Abstract
Maritime surveillance video (MSV) target detection systems are important for maritime security and ocean economy. Hindered by many complex factors, the existing MSV target detection systems have low detection accuracy. These factors include target distance, potential occlusion from rain and fog, and limited computing power of edge devices. To overcome these factors, a high performance and lightweight maritime target detection algorithm (HPMTD) is proposed in this paper. HPMTD consists of three modules: feature extraction, shallow feature progressive fusion (SFPF), and multi-scale sensing head. In the feature extraction module, a global coordinate attention-optimized offset regression module is proposed for deformable convolution. Thus, the ability to handle low visibility and target occlusion issues is enhanced. In the SFPF module, the ghost dynamic convolution combined with low-cost adaptive spatial feature fusion is proposed. In this way, lightweight design can be realized, and multi-scale target-detecting capacity can be increased. Furthermore, multi-scale sensing head is incorporated to learn and fuse scale features more effectively, thus improving localization accuracy. To evaluate the performance of the proposed algorithm, the Singapore Maritime Dataset is adopted in our experiments. The experimental results show that the proposed algorithm can achieve a nearly 10 percent mean average precision value improvement with nearly half the model size, compared with counterparts. Furthermore, the proposed algorithm runs three times faster with only half of the computation resources, and maintains nearly same accuracy in the maritime surface with low visibility. These results demonstrate that the HPMTD achieves lightweight and high-precision detection of marine targets.
1. Introduction
As nations throughout the world focus more on expanding the ocean economy, protecting ocean rights and interests, and ensuring maritime security, research into detecting and identifying maritime targets in surveillance videos recordings has become a critical essential technology and research hotspot [1].
Early researchers employ traditional algorithms [2] such as the Hough transform [3] and Gaussian mixture model [4] to detect maritime targets. With the development of convolutional neural networks, many researchers increasingly employ deep learning-based algorithms for maritime target detection. For example, improved multiscale attention modules based on a convolutional neural network (CNN) model [5,6,7] are used to enhance target detection accuracy in marine environments. Semantic enhancement modules based on a transformer model [8,9,10] are used to enhance the model’s representation of dense targets. SafeSea [11] enhances maritime model training by generating synthetic data that include diverse weather condition backgrounds.
Although the application of these models and algorithms has promoted the development of target detection technology in video surveillance systems, there are still many challenges for maritime target detection and recognition. Firstly, the diversity of scales and types of maritime targets is an important challenge. In maritime video surveillance images, various types and sizes of ships appear from close and far away, such as small sailboats, large oil tankers, container ships, etc. Due to the significant changes in the scale of the objects in the image data, small targets are readily lost, and the detection performance for large and tiny targets varies noticeably. Secondly, the complexity of the marine environment is also a challenge. The marine environment is relatively more complex than that of land, being prone to adverse weather conditions such as rain and fog, and having low-visibility scenes such as early day, night, cloudy days, and so on. It is necessary to establish models that describe different conditions to achieve full coverage of various weather and lighting conditions. On the other hand, the dynamic characteristics of the water surface pose challenges for background modeling and subtraction, such as surges, ship wakes, surface waves, and so on. Furthermore, the limited computing power of monitoring terminals is another issue. Marine surveillance cameras are usually installed near shore, on islands or floats, and need to be deployed on low power (less than 50 W)–low calculation power (less than 50 TOPS) edge computing terminals such as the NVIDIA Jetson series. This also limits the amount of computation required for the algorithm.
RCFNet [12] realizes detection in uncertain scenes and small objects through multimodal fusion, which requires the assistance of one or more efficient sensors. AodeMar [13] proposes a multi-scale feature semantic correlation block that optimizes the Swin Transformer’s self-attentive encoder to alleviate the occlusion problem in detection. LRTransDet [14] combines a convolutional neural backbone network to reduce the size of the Vision Transformer model, and adds a faster weighted feature fusion module and coordinate attention mechanism to improve the overall performance in feature fusion. S-DETR [15] effectively reduces the computation and size of the Detection Transformer model using sparse query awareness. Transformer-based detection models mitigate different detection problems such as variable marine weather and severe occlusion, but the model size is still large. In real deployment, model size and real-time speed are indispensable, as the monitoring model requires confidentiality for edge computing terminal deployment. MDD-ShipNet [10] enhances fog removal by designing a math-data-integrated defogging mechanism and introduces a weighted bidirectional feature pyramid network to improve detection diversity. Light-SDNet [16] adds lightweight ghost and depth-wise convolutions to models. You Only Look Once (YOLO) models are also widely used in marine scenarios [17]. YOLOv8-FAS [18], FE-YOLO [19], and YOLO-RSSD [20] use multi-scale weighted feature fusion to improve the detection efficiency of small ships. Consequently, deploying maritime target detection in real time on terminal devices while ensuring high accuracy remains a challenge.
