1. Introduction
Vehicle tracking has a wide range of applications in various fields, such as intelligent transportation and environmental monitoring [
1,
2], as well as emergency response and disaster management [
3]. Owing to the adaptability and safety of UAVs, vehicle tracking from a drone’s viewpoint has garnered significant research interest in recent years [
4,
5,
6]. When multiple vehicles are in the UAV view, the vehicle-tracking task is transformed into a multi-object tracking (MOT) task. During the tracking process, when the UAV and vehicles are moving at the same time, it leads to a variation in the scale of vehicle targets, which leads to missed detection and identity-switching of vehicle targets, thus greatly increasing the difficulty of MOT [
7,
8,
9].
In the field of computer vision, the application of MOT has shifted from traditional techniques to those centered around the advancements in deep learning. Traditional methods depend on manual feature design, which is cumbersome and inefficient. In contrast, MOT approaches leveraging deep neural networks have emerged as the dominant paradigm, offering enhanced adaptability and robustness across various scenarios. These advanced techniques are primarily classified into Tracking-Based Detection (TBD) and Joint Detection Tracking (JDT). The TBD algorithm [
10,
11,
12] employs a two-stage design structure, separating the detection and tracking modules, allowing these two modules to be optimized independently. However, this design may result in suboptimal solutions. Conversely, the JDT algorithm [
13,
14,
15] combines detection models in one framework by adding prediction modules or embedding branches to detectors. While this integration enhances inference speed and surpasses the TBD algorithm in straightforward scenarios, it exhibits limited effectiveness in complex environments. Therefore, in the domain of UAV vision, MOT primarily adopts the TBD paradigm. Compared to popular methods, we also employ a detection-based MOT framework for UAV vision. TBD-based trackers link detected targets across frames to form complete trajectories using appearance, motion, and additional characteristics.
The TBD framework primarily depends on object detection tasks, with the majority of tracking systems employing deep neural networks for re-identification (ReID) to capture distinctive visual characteristics that enable target differentiation. In the actual target tracking process, variations in the distance between the vehicle and the UAV, as well as in the camera angle, can lead to significant differences in size, aspect ratio, and texture details of the same target, thus affecting the process of target detection and re-recognition based on appearance features. Many researchers [
16,
17] have used multi-scale feature-fusion methods to combine information from different levels of features to maximize the use of multi-scale output. However, the fusion process often involves simple concatenation operations, which do not objectively reflect the correlation between different levels of features and lack information interaction. Therefore, how to efficiently perform feature fusion remains a future research direction.
Vehicle re-identification methods commonly utilize convolutional neural networks (CNNs) for vehicle feature extraction, followed by distance metric loss to optimize the distances between these features. For UAV-based vehicle re-identification, vehicles under different viewpoints often exhibit fundamentally distinct visual appearances, leading to different feature distributions at the feature level. As discussed in existing work [
18], the feature distance for the same vehicle from different angles can be larger than for different vehicles from the same angle. Refs. [
18,
19] incorporated viewpoint features to enhance the robustness of features against viewpoint variations. Additionally, different scales of information exhibit distinct distributions in the feature space [
20], highlighting the critical role of hierarchical feature learning in re-identification tasks. Therefore, designing multi-scale feature-fusion strategies is essential to enhance the robustness of features against scale differences.
To overcome the challenges of missed detections and false positives arising from scale variations on UAV platforms, we propose an efficient multi-object tracking algorithm with multi-scale feature fusion for scale-variant vehicle targets in drone view based on BoT-SORT [
21]. In the detection phase, unlike other detection methods that employ concatenation operations for feature fusion, we propose a multi-scale feature alignment and aggregation object detection approach based on YOLOv8 [
22]. We mainly introduce the Feature Alignment Aggregation Module (FAAM) in the neck part of the network to solve the problem of feature misalignment and propose the Bidirectional Path Aggregation Network (BPAN) network to enhance the multi-scale feature-fusion capability. In the vehicle re-identification process for extracting appearance features, we introduce a Feature Pyramid Network (FPN) [
23] based on the OSNet architecture [
24] to capture pixel dependencies across multiple feature maps. Subsequently, the FPN aggregates features from different levels, resulting in features that simultaneously incorporate low-level information and high-level semantics. Additionally, we incorporate the Convolutional Block Attention Module(CBAM) [
25] attention mechanism to assist the model in concentrating on regions of the image that contain important information, thereby boosting the accuracy of the re-identification model.
By optimizing detection and appearance feature extraction as two separate tasks, the FB-YOLOv8 method enhances target localization accuracy. The improved re-identification approach then extracts richer appearance features based on the provided target locations, offering reliable distance metrics for trajectory association. Experimental results indicate that the introduced module achieves significant tracking and association performance when targets undergo scale variations, showcasing the excellence of the proposed approach on the UAVDT dataset [
26]. The key contributions are outlined below:
(1) We propose an FB-YOLOv8 network to achieve higher detection precision of multi-scale objects in intricate scenarios. This framework addresses the challenge of scale variation in vehicle tracking by incorporating a Feature Alignment Aggregation Module (FAAM) and a Bidirectional Path Aggregation Network (BPAN), which significantly improves the detection capabilities in environments featuring various object dimensions and viewpoints.
(2) We propose a multi-scale feature-fusion network based on the OSNet backbone (MSFF-OSNet) for vehicle re-identification. By integrating OSNet with a Feature Pyramid Network (FPN) and Convolutional Block Attention Module (CBAM) attention mechanism, our approach not only captures pixel dependencies across multiple feature maps but also focuses on salient image regions.
(3) We propose a MOT algorithm with multi-scale feature fusion and the experimental results on the UAVDT dataset demonstrate the superiority of the proposed method. The fusion of the FB-YOLOv8 detection network with the MSFF-OSNet re-identification network reduces missed detections and identity switches.
The subsequent sections are organized as follows:
Section 2 offers an overview of prior research.
Section 3 introduces the specific detection method and re-identification method that constitute our tracking framework.
Section 4 showcases the experimental results on the UAVDT dataset, which illustrates the efficacy of the introduced tracking approach in contrast to state-of-the-art methods. Conclusively,
Section 5 summarizes the paper.
