
R-SABMNet: A YOLOv8-Based Model for Oriented SAR Ship Detection with Spatial Adaptive Aggregation

Abstract
1. Introduction
- The SG-AFA module is proposed to aggregate global spatial information. This module enhances the sensitivity to ship features and improves the feature representation of key regions. As a result, it effectively suppresses land scattering interference and boosts the accuracy in intricate scenarios.
- The BSMF method is proposed, using a balanced shifted-window attention mechanism. This module enhances local detail and establishes global dependencies, enabling the handling of scale-variant targets.
- The GWD is introduced as the regression loss to perform the computation of the differentiable Rotated IOU. It addresses localization errors due to angle and scale inconsistencies in dense scenes.
- The experiments are conducted on various public SAR datasets. The results demonstrate that our method surpasses existing mainstream methods across various detection metrics, particularly in complex coastline scenes and multi-scale scenarios.
2. Related Works
2.1. Traditional Detection Methods
2.2. Deep Learning-Driven Detection Methods
2.3. Research on the Related Key Points
2.4. Baseline Model Selection
3. Proposed Methods
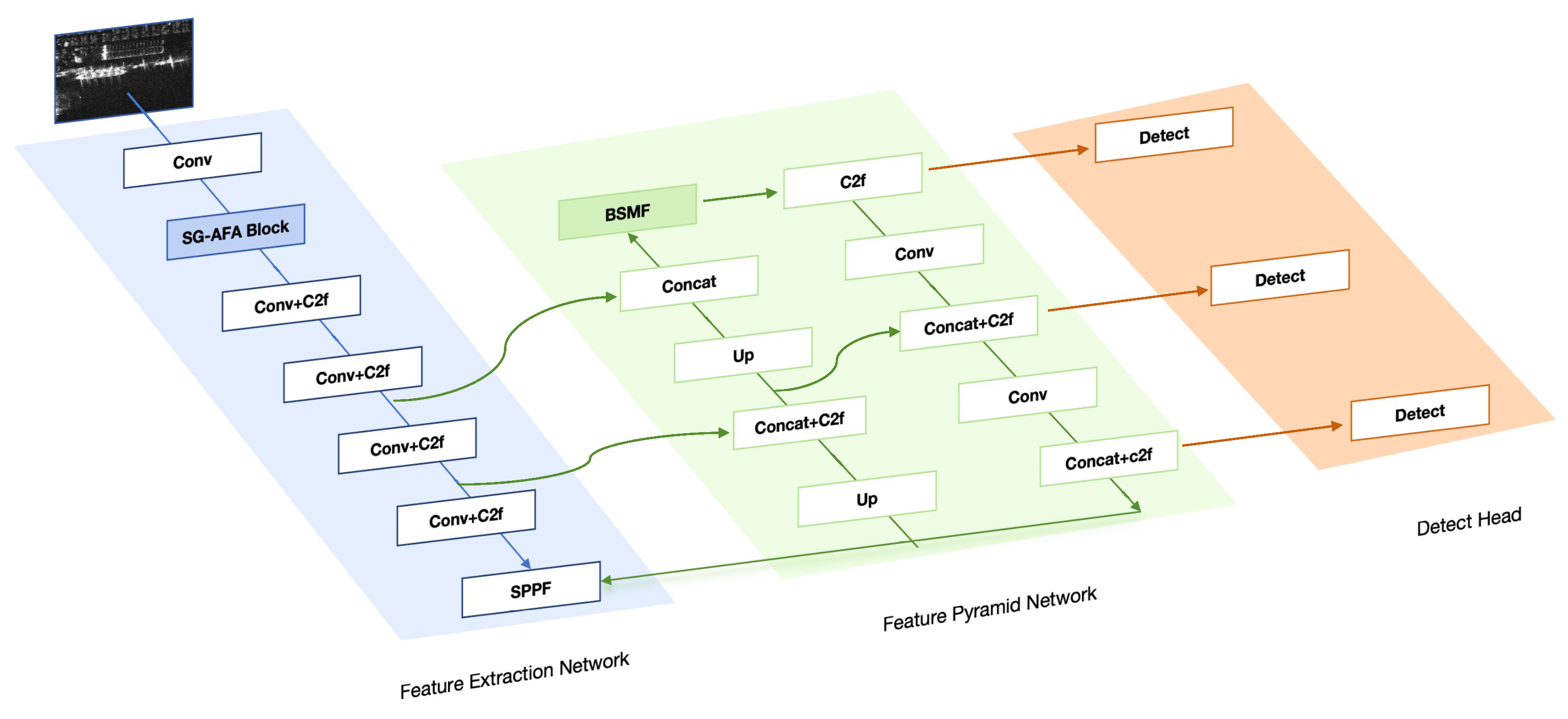
3.1. Model Structure of R-SABMNet
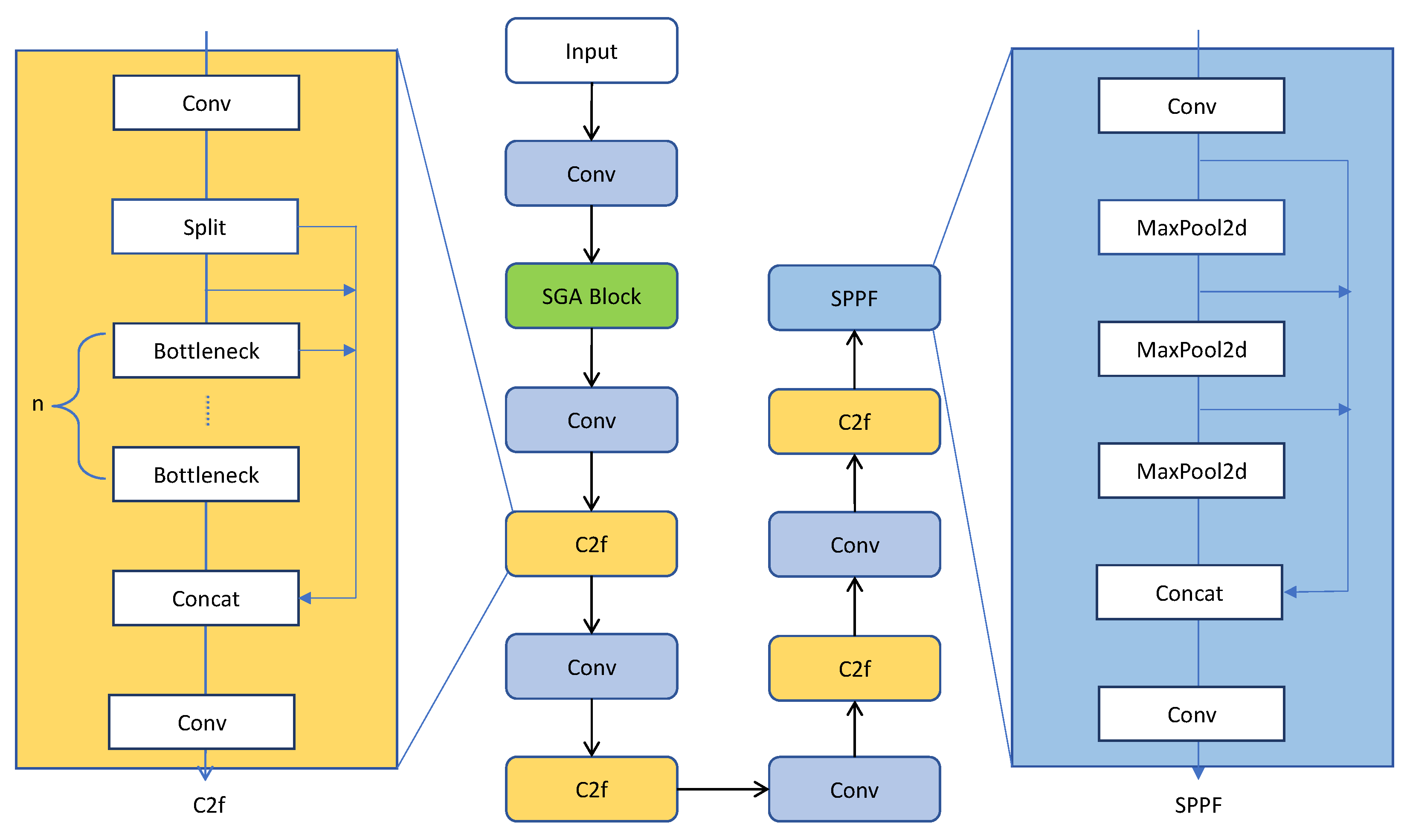
3.2. Feature Extraction Network Based on SG-AFA Module
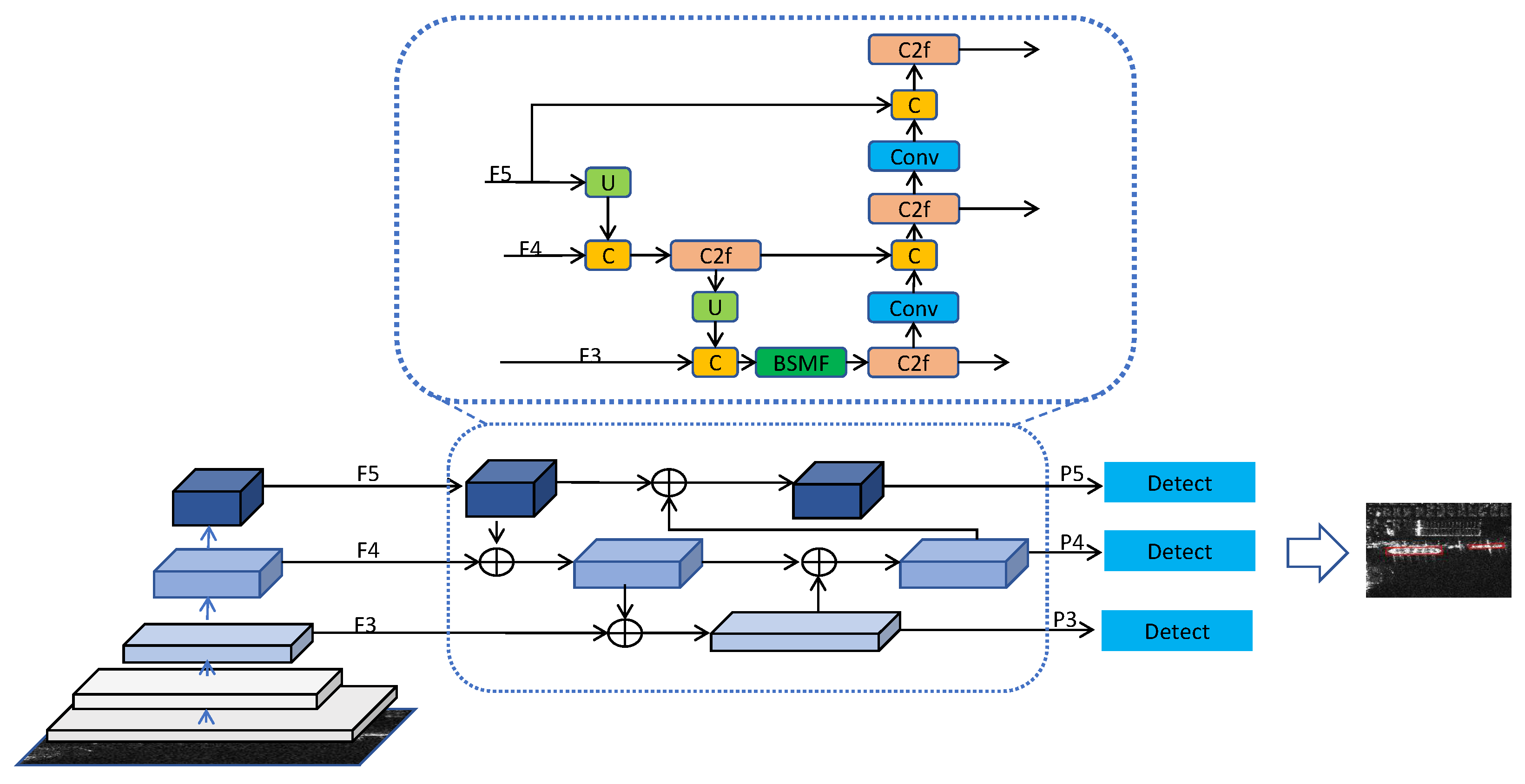
3.3. Feature Pyramid Network with BSMF Module
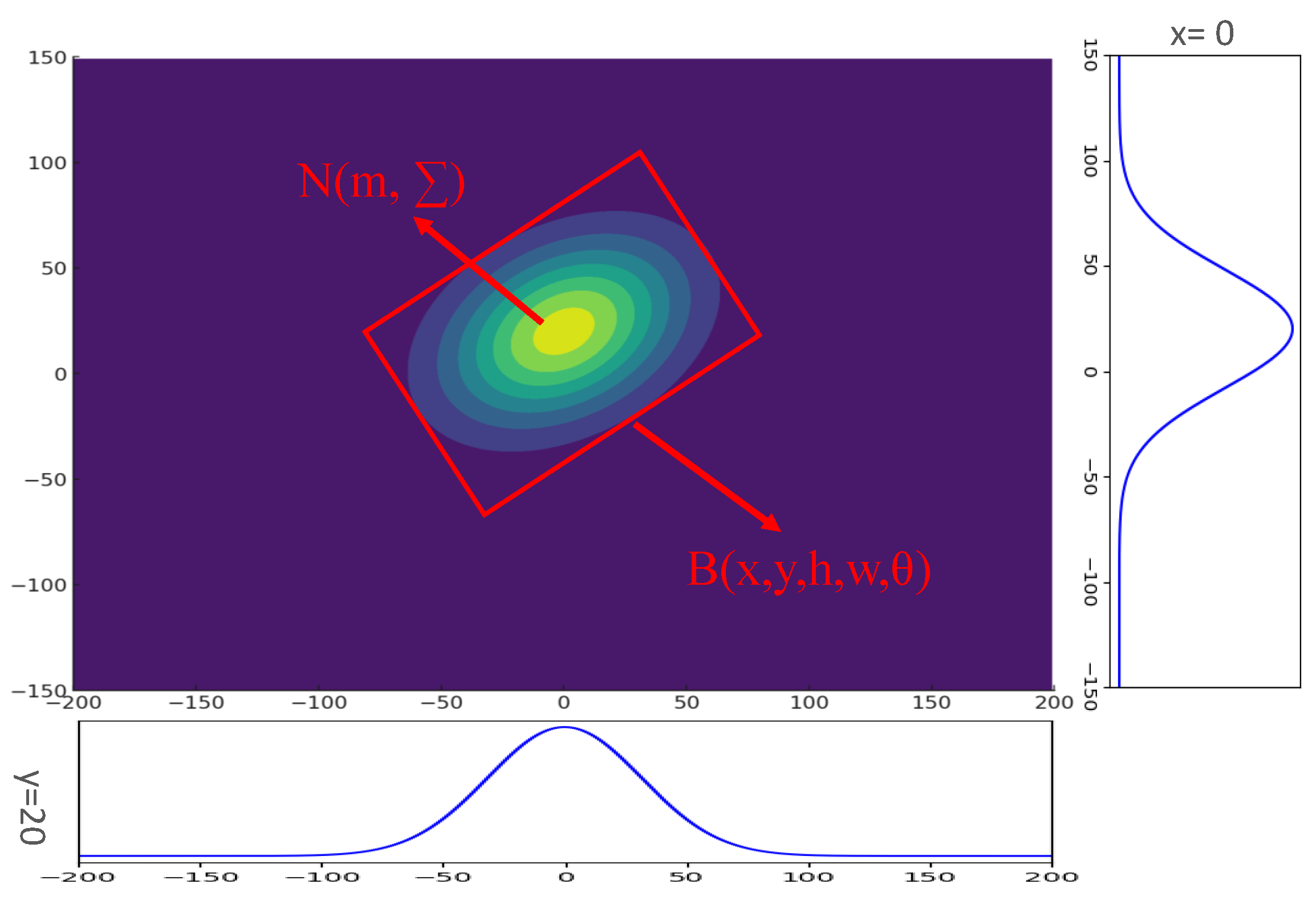
3.4. Improved Detect Head with GWD
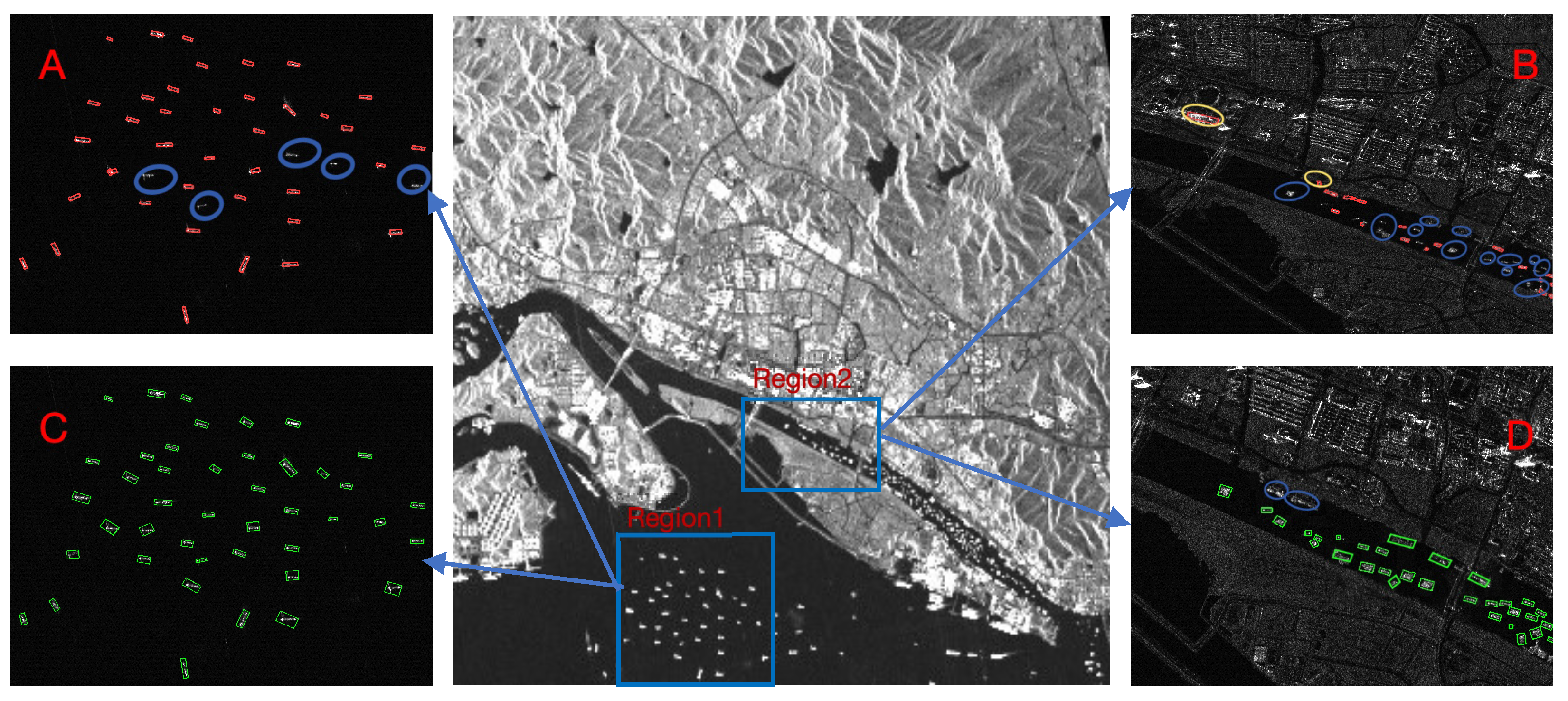
4. Results
4.1. Datasets
