1. Introduction
Remote sensing (RS) images often cover large areas with high spatial resolution, so they contain a large amount of ground object information in RS scenes. Object detection networks enable the accurate and rapid identification of ground objects from complex RS scenes, with widespread applications in urban development, geological disaster prevention and agricultural monitoring. However, due to the complexity of RS scenes and the multi-scale, multi-orientation characteristics of RS objects, efficiently modeling the morphological variations of these objects to meet the precise and rapid detection needs in RS contexts remains a prominent research topic.
Currently, RS object detectors are categorized into two types: two-stage and one-stage detectors. Two-stage detectors typically consist of a region proposal network (RPN) and a detection head. Detectors such as CAD-Net [
1], Mask-OBB [
2], ORPN [
3], and APE [
4] generate a series of anchors from feature maps of each stage of the RPN, and then preliminarily refine and classify these proposed anchors. In the second stage, the detection head performs operations such as ROIPooling or ROIAlign based on anchor regions to extract fine-grained features from feature maps, further classifying and precisely localizing anchors. In order to simplify the detection process and speed up the detection speed, the core goal of one-stage detectors such as O2-DNet [
5] and DRN [
6] is to extract features of the input RS images and proposed anchors of different sizes on feature maps, and complete the classification of the object and the positioning of the bounding box (BBox) at the detection head at one time, so as to achieve the purpose of rapid detection. However, one-stage detectors lack a positive-negative sample assignment mechanism and do not incorporate ROIPooling or ROIAlign operations. As a result, background noise is mixed into the subsequent extraction of orientation features, interfering with the detection results.
Compared to natural scenes, RS images possess broad fields of view and bird’s-eye perspectives, leading to object distributions at arbitrary scales and orientations. To address the significant differences in scales of object, traditional strategies predominantly employ feature pyramid networks (FPN) [
7] or make improvements based on FPN [
8]. Additionally, ignoring computational overhead, Transformer-based models leverage powerful global modeling capabilities, offering a novel approach to managing image scale disparities. STO-DETR [
9] utilizes the Swin-Transformer as a backbone network to extract features from input images, accurately locating small objects among various scales of RS objects through the global modeling capability of the Transformer. FPNFormer [
10] integrates the Transformer mechanism with feature pyramids, constructing a Transformer-based feature pyramid that mitigates inaccuracies in detection caused by significant scale differences in remote sensing objects by capturing global features across multiple scales. However, these multi-scale extraction methods are only improved for objects with obvious scale differences, and do not consider the difference between fine scales, which leads to the misalignment of scale features and objects, and it is easy to mix background noise in the subsequent orientation feature extraction. Existing methods employing large-kernel convolutions [
11,
12] aim to address the issue of scale variation in object detection. These approaches often utilize attention mechanisms to capture multi-scale distribution differences. However, the additional attention mechanism increases the computational complexity in the inference stage and cannot meet the needs of real-time detection of remote sensing images.
We consider that in RS images, not only are there significant differences in object scales, but the multi-orientationality of objects also poses challenges for object detection. Some methods [
13,
14,
15] utilize rotated anchors to locate objects in arbitrary orientations. However, achieving well spatial alignment between rotated anchors and RS objects is difficult, which can hinder the provision of sufficient orientation features for regression. Chen et al. [
16] proposed a conversion algorithm from horizontal BBoxes to rotated ones to solve the detection of arbitrarily oriented dense objects in RS images. Unlike traditional methods that present many multi-rotated anchors, this approach rotates the proposed horizontal BBoxes to appropriate angles by calculating the relationship function between angles and distances. This results in higher-quality rotated anchors, facilitating subsequent positional corrections. Pu et al. [
17] designed a rotational convolution that predicts the direction of rotation by adjusting the input conditional parameters and using a fully connected layer. This operation allows the convolution kernel to adapt to the rotation angle, so as to meet the feature extraction of the rotated object. However, the above-mentioned orientation feature extraction method is achieved by changing the position of the convolution kernel sampling points, and a single label cannot respond well to the direction changes of the object during supervised training, lacking strong supervision information. Adopting a dense angle rotation strategy will address the problem of increased parameter and computational complexity.
