
GLFFNet: Global–Local Feature Fusion Network for High-Resolution Remote Sensing Image Semantic Segmentation

Abstract
1. Introduction
- A dual-branch network named GLFFNet is proposed for the semantic segmentation of HR2S images, which reduces the loss of detailed information during global feature extraction by the MSFR module and enhances the fusion efficiency of global and local features through the SBF module.
- An MSFR module is proposed to enhance and integrate adjacent global features. The MSFR module supplements the upper-layer features with details from the lower layer, reducing the loss of detailed information during global feature extraction.
- An SBF module is introduced to facilitate efficient fusion of global and local features which performs adaptive fusion after narrowing the semantic differences between global and local features, resulting in more refined and comprehensive features.
2. Related Work
Mamba in Semantic Segmentation Tasks
3. Proposed Method
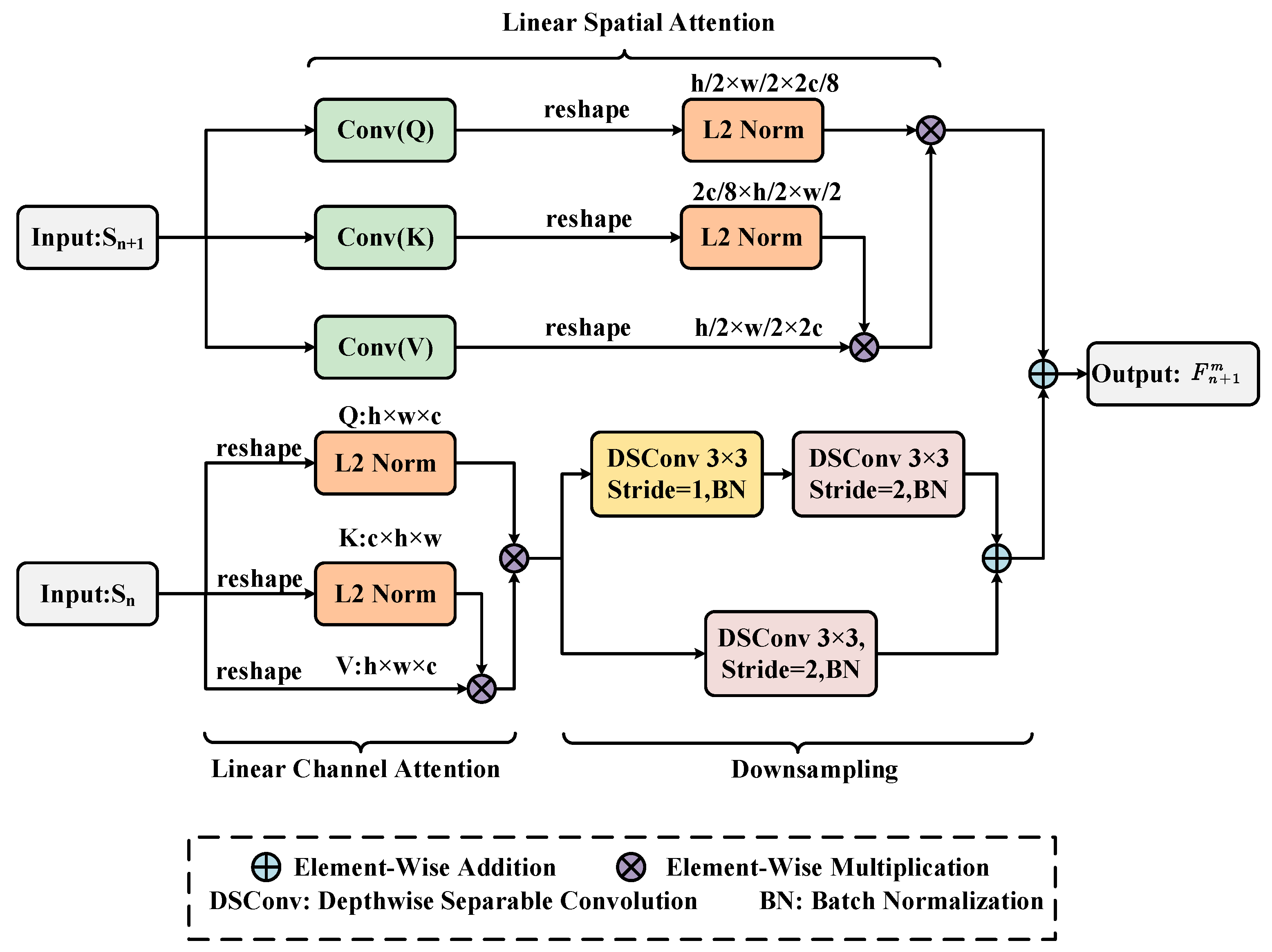
3.1. Global Feature Extraction and Enhancement
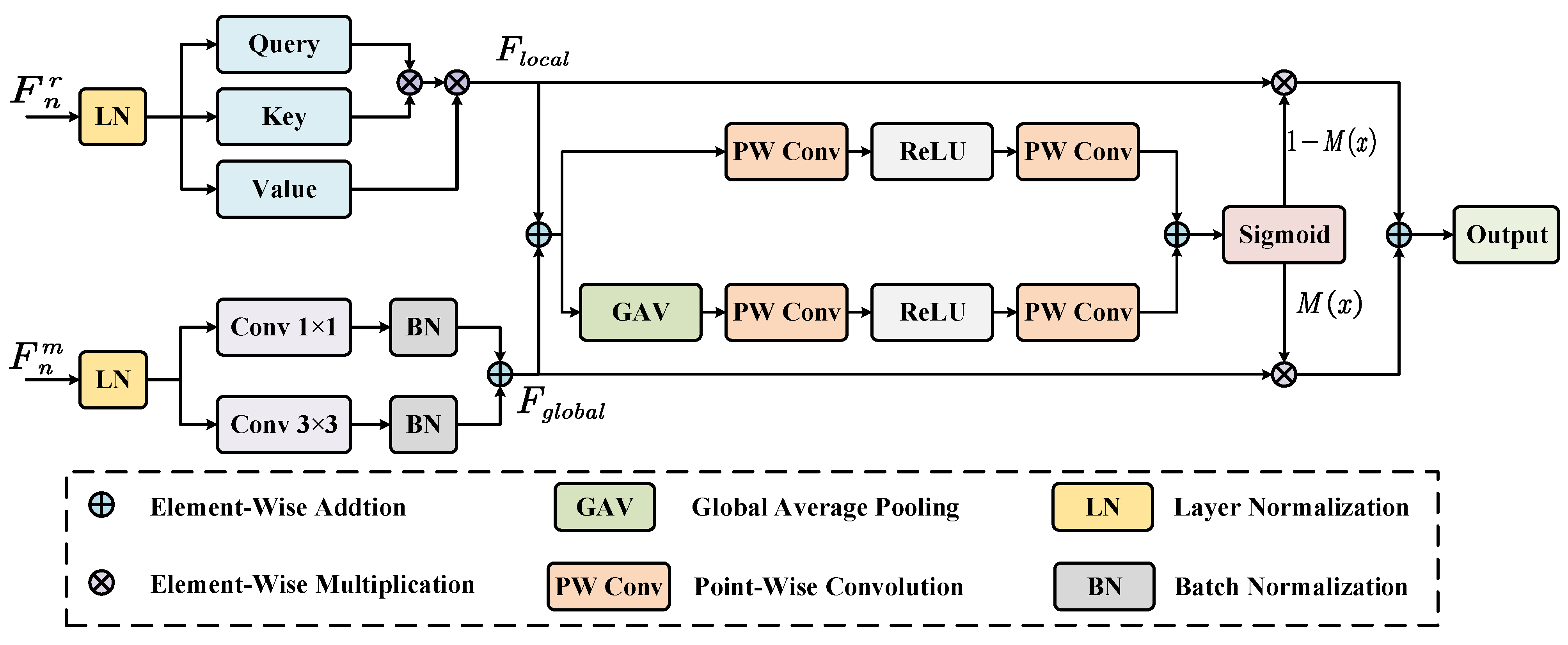
3.2. Global–Local Feature Fusion
4. Experiments
4.1. Dataset
4.2. Experimental Setting
4.3. Evaluation Metrics
4.4. Comparison Experiment
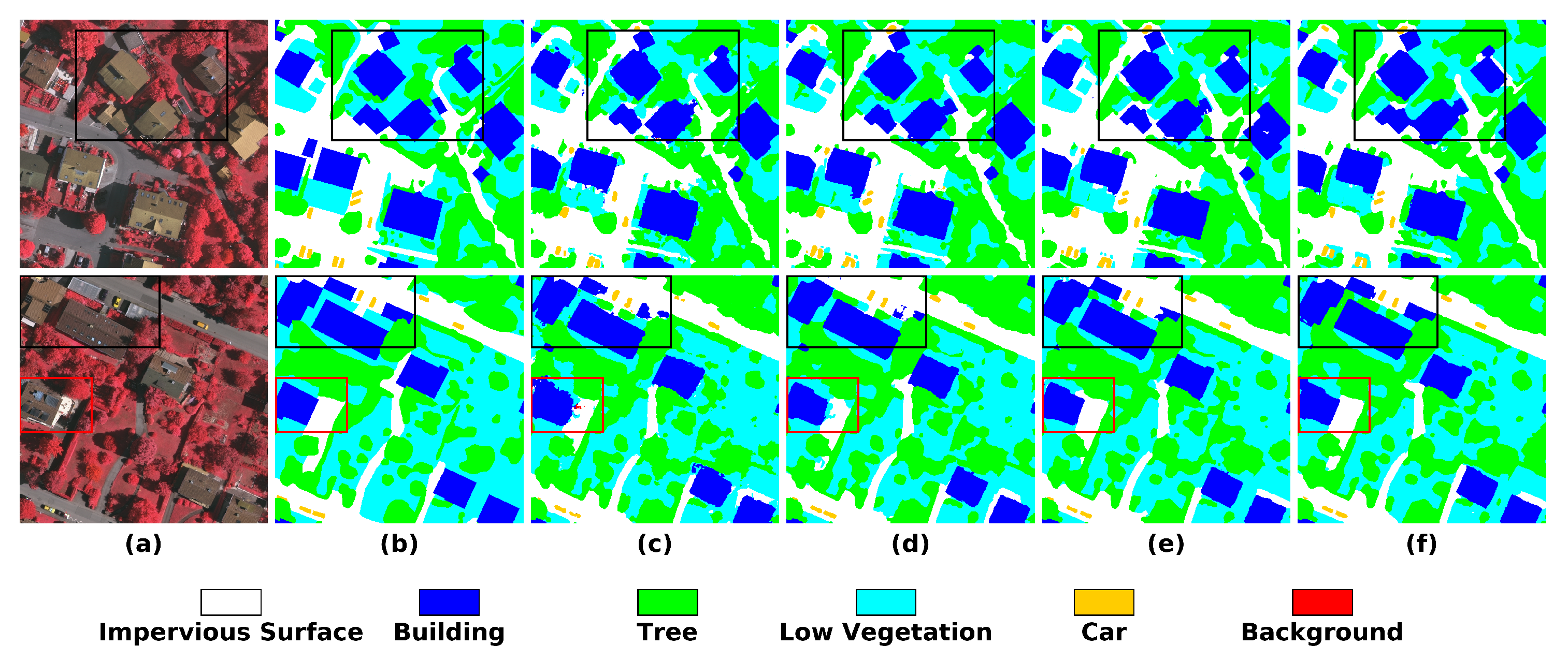
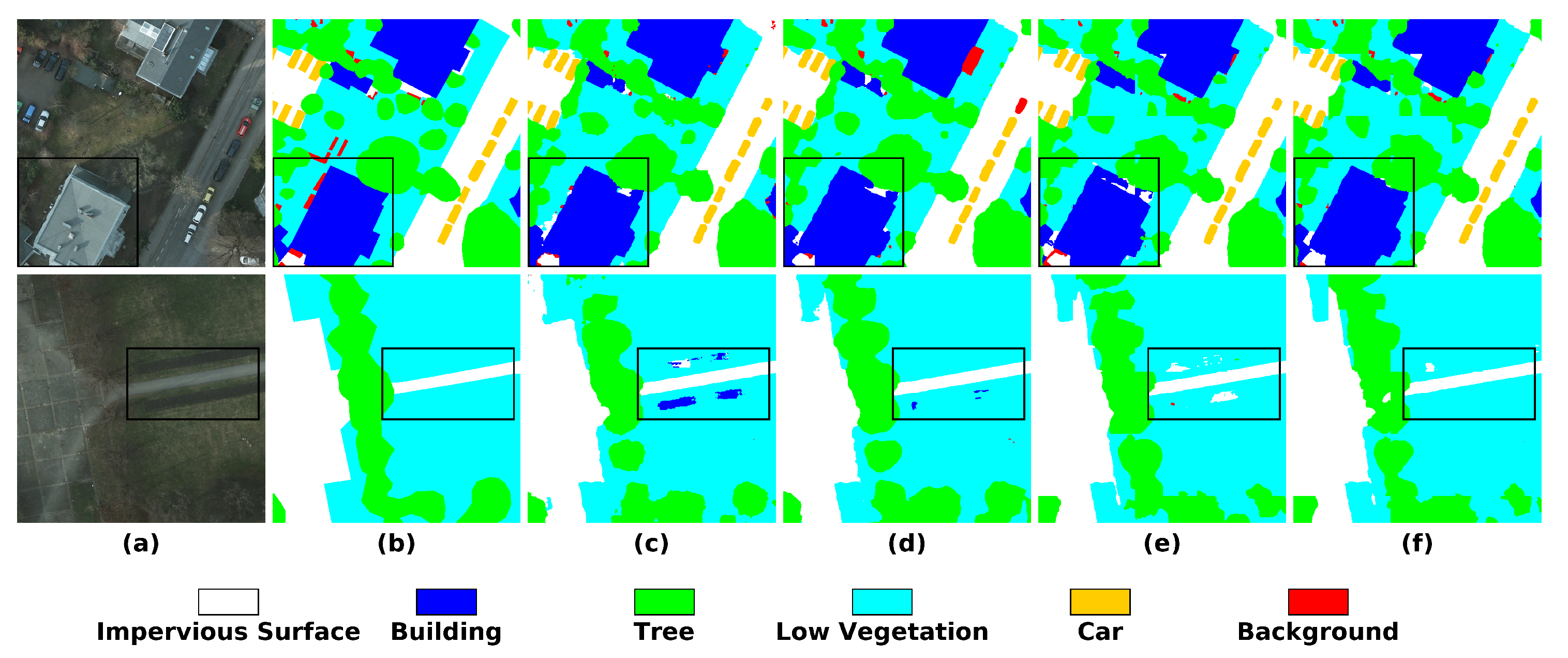
4.4.1. Results on Vaihingen
4.4.2. Results on Potsdam
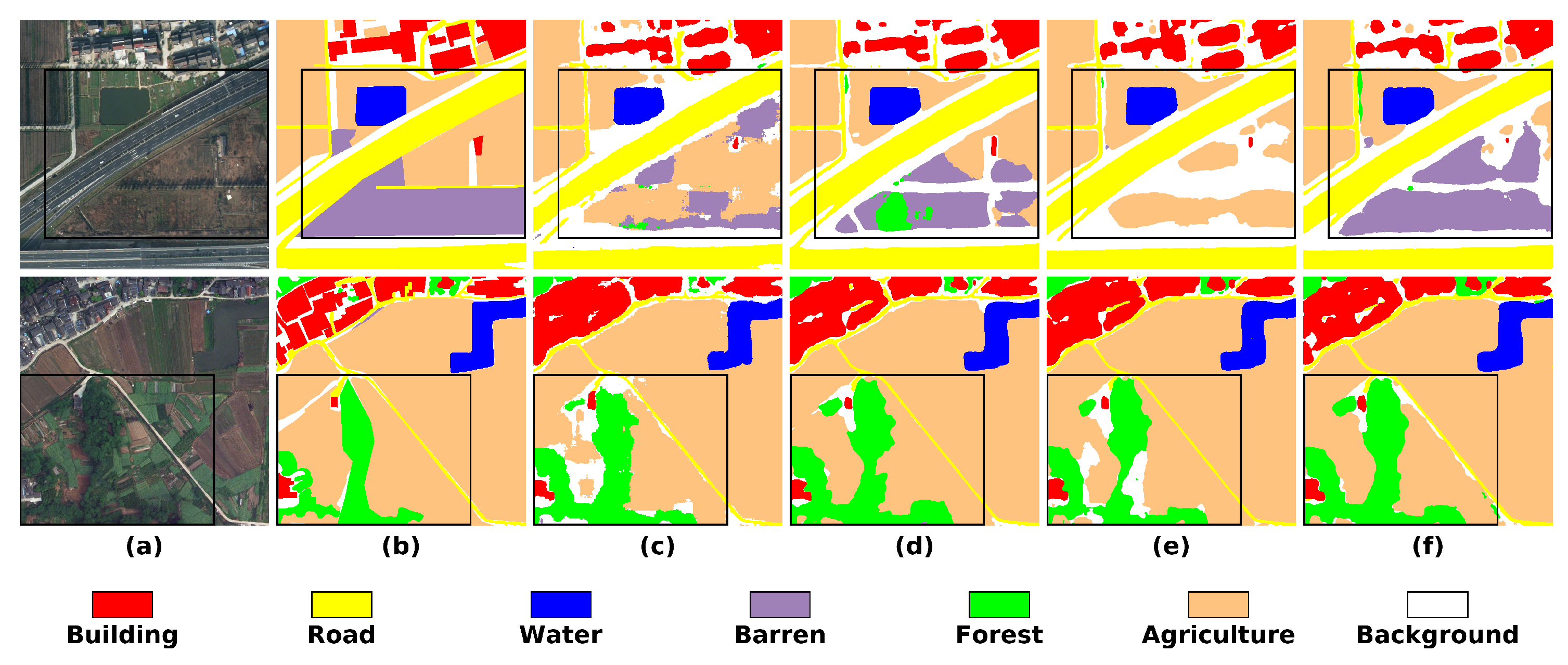
4.4.3. Results on LoveDA
4.5. Ablation Study
4.6. Model Complexity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. State Space Models
Appendix A.2. Mamba
References
- Wang, X.; Wang, H.; Jing, Y.; Yang, X.; Chu, J. A Bio-Inspired Visual Perception Transformer for Cross-Domain Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2024, 16, 1514. [Google Scholar] [CrossRef]
- Alganci, U.; Soydas, M.; Sertel, E. Comparative research on deep learning approaches for airplane detection from very high-resolution satellite images. Remote Sens. 2020, 12, 458. [Google Scholar] [CrossRef]
