

Research on 3D Reconstruction Methods for Incomplete Building Point Clouds Using Deep Learning and Geometric Primitives

 , ,
, , 
Abstract
1. Introduction
- (1)
- We propose a point cloud completion method tailored to building scenes. This method utilizes a multiscale feature fusion approach based on a GAN to complete missing building point cloud data. Geometric constraints are incorporated into both the feature extraction process and the loss function, significantly improving the accuracy of feature extraction and the prediction of missing regions.
- (2)
- A novel method for LoD-2 building model reconstruction is introduced, reformulating the task as a binary labeling problem. Planes extracted from the point cloud are segmented into candidate surfaces, and a weighted energy term, customized to building characteristics, is used to calculate the weight of each surface. Suitable surfaces are then selected to create a lightweight LoD-2 3D building model.
2. Related Work
2.1. Point Cloud Completion
2.2. Building Reconstruction from Point Cloud Data
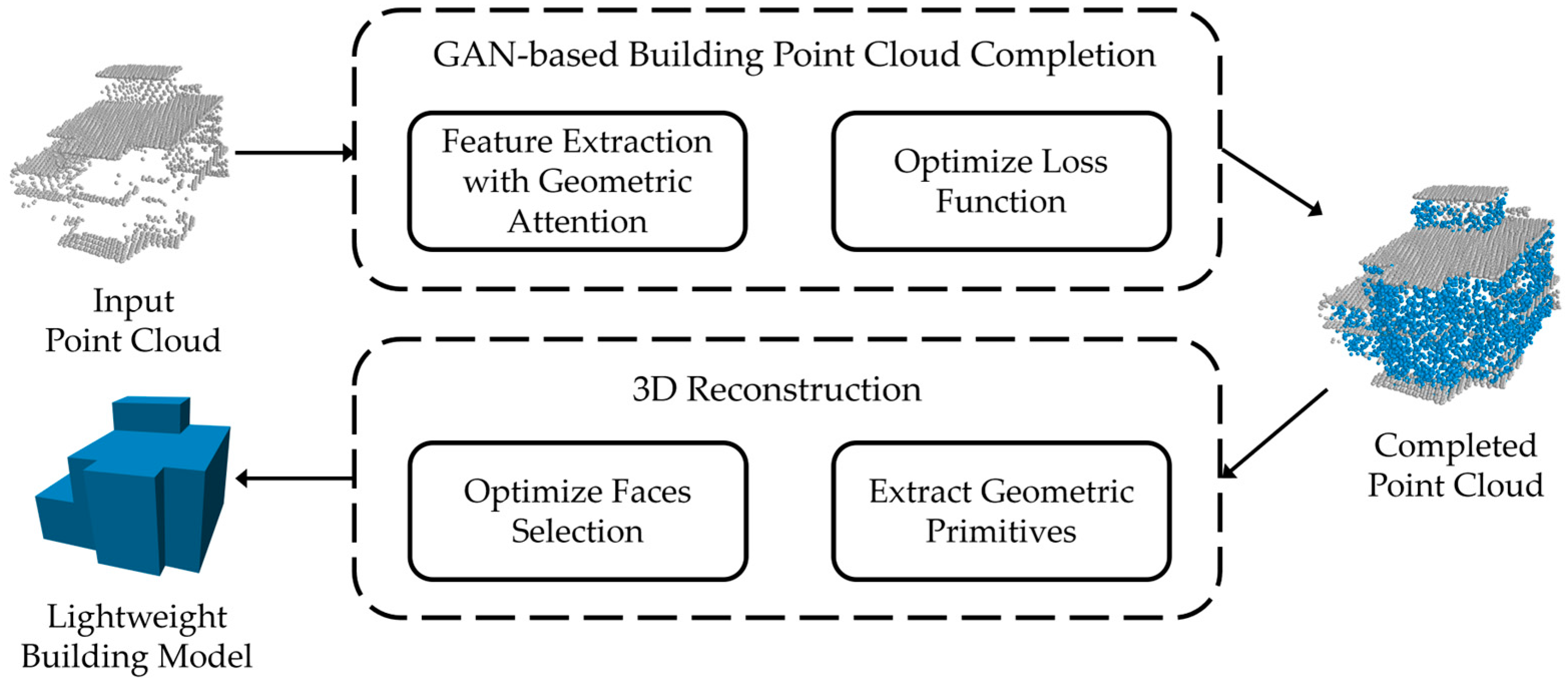
3. Method
3.1. Completion of Missing Building Point Clouds Using GANs and Multiresolution Feature Fusion
3.1.1. Multiresolution–Resolution Feature Extraction with Geometric Constraints
- (1)
- Curvature calculation for each point. For a sampled point , its neighborhood point set is determined using the k-nearest neighbors (KNN) method. The curvature of point is then computed using principal component analysis [37]. The detailed process is outlined in Equations (1)–(3). Let the neighborhood points be , …, . First, the mean of the neighborhood points is calculated as follows:where represents the coordinate vector of the -th point in the neighborhood. Next, the covariance matrix is computed as follows:
- (2)
