
Hybrid Filtering Technique for Accurate GNSS State Estimation



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- An end-to-end differentiable architecture to improve model-based priors and noise statistics within GNSS state estimation algorithms.
- A gradient descent optimizer demonstration to learn noise statistics automatically, thereby eliminating the need for manual tuning.
- An unsupervised training method based on the maximum likelihood approach that extends the EKF by preserving its probabilistic interpretability, thus ensuring convergence.
- Efficient and simpler implementation and flexibility compared to both the UKF and EKF.
2. Background and Motivation
2.1. GNSS Model Overview
2.2. Discrete Time Extended Kalman Filter
2.3. Hybrid Model for Accurate GNSS
3. Materials and Methods
3.1. Differentiable Kalman Filter
3.2. The Loss Function
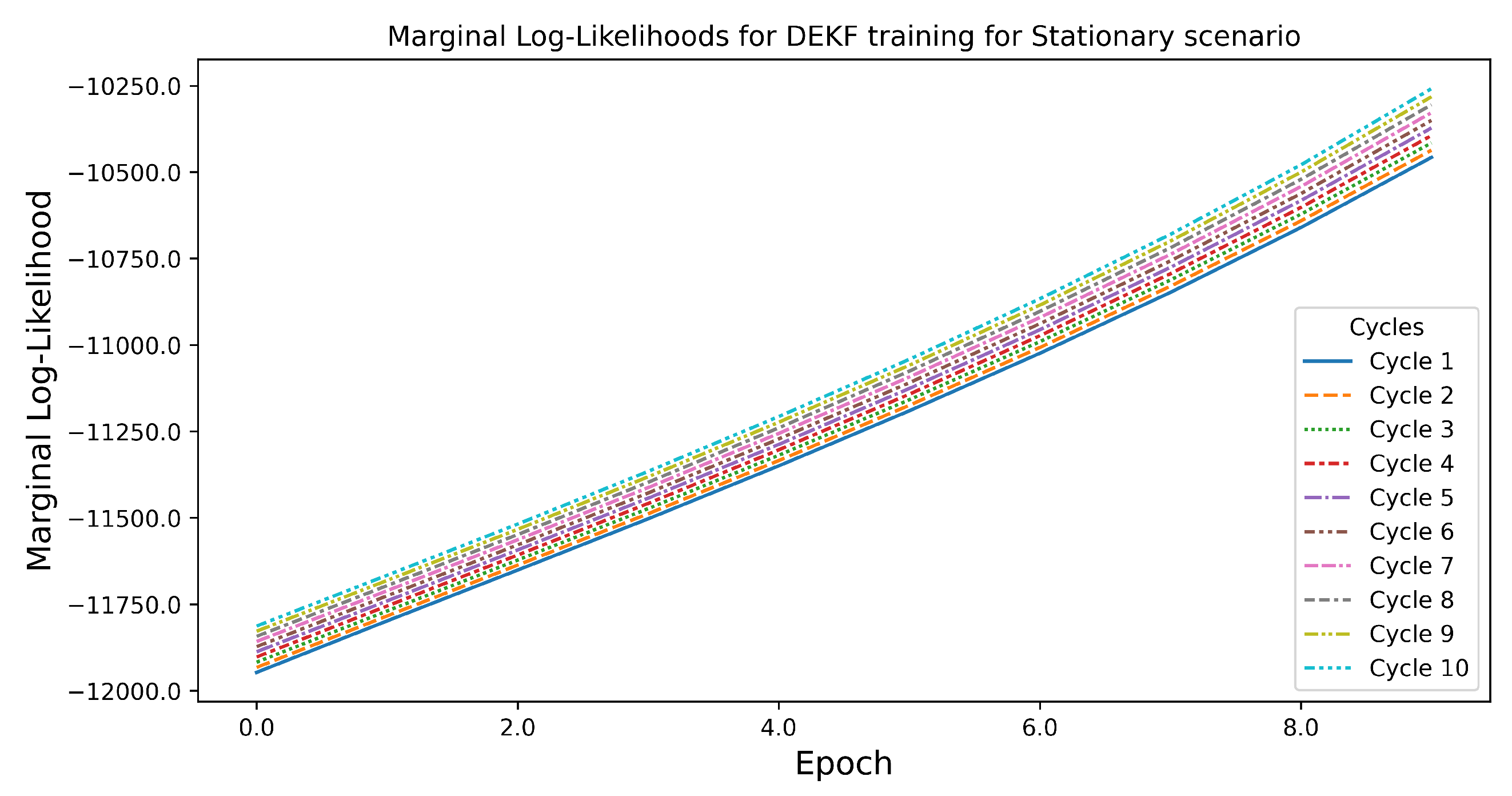
3.3. Training Algorithm
| Algorithm 1 Training Optimization algorithm |
|
4. Results
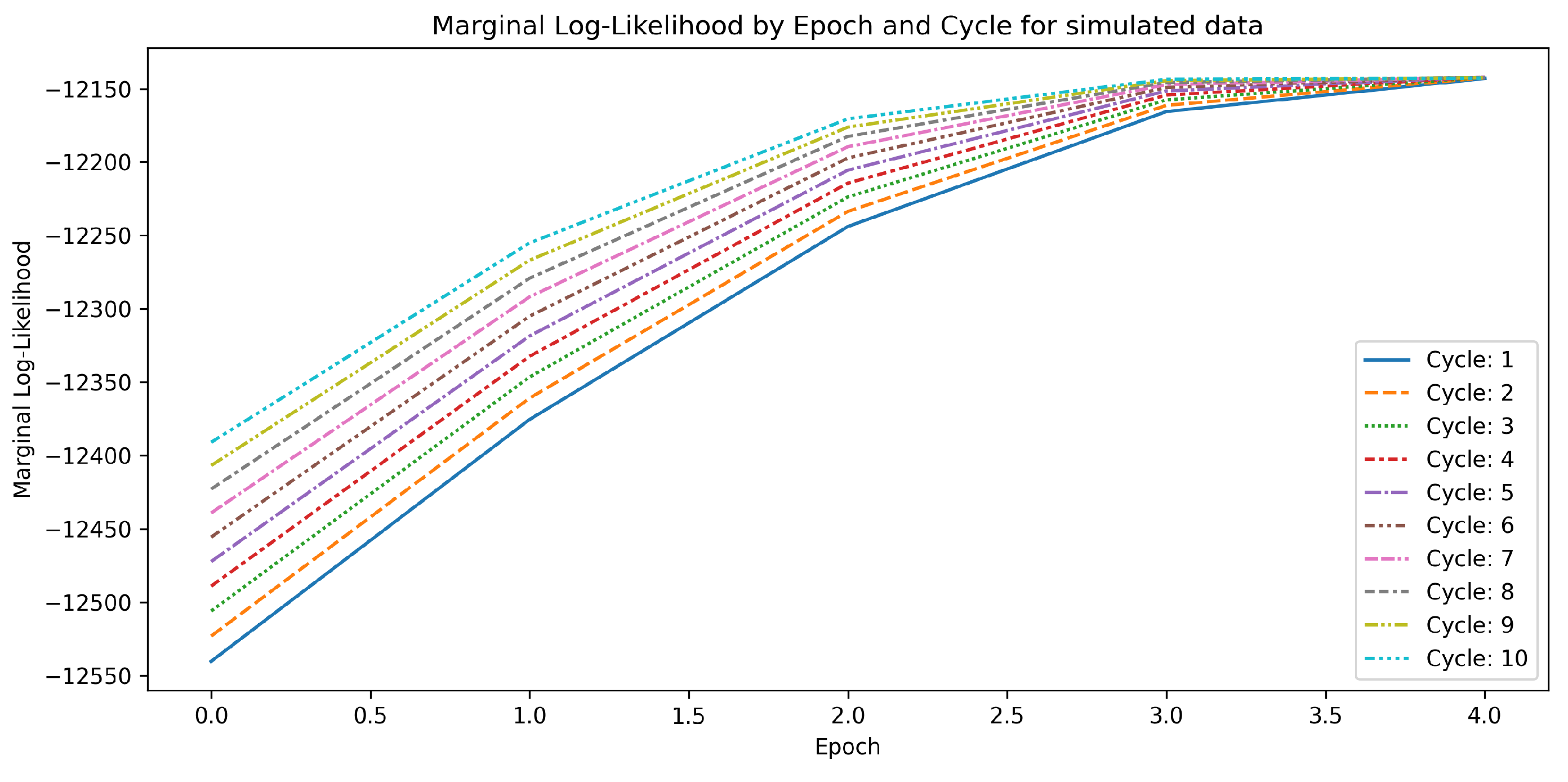
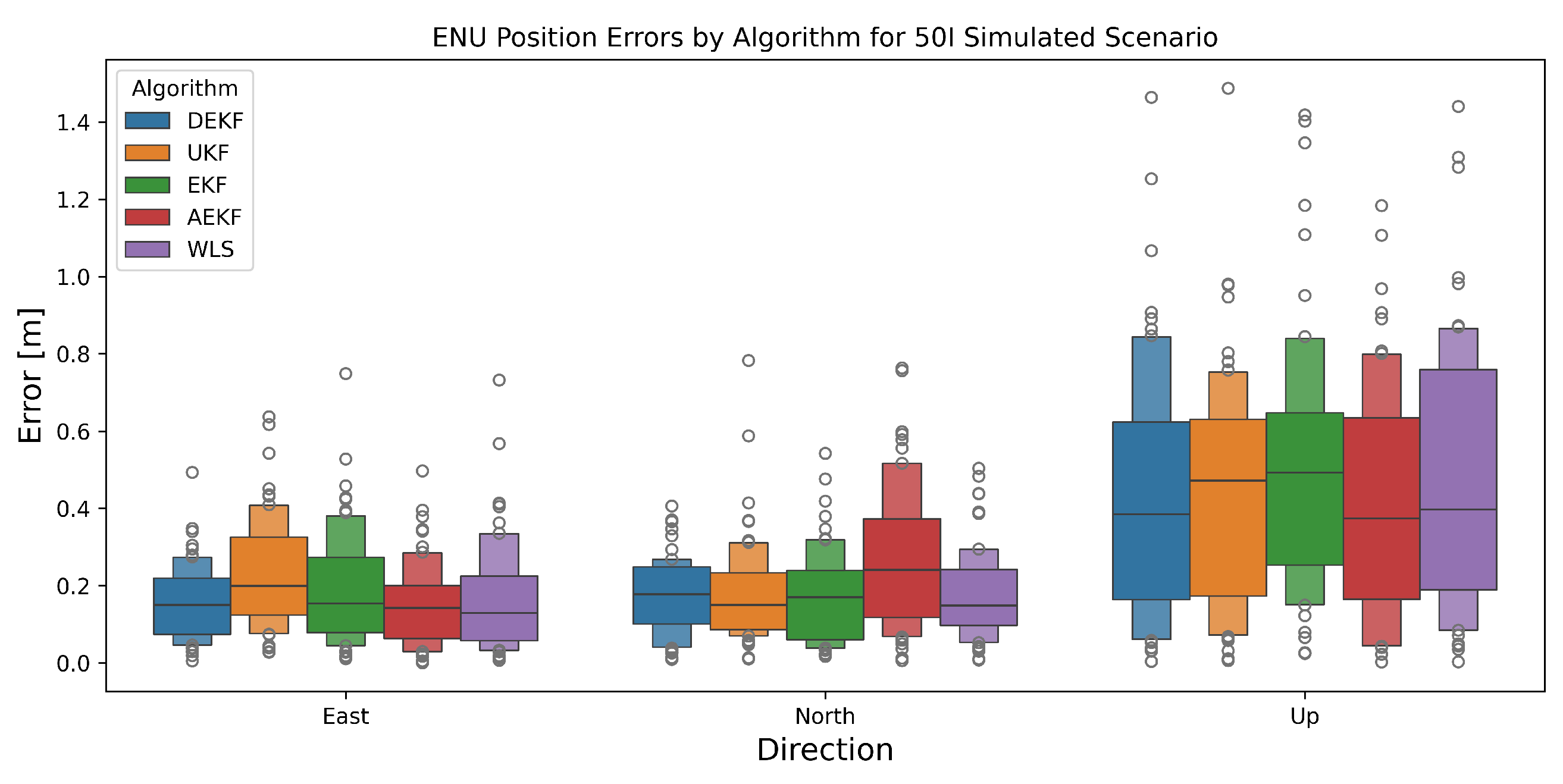
4.1. Simulation
4.2. Real-World Scenarios
4.2.1. Experimental Methods
- 1.
