
DVR: Towards Accurate Hyperspectral Image Classifier via Discrete Vector Representation

 , ,
, , 
Abstract
1. Introduction
- We propose a novel discrete vector representation (DVR) strategy. Distinguished from previous approaches of optimizing network structures, DVR offers a fresh perspective on optimizing the distribution of category features to mitigate the misclassification problem. Moreover, it can be effortlessly incorporated into various existing HSI classification methods, thus improving their classification accuracy.
- We develop the AM, DVCM, and AC to form a complete DVR strategy. The AM aligns the encoded features with the semantic space of the codebook. The DVCM is able to capture essential and stable feature representations in its codebook. The AC enhances classification performance by utilizing representative code information from the codebook. These three components are integrated to improve the discriminability of feature categories and reduce misclassifications.
- Our comprehensive evaluations demonstrate that the proposed DVR approach with feature distribution optimization can enhance the performance of HSI classifiers. Through extensive experiments and visual analyses conducted on different HSI benchmarks, our DVR approach consistently surpasses other state-of-the-art backbone networks in terms of both classification accuracy and model stability, while requiring merely a minimal increase in parameters.
2. Related Work
2.1. Convolutional Neural Networks for HSI Classification
2.2. Vision Transformers for HSI Classification
2.3. Schemes for Enhancing Model Performance
3. Methods
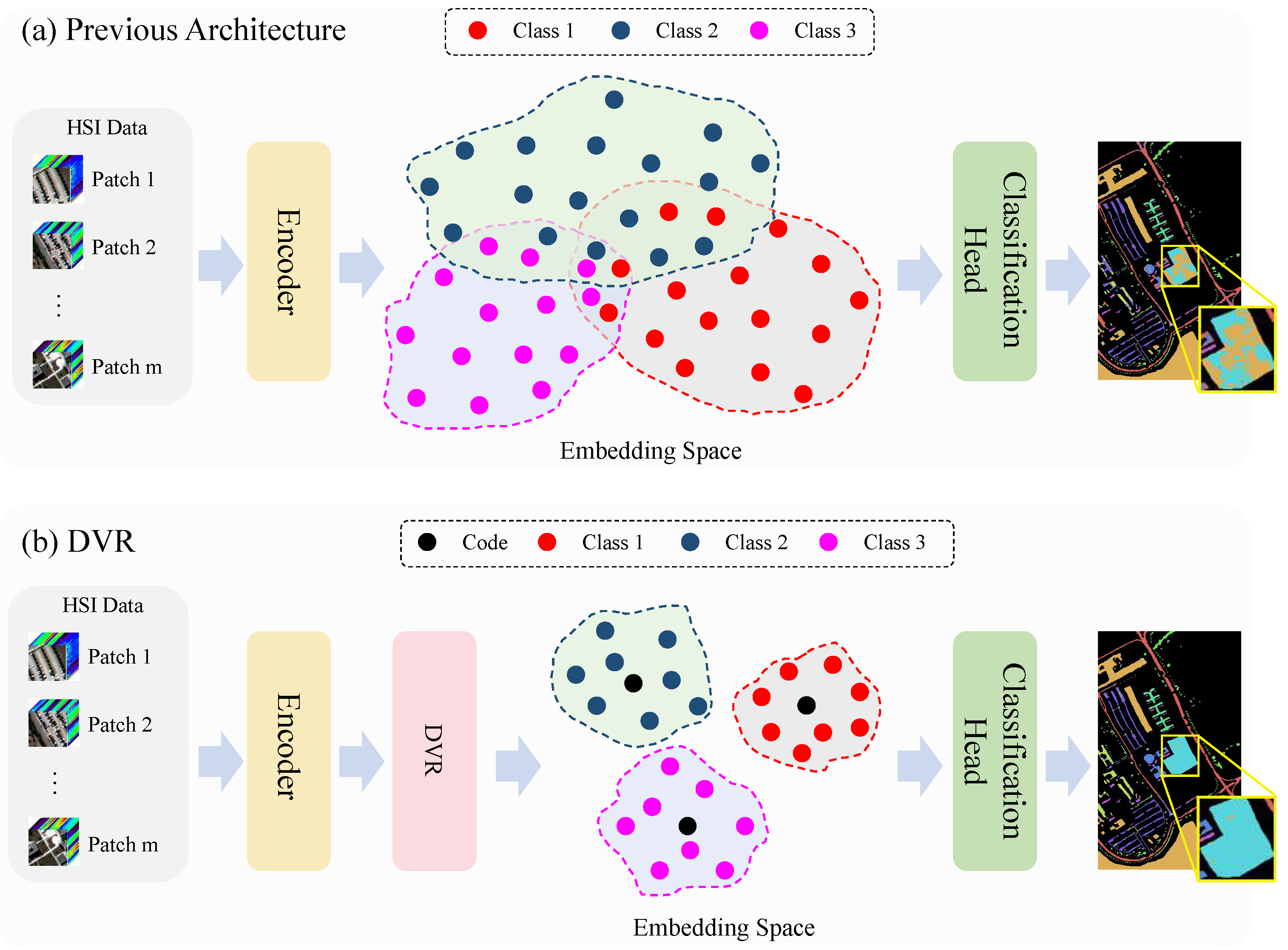
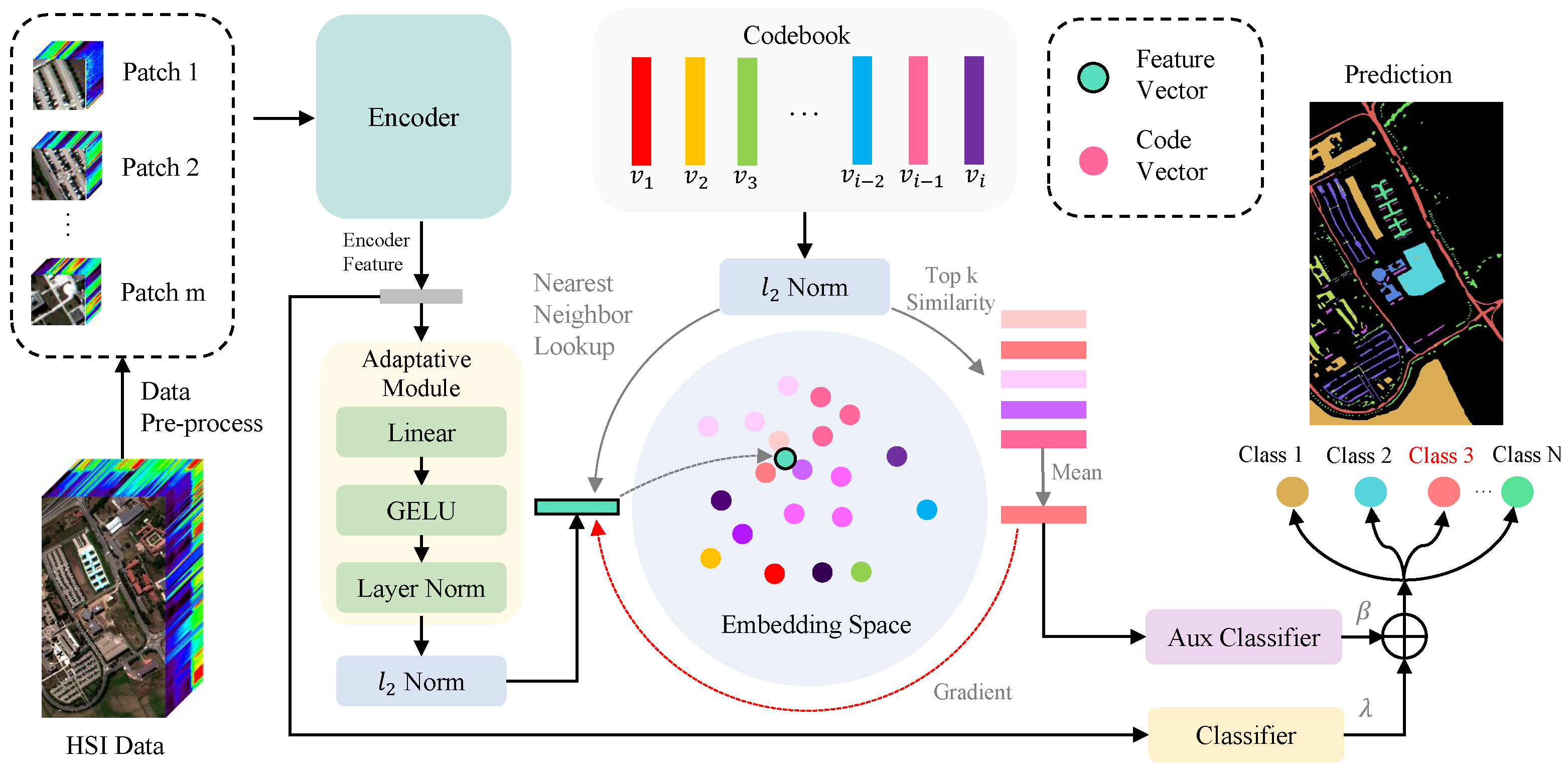
3.1. Overall Architecture
3.2. Discrete Vector Representation Strategy
| Algorithm 1: Inference of DVR |
 |
3.3. Train Strategy
4. Experiment Results
4.1. Data Description
4.1.1. Salinas
4.1.2. Pavia University
4.1.3. HyRANK-Loukia
4.1.4. WHU-Hi-HanChuan
4.2. Experiment Setups
4.2.1. Implementation Details
4.2.2. Evaluation Metrics
4.2.3. Baseline Models
4.3. Comparative Experiments
4.3.1. Quantitative Assessment
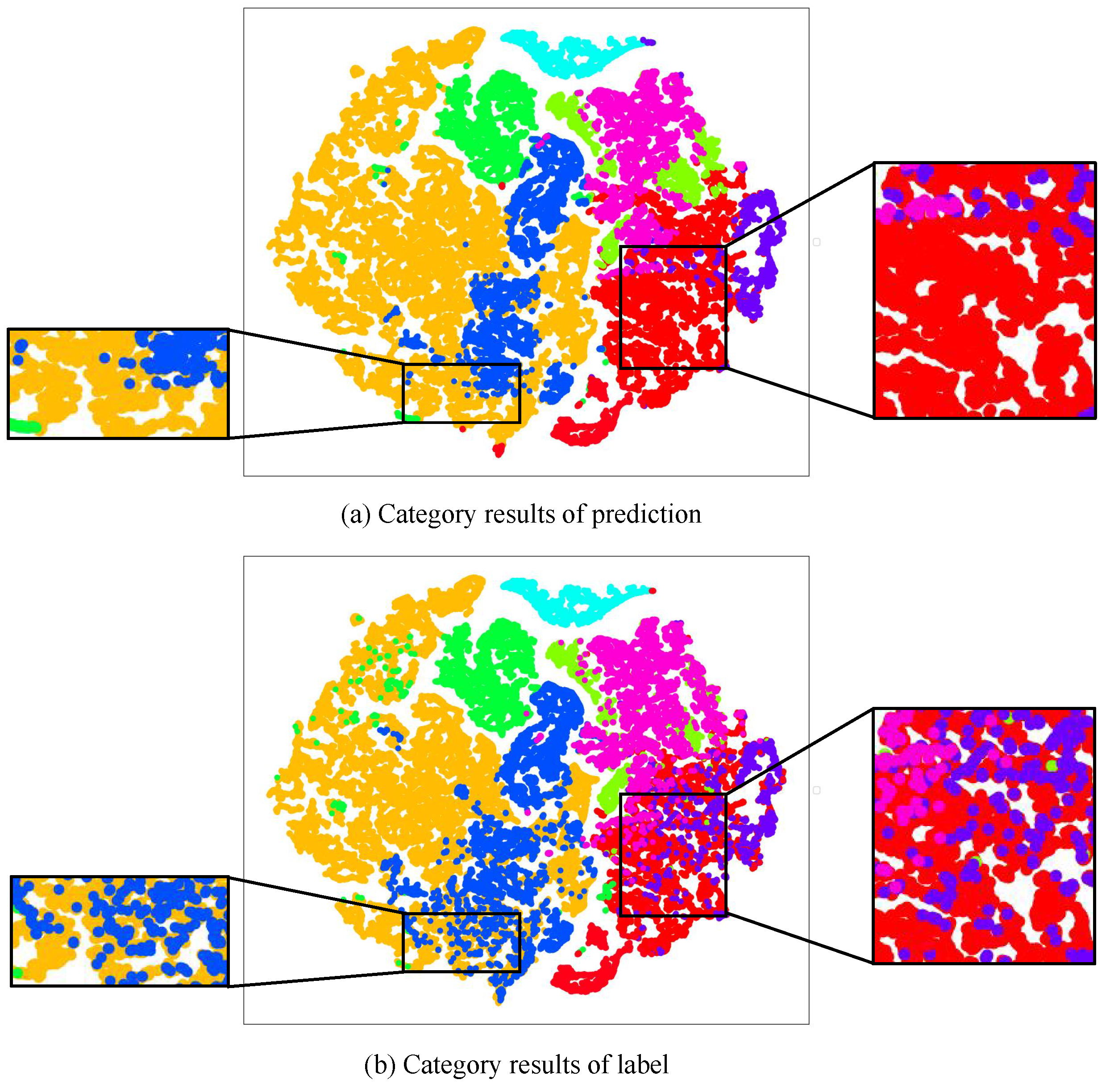
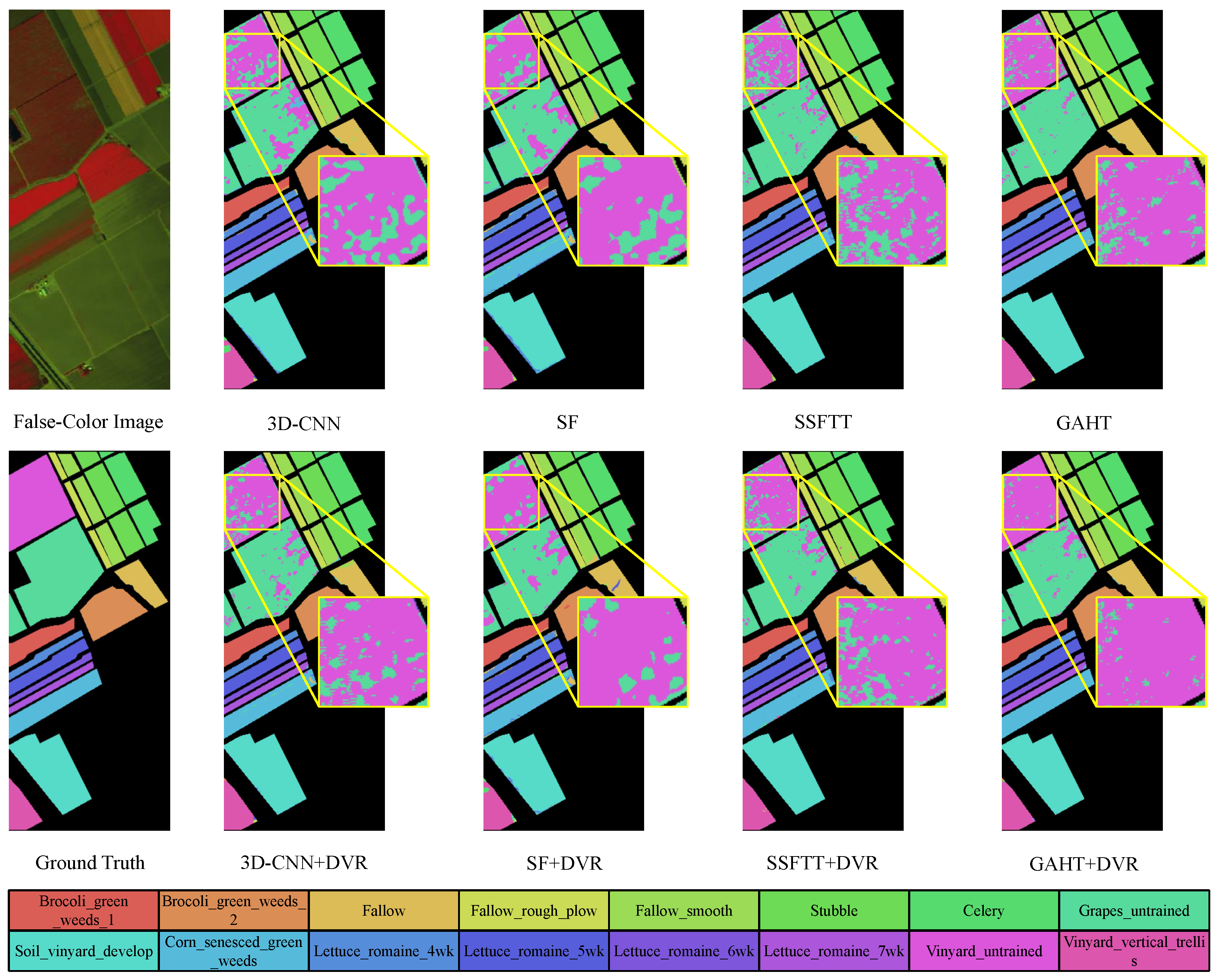
4.3.2. Visual Evaluation
4.4. Ablation Study
4.4.1. Impact of DVCM
4.4.2. Codebook Size
4.4.3. Codebook Dimension
4.4.4. Top-k Selection
4.4.5. Impact of AC
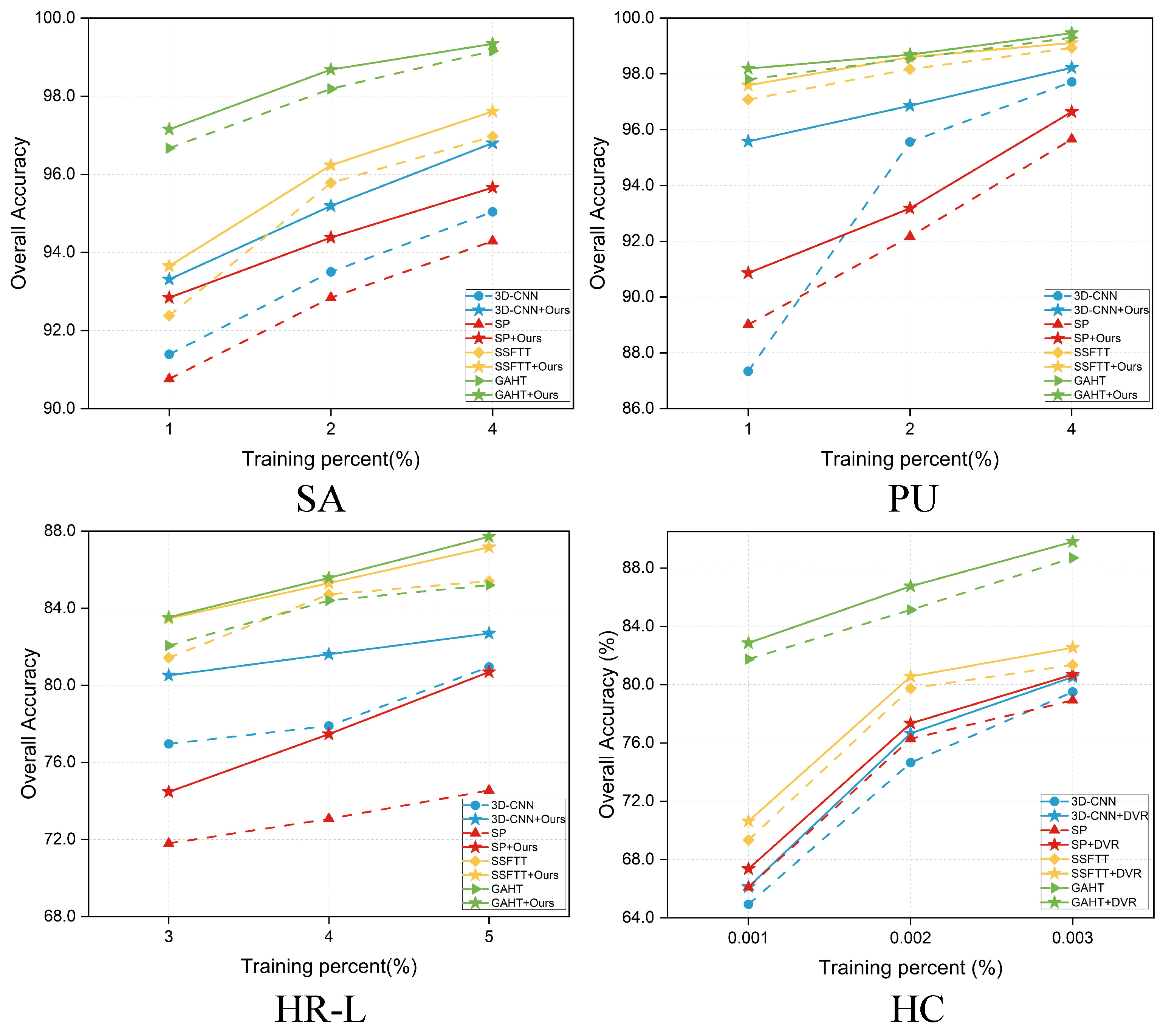
4.5. Robustness Evaluation
4.6. Computational Cost
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral remote sensing data analysis and future challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Hu, C. Hyperspectral reflectance spectra of floating matters derived from Hyperspectral Imager for the Coastal Ocean (HICO) observations. Earth Syst. Sci. Data 2022, 14, 1183–1192. [Google Scholar] [CrossRef]
- Grøtte, M.E.; Birkeland, R.; Honoré-Livermore, E.; Bakken, S.; Garrett, J.L.; Prentice, E.F.; Sigernes, F.; Orlandić, M.; Gravdahl, J.T.; Johansen, T.A. Ocean color hyperspectral remote sensing with high resolution and low latency—The HYPSO-1 CubeSat mission. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–19. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Kumar, B.; Dikshit, O.; Gupta, A.; Singh, M.K. Feature extraction for hyperspectral image classification: A review. Int. J. Remote Sens. 2020, 41, 6248–6287. [Google Scholar] [CrossRef]
