1. Introduction
The automatic segmentation and classification of 3D urban data have gained widespread interest and importance in the scientific community due to the increasing demand of urban landscape analysis and cartography for different popular applications, coupled with the advances in 3D data acquisition technology. The automatic extraction (or partially supervised) of important urban scene structures such as roads, vegetation, lamp posts, and buildings from 3D data has been found to be an attractive approach to urban scene analysis, because it can tremendously reduce the resources required for analyzing the data for subsequent use in 3D city modeling and other algorithms.
A common way to quickly collect 3D data of urban environments is by using an airborne LiDAR [
1,
2], where the LiDAR scanner is mounted in the bottom of an aircraft. Although this method generates a 3D scan in a very short time period, there are a number of limitations in 3D urban data collected from this method, such as a limited viewing angle. These limitations are overcome by using a mobile terrestrial or ground based LiDAR system in which, unlike the airborne LiDAR system, the 3D data obtained is dense and the point of view of the images is closer to the urban landscapes. However, this leads to both advantages and disadvantages when processing the data. The disadvantages include the demand for more processing power required to handle the increased volume of 3D data. On the other hand, the advantage is the availability of a more detailed sampling of the object’s lateral views, which provides a more comprehensive model of the urban structures including building facades, lamp posts,
etc.
Over the last few years an important number of projects has been undertaken globally to analyze and model 3D urban environments. The presented work is also realized as part of the French government project ANR iSpace&Time, which involves classification, modeling and simulation of urban environment for 4D Visualization of cities.
Our work revolves around the segmentation and then classification of ground based 3D data of urban scenes. The aim is to provide an effective pre-processing step for different subsequent algorithms or as an add-on boost for more specific classification algorithms. The main contribution of our work includes: (1) a voxel based segmentation using a proposed Link-Chain method; (2) classification of these segmented objects using geometrical features and local descriptors; (3) introduction of a new evaluation metric that combines both segmentation and classification results simultaneously; (4) evaluation of the proposed algorithm on standard data sets using 3 different evaluation methods; (5) study of the effect of voxel size on the classification accuracy; (6) study of the effect of incorporating reflectance intensity with RGB color on the classification results.
3. Voxel Based Segmentation
The proposed voxel based segmentation method consists of three main parts, which are the voxelisation of data, the transformation of voxels into super-voxels and the clustering by link-chain method.
3.1. Voxelisation of Data
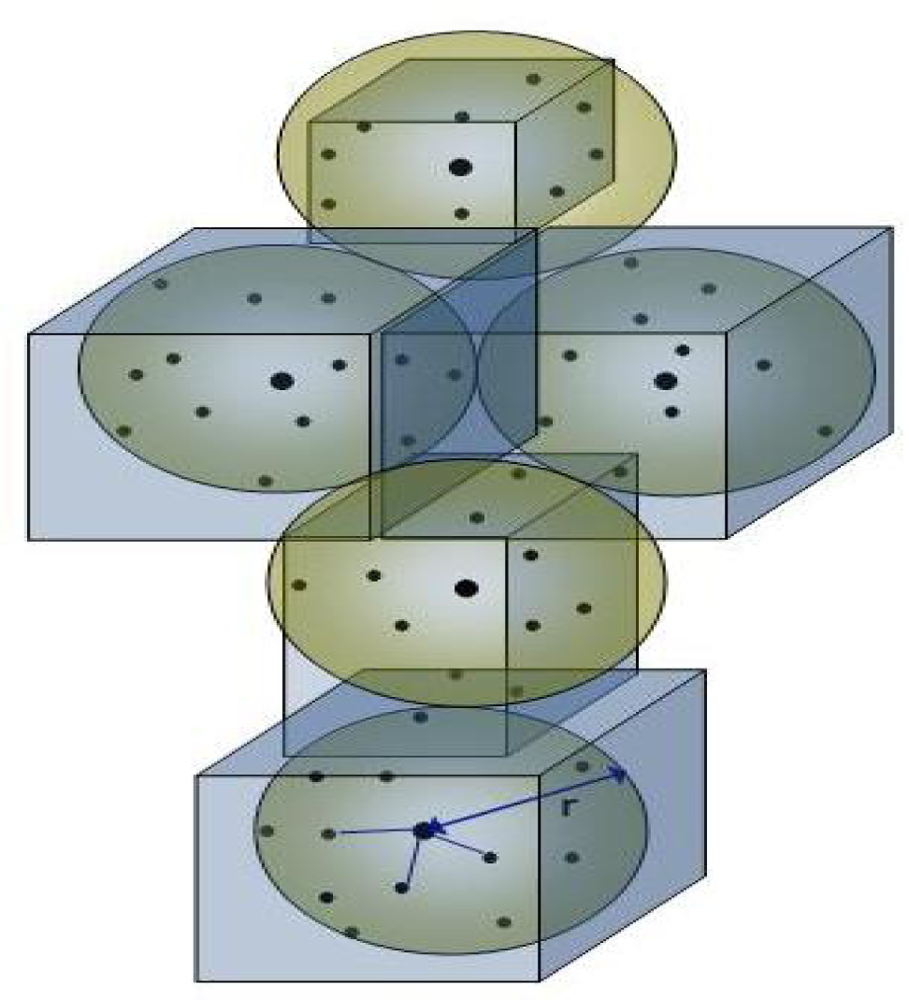
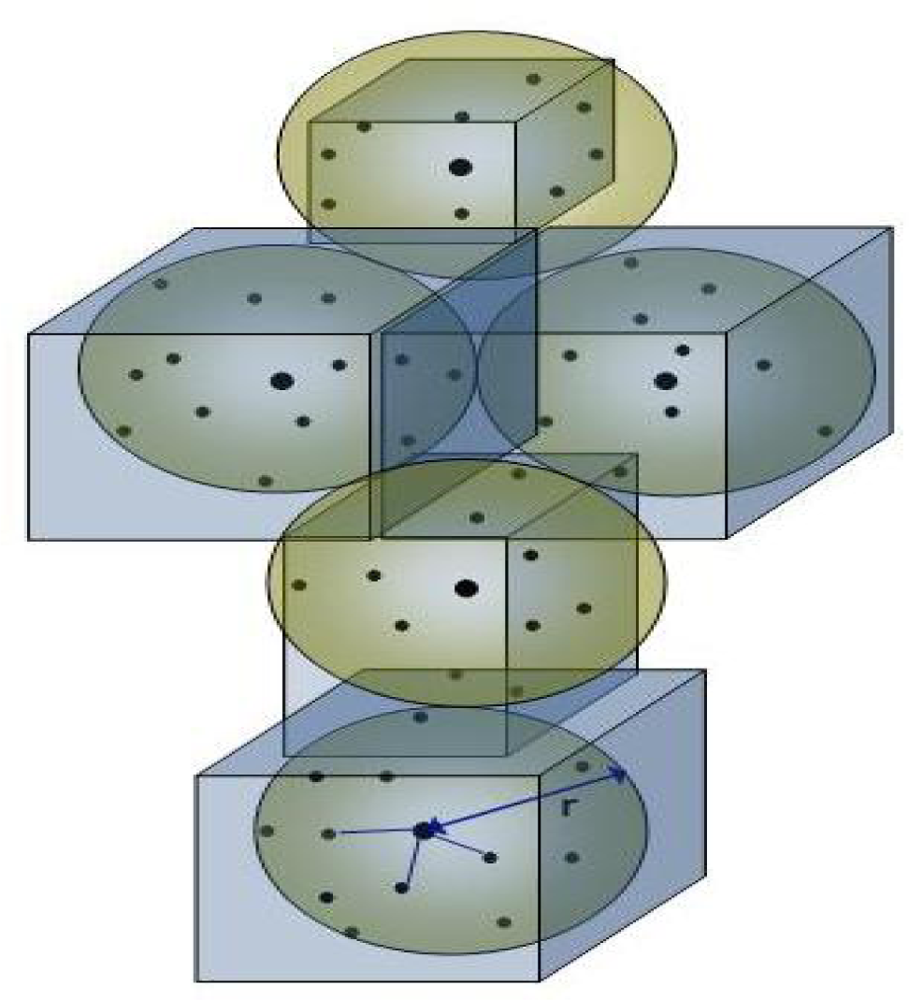
When dealing with large 3D data sets, the computational cost of processing all individual points is very high, making it impractical for real time applications. It is therefore sought to reduce these points by grouping together or removing redundant or un-useful points. Similarly, in our work the individual 3D points are clustered together to form a higher level representation or voxel as shown in
Figure 1.
