Highlights
What are the main findings?
- We propose MMA-Net, a novel dual-branch network that integrates CLMF and MSMA modules to achieve state-of-the-art performance, with mIoU scores of 88.74% and 84.92% on the Potsdam and Vaihingen datasets, respectively.
- The CLMF module uses a two-stage fusion strategy to effectively preserve spatial details and suppress DSM noise. The MSMA module innovatively incorporates multi-scale depthwise separable convolutions into the attention block, which significantly boosts the model’s ability to perceive and segment ground objects of vastly different sizes.
What is the implication of the main finding?
- MMA-Net provides a robust solution for accurate semantic segmentation of high-resolution remote sensing images, particularly improving boundary clarity and small-object recognition, which is critical for applications such as urban planning and disaster monitoring.
- The proposed modular design offers a generalizable framework for multimodal data fusion, demonstrating significant potential for extending to other remote sensing tasks involving multi-source data.
Abstract
Semantic segmentation of high-resolution remote sensing images is of great application value in fields like natural disaster monitoring. Current multimodal semantic segmentation methods have improved the model’s ability to recognize different ground objects and complex scenes by integrating multi-source remote sensing data. However, these methods still face challenges such as blurred boundary segmentation and insufficient perception of multi-scale ground objects when achieving high-precision classification. To address these issues, this paper proposes MMA-Net, a semantic segmentation network enhanced by two key modules: cross-layer multimodal fusion module and multi-scale multi-attention module. These modules effectively improve the model’s ability to capture detailed features and model multi-scale ground objects, thereby enhancing boundary segmentation accuracy, detail feature preservation, and consistency in multi-scale object segmentation. Specifically, the cross-layer multimodal fusion module adopts a staged fusion strategy to integrate detailed information and multimodal features, realizing detail preservation and modal synergy enhancement. The multi-scale multi-attention module combines cross-attention and self-attention to leverage long-range dependencies and inter-modal complementary relationships, strengthening the model’s feature representation for multi-scale ground objects. Experimental results show that MMA-Net outperforms state-of-the-art methods on the Potsdam and Vaihingen datasets. Its mIoU reaches 88.74% and 84.92% on the two datasets, respectively. Ablation experiments further verify that each proposed module contributes to the final performance.
1. Introduction
As a core task in the intelligent interpretation of Earth observation, the semantic segmentation of high-resolution remote sensing images (HRRSI) enables pixel-level classification of ground objects. This technique provides critical data support for a wide range of applications, including natural disaster monitoring [1,2], object extraction [3,4], land cover mapping [5,6,7], and urban planning [8,9,10]. With the rapid development of remote sensing sensor technology, HRRSI has been widely applied. While its abundant spatial details and complex spectral information enhance the potential for ground object identification, they also pose numerous challenges: HRRSI contains ground objects with rich details and complex spatial structures, along with significant spectral similarity and intra-class variability. These issues cause semantic segmentation methods to frequently suffer from problems such as ambiguous edge segmentation, insufficient ability to perceive and model multi-scale ground objects, and category confusion, which restrict the further improvement of segmentation accuracy.
Traditional semantic segmentation methods for remote sensing images mainly rely on single-modal data, such as optical images, infrared images, and multispectral images. However, these approaches [11,12] often exhibit limitations in complex scenarios, as single-modal data may lack sufficient information to accurately discriminate between different categories of ground objects. Consequently, multimodal remote sensing image semantic segmentation technology has attracted the attention of researchers.
Multimodal semantic segmentation techniques leverage the complementarity of multi-source data to enhance feature representation capabilities. Although existing multimodal approaches demonstrate improved model performance compared to unimodal methods, they face several challenges. Methods such as SwinFusion [13] and FTransUNet [14] experience a gradual loss of shallow spatial details during encoder downsampling, resulting in incomplete segmentation of small-scale objects and blurred boundary localization. Most multimodal fusion strategies, such as SA-Gate [15], rely on simple operations like concatenation or summation. These approaches fail to fully exploit cross-modal long-range dependencies and complementarity, resulting in superficial fusion effects that struggle to effectively resolve category confusion issues.
To address the challenges mentioned above, this paper proposes a high-resolution remote sensing image segmentation network (MMA-Net) based on multimodal fusion and a multi-scale multi-attention mechanism. Unlike existing methods such as FTransUNet and LMFNet, MMA-Net introduces a more holistic and synergistic fusion strategy that explicitly addresses both feature-level hierarchy and cross-modal dependencies through dedicated module designs. The main contributions of this study are as follows:
- (1)
- We propose MMA-Net, a novel dual-branch encoder–decoder architecture that systematically integrates the Cross-Layer Multimodal Fusion (CLMF) module and the Multi-Scale Multi-Attention (MSMA) module. This design enables complementary feature enhancement across both spatial and semantic dimensions, leading to significant improvements in semantic segmentation accuracy. In experiments on the ISPRS Vaihingen and Potsdam datasets, the model achieved mIoU scores of 84.92% and 88.74%, respectively, outperforming state-of-the-art methods by 0.76% to 1.43%.