3. Methodology
3.1. Overall Framework
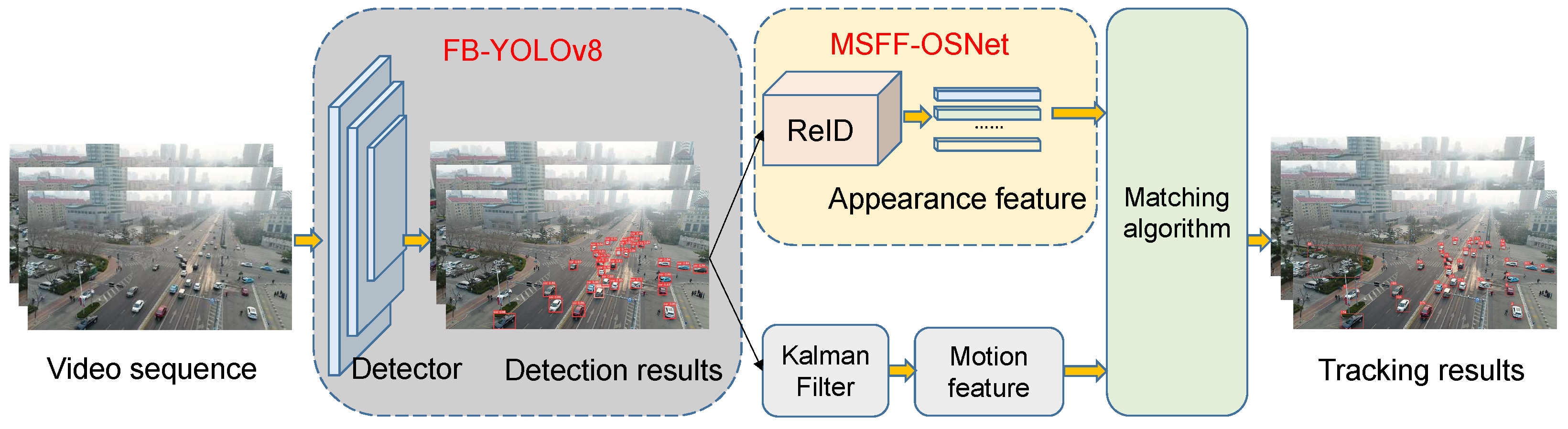
In our multi-object tracking method, two innovative modules are introduced to enhance the accuracy and stability of tracking targets with varying scales. The framework of our proposed tracking system is shown in
Figure 2. Firstly, each frame from the video sequence is sequentially fed into the tracker, where the FB-YOLOv8 detector is utilized to obtain more accurate target bounding boxes and their categories within the sequence. Subsequently, the detection results are fed into a multi-scale feature-fusion appearance feature-extraction network (MSFF-OSNet) to acquire the appearance features. Concurrently, the Kalman filter algorithm predicts the bounding boxes of targets in the following frames by utilizing the detection outcomes of the current frame. The FB-YOLOv8 is aimed at enhancing detection performance and mitigating the issue of missed detections, while the MSFF-OSNet is designed to extract more discriminative identity features, reducing the occurrence of identity switches. The outputs of these two modules are ultimately quantified as distances of feature vectors and used to formulate the association process as a global allocation problem. Finally, a matching algorithm is employed to associate the detected targets with existing trajectories.
3.2. FB-YOLOv8
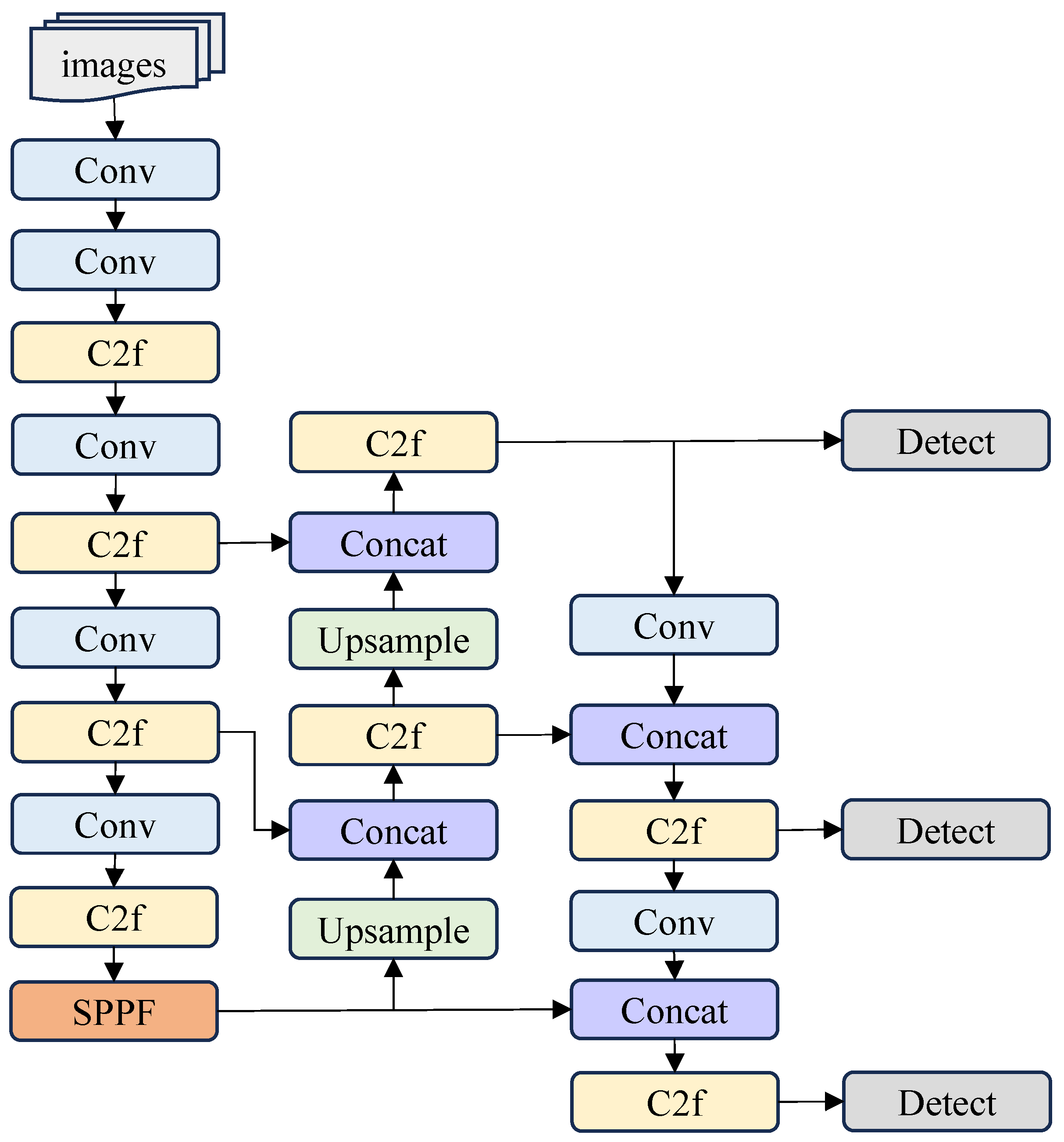
To achieve better object detection, we chose the YOLOv8 algorithm as the base model. The versions of YOLOv8 include YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x. Since YOLOv8n is the lightest version in the YOLOv8 series, it focuses on speed and real-time performance while maintaining good detection accuracy. Therefore, we select YOLOv8n as the baseline of our method. The architectural configuration of YOLOv8 is illustrated in
Figure 3. Although the YOLOv8 algorithm is already quite efficient, the detection performance under multi-scale-changing scenarios is suboptimal. The reason is that the network only employs concatenation operations when fusing the extracted multiple features. This fusion method lacks interactive information exchange, which leads to suboptimal detection results for targets of varying sizes. Therefore, we propose an FB-YOLOv8 model to obtain higher detection accuracy when UAV images undergo multi-scale changes.
