
SAR-DRBNet: Adaptive Feature Weaving and Algebraically Equivalent Aggregation for High-Precision Rotated SAR Detection

 , ,
, ,
Highlights
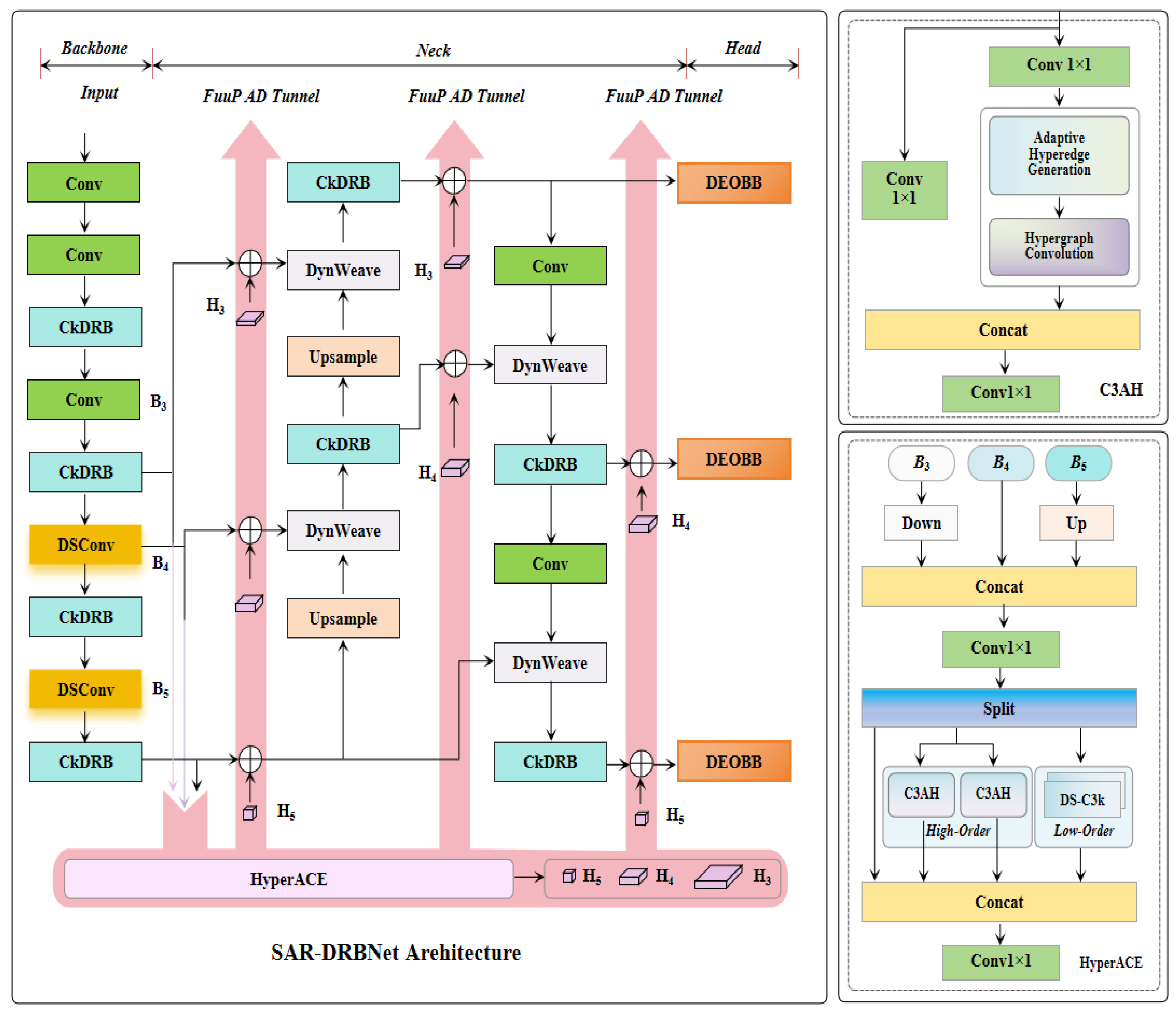
- Proposed SAR-DRBNet, a high-precision rotated object detection method based on YOLOv13, integrating three novel modules: DEOBB (Detail-Enhanced Oriented Bounding Box Detect Head), CkDRB (Ck-MultiDilated Reparam Block), and DynWeave (Dynamic Feature Weaving Module).
- DEOBB enhances small target perception and rotation invariance via multi-branch enhanced convolution, while CkDRB utilizes re-parameterization and dilated convolutions to efficiently extract multi-scale features and suppress SAR speckle noise.
- Extensive experiments on HRSID, RSDD-SAR, and DSSDD datasets demonstrate that SAR-DRBNet outperforms state-of-the-art OBB detectors, achieving an optimal balance between accuracy and efficiency with strong cross-dataset generalization.
- Demonstrates the effectiveness of “Algebraically Equivalent Aggregation” (via CkDRB) in resolving the conflict between inference speed and noise suppression capability in complex SAR imagery.
