
Can Separation Enhance Fusion? An Efficient Framework for Target Detection in Multimodal Remote Sensing Imagery


 , and
, and
Abstract
:1. Introduction
2. Related Work
2.1. Unimodal Remote Sensing Target Detection
2.2. Multimodal Remote Sensing Target Detection
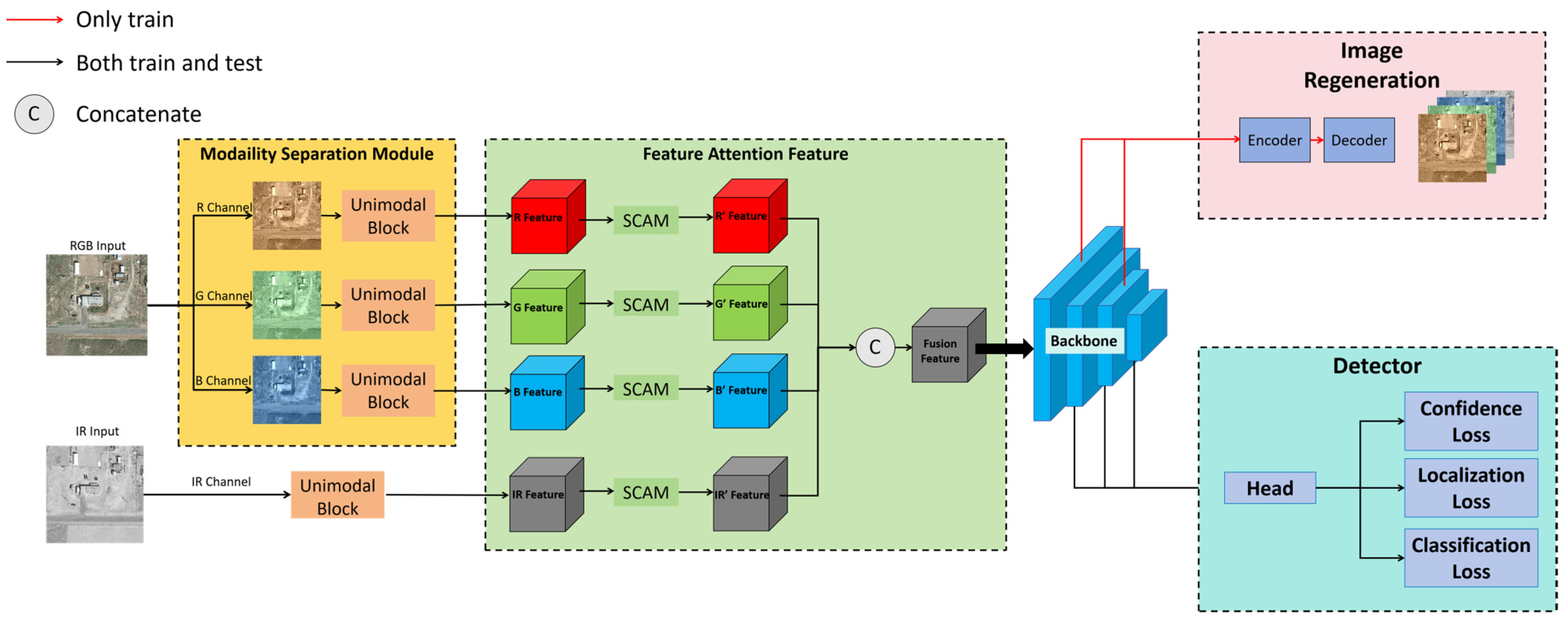
3. Our Method
3.1. Unimodal Block in the MSM
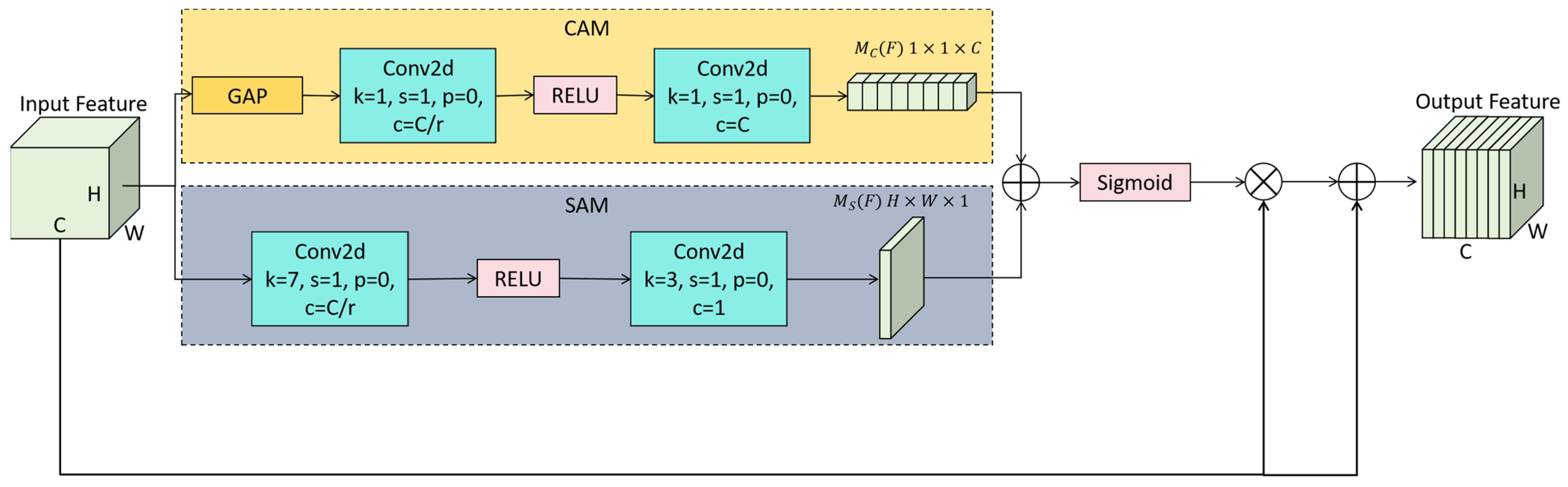
3.2. Feature Attention Fusion Module
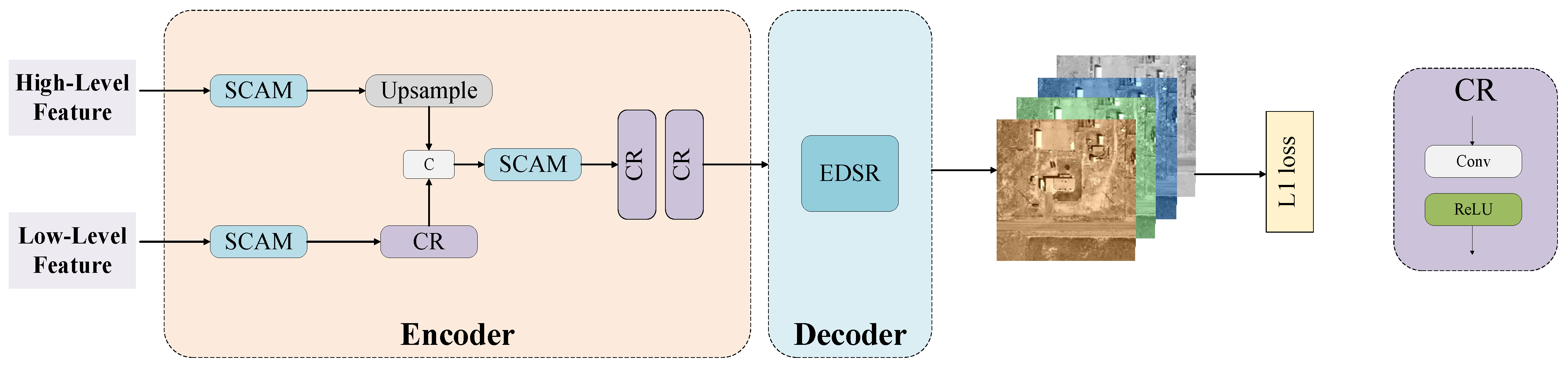
3.3. Image Regeneration Module
3.4. Loss Function
4. Experimental Results
4.1. Datasets
4.2. Detection Metrics
4.3. Experimental Settings
4.4. Multimodal Remote Sensing Target Detection Results
4.5. Ablation Experiments
4.6. Unimodal Target Detection Adaptation Experiments
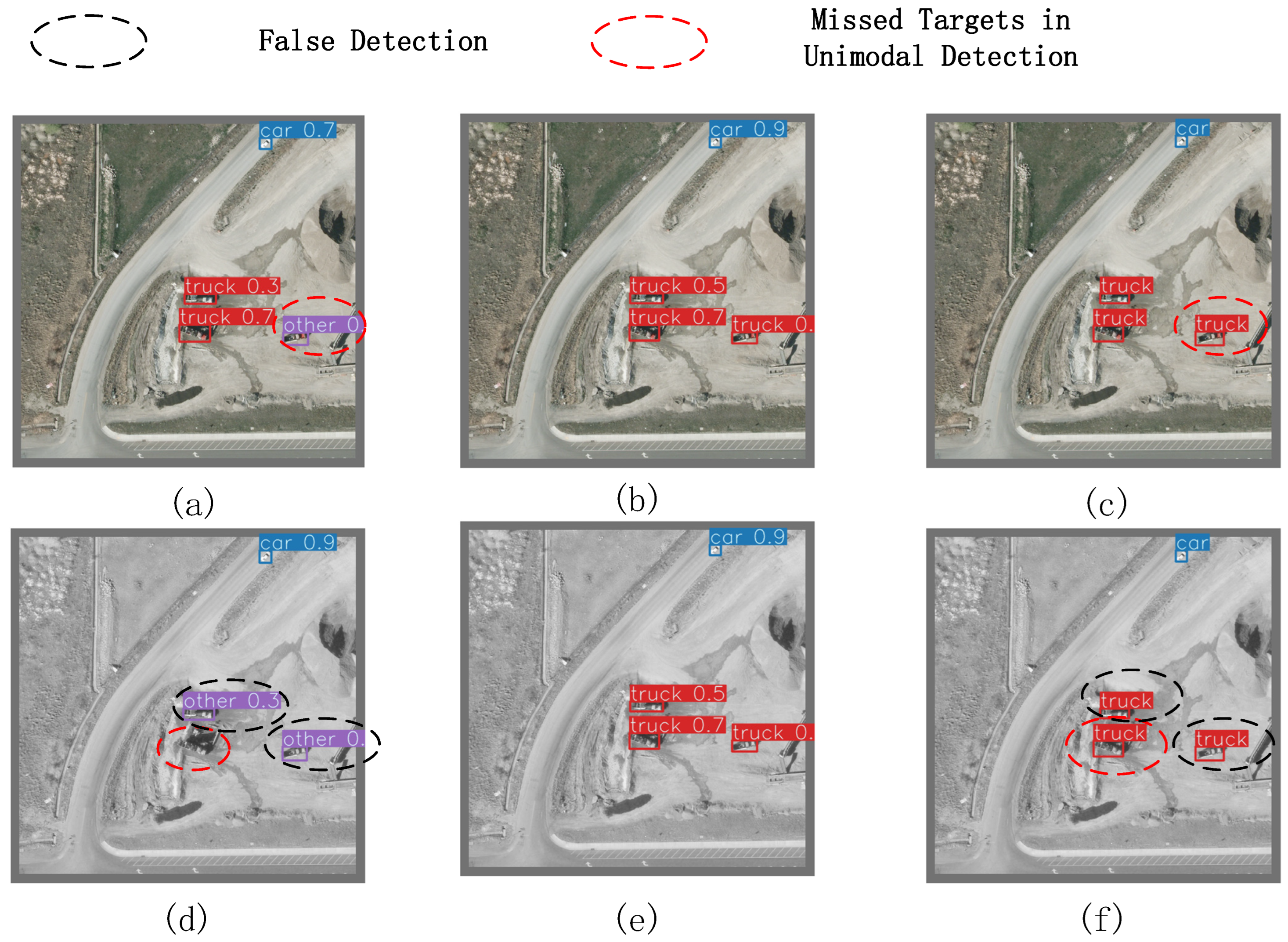
5. Discussion: Why Separation Before Fusion Works?
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gui, S.; Song, S.; Qin, R.; Tang, Y. Remote Sensing Object Detection in the Deep Learning Era—A Review. Remote Sens. 2024, 16, 327. [Google Scholar] [CrossRef]
- Wang, X.; Wang, A.; Yi, J.; Song, Y.; Chehri, A. Small Object Detection Based on Deep Learning for Remote Sensing: A Comprehensive Review. Remote Sens. 2023, 15, 3265. [Google Scholar] [CrossRef]
- Gerhards, M.; Schlerf, M.; Mallick, K.; Udelhoven, T. Challenges and future perspectives of multi-/Hyperspectral thermal infrared remote sensing for crop water-stress detection: A review. Remote Sens. 2019, 11, 1240. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-Aligned One-Stage Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE Computer Society: Los Alamitos, CA, USA, 2021; pp. 3490–3499. [Google Scholar]