For
p data points, a number of
s voxels, where
s << p, are computed based on
r-NN, where
r is the radius of ellipsoid. The maximum size of the voxel 2
r depends upon the density of the 3D point cloud (the choice of this maximum voxel size is discussed in Section 6.5). In order to create the voxels, first a 3D point is selected as centre and using an
r-NN with a fixed diameter (equal to maximum voxel size), all the 3D points in the vicinity are selected. All these 3D points now belong to this first voxel. Then, based on the maximum and minimum values of the 3D points contained in this voxel, the actual voxel size is determined. The same step is then repeated for other 3D points that are not part of the earlier voxel until all 3D points are considered (see
Algorithm 1). In [
20], color values are also added in this step but it is observed that for relatively smaller voxel sizes, the variation in properties such as color is not profound and just increases computational cost. For these reasons, we have only used distance as a parameter in this step. The other properties are used in the next step of clustering the voxels to form objects. Also we have ensured that each 3D point that belongs to a voxel is not considered for further voxelisation. This not only prevents over segmentation but also reduces processing time.
Algorithm 1.
Segmentation
Algorithm 1.
Segmentation
| 1: | repeat |
| 2: | Select a 3D point for voxelisation |
| 3: | Find all neighboring points to be included in the voxel using r-NN within the specified maximum voxel length |
| 4: | Transform voxel into s-voxel by first finding and then assigning to it all the properties found by using PCA, including surface normal. |
| 5: | until all 3D points are used in a voxel |
| 6: | repeat |
| 7: | Specify an s-voxel as a principal link |
| 8: | Find all secondary links attached to the principal link |
| 9: | until all s-voxels are used |
| 10: | Link all principal links to form a chain removing redundant links in the process |
For the voxels we use a cuboid because of its symmetry, as it avoids fitting problems while grouping and also minimizes the effect of voxel shape during feature extraction. Although the maximum voxel size is predefined, the actual voxel sizes vary according to the maximum and minimum values of the neighboring points found along each axis to ensure the profile of the structure.
3.3. Clustering by Link-Chain Method
When the 3D data is converted into
s-voxels, the next step is to group these
s-voxels to segment into distinct objects. Usually for such tasks, a region growing algorithm [
33] is used in which the properties of the whole growing region may influence the boundary or edge conditions. This may sometimes lead to erroneous segmentation. Also common in such type of methods is a node based approach [
5] in which at every node, boundary conditions have to be checked in all 5 different possible directions. In our work, we have proposed a link-chain method instead to group these
s-voxels together into segmented objects.
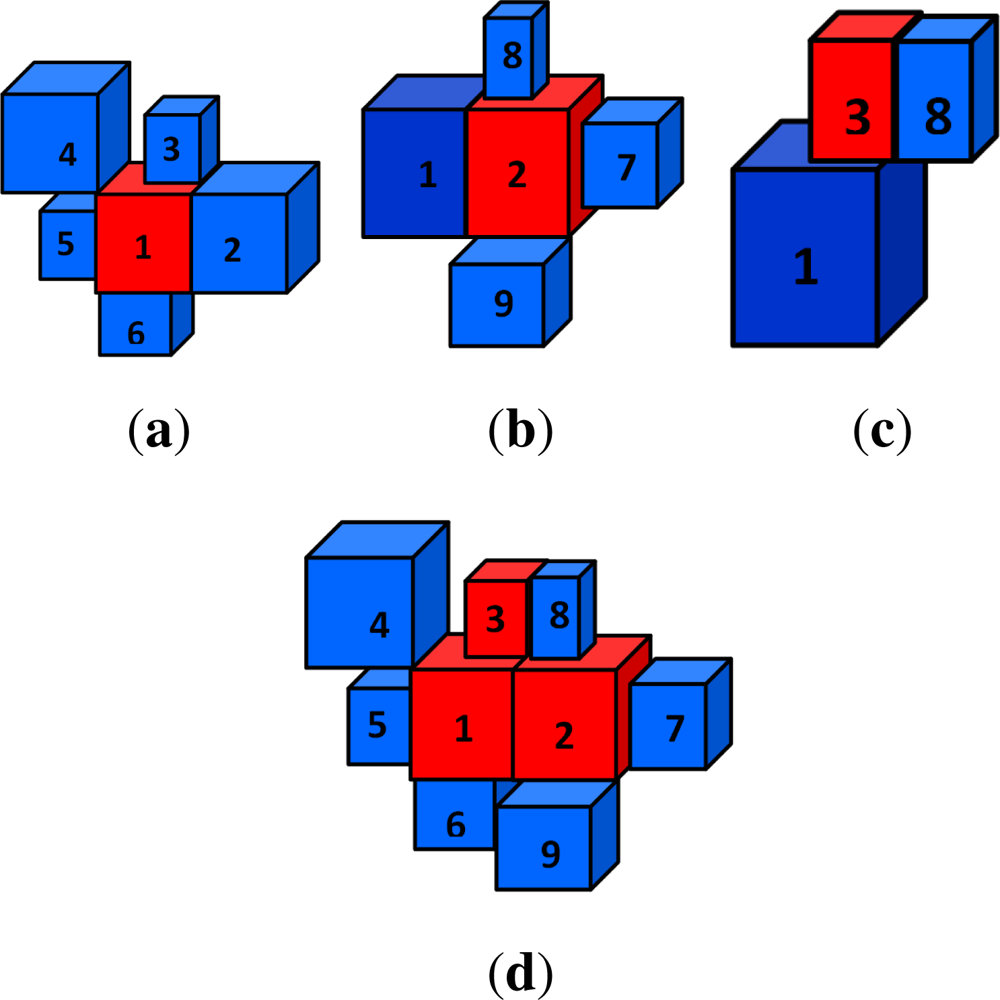
In this method, each
s-voxel is considered as a link of a chain. Unlike the classical region growing algorithm, where a region is progressively grown from a seed (carefully selected start point), in the proposed method any
s-voxel can be taken as a principal link and all secondary links attached to this principal link are found. The same is repeated for all
s-voxels till all
s-voxels are taken into account (see
Algorithm 1 for details). Thus there is no need of a specific start point, no preference for choice of principal link nor any directional constraint,
etc. In the final step, all the principal links are linked together to form a continuous chain removing redundant secondary links in the process as shown in
Figure 2. These clusters of
s-voxels represent the segmented objects.