- (2)
- This paper proposes a novel Cross-Layer Multimodal Fusion (CLMF) module, which adopts a two-stage fusion strategy of “cross-layer fusion followed by multi-modal fusion” to effectively address the loss of spatial detail (shallow features) during the encoder’s downsampling process. In the Cross-Layer Fusion (CLF) stage, adjacent hierarchical features are integrated via concatenation and channel attention weighting, enabling a dynamic combination of shallow details and high-level semantics. The Multi-Modal Fusion (MMF) stage incorporates a redundancy filtering mechanism to suppress noise and interference caused by directly integrating raw DSM features.
- (3)
- This paper proposes an MSMA, which integrates Self-Attention (SA) and Cross-Attention (CA) to enable simultaneous capture of intra-modal local context and inter-modal complementary features. Adopting a three-layer structural design, this block effectively models the long-range correlations between RGB and DSM modalities. Moreover, we innovatively incorporate multi-scale depthwise separable convolutions into the attention block, which enhances the network’s ability to model ground objects of varying scales without significantly increasing computational cost.
This paper is organized into six sections. Section 1 presents the research background and significance of multimodal remote sensing image semantic segmentation, analyzes the limitations of existing methods, and outlines the scope and contributions of this study. Section 2 reviews related work on both single-modal and semantic segmentation of multimodal remote sensing imagery. Section 3 elaborates on the overall architecture of MMA-Net and details the design of each module. Section 4 evaluates the efficacy of the proposed method through comprehensive experiments. Section 5 provides a discussion of the findings, and Section 6 concludes with a synthesis of the study.
2. Related Work
Semantic segmentation of remote sensing imagery focuses on enabling machines to automatically identify the semantic categories of surface features within images, constituting a fundamental task in Earth observation data interpretation. With the continuous advancement of deep learning technologies, a rich research system has been formed in this field, ranging from single-modal to multimodal approaches, and from Convolutional Neural Networks (CNNs) to Transformers. This section systematically reviews the related research progress and analyzes the limitations of existing methods from two dimensions: single-modal and multimodal semantic segmentation.
2.1. Single-Modal Remote Sensing Image Semantic Segmentation Methods
Early semantic segmentation approaches depended on handcrafted features—such as texture and shape descriptors—yet their generalizability remained constrained in the intricate scenes of HRRSI. The rise of deep learning provided a powerful tool for automatic feature extraction. Among these, the FCN proposed by Long et al. [16] was the first end-to-end semantic segmentation model. Through the substitution of fully connected layers with convolutional layers, this approach enables pixel-wise classification of images of arbitrary dimensions. However, the decoder of FCN adopts a relatively simple upsampling method, which leads to blurring at the edges of segmentation results and loss of detailed information, thus failing to meet the demands of HRRSI for identifying fine structures.
To solve the limitations of FCN, researchers have proposed a series of improved architectures. UNet [17] adopts a symmetric encoder–decoder structure, where shallow low-level features from the encoder are fused with high-level semantic features from the decoder via skip connections. This substantially enhances the segmentation precision for small objects and intricate boundaries, making it a classic framework for subsequent remote sensing semantic segmentation methods. DeepLabV3+ [18] introduces Atrous Convolution to expand the receptive field and combines Atrous Spatial Pyramid Pooling (ASPP) to capture multi-scale features, further enhancing adaptability to ground objects of different sizes. MFATrack [19] captures shallow context and deep details in RGB and thermal infrared images through a multi-scale full-feature fusion strategy. By integrating an auto-attention interaction module to enhance target features, it improves accuracy while maintaining real-time performance. Targeting the characteristics of variable scales and complex boundaries of ground objects in high-resolution remote sensing images, BSNet [20] proposes dynamic hybrid gradient convolution technology, which can dynamically adjust gradient fusion strategies according to local features to accurately capture subtle edges and contours of small-scale targets. HMANet [21] strengthens the modeling of global context through a regional attention mechanism, improving the overall segmentation consistency of large-scale ground objects (e.g., urban blocks). However, single-modal data struggles to address the challenges of “large intra-class variance and small inter-class variance” in high-resolution remote sensing images. In complex scenarios such as illumination variations, shadowed areas, and spectral confusion, their information representation capacity is limited, which can easily lead to misclassification and omission.
2.2. Multimodal Remote Sensing Image Semantic Segmentation Methods
Multimodal semantic segmentation leverages the complementary nature of different modalities, compensating for the limitations of single data sources in feature representation and thereby enhancing overall feature characterization capabilities. Among these, DSM data, which encompasses elevation information of ground objects, is used to assist in distinguishing between spectrally similar but height-different objects [11,22], making it one of the core auxiliary modalities in remote sensing multimodal segmentation. When classified according to the fusion stage, multimodal fusion approaches fall into three categories:
- ①
- Data-level fusion: This method involves directly concatenating or enhancing raw data before feeding it into the network [23]. However, this approach easily introduces multi-modal redundant information and fails to account for differences in physical properties between modalities, resulting in inefficient feature learning.
