1. Introduction
Hyperspectral Imaging (HSI) is an advanced remote sensing technology that captures detailed spectral information across hundreds or thousands of narrow and contiguous wavelength bands. This capability provides far more comprehensive data than conventional RGB imagery, enabling in-depth insights into the physical and chemical properties of observed objects. The rich spectral data acquired through HSI supports a wide range of applications, including remote sensing, environmental monitoring, precision agriculture, biomedical imaging, and cultural heritage preservation. However, the high-dimensional nature of HSI data poses significant challenges, such as data redundancy and increased computational complexity, which can hinder efficient data processing and analysis. These issues necessitate the development and application of effective dimensionality reduction techniques to optimize data utility and usability.
To address these challenges, hyperspectral band selection focuses on identifying and retaining a subset of the most informative spectral bands while discarding redundant or less significant ones. The goal of band selection is to preserve the essential spectral characteristics of the data while substantially reducing the dimensionality. This process not only alleviates computational burdens but also helps mitigate issues related to the curse of dimensionality [
1], thereby enhancing the efficiency and accuracy of subsequent analysis and classification tasks. A detailed categorization of band selection methods can be referred to in [
2]. In this work, we aim to develop an unsupervised hybrid band selection approach based on smoothness and sparsity but without prior knowledge of the label information, which can be practically beneficial when the labeled data are insufficient or even unavailable.
Recent advancements in supervised hyperspectral band selection methods have leveraged deep learning techniques to improve performance. These approaches often utilize convolutional neural networks (CNNs) and attention mechanisms to identify the most informative spectral bands. For instance, the CNN Embedded Genetic Algorithm (CNNeGA) method [
3] combines the feature extraction capabilities of CNNs with the optimization power of genetic algorithms (GAs). In this approach, a CNN is trained to extract spectral–spatial features from hyperspectral images, which are then used as inputs to a GA for band selection. Additionally, the Deep Reinforcement Learning for Semisupervised Hyperspectral Band Selection method [
4] employs a deep reinforcement learning framework for band selection. In this approach, an agent is trained to select the most informative bands through interactions with the data environment, which is guided by a reward signal that reflects classification performance.
Despite these advancements in supervised methods, unsupervised approaches offer several compelling advantages for hyperspectral band selection. They can operate without labeled training data, which are often scarce or expensive to obtain in hyperspectral imaging applications. This characteristic provides significant flexibility and generalizability, as these techniques are not biased towards specific tasks or classes. In this work, we aim to develop an unsupervised hybrid band selection approach based on smoothness and sparsity but without prior knowledge of label information. This approach can be particularly beneficial when labeled data are insufficient or unavailable, leveraging the inherent strengths of unsupervised methods to extract meaningful spectral information from hyperspectral imagery.
Many band selection methods convert hyperspectral data into a matrix by treating each band image as a high-dimensional point and then identifying the most important bands based on their geometric or statistical similarities. For example, ranking-based methods such as Maximum-Variance Principal Component Analysis (MVPCA) [
5] prioritize bands by leveraging variance-based criteria. The enhanced Fast Density Peak-based Clustering (E-FDPC) algorithm [
6] aims to identify density peaks within the spectral space, effectively selecting the most discriminative bands. Additionally, the Optimal Neighborhood Reconstruction (ONR) method [
7] selects bands by reconstructing local neighborhoods, focusing on minimizing reconstruction error while preserving both local and global spectral structures. To automatically determine the minimum number of necessary bands, the Fast Neighborhood Grouping (FNGBS) method [
8] employs a coarse–fine strategy and partitions the hyperspectral image into several groups based on local density and information entropy. As an improved version of E-FDPC, the Similarity-based Ranking Strategy with Structural Similarity (SR-SSIM) [
9] offers another unique perspective on band selection, prioritizing bands based on their contribution to the overall structural similarity of the hyperspectral image. The SR-SSIM preserves both the spectral and spatial structures of hyperspectral data, maintaining the essential characteristics of the original dataset through the selected bands. However, transforming hyperspectral data into their matrix form can disrupt the spatial–spectral relationships inherent in the original tensor structure, potentially reducing the effectiveness of subsequent analysis. These limitations highlight the need for efficient and memory-conscious methods capable of directly operating on the tensor structure of the hyperspectral data while preserving their inherent spatial–spectral relationships.
To further improve the efficiency and accuracy of the aforementioned methods, recent band selection approaches have been employed that integrate spatial and spectral smoothness information into the selection process. For instance, graph-based methods explore the spatial smoothness encoded in a Laplacian graph. The Marginalized Graph Self-Representation (MGSR) method [
10] uses superpixel segmentation to create a region-wise similarity graph and learns the band importance through solving a minimization problem according to the sparse self-representation of the hyperspectral data under the graph structure. Building on this concept, the Tensor Graph Self-Representation (TGSR) method [
11] utilizes the inherent tensor structure of hyperspectral data, simultaneously exploiting spectral–spatial relationships to provide a more comprehensive representation for band selection. To enhance the efficiency of graph-based frameworks, a Fast and Robust Principal Component Analysis on Laplacian Graph (FRPCALG) method [
12] was proposed, which incorporates a graph regularization term based on a band-wise Laplacian graph into a robust PCA framework. This integration preserves spectral correlation while maintaining a sparse and low-rank representation of the data matrix. Recently, the Matrix Hyperspectral Band Selection based on CUR decomposition approach (MHBSCUR) [
13] has been proposed to integrate matrix CUR decomposition into the graph-based framework. Here, the matrix CUR decomposition is a low-rank factorization method that approximates a given matrix by selecting a small subset of its rows and columns, improving algorithmic efficiency. However, graph-based strategies often incur additional computational overhead due to the graph construction process. Furthermore, storing graph information can require a significant amount of memory, especially for large-scale hyperspectral datasets. These challenges may limit their applicability to smaller datasets or necessitate substantial computational resources. As an alternative to graph-based regularization, Total Variation (TV) [
14] offers promising performance and has been widely used in signal and image processing to promote smoothness while preserving features such as edges. TV has been extended from 2D to 3D, such as 3DTV [
15], and applied for hyperspectral data recovery and processing, such as hyperspectral image denoising [
16], super-resolution reconstruction [
17], and unmixing [
18,
19,
20], due to its ability to preserve sharp edges while reducing noise. To address the staircase artifacts caused by traditional TV, several generalizations and extensions of TV have been introduced to improve reconstruction accuracy, such as Total Generalized Variation (TGV) [
21] and Higher-Degree Total Variation (HDTV) [
22]. The fast Fourier transform enables the efficient implementation of finite difference operators in TV, even for hyperspectral data. However, TV and its variants have not been fully explored in the context of hyperspectral band selection.
To address the aforementioned challenges, we propose a novel tensor-based hyperspectral band selection model [
23] that decomposes hyperspectral data into a low-rank, smooth component and a sparse component. Specifically, we develop a Generalized 3D Total Variation (G3DTV) regularization which applies the
norm to derivatives to enhance the smoothness across both spatial and spectral domains. Different from 3D total variation [
15] involving high-order derivatives, G3DTV exploits the high sparsity of first-order derivatives. By promoting smooth transitions in spectral response among selected bands, our model demonstrates improved robustness to outliers and noise, leading to more reliable results in practical applications. Using the Alternating Direction Method of Multipliers (ADMM) [
24,
25,
26], we develop an efficient algorithm to solve the proposed model, resulting in three types of subproblems. Two of the subproblems admit closed-form solutions based on the proximal operator of
norm when
. For the subproblem involving the low-rank constraint, in light of [
13,
27,
28], we employ a tensor CUR decomposition to rewrite a low-rank tensor as a product of three smaller factor tensors, which are updated efficiently within a gradient descent framework. In this work, we adopt the t-CUR decomposition [
29] to accelerate the computation, which differs from the tensor CUR decompositions extended from the matrix case such as the Fiber and Chidori CUR decompositions [
30,
31,
32,
33]. The innovative integration of low rankness, captured by t-CUR, and smoothness, represented by G3DTV, enables our algorithm to effectively characterize the underlying complex geometry of HSI data. This makes our method particularly well suited for handling large-scale datasets while ensuring robust band selection performance.