4.2. Performance Evaluation Metrics
4.3. Experiment Details
4.4. Comparison with Other Classical Methods
4.5. Ablation Studies
4.5.1. Effect of SG-AFA Module
4.5.2. Effect of BSMF Module
4.5.3. Effect of GWD
4.6. Generalization Ability Test
4.7. Comparison of Model Inference Speed
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yasir, M.; Jianhua, W.; Mingming, X.; Hui, S.; Zhe, Z.; Shanwei, L.; Colak, A.T.I.; Hossain, M.S. Ship detection based on deep learning using SAR imagery: A systematic literature review. Soft Comput. 2023, 27, 63–84. [Google Scholar] [CrossRef]
- Steenson, B.O. Detection performance of a mean-level threshold. IEEE Trans. Aerosp. Electron. Syst. 1968, AES-4, 529–534. [Google Scholar] [CrossRef]
- Novak, L.M.; Burl, M.C.; Irving, W. Optimal polarimetric processing for enhanced target detection. IEEE Trans. Aerosp. Electron. Syst. 1993, 29, 234–244. [Google Scholar] [CrossRef]
- Li, J.; Xu, C.; Su, H.; Gao, L.; Wang, T. Deep learning for SAR ship detection: Past, present and future. Remote Sens. 2022, 14, 2712. [Google Scholar] [CrossRef]
- Leng, X.; Ji, K.; Song, H. Key factors influencing ship detection in spaceborne SAR imagery. Remote Sens. Inf. 2016, 31, 3–12. [Google Scholar]
- Zhao, W.; Huang, L.; Liu, H.; Yan, C. Scattering-Point-Guided Oriented RepPoints for Ship Detection. Remote Sens. 2024, 16, 933. [Google Scholar] [CrossRef]
- Zhang, C.; Gao, G.; Liu, J.; Duan, D. Oriented ship detection based on soft thresholding and context information in SAR images of complex scenes. IEEE Trans. Geosci. Remote Sens. 2023, 62, 5200615. [Google Scholar] [CrossRef]
