1. Introduction
Hyperspectral imaging is a cutting-edge remote sensing technique that collects comprehensive spectral data across numerous adjacent bands covering the visible, near-infrared, and shortwave infrared portions of the electromagnetic spectrum. In contrast to conventional RGB images, which are confined to three color channels, hyperspectral images (HSI) offer an extensive spectral profile for each pixel. This enables accurate identification and distinction of materials based on their distinctive spectral signatures. This capability makes HSI highly valuable in applications such as agriculture [
1], disaster monitoring [
2], environmental monitoring [
3], geological surveys [
4], mineral exploration [
5], material testing [
6], military reconnaissance [
7], and other fields [
8,
9,
10]. For instance, in urban planning, HSI facilitates the precise mapping of infrastructure materials, enabling data-driven decisions for infrastructure maintenance and sustainable city development.
Hyperspectral image classification (HSIC) is a key task in hyperspectral image analysis [
11], which involves assigning a specific class label to each pixel based on its spectral and spatial characteristics. By utilizing the abundant spectral information, it enables the differentiation of various materials and land cover types, such as forests, bodies of water, and built environments. Due to challenges such as high data dimensionality [
12], spatial variability [
13], and limited labeled samples [
14], the classification of hyperspectral images often requires the development of advanced machine learning or deep learning algorithms that can efficiently extract and integrate spectral-spatial features to achieve accurate and robust classification results.
During the early stages of exploration in HSIC, statistical methods emerged as a prominent research trend. These methods include Principal Component Analysis (PCA) [
15], k-Nearest Neighbors (KNN) [
16], and Random Forests (RF) [
17,
18], which have played significant roles in processing and analyzing HSI data. Fang et al. [
19] introduced a novel approach using local covariance matrices (CM) to model the relationships between spectral bands and spatial-contextual information in hyperspectral images, facilitating more effective feature extraction. Guo et al. [
20] applied Support Vector Machines (SVM) [
21] for HSIC and enhanced classification performance by designing multiple customized kernels to extract and analyze the relevant information in the spectral curves. Moreover, traditional deep learning models such as Stacked Autoencoders (SAE) [
22] and Deep Belief Networks (DBN) [
23] have also been applied to HSIC, leveraging their ability to learn hierarchical feature representations from raw hyperspectral data. Additionally, techniques for feature extraction, including Extended Morphological Profiles (EMP) [
24] and Extended Multi-Attribute Profiles (EMAP) [
25], have been introduced to capture both spatial and spectral data, enhancing classification accuracy when integrated with different classifiers. Despite these advancements, traditional methods often struggle with capturing complex spatial-spectral relationships and require extensive manual feature engineering. These limitations highlight the need for more sophisticated deep learning approaches in HSIC.
In addition to traditional methods, recent progress in deep learning has introduced Convolutional Neural Networks (CNNs) [
26] as an effective approach for HSIC. By automatically extracting hierarchical spectral-spatial features, CNN-based models reduce the reliance on manually engineered features and prior statistical assumptions, and can reveal complex patterns often overlooked by conventional techniques [
27]. This shift has led to more accurate and robust classification results, making CNNs a promising direction in the ongoing exploration of hyperspectral data analysis. Initially, a 1D-CNN structure was proposed [
28,
29] for HSIC, operating along the spectral dimension to capture subtle variations in hyperspectral data. The 2D-CNN structure [
30] used for HSIC extends feature extraction to both the horizontal and vertical spatial dimensions, allowing the network to capture spatial patterns and contextual relationships within the HSI data.
