
How Accurately and in What Detail Can Land Use and Land Cover Be Mapped Using Copernicus Sentinel and LUCAS 2022 Data?


Abstract
1. Introduction
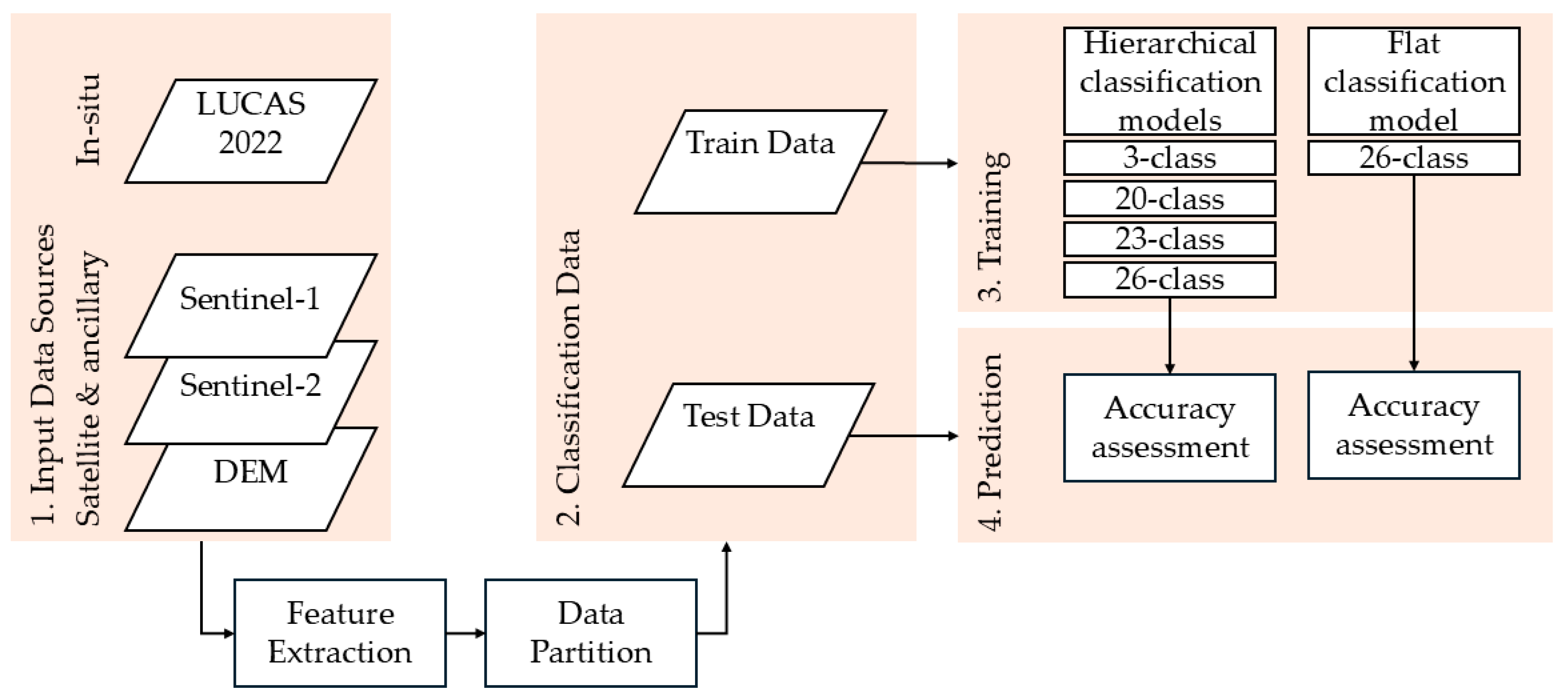
2. Materials and Methods
2.1. Field Data
2.2. Classification Schemes
- Phase 1 (P3): Samples were first categorized into three broad Level-1 classes: 200—Arable land, 300—Woodland and Shrubland, and 500—Grassland, as outlined in Table 1.
- Phase 2 (P20): Samples classified as Arable land were further divided into 18 detailed sub-classes, resulting in a total of 20 classes.
- Phase 3: Samples assigned to Woodland and Shrubland underwent further analysis across three sub-levels:
- ○
- Phase 3-1 (P22): Woodland and Shrubland were split into three categories: B78—Permanent Crops (including: B71—Apple fruit, B72—Pear fruit, B73—Cherry fruit, B74—Nuts trees, B75—Other fruit trees and berries, B76—Oranges, B77—Other citrus fruit, B81—Olive groves, B82—Vineyards, B83—Nurseries, B84—Permanent industrial crops), C123—Broadleaved, Coniferous, and Mixed Woodlands (covering: C10—Broadleaved woodland, C21—Spruce-dominated coniferous woodland, C22—Pine-dominated coniferous woodland, C23—Other coniferous woodland, C31—Spruce-dominated mixed woodland, C32—Pine-dominated mixed woodland, C33—Other mixed woodland), and D12—Shrubland (encompassing: D10—Shrubland with sparse tree cover, D20—Shrubland without tree cover), yielding 22 classes in total.