- Grover, A.; Kumar, S.; Kumar, A. Ship detection using Sentinel-1 SAR data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 317–324. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, P.; Qian, L.; Qin, S.; Liu, X.; Ma, Y.; Cheng, G. Recognition and depth estimation of ships based on binocular stereo vision. J. Mar. Sci. Eng. 2022, 10, 1153. [Google Scholar] [CrossRef]
- Zhang, F.; Yao, X.; Tang, H.; Yin, Q.; Hu, Y.; Lei, B. Multiple mode SAR raw data simulation and parallel acceleration for Gaofen-3 mission. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2115–2126. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, L.; Lü, Y.; Han, P.; Li, J. Center based model for arbitrary-oriented ship detection in remote sensing images. Acta Photonica Sin. 2020, 49, 0410005. [Google Scholar] [CrossRef]
- Li, C.; Xu, H.; Qian, K.; Deng, B.; Feng, Z. Survey of ship detection technology based on deep learning. J. Ordnance Equip. Eng. 2021, 42, 57–63. [Google Scholar]
- Gao, G.; Zhang, C.; Zhang, L.; Duan, D. Scattering characteristic-aware fully polarized SAR ship detection network based on a four-component decomposition model. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5222722. [Google Scholar] [CrossRef]
- Wang, J.; Lu, C.; Jiang, W. Simultaneous ship detection and orientation estimation in SAR images based on attention module and angle regression. Sensors 2018, 18, 2851. [Google Scholar] [CrossRef]
- Zhou, K.; Zhang, M.; Wang, H.; Tan, J. Ship detection in SAR images based on multi-scale feature extraction and adaptive feature fusion. Remote Sens. 2022, 14, 755. [Google Scholar] [CrossRef]
- Shiqi, C.; Ronghui, Z.; Jun, Z. Regional attention-based single shot detector for SAR ship detection. J. Eng. 2019, 2019, 7381–7384. [Google Scholar] [CrossRef]
