
Attribute-Based Learning for Remote Sensing Image Captioning in Unseen Scenes





Abstract

1. Introduction
2. Related Studies
2.1. Retrieval-Based and Detection-Based Remote Sensing Image Captioning Methods
2.2. Remote Sensing Image Captioning Methods for Unseen or Novel Scenes
2.3. Encoder–Decoder-Based Remote Sensing Image Captioning Methods
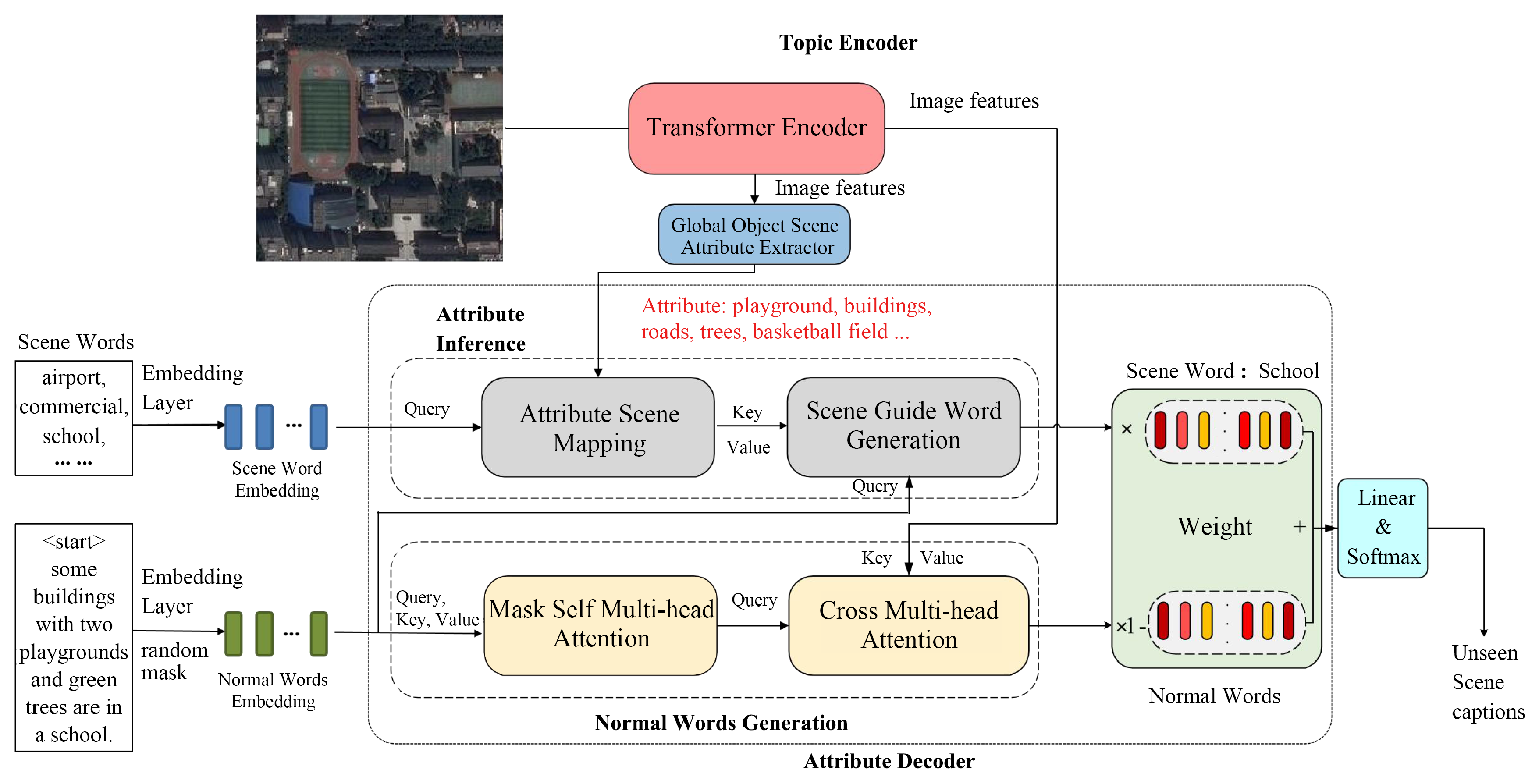
3. Methods
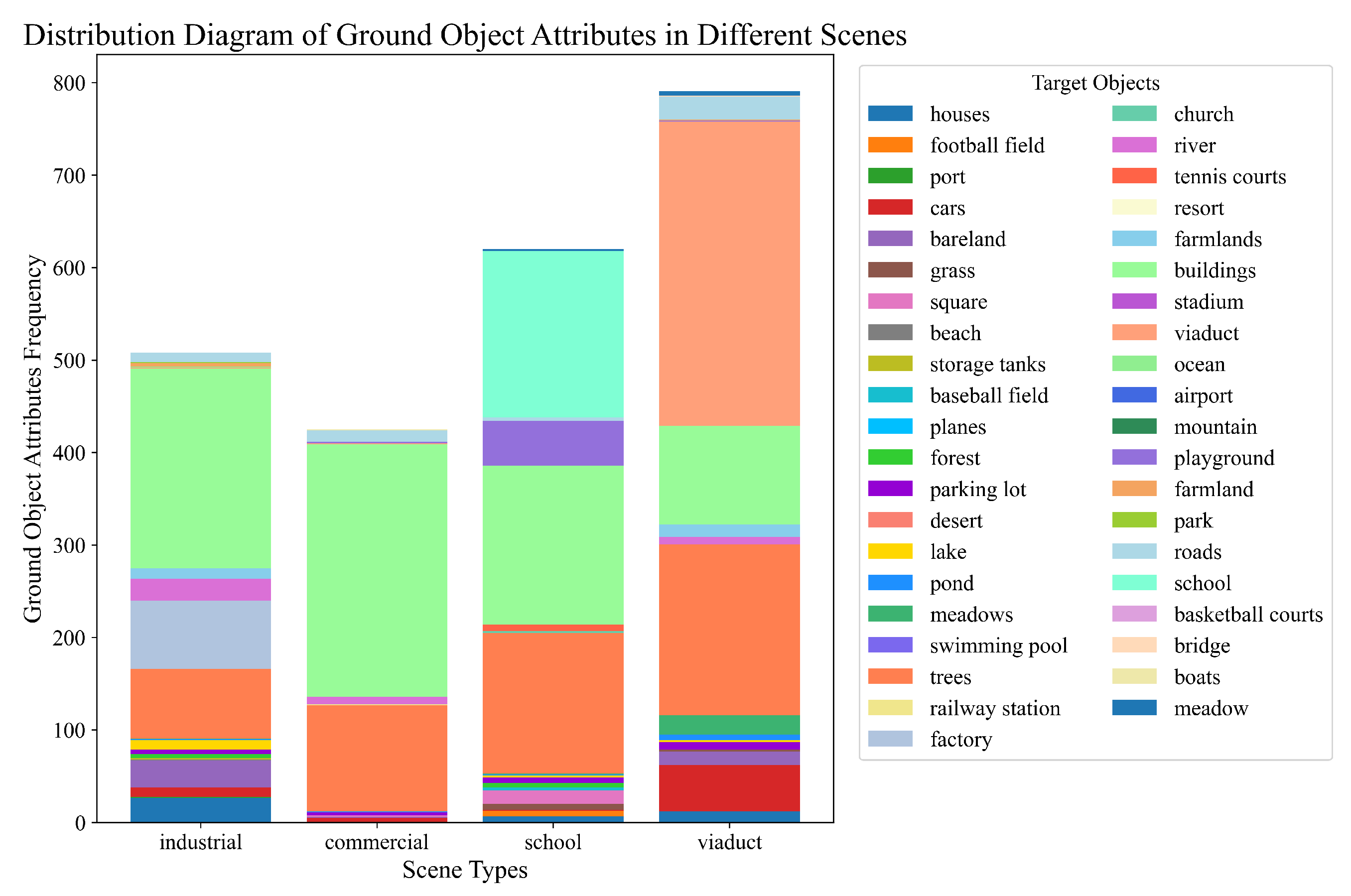
3.1. Global Object Scene Attribute Extractor
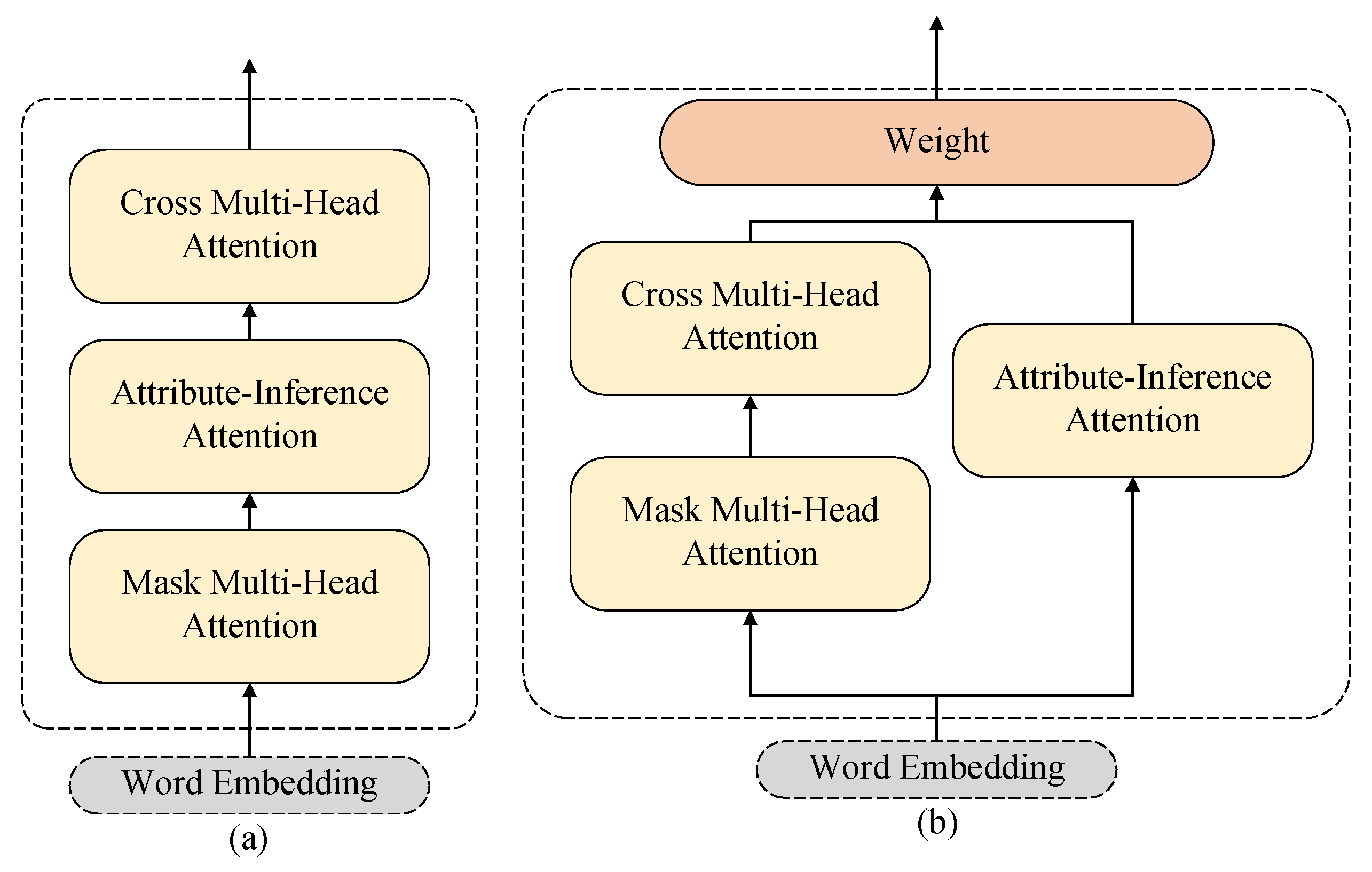
3.2. Attribute-Guided Decoder
3.3. Attribute Loss Function
4. Experiments
4.1. Dataset
4.2. Evaluation Metrics
4.3. Experimental Setting
4.4. Experimental Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| MLAT [4] | 62.94 | 48.89 | 39.45 | 32.41 | 29.83 | 54.06 | 165.5 |
| SCAMET [40] | 47.00 | 31.40 | 22.56 | 16.89 | 12.61 | 34.83 | 78.1 |
| HCNet [14] | 64.50 | 50.58 | 41.39 | 34.51 | 37.12 | 56.74 | 176.8 |