Let
VP be a principal link and
Vn be the
nth secondary link. Each
Vn is linked to
VP if and only if the following three conditions are fulfilled:
where, for the principal and secondary link
s-voxels respectively:
VPX,Y,Z, VnX,Y,Z are the geometrical centers;
VPR,G,B, VnR,G,B are the mean R, G & B values;
VPI, VnI are the mean laser reflectance intensity values;
wC is the color weight equal to the maximum value of the two variances Var(R, G, B), i.e., max(VPVar(R,G,B), VnVar(R,G,B));
wI is the intensity weight equal to the maximum value of the two variances Var(I).
wD is the distance weight given as
. Here sX,Y,Z is the voxel size along X, Y & Z axis respectively. cD is the inter-distance constant (along the three dimensions) added depending upon the density of points and also to overcome measurement errors, holes and occlusions, etc. The value of cD needs to be carefully selected depending upon the data (see Section 6.5 for more details on the selection of this value). The orientation of normals is not considered in this stage to allow the segmentation of complete 3D objects as one entity instead of just planar faces.
This segmentation method ensures that only the adjacent boundary conditions are considered for segmentation with no influence of a distant neighbor’s properties. This may prove to be more adapted to sharp structural changes in the urban environment. An overview of the segmentation method is presented in
Algorithm 1. The programming structure adopted for implementation is based on standard graph-based algorithms [
34].
With this method 18, 541, 6, 928 and 7, 924 s-voxels obtained from processing 3 different data sets were successfully segmented into 237, 75 and 41 distinct objects respectively.
4. Classification of Segmented Objects
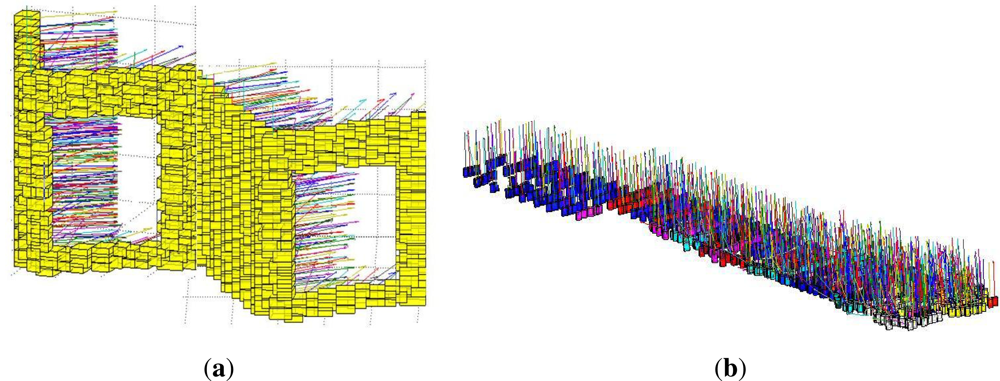
In order to classify these segmented objects, we assume the ground to be flat and use it as separator between objects. For this purpose we first classify and segment out the ground from the scene and then the rest of the objects. This step leaves the remaining objects as if suspended in space,
i.e., distinct and well separated, making them easier to be classified as shown in
Figure 3. In order to classify these segmented objects, a method is used that compares the geometrical models and local descriptors of these already segmented objects with a set of standard, predefined thresholds. The object types are so distinctly different that a simple choice of values for these differentiating thresholds is sufficient.
The ground or roads followed by these objects are classified using geometrical and local descriptors based on the constituting super-voxels. These mainly include:
- a.
Surface normals: The orientation of the surface normals is found essential for the classification of ground and building faces. For ground object the surface normals are predominantly (threshold values greater than 80%) along Z-axis (height axis), whereas for building faces the surface normals are predominantly (threshold values greater than 80%) parallel to the X-Y axis (ground plane), see
Figure 4.
- b.
Geometrical center and barycenter: The height difference between the geometrical center and the barycenter along with other properties is very useful in distinguishing objects like trees and vegetation, etc., where h(
barycenter − geometrical center) > 0, with h being the height function.
- c.
Color and intensity: Intensity and color are also an important discriminating factor for several objects.
- d.
