Adaptive Dual-Domain Dynamic Interactive Network for Oriented Object Detection in Remote Sensing Images

Abstract
1. Introduction
- (1)
- We proposed a spatial adaptive selection module to extract features of different scales of the object so that the model could dynamically learn contextual information according to the object characteristics to match the receptive field size more suitable for the object itself, thereby constructing more accurate spatial position information;
- (2)
- In order to make up for the shortcomings of single domain information, we proposed a frequency adaptive selection module to extract direction information by converting spatial domain features into the frequency domain, effectively enhancing the network’s ability to model direction diversity;
- (3)
- In the dual-domain feature interaction module, we interactively fused the features extracted from the spatial domain and the frequency domain to bridge the complementary information and to achieve the purpose of generating enhanced features, effectively improving the expressiveness of object features;
- (4)
- The AD3I-Net we proposed fully exploited the interaction relationship between the different domains, improved the ability to capture object features, and gave them rich spatial position and direction information. The performance of this method on the HRSC2016 dataset and the DIOR-R dataset was better than many advanced methods and had a certain competitiveness. At the same time, this also confirmed the effectiveness of frequency domain learning in the task of oriented object detection in remote sensing images.
2. Related Works
2.1. Oriented Object Detection
2.2. Frequency Domain Learning in Image Processing
2.3. Feature Fusion Network
3. Methods
3.1. Overall Structure
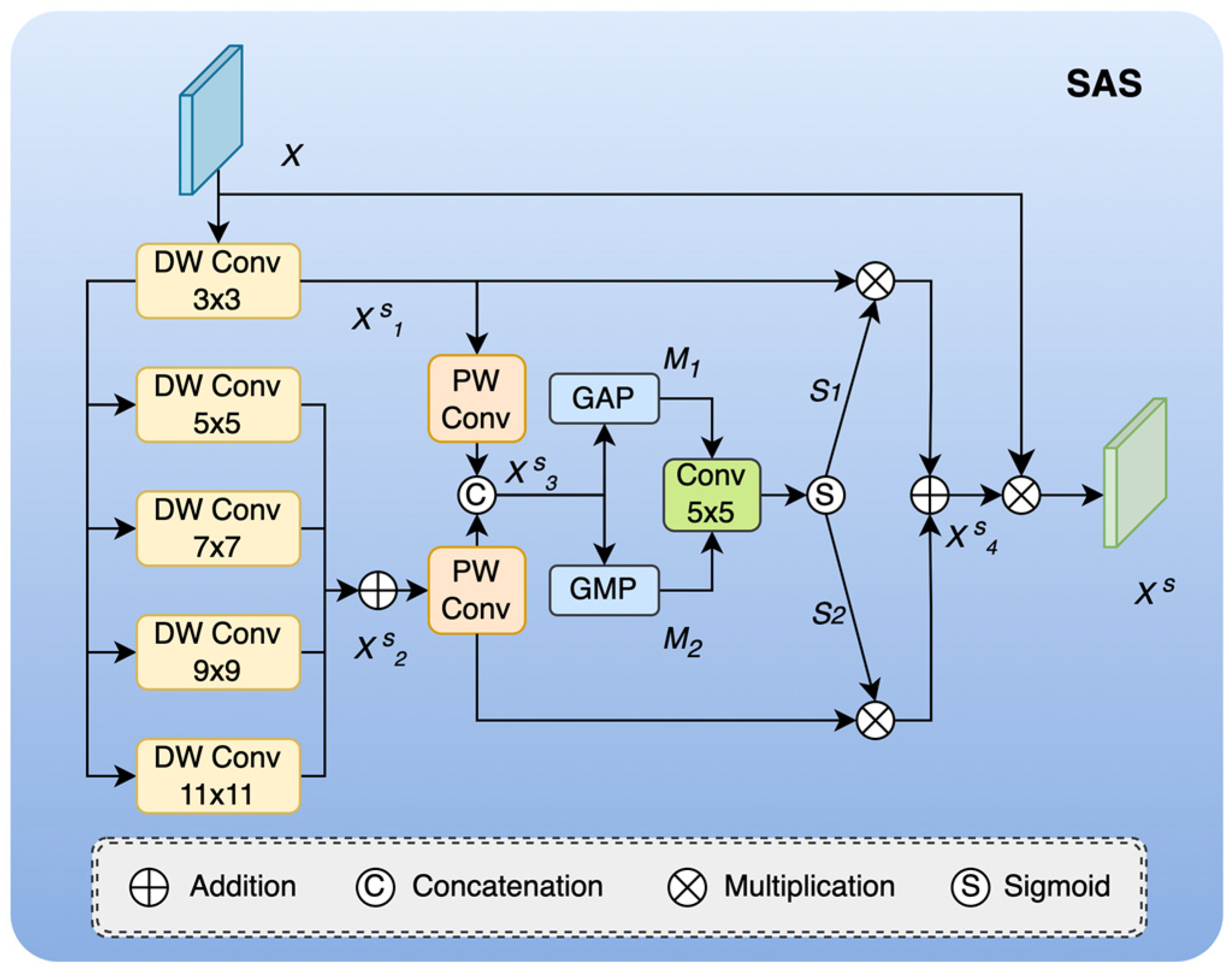
3.2. Spatial Adaptive Selection Module
3.3. Frequency Adaptive Selection Module
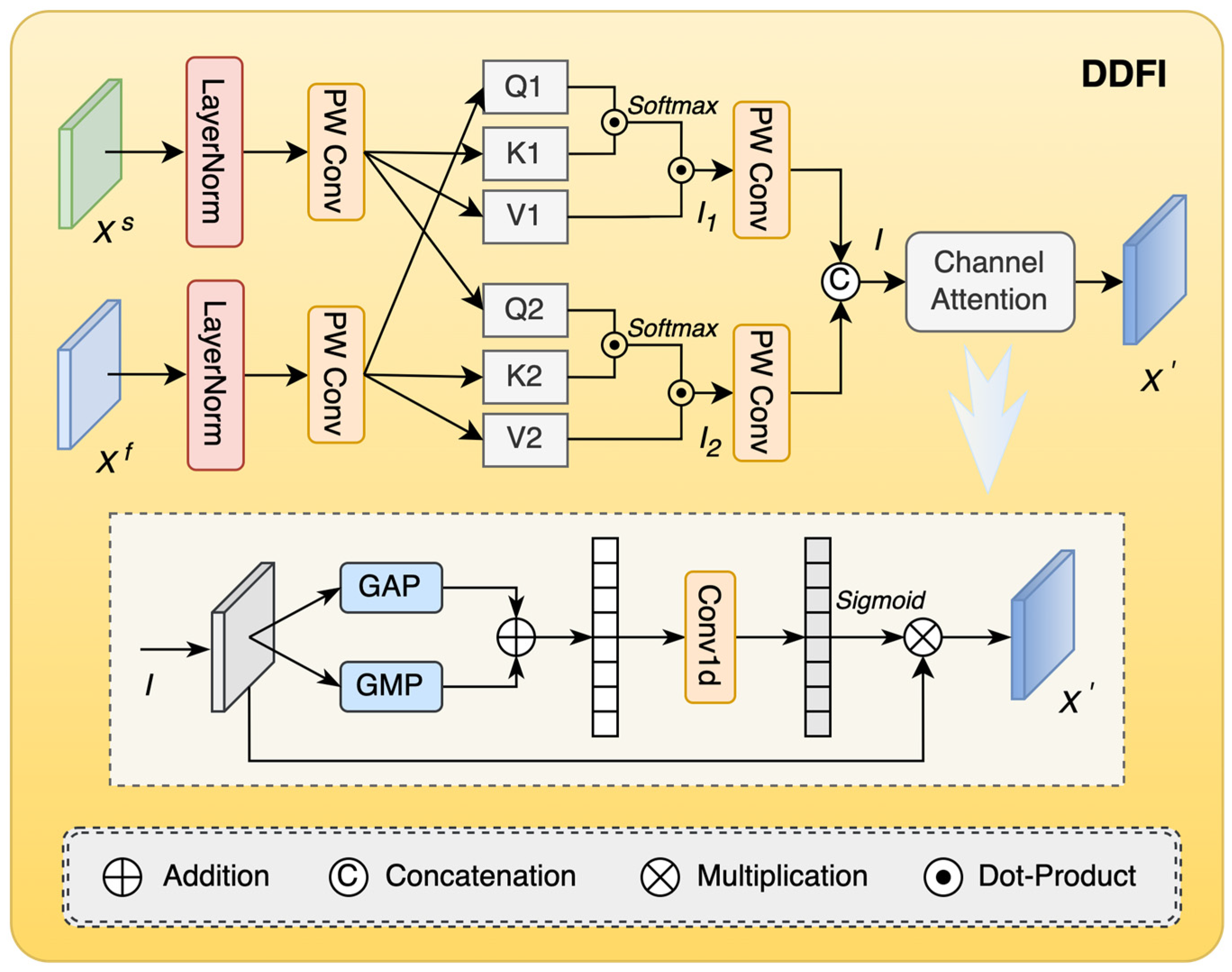
3.4. Dual-Domain Feature Interaction Module
3.5. Loss Function
4. Experimental Results and Discussions
4.1. Datasets
4.1.1. HRSC2016 Dataset
4.1.2. DIOR-R Dataset
4.2. Implementation Details
4.3. Ablation Study
4.4. Experimental Results and Discussion
4.4.1. Results on the HRSC2016 Dataset
4.4.2. Results on the DIOR-R Dataset
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AD3I-Net | Adaptive Dual-Domain Dynamic Interaction Network |
| SAS | Spatial Adaptive Selection |
| FAS | Frequency Adaptive Selection |
| DDFI | Dual-Domain Feature Interaction |
| RCNN | Region Convolutional Neural Network |
| RPN | Region Proposal Networks |
| mAP | Mean Average Precision |
