1. Introduction
Landslides occur due to gravitational or other factors, causing soil or rock masses to slide along vulnerable surfaces of slopes, thereby posing a significant threat to human lives, the socio-economy, and the natural environment [
1]. Rapid and accurate landslide detection is vital for post-disaster emergency response and comprehensive damage assessment [
2]. Traditional manual field survey methods have significantly limited effective applications in post-disaster large-scale landslide detection tasks due to their substantial cost and relative inefficiency [
3].
The rapid advancements in aerospace and sensor technologies have provided researchers with an expanding repository of high-quality remote sensing images, thereby enabling the non-contact detection of landslides using these images [
4]. Currently, landslide detection based on remote sensing images primarily encompasses four methodologies: visual interpretation, pixel-based, object-based, and deep learning methods. Visual interpretation requires rich experience and is greatly influenced by human subjectivity [
5]. The pixel-based approach designates each pixel as the classification unit and performs classification by extracting features from individual pixels. But it overlooks the contextual information from neighboring pixels and is susceptible to interference from similar spectral information features [
6]. The object-based method groups neighboring pixels with similar attributes into the homogeneous patches. Compared to the pixel-based method, these approaches take into account spatial, spectral, and shape features [
7]. However, achieving optimal segmentation often requires iterative parameter adjustments, making the classification process more complex and not suitable for large-scale data processing. Over the past few years, deep learning techniques have gained widespread application in extracting information from remote sensing imagery, attributable to their robust feature extraction capabilities [
8]. Now, landslide detection approaches utilizing deep learning are categorized into object detection [
9,
10] and semantic segmentation [
11,
12] techniques. Among them, semantic segmentation is a pixel-level categorization that distinguishes between the foreground and background by determining the category to which each pixel belongs.
The rapid development of convolutional neural networks (CNNs) has significantly propelled research in semantic segmentation of remote sensing images [
13]. Long et al. [
14] introduced the Fully Convolutional Network (FCN), which pioneered end-to-end pixel-level image segmentation. Subsequently, numerous scholars have developed a series of enhanced models based on this architecture for landslide detection [
15,
16]. For example, Li and Guo [
17] utilized MobileNetV2 for extracting landslide features, effectively enhancing the detection speed. Qi et al. [
18] significantly improved the accuracy of landslide detection by combining the residual structure with the UNet model to design Res-Unet. Although CNN-based models can achieve good segmentation performance, they depend on convolutional kernels for feature extraction, which limits their ability to capture global semantic information in remote sensing images due to fixed receptive field sizes. Nevertheless, capturing global contextual information is essential for landslide detection tasks. Researchers commonly adopt two methods to address this issue. One approach involves modifying the convolution operation, such as employing large convolutional kernels, dilated convolutions, or employing feature pyramid pooling, thereby expanding the receptive field. For instance, Chen et al. [
19] proposed DeepLabV3+, which integrates Atrous Spatial Pyramid Pooling (ASPP), leveraging dilated convolutions to substantially expand the receptive field while preserving the parameter count. Xia et al. [
20] introduced the ASPP module to improve the model’s capability to capture multi-scale contextual information from high-resolution remote sensing images. The alternative approach focused on optimizing the weight distribution across channel or spatial dimensions through the integration of attention mechanisms within CNN architectures, thereby emphasizing information pertinent to landslides. Generally, attention mechanisms are broadly categorized into three types: channel attention, spatial attention, and mixed attention. Chen et al. [
21] integrated channel attention with Unet for landslide detection in Sentinel-2A images. However, both of these approaches concentrate on optimizing the CNN structure and do not fully address the inherent limitations of convolution operation. Meanwhile, CNNs based on the encoder–decoder structure overlook the inherent semantic disparity between shallow feature maps in the encoder and deeper counterparts in the decoder. The semantic levels of image features captured by shallow and deep feature maps are inconsistent due to variations in the number of related operations. However, most current semantic segmentation models only adopt simple skip connections to directly concatenate shallow and deep feature maps, thus overlooking the aforementioned semantic disparity, thereby impacting the segmentation model’s overall performance. To address this issue, researchers have undertaken numerous efforts. For instance, Zhou et al. [
22] introduced UNet++, which effectively linked feature maps from corresponding stages of the encoder and decoder through a sequence of nested dense skip connections. Pang et al. [
23] proposed SENet, aiming to enhance the representation of shallow feature maps through depth-separable Atrous Spatial Pyramid Pooling, thereby narrowing the semantic gap.