Compared to 1D-CNN and 2D-CNN, the 3D-CNN structure [
31] treats the hyperspectral cube as a three-dimensional volume, enabling simultaneous learning of spectral and spatial features. By convolving across the spectral dimension and both spatial dimensions, 3D-CNNs can more comprehensively capture the intrinsic spectral-spatial correlations present in HSIs, but this comes at the cost of increased computational complexity. Roy et al. [
32] proposed HybridSN, a hybrid spectral CNN that combined a 3D-CNN for joint spatial-spectral feature extraction followed by a 2D-CNN for spatial feature refinement. This hybrid architecture reduced computational complexity compared to pure 3D-CNNs while achieving satisfactory classification performance. Zhang et al. [
33] introduced the spectral partitioning residual network (SPRN) for HSIC. This method divides the input spectral bands into distinct, non-overlapping subbands and employs enhanced residual blocks for extracting spectral-spatial features. After feature extraction, the results are combined and passed to a classifier. This strategy effectively utilizes the spectral and spatial richness of hyperspectral data, ensuring computational efficiency. Chang et al. [
34] proposed an iterative random training sampling (IRTS) method to address the issue of inconsistent classification in HSIC, which arises from random training sampling (RTS). Unlike the traditional K-fold method, IRTS reduces uncertainty by iteratively augmenting the image cube with spatially filtered classification maps. However, CNNs are primarily sensitive to local features and require deep stacking to expand the receptive field, which makes them less effective at capturing global features or long-range dependencies [
35]. This limitation restricts their further development.
Recently, both Transformer [
36] models and Vision Transformers (ViT) [
37] have been introduced for HSIC. Transformers, known for their ability to capture long-range dependencies through self-attention mechanisms, are effective at modeling both spectral and spatial relationships in hyperspectral data. Unlike CNNs, which focus on local features, Transformers can learn global contextual information, making them well-suited for the complex nature of HSIC. As variants of the Transformer architecture, ViTs leverage this structure to learn rich spatial and spectral representations. This patch-based representation approach provides valuable insights for applying transformers to HSI, enabling the effective capture of spatial-spectral information in HSIs. Hong et al. [
35] proposed SpectralFormer, a novel backbone for hyperspectral image classification that leveraged transformers to capture spectral sequences. Unlike traditional transformers, SpectralFormer learns local spectral patterns from neighboring bands and uses skip connections to preserve information. The model outperforms classic Transformers and state-of-the-art networks on multiple HS datasets, proving the potential of Transformer-based models in HSIC tasks. Song et al. [
38] proposed a hierarchical spatial-spectral transformer to overcome CNN’s limitations in modeling spatial-spectral correlations, achieving joint feature extraction through a lightweight hierarchical architecture that replaces convolutions with self-attention mechanisms to capture pixel-level dependencies. Cao et al. [
39] employed Swin Transformer blocks to overcome CNN’s limitations in inefficient spectral sequence utilization and weak global dependency modeling, achieving simultaneous extraction of spatial-spectral features for enhanced hyperspectral image classification. Tu et al. [
40] proposed the LSFAT for hyperspectral image classification. LSFAT captures multiscale features and long-range dependencies by introducing a pixel aggregation strategy. Moreover, the approach incorporates neighborhood-based embedding and attention mechanisms to dynamically generate multiscale features and capture spatial semantics, leading to promising classification outcomes. Song et al. [
41] introduced the Bottleneck Spatial–Spectral Transformer (BS2T) for hyperspectral image classification, overcoming the challenges of long-range dependencies and limited receptive fields. By integrating advanced mechanisms to model global dependencies, the approach significantly improves the representation of both spatial and spectral features. Ahmad et al. [
42] proposed an innovative hierarchical structure for HSIC by integrating a feature pyramid and Transformer. The input was divided into hierarchical segments with varying abstraction levels, organized in a pyramid-like structure. Transformer modules were applied at each level to efficiently capture both local and global contexts, enhancing the model’s ability to capture spatial–spectral correlations and long-range dependencies. Transformers are effective in hyperspectral image classification (HSIC) for capturing long-range dependencies and spatial–spectral correlations. However, they lack strong local spatial feature extraction capabilities, making them less effective at capturing fine-grained details compared to CNNs [
43].