The aim of this paper is to design a high-performance and lightweight algorithm for maritime target detection, named HPMTD. Firstly, a deformable convolution with an attention mechanism is used to build an efficient feature extraction module to address low-visibility weather and occlusion of maritime targets. Then, a shallow feature progressive fusion network (SFPF) is built using adaptive spatial feature fusion (ASFF, [21]) in combination with ghost dynamic convolution (Ghost-D), which greatly improves detection efficiency while keeping a lightweight design. Finally, a multi-scale enhanced attention module is incorporated to improve the learning capability of fused scale features and assist the model in focusing on detection targets while reducing background interference, further enhancing the model’s localization accuracy.
The main contributions of this paper are as follows:
(1) A feature extraction module with attention-based deformable convolution is constructed. The offset regression module is optimized by introducing an enhanced coordinate attention (CA) module to facilitate the learning of deformable convolution offsets, thereby enhancing the feature extraction capability and improving model detection performance.
(2) A lightweight shallow feature progressive fusion network is constructed. Specifically, Ghost-D is constructed as a feature fusion transition layer by combining the ghost convolution and the dynamic convolution to reduce the network parameters and computation, and ASFF is used to reduce the feature loss and degradation problem during multi-scale fusion to cope with various uncertain scenarios in the ocean. Meanwhile, a small target detection layer is added to alleviate the problem of target scale diversity.
(3) Introducing a scale-aware attention module into the multi-scale sensing head to learn and fuse the target scale features better and improve the accuracy of target detection.
The following chapters are arranged as follows: Section 2 introduces the relevant work on the improvement points of this paper. Section 3 introduces the overall network architecture of HPMTD built in this paper, while Section 4 further conducts model comparison experiments and ablation experiments on HPMTD. Finally, Section 5 summarizes the overall effect of HPMTD.
2. Related Work
2.1. Def Ormable Convolution Target Detection
To achieve efficient target detection, deformable convolutional series networks (DCNs) are commonly used to improve target feature extraction, enhancing its shape adaptation [22,23,24]. Trans-DCN and DCN-BBAV [25,26] use DCNv2 to optimize the feature fusion and the backbone network to achieve an efficient feature extraction encoder. DSAN [27] presents deformable spatial attention constructed from DSCN to reduce the number of parameters and the computation of DCNv3.
DCNv3 uses numerous ways to combine feature subspaces from diverse locations to gather richer information; nevertheless, this significantly increases computational requirements, making it unsuitable for deploying lightweight networks. DCNv2 is more suitable for lightweight networks.
2.2. Lightweight in Target Detection
Maritime surveillance cameras are typically installed near shores, islands, or buoys. Due to limitations such as cost, geographical conditions, communication networks, and power supply, models with fewer parameters are more advantageous for practical deployment. Lightweight convolutions [28,29] have been a research focus in maritime target detection. GSNet [30] builds a lightweight detection model by integrating ghost modules into the feature fusion module and detection head through a neural architecture search. DSC-Ghost-Conv [31] proposes a novel compact convolution module by combining depth-separable convolution and ghost convolution.
Effective multi-scale feature fusion can integrate low-level features and high-level features from different scales, significantly improving detection efficiency. In our previous research, we also found that feature fusion can remain lightweight while being efficient [32]. On this basis, a more lightweight ghost dynamic convolution is utilized to enhance feature fusion performance.
3. The Proposed Method
3.1. Architecture of the HPMTD
The basic architecture of HPMTD is shown in Figure 1. It mainly consists of three modules: feature extraction, shallow feature progressive fusion (SFPF), and a multi-scale sensing head.
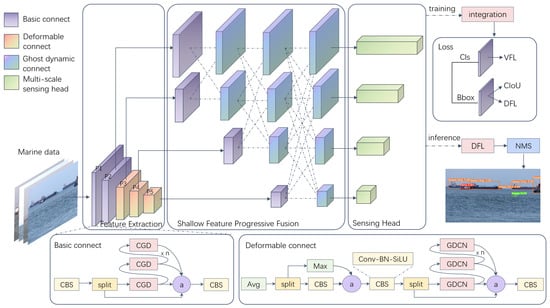
Figure 1.
Architecture of the HPMTD.
The feature extraction is divided into two parts, P1–P2 and P3–P5. P1–P2 is the basic connection layer to avoid insufficient high-level semantic feature information in the shallow part of the model. P3–P5 are deformable convolution connection layers. To solve the previously mentioned problem, DCNv2 is chosen as the deformable connection layer. It enhances the attention capability to target feature areas without incurring significant inference overhead. Furthermore, global coordinate attention (GCA) is introduced to assist in the regression of offsets, suppressing interference from the surrounding environment and capturing more accurate semantic information. In Figure 1, CBS represents the Convolution-BatchNorm-SiLU structure, and CGD represents the transition layer using the Ghost-D (see Section 3.3 for details). GDCN represents the optimized DCNv2, the specific details of which are introduced in Section 3.2.
