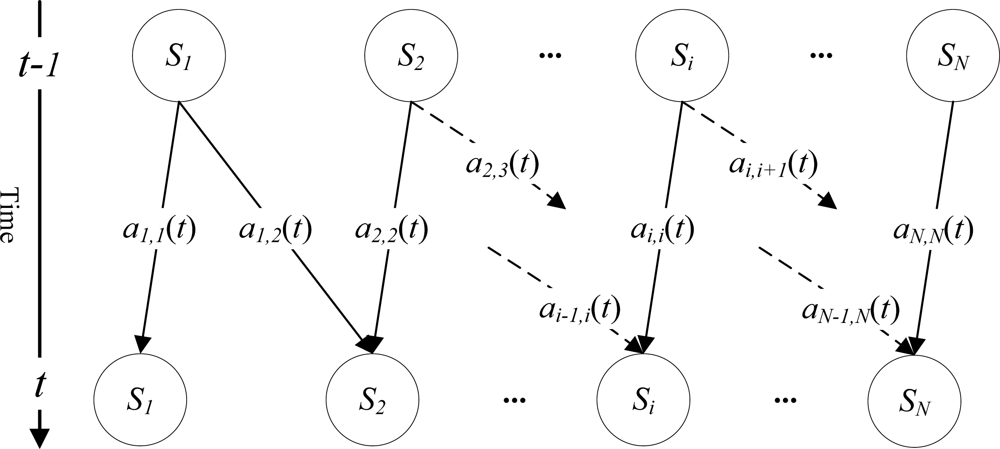
4.1. Specifying an HMM
4.2. Mixture Model in HMMs
4.3. NASS’s CPRs Normalization
4.4. HMM Parameters Determination
4.4.1. Initial Probability Distribution
4.4.2. Stage Transition Probability Matrix
4.4.3. Observation Probability Matrix
4.5. Progress Percents Estimation
5. Results and Discussions
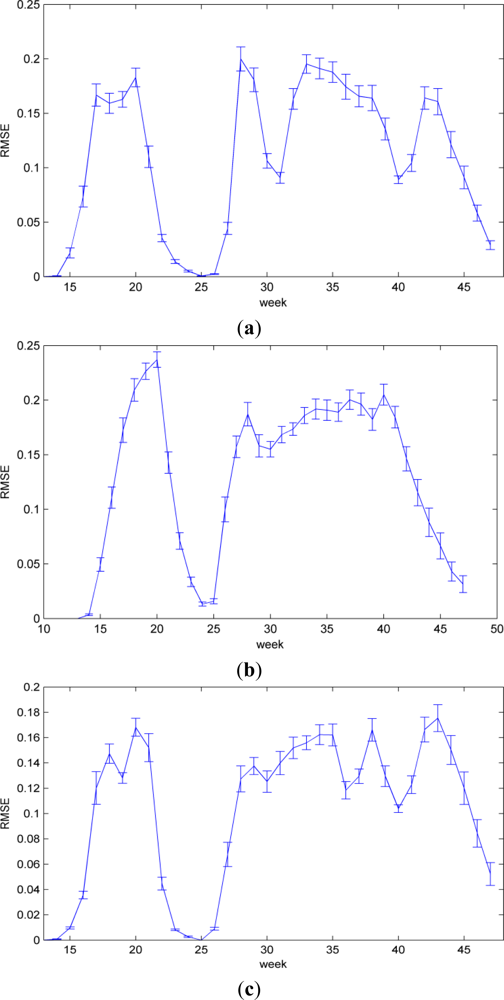
5.1. RMSE Results
5.2. Accuracy Comparison
5.3. Performance and Analysis
- (1)
- The accuracy of NASS’s CPRs. The NASS’s CPRs are surveyed data, and mainly depended on the subjective assessment of investigators. Thus, a bias error is inevitably introduced in the NASS’s CPRs data [41];
- (2)
- The quality of MODIS NDVI. Noise has inevitably disturbed the daily MODIS-NDVI images, e.g., cloud cover, missing data, mixed pixels, or some of the systematic errors that reduce the index value of daily MODIS-NDVI images;
- (3)
- The reliability of meteorological data, regarding to the observation data of weather stations, data missing, instrumentation, or observation station location change may affect the data homogeneity and spatial coverage;
- (4)
- Irregularities in raining and temperature pattern in different years, e.g., extensive drought occurs in a particular year, can significantly affect the stability of results. It would specially impacted on HMM parameters training, e.g., the stage transition probability matrix.
