1. Introduction
The detection and segmentation of clouds and cloud shadows are of great significance in remote sensing image processing. They are of great help for surface feature extraction, climate detection, and so on. The detection of clouds and shadows can effectively reduce their interference in ground object recognition, especially in areas such as vegetation cover, land use change, and water resource monitoring. This can help predict the trend of climate change. At the same time, observing cloud shadow changes can better evaluate the spatiotemporal distribution of solar energy resources, providing a scientific basis for solar power plant site selection and agricultural, industrial, and other production activities. Therefore, the detection and segmentation of clouds and cloud shadows is an important issue in the field of remote sensing.
The traditional cloud and shadow detection methods are mainly divided into three categories: Category 1, based on statistics, is divided into two sub-categories—one is the statistical equation method, which uses data samples to build mathematical models, calculates parameters such as brightness and reflectivity [
1] to detect cloud layers, and identifies cloud shadows based on geometric relationships [
2,
3,
4]; the other is cluster analysis [
5], which clusters and groups remote-sensing image pixels to identify and distinguish cloud layers. Category 2, based on spectral thresholding, threshold detection is set using the spectral characteristics of single or multi-phase images. The grayscale value or reflectance of each pixel in the image is compared with a predefined threshold, and the pixels are classified as cloud shadows or non-cloud shadows based on the results [
6,
7,
8,
9,
10,
11,
12]. Category 3, based on morphological and texture features, detection and segmentation are achieved based on the typical features of clouds and shadows [
13]. However, traditional methods face detection challenges for different types of clouds and cloud shadows. For example, threshold methods are prone to missed or false detections in complex backgrounds, and light reflections can cause significant interference, requiring additional discrimination rules and increasing algorithm complexity and computational complexity. Due to noise interference and complex backgrounds, traditional methods often exhibit low detection accuracy and rough boundary delineation, which directly limits their effectiveness in extracting precise edge features.
With the continuous advancement of deep learning technology, semantic segmentation networks have been introduced into remote sensing image processing. Network models based on CNNs (convolutional neural networks) perform well in image classification tasks and lay the foundation for the development of pixel-level classification tasks, namely semantic segmentation. Long et al. [
14] first introduced the concept of FCNs (fully convolutional networks) in 2015 and achieved image segmentation by improving the CNN network to classify image pixels. While FCN demonstrated segmentation capabilities, its limited capacity to recover spatial details motivated subsequent innovations. SegNet (a deep convolutional encoder–decoder architecture for image segmentation) introduces an encoder–decoder structure and achieves pixel-level classification through max-pooling index passing [
15], yet still struggles with fine-grained feature reconstruction. Ronneberger et al. [
16] designed the Unet (U-shaped network) based on encoder and decoder implementation, which achieved a key breakthrough. By establishing skip connections between the encoder and decoder, the detailed information of the image is effectively preserved. The UNet++ (nested U-net architecture) proposed by Zhou et al. [
17] further optimized and improved the UNet structure in medical image segmentation, effectively enhancing the network’s feature expression ability through nested and densely connected modules. Chen et al. [
18] proposed an image segmentation method called DeepLab, which adopts the DCNN (deep convolutional neural network) structure, expands the receptive field of each layer of the network with multiple different network layers and atrous convolution, and uses CRF (fully connected random field) to refine feature information, achieving the accurate semantic segmentation of images. But CRF introduces computational complexity while providing limited feature interaction learning. Clouds and shadows span a wide range of scales. Clouds may span hundreds of square kilometers in a dispersed form, while shadows often appear as small-scale features with sharp edges. Thus, the network is required to have the capability of capturing both fine-grained boundaries and broader contextual cues. However, existing networks often overlook the interaction between local and global features, making it difficult to accurately understand information in the presence of complex features or interference noise.
At present, there are several problems with cloud and cloud shadow detection and segmentation:
Shape complexity: The sizes and shapes of cloud shadows are complex and varied, and the extraction of edge information is rough;
Noise interference: There are often issues such as noise and shadows in cloud shadow remote sensing images, making it difficult for networks to distinguish between clouds and cloud shadows;
Irregular distribution: Cloud structures are not fixed and their distribution range is irregular, which can lead to incomplete detection and segmentation, as well as missing feature information.
In response to the above issues, this article proposes an improved semantic segmentation network model within the Unet model, which has the following improvements compared to the above methods:
An edge feature extraction branch network has been added within the network to enhance the extraction of edge features.
The downsampling operation in the semantic segmentation branch network has been changed to an improved ASPP (atrous spatial pyramid pooling) module, the receptive field of the network has been expanded, the network’s ability to extract multi-scale features has been enhanced, and thus it is possible to obtain a broader range of contextual information.
Embedding the CBAM (Convolutional Block Attention Module) dual-attention mechanism in the skip connection part of the semantic segmentation branch network not only improves the expression ability of key features but also suppresses noise and irrelevant information and helps the model adaptively select important feature channels and spatial positions, reducing computational complexity to a certain extent and improving the model’s running speed and efficiency.
The integration of feature information obtained from two branch networks through feature fusion, optimizing the final extracted features and improving segmentation accuracy.