- Liu, S.; Kong, W.; Chen, X.; Xu, M.; Yasir, M.; Zhao, L.; Li, J. Multi-scale ship detection algorithm based on a lightweight neural network for spaceborne SAR images. Remote Sens. 2022, 14, 1149. [Google Scholar] [CrossRef]
- Zhu, H.; Xie, Y.; Huang, H.; Jing, C.; Rong, Y.; Wang, C. DB-YOLO: A duplicate bilateral YOLO network for multi-scale ship detection in SAR images. Sensors 2021, 21, 8146. [Google Scholar] [CrossRef] [PubMed]
- Zhu, M.; Hu, G.; Li, S.; Zhou, H.; Wang, S. FSFADet: Arbitrary-oriented ship detection for SAR images based on feature separation and feature alignment. Neural Process. Lett. 2022, 54, 1995–2005. [Google Scholar] [CrossRef]
- Fang, M.; Gu, Y.; Peng, D. FEVT-SAR: Multi-category Oriented SAR Ship Detection Based on Feature Enhancement Vision Transformer. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 18, 2704–2717. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Li, J.; Xia, G.S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602511. [Google Scholar] [CrossRef]
- Zhang, Y.; Hao, Y. A survey of SAR image target detection based on convolutional neural networks. Remote Sens. 2022, 14, 6240. [Google Scholar] [CrossRef]
- Li, D.; Liang, Q.; Liu, H.; Liu, Q.; Liu, H.; Liao, G. A novel multidimensional domain deep learning network for SAR ship detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5203213. [Google Scholar] [CrossRef]
- Huang, Q.; Zhu, W.; Li, Y.; Zhu, B.; Gao, T.; Wang, P. Survey of target detection algorithms in SAR images. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; IEEE: New York, NY, USA, 2021; pp. 1756–1765. [Google Scholar]