- Zhou, G.; Chen, W.; Gui, Q.; Li, X.; Wang, L. Split depth-wise separable graph-convolution network for road extraction in complex environments from high-resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5614115. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, Y.; Zhang, Y.; Zhong, L.; Wang, J.; Chen, J. DKDFN: Domain knowledge-guided deep collaborative fusion network for multimodal unitemporal remote sensing land cover classification. ISPRS J. Photogramm. Remote Sens. 2022, 186, 170–189. [Google Scholar] [CrossRef]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; Ding, H.; Huang, X. SemiCDNet: A semisupervised convolutional neural network for change detection in high resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5891–5906. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Li, X.; Lei, L.; Kuang, G. Multilevel adaptive-scale context aggregating network for semantic segmentation in high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 6003805. [Google Scholar] [CrossRef]
- Tao, W.B.; Tian, J.W.; Liu, J. Image segmentation by three-level thresholding based on maximum fuzzy entropy and genetic algorithm. Pattern Recognit. Lett. 2003, 24, 3069–3078. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Wang, H.; Qiao, L.; Li, H.; Li, X.; Li, J.; Cao, T.; Zhang, C. Remote sensing image semantic segmentation method based on small target and edge feature enhancement. J. Appl. Remote Sens. 2023, 17, 044503. [Google Scholar] [CrossRef]
- Su, Z.; Li, W.; Ma, Z.; Gao, R. An improved U-Net method for the semantic segmentation of remote sensing images. Appl. Intell. 2022, 52, 3276–3288. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607713. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Su, J.; Zhang, C. Multistage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8009205. [Google Scholar] [CrossRef]
- Cui, J.; Liu, J.; Wang, J.; Ni, Y. Global Context Dependencies Aware Network for Efficient Semantic Segmentation of Fine-Resolution Remoted Sensing Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 2505205. [Google Scholar] [CrossRef]