- Redmon, J. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, Z.; Zhan, J.; Duan, C.; Guan, X.; Lu, P.; Yang, K. A Review of Vehicle Detection Techniques for Intelligent Vehicles. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 3811–3831. [Google Scholar] [CrossRef] [PubMed]
- Spinello, L.; Triebel, R.; Siegwart, R. Multiclass Multimodal Detection and Tracking in Urban Environments. Int. J. Rob. Res. 2010, 29, 1498–1515. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Xu, M.; Zhang, H.; Xiao, G. STDFusionNet: An Infrared and Visible Image Fusion Network Based on Salient Target Detection. IEEE Trans. Instrum. Meas. 2021, 70, 5009513. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. MDLatLRR: A Novel Decomposition Method for Infrared and Visible Image Fusion. IEEE Trans. Image Process. 2020, 29, 4733–4746. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Y. Infrared and Visible Image Fusion via Gradientlet Filter. Comput. Vis. Image Underst. 2020, 197, 103016. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Dhuli, R. Two-Scale Image Fusion of Visible and Infrared Images Using Saliency Detection. Infrared Phys. Technol. 2016, 76, 52–64. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Image Fusion with Convolutional Sparse Representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and Visible Image Fusion via Gradient Transfer and Total Variation Minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and Visible Image Fusion Based on Visual Saliency Map and Weighted Least Square Optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Gómez-Chova, L.; Tuia, D.; Moser, G.; Camps-Valls, G. Multimodal Classification of Remote Sensing Images: A Review and Future Directions. Proc. IEEE 2015, 103, 1560–1584. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part v 13. Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Drummond, O. Signal and Data Processing of Small Targets 2015. Proc. SPIE 2015, 9596, 959601-1. [Google Scholar]