- (5)
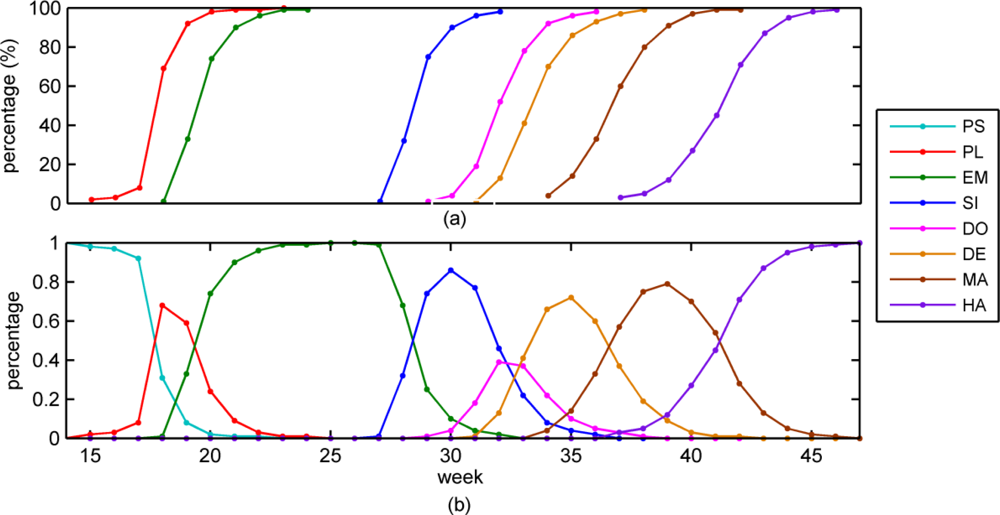
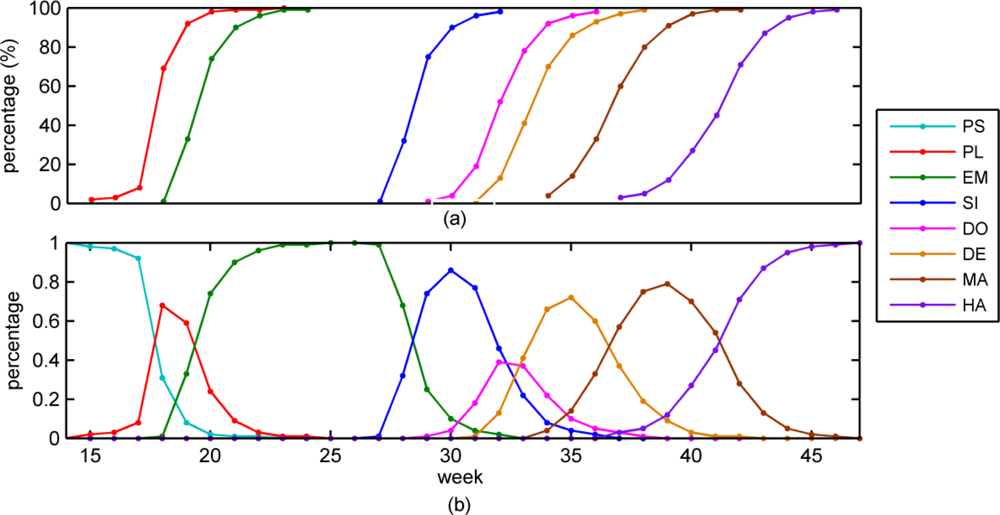
- The insufficiency of temporal resolution. The temporal resolution of data is an important factor that affects the accuracy of corn progress stages estimation. As shown in Figure 4, the emerged stage just 9.5 days delays to planted stage, and dent stage approximate 15.4 days delays to dough stage. Accurate distinction between these growth stages requires a higher temporal resolution. It is really intractable that we have to trade off temporal resolution and data quality.
6. Conclusion
Acknowledgments
References
- USDA-OCE: Weekly Weather and Crop Bulletin. Available online: http://www.usda.gov/oce/weather/pubs/Weekly/Wwcb/index.htm (accessed on 18 November 2012).