| ViECap [27] | 62.96 | 48.38 | 38.75 | 31.80 | 31.84 | 52.13 | 159.5 |
| DeCap [41] | 50.98 | 34.57 | 25.09 | 18.83 | 22.87 | 40.74 | 99.03 |
| * [39] | 10.88 | 2.60 | 0.29 | 0.00 | 5.65 | 10.39 | 2.18 |
| MTT [3] | 64.58 | 51.07 | 41.90 | 34.90 | 30.84 | 58.02 | 194.7 |
| DCA | 66.64 | 53.05 | 43.84 | 36.86 | 30.91 | 57.46 | 194.6 |
| AS | 66.77 | 53.06 | 43.49 | 36.30 | 30.18 | 55.30 | 188.9 |
| SALCap (ours) | 68.64 | 55.22 | 45.82 | 38.65 | 31.05 | 57.70 | 200.1 |
| Method | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| MLAT [4] | 49.92 | 33.60 | 24.44 | 18.33 | 22.27 | 39.59 | 40.59 |
| SCAMET [40] | 40.74 | 23.76 | 15.16 | 9.89 | 11.23 | 29.06 | 27.84 |
| HCNet [14] | 50.84 | 33.52 | 25.66 | 19.68 | 23.10 | 43.05 | 35.68 |
| ViECap [27] | 50.93 | 33.02 | 22.94 | 16.58 | 20.30 | 38.93 | 39.96 |
| DeCap [41] | 41.64 | 21.65 | 12.20 | 6.86 | 16.72 | 27.77 | 26.68 |