In summary, some existing RS object detection models recognize the differences in object scale and orientation and make targeted improvements. However, these methods treat scale and orientation issues separately, failing to consider the more profound correlation between them and neglecting the impact of scale on orientational representation. This oversight leads to spatial misalignment in RS object detection. Specifically, this misalignment can be categorized into the following three aspects:
(a) Scale Misalignment: The scales of RS objects change progressively, particularly among different object types. For instance, as illustrated in
Figure 1, the size discrepancies result in varying scales: the pixel areas of a car are approximately 20 × 20, while a yacht and a cargo ship occupy roughly 150 × 90 and 400 × 200 pixels, respectively. Current RS detectors typically construct FPNs that fuse fixed-level feature maps from the backbone. However, there may be three different pixel size differences among ship types, namely 400 × 200, 350 × 150, and 200 × 100. This could substantially increase the computational complexity if additional spatial pyramids are set up for these three scales. Moreover, using Transformers for global feature extraction may introduce significant background noise, which can negatively impact the subsequent refinement of anchors. Therefore, existing methods for handling scales have difficulty adapting to more subtle scale changes in RS scenarios.
(b) Relationship Between Scale Misalignment and Orientation: Inadequate precision in acquiring scale features can hinder the network’s ability to extract orientation features from the pyramid’s feature maps, resulting in inaccurate regression of the rotated BBoxes. As shown in
Figure 1b, when the detection head receives an excessively large scale feature for positioning, these large-scale features encompass the object’s scale information and capture noise from the surrounding environment. This interference complicates the regression localization of the object, causing the predicted rotated BBox to include not only the object itself but also elements from the surrounding environment. Consequently, the orientation of the rotated BBox fails to reflect the object’s proper orientation. Conversely, when scale features are