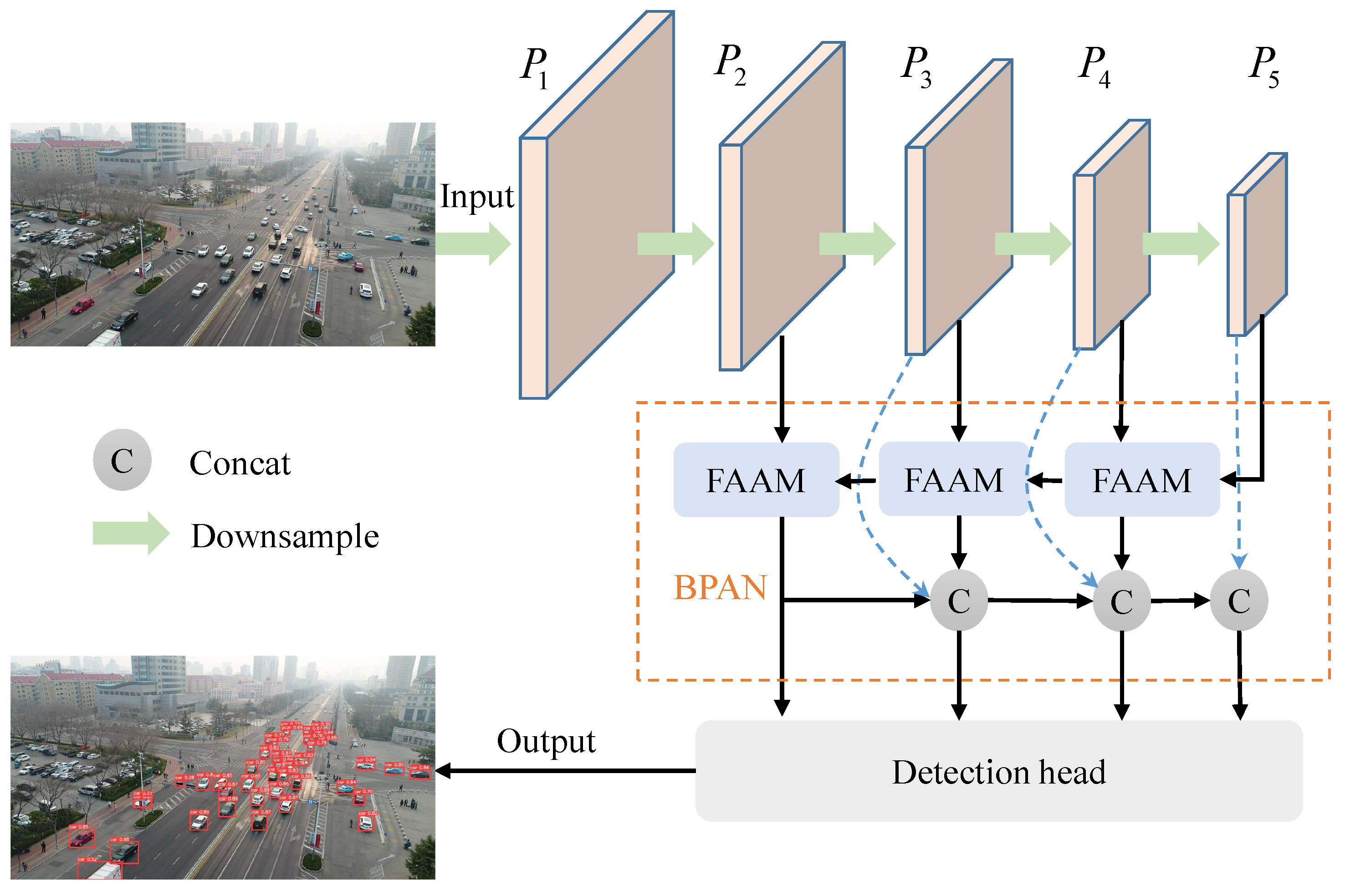
The comprehensive structure of the FB-YOLOv8 module is depicted in
Figure 4. To align different resolution feature maps, we integrate a Feature Alignment Aggregation Module (FAAM) in the neck and propose a Bidirectional Path Aggregation Network (BPAN) to additionally improve the network’s ability for multi-scale fusion. Meanwhile, a shallow detection head is appended in the prediction stage to enhance the detection ability of tiny targets.
3.2.1. Feature Alignment Aggregation Module
As the network layer deepens, the feature information derived from the shallow and deep networks becomes increasingly inconsistent. The shallow network tends to capture texture, color, and edge-based features to obtain a detailed representation of the object contour. In contrast, the features derived from the deep network are more generalized with high-level semantics, but they miss the fine contour details that the shallow network supplies. Upsampling the low-resolution features and concatenating them with high-resolution features does not take into account the spatial and semantic information alignment between features. To address the issue of inaccurate segmentation edges caused by this problem, Huang et al. [
58] introduced AlignSeg, which includes two main components: the AlignFA for feature aggregation and the AlignCM for context modeling. AlignFA uses a simple trainable interpolation method to learn pixel transformation offsets, which effectively relieves the feature misalignment problem due to multi-resolution feature fusion. For small targets, as the number of layers deepens, the spatial information gradually weakens, so it needs to be better integrated with high-resolution features to enhance spatial information. Drawing inspiration from the AlignSeg network, we introduce the FAAM, which is integrated into the neck pyramid network to align two adjacent features of different resolutions. The alignment operation enables the features of different resolutions to correspond in space, thus enhancing the model’s capability to handle both detail and global information and improving the detection algorithm’s ability to accurately locate tiny targets.
The structural configuration of the FAAM is illustrated in
Figure 5. We first upsample the low-resolution feature
-based bilateral interpolation. Then,
and the high-resolution feature
are connected in series. The concatenated features are processed through a depthwise separable convolution module consisting of depthwise convolution and pointwise convolution to predict an offset. A deep convolution layer with a kernel size of 3 × 3 is used to extract the local spatial information surrounding each sampling location, which is then fed into pointwise convolution to produce a two-dimensional offset
. The offset
and high-resolution feature
are input into the alignment function to acquire a spatially aligned high-resolution feature map. Finally, the aligned feature map is combined with the upsampled feature map to create a fusion feature map that contains both detailed information and global information. Mathematically, feature alignment can be expressed as:
the
means the process of depth separable convolution learning offset.
Assuming that the spatial coordinates for each location on the feature map are
,
, and the offset map is
, the output of the offset alignment function
is:
and
denotes the two-dimensional offset of the learned position
.