- He, X.; Wang, Z.; Bai, L.; Fan, M.; Chen, Y.; Chen, L. Attention-Enhanced Urban Fugitive Dust Source Segmentation in High-Resolution Remote Sensing Images. Remote Sens. 2024, 16, 3772. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, C.; Gao, Y.; Shi, Z.; Xie, F. Semantic segmentation of remote sensing image based on regional self-attention mechanism. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8010305. [Google Scholar] [CrossRef]
- Song, W.; Zhou, X.; Zhang, S.; Wu, Y.; Zhang, P. GLF-Net: A Semantic Segmentation Model Fusing Global and Local Features for High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 4649. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A Novel Transformer Based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506105. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Sun, Y.; Wang, M.; Huang, X.; Xin, C.; Sun, Y. Fast Semantic Segmentation of Ultra-High-Resolution Remote Sensing Images via Score Map and Fast Transformer-Based Fusion. Remote Sens. 2024, 16, 3248. [Google Scholar] [CrossRef]
- Wang, H.; Li, X.; Huo, L.; Hu, C. Global and edge enhanced transformer for semantic segmentation of remote sensing. Appl. Intell. 2024, 54, 5658–5673. [Google Scholar] [CrossRef]
- Song, W.; Nie, F.; Wang, C.; Jiang, Y.; Wu, Y. Unsupervised Multi-Scale Hybrid Feature Extraction Network for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2024, 16, 3774. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Wu, H.; Huang, P.; Zhang, M.; Tang, W. CTFNet: CNN-Transformer Fusion Network for Remote-Sensing Image Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5000305. [Google Scholar] [CrossRef]
- Weng, L.; Pang, K.; Xia, M.; Lin, H.; Qian, M.; Zhu, C. Sgformer: A Local and Global Features Coupling Network for Semantic Segmentation of Land Cover. IEEE J. Sel. Top Appl. Earth Obs. Remote Sens. 2023, 16, 6812–6824. [Google Scholar] [CrossRef]
- Wang, Z.; Xia, M.; Weng, L.; Hu, K.; Lin, H. Dual Encoder–Decoder Network for Land Cover Segmentation of Remote Sensing Image. IEEE J. Sel. Top Appl. Earth Obs. Remote Sens. 2024, 17, 2372–2385. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Ma, X.; Zhang, X.; Pun, M.O. RS3Mamba: Visual State Space Model for Remote Sensing Image Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2024, 21, 6011405. [Google Scholar] [CrossRef]