2. Methods
2.1. EDFF-Unet Architecture
Unet is a commonly used convolutional neural network with a symmetrical structure resembling a “U” shape. It is widely used in various scenarios and consists of an encoder, decoder, and skip connections connecting the two. The encoder part is usually built by stacking multiple convolution modules in sequence. In each convolution module, the feature information in the image is carefully mined through convolutional layers and then activated by activation functions. A pooling layer is introduced to gradually abstract the features in the image and extract deeper semantic information. The decoder is also composed of multiple convolution modules, which use upsampling to gradually restore the image’s resolution. During the upsampling process, the decoder will use skip connections to fuse the feature maps of the corresponding resolution levels in the encoder, achieving the combination of low-level detail features and high-level semantic features and improving the accuracy and refinement of image segmentation.
This article constructs a network structure, as shown in
Figure 1, based on the Unet network architecture. The network has three parts: an edge detection sub-network (ED), an Unet semantic segmentation sub-network, and a feature fusion module.
The implementation steps of EDFF-Unet mainly include: (1) changing the downsampling of the semantic segmentation sub-network to an improved ASPP spatial pyramid pooling module and embedding an attention mechanism module (CBAM) into the skip connections to obtain semantic segmentation feature maps through upsampling; (2) obtaining the contour feature information of the input image through four consecutive convolutional layers in the edge detection (ED) sub-network, thereby obtaining the edge detection feature map; (3) using the feature fusion module (FF) to weigh and fuse the input feature map, semantic segmentation feature map, and edge detection feature map. Then, global average pooling and global max pooling operations are applied to compute spatial statistics for each feature channel. Finally, the weighted features are processed by a convolutional layer and normalized via a Sigmoid activation function to generate the refined output image.
2.2. Edge Detection Subnet (ED)
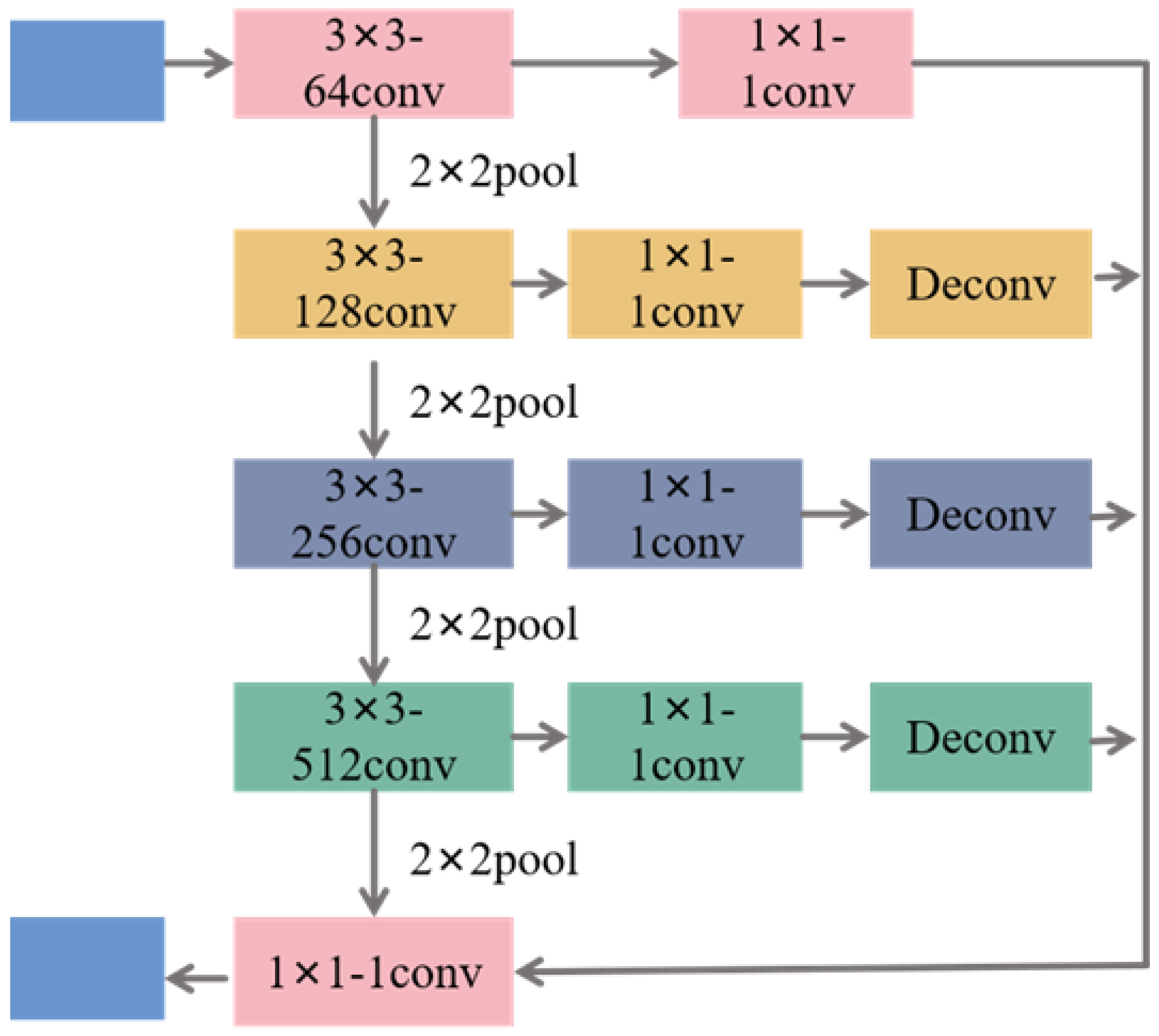
A branch network for edge feature extraction was designed to address the issues of target edge blurring and the loss of edge information during cloud shadow segmentation. This network synchronizes the semantic segmentation task with the edge feature extraction task. The edge detection sub-network extracts visually significant edges and object boundaries from images to obtain boundary information of cloud shadows and perform a more accurate semantic segmentation of images. The detailed network structure of the edge detection sub-network is shown in
Figure 2.