Combining CNNs and ViTs leverages the strengths of both models to extract both local features and global context. While CNNs excel at capturing local spatial details but struggle with global dependencies, ViTs effectively model global relationships through self-attention but lack strong local feature extraction capabilities. This integration addresses both local and global feature extraction challenges, enabling more accurate and robust image classification [
44,
45,
46,
47,
48]. Liu et al. [
44] improved the ViT structure with a CNN sliding window mechanism to reduce computational complexity and extract multi-scale features. Guo et al. [
45] proposed a hybrid architecture that combined CNNs and ViTs in series. They employed CNNs as local feature extractors, placed before standard transformer blocks, to enhance the representation of locally extracted features. Additionally, they improved computational efficiency by compressing the feature map dimensions during the multi-head attention calculation. This approach effectively leveraged the strengths of both CNNs and transformers, resulting in enhanced feature extraction and more efficient processing. Chen et al. [
46] proposed a parallel dual-stream classification framework that combined MobileNet and ViT. In this framework, after each feature extraction stage, ViT and MobileNet engaged in bidirectional information exchange, facilitating the fusion of both local and global features. Additionally, the framework incorporated further design considerations, such as optimizing the number of ViT tokens, selecting the appropriate CNN network, and refining the information exchange method. These innovations ensure that the classification framework achieves both high accuracy and computational efficiency. Zhao et al. [
47] and Xu et al. [
48] also adopted similar approaches in hyperspectral image classification, proposing parallel and serial hybrid CNN and ViT architectures, respectively, and achieving promising performance. The various works mentioned above that combine ViTs and CNNs have demonstrated the potential of hybrid architectures. Arshad et al. [
49] proposed a Hierarchical Attention Transformer to overcome the limited training sample issue in HSIC, combining CNN’s local feature learning and ViT’s global modeling through window-based self-attention with dedicated tokens for dual-scale representation. These hybrid structures have achieved superior performance compared to single architectures, effectively leveraging the strengths of both CNNs for local feature extraction and ViTs for global context modeling. However, this integration has also introduced increased structural complexity and computational cost. Therefore, careful design and optimization of the hybrid framework are crucial to ensure their suitability and efficiency in HSIC tasks.
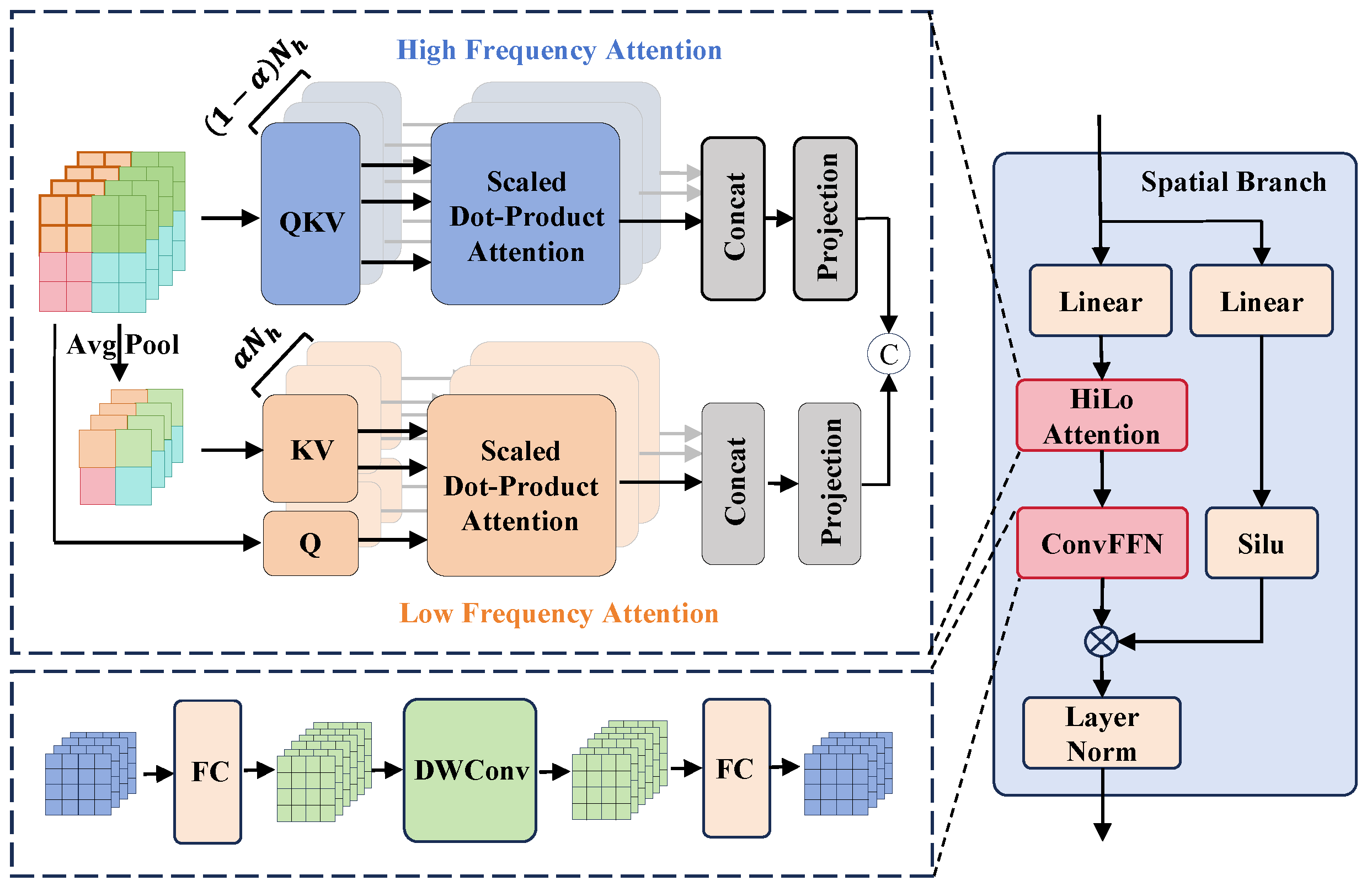