- Liu, M.; Dan, J.; Lu, Z.; Yu, Y.; Li, Y.; Li, X. CM-UNet: Hybrid CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation. arXiv 2024, arXiv:2405.10530. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv 2024, arXiv:2401.09417. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Liu, Y. Vmamba: Visual state space model. arXiv 2024, arXiv:2401.10166. [Google Scholar]
- Yang, C.; Chen, Z.; Espinosa, M.; Ericsson, L.; Wang, Z.; Liu, J.; Crowley, E.J. Plainmamba: Improving non-hierarchical mamba in visual recognition. arXiv 2024, arXiv:2403.17695. [Google Scholar]
- Huang, T.; Pei, X.; You, S.; Wang, F.; Qian, C.; Xu, C. Localmamba: Visual state space model with windowed selective scan. arXiv 2024, arXiv:2403.09338. [Google Scholar]
- Zhang, Q.; Geng, G.; Zhou, P.; Liu, Q.; Wang, Y.; Kang, L. Link Aggregation for Skip Connection–Mamba: Remote Sensing Image Segmentation Network Based on Link Aggregation Mamba. Remote Sens. 2024, 16, 3622. [Google Scholar] [CrossRef]
- Ding, H.; Xia, B.; Liu, W.; Zhang, Z.; Zhang, J.; Wang, X.; Xu, S. A novel mamba architecture with a semantic transformer for efficient real-time remote sensing semantic segmentation. Remote Sens. 2024, 16, 2620. [Google Scholar] [CrossRef]
- Zhu, E.; Chen, Z.; Wang, D.; Shi, H.; Liu, X.; Wang, L. UNetMamba: An Efficient UNet-Like Mamba for Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2025, 22, 6001205. [Google Scholar] [CrossRef]
- Tsai, T.Y.; Lin, L.; Hu, S.; Chang, M.C.; Zhu, H.; Wang, X. UU-Mamba: Uncertainty-aware U-Mamba for Cardiac Image Segmentation. In Proceedings of the 2024 IEEE 7th International Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 7–9 August 2024; pp. 267–273. [Google Scholar] [CrossRef]
- Xu, Z.; Tang, F.; Chen, Z.; Zhou, Z.; Wu, W.; Yang, Y.; Liang, Y.; Jiang, J.; Cai, X.; Su, J. Polyp-mamba: Polyp segmentation with visual mamba. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Marrakesh, Morocco, 6–10 October 2024; pp. 510–521. [Google Scholar]
- Wang, J.; Chen, J.; Chen, D.; Wu, J. LKM-UNet: Large Kernel Vision Mamba UNet for Medical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Marrakesh, Morocco, 6–10 October 2024; pp. 360–370. [Google Scholar]