In the edge detection sub-network, the convolutional layers are divided into four stages, with a pooling layer inserted between each convolutional stage to reduce the dimensionality of the extracted features. The first convolutional layer employs a kernel initialized via He normal initialization. The second, third, and fourth convolutional layers also use kernels. To maintain spatial consistency with the input image, a convolutional operation is applied at each stage, followed by a deconvolution operation to restore the feature map resolution. Finally, the feature maps obtained from the four stages are fused through a convolution operation and Sigmoid activation function. This can effectively obtain the contour of the image and obtain more precise and more complete edge information of the image target.
For the input feature map,
where
represents the number of network layers and
.
indicates the size of the convolutional kernel at the layer level
;
indicates the number of output channels for the convolutional layer
;
indicates the size of the pooling kernel; and
represents the size of the deconvolution kernel.
2.3. Attention Mechanism CBAM
CBAM, as an adaptive feature importance learning mechanism widely used in convolutional neural networks, can improve network performance. When given a feature map, the module autonomously infers attention weight values along two independent dimensions and then multiplies the generated attention weight map by the input feature map for adaptive refinement processing. The structure of CBAM is shown in
Figure 3.
This mechanism consists of two parts—a channel attention module and a spatial attention module. The channel attention module learns and highlights the importance of each channel in feature extraction through weighted averaging processing. By using global average pooling and global max pooling (where the pooling kernel size equals the spatial dimensions of the input feature map), the spatial dimensions of the input features are compressed to 1, generating two channel descriptors. These descriptors are then fed into a shared multi-layer perceptron (MLP) for feature transformation, producing a channel attention map. Finally, the values of the attention map are normalized to the range [0, 1] via a Sigmoid function. The spatial attention module learns and emphasizes the importance of each spatial position in feature extraction through weighted averaging, effectively highlighting the target area and suppressing irrelevant information. By performing channel-wise average pooling and max pooling on the input feature map (assuming the input feature map is
, which becomes
after average pooling, while max pooling retains
), two spatial descriptors are obtained. These descriptors are concatenated along the channel dimension and fed into a 7 × 7 convolutional layer to generate a spatial attention map. Finally, the values of the spatial attention map are normalized to the range [0, 1] via a Sigmoid function. Through the above mechanism, the influence of noise in cloud images can be reduced, important regional features can be highlighted, and the segmentation effect of clouds and cloud shadows can be improved. The operation process of CBAM fusion attention can be defined as
where
represents the input feature map;
represents the Sigmoid function;
represents the feature map after channel attention;
is the input characteristic graph of spatial attention;
represents the feature map after spatial attention; the “;” in Formula 6 represents concatenating
and
in the channel dimension; the “
” in Formulas (5) and (7) represents the Hadamard product; and
represents the weight feature vector output after CBAM fusion attention operation.
2.4. Improved ASPP Hollow Space Pyramid Pooling Module
The Unet network can capture features at different levels through an encoder–decoder structure, but its ability to extract multi-scale information is relatively limited. In the encoder stage, it mainly focuses on extracting local information, while in the decoder stage, although upsampling and feature fusion are performed, it may still be difficult to effectively integrate local information with global information, resulting in insufficient utilization of receptive fields and affecting the understanding of the overall structure and target of the image.