- Yang, X.; Cao, W.; Lu, Y.; Zhou, Y. QTN: Quaternion transformer network for hyperspectral image classification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7370–7384. [Google Scholar] [CrossRef]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef]
- Pal, M.; Foody, G.M. Feature selection for classification of hyperspectral data by SVM. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2297–2307. [Google Scholar] [CrossRef]
- Fan, J.; Chen, T.; Lu, S. Superpixel guided deep-sparse-representation learning for hyperspectral image classification. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 3163–3173. [Google Scholar] [CrossRef]
- Li, J.; Zhao, X.; Li, Y.; Du, Q.; Xi, B.; Hu, J. Classification of hyperspectral imagery using a new fully convolutional neural network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 292–296. [Google Scholar] [CrossRef]
- Hu, J.F.; Huang, T.Z.; Deng, L.J.; Jiang, T.X.; Vivone, G.; Chanussot, J. Hyperspectral image super-resolution via deep spatiospectral attention convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 7251–7265. [Google Scholar] [CrossRef] [PubMed]
- Pu, C.; Huang, H.; Shi, X.; Wang, T. Semisupervised spatial-spectral feature extraction with attention mechanism for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Hamida, A.B.; Benoit, A.; Lambert, P.; Amar, C.B. 3-D deep learning approach for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef]
- Cao, X.; Xu, L.; Meng, D.; Zhao, Q.; Xu, Z. Integration of 3-dimensional discrete wavelet transform and Markov random field for hyperspectral image classification. Neurocomputing 2017, 226, 90–100. [Google Scholar] [CrossRef]
- Cao, X.; Zhou, F.; Xu, L.; Meng, D.; Xu, Z.; Paisley, J. Hyperspectral image classification with Markov random fields and a convolutional neural network. IEEE Trans. Image Process. 2018, 27, 2354–2367. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; He, N.; Fang, L.; Ghamisi, P. Multiscale densely-connected fusion networks for hyperspectral images classification. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 246–259. [Google Scholar] [CrossRef]
- Ran, R.; Deng, L.J.; Zhang, T.J.; Chang, J.; Wu, X.; Tian, Q. KNLConv: Kernel-space non-local convolution for hyperspectral image super-resolution. IEEE Trans. Multimed. 2024, 26, 8836–8848. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–spatial feature tokenization transformer for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522214. [Google Scholar] [CrossRef]
- Mei, S.; Song, C.; Ma, M.; Xu, F. Hyperspectral image classification using group-aware hierarchical transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5539014. [Google Scholar] [CrossRef]
- Song, L.; Feng, Z.; Yang, S.; Zhang, X.; Jiao, L. Interactive Spectral-Spatial Transformer for Hyperspectral Image Classification. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 8589–8601. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Hang, R.; Zhang, B.; Chanussot, J. Deep encoder–decoder networks for classification of hyperspectral and LiDAR data. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Van Den Oord, A.; Vinyals, O.; Kavukcuoglu, K. Neural discrete representation learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 6309–6318. [Google Scholar]