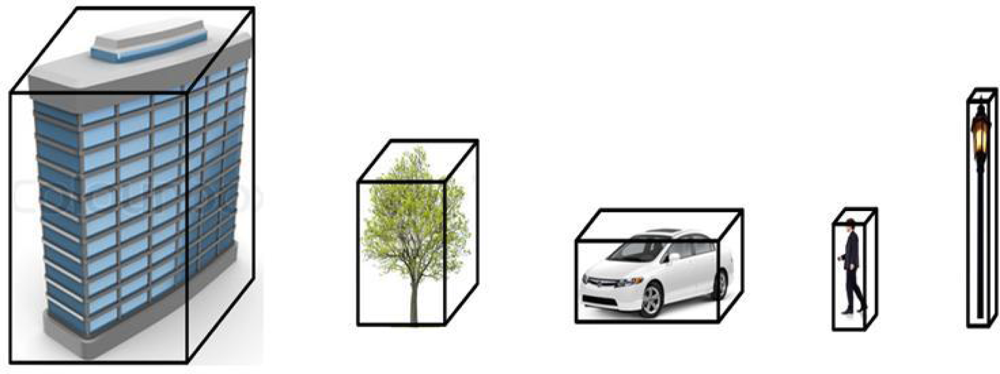
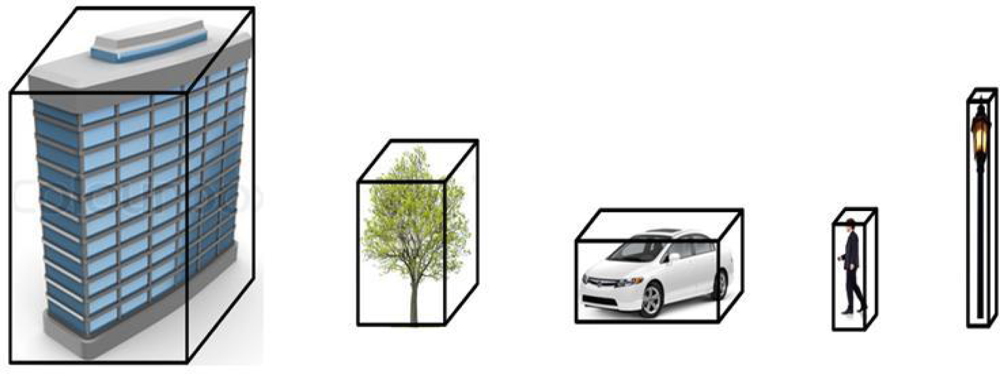
Geometrical shape: Along with the abovementioned descriptors, geometrical shape plays an important role in classifying objects. In 3D space, where pedestrians and poles are represented as long and thin with poles being longer, cars and vegetation are broad and short. Similarly, as roads represent a low flat plane, the buildings are represented as large (both in width and height) vertical blocks (as shown in
Figure 5). The values for these comparison threshold on the shape and size for each of the object types are set accordingly.
Using these descriptors we successfully classify urban scenes into 5 different classes (mostly present in our scenes), i.e., buildings, roads, cars, poles and trees. The object types chosen for classification are so distinctly different that if they are correctly segmented out, a simple classification method like the one proposed may be sufficient. The classification results and a new evaluation metric are discussed in the following sections.
5. Evaluation Metrics
Over the years, as new segmentation and classification methods are introduced, different evaluation metrics have been proposed to evaluate their performances. In previous works, different evaluation metrics are introduced for both segmentation results and classifiers independently. Thus in our work we present a new evaluation metric that incorporates both segmentation and classification together.
The evaluation method is based on comparing the total percentage of
s-voxels successfully classified as a particular object. Let
Ti,
i ∈ {1, ⋯
, N}, be the total number of
s-voxels distributed into objects belonging to
N number of different classes,
i.e., this serves as the ground truth, and let
tji,
i ∈ {1, ⋯
, N}, be the total number of
s-voxels classified as a particular class of type-
j and distributed into objects belonging to
N different classes (for example an
s-voxel classified as part of the building class may actually belong to a tree). Then the ratio
Sjk (
j is the class type as well as the row number of the matrix and
k ∈ {1, ⋯
, N}) is given as:
These values of Sjk are calculated for each type of class and are used to fill up each element of the confusion matrix, row by row (refer to tables in Section 6.1 for instance). Each row of the matrix represents a particular class.
Thus, for a class of type-1 (
i.e., first row of the matrix) the values of:
True Positive rate TP = S11 (i.e., the diagonal of the matrix represents the TPs)
False Positive rate
True Negative rate TN = (1 − FP)
False Negative rate FN = (1 − TP)
The diagonal of this matrix or
TPs gives the Segmentation ACCuracy (
SACC), similar to the voxel scores recently introduced by Douillard
et al. [
35]. The effects of unclassified
s-voxels are automatically incorporated in the segmentation accuracy. Using the above values, the Classification ACCuracy (
CACC) is given as:
This value of
CACC is calculated for all
N types of classes of objects present in the scene. Overall Classification ACCuracy (
OCACC) can then be calculated as
where
N is the total number of object classes present in the scene. Similarly, the Overall Segmentation ACCuracy (
OSACC) can also be calculated. The values of
Ti and
tji used above are laboriously evaluated by hand matching the voxelised data output and the final classified
s-voxels and points.
6. Results
In order to test our algorithm two different data sets were used:
The 3D Urban Data challenge data set not only is one of the most recent data set but also contains the corresponding RGB and reflectance intensity values necessary to validate the proposed method. The proposed method is also suitable and well adapted for directly geo-referenced 3D point clouds obtained from mobile data acquisition and mapping techniques [
37].