- Zhang, X.; Friedl, M.; Schaaf, M.; Strahler, A.H.; Hodges, J.C.F.; Gao, F.; Reed, B.C.; Huete, A. Monitoring vegetation phenology using MODIS. Remote Sens. Environ 2003, 84, 471–475. [Google Scholar]
- Hird, J.N.; McDermid, G.J. Noise reduction of NDVI time series: An empirical comparison of selected techniques. Remote Sens. Environ 2009, 113, 248–258. [Google Scholar]
- Atkinson, P.M.; Jeganathan, C.; Dash, J.; Atzberger, C. Inter-comparison of four models for smoothing satellite sensor time-series data to estimate vegetation phenology. Remote Sens. Environ 2012, 123, 400–417. [Google Scholar]
- Ricotta, C.; Avena, G.C. The remote sensing approach in broad-scale phenological studies. Appl. Veg. Sci 2000, 3, 117–122. [Google Scholar]
- Sasaoka, K.; Chiba, S.; Saino, T. Climatic forcing and phytoplankton phenology over the subarctic north pacific from 1998 to 2006, as observed from ocean color data. Geophys. Res. Lett 2011. [Google Scholar] [CrossRef]
- White, M.A.; de Beurs, K.M.; Didan, K.; Inouye, D.W.; Richardson, A.D.; Jensen, O.P.; O’Keefe, J.; Zhang, G.; Nemani, R.R.; van LeeuWen, W.J.D.; et al. Intercomparison, interpretation, and assessment of spring phenology in north america estimated from remote sensing for 1982–2006. Glob. Chang. Biol 2009, 15, 2335–2359. [Google Scholar]
- Diepen, C.A.; Wolf, J.; van Keulen, H. WOFOST: A simulation model of crop production. Soil Use Manage 1989, 5, 16–24. [Google Scholar]
- Stöckle, C.O.; Donatelli, M.; Nelson, R. Cropsyst, a cropping systems simulation model. Eur. J. Agron 2003, 18, 289–307. [Google Scholar]
- Jones, J.W.; Tsuji, G.Y.; Hoogenboom, G.; Hunt, L.A.; Thornton, P.K.; Wilkens, P.W.; Imamura, D.T.; Bowen, W.T.; Singh, U. Decision Support System for Agrotechnology Transfer: DSSAT V3. In Understanding Options for Agricultural Production; Tsuji, G.Y., Hoogenboom, G., Thornton, P., Eds.; Kluwer Academic Publishers: Boston, MA, USA, 1998; pp. 157–177. [Google Scholar]
- Saxton, K.E.; Porterand, M.A.; McMahon, T.A. Climatic impacts on dryland winter wheat by daily soil water and crop stress simulations. Agr. For. Meteorol 1992, 58, 177–192. [Google Scholar]
- Kroes, J.G.; Dam, J.C.V.; Groenendijk, P.; Hendriks, R.F.A.; Jacobs, C.M.J. SWAP Version 3.2: Theory Description and User Manual; Alterra Report; Alterra: Wageningen, The Netherlands, 2008. [Google Scholar]
- De Beurs, K.M.; Henebry, G.M. Spatio-Temporal Statistical Methods for Modelling Land Surface Phenology. In Phenological Research: Methods for Environmental and Climate Change Analysis; Hudson, I.L., Keatley, M.R., Eds.; Springer-Verlag: New York, NY, USA, 2010. [Google Scholar]
- Toukiloglou, P. Comparison of AVHRR, MODIS and VEGETATION for Land Cover Mapping and Drought Monitoring at 1 km Spatial Resolution. 2007. [Google Scholar]
- Reed, B.C.; Brown, J.F.; Vanderzee, D.; Loveland, T.R.; Merchant, J.W.; Donald, D.O. Measuring phenological variability from satellite imagery. J. Veg. Sci 1994, 5, 703–714. [Google Scholar]
- Ren, J.; Chen, Z.; Zhou, Q. Regional yield estimation for winter wheat with MODIS-NDVI data in Shandong, China. Int. J. Appl. Earth Obs. Geoinf 2008, 10, 403–413. [Google Scholar]
- Atzberger, C. Advances in remote sensing of agriculture: Context description, existing operational monitoring systems and major information needs. Remote Sens 2013, 5, 949–981. [Google Scholar]
- Culbert, P.D.; Pidgeon, A.M.; Louis, V.S.; Bash, D.; Radeloff, V.C. The impact of phenological variation on texture measures of remotely sensed imagery. IEEE J. Sel. Top. Appl. Earth Observ 2009, 2, 299–309. [Google Scholar]
- Shen, Y.; Di, L.; Yu, G.; Wu, L. Correlation between corn progress stages and fractal dimension from MODIS-NDVI time series. IEEE Geosci. Remote Sens. Lett 2013, 10, 1–5. [Google Scholar]
- USDA-NASS: National Crop Progress Terms and Definitions. Available online: http://www.nass.usda.gov/Publications/NationalCropProgress/TermsandDefinitions/index.asp (accessed on 18 November 2012).