A Transformer [
24] was initially applied in the field of Natural Language Processing (NLP) and demonstrated exceptional performance within this domain. Its self-attention mechanism can capture the long-distance dependencies between pixels, which can better identify the shape and structure of targets. Based on this, researchers have increasingly integrated Transformers into image semantic segmentation, thus providing a solution to the problem that semantic segmentation methods based on CNNs struggle to globally model image information. Currently, Transformer models used for image semantic segmentation tasks can generally be classified into two types. The first category refers to a pure Transformer architecture solely relying on the self-attention mechanism for feature extraction and pixel classification. For instance, Cao et al. [
25] constructed SwinUNet, a symmetric encoder–decoder structure based on Swin Transformer Blocks. The alternate category combines CNNs and Transformers in different ways, aiming to leverage the strengths of each model type to obtain a more comprehensive representation of semantic features [
26,
27,
28]. These works fully demonstrate the suitability of the Transformer models in performing semantic segmentation on images. Given the powerful ability of Transformers in global context modeling, researchers have advanced the application of the Transformer architecture to landslide detection using remote sensing imagery. Lv et al. [
29] integrated enhanced shape information with the Vision Transformer (ViT) model to perform landslide detection in optical imagery. Tang et al. [
30] adopted the SegFormer for coseismic landslide detection, complemented by image processing techniques to eliminate spurious gaps in segmentation outcomes. Although the Transformer model excels at capturing the global context, it faces challenges in extracting fine-grained information from images [
31,
32]. In response to this challenge, researchers have explored the integration of CNNs and Transformers for landslide detection. For example, Li et al. [
33] innovatively applied a modified version of VGG-16 integrated with a Multi-scale Lightweight Transformer (MLT) module to precisely identify landslide features in high-resolution remote sensing images. Similarly, Yang et al. [
34] employed an alternative approach by utilizing the ResUNet and ViT models as robust encoders, augmented with the CBAM, to improve the efficacy of landslide detection. Notably, these methods all utilize a tandem architecture, wherein images are initially preprocessed and resized by CNNs before being input into the Transformer component for subsequent processing. While these methods have shown promising potential for landslide detection, research on hybrid models that combine CNNs and Transformers remains in the early stages of exploration.
Therefore, exploring effective approaches to integrating the strengths of CNNs and Transformers, while concurrently bridging the semantic gap between encoder and decoder layer feature mappings, is worthwhile for obtaining better feature representations and applying them to landslide detection. In this study, we propose a new semantic segmentation model named DBSANet for landslide detection. DBSANet employs a dual-branch parallel structure of ResNet and Swin Transformer to acquire local and global feature information from remote sensing images. To fully leverage the performance of the hybrid network, we propose an innovative Feature Fusion Module (FFM) designed to aggregate the local feature information captured by ResNet with the global context information obtained from Swin Transformer. Additionally, to bridge the semantic gap between the encoder and decoder, we design a Spatial Gated Attention Module (SGAM) and embed it into the skip connection part.
4. Discussion
To comprehensively assess the performance of DBSANet, this study selects seven classic semantic segmentation models for comparative analysis, organizing them into three distinct categories according to their architectural features. The initial category comprises models that are exclusively based on CNNs, exemplified by UNet, Deeplabv3+, and ResUNet. The second category is fully based on the Transformer architecture, represented by SwinUNet. The third category is a hybrid of a CNN and Transformer, including TransUNet, TransFuse, and UNetFormer. Through these comparative experiments, our objective is to conclusively showcase the superior efficacy of DBSANet in landslide detection tasks.