Despite the achievements of the aforementioned methods, some shortcomings still exist. On the one hand, introducing spatial information for HSI classification may not always be beneficial. Classification of the central pixels in HSI cubes can be compromised by irrelevant information from non-target categories. On the other hand, when ViT extracts global features from HSI cube, it may overlook some useful information due to significant intra-class spectral variability. To resolve these problems, we propose a novel central pixel-based dual-branch network (CPDB-Net). The main contributions are as follows:
A dual-branch structure based on central pixels is proposed to effectively separate the central spectral feature extraction process from the common global process. This architecture reinforces the importance of central pixel features in classification while reducing interference from surrounding regions, thereby enhancing classification accuracy.
An improved spatial branch architecture based on ViT is designed to enhance the model’s performance by effectively adjusting the focus on high- and low-frequency information. This design can mitigate the impact of intra-class variability and improves global feature extraction, leading to more robust feature representation.
The experimental results demonstrate that the proposed method achieves superior performance compared to several representative competitors. This highlights the performance advantages of CPDB-Net.
3. Results
3.1. Datasets Description
The performance of the proposed CPDB-Net method will be evaluated on three widely used datasets in the field of hyperspectral image classification: Indian Pines, Pavia University, and Houston 2013.
3.1.1. Indian Pines
The Indian Pines dataset was collected by an Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) in June 1992, focusing on agricultural regions in Northwestern Indiana, USA. It contains 145 × 145 pixels with a spatial resolution of 20 × 20 m and 220 spectral bands spanning from 400 to 2500 nm. In order to maintain the integrity of the data, 20 spectral bands were excluded, resulting in a final dataset containing 200 bands for further analysis. The dataset is renowned for its diverse vegetation types and varying soil conditions, making it a commonly used benchmark for hyperspectral image classification.
Figure 4 presents the false color and ground-truth maps, and
Table 1 provides the allocation of training and testing samples across the different classes.
3.1.2. Pavia University
The Pavia University dataset was acquired by the Reflective Optics System Imaging Spectrometer (ROSIS) sensor over the University of Pavia, Italy. This dataset comprises 610 × 340 pixels with a high spatial resolution of 1.3 × 1.3 m and includes 103 spectral bands ranging from 430 to 860 nm. The dataset features nine land cover classes, such as buildings, trees, roads, bare soil, and water, representing a variety of urban materials and structures. This diversity facilitates the evaluation of hyperspectral classifiers in distinguishing between different urban land cover types based on their spectral characteristics.
Figure 5 presents the false color and ground-truth maps, whereas
Table 2 outlines the allocation of training and testing samples across each class.
