3.1. Dataset Preparation
This study uses both real and synthetic datasets for training and testing. The parameters of the six datasets are detailed in
Table 1. The training datasets are generated by combining real background images with simulated aerial targets. The background data are sourced from on-orbit remote sensing IR images, while the aerial targets are simulated using a two-dimensional Gaussian model that reflects realistic motion trajectories and grayscale variations. The camera is simulated to operate in staring mode. As shown in
Table 1, Dataset 1 contains 11,600 images, Dataset 2 contains 13,400 images, Dataset 3 contains 13,400 images, Dataset 4 contains 399 images, Dataset 5 contains 169 images, and Dataset 6 contains 399 images.
The Society of Photo-Optical Instrumentation Engineers (SPIE) defines small targets as those occupying less than 0.15% of the entire image. Dataset 1 has an image resolution of 512 × 512 pixels, with target sizes set to 11 × 11 pixels. Each scene contains 1–3 targets, moving at a speed of 1–1.4 pixels per frame. The SNR is defined as the ratio of the target’s central grayscale value to the standard deviation of the image grayscale, with the mean SNR set to 2. To simulate relatively stationary observation conditions, platform jitter is set to subpixel levels. The background data are derived from images captured by an on-orbit MWIR camera, encompassing various background types such as cityscapes, clouds, sea, and land. The dataset consists of 58 scene sequences, each containing 200 frames.
In Datasets 2 and 3, the background data are derived from the QLSAT-2 high-resolution optical camera, the core payload of QLSAT-2 developed by the Shanghai Institute of Technical Physics (SITP). The QLSAT-2 long-wave infrared (LWIR) camera has a ground resolution of 14 m at an altitude of 500 km. Both datasets use real remote sensing LWIR images as backgrounds, including scenes such as cities, land, and clouds. In real scenarios, a satellite platformingjitter follows a distribution with a standard deviation of approximately 0.004°, resulting in platform speeds set between zero and three pixels per frame. The original imaging size of the targets in Dataset 2 is 11 × 11 pixels, with a mean SNR of 4. In Dataset 3, the target size is 5 × 5 pixels, and the mean SNR is also set to 4.
Datasets 4 and 6 are sourced from the public NUDT-SIRST dataset, which features moving UAVs in a sky background [
46]. The MWIR image size is 256 × 256 pixels. Dataset 4 contains 399 frames, with two targets, an average motion speed of 0.4 pixels per frame, and an average SNR of 4.34. Dataset 6 includes 399 frames, with two targets, an average speed of 0.5 pixels per frame, and an average SNR of 3.75.
Dataset 5 comprises real remote sensing data captured by the QLSAT-2 LWIR camera, focusing on a civil aircraft near a civilian airport in staring mode. The target size in Dataset 5 is 5 × 5 pixels, with a mean SNR ranging from 2 to 5. The average target velocity is 0.63 pixels per frame, while the platform velocity ranges from one to two pixels per frame.
The trigger rate is set within the range of 3–10% for Dataset 1, 5–10% for Datasets 2, 3, and 5, and 2–8% for Datasets 4 and 6. The testing showed that accumulating five event frames yielded the best performance.
The simulation datasets (Datasets 1, 2, and 3) are divided into training, validation, and test sets with an 8:1:1 ratio. To evaluate the model’s generalizability, real IR image sequences are used for testing.
To further advance research in IR event processing algorithms, this paper includes Dataset 3, named SITP-QLEF, as an IR event frame dataset.