4.1. Comparison with Other CNNs
Table 5 and
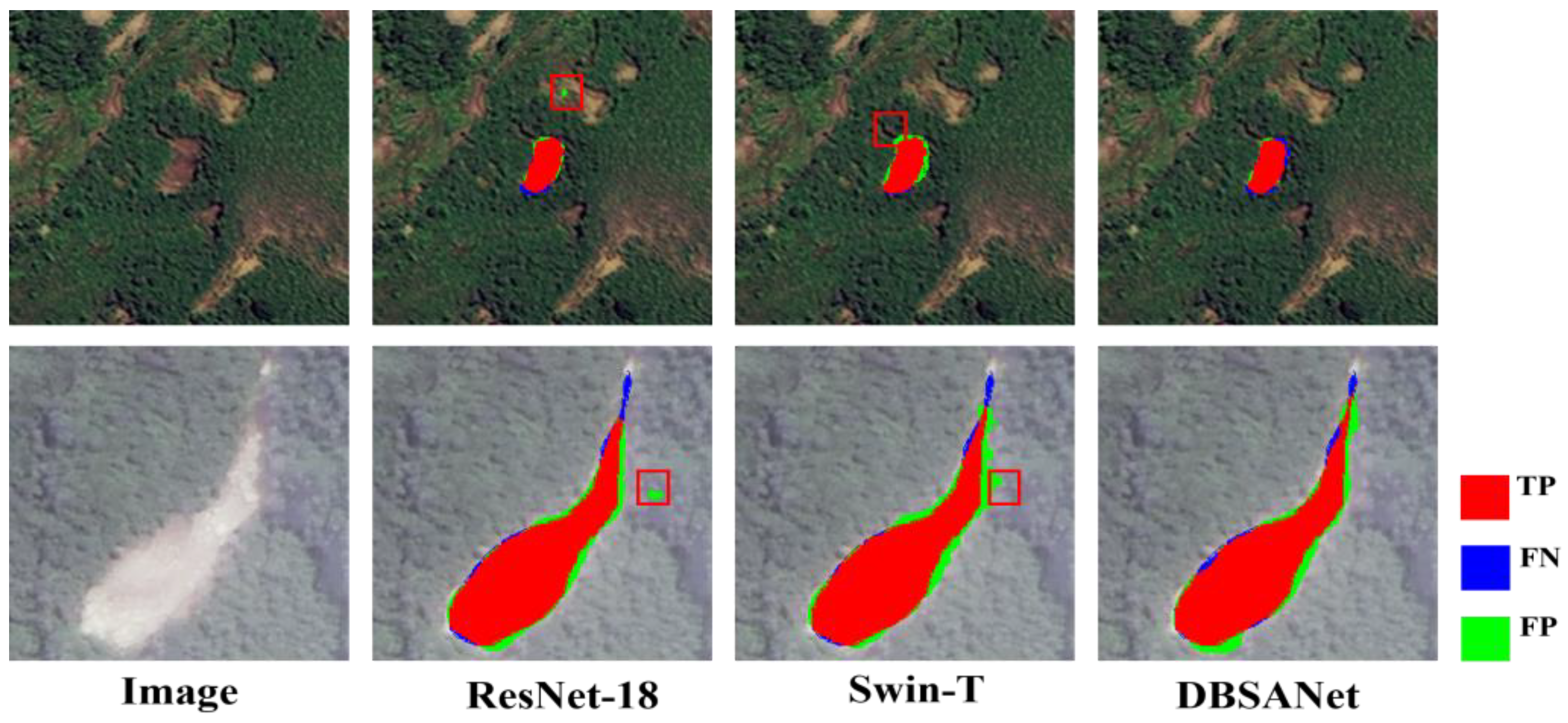
Table 6 present the experimental results for various models evaluated on the Bijie dataset and the Luding dataset. The data clearly indicate that DBSANet outperforms all other models across the three performance metrics. Specifically, compared to the other seven models for comparison, DBSANet exhibits average enhancements of 4.91% in the IoU, 0.57% in the accuracy, and 3.25% in the F1_score. Likewise, on the Luding dataset, DBSANet displays exceptional performance, demonstrating average improvements of 2.96%, 1.08%, and 1.97% in the IoU, accuracy, and F1_score, respectively. It has achieved superior performance on both the Bijie and Luding datasets, further suggesting that our model can more precisely align the overlapping regions between the actual and predicted landslide areas during detection. This not only reduces the false alarm rate, defined as the incorrect identification of non-landslide areas as landslide areas, but also lowers the missed detection rate, which refers to the failure to identify actual landslide regions. To visually compare the landslide detection performance of DBSANet with other models, we visualized the prediction outcomes for each model, as depicted in
Figure 12 and
Figure 13. The figure clearly illustrates that true positives (TPs) dominate the area in the DBSANet visualization results, while false positives (FPs) and false negatives (FNs) occupy comparatively smaller areas, thereby effectively demonstrating the network’s efficacy in the landslide detection task.