The SFPF gradually fuses network features from shallow layers to deep layers, and employs ASFF to establish cross-scale feature fusion modules to enhance the interaction between levels and capture the detail information and global semantic information better. As with the feature extraction setup, the fusion module is preceded by a basic connection layer for one feature transformation, then introduces Ghost-D as the fusion connection layers, lowering network parameters and computing costs to achieve lightweight design. Simultaneously, the feature extraction module incorporates Ghost-D as a fusion connection layer to further reduce the overall network parameters. This integration enhances efficiency while maintaining performance in feature extraction.
The multi-scale sensing head adopts a decoupled head structure to separate the classification task from regression task. The regression task is used to predict the target bounding box position. The classification branch uses varifocal loss (VFL) to measure the classification accuracy. The regression branch uses complete IoU loss (CIoU) to measure the position accuracy of the prediction box. Distribution focal loss (DFL) calculates the difference between the predicted feature point and the real feature point to help locate the feature point location more quickly. The addition of a multi-separated and enhancement attention module (MultiSEAM [33]) helps the model focus on the detection target.
The overall workflow of the model is as follows: the images are input into the feature extraction network and are first processed by the P1–P2 basic connection layer. Then, the improved deformable convolution module P3–P5 is used for feature extraction. To make the model more lightweight, downsampling combined with improved deformable convolution is used. Then, after a feature transformation to achieve fusion transition, the multi-scale feature fusion process based on SFPF is performed to obtain the required feature information of the detection head. Finally, the multi-scale sensing head uses decoupled heads to calculate classification loss and regression loss in training mode, and uses the DFL layer to fuse the detection head information. The final detection and recognition results output through non-maximum suppression (NMS) during inference are then obtained.
3.2. Improvement of Feature Extraction Module
In order to better handle the occlusion and low-visibility problems of maritime targets and adapt to different target shapes and local details, the DCNv2 is introduced to the HPMTD model. Specifically, the convolution range R is expanded by adding an offset . A constraint is imposed on the offset , while a weight is predicted for each sampling point. The process is expressed by Equation (1):
where p is the feature at on the input–output feature map. Take the size of the convolution kernel 3*3 as an example. For any point on the input feature map, represents the value of the element at the position on the output feature map. It is obtained by the convolution kernel and input feature map. The variable represents the offset of each point in the convolutional kernel relative to the center point, and the movement range is . The variable denotes the weight corresponding to the point n, denotes the learnable offset for deformable convolution, and denotes the modulation parameter of weights for the position n of the sampling point.
To improve the learning performance of deformable convolution offsets, an attention module is introduced to impose constraints on the offset in the offset regression module. The overall structure is illustrated in Figure 2. By adding offset attention, adaptive weighting of the importance of different channels is performed in the channel dimension while modeling the correlation between pixels in the spatial dimension.
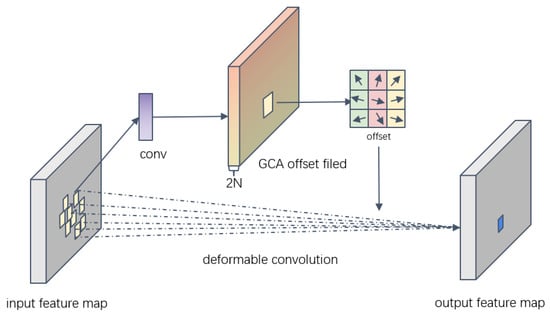
Figure 2.
Structure of deformable convolutional structures with attention.
The offset constraint utilizes CA [34], which has fewer parameters, as the basic attention mechanism. A global spatial information encoding branch is then incorporated to simulate the spatial relationships between pixels in the feature map, resulting in the creation of GCA. Introducing GCA to optimize the deformable convolutional offset regression module (GDCN) helps the learning of the deformable convolutional offset, enhances the feature extraction ability of the network, and improves the detection performance of the model.