- Xiaolin, F.; Fan, H.; Ming, Y.; Tongxin, Z.; Ran, B.; Zenghui, Z.; Zhiyuan, G. Small Object Detection in Remote Sensing Images Based on Super-Resolution. Pattern Recognit. Lett. 2022, 153, 107–112. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, M.; Wang, Y.; Zhu, Y.; Zhang, Z. Object Detection in High Resolution Remote Sensing Imagery Based on Convolutional Neural Networks with Suitable Object Scale Features. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2104–2114. [Google Scholar] [CrossRef]
- Courtrai, L.; Pham, M.T.; Lefèvre, S. Small Object Detection in Remote Sensing Images Based on Super-Resolution with Auxiliary Generative Adversarial Networks. Remote Sens. 2020, 12, 3152. [Google Scholar] [CrossRef]
- Bashir, S.M.A.; Wang, Y. Small Object Detection in Remote Sensing Images with Residual Feature Aggregation-Based Super-Resolution and Object Detector Network. Remote Sens. 2021, 13, 1854. [Google Scholar] [CrossRef]
- Diaz-Cely, J.; Arce-Lopera, C.; Mena, J.C.; Quintero, L. The Effect of Color Channel Representations on the Transferability of Convolutional Neural Networks. In Proceedings of the 2019 Computer Vision Conference (CVC), Vdara Hotel and Spa, Las Vegas, NV, USA, 25–26 April 2019. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Glenn, J. YOLOv5 Release v7.0. 2022. Available online: https://github.com/ultralytics/yolov5/releases/tag/v7.0 (accessed on 18 September 2024).
- Glenn, J. YOLOv8 Release v8.3.0. 2024. Available online: https://github.com/ultralytics/ultralytics/releases/tag/v8.3.0 (accessed on 18 September 2024).
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605415. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Wang, L.; Li, D.; Zhu, Y.; Tian, L.; Shan, Y. Dual Super-Resolution Learning for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3774–3783. [Google Scholar]