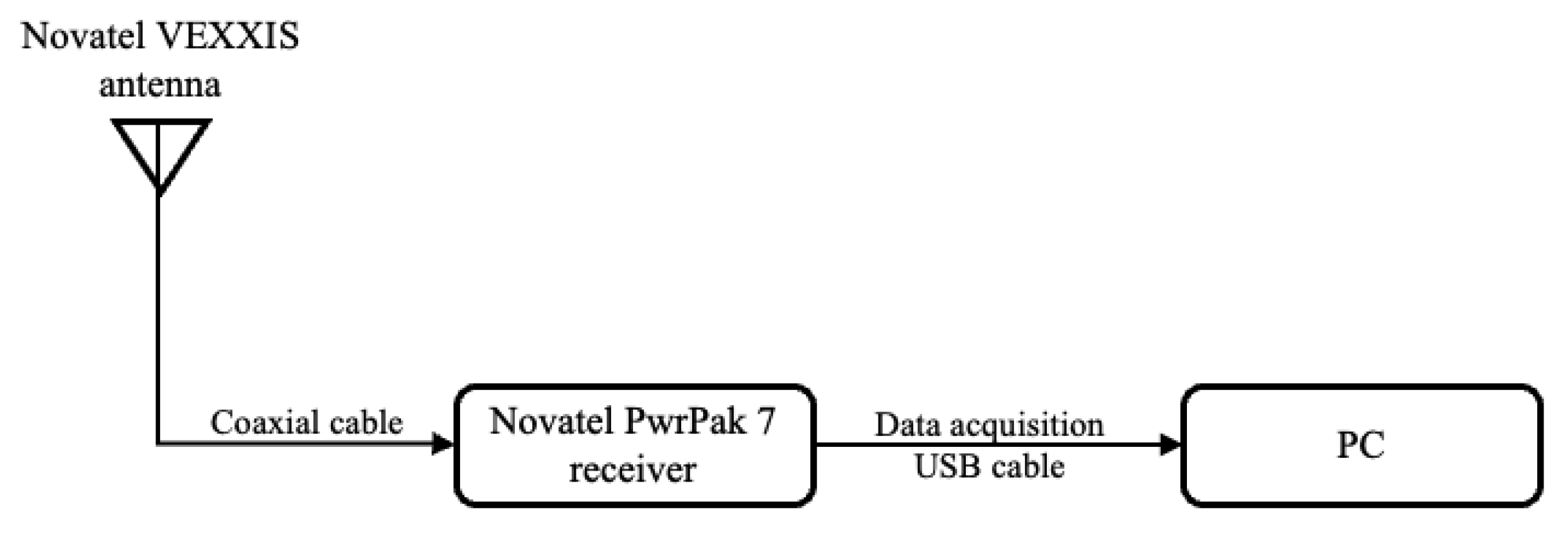
- A real-world scenario featuring a stationary receiver exposed to various noise parameters with the filter tuned to detect the corresponding noise statistics. Novatel PwrPak7 GNSS receiver, NovAtel Inc., Calgary, CA, USA with Novatel VEXXIS GNSS-802 antenna, NovAtel Inc., Calgary, CA, USA is used with a PC to collect GPS measurements as shown in Figure 6 from the L1 and L2 frequencies, sampled at 1 Hz. The pictures of the Novatel antenna and Novatel receiver are shown in Figure 7.
- 2.
- A real-world scenario involving a dynamic receiver processing GNSS signals, potentially perturbed by dynamic noise. Google Pixel 4 mobile data were used from [36] in a moving vehicle to obtain measurements from at least 7 GPS satellites at L1 frequency, sampled at 1 Hz.
4.2.2. Data Preprocessing
- 1.
- Ionospheric Correction;
- 2.
- Tropospheric Correction;
- 3.
- Satellite Clock Correction.
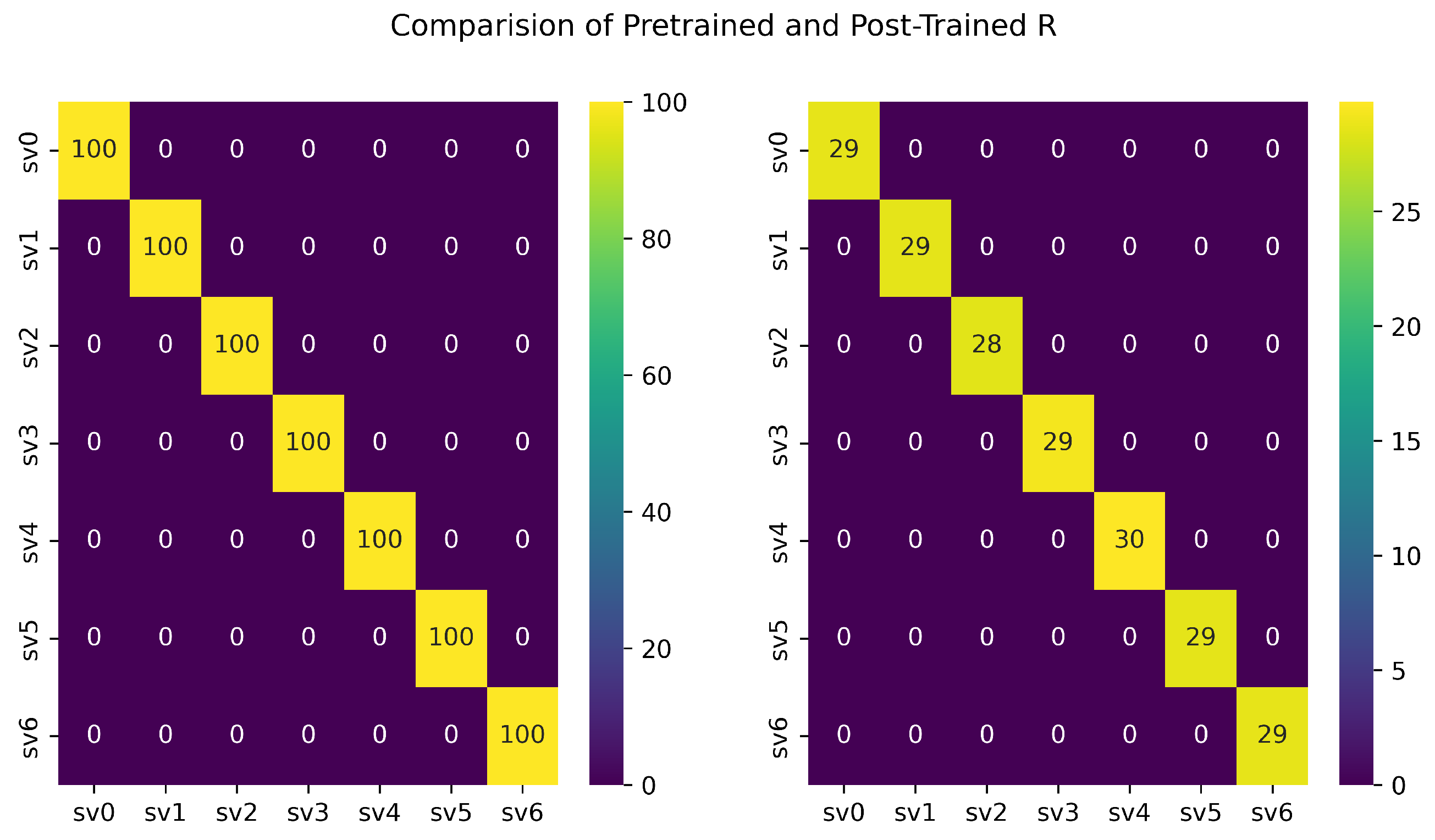
4.2.3. The Stationary Scenario
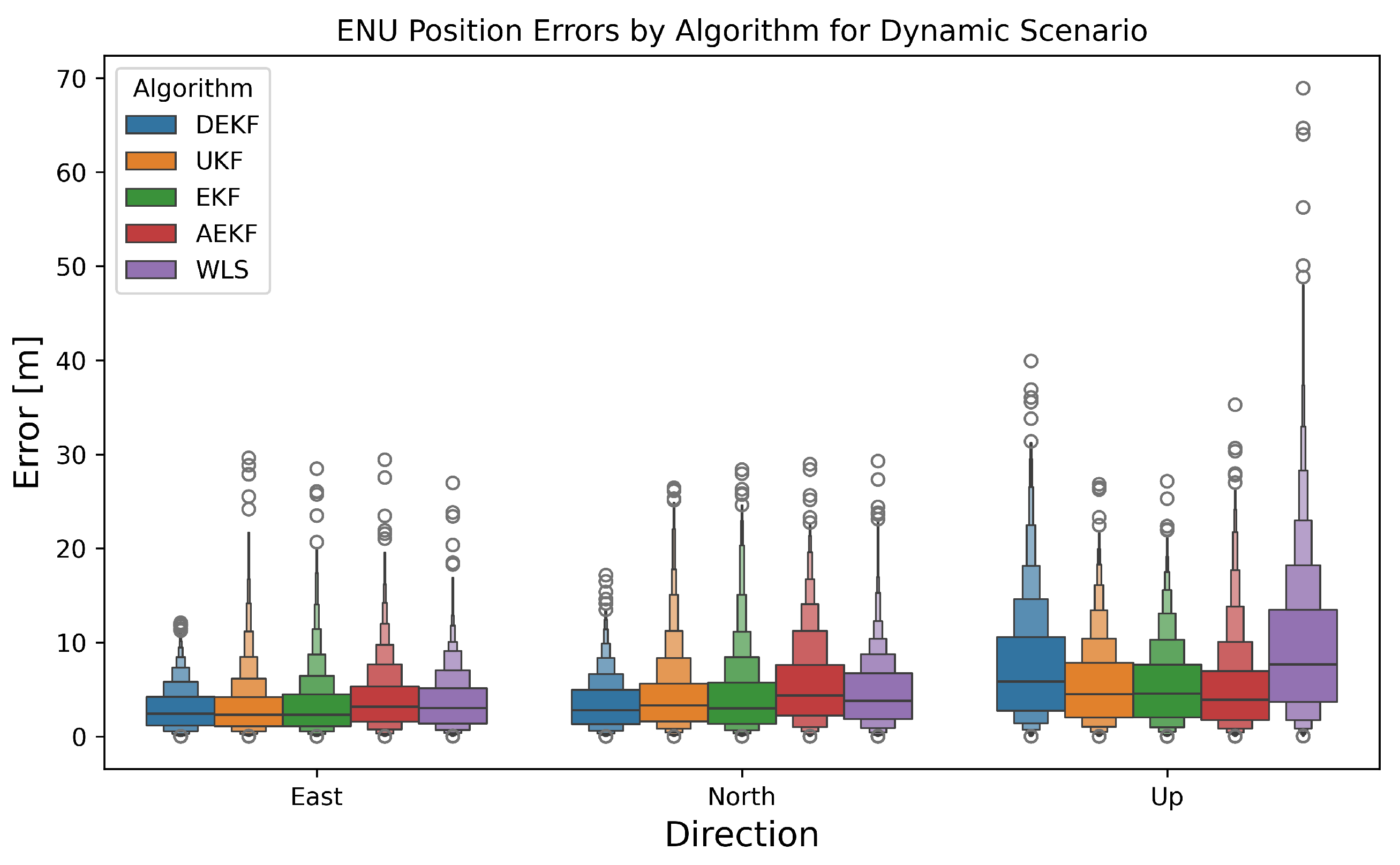
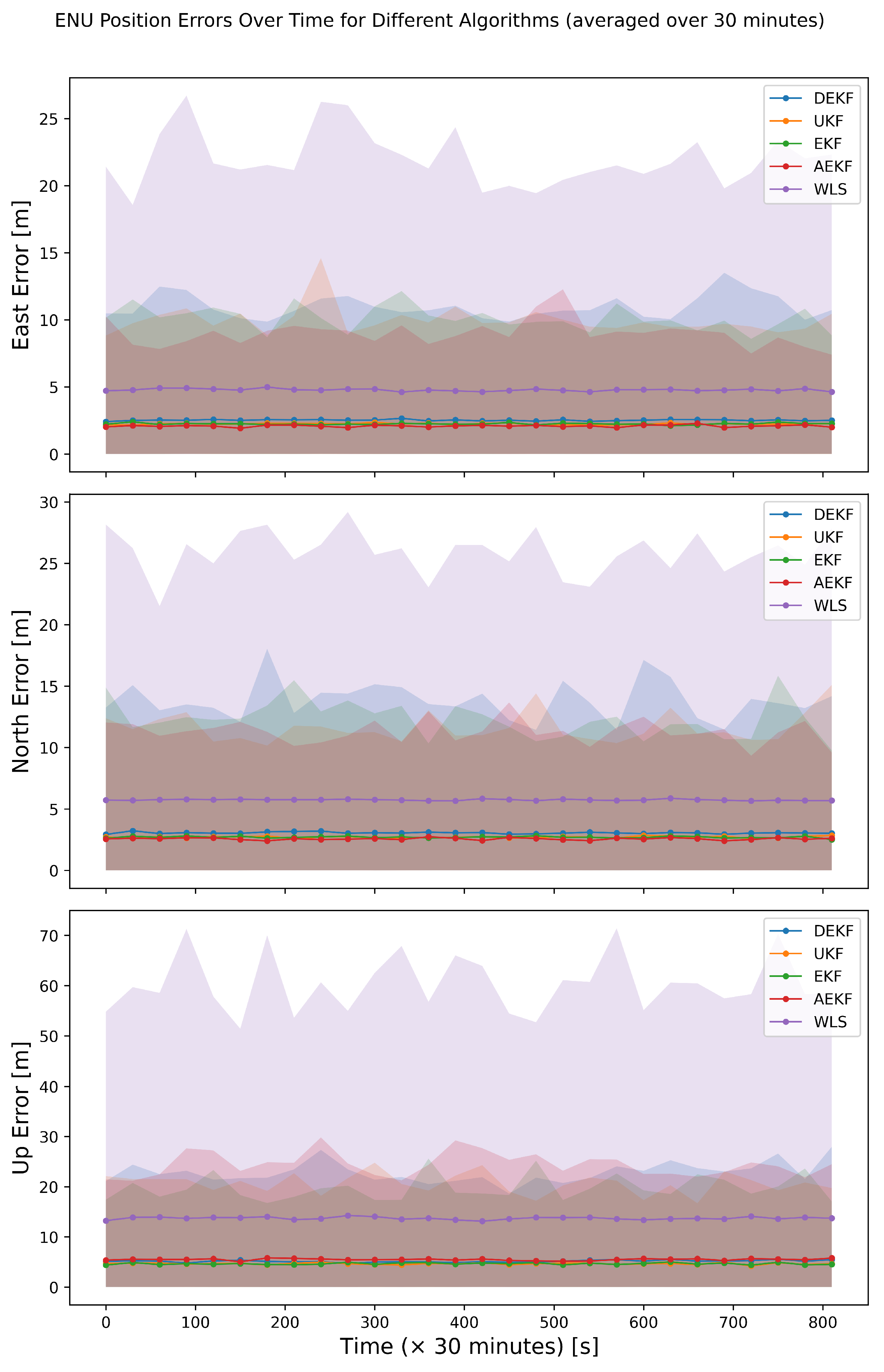
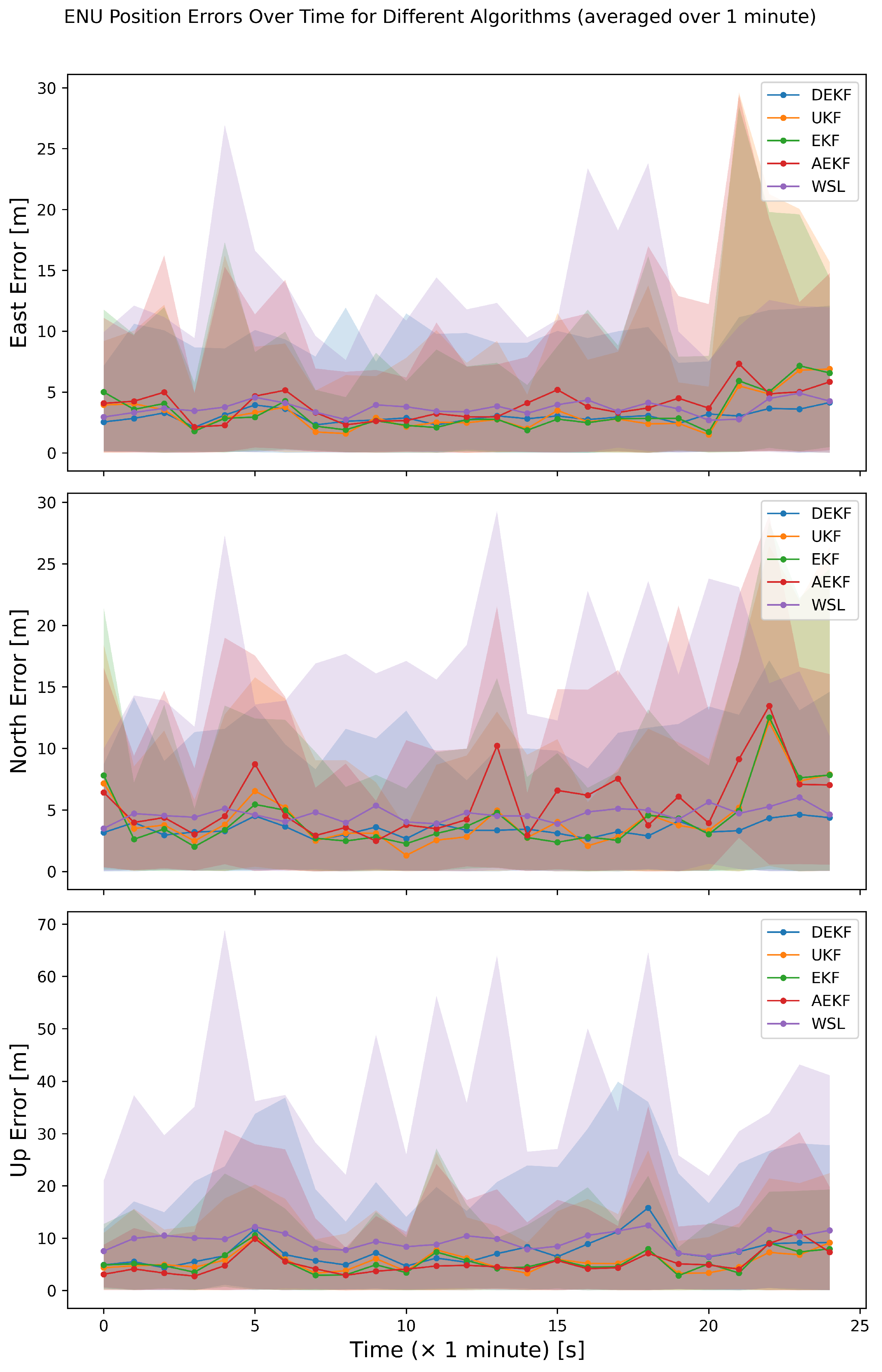
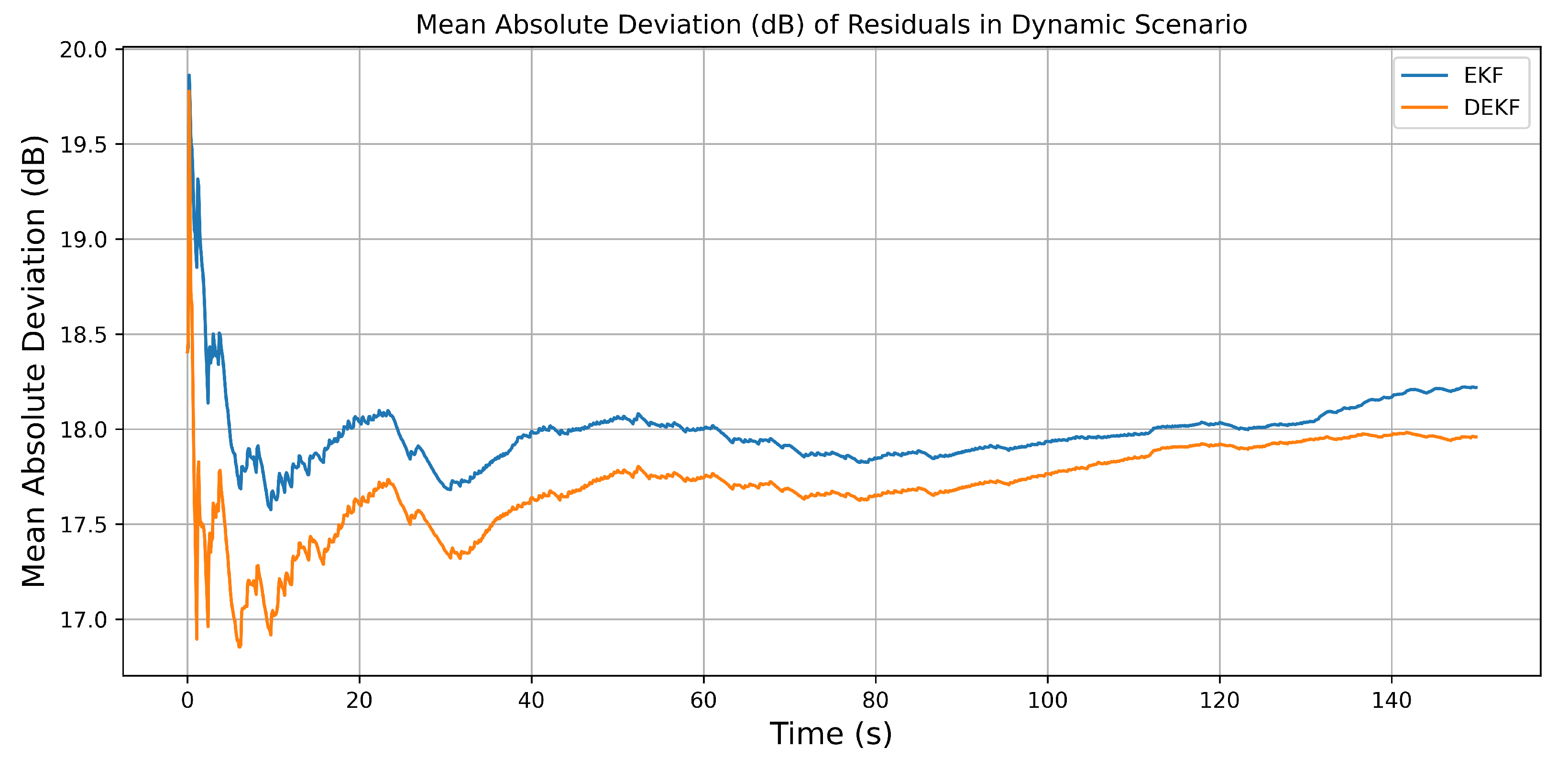
4.2.4. The Dynamic Scenario
5. Discussion
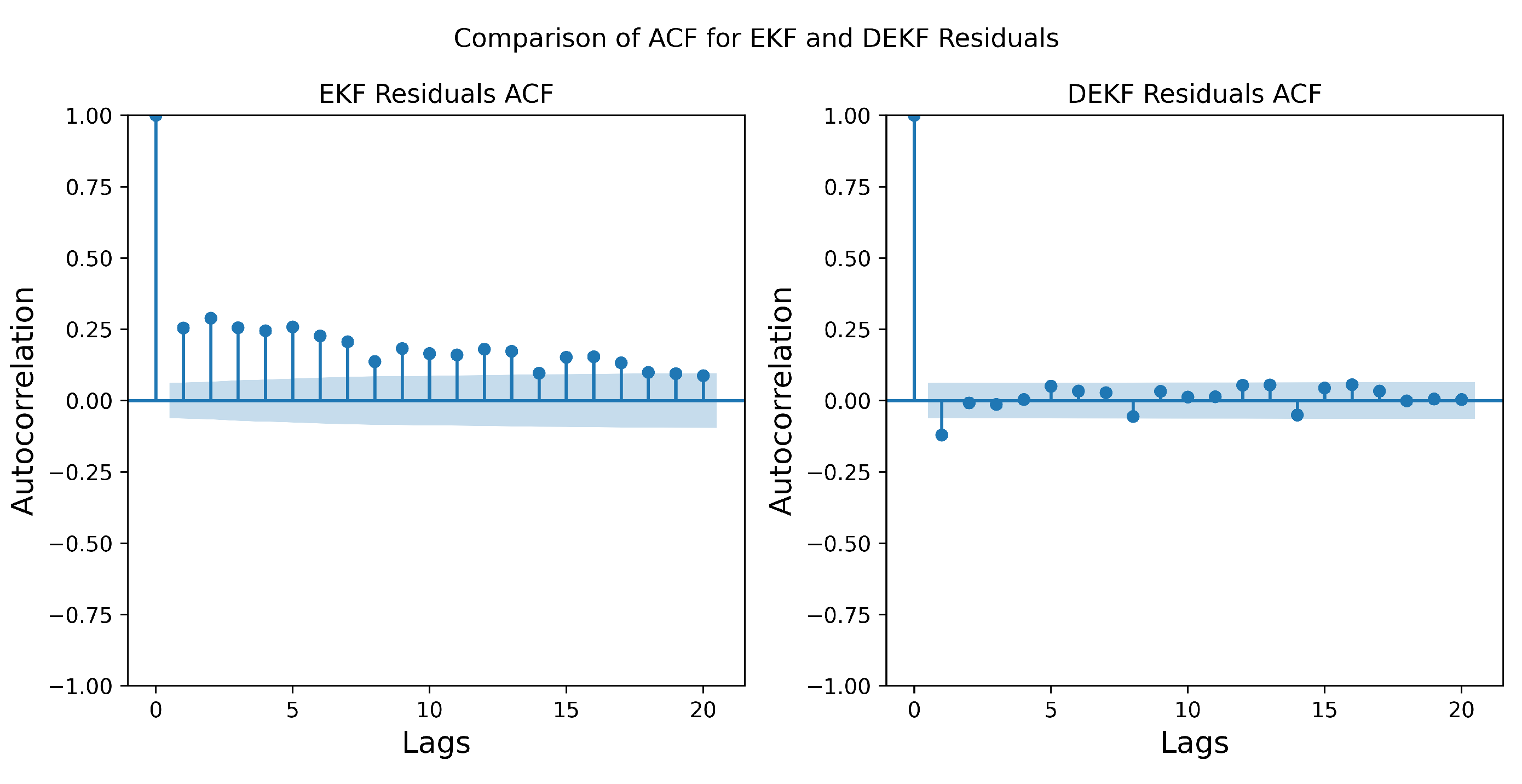
5.1. Simulated Scenario
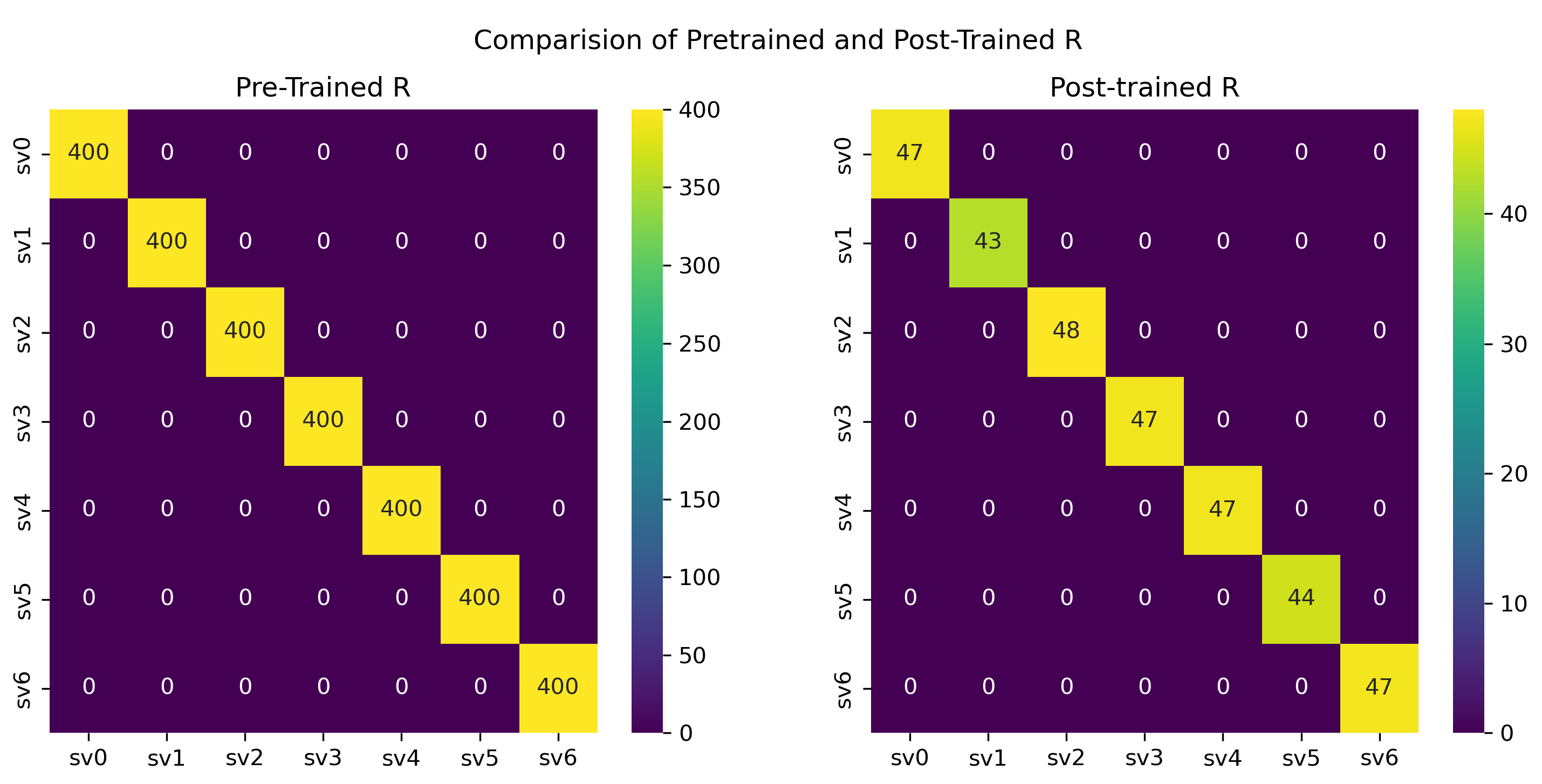
5.2. Static Scenario
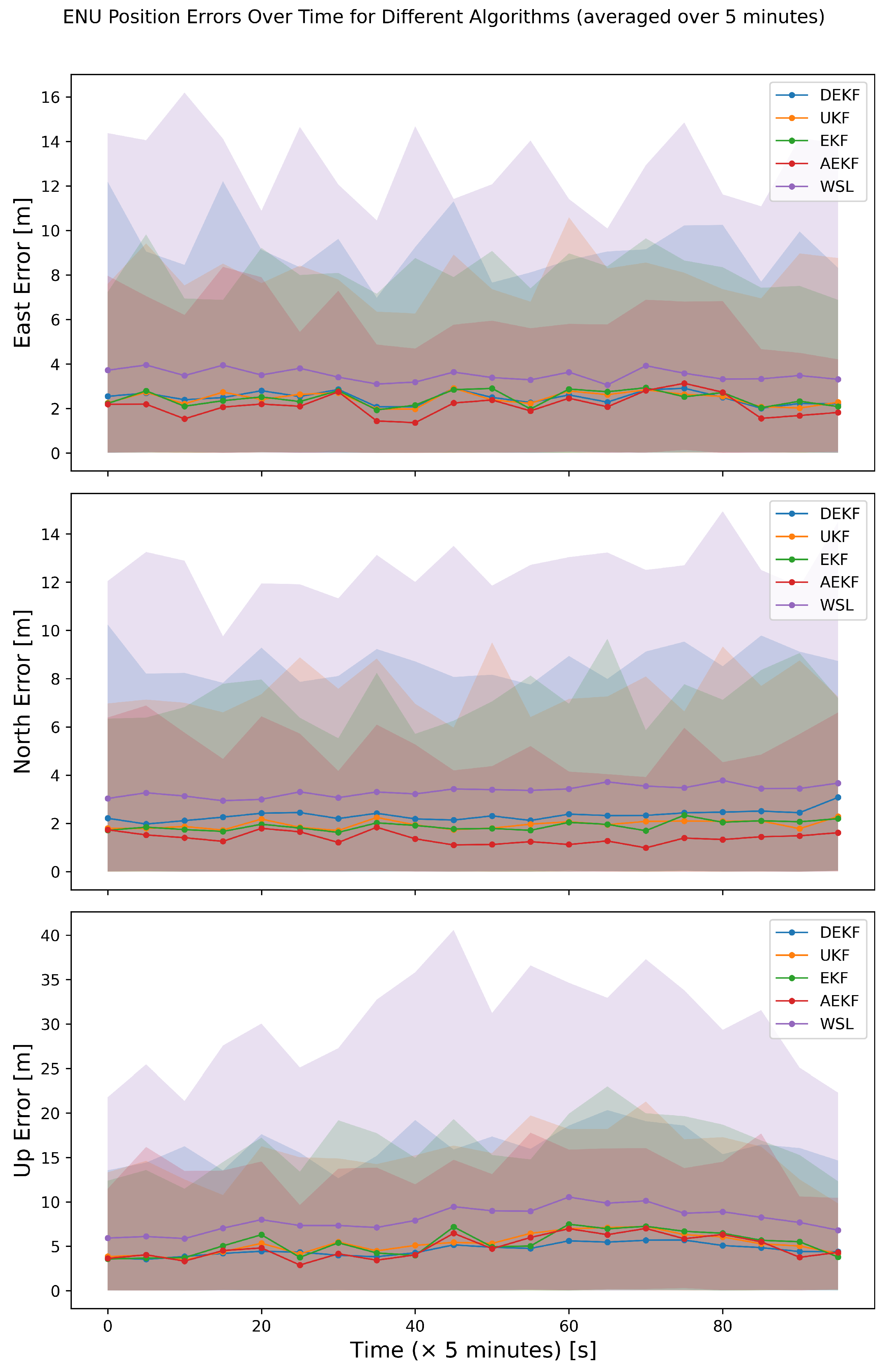
5.3. Dynamic Scenario
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hofmann-Wellenhof, B.; Lichtenegger, H.; Wasle, E. GNSS—Global Navigation Satellite Systems: GPS, GLONASS, Galileo, and More; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Seeber, G. Satellite Geodesy; Walter de Gruyter: Berlin, Germany, 2003. [Google Scholar]