| GAP | Global Average Pooling |
| GMP | Global Max Pooling |
References
- Cheng, G.; Si, Y.; Hong, H.; Yao, X.; Guo, L. Cross-Scale Feature Fusion for Object Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 431–435. [Google Scholar] [CrossRef]
- Chen, W.; Miao, S.; Wang, G.; Cheng, G. Recalibrating Features and Regression for Oriented Object Detection. Remote Sens. 2023, 15, 2134. [Google Scholar] [CrossRef]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.-M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 16748–16759. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Proceedings, Part VIII 16, Glasgow, UK, 23–28 August 2020; pp. 677–694. [Google Scholar]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking Rotated Object Detection with Gaussian Wasserstein Distance Loss. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021. [Google Scholar]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A context-aware detection network for objects in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Li, M.; Guo, W.; Zhang, Z.; Yu, W.; Zhang, T. Rotated region based fully convolutional network for ship detection. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 673–676. [Google Scholar]
- Yan, Z.; Song, X.; Zhong, H.; Zhu, X. Object detection in optical remote sensing images based on transfer learning convolutional neural networks. In Proceedings of the 2018 5th IEEE International Conference on Cloud Computing and Intelligence Systems (CCIS), Nanjing, China, 23–25 November 2018; pp. 935–942. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G.-S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2786–2795. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Dai, P.; Yao, S.; Li, Z.; Zhang, S.; Cao, X. ACE: Anchor-free corner evolution for real-time arbitrarily-oriented object detection. IEEE Trans. Image Process. 2022, 31, 4076–4089. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Wang, J.; Li, K.; Xie, X.; Lang, C.; Yao, Y.; Han, J. Anchor-free oriented proposal generator for object detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5625411. [Google Scholar] [CrossRef]
- Li, J.; Tian, Y.; Xu, Y.; Zhang, Z. Oriented object detection in remote sensing images with anchor-free oriented region proposal network. Remote Sens. 2022, 14, 1246. [Google Scholar] [CrossRef]
- Li, W.; Chen, Y.; Hu, K.; Zhu, J. Oriented reppoints for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1829–1838. [Google Scholar]
- Ma, T.; Mao, M.; Zheng, H.; Gao, P.; Wang, X.; Han, S.; Ding, E.; Zhang, B.; Doermann, D. Oriented object detection with transformer. arXiv 2021, arXiv:2106.03146. [Google Scholar]