set too small, the receptive field cannot capture the overall contour characteristics of the object, leading to the absence of holistic orientation features. In this case, the predicted BBox is confined within the overall contour of the object, rendering the expressed rotated orientation unrepresentative of the object’s actual orientation.
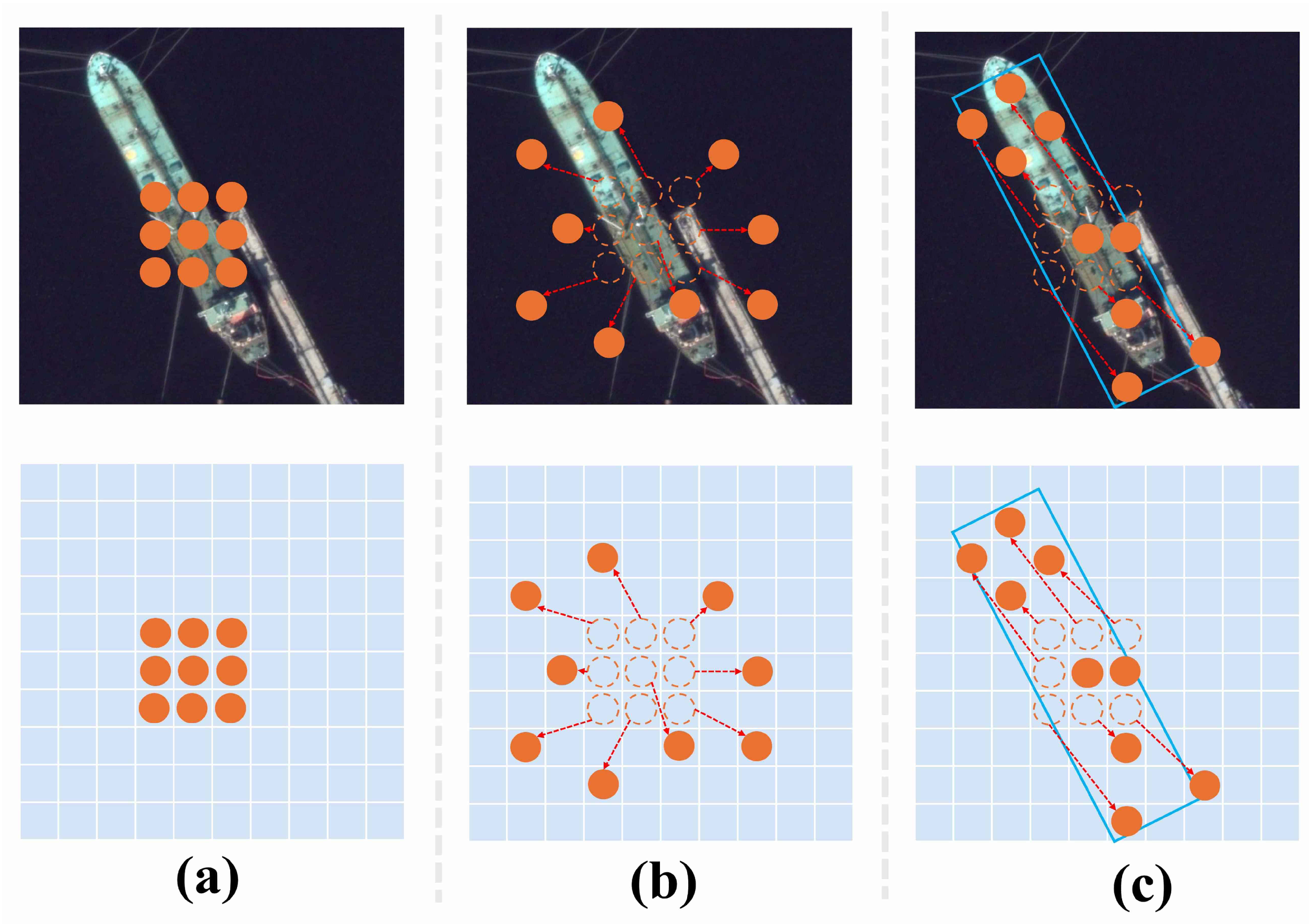
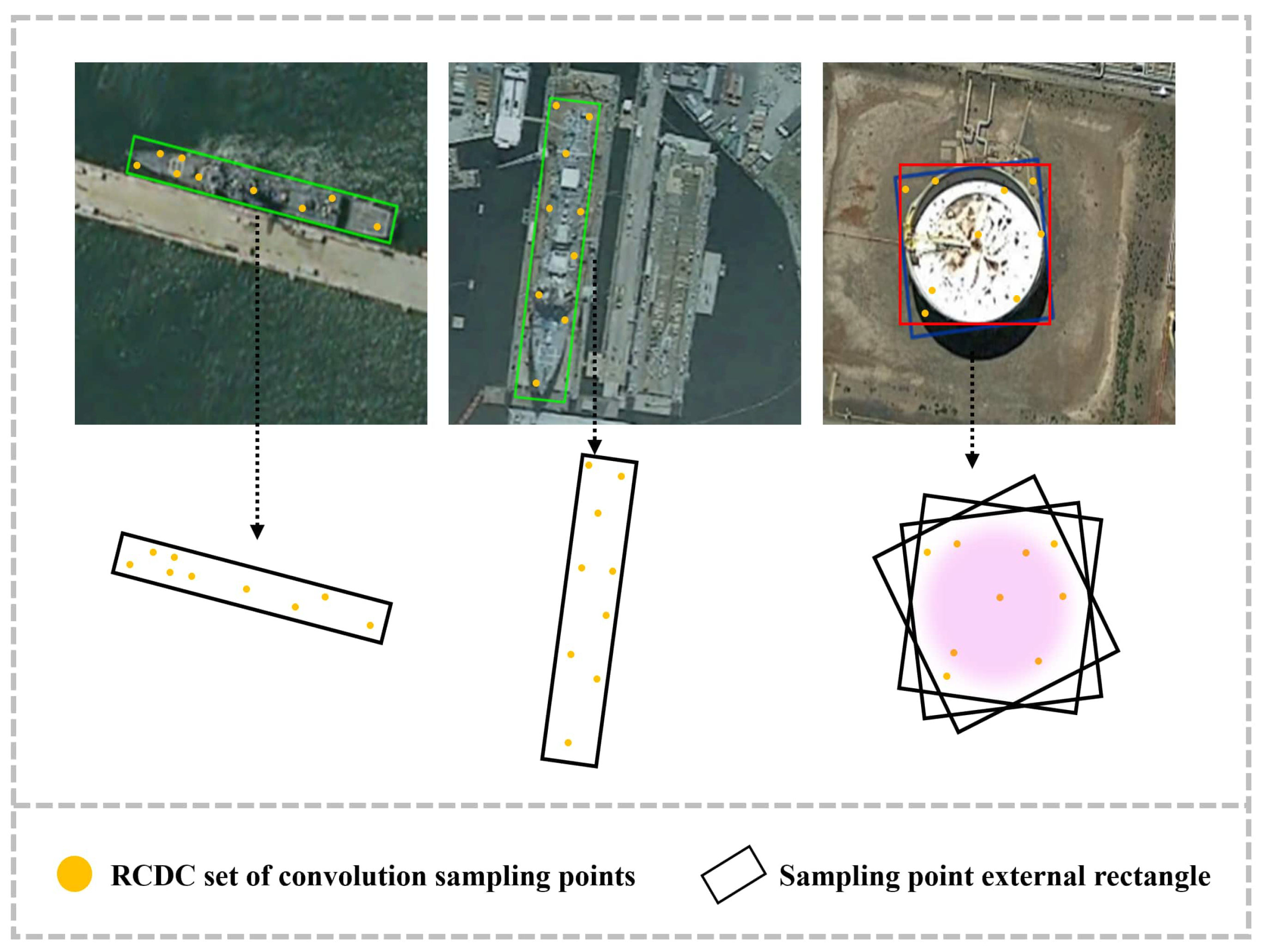
(c) Orientational Misalignment: Some existing deformable convolutions adapt to the direction of the object by changing the position of the sampling points of the convolution kernel, but the learning task is complex because the convolution kernel needs to learn the offset of any position on the complete feature map to determine the position of the sampling points. In addition, during training, the supervision provided by a single position and class label is limited, which cannot provide efficient supervision guidance for determining the sampling position of the convolutional kernel. As a result, the sampling locations can deviate significantly, introducing noise into the orientation features and interfering detection accuracy.