The organization of the remainder of this paper is as follows:
Section 2 introduces fundamental concepts and definitions in tensor algebra, along with a detailed definition of the proposed G3DTV regularization. This section provides the necessary theoretical background for understanding the proposed method.
Section 3 presents our novel band selection method in detail, outlining the derivation of our algorithm based on ADMM, implementation, and key features.
Section 4 demonstrates the performance of the proposed method through a series of comprehensive numerical experiments. We evaluate our algorithm using benchmark remote sensing datasets, comparing its performance with state-of-the-art band selection techniques. In
Section 5, we discuss parameter selection methods, including grid search and Bayesian Optimization, analyze the impact of noise on the performance of our algorithm, and explore alternative classifiers to demonstrate the robustness of our approach. Finally, conclusions and future work are presented in
Section 6.
2. Preliminaries
In this section, we introduce fundamental definitions and notation about third-order tensors [
34]. Unless otherwise specified, let
and
, with the
kth frontal slice (or face) of
denoted by
. We also denote the fast Fourier transform of
along the third dimension as
and the inverse FFT of
as
. We define the identity tensor
as the tensor where the first frontal slice is the identity matrix, and all other frontal slices are zeros. Thus,
is a tensor where each frontal slice is the identity matrix. The zero tensor is denoted by
. For a finite set
I, we use
to denote its cardinality. We also define
.
In addition, we define three commonly used tensor norms. The norm of a tensor , denoted as , is the sum of the absolute values of all its entries. The Frobenius norm of , denoted as , is the square root of the sum of the squared absolute values of all its entries. This norm is analogous to the Frobenius norm for matrices. The norm of , denoted as , is the maximum absolute value among its entries.
Definition 1 ([
34]).
The block circulant operator, denoted as , converts a tensor to a block circulant matrix and is defined as follows: Definition 2 ([
34]).
The operator unfold(·) and its inversion fold(·) for the conversion between tensors and matrices are defined as Definition 3 ([
34]).
The block diagonal matrix form of , denoted by , is defined as a block diagonal matrix with diagonal blocks , i.e., Definition 4 ([
34]).
The t-product of the tensors and is defined asThe t-product can also be converted to matrix multiplication in the Fourier domain such that is equivalent to bdiag. Note that, given the appropriate dimensions, .
Definition 5 ([
35]).
A tensor is orthogonal if , for all , and is the complex conjugate transpose of , which is defined as for all . Definition 6 ([
29]).
The pseudoinverse (or Moore–Penrose inverse) of the tensor , denoted by , is defined by taking the pseudoinverse of each frontal slice in the Fourier domain: Definition 7 ([
35]).
A tensor is f-diagonal if each frontal slice is diagonal for all . Definition 8 ([
35]).
The tensor Singular Value Decomposition (t-SVD) induced by the t-product is where and are orthogonal, and the core tensor is f-diagonal. Moreover, the t-SVD rank of tensor is defined as . Definition 9 ([
29]).
The multirank of a tensor is defined as the vector , where Definition 10 ([
29]).
Consider a tensor . Let and be index subsets, and define , , and . The t-CUR decomposition of is , where is the pseudoinverse of as defined in (1) above. Figure 1 depicts this low-rank decomposition, where and . Definition 11 ([
29]).
Consider a tensor with the multirank and the t-SVD rank . If the index sets I and J, as defined in the t-CUR decomposition in Definition 10, satisfy and the core tensor in the t-CUR decomposition has multirank , then the recovery is exact, i.e., . Definition 12. The proximal operator of is defined aswhere is an integer. Note that the proximal operator
when
can be computed using Algorithms 1 and 2 in [
36]. If
, then this is the soft thresholding operator [
37].
In addition, to describe smoothness while preserving edge sharpness, the traditional two-dimensional total variation [
14] has been extended to 3D images, such as 3DTV [
15] and the spatial–spectral total variation for hyperspectral images [
16]. Motivated by our recent work on the power of the
norm regularizer [
38], we propose a novel generalized 3D total variation regularization to further enhance the sparsity of derivatives.
Definition 13. The Generalized 3D Total Variation (G3DTV) regularization of a third-order tensor is defined aswhere is an integer, and represents the finite difference operator along the ith mode. In our experiments, was set as the forward difference operator with Neumann boundary conditions.
3. Proposed Method
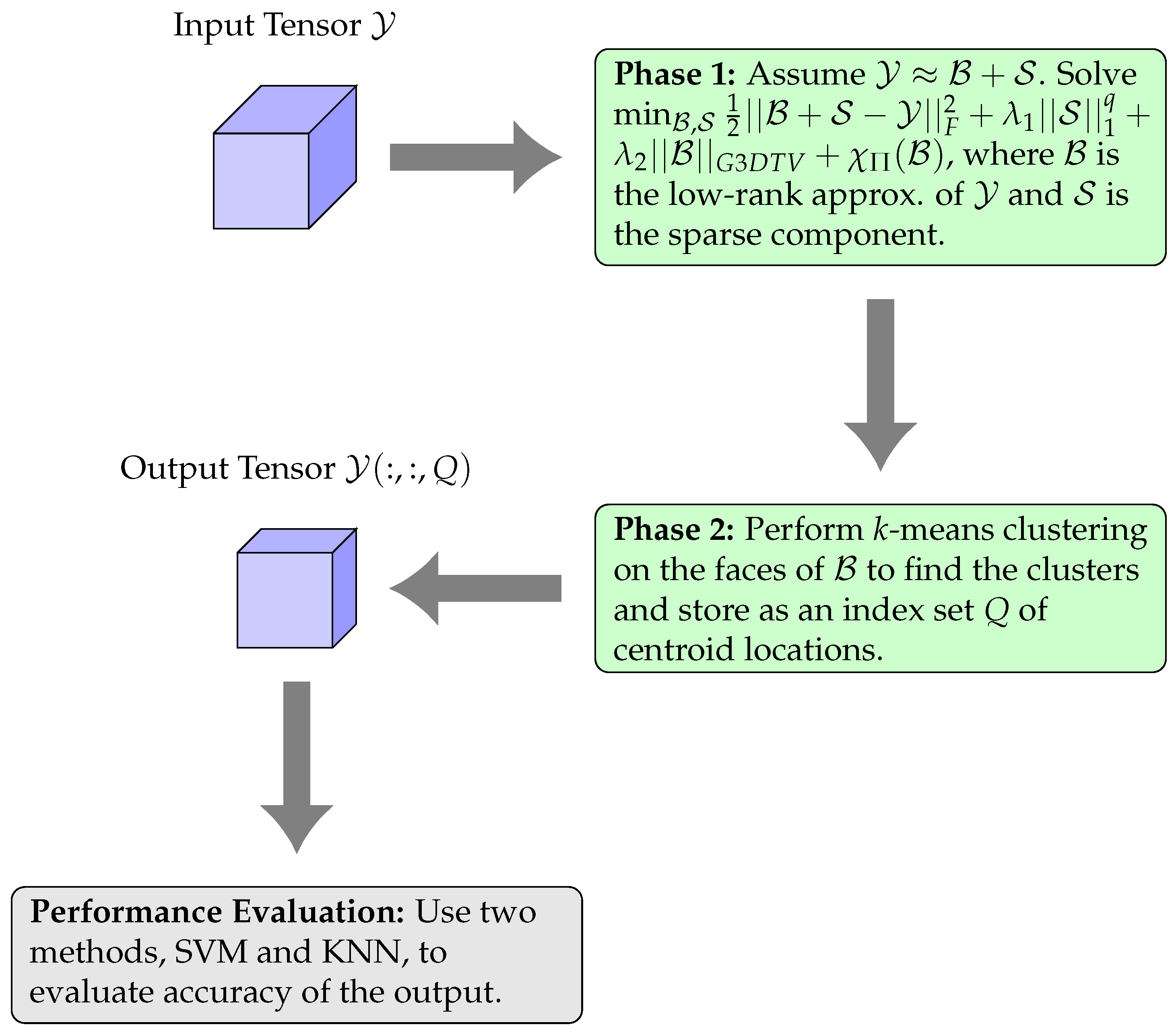
Equipped with the basic knowledge of tensors, we present a novel tensor-based hyperspectral band selection approach, which consists of two phases. In Phase 1, we develop a tensor-based model that decomposes the input tensor
into a low-rank and smooth component
and a sparse component
. In Phase 2, we perform
k-means clustering on the frontal slices of
to identify the most important clusters and store their corresponding centroids in an index set
Q. The algorithm then outputs the band-selected tensor
, and we evaluate the accuracy using two data classification methods, i.e., K-Nearest Neighbors (KNNs) and Support Vector Machine (SVM). The entire pipeline is illustrated in
Figure 2. It is worth noting that the use of
k-means clustering [
39] and performance evaluation through classification algorithms are well-established practices in the band selection literature. In what follows, we will dive into the details of Phase 1 of the algorithm, which is the core of our novel contributions.