Algorithm 1 provides the algorithm flow of the GCA mechanism. First, CA uses adaptive average pooling to reduce the height and width of the feature map to 1, generating and . Next, CA processes and using convolution functions and a sigmoid activation function to generate weight coefficients for each channel. Finally, the obtained weights are applied to the original feature map to perform channel weighting operations. Building on CA, global average pooling is introduced to enhance the spatial relationship of the feature map. By applying the weighted channel attention in both the vertical and the horizontal directions to the global directional features, three features are fused to assist in judgment, thereby balancing the attention direction of the input feature information.
| Algorithm 1: Global Coordinate Attention Algorithm |
| Input: number of channels c, input feature map; Output: weighted feature map
|
| . |
|
| . |
| . |
|
| . |
| . |
|
| . |
|
| . |
3.3. Construction of Shallow Feature Progressive Fusion Module
The purpose of the SFPF is to integrate low-level features and high-level features at different scales to improve the efficiency of target detection. Due to the size differences and different distances of maritime targets, the photographed images usually appear as small targets and may also be occluded, which requires the feature fusion stage to pay more attention to the information of small targets. Therefore, the shallow network feature P2 is introduced to construct a shallow feature progressive fusion structure for fusion processing.
The SFPF structure is shown in Figure 3, where it can be seen that 1 × 1 convolution and bilinear interpolation are used for feature upsampling. Downsampling is based on different convolution kernels and strides. CBS (Convolution-BatchNorm-SiLU) represents traditional convolution, and CGD represents the transition layer using the Ghost-D. The specific details of the CGD are shown in Figure 4. The shallow stage P2 focuses more on information about small targets, so the feature information extracted by P2 will be integrated into the feature maps of the subsequent four detection heads. Conversely, the P5 layer that focuses on large targets does not need too much attention. A progressive structure is adopted to gradually fuse the deep network from the shallow network. In this way, the large semantic gap between non-adjacent levels can be avoided.
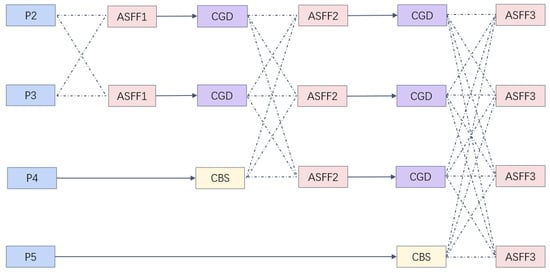
Figure 3.
Shallow-feature progressive fusion module structure. Black arrows indicate ordinary convolution, and dotted lines represent cross-scale fusion connections in ASFF.
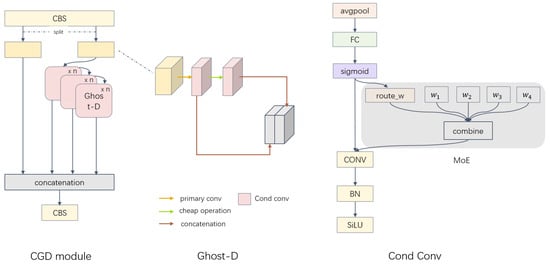
Figure 4.
Fusion transition layer architecture for connection-based modeling.
The ASFF operation adaptively learns the fusion spatial weights of each scale feature map, enhancing the interaction between non-adjacent layers and preventing the loss or degradation of feature information during transmission and interaction. This improves the scale invariance of features with almost no additional overhead. To further lighten the model, ghost convolution is used instead of ordinary convolution, and dynamic convolution is combined with ghost convolution as a fusion transition layer connecting the middle of the model to further improve detection efficiency. After the transition layer, ASFF is used to fuse cross-scale feature information.
In Figure 4, the CGD has two branching modules: the main gradient flow branch and the secondary gradient flow branch. The secondary gradient flow branch is similar to the hopping layer connection to splice with the main gradient flow branch. Ghost-D is the main gradient flow branch. It can be divided into two parts: the primary branch and the ghost branch. The backbone branch primary conv(1 × 1) convolution aggregates information features between channels, while the extra branch’s cheap operation is used to introduce additional information. The computational effort is further reduced by using conditionally parameterized convolutions (CondConv, [35]) instead of traditional convolution. Finally, the two sets of feature maps are stitched together to obtain the final output. Compared with traditional convolution, the branching module of Ghost-D effectively reduces the redundant computation brought by the ordinary convolution in bottleneck and reduces the number of parameters without weakening the feature extraction ability. Higher feature extraction is achieved with fewer parameters and richer information is gained about the gradient flow. The main difference between dynamic convolution CondConv and traditional convolution is MoE’s efficient dynamic convolution layer, which increases the number of parameters many times with little additional FLOP.
A dynamic convolution with m dynamic experts can be written as Equation (9), where is the output feature map and is the input feature map. The symbol ∗ is the convolution operation. is the i-th convolution weight tensor. The coefficient is dynamically generated based on input samples.
Here, the number of m experts is set to 4. Equation (3) shows the generation of . For input X, global average pooling is first performed on the input to obtain a vector with a channel size equal to . An m-dimensional vector is then obtained by the fully connected function, and then the dynamic coefficient is generated by a sigmoid constraining the values to [0, 1].