- Validates that dynamic feature weaving (DynWeave), through global–local dual attention, significantly improves robustness against scale diversity and complex backgrounds, providing a stable and efficient technical solution for rotated SAR detection.
Abstract
1. Introduction
- (1)
- To enhance feature perception for rotated small targets in SAR imagery, a DEOBB detection head is proposed. By incorporating multi-branch enhanced convolutions, the detection head performs multi-channel feature extraction and detail enhancement, enabling accurate regression of rotated object boundaries and high-fidelity feature representation. This design significantly improves detection accuracy and rotation invariance for small rotated targets.
- (2)
- To address multi-scale target representation and speckle noise interference in SAR images, the CkDRB module is introduced. This module combines multi-branch dilated convolutions with a reparameterization mechanism to efficiently extract features of targets at different scales while suppressing noise, achieving a favorable balance between detection performance and computational efficiency.
- (3)
- To further enhance feature representation for rotated small targets, the DynWeave module is designed by integrating global–local dual attention mechanisms with dynamic large-kernel convolutions. This module adaptively fuses features across different scales and orientations, effectively improving rotation robustness and feature discrimination capability in complex scenes, thereby enhancing overall detection accuracy and stability.
2. Related Work
2.1. Two-Stage Detection Methods
2.2. Single-Stage Detection Methods
2.3. Transformer-Based Detection Methods
3. Materials and Methods
3.1. Detail-Enhanced Oriented Bounding Box Detection Head (DEOBB)
- (1)
- Group-Normalized Detail-Enhanced Convolution
- (2)
- Oriented Bounding Box Prediction
3.2. Ck-MultiDilated Reparameterization Block (CkDRB)
| Algorithm 1: Ck-MultiDilated Reparameterization Block (CkDRB) | |
| 1: | Input: ; main-branch depthwise kernel (large-kernel DWConv) and BN parameters ; auxiliary dilated depthwise kernels with dilation rates and branch-wise BN parameters . |
| 2: | //Training-time forward (code-consistent): branch-wise BN then summation |
| 3: | |
| 4: | for to do |
| 5: | |
| 6: | end for |
| 7: | //Inference-time re-parameterization |
| 8: | |
| 9: | |
| 10: | for to do |
| 11: | |
| 12: | |
| 13: | |
| 14: | |
| 15: | end for |
| 16: | |
| 17: | Output: training output or inference output |
| Note. * denotes depthwise convolution (DWConv, groups = C) with same padding; indicates depthwise convolution with dilation rate . In training, the output is obtained by summing the branch-wise BN-normalized responses from the main and dilated branches. In inference, BN is fused into each branch to produce (); each dilated kernel is expanded to an equivalent dense kernel and center-aligned/padded to the main kernel size, after which all kernels and biases are accumulated into a single deployable (, ). | |
3.3. Dynamic Feature Weaving Module (Complete Formulation)
- (1)
- Channel Unification and Spatial Alignment
- (2)
- Global Channel Attention with Joint–Split Weaving
- (3)
- Local Spatial Attention with Dual Spatial Weaving
- (4)
- Dynamic Large-Kernel Enhancement and Gated Output
| Algorithm 2: Dynamic Feature Weaving (DynWeave) | |
| 1: | Input: Deep features , Skip connection features |
| 2: | Initialize target dimension |
| 3: | , |
| 4: | if then |
| 5: | //Attention & Weaving |
| 6: | |
| 7: | |
| 8: | |
| 9: | |
| 10: | |
| 11: | //Fusion & Dynamic Enhancement |
| 12: | |
| 13: | |
| 14: | Output: Fused feature map |
| Note: represents the Sigmoid function; denotes element-wise multiplication; denotes depth-wise convolution used for local spatial context. | |
4. Results
4.1. Experimental Platform and Evaluation Metrics
4.2. Datasets
- (1)
- High-Resolution SAR Images Dataset (HRSID)
- (2)