3.2. Evaluation Metrics
The commonly used evaluation metrics for target detection are precision and recall:
where
is true positive,
is false positive, and
is false negative. The F1 score is defined as
Since target detection involves both classification and localization tasks, the Intersection over Union (IoU) metric is employed to compare the predicted and true target regions. IoU is defined as follows:
where
is the area of the predicted bounding box, and
is the area of the ground truth bounding box. The IoU ranges from 0 to 1, with values closer to 1 indicating higher prediction accuracy. When the IoU exceeds a specified threshold, the detection is considered positive. In practical scenarios, precision and recall often trade off against each other. To evaluate the overall balance between these two metrics, the mean average precision (mAP) is employed, which serves as a crucial metric in DL-based target detection tasks:
where
m represents the number of classes, and
refers to the average precision, calculated as the area under the precision–recall curve. The paper uses mAP@0.5 and mAP@0.5:0.95 as evaluation metrics. The mAP@0.5 denotes the mAP at an IoU threshold of 0.5, while the mAP@0.5:0.95 represents the mAP averaged over IoU thresholds ranging from 0.5 to 0.95, in increments of 0.05.
DR and FR are widely used evaluation metrics and are calculated as follows:
where
represents the number of correctly detected targets,
is the total number of true targets,
refers to the number of incorrectly detected targets, and
denotes the total number of pixels in the detected image. This paper evaluates the model’s processing speed using parameters such as parameter count (PC), floating point operations (FLOPs), inference time, and frames per second (FPS).
3.3. Quantitative Results
To evaluate the performance of the proposed network, comparisons were made with SOTA data-driven target detection algorithms, including RT-DETR-l, YOLOv8n, YOLOv8s-worldv2, YOLOv9t, YOLOv10n, and YOLO11n. Each algorithm was trained on Datasets 1, 2, and 3, and subsequently tested on Datasets 4, 5, and 6. Experiments were conducted on an Intel(R) Core(TM) i9-14900HX 2.20 GHz CPU and an NVIDIA GeForce RTX 4060 Laptop GPU. All algorithms were trained for 200 epochs, with an early stopping strategy employed to mitigate overfitting. The optimizer for the proposed network was stochastic gradient descent (SGD) with a learning rate of 0.01. The best-performing results are highlighted in bold within the tables.
In Dataset 1, the detection scene remains relatively stationary relative to the detector. Despite the complex remote sensing background, the adaptive event-triggered mechanism effectively suppresses the background, leading to fewer background events and minimal interference with target detection. Notably, the SNR of the targets in Dataset 1 is lower than in other datasets, yet this does not impact the overall detection performance. Even when the targets are embedded in a complex background, the proposed algorithm successfully detects dim aerial targets, demonstrating its robust capability in capturing weak and moving targets. As shown in
Table 2, the proposed method significantly outperforms other algorithms on Dataset 1. It achieves an mAP@0.5 of 96.8%, representing an improvement of 8.28% over the latest YOLO11n. The mAP@0.5:0.95 reaches 85.2%, the highest among the compared algorithms, with a substantial improvement of 33.13% over YOLO11n. The method also demonstrates superior performance in other metrics, achieving a mean F1 score of 93.6%, surpassing the SOTA benchmarks. Additionally, when the FR is 7
, the DR of this method reaches 97.1%. With only 2.9 M parameters, 6.6 G FLOPs, a 2.4 ms inference time, and a frame rate of 285.1 FPS, this method not only ranks highly in computational efficiency, but also delivers exceptional target detection performance, far surpassing the other compared algorithms. It can be concluded that this algorithm is effective in accurately detecting dim, moving targets in relatively static and complex scenes.