3.4. Improvement of Multi-Scale Sensing Head
To better learn different scale feature information and help the model focus on detection targets, a scale-aware attention module is introduced. Firstly, to obtain more comprehensive and multi-scale information, MultiSEAM adopts three groups of CBS modules with residual connections to learn the importance of different channels through using different strides and reducing the number of parameters. The average of the features of the four channels is calculated, and then information from each channel is fused through a fully connected layer, thereby enhancing the connectivity between channels. Finally, the output log of the fully connected layer is processed using an exponential function. This exponential normalization provides a monotonic mapping relationship, making the result more tolerant to position errors.
Figure 5 shows the structure diagram of the multi-scale sensing head with the added scale-aware module. First, CBS is used for feature fusion and transformation, then the MultiSEAM module is used to enhance the ability to focus on target areas and stronger feature expression. After that, the obtained prediction results are used for classification loss calculation using VFL and bounding box loss calculation using CIOU and DFL.
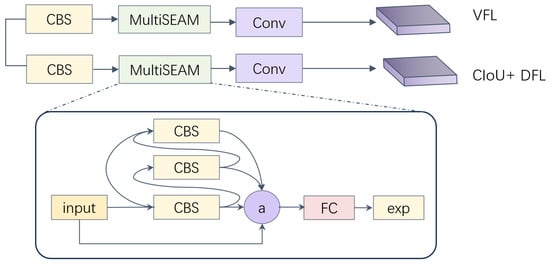
Figure 5.
Structure of the multi-scale sensing head.
4. Experiment and Analysis of Results
4.1. Dataset Preparation and Evaluation Indicators
The Singapore Maritime Dataset (SMD) [36] includes coastal surveillance data from a variety of environments. This dataset contains occlusions and category imbalances that are common in marine environments. Furthermore, the presence of inaccurate labels and loosely defined bounding boxes within the ground truth data presents multifaceted challenges for maritime target detection models.
The video data in the SMD are sampled every five frames, yielding a total of 6350 maritime images, which are randomly divided into training, validation, and test sets in a 6:2:2 ratio, and the dataset is organized into the structure of the COCO dataset. The SMD dataset contains nine categories: ferry, buoy, vessel, speedboat, boat, kayak, sail, bird, and other.
To comprehensively assess the performance and accuracy of our proposed target detection model, we employed a set of widely recognized evaluation metrics in the field of target detection. These metrics include precision (P), recall (R), and mean average precision (mAP) with intersection over union (IoU) thresholds ranging from 0.5 to 0.95 in 0.05 steps, which collectively provide insights into the model’s detection accuracy. Additionally, we considered the number of parameters (Params) and giga floating-point operations per second (GFLOPs) to evaluate the model’s computational efficiency and resource requirements.
4.2. Experimental Environment Setup
Experiments were performed on an Nvidia GeForce RTX 3090 GPU and conducted using a gradient descent algorithm with momentum as the model optimization algorithm, with the momentum value taken as 0.937, while maintaining a consistent input image size of 640 × 640 pixels and a batch size of 16 throughout the training process. Notably, we opted to train the model from scratch, foregoing the use of pre-trained weights, and conducted the training over a span of 250 epochs to ensure thorough model convergence. Furthermore, to optimize the learning process, we initialized the learning rate at 0.01 and implemented a linear decay strategy for its adjustment, complemented by a warm-up strategy during the first 15 epochs—gradually increasing the learning rate from 0 to its initial value.
4.3. Comparison of Different Algorithms
To assess HPMTD against other detection models, we measured mAP, model parameters, GFLOPs, and inference latency on the SMD dataset. Table 1 shows the comparative effectiveness of this paper’s algorithm with the current state-of-the-art mainstream detection models. The mAP and overall mAP metrics for different categories are shown separately. The mAP in the table indicates overall mAP, with IoU thresholds ranging from 0.5 to 0.95 in 0.05 steps. Small models, large models, and the real-time Transformer RTDETR [37] were selected for comparison. In this paper, RTMDet-m [38], YOLOv6s [39], and YOLOv8s [40] are regarded as small models; YOLOv7 [41] and YOLOv8m are regarded as large models. HPMTD has 8.7% higher mAP than YOLOv6s and 5.1% higher mAP than YOLOv8s while being more compact and lightweight. Compared to the latest RTDETR models, HPMTD’s mAP is comparable, with half the computational effort and 3.2 times the speed-up. Yolov7 seems to have difficulty converging when there are a lot of particularly small and difficult to detect targets in the dataset. This also results in YOLOv7 being lower than other model metrics overall. HPMTD achieves good results in terms of both model size and model accuracy. The HPMTD model is only 1/4 the size of YOLOv7, but its mAP is 6.1% higher than that of the existing YOLOv7 and 1.5% higher than that of YOLOv8m. At the same time, HPMTD has a better detection effect on small targets such as boats and kayaks than others CNN models.