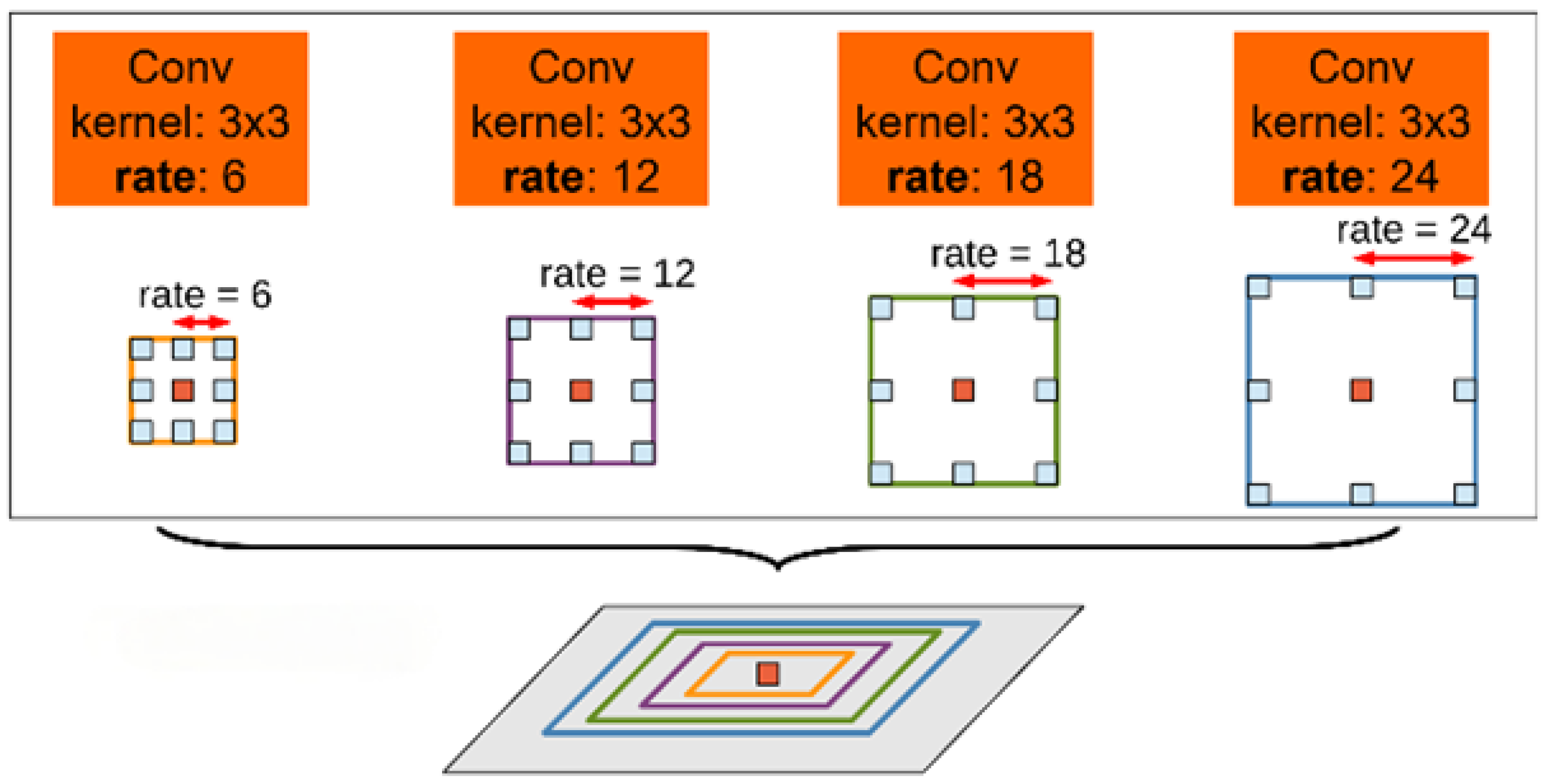
Hollow convolution [
18] has always been favored by researchers in the field of segmentation as a means of effectively expanding the receptive field of ordinary convolution kernels. Its ability lies in significantly expanding the receptive field of the convolutional kernel without increasing the number of model parameters and computational complexity. As shown in
Figure 4, adding intervals to a regular convolution kernel to form a dilated convolution allows the kernel to cover a larger range without changing the size or number of layers. The relationship between the convolution kernel’s range of dilated convolution and its dilation rate is shown in the Formula (8).
where
is the void rate;
is the range of the initial convolution kernel; and
is the actual receptive field size of dilated convolution.
Therefore, the plan is to change the downsampling operation of the original Unet network to the ASPP atrous space pyramid pooling module. This module originally included four parallel
convolutions with different hole rates, expanding the receptive field of the convolution kernel and obtaining contextual information of the image at multiple scales through a dimensionality reduction in input features. Its structure is shown in
Figure 5.
However, the original ASPP lacked the balanced processing of local and global features, resulting in the insufficient extraction of some information. Therefore, this paper adds an Avgpool and a Maxpool to the ASPP module.
AvgPool: By averaging the local regions of the feature map, more global contextual information can be retained, which helps the network capture the overall structure of the image.
MaxPool: By performing maximum value operations on local regions of the feature map, more local detail information can be preserved, which helps the network capture detailed features such as the edges and textures of the image.
By combining AvgPool and MaxPool, the module can simultaneously preserve global contextual information and local detail information, thereby achieving a better balance in the feature extraction process. This combination can enhance the network’s ability to extract multi-scale features, especially when dealing with complex segmentation tasks, and to better cope with targets of different scales. Considering that the feature maps of AvgPool and MaxPool may not be consistent in scale and semantics, in the improved ASPP, the output feature maps of AvgPool and MaxPool will undergo a
convolution for channel adjustment and semantic alignment, and then be fused by element-wise addition or channel concatenation, supplemented by batch normalization (BatchNorm) and activation function (ReLU), to ensure that features from different sources have consistent scale and semantic expression before fusion, thereby avoiding information conflicts. The improved ASPP is shown in
Figure 6.