- Mao, C.; Jiang, L.; Dehghani, M.; Vondrick, C.; Sukthankar, R.; Essa, I. Discrete Representations Strengthen Vision Transformer Robustness. In Proceedings of the International Conference on Learning Representations (ICLR), Online, 25–29 April 2022. [Google Scholar]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Mei, S.; Chen, X.; Zhang, Y.; Li, J.; Plaza, A. Accelerating convolutional neural network-based hyperspectral image classification by step activation quantization. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral image classification with deep feature fusion network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Zhao, X.; Tao, R.; Li, W.; Li, H.C.; Du, Q.; Liao, W.; Philips, W. Joint classification of hyperspectral and LiDAR data using hierarchical random walk and deep CNN architecture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7355–7370. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- He, M.; Li, B.; Chen, H. Multi-scale 3D deep convolutional neural network for hyperspectral image classification. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3904–3908. [Google Scholar]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Mei, S.; Ji, J.; Geng, Y.; Zhang, Z.; Li, X.; Du, Q. Unsupervised spatial–spectral feature learning by 3D convolutional autoencoder for hyperspectral classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6808–6820. [Google Scholar] [CrossRef]
- Xue, Z.; Xu, Q.; Zhang, M. Local transformer with spatial partition restore for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4307–4325. [Google Scholar] [CrossRef]
- Hendrycks, D.; Basart, S.; Mu, N.; Kadavath, S.; Wang, F.; Dorundo, E.; Desai, R.; Zhu, T.; Parajuli, S.; Guo, M.; et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 8340–8349. [Google Scholar]
- Steiner, A.; Kolesnikov, A.; Zhai, X.; Wightman, R.; Uszkoreit, J.; Beyer, L. How to train your vit? data, augmentation, and regularization in vision transformers. arXiv 2021, arXiv:2106.10270. [Google Scholar]
- Wang, H.; Ge, S.; Lipton, Z.; Xing, E.P. Learning robust global representations by penalizing local predictive power. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 10506–10518. [Google Scholar]
- Huang, Z.; Wang, H.; Xing, E.P.; Huang, D. Self-challenging improves cross-domain generalization. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 124–140. [Google Scholar]
- Hu, Q.; Zhang, G.; Qin, Z.; Cai, Y.; Yu, G.; Li, G.Y. Robust semantic communications with masked VQ-VAE enabled codebook. IEEE Trans. Wirel. Commun. 2023, 22, 8707–8722. [Google Scholar] [CrossRef]
- Xi, B.; Li, J.; Diao, Y.; Li, Y.; Li, Z.; Huang, Y.; Chanussot, J. Dgssc: A deep generative spectral-spatial classifier for imbalanced hyperspectral imagery. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1535–1548. [Google Scholar] [CrossRef]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. In Proceedings of the International Conference on Machine Learning (ICML), Honolulu, HI, USA, 23–29 July 2023; pp. 23803–23828. [Google Scholar]
- Zhong, Y.; Hu, X.; Luo, C.; Wang, X.; Zhao, J.; Zhang, L. WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF. Remote Sens. Environ. 2020, 250, 112012. [Google Scholar] [CrossRef]
- Brito, J.A.; McNeill, F.E.; Webber, C.E.; Chettle, D.R. Grid search: An innovative method for the estimation of the rates of lead exchange between body compartments. J. Environ. Monit. 2005, 7, 241–247. [Google Scholar] [CrossRef] [PubMed]