| MTT [3] | 49.42 | 32.21 | 24.61 | 18.07 | 21.05 | 36.73 | 39.41 |
| DCA | 50.28 | 31.54 | 23.82 | 18.21 | 20.46 | 36.74 | 43.52 |
| AS | 50.44 | 31.28 | 22.76 | 17.80 | 20.17 | 35.55 | 42.36 |
| SALCap (ours) | 51.30 | 33.88 | 24.65 | 18.87 | 21.11 | 37.86 | 47.76 |
| Method | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| MLAT [4] | 77.55 | 65.49 | 57.84 | 52.30 | 33.02 | 63.98 | 129.82 |
| SCAMET [40] | 55.85 | 38.04 | 26.46 | 18.91 | 18.49 | 41.34 | 24.96 |
| HCNet [14] | 78.49 | 64.90 | 56.48 | 52.06 | 30.53 | 64.09 | 131.06 |
| ViECap [27] | 56.73 | 38.81 | 28.17 | 21.62 | 20.37 | 42.08 | 49.86 |
| DeCap [41] | 68.80 | 50.50 | 37.70 | 28.30 | 23.90 | 48.90 | 63.60 |
| MTT [3] | 78.75 | 65.71 | 56.88 | 50.13 | 30.87 | 62.50 | 117.74 |
| DCA | 73.51 | 58.58 | 46.74 | 37.96 | 24.96 | 54.13 | 88.95 |
| AS | 77.86 | 65.03 | 56.32 | 49.70 | 31.28 | 62.85 | 120.02 |
| SALCap (ours) | 79.25 | 65.92 | 56.88 | 49.94 | 30.99 | 63.17 | 118.04 |