- ○
- Phase 3-2 (P23): The B78—Permanent Crops category was further separated into B7—Orchards (B71–B88) and B8-Groves (B81–B84), increasing the total number of classes to 23.
- ○
- Phase 3-3 (P26): C123 and D12 classes were also divided into C10— Broadleaved woodland, C20—Coniferous woodland, C30—Mixed woodland, and D10—Shrubland with sparse tree cover, D20—Shrubland without tree cover, correspondingly bringing the total to 26 classes. The distribution of classification points in this scheme over EU-27 is displayed in Figure 2.
2.3. Earth Observation Data
2.3.1. Sentinel-2 Data
2.3.2. Sentinel-1 Data
2.3.3. Texture Data
2.3.4. Auxiliary Temperature and Elevation Data
2.4. Classification Process
2.4.1. Classification Method
2.4.2. Train and Test Data
2.4.3. Train Data Balancing
3. Results
3.1. Overall Accuracy and Kappa Scores
3.2. Visual Analysis of Classification Maps
3.3. Class-Specific Performance Analysis Based on F1-Scores
3.3.1. Large Sample Count Arable Land Classes
3.3.2. Medium-Sample Arable Land Classes
3.3.3. Small-Sample Arable Land Classes
3.3.4. Permanent Crops and Orchards
3.3.5. Grassland, Woodland, and Shrubland Classes
3.4. Performance Based on Producer’s Accuracy
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- European Commission: Joint Research Centre; Soille, P.; Lumnitz, S.; Albani, S. From Foresight to Impact. In Proceedings of the 2023 Conference on Big Data from Space (BiDS’23), Vienna, Austria, 6–9 November 2023; Publications Office of the European Union: Luxembourg, 2023. [Google Scholar]
- Common Agricultural Policy for 2023–2027. 28 CAP Strategic Plans at a Glance. Available online: https://agriculture.ec.europa.eu/document/download/a435881e-d02b-4b98-b718-104b5a30d1cf_en?filename=csp-at-a-glance-eu-countries_en.pdf (accessed on 23 November 2023).
- Sishodia, R.P.; Ray, R.L.; Singh, S.K. Applications of Remote Sensing in Precision Agriculture: A Review. Remote Sens. 2020, 12, 3136. [Google Scholar] [CrossRef]
- Machefer, M.; Zampieri, M.; van der Velde, M.; Dentener, F.; Claverie, M.; d’Andrimont, R. Earth Observation based multi-scale analysis of crop diversity in the European Union: First insights for agro-environmental policies. Agric. Ecosyst. Environ. 2024, 374, 109143. [Google Scholar] [CrossRef]
- Abdi, A.M.; Carrié, R.; Sidemo-Holm, W.; Cai, Z.; Boke-Olén, N.; Smith, H.G.; Eklundh, L.; Ekroos, J. Biodiversity decline with increasing crop productivity in agricultural fields revealed by satellite remote sensing. Ecol. Indic. 2021, 130, 108098. [Google Scholar] [CrossRef]
- Guilpart, N.; Bertin, I.; Valantin-Morison, M.; Barbu, C.M. How much agricultural land is there close to residential areas? An assessment at the national scale in France. Build. Environ. 2022, 226, 109662. [Google Scholar] [CrossRef]
- MohanRajan, S.N.; Loganathan, A.; Manoharan, P. Survey on Land Use/Land Cover (LU/LC) change analysis in remote sensing and GIS environment: Techniques and Challenges. Environ. Sci. Pollut. Res. Int. 2020, 27, 29900–29926. [Google Scholar] [CrossRef]
- Potapov, P.; Turubanova, S.; Hansen, M.C.; Tyukavina, A.; Zalles, V.; Khan, A.; Song, X.-P.; Pickens, A.; Shen, Q.; Cortez, J. Global maps of cropland extent and change show accelerated cropland expansion in the twenty-first century. Nat. Food 2022, 3, 19–28. [Google Scholar] [CrossRef]
- Chen, B.; Tu, Y.; An, J.; Wu, S.; Lin, C.; Gong, P. Quantification of losses in agriculture production in eastern Ukraine due to the Russia-Ukraine war. Commun. Earth Environ. 2024, 5, 336. [Google Scholar] [CrossRef]
- Panek-Chwastyk, E.; Dąbrowska-Zielińska, K.; Kluczek, M.; Markowska, A.; Woźniak, E.; Bartold, M.; Ruciński, M.; Wojtkowski, C.; Aleksandrowicz, S.; Gromny, E.; et al. Estimates of Crop Yield Anomalies for 2022 in Ukraine Based on Copernicus Sentinel-1, Sentinel-3 Satellite Data, and ERA-5 Agrometeorological Indicators. Sensors 2024, 24, 2257. [Google Scholar] [CrossRef]