The improved ASPP process is as follows: (1) The first convolutional layer employs a convolutional kernel to perform preliminary feature extraction on the input feature map, generating initial representations of cloud patterns. (2) The second convolutional layer utilizes a convolutional kernel with a dilation rate of 6, enabling the capture of broader contextual information across larger spatial regions in the feature map. (3) The third convolutional layer adopts a kernel with an increased dilation rate of 12, further expanding the receptive field to extract large-scale features that characterize interactions between clouds and their shadows. (4) The fourth convolutional layer incorporates a kernel with a maximum dilation rate of 18, facilitating the extraction of the most extensive contextual information from the feature map. (5) The max pooling layer operates on local regions of the input feature map by selecting maximum values, thereby enhancing sensitivity to abrupt intensity variations and precisely capturing fine-grained shadow boundaries through localized detail preservation. (6) The average pooling layer computes spatial averages over local regions, effectively suppressing noise while stabilizing global contextual information, which is critical for the robust identification of large-scale shadow regions. (7) The fusion layer concatenates feature maps from different convolutional and pooling layers, and the convolutional layer convolves the fused feature maps to obtain the result.
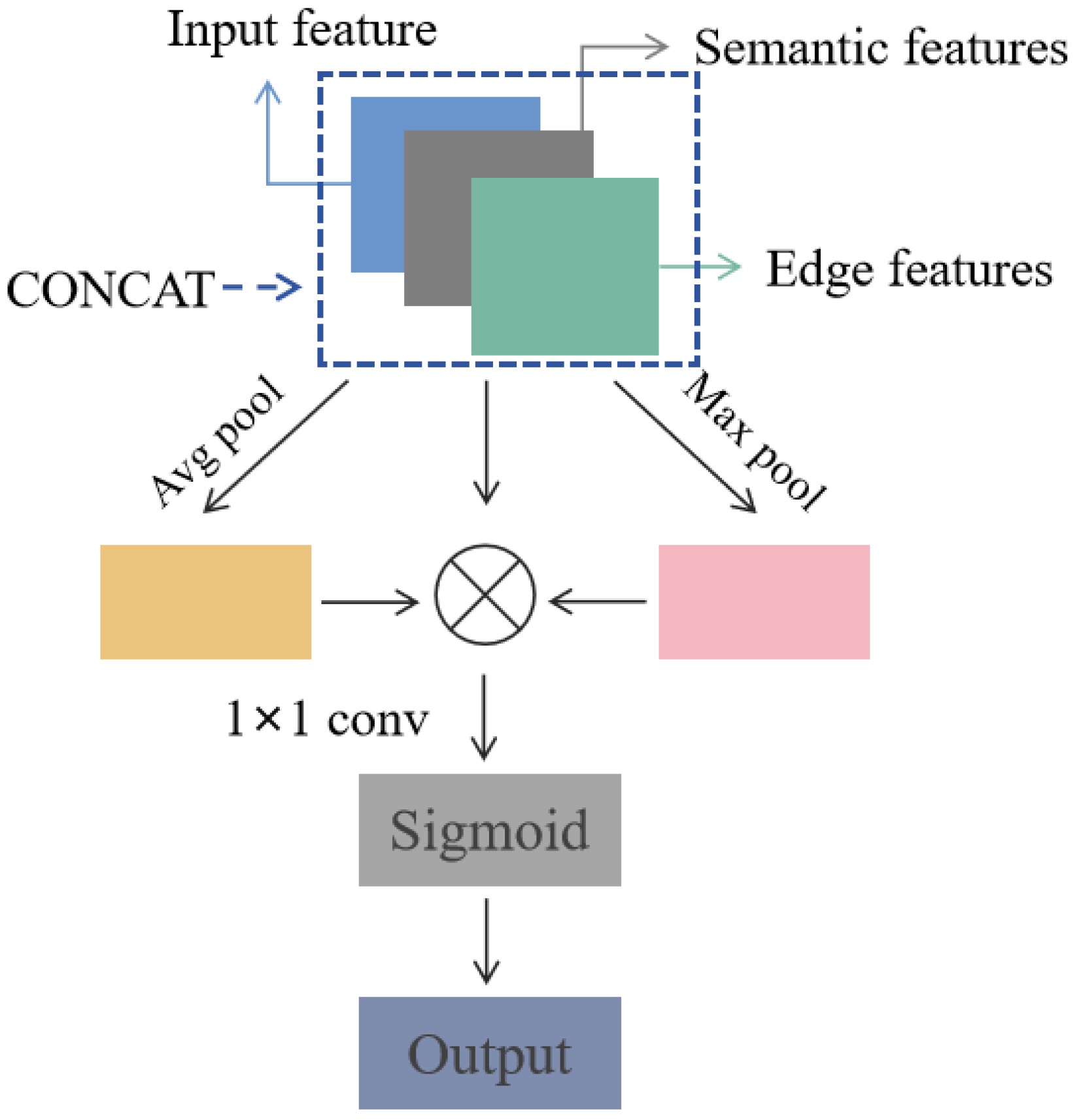
2.5. Feature Fusion Module (FF)
When the semantic segmentation sub-network and the edge detection sub-network extract semantic features and edge features, respectively, they are fused. The concat fusion method can fully preserve the original information of each participating feature map without losing features. Therefore, this paper designs a feature fusion module based on the concat fusion method to weigh and fuse the two features. The structure of the feature fusion module is shown in
Figure 7.
