1. Introduction
As a common geological disaster, a landslide poses a serious threat to the safety of human life and property. Not only does it cause huge direct economic losses, but it can also cause long-term casualties and environmental damage [
1]. A landslide occurs when soil or rock formations on a slope move downward, either as a cohesive mass or in fragments, along a particular weak surface or zone. This movement is triggered by various natural factors, including river erosion, groundwater activity, rainwater saturation, and earthquakes, as well as human activities such as slope excavation and construction [
2]. The occurrence of landslides is highly uncertain, involving a variety of factors such as lithology, faults, altitude, and slope, which makes it extremely difficult to predict the exact time and location of the landslides [
3]. Therefore, post-disaster assessment of landslides is particularly important, as it not only reveals the specific damage caused by landslides but also provides a scientific basis for the formulation of post-disaster response strategies and emergency rescue plans [
4]. Through post-disaster evaluation, we can learn more about the scope, extent, and affected area of landslide disasters, which provides an important reference for post-disaster reconstruction and recovery [
5]. At the same time, the assessment results can also provide guidance and support for future disaster prevention efforts, helping us to better understand and respond to landslide disasters. Therefore, post-disaster landslide evaluation is a major focus of geological disaster research at present.
With the development of remote sensing technology, landslide recognition technology is becoming more and more accurate, and identifying the landslide area contained in remote sensing images plays an important role in post-disaster assessment. The traditional method is often to recognize the landslide area of the remote sensing image employing manual visual judgment [
6]. For example, in 2009, Tsai, Fand, et al. [
7] used multi-temporal satellite images to conduct a post-disaster assessment of landslides in southern Taiwan by comparing them with other geospatial data; they accurately identified the impact range of landslides. In 2010, F. Fiorucci et al. [
8] conducted a visual analysis of the landslide in the Apennines Mountains through aerial orthophoto and satellite images, and finally determined the impact range of the landslide and analyzed the causes of the landslide. Although the visual interpretation method can accurately identify the extent of the impact of the landslide, the uncertainty caused by manual interpretation is very high.
With recent advancements in computer technology, many methods have emerged in this regard, mainly in machine learning and deep learning, and common machine learning algorithms include logistic regression [
9], support vector machines [
10], random forests [
11]. Since 2005, Tolga Can et al. [
12] have been using logistic regression analysis to analyze the factors that cause landslides, and the frequency of use is increasing. In 2013, Biswajeet Pradhan et al. compared decision trees, support vector machines, and adaptive neural fuzzy inference systems to evaluate landslides, and concluded that the sensitivity of the model to the landslide domain on the map is reliable. In 2017, Wei Chen et al. [
13] compared machine learning methods such as the logistic model tree [
14], random forest, and categorical regression tree (CART) model, and proved the reliability of their methods in landslide sensitivity spatial prediction.
The development of computers has driven the development of machine learning, and a range of deep learning methods have emerged. Unlike traditional machine learning approaches, deep learning is a highly effective, supervised method [
15] that is both time-efficient and cost-efficient. It encompasses a wide range of architectures and topologies, making it suitable for addressing numerous complex problems. Deep learning is considered to be the best option for discovering complex architectures in high-dimensional data by using backpropagation algorithms.
With the continuous development of deep learning, many algorithm models have emerged, such as AlexNet [
16], RCNN [
17], Fast RCNN [
18], YOLO [
19], SSD [
20], and an increasing number of scholars are applying deep learning across various fields, including remote sensing. In deep learning applications for remote sensing, scholars mainly focus on detection tasks and segmentation tasks. The detection task is a type of recognition method that can identify the slip area, while the segmentation task is a pixel-based recognition method that can classify each pixel of the picture to better evaluate the landslide area.