- Generating geometric attention weights. After computing the curvature values for each point, these values are combined with the point’s position and normal vector information as input data for feature extraction. The processed input data have a format of , where is the number of sampled points, and the four dimensions include 3D position data and the one-dimensional curvature value. To allow the model to dynamically adjust its focus on individual points based on their curvature, attention weights for each point need to be generated. The attention weight for each point is calculated from the curvature value using Equation (4). To generate the attention weights, the curvature values are first normalized using the min–max scaling method. The normalized values are then passed through a multilayer perceptron (MLP), which generates the attention weights for each point based on its curvature.
| Algorithm 1 Generating Geometric Attention Weights | |
| Require: Point positions , curvature values | |
| Ensure: Attention weights | |
| 1: | |
| 2: | {Initialize feature matrix} |
| 3: | for each point do |
| 4: | |
| 5: | Append to |
| 6: | end for |
| 7: | |
| 8: | {Apply Gumbel Softmax with temperature τ} |
| 9: | return |
- (3)
- Feature extraction. The complete process of feature extraction is illustrated in the upper part of Figure 2. In the feature extraction stage, an MLP is used to progressively increase the dimensionality of each point’s feature information, with dimensions of (64, 128, 256, 512, 1024). Unlike traditional approaches that extract global features from the last layer, this paper incorporates the CMLP mechanism from PF-Net [20] to retain and integrate features from multiple levels. For the last four layers of the MLP, the outputs are multiplied by the attention weight and then subjected to max pooling, producing multidimensional feature vectors (with sizes neurons for = 1, …, 4). These feature vectors are concatenated to form the final latent vector , which combines both high-dimensional and low-dimensional features, resulting in a total dimensionality of 1920. Given that there are two resolutions of input data, two 1920-dimensional feature vectors are generated. These vectors are concatenated to create the final latent feature representation . Finally, an additional MLP layer [1,2] integrates into the ultimate feature vector .