In the feature fusion module, the input feature map, semantic feature map, and edge feature map are first concatenated and fused. The number of channels for the input feature map, semantic feature map, and edge feature map is
, and
. The spatial dimensions are all
. After splicing, the number of channels in the fused feature map is
, and the spatial dimension remains
. Then, the global average of the corresponding feature channels is obtained through average pooling and max pooling operations. Both global average pooling and maximum pooling use spatial global pooling, with an output dimension of
. And the weights of the feature channels are allocated through multiplication calculation to extract adequate feature information. Then, using a
convolution operation to perform channel dimensionality reduction on the features, integrating cross-channel information through linear transformation, the spatial dimension of the output feature map remains
. Finally, the Sigmoid classifier is used for prediction to obtain the final result. The calculation process of the multiplication is shown in Formula (9).
where
represents the feature value of the th channel on the weighted fused feature map;
represents the feature value of the
channel on the feature map;
represents the weight coefficient of the
channel; and
represents the number of feature channels.
3. Experiment
3.1. GF1_WHU Dataset
GF1_WHU (GF-1 Cloud and Cloud Shadow Coverage Verification Dataset) [
19] was released by the SENSIMAGE Laboratory at Wuhan University and is widely used in cloud detection and cloud shadow segmentation tasks. This dataset includes 108 GF-1 Wide Field of View (WFV) 2A level images and their corresponding reference masks collected from May 2013 to August 2016. The corresponding ground truth masks are divided into four categories: background pixels are 0, transparent area pixels are 1, cloud shadow area pixels are 128, and cloud area pixels are 255. Each image in the dataset consists of four multispectral bands, including three visible R, G, and B bands and one near-infrared band, with a spatial resolution of 16 m. All four multispectral bands of the GF1_WHU dataset were utilized for cloud detection. The combination of multi-band information is beneficial for improving the accuracy of cloud and cloud shadow detection. As shown in
Figure 8, the GF1_WHU dataset contains images of different cloud types (such as cumulus, stratus, cirrus, etc.), cloud cover, cloud shadow patterns, and different geographical environments. The data types and contents are rich and diverse, providing sufficient materials for this study.
3.2. HRC_WHU Dataset
HRC_WHU (High Resolution Classification Dataset of Wuhan University) is a high-precision remote sensing image semantic segmentation benchmark dataset released by the School of Remote Sensing Information Engineering of Wuhan University. It is designed for tasks such as building extraction and land use classification, and consists of 150 high-resolution remote sensing images with resolutions mainly ranging from 0.5 to 15 m. The original size is 1280 × 720. This dataset covers multiple urban scenes in China, including diverse geographical environments such as cities, suburbs, and rural areas.
3.3. Evaluating Indicator
The experiment evaluates the effectiveness of the model using four indicators—pixel accuracy (PA), average pixel accuracy (MPA), F1, and the mean intersection-to-union ratio (MIOU). The specific calculation formulas are as follows:
PA is defined as the proportion of correctly classified pixels to all pixels.
MPA is computed by the ratio of the number of correctly classified pixels for each class to the total number of pixels for that class, and then the average is taken.
F1 is the harmonic mean of accuracy and recall, reflecting the overall performance of the model.
MIOU measures the degree of overlap between predicted and actual cloud and shadow regions.
in Formulas (10)–(13) above,
is the number of categories;
is the class
pixel and is predicted to be the number of class
pixels;
is the class
pixel and is predicted to be the number of class
pixels;
is the class
pixel and is predicted to be the number of class
pixels;
indicates that the
sample is correctly divided into cloud and cloud shadow;
indicates that the
sample background pixel is incorrectly divided into cloud and cloud shadow; and
indicates that the cloud and cloud shadow of sample
are wrongly divided into background pixels.
This study also introduces an evaluation metric—Border Intersection Union (Border IoU), which is used to evaluate the accuracy of target boundary regions in image segmentation. Its calculation formula is as follows:
Expand the boundaries of the Ground Truth (GT) and Prediction (Pred) masks through morphological dilation to generate boundary regions of a specified width:
where
represents the true boundary area;
represents the predicted boundary region; “
” represents morphological dilation operation; and
represents the expansion radius.
3.4. Hyperparametric Experiment
This article adopts a joint loss function strategy as the loss function, using Dice coefficient loss and smoothed version L1 loss in combination. The joint use of these two loss functions can optimize model performance at multiple levels, ensuring both the overlap of segmentation regions and the better spatial fit of predicted segmentation regions to the actual region. At the same time, it also considers the measurement of the difference between predicted and actual values at the pixel level, thereby ensuring pixel-level accuracy. This joint loss function helps the segmentation results to be more in line with the actual situation in terms of details while ensuring the reliable performance of the model in segmentation tasks with different scale structures. Cloud and shadow boundaries often exhibit irregularity, and joint loss can ensure approximate coverage of the cloud shadow area through Dice loss, while constraining the offset error of boundary pixels through Smooth L1 loss. The specific formula is as follows:
where
and
represent weight coefficients,
represents the Dice coefficient loss function, and
represents the smooth version L1 loss function.