6.1. 3D Data Sets of Blaise Pascal University
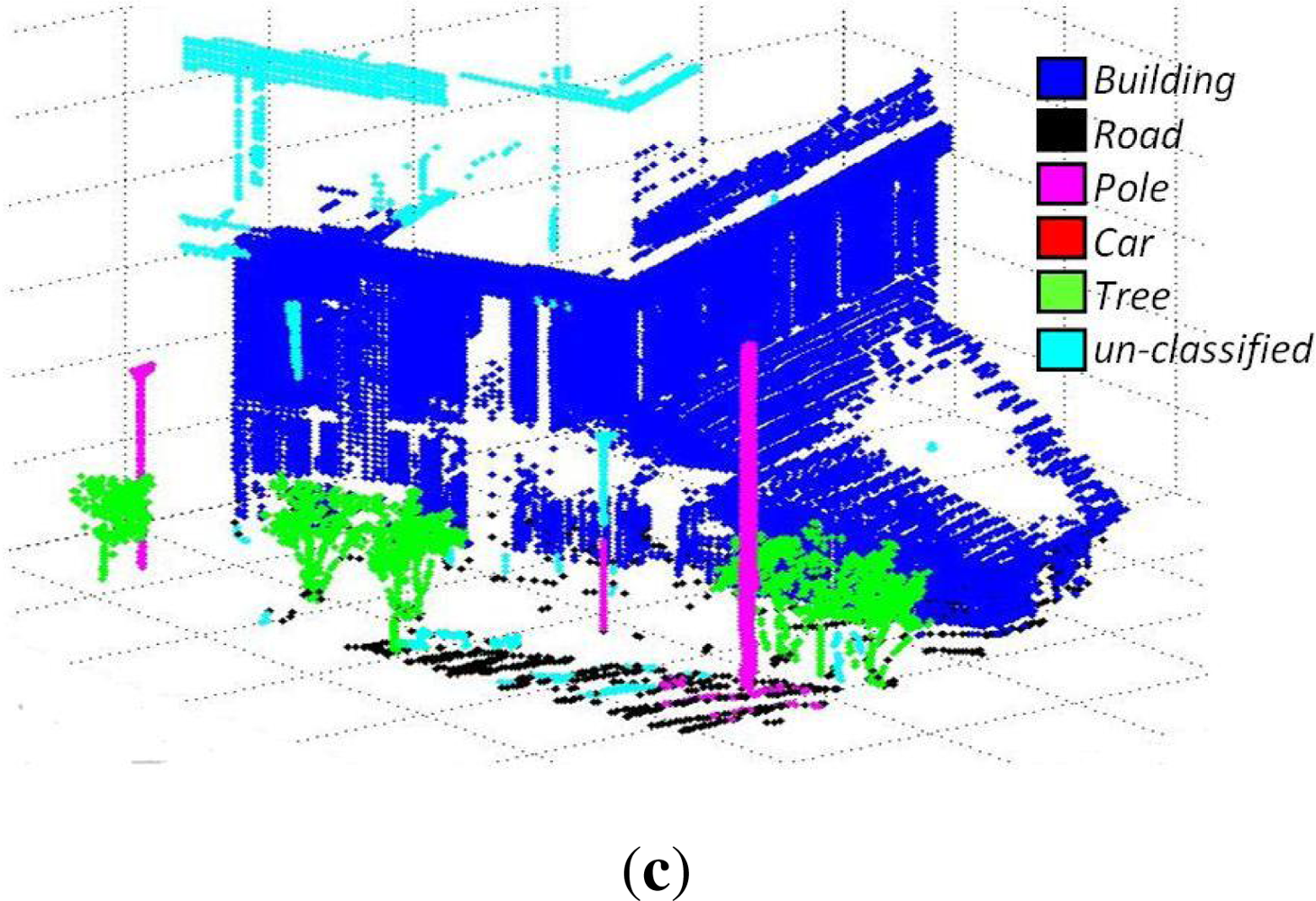
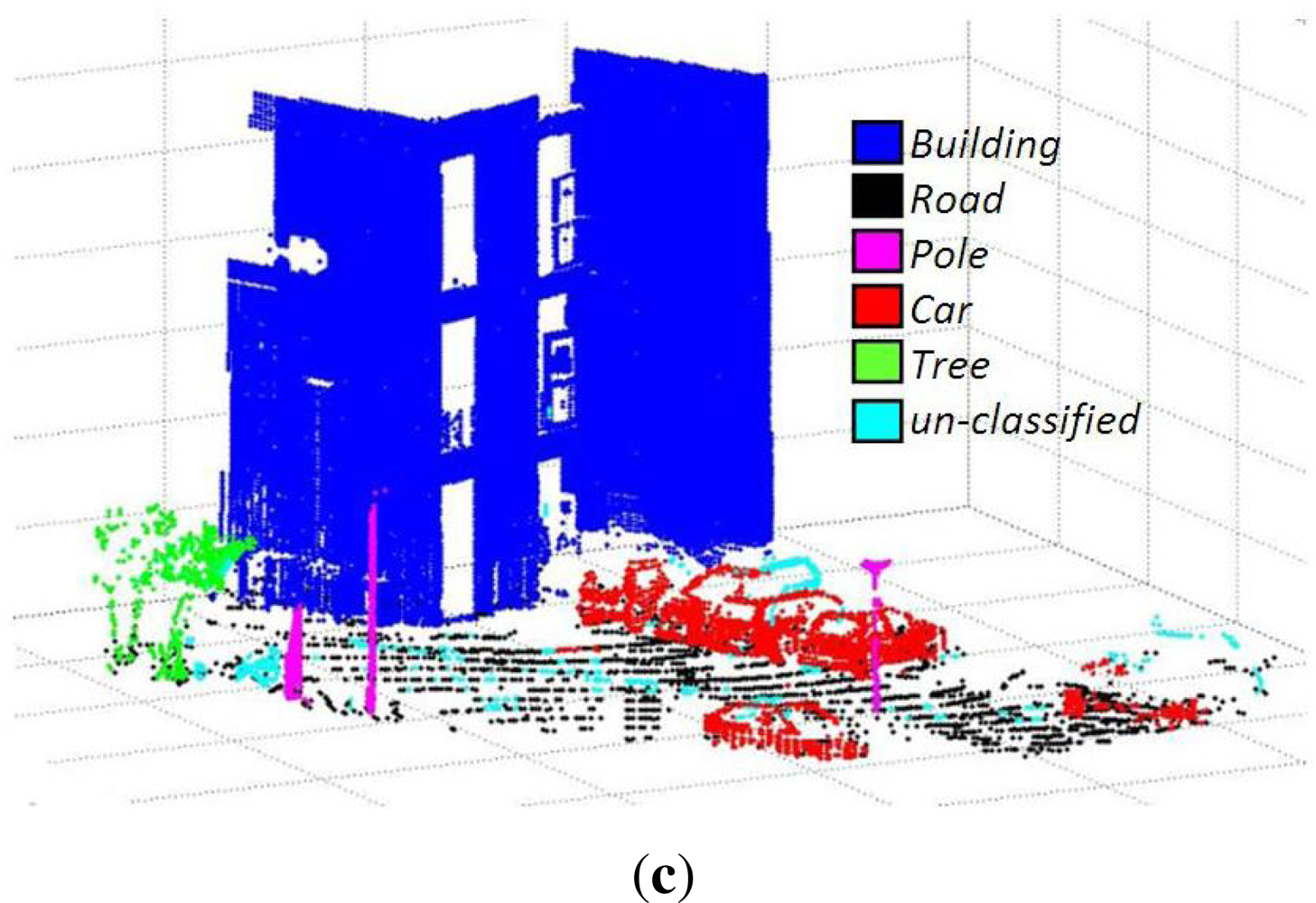
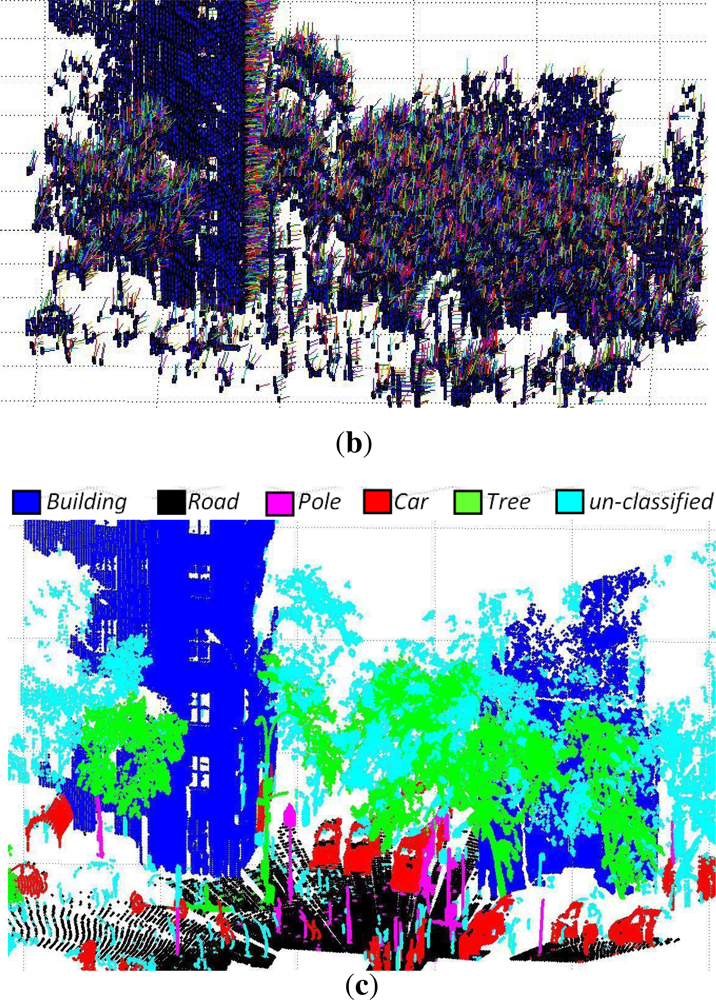
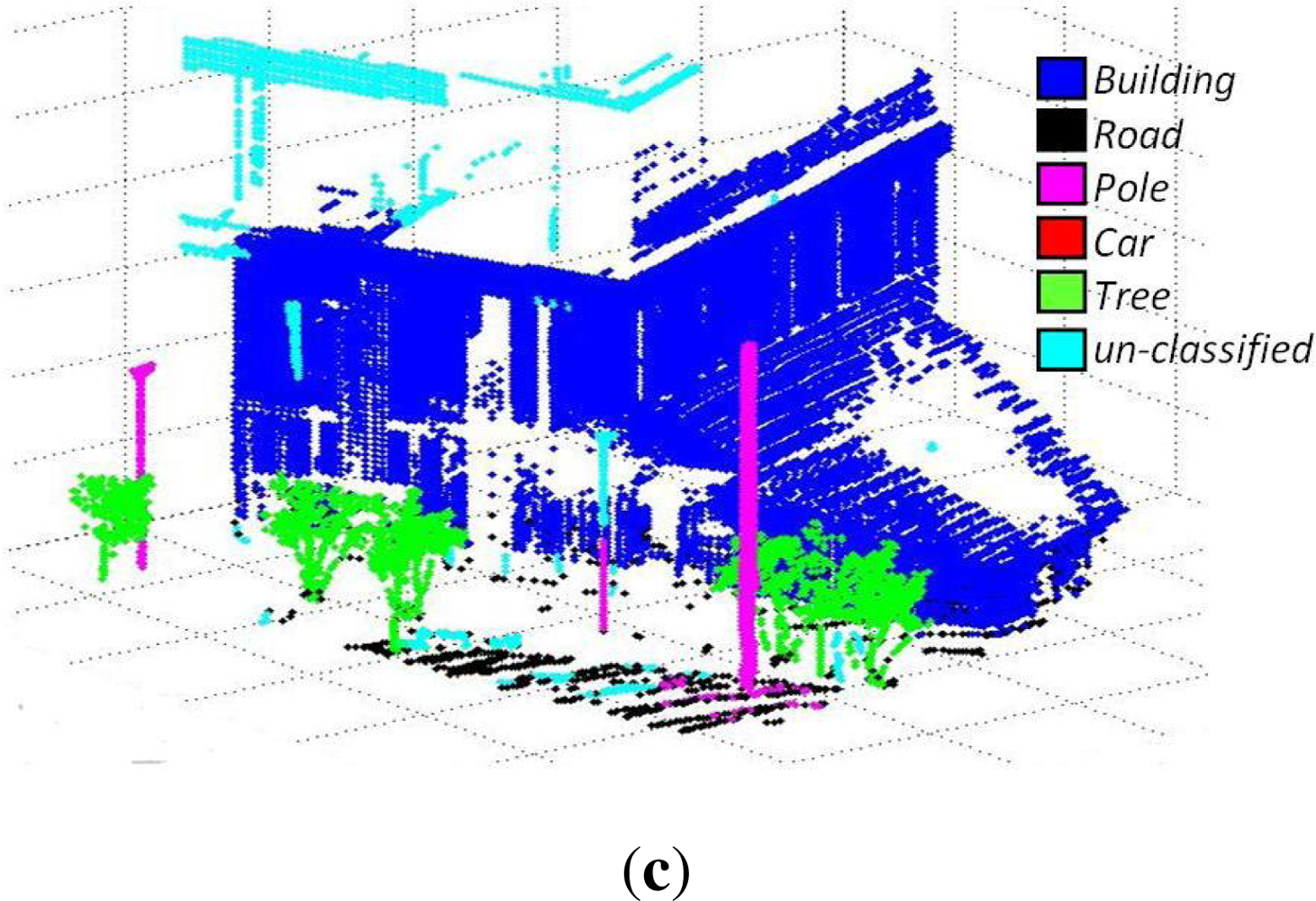
These data sets consist of 3D data acquired from different urban scenes on the Campus of Blaise Pascal University in Clermont-Ferrand, France, using a LEICA HDS-3000 3D laser scanner. The results of three such data sets are discussed here. The data sets consist of 27, 396, 53, 676 and 110, 392 3D points respectively. These 3D points were coupled with corresponding RGB and reflectance intensity values. The results are summarized in
Table 1 and shown in
Figures 6,
7 and
8 respectively. The evaluation results using the new evaluation metrics for the three data sets are presented in
Tables 2,
3 and
4 respectively. These results are evaluated using a value of maximum voxel size equal to 0.3 m and
cD = 0.25 m.