- Dai, L.; Liu, H.; Tang, H.; Wu, Z.; Song, P. Ao2-detr: Arbitrary-oriented object detection transformer. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 2342–2356. [Google Scholar] [CrossRef]
- Zhou, Q.; Yu, C.; Wang, Z.; Wang, F. D2Q-DETR: Decoupling and Dynamic Queries for Oriented Object Detection with Transformers. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Wang, X.; Chen, H.; Chu, X.; Wang, P. AODet: Aerial Object Detection Using Transformers for Foreground Regions. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4106711. [Google Scholar] [CrossRef]
- Ehrlich, M.; Davis, L.S. Deep residual learning in the jpeg transform domain. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3484–3493. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Rao, Y.; Zhao, W.; Zhu, Z.; Lu, J.; Zhou, J. Global filter networks for image classification. Adv. Neural Inf. Process. Syst. 2021, 34, 980–993. [Google Scholar]
- Zhong, Y.; Li, B.; Tang, L.; Kuang, S.; Wu, S.; Ding, S. Detecting camouflaged object in frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4504–4513. [Google Scholar]
- Yang, Y.; Yuan, G.; Li, J. SFFNet: A Wavelet-Based Spatial and Frequency Domain Fusion Network for Remote Sensing Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 3000617. [Google Scholar] [CrossRef]
- Chen, L.; Gu, L.; Zheng, D.; Fu, Y. Frequency-Adaptive Dilated Convolution for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 3414–3425. [Google Scholar]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet Convolutions for Large Receptive Fields. In Proceedings of the 18th European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 363–380. [Google Scholar]
- Kong, L.; Dong, J.; Ge, J.; Li, M.; Pan, J. Efficient Frequency Domain-based Transformers for High-Quality Image Deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 5886–5895. [Google Scholar]
- Patro, B.N.; Namboodiri, V.P.; Agneeswaran, V.S. SpectFormer: Frequency and Attention is what you need in a Vision Transformer. arXiv 2023, arXiv:2304.06446. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Ngo, C.-W.; Mei, T. Wave-ViT: Unifying Wavelet and Transformers for Visual Representation Learning. In Proceedings of the 17th European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 328–345. [Google Scholar]