The Dice coefficient is an indicator used to measure the similarity between two sets. Especially in the field of image segmentation processing, the Dice coefficient is used as a loss function to help evaluate the similarity between predicted results and actual results. The Dice coefficient is based on the size of two sets and the size of their intersection. Given the two sets A and B, the Dice coefficient formula is as follows:
The Dice loss function is a loss function based on the Dice coefficient, which aims to minimize the Dice coefficient and improve the similarity between the segmentation result and the actual label. In practical applications, continuous probability values are usually used instead of binary results, and to avoid dividing by zero, a small smoothing term
is added to the formula. Therefore, the Dice coefficient loss function in this article is expressed as:
where
and
represent the predicted value and true value of the
pixel.
The SmoothL1 loss function is a combination of L1 loss and L2 loss. When the difference between the predicted value and the actual value is small (less than beta, assumed to be 1.0 here), its calculation method is similar to L2 loss (squared error); when the difference is significant, its calculation method is similar to L1 loss (absolute error), enhancing the robustness of the model to outliers. Near zero, the gradient of the SmoothL1 loss function is continuous and smoothly changing, which makes the parameter updates of the model more stable and continuous during the training process. SmoothL1Loss is represented as:
where
represents the output of the model and
represents the label of the model.
Experiments were conducted with different weights, and the performance comparison and quantification results of different weights are shown in
Table 1:
By continuously adjusting the value of
and
to analyze the network performance, the optimal extraction accuracy can be obtained. The PA, MPA, F1, and MioU indexes of the model performance are evaluated. It can be seen from
Table 1 that when
,
, the evaluation index was the highest and the image segmentation effect was the best.
3.5. Ablation Experiment
In order to verify the effectiveness of each module in this method, ablation experiments were conducted on the edge detection module, attention mechanism module, and hollow space pyramid pooling module. MioU, PA, and MPA were used as the evaluation criteria for experimental effectiveness. The specific experimental results are shown in
Table 2. Where √ represents adding the module, and × represents not adding the module.
Table 2 experimental results show that the indicators of the edge detection module, attention mechanism module, and hollow space pyramid pooling module are improved by adding them separately. When the two modules are added at the same time, the best effect is achieved. When the edge detection module, attention mechanism module, and hollow space pyramid pooling module are added at the same time, PA, MPA, and MioU are increased by 5.54%, 6.96%, and 3.96%, respectively. This shows that embedding an edge detection module, attention mechanism module, and hollow space pyramid pooling module into the basic feature extraction network has a good effect on improving the accuracy of the model.
From the visualization results of the ablation experiment in
Figure 9, it can be further seen that EDFF-Unet can significantly improve the segmentation performance of cloud and cloud shadow, and reduce missed detection and false detection.
To further validate the effectiveness of the feature fusion module, we selected the following three baseline methods for comparison:
Direct addition fusion (Add): Directly add the input feature map, semantic feature map, and edge feature map element-by-element;
Multiply element-by-element (Multiply): Multiply the input feature map, semantic feature map, and edge feature map element-by-element, and directly output the fused feature map;
Attention fusion (Channel Attention): Introducing a channel attention mechanism (SE Block) after concatenation to replace the pooling weight allocation strategy in this paper.
All feature maps are uniformly adjusted to the same spatial size through adaptive pooling, and mapped to a uniform number of channels through
convolution to ensure the smooth experimentation of Add and Multiply. The experimental results were quantified using MIoU, and the results obtained from the GF1_WHU dataset are shown in
Table 3:
The experiment shows that the fusion feature module proposed in this paper exhibits good performance on the GF1_WHU dataset. Compared with other baseline methods, the fusion module in EDFF-Unet can improve the segmentation ability of cloud images.
Because edge detection is a prominent feature of this method, the effectiveness of edge detection will be validated for different cloud types. The study selects three different cloud types from the GF1_WHU dataset—cumulus clouds, stratus clouds, and cirrus clouds—to demonstrate the effectiveness of edge detection, and quantifies the experimental results of the edge detection using Border IoU.
The specific experimental results are shown in
Table 4. From the table, it can be seen that the edge detection module has good detection performance for different types of cloud images, effectively enhancing boundary features. The segmentation accuracy (Border IoU) in the edge region is slightly better than the segmentation effect (MIoU) in the overall region, indicating that the edge detection model effectively improves the overall segmentation effect.