3.1.3. Houston 2013
The Houston dataset centers on an urban region near the University of Houston campus, USA. It was acquired by the National Center for Airborne Laser Mapping (NCALM) for the 2013 IEEE GRSS Data Fusion Contest [
51]. It consists of 349 × 1905 pixels with a spatial resolution of 2.5 × 2.5 m and includes 144 spectral bands ranging from 380 to 1050 nm. This dataset features a rich variety of urban materials, such as asphalt, concrete, vegetation, and water bodies, under diverse environmental conditions. The Houston 2013 dataset is renowned for its complexity and diversity, presenting significant challenges for hyperspectral image classification methods.
Figure 6 presents the true color and ground-truth maps, whereas
Table 3 provides the allocation of training and testing samples across the different classes.
3.2. Experimental Setup
To objectively evaluate the performance of the proposed CPDB-Net, several representative methods in the HSIC field were selected for comparison:
SSRN [
31]: A CNN-based hyperspectral image classification (HSIC) algorithm. Its innovative integration of skip connections within the 3D-CNN architecture has established SSRN as a classic CNN-based method, leading to extensive citations in numerous subsequent studies.
DBDA [
52]: A CNN-based algorithm that employs a dual-branch structure, with each branch dedicated to extracting spatial and spectral features, respectively. This method demonstrates superior performance under limited training samples and has inspired numerous dual-branch designs.
LSFAT [
40]: An algorithm built on the ViT architecture, which has showcased substantial potential in tackling the HSIC problem and is becoming a classic approach in ViT-based methods.
SSFTT [
53]: A representative ViT-based method that improves the patching strategy for spectral information. Its innovative design has been widely recognized and frequently cited in the field.
CT-Mixer [
54]: A state-of-the-art hybrid architecture that integrates CNN and ViT structures. By effectively combining their respective strengths, CT-Mixer achieves competitive performance and serves as a representative work of CNN–ViT hybrid approaches.
SS-Mamba [
55]: Employs a dual-branch spatial-spectral architecture based on the recent Mamba model [
56] for hyperspectral image classification. This innovative approach leverages Mamba’s strengths, resulting in outstanding classification performance.
The aforementioned methods encompass CNN, ViT, and CNN–ViT hybrid architectures, as well as the latest approaches based on the Mamba model, providing a comprehensive basis for comparison.
In the experimental setup, the input HSI patch size is set to (i.e., ). In the spatial branch, patch embedding is performed using a convolutional layer, reducing the input to a feature map to mitigate excessive computational load. Furthermore, in the spectral branch, only the central region is utilized as input. The spectral mapping and embedding dimensions are configured to 128 and 96, respectively. For optimization, the Adam optimizer was employed with an initial learning rate of 0.001 and a weight decay of 0.0001. A cosine annealing learning rate scheduler was utilized, with set to 5 and set to 2. During training, we performed 10 random splits of the dataset into training and testing samples. Each split was trained for 300 epochs, and the test results were averaged to evaluate the classification performance. Additionally, the attention head allocation ratio was set to 0.4 for the Pavia University dataset and 0.6 for the other datasets. The hyperparameters mentioned above were initially set based on experience and were further fine-tuned according to experimental results.
The classification methods were evaluated using overall accuracy (OA), average accuracy (AA), and the Kappa coefficient (Kappa) as key performance metrics. To ensure stable and consistent results, each experiment was repeated ten times with different random initializations. In each independent iteration, training samples were randomly selected from the complete set of labeled data.
3.3. Ablation Experiment
To evaluate the effectiveness of the proposed spectral and spatial branches, we conducted ablation studies on three datasets: Indian Pines, Pavia University, and Houston 2013. The ablation experiments were designed to assess the individual and combined contributions of the central spectral branch and the improved spatial branch to the overall performance of the proposed CPDB-Net. Here, “Base” refers to the original ViT architecture as the spatial branch, “Spectral Branch” refers to the CNN-based central spectral branch alone, “Base+Spectral Branch” indicates the combination of the central spectral branch with the base spatial branch, and “Ours” refers to the complete version of the proposed CPDB-Net, which simultaneously utilizes the central spectral branch and the improved spatial branch, incorporating HiLo attention for classification. The results of the ablation experiments, presented in
Table 4,
Table 5 and
Table 6, consistently demonstrate the effectiveness of the proposed central pixel dual-branch structure and the improved spatial branch structure across all three datasets.
