1. Introduction
Place recognition (PR) is a fundamental problem in robotics and computer vision, aiming to determine whether a robot or autonomous vehicle has revisited a known location by comparing current sensor data with a pre-existing database or map. This capability is essential for autonomous navigation tasks such as localization error correction, loop closure detection, and re-localization.
Among various PR approaches, visual-based and LiDAR-based methods are the most prominent [
1]. Visual-based Place Recognition (VPR) leverages rich texture and color information but is highly sensitive to illumination changes, seasonal variations, and occlusions, which limits its reliability in large-scale outdoor environments, especially for autonomous vehicles or robots in outdoor navigation [
2,
3]. In contrast, LiDAR-based Place Recognition (LPR) benefits from precise geometric structure information, long-range perception, and accurate depth measurement, making it more robust to environmental changes and a preferred choice for mobile robot navigation in outdoor environments [
4].
Deep learning has significantly advanced LPR by enabling robust feature extraction from 3D point clouds [
5]. However, directly processing raw 3D point clouds is computationally expensive due to their unordered, sparse, and large-scale nature, limiting both efficiency and generalization across different LiDAR sensors and environments [
6]. To improve computational efficiency, 2D projection-based methods have been widely adopted, including spherical and bird’s-eye view (BEV) projections. Spherical projection mitigates sparsity issues by converting 3D point clouds into range images, achieving promising results across various scenes [
7,
8]. However, it introduces scale and motion distortions, compromising geometric consistency [
9]. In contrast, BEV projection preserves geometric structures, maintains stable scale and edge information, and has demonstrated superior generalization in LPR tasks [
10]. These advantages make BEV-based approaches a more effective and scalable solution for robust place recognition.
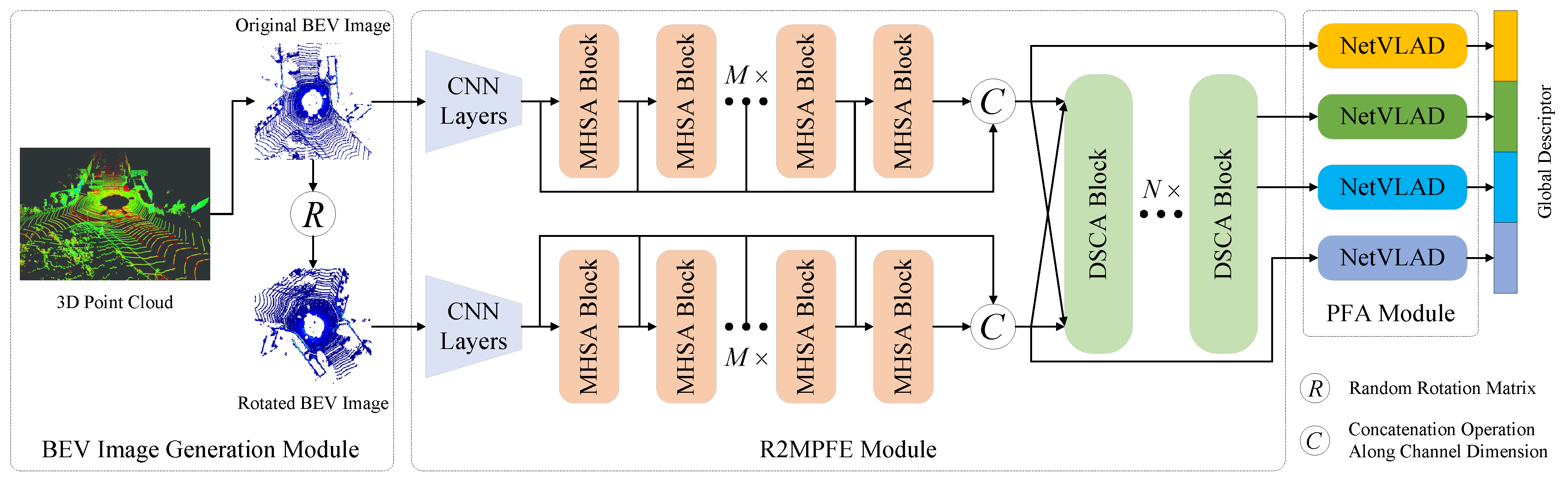
Despite their advantages, existing BEV-based LPR methods primarily rely on CNNs for local feature extraction, which are inherently constrained by limited receptive fields, hindering their ability to capture global contextual information. Moreover, viewpoint variation remains a significant challenge as mobile robots may observe the same location from different perspectives [
11]. BEVPlace++ [
10], the current state-of-the-art BEV-based LPR model, enhances viewpoint robustness by designing a Rotation Equivariant Module (REM) and cascading it with NetVLAD [
12] to generate rotation-invariant global feature descriptors. However, REM requires multiple fixed-angle rotations of the input BEV image, followed by the extraction of local features from each rotated sample using ResNet [
13]. The
N rotated feature maps are then reversed to their original orientation, and the final feature map is obtained by max-pooling these
N feature maps. This design increases the computational cost of the model and does not fully exploit the deep relationships between the local feature tensors of the
N samples.