3.1.2. Generation of Missing Point Cloud Regions
| Algorithm 2 Two-Level Point Generation with Coarse and detail Layers | |
| Require: Final feature vector | |
| Ensure: Two-layer point clouds | |
| 1: | |
| 2: | |
| 3: | |
| 4: | |
| 5: | for each point in do |
| 6: | |
| 7: | Append to |
| 8: | end for |
| 9: | return , |
3.2. Three-Dimensional Surface Reconstruction of Buildings from Completed Point Clouds
3.2.1. Point Cloud Optimization
3.2.2. Reconstruction of LoD-2 Building Models
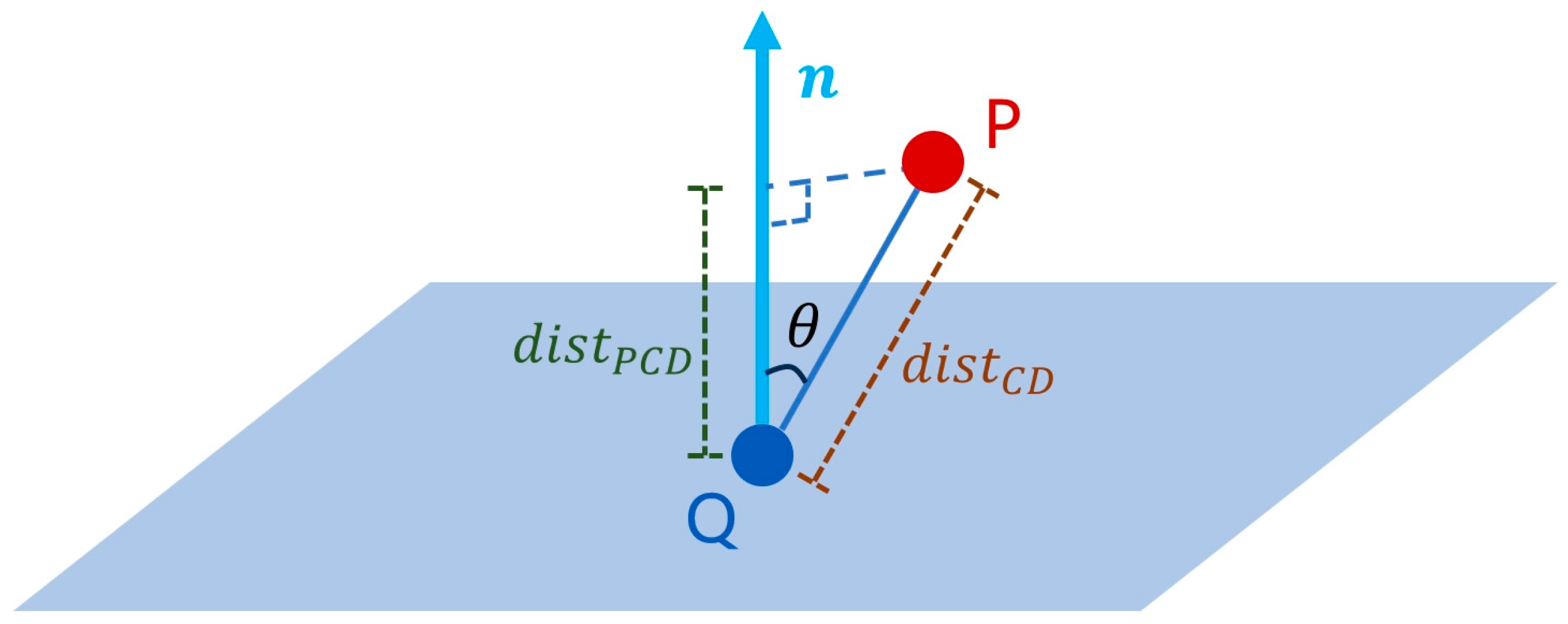
- (1)
- Point fitting. This energy term evaluates the degree of support that candidate polygons have from the input point cloud. It selects polygons that are well-aligned with the input point cloud and are supported by densely sampled regions [42]. The point fitting energy term is defined as follows:where is the total number of points in , and is the number of candidate polygons. The binary variable indicates whether the candidate polygon is selected. The term represents the weighted sum of points near the candidate polygon , measuring its support. The term is the Euclidean distance between a point and the polygon , with being a distance threshold. The confidence term assesses the quality of the point cloud in the region around point . Here, are the three eigenvalues of the local covariance matrix of point at the -th scale. The expression evaluates the quality of planar fitting in the local neighborhood, where values close to 1 indicate well-aligned points, and values close to 0 indicate a line or point cluster. The ratio measures the sampling uniformity of point in the local neighborhood, with values close to 1 indicating more uniform sampling.