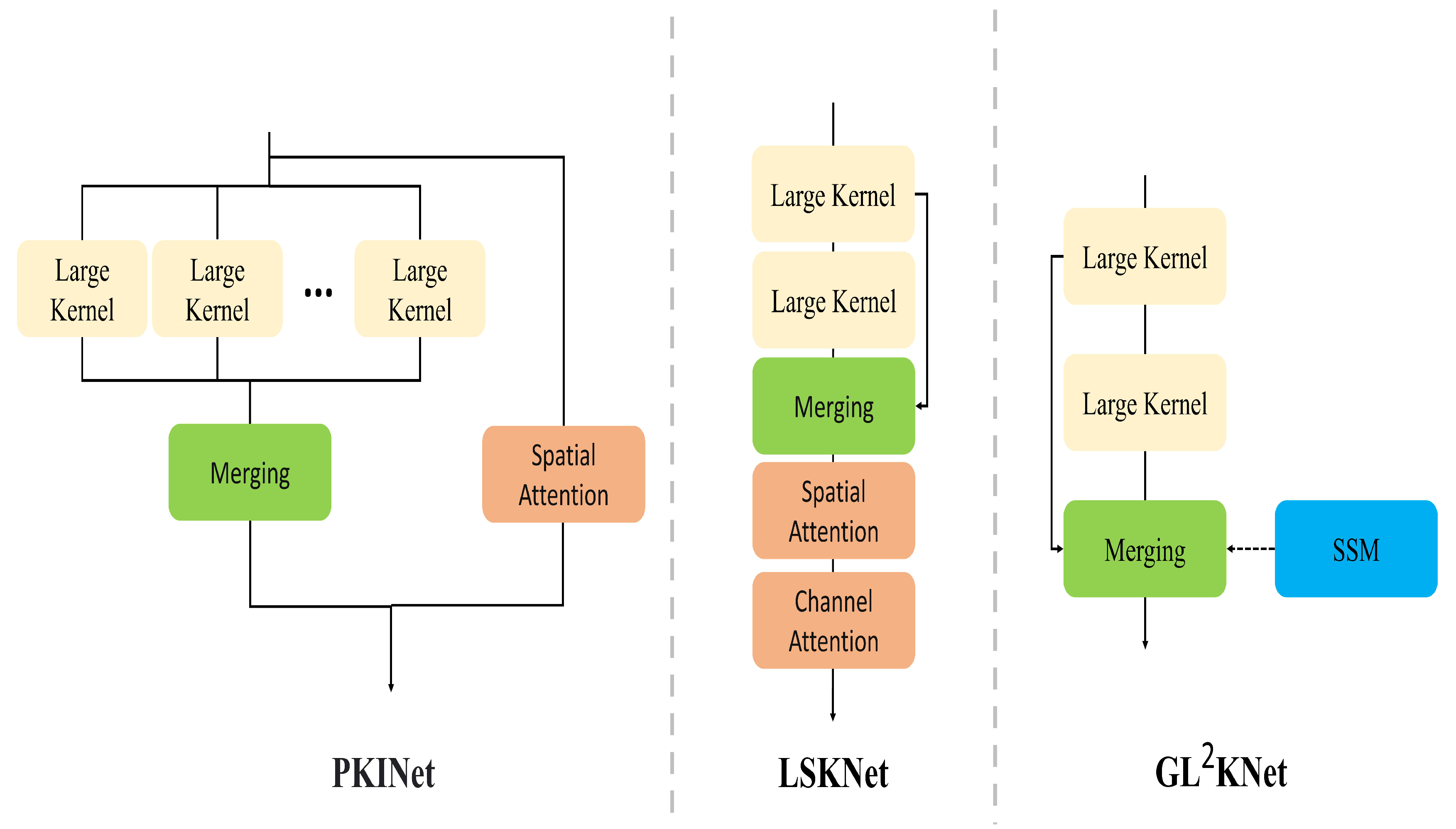
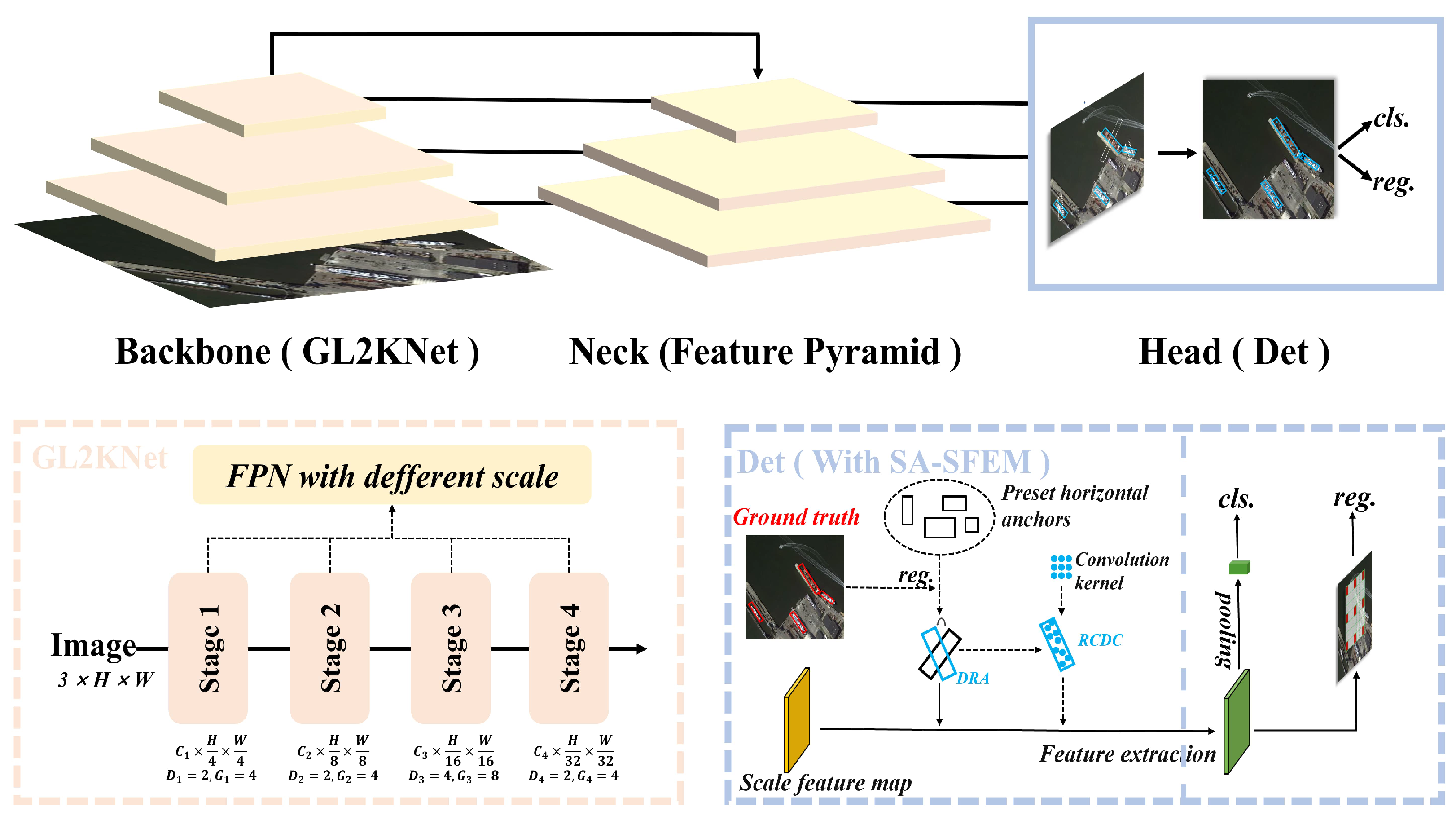
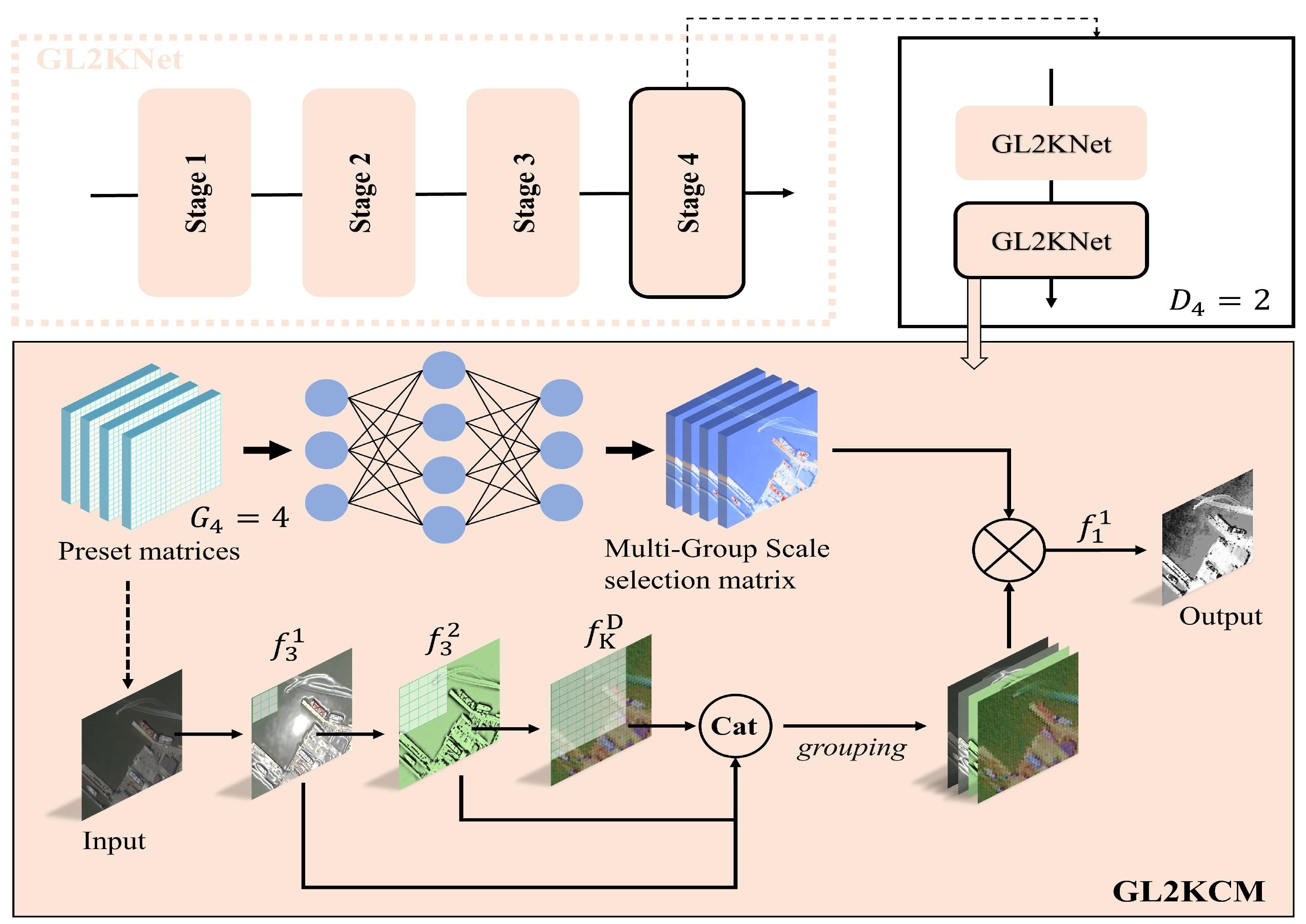
The analysis above shows that the key to resolving spatial misalignment in RS object detection lies in orientation refinement based on scale. To address the scale and orientation misalignment issues for objects, we propose the Scale First Refinement-Angle Detection Network (SFRADNet), which aims to resolve both scale and directional misalignment issues for arbitrarily oriented remote sensing targets. SFRADNet consists of two main components: the group learning large kernel network (GL2KNet) and the Shape-Aware Spatial Feature Extraction Module (SA-SFEM).The GL2KNet dynamically adjusts the receptive field coverage through inter-layer feature aggregation, addressing the issue of