3.6. Experimental Results Display
The
Table 2 experimental results show the indicators of the edge detection module, attention mechanism module, and improved ASPP. In order to evaluate the performance of the proposed network and verify the effectiveness and feasibility of EDFF-Unet, it was qualitatively and quantitatively compared with classical segmentation networks such as Unet, FCN, PAN, and the recent models ViT D-UNet and DBNet on the GF1_WHU dataset. The comparison results are shown in
Table 5. From the table, it can be seen that, compared to other algorithms, the model proposed in this paper performs better in cloud and cloud shadow recognition. In addition to MPA, PA, F1, and MIoU are 0.25%, 0.18% and 0.67% ahead of the sub-excellent networks, respectively. The quantitative evaluation results show that the proposed method is more accurate and robust than other comparison methods and has a better segmentation ability for clouds and shadows with different shapes and distributions.
Figure 10 shows the visual comparison results of the GF1_WHU dataset. Compared with the current cutting-edge ViT-D-UNet and DBNet, the network proposed in this study shows higher detection accuracy in the fuzzy feature area and can more accurately define the target boundary. It is worth noting that this network still has excellent detection performance for targets of different sizes and irregular shapes.
As shown in
Figure 11, this network reduces false detection and missed detection in target detection compared with other existing networks. In the figure, the green rectangular area indicates correct detection, and the red rectangular area indicates false detection and missed detection.
In order to further investigate the performance of the model and verify its generalization, this study compares multiple datasets [
30,
31,
32] and ultimately chooses the HRC_WHU dataset. The HRC_WHU dataset has cloud images that are not consistent in style with the GF1_WHU dataset, such as the cloud images with dense building obstructions in the HRC_WHU dataset. The model in this article was compared with some popular models and the experimental results are shown in
Table 6:
From the results, EDFF-Unet still maintains optimal performance on the HRC_WHU dataset. The model still leads by 0.34% in the MIoU metric.
In order to verify the effectiveness and accuracy of the edge detection module in this study, comparative experiments were conducted on the edge detection performance of different networks, and Border IoU and MIoU were used to quantify the effect. Experiments were conducted on two datasets, the GF1_WHU dataset and the HRC_WHU dataset, and the experimental results are shown in
Table 7:
The experimental results show that, compared to other networks, the edge detection module EDFF-Unet has better performance and good accuracy. On the GF1_WHU and HRC_WHU datasets, EDFF-Unet has the highest Border IoU and MIoU, demonstrating its strong ability to capture complex boundaries and multi-scale features in remote sensing images. On the GF1_WHU dataset, the Border IoU reached 93.64%, which is 0.5% higher than the Border IoU value of the next best network; on the HRC_WHU dataset, the Border IoU reached 88.42%, which is 0.3% higher than the Border IoU value of the next best network.
On the basis of the above comparative experiments, it can be concluded that EDFF-Unet has a superior segmentation ability. In order to further verify the performance of EDFF-Unet and eliminate the influence of chance, this study continues to use an independent two-sample t-test to demonstrate the statistical test results, supporting the conclusion that EDFF-Unet has superior performance. Conduct 3 tests on EDFF-Unet and the comparison model on the GF1_WHU dataset, and calculate the average MIoU of the three experiments and the mean difference in the EDFF-Unet compared to each comparison model (Average MIoU of EDFF-Unet—Average MIoU of the comparison model). By checking the normality and homogeneity of the variance of the data, it was found that the data follows a normal distribution and has homogeneity of variance, meeting the conditions of an independent two-sample t-test. The specific steps are as follows:
Set the null hypothesis and alternative hypothesis: The null hypothesis ()—there is no significant difference in the mean performance indicators between EDFF-Unet and the comparable model. Alternative hypothesis ()—EDFF-Unet performs significantly better than the comparison model.
Set significance level: Set = 0.05; if , reject the null hypothesis.
Calculate
t(
df) and
to determine significance.
where
represents the variance of mIoU values for EDFF-Unet in three tests;
represents the variance of mIoU values for the comparable model in three tests.
The experimental results are shown in the following
Table 8. Through repeated experiments, independent two-sample
t-tests, and result visualization, this analysis has verified the statistical significance of the performance advantages of EDFF-Unet. EDFF-Unet has superior detection and segmentation capabilities compared to other comparable networks.
5. Conclusions
The EF-Uet model uses a semantic segmentation sub-network and edge detection sub-network to segment cloud and cloud shadow images. Then, a feature fusion module is used to realize the fusion of semantic features and edge features. The attention mechanism and the improved ASPP hole space pyramid pool module are deployed in the semantic segmentation sub-network so that the model can adaptively adjust the feature expression of cloud and cloud shadow feature maps and improve the ability of the model to capture key information. At the same time, abundant multi-scale information is captured at the local feature level, which effectively reduces the number of parameters compared with the ordinary convolution operation. The fusion of edge features and semantic features effectively improves the ability of the edge feature extraction of the model and obtains more precise and complete image target edge information. The comparative reality of the GF1_WHU dataset experiment verifies the network’s good performance. Compared with the initial model, the PA, MPA, F1, and MIoU indexes of the algorithm in this paper are improved by 2.85%, 2.96%, 3.23%, and 4.76%, respectively. In terms of the visual image segmentation results, the model achieved accurate segmentation results for the edge, fuzzy, and abstract features. Future research will try some new architectures, such as transformer-based architecture fusion, to analyze image features from different angles and further improve segmentation performance in complex scenes.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}