In terms of landslide detection, M. I. Sameen et al. [
21] proposed integrating the residual network into the landslide detection model and fusing spectral bands with terrain data, which improved the accuracy of landslide detection to an accuracy rate of 81.6%. Cheng et al. [
22] proposed an improved landslide detection model, YOLO-SA based on YOLOv4 [
23], which reduced the parameters of the model and added an attention mechanism to improve the accuracy of the model, with an accuracy rate of 94.08%, using Qiaojia County and Ludian County of Yunnan Province in China as the study areas. Jian Xiaoting et al. [
24] used the Faster R-CNN model for landslide detection; the AP obtained was 92.42%. Tao Wang et al. [
25] improved the YOLOv5 model, added adaptive spatial feature fusion, and introduced the convolutional block attention mechanism (CBAM) under its basic framework, and the overall performance of the model increased by 1.64%.TAN. Other researchers [
26] fused the digital elevation model (DEM) with the landslide recognition model and finally improved the IoU and F1 by 9.3% and 6.8%, respectively.
Remote sensing algorithms can accurately identify landslide locations. On the other hand, remote sensing landslide segmentation tasks can precisely demarcate the boundaries of landslides and determine the proportion of landslide areas within the overall image. Consequently, remote sensing landslide segmentation algorithms are effective tools for studying changes in landslide areas and for calculating landslide extents. For common segmentation models, such as U-Net [
27], PSNet [
28], DeepLabv3 [
29], and SegNet [
30], many scholars have studied the segmentation task in the field of landslide segmentation. Soares et al. [
31] utilized DEM (digital elevation model) data as the basis for training and employed the U-Net model to automatically identify and segment landslide areas in Novo Fribourg City, which is situated in the mountainous region of Rio de Janeiro, southeastern Brazil. The model achieved F1 scores of 0.55 and 0.58 on two distinct test datasets. C Fang et al. [
32] introduced a lightweight attention mechanism into the U-Net model to obtain an F1 score of 87.45%, and Zhun Li [
33] adopted the MobileNetV2 structure of the backbone network of PSPNet to reduce network parameters, improve the network convergence speed, and improve the accuracy of object division. Du et al. [
34] conducted a comparative analysis of six prevalent deep learning models for semantic segmentation tasks, utilizing a custom-built landslide dataset from the Yangtze River coastal region. The evaluation concluded with the GCN model, achieving an accuracy of 0.542, and the DeepLabv3 model achieved a mean intersection over union (mIoU) score of 0.740. Lu Yun [
35] improved the performance of the Mask R-CNN by incorporating the CBAM attention mechanism and enhancing the feature pyramid network with bottom-up channels, resulting in an accuracy of 92.6%. This method ensures the comprehensive integration of semantic features across all channels.
Although many scholars have made many remarkable achievements in the task of landslide segmentation, there are still some problems to be solved in this field.
Unbalanced landslide data: Landslides vary in size and shape, from small local landslides to large regional landslides. Landslides are unevenly distributed on remote sensing images, and the balance of data has a great impact on the model’s recognition ability. Different types of landslides appear significantly different on images, from small shallow landslides to large deep landslides, and their characteristics and influencing factors are different. In particular, the imbalance of positive and negative samples will cause the model to be biased toward categories with fewer samples, affecting the model’s recognition ability.
Model recognition capability: The terrain in mountainous canyon areas is complex and the vegetation coverage varies greatly. It is difficult to distinguish landslide areas in remote sensing images. In some areas, the vegetation coverage varies greatly, resulting in discontinuity, while some areas with human activities are not landslides, which increases the difficulty of model recognition.
Post-processing: Most researchers crop high-resolution images and then use these cropped images to identify landslides, a method that lacks engineering capabilities.
Given this, this paper proposes a Van–UPerAttnSeg cross-fusion model, which comprehensively optimizes the segmentation task from three key dimensions. First, the data-balancing algorithm is designed, second, the model network is optimized, and third, the post-processing process is improved. Compared with other models, the Van–UPerAttnSeg model showed better data. It is worth noting that all the evaluation indicators in this paper are calculated directly on the original diagram, which ensures that the research results are not only theoretical but also have high engineering application value. The key contributions of this article are as follows.