- Gomes, V.; Queiroz, G.; Ferreira, K. An Overview of Platforms for Big Earth Observation Data Management and Analysis. Remote Sens. 2020, 12, 1253. [Google Scholar] [CrossRef]
- Ghassemi, B.; Izquierdo-Verdiguier, E.; Verhegghen, A.; Yordanov, M.; Lemoine, G.; Moreno Martínez, Á.; de Marchi, D.; van der Velde, M.; Vuolo, F.; d’Andrimont, R. European Union crop map 2022: Earth observation’s 10-meter dive into Europe’s crop tapestry. Sci. Data 2024, 11, 1048. [Google Scholar] [CrossRef]
- Zioti, F.; Ferreira, K.R.; Queiroz, G.R.; Neves, A.K.; Carlos, F.M.; Souza, F.C.; Santos, L.A.; Simoes, R.E. A platform for land use and land cover data integration and trajectory analysis. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102655. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- d’Andrimont, R.; Yordanov, M.; Martinez-Sanchez, L.; Eiselt, B.; Palmieri, A.; Dominici, P.; Gallego, J.; Reuter, H.I.; Joebges, C.; Lemoine, G.; et al. Harmonised LUCAS in-situ land cover and use database for field surveys from 2006 to 2018 in the European Union. Sci. Data 2020, 7, 352. [Google Scholar] [CrossRef] [PubMed]
- d’Andrimont, R.; Verhegghen, A.; Lemoine, G.; Kempeneers, P.; Meroni, M.; van der Velde, M. From parcel to continental scale—A first European crop type map based on Sentinel-1 and LUCAS Copernicus in-situ observations. Remote Sens. Environ. 2021, 266, 112708. [Google Scholar] [CrossRef]
- Ghassemi, B.; Dujakovic, A.; Żółtak, M.; Immitzer, M.; Atzberger, C.; Vuolo, F. Designing a European-Wide Crop Type Mapping Approach Based on Machine Learning Algorithms Using LUCAS Field Survey and Sentinel-2 Data. Remote Sens. 2022, 14, 541. [Google Scholar] [CrossRef]
- Ghassemi, B.; Immitzer, M.; Atzberger, C.; Vuolo, F. Evaluation of Accuracy Enhancement in European-Wide Crop Type Mapping by Combining Optical and Microwave Time Series. Land 2022, 11, 1397. [Google Scholar] [CrossRef]
- Waśniewski, A.; Hościło, A.; Chmielewska, M. Can a Hierarchical Classification of Sentinel-2 Data Improve Land Cover Mapping? Remote Sens. 2022, 14, 989. [Google Scholar] [CrossRef]
- Avci, M.; Akyurek, Z. A Hierarchical Classificaton of Landsat Tm Imagery for Landcover Mapping. Geogr. Pannonica 2004, 22, 4087. [Google Scholar]
- Demirkan, D.Ç.; Koz, A.; Düzgün, H.Ş. Hierarchical classification of Sentinel 2-a images for land use and land cover mapping and its use for the CORINE system. J. Appl. Rem. Sens. 2020, 14, 026524. [Google Scholar] [CrossRef]
- Peña, J.; Gutiérrez, P.; Hervás-Martínez, C.; Six, J.; Plant, R.; López-Granados, F. Object-Based Image Classification of Summer Crops with Machine Learning Methods. Remote Sens. 2014, 6, 5019–5041. [Google Scholar] [CrossRef]
- Gavish, Y.; O’Connell, J.; Marsh, C.J.; Tarantino, C.; Blonda, P.; Tomaselli, V.; Kunin, W.E. Comparing the performance of flat and hierarchical Habitat/Land-Cover classification models in a NATURA 2000 site. ISPRS J. Photogramm. Remote Sens. 2018, 136, 1–12. [Google Scholar] [CrossRef]
- d’Andrimont, R.; Yordanov, M.; Sedano, F.; Verhegghen, A.; Strobl, P.; Zachariadis, S.; Camilleri, F.; Palmieri, A.; Eiselt, B.; Rubio Iglesias, J.M.; et al. Advancements in LUCAS Copernicus 2022: Enhancing Earth Observation with Comprehensive In-Situ Data on EU Land Cover and Use. Earth Syst. Sci. Data 2024, 16, 5723–5735. [Google Scholar] [CrossRef]
- European Commission, Joint Research Centre. LUCAS Copernicus 2022; European Commission, Joint Research Centre (JRC): Brussels, Belgium, 2023. [Google Scholar]