- Nan, G.; Zhao, Y.; Fu, L.; Ye, Q. Object Detection by Channel and Spatial Exchange for Multimodal Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 8581–8593. [Google Scholar] [CrossRef]
- Qingyun, F.; Zhaokui, W. Cross-Modality Attentive Feature Fusion for Object Detection in Multispectral Remote Sensing Imagery. Pattern Recognit. 2022, 130, 108786. [Google Scholar] [CrossRef]
- Fei, X.; Guo, M.; Li, Y.; Yu, R.; Sun, L. ACDF-YOLO: Attentive and Cross-Differential Fusion Network for Multimodal Remote Sensing Object Detection. Remote Sens. 2024, 16, 3532. [Google Scholar] [CrossRef]
- Sharma, M.; Dhanaraj, M.; Karnam, S.; Chachlakis, D.G.; Ptucha, R.; Markopoulos, P.P.; Saber, E. YOLOrs: Object Detection in Multimodal Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1497–1508. [Google Scholar] [CrossRef]
- Li, W.; Li, A.; Kong, X.; Zhang, Y.; Li, Z. MF-YOLO: Multimodal Fusion for Remote Sensing Object Detection Based on YOLOv5s. In Proceedings of the 2024 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Tianjin, China, 8–10 May 2024; pp. 897–903. [Google Scholar]
- Guan, D.; Cao, Y.; Yang, J.; Cao, Y.; Yang, M.Y. Fusion of Multispectral Data through Illumination-Aware Deep Neural Networks for Pedestrian Detection. Inf. Fusion 2019, 50, 148–157. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-Aware Faster R-CNN for Robust Multispectral Pedestrian Detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral Deep Neural Networks for Pedestrian Detection. arXiv 2016, arXiv:1611.02644. [Google Scholar]