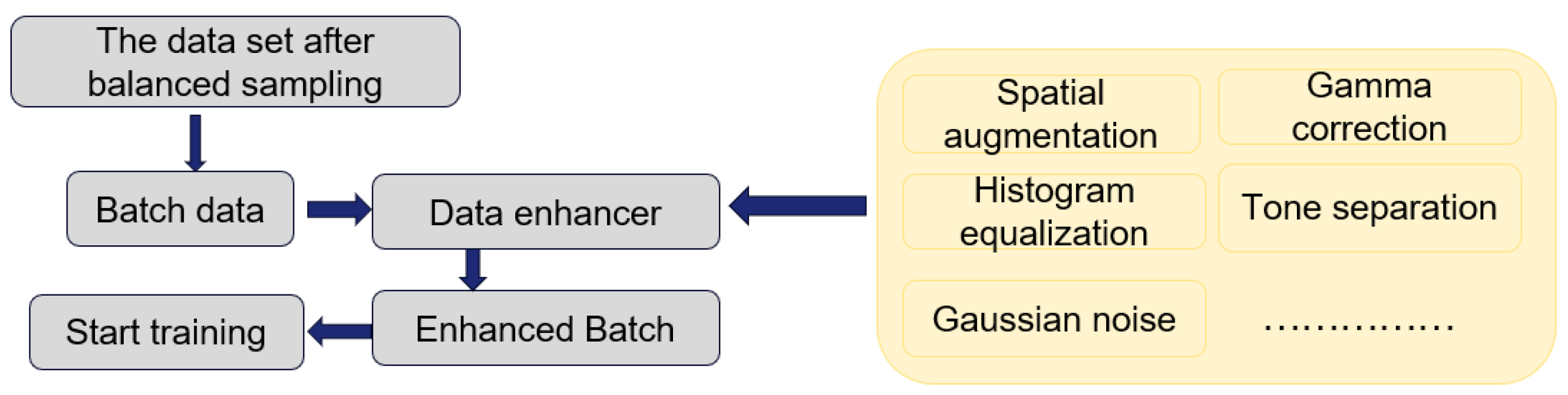
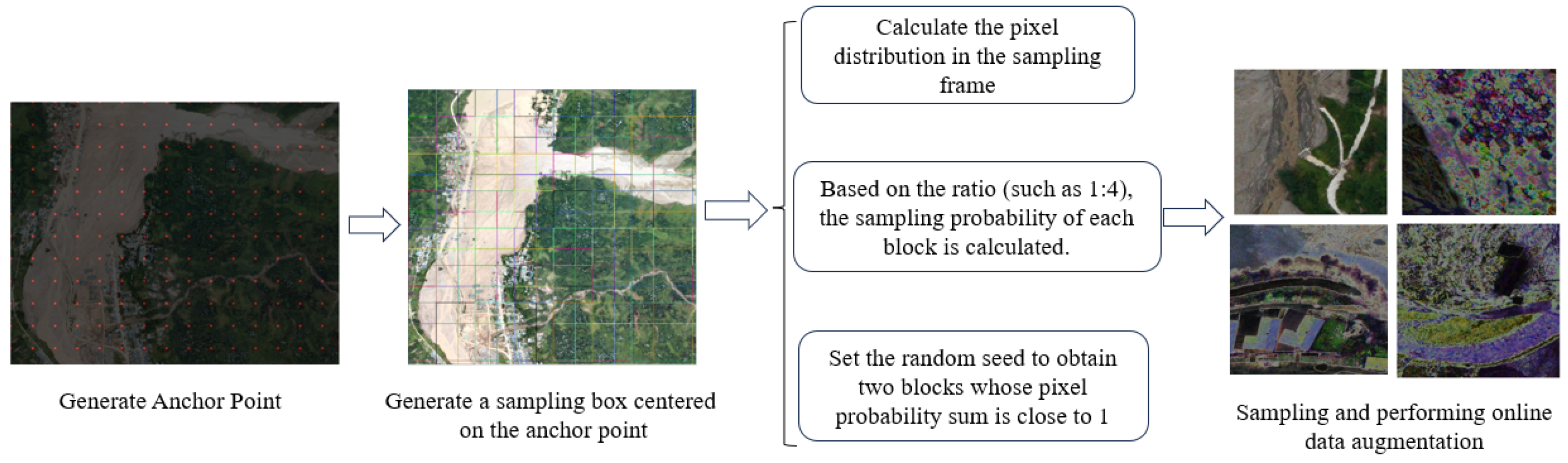
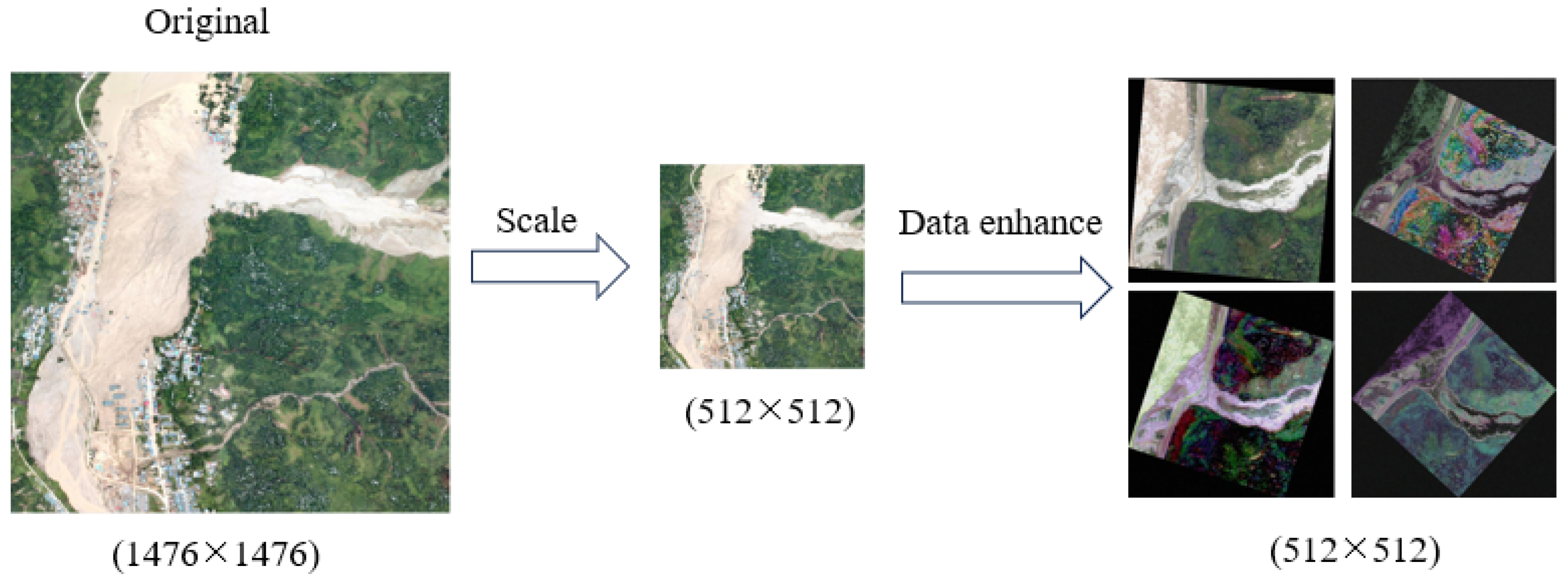
This paper designs an efficient data enhancement algorithm to solve the data problem through online balanced sampling and online data enhancement. Through this method, the dataset reaches a relatively balanced state between categories, reduces the deviation in the segmentation task, and increases the robustness of the model through online enhancement.