3.2.2. Bidirectional Path Aggregation Network
The deep features in the convolutional network contain richer semantic features, and the shallow features contain more location information. However, this feature representation brings challenges to object detection tasks. Although the deep layer can capture semantic features, the spatial resolution of its feature map is low, which is unfavorable for precise detection of the target’s location information. This constraint is especially pronounced during detecting small objects. In addition, the shallow layer contains a higher amount of positional information, yet it is deficient in semantic features, which leads to suboptimal outcomes in image classification tasks. To address this issue, a Feature Pyramid Network (FPN) is utilized, which implements a top-down information propagation strategy to efficiently integrate and represent features across multiple scales. Recursive-FPN [
59] introduced a recursive feature-fusion technique to handle multi-scale features more effectively. To enhance the multi-scale feature fusion within FPN, BiFPN [
60] brings forward a bidirectional feature-fusion approach. Drawing inspiration from the BiFPN architecture and integrating the PANet structure from the neck section of YOLOv8, we introduce a novel approach termed the Bidirectional Path Fusion Network (BPAN). It fuses the original input nodes at the same resolution as the output node features and fuses more features without increasing too much cost to promote the flow of information. The architectures of both BiFPN and the proposed BPAN are depicted in
Figure 6.
The BPAN module we proposed receives the four feature maps produced by the backbone as its input, represented from bottom to top as Among them, the feature map of possesses the highest resolution, with each following feature map having half the resolution of its predecessor. We draw inspiration from the BiFPN model and opt to integrate bidirectional skip connections within the intermediate layers of the module. This approach not only effectively captures feature information across different scales but also mitigates concerns such as excessive parameter growth, oversized model complexity, and feature degradation. Concurrently, we introduce an additional shallow detection head to the existing three, thereby enhancing the detection precision for small targets further.
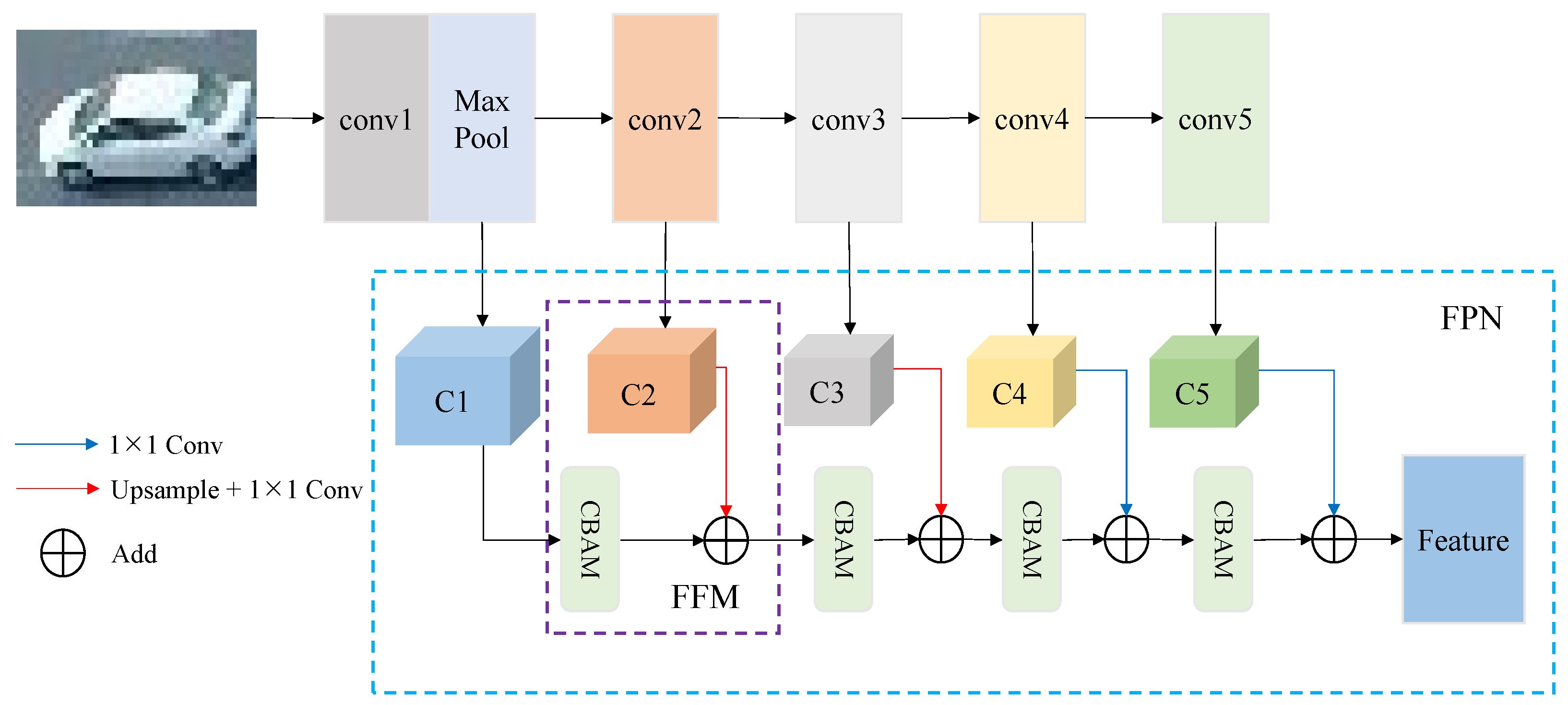
3.3. MSFF-OSNet
When tracking vehicle targets in UAV videos, factors such as distance variation and angle changes cause the same vehicle to exhibit different appearances at different times, increasing intra-class variability in vehicle appearance features and affecting the accuracy of multi-object matching. To boost the distinctive characteristics of the targets, we propose a multi-scale feature fusion appearance feature-extraction network based on the OSNet backbone (MSFF-OSNet). This network incorporates a feature pyramid structure in the backbone to extract feature information representing different semantics and scales from various stages of the backbone. Additionally, the CBAM attention mechanism is introduced during the fusion of multilevel features to focus on more salient information, thereby extracting more robust features. These features are then used for appearance feature matching and association, effectively reducing issues such as ID switching caused by vehicle scale variations. The network structure is depicted in
Figure 7.
OSNet employs multiple Lite layers to form multiple convolutional stream branches, thereby bolstering its capability to comprehend objects across different levels of detail. The unified aggregation gate (AG) improves multi-scale feature learning and adaptability to different input images, thereby enhancing performance across scales. Additionally, OSNet incorporates depthwise separable convolutions, significantly decreasing the number of parameters in the model. Overall, the lightweight OSNet effectively combines multiple uniform scale features with dynamic aggregation gates and demonstrates exceptional capability in learning non-uniform scale features. Consequently, in scenarios involving variable-scale vehicle tracking, replacing the original ResNet50 re-identification network in the tracker with the OSNet network yields superior performance.
The feature pyramid is an hourglass-shaped structure composed of two pathways: bottom-up and top-down. The bottom-up pathway typically consists of a convolutional network for feature extraction, where the feature map scale decreases progressively, enabling the detection of higher-level structures and increasing the semantic information of the network layers. In contrast, the top-down pathway constructs higher-resolution feature maps based on layers with richer semantics. The standard feature pyramid upsamples high-level, low-scale features and complements them with low-level, high-scale feature information, thereby achieving the extraction of features at different scales. The proposed multi-scale feature-extraction network in this study removes the upsampling part of the standard feature pyramid. When fusing features of different scales, it captures key information through the adaptive feature recalibration of an attention mechanism, better integrating shallow detail features with deep semantic features.