- Chen, Y.; Shi, J.; Mertz, C.; Kong, S.; Ramanan, D. Multimodal Object Detection via Bayesian Fusion. arXiv 2021, arXiv:2104.02904. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Hastie, T. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle Detection in Aerial Imagery: A Small Target Detection Benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object Detection in Optical Remote Sensing Images: A Survey and a New Benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A Survey on Object Detection in Optical Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Yang, Y.; Sun, X.; Diao, W.; Li, H.; Wu, Y.; Li, X.; Fu, K. Adaptive Knowledge Distillation for Lightweight Remote Sensing Object Detectors Optimizing. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5623715. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature Fusion Attention Network for Single Image Dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Zhang, Y.; Cheng, J.; Su, Y.; Wu, Y.; Ma, Q. ORBNet: Original Reinforcement Bilateral Network for High-Resolution Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 15900–15913. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Model | Car | Pickup | Camper | Truck | Other | Tractor | Boat | Van | mAP50 (%) | Params (M) | GFLOPS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 [53] | IR | 80.2 | 67.0 | 65.5 | 47.8 | 25.8 | 40.1 | 32.7 | 53.3 | 51.5 | 61.53 | 49.55 |
| RGB | 83.1 | 71.5 | 69.1 | 59.3 | 48.9 | 67.3 | 33.5 | 55.7 | 61.1 | 61.53 | 49.55 | |
| Muti | 84.5 | 72.6 | 67.1 | 61.9 | 43.0 | 65.2 | 37.1 | 58.2 | 61.2 | 61.53 | 49.68 | |
| YOLOv4 [26] | IR | 80.4 | 67.9 | 68.8 | 53.7 | 30.0 | 44.2 | 25.4 | 51.4 | 52.7 | 52.50 | 38.16 |
| RGB | 83.7 | 73.4 | 71.2 | 59.1 | 51.7 | 65.9 | 34.3 | 60.3 | 62.4 | 52.50 | 38.16 | |
| Muti | 85.4 | 72.8 | 72.3 | 62.8 | 48.9 | 68.9 | 34.2 | 54.6 | 62.5 | 52.50 | 38.23 | |
| YOLOv5s [27] | IR | 77.3 | 65.3 | 66.5 | 51.6 | 25.9 | 42.4 | 21.9 | 48.9 | 49.9 | 7.07 | 5.24 |