Datasets 4 and 6 were used to evaluate the performance of the model trained on Dataset 1. The backgrounds in Datasets 4 and 6 consist of sky scenes, leading to fewer triggered background events. As a result, the model trained on Dataset 1 transfers effectively to Datasets 4 and 6. Since the target SNR in Dataset 4 is higher than in Dataset 6, the overall detection performance in Dataset 4 surpasses that in Dataset 6. In real detection scenarios, the camera platform may undergo maneuvers to track the target accurately, resulting in a sharp increase in triggered events and abrupt changes in the shape of target events. Consequently, the test results on real datasets tend to be lower than those on synthetic datasets. Nevertheless, the proposed algorithm demonstrates good stability. As shown in
Table 3, the proposed method achieves an mAP@0.5 of 94.9%, reflecting a 12.31% improvement over YOLO11n and a performance 7.41 times higher than YOLOv8n. The mAP@0.5:0.95 reaches 65.3%, representing an 81.39% improvement over YOLO11n and a remarkable 36.69-fold increase compared to YOLOv8n. Furthermore, the proposed method achieves an F1 score of 90.2%, which is 13.72% higher than YOLO11n and 4.1 times greater than YOLOv8n. When the FR is 1.2
, the DR reaches 94.6%. In Dataset 6, the F1 score is 77.9%, and the DR is 83.9%. As shown in
Table 4, the mAP@0.5 is 80.4%, which is 2.05 times larger than that of YOLOv8s-worldv2 and 1.08 times higher than that of YOLOv10n. The proposed algorithm outperforms the compared algorithms in mAP@0.5, F1 score, and DR on real Datasets 4 and 6, emphasizing its superiority in stability and adaptability to varying backgrounds.
To simulate real detection conditions, Dataset 2 increased the platform’s movement speed, leading to background events that capture edge information.
Table 5 highlights the superior performance of the proposed method on Dataset 2. The mAP@0.5 achieved by this method is 96.5%, surpassing YOLOv9t by 25.65% and YOLOv8n by 6.75%. Additionally, the mAP@0.5:0.95 reaches 89.8%, which is 61.8% higher than YOLOv9t and 31.29% greater than RT-DETR-l. The method also achieves an F1 score of 96.2%, outperforming YOLOv9t by 20.68% and YOLOv8n by 11.39%. These results demonstrate that as the platform’s motion speed increases, the proposed model exhibits excellent adaptability, effectively and accurately extracting target events from background events.
Compared to Dataset 2, the targets in Dataset 3 are smaller, resulting in fewer triggered target events. As a consequence, the detection performance on Dataset 3 is slightly lower than that on Dataset 2; however, the proposed algorithm still demonstrates good detection performance. As shown in
Table 6, when detecting a target with an original SNR of 4 and a size of 5 × 5 pixels under platform jitter conditions, the proposed algorithm achieves an mAP@0.5 of 96.3%, an mAP@0.5:0.95 of 75.6%, and an F1 score of 93.0%, outperforming all other algorithms. Additionally, the DR reaches 97.5% when the FR is 4.3
. This suggests that the algorithm is capable of adapting to small-sized moving target detection tasks under platform jitter conditions.
The background data for Datasets 3 and 5 come from the same satellite payload. Dataset 3 simulates a target detection scenario with the camera in staring mode, where the target size, motion speed, and other parameters are similar to those in Dataset 5. Theoretically, the training results from Dataset 3 should transfer well to Dataset 5. However, the experimental results show that only the proposed algorithm and YOLOv8s-worldv2 demonstrate good stability and generalization when applied to Dataset 5. When the model trained on Dataset 3 was tested using Dataset 5, as shown in
Table 7, the proposed method achieved an mAP@0.5 of 95%, an mAP@0.5:0.95 of 54.9%, and an F1 score of 88.6%, significantly surpassing the performance of other algorithms. Notably, the DR reaches 100% when the FR is 2
.
Based on the above analysis, due to the proposed algorithm’s strong background adaptability and considering the scarcity of remote sensing image sequences, future work can involve extensive training on synthetic datasets followed by transferring the trained model to real datasets for application.