- Boegh, E.; Soegaard, H.; Broge, N.; Hasager, C.B.; Jensen, N.O.; Schelde, K.; Thomsen, A. Airborne multispectral data for quantifying leaf area index, nitrogen concentration, and photosynthetic efficiency in agriculture. Remote Sens. Environ. 2002, 81, 179–193. [Google Scholar] [CrossRef]
- JIANG, Z.; HUETE, A.; DIDAN, K.; MIURA, T. Development of a two-band enhanced vegetation index without a blue band. Remote Sens. Environ. 2008, 112, 3833–3845. [Google Scholar] [CrossRef]
- Pasqualotto, N.; Delegido, J.; van Wittenberghe, S.; Rinaldi, M.; Moreno, J. Multi-Crop Green LAI Estimation with a New Simple Sentinel-2 LAI Index (SeLI). Sensors 2019, 19, 904. [Google Scholar] [CrossRef] [PubMed]
- Wulf, H.; Stuhler, S. Sentinel-2: Land Cover, Preliminary User Feedback on Sentinel-2A Data. In Proceedings of the Sentinel-2A Expert Users Technical Meeting, Frascati, Italy, 29–30 September 2015. [Google Scholar]
- Kriegler, F.J.; Malila, W.A.; Nalepka, R.F.; Richardson, W. Preprocessing Transformations and Their Effects on Multispectral Recognition. In Proceedings of the Sixth International Symposium on Remote Sensing of Environment, Ann Arbor, MI, USA, 13–16 October 1969; Volume II, p. 97. [Google Scholar]
- Qi, J.; Chehbouni, A.; Huete, A.R.; Kerr, Y.H.; Sorooshian, S. A modified soil adjusted vegetation index. Remote Sens. Environ. 1994, 48, 119–126. [Google Scholar] [CrossRef]
- van Deventer, A.P.; Ward, A.D.; Gowda, P.H.; Lyon, J.G. Using thematic mapper data to identify contrasting soil plains and tillage practices. Photogramm. Eng. Remote Sens. 1997, 63, 87–93. [Google Scholar]
- Huete, A. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Bouhennache, R.; Bouden, T.; Taleb-Ahmed, A.; Cheddad, A. A new spectral index for the extraction of built-up land features from Landsat 8 satellite imagery. Geocarto Int. 2019, 34, 1531–1551. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Jacques, D.C.; Kergoat, L.; Hiernaux, P.; Mougin, E.; Defourny, P. Monitoring dry vegetation masses in semi-arid areas with MODIS SWIR bands. Remote Sens. Environ. 2014, 153, 40–49. [Google Scholar] [CrossRef]
- Blackburn, G.A. Quantifying Chlorophylls and Caroteniods at Leaf and Canopy Scales. Remote Sens. Environ. 1998, 66, 273–285. [Google Scholar] [CrossRef]
- dos Santos, E.P.; Da Silva, D.D.; do Amaral, C.H. Vegetation cover monitoring in tropical regions using SAR-C dual-polarization index: Seasonal and spatial influences. Int. J. Remote Sens. 2021, 42, 7581–7609. [Google Scholar] [CrossRef]
- Gini, R.; Sona, G.; Ronchetti, G.; Passoni, D.; Pinto, L. Improving Tree Species Classification Using UAS Multispectral Images and Texture Measures. IJGI 2018, 7, 315. [Google Scholar] [CrossRef]
- Conners, R.W.; Trivedi, M.M.; Harlow, C.A. Segmentation of a high-resolution urban scene using texture operators. Comput. Vis. Graph. Image Process. 1984, 25, 273–310. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man. Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef]
- Chatziantoniou, A.; Psomiadis, E.; Petropoulos, G. Co-Orbital Sentinel 1 and 2 for LULC Mapping with Emphasis on Wetlands in a Mediterranean Setting Based on Machine Learning. Remote Sens. 2017, 9, 1259. [Google Scholar] [CrossRef]
- Mohammadpour, P.; Viegas, D.X.; Viegas, C. Vegetation Mapping with Random Forest Using Sentinel 2 and GLCM Texture Feature—A Case Study for Lousã Region, Portugal. Remote Sens. 2022, 14, 4585. [Google Scholar] [CrossRef]
- Nizalapur, V.; Vyas, A. Texture analysis for land use land cover (lulc) classification in parts of ahmedabad, gujarat. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 275–279. [Google Scholar] [CrossRef]
- Hulley, G.; Hook, S. MODIS/Terra Land Surface Temperature/3-Band Emissivity Monthly L3 Global 0.05Deg CMG V061; NASA EOSDIS Land Processes Distributed Active Archive Center: Sioux Falls, SD, USA, 2021.