| RGB | 80.1 | 68.0 | 66.1 | 51.5 | 45.8 | 64.4 | 21.6 | 40.9 | 54.8 | 7.07 | 5.24 | |
| Muti | 80.8 | 68.4 | 69.1 | 54.7 | 46.7 | 64.2 | 24.2 | 45.9 | 56.8 | 7.07 | 5.32 | |
| YOLOv5m [27] | IR | 79.2 | 67.3 | 65.4 | 51.7 | 26.7 | 44.3 | 26.6 | 56.1 | 52.2 | 21.06 | 16.13 |
| RGB | 81.1 | 70.3 | 65.5 | 54.0 | 46.8 | 66.7 | 36.2 | 49.9 | 58.8 | 21.06 | 16.13 | |
| Muti | 82.5 | 72.3 | 68.4 | 59.2 | 46.2 | 66.2 | 33.5 | 57.1 | 60.6 | 21.06 | 16.24 | |
| YOLOv5l [27] | IR | 80.1 | 68.6 | 65.4 | 53.5 | 30.3 | 45.6 | 27.2 | 61.9 | 54.1 | 46.63 | 36.55 |
| RGB | 81.4 | 71.7 | 68.2 | 57.4 | 45.8 | 70.7 | 35.9 | 55.4 | 60.8 | 46.63 | 36.55 | |
| Muti | 82.8 | 72.32 | 69.9 | 63.9 | 48.4 | 63.1 | 40.1 | 56.4 | 62.1 | 46.64 | 36.70 | |
| YOLOv5x [27] | IR | 79.0 | 66.7 | 65.9 | 58.5 | 31.4 | 41.4 | 31.6 | 59.0 | 54.2 | 87.24 | 69.52 |
| RGB | 81.7 | 72.2 | 68.3 | 59.1 | 48.5 | 66.0 | 39.1 | 61.8 | 62.1 | 87.24 | 69.52 | |
| Muti | 84.3 | 72.95 | 70.1 | 61.1 | 49.9 | 67.3 | 38.7 | 56.6 | 62.6 | 87.24 | 69.71 | |
| YOLOrs [39] | IR | 82.0 | 73.9 | 63.8 | 54.2 | 44.0 | 54.4 | 22.0 | 43.4 | 54.7 | - | - |
| RGB | 85.2 | 72.9 | 70.3 | 50.6 | 42.7 | 76.8 | 18.6 | 38.9 | 57.0 | - | - | |
| Muti | 84.1 | 78.3 | 68.8 | 52.6 | 46.7 | 67.9 | 21.5 | 57.9 | 59.7 | - | - | |
| SuperYOLO (YOLOv5s) [33] | IR | 87.9 | 81.4 | 76.9 | 61.6 | 39.4 | 60.6 | 46.1 | 71.0 | 65.6 | 4.82 | 16.61 |
| RGB | 90.3 | 82.7 | 76.7 | 68.5 | 53.7 | 79.5 | 58.1 | 70.3 | 72.5 | 4.82 | 16.61 | |
| Muti | 91.1 | 85.7 | 79.3 | 70.2 | 57.3 | 80.4 | 60.2 | 76.5 | 75.0 | 4.84 | 17.98 | |
| YOLOFusion (YOLOv5s) [37] | IR | 86.7 | 75.9 | 66.6 | 77.1 | 43.0 | 62.3 | 70.7 | 84.3 | 70.8 | - | - |
| RGB | 91.1 | 82.3 | 75.1 | 78.3 | 33.3 | 81.2 | 71.8 | 62.2 | 71.9 | - | - | |
| Muti | 91.7 | 85.9 | 78.9 | 78.1 | 54.7 | 71.9 | 71.7 | 75.2 | 75.9 | 12.5 | - | |