Taking the Pavia University dataset as an example (
Table 5), the proposed CPDB-Net significantly outperforms the “Base” model, with improvements of 2.09%, 1.64%, and 2.72% in OA, AA, and Kappa, respectively. These results highlight the importance of incorporating both the central spectral branch and the improved spatial branch for accurate classification. Moreover, CPDB-Net achieves substantial enhancements over the “Spectral Branch” model, with increases of 6.63%, 4.72%, and 8.57% in OA, AA, and Kappa, respectively. The “Base+Spectral Branch” model, which combines the central spectral branch with the base spatial branch, also exhibits notable improvements over the individual “Base” and “Spectral Branch” models. These results underscore the complementary nature of the spectral and spatial branches and the benefits of their integration.
Further analysis reveals that the complete CPDB-Net outperforms the “Base+Spectral Branch” model, with improvements of 0.91%, 0.35%, and 1.18% in OA, AA, and Kappa, respectively. This comparison highlights the effectiveness of the HiLo attention mechanism incorporated in the improved spatial branch, which enhances the model’s ability to capture both high-frequency details and low-frequency global contextual information to further mitigate the impact of intra-class variability.
The ablation study results on the Indian Pines and Houston 2013 datasets (
Table 4 and
Table 6) exhibit similar trends, confirming the generalizability and robustness of the proposed CPDB-Net across different datasets.
3.4. Comparative Experiments
To comprehensively evaluate the effectiveness of CPDB-Net,
Table 7,
Table 8 and
Table 9 present the classification performance of the proposed method alongside selected benchmark methods on the Indian Pines, Pavia University, and Houston 2013 datasets. The experimental results demonstrate consistent superiority across all three metrics (OA, AA, Kappa). The significant performance improvements validate the effectiveness of our dual-branch design in preserving crucial central pixel information while leveraging global contextual features. Specifically, on the Indian Pines dataset, CPDB-Net improves OA by 3.23%, AA by 11.07%, and Kappa by 3.64% compared with the CNN-based representative method SSRN. Compared with the ViT-based method SSFTT, it enhances OA by 2.57%, AA by 1.85%, and Kappa by 2.88%. Compared with the hybrid architecture method CT-Mixer, CPDB-Net achieves increases of 2.8% in OA, 1.95% in AA, and 3.15% in Kappa. Even when compared with the latest Mamba-based method SS-Mamba, CPDB-Net improves OA by 0.88%, AA by 0.69%, and Kappa by 1.22%.
Further analysis reveals an interesting finding: ViT-based and hybrid methods do not consistently outperform CNN-based approaches across all three datasets. Specifically, on the Indian Pines dataset, SSFTT and CT-Mixer achieve increases in OA of 0.66% and 0.43%, respectively, compared with SSRN. However, on the Pavia University dataset, SSFTT and CT-Mixer result in decreases in OA by 2.11% and 0.39%, respectively, relative to SSRN. Similarly, on the Houston 2013 dataset, SSFTT and CT-Mixer show reductions in OA by 0.44% and 0.59%, respectively, compared with SSRN. This performance inconsistency is likely due to the relatively complex architectures of these methods, which may not perform optimally with a limited number of samples. This observation further justifies our motivation to design a specialized dual-branch architecture rather than simply combining CNN and ViT.
It is worth noting that SS-Mamba, using the latest Mamba architecture, achieves highly powerful classification performance. Nevertheless, our proposed CPDB-Net surpasses SS-Mamba with improvements of 1.08% in OA, 0.69% in AA, and 1.22% in Kappa on the Indian Pines dataset, and also demonstrates performance gains on the Pavia University and Houston 2013 datasets. These consistent improvements across different datasets demonstrate the robustness of our CPDB-Net in handling spectral variability. CPDB-Net exhibits competitive effectiveness compared with the latest Mamba model.