- Leng, X.; Ji, K.; Yang, K.; Zou, H. A bilateral CFAR algorithm for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1536–1540. [Google Scholar] [CrossRef]
- Liu, T.; Zhang, J.; Gao, G.; Yang, J.; Marino, A. CFAR ship detection in polarimetric synthetic aperture radar images based on whitening filter. IEEE Trans. Geosci. Remote Sens. 2019, 58, 58–81. [Google Scholar] [CrossRef]
- Wang, S.; Wang, M.; Yang, S.; Jiao, L. New hierarchical saliency filtering for fast ship detection in high-resolution SAR images. IEEE Trans. Geosci. Remote Sens. 2016, 55, 351–362. [Google Scholar] [CrossRef]
- Kapur, J.N.; Sahoo, P.K.; Wong, A.K. A new method for gray-level picture thresholding using the entropy of the histogram. Comput. Vis. Graph. Image Process. 1985, 29, 273–285. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L.; Kastens, J.H. Analysis of time-series MODIS 250 m vegetation index data for crop classification in the US Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef]
- Fan, W.; Zhou, F.; Bai, X.; Tao, M.; Tian, T. Ship detection using deep convolutional neural networks for PolSAR images. Remote Sens. 2019, 11, 2862. [Google Scholar] [CrossRef]
- Wu, F.; He, J.; Zhou, G.; Li, H.; Liu, Y.; Sui, X. Improved Oriented Object Detection in Remote Sensing Images Based on a Three-Point Regression Method. Remote Sens. 2021, 13, 4517. [Google Scholar] [CrossRef]
- Du, L.; Wang, Z.; Wang, Y.; Wei, D.; Li, L. Survey of research progress on target detection and discrimination of single-channel SAR images for complex scenes. J. Radars 2020, 9, 34–54. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 821–830. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Ge, Z. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Zhan, X.; Shi, J.; Wei, S.; Pan, D.; Li, J.; Su, H.; Zhou, Y.; et al. LS-SSDD-v1. 0: A deep learning dataset dedicated to small ship detection from large-scale Sentinel-1 SAR images. Remote Sens. 2020, 12, 2997. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense attention pyramid networks for multi-scale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Weixing, W.; Ting, C.; Sheng, L.; Enmei, T. Remote sensing image automatic registration on multi-scale harris-laplacian. J. Indian Soc. Remote Sens. 2015, 43, 501–511. [Google Scholar] [CrossRef]
- Sun, Z.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. BiFA-YOLO: A novel YOLO-based method for arbitrary-oriented ship detection in high-resolution SAR images. Remote Sens. 2021, 13, 4209. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Guo, H.; Yang, X.; Wang, N.; Gao, X. A CenterNet++ model for ship detection in SAR images. Pattern Recognit. 2021, 112, 107787. [Google Scholar] [CrossRef]
- Zhang, J.; Sheng, W.; Zhu, H.; Guo, S.; Han, Y. MLBR-YOLOX: An efficient SAR ship detection network with multilevel background removing modules. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 5331–5343. [Google Scholar] [CrossRef]
- Wan, H.; Chen, J.; Huang, Z.; Xia, R.; Wu, B.; Sun, L.; Yao, B.; Liu, X.; Xing, M. AFSar: An anchor-free SAR target detection algorithm based on multiscale enhancement representation learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5219514. [Google Scholar] [CrossRef]
