1. Introduction
Change detection (CD) techniques extract altered regions from bi-temporal remote sensing images, providing a crucial means to monitor Earth’s surface changes over time [
1]. CD plays a vital role in environmental monitoring [
2], disaster assessment, and urban planning, enabling the tracking of deforestation, glacier retreat, damage assessment, and urban development. This information facilitates informed decision-making and effective resource management [
3,
4]. Consequently, CD has become an indispensable tool with significant societal and environmental benefits, and the development of accurate and efficient CD methods remains an active research area [
5].
In the era of interconnected satellite constellations [
6], the increasing demand for accurate and timely CD from bi-temporal images faces challenges from visual style interferences caused by varying acquisition conditions. These interferences, primarily stemming from radiation differences, atmospheric effects, and seasonal variations, introduce significant difficulties in accurately identifying genuine changes, as shown in
Figure 1. These non-change-related pixel value variations manifest as spectral, textural, and semantic discrepancies between images, leading to false detections. For instance, illumination variations can cause shifts in spectral signatures, making similar objects appear different. Atmospheric conditions like haze can weaken textural features, potentially obscuring genuine changes or introducing spurious ones. Moreover, seasonal changes, such as vegetation growth cycles, can lead to substantial semantic changes, even if irrelevant to the user’s objective. Consequently, these visual style discrepancies pose a significant obstacle to achieving high accuracy in CD, particularly in measuring the similarity between unchanged and changed areas across spectral, textural, and semantic domains. This necessitates the development of robust CD algorithms that can effectively mitigate the impact of such interferences.
Current CD research primarily focuses on mitigating visual style interferences through specialized datasets, sophisticated feature enhancements, and refined deep supervision. However, accurately quantifying background similarity amid complex visual style variations and establishing robust evaluation protocols remain challenging, as exemplified by the false detections arising from complex backgrounds in
Figure 1. Traditional and machine learning CD methods struggle with varying visual styles [
7], particularly radiation and non-linear weather/phenological changes. Deep learning, such as Siamese networks for CD, has emerged as a dominant approach due to its capacity for high-dimensional semantic understanding [
8]. Dedicated visual CD datasets [
9,
10] facilitate method adaptation to specific interference patterns, yet they often lack the full spectrum of real-world variations. Methods explicitly addressing visual style interferences primarily leverage feature enhancement strategies, including difference feature enhancement [
11,
12], multi-level feature fusion [
13,
14,
15], and global semantic enhancement [
16,
17,
18], to suppress false positives. Deep supervision methods, employing techniques like metric learning [
9] and multi-scale supervision [
19], also play a vital role. However, these approaches often lack effective feature constraints and measurements, hindering accurate similarity measurement in complex backgrounds by failing to establish consistent feature contrast during Siamese feature extraction. Furthermore, robustly quantifying visual style interference errors remains challenging, hindering comprehensive method assessment. Next, we provide a detailed introduction to the progress in related work for these two challenges.
Recent advances in deep learning [
8] for change detection have achieved significant progress through encoder–decoder architectures that leverage weight-shared, pre-trained backbones to extract multi-temporal features [
14,
20,
21,
22]. Researchers enhance robustness via multi-task learning [
23,
24], training constraints [
25,
26,
27], and deep supervision [
19], with innovations including pyramid networks for salient feature refinement [
28], multi-scale fusion frameworks like MSFF-CDNet [
29], and temporal modeling with P2V-CD [
18]. SEIFNet further integrates global-local cues to refine boundaries [
30], while deep supervision strategies suppress noise through multi-level supervision [
31], atrous spatial pyramid pooling [
32], attention-based fusion [
33], and GAN constraints [
34]. However, despite these efforts, Siamese CD frameworks remain limited by unsystematic designs, sensitivity to interference, and insufficient utilization of advanced structures. Crucially, existing methods often neglect comprehensive constraints on bi-temporal backbone features, failing to ensure comparable and identically distributed representations during Siamese feature extraction [
1,
2,
19], which undermines their robustness in complex scenarios.