- ②
- Decision-level fusion: This approach first generates classification results from single-modal models separately, then fuses decisions via voting, weighting, or other methods [24]. This approach offers high flexibility but neglects early feature interactions between modalities, making it difficult to capture deep semantic correlations.
- ③
- Feature-level fusion: Fuses features across diverse modalities within the network’s intermediate layers, which is currently the mainstream strategy. Early methods such as FuseNet [25] and vFuseNet [26] adopted simple concatenation or summation for feature fusion, failing to fully explore inter-modal dependencies. In recent years, attention mechanisms have found extensive application in feature-level fusion. For example, ASFFuse [27] dynamically adjusts modal weights through spatial and channel attention, while SA-Gate [15] and CFNet [28] use gating mechanisms to filter effective features, significantly improving fusion efficiency.
As the advantages of Transformer in global modeling become increasingly prominent, Transformer-based multimodal fusion methods have emerged as a new trend. TransFuser [29] introduces a Transformer layer after the convolutional block and designs a BiFusion module to fuse the fine-grained local details from CNNs with the global dependencies captured by Transformers. SwinFusion [13] adopts Swin Transformer as its backbone and realizes deep interaction of multimodal features through self-attention mechanisms. In the remote sensing field, HMANet [21] enhances the modeling of global context through a regional attention mechanism, improving the overall segmentation consistency of large-scale ground objects. FTransUNet [14] combines CNNs and Transformers, utilizing self-attention for capturing long-range dependencies and increasing the recognition accuracy of complex ground object boundaries. LMFNet [30] designs multimodal feature fusion reconstruction layers and self-attention fusion layers to enhance complementarity between different modalities, while improving the model’s ability to recognize small-scale features through a max feature merging strategy. EDFT [31] and MFTransNet [32] further strengthen inter-modal complementarity through depth-aware self-attention modules. FTransDeepLab [33] builds upon the DeepLabv3+ encoder architecture by stacking multi-scale Segformer modules to enhance long-range dependency modeling and multi-scale feature extraction. However, existing multimodal methods still suffer from two major limitations. Firstly, the gradual loss of shallow details during the downsampling process leads to poor segmentation accuracy, compromising the model’s adaptability to multi-scale targets and resulting in inadequate feature representation. Secondly, they overlook the oversimplification of existing multimodal fusion methods, which fail to establish a cross-modal global dependency model and thus cannot fully leverage the deep complementarity between RGB and DSM data.
3. Methods
This paper proposes MMA-Net, a semantic segmentation network based on a dual-branch encoder–decoder architecture. The proposed model facilitates effective interaction between high-level and low-level features, as well as across multimodal data, through the CLMF module. Meanwhile, the MSMA enhances the network’s ability to capture objects at different scales. This section first introduces the overall network architecture, followed by a detailed explanation of the design principles and functions of the CLMF and MSMA modules.
3.1. Overview
MMA-Net builds on a dual-branch encoder–decoder architecture, using a CNN backbone (ResNet-50) to process both RGB images and DSM data modalities. Through a phased, multi-level feature fusion and enhancement mechanism, it achieves efficient integration of multimodal and multi-scale information. During the encoding phase, the preprocessed RGB and DSM images with a resolution of 256 × 256 are fed into a weight-shared backbone network. The network extracts multi-scale features ( − , − ) through five convolutional blocks, with the resolution decreasing from 128 × 128 to 8 × 8 and the number of channels increasing from 64 to 1024. The first four layers ( − , − ) of features are integrated with adjacent hierarchical and multi-modal information via the CLMF. The fifth layer (, ) is flattened and input into the MSMA, where semantic features are enhanced through multi-attention mechanisms and multi-scale convolutions. The decoder progressively restores the spatial resolution to 256 × 256 using skip connections that fuse multi-level encoder features, followed by cascaded upsampling, ultimately generating pixel-wise segmentation results. The overall framework of MMA-Net is illustrated in Figure 1.
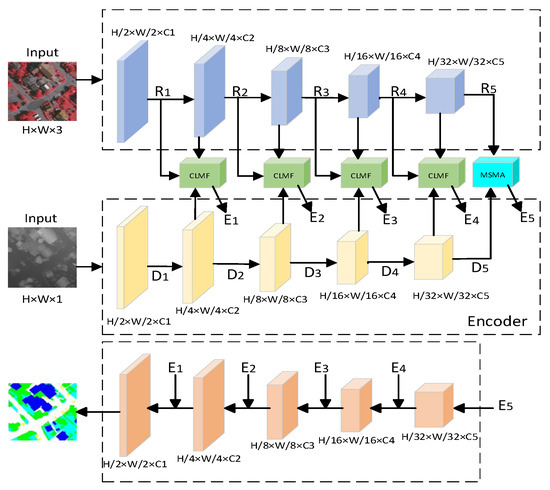
Figure 1.