To address the aforementioned issues, this study proposes a local feature extraction method that leverages the MHSA [
14] to extract patch features containing multi-level global spatial contextual information from BEV images of 3D point clouds, thereby overcoming the limitations of existing methods in capturing global contextual information. Furthermore, we observe that in various computer vision tasks, such as audio classification [
15] and object detection [
16], researchers frequently employ cross-attention to fuse features from different perspectives or cross modalities to enhance the classification or detection accuracy of models. Similarly, Joo et al. [
17] utilized cross-attention to integrate spatial and intensity information from LiDAR to improve LPR performance. Inspired by these approaches, and aiming to enhance the robustness of the LPR model to viewpoint variations while avoiding increased computational burden, we applied a random rotation operation to the original BEV image and then separately encoded local features from both the original BEV image and its randomly rotated version. Subsequently, we correlated these two sets of local features using self-attention and MHCA [
18], establishing deep relationships between high-dimensional patch features of the original BEV image and its rotated counterpart to extract rotation-robust local features. Finally, a combined NetVLAD layer was used to aggregate patch features from the original feature space and local features from the rotation interaction space into lightweight, compact, and viewpoint-robust global place feature descriptors.
The main contributions of this work are summarized as follows:
We propose the R2SCAT-LPR model, which integrates Transformers based on self-attention and cross-attention mechanisms to extract global feature descriptors containing multi-level global contextual information that are robust to rotation variations from 2D BEV images of 3D point clouds for LPR tasks.
We designed the R2MPFE module, which leverages cascaded MHSA blocks to extract patch features from BEV images, enhancing the model’s ability to capture global contextual information. By combining the outputs of each MHSA block, we constructed multi-level patch features that encompass both low-level fine-grained details and high-level semantic information.
We designed the DSCA module, which adopts a dual-branch structure composed of self-attention and MHCA. This module establishes intrinsic relationships between multi-level patch features corresponding to the original BEV image and its randomly rotated version, capturing local features robust to rotation changes.
Extensive experiments on three datasets validate the proposed model’s robustness to viewpoint variations, generalization capability, and practical deployability. The source code and pre-trained models will be released at
https://github.com/shenhai911/r2scat-lpr.git, accessed on 9 March 2025.
5. Discussion
This section provides an in-depth analysis and discussion of the experimental results.
5.1. Discussion of Place Recognition Performance
The quantitative results demonstrate that our R2SCAT-LPR model performs exceptionally well across multiple sequences of the KITTI dataset, significantly outperforming state-of-the-art handcrafted and learning-based methods in terms of maximum scores on individual sequences as well as their averages. This confirms the superiority of our proposed model.
From the qualitative results, the comparison of PR curves and Top-1 retrieval results reveals that different methods performed significantly better on sequence 00 than on sequences 02 and 08. Sequence 08 primarily consisted of reverse loop closures, which were more challenging than those in sequence 00. Sequence 02, in addition to reverse loop closures, contained multiple geometrically similar repetitive scenes, further increasing the difficulty for the model’s feature representation capabilities. Our model outperformed the comparison methods on both metrics, as shown in
Table 3, which visually demonstrates the superiority of our model’s performance. This was especially evident in its ability to reduce false negatives in complex scenes and improve place recognition accuracy.
5.2. Discussion of Viewpoint Variation Robustness
The quantitative results from the comparison experiments on randomly rotated sequences from the KITTI dataset highlight the importance of rotation-robust/invariant design in ensuring LPR model performance. Although our model experienced slightly greater degradation in average performance compared to BEVPlace and BEVPlace++, its maximum scores for individual sequences, along with their averages, still surpassed all comparison methods, including BEVPlace and BEVPlace++, further confirming the effectiveness of our model’s rotation-robust design.
Qualitative results from the PR curve comparisons in
Figure 5d–f reinforce our model’s superiority over the current best learning-based methods. The smaller differences between the features extracted by BEVPlace and BEVPlace++ from rotated BEV images, compared to those from the original BEV images rotated by the same angle (see
Figure 7f with
Figure 7i and
Figure 7g with
Figure 7j), were attributed to the rotation-invariant designs of BEVPlace and BEVPlace++. BEVPlace uses group convolutions combined with scale changes and rotation augmentation strategies, while BEVPlace++ covers rotation angles from
to
. In contrast, R2SCAT-LPR employs only a single random rotation augmentation, which enhances the model’s robustness to rotation variations and improves computational efficiency but limits its ability to achieve full rotation invariance, as reflected in the Cmp value differences in
Table 4.
Additionally, the feature map comparisons show that R2SCAT-LPR places more emphasis on semantically rich regions of the scene (e.g., road edges, vehicles), thereby minimizing interference from background information. Combined with the quantitative metrics in
Table 3 and
Table 4, these results indicate that factors affecting overall model performance include not only rotation invariance but also the ability to capture global contextual information in a scene. R2SCAT-LPR compensates for the limitations of rotation-invariant design through a specially designed contextual information capture mechanism, leading to superior overall performance compared to other methods.