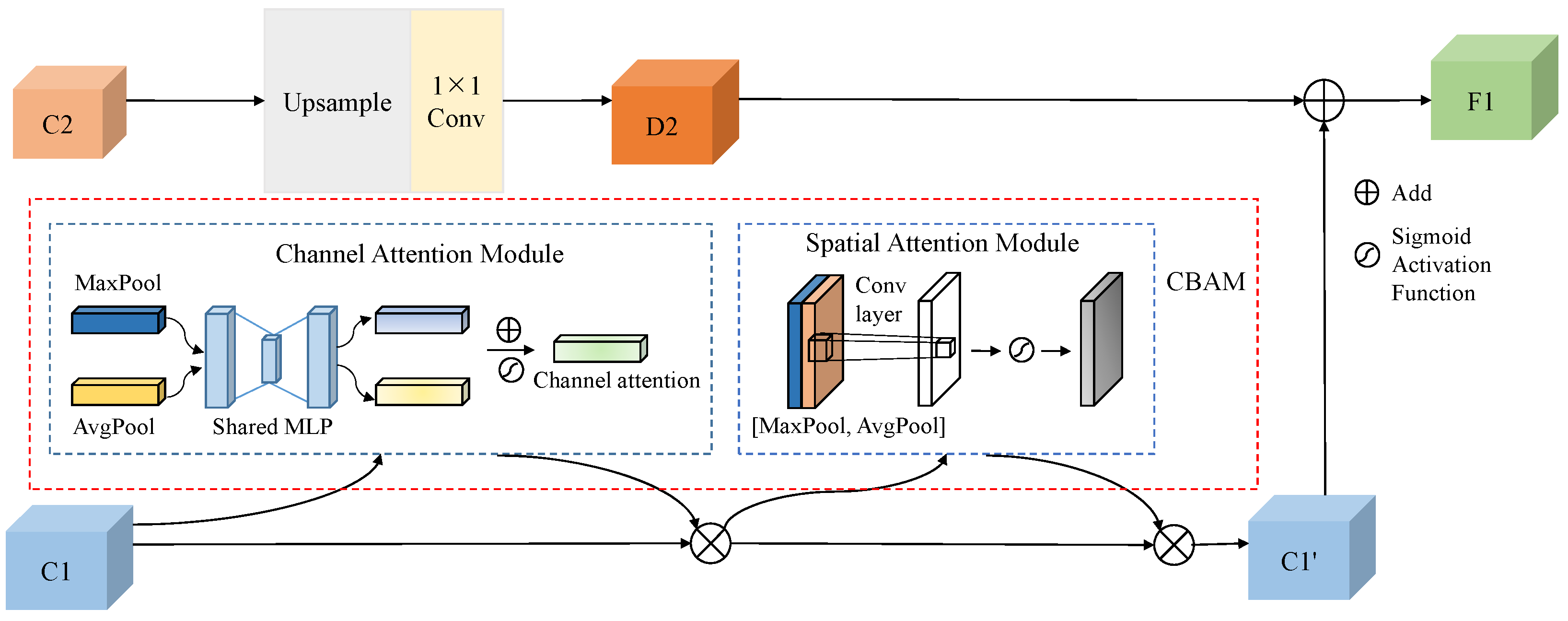
Specifically, the OSNet network fuses feature maps C1 to C5 of different scales from Conv1 to Conv5, and the feature-fusion module is depicted in
Figure 8. The features C2 and C3 are upsampled and adjusted in channel number using a 1 × 1 convolutional layer to match C1 and C2, respectively, while the features C4 and C5 are adjusted in channel number using a 1 × 1 convolutional layer to match C3 and C4, respectively. Taking the fusion of C1 and C2 as an example, C2 is upsampled and adjusted in channel number using a 1 × 1 convolutional layer to match C1, resulting in D2. The enhanced features of C1 obtained through the CBAM attention module are then element-wise added to D2 and passed to the next layer. Similarly, the same operation is performed on subsequent feature maps to generate the ultimate output feature map.
CBAM comprises two separate sub-modules, CAM (Channel Attention Module) and SAM (Spatial Attention Module), which reconstruct the feature map to highlight key information. CAM emphasizes the interconnections among the channels of the feature map, evaluating the importance of each pixel. After processing through global max pooling, average pooling, and a multilayer perceptron (MLP), the input feature map undergoes dimensionality reduction and expansion, followed by summation and Sigmoid activation, ultimately yielding the channel attention
. CAM can be expressed as:
The max pooling and average pooling operations in the SAM module serve to compress the channels, reducing their number to one after convolution, followed by Sigmoid activation. This enables the network model to focus more on the important pixel regions while disregarding less relevant areas. SAM can be expressed as:
In the above two equations, represents the input feature map, denotes average pooling, represents global max pooling, stands for the multilayer perceptron, denotes the Sigmoid activation function, and represents a convolutional kernel with a side length of 5.
Therefore, the overall expression of the CBAM module can be derived as:
is upsampled and adjusted in channel number to obtain
, expressed as follows:
Finally, the output feature F obtained from the feature-fusion module after processing
and
is expressed as follows:
3.4. Matching Strategy
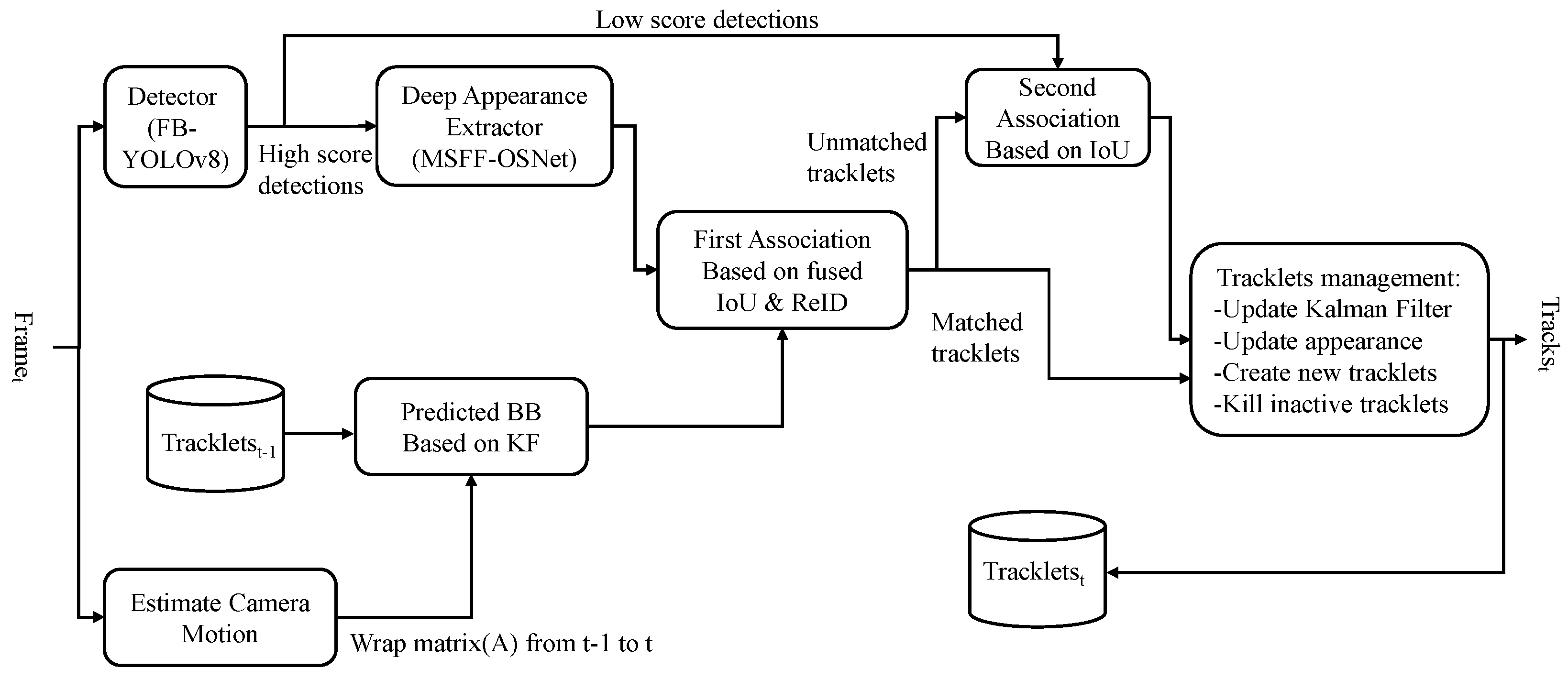
In this part, we offer a detailed description of the matching approach used by our tracking system to correlate identified objects between successive frames. Our research is founded on the framework of the BoT-SORT tracker.