- Rotated Ship Detection Dataset in SAR Images (RSDD-SAR)
- (3)
- Dual-Polarimetric SAR Ship Detection Dataset (DSSDD)
4.3. Ablation Study and Comparison Experiments
4.3.1. Ablation Experiments on the HRSID Dataset
4.3.2. Ablation Experiments on the DSSDD Dataset
4.3.3. Ablation Experiments on the RSDD Dataset
4.3.4. Model Comparison Experiments on the HRSID Dataset
4.3.5. Model Comparison Experiments on the DSSDD Dataset
4.3.6. Model Comparison Experiments on the RSDD Dataset
4.3.7. Visualization Analysis of the Speckle Noise Suppression Effect of CkDRB
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, Z.; Leng, X.; Zhang, X.; Xiong, B.; Ji, K.; Kuang, G. Ship recognition for complex SAR images via dual-branch transformer fusion network. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Sun, Z.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. BiFA-YOLO: A novel YOLO-based method for arbitrary-oriented ship detection in high-resolution SAR images. Remote Sens. 2021, 13, 4209. [Google Scholar] [CrossRef]
- Liu, T.; Yang, Z.; Yang, J.; Gao, G. CFAR ship detection methods using compact polarimetric SAR in a K-Wishart distribution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3737–3745. [Google Scholar] [CrossRef]
- Jamali, A.; Roy, S.K.; Beni, L.H.; Pradhan, B.; Li, J.; Ghamisi, P. Residual wave vision U-Net for flood mapping using dual polarization Sentinel-1 SAR imagery. Int. J. Appl. Earth Obs. Geoinf. 2024, 127, 103662. [Google Scholar] [CrossRef]
- Han, S.; Wang, J.; Zhang, S. Former-CR: A transformer-based thick cloud removal method with optical and SAR imagery. Remote Sens. 2023, 15, 1196. [Google Scholar] [CrossRef]
- Duan, Y.; Sun, K.; Li, W.; Wei, J.; Gao, S.; Tan, Y.; Zhou, W.; Liu, J.; Liu, J. WCMU-net: An effective method for reducing the impact of speckle noise in SAR image change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 18, 2880–2892. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Li, S. Study on Coherent Speckle Noise Suppression in the SAR Images Based on Regional Division. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 11703–11715. [Google Scholar] [CrossRef]
- Hu, Q.; Peng, Y.; Zhang, C.; Lin, Y.; Kintak, U.; Chen, J.J.B. Building Instance Extraction via Multi-Scale Hybrid Dual-Attention Network. Buildings 2025, 15, 3102. [Google Scholar] [CrossRef]
- Chang, S.; Tang, S.; Deng, Y.; Zhang, H.; Liu, D.; Wang, W. An Advanced Scheme for Deceptive Jammer Localization and Suppression in Elevation Multichannel SAR for Underdetermined Scenarios. IEEE Trans. Aerosp. Electron. Syst. 2025, 61, 1–18. [Google Scholar] [CrossRef]
- Deng, Y.; Tang, S.; Chang, S.; Zhang, H.; Liu, D.; Wang, W. A Novel Scheme for Range Ambiguity Suppression of Spaceborne SAR Based on Underdetermined Blind Source Separation. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–15. [Google Scholar] [CrossRef]
- Chang, S.; Deng, Y.; Zhang, Y.; Zhao, Q.; Wang, R.; Jia, X. An Advanced Scheme for Range Ambiguity Suppression of Spaceborne SAR Based on Cocktail Party Effect. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 2075–2078. [Google Scholar]
- Chang, S.; Deng, Y.; Zhang, Y.; Zhao, Q.; Wang, R.; Zhang, K. An Advanced Scheme for Range Ambiguity Suppression of Spaceborne SAR Based on Blind Source Separation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Kaplan, L.M. Improved SAR target detection via extended fractal features. IEEE Trans. Aerosp. Electron. Syst. 2001, 37, 436–451. [Google Scholar] [CrossRef]
- Martí-Cardona, B.; López-Martínez, C.; Dolz-Ripollés, J. Local Isotropy Indicator for SAR Image Filtering: Application to Envisat/ASAR Images of the Doñana Wetland (November 2014). IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 8, 1614–1622. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Du, L.; Zhang, R.; Wang, X. Overview of two-stage object detection algorithms. J. Phys. Conf. Ser. 2020, 1544, 012033. [Google Scholar] [CrossRef]