Overall architecture of the proposed MMA-Net.
3.2. Cross-Layer Multimodal Fusion Module (CLMF)
Semantic segmentation of HRRSI necessitates not only the integration of high-level and low-level features in RGB images (encompassing shallow details and deep semantic information) but also the effective utilization of elevation data contained in DSM to differentiate ground objects with similar spectral characteristics. However, existing multimodal fusion methods (such as FTransUNet and LMFNet) generally adopt a “single unified spatial fusion” approach, which directly places features from different modalities into a unified feature space for processing. This approach overlooks the hierarchical differences between the shallow details of RAG and the elevation semantics of DSM, and also fails to address the issue of redundant interference in the raw features of DSM. During this process, the feature maps of the two modalities always maintain the same spatial size and channel dimension, providing a scale-aligned basis for subsequent multi-modal feature fusion. The structure of the proposed CLMF module is shown in Figure 2, and its specific procedure is described below.
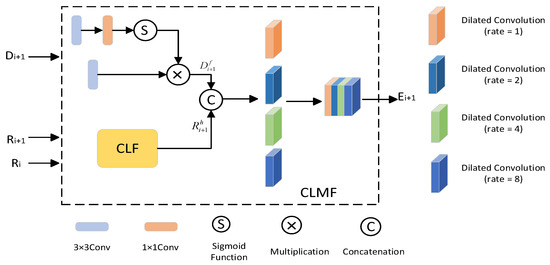
Figure 2.
Structure diagram of the proposed CLMF module, where CLF refers to the Cross-Layer Feature Fusion module.
- (1)
- Cross-Layer Feature Fusion (CLF)
The purpose of this sub-module is to achieve collaborative optimization of “details—semantics” by dynamically fusing adjacent levels of RGB features, thereby addressing the segmentation gap between high-level and low-level representations. Shallow-level features preserve rich detailed information yet are deficient in high-level semantic content, making them difficult to directly use for category judgment. In contrast, deep features, after multiple convolutions and downsampling, have been abstracted into semantically discriminative features but lose fine spatial position information, which hinders the localization of small targets. Through the cross-layer feature fusion mechanism, high-level semantic information and low-level detailed features are effectively integrated. This not only preserves the accuracy of spatial position information but also enhances the expressive ability of multi-scale contextual features, thus realizing the collaborative optimization of semantic information and structural details in target localization tasks. The particular architecture of this module is depicted in Figure 3.
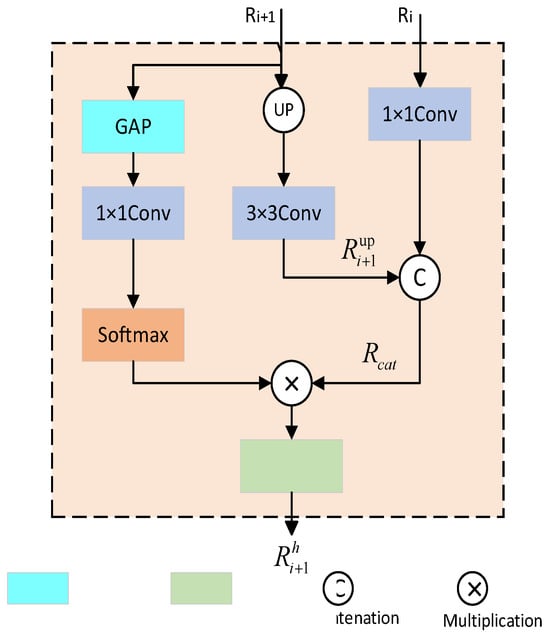
Figure 3.
CLF cross-layer fusion module.
Two features from different layers are extracted from the CNN encoder, denoted as and respectively. Owing to the discrepancy in the channel count between the shallow feature and the deep feature , a 1 × 1 convolution operation is first applied to to adjust its channel number to match that of . The deep feature is upsampled using bilinear interpolation to restore its spatial size to be consistent with . Feature mapping is performed through a 3 × 3 convolution layer to obtain , which adapts to the features of the lower level. Then, the adjusted and are concatenated along the channel dimension, resulting in a feature that integrates shallow details and high-level semantics. This step directly associates adjacent hierarchical features, enabling high-level semantic information to “guide” the weight allocation of shallow details and enhancing the semantic relevance of detailed features. To further highlight the semantically relevant key channels in the concatenated features (e.g., edge channels of buildings, texture channels of vegetation), dynamic attention weights are generated using the deep feature : First, global average pooling (GAP) is applied to compress the spatial dimension of to 1 × 1, obtaining a 1 × 1 × C channel description vector that reflects the global importance of each channel. Applying a 1 × 1 convolution (to compress the number of channels for reducing computational complexity) and a Softmax activation function to the vector output by GAP, a normalized channel weight of size C × 1 × 1 is generated. The optimized RGB feature is obtained by multiplying with these weights channel-wise to enhance the responses of important features and suppress irrelevant information, and applying max pooling to highlight salient features. The specific process is shown in Equation (1):
Among them, the GAP operation realizes the aggregation of spatial information into channel information, represents the pixel-level channel concatenation operation, and denotes bilinear interpolation upsampling.