In the experiments conducted on the Bijie dataset, ResUNet exhibited a superior performance among the CNN-based models when compared to UNet and Deeplabv3+, indicating that the adoption of the ResNet structure can achieve a better feature representation on the Bijie dataset. Compared to traditional CNN-based methods, SwinUNet introduces a self-attention mechanism for feature extraction. Although it adopts a similar network structure to UNet, its relatively simple network architecture somewhat limits its performance in landslide detection tasks. As a consequence, its overall performance falls short when compared to other benchmark models. The segmentation results depicted in
Figure 12 reveal a degree of boundary blurring in the landslide region when using SwinUNet. This observation suggests that SwinUNet’s reliance on a self-attention mechanism for global information interaction, in contrast to CNNs, might compromise the precision of local detail processing. Conversely, TransUNet, TransFuse, and UNetFormer adeptly amalgamate the CNN’s and Transformer’s strengths, albeit through distinct integration strategies. TransUNet employs a hybrid encoder strategy. Initially, CNNs are utilized for feature extraction, followed by partitioning the resulting feature maps into patches and transforming them into one-dimensional vectors. These vectors are then integrated into the Transformer framework to enhance global comprehension. In contrast, TransFuse concurrently processes the CNN’s and Transformer’s features, employing novel fusion techniques to effectively amalgamate features derived from parallel branches. UNetFormer follows a structure akin to UNet but enhances the fusion of global and local information by substituting the decoder with a Transformer. These hybrid models demonstrated significant improvements in IoU metrics—5.78%, 6.58%, and 7.44%, respectively—compared to SwinUNet’s pure Transformer architecture, underscoring the efficacy of hybrid model architectures in landslide detection tasks. In comparison to the previously mentioned CNN-based models, pure Transformer architecture models, and hybrid models, DBSANet, as proposed in this study, demonstrates notable performance advantages in the context of landslide detection tasks. More specifically, when compared to the top-performing models within each respective category (ResUNet, SwinUNet, and UNetFormer), DBSANet exhibits improvements of 2.38%, 10.81%, and 3.37% in the IoU metric performance, thus unequivocally showcasing DBSANet’s superiority in the realm of landslide detection tasks.
In the Luding dataset experiments, while comparison models like UNet stand out among CNN-based models and UNetFormer achieves the top performance among the CNN and Transformer hybrid models, their evaluation metrics still do not surpass those of DBSANet proposed in this study. Particularly noteworthy is that, compared to the top-performing model in each category, the DBSANet proposed in this study has achieved improvements in the IoU values of 2.19%, 2.66%, and 2.47%, respectively. This underscores the broad applicability of DBSANet across various landslide datasets and its efficacy in landslide detection.
4.2. Comparison of Model Efficiency
To facilitate a clear comparison of computational efficiency among different models, this study quantifies the computational efficiency based on the model parameters, average training time for each epoch, and inference speed per image, with the experimental results detailed in
Table 7. As illustrated in the table, DBSANet does not lead to excessive memory consumption; however, it is worth noting that the dual-branch structure adopted by the model also enhances the training time of the model to some extent. Compared to models based on CNNs or pure Transformer structures, DBSANet makes a trade-off between efficiency and accuracy, but leans more towards the latter. Furthermore, in contrast to the hybrid model, DBSANet attains superior results in landslide detection using fewer parameters.