- Sun, Z.; Dai, M.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. An anchor-free detection method for ship targets in high-resolution SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7799–7816. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR ship detection dataset (SSDD): Official release and comprehensive data analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2849–2858. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3163–3171. [Google Scholar]
- Lin, T. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Gao, G.; Chen, Y.; Feng, Z.; Zhang, C.; Duan, D.; Li, H.; Zhang, X. R-LRBPNet: A Lightweight SAR Image Oriented Ship Detection and Classification Method. Remote Sens. 2024, 16, 1533. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SSDD+ | HRSID | |
|---|---|---|
| Number of Images | 1160 | 5640 |
| Number of Ships | 2551 | 16,965 |
| Image Size (Pixels) | 500 × 500 | 800 × 800 |
| Resolution (m) | 1–15 | 0.5–3 |
| Polarization Mode | VV, VH, HH, HV | VV, HV, HH |
| Module | Precision (%) | Recall (%) | AP (%) | |
|---|---|---|---|---|
| Two-Stage | R-FasterRCNN | 90.74 | 91.49 | 89.62 |
| O-RCNN | 92.83 | 91.36 | 90.15 | |
| ROI | 88.42 | 89.28 | 87.65 | |
| One-Stage | R-FCOS | 83.55 | 87.73 | 82.91 |
| R3Det | 84.41 | 85.64 | 83.72 | |
| R-RetinaNet | 86.56 | 88.19 | 87.61 | |
| R-YOLOv7 | 83.55 | 87.73 | 82.91 | |
| R-LRBPNet | 94.93 | 92.54 | 94.86 | |
| R-YOLOv8 (baseline) | 94.17 | 91.34 | 94.06 | |
| Ours | 96.32 | 93.13 | 95.28 |
| Module | Precision (%) | Recall (%) | AP (%) | |
|---|---|---|---|---|
| Two-Stage | R-FasterRCNN | 80.62 | 81.04 | 77.87 |
| O-RCNN | 85.35 | 84.61 | 80.2 | |
| ROI | 84.19 | 82.48 | 78.76 | |
| One-Stage | R-FCOS | 78.77 | 74.91 | 73.15 |
| R3Det | 79.86 | 75.29 | 77.45 | |