- Cao, Y.; Wu, Y.; Li, M.; Liang, W.; Hu, X. DFAF-Net: A Dual-Frequency PolSAR Image Classification Network Based on Frequency-Aware Attention and Adaptive Feature Fusion. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5224318. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Tian, J.; Chanussot, J.; Li, W.; Tao, R. ORSIm Detector: A Novel Object Detection Framework in Optical Remote Sensing Imagery Using Spatial-Frequency Channel Features. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5146–5158. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Shang, R. RADet: Refine Feature Pyramid Network and Multi-Layer Attention Network for Arbitrary-Oriented Object Detection of Remote Sensing Images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef]
- Zhen, P.; Wang, S.; Zhang, S.; Yan, X.; Wang, W.; Ji, Z.; Chen, H.-B. Towards Accurate Oriented Object Detection in Aerial Images with Adaptive Multi-level Feature Fusion. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 6. [Google Scholar] [CrossRef]
- Sun, P.; Zheng, Y.; Zhou, Z.; Xu, W.; Ren, Q. R4 Det: Refined single-stage detector with feature recursion and refinement for rotating object detection in aerial images. Image Vis. Comput. 2020, 103, 104036. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship Rotated Bounding Box Space for Ship Extraction From High-Resolution Optical Satellite Images With Complex Backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic Refinement Network for Oriented and Densely Packed Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, 14–19 June 2020; pp. 11204–11213. [Google Scholar]
- Wang, J.; Yang, W.; Li, H.-C.; Zhang, H.; Xia, G.-S. Learning Center Probability Map for Detecting Objects in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4307–4323. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q.; Soc, I.C. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2844–2853. [Google Scholar]
- Guo, Z.; Liu, C.; Zhang, X.; Jiao, J.; Ji, X.; Ye, Q.; Ieee Comp, S.O.C. Beyond Bounding-Box: Convex-hull Feature Adaptation for Oriented and Densely Packed Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 8788–8797. [Google Scholar]
- Hou, L.; Lu, K.; Xue, J.; Li, Y.; Assoc Advancement Artificial, I. Shape-Adaptive Selection and Measurement for Oriented Object Detection. In Proceedings of the 36th AAAI Conference on Artificial Intelligence/34th Conference on Innovative Applications of Artificial Intelligence/12th Symposium on Educational Advances in Artificial Intelligence, Virtual, 22 February–1 March 2022; pp. 923–932. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.-S.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-Oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.-Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Chen, Z.; Chen, K.; Lin, W.; See, J.; Yu, H.; Ke, Y.; Yang, C. Piou loss: Towards accurate oriented object detection in complex environments. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Proceedings, Part V 16, Glasgow, UK, 23–28 August 2020; pp. 195–211. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T.; Assoc Advancement Artificial, I. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. In Proceedings of the 35th AAAI Conference on Artificial Intelligence/33rd Conference on Innovative Applications of Artificial Intelligence/11th Symposium on Educational Advances in Artificial Intelligence, Virtual, 2–9 February 2021; pp. 3163–3171. [Google Scholar]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L.; Assoc Advancement Artificial, I. Dynamic Anchor Learning for Arbitrary-Oriented Object Detection. In Proceedings of the 35th AAAI Conference on Artificial Intelligence/33rd Conference on Innovative Applications of Artificial Intelligence/11th Symposium on Educational Advances in Artificial Intelligence, Virtual, 2–9 February 2021; pp. 2355–2363. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.-S. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5602511. [Google Scholar] [CrossRef]
- Cheng, G.; Yao, Y.; Li, S.; Li, K.; Xie, X.; Wang, J.; Yao, X.; Han, J. Dual-Aligned Oriented Detector. Ieee Trans. Geosci. Remote Sens. 2022, 60, 5618111. [Google Scholar] [CrossRef]
- Yao, Y.; Cheng, G.; Wang, G.; Li, S.; Zhou, P.; Xie, X.; Han, J. On Improving Bounding Box Representations for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5600111. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Z.; Xu, W.; Chen, L.; Wang, G.; Yan, L.; Zhong, S.; Zou, X. Learning Oriented Object Detection via Naive Geometric Computing. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 10513–10525. [Google Scholar] [CrossRef]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 9756–9765. [Google Scholar]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning High-Precision Bounding Box for Rotated Object Detection via Kullback-Leibler Divergence. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–14 December 2021. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | SAS | FAS | DDFI | mAP50 | Params(M) | FLOPs(G) |
|---|---|---|---|---|---|---|
| Baseline | - | - | - | 63.42 | 31.95 | 126.71 |
| AD3I-Net | ✓ | - | - | 64.20 | 32.81 | 129.35 |
| - | ✓ | - | 64.57 | 32.34 | 128.08 | |
| ✓ | ✓ | ✓ | 65.65 | 33.42 | 134.26 |
| Method | Pretrained | Backbone | mAP(07) | mAP(12) |
|---|---|---|---|---|
| RetinaNet-O [35] | IN | Res50 | 73.42 | 77.83 |
| RRPN [36] | IN | Res101 | 79.08 | 85.64 |