As depicted in
Figure 2, we begin with an initial hyperspectral tensor
with
spectral bands, each composed of
spatial pixels. We introduce an indicator function to take care of the rank constraint. Let
. Then, we introduce an indicator function
defined as
if
and as
if otherwise. According to the assumption that the most informative bands are able to preserve spectral relationships and smooth transitions across neighboring bands, we decompose
into a sum of a spatial–spectral smooth tensor
, which is low-rank and a sparse tensor
via the following model:
where
is an integer. The positive parameter
is the regularization parameter for controlling the sparsity of the outlier tensor
, and
controls the spatial–spectral smoothness of the tensor
. Here, the third term is the G3DTV of
as defined in Definition 13, i.e.,
. The parameter
p in the G3DTV and
q in the sparsity regularizer are positive integers. Our numerical experiments have shown that
and
lead to the best performance. In order to apply the ADMM framework to minimize (
4), we introduce the auxiliary variables
and rewrite (
4) as
Then, the augmented Lagrangian reads as
Here,
are dual variables, and
is the penalty parameter. Applying the ADMM algorithm leads to solving three types of subproblems in each iteration. That is, by minimizing
with respect to
,
, and
at each iteration, we obtain the following algorithm:
Here,
and
are updated for
. The
subproblem is essentially a rank-constrained least-squares problem which has no closed-form solution. Inspired by the fast gradient descent method in robust PCA [
27] and its variants [
13,
28], we employ gradient descent while maintaining the rank constraint. At the
jth iteration, we denote the respective estimate of
from the previous iteration by
and then define the objective function
f of the
subproblem without the indicator function as follows:
Then,
is updated via
To handle the rank constraint, we employ the t-CUR decomposition [
29] instead of the skinny t-SVD to reduce computational costs, especially for large tensors. By applying gradient descent with step size
, we obtain the updating scheme for
as
, where the gradient is
Then, the factor tensors in the t-CUR decomposition of
are updated as
Here,
I and
J are the respective row and column index sets. Based on the Definition 10, we update
as
Both the
subproblem and the
subproblem have closed-form solutions using the proximal operators in the Definition 12. By fixing other variables in the respective
subproblem and
subproblem in (
5), we update
and
as
The algorithm terminates when the convergence condition is met, i.e., the maximum absolute error between two successive solutions falls below a tolerance
where
is a predefined tolerance, e.g.,
for our experiments. While other band selection methods may use a combination of multiple convergence criteria, such as changes in the objective function value or gradient norms, we stick to this single criterion to save computational time and simplify the procedure. Finally, we apply a classifier such as
k-means on the frontal slices of
to find the desired
k clusters. The fiber indices of the bands closest to the cluster centroids are stored in the set
Q. Thus, the corresponding bands from the original tensor
constitute the desired subset of bands.
The main computational cost of Phase 1 in Algorithm 1 is due to the update of
using the t-product. The per-iteration complexity is
. When
, the term
dominates the complexity. This creates a computational trade-off when applying the t-CUR decomposition, as selecting larger values for
and
leads to increased computational complexity. In Phase 2, the application of
k-means clustering requires
operations, provided we have a fixed number of
iterations in the
k-means clustering. The complexity of this step is directly proportional to the number of selected bands
k and the dimensions of the hyperspectral image. Therefore, the overall computational complexity of the algorithm is
.
| Algorithm 1 Hyperspectral Band Selection Based on Tensor CUR Decomposition (THBSCUR) |
Input: , maximum number of iterations T, number of sampled rows and columns and , number of desired bands k, step size , parameters and tolerance Output: The index Q of the desired band set. 1. Optimize the model in ( 4) using ADMM: Initialize:
for
do Update , and as in ( 6) Update by solving ( 8) Update by solving () Update Check the convergence condition ( 10) if converged then Exit and set end if end for Set 2. Cluster frontal slices of using a clustering method such as k-means or spectral clustering to find the index set Q which indicates the bands closest to the k cluster centroids.
|
5. Discussion
In this section, we discuss key aspects of the proposed THBSCUR algorithm that may impact its performance in hyperspectral band selection. We begin by providing detailed guidance on parameter selection using both a traditional grid search method and Bayesian Optimization. We offer insights into optimal parameter ranges for different datasets and discuss the impact of noise on these choices. Then we show the performance of our algorithm in the noisy setting, providing recommendations for parameter adjustments. Finally, we extend our analysis to include additional classifiers, such as the convolutional neural network (CNN) [
41], to further validate the effectiveness of our method across different classification approaches in calculating overall accuracy. Throughout this discussion, we aim to provide a comprehensive understanding of the proposed algorithm, practical implementation considerations, and the robustness across various scenarios and classification techniques.
5.1. Parameter Selection via Bayesian Optimization
In the previous sections, we presented the numerical experiment results for the proposed THBSCUR method, which were obtained using Bayesian Optimization [
42] for parameter tuning. In this section, we will delve deeper into the details of this optimization process and compare it to the exhaustive grid search commonly used in practice.
Bayesian Optimization-based parameter selection is a powerful and efficient strategy for tuning parameters in unsupervised algorithms. It is particularly useful in machine learning, where the objective function can be the performance of a model, such as loss or accuracy, and the parameters to be optimized may include regularization coefficients and learning rates. Unlike a grid search which evaluates the objective function exhaustively, Bayesian Optimization uses a probabilistic model and acquisition function to explore the parameter space by prioritizing the most promising regions based on prior evaluations, often leading to faster convergence.
In our approach, the parameters to be optimized are
and
, which are critical to the performance of THBSCUR. Next, we consider a Bayesian Optimization problem that maximizes the overall classification accuracy of the THBSCUR-based feature selection on hyperspectral data. That is, we solve the following problem:
where the parameter space
(refer to
Section 5.2 for more details),
k represents the number of spectral bands selected, and OA is defined in
Section 4.1. Since there is no analytical expression for the objective function, a probabilistic surrogate model is used to approximate the unknown OA for various combinations of parameters. The surrogate model is a Gaussian Process (GP), which is fully specified by a mean function and a covariance function. The GP model captures both the estimated value of the objective function, which in this case is the overall accuracy, and the uncertainty around this estimate.
The next step in Bayesian Optimization involves strategically selecting the next set of parameters to evaluate. This is accomplished by minimizing an acquisition function, which balances the exploration of uncertain areas with the exploitation of promising regions. Common choices for the acquisition function include the Expected Improvement (EI), Probability of Improvement (PI), and Lower Confidence Bound (LCB).
In our experiments, we used the “bayesopt” function in MATLAB to implement Bayesian Optimization and adopted the “expected-improvement-plus” acquisition function, which is an enhanced version of the EI to prevent the overexploitation of some areas.
5.2. Optimal Parameters for Grid Search and Bayesian Optimization
In this section, we discuss optimal parameters for each test dataset using grid search and Bayesian Optimization, along with general guidelines. Before delving into specific tuning processes, it is important to understand the key parameters in the tensor CUR decomposition that influence the performance of our band selection method.