Table 1.
The experimental results with different target detection models on the SMD dataset.
In summary, the algorithm proposed in this paper focuses more on the improvement of difficult sample detection. This makes the algorithm show better indicators on the daily and difficult-to-detect dataset of SMD. HPMTD achieves a more lightweight and efficient detection standard, which effectively realizes lightweight and high-precision ship detection.
In Figure 6, the SMD results from S-DETR [15], FE-YOLO [19], and the model adopted in [32] (named ABAO-MTD) are compared with those of HPMTD, and the yellow box is used to distinguish the differences between HPMTD and other models. The left side shows other models, which are, from top to bottom, the S-DETR model, the FE-YOLO model, and the ABAO-MTD model, and the right side shows the comparison of the effect of the HPMTD model. HPMTD has a significant advantage in detecting very small targets that are difficult to detect, such as an aircraft in the sky (in S-DETR) and a person on a ship (in ABAO-MTD). HPMTD also has an obvious advantage in detecting severely occluded targets, such as the occluded ferry in FE-YOLO. In addition, the detection frame is closer to the target itself, and the detection effect of HPMTD is more stable.

Figure 6.
The above figure shows the results of different models compared with HPMTD on the SMD dataset. The left side shows the other models, which are, from top to bottom, the S-DETR model, the FE-YOLO model, and the ABAO-MTD model, and the right side shows the HPMTD model comparison.
4.4. Comparison Experiments
To evaluate the effectiveness of GDCN, which is the proposed deformable convolution with GCA in the model, we analyzed and compared three configurations: traditional convolution, DCNv2, and DCNV3. The experimental results are presented in Table 2. From Table 2, it can be observed that DCNv2 exhibits no significant time difference compared to traditional convolution, whereas DCNv3 shows nearly double the times. Notably, GDCN improves the mAP by 1.5% over traditional convolution without increasing the computational time.
Table 2.
Comparison experiment of DCNv2 before and after improvement on the SMD dataset.
Table 3 shows the comparative effects of three different feature fusions. They are PAFPN, HSFPN, and SFPF. All of them incorporate P2 connection layers. For quantitative comparison, the feature extraction modules all use GDCN. The number of parameters and computation amount of SFPF are lighter compared to PAFPN and HSFPN, but the P, R, and mAP metrics are improved in all aspects. The computation amount of SFPF is only half of that of HSFPN, and the mAP index is 1.2% higher.
Table 3.
Comparative experiments on the fusion of different features.
4.5. Ablation Experiments
This section presents the ablation studies to illustrate the effects of GDCN, SFPF, and MultiSEAM in the detection algorithm. They represent three modules: the feature extraction module, the feature fusion module, and the detection head module, respectively. The ablation studies are shown in Table 4, where ✓ and ✗ denote the detection model with or without relevant modules, respectively. The GDCN module in the table incorporates Ghost-D. As seen in the second row, when using the GDCN module alone, the parameter count decreases by 2.54 M, while the mAP improves by 1.9% compared to the baseline model. With the SFPF module alone, the parameter count decreases by 4.06 M, while the mAP improves by 3.7% compared to the baseline model. When SFPF is combined with the GDCN module, the parameter count further decreases by 0.98 M, and the mAP increases by 0.9%. Finally, HPMTD achieves 98.4% accuracy on the mAP0.5 index.
Table 4.
Ablation experiments.
Examples of HPMTD detection effects on the SMD test set are displayed in Figure 7. It includes the HPMTD model’s detection results for maritime targets in a variety of weather situations, including sunny, overcast, and foggy. As can be seen from Figure 7, HPMTD detects targets and their corresponding categories accurately on the maritime targets, such as vessels, ferries, and sailboats. Buoys and other small targets are also detected accurately under sunny conditions.

Figure 7.
Detection effects in different weather.
Figure 8 shows using the HPMTD model to detect data collected in foggy weather. From the detection effect, it can be seen that the model can detect sea vessels better even in foggy weather. It has certain robustness.

Figure 8.
Detection effect of foggy scene in the field.
5. Conclusions
The aim of this paper is to propose a deep learning-based target detection algorithm for sea area, and the experimental results show that the proposed model has achieved significant improvement and optimization in terms of scale change, target size difference, and complex scenes. For many scenes in practical applications, there are weather effects, occlusion, etc., which can be further explored in terms of the applicability of the model.