4.3. Application of DBSANet in Other Scenarios
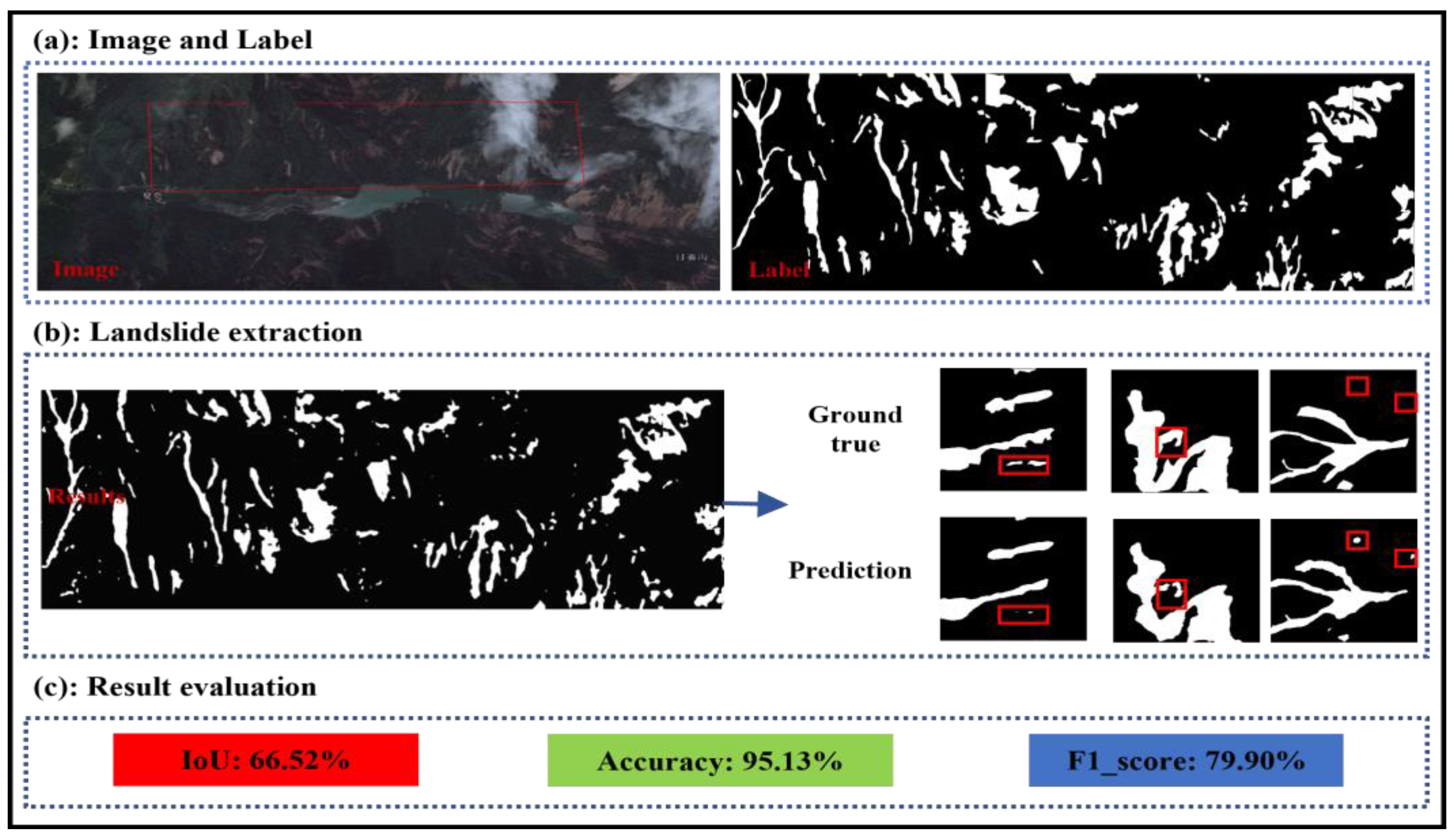
In order to further validate the generalization of the DBSANet model, we identified the Rizhaigou watershed in Jiuzhaigou County as the experimental site. The region’s abundant rainfall, in conjunction with its intricate geological formations, frequently precipitates the occurrence of landslides alongside the rivers. In the preliminary phase of the experiment, we successfully obtained landslide samples from this area by combining GF-2 satellite imagery with Google Earth imagery through visual interpretation. Subsequently, building upon the training results from the Luding dataset, we fine-tuned the model and performed an extensive evaluation on GF-2 imagery obtained from the Rizhaigou watershed. The experimental results are shown in
Figure 14.