- Shah, S.; Tembhurne, J.V. Object detection using convolutional neural networks and transformer-based models: A review. J. Electr. Syst. Inf. Technol. 2023, 10, 54. [Google Scholar] [CrossRef]
- Lei, M.; Li, S.; Wu, Y.; Hu, H.; Zhou, Y.; Zheng, X.; Ding, G.; Du, S.; Wu, Z.; Gao, Y. YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception. arXiv 2025, arXiv:2506.17733. [Google Scholar]
- Rohling, H. Radar CFAR thresholding in clutter and multiple target situations. IEEE Trans. Aerosp. Electron. Syst. 2007, AES-19, 608–621. [Google Scholar] [CrossRef]
- Song, S.; Xu, B.; Yang, J. SAR target recognition via supervised discriminative dictionary learning and sparse representation of the SAR-HOG feature. Remote Sens. 2016, 8, 683. [Google Scholar] [CrossRef]
- Dellinger, F.; Delon, J.; Gousseau, Y.; Michel, J.; Tupin, F. SAR-SIFT: A SIFT-like algorithm for SAR images. IEEE Trans. Geosci. Remote Sens. 2014, 53, 453–466. [Google Scholar] [CrossRef]
- Li, H.L.; Chen, S.W. General Polarimetric Correlation Pattern: A Visualization and Characterization Tool for Target Joint-Domain Scattering Mechanisms Investigation. IEEE Trans. Geosci. Remote Sens. 2026, 64, 1–17. [Google Scholar] [CrossRef]
- Li, H.-L.; Chen, S.-W. Polyhedral corner reflectors multi-domain joint characterization with fully polarimetric radar. IEEE Trans. Antennas Propag. 2025, 73, 10679–10693. [Google Scholar] [CrossRef]
- Li, H.-L.; Liu, S.-W.; Chen, S.-W.J. PolSAR ship characterization and robust detection at different grazing angles with polarimetric roll-invariant features. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–18. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and excitation rank faster R-CNN for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 751–755. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense attention pyramid networks for multi-scale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Zhang, X.; Huo, C.; Xu, N.; Jiang, H.; Cao, Y.; Ni, L.; Pan, C. Multitask learning for ship detection from synthetic aperture radar images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8048–8062. [Google Scholar] [CrossRef]
- Wu, Z.; Hou, B.; Ren, B.; Ren, Z.; Wang, S.; Jiao, L. A deep detection network based on interaction of instance segmentation and object detection for SAR images. Remote Sens. 2021, 13, 2582. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X. Quad-FPN: A novel quad feature pyramid network for SAR ship detection. Remote Sens. 2021, 13, 2771. [Google Scholar] [CrossRef]
- Chai, B.; Nie, X.; Zhou, Q.; Zhou, X. Enhanced cascade R-CNN for multiscale object detection in dense scenes from SAR images. IEEE Sens. J. 2024, 24, 20143–20153. [Google Scholar] [CrossRef]
- Zhan, S.; Zhong, M.; Yang, Y.; Lu, G.; Zhou, X. MFT-Reasoning RCNN: A Novel Multi-Stage Feature Transfer Based Reasoning RCNN for Synthetic Aperture Radar (SAR) Ship Detection. Remote Sens. 2025, 17, 1170. [Google Scholar] [CrossRef]
- Kamirul, K.; Pappas, O.; Achim, A. Sparse R-CNN OBB: Ship Target Detection in SAR Images Based on Oriented Sparse Proposals. arXiv 2024, arXiv:2409.07973. [Google Scholar] [CrossRef]
- Jiang, M.; Gu, L.; Li, X.; Gao, F.; Jiang, T. Ship contour extraction from SAR images based on faster R-CNN and Chan–Vese model. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Chen, J.; Shen, Y.; Liang, Y.; Wang, Z.; Zhang, Q. Yolo-sad: An efficient SAR aircraft detection network. Appl. Sci. 2024, 14, 3025. [Google Scholar] [CrossRef]
- Chen, P.; Wang, Y.; Liu, H. GCN-YOLO: YOLO based on graph convolutional network for SAR vehicle target detection. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, C.; Filaretov, V.F.; Yukhimets, D.A. Multi-scale ship detection algorithm based on YOLOv7 for complex scene SAR images. Remote Sens. 2023, 15, 2071. [Google Scholar] [CrossRef]
- Guan, T.; Chang, S.; Wang, C.; Jia, X. SAR Small Ship Detection Based on Enhanced YOLO Network. Remote Sens. 2025, 17, 839. [Google Scholar] [CrossRef]