In the tensor CUR decomposition, the numbers of selected rows and columns, denoted as
and
, are key factors influencing both approximation quality and computational efficiency. There are a few common approaches to determining these parameters. One simple approach is to choose a target rank
k, i.e., the number of bands, for the approximation. Another approach, which we adopt here, is to choose
and
as small multiples of
k as
and
, respectively [
43]. Throughout our experiments, we set
and
to
and
, respectively. The logarithmic factor provides a slight oversampling beyond the rank
k, which helps to ensure that enough information is captured to accurately represent the
k-dimensional subspace of the data. This oversampling accounts for potential noise or minor variations in the data that might not be captured by selecting exactly
k columns and rows.
For the THBSCUR algorithm, we compared two methods of parameter tuning for the parameters , , , and : grid search and BO. The ranges for the grid search approach were defined as follows:
, ;
, .
As the number of selected bands increases, the optimal choices for and become stable, while and require more careful tuning. We suggest starting with and set to 1 and then fine-tuning based on the specific dataset. Importantly, there exist multiple combinations of parameter choices that may lead to optimal overall accuracy. It is worth noting that the optimal parameters found through grid search may differ from those identified using Bayesian Optimization, as the latter explores the parameter space more efficiently and can potentially discover better combinations.
The optimal parameters for the SVM classifier on the Indian Pines dataset, obtained by grid search and presented in
Table 1, reveal distinct patterns across different numbers of selected bands. The parameter
demonstrated the highest variability, with a Standard Deviation (SD) of
, indicating that the algorithm is particularly sensitive to the number of selected bands.
The parameter remained constant at for all k values, indicating that the sparsity control for one aspect of the decomposition is consistent across different band selection scenarios. In contrast, showed some variation, with a standard deviation of , primarily due to a single outlier value of at . The parameter , which governs the step size in the update, displayed considerable variability with a standard deviation of , taking on values of , 1, and 10 across different k values.