The CLF module enables RGB features to preserve the spatial precision of shallow features while enhancing scene comprehension through high-level semantic guidance. This process establishes a robust feature foundation for subsequent multi-modal fusion.
- (2)
- Multi-Modal Feature Fusion (MMF)
DSM data documents the elevation details of surface features and assumes an irreplaceable role in distinguishing ground objects with similar spectra but different heights. However, DSM data is often contains noise and redundant information due to limitations in sensor accuracy, terrain undulations, and environmental interference. Directly fusing such data with RGB features could introduce invalid information or mislead the model. To address this, the multi-modal feature fusion module achieves efficient complementarity between RGB and DSM features through a two-step operation of “redundancy filtering—multi-scale fusion”. The specific process is as follows:
To mitigate noise and redundancy in DSM data, we design a parallel convolutional branch for feature filtering. One branch applies a 3 × 3 convolution to the DSM feature to extract basic elevation features and retain valid structural information. The other branch first extracts details from via a 3 × 3 convolution, then compresses the number of channels through a 1 × 1 convolution, and finally generates a filtering mask between 0 and 1 using the sigmoid activation function. The outputs of the two branches are multiplied element-wise to retain elevation features in high-importance regions and suppress noise and redundancy in low-importance regions, resulting in the filtered DSM feature . The specific process is shown in Equation (2):
wherein: denotes the sigmoid function, and represents the filtered feature of the ()-th layer.
In high-resolution remote sensing images, ground objects exhibit substantial scale variations, which cannot be effectively captured using convolution operations with a fixed receptive field. To address this, multi-modal feature fusion adopts multi-scale dilated convolutions to expand the receptive field. Specifically, the filtered DSM feature and the cross-layer fused RGB feature are concatenated along the channel dimension to obtain the fused joint feature. Subsequently, dilated convolutions with dilation rates of 1, 2, 4, and 8 are applied in parallel to this joint feature to capture feature information of small-scale, medium-scale, large-scale, and extra-large-scale objects respectively. Finally, the multi-scale features are processed through a 1 × 1 convolution to integrate channel information, resulting in the final multi-modal fused feature . The detailed procedure is illustrated in Equation (3):
wherein: denotes the dilated convolution operation with a dilation rate of applied to feature , and represents the concatenation operation.
The high-level features of the two modalities extracted from the 5th block of the CNN backbone network undergo spatial alignment and channel unification. Subsequently, two embedding layers and a reshaping operation are used to flatten the features into a sequence form. Position encoding is added to the flattened patch tokens to preserve positional information, resulting in vectorized patches and . These enriched feature sequences are fed into the MSMA to achieve deeper multimodal fusion and multiscale enhancement, strengthening the interactive representation capability between multimodal inputs and improving the model’s perception ability for targets of different scales.
3.3. Multi-Scale Multi-Attention (MSMA)
The MSMA module is designed to decouple modal fusion from multi-scale modeling, thereby enhancing feature representation for multimodal targets and improving perception in scale-sensitive regions such as roads and riverbanks. After processing by the CLMF, the features already have good modal complementarity and scale adaptability. However, the segmentation of ground objects with similar spectra and variable scales still requires refined modeling of deep features. Existing methods are limited to “single-modal self-attention” or “unidirectional cross-attention,” making it difficult to fully explore bidirectional complementary relationships across modalities. In multi-scale modeling, reliance on “fixed receptive field convolutions” hinders adaptation to scenes with varying scales. To address this, the proposed MSMA module overcomes existing limitations through a “multi-modal attention-multi-scale augmentation” cascade architecture. On one hand, it employs multi-branch depth-separable convolutions to enable dynamic receptive field adjustment. On the other hand, it achieves dynamic feature optimization through the synergistic interaction between attention mechanisms and multi-scale convolutions. Its structure is shown in Figure 4.
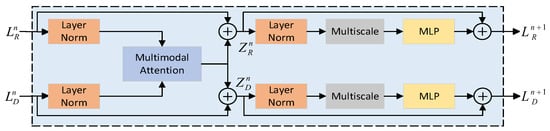
Figure 4.
Multi-Scale Multi-Attention module.
The MSMA module consists of three layers. Let and denote the features of the -th layer in the optical image branch and DSM branch, respectively, where . Notably, the dimensions of the feature maps remain consistent throughout all layers. The input features of the two modalities are first processed by Layer Norm to reduce distribution shifts and improve feature stability. The processed features then enter the multimodal attention module, which simultaneously performs self-attention and cross-attention to capture intra-modal dependencies and establish inter-modal associations respectively. The output of the attention module is connected with the original input via a residual connection and undergoes LayerNorm again, providing normalized input for the subsequent nonlinear module. Then, the features are input into the multi-scale module, which adopts a multi-branch dilated convolution structure to capture spatial structural features under different receptive fields. Finally, a standard feed-forward neural network is used to further perform nonlinear mapping on the fused features and enhance their expressive ability.