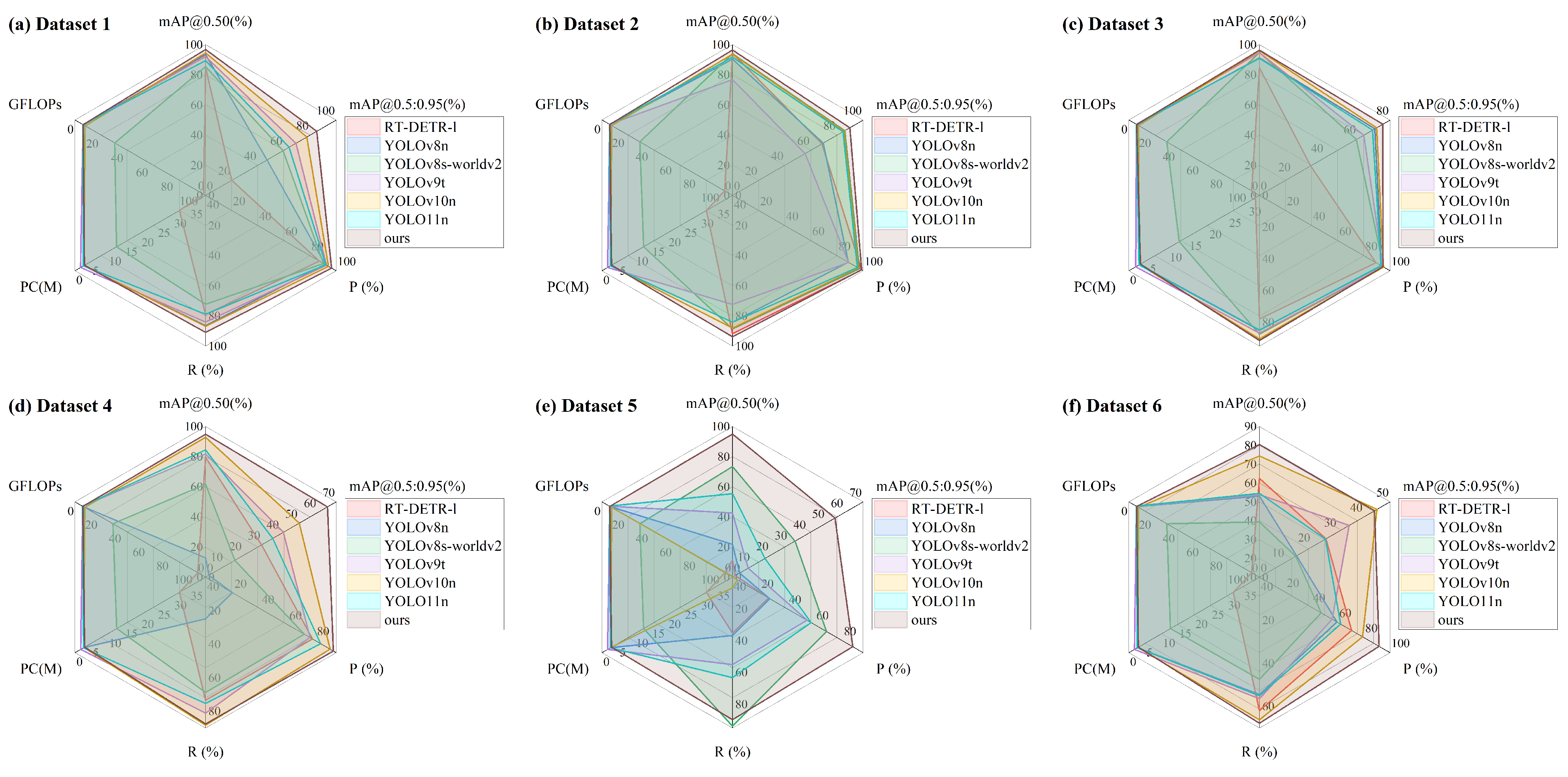
As illustrated in
Figure 4, the proposed algorithm demonstrates the best comprehensive performance. It not only surpasses other algorithms in terms of mAP, P, and R, but also exhibits notable advantages in model parameters and computational complexity. These results confirm that the algorithm is well-suited for a variety of complex environments, showcasing strong generalization capabilities as well as stable and efficient target detection performance.
3.4. Visual Results
Figure 5 shows the target event detection results of various algorithms, with scenes from Datasets 1 to 6 displayed in sequence, two scenes per dataset.