A persistent challenge in optical remote sensing CD is visual style interference caused by radiometric, seasonal, and phenological variations [
20,
35]. While specialized datasets like LEVIR-CD+ [
9] and S2Looking [
10] improve adaptability, feature enhancement strategies dominate current solutions, including difference amplification [
12], multi-level fusion [
19], and global semantic integration [
30]. Techniques such as multi-level difference enhancement [
36] and similarity-aware attention networks [
37] aim to suppress false positives, yet critical gaps persist: (1) inadequate constraints during Siamese feature extraction hinder consistent feature contrast in complex backgrounds, and (2) robust protocols for quantifying style interference errors remain underdeveloped. Traditional and deep learning methods struggle to disentangle style variations from genuine changes [
7], while existing datasets lack real-world heterogeneity [
11,
13]. This limitation perpetuates false detections in scenarios with large visual style differences (
Figure 1), underscoring the need for systematic feature constraints and standardized evaluation metrics [
14,
15,
16,
17,
18].
To address the challenges in robustly measuring background similarity and quantitatively evaluating errors, we propose the Representation Consistency Change Detection (RCCD) framework. This framework is explicitly designed to handle remote sensing images with cross-visual style variations, aiming to achieve robust CD by enforcing representation consistency between bi-temporal global style and local spatial consistency of features throughout the encoding and decoding pipeline. RCCD comprises an encoder, a decoder, and a deep supervisor. The encoder utilizes a pre-trained network with shared weights for multi-level feature extraction. The Unified Decoder and Detector (UDD), equipped with skip connections and residual units, performs scale-wise decoding to generate the CD map. The Representation Consistency (RC) deep supervisor, active only during training, operates at all scales throughout the encoding and decoding process. It consists of local spatial contexts based on the large kernel convolution supervised (LS) module and the Global content-aware Style transfer (GS) module, constraining feature representation consistency includes local context and global style promoting effective CD. The LS module comprehensively assesses correlations between background and target regions in the bi-temporal features. The GS module computes the similarity of channel-wise auto-correlation Gram matrices, implicitly performing style distribution transfer to harmonize global feature representations. Furthermore, we introduce a novel validation method for visual style errors by utilizing Otsu’s method to segment CD datasets into subsets with varying degrees of visual style differences based on content and style similarity measurements of pre-trained backbone features. This enables quantitative assessment of the effectiveness of cross-visual style CD algorithms. We rigorously evaluate RCCD on the LEVIR-CD+ and S2Looking datasets, including their subsets with significant visual style differences. Our results demonstrate that RCCD substantially improves cross-visual style CD performance, achieving state-of-the-art (SOTA) results.
RCCD framework: A novel fully convolutional Siamese neural network training framework with an encoder, decoder, and deep supervisor module, enabling efficient and effective mitigation of cross-visual style errors without incurring extra computational costs during inference.