| MF-YOLO (YOLOv5s) [40] | Muti | 92.0 | 86.6 | 78.2 | 72.6 | 57.4 | 82.9 | 64.6 | 78.6 | 76.5 | 4.77 | - |
| HyperYOLO (YOLOv7) [36] | Muti | - | - | - | - | - | - | - | - | 76.7 | 3.50 | 14.01 |
| Sep-Fusion (YOLOv5s, ours) | IR | 87.3 | 81.5 | 72.3 | 70.6 | 45.8 | 67.9 | 49.3 | 62.1 | 67.4 | 4.83 | 16.72 |
| RGB | 88.3 | 83.5 | 70.2 | 74.1 | 63.4 | 74.2 | 59.3 | 74.8 | 73.5 | 4.85 | 17.91 | |
| Muti | 90.8 | 87.4 | 76.3 | 79.7 | 68.0 | 77.8 | 62.1 | 77.3 | 77.4 | 4.86 | 18.69 | |
| Sep-Fusion (YOLOv8s, ours) | IR | 87.2 | 81.5 | 68.1 | 74.1 | 57.8 | 70.4 | 54.3 | 65.0 | 69.8 | 8.75 | 22.47 |
| RGB | 87.0 | 82.4 | 76.6 | 73.1 | 59.2 | 73.4 | 63.4 | 73.9 | 73.6 | 8.77 | 24.29 | |
| Muti | 88.9 | 88.1 | 77.2 | 80.3 | 66.4 | 77.0 | 66.9 | 78.2 | 77.9 | 8.78 | 25.41 |
| Method | MSM | SCAM | mAP50 (%) |
|---|---|---|---|
| Sep-Fusion0 | 69.1 | ||
| Sep-Fusion1 | √ | 71.3 | |
| Sep-Fusion2 | √ | 74.2 | |
| Sep-Fusion | √ | √ | 77.4 |
| NWPU VHR-10 | DIOR | |||||
|---|---|---|---|---|---|---|
| Method | mAP50 (%) | Params (M) | GFLOPS | mAP50 (%) | Params (M) | GFLOPS |
| Faster R-CNN [5] | 77.80 | 41.17 | 127.70 | 54.10 | 60.21 | 182.20 |
| RetainNet [54] | 89.40 | 36.29 | 123.27 | 65.70 | 55.49 | 180.62 |
| YOLOv3 [53] | 88.30 | 61.57 | 121.27 | 57.10 | 61.95 | 122.22 |
| GFL [49] | 88.80 | 19.13 | 91.73 | 68.00 | 19.13 | 97.43 |
| FCOS [30] | 89.65 | 31.86 | 116.63 | 67.60 | 31.88 | 123.51 |
| ATSS [55] | 90.50 | 18.96 | 89.90 | 67.70 | 18.98 | 95.50 |
| MobileNetV2 [56] | 76.90 | 10.29 | 71.49 | 58.20 | 10.32 | 76.10 |
| ShuffleNet [57] | 83.00 | 12.10 | 82.17 | 61.30 | 12.12 | 87.31 |
| ADSR [58] | 90.92 | 11.57 | 26.65 | 70.10 | 13.10 | 41.60 |
| SuperYOLO [33] | 93.30 | 7.68 | 20.86 | 71.82 | 7.70 | 20.93 |