These results indicate that grid search can identify discrete, widely spaced optimal values for and while maintaining more consistent values for and (with one exception). This discretization is a characteristic of the grid search method, which may miss the fine-grained optimal parameter values that could exist between the tested grid points. The high variability in and highlights the need of careful parameter tuning in the THBSCUR algorithm for different band selection scenarios.
To allow for a more refined exploration of the parameter space, we additionally employed BO to further refine the parameter selection process for the THBSCUR algorithm. In our implementation, the ranges for the four optimizable variables were defined as follows:
These ranges were chosen based on insights gained from the initial grid search on the THBSCUR algorithm. The Bayesian Optimization approach complements grid search by providing a more refined exploration of the parameter space, uncovering optimal parameter combinations that were missed in the discrete grid search. For implementation details, refer to
Section 5.1.
The optimal parameters for the SVM classifier on the Indian Pines dataset, as shown in
Table 2, reveal interesting patterns across different numbers of selected bands. The parameter
exhibited the highest variability, with a standard deviation of
. The parameters
and
, which control the sparsity of the decomposition, showed relatively consistent values across different
k, with means of
and
, respectively. The parameter
, governing the threshold in the iterative process, also displayed high variability with a standard deviation of
. This variability in
and
indicates that these parameters are particularly sensitive to the number of selected bands, while the sparsity-controlling parameters
and
remain more stable.
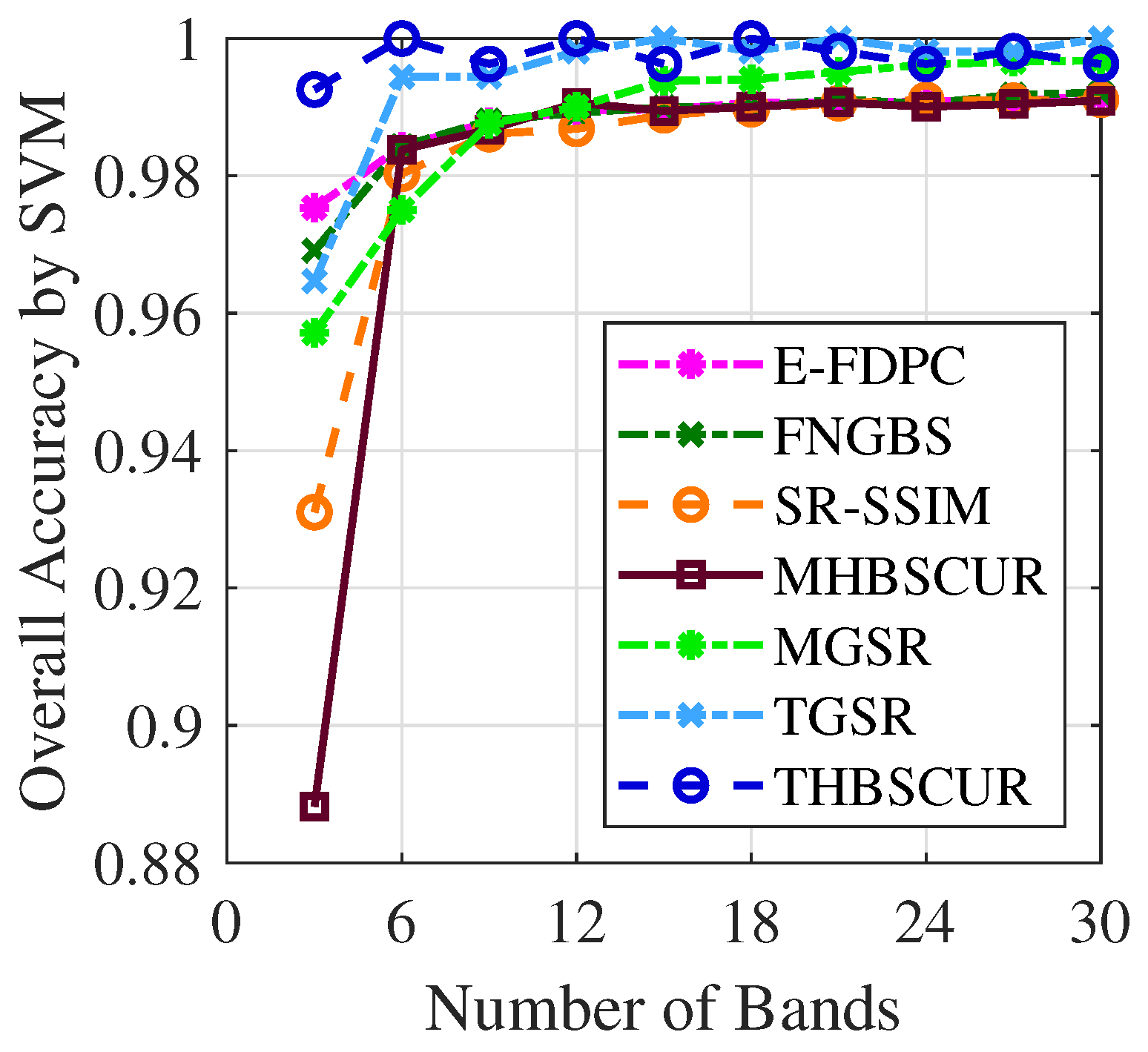
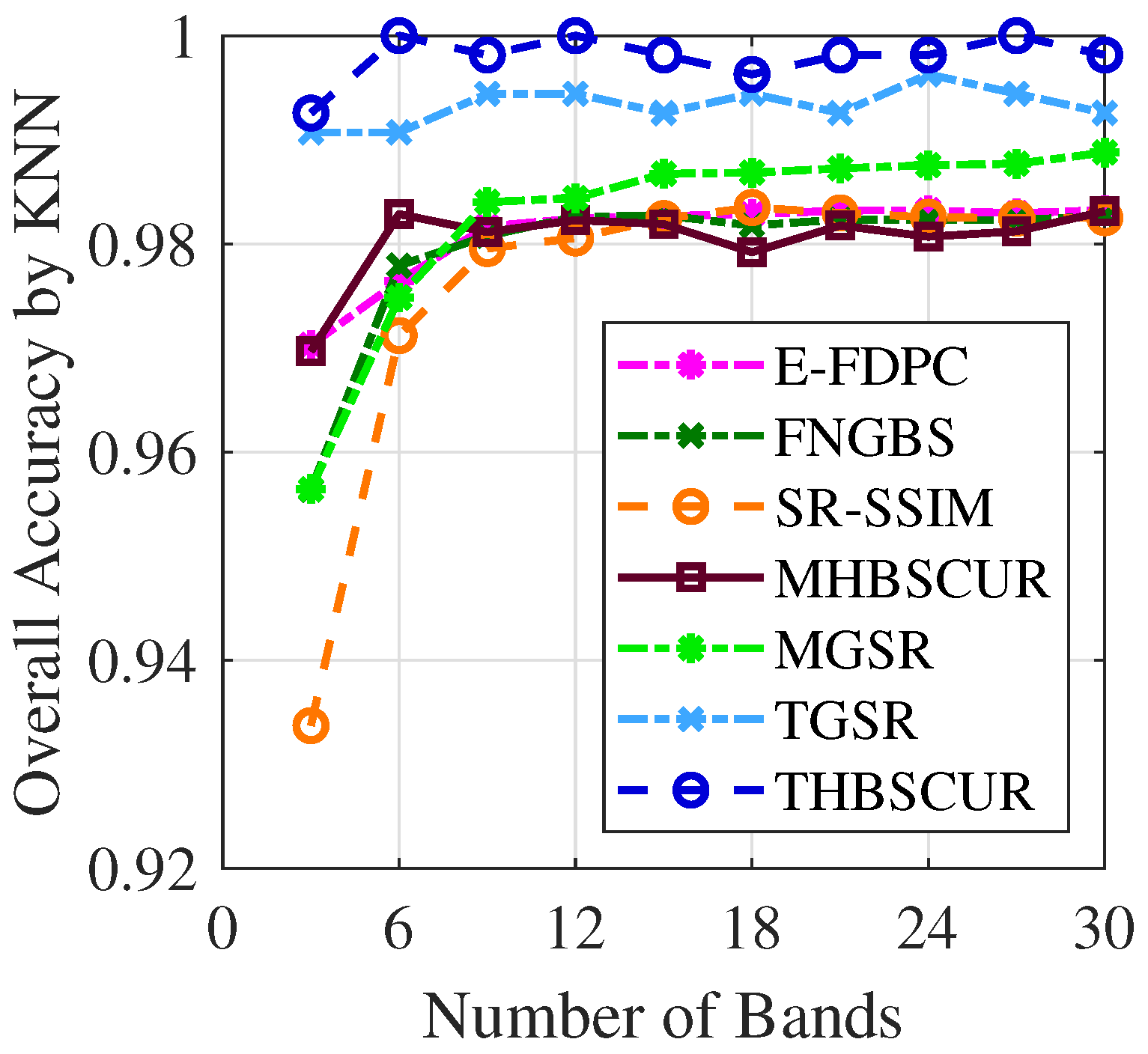
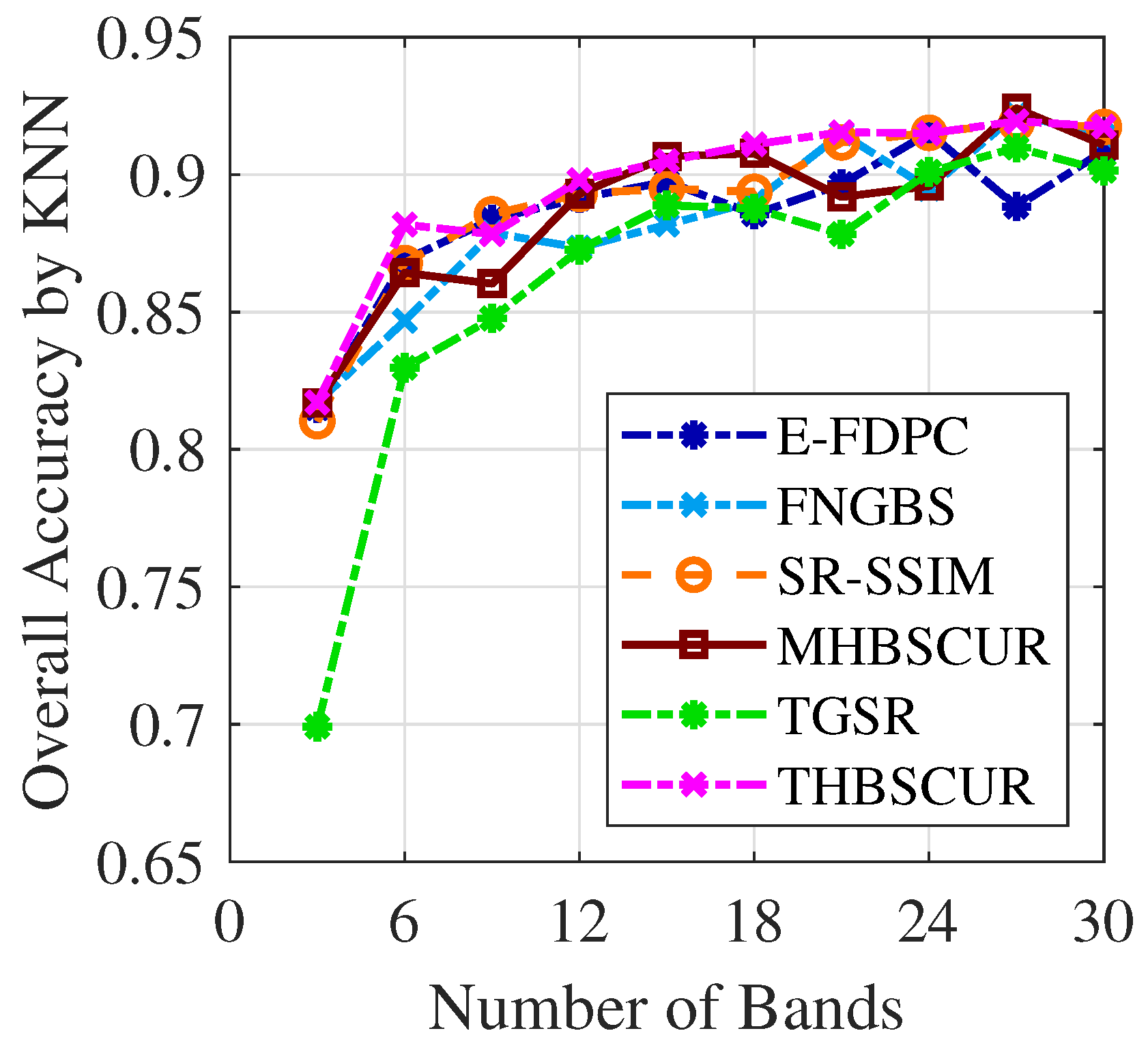
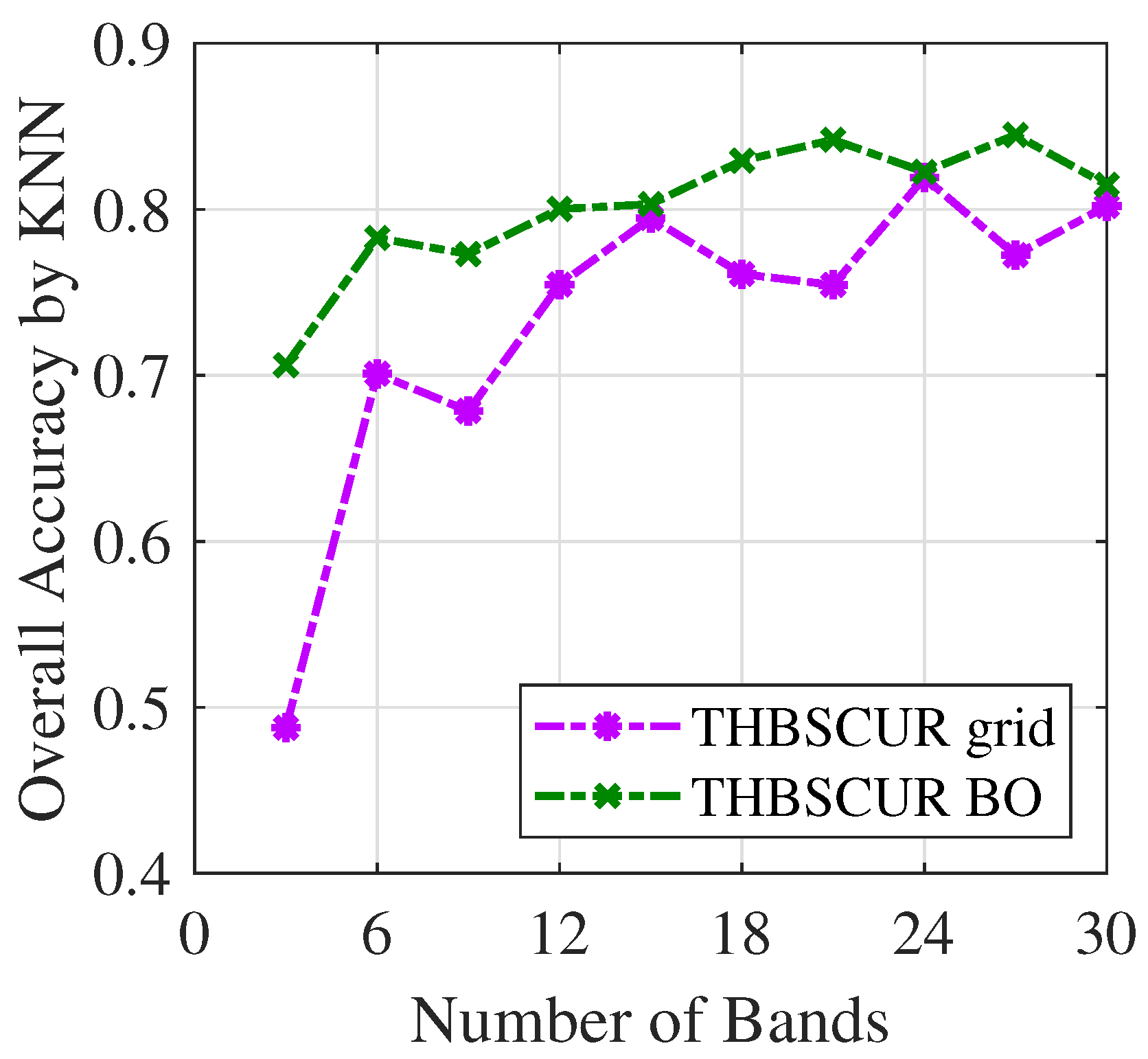
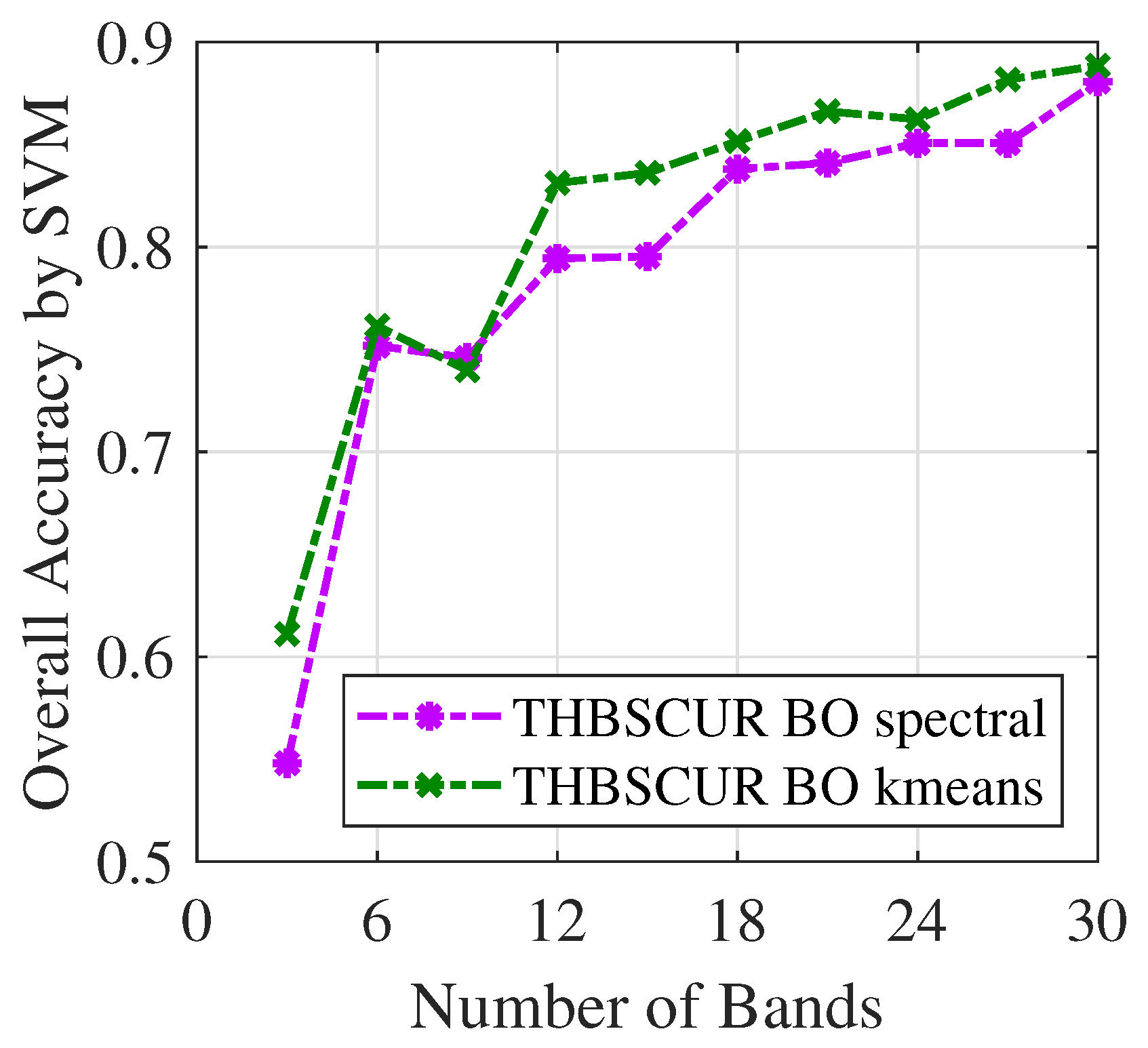
Figure 10 and
Figure 11 demonstrate the success of the BO results with the THBSCUR algorithm applied to the Indian Pines dataset. The graphs show a consistent improvement in the classification accuracy across all numbers of selected bands when compared to grid search. This improvement is evident for both the SVM and KNNs classifiers, with BO-optimized parameters yielding higher accuracy levels regardless of the number of bands selected. This consistent superiority of the BO-tuned method underscores its effectiveness in fine-tuning the THBSCUR algorithm parameters, leading to more robust and accurate hyperspectral band selection across various scenarios.