| Method | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| MLAT [4] | 46.20 | 24.10 | 12.89 | 6.24 | 10.24 | 29.50 | 3.68 |
| SCAMET [40] | 54.40 | 36.20 | 23.70 | 15.00 | 17.10 | 39.40 | 7.20 |
| HCNet [14] | 60.57 | 40.70 | 30.95 | 24.75 | 19.23 | 41.79 | 14.51 |
| ViECap [27] | 47.94 | 26.38 | 14.98 | 7.91 | 14.84 | 32.08 | 6.62 |
| DeCap [41] | 60.68 | 39.26 | 26.14 | 16.69 | 18.70 | 41.19 | 9.88 |
| MTT [3] | 56.87 | 37.49 | 24.57 | 14.34 | 15.02 | 41.98 | 11.59 |
| DCA | 59.53 | 39.53 | 25.37 | 15.87 | 16.47 | 40.45 | 11.60 |
| AS | 62.91 | 42.94 | 32.17 | 24.95 | 19.12 | 45.23 | 12.86 |
| SALCap (ours) | 66.38 | 46.17 | 35.28 | 27.70 | 20.02 | 48.21 | 14.64 |
4.5. Discussion and Analysis
4.6. Ablation Experiments
- (1)
- The attribute inference module (Attr) is removed, and the classification loss function is obtained using the entire sentence for classification.