- Teunissen, P.J.; Montenbruck, O. Springer Handbook of Global Navigation Satellite Systems; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10. [Google Scholar]
- Iqbal, A.; Mahmood, H.; Farooq, U.; Kabir, M.A.; Asad, M.U. An Overview of the Factors Responsible for GPS Signal Error: Origin and Solution. In Proceedings of the 2009 International Conference on Wireless Networks and Information Systems, Shanghai, China, 28–29 December 2009; pp. 294–299. [Google Scholar] [CrossRef]
- Kaplan, E.; Hegarty, C. Understanding GPS/GNSS: Principles and Applications, 3rd ed.; GNSS Technology and Applications Series; Artech House Publishers: London, UK, 2017; ISBN 9781630814427. [Google Scholar]
- Gruber, M. An Approach to Target Tracking; Technical Note 1967-8; Massachusetts Institute of Technology Lincoln Laboratory: Lexington, MA, USA, 1967. [Google Scholar]
- Julier, S.; Uhlmann, J. Unscented filtering and nonlinear estimation. Proc. IEEE 2004, 92, 401–422. [Google Scholar] [CrossRef]
- Li, K.; Zhou, G.; Kirubarajan, T. A general model-based filter initialization approach for linear and nonlinear dynamic systems. Digit. Signal Process. 2021, 111, 102978. [Google Scholar] [CrossRef]
- Guo, Y.; Chai, S.; Cui, L. GNSS Precise Point Positioning Based on Dynamic Kalman Filter with Attenuation Factor. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 4734–4738. [Google Scholar] [CrossRef]