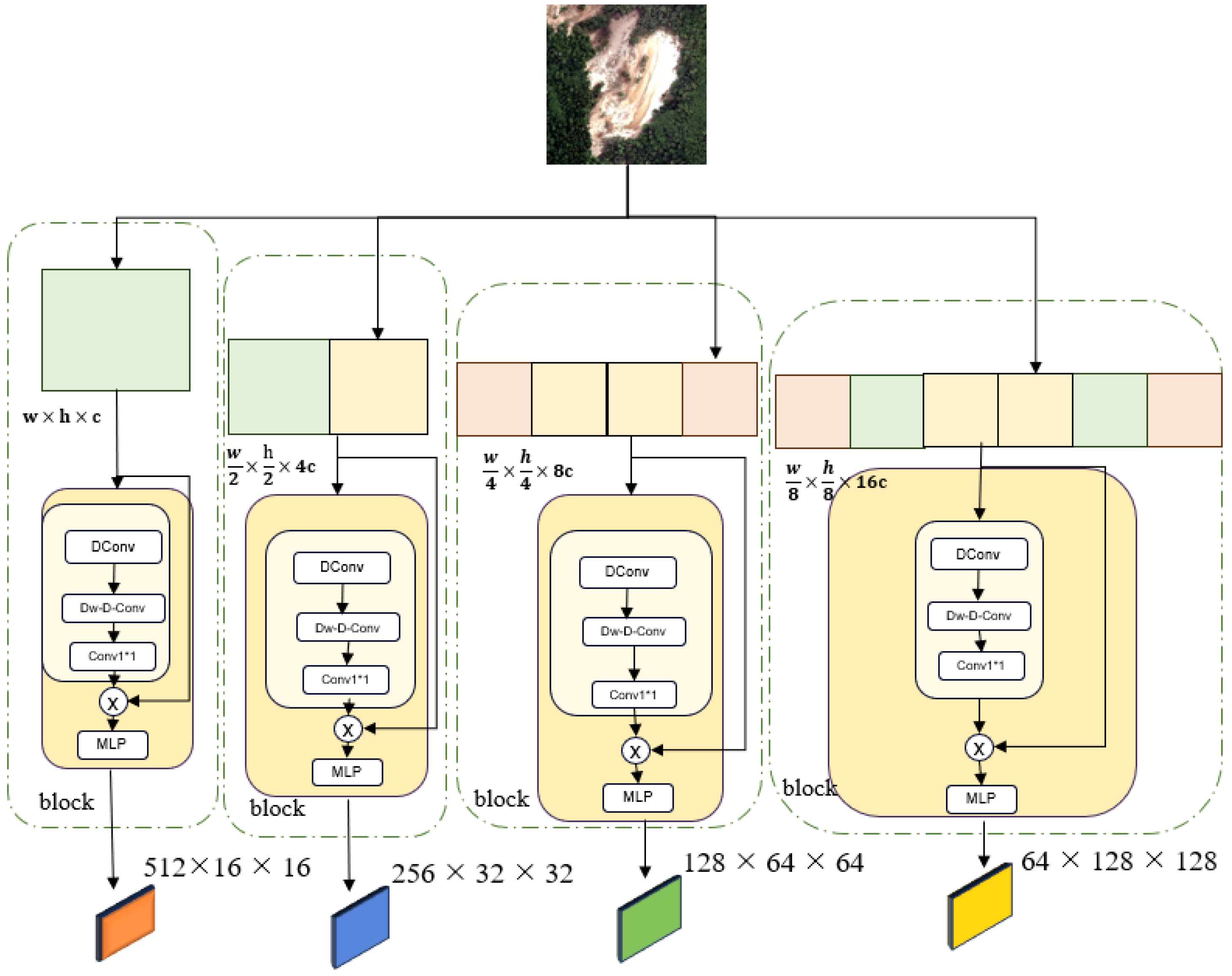
This paper proposes a new landslide recognition model, Van–UPerAttnSeg. An encoder–decoder structure is used to identify landslides. The Van network is introduced in the encoder to extract multi-level features of landslides. In the decoder, a pyramid structure is introduced to fuse multi-scale features, and the fused features are further processed with the help of the CBAM module.
In the post-processing stage, this paper proposes a sliding window-based Gaussian blur algorithm that can address image boundary issues and significantly reduce the requirements for computing devices. Through this method, the model can generate high-quality segmentation results more efficiently when processing high-resolution images, further enhancing the model’s practicality and engineering.
4. Experiment
In this section, we will carry out the following research work: First, by comparing and analyzing the impact of different data-sampling methods on model performance indicators, we will lay the foundation for subsequent experiments; second, a comparative experiment will be conducted between the Van–UPerAttnSeg model and the current mainstream models, and the experimental results will be analyzed through visualization; finally, ablation experiments are conducted on this model to quantitatively evaluate the contribution of each module to model performance, thereby verifying the necessity and importance of each module.
4.1. Comparative Experiments
In order to verify the effectiveness of the balanced sampling method, a comparative experiment is set up and compared with non-sampling and uniform sampling.
NO: Reduce the image ratio to 512 × 512 and then use the online image enhancement method.
Uniformity: Samples are sampled sequentially according to the anchor points, and the sample tile size is 512 × 512.
Ours: Samples are sampled to balance the positive and negative samples in the dataset using the methods described in this article.