- (2)
- The attribute loss function (CLS) is removed, and only the masked cross-entropy loss function is used. Without additional constraints on the model, the attribute reasoning module is used to obtain sentences.
5. Conclusions and Future Studies
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qu, B.; Li, X.; Tao, D.; Lu, X. Deep semantic understanding of high resolution remote sensing image. In Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems (Cits), Kunming, China, 6–8 July 2016; pp. 1–5. [Google Scholar]
- Hoxha, G.; Melgani, F.; Demir, B. Toward remote sensing image retrieval under a deep image captioning perspective. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4462–4475. [Google Scholar] [CrossRef]
- Ren, Z.; Gou, S.; Guo, Z.; Mao, S.; Li, R. A mask-guided transformer network with topic token for remote sensing image captioning. Remote Sens. 2022, 14, 2939. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, R.; Shi, Z. Remote-sensing image captioning based on multilayer aggregated transformer. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506605. [Google Scholar]
- Ni, Z.; Zong, Z.; Ren, P. Incorporating object counts into remote sensing image captioning. Int. J. Digit. Earth 2024, 17, 2392847. [Google Scholar] [CrossRef]
- Zhou, H.; Xia, L.; Du, X.; Li, S. FRIC: A framework for few-shot remote sensing image captioning. Int. J. Digit. Earth 2024, 17, 2337240. [Google Scholar]
- Ordonez, V.; Han, X.; Kuznetsova, P.; Kulkarni, G.; Mitchell, M.; Yamaguchi, K.; Stratos, K.; Goyal, A.; Dodge, J.; Mensch, A.; et al. Large scale retrieval and generation of image descriptions. Int. J. Comput. Vis. 2016, 119, 46–59. [Google Scholar]
- Kuznetsova, P.; Ordonez, V.; Berg, A.; Berg, T.; Choi, Y. Collective generation of natural image descriptions. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Jeju Island, Republic of Korea, 8–14 July 2012; pp. 359–368. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Ordonez, V.; Dhar, S.; Li, S.; Choi, Y.; Berg, A.C.; Berg, T.L. Babytalk: Understanding and generating simple image descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2891–2903. [Google Scholar]
- Gupta, A.; Mannem, P. From image annotation to image description. In Proceedings of the International Conference on Neural Information Processing, Doha, Qatar, 12–15 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 196–204. [Google Scholar]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual instruction tuning. Adv. Neural Inf. Process. Syst. 2024, 36, 34892–34916. [Google Scholar]
- Chu, X.; Su, J.; Zhang, B.; Shen, C. VisionLLaMA: A Unified LLaMA Interface for Vision Tasks. arXiv 2024, arXiv:2403.00522. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Yang, Z.; Li, Q.; Yuan, Y.; Wang, Q. HCNet: Hierarchical Feature Aggregation and Cross-Modal Feature Alignment for Remote Sensing Image Captioning. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5624711. [Google Scholar] [CrossRef]
- Hoxha, G.; Melgani, F.; Slaghenauffi, J. A new CNN-RNN framework for remote sensing image captioning. In Proceedings of the 2020 Mediterranean and Middle-East Geoscience and Remote Sensing Symposium (M2GARSS), Tunis, Tunisia, 9–11 March 2020; pp. 1–4. [Google Scholar]
- Chowdhary, C.L.; Goyal, A.; Vasnani, B.K. Experimental assessment of beam search algorithm for improvement in image caption generation. J. Appl. Sci. Eng. 2019, 22, 691–698. [Google Scholar]
- Li, Z.; Zhao, W.; Du, X.; Zhou, G.; Zhang, S. Cross-modal retrieval and semantic refinement for remote sensing image captioning. Remote Sens. 2024, 16, 196. [Google Scholar] [CrossRef]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Shi, Z.; Zou, Z. Can a machine generate humanlike language descriptions for a remote sensing image? IEEE Trans. Geosci. Remote Sens. 2017, 55, 3623–3634. [Google Scholar]