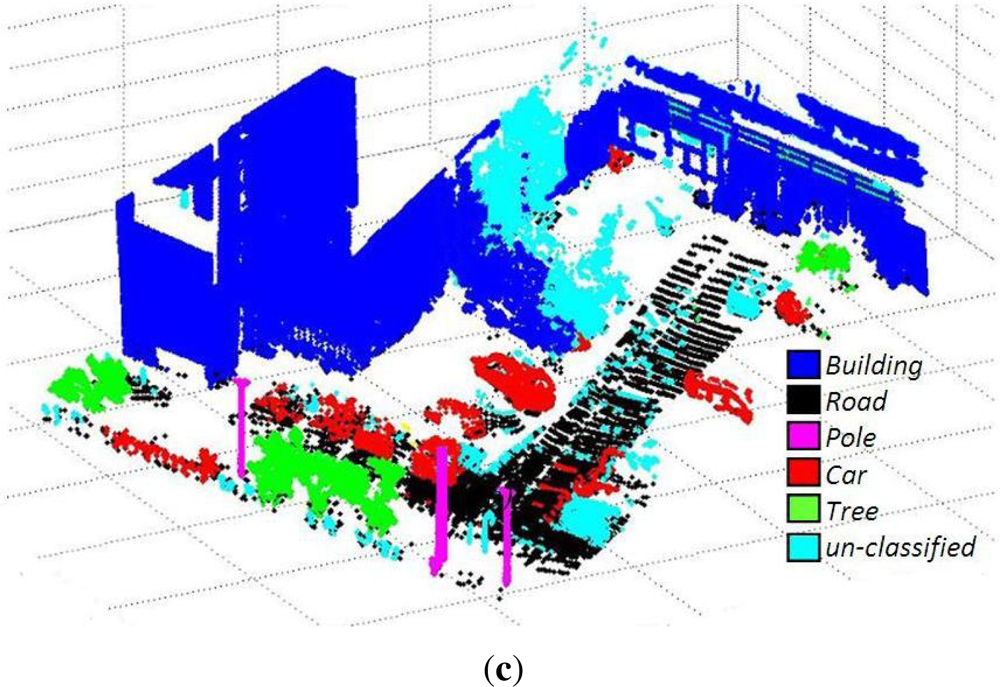
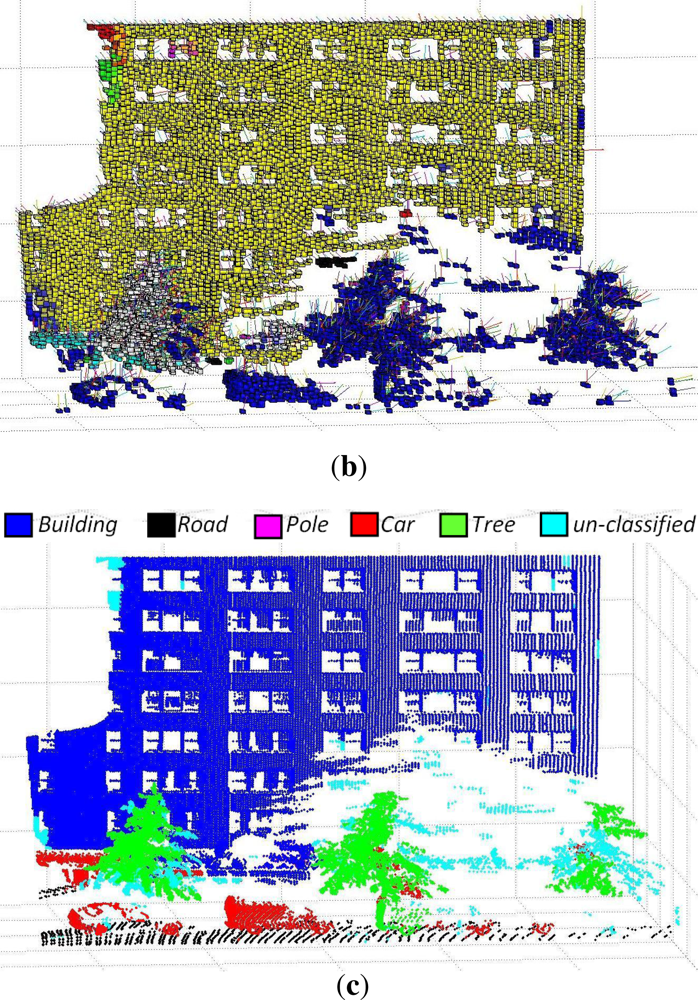
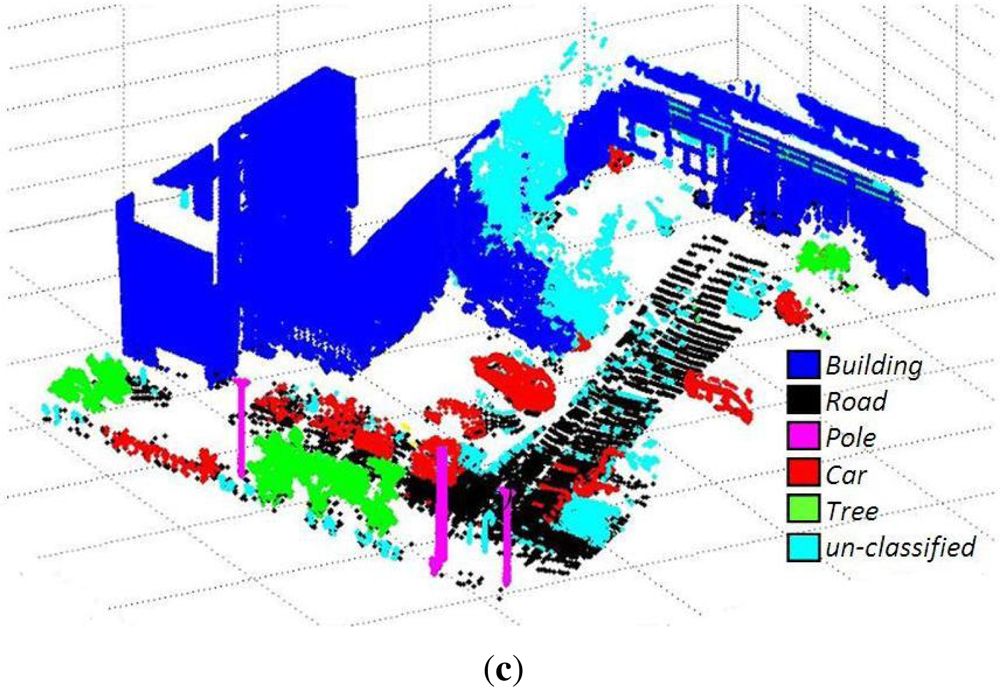
6.2. 3D Urban Data Challenge Data Set
The algorithm was further tested on the data set of the recently concluded 3D Urban Data Challenge 2011, acquired and used by the authors of [
36]. This standard data set contains a rich collection of 3D urban scenes of the New York city mainly focusing on building facades and structures. These 3D points are coupled with the corresponding RGB and reflectance intensity values. A value of maximum voxel size equal to 0.5 m and
cD = 0.15 m were used for this data set. Results (image results will be available in our website along with performance measures for comparison, after paper acceptance) of different scenes from this data set are shown in
Figures 9,
10 and
11 and
Tables 5,
6 and
7.