- NASA/METI/AIST/Japan Space Systems, and U.S./Japan ASTER Science Team. ASTER Global Digital Elevation Model V003; LP DAAC: Sioux Falls, SD, USA, 2019. [CrossRef]
- Izquierdo-Verdiguier, E.; Zurita-Milla, R. An evaluation of Guided Regularized Random Forest for classification and regression tasks in remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102051. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Criminisi, A. Decision Forests: A Unified Framework for Classification, Regression, Density Estimation, Manifold Learning and Semi-Supervised Learning. FNT Comput. Graph. Vis. 2011, 7, 81–227. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inform. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Barriere, V.; Claverie, M.; Schneider, M.; Lemoine, G.; d’Andrimont, R. Boosting crop classification by hierarchically fusing satellite, rotational, and contextual data. Remote Sens. Environ. 2024, 305, 114110. [Google Scholar] [CrossRef]
- Ratanopad Suwanlee, S.; Keawsomsee, S.; Izquierdo-Verdiguier, E.; Som-Ard, J.; Moreno-Martinez, A.; Veerachit, V.; Polpinij, J.; Rattanasuteerakul, K. Mapping sugarcane plantations in Northeast Thailand using multi-temporal data from multi-sensors and machine-learning algorithms. Big Earth Data 2025, 1–30. [Google Scholar] [CrossRef]
- d’Andrimont, R.; Verhegghen, A.; Meroni, M.; Lemoine, G.; Strobl, P.; Eiselt, B.; Yordanov, M.; Martinez-Sanchez, L.; van der Velde, M. LUCAS Copernicus 2018: Earth-observation-relevant in situ data on land cover and use throughout the European Union. Earth Syst. Sci. Data 2021, 13, 1119–1133. [Google Scholar] [CrossRef]
- Copernicus Land Monitoring Service: High Resolution Vegetation Phenology and Productivity (Hr-Vpp), Seasonal Trajectories and VPP Parameters. Available online: https://land.copernicus.eu/en/technical-library/product-user-manual-of-seasonal-trajectories/@@download/file (accessed on 24 September 2024).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level-1 | Level-2 | ||
|---|---|---|---|
| EU-Map Code | EU-Map Code | Classes or Categories | Level-3 LUCAS Land Cover |
| 200 | Arable land | See below | |
| 211 | Common wheat | B11—Common wheat | |
| 212 | Durum wheat | B12—Durum wheat | |
| 213 | Barley | B13—Barley | |
| 214 | Rye | B14—Rye | |
| 215 | Oats | B15—Oats | |
| 216 | Maize | B16—Maize | |
| 217 | Rice | B17—Rice | |
| 218 | Triticale | B18—Triticale | |
| 219 | Other cereals | B19—Other cereals | |
| 221 | Potatoes | B21—Potatoes | |
| 222 | Sugar beet | B22—Sugar beet | |
| 223 | Other root crops | B23—Other root crops | |
| 230 | Other non-permanent industrial crops | B34—Cotton | B35—Other fiber and oleaginous crops | B36—Tobacco | B37—Other non-permanent industrial crops | |
| 231 | Sunflower | B31—Sunflower | |
| 232 | Rape and turnip rape | B32—Rape and turnip rape | |
| 233 | Soya | B33—Soya | |
| 240 | Dry pulses, vegetables, and flowers | B41—Dry pulses | B42—Tomatoes | B43—Other fresh vegetables | B44—Floriculture and ornamental plants | B45—Strawberries | |
| 250 | Fodder crops | B51—Clovers | B52—Lucerne | B53—Other leguminous and mixtures for fodder | B54—Mixed cereals for fodder | |
| 300 | Woodland and Shrubland | B71—Apple fruit, B72—Pear fruit, B73—Cherry fruit, B74—Nuts trees, B75—Other fruit trees and berries, B76—Oranges, B77—Other citrus fruit | B81—Olive groves, B82—Vineyards, B83—Nurseries, B84—Permanent industrial crops | C10—Broadleaved woodland | C21—Spruce-dominated coniferous woodland | C22—Pine-dominated coniferous woodland | C23—Other coniferous woodland | C31—Spruce-dominated mixed woodland | C32—Pine-dominated mixed woodland | C33—Other mixed woodland | D10—Shrubland with sparse tree cover | D20—Shrubland without tree cover | |