5.3. Effects of Noise
In addition to the optimal parameter ranges outlined in
Table 1 and
Table 2, it is important to consider the effects of noise on parameter selection for THBSCUR. Hyperspectral data are often polluted by noise, commonly modeled as Gaussian noise, which can significantly impact the performance of band selection algorithms. To address this, we applied parameter adjustments to accommodate the deviations from the original signal introduced by the noise.
In scenarios where Gaussian noise with varying standard deviation levels is introduced into the dataset, we propose the following guidelines for selecting 15 bands from the Indian Pines dataset. The parameters
and
, which control the trade-off between the sparsity term and the G3DTV regularization term, may require adjustment to mitigate the effects of noise. For noisy cases,
and
consistently yield optimal results across different noise levels. Notably, for each noise level, multiple combinations of
and
can lead to optimal outcomes. Tuning
is particularly critical, as optimal results can still be achieved with varying
values. The optimal parameters for
are presented in
Table 3.
5.4. Method Selection for Phase 2
In Phase 2 of our algorithms, we applied the
k-means clustering to group the spectral bands and ultimately generate a final index set of
k representative bands. This process begins with the refined band representation
obtained in the previous phase and treating each frontal slice of
as a data point for further classification. The
k-means algorithm begins by randomly choosing
k cluster centers from the band data. Each band is then assigned to the nearest cluster center, and the cluster centers are updated as the mean of all bands assigned to each cluster. This iterative process continues until convergence, resulting in a set of representative bands that capture the representative information from the original spectral data. By default, the
k-means algorithm in MATLAB uses Euclidean distance. However, we opted to use Manhattan distance instead, as the Euclidean distance-based approach may fail to converge in our experiments. This modification significantly improved the robustness and stability of the clustering process, particularly because the Manhattan distance is more robust in the presence of outliers [
44,
45].