- (2)
- Building geometry feature. This study focuses on general buildings, which are typically composed of vertical walls and horizontal roofs. To reconstruct models that better align with the structural characteristics of buildings, we introduce a building geometry feature energy term:
4. Experiments
4.1. Building Point Cloud Dataset
4.2. Completion of Incomplete Building Point Clouds
4.2.1. Quantitative Analysis for Point Cloud Completion
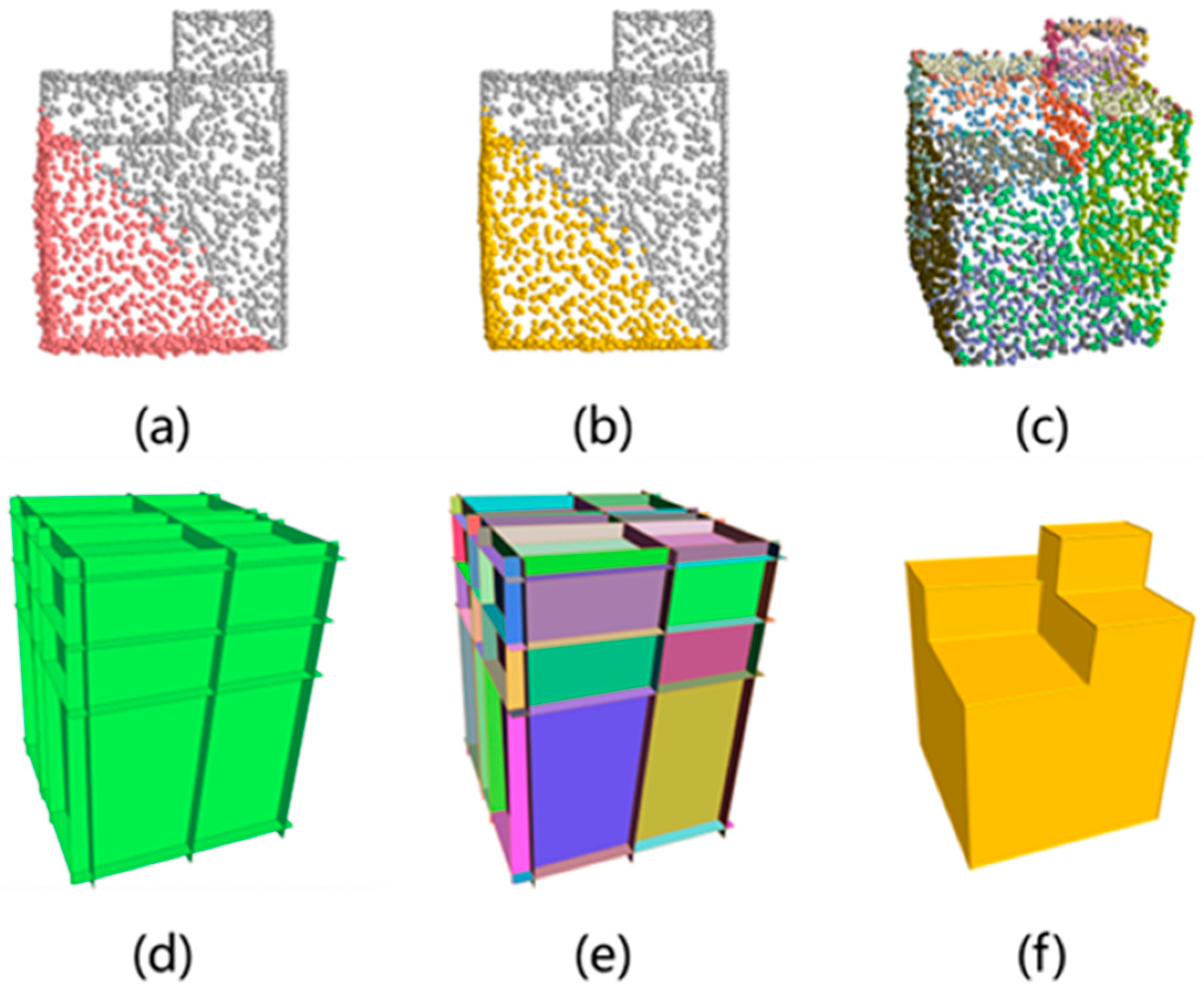
4.2.2. Qualitative Analysis for Point Cloud Completion
4.2.3. Robustness Testing
4.3. Building Model Reconstruction Experiments
4.3.1. Qualitative Analysis for Reconstruction
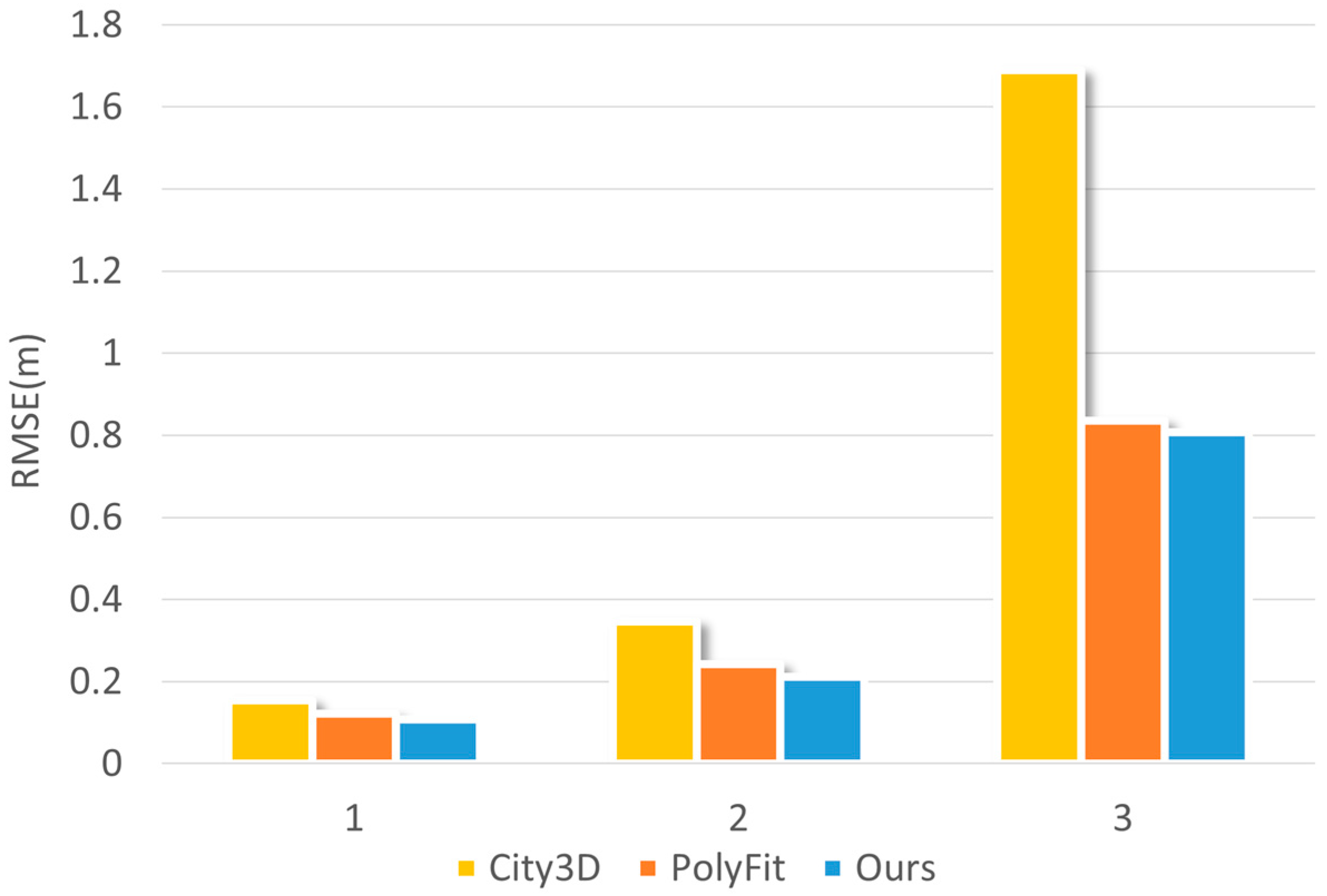
4.3.2. Quantitative Analysis for Reconstruction
4.4. Complex Data Testing
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Peters, R.; Dukai, B.; Vitalis, S.; van Liempt, J.; Stoter, J. Automated 3D reconstruction of LoD2 and LoD1 models for all 10 million buildings of the Netherlands. Photogramm. Eng. Remote Sens. 2022, 88, 165–170. [Google Scholar] [CrossRef]
- Dehbi, Y.; Henn, A.; Gröger, G.; Stroh, V.; Plümer, L. Robust and fast reconstruction of complex roofs with active sampling from 3D point clouds. Trans. GIS 2021, 25, 112–133. [Google Scholar] [CrossRef]
- Wang, F.; Zhou, G.; Hu, H.; Wang, Y.; Fu, B.; Li, S.; Xie, J. Reconstruction of LoD-2 Building Models Guided by Façade Structures from Oblique Photogrammetric Point Cloud. Remote Sens. 2023, 15, 400. [Google Scholar] [CrossRef]
- Kim, V.G.; Li, W.; Mitra, N.J.; Chaudhuri, S.; DiVerdi, S.; Funkhouser, T. Learning part-based templates from large collections of 3D shapes. ACM Trans. Graph. 2013, 32, 1–12. [Google Scholar] [CrossRef]
- Li, Y.; Dai, A.; Guibas, L.; Nießner, M. Database-assisted object retrieval for real-time 3D reconstruction. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2015; Volume 34, pp. 435–446. [Google Scholar]
- Nan, L.; Xie, K.; Sharf, A. A search-classify approach for cluttered indoor scene understanding. ACM Trans. Graph. 2012, 31, 1–10. [Google Scholar] [CrossRef]