| DRN [37] | IN | Houglass34 | - | 92.70 |
| CenterMap [38] | IN | Res50 | - | 92.80 |
| RoI Trans. [39] | IN | Res101 | 86.20 | - |
| CFA [40] | IN | Res50 | 87.10 | 91.60 |
| SASM [41] | IN | Res50 | 87.90 | 91.80 |
| AO2-DETR [16] | IN | Res50 | 88.12 | 97.47 |
| Gliding Vertex [42] | IN | Res101 | 88.20 | - |
| R-DINO [43] | IN | Res50 | 88.80 | 95.24 |
| PIoU [44] | IN | DLA34 | 89.20 | - |
| R3Det [45] | IN | Res101 | 89.26 | 96.01 |
| DAL [46] | IN | Res101 | 89.77 | - |
| GWD [5] | IN | Res50 | 89.85 | 97.37 |
| S2Anet [47] | IN | Res101 | 90.17 | 95.01 |
| DODet [48] | IN | Res50 | 90.18 | 95.84 |
| AOPG [12] | IN | Res50 | 90.34 | 96.22 |
| Oriented R-CNN [10] | IN | Res101 | 90.40 | 96.50 |
| ReDet [9] | IN | ReRes50 | 90.46 | 97.63 |
| QPDet [49] | IN | Res101 | 90.52 | 96.64 |
| CGCDet [50] | IN | Res50 | 90.57 | 97.86 |
| RTMDet-R [51] | CO | CSPNeXt | 90.60 | 97.10 |
| AD3I-Net (ours) | IN | Res50 | 90.70 | 97.85 |
| Method | APL | APO | BC | BF | BR | CH | DAM | ESA | ETS | GF | GTF | HA | OP | SH | STA | STO | TC | TS | VE | WM | mAP50 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RetinaNet-O [35] | 59.54 | 25.03 | 81.01 | 70.08 | 28.26 | 72.02 | 21.26 | 55.35 | 56.77 | 65.70 | 70.28 | 30.52 | 44.37 | 77.02 | 59.01 | 59.39 | 81.18 | 38.43 | 39.10 | 61.58 | 54.83 |
| SASM [41] | 61.41 | 46.03 | 82.04 | 73.22 | 29.41 | 71.03 | 30.63 | 69.22 | 53.91 | 70.04 | 77.02 | 39.33 | 47.51 | 78.62 | 66.14 | 62.92 | 79.93 | 54.41 | 40.62 | 63.01 | 59.81 |
| GWD [5] | 69.68 | 28.83 | 81.49 | 74.32 | 29.62 | 72.67 | 27.13 | 76.45 | 63.14 | 77.19 | 78.94 | 39.11 | 42.18 | 79.10 | 70.41 | 58.69 | 81.52 | 47.78 | 44.47 | 62.63 | 60.31 |
| R3Det [45] | 62.55 | 43.44 | 81.48 | 71.72 | 36.49 | 72.63 | 27.02 | 79.5 | 64.41 | 77.36 | 77.17 | 40.53 | 53.33 | 79.66 | 69.22 | 61.10 | 81.54 | 52.18 | 43.57 | 64.13 | 61.91 |
| Gliding Vertex [42] | 62.67 | 38.56 | 81.20 | 71.94 | 37.73 | 72.48 | 22.81 | 78.62 | 69.04 | 77.89 | 82.13 | 46.22 | 54.76 | 81.03 | 74.88 | 62.54 | 81.41 | 54.25 | 43.22 | 65.13 | 62.91 |
| R-DINO [43] | 44.50 | 52.70 | 80.60 | 71.00 | 44.40 | 73.00 | 29.20 | 72.50 | 83.10 | 72.40 | 76.50 | 43.50 | 55.30 | 80.70 | 61.80 | 69.60 | 81.20 | 58.00 | 51.70 | 61.20 | 63.10 |
| Rotated FCOS [52] | 62.31 | 42.18 | 81.32 | 75.34 | 39.26 | 74.89 | 26.00 | 77.42 | 68.67 | 73.94 | 78.73 | 41.28 | 54.19 | 80.61 | 66.92 | 69.17 | 87.20 | 52.31 | 47.08 | 65.21 | 63.21 |
| Rotated ATSS [53] | 62.19 | 44.63 | 81.42 | 71.55 | 41.08 | 72.37 | 30.56 | 78.54 | 67.50 | 75.69 | 79.11 | 42.77 | 56.31 | 80.92 | 67.78 | 69.24 | 81.62 | 55.45 | 47.79 | 64.10 | 63.52 |