To provide qualitative analysis,
Figure 7,
Figure 8 and
Figure 9 present visualizations of the classification results across different datasets. The visual comparison shows that our method achieves more complete and consistent performance along the edges of similar land cover classes compared to the baseline methods. This superior boundary preservation ability particularly validates our dual-branch design in reducing spatial interference. Particularly, in
Figure 7, within the upper rear and slightly lower central regions, our method exhibits fewer errors at the boundaries of large aggregated areas of the same land cover class. In
Figure 8, where the land cover shapes are highly irregular, our method demonstrates superior ability in handling dispersed land covers and edge regions. These visualization results strongly support the effectiveness of the central pixel dual-branch structure.
3.5. Parameter Analysis
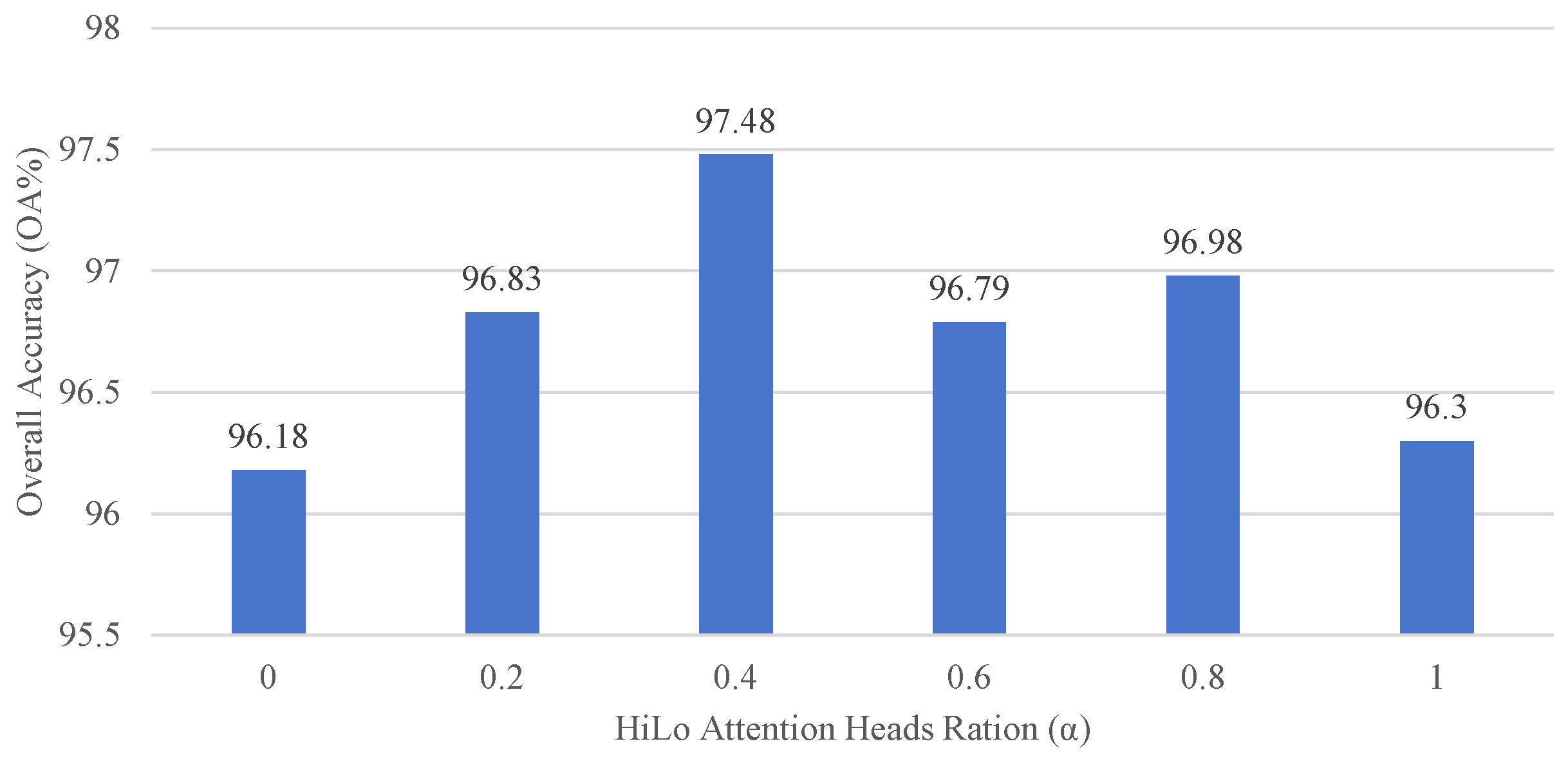
To investigate the key parameters of the proposed algorithm, experiments were conducted on the Pavia University dataset.