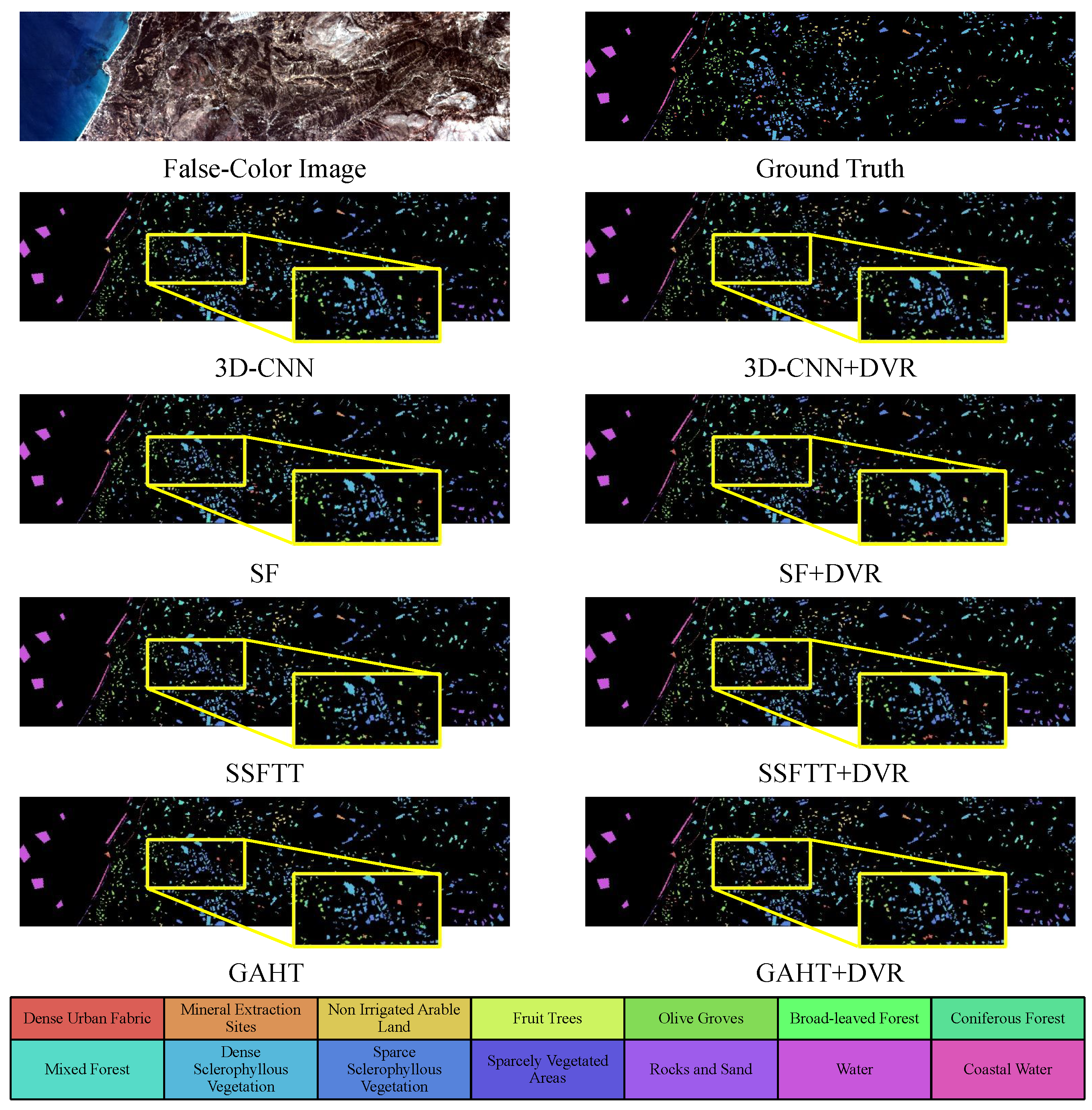



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Definition |
|---|---|
| x | An original HSI data |
| An HSI data patch | |
| Encoder | |
| e | The feature vector from encoder |
| The standard Gaussian cumulative distribution function | |
| h | The feature vector from the Adaptive Module |
| v | The code in the codebook |
| z | The index of top k nearest vectors in the codebook |
| The k minest-distance items | |
| The decay factor | |
| sg[·] | The stop-gradient operator |
| o | The final output combining two classifiers |
| a | The output of the auxiliary classifier |
| p | The output of the primary classifier |
| t | The ground truth |
| The weight of primary classifier | |
| The weight of auxiliary classifier |
| SA (1% for Training) | PU (1% for Training) | ||||||||
| NO. | Class Name | Train | Val. | Test | NO. | Class Name | Train | Val. | Test |
| 1 | Broccoli_green_weeds_1 | 40 | 40 | 1929 | 1 | Asphalt | 132 | 133 | 6366 |
| 2 | Broccoli_green_weeds_2 | 74 | 75 | 3577 | 2 | Meadows | 373 | 373 | 17,903 |
| 3 | Fallow | 40 | 39 | 1897 | 3 | Gravel | 42 | 42 | 2015 |
| 4 | Fallow_rough_plow | 28 | 28 | 1338 | 4 | Trees | 62 | 61 | 2940 |
| 5 | Fallow_smooth | 53 | 54 | 2571 | 5 | Metal Sheets | 27 | 27 | 1291 |
| 6 | Stubble | 79 | 79 | 3801 | 6 | Bare Soil | 100 | 101 | 4828 |
| 7 | Celery | 71 | 72 | 3436 | 7 | Bitumen | 27 | 26 | 1277 |
| 8 | Grapes_untrained | 225 | 226 | 10,820 | 8 | Bricks | 73 | 74 | 3535 |
| 9 | Soil_vinyard_develop | 124 | 124 | 5955 | 9 | Shadows | 19 | 19 | 909 |
| 10 | Corn_sensced_green_weeds | 65 | 66 | 3147 | - | - | - | - | - |
| 11 | Lettuce_romaine_4wk | 22 | 21 | 1025 | - | - | - | - | - |
| 12 | Lettuce_romaine_5wk | 39 | 38 | 1850 | - | - | - | - | - |
| 13 | Lettuce_romaine_6wk | 19 | 18 | 879 | - | - | - | - | - |
| 14 | Lettuce_romaine_7wk | 22 | 21 | 1027 | - | - | - | - | - |
| 15 | Vinyard_untrained | 145 | 146 | 6977 | - | - | - | - | - |
| 16 | Vinyard_vertical_trellis | 36 | 36 | 1735 | - | - | - | - | - |
| Total | - | 1082 | 1083 | 51,964 | - | - | 855 | 856 | 41,065 |
| HR-L (3% for Training) | HC (0.2% for Training) | ||||||||
| NO. | Class Name | Train | Val. | Test | NO. | Class Name | Train | Val. | Test |
| 1 | Dense Urban Fabric | 8 | 9 | 271 | 1 | Strawberry | 89 | 90 | 44,556 |
| 2 | Mineral Extraction Sites | 2 | 2 | 63 | 2 | Cowpea | 46 | 45 | 22,662 |
| 3 | Non Irrigated Arable Land | 17 | 16 | 509 | 3 | Soybean | 21 | 20 | 10,246 |
| 4 | Fruit Trees | 3 | 2 | 74 | 4 | Sorghum | 10 | 11 | 5332 |
| 5 | Olive Groves | 42 | 42 | 1317 | 5 | Water spinach | 2 | 3 | 1195 |
| 6 | Broad-leaved Forest | 6 | 7 | 210 | 6 | Watermelon | 9 | 9 | 4515 |
| 7 | Coniferous Forest | 15 | 15 | 470 | 7 | Greens | 12 | 12 | 5879 |
| 8 | Mixed Forest | 32 | 32 | 1008 | 8 | Trees | 36 | 36 | 17,906 |
| 9 | Dense Sclerophyllous Vegetation | 114 | 114 | 3565 | 9 | Grass | 19 | 19 | 9431 |
| 10 | Sparse Sclerophyllous Vegetation | 84 | 84 | 2635 | 10 | Red roof | 21 | 21 | 10,474 |
| 11 | Sparcely Vegetated Areas | 12 | 12 | 380 | 11 | Gray roof | 34 | 34 | 16,843 |
| 12 | Rocks and Sand | 14 | 15 | 458 | 12 | Plastic | 8 | 7 | 3664 |
| 13 | Water | 42 | 42 | 1309 | 13 | Bare soil | 18 | 18 | 9080 |
| 14 | Coastal Water | 14 | 13 | 424 | 14 | Road | 37 | 37 | 18,486 |
| - | - | - | - | - | 15 | Bright object | 2 | 2 | 1132 |
| - | - | - | - | - | 16 | Water | 151 | 151 | 75,099 |