- Ma, J.; Li, F.; Wang, B. U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv 2024, arXiv:2401.04722. [Google Scholar]
- Ruan, J.; Xiang, S. Vm-unet: Vision mamba unet for medical image segmentation. arXiv 2024, arXiv:2402.02491. [Google Scholar]
- Liu, J.; Yang, H.; Zhou, H.Y.; Xi, Y.; Yu, L.; Li, C.; Liang, Y.; Shi, G.; Yu, Y.; Zhang, S.; et al. Swin-umamba: Mamba-based unet with imagenet-based pretraining. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Marrakesh, Morocco, 6–10 October 2024; pp. 615–625. [Google Scholar]
- Liao, W.; Zhu, Y.; Wang, X.; Pan, C.; Wang, Y.; Ma, L. Lightm-unet: Mamba assists in lightweight unet for medical image segmentation. arXiv 2024, arXiv:2403.05246. [Google Scholar]
- Zhu, Q.; Cai, Y.; Fang, Y.; Yang, Y.; Chen, C.; Fan, L.; Nguyen, A. Samba: Semantic segmentation of remotely sensed images with state space model. Heliyon 2024, 10, e38495. [Google Scholar] [CrossRef]
- Chen, K.; Chen, B.; Liu, C.; Li, W.; Zou, Z.; Shi, Z. RSMamba: Remote Sensing Image Classification With State Space Model. IEEE Geosci. Remote Sens. Lett. 2024, 21, 8002605. [Google Scholar] [CrossRef]
- Hu, Y.; Ma, X.; Sui, J.; Pun, M.O. PPMamba: A Pyramid Pooling Local Auxiliary SSM-Based Model for Remote Sensing Image Semantic Segmentation. arXiv 2024, arXiv:2409.06309. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional feature fusion. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3560–3569. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Qu, H.; Ning, L.; An, R.; Fan, W.; Derr, T.; Liu, H.; Xu, X.; Li, Q. A survey of mamba. arXiv 2024, arXiv:2408.01129. [Google Scholar]
- Pechlivanidou, G.; Karampetakis, N. Zero-order hold discretization of general state space systems with input delay. IMA J. Math. Control. Inf. 2022, 39, 708–730. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T.; Ermon, S.; Rudra, A.; Ré, C. Hippo: Recurrent memory with optimal polynomial projections. Adv. Neural Inf. Proces. Syst. 2020, 33, 1474–1487. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Imp. Surf. | Building | Low Veg. | Tree | Car | mF1 (%) | mIoU (%) |