- Xiao, G.; Yang, C.; Wei, H.; Xiao, Z.; Zhou, P.; Li, P.; Dai, Q.; Zhang, B.; Yu, C. PPP ambiguity resolution based on factor graph optimization. GPS Solut. 2024, 28, 178. [Google Scholar] [CrossRef]
- Kanhere, A.V.; Gupta, S.; Shetty, A.; Gao, G. Improving GNSS Positioning Using Neural-Network-Based Corrections. Navig. J. Inst. Navig. 2022, 69. [Google Scholar] [CrossRef]
- Lee, J.; Lee, Y.; Kim, J.; Kosiorek, A.; Choi, S.; Teh, Y.W. Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Proceedings of Machine Learning Research. Chaudhuri, K., Salakhutdinov, R., Eds.; Volume 97, pp. 3744–3753. [Google Scholar]
- Liu, Z.; Liu, J.; Xu, X.; Wu, K. DeepGPS: Deep Learning Enhanced GPS Positioning in Urban Canyons. IEEE Trans. Mob. Comput. 2024, 23, 376–392. [Google Scholar] [CrossRef]
- Zhang, G.; Xu, P.; Xu, H.; Hsu, L.T. Prediction on the Urban GNSS Measurement Uncertainty Based on Deep Learning Networks With Long Short-Term Memory. IEEE Sens. J. 2021, 21, 20563–20577. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Mohanty, A.; Gao, G. Learning GNSS Positioning Corrections for Smartphones Using Graph Convolution Neural Networks. Navig. J. Inst. Navig. 2023, 70. [Google Scholar] [CrossRef]
- Kloss, A.; Martius, G.; Bohg, J. How to train your differentiable filter. Auton. Robot. 2021, 45, 561–578. [Google Scholar] [CrossRef]
- Haarnoja, T.; Ajay, A.; Levine, S.; Abbeel, P. Backprop KF: Learning Discriminative Deterministic State Estimators. arXiv 2016, arXiv:arXiv:1605.07148. [Google Scholar]