| Total | - | 405 | 405 | 12,693 | - | - | 515 | 515 | 256,500 |
| Method | 3D-CNN [13] | 3D-CNN + DVR | SF [18] | SF + DVR | SSFTT [20] | SSFTT + DVR | GAHT [21] | GAHT + DVR | |
|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||
| 1 | 96.48 ± 1.12 | 98.75 ± 1.04 | 95.80 ± 0.83 | 96.91 ± 0.18 | 99.87 ± 0.26 | 99.47 ± 0.85 | 100.00 ± 0.00 | 99.93 ± 0.14 | |
| 2 | 99.92 ± 0.03 | 99.78 ± 0.36 | 99.06 ± 0.45 | 99.03 ± 0.44 | 99.67 ± 0.27 | 99.85 ± 0.12 | 99.99 ± 0.01 | 100.00 ± 0.00 | |
| 3 | 91.47 ± 2.28 | 96.29 ± 0.52 | 94.42 ± 2.81 | 91.85 ± 3.38 | 96.02 ± 3.74 | 97.44 ± 1.91 | 99.40 ± 0.28 | 99.03 ± 1.24 | |
| 4 | 98.07 ± 0.39 | 98.73 ± 0.69 | 93.44 ± 1.70 | 95.80 ± 1.52 | 99.39 ± 0.41 | 99.08 ± 0.69 | 98.55 ± 1.66 | 98.70 ± 1.49 | |
| 5 | 95.60 ± 2.34 | 95.50 ± 2.73 | 92.31 ± 3.04 | 90.18 ± 2.60 | 97.07 ± 2.51 | 98.28 ± 1.23 | 99.06 ± 0.61 | 99.28 ± 0.63 | |
| 6 | 99.34 ± 0.45 | 99.82 ± 0.18 | 99.51 ± 0.57 | 99.45 ± 0.54 | 99.42 ± 0.97 | 99.86 ± 0.17 | 99.99 ± 0.02 | 100.00 ± 0.00 | |
| 7 | 99.45 ± 0.27 | 99.80 ± 0.17 | 98.87 ± 0.46 | 98.64 ± 0.67 | 99.09 ± 0.58 | 99.56 ± 0.42 | 99.89 ± 0.19 | 99.99 ± 0.01 | |
| 8 | 84.13 ± 2.04 | 87.86 ± 2.42 | 85.58 ± 2.32 | 85.88 ± 1.81 | 89.52 ± 2.39 | 88.18 ± 3.05 | 93.66 ± 1.29 | 93.64 ± 1.15 | |
| 9 | 97.33 ± 1.46 | 98.79 ± 1.06 | 96.99 ± 0.91 | 99.12 ± 0.81 | 99.15 ± 0.61 | 99.27 ± 0.55 | 99.96 ± 0.06 | 99.96 ± 0.06 | |
| 10 | 90.59 ± 1.68 | 93.01 ± 2.10 | 88.20 ± 2.43 | 89.60 ± 1.32 | 92.76 ± 2.19 | 94.70 ± 0.81 | 96.71 ± 2.25 | 97.98 ± 2.03 | |
| 11 | 81.57 ± 9.03 | 94.71 ± 3.37 | 89.02 ± 1.11 | 91.90 ± 2.51 | 98.15 ± 1.09 | 96.91 ± 2.03 | 98.76 ± 0.73 | 99.31 ± 0.38 | |
| 12 | 99.34 ± 0.38 | 98.49 ± 1.32 | 98.76 ± 0.65 | 98.91 ± 0.67 | 99.90 ± 0.10 | 99.79 ± 0.23 | 99.83 ± 0.20 | 99.74 ± 0.21 | |
| 13 | 97.77 ± 2.50 | 94.08 ± 6.89 | 93.54 ± 7.05 | 96.39 ± 5.40 | 96.44 ± 4.04 | 98.44 ± 1.50 | 97.84 ± 2.22 | 98.57 ± 2.04 | |
| 14 | 96.19 ± 3.14 | 97.06 ± 1.78 | 95.54 ± 2.02 | 96.97 ± 1.38 | 95.94 ± 2.51 | 95.27 ± 2.70 | 97.98 ± 1.71 | 98.02 ± 1.07 | |
| 15 | 75.29 ± 3.66 | 80.50 ± 3.47 | 76.63 ± 4.94 | 82.88 ± 2.76 | 78.62 ± 4.27 | 84.85 ± 3.04 | 89.69 ± 1.32 | 91.76 ± 2.61 | |
| 16 | 90.83 ± 4.59 | 93.38 ± 5.32 | 93.50 ± 4.55 | 92.64 ± 2.71 | 96.75 ± 1.55 | 95.45 ± 3.46 | 97.72 ± 2.04 | 98.61 ± 0.35 | |
| OA (%) | 90.89 ± 0.55 | 93.28 ± 0.32 | 91.04 ± 0.63 | 92.26 ± 0.11 | 93.69 ± 0.34 | 94.49 ± 0.33 | 96.80 ± 0.41 | 97.20 ± 0.21 | |
| AA (%) | 93.33 ± 0.67 | 95.41 ± 0.44 | 93.20 ± 0.61 | 94.13 ± 0.29 | 96.11 ± 0.42 | 96.65 ± 0.22 | 98.07 ± 0.18 | 98.41 ± 0.36 | |
| × 100 | 89.86 ± 0.61 | 92.51 ± 0.35 | 90.03 ± 0.71 | 91.39 ± 0.12 | 92.97 ± 0.39 | 93.86 ± 0.37 | 96.43 ± 0.45 | 96.88 ± 0.24 | |
| Train time(s) | 173.65 ± 0.44 | 184.17 ± 1.37 | 192.51 ± 1.08 | 221.42 ± 1.05 | 171.98 ± 3.26 | 193.48 ± 1.71 | 222.26 ± 1.33 | 243.29 ± 1.31 | |
| Test time(s) | 6.98 ± 0.21 | 8.52 ± 0.05 | 19.29 ± 0.05 | 22.43 ± 0.19 | 6.91 ± 0.12 | 8.68 ± 0.12 | 10.12 ± 0.45 | 11.61 ± 0.38 | |
| Method | 3D-CNN [13] | 3D-CNN + DVR | SF [18] | SF + DVR | SSFTT [20] | SSFTT + DVR | GAHT [21] | GAHT + DVR | |
|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||
| 1 | 93.48 ± 1.07 | 95.38 ± 1.68 | 87.87 ± 1.79 | 90.81 ± 0.94 | 95.84 ± 0.94 | 97.20 ± 0.90 | 97.67 ± 1.16 | 97.43 ± 0.69 | |
| 2 | 97.35 ± 1.71 | 99.12 ± 0.36 | 96.29 ± 1.94 | 98.07 ± 0.39 | 99.25 ± 0.77 | 99.39 ± 0.31 | 99.69 ± 0.09 | 99.67 ± 0.18 | |