|---|---|---|---|---|---|---|---|
| MANet [13] | 96.28/92.82 | 94.39/89.37 | 83.38/71.50 | 89.72/81.36 | 86.67/76.48 | 90.09 | 82.31 |
| MAResU-Net [14] | 96.59/93.42 | 94.86/90.23 | 84.22/72.74 | 89.67/81.27 | 84.73/73.51 | 90.01 | 82.23 |
| GCDNet [15] | 95.98/92.27 | 93.79/88.32 | 83.25/71.30 | 89.44/80.90 | 86.41/76.08 | 89.77 | 81.77 |
| Swin-Unet [22] | 94.57/89.70 | 93.93/88.56 | 83.04/71.00 | 89.32/80.71 | 83.45/71.60 | 88.86 | 80.32 |
| VM-UNet [45] | 96.58/93.39 | 94.74/90.01 | 83.66/71.92 | 89.63/81.21 | 84.97/73.88 | 89.92 | 82.08 |
| UNetFormer [26] | 96.64/93.51 | 95.53/91.44 | 83.03/70.98 | 89.16/80.45 | 87.05/77.08 | 90.28 | 82.69 |
| TransUNet [27] | 95.39/91.18 | 95.66/91.68 | 84.71/73.47 | 90.00/81.81 | 87.19/77.29 | 90.59 | 83.09 |
| RS3Mamba [32] | 95.15/90.76 | 94.49/89.56 | 83.79/72.11 | 89.29/80.65 | 86.07/75.55 | 89.76 | 81.72 |
| GLFFNet(Ours) | 96.84/93.87 | 95.71/91.78 | 84.35/72.95 | 89.89/81.65 | 88.75/79.78 | 91.11 | 84.01 |
| Method | Imp. Surf. | Building | Low Veg. | Tree | Car | mF1 (%) | mIoU (%) |
|---|---|---|---|---|---|---|---|
| MANet [13] | 92.97/86.87 | 95.59/91.56 | 86.09/75.58 | 87.61/77.95 | 95.65/91.67 | 91.58 | 84.73 |
| MAResU-Net [14] | 93.19/87.26 | 96.20/92.69 | 86.47/76.16 | 87.88/78.38 | 95.68/91.73 | 91.88 | 85.24 |
| GCDNet [15] | 93.56/87.90 | 95.96/92.23 | 86.83/76.73 | 88.51/79.40 | 95.76/91.86 | 92.12 | 85.62 |
| Swin-Unet [22] | 93.00/86.93 | 95.52/91.42 | 86.11/75.61 | 87.63/77.98 | 94.30/89.21 | 91.31 | 84.23 |
| VM-UNet [45] | 93.77/88.28 | 96.21/92.70 | 86.70/76.53 | 87.42/77.65 | 95.27/90.97 | 91.88 | 85.23 |
| UNetFormer [26] | 93.77/88.28 | 96.48/93.20 | 86.61/76.38 | 88.09/78.72 | 95.81/91.96 | 92.15 | 85.71 |
| TransUNet [27] | 94.29/89.20 | 96.78/93.77 | 88.01/78.59 | 89.08/80.31 | 96.16/92.60 | 92.86 | 86.89 |
| RS3Mamba [32] | 93.83/88.38 | 96.83/93.86 | 87.61/77.96 | 88.39/79.20 | 95.56/91.50 | 92.45 | 86.18 |
| GLFFNet(Ours) | 94.47/89.52 | 97.30/94.75 | 88.46/79.32 | 89.53/81.05 | 96.39/93.04 | 93.23 | 87.54 |
| Method | Background | Building | Road | Water | Barren | Forest | Agricultural | mF1 (%) | mIoU (%) |
|---|---|---|---|---|---|---|---|---|---|