- Elliott, R.J.; Siu, T.K. An HMM approach for optimal investment of an insurer. Int. J. Robust Nonlinear Contr 2012, 22, 778–807. [Google Scholar]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar]
- Krogh, A.; Brown, M.; Mian, I.S.; Sjölander, K.; Haussler, D. Hidden Markov models in computational biology: Applications to protein modeling. J. Mol. Biol 1994, 235, 1501–1531. [Google Scholar]
- Aurdal, L.; Bang, H.R.; Eikvil, L.; Solberg, R.; Vikhamar, D.; Solberg, A. Hidden Markov Models Applied to Vegetation Dynamics Analysis Using Satellite Remote Sensing. Proceedings of International Workshop on the Analysis of Multi-Temporal Remote Sensing Images, Biloxi, MS, USA, 16–18 May 2005; pp. 220–224.
- Leite, P.; Feitosa, R.; Formaggio, A.; Costa, G.; Pakzad, K.; Sanches, I. Hidden Markov models for crop recognition in remote sensing image sequences. Pattern Recognition Lett 2011, 32, 19–26. [Google Scholar]
- Viovy, N.; Saint, G. Hidden Markov models applied to vegetation dynamics analysis using satellite remote sensing. IEEE Trans. Geosci. Remote Sens 1994, 32, 906–917. [Google Scholar]
- The United States Historical Climatology Network (USHCN). Available online: http://cdiac.ornl.gov/epubs/ndp/ushcn/ushcn.html (accessed on 18 November 2012).
- Holben, B.N. Characteristics of maximum-value composite images from temporal AVHRR data. Int. J. Remote Sens 1986, 7, 1417–1434. [Google Scholar]
- Wiebold, B. Growing Degree Days and Corn Maturity; Technical Report; University of Missouri: Columbia, MO, USA, 2002. [Google Scholar]
- Thiessen, A.H. Precipitation averages for large areas. Mon. Wea. Rev 1911, 39, 1082–1089. [Google Scholar]
- Trudgill, D.L.; Honek, A.; Li, D.; van Straalen, N.M. Thermal time-concepts and utility. Ann. Appl. Biol 2005, 146, 1–14. [Google Scholar]
- McMaster, G.S.; Wilhelm, W.W. Growing degree-days: One equation, two interpretations. Agr. Forest Meteorol 1997, 87, 291–300. [Google Scholar]
- Jaakkola, T.S. Machine Learning, Lecture Notes 19: Hidden Markov Models (HMMs). 2006. Available online: http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-867-machine-learning-fall-2006/lecture-notes/lec19.pdf (accessed on 18 November 2012).
- Srihari, S.N. Machine Learning and Probabilistic Graphical Models Course: Hidden Markov Models. 2011. Available online: http://www.cedar.buffalo.edu/srihari/CSE574/index.html (accessed on 18 November 2012).
- Knab, B.; Schliep, A.; Steckemetz, B.; Wichern, B. Model-Based Clustering with Hidden Markov Models and its Application to Financial Time-Series Data. In Between Data Science and Applied Data Analysis; Schader, M., Gaul, W., Vichi, M., Eds.; Springer: New York, NY, USA, 2003; pp. 561–569. [Google Scholar]
- Seifert, M.; Strickert, M.; Schliep, A.; Grosse, I. Exploiting prior knowledge and gene distances in the analysis of tumor expression profiles with extended Hidden Markov Models. Bioinformatics 2011, 27, 1645–1652. [Google Scholar]
- Sacks, W.J.; Kucharik, C.J. Crop management and phenology trends in the U.S. corn belt: Impacts on yields, evapotranspiration and energy balance. Agr. Forest Meteorol 2011, 151, 882–894. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. Roy. Stat. Soc. B 1977, 39, 1–38. [Google Scholar]
- Heij, C.; de Boer, P.; Franses, P.H.; Kloek, T.; van Dijk, H.K. Econometric Methods with Applications in Business and Economics; Oxford University Press Inc: New York, NY, USA, 2004. [Google Scholar]
- Yu, G.; Di, L.; Yang, Z.; Shen, Y.; Zhang, B.; Chen, Z. Corn Growth Stage Estimation Using Time Series Vegetation Index. Proceedings of 2012 First International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Shanghai, China, 2–4 August 2012; pp. 1–6.