| 3 | 47.78 ± 7.32 | 81.17 ± 3.20 | 68.40 ± 8.13 | 67.77 ± 5.64 | 89.23 ± 3.27 | 89.48 ± 3.03 | 90.23 ± 4.01 | 90.00 ± 2.58 | |
| 4 | 94.45 ± 1.36 | 96.42 ± 1.20 | 89.70 ± 3.27 | 90.90 ± 2.00 | 97.86 ± 0.79 | 97.81 ± 0.60 | 97.19 ± 0.87 | 97.83 ± 0.33 | |
| 5 | 99.74 ± 0.23 | 99.89 ± 0.15 | 100.00 ± 0.00 | 99.97 ± 0.04 | 99.98 ± 0.03 | 99.94 ± 0.09 | 100.00 ± 0.00 | 100.00 ± 0.00 | |
| 6 | 56.84 ± 4.53 | 92.62 ± 2.19 | 79.94 ± 6.92 | 83.43 ± 1.42 | 98.50 ± 0.77 | 99.23 ± 0.23 | 98.25 ± 1.25 | 99.48 ± 0.40 | |
| 7 | 66.66 ± 8.18 | 82.10 ± 5.90 | 58.25 ± 6.65 | 55.36 ± 5.36 | 92.66 ± 3.83 | 91.34 ± 3.52 | 92.82 ± 5.66 | 98.27 ± 0.78 | |
| 8 | 90.91 ± 1.29 | 91.32 ± 1.83 | 80.69 ± 1.18 | 87.27 ± 1.25 | 90.08 ± 4.58 | 95.33 ± 1.65 | 94.15 ± 1.94 | 95.39 ± 1.09 | |
| 9 | 99.01 ± 0.75 | 99.38 ± 0.36 | 95.82 ± 1.40 | 92.18 ± 0.46 | 99.81 ± 0.13 | 99.61 ± 0.33 | 99.68 ± 0.10 | 99.63 ± 0.27 | |
| OA (%) | 87.95 ± 1.31 | 95.53 ± 0.35 | 88.80 ± 0.94 | 90.90 ± 0.50 | 97.08 ± 0.64 | 97.85 ± 0.22 | 97.89 ± 0.30 | 98.29 ± 0.12 | |
| AA (%) | 82.91 ± 1.93 | 93.04 ± 0.49 | 84.11 ± 1.86 | 85.09 ± 0.93 | 95.91 ± 0.90 | 96.59 ± 0.52 | 96.63 ± 0.59 | 97.52 ± 0.07 | |
| × 100 | 83.70 ± 1.77 | 94.06 ± 0.46 | 85.09 ± 1.26 | 87.84 ± 0.66 | 96.14 ± 0.8 | 97.16 ± 0.29 | 97.19 ± 0.41 | 97.74 ± 0.16 | |
| Train time(s) | 161.01 ± 1.09 | 179.40 ± 2.79 | 221.72 ± 11.13 | 237.73 ± 0.66 | 171.68 ± 0.34 | 187.51 ± 1.27 | 207.99 ± 0.99 | 220.48 ± 1.52 | |
| Test time(s) | 9.05 ± 0.45 | 11.92 ± 0.09 | 29.38 ± 7.23 | 33.62 ± 0.28 | 9.15 ± 0.37 | 12.48 ± 0.50 | 17.63 ± 0.42 | 18.79 ± 0.19 | |
| Method | 3D-CNN [13] | 3D-CNN + DVR | SF [18] | SF + DVR | SSFTT [20] | SSFTT + DVR | GAHT [21] | GAHT + DVR | |
|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||
| 1 | 40.07 ± 3.94 | 47.08 ± 7.23 | 46.49 ± 10.08 | 40.37 ± 7.08 | 64.28 ± 6.01 | 53.58 ± 6.20 | 64.06 ± 10.27 | 71.14 ± 5.08 | |
| 2 | 87.62 ± 8.60 | 83.81 ± 16.69 | 96.83 ± 4.92 | 96.83 ± 6.35 | 86.35 ± 8.61 | 79.37 ± 6.02 | 90.48 ± 10.43 | 90.79 ± 5.35 | |
| 3 | 76.54 ± 6.78 | 81.69 ± 5.55 | 64.95 ± 6.10 | 65.78 ± 5.99 | 80.51 ± 7.05 | 84.83 ± 1.93 | 84.09 ± 5.91 | 85.78 ± 2.23 | |
| 4 | 3.78 ± 4.63 | 44.05 ± 9.65 | 2.97 ± 3.86 | 5.95 ± 4.41 | 38.11 ± 14.29 | 42.70 ± 14.32 | 35.41 ± 13.63 | 33.24 ± 4.32 | |
| 5 | 77.86 ± 2.67 | 84.87 ± 2.36 | 71.28 ± 5.70 | 77.01 ± 2.74 | 87.64 ± 2.87 | 91.94 ± 0.66 | 89.61 ± 4.25 | 89.96 ± 3.10 | |
| 6 | 40.29 ± 5.82 | 62.29 ± 7.79 | 24.48 ± 10.40 | 18.29 ± 9.40 | 55.05 ± 9.13 | 53.62 ± 4.82 | 42.48 ± 12.53 | 49.24 ± 4.91 | |
| 7 | 48.21 ± 8.23 | 60.89 ± 5.53 | 41.62 ± 4.38 | 47.62 ± 2.47 | 65.53 ± 5.40 | 66.21 ± 5.04 | 61.66 ± 5.25 | 60.81 ± 6.70 | |
| 8 | 61.53 ± 9.13 | 74.13 ± 2.70 | 63.81 ± 5.04 | 63.19 ± 3.17 | 70.42 ± 5.28 | 71.17 ± 7.46 | 71.31 ± 7.90 | 68.69 ± 6.24 | |
| 9 | 82.19 ± 2.53 | 78.59 ± 1.35 | 68.59 ± 2.19 | 74.42 ± 3.34 | 81.91 ± 3.28 | 85.80 ± 2.27 | 83.94 ± 2.10 | 83.36 ± 2.42 | |
| 10 | 76.70 ± 2.54 | 81.18 ± 0.86 | 71.51 ± 2.58 | 75.29 ± 2.34 | 81.65 ± 2.57 | 82.09 ± 1.22 | 76.51 ± 3.31 | 82.05 ± 2.45 | |
| 11 | 43.42 ± 15.16 | 61.63 ± 4.54 | 53.63 ± 11.62 | 57.58 ± 5.41 | 65.00 ± 10.93 | 71.00 ± 4.40 | 72.84 ± 5.65 | 72.42 ± 4.49 | |
| 12 | 91.75 ± 1.57 | 92.45 ± 1.19 | 90.04 ± 6.52 | 90.57 ± 3.48 | 93.97 ± 1.03 | 92.49 ± 1.01 | 92.93 ± 3.25 | 92.88 ± 2.85 | |
| 13 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | |
| 14 | 100.00 ± 0.00 | 99.86 ± 0.19 | 100.00 ± 0.00 | 99.72 ± 0.57 | 100.00 ± 0.00 | 99.95 ± 0.09 | 99.81 ± 0.23 | 99.67 ± 0.35 | |
| OA (%) | 77.07 ± 0.63 | 80.69 ± 0.41 | 71.12 ± 0.47 | 74.26 ± 0.24 | 82.22 ± 0.76 | 83.97 ± 0.19 | 81.98 ± 0.62 | 83.07 ± 0.59 | |
| AA (%) | 66.43 ± 0.74 | 75.18 ± 1.39 | 64.01 ± 1.25 | 65.19 ± 0.81 | 76.46 ± 1.30 | 76.77 ± 1.09 | 76.08 ± 2.20 | 77.15 ± 0.58 | |
| × 100 | 72.46 ± 0.72 | 77.08 ± 0.46 | 65.66 ± 0.52 | 69.27 ± 0.22 | 78.82 ± 0.86 | 80.87 ± 0.22 | 78.51 ± 0.70 | 79.79 ± 0.67 | |
| Train time | 165.27 ± 7.74 | 175.99 ± 2.25 | 257.05 ± 1.01 | 261.42 ± 3.28 | 185.41 ± 0.34 | 195.18 ± 1.05 | 219.04 ± 0.97 | 230.73 ± 2.03 | |
| Test time | 10.94 ± 1.41 | 12.13 ± 0.13 | 53.05 ± 0.54 | 58.35 ± 1.63 | 13.73 ± 0.30 | 15.45 ± 0.27 | 21.95 ± 0.56 | 22.50 ± 0.14 | |
| Method | 3D-CNN [13] | 3D-CNN + DVR | SF [18] | SF + DVR | SSFTT [20] | SSFTT + DVR | GAHT [21] | GAHT + DVR | |
|---|---|---|---|---|---|---|---|---|---|
| Class | |||||||||
| 1 | 92.14 ± 3.07 | 90.99 ± 2.77 | 90.57 ± 1.54 | 93.39 ± 2.15 | 94.27 ± 1.54 | 92.41 ± 3.98 | 96.35 ± 0.49 | 95.42 ± 0.97 | |
| 2 | 79.04 ± 1.47 | 78.48 ± 1.97 | 70.53 ± 3.35 | 66.02 ± 9.33 | 80.10 ± 4.21 | 81.49 ± 2.44 | 86.13 ± 1.73 | 84.97 ± 3.84 | |
| 3 | 58.81 ± 6.87 | 59.98 ± 4.90 | 61.89 ± 9.70 | 65.80 ± 8.61 | 58.05 ± 6.82 | 56.30 ± 10.70 | 79.62 ± 4.41 | 80.00 ± 6.30 | |
| 4 | 67.01 ± 9.84 | 77.48 ± 3.08 | 49.48 ± 13.68 | 59.50 ± 12.21 | 70.55 ± 11.83 | 78.56 ± 6.22 | 90.32 ± 5.85 | 92.34 ± 2.13 | |
| 5 | 5.56 ± 7.86 | 8.82 ± 7.08 | 8.02 ± 4.94 | 18.56 ± 10.94 | 13.84 ± 5.70 | 7.25 ± 6.24 | 7.50 ± 13.47 | 28.44 ± 12.78 | |
| 6 | 1.79 ± 2.25 | 9.52 ± 7.55 | 7.15 ± 4.43 | 5.44 ± 3.24 | 14.05 ± 4.99 | 3.39 ± 3.88 | 10.17 ± 6.58 | 26.82 ± 5.03 | |
| 7 | 84.74 ± 8.08 | 80.73 ± 6.04 | 47.31 ± 12.25 | 50.02 ± 11.56 | 64.48 ± 20.83 | 75.23 ± 16.35 | 73.70 ± 5.03 | 78.28 ± 7.55 | |
| 8 | 66.40 ± 2.72 | 61.88 ± 2.10 | 65.11 ± 2.05 | 65.76 ± 2.38 | 69.33 ± 8.39 | 76.31 ± 3.94 | 73.61 ± 4.71 | 73.93 ± 4.08 | |
| 9 | 23.92 ± 6.13 | 32.48 ± 4.94 | 21.18 ± 5.47 | 29.11 ± 8.46 | 48.11 ± 17.59 | 27.40 ± 13.18 | 49.87 ± 7.43 | 66.21 ± 5.78 | |
| 10 | 37.82 ± 10.60 | 54.09 ± 7.42 | 77.56 ± 3.68 | 68.90 ± 2.85 | 87.80 ± 8.67 | 86.33 ± 4.66 | 92.33 ± 4.08 | 92.09 ± 3.77 | |
| 11 | 52.83 ± 15.64 | 62.28 ± 7.31 | 71.08 ± 3.52 | 79.54 ± 4.91 | 70.01 ± 14.16 | 83.43 ± 7.05 | 84.58 ± 5.08 | 87.59 ± 8.24 | |
| 12 | 1.92 ± 3.51 | 0.04 ± 0.07 | 19.11 ± 10.26 | 21.27 ± 13.21 | 15.13 ± 12.45 | 15.03 ± 7.96 | 12.91 ± 11.95 | 30.84 ± 11.22 | |
| 13 | 26.81 ± 10.61 | 32.51 ± 8.36 | 36.12 ± 7.87 | 44.36 ± 2.80 | 36.60 ± 13.85 | 40.51 ± 16.04 | 50.91 ± 4.65 | 60.85 ± 5.75 | |
| 14 | 75.46 ± 4.03 | 79.92 ± 2.65 | 82.53 ± 5.47 | 79.30 ± 6.19 | 74.67 ± 6.09 | 82.70 ± 4.69 | 90.03 ± 2.54 | 88.15 ± 4.97 | |
| 15 | 33.50 ± 19.37 | 30.09 ± 22.28 | 24.98 ± 12.50 | 22.33 ± 12.02 | 47.60 ± 22.82 | 39.89 ± 15.42 | 0.30 ± 0.60 | 17.70 ± 21.52 | |
| 16 | 98.43 ± 1.25 | 99.04 ± 0.67 | 98.37 ± 0.50 | 98.06 ± 0.78 | 98.43 ± 1.05 | 97.30 ± 2.50 | 99.23 ± 0.48 | 99.12 ± 0.87 | |
| OA (%) | 74.64 ± 1.44 | 76.66 ± 0.52 | 76.28 ± 0.51 | 77.34 ± 0.45 | 79.74 ± 1.65 | 80.56 ± 1.59 | 85.13 ± 0.62 | 86.75 ± 0.77 | |
| AA (%) | 50.39 ± 2.98 | 53.65 ± 1.09 | 51.94 ± 1.55 | 54.21 ± 1.06 | 58.94 ± 2.42 | 58.97 ± 1.89 | 62.35 ± 1.68 | 68.92 ± 2.14 | |