In order to solve the problem of how to achieve high-precision maritime target detection in real-time deployment on terminal equipment, this paper designs a lightweight and efficient marine target detection network model framework, HPMTD, from the perspective of the model. By introducing GCA to optimize the offset regression module, it helps with the learning of the deformable convolutional offset, enhances the feature extraction ability of the network, and improves the detection performance of the model. The adaptive fusion module based on the ASFF was used to build a progressive feature fusion module with a small target layer to reduce the problem of feature loss and degradation in the process of multi-scale fusion so as to cope with various uncertain scenarios in the ocean. The Ghost-D module is constructed as a feature fusion layer to reduce network parameters and computational costs, achieve lightweight and solving the problem of diversity of target scales. By introducing the scale-aware attention module into the detection head, the positioning ability and detection accuracy of the detection target are improved when the image resolution and quality are low. The results of comparison and ablation experiments show that the calculation cost of the HPMTD model is only half of that of RTDETR and the speed is increased by three times when the accuracy of the HPMTD model is the same.
Author Contributions
S.S.: writing—original draft, writing—review and editing, conceptualization, formal analysis, investigation, data curation, methodology, resources, supervision, software, visualization, validation. Z.X.: writing—original draft, writing—review and editing, conceptualization, formal analysis, investigation, methodology, validation, visualization, supervision, funding acquisition. X.C.: writing—original draft, writing—review and editing, conceptualization, formal analysis, funding acquisition, investigation, methodology, resources, supervision, validation. J.Z.: writing—original draft, writing—review and editing, funding acquisition. J.Y.: writing—review and editing, software, visualization. N.J.: writing—review and editing, software, visualization. All authors have read and agreed to the published version of the manuscript.
Funding
This work was financially supported by the science and technology key projects of the Xiamen Ocean and Fishery Development Special Fund Project (No. 21CZB013HJ15); the Xiamen Key Laboratory of Marine Intelligent Terminal R&D and Application (No. B2024008); the Education Department Foundation of Fujian Province (JAT190531); the Fujian Provincial Natural Science Foundation of China (No. 2024J01120); the National Science Foundation of Xiamen, China (No. 3502Z202372013); the Open Project of the Key Laboratory of Underwater Acoustic Communication and Marine Information Technology (Xiamen University) of the Ministry of Education, China (No. UAC202304); the Fujian Province Young and Middle-aged Teacher Education Research Project (No. JAT220182); the Jimei University Startup Research Project (No. ZQ2022015); and the Scientific Research Foundation of Jimei University (No. ZP2023010).
Data Availability Statement
The dataset presented in this study can be downloaded here: https://sites.google.com/site/dilipprasad/home/singapore-maritime-dataset, (accessed on 10 January 2017).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Felski, A.; Zwolak, K. The ocean-going autonomous ship—Challenges and threats. J. Mar. Sci. Eng. 2020, 8, 41. [Google Scholar] [CrossRef]
- Lyu, H.; Shao, Z.; Cheng, T.; Yin, Y.; Gao, X. Sea-surface object detection based on electro-optical sensors: A review. IEEE Intell. Transp. Syst. Mag. 2022, 15, 190–216. [Google Scholar] [CrossRef]
- Fefilatyev, S.; Goldgof, D.; Shreve, M.; Lembke, C. Detection and tracking of ships in open sea with rapidly moving buoy-mounted camera system. Ocean Eng. 2012, 54, 1–12. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, J.; Chen, Z.; Kang, Z. Ship target detection algorithm for maritime surveillance video based on gaussian mixture model. J. Phys. Conf. Ser. 2018, 1098, 012021. [Google Scholar] [CrossRef]
- Fu, H.; Song, G.; Wang, Y. Improved YOLOv4 marine target detection combined with CBAM. Symmetry 2021, 13, 623. [Google Scholar] [CrossRef]
- Chang, L.; Chen, Y.T.; Wang, J.H.; Chang, Y.L. Modified yolov3 for ship detection with visible and Infrared images. Electronics 2022, 11, 739. [Google Scholar] [CrossRef]
- Zheng, J.; Sun, S.; Zhao, S. Fast ship detection based on lightweight YOLOv5 network. IET Image Process. 2022, 16, 1585–1593. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, S.; Zhao, J.; Yao, R.; Xue, Y.; El Saddik, A. CLT-Det: Correlation learning based on transformer for detecting dense objects in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, L.; Meng, H.; Zhang, Z.; Yang, C. Ship Detection in Maritime Scenes under Adverse Weather Conditions. Remote Sens. 2024, 16, 1567. [Google Scholar] [CrossRef]