6.3. Comparison of Results with Existing Evaluation Methods
The classification results were also evaluated using already existing methods along with the proposed evaluation metrics for comparison purpose. Firstly, F-measure is used, which is one of the more frequently used metrics based on the calculation of Recall and Precision as described in [
38]. Secondly, V-measure is used, which is a conditional entropy based metrics based on the calculation of Homogeneity and Completeness as presented in [
39]. The later method overcomes the problem of matching suffered by the former and evaluates a solution independent of the algorithm, size of the data set, number of classes and number of clusters as explained in [
39]. Another advantage of using these two metrics is that, just like the proposed metrics, they have the same bounded score. For all three metrics, the score varies from 0 to 1 and higher score signifies better classification results and vice versa. The results are summarized in
Table 8.
From
Table 8 it can be seen that the results evaluated by all three evaluation metrics are consistent with data set 2 receiving the highest scores and data set 3 the lowest. The results not only validate the proposed metrics but also indicate that it can be used as an alternative evaluation method. The results evaluated using these standard existing evaluation methods also permits to compare the performance of the proposed algorithm with other published techniques evaluated using them.
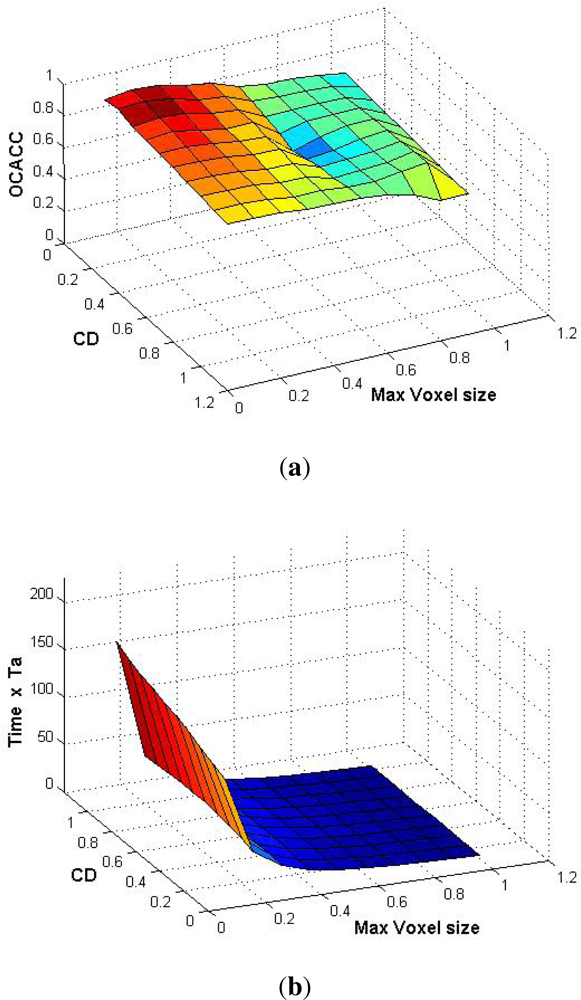
6.5. Effect of Voxel Size on Classification Accuracy and Choice of Optimal Values
Because the properties of s-voxels are constant mainly over the whole voxel length and these properties are then used for segmentation and classification, their size impacts the classification process. However, as the voxel size changes, the inter-distance constant cD also needs to be adjusted accordingly.
The effect of voxel size on the classification result was studied. The maximum voxel size and the value of
cD were varied from 0.1 m to 1.0 m on data set 1 and corresponding classification accuracy was calculated. The results are shown in
Figure 12(a). Then for the same variation of maximum voxel size and
cD, the variation in processing time was studied as shown in
Figure 12(b).
An arbitrary value of time Ta is chosen for comparison purposes (along Z-axis time varies from 0 to 200Ta). This makes the comparison results independent of the processor used, even though the same computer was used for all computations.
The results show that with smaller voxel size the segmentation and classification results are improved (with a suitable value of
cD) but the computational cost increases. It is also evident that variation in value of
cD has no significant impact on time
t. It is also observed that after a certain reduction in voxel size, the classification result does not improve much but the computational cost continues to increase manifolds. As both
OCACC and time (both plotted along Z-axis) are independent, using and combining the results of the two 3D plots in
Figure 12 we can find the optimal value (in terms of
OCACC and
t) of maximum voxel size and
cD depending upon the final application requirements. For our work, we have chosen a maximum voxel size of 0.3 m and
cD = 0.25 m.
6.6. Influence of RGB Color and Reflectance Intensity
The effect of incorporating RGB Color and reflectance intensity values on the segmentation and classification was also studied. The results are presented in
Table 9.
It is observed that incorporating RGB color alone is not sufficient in an urban environment due to the fact that it is heavily affected by illumination variation (part of an object may be under shade or reflect bright sunlight) even in the same scene. This deteriorates the segmentation process and hence the classification. This is perhaps responsible for the lower classification accuracy as seen in the first part of
Table 9. It is the reason why intensity values are incorporated as they are more illumination invariant and found to be more consistent. The improved classification results are presented in the second part of
Table 9.
6.7. Considerations for Further Improvements
The evaluated results of the proposed method on real and standard data sets show great promise. In order to complete this performance evaluation, comparison with other existing segmentation and classification methods is underway. While the method has successfully classified the urban environment into 5 basic object classes, an extension of this method to introduce more object classes is also being considered. One possible way could be to increase the number of features being used and train the classifier.
7. Conclusions
In this work we have presented a super-voxel based segmentation and classification method for 3D urban scenes. For segmentation a link-chain method is proposed. It is followed by the classification of objects using local descriptors and geometrical models. In order to evaluate our work we have introduced a new evaluation metric that incorporates both segmentation and classification results. The results show an overall segmentation accuracy (OSACC) of 87% and an overall classification accuracy (OCACC) of about 90%. The results indicate that with good segmentation, a simplified classification method like the one proposed is sufficient.
Our study shows that the classification accuracy improves by reducing voxel size (with an appropriate value of cD) but at the cost of processing time. Thus a choice of an optimal value, as discussed, is recommended. The study also demonstrates the importance of using laser reflectance intensity values along with RGB colors in the segmentation and classification of urban environment, as they are more illumination invariant and more consistent.
The proposed method can also be used as an add-on boost for other classification algorithms.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}