To effectively capture intramodal local dependencies and inter-modal complementary relationships, MSMA adopts a parallel design of “self-attention + cross-attention” to enhance interactions between modalities while preserving the information within each modality. Its specific structure is shown in Figure 5.
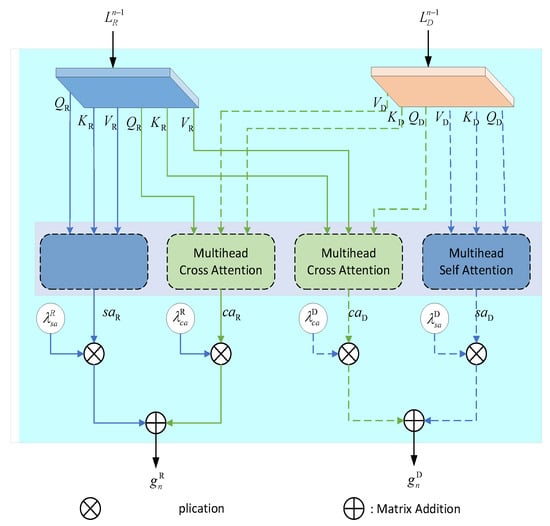
Figure 5.
Multimodal attention module.
First, and denote the input features from the two modalities respectively. In each layer, the input features are mapped through linear projections (using , respectively) to obtain the matrices of , , and . The specific operations are as follows (Equations (4) and (5)):
Next, multi-head attention is used to compute SA and CA. Each modality calculates its internal relationships through self-attention respectively, and the process can be expressed as Equations (6) and (7):
where: denotes the softmax function, is a normalization constant, and is the scaling factor for the feature dimension.
Self-attention calculates the internal dependency relationships within each modality.
In cross-attention (CA), cross-information between the two modalities is captured by exchanging queries and keys between modalities, enhancing mutual correlations between modalities. This process may be formulated as Equations (8) and (9):
Subsequently, to balance the contributions of SA and CA, an adaptive mechanism is employed to fuse SA and CA. The specific process can be expressed as Equations (10) and (11):
where: , , , are learnable weighting coefficients.
Using multi-head attention, the input is projected into multiple distinct subspaces, allowing each attention head to learn different feature relationships in parallel. The outputs from each attention head are concatenated and then fused via a linear transformation, yielding the final multimodal feature representation. The outputs of all self-attention and cross-attention are fused via element-wise addition and connected with the input features through a residual connection. The entire process can be expressed as Equations (12) and (13):
To better capture information about ground objects with significant scale variations in remote sensing data, the multi-scale module further enhances the model’s ability to model local and global information in complex scenes by fusing features of different scales. It enables more accurate segmentation and recognition, especially for regions with blurred object boundaries or large morphological variations. Its structure is shown in Figure 6. Before being input to the multi-scale module, the features first pass through a LayerNorm layer. Then, the input features undergo a 1 × 1 convolution to adjust the number of channels, reducing the channel dimension C to 1/4 of its original size. Subsequently, three parallel depth-wise separable convolutions are used to capture spatial information at different scales, where , , and represent three depth-wise separable convolution operations with different receptive fields. The dilation rates correspond to {(1,3,5)}, {(3,5,7)}, and {(5,7,9)} for each Multiscale module in the three multi-scale MSMA blocks, respectively. Then, a 1 × 1 convolution is applied to integrate information across channels. The features from the three branches are fused via element-wise addition. Finally, adaptive pooling is used to adjust the spatial dimensions, and a 1 × 1 convolution restores the channel dimension to the original feature size. The specific process can be expressed as Equations (14)–(17):

Figure 6.
Multiscale module in the MSMA module.
3.4. Loss Function
This paper employs the cross-entropy loss function as the optimization objective for model training. This loss function effectively measures the distributional discrepancy between predicted probabilities and true labels, precisely penalizing the model’s prediction bias across various categories. Loss function is expressed as (18):
where i represents the index of the six target categories; is the binary true label indicator variable, such that = 1 if the true category of the pixel is the i class, and = 0 otherwise. is the probability that the predicted map belongs to the labeled class i.
4. Results
4.1. Dataset
We utilize two public remote sensing datasets from ISPRS: Potsdam and Vaihingen. Descriptions of these two datasets are provided below.
The Potsdam dataset comprises 38 high-resolution images, each with a size of 6000 × 6000 and a ground sampling distance (GSD) of 5 cm. Included in this dataset are channels for near-infrared, red, green, and blue, along with both DSMs and nDSMs. We divide the dataset into 24 images for training and 16 for testing. The test set consists of images with the following IDs: 2_14, 2_15, 3_14, 3_15, 4_14, 4_15, 4_16, 5_12, 5_13, 5_14, 6_12, 6_13, 6_14, and 7_13. In our experiments, we use only the red, green, and blue channels together with their corresponding nDSM images.