- Sakamoto, T.; Wardlow, B.D.; Gitelson, A.A. Detecting spatiotemporal changes of corn developmental stages in the U.S. corn belt using MODIS WDRVI data. IEEE Trans. Geosci. Remote Sens 2011, 49, 1926–1936. [Google Scholar]
- Lee, L. High-order hidden Markov model and application to continuous mandarin digit recognition. J. Inf. Sci. Eng 2011, 27, 1919–1930. [Google Scholar]
- Mari, J.F.; Haton, J.P.; Kriouile, A. Automatic word recognition based on second-order hidden Markov models. IEEE Trans. Speech Audio Proc 1997, 5, 22–25. [Google Scholar]
- Seifert, M.; Cortijo, S.; Colomé-Tatché, M.; Johannes, Frank; Roudier, F.; Colot, V. MeDIP-HMM: Genome-wide identification of distinct DNA methylation states from high-density tiling arrays. Bioinformatics 2012. [Google Scholar] [CrossRef]
- Seifert, M.; Gohr, A.; Strickert, M.; Grosse, I. Parsimonious higher-order hidden Markov models for improved array-CGH analysis with applications to Arabidopsis thaliana. PLoS Comp. Biol 2012, 8, 1–15. [Google Scholar]
- Derrode, S.; Carincotte, C.; Bourennane, S. Unsupervised Image Segmentation Based on High-Order Hidden MARKOV Chains. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Marseille, France, 17–21 May 2004; pp. 769–772.
Appendix

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | ID | SA | Name | Lat (°N) | Lon (°W) | Elev (m) | No | ID | SA | Name | Lat (°N) | Lon (°W) | Elev (m) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 130112 | IA | ALBIA 3 NNE | 41.07 | 92.79 | 268.2 | 48 | 116579 | IL | PANA 3E | 39.37 | 89.02 | 213.4 |
| 2 | 130133 | IA | ALGONA 3 W | 43.07 | 94.31 | 377.6 | 49 | 116610 | IL | PARIS WTR WKS | 39.64 | 87.69 | 207.3 |
| 3 | 130600 | IA | BELLE PLAINE | 41.88 | 92.28 | 246.9 | 50 | 116910 | IL | PONTIAC | 40.89 | 88.64 | 198.1 |
| 4 | 131402 | IA | CHARLES CITY | 43.08 | 92.67 | 309.1 | 51 | 117551 | IL | RUSHVILLE | 40.12 | 90.56 | 201.2 |
| 5 | 131533 | IA | CLARINDA | 40.72 | 95.02 | 298.7 | 52 | 118147 | IL | SPARTA 1 W | 38.12 | 89.72 | 163.1 |
| 6 | 131635 | IA | CLINTON #1 | 41.79 | 90.26 | 178.3 | 53 | 118740 | IL | URBANA | 40.08 | 88.24 | 219.8 |
| 7 | 132724 | IA | ESTHERVILLE 2 N | 43.43 | 94.82 | 396.8 | 54 | 118916 | IL | WALNUT | 41.55 | 89.6 | 210.3 |
| 8 | 132789 | IA | FAIRFIELD | 41.02 | 91.96 | 225.6 | 55 | 119241 | IL | WHITE HALL 1 E | 39.44 | 90.38 | 176.8 |
| 9 | 132864 | IA | FAYETTE | 42.85 | 91.82 | 344.4 | 56 | 119354 | IL | WINDSOR | 39.44 | 88.6 | 210.3 |
| 10 | 132977 | IA | FOREST CITY 2 NNE | 43.28 | 93.63 | 396.2 | 57 | 250130 | NE | ALLIANCE 1WNW | 42.11 | 102.9 | 1,217.4 |