| MANet [13] | 69.75/53.55 | 76.19/61.54 | 68.02/51.54 | 79.31/65.72 | 42.95/27.35 | 58.26/41.10 | 70.69/54.67 | 66.45 | 50.78 |
| MAResU-Net [14] | 69.83/53.65 | 76.65/62.15 | 70.29/54.19 | 77.76/63.62 | 49.72/33.09 | 59.85/42.71 | 71.01/55.05 | 67.87 | 52.06 |
| GCDNet [15] | 67.88/51.38 | 70.95/54.97 | 70.49/54.43 | 77.44/63.19 | 41.23/25.97 | 55.23/38.15 | 66.28/49.57 | 64.21 | 48.24 |
| Swin-Unet [22] | 68.92/52.58 | 72.70/57.11 | 67.32/50.73 | 80.46/67.31 | 47.52/31.16 | 60.13/42.99 | 65.81/49.04 | 66.12 | 50.13 |
| VM-UNet [45] | 69.42/53.17 | 75.63/60.82 | 69.69/53.49 | 80.68/67.62 | 50.75/34.00 | 53.92/36.91 | 66.87/50.23 | 66.71 | 50.89 |
| UNetFormer [26] | 66.75/50.09 | 76.17/61.51 | 71.43/55.56 | 80.77/67.75 | 46.69/30.46 | 59.74/42.59 | 67.77/51.25 | 67.05 | 51.32 |
| TransUNet [27] | 70.16/54.04 | 77.79/63.65 | 72.45/56.80 | 80.57/67.46 | 51.17/34.38 | 58.50/41.34 | 72.24/56.55 | 68.98 | 53.46 |
| RS3Mamba [32] | 70.42/54.35 | 78.86/65.10 | 71.94/56.18 | 82.54/70.27 | 50.30/33.60 | 57.03/39.89 | 75.16/60.20 | 69.46 | 54.23 |
| GLFFNet(Ours) | 68.27/51.83 | 79.01/65.31 | 71.28/55.37 | 80.41/67.24 | 53.14/36.19 | 60.33/43.19 | 78.03/63.98 | 70.07 | 54.73 |
| ResNet | VMamba | MSFR | SBF | Imp. Surf. | Building | Low Veg. | Tree | Car | mF1 (%) | mIoU (%) |
|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 92.01 | 87.3 | 70.33 | 79.55 | 62.47 | 87.43 | 78.33 | |||
| ✓ | ✓ | 93.52 | 90.51 | 72.34 | 80.46 | 77.27 | 90.39 (↑2.96) | 82.82 (↑4.49) | ||
| ✓ | ✓ | ✓ | 93.66 | 90.85 | 73.25 | 81.37 | 78.86 | 90.88 (↑0.49) | 83.60 (↑0.78) | |
| ✓ | ✓ | ✓ | ✓ | 93.87 | 91.78 | 72.95 | 81.65 | 79.78 | 91.11 (↑0.23) | 84.01 (↑0.41) |
| ResNet | VMamba | MSFR | SBF | Imp. Surf | Building | Low veg. | Tree | Car | mF1 (%) | mIoU (%) |
|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 86.38 | 90.14 | 74.06 | 75.33 | 89.61 | 90.61 | 83.10 | |||
| ✓ | ✓ | 89.23 | 94.38 | 78.7 | 80.96 | 92.68 | 93.03 (↑2.42) | 87.19 (↑4.09) | ||
| ✓ | ✓ | ✓ | 89.27 | 94.48 | 79.08 | 80.96 | 93.11 | 93.14 (↑0.11) | 87.38 (↑0.19) | |
| ✓ | ✓ | ✓ | ✓ | 89.52 | 94.75 | 79.32 | 81.05 | 93.04 | 93.23 (↑0.09) | 87.54 (↑0.16) |