| ReDet [9] | 63.22 | 44.18 | 81.26 | 72.11 | 43.83 | 72.72 | 28.45 | 79.10 | 69.78 | 78.69 | 77.18 | 48.24 | 56.81 | 81.17 | 69.17 | 62.73 | 81.42 | 54.90 | 44.04 | 66.37 | 63.81 |
| RoI Trans. [39] | 63.18 | 44.33 | 81.26 | 71.91 | 42.19 | 72.64 | 29.42 | 79.30 | 69.67 | 77.33 | 82.88 | 48.09 | 57.03 | 81.18 | 77.32 | 62.45 | 81.38 | 54.34 | 43.91 | 66.30 | 64.31 |
| QPDet [49] | 63.22 | 41.39 | 88.55 | 71.97 | 41.23 | 72.63 | 69.00 | 28.82 | 78.90 | 70.07 | 83.01 | 47.83 | 55.54 | 81.23 | 72.15 | 62.66 | 89.05 | 58.09 | 43.38 | 65.36 | 64.20 |
| S2ANet [47] | 67.98 | 44.44 | 81.39 | 71.63 | 42.66 | 72.72 | 27.08 | 79.03 | 70.40 | 75.56 | 81.02 | 43.41 | 56.45 | 81.12 | 68.00 | 70.03 | 87.07 | 53.88 | 51.12 | 65.31 | 64.50 |
| Oriented RCNN [10] | 63.31 | 43.10 | 81.17 | 71.89 | 44.78 | 72.64 | 33.78 | 80.12 | 69.67 | 77.92 | 83.11 | 46.29 | 58.31 | 81.17 | 74.54 | 62.32 | 81.29 | 56.30 | 43.78 | 65.26 | 64.53 |
| KLD [54] | 66.52 | 46.80 | 81.43 | 71.76 | 40.81 | 78.25 | 29.01 | 79.23 | 66.63 | 78.68 | 80.19 | 44.88 | 57.23 | 80.91 | 74.17 | 68.02 | 81.48 | 54.63 | 47.80 | 64.41 | 64.63 |
| RepPoints [14] | 63.48 | 51.20 | 86.55 | 69.68 | 42.92 | 75.09 | 31.82 | 74.11 | 68.46 | 77.52 | 76.54 | 41.76 | 56.67 | 87.62 | 64.42 | 71.79 | 81.61 | 55.83 | 52.79 | 66.18 | 64.80 |
| CGCDet [50] | 68.46 | 38.34 | 86.21 | 79.12 | 38.97 | 73.52 | 26.84 | 74.72 | 66.00 | 67.49 | 84.45 | 48.02 | 56.05 | 81.25 | 79.32 | 72.17 | 88.56 | 50.69 | 51.72 | 65.84 | 64.88 |
| AD3I-Net (ours) | 63.20 | 42.50 | 89.46 | 80.40 | 42.59 | 72.58 | 30.31 | 79.97 | 68.12 | 77.83 | 82.66 | 46.58 | 56.95 | 80.65 | 73.45 | 70.84 | 81.58 | 63.79 | 43.84 | 65.61 | 65.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Yang, T.; Wang, S.; Su, H.; Sun, H. Adaptive Dual-Domain Dynamic Interactive Network for Oriented Object Detection in Remote Sensing Images. Remote Sens. 2025, 17, 950. https://doi.org/10.3390/rs17060950
Zhao Y, Yang T, Wang S, Su H, Sun H. Adaptive Dual-Domain Dynamic Interactive Network for Oriented Object Detection in Remote Sensing Images. Remote Sensing. 2025; 17(6):950. https://doi.org/10.3390/rs17060950
Chicago/Turabian StyleZhao, Yongxian, Tao Yang, Shuai Wang, Hailin Su, and Haijiang Sun. 2025. "Adaptive Dual-Domain Dynamic Interactive Network for Oriented Object Detection in Remote Sensing Images" Remote Sensing 17, no. 6: 950. https://doi.org/10.3390/rs17060950
APA StyleZhao, Y., Yang, T., Wang, S., Su, H., & Sun, H. (2025). Adaptive Dual-Domain Dynamic Interactive Network for Oriented Object Detection in Remote Sensing Images. Remote Sensing, 17(6), 950. https://doi.org/10.3390/rs17060950