- Wang, N.; Wang, Y.; Feng, Y.; Wei, Y. MDD-ShipNet: Math-Data Integrated Defogging for Fog-Occlusion Ship Detection. IEEE Trans. Intell. Transp. Syst. 2024, 25, 15040–15052. [Google Scholar] [CrossRef]
- Tran, M.; Shipard, J.; Mulyono, H.; Wiliem, A.; Fookes, C. SafeSea: Synthetic Data Generation for Adverse & Low Probability Maritime Conditions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024; pp. 821–829. [Google Scholar] [CrossRef]
- Wei, Q.; Jiang, X.; Liu, Y.; Su, Q.; Yu, M. Small Object Detection on the Water Surface Based on Radar and Camera Fusion. In Proceedings of the ICASSP 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 8381–8385. [Google Scholar] [CrossRef]
- Wang, N.; Wang, Y.; Feng, Y.; Wei, Y. AodeMar: Attention-Aware Occlusion Detection of Vessels for Maritime Autonomous Surface Ships. IEEE Trans. Intell. Transp. Syst. 2024, 25, 13584–13597. [Google Scholar] [CrossRef]
- Feng, K.; Lun, L.; Wang, X.; Cui, X. LRTransDet: A real-time SAR ship-detection network with lightweight ViT and multi-scale feature fusion. Remote Sens. 2023, 15, 5309. [Google Scholar] [CrossRef]
- Xing, Z.; Ren, J.; Fan, X.; Zhang, Y. S-DETR: A transformer model for real-time detection of marine ships. J. Mar. Sci. Eng. 2023, 11, 696. [Google Scholar] [CrossRef]
- Zhang, M.; Rong, X.; Yu, X. Light-SDNet: A lightweight CNN architecture for ship detection. IEEE Access 2022, 10, 86647–86662. [Google Scholar] [CrossRef]
- Xu, Z.; Xu, D.; Lin, L.; Song, L.; Song, D.; Sun, Y.; Chen, Q. Integrated Object Detection and Communication for Synthetic Aperture Radar Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 294–307. [Google Scholar] [CrossRef]
- Xing, B.; Wang, W.; Qian, J.; Pan, C.; Le, Q. A lightweight model for real-time monitoring of ships. Electronics 2023, 12, 3804. [Google Scholar] [CrossRef]
- Xu, D.; Wu, Y. FE-YOLO: A feature enhancement network for remote sensing target detection. Remote Sens. 2021, 13, 1311. [Google Scholar] [CrossRef]
- Si, J.; Song, B.; Wu, J.; Lin, W.; Huang, W.; Chen, S. Maritime Ship Detection Method for Satellite Images Based on Multiscale Feature Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 6642–6655. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar] [CrossRef]
- Wang, W.; Dai, J.; Chen, Z.; Huang, Z.; Li, Z.; Zhu, X.; Hu, X.; Lu, T.; Lu, L.; Li, H.; et al. Internimage: Exploring large-scale vision foundation models with deformable convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 14408–14419. [Google Scholar] [CrossRef]
- Huang, Z.; Guo, B.; Deng, X.; Guo, W.; Min, X. Trans-DCN: A High-Efficiency and Adaptive Deep Network for Bridge Cable Surface Defect Segmentation. Remote Sens. 2024, 16, 2711. [Google Scholar] [CrossRef]
- Chen, H.; Wang, K. Fusing DCN and BBAV for Remote Sensing Image Object Detection. Int. J. Cogn. Inform. Nat. Intell. 2023, 17, 1–16. [Google Scholar] [CrossRef]
- Yu, Z.; Zhang, X.; Zhao, L.; Xiao, G. DSAN: Exploring the Relationship between Deformable Convolution and Spatial Attention. TechRxiv 2024. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar] [CrossRef]
- Yao, F.; Wang, S.; Ding, L.; Zhong, G.; Bullock, L.B.; Xu, Z.; Dong, J. Lightweight network learning with zero-shot neural architecture search for uav images. Knowl. Based Syst 2022, 260, 110142. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, S. Dsc-ghost-conv: A compact convolution module for building efficient neural network architectures. Multimed. Tools Appl. 2023, 83, 36767–36795. [Google Scholar] [CrossRef]
- Zheng, J.; Zhao, S.; Xu, Z.; Zhang, L.; Liu, J. Anchor boxes adaptive optimization algorithm for maritime object detection in video surveillance. Front. Mar. Sci. 2023, 10, 1290931. [Google Scholar] [CrossRef]
- Chen, W.; Huang, H.; Peng, S.; Zhou, C.; Zhang, C. YOLO-face: A real-time face detector. Vis. Comput. 2021, 37, 805–813. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar] [CrossRef]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. Adv. Neural Inf. Process. Syst. 2019, 117, 1307–1318. [Google Scholar] [CrossRef]
- Prasad, D.K.; Rajan, D.; Rachmawati, L.; Rajabally, E.; Quek, C. Video Processing from Electro-optical Sensors for Object Detection and Tracking in Maritime Environment: A Survey. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1993–2016. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs beat YOLOs on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar] [CrossRef]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. RTMDet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Joher, G.; Chaurasia, A.; Qiu, J. YOLOv8. Available online: https://github.com/ultralytics/ultralytics (accessed on 27 August 2024).
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).