- Mitra, N.J.; Pauly, M.; Wand, M.; Ceylan, D. Symmetry in 3D Geometry: Extraction and Applications. Comput. Graph. Forum 2013, 32, 1–23. [Google Scholar] [CrossRef]
- Pauly, M.; Mitra, N.J.; Wallner, J.; Pottmann, H.; Guibas, L.J. Discovering structural regularity in 3D geometry. In ACM SIGGRAPH 2008 Papers; ACM: New York, NY, USA, 2008; pp. 1–11. [Google Scholar]
- Zhao, W.; Gao, S.; Lin, H. A robust hole filling algorithm for triangular mesh. Vis. Comput. 2007, 23, 987–997. [Google Scholar] [CrossRef]
- Dai, A.; Ruizhongtai Ci, C.; Nießner, M. Shape completion using 3D-encoder-predictor CNNs and shape synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5868–5877. [Google Scholar]
- Xie, H.; Yao, H.; Zhou, S.; Mao, J.; Zhang, S.; Sun, W. GRNet: Gridding Residual Network for Dense Point Cloud Completion. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12354, pp. 581–597. [Google Scholar]
- Han, X.; Li, Z.; Huang, H.; Kalogerakis, E.; Yu, Y. High-resolution shape completion using deep neural networks for global structure and local geometry inference. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 85–93. [Google Scholar]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. FoldingNet: Point Cloud Auto-Encoder via Deep Grid Deformation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 206–215. [Google Scholar]
- Yuan, W.; Khot, T.; Held, D.; Mertz, C.; Hebert, M. PCN: Point Completion Network. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 728–737. [Google Scholar]
- Tchapmi, L.P.; Kosaraju, V.; Rezatofighi, H.; Reid, I.; Savarese, S. TopNet: Structural point cloud decoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 383–392. [Google Scholar]
- Vaswani, A. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Chen, Y.; Zhou, J.; Ge, Y.; Dong, J. Uncovering the rapid expansion of photovoltaic power plants in China from 2010 to 2022 using satellite data and deep learning. Remote Sens. Environ. 2024, 305, 114100. [Google Scholar] [CrossRef]
- Li, S.; Gao, P.; Tan, X.; Wei, M. Proxyformer: Proxy alignment assisted point cloud completion with missing part sensitive transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 9466–9475. [Google Scholar]