| 500 | Grassland | B55—Temporary grasslands | E10—Grassland with sparse tree/shrub cover | E20—Grassland without tree/shrub cover | E30—Spontaneously vegetated surfaces |
| P3 | P20 | P22 | P23 | P26 |
|---|---|---|---|---|
| 200 | 211 | 211 | 211 | 211 (B11) |
| 212 | 212 | 212 | 212 (B12) | |
| 213 | 213 | 213 | 213 (B13) | |
| 214 | 214 | 214 | 214 (B14) | |
| 215 | 215 | 215 | 215 (B15) | |
| 216 | 216 | 216 | 216 (B16) | |
| 217 | 217 | 217 | 217 (B17) | |
| 218 | 218 | 218 | 218 (B18) | |
| 219 | 219 | 219 | 219 (B19) | |
| 221 | 221 | 221 | 221 (B21) | |
| 222 | 222 | 222 | 222 (B22) | |
| 223 | 223 | 223 | 223 (B23) | |
| 230 | 230 | 230 | 230 (B34 |B35 |B36 |B37) | |
| 231 | 231 | 231 | 231 (B31) | |
| 232 | 232 | 232 | 232 (B32) | |
| 233 | 233 | 233 | 233 (B33) | |
| 240 | 240 | 240 | 240 (B41 | B42 | B43 | B44 | B45) | |
| 250 | 250 | 250 | 250 (B51 | B52 | B53 | B54) | |
| 300 | 300 | B78 | B7 | B7 (B71 | B72 | B73 | B74 | B75 | B76 | B77) |
| B8 | B8 (B81 | B82 | B83 | B84) | |||
| C123 | C123 | C10 | ||
| C20 (C21 | C22 | C23) | ||||
| C30 (C31 | C32 | C33) | ||||
| D12 | D12 | D10 | ||
| D20 | ||||
| 500 | 500 | 500 | 500 | 500 (B55 | E10 | E20 | E30) |
| Feature Name | Description |
|---|---|
| Spectral Bands | B2: Blue (WL: 496.6 nm (S2A)/492.1 nm (S2B)) |
| B3: Green (WL: 560 nm (S2A)/559 nm (S2B)) | |
| B4: Red (WL: 664.5 nm (S2A)/665 nm (S2B)) | |
| B5: Red Edge 1 (WL: 703.9 nm (S2A)/703.8 nm (S2B)) | |
| B6: Red Edge 2 (WL: 740.2 nm (S2A)/739.1 nm (S2B)) | |
| B7: Red Edge 3 (WL: 782.5 nm (S2A)/779.7 nm (S2B)) | |
| B8: NIR (WL: 835.1 nm (S2A)/833 nm (S2B)) | |
| B8A: NIR narrow (WL: 864.8 nm (S2A)/864 nm (S2B)) | |
| B11: SWIR 1 (WL: 1613.7 nm (S2A)/1610.4 nm (S2B)) | |
| B12: SWIR 2 (WL: 2202.4 nm (S2A)/2185.7 nm (S2B)) | |
| Spectral Indices and biophysical parameter | |
| Feature Name | Description |
|---|---|
| Microwave features | VV: Single co-polarization, vertical transmit/vertical receive |
| VH: Dual-band cross-polarization, vertical transmit/horizontal receive | |
| VV/VH: The ratio between the VV polarization and the VH polarization | |
| Texture Feature Name | Formulation | Application |
|---|---|---|
| Cont | Analyzes the local variations in an image. Having a high contrast value indicates that there is a large difference between the intensities of neighboring pixels. | |
| Corr | Measures the linear relationship between pixel pairs. A higher correlation value means a more predictable texture. | |
| Diss | Calculates the average intensity difference between neighboring pixels. The greater the dissimilarity value, the greater the heterogeneity of the texture. | |
| Ent | Measures image disorder or complexity. When the image is not texturally uniform, the entropy is large. The entropy of complex textures tends to be high. | |
| IDM | Describes how close the GLCM distribution is to the GLCM diagonal. A high homogeneity value implies that elements are concentrated along the diagonal, inferring a more uniform texture. |
| LUCAS Level-1 Land Cover | LUCAS Level-3 Land Cover | Total Class Count | Initial Training Sample Count | Balanced Training Sample Count |
|---|---|---|---|---|
| B—Cropland | B11—Common wheat | 8145 | 4211 | 4211 |