- Li, Y.; Zhang, X.; Cheng, X.; Tang, X.; Jiao, L. Learning consensus-aware semantic knowledge for remote sensing image captioning. Pattern Recognit. 2024, 145, 109893. [Google Scholar]
- Demirel, B.; Cinbis, R.G.; Ikizler-Cinbis, N. Image captioning with unseen objects. arXiv 2019, arXiv:1908.00047. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Wang, P.; Bai, S.; Tan, S.; Wang, S.; Fan, Z.; Bai, J.; Chen, K.; Liu, X.; Wang, J.; Ge, W.; et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv 2024, arXiv:2409.12191. [Google Scholar]
- Fei, J.; Wang, T.; Zhang, J.; He, Z.; Wang, C.; Zheng, F. Transferable decoding with visual entities for zero-shot image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 3136–3146. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on attention for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4634–4643. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Meng, L.; Wang, J.; Yang, Y.; Xiao, L. Prior Knowledge-Guided Transformer for Remote Sensing Image Captioning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4706213. [Google Scholar]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring models and data for remote sensing image caption generation. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2183–2195. [Google Scholar]
- Cheng, Q.; Huang, H.; Xu, Y.; Zhou, Y.; Li, H.; Wang, Z. NWPU-captions dataset and MLCA-net for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–19. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Zeng, Z.; Zhang, H.; Lu, R.; Wang, D.; Chen, B.; Wang, Z. Conzic: Controllable zero-shot image captioning by sampling-based polishing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 23465–23476. [Google Scholar]
- Gajbhiye, G.O.; Nandedkar, A.V. Generating the captions for remote sensing images: A spatial-channel attention based memory-guided transformer approach. Eng. Appl. Artif. Intell. 2022, 114, 105076. [Google Scholar]
- Li, W.; Zhu, L.; Wen, L.; Yang, Y. Decap: Decoding clip latents for zero-shot captioning via text-only training. arXiv 2023, arXiv:2303.03032. [Google Scholar]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar]
- Kuckreja, K.; Danish, M.S.; Naseer, M.; Das, A.; Khan, S.; Khan, F.S. Geochat: Grounded large vision-language model for remote sensing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 27831–27840. [Google Scholar]
- Wang, J.; Zheng, Z.; Chen, Z.; Ma, A.; Zhong, Y. Earthvqa: Towards queryable earth via relational reasoning-based remote sensing visual question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 5481–5489. [Google Scholar]












| Attr | CLS | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | METEOR | ROUGE-L | CIDEr |
|---|---|---|---|---|---|---|---|---|
| × | × | 64.58 | 51.07 | 41.90 | 34.90 | 30.84 | 58.02 | 194.7 |
| ✔ | × | 66.77 | 53.06 | 43.49 | 36.30 | 30.18 | 55.30 | 188.9 |
| ✔ | ✔ | 68.64 | 55.22 | 45.82 | 38.65 | 31.05 | 57.70 | 200.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Z.; Liu, H.; Ren, Z.; Jiao, L.; Gou, S.; Li, R. Attribute-Based Learning for Remote Sensing Image Captioning in Unseen Scenes. Remote Sens. 2025, 17, 1237. https://doi.org/10.3390/rs17071237
Guo Z, Liu H, Ren Z, Jiao L, Gou S, Li R. Attribute-Based Learning for Remote Sensing Image Captioning in Unseen Scenes. Remote Sensing. 2025; 17(7):1237. https://doi.org/10.3390/rs17071237
Chicago/Turabian StyleGuo, Zhang, Haomin Liu, Zihao Ren, Licheng Jiao, Shuiping Gou, and Ruimin Li. 2025. "Attribute-Based Learning for Remote Sensing Image Captioning in Unseen Scenes" Remote Sensing 17, no. 7: 1237. https://doi.org/10.3390/rs17071237
APA StyleGuo, Z., Liu, H., Ren, Z., Jiao, L., Gou, S., & Li, R. (2025). Attribute-Based Learning for Remote Sensing Image Captioning in Unseen Scenes. Remote Sensing, 17(7), 1237. https://doi.org/10.3390/rs17071237