- Liu, W.; Lai, Z.; Bacsa, K.; Chatzi, E. Neural extended Kalman filters for learning and predicting dynamics of structural systems. Struct. Health Monit. 2024, 23, 1037–1052. [Google Scholar] [CrossRef]
- Revach, G.; Shlezinger, N.; Ni, X.; Escoriza, A.L.; van Sloun, R.J.G.; Eldar, Y.C. KalmanNet: Neural Network Aided Kalman Filtering for Partially Known Dynamics. IEEE Trans. Signal Process. 2022, 70, 1532–1547. [Google Scholar] [CrossRef]
- Guo, Y.; Vouch, O.; Zocca, S.; Minetto, A.; Dovis, F. Enhanced EKF-based time calibration for GNSS/UWB tight integration. IEEE Sens. J. 2022, 23, 552–566. [Google Scholar] [CrossRef]
- Shumway, R.H.; Stoffer, D.S. An Approach to Time Series Smoothing and Forecasting Using the EM Algorithm. J. Time Ser. Anal. 1982, 3, 253–264. [Google Scholar] [CrossRef]
- Li, X.; Wang, Z.; Zhang, L. Co-estimation of capacity and state-of-charge for lithium-ion batteries in electric vehicles. Energy 2019, 174, 33–44. [Google Scholar] [CrossRef]
- Kiers, H.A. Weighted least squares fitting using ordinary least squares algorithms. Psychometrika 1997, 62, 251–266. [Google Scholar] [CrossRef]
- Li, X.; Huang, J.; Li, X.; Shen, Z.; Han, J.; Li, L.; Wang, B. Review of PPP–RTK: Achievements, challenges, and opportunities. Satell. Navig. 2022, 3, 28. [Google Scholar] [CrossRef]
- Sunahara, Y.; Kohji, Y. An approximate method of state estimation for non-linear dynamical systems with state-dependent noise. Int. J. Control 1970, 11, 957–972. [Google Scholar] [CrossRef]
- Triantafyllopoulos, K. The Kalman Filter. In Bayesian Inference of State Space Models: Kalman Filtering and Beyond; Springer International Publishing: Cham, Switzerland, 2021; pp. 63–109. [Google Scholar] [CrossRef]