| R-RetinaNet | 83.72 | 81.45 | 80.23 | |
| R-YOLOv7 | 89.6 | 85.37 | 84.38 | |
| R-LRBPNet | 91.35 | 87.59 | 88.74 | |
| R-YOLOv8 (baseline) | 90.72 | 86.35 | 87.8 | |
| Ours | 92.56 | 89.43 | 90.69 |
| Experiment | SG-AFA | BSMF | GWD | P (%) | R (%) | AP (%) |
|---|---|---|---|---|---|---|
| 1 | - | - | - | 94.17 | 91.34 | 94.06 |
| 2 | ✓ | - | - | 95.64 | 91.96 | 94.71 |
| 3 | ✓ | ✓ | - | 96.21 | 91.99 | 94.83 |
| 4 | ✓ | ✓ | ✓ | 96.32 | 93.13 | 95.28 |
| Model | MacBook Pro (13-Inch) | RTX4060 GPU | ||||
|---|---|---|---|---|---|---|
| Pre (ms) | Infer (ms) | Post (ms) | Pre (ms) | Infer (ms) | Post (ms) | |
| YOLOv8 | 0.7 | 6.5 | 6.9 | 0.4 | 4.8 | 5.3 |
| YOLOv11 | 0.8 | 6.3 | 6.0 | 0.5 | 3.9 | 4.2 |
| R-SABMNet | 0.8 | 6.7 | 5.3 | 0.5 | 3.6 | 3.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Duan, W.; Fu, X.; Lv, X. R-SABMNet: A YOLOv8-Based Model for Oriented SAR Ship Detection with Spatial Adaptive Aggregation. Remote Sens. 2025, 17, 551. https://doi.org/10.3390/rs17030551
Li X, Duan W, Fu X, Lv X. R-SABMNet: A YOLOv8-Based Model for Oriented SAR Ship Detection with Spatial Adaptive Aggregation. Remote Sensing. 2025; 17(3):551. https://doi.org/10.3390/rs17030551
Chicago/Turabian StyleLi, Xiaoting, Wei Duan, Xikai Fu, and Xiaolei Lv. 2025. "R-SABMNet: A YOLOv8-Based Model for Oriented SAR Ship Detection with Spatial Adaptive Aggregation" Remote Sensing 17, no. 3: 551. https://doi.org/10.3390/rs17030551
APA StyleLi, X., Duan, W., Fu, X., & Lv, X. (2025). R-SABMNet: A YOLOv8-Based Model for Oriented SAR Ship Detection with Spatial Adaptive Aggregation. Remote Sensing, 17(3), 551. https://doi.org/10.3390/rs17030551