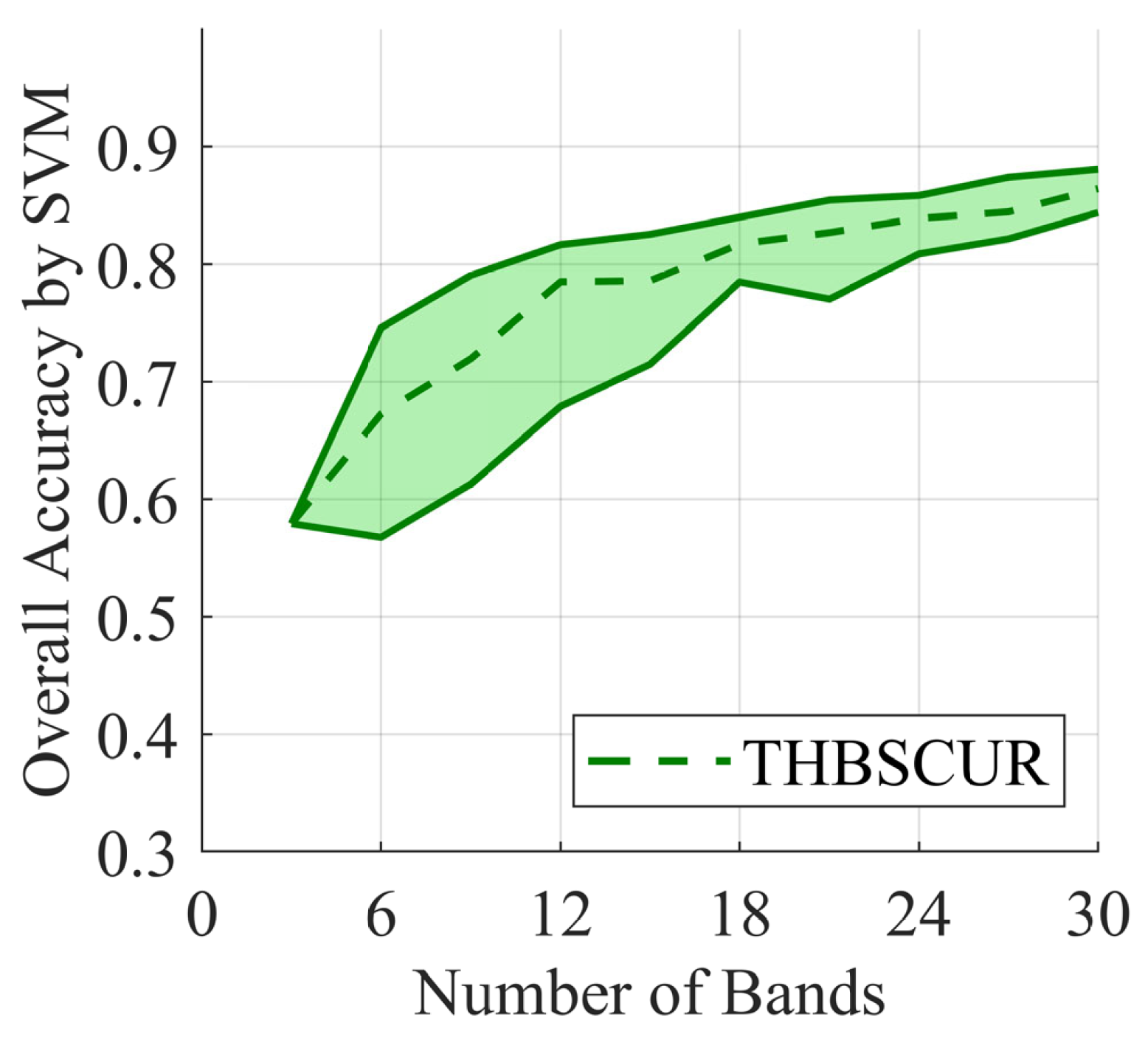
To evaluate the stability and robustness of the
k-means clustering process, we conducted 50 trials with random centroid initializations and visualized the results using an envelope plot in
Figure 12. This plot highlights the variability in performance by displaying the maximum, minimum, and mean SVM accuracies across all trials for the Indian Pines dataset. The shaded region between the max and min values represents the range of possible outcomes, while a dashed line indicates the mean accuracy. In our experiments, the envelope plot consistently demonstrated a narrow band, signifying minimal variation across trials and showcasing the stability of our
k-means-based band selection.
While
k-means is effective for hyperspectral band selection, there are several alternative clustering methods that could be considered for band selection. One advantage of
k-means is its relative high speed, making it an efficient choice for clustering in this context; alternative methods may not offer the same level of computational efficiency. To explore the effectiveness of other clustering approaches, we implemented and tested three additional methods: spectral clustering, fuzzy c-means [
46], and Density-based Spatial Clustering of Applications with Noise (DBSCAN) [
47] using MATLAB implementations.
Table 4 details the computational complexity of the methods mentioned in this section.
We first implemented spectral clustering using the “
spectralcluster” function in MATLAB, which leverages graph-based techniques to partition the spectral bands. Spectral clustering transforms the data into a lower-dimensional space using the eigenvalues of a similarity matrix, capturing complex relationships between bands that may not be evident in the original high-dimensional space. When applied to hyperspectral band selection, spectral clustering produced comparable results compared to the
k-means approach.
Figure 13 demonstrates the performance of the spectral clustering method as opposed to the
k-means method for the Indian Pines dataset.
The fuzzy c-means algorithm, which allows for soft cluster assignments, showed moderate performance. With optimized parameters, it achieved an overall accuracy of 0.6 for the Indian Pines dataset using an SVM classifier to assess the performance. This result, while not surpassing our k-means approach, demonstrates that fuzzy clustering could be a viable alternative for hyperspectral band selection.
In contrast, the DBSCAN algorithm struggled to perform well in this context. Despite its ability to discover clusters, DBSCAN only averaged about 0.2 for overall accuracy across our experiments. This poor performance can be attributed to several factors, including the high-dimensional nature of hyperspectral data and the sensitivity of the algorithm to its input parameters (epsilon and minimum points). The density-based approach of DBSCAN may not be well suited to the spectral characteristics of hyperspectral bands, where the concept of density in high-dimensional space becomes less intuitive.
These results underscore the effectiveness of our k-means-based approach for hyperspectral band selection. While fuzzy c-means shows potential with moderate performance, and spectral clustering demonstrates competitive results, the significant underperformance of DBSCAN highlights the challenges of applying density-based clustering to this specific problem domain. Our findings suggest that centroid-based clustering methods such as k-means and fuzzy c-means, along with graph-based clustering methods like spectral clustering, are well suited for hyperspectral band selection tasks.
5.5. Classifier Selection for Evaluation
In addition to SVM and KNNs, we also calculated the overall accuracy with CNN as the classifier. In this experiment, we evaluated the performance of the previously considered methods on the Indian Pines dataset.