| B12—Durum wheat | 936 | 576 | 1000 | |
| B13—Barley | 3929 | 2104 | 2104 | |
| B14—Rye | 1019 | 550 | 1000 | |
| B15—Oats | 1153 | 597 | 1000 | |
| B16—Maize | 6338 | 3419 | 3419 | |
| B17—Rice | 44 | 27 | 918 | |
| B18—Triticale | 1007 | 516 | 1000 | |
| B19—Other cereals | 217 | 116 | 1000 | |
| B21—Potatoes | 751 | 381 | 1000 | |
| B22—Sugar beet | 710 | 341 | 1000 | |
| B23—Other root crops | 233 | 114 | 1000 | |
| B31—Sunflower | 1533 | 901 | 1000 | |
| B32—Rape and turnip rape | 2767 | 1478 | 1478 | |
| B33—Soya | 439 | 254 | 1000 | |
| B34—Cotton | 143 | 95 | 1000 | |
| B35—Other fiber and oleaginous crops B36—Tobacco B37—Other non—permanent industrial crops | 467 | 229 | 1000 | |
| 19 | 9 | 335 | ||
| 99 | 49 | 1000 | ||
| B41—Dry pulses | 558 | 305 | 1000 | |
| B42—Tomatoes | 64 | 40 | 1000 | |
| B43—Other fresh vegetables | 435 | 239 | 1000 | |
| B44—Floriculture and ornamental plants | 46 | 21 | 996 | |
| B45—Strawberries | 43 | 21 | 1000 | |
| B51—Clovers | 370 | 182 | 1000 | |
| B52—Lucerne | 1101 | 656 | 1000 | |
| B53—Other leguminous and mixtures for fodder | 765 | 383 | 1000 | |
| B54—Mixed cereals for fodder | 373 | 229 | 1000 | |
| B55—Temporary grasslands | 2509 | 1329 | 1329 | |
| B71—Apple fruit | 651 | 338 | 1000 | |
| B72—Pear fruit | 133 | 67 | 1000 | |
| B73—Cherry fruit | 185 | 109 | 1000 | |
| B74—Nuts trees | 673 | 427 | 1000 | |
| B75—Other fruit trees and berries | 514 | 303 | 1000 | |
| B76—Oranges | 93 | 60 | 1000 | |
| B77—Other citrus fruit | 50 | 30 | 955 | |
| B81—Olive groves | 1580 | 1043 | 1043 | |
| B82—Vineyards | 1068 | 651 | 1000 | |
| B83—Nurseries | 73 | 37 | 1000 | |
| B84—Permanent industrial crops | 97 | 58 | 1000 | |
| C—Woodland | C10—Broadleaved woodland | 22,613 | 12,978 | 12,978 |
| C21—Spruce-dominated coniferous woodland | 3849 | 1945 | 1945 | |
| C22—Pine-dominated coniferous woodland | 5102 | 2642 | 2642 | |
| C23—Other coniferous woodland | 1278 | 697 | 1000 | |
| C31—Spruce-dominated mixed woodland | 3558 | 1850 | 1850 | |
| C32—Pine-dominated mixed woodland | 2666 | 1318 | 1318 | |
| C33—Other mixed woodland | 2445 | 1288 | 1288 | |
| D—Shrubland | D10—Shrubland with sparse tree cover | 3839 | 2263 | 2263 |
| D20—Shrubland without tree cover | 3788 | 2191 | 2191 | |
| E—Grassland | E10—Grassland with sparse tree/shrub cover | 3623 | 2101 | 2101 |
| E20—Grassland without tree/shrub cover | 22,499 | 11,316 | 11,316 | |
| E30—Spontaneously vegetated surfaces | 4639 | 2681 | 2681 |
| Classification Phase | OA and K for the Balanced Dataset |
|---|---|
| P3 | 84.3%, 0.75 |
| P20 | 76.5%, 0.66 |
| P22 | 69.2%, 0.61 |
| P23 | 69.0%, 0.61 |
| P26 | 62.2%, 0.56 |
| P52 | 57.2%, 0.52 |
| Class Name | Label | Test Count | F1-Balance-Flat | F1-Original-Flat | F1-Balance-Hierarchical | F1-Original-Hierarchical |
|---|---|---|---|---|---|---|
| Common wheat | 211 | 2090 | 70.2% | 69.2% | 70.0% | 67.4% |
| Durum wheat | 212 | 284 | 36.9% | 31.5% | 34.8% | 33.0% |
| Barley | 213 | 1028 | 56.1% | 55.1% | 56.9% | 54.9% |
| Rye | 214 | 273 | 37.9% | 27.6% | 39.4% | 36.8% |
| Oats | 215 | 310 | 30.7% | 24.1% | 34.7% | 24.9% |
| Maize | 216 | 1641 | 79.6% | 77.6% | 77.7% | 74.6% |
| Rice | 217 | 15 | 28.6% | 0.0% | 34.8% | 0.0% |
| Triticale | 218 | 261 | 25.9% | 7.8% | 22.5% | 16.7% |
| Other cereals | 219 | 61 | 30.8% | 6.3% | 27.3% | 20.3% |
| Potatoes | 221 | 184 | 65.1% | 65.4% | 65.3% | 64.5% |
| Sugar beet | 222 | 169 | 79.9% | 79.5% | 80.6% | 81.7% |