- Huang, Z.; Yu, Y.; Xu, J.; Ni, F.; Le, X. PF-Net: Point Fractal Network for 3D Point Cloud Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7662–7670. [Google Scholar]
- Sarmad, M.; Lee, H.J.; Kim, Y.M. RL-GAN-Net: A Reinforcement Learning Agent Controlled GAN Network for Real-Time Point Cloud Shape Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5898–5907. [Google Scholar]
- Li, W.; Chen, Y.; Fan, Q.; Yang, M.; Guo, B.; Yu, Z. I-PAttnGAN: An Image-Assisted Point Cloud Generation Method Based on Attention Generative Adversarial Network. Remote Sens. 2025, 17, 153. [Google Scholar] [CrossRef]
- Ge, B.; Chen, S.; He, W.; Qiang, X.; Li, J.; Teng, G.; Huang, F. Tree Completion Net: A Novel Vegetation Point Clouds Completion Model Based on Deep Learning. Remote Sens. 2024, 16, 3763. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Y.; Zeng, H.; Zhu, H. Volume Estimation of Oil Tanks Based on 3D Point Cloud Completion. IEEE Trans. Instrum. Meas. 2024, 73, 2532810. [Google Scholar]
- Xia, Y.; Xu, Y.; Wang, C.; Stilla, U. VPC-Net: Completion of 3D Vehicles from MLS Point Clouds. ISPRS J. Photogramm. Remote Sens. 2021, 174, 166–181. [Google Scholar] [CrossRef]
- Boissonnat, J.-D. Geometric structures for three-dimensional shape representation. ACM Trans. Graph. 1984, 3, 266–286. [Google Scholar] [CrossRef]
- Edelsbrunner, H.; Mücke, E.P. Three-dimensional alpha shapes. ACM Trans. Graph. 1994, 13, 43–72. [Google Scholar] [CrossRef]
- Bernardini, F.; Mittleman, J.; Rushmeier, H.; Silva, C.; Taubin, G. The ball-pivoting algorithm for surface reconstruction. IEEE Trans. Vis. Comput. Graph. 1999, 5, 349–359. [Google Scholar] [CrossRef]
- Carr, J.C.; Beatson, R.K.; Cherrie, J.B.; Mitchell, T.J.; Fright, W.R.; McCallum, B.C.; Evans, T.R. Reconstruction and representation of 3D objects with radial basis functions. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), Los Angeles, CA, USA, 12–17 August 2001; pp. 67–76. [Google Scholar]