On the one hand, BoT-SORT proposes a method that integrates IoU and ReID through cosine distance fusion, effectively addressing the issue of ID switches caused by appearance variations throughout the tracking process. Specifically, the algorithm integrates the IoU distance matrix and the cosine distance matrix for matching. The IoU distance indicates the level of intersection between the bounding boxes of the targets, while the cosine similarity measures the resemblance between the appearance features of targets. During the matching process, BoT-SORT initially processes the IoU scores, rejecting candidate boxes with low cosine similarity or those that are spatially distant. In other words, the algorithm excludes candidate targets that exhibit significant deviations in appearance or minimal positional overlap with the current trajectory. Subsequently, The smallest value from each element in the matrix is used as the ultimate value for the cost matrix C. The mathematical expression for the IoU-ReID fusion pipeline is as follows:
where
denotes the
element of the cost matrix
C.
represents the IoU distance between the predicted bounding box of the
i-th tracklet and the bounding box of the
j-th detection, quantifying the motion cost.
represents the cosine distance between the mean appearance descriptor of the
i-th tracklet and the descriptor of the
j-th detection.
is the newly defined appearance cost. The neighborhood threshold
, set to 0.5, is used to discard improbable pairs of tracklets and detections. The appearance threshold
, set to 0.25, distinguishes positive associations between tracklet appearance states and detection embedding vectors from negative ones.
On the other hand, while most trackers employ a Kalman filter state vector as represented by (
11), BoT-SORT utilizes a state vector as defined by (
12), which directly estimates the width and height of the targets, making it more adaptable to changes in aspect ratio when the target undergoes scale variations.
Overall, the FB-YOLOv8 model is first utilized to acquire the positions of target vehicles in video frames. Subsequently, the positional information is fed into BoT-SORT, which assigns a distinct identifier to every target vehicle and tracks them accordingly. The framework of the BoT-SORT tracker is depicted in
Figure 9.
Firstly, the input image sequence is processed by FB-YOLOv8 to obtain detection results. By setting high-confidence and low-confidence thresholds, the predicted detection boxes are divided into three categories: high-confidence, low-confidence, and those below the low-confidence threshold, which are directly discarded. Detection boxes with confidence scores above high confidence are prioritized for the first round of association matching with the trajectory boxes predicted by the Kalman filter. This first round of matching considers both the IoU distance between the boxes and the cosine similarity of the target’s appearance features. A successful match indicates successful target tracking, and the target trajectory is updated. High-confidence detection boxes that fail to match existing trajectories may represent new targets, requiring the creation of new trajectories. The remaining unmatched trajectories are subsequently entered into a second phase of association matching with low-confidence detection boxes. This second phase of matching relies solely on the IoU distance. Upon successful matching, the corresponding trajectory is subsequently updated. Trajectories that are still unmatched following the second phase of matching are retained for up to 30 frames for potential re-tracking. If no match is found within these 30 frames, the trajectory is discarded.
4. Experiments
4.1. Datasets and Implementation Details
Our algorithm is trained and verified on the UAVDT dataset. UAVDT serves as an extensive and complex testing ground for large-scale unmanned aerial vehicle detection and tracking challenges, with a total of 100 video sequences, about 80,000 frames, and an image size of 1024 × 540. It is mainly used for three important basic tasks, namely target detection, single-target tracking, and multi-target tracking. There are 50 video sequences for multi-target tasks, which are divided into 30 training set videos and 20 test set videos. The target categories are divided into three classes, including car, truck, and bus.
The size of the training and test images of UAVDT is set to 1024 × 1024, and the batch size is set to 4. The optimizer used is SGD, the learning rate is 0.01, the momentum is 0.9, and the weight attenuation coefficient is 0.0005. The number of training epochs is set to 300, which converges after more than 50 rounds. The experimental computer is furnished with a 12th Gen Intel (R) Core (TM) i7-12700 2.10 GHz processor and an NVIDIA RTX 3080 GPU equipped with 10 GB of memory. The experimental platform is Pycharm software (version 2022.1), and the framework is PyTorch 1.13.1.
4.2. Object Detector Experiments
To illustrate the efficacy of FB-YOLOv8, our approach is benchmarked against various cutting-edge models using the UAVDT dataset. The evaluation indicators include mean average precision at the IoU threshold of 0.5 (mAP50), parameters (params), and giga floating point operation (GFLOP). The outcomes of the comparison are listed in
Table 1. The PR curves of the baseline model and the improved model are shown in
Figure 10. Our method attains 34.7% in mAP50, which is improved from 32.2% to 34.7% compared with the baseline method YOLOv8n. Regarding resource requirements, our approach exhibits a computational complexity of 12.6 GFLOPs and encompasses 2.97 million parameters, which is 0.04 million less than the original YOLOv8n model parameter number. Our method surpasses other approaches, boasting the top mAP50 metric.
The ablation study on the UAVDT test set demonstrates the contributions of the FAAM and BPAN modules in FB-YOLOv8. The experimental results are shown in
Table 2. The baseline model achieves an mAP50 of 32.2%. Adding FAAM alone improves mAP50 to 33.1%, with gains in car (68.2%) and truck (7.1%) detection. BPAN alone raises mAP50 to 33.4%, primarily enhancing car detection (69.9%). Combining both modules yields the highest mAP50 of 34.7%, with car detection peaking at 75.5% and truck detection at 7.2%, though bus detection slightly drops to 21.4%. This highlights the complementary role of FAAM and BPAN in improving overall detection performance, particularly for cars and trucks.