| Other root crops | 223 | 64 | 21.1% | 5.9% | 20.5% | 5.9% |
| Other non-permanent industrial crops | 230 | 183 | 40.5% | 32.8% | 40.8% | 32.9% |
| Sunflower | 231 | 440 | 74.8% | 74.3% | 75.7% | 72.6% |
| Rape and turnip rape | 232 | 742 | 76.8% | 76.6% | 76.7% | 76.1% |
| Soya | 233 | 125 | 54.5% | 42.9% | 57.7% | 38.6% |
| Dry pulses, vegetables, and flowers | 240 | 322 | 41.8% | 33.9% | 34.6% | 38.6% |
| Fodder crops | 250 | 707 | 30.7% | 12.9% | 31.7% | 26.5% |
| Grassland | 500 | 8589 | 72.7% | 71.8% | 70.9% | 72.8% |
| Orchards | B7 | 635 | 25.6% | 8.2% | 24.8% | 12.1% |
| Groves | B8 | 890 | 39.9% | 40.4% | 39.5% | 43.5% |
| Broadleaved woodland | C10 | 6388 | 71.3% | 71.1% | 68.8% | 68.6% |
| Coniferous woodland | C20 | 2611 | 73.5% | 73.7% | 73.5% | 73.1% |
| Mixed woodland | C30 | 2183 | 53.8% | 54.2% | 53.4% | 54.4% |
| Shrubland with sparse tree cover | D10 | 1105 | 9.2% | 11.1% | 10.5% | 12.6% |
| Shrubland without tree cover | D20 | 1084 | 28.0% | 27.4% | 32.6% | 32.8% |
| OA | 64.8% | 64.3% | 62.2% | 63.3% | ||
| K | 0.58 | 0.57 | 0.56 | 0.57 | ||
| Class Name | Label | Test Count | PA-Balance-Flat | PA-Balance-Hierarchical |
|---|---|---|---|---|
| Common wheat | 211 | 2090 | 75.1% | 78.8% |
| Durum wheat | 212 | 284 | 30.3% | 33.8% |
| Barley | 213 | 1028 | 54.5% | 57.8% |
| Rye | 214 | 273 | 29.7% | 34.1% |
| Oats | 215 | 310 | 23.2% | 28.7% |
| Maize | 216 | 1641 | 80.5% | 83.4% |
| Rice | 217 | 15 | 20.0% | 26.7% |
| Triticale | 218 | 261 | 18.0% | 15.7% |
| Other cereals | 219 | 61 | 23.0% | 24.6% |
| Potatoes | 221 | 184 | 59.8% | 59.2% |
| Sugar beet | 222 | 169 | 78.7% | 78.7% |
| Other root crops | 223 | 64 | 12.5% | 12.5% |
| Other non-permanent industrial crops | 230 | 183 | 32.2% | 33.3% |
| Sunflower | 231 | 440 | 70.0% | 73.9% |
| Rape and turnip rape | 232 | 742 | 68.1% | 68.3% |
| Soya | 233 | 125 | 44.0% | 48.0% |
| Dry pulses, vegetables, and flowers | 240 | 322 | 47.2% | 50.6% |
| Fodder crops | 250 | 707 | 23.2% | 35.4% |
| Grassland | 500 | 8589 | 83.1% | 62.0% |
| Orchards | B7 | 635 | 23.8% | 30.9% |
| Groves | B8 | 890 | 34.3% | 44.3% |
| Broadleaved woodland | C10 | 6388 | 77.3% | 83.7% |
| Coniferous woodland | C20 | 2611 | 73.0% | 74.1% |
| Mixed woodland | C30 | 2183 | 46.3% | 46.5% |
| Shrubland with sparse tree cover | D10 | 1105 | 5.2% | 6.4% |
| Shrubland without tree cover | D20 | 1084 | 20.4% | 28.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghassemi, B.; Izquierdo-Verdiguier, E.; d’Andrimont, R.; Vuolo, F. How Accurately and in What Detail Can Land Use and Land Cover Be Mapped Using Copernicus Sentinel and LUCAS 2022 Data? Remote Sens. 2025, 17, 1379. https://doi.org/10.3390/rs17081379
Ghassemi B, Izquierdo-Verdiguier E, d’Andrimont R, Vuolo F. How Accurately and in What Detail Can Land Use and Land Cover Be Mapped Using Copernicus Sentinel and LUCAS 2022 Data? Remote Sensing. 2025; 17(8):1379. https://doi.org/10.3390/rs17081379
Chicago/Turabian StyleGhassemi, Babak, Emma Izquierdo-Verdiguier, Raphaël d’Andrimont, and Francesco Vuolo. 2025. "How Accurately and in What Detail Can Land Use and Land Cover Be Mapped Using Copernicus Sentinel and LUCAS 2022 Data?" Remote Sensing 17, no. 8: 1379. https://doi.org/10.3390/rs17081379
APA StyleGhassemi, B., Izquierdo-Verdiguier, E., d’Andrimont, R., & Vuolo, F. (2025). How Accurately and in What Detail Can Land Use and Land Cover Be Mapped Using Copernicus Sentinel and LUCAS 2022 Data? Remote Sensing, 17(8), 1379. https://doi.org/10.3390/rs17081379