Figure 5a presents the original images alongside zoomed-in views of the true targets. The backgrounds in Datasets 4 and 6 consist of the sky and clouds, while the backgrounds in the other datasets feature real IR remote sensing scenes, such as land, cities, and rivers. These complex backgrounds introduce considerable clutter, which challenges the accuracy of target detection.
By converting the original images into event frames, the intricate background textures are effectively suppressed, leaving only the objects with motion or grayscale changes. In Datasets 1, 4, and 6, where the platform remains relatively stationary, most events in the event frames correspond to target events. However, in Datasets 2 and 3, platform motion introduces distinct background edges in the event frames. Among the various backgrounds, urban scenes generate the most events, which increases the FR. The zoomed-in views of the target events in
Figure 5h reveal a polarity distribution in the target event regions, reflecting the motion trajectories of the targets. As shown in
Figure 5h, the proposed algorithm accurately detects the positions of all targets, demonstrating robust adaptability to complex backgrounds.
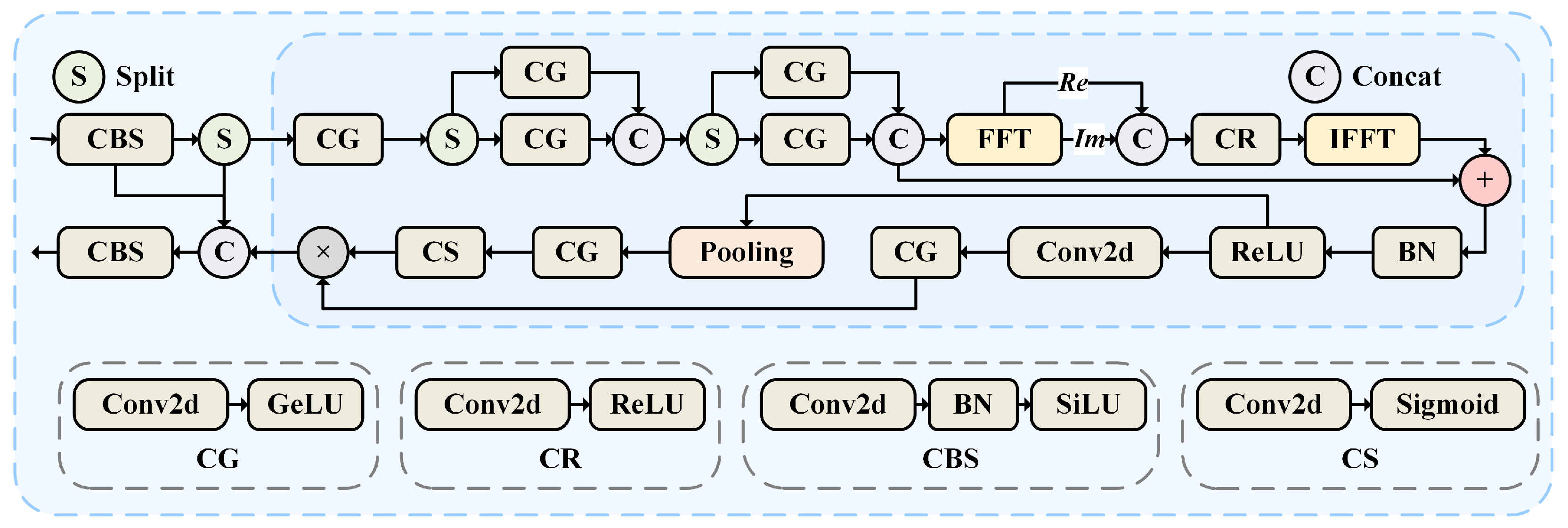
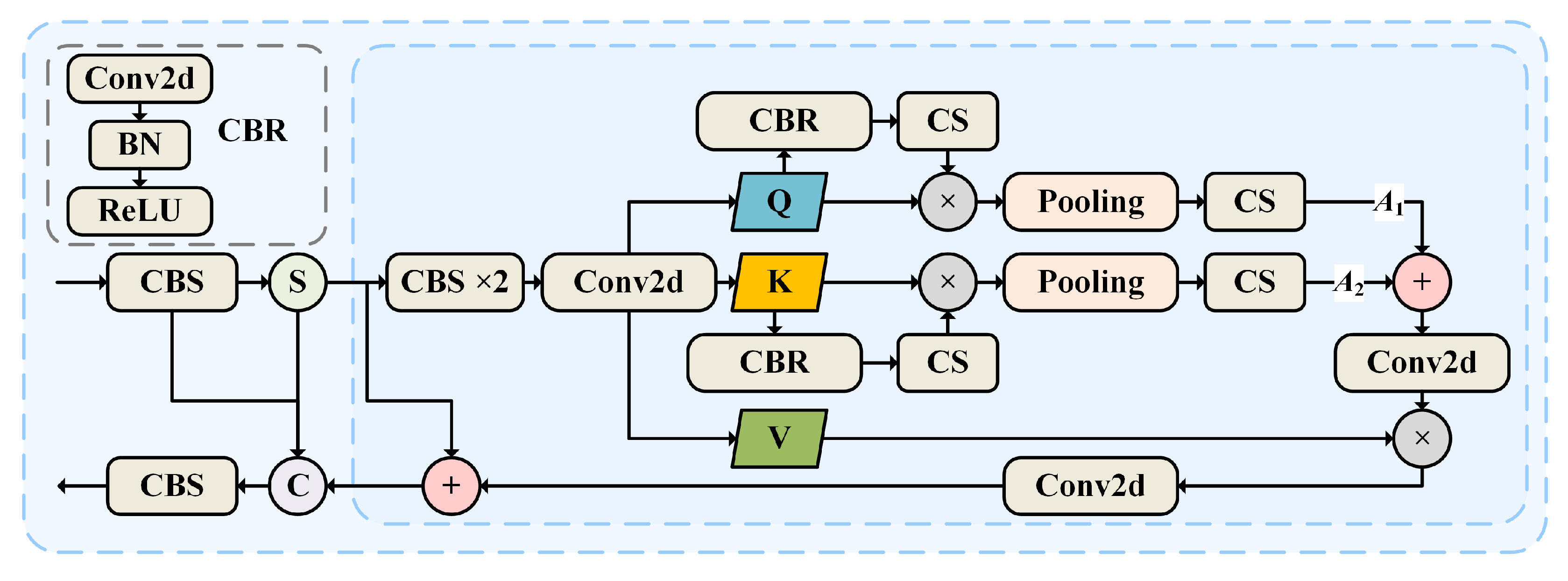
3.5. Ablation Experiment
To comprehensively evaluate the impact of each component on detection performance, ablation experiments were conducted on Datasets 1, 2, and 3. In
Table 8, A refers to the method of converting traditional images to event frames, B represents the temporal accumulation enhancement of event frames, C denotes the JSCA block, and D denotes the SFDF block.
As shown in
Table 8, directly converting the original images into event frames and inputting them into the benchmark network results in a decrease in detection performance. However, when five-frame cumulative event frames are used as input, the FR decreases significantly across all datasets, while the DR exceeds 90%. The five-frame accumulation method produces the best performance for this network.
Furthermore, incorporating the JSCA block into the neck of the network reduces the FR by 17.59% on Dataset 1 and increases the DR by 6.02%. On Datasets 2 and 3, the DR improves by 5.09% and 3.41%, respectively, with only a slight increase in FR. This demonstrates that applying the Joint Spatial-Channel Attention mechanism significantly enhances the network’s feature extraction capability. Adding the SFDF block to the backbone further improves performance, with a 59.22% decrease in FR and a 1.08% increase in DR on Dataset 3, highlighting the effectiveness of incorporating frequency domain information for enhanced detection accuracy.
The ablation experiments underscore the critical role of event-frame conversion and accumulation in improving network performance. Additionally, integrating frequency domain information and attention mechanisms significantly enhances the network’s feature extraction ability and overall stability.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}