| 11 | 132999 | IA | FORT DODGE 5NNW | 42.58 | 94.2 | 347.5 | 58 | 250375 | NE | ASHLAND NO 2 | 41.04 | 96.38 | 326.1 |
| 12 | 134063 | IA | INDIANOLA 2W | 41.37 | 93.65 | 287.1 | 59 | 250435 | NE | AUBURN 5 ESE | 40.37 | 95.75 | 283.5 |
| 13 | 134142 | IA | IOWA FALLS | 42.52 | 93.25 | 344.4 | 60 | 250640 | NE | BEAVER CITY | 40.13 | 99.83 | 658.4 |
| 14 | 134735 | IA | LE MARS | 42.78 | 96.15 | 364.2 | 61 | 251145 | NE | BRIDGEPORT | 41.67 | 103.1 | 1,117.4 |
| 15 | 134894 | IA | LOGAN | 41.64 | 95.79 | 301.8 | 62 | 251200 | NE | BROKEN BOW 2 W | 41.41 | 99.68 | 762 |
| 16 | 135769 | IA | MT AYR | 40.71 | 94.24 | 359.7 | 63 | 252020 | NE | CRETE | 40.62 | 96.95 | 437.4 |
| 17 | 135796 | IA | MT PLEASANT 1 SSW | 40.95 | 91.56 | 222.5 | 64 | 252100 | NE | CURTIS 3NNE | 40.67 | 100.49 | 829.4 |
| 18 | 135952 | IA | NEW HAMPTON | 43.05 | 92.31 | 349.9 | 65 | 252205 | NE | DAVID CITY | 41.25 | 97.13 | 490.7 |
| 19 | 137147 | IA | ROCK RAPIDS | 43.43 | 96.17 | 411.5 | 66 | 252820 | NE | FAIRBURY 5S | 40.07 | 97.17 | 411.5 |
| 20 | 137161 | IA | ROCKWELL CITY | 42.4 | 94.63 | 364.2 | 67 | 252840 | NE | FAIRMONT | 40.64 | 97.59 | 499.9 |
| 21 | 137979 | IA | STORM LAKE 2 E | 42.63 | 95.17 | 434.3 | 68 | 253175 | NE | GENEVA | 40.53 | 97.6 | 496.8 |
| 22 | 138296 | IA | TOLEDO 3N | 42.04 | 92.58 | 289.3 | 69 | 253185 | NE | GENOA 2 W | 41.45 | 97.76 | 484.6 |
| 23 | 138688 | IA | WASHINGTON | 41.28 | 91.71 | 210.3 | 70 | 253365 | NE | GOTHENBURG | 40.94 | 100.15 | 787.9 |
| 24 | 110072 | IL | ALEDO | 41.2 | 90.75 | 219.5 | 71 | 253615 | NE | HARRISON | 42.69 | 103.88 | 1,478.3 |
| 25 | 110187 | IL | ANNA 2 NNE | 37.48 | 89.23 | 195.1 | 72 | 253630 | NE | HARTINGTON | 42.62 | 97.26 | 417.6 |
| 26 | 110338 | IL | AURORA | 41.78 | 88.31 | 201.2 | 73 | 253660 | NE | HASTINGS 4N | 40.65 | 98.38 | 591.3 |
| 27 | 111280 | IL | CARLINVILLE | 39.29 | 89.87 | 189.3 | 74 | 253735 | NE | HEBRON | 40.18 | 97.59 | 451.1 |
| 28 | 111436 | IL | CHARLESTON | 39.48 | 88.17 | 198.1 | 75 | 253910 | NE | HOLDREGE | 40.45 | 99.38 | 707.1 |
| 29 | 112140 | IL | DANVILLE | 40.14 | 87.65 | 170.1 | 76 | 254110 | NE | IMPERIAL | 40.52 | 101.66 | 999.7 |
| 30 | 112193 | IL | DECATUR WTP | 39.83 | 88.95 | 189 | 77 | 254440 | NE | KIMBALL 2NE | 41.25 | 103.63 | 1,435 |
| 31 | 112483 | IL | DU QUOIN 4 SE | 37.99 | 89.19 | 128 | 78 | 254900 | NE | LODGEPOLE | 41.15 | 102.64 | 1,168 |
| 32 | 113335 | IL | GALVA | 41.17 | 90.04 | 246.9 | 79 | 254985 | NE | LOUP CITY | 41.28 | 98.97 | 627.3 |
| 33 | 113879 | IL | HARRISBURG | 37.74 | 88.52 | 111.3 | 80 | 255080 | NE | MADISON | 41.83 | 97.45 | 481.6 |