- Tan, X.; Leng, X.; Luo, R.; Sun, Z.; Ji, K.; Kuang, G. YOLO-RC: SAR ship detection guided by characteristics of range-compressed domain. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 18834–18851. [Google Scholar] [CrossRef]
- Yan, C.; Peng, X. DA-YOLO: A dynamic adaptive network for SAR ship detection. Earth Sci. Inform. 2025, 18, 536. [Google Scholar] [CrossRef]
- Jiang, S.; Zhou, X. DWSC-YOLO: A lightweight ship detector of SAR images based on deep learning. J. Mar. Sci. Eng. 2022, 10, 1699. [Google Scholar] [CrossRef]
- Zhang, C.; Yu, R.; Wang, S.; Zhang, F.; Ge, S.; Li, S.; Zhao, X. Edge-Optimized Lightweight YOLO for Real-Time SAR Object Detection. Remote Sens. 2025, 17, 2168. [Google Scholar] [CrossRef]
- He, H.; Hu, T.; Xu, S.; Xu, H.; Song, L.; Sun, Z. PPDM-YOLO: A Lightweight Algorithm for SAR Ship Image Target Detection in Complex Environments. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 22690–22705. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, D.; Wu, B.; An, D. NST-YOLO11: ViT merged model with neuron attention for arbitrary-oriented ship detection in SAR images. Remote Sens. 2024, 16, 4760. [Google Scholar] [CrossRef]
- Chen, H.; Chen, C.; Wang, F.; Shi, Y.; Zeng, W. RSNet: A Light Framework for The Detection of SAR Ship Detection. arXiv 2024, arXiv:2410.23073. [Google Scholar]
- Zhang, Y.; Sun, Z.; Chang, S.; Tang, B.; Hou, B. SegS-YOLO: A YOLO-Based Instance Segmentation Approach for Small-Scale Ship Targets in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2026, 19, 2658–2679. [Google Scholar] [CrossRef]
- Xia, R.; Chen, J.; Huang, Z.; Wan, H.; Wu, B.; Sun, L.; Yao, B.; Xiang, H.; Xing, M. CRTransSar: A visual transformer based on contextual joint representation learning for SAR ship detection. Remote Sens. 2022, 14, 1488. [Google Scholar] [CrossRef]
- Zhou, Y.; Jiang, X.; Xu, G.; Yang, X.; Liu, X.; Li, Z. PVT-SAR: An arbitrarily oriented SAR ship detector with pyramid vision transformer. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 291–305. [Google Scholar] [CrossRef]
- Zhao, S.; Luo, Y.; Zhang, T.; Guo, W.; Zhang, Z. A domain specific knowledge extraction transformer method for multisource satellite-borne SAR images ship detection. ISPRS J. Photogramm. Remote Sens. 2023, 198, 16–29. [Google Scholar] [CrossRef]
- Feng, Y.; You, Y.; Tian, J.; Meng, G. OEGR-DETR: A novel detection transformer based on orientation enhancement and group relations for SAR object detection. Remote Sens. 2023, 16, 106. [Google Scholar] [CrossRef]
- Fang, M.; Gu, Y.; Peng, D. FEVT-SAR: Multi-category oriented SAR ship detection based on feature enhancement vision transformer. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 18, 2704–2717. [Google Scholar] [CrossRef]
- Sun, Z.; Zhang, X.; Leng, X.; Wu, X.; Xiong, B.; Ji, K.; Kuang, G. KFIA-Net: A knowledge fusion and imbalance-awarenetwork for multi-category SAR ship detection. Int. J. Appl. Earth Obs. Geoinf. 2026, 146, 105127. [Google Scholar] [CrossRef]
- Yang, Z.; Xia, X.; Liu, Y.; Wen, G.; Zhang, W.E.; Guo, L. LPST-Det: Local-perception-enhanced swin transformer for SAR ship detection. Remote Sens. 2024, 16, 483. [Google Scholar] [CrossRef]
- Zhou, S.; Zhang, M.; Wu, L.; Yu, D.; Li, J.; Fan, F.; Zhang, L.; Liu, Y. Lightweight sar ship detection network based on transformer and feature enhancement. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4845–4858. [Google Scholar] [CrossRef]
- Sivapriya, M.; Suresh, S. ViT-DexiNet: A vision transformer-based edge detection operator for small object detection in SAR images. Int. J. Remote Sens. 2023, 44, 7057–7084. [Google Scholar] [CrossRef]
- Qin, C.; Zhang, L.; Wang, X.; Li, G.; He, Y.; Liu, Y. RDB-DINO: An improved end-to-end transformer with refined de-noising and boxes for small-scale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2024, 63, 1–17. [Google Scholar] [CrossRef]