- Stone, J.V. Bayes’ Rule: A tutorial Introduction to Bayesian Analysis; Sebtel Press, 2013. [Google Scholar] [CrossRef]
- Baydin, A.G.; Pearlmutter, B.A.; Radul, A.A. Automatic differentiation in machine learning: A survey. arXiv 2015, arXiv:1502.05767. [Google Scholar]
- Zaheer, R.; Shaziya, H. A Study of the Optimization Algorithms in Deep Learning. In Proceedings of the 2019 Third International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 10–11 January 2019; pp. 536–539. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM algorithm. J. R. Stat. Soc. Ser. (Methodol.) 1977, 39, 1–38. [Google Scholar] [CrossRef]
- Rauch, H.E.; Tung, F.; Striebel, C.T. Maximum likelihood estimates of linear dynamic systems. AIAA J. 1965, 3, 1445–1450. [Google Scholar] [CrossRef]
- Safran Electronics & Defense. User Manual—Skydel Software Defined GNSS Simulator. 2024. Available online: https://safran-navigation-timing.com/document/user-manual-skydel-software-defined-gnss-simulator/ (accessed on 17 April 2025).
- Elgamoudi, A.; Benzerrouk, H.; Elango, G.A.; Landry, R.J. Quasi-real RFI source generation using orolia skydel LEO satellite simulator for accurate geolocation and tracking: Modeling and experimental analysis. Electronics 2022, 11, 781. [Google Scholar] [CrossRef]
- Kujur, B.; Khanafseh, S.; Pervan, B. Experimental validation of optimal INS monitor against GNSS spoofer tracking error detection. In Proceedings of the 2023 IEEE/ION Position, Location and Navigation Symposium (PLANS), Monterey, CA, USA, 24–27 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 592–596. [Google Scholar]