imprecise scale feature extraction for targets of arbitrary sizes. GL2KNet is constructed by stacking different numbers of Group Learning Large Kernel Convolution Modules (GL2KCMs) at various stages. Within each module, multiple layers of small dilated convolutional kernels are used to replace large convolutional kernels with the same receptive field, enabling the extraction of more refined scale features from the target’s neighborhood. Furthermore, Scale Selection Matrix (SSMatrix) is employed to capture spatial feature distribution differences at fine scales, followed by weighted fusion within the layer, achieving more accurate scale feature extraction. Unlike other large-kernel convolution methods, our model does not rely on attention mechanisms during inference, thereby avoiding the computational overhead associated with complex attention operations and maintaining high inference efficiency. Building upon the fine-scale features of the object, the SA-SFEM first performs preliminary refinements on horizontal anchors to form Directed Guide Boxes (DGBoxes). Utilizing the angular information from the DGBoxes, the convolution kernels are rotated accordingly, and uniform sampling is conducted based on the location and shape of the DGBoxes. the convolution kernel can dynamically change according to the shape of the object to form Region-Constrained Deformable Convolutions (RCDCs). RCDCs provide strong supervisory information during training, making them more sensitive to the object’s orientation and effectively alleviating orientational misalignment. The main contributions of this paper are as follows:
- 1.