- Li, T.; Wang, C.; Tian, S.; Zhang, B.; Wu, F.; Tang, Y.; Zhang, H. TACMT: Text-Aware Cross-Modal Transformer for Visual Grounding on High-Resolution SAR Images. ISPRS J. Photogramm. Remote Sens. 2025, 222, 152–166. [Google Scholar] [CrossRef]
- Zhang, Y.; Cao, J.; You, Y.; Qiao, Y. DenSe-AdViT: A novel Vision Transformer for Dense SAR Object Detection. arXiv 2025, arXiv:2504.13638. [Google Scholar]
- Luo, Z.; Zeng, Z.; Tang, W.; Wan, J.; Xie, Z.; Xu, Y. Dense dual-branch cross attention network for semantic segmentation of large-scale point clouds. IEEE Trans. Geosci. Remote Sens. 2023, 62, 1–16. [Google Scholar] [CrossRef]
- Luo, Z.; Zeng, Z.; Wan, J.; Tang, W.; Jin, Z.; Xie, Z.; Xu, Y. D2T-Net: A dual-domain transformer network exploiting spatial and channel dimensions for semantic segmentation of urban mobile laser scanning point clouds. Int. J. Appl. Earth Obs. Geoinf. 2024, 132, 104039. [Google Scholar] [CrossRef]
- Luo, Z.; Zeng, T.; Jiang, X.; Peng, Q.; Ma, Y.; Xie, Z.; Pan, X. Dense Supervised Dual-Aware Contrastive Learning for Airborne Laser Scanning Weakly Supervised Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–15. [Google Scholar] [CrossRef]
- Zhang, Y.; Ding, X.; Yue, X. Scaling up your kernels: Large kernel design in convnets towards universal representations. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 11692–11707. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Congan, X.; Hang, S.; Jianwei, L.; Yu, L.; Libo, Y.; Long, G.; Wenjun, Y.; Taoyang, W. RSDD-SAR: Rotated ship detection dataset in SAR images. J. Radars 2022, 11, 581–599. [Google Scholar]
- Hu, Y.; Li, Y.; Pan, Z. A dual-polarimetric SAR ship detection dataset and a memory-augmented autoencoder-based detection method. Sensors 2021, 21, 8478. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Hou, B.; Wu, Z.; Ren, B.; Yang, C. FCOSR: A simple anchor-free rotated detector for aerial object detection. Remote Sens. 2023, 15, 5499. [Google Scholar] [CrossRef]
- Yang, S.; Pei, Z.; Zhou, F.; Wang, G. Rotated faster R-CNN for oriented object detection in aerial images. In Proceedings of the 2020 3rd International Conference on Robot Systems and Applications, Chengdu, China, 13 July 2020; pp. 35–39. [Google Scholar]
- Zhang, Y.; Chen, C.; Hu, R.; Yu, Y. ESarDet: An efficient SAR ship detection method based on context information and large effective receptive field. Remote Sens. 2023, 15, 3018. [Google Scholar] [CrossRef]
- He, R.; Han, D.; Shen, X.; Han, B.; Wu, Z.; Huang, X. AC-YOLO: A lightweight ship detection model for SAR images based on YOLO11. PLoS ONE 2025, 20, e0327362. [Google Scholar] [CrossRef]
- Hu, R.; Lin, H.; Lu, Z.; Xia, J. Despeckling Representation for Data-Efficient SAR Ship Detection. IEEE Geosci. Remote Sens. Lett. 2024, 22, 1–5. [Google Scholar] [CrossRef]
- Feng, Y.; Huang, J.; Du, S.; Ying, S.; Yong, J.-H.; Li, Y.; Ding, G.; Ji, R.; Gao, Y. Hyper-yolo: When visual object detection meets hypergraph computation. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 47, 2388–2401. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Yeh, I.-H.; Mark Liao, H.-Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environmental Parameter | Value |
|---|---|
| Operating system | Ubuntu 18.04 |
| Deep learning framework | Pytorch 2.1.1 |
| Programming language | Python 3.8 |
| CPU | Intel Xeon Scale 8358 |
| GPU | NVIDIA A100 (SXM4, 80 GB) |
| RAM | 256 GB |
| Hyperparameters | Value |
|---|---|
| Learning Rate | 0.01 |
| Image Size | 640 × 640 |
| Momentum | SGD |
| Batch Size | 32 |
| Weight decay | 0.0005 |
| Optimizer | SGD |
| Epoch | 300 |
| Weight Decay | 0.0005 |
| Dataset | HRSID | RSDD-SAR | DSSDD |
|---|---|---|---|
| Images | 5604 | 7000 | 1236 |
| Image Size/Res. | 800 × 800 pixels/0.5–3 m | 512 × 512 pixels/ multi-resolution | 256 × 256 pixels/ ~9 m × 14 m |
| Polarization | VV, HV, HH | Multiple polarization modes (GF-3, TerraSAR-X) | VV, VH |
| Key Strengths | Large, high-resolution, fine-grained; ideal for training complex models | Arbitrary object orientations, large aspect ratios, high proportion of small targets, diverse scenes | Dual-polarization pseudo-color fusion, 98% of targets are small targets |