The Vaihingen dataset comprises 33 orthorectified image files, containing three spectral bands (red, green, near-infrared) and nDSM data with identical resolution. It exhibits a spatial resolution of 9 cm, an average pixel dimension of 2494 × 2494, and a GSD of 5 cm. We allocate 16 images for training and 17 for testing. The test images are identified by the following IDs: 3, 6, 9, 12, 15, 18, 21, 22, 24, 26, 29, 30, 32, 33, 35, 37, and 38. Corresponding nDSM data are also used during both training and testing phases.
Figure 7 presents some sample data from the two datasets, depicting six categories: impervious surfaces (white), low-lying vegetation (cyan), buildings (blue), cars (yellow), trees (green), and clutter background (red).

Figure 7.
Samples of the Vaihingen and Potsdam datasets.
To better understand the dataset characteristics and guide the model design and evaluation, we analyze the class distribution in both datasets, as shown in Figure 8 below.

Figure 8.
Proportions of various categories in the Vaihingen and Potsdam datasets. (a) Vaihingen; (b) Potsdam.
4.2. Evaluation Metrics
To comprehensively quantify the performance of the model in the task of semantic segmentation for multimodal HRRSI, this paper adopts three commonly used evaluation metrics: OA, mIoU, and mF1. The specific definitions of each metric are as follows:
OA measures the global classification correctness over all pixels. The specific calculation formula is as follows in Equation (19):
where C denotes the total number of classes. , , , and represent the number of true positives, false positives, true negatives, and false negatives for class c, respectively. This formula is also used to evaluate the OA values of each category.
mIoU evaluates segmentation accuracy. The formula is presented as follows in Equations (20) and (21):
The mean F1 score represents the harmonic average of precision and recall across each category. The formula is presented as follows in Equations (22)–(25):
where represents the proportion of pixels that are actually of category c among those predicted as category c, and denotes the proportion of pixels actually belonging to class c that are correctly predicted.
4.3. Experimental Details
We employ ResNet-50, pre-trained on the ImageNet dataset [34], as the backbone network. For comparative methods, single-modal experiments are trained using only RGB data, while multi-modal methods utilize both RGB and corresponding DSM data. To ensure fairness, all methods are conducted under identical experimental conditions, with training and testing performed on an NVIDIA GeForce RTX 3090 24G GPU. During network training, depth values in DSM images are normalized to the range [0, 255]. All models are optimized using the Stochastic Gradient Descent (SGD) algorithm with a learning rate of 0.0007 and a momentum of 0.9, trained for 150 epochs and the batch size is set to 10 during training. Data augmentation is achieved by performing random horizontal and vertical flipping operations.
4.4. Performance Comparison
In this paper, the performance of the proposed MMA-Net is benchmarked against 8 state-of-the-art methods: HRCNet [35], MANet [36], SSNet [37], CMANet [38], CIMFNet [12], VSGNet [39], FTransUNet [14], and LMFNet [30]. Among these, HRCNet, MANet, and SSNet are single-modal methods trained exclusively on RGB data, serving to illustrate the contribution of multimodal DSM information. The remaining methods all use both RGB and nDSM images as input. Quantitative comparison results are presented in Table 1 and Table 2.

Table 1.
Shows the experimental results on the Vaihingen dataset.
Table 2.
Presents the experimental results on the Potsdam dataset.
4.4.1. Metrics Comparison
- (1)
- Vaihingen Dataset
As shown in Table 1, the proposed method achieves significant improvements in OA, mF1, and mIoU, reaching 92.77%, 92.53%, and 84.92% respectively. These results represent gains of 1.68%, 0.95%, and 0.76% over the best-performing baseline methods. This result confirms that the proposed MMA-Net can effectively extract information from nDSM images and successfully fuse it with features from RGB images, owing to the designed CLMF. Specifically, compared to single-modal semantic segmentation methods, multi-modal ones perform better in segmenting trees and low-lying vegetation, which indicates that introducing nDSM data during semantic segmentation is beneficial. When compared with other multi-modal methods, the proposed multi-modal approach achieves 1.30% and 0.76% improvements in the segmentation accuracy of trees and buildings, respectively. This enhanced performance stems from MMA-Net’s ability to effectively leverage the distinct elevation characteristics of these categories through DSM data. Many classification methods fail to adequately consider local and overall information; in contrast, our method achieves a 1.46% improvement in car category segmentation. This is attributed to the designed cross-layer fusion and multi-scale modules, which enhance the model’s ability to model local and global information in complex scenes. These experimental results indicate that the proposed MMA-Net method possesses superior generalization capability.