| Sep-Fusion (YOLOv5s, ours) | 93.70 | 7.73 | 21.32 | 72.40 | 7.75 | 21.39 |
| Method | Modality | Car | Pickup | Camper | Truck | Other | Tractor | Boat | Van | mAP50 (%) |
|---|---|---|---|---|---|---|---|---|---|---|
| Sep-Fusion | IR | 80.1 | 79.7 | 75.3 | 60.5 | 35.4 | 23.2 | 45.0 | 71.0 | 58.8 |
| RGB | 86.3 | 80.6 | 74.3 | 75.7 | 51.7 | 64.7 | 62.0 | 71.5 | 70.9 | |
| R + IR | 85.1 | 77.9 | 77.0 | 71.3 | 32.1 | 49.3 | 33.0 | 71.6 | 62.1 | |
| G + IR | 87.0 | 84.3 | 73.7 | 69.8 | 47.2 | 59.7 | 37.6 | 70.8 | 66.3 | |
| B + IR | 86.9 | 83.3 | 72.1 | 80.2 | 56.7 | 53.1 | 57.2 | 69.9 | 69.9 | |
| RGB + IR | 89.7 | 83.7 | 74.7 | 75.6 | 54.4 | 75.5 | 54.1 | 70.5 | 72.3 | |
| R + G + B + IR | 89.2 | 84.9 | 75.8 | 74.4 | 61.9 | 73.6 | 62.3 | 72.0 | 74.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Jia, J.; Liu, R.; Cao, Q.; Feng, J.; Li, D.; Wang, L. Can Separation Enhance Fusion? An Efficient Framework for Target Detection in Multimodal Remote Sensing Imagery. Remote Sens. 2025, 17, 1350. https://doi.org/10.3390/rs17081350
Wang Y, Jia J, Liu R, Cao Q, Feng J, Li D, Wang L. Can Separation Enhance Fusion? An Efficient Framework for Target Detection in Multimodal Remote Sensing Imagery. Remote Sensing. 2025; 17(8):1350. https://doi.org/10.3390/rs17081350
Chicago/Turabian StyleWang, Yong, Jiexuan Jia, Rui Liu, Qiusheng Cao, Jie Feng, Danping Li, and Lei Wang. 2025. "Can Separation Enhance Fusion? An Efficient Framework for Target Detection in Multimodal Remote Sensing Imagery" Remote Sensing 17, no. 8: 1350. https://doi.org/10.3390/rs17081350
APA StyleWang, Y., Jia, J., Liu, R., Cao, Q., Feng, J., Li, D., & Wang, L. (2025). Can Separation Enhance Fusion? An Efficient Framework for Target Detection in Multimodal Remote Sensing Imagery. Remote Sensing, 17(8), 1350. https://doi.org/10.3390/rs17081350