If the data length is the same, the specific metrics are in
Table 6:
For this process, we compare a total of eight models using this public dataset. The models—specifically, U-Net, PSPNet, U-Net++, LinkNet [
43], MAnet [
44], DeepLabv3, DeepLabv3+ [
45], and FPN [
46]—are categorized alongside other generic semantic segmentation models using the same dataset. We use ResNet34 as the backbone network in these general models. To accelerate convergence, pre-trained weights are used; the base weights from the official pre-trained model are applied to the model proposed in this paper. After comparison, the specific indicators are in
Table 7, except for mDice, and the rest are the indicators on the validation set under the positive sample.
Table 6 illustrates the significant impact of different data processing methods on model performance. Specifically, the results of the first row show that the method is relatively ineffective. The main reason is that the scaling operation of the image will significantly weaken the model’s ability to perceive image features, and also reduce the efficiency of the model’s capture of contextual information, resulting in bias in the model’s feature extraction and understanding. For the results of the second row, we can see that this method leads to an imbalance in the distribution of data, and the ratio of positive and negative samples is unbalanced, which directly affects the training effect of the model. Unbalanced data can make the model tend to learn the features of the majority class and ignore the features of the minority, which will reduce the overall performance of the model. In contrast, our proposed balanced sampling method performs best across all metrics. This shows that balanced sampling can effectively balance the proportion of positive and negative samples, and ensure that the model can fully learn the features of each category during the training process. This balance not only improves the generalization ability of the model and enables it to better adapt to the data distribution in different scenarios, but also enhances the robustness of the model so that it can maintain stable performance in the face of complex data. Therefore, the balanced sampling method has significant advantages in improving the performance of the model.
The experimental results in
Table 7 show the performance comparison between different models under the condition of consistent data augmentation methods and loss functions. Specifically, except for the recall rate, the other indicators of the proposed model are significantly better than those of other models. Among them, the Dice score is the core indicator for measuring the performance of the segmentation model, which directly reflects the accuracy and completeness of the model for the segmentation of the target area. The mDice score further integrates the overall segmentation ability of the model. Therefore, the excellent performance of the Dice score and the average Dice score fully demonstrate the excellent performance of the proposed model in the segmentation task. This shows that the proposed model can more accurately identify and segment the target area when dealing with complex boundaries and detail segmentation, especially in the segmentation of key categories (category 1). The results show that the proposed model has a significant advantage in segmentation ability, which not only balances the performance differences between different categories but also outperforms other models in key indicators, supporting the high efficiency and reliability of the model in practical applications. This further verifies the superiority of the proposed model in complex scenes and its potential in engineering applications.
To comprehensively assess the model’s performance and conduct a thorough analysis, this paper selects three representative images with different regional characteristics in the validation set for predictive analysis. These images cover not only landslide disaster scenarios, but also other complex scenarios that are similar to the characteristics of landslides, such as roads and other natural or man-made objects that may resemble the morphology of landslides. This diverse selection of scenarios aims to more realistically simulate the challenges that the model may face in real-world applications while validating the model’s ability and robustness in distinguishing between different class features. The picture is shown in
Figure 9:
Through the visualization of the labels and predicted images above, it can be observed that our model network outperforms other models. Compared to other CNN models, there may be some difficulties in processing global information. Our model employs a large kernel attention mechanism, enhancing the model’s perception of images from four aspects: local perception ability, long-distance dependency, spatial adaptability, and channel applicability, thereby extracting deep features of the images.
To better demonstrate the capabilities of the model, we visualize its output on the original image by generating a corresponding heatmap, as shown in
Figure 10:
As can be seen from the figure, there are significant differences in the segmentation ability of different models when dealing with complex scenes. In the process of identification, some models have a high false positive rate (misjudging the non-landslide area as a landslide) and a false negative rate (missing the actual landslide area), which reflects their shortcomings in distinguishing the target features from the background interference. This phenomenon stems from the model’s limited ability to perceive local details of the image and the insufficient ability to capture long-distance dependencies.
In contrast, the model proposed in this paper performs well among all the comparison models. The main reason for this is that the large kernel attention mechanism is introduced into the model. This mechanism significantly enhances the model’s ability to perceive local features of the image, improves its ability to model long-distance dependence, and optimizes spatial adaptability and channel adaptability. Through this mechanism, the model can more accurately identify the subtle features of the landslide area and effectively suppress the interference of background noise, to achieve a more accurate segmentation effect in complex scenes.