- Fu, G.M.; Khider, M.; Van Diggelen, F. Android raw GNSS measurement datasets for precise positioning. In Proceedings of the 33rd International Technical Meeting of the Satellite Division of the Institute of Navigation (ION GNSS+ 2020), Online, 22–25 September 2020; pp. 1925–1937. [Google Scholar]
- Klobuchar, J.A. Ionospheric Time-Delay algorithm for Single-Frequency GPS Users. IEEE Trans. Aerosp. Electron. Syst. 1987, AES-23, 325–331. [Google Scholar] [CrossRef]
- Leandro, R.F.; Santos, M.C.; Langley, R.B. UNB Neutral Atmosphere Models: Development and Performance. In Proceedings of the 2006 National Technical Meeting of the Institute of Navigation, Monterey, CA, USA, 18–20 January 2006. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Verma, J.; Bhattarai, N.; Bandi, T.N. Hybrid Filtering Technique for Accurate GNSS State Estimation. Remote Sens. 2025, 17, 1552. https://doi.org/10.3390/rs17091552
Verma J, Bhattarai N, Bandi TN. Hybrid Filtering Technique for Accurate GNSS State Estimation. Remote Sensing. 2025; 17(9):1552. https://doi.org/10.3390/rs17091552
Chicago/Turabian StyleVerma, Jahnvi, Nischal Bhattarai, and Thejesh N. Bandi. 2025. "Hybrid Filtering Technique for Accurate GNSS State Estimation" Remote Sensing 17, no. 9: 1552. https://doi.org/10.3390/rs17091552
APA StyleVerma, J., Bhattarai, N., & Bandi, T. N. (2025). Hybrid Filtering Technique for Accurate GNSS State Estimation. Remote Sensing, 17(9), 1552. https://doi.org/10.3390/rs17091552