Representation consistency deep supervised learning: A method integrating target local spatial context and global content awareness, constructing a loss function that effectively suppresses image pairs with significant visual style differences, promoting robust CD.
Visual style errors validation: A novel method leveraging pre-trained networks to partition datasets based on visual style differences, enabling quantitative assessment of cross-visual style CD algorithms.
SOTA performance: RCCD achieves SOTA accuracy, substantially improving cross-visual style error suppression in challenging scenarios. The code is available on GitHub:
https://github.com/wjj282439449/RCCD (accessed on 3 October 2024).
This paper proceeds as follows:
Section 2 presents our methodology;
Section 3 details our experimental setup and results;
Section 4 discusses the implications and limitations; and
Section 5 concludes the paper.
4. Discussion
The proposed RCCD framework demonstrates significant advancements in handling cross-visual style challenges for remote sensing CD. Our experimental results reveal three critical insights: First, enforcing representation consistency at both encoding and decoding stages proves more effective than single-stage constraints (
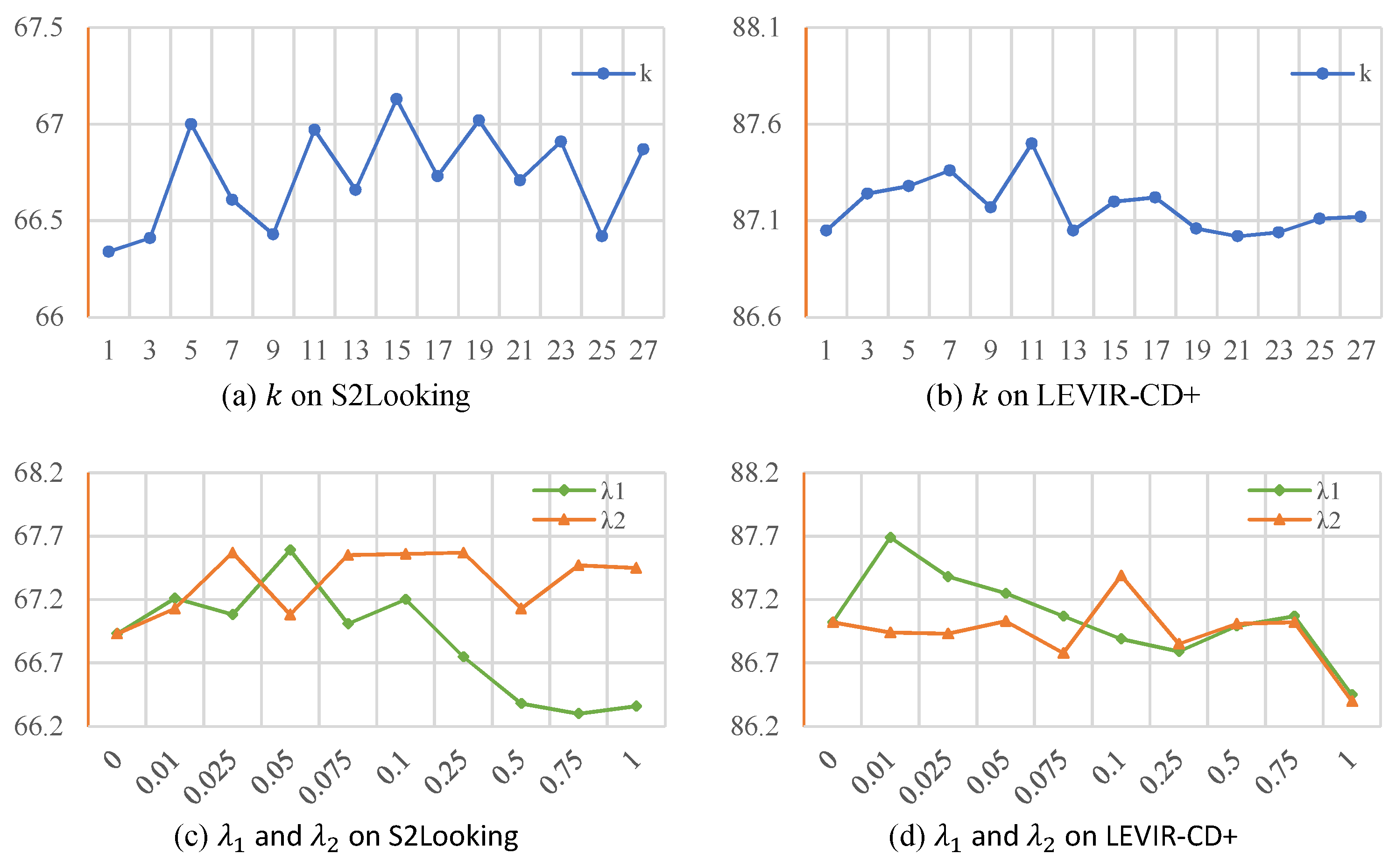
Table 7), particularly for datasets combining global style variations and local content discrepancies. This hierarchical consistency learning aligns with recent findings in domain adaptation, suggesting that multi-level feature alignment better captures cross-domain relationships. Second, the dataset-specific optimal kernel sizes for LS modules (15 for S2Looking vs. 11 for LEVIR-CD+) correlate with spatial resolution differences (0.65 m vs. 0.5 m), establishing a practical guideline for kernel size selection as 23× ground resolution. Third, our visual style validation method provides a novel quantitative framework for CD algorithm evaluation, addressing a critical gap in current benchmarking practices.
The effectiveness of RCCD stems from its dual mechanism: (1) The GS module acts as a global style normalizer through Gram matrix alignment, reducing domain shifts caused by seasonal/illumination variations. (2) The LS module functions as a local context stabilizer, mitigating false alarms from transient environmental changes through large receptive field analysis. This dual approach outperforms existing single-strategy solutions like metric learning or attention mechanisms, particularly in complex scenarios combining both global and local variations. However, two limitations warrant discussion: (1) The current LS module focuses on rectangular context regions, potentially missing irregular-shaped contexts. Future work could explore deformable convolutions for adaptive context shaping. (2) While our style validation method effectively identifies challenging samples, it relies on pre-trained features that may not optimally represent CD-specific characteristics. Developing task-oriented style metrics could further enhance validation accuracy.
Practically, RCCD’s robustness enables reliable CD in applications requiring cross-seasonal analysis, such as post-disaster assessment and illegal construction monitoring. The framework’s modular design permits integration with various backbone architectures, suggesting broad applicability beyond building CD. Future research directions include extending RCCD to multi-temporal CD scenarios and investigating self-supervised adaptation for unseen style variations.



 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}