The results in
Table 1 are tested on the test set officially released by UAVDT. Since our method primarily enhances the handling of multi-scale variations of targets in UAV images, and some of the video sequences have environmental factors such as fog, the mAP50 on the test set is only 2.5% higher than the baseline. To evaluate the effect of this algorithm on multi-scale-variation scenarios and screen out video sequences with environmental factors such as fog, four video sequences—M1001, M0801, M0802, and M1301—are used as new test sets. The outcomes of the tests are presented in
Table 3.
Due to the utilization of our feature alignment aggregation module, our method enhances the effect of feature fusion and improves the detection capability for targets of different scales. The mAP50 value of FB-YOLOv8 reaches 54.7%, which represents a 4.4% improvement over the baseline method, proving the efficiency of our approach in multi-scale-variation scenarios. In these video sequences, where small targets constitute the majority, the alignment operation in our method enables features of different resolutions to spatially correspond, thus enhancing the ability of the model to process both detailed and global information. This greatly enhances the model’s capability to accurately localize small targets, resulting in a substantial increase in detection accuracy. Furthermore, we test the four video sequences of M1001, M0801, M0802, and M1301, respectively, and the outcomes are presented in
Table 4. The results indicate that our method outperforms the baseline method on each video sequence with multi-scale variation.
YOLOv8n and our proposed method detect the visualization results on the UAVDT dataset as depicted in
Figure 11. Our model performs better in multi-scale-changing scenes, can more accurately identify distant, dense small targets, and can better adapt to complex environmental conditions.
4.3. Re-Identification Experiments
The vehicle re-identification experiment aims to tackle the problem caused by the alterations in the appearance of the same vehicle as a result of varying camera angles and distances. These variations tend to diminish the efficacy of traditional object detection and tracking methods. By training the ReID model to correlate the diverse appearance motifs of the same vehicle across various scenes, the recognition accuracy and tracking stability in scenarios with scale variations are enhanced.
We generate a vehicle re-identification dataset with scale variations following the format of the Market-1501 dataset and then conduct experiments on this dataset. We selected sequences from the UAVDT training set, including M0101, M0201, M0501, M0605, M0703, M1304, M1305 and M1306, which represent diverse scenarios. The annotated targets were cropped and organized into a vehicle ReID dataset following the format of the Market-1501 dataset. By localizing and cropping vehicles from 5586 original images, a total of 97,890 images were obtained, encompassing 431 vehicle instances. A comparison between the original images and re-identification data in the UAVDT dataset is illustrated in
Figure 12.
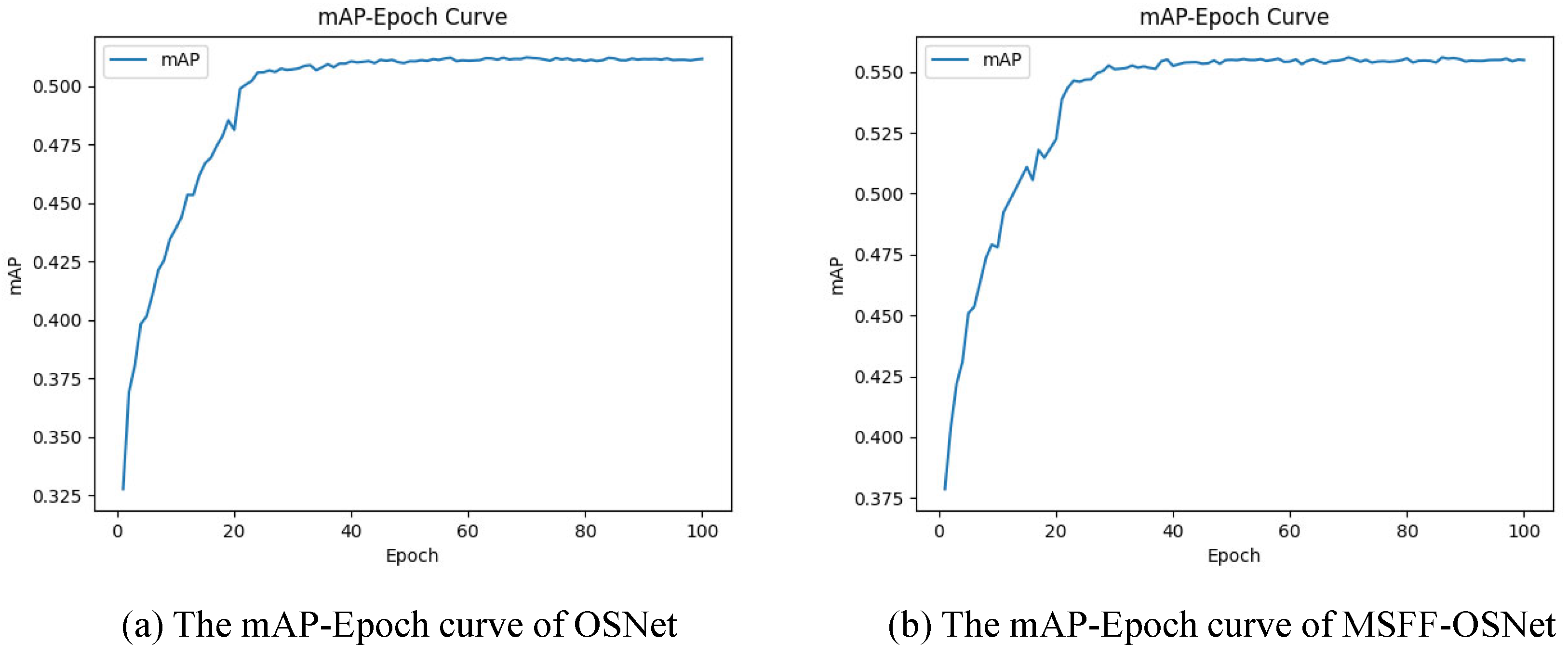
The MSFF-OSNet model proposed by us was employed to train this vehicle re-identification data, resulting in the acquisition of trained weights. The mAP-Epoch curves obtained from the OSNet network model and the MSFF-OSNet network model training are shown in
Figure 13. Based on the curve, it can be seen that the mAP value of MSFF-OSNet on the re-identification dataset is 55.5%, which is 4.3% higher than the mAP value of OSNet. This indicates that the re-recognition accuracy of MSFF-OSNet is improved. In MSFF-OSNet, we use a convolutional attention mechanism to guide the re-identification network in adaptively capturing salient vehicle cues. In
Figure 14, we present the activation map visualizations and performance graphs of MSFF-OSNet and OSNet. It is evident that the OSNet re-identification network struggles to concentrate on key features and may catch something salient but unrelated to the vehicle without guidance. Therefore, based on the analysis of the activation visualization maps, it can be concluded that our proposed improved re-identification network is capable of extracting more fine-grained and discriminative features for targets with varying angles and levels of clarity.