As illustrated in the figure, the DBSANet model effectively identified the majority of landslide areas within the experimental region. Specifically, the model’s performance metrics were as follows: the IoU was 66.52%, the accuracy was 95.13%, and the F1-score was 79.90%. However, it is important to note that while these metrics reflect a certain performance level, they have not yet reached optimal levels. This is primarily due to the fact that applying a trained model to an unexplored region presents a considerable challenge. Most prior studies have conducted training and validation within the same region, thus avoiding challenges such as geological structure disparities and variations in image features. In contrast, the images in the Luding dataset were captured shortly after an earthquake, displaying notable differences from the test images of the Rizhaigou watershed (acquired in May 2023). Furthermore, as observed in the prediction results presented in
Figure 14, the DBSANet model erroneously classified non-landslide areas as landslides in some instances (indicated by red boxes). This misidentification may arise from two primary factors: first, the manual labeling of landslide tags inherently involves subjectivity, and labeling errors may lead the model to acquire erroneous information; second, the majority of landslides in the Rizhaigou watershed are aged, and the vegetation on the slopes has developed over an extended period, causing the landslide boundaries to become blurred and difficult to define accurately. This alteration in vegetation cover undoubtedly exacerbates the challenges associated with landslide detection. In summary, while the DBSANet model has shown the capacity to accurately identify landslide positions in other application contexts, the experimental results from the Rizhaigou watershed show that the model still requires improvement in determining the specific scope of landslides.
4.4. Limitations and Future Work
The DBSANet model employs a dual-branch parallel structure consisting of a ResNet and Swin Transformer as its encoder. The Swin Transformer branch effectively captures long-range dependencies across various regions of the image, whereas the ResNet branch extracts local feature information, thereby facilitating the model’s acquisition of more comprehensive feature representations. From
Table 5 and
Table 6, it is evident that the model demonstrates a substantial enhancement in landslide detection performance. However, the analysis of
Figure 10 and
Figure 11 reveals the difficulties associated with accurately delineating the extent of landslides, particularly when they are incomplete, such as during the emergence of nascent vegetation. This limitation can be attributed to the restricted sample size of the landslide dataset employed in this study, which impedes the model’s ability to represent all possible types of landslides. Consequently, the emergence of new vegetation on the landslide surface presents a significant challenge for the model, hindering its ability to precisely delineate the landslide boundaries.
In future research, we will gather landslide data across various scenarios to enhance the diversity of features available for model training. Furthermore, to improve the generalizability and adaptability of the model across various application scenarios, we will integrate a diverse range of multi-source remote sensing data—including, but not limited to, digital elevation models, and slope information—into the dataset construction, which is anticipated to further enhance the model’s performance in real-world contexts, given the substantial influence of these factors on landslide occurrences.
5. Conclusions
In this study, we propose a semantic segmentation model named DBSANet, which is based on a U-shaped encoder–decoder architecture for landslide detection in remote sensing images. Inspired from the Transformer’s global modeling via self-attention and the CNN’s adept feature extraction capabilities, the DBSANet encoder integrates a dual-branch parallel structure of a Transformer and CNN. This design facilitates the concurrent acquisition of both comprehensive contextual information and low-level spatial details of images. Given the inherent structural disparities in feature representations between the CNN and Transformer during extraction, we propose an FFM designed to merge features from both branches, thereby effectively integrating their complementary attributes. Additionally, in order to bridge the semantic gap between the encoder and decoder and thereby enhance the overall model performance, we design an SGAM integrated within the skip connection segment. This module aims to heighten the model’s emphasis on pivotal areas by aligning the decoder feature maps with those of the encoder, effectively bridging the semantic gap between them. To thoroughly and systematically assess the criticality of each module within the model, we carefully designed and executed a series of ablation experiments. The final results of the experiments unequivocally demonstrate that these modules play indispensable roles. To further verify the efficacy and generalizability of DBSANet, experiments were performed on the Bijie and Luding datasets. The experimental results demonstrated that DBSANet markedly exceeded the performance of the other comparative models in terms of the semantic segmentation accuracy. This further demonstrates that the meticulously designed DBSANet in this study effectively integrates the advantages of CNNs and Transformers, thereby enhancing the accuracy of landslide detection, and also provides substantial technical support for the deployment of the hybrid model in landslide detection applications.
Although the remarkable performance exhibited by DBSANet in a variety of experiments is impressive, two limitations persist. First, the incorporation of a dual-branch encoder inherently leads to an increase in the number of parameters, thereby extending the training duration. Second, in scenarios where the surface of landslide bodies is obscured by emerging vegetation, DBSANet encounters difficulties in precisely delineating the landslide boundaries. To address these limitations, future research will concentrate on enhancing efficiency while preserving high accuracy, and applying this equilibrium to landslide detection tasks. Furthermore, we plan to explore ways to integrate multi-source data into the landslide detection process, ensuring that the model can effectively learn and extract crucial features in diverse, complex scenarios, thereby enhancing the recognition of landslide boundaries and improving the model’s generalization performance.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}