| Dataset | Split Strategy | Train (Images/Patches) | Train Instances | Val (Images/Patches) | Val Instances |
|---|---|---|---|---|---|
| HRSID | Custom (8:2) | 4483 images | 13,344 | 1121 images | 3607 |
| RSDD-SAR | Official | 5600 patches | 8144 | 1400 patches | 2119 |
| DSSDD | Official | 856 patches | 2277 | 380 patches | 1139 |
| Dataset | Total Inst. | Small Inst. (%) (A < 1024) | Area A (px2) P5/P50/P95 | w (px) P5/P50/P95 | w (px) P5/P50/P95 |
|---|---|---|---|---|---|
| HRSID | 16,951 | 13,330 (78.64%) | 78.00/540.19/2315.29 | 13.42/45.12/99.67 | 5.30/12.02/25.61 |
| RSDD-SAR | 10,263 | 8331 (81.18%) | 101.75/506.95/2052.88 | 16.00/43.61/97.65 | 6.06/11.38/22.40 |
| DSSDD | 3416 | 3416 (100.00%) | 59.49/138.23/305.34 | 10.00/18.03/30.00 | 5.63/7.66/10.71 |
| Model | Precision ↑ | Recall ↑ | F1 ↑ | mAP50 ↑ | mAP50–95 ↑ | Params | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| Baseline | 0.91573 | 0.85303 | 0.883269 | 0.93792 | 0.66690 | 2.5 M | 6.4 | 40.5 |
| +DEOBB | 0.91292 | 0.86713 | 0.889436 | 0.93975 | 0.67436 | 2.1 M | 5.9 | 39.6 |
| +CkDRB | 0.91884 | 0.87462 | 0.896185 | 0.94455 | 0.69224 | 6.4 M | 18.2 | 47.6 |
| +DynWeave | 0.91953 | 0.87795 | 0.898259 | 0.94872 | 0.69768 | 7.0 M | 19.3 | 43.8 |
| Model | Precision ↑ | Recall ↑ | F1 ↑ | mAP50 ↑ | mAP50–95 ↑ | Params | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| Baseline | 0.94675 | 0.95088 | 0.94878 | 0.98543 | 0.70081 | 2.5 M | 6.4 | 60.8 |
| +DEOBB | 0.95335 | 0.96576 | 0.95951 | 0.98664 | 0.79347 | 2.1 M | 5.9 | 60.1 |
| +CkDRB | 0.95992 | 0.96722 | 0.96356 | 0.98687 | 0.80305 | 6.4 M | 18.2 | 67.0 |
| +DynWeave | 0.96414 | 0.96783 | 0.96598 | 0.98725 | 0.81167 | 7.0 M | 19.3 | 57.7 |
| Model | Precision ↑ | Recall ↑ | F1 ↑ | mAP50 ↑ | mAP50–95 ↑ | Params | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| Baseline | 0.94623 | 0.91076 | 0.92817 | 0.9710 | 0.73793 | 2.5 M | 6.4 | 61.3 |
| +DEOBB | 0.94674 | 0.9136 | 0.92987 | 0.97178 | 0.73934 | 2.1 M | 5.9 | 59.4 |
| +CkDRB | 0.94695 | 0.92162 | 0.93412 | 0.97245 | 0.74636 | 6.4 M | 18.2 | 65.8 |
| +DynWeave | 0.94985 | 0.92218 | 0.93581 | 0.97246 | 0.74612 | 7.0 M | 19.3 | 60.2 |
| Model | Precision ↑ | Recall ↑ | F1 ↑ | mAP50 ↑ | mAP50–95 ↑ | Params | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| Rotated FCOS [65] | 0.91070 | 0.87100 | 0.89039 | 0.8040 | 32.7 M | 207.7 | 29.7 | |
| R-FasterRCNN [66] | 0.91085 | 0.85100 | 0.87994 | 0.80120 | 36.4 M | 215.9 | 16.5 | |
| ESarDet-OBB [67] | 0.91161 | 0.71429 | 0.80098 | 0.81159 | 0.59072 | 3.5 M | 9.7 | 69.4 |
| AC-YOLO-OBB [68] | 0.91915 | 0.84201 | 0.87889 | 0.93524 | 0.6732 | 1.8 M | 5.5 | 98.8 |
| DS-YOLO-OBB [69] | 0.91233 | 0.87278 | 0.89212 | 0.94732 | 0.68996 | 9.4 M | 25.6 | 124.3 |
| Hyper-YOLO-OBB [70] | 0.91771 | 0.85998 | 0.88791 | 0.94183 | 0.68258 | 2.8 M | 7.9 | 103.9 |
| YOLOv5n-OBB | 0.91761 | 0.87046 | 0.89341 | 0.94314 | 0.68418 | 2.6 M | 7.3 | 138.4 |
| YOLOv6-OBB [71] | 0.90892 | 0.83874 | 0.87242 | 0.92795 | 0.66048 | 4.3 M | 11.8 | 157.9 |
| YOLOv8n-OBB | 0.89378 | 0.84170 | 0.86695 | 0.91702 | 0.65310 | 3.1 M | 8.3 | 142.5 |
| YOLOv9t-OBB [72] | 0.92244 | 0.85354 | 0.89125 | 0.94346 | 0.69362 | 2.0 M | 7.8 | 64.7 |
| YOLOv10n-OBB [73] | 0.9154 | 0.84577 | 0.88379 | 0.94374 | 0.70387 | 2.3 M | 6.8 | 122.4 |
| YOLOv11n-OBB | 0.91783 | 0.85298 | 0.88421 | 0.93830 | 0.67669 | 2.7 M | 6.6 | 114.8 |
| YOLOv12n-OBB [74] | 0.91185 | 0.85076 | 0.88024 | 0.93349 | 0.66740 | 2.6 M | 6.1 | 60.4 |
| YOLOv13n-OBB [18] | 0.91573 | 0.85303 | 0.88327 | 0.93792 | 0.66690 | 2.5 M | 6.4 | 40.5 |
| Ours (SAR-DRBNet) | 0.91953 | 0.87795 | 0.89826 | 0.94872 | 0.69768 | 7.0 M | 19.3 | 43.8 |
| Model | Precision ↑ | Recall ↑ | F1 ↑ | mAP50 ↑ | mAP50–95 ↑ | Params | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| Rotated FCOS [65] | 0.9177 | 0.8710 | 0.8012 | 0.9177 | 32.7 M | 207.7 | 26.9 | |