| ResNet | VMamba | MSFR | SBF | Background | Building | Road | Water | Barren | Forest | Agricultural | mF1 (%) | mIoU (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 50.57 | 56.62 | 52.38 | 62.33 | 21.78 | 40.86 | 46.02 | 63.12 | 47.22 | |||
| ✓ | ✓ | 53.80 | 53.80 | 57.14 | 69.69 | 36.15 | 36.97 | 57.88 | 68.99 (↑5.87) | 53.59 (↑6.37) | ||
| ✓ | ✓ | ✓ | 55.50 | 64.38 | 51.99 | 69.97 | 34.17 | 40.45 | 62.18 | 69.38 (↑0.39) | 54.09 (↑0.5) | |
| ✓ | ✓ | ✓ | ✓ | 51.83 | 65.31 | 55.37 | 67.24 | 36.19 | 43.19 | 63.98 | 70.07 (↑0.69) | 54.73 (↑0.64) |
| Method | FLOPs (G) | Parameter (M) | ATT (s) | mF1 (%) | mIoU (%) |
|---|---|---|---|---|---|
| MANet | 155.51 | 35.86 | 56.23 | 90.09 | 82.31 |
| MAResU-Net | 70.21 | 26.28 | 39.68 | 90.01 | 82.23 |
| GCDNet | 562.26 | 60.56 | 276.34 | 89.77 | 81.77 |
| Swin-Unet | 62.05 | 27.15 | 61.68 | 88.86 | 80.32 |
| VM-Unet | 32.96 | 22.04 | 132.19 | 89.92 | 82.08 |
| UNetFormer | 23.48 | 11.68 | 46.08 | 90.28 | 82.69 |
| TransUNet | 258.89 | 93.23 | 293.68 | 90.59 | 83.09 |
| RS3Mamba | 126.6 | 49.66 | 300.77 | 89.76 | 81.72 |
| GLFFNet(ours) | 154.46 | 64.22 | 283.79 | 91.11 | 84.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, S.; Zhao, L.; Xiao, Q.; Ding, J.; Li, X. GLFFNet: Global–Local Feature Fusion Network for High-Resolution Remote Sensing Image Semantic Segmentation. Remote Sens. 2025, 17, 1019. https://doi.org/10.3390/rs17061019
Zhu S, Zhao L, Xiao Q, Ding J, Li X. GLFFNet: Global–Local Feature Fusion Network for High-Resolution Remote Sensing Image Semantic Segmentation. Remote Sensing. 2025; 17(6):1019. https://doi.org/10.3390/rs17061019
Chicago/Turabian StyleZhu, Saifeng, Liaoying Zhao, Qingjiang Xiao, Jigang Ding, and Xiaorun Li. 2025. "GLFFNet: Global–Local Feature Fusion Network for High-Resolution Remote Sensing Image Semantic Segmentation" Remote Sensing 17, no. 6: 1019. https://doi.org/10.3390/rs17061019
APA StyleZhu, S., Zhao, L., Xiao, Q., Ding, J., & Li, X. (2025). GLFFNet: Global–Local Feature Fusion Network for High-Resolution Remote Sensing Image Semantic Segmentation. Remote Sensing, 17(6), 1019. https://doi.org/10.3390/rs17061019