We conduct a focused analysis and review of the phenomenon of multiple misalignments in current RS object detection, particularly how severe scale misalignment significantly impacts subsequent orientational alignment.
- 2.
To address the issue of imprecise scale feature extraction in current methods, we propose GL2KNet, a novel backbone capable of performing diversified and fine-grained modeling of targets at different scales. During the inference, GL2KNet eliminates the need for attention mechanisms and instead employs a SSMatrix for weighted feature fusion. This approach not only enhances the precision of scale feature extraction but also significantly improves inference efficiency, making it more suitable for real-time applications.
- 3.
We propose the SA-SFEM, which introduces a novel deformable convolution using DGBoxes as supervision. This allows the convolution kernel sampling points to better align with object morphology, improving orientation feature extraction and addressing the weak supervision of previous deformable convolutions. Additionally, it can be combined with the GL2KNet to enable accurate object detection with appropriately scale features.
The remainder of the paper is organized as follows.
Section 2 reviews the related works and analyzes the existing problems. In
Section 3, a detailed description of the proposed SFRADNet is presented. In
Section 4, extensive experiments are conducted and the results are discussed. Conclusions are summarized in
Section 5.
5. Conclusions
RS objects have the characteristics of arbitrary scale and multi-directional distribution. Existing detectors typically utilize FPN and deformable/rotated convolution to adapt to changes in object scale and orientation. However, these methods solve scale and orientation issues separately, ignoring their deeper coupling relationships. In this paper, we propose a one-stage detection network called Scale First-Refinement Angle Detection Network (SFRADNet) for detecting RS objects at arbitrary scale and orientation. The proposed network comprises two parts: the GL2KNet and the SA-SFEM. These two modules work synergistically to accurately classify and localize objects with arbitrary scales and multiple orientations in RS images. GL2Knet, serving as the backbone of SFRADNet, is composed of stacked GL2KCMs. Within the GL2KCM, we construct a diversity of receptive fields with varying dilation rates to capture features across different spatial coverage ranges, and then utilize a SSMatrix for diversified scale fusion. Compared to traditional large-kernel convolution networks, GL2KCM does not involve complex attention calculations during inference, significantly reducing the number of parameters and computational load. On the basis of obtaining precise scale features, we employ SA-SFEM for the extraction of orientational features. In SA-SFEM, a novel deformable convolution named RCDC is proposed, which uses DGBox as supervision information to guide the deformation of the convolution kernel sampling points. With the participation of RCDC, SA-SFEM shows exhibits heightened sensitivity to the object’s rotation angle, effectively mitigating orientation misalignment. Experimental results demonstrate the efficacy of the collaborative operation between these two modules. When compared to advanced detectors, our model achieves the highest mAP of on the DOTA-v1.0 dataset.
Although SFRADNet demonstrates superior detection performance with accurate angle alignment and scale matching across multiple datasets, along with a lightweight design, its real-time inference capability remains limited. In future work, we will continue to explore improvements in model efficiency and deployability on edge devices.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}