The ablation studies are conducted to quantitatively assess the impact of integrating FPN and CBAM into the MSFF-OSNet framework. The results are presented in
Table 5. It demonstrates that compared to the baseline method, adding only FPN improves IDF1 by 0.4% and reduces the number of IDSW from 1072 to 654. Further incorporating CBAM on this basis enhances IDF1 and MOTA by an additional 1.3% and 0.4%, respectively, and reduces the number of identity switches from 1072 to 552. These findings substantiate our claim that the combination of FPN and CBAM effectively mitigates the identity-switching problem.
4.4. Tracking Experiments
In order to facilitate an extensive comparison, we have performed a series of experiments on the UAVDT dataset and benchmarked the outcomes against other well-established algorithms. The results are detailed in
Table 6. The UAVDT dataset includes a range of difficult scenarios, such as fast-moving targets, intricate backgrounds, and varying scales, which impose stringent requirements on MOT algorithms. The results demonstrate that our tracker attains optimal performance across various metrics, particularly in MOTA, IDF1, and IDSW.
The findings from our experiments indicate that our tracking system exhibits impressive results on the UAVDT dataset, yielding MOTA and IDF1 scores of 48.7% and 80.8%, respectively. Significantly, our tracker surpasses the current leading trackers in performance. For instance, our method significantly surpasses Deep OC-SORT, with MOTA increasing substantially from 39.9% to 48.7% and IDF1 improving markedly from 79.9% to 80.8%. FairMOT, a representative high-precision one-shot tracker, is also exceeded by 7.1% in MOTA and achieves a high IDF1 score (80.8% compared to 80.3%). AsyUAV is a method specialized for multi-target tracking in UAV view, and our method outperforms it by 0.7% in MOTA and 71 in IDSW reduction. Furthermore, compared to other trackers, our method significantly decreases the occurrences of missed detections and ID switches. These results indicate that our approach efficiently boosts tracking accuracy and stability.
4.5. Ablation Study
To assess the effectiveness of the two primary networks, FB-YOLOv8 and MSFF-OSNet, in the complete tracking system, ablation studies are conducted. Specifically, FB-YOLOv8 is primarily employed to improve detection capabilities, while MSFF-OSNet is used to improve the association accuracy of the same target at diverse scales. The results are summarized in
Table 7. To minimize the influence of other environmental factors, such as rain and fog, we selected several sequences, M1001, M0801, M0802, and M1301, with distinct scale-variation characteristics as a new test set, further validating the effectiveness of our method in addressing scale-variation challenges. The test results obtained are displayed in
Table 8.
4.5.1. Effectiveness of FB-YOLOv8
FB-YOLOv8 is responsible for generating information, such as the location and confidence of the detected targets. From the initial two rows of
Table 7, it is clear that incorporating FB-YOLOv8 into the baseline model leads to a notable enhancement in MOTA, rising from 40.2% to 48.1%, while IDF1 also sees an uptick from 61.8% to 67.9%. These improvements demonstrate the efficacy of our FB-YOLOv8 module in boosting detection capabilities and tracking accuracy. From the initial two rows of
Table 8, the addition of FB-YOLOv8 markedly enhances the precision of target tracking in scenarios of varying scale, with MOTA rising from 58.8% to 66.7%.
4.5.2. Effectiveness of MSFF-OSNet
The MSFF-OSNet has effectively augmented the stability of the tracker amid scale variations. As delineated in the first and third rows of
Table 7, MSFF-OSNet has improved IDF1 scores from 61.8% to 63.5% and reduces the number of identity switches from 1072 to 552, demonstrating its capability to enhance the accuracy of target ID association and improve tracking stability. Moreover, using FB-YOLOv8 with MSFF-OSNet further enhances tracking performance significantly. The fourth row of
Table 7 illustrates that our tracking system achieves a MOTA score of 48.7%, an IDF1 score of 67.9%, and decreases the IDSW from 1072 to 278. As depicted in the first and third rows of
Table 8, the addition of MSFF-OSNet significantly improves target tracking stability in scale-varying scenarios, reducing association matching errors, with IDF1 increasing from 73.6% to 75.1% and IDSW decreasing from 198 to 152. The combination of the two modules results in an increase in MOTA from 58.8% to 67.1%, a rise in IDF1 from 73.6% to 77.3%, and a reduction in IDSW by 112 instances. This demonstrates that our tracker has achieved improvements in both tracking accuracy and stability under scale-varying scenarios.
4.6. Visualization and Analysis
To clearly illustrate the benefits of our tracker in scenarios with scale variations, we have compared the visual results of our proposed tracker and the baseline tracker across different UAV motion patterns, as depicted in
Figure 15. When vehicles traverse an intersection, the relative viewing angle with respect to the drone changes, leading to significant alterations in the appearance of the same vehicle. As depicted in the first scenario of
Figure 15, vehicles with IDs 14, 29, and 24 are missed during the turning process at the intersection, and subsequently, ID switches occur when the targets are re-acquired. This indicates that the baseline method is susceptible to the influence of target-scale variations, whereas our approach demonstrates remarkable adaptability to changes in target appearance throughout the process, maintaining stable and continuous tracking. In contrast to the favorable visibility conditions during daylight, nighttime tracking presents a more formidable challenge. In the second nocturnal scenario, variations in the distance between the drone and the targets induce changes in the targets’ scale, a situation where the baseline method demonstrates inadequacies. Specifically, vehicles with ID numbers 18 and 200 are subject to missed detections and identity switches, respectively. However, our method is capable of consistently detecting and tracking these targets with stability. These findings prove that our method is not only proficient in accurately detecting targets undergoing scale variations but also able to maintain continuous and stable tracking of these targets.
5. Conclusions
To tackle the problem of scale variation in vehicle tracking from a UAV perspective, we propose a novel multi-object tracking method based on the TBD framework. To improve the accuracy of target localization in scenarios with multi-scale variations, we have enhanced the general-purpose object detection algorithm YOLOv8 by introducing a novel multi-scale feature alignment aggregation method named FB-YOLOv8. Furthermore, achieving accurate association matching on the basis of high-quality detection is also of paramount importance. To enhance the accuracy of association when targets undergo scale variations, we propose a multi-scale feature-fusion appearance feature-extraction network (MSFF-OSNet) based on the OSNet backbone. This re-identification network is capable of extracting discriminative features of the targets, enhancing the similarity among the same targets, and increasing the disparity among different targets, thereby improving the accuracy of target association. Owing to the integration of these two components, our tracker is adept at detecting targets and maintaining the continuity of their trajectories even in the challenging scenario of scale variation. On the one hand, an analysis of numerous publicly available vehicle datasets captured by UAV revealed that only the UAVDT dataset aligns with the scale-variation scenarios required for our study. Consequently, we have only utilized the UAVDT dataset for validation purposes. In the future, we intend to capture and compile a dataset with scale variations from a UAV perspective and then make it publicly available to facilitate academic research. On the other hand, while the MSFF-OSNet module improves tracking performance, it also increases computational load. For real-time tracking in UAV applications, computational resources are a critical factor to consider. Therefore, we plan to further investigate the lightweight version of the model in future research.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}