Figure 10 presents the experimental results for different allocation ratios
of high and low-frequency attention heads in HiLo attention, which is varied from 0 to 1 with a step size of 0.2. It is important to note that the classification performance is suboptimal when
is set to extreme values (0 or 1). This can be attributed to the fixed local window size, which does not guarantee that all pixels within the window belong to the same category. Consequently, placing excessive emphasis on low-frequency attention can lead to the extraction of non-representative features. Conversely, focusing too much on high-frequency attention is akin to merely windowing the original ViT, which constrains its ability to capture global features. Therefore, a moderate value of
yields superior performance by effectively leveraging both high and low-frequency information.
Another key parameter in the proposed method is the size of the central spectral branch. To analyze its impact on classification performance, experiments were conducted with the central region size ranging from 3 × 3 to 9 × 9, with a step size of 2.
Figure 11 shows the experimental results for different sizes of the central spectral branch. A clear trend can be observed: as the size of the central region increases, the classification accuracy exhibits a corresponding decrease. This phenomenon can be explained by the fact that larger central regions are more prone to interference from neighboring pixels, which can negatively impact the critical central pixel features essential for accurate classification. Consequently, employing a smaller central pixel region proves to be more effective in achieving optimal classification performance, as it minimizes the influence of potentially irrelevant or misleading information from the surrounding context.
To further explore the effectiveness of the group convolution strategy employed in the Spectral Branch, grouping strategies experiments were conducted.
Table 10 illustrates the performance differences of CPDB-Net on the Pavia University dataset using various grouping strategies. The results reveal that there is a notable distinction between multi-scale group convolutions and standard group convolutions (for instance,
g = 4, 8, 16 compared to
g = 8, 8, 8). Within each category, whether multi-scale or standard, the performance variations among different group configurations are relatively minor. This indicates that multi-scale group convolutions can enhance the CNN’s ability to extract central spectral features more effectively. Additionally, it was observed that even the least effective strategy (
g = 8, 8, 8) achieved an overall accuracy (OA) improvement of 0.81% over the “Base” method presented in
Table 5. This observation underscores that even when the CNN branch performs suboptimally, it remains effective within a center pixel-based dual-branch framework, thereby reinforcing the efficacy of this structural design.
Additionally, experiments with varying sample sizes were set up to evaluate the robustness of our method under extreme data conditions. Specifically, experiments were performed on the Pavia University dataset using 1, 5, 10, and 15 samples per class. Notably, our approach demonstrates strong performance even under relatively limited settings (20 samples per class). However, as
Figure 12 indicates, there is a significant performance drop with extremely scarce samples. This highlights the need for future exploration into specialized few-shot and unsupervised techniques to further enhance robustness in data-scarce scenarios.
3.6. Computational Efficiency Analysis
Computational efficiency analysis remains a critical component for evaluating model performance, as high computational efficiency directly correlates with a model’s practical deployment potential. Computational efficiency is assessed using three metrics: Params (parameter count), FLOPs (floating-point operations), and MACs (multiply-accumulate operations), with lower values generally indicating superior performance. As shown in
Table 11, our proposed method achieves both the highest performance (highest OA score) and significant computational efficiency advantages over comparable methods. Specifically, compared to the CNN–ViT hybrid model CT-Mixer, CPDB-Net reduces parameters by 0.35 million and achieves 0.41 fewer FLOPs. When benchmarked against the computation-efficient state-of-the-art method SS-Mamba, our model further demonstrates a reduction of 0.73 million parameters and 0.22 fewer FLOPs. These performance gains stem from the model’s streamlined architecture design and the incorporation of effective intuitive priors, thereby reinforcing the value and practicality of CPDB-Net.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}