| × 100 | 69.88 ± 1.81 | 72.40 ± 0.59 | 72.07 ± 0.59 | 73.34 ± 0.53 | 76.12 ± 1.98 | 77.20 ± 1.80 | 82.53 ± 0.74 | 84.46 ± 0.88 | |
| Train time(s) | 150.60 ± 1.09 | 161.40 ± 1.93 | 272.96 ± 1.45 | 286.50 ± 2.16 | 165.61 ± 1.44 | 181.70 ± 1.45 | 214.08 ± 0.80 | 229.91 ± 1.58 | |
| Test time(s) | 28.18 ± 0.07 | 32.67 ± 0.10 | 118.27 ± 0.43 | 125.34 ± 0.68 | 28.04 ± 0.07 | 32.16 ± 0.10 | 27.66 ± 0.11 | 33.88 ± 1.34 | |
| Dataset | Codebook Size | Codebook Dim | Top-k |
|---|---|---|---|
| SA | 100 | 64 | 5 |
| PU | 70 | 64 | 5 |
| HR-L | 100 | 64 | 5 |
| HC | 100 | 64 | 5 |
| Backbone | AM | DVCM | AC | OA (%) |
|---|---|---|---|---|
| SpectralFormer | × | × | × | 88.80 ± 0.94 |
| SpectralFormer | ✓ | × | ✓ | 89.32 ± 0.85 |
| SpectralFormer | ✓ | ✓ | ✓ | 90.90 ± 0.50 |
| Backbone | Dataset | Codebook Size | OA (%) |
|---|---|---|---|
| SpectralFormer | SA | 70 | 91.99 ± 0.55 |
| SpectralFormer | SA | 100 | 92.26 ± 0.11 |
| SpectralFormer | SA | 150 | 91.93 ± 0.48 |
| SpectralFormer | PU | 70 | 90.90 ± 0.50 |
| SpectralFormer | PU | 100 | 90.63 ± 0.71 |
| SpectralFormer | PU | 150 | 90.38 ± 0.94 |
| SpectralFormer | HR-L | 70 | 74.02 ± 0.61 |
| SpectralFormer | HR-L | 100 | 74.26 ± 0.24 |
| SpectralFormer | HR-L | 150 | 73.90 ± 0.48 |
| SpectralFormer | HC | 70 | 77.05 ± 0.51 |
| SpectralFormer | HC | 100 | 77.34 ± 0.45 |
| SpectralFormer | HC | 150 | 77.10 ± 0.62 |
| Backbone | Dataset | Codebook Dim | OA (%) |
|---|---|---|---|
| SpectralFormer | PU | 32 | 90.52 ± 0.60 |
| SpectralFormer | PU | 64 | 90.90 ± 0.50 |
| SpectralFormer | PU | 128 | 90.59 ± 0.40 |
| SpectralFormer | PU | 256 | 90.30 ± 0.60 |
| SpectralFormer | PU | 512 | 90.58 ± 0.60 |
| Backbone | Dataset | Top-k | OA (%) |
|---|---|---|---|
| SpectralFormer | PU | 1 | 90.79 ± 0.58 |
| SpectralFormer | PU | 5 | 90.90 ± 0.50 |
| SpectralFormer | PU | 10 | 90.75 ± 0.51 |
| Method | Dataset | AC | OA (%) |
|---|---|---|---|
| SpectralFormer | PU | × | 88.80 ± 0.94 |
| SpectralFormer+DVR | PU | × | 90.66 ± 0.81 |
| SpectralFormer+DVR | PU | ✓ | 90.90 ± 0.50 |
| Backbone | AM | DVCM | AC | Total Params | Trainable Params | FLOPs |
|---|---|---|---|---|---|---|
| SpectralFormer | × | × | × | 352,405 | 352,405 | 16.235776M |
| SpectralFormer | ✓ | × | × | 356,565 (1.18%) | 356,565 (1.18%) | 16.239872M (0.025%) |
| SpectralFormer | ✓ | ✓ | × | 374,625 (6.31%) | 356,565 (1.18%) | 16.244352M (0.053%) |
| SpectralFormer | ✓ | ✓ | ✓ | 375,665 (6.61%) | 357,605 (1.48%) | 16.245376M (0.059%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Wang, H.; Zhang, X.; Wang, J.; Zhang, T.; Zhuang, P. DVR: Towards Accurate Hyperspectral Image Classifier via Discrete Vector Representation. Remote Sens. 2025, 17, 351. https://doi.org/10.3390/rs17030351
Li J, Wang H, Zhang X, Wang J, Zhang T, Zhuang P. DVR: Towards Accurate Hyperspectral Image Classifier via Discrete Vector Representation. Remote Sensing. 2025; 17(3):351. https://doi.org/10.3390/rs17030351
Chicago/Turabian StyleLi, Jiangyun, Hao Wang, Xiaochen Zhang, Jing Wang, Tianxiang Zhang, and Peixian Zhuang. 2025. "DVR: Towards Accurate Hyperspectral Image Classifier via Discrete Vector Representation" Remote Sensing 17, no. 3: 351. https://doi.org/10.3390/rs17030351
APA StyleLi, J., Wang, H., Zhang, X., Wang, J., Zhang, T., & Zhuang, P. (2025). DVR: Towards Accurate Hyperspectral Image Classifier via Discrete Vector Representation. Remote Sensing, 17(3), 351. https://doi.org/10.3390/rs17030351