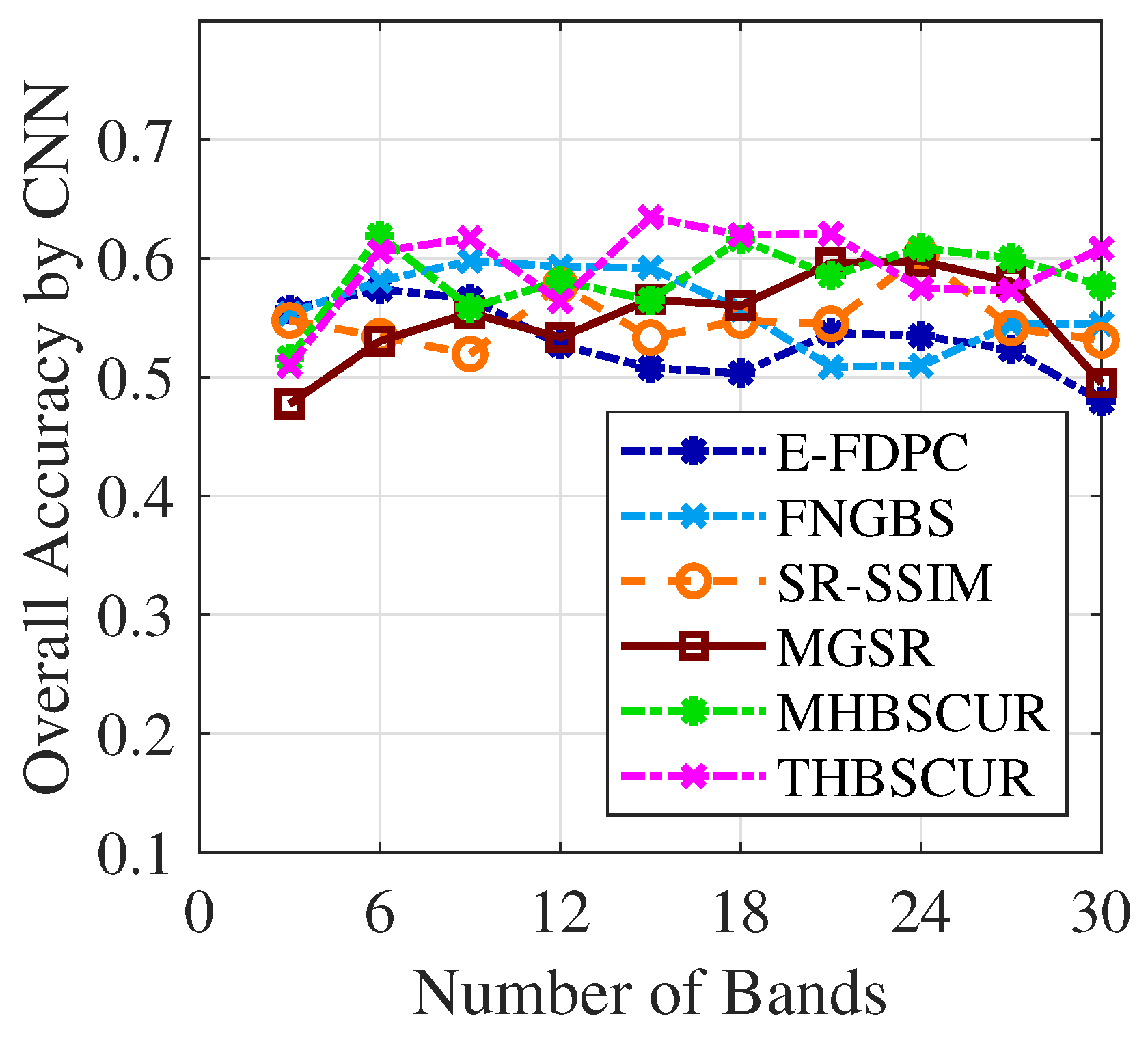
Figure 14 plots the resulting OA curves. For the Indian Pines dataset, it is difficult to distinguish the performance of the different methods, as the accuracy curves are closely clustered. However, the proposed method demonstrated high overall accuracy across different numbers of selected bands as compared to the state-of-the-art methods. Interestingly, CNN classification in this case reported lower overall accuracy than SVM or KNNs classification for the same selected bands.
The CNN network utilized here consists of two convolutional layers with 6 and 16 filters respectively, with each followed by ReLU activation, batch normalization, and max pooling. These layers extract hierarchical spectral features from the input bands. The convolutional layers are followed by three fully connected layers of sizes 120, 84, and k (number of bands), with ReLU activations between them. The final layer uses softmax activation for multiclass classification. The network was trained using the Adam optimizer for 25 epochs, with a learning rate schedule that dropped by a factor of 0.1 every 15 epochs. After training, the network classified the test data, and the overall accuracy was calculated as the proportion of correctly classified samples.
It is worth noting that while CNN demonstrated lower accuracy than SVM and KNNs, it still yielded decent results. This performance could potentially be improved through further optimization of the network architecture and training process.
Other classifiers that have been used to evaluate the performance of hyperspectral band selection in the literature include Classification and Regression Trees (CART) and Linear Discriminant Analysis (LDA) [
48,
49,
50]. CART is a non-parametric decision tree learning technique that produces either classification or regression trees depending on whether the dependent variable is categorical or numeric [
51]. It recursively partitions the feature space into subsets where the instances share similar values of the target variable. LDA is a method used to find a linear combination of features that characterizes or separates two or more classes of objects or events [
52]. The resulting combination may be used as a linear classifier or for dimensionality reduction before later classification.
Both CART and LDA have been applied to hyperspectral data classification tasks to assess the effectiveness of band selection methods, as they offer different approaches to the classification problem and can provide insights into the discriminative power of the selected spectral bands. Ultimately, we chose to report results from SVM and KNNs due to their robust performance across various datasets and their ability to achieve consistent performance evaluation without extensive hyperparameter tuning or architectural modifications.



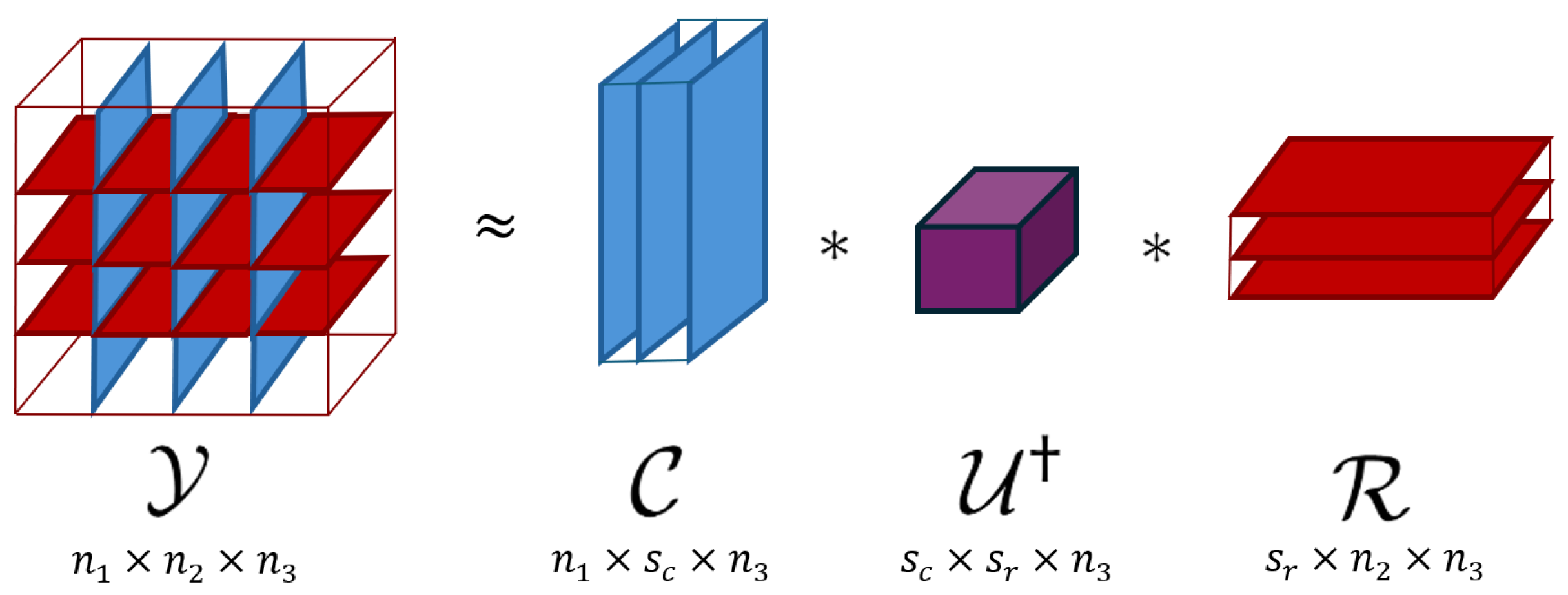




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}