- Kazhdan, M.; Bolitho, M.; Hoppe, H. Poisson surface reconstruction. In Proceedings of the Fourth Eurographics Symposium on Geometry Processing (SGP ‘06), Sardinia, Italy, 26–28 June 2006; Eurographics Association: Goslar, Germany, 2006; pp. 61–70. [Google Scholar]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient RANSAC for Point-Cloud Shape Detection. Comput. Graph. Forum 2007, 26, 214–226. [Google Scholar] [CrossRef]
- Li, M.; Nan, L.; Smith, N.G.; Wonka, P. Reconstructing building mass models from UAV images. Comput. Graph. 2016, 54, 84–93. [Google Scholar] [CrossRef]
- Lin, H.C.; Gao, J.; Zhou, Y.; Lu, G.; Ye, M.; Zhang, C.; Liu, L.; Yang, R. Semantic Decomposition and Reconstruction of Residential Scenes from LiDAR Data. ACM Trans. Graph. 2013, 32, 66. [Google Scholar] [CrossRef]
- Huang, J.; Stoter, J.; Peters, R.; Nan, L. City3D: Large-Scale Building Reconstruction from Airborne LiDAR Point Clouds. Remote Sens. 2022, 14, 2254. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Birdal, T.; Ilic, S. A point sampling algorithm for 3D matching of irregular geometries. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 6871–6878. [Google Scholar]
- Pauly, M.; Keiser, R.; Gross, M. Multi-scale feature extraction on point-sampled surfaces. Comput. Graph. Forum 2003, 22, 281–289. [Google Scholar] [CrossRef]
- Zhou, Y.; Ren, T.; Zhu, C.; Sun, X.; Liu, J.; Ding, X.; Xu, M.; Ji, R. TRAR: Routing the Attention Spans in Transformer for Visual Question Answering. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 2054–2064. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L.J. A Point Set Generation Network for 3D Object Reconstruction from a Single Image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2463–2471. [Google Scholar]
- Nan, L.; Wonka, P. PolyFit: Polygonal Surface Reconstruction from Point Clouds. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2372–2380. [Google Scholar]
- Nan, L.; Sharf, A.; Zhang, H.; Cohen-Or, D.; Chen, B. SmartBoxes for interactive urban reconstruction. In Proceedings of the ACM SIGGRAPH 2010 Papers (SIGGRAPH ‘10), Los Angeles, CA, USA, 26–30 July 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 1–10. [Google Scholar]
- Gurobi. Gurobi Optimization. Available online: http://www.gurobi.com/ (accessed on 15 June 2024).