5.3. Discussion of Generalization Ability
We evaluated the generalization capability of the proposed model on the NCLT and OffRoad-LPR datasets. As shown in
Table 2, the three datasets exhibited significant differences in both scene types and LiDAR types, leading to notable variations in point cloud distribution, which posed substantial challenges to the model’s generalization performance. Additionally, the NCLT dataset contained more loop closures, while the OffRoad-LPR scenes were larger in scale and featured terrain significantly different from the structured urban or campus traffic environments. The quantitative metrics in
Table 5 and the qualitative results in
Figure 8 indicate that R2SCAT-LPR demonstrates superior adaptability to different types of scenes and LiDAR sensors compared to other methods. However, in contrast to the near-saturated performance achieved on the KITTI dataset, there is still considerable room for improvement in R2SCAT-LPR’s performance on the NCLT and OffRoad-LPR datasets.
5.4. Discussion of Ablation Studies
The ablation experiments on the KITTI dataset show that the rotation augmentation module (RA and DSCA) is crucial for enhancing model performance. Removing these modules significantly degrades performance, particularly in complex scenes (e.g., sequences “02” and “08”). Furthermore, the number of MHSA and DSCA modules, the number of MHCA heads, and the number of NetVLAD layers all significantly impact model performance. These results indicate that a balanced configuration of modules and parameters can optimize model size, computational efficiency, and performance, ensuring the model’s practicality and reliability in real-world applications.
5.5. Discussion of Model’s Efficiency
We evaluated the runtime efficiency of the model on the OffRoad-LPR dataset. As described in
Section 4.1.2, we deployed the model on a vehicle-mounted computer equipped with an Intel i7-11800H CPU and an NVIDIA RTX 3070 GPU with 8GB of VRAM. The model’s parameter scale, Floating Point Operations Per Second (FLOPs), feature encoding time for a single BEV image, and place recognition searching time are presented in
Table 11. The data in the table indicate that OT achieved the highest efficiency, benefitting from its backbone network combining fully convolutional and Transformer architectures. In contrast, although BEVPlace had the smallest parameter scale, it required up to 25 data augmentation operations internally, resulting in the lowest computational efficiency. Compared to BEVPlace++, our model, despite having a larger parameter scale, significantly reduced data augmentation and feature extraction time by employing weight sharing and using only a single random rotation enhancement in the design for rotational robustness. As a result, the FLOPs of our model were lower than those of BEVPlace++, and the total processing time for a single BEV image was approximately 12.28 ms, meeting the real-time requirements of UGV platforms or robots. This demonstrates the strong deployment potential of our model.
6. Conclusions
In this work, we proposed a novel viewpoint-robust LPR model, R2SCAT-LPR, which incorporates self-attention and cross-attention mechanisms as its core components. In the local feature extraction stage, we designed the R2MPFE module, which utilizes cascaded MHSA blocks to extract patch features containing multi-level global contextual information from 2D BEV images of 3D point clouds. To enhance rotation robustness, we extracted additional multi-level patch features from the randomly rotated counterpart of the original BEV image using the weight-shared R2MPFE module. In the feature interaction phase, we constructed a dual-branch DSCA module based on self-attention and MHCA blocks to establish intrinsic relationships between multi-level patch features corresponding to the original BEV image and its randomly rotated version, capturing rotation-robust local features. In the feature aggregation phase, we employed four parallel NetVLAD blocks to aggregate multi-level patch features from the original feature space and local features from the rotation interaction space, concatenating the resulting descriptors into a compact global feature descriptor for place recognition. Experiments on the KITTI, NCLT, and OffRoad-LPR datasets validated the effectiveness of the model’s component designs and demonstrate its superiority over state-of-the-art methods in terms of place recognition accuracy and generalization performance.
However, our experiments revealed several limitations of our model and potential directions for future improvement: (1) Rotation Robustness Design: Experimental results on the KITTI dataset show that the model’s performance on sequence “00” nearly reached saturation, while there was still room for improvement on sequences “02” and “08”. This indicates that the current rotation-robust design has limitations compared to a more rigorous rotation-invariant design. Future work should focus on in-depth research into the design of rotation-invariant network architectures. (2) Model Generalization Ability: Although our model achieved significant performance improvements on multiple sequences of the KITTI dataset, its performance on the NCLT and OffRoad-LPR datasets still has considerable room for improvement. This suggests that the model’s generalization ability across different types of scenes and sensor configurations needs to be further enhanced, which will be an important direction for future research. (3) Model Efficiency: Although our model has a certain advantage in processing time compared to baseline methods, there is still room for optimization in terms of parameter size and FLOPs. Additionally, the brute-force search strategy adopted in the place recognition searching stage may have led to increased retrieval time as the scene scale grew. Therefore, exploring more lightweight model architectures and adopting more efficient retrieval strategies will be critical for future improvements.




 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}