4.2. Ablation Experiment
This section details ablation experiments that investigate the contribution and mechanism of each model module. In terms of experimental design, all ablation experiments were conducted based on the pre-trained model to ensure fairness and comparability of the experimental conditions. During the training process, each experimental group maintained 50 training rounds to fully evaluate the impact of each module on the performance of the model. By comparing the experimental results under different module combinations, we can quantitatively analyze the independent contribution of each component and its importance in the overall model.
In order to deeply analyze the impact of each module on the performance of the model, this study conducted a detailed split experiment on the loss function and decoder. Specifically, the loss function is deconstructed into Dice loss and labeled smooth limited cross-entropy loss (LCE), while the decoder is divided into the FPN module and CBAM module. Through ablation experiments on each module in turn, we observed that the method proposed in this paper has achieved significant improvement in the Dice index and the mDice index. The specific experimental data are shown in
Table 8.
4.3. Post-Processing Comparison
Because most methods choose to conduct model training and prediction at low resolution, this often results in insufficient accuracy in the image assessment outcomes following landslide disasters. To restore the true resolution of aerial images, considering that the image resolution used during our training was 512 × 512, we adopted a strategy to ensure the model’s adequate perception of the images. Specifically, we sampled the predicted images with a step size of 256, dividing them into multiple image blocks of size 512 × 512, and sequentially input these image blocks into the model for prediction. After obtaining the prediction results of all image blocks, we re-fused these results based on the sampling coordinates to obtain the prediction results of the original image, and this process effectively smoothed the image. To intuitively demonstrate the effectiveness of this method, we conducted whole image prediction and image block stitching prediction with a step size of 256 and visualized the predicted images for both cases for comparison. The details are in
Figure 11:
Through the comparison of the above figure, we can feel a significant difference between the whole graph prediction method and the prediction method we propose. Taking the first and fifth columns of the images as an example, there is an obvious lack of landslide area in the visualization results of the whole map prediction, but our prediction method can completely and accurately identify the entire landslide area. The root of this difference lies in how the model is trained and how well it perceives contextual information. Our model is trained on 512 × 512 size images, which enables the model to focus more on detailed information when processing high-resolution images but also leads to insufficient perception of global context information in whole map prediction. Looking further at the pictures in columns 3, 4, and 6, we can see that our prediction method is significantly better than the whole map prediction method in terms of detail processing. Not only does our method accurately identify the overall extent of the landslide area, but it also better captures the subtle structure and edge information within the area, resulting in better detail. This indicates that our prediction method can more effectively balance the relationship between local details and global information when dealing with complex scenarios, to achieve more accurate and reliable prediction results.
6. Conclusions
In this paper, a new segmentation model based on Van–UPerAttnSeg is proposed for the landslide segmentation problem. In this process, a new data-sampling method is proposed to solve the problem of uneven data distribution. Compared with the two methods of no sampling and random sampling, it can be concluded that the balanced sampling method improves the generalization ability of the model.
In this paper, the model introduces a combination of label smoothing, maximum suppression cross-entropy, and Dice loss, which enhances the model’s convergence speed. Evaluation metrics such as the Dice score and average Dice score have shown improvement in comparison experiments with other common loss functions.
In terms of model comparison, this paper primarily compares eight classic models. For each metric, the proposed Van–UPerAttnSeg segmentation model has shown improvements over other models in the five evaluation metrics of Precision, Recall, Dice, and mDice presented in this paper.
All indicators in this article are calculated based on the original image, including high-resolution images. This article uses 512 × 512-sized patches for training to better adapt to the image’s field of view, and consequently, the predicted patch size is also 512 × 521. This approach not only better adapts the features of the patches but also reduces dependence on the GPU. Therefore, this article proposes a Gaussian fusion post-processing method, which is more meaningful for reference.
The research presented in this article highlights the excellent performance of the Van–UPerAttnSeg model in landslide segmentation tasks, and the proposed post-processing method holds significant importance for post-disaster assessment and reconstruction of landslides.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}