| R-FasterRCNN [66] | 0.91085 | 0.8510 | 0.8012 | 0.91085 | 36.4 M | 215.9 | 18.1 | |
| ESarDet-OBB [67] | 0.94962 | 0.5338 | 0.68343 | 0.71286 | 0.58991 | 3.5 M | 9.7 | 70.0 |
| AC-YOLO-OBB [68] | 0.95428 | 0.95292 | 0.95360 | 0.98683 | 0.81065 | 1.8 M | 5.5 | 132.2 |
| DS-YOLO-OBB [69] | 0.9519 | 0.9640 | 0.95791 | 0.98614 | 0.80953 | 9.4 M | 25.6 | 161.2 |
| Hyper-YOLO-OBB [70] | 0.9646 | 0.9569 | 0.96073 | 0.98605 | 0.80755 | 2.8 M | 7.9 | 130.7 |
| YOLOv5n-OBB | 0.95714 | 0.95314 | 0.95514 | 0.98724 | 0.81165 | 2.6 M | 7.3 | 171.9 |
| YOLOv6-OBB [71] | 0.96658 | 0.96481 | 0.96569 | 0.98720 | 0.81368 | 4.3 M | 11.8 | 197.5 |
| YOLOv8n-OBB | 0.95465 | 0.96839 | 0.96147 | 0.98602 | 0.81533 | 3.1 M | 8.3 | 188.7 |
| YOLOv9t-OBB [72] | 0.95027 | 0.97542 | 0.96268 | 0.98633 | 0.80597 | 2.0 M | 7.8 | 81.2 |
| YOLOv10n-OBB [73] | 0.95583 | 0.96905 | 0.96239 | 0.98684 | 0.81099 | 2.3 M | 6.8 | 157.5 |
| YOLOv11n-OBB | 0.96152 | 0.96531 | 0.96341 | 0.98644 | 0.80976 | 2.7 M | 6.6 | 144.9 |
| YOLOv12n-OBB [74] | 0.96197 | 0.96839 | 0.96516 | 0.98632 | 0.81117 | 2.6 M | 6.1 | 86.3 |
| YOLOv13n-OBB [18] | 0.94675 | 0.95088 | 0.94878 | 0.98543 | 0.70081 | 2.5 M | 6.4 | 60.8 |
| Ours (SAR-DRBNet) | 0.96414 | 0.96783 | 0.96598 | 0.98725 | 0.81167 | 7.0 M | 19.3 | 57.7 |
| Model | Precision ↑ | Recall ↑ | F1 ↑ | mAP50 ↑ | mAP50–95 ↑ | Params | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| Rotated FCOS [60] | 0.92300 | 0.89610 | 0.90970 | 0.95900 | 32.7 M | 207.7 | 27.2 | |
| R-FasterRCNN [61] | 0.93440 | 0.85700 | 0.89410 | 0.92700 | 36.4 M | 215.9 | 17.4 | |
| ESarDet-OBB [62] | 0.94696 | 0.81681 | 0.87708 | 0.88508 | 0.69041 | 3.5 M | 9.7 | 75.0 |
| AC-YOLO-OBB [63] | 0.93996 | 0.8966 | 0.91777 | 0.96573 | 0.74055 | 1.8 M | 5.5 | 133.2 |
| DS-YOLO-OBB [64] | 0.92813 | 0.91643 | 0.92224 | 0.96702 | 0.74531 | 9.4 M | 25.6 | 152.0 |
| Hyper-YOLO-OBB [65] | 0.93475 | 0.93107 | 0.93291 | 0.97244 | 0.74615 | 2.8 M | 7.9 | 134.7 |
| YOLOv5n-OBB | 0.94689 | 0.92635 | 0.93551 | 0.97156 | 0.74665 | 2.6 M | 7.3 | 174.0 |
| YOLOv6-OBB [66] | 0.92541 | 0.9239 | 0.92465 | 0.97158 | 0.74710 | 4.3 M | 11.8 | 202.6 |
| YOLOv8n-OBB | 0.93544 | 0.92493 | 0.93016 | 0.97199 | 0.73964 | 3.1 M | 8.3 | 187.3 |
| YOLOv9t-OBB [67] | 0.9388 | 0.92257 | 0.93061 | 0.97195 | 0.73469 | 2.0 M | 7.8 | 80.4 |
| YOLOv10n-OBB [68] | 0.94487 | 0.92351 | 0.93407 | 0.97213 | 0.74174 | 2.3 M | 6.8 | 155.6 |
| YOLOv11n-OBB | 0.94886 | 0.91785 | 0.93309 | 0.97140 | 0.74577 | 2.7 M | 6.6 | 140.1 |
| YOLOv12n-OBB [69] | 0.9392 | 0.92631 | 0.93271 | 0.97217 | 0.74198 | 2.6 M | 6.1 | 84.0 |
| YOLOv13n-OBB [17] | 0.94623 | 0.91076 | 0.92816 | 0.97100 | 0.73793 | 2.5 M | 6.4 | 61.3 |
| Ours (SAR-DRBNet) | 0.94985 | 0.92218 | 0.93581 | 0.97246 | 0.74612 | 7.0 M | 19.3 | 60.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Share and Cite
Lei, L.; Chang, S.; Sun, Z.; Zheng, X.; Liao, C.; Wei, W.; Ma, L.; Zhong, P. SAR-DRBNet: Adaptive Feature Weaving and Algebraically Equivalent Aggregation for High-Precision Rotated SAR Detection. Remote Sens. 2026, 18, 619. https://doi.org/10.3390/rs18040619
Lei L, Chang S, Sun Z, Zheng X, Liao C, Wei W, Ma L, Zhong P. SAR-DRBNet: Adaptive Feature Weaving and Algebraically Equivalent Aggregation for High-Precision Rotated SAR Detection. Remote Sensing. 2026; 18(4):619. https://doi.org/10.3390/rs18040619
Chicago/Turabian StyleLei, Lanfang, Sheng Chang, Zhongzhen Sun, Xinli Zheng, Changyu Liao, Wenjun Wei, Long Ma, and Ping Zhong. 2026. "SAR-DRBNet: Adaptive Feature Weaving and Algebraically Equivalent Aggregation for High-Precision Rotated SAR Detection" Remote Sensing 18, no. 4: 619. https://doi.org/10.3390/rs18040619
APA StyleLei, L., Chang, S., Sun, Z., Zheng, X., Liao, C., Wei, W., Ma, L., & Zhong, P. (2026). SAR-DRBNet: Adaptive Feature Weaving and Algebraically Equivalent Aggregation for High-Precision Rotated SAR Detection. Remote Sensing, 18(4), 619. https://doi.org/10.3390/rs18040619