- 3D Model of the City of Adelaide. Available online: https://data.sa.gov.au/data/dataset/3d-model (accessed on 5 March 2024).
- Zhang, J.; Chen, X.; Cai, Z.; Pan, L.; Zhao, H.; Yi, S.; Yeo, C.K.; Dai, B.; Loy, C.C. Unsupervised 3D Shape Completion through GAN Inversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1768–1777. [Google Scholar]
- Zhou, H.; Cao, Y.; Chu, W.; Zhu, J.; Lu, T.; Tai, Y.; Wang, C. SeedFormer: Patch Seeds based Point Cloud Completion with Upsample Transformer. arXiv 2022, arXiv:2207.10315. [Google Scholar]
- Gadelha, M.; Wang, R.; Maji, S. Multiresolution tree networks for 3D point cloud processing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 103–118. [Google Scholar]
- Lin, C.-H.; Kong, C.; Lucey, S. Learning efficient point cloud generation for dense 3D object reconstruction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; p. 32. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PCN | PF-Net | SI | SeedFormer | Ours | |
|---|---|---|---|---|---|
| Gt_Pre | 0.976 | 0.740 | 0.573 | 0.436 | 0.508 |
| Pre_Gt | 1.181 | 0.504 | 0.635 | 0.633 | 0.404 |
| CD | 2.157 | 1.245 | 1.208 | 1.069 | 0.912 |
| Building in Figure 9 | Method | Faces | Time (s) |
|---|---|---|---|
| 1 | City3D | 8 | 10.63 |
| PolyFit | 9 | 4.52 | |
| Ours | 8 | 5.18 | |
| 2 | City3D | 8 | 16.24 |
| PolyFit | 16 | 6.82 | |
| Ours | 11 | 7.96 | |
| 3 | City3D | 18 | 28.91 |
| PolyFit | 33 | 10.79 | |
| Ours | 25 | 13.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Z.; Lu, Y.; Shao, S.; Qin, Y.; Lu, M.; Song, Z.; Sun, D. Research on 3D Reconstruction Methods for Incomplete Building Point Clouds Using Deep Learning and Geometric Primitives. Remote Sens. 2025, 17, 399. https://doi.org/10.3390/rs17030399
Ding Z, Lu Y, Shao S, Qin Y, Lu M, Song Z, Sun D. Research on 3D Reconstruction Methods for Incomplete Building Point Clouds Using Deep Learning and Geometric Primitives. Remote Sensing. 2025; 17(3):399. https://doi.org/10.3390/rs17030399
Chicago/Turabian StyleDing, Ziqi, Yuefeng Lu, Shiwei Shao, Yong Qin, Miao Lu, Zhenqi Song, and Dengkuo Sun. 2025. "Research on 3D Reconstruction Methods for Incomplete Building Point Clouds Using Deep Learning and Geometric Primitives" Remote Sensing 17, no. 3: 399. https://doi.org/10.3390/rs17030399
APA StyleDing, Z., Lu, Y., Shao, S., Qin, Y., Lu, M., Song, Z., & Sun, D. (2025). Research on 3D Reconstruction Methods for Incomplete Building Point Clouds Using Deep Learning and Geometric Primitives. Remote Sensing, 17(3), 399. https://doi.org/10.3390/rs17030399