| 34 | 114108 | IL | HILLSBORO | 39.15 | 89.48 | 192 | 81 | 255310 | NE | MC COOK | 40.22 | 100.62 | 796.1 |
| 35 | 114198 | IL | HOOPESTON 1 NE | 40.47 | 87.66 | 216.4 | 82 | 255470 | NE | MERRIMAN | 42.92 | 101.71 | 986 |
| 36 | 114442 | IL | JACKSONVILLE 2E | 39.73 | 90.2 | 185.9 | 83 | 255565 | NE | MINDEN | 40.52 | 98.95 | 658.4 |
| 37 | 114823 | IL | LA HARPE | 40.58 | 90.97 | 210.3 | 84 | 256135 | NE | OAKDALE | 42.07 | 97.97 | 521.2 |
| 38 | 115079 | IL | LINCOLN | 40.15 | 89.34 | 177.7 | 85 | 256570 | NE | PAWNEE CITY | 40.12 | 96.16 | 378 |
| 39 | 115326 | IL | MARENGO | 42.29 | 88.65 | 248.4 | 86 | 256970 | NE | PURDUM | 42.07 | 100.25 | 819.9 |
| 40 | 115712 | IL | MINONK | 40.91 | 89.03 | 228.6 | 87 | 257070 | NE | RED CLOUD | 40.1 | 98.52 | 524.3 |
| 41 | 115768 | IL | MONMOUTH | 40.92 | 90.64 | 227.1 | 88 | 257515 | NE | SAINT PAUL 4N | 41.27 | 98.47 | 541 |
| 42 | 115833 | IL | MORRISON | 41.80 | 89.97 | 183.8 | 89 | 257715 | NE | SEWARD | 40.9 | 97.09 | 438.9 |
| 43 | 115901 | IL | MT CARROLL | 42.1 | 89.98 | 195.1 | 90 | 258395 | NE | SYRACUSE | 40.68 | 96.19 | 335.3 |
| 44 | 115943 | IL | MT VERNON 3 NE | 38.35 | 88.85 | 149.4 | 91 | 258465 | NE | TECUMSEH 1S | 40.35 | 96.19 | 338.3 |
| 45 | 116446 | IL | OLNEY 2S | 38.7 | 88.08 | 146.3 | 92 | 258480 | NE | TEKAMAH | 41.79 | 96.23 | 338.3 |
| 46 | 116526 | IL | OTTAWA 5SW | 41.33 | 88.91 | 160 | 93 | 258915 | NE | WAKEFIELD | 42.27 | 96.86 | 423.7 |
| 47 | 116558 | IL | PALESTINE | 39 | 87.62 | 140.2 |


Share and Cite
Shen, Y.; Wu, L.; Di, L.; Yu, G.; Tang, H.; Yu, G.; Shao, Y. Hidden Markov Models for Real-Time Estimation of Corn Progress Stages Using MODIS and Meteorological Data. Remote Sens. 2013, 5, 1734-1753. https://doi.org/10.3390/rs5041734
Shen Y, Wu L, Di L, Yu G, Tang H, Yu G, Shao Y. Hidden Markov Models for Real-Time Estimation of Corn Progress Stages Using MODIS and Meteorological Data. Remote Sensing. 2013; 5(4):1734-1753. https://doi.org/10.3390/rs5041734
Chicago/Turabian StyleShen, Yonglin, Lixin Wu, Liping Di, Genong Yu, Hong Tang, Guoxian Yu, and Yuanzheng Shao. 2013. "Hidden Markov Models for Real-Time Estimation of Corn Progress Stages Using MODIS and Meteorological Data" Remote Sensing 5, no. 4: 1734-1753. https://doi.org/10.3390/rs5041734
APA StyleShen, Y., Wu, L., Di, L., Yu, G., Tang, H., Yu, G., & Shao, Y. (2013). Hidden Markov Models for Real-Time Estimation of Corn Progress Stages Using MODIS and Meteorological Data. Remote Sensing, 5(4), 1734-1753. https://doi.org/10.3390/rs5041734