- (2)
- Potsdam Dataset
As indicated in Table 2, the proposed method exhibits a consistent trend on the Potsdam dataset, achieving mIoU, mF1, and OA values of 88.74%, 93.67%, and 94.65%, respectively. These results represent improvements of 1.43%, 1.38%, and 2.35% over existing methods, demonstrating enhanced segmentation accuracy across all categories. Notably, the model shows particular effectiveness in classifying small-scale objects such as cars. These performance gains can be attributed to the synergistic interaction between the CLMF module and the MSMA module within MMA-Net.
4.4.2. Visualization Results Comparison
Figure 9 below shows the visualization results of experiments on the two datasets. The proposed method achieves more accurate classification results for small-scale targets such as buildings and cars, achieved primarily through the coordinated action of the CLMF and MSMA modules. Specifically, the CLMF enhances both local and global information representation by first fusing adjacent-layer RGB features and then integrating them with DSM data. Meanwhile, the MSMA module enables the model to adaptively focus on salient information across feature spaces at different scales, thereby improving comprehension and processing of complex data. Purple boxes highlight key differences between our method and comparative approaches. In the first row, our method accurately identifies low vegetation, consistent with quantitative results. The second row reveals a clear contrast: while existing methods often produce scattered artifacts at object boundaries, our approach achieves precise building edge segmentation. The third and fourth rows demonstrate our method’s capability to correctly identify relevant categories in complex environments. The fifth row shows that our method provides more accurate car detection, benefiting from the multi-scale attention module’s ability to capture small-target features. Finally, the sixth row illustrates complete building recognition even in challenging scenarios.

Figure 9.
Visualization results of the proposed method and comparison methods. (a) Image; (b) nDSM; (c) GT; (d) Ours; (e) FTransUNet; (f) VSGNet; (g) LMFNet; (h) CIMFNet; (i) CMANet; (j) SSNet; (k) MANet; (l) HRCNet.
4.4.3. Few-Shot Class Segmentation Performance Validation
The class imbalance problem in HRRSI poses a significant challenge for semantic segmentation. As shown in Figure 8, both datasets exhibit strongly skewed category distributions. In the Vaihingen dataset, the “car” class constitutes only 1.21% of pixels—approximately 23 times fewer than the “impervious surface” class (27.94%). Similarly, in the Potsdam dataset, “car” accounts for merely 1.74%, about 16 times lower than “impervious surface” (29.02%). Such extreme imbalance causes categories with limited samples, such as cars and low vegetation, to be easily overwhelmed by dominant classes during training, thereby limiting segmentation accuracy. To address this issue, MMA-Net demonstrates strong performance in segmenting under-represented categories. As reported in Table 2 and Table 3, on the Vaihingen dataset, our method improves the IoU of the “car” class by 1.46% over FTransUNet, reaching 92.73%. On the Potsdam dataset, the “car” class IoU exceeds that of FTransUNet by 1.37%, and “low vegetation” IoU increases by 1.59%. These results confirm the model’s robustness under imbalanced data conditions.
Table 3.
Ablation experiments of the proposed method, where CLMF (no CLF) denotes the fusion module without cross-layer interaction. √ indicates that the corresponding module is included, while × indicates that it is not.
These improvements stem from several deliberate design choices: The CLMF module incorporates elevation cues from DSM, providing discriminative information for rare classes such as height differences between cars and roads, or between low vegetation and trees, thus reducing confusion caused by spectral similarity. In the MSMA module, multi-scale depthwise separable convolutions enhance local feature extraction for small objects. When coupled with attention mechanisms, the model dynamically emphasizes sparse pixels from minor classes, effectively alleviating the dominance of majority-class features.
4.5. Ablation Experiments
To validate the effectiveness of the proposed CLMF and MSMA modules and their contributions to overall performance, this section conducts ablation studies from two perspectives. First, by incrementally integrating the CLMF and MSMA modules, we systematically analyze the individual and combined impacts of each component on segmentation performance through both quantitative and qualitative assessments. Second, we conduct comparative experiments with different MSMA depths (1 to 4 layers) to investigate how the depth of attention modeling affects multi-scale feature fusion capability and computational efficiency. All experiments are constructed using ResNet50 as the backbone network for the baseline, with all other hyperparameters held consistent.
- (1)
- Impact of Individual Modules
To validate the efficacy and significance of the proposed modules, ablation experiments were performed by eliminating specific components under the premise that all other conditions remain unaltered. As depicted in Table 3, the baseline network uses ResNet50, with the CLMF module replaced by convolution and simple addition operations; other settings remain consistent with the complete MMA-Net. It can be clearly seen from Table 3 that removing either CLMF or MSMA will lead to a decline in experimental performance, thereby affirming the efficacy of each individual module.
The following ablation experiments are all based on the Potsdam dataset. First, we introduce the CLMF module without CLF, which improves mIoU to 82.67%, demonstrating the effectiveness of incorporating DSM elevation information. However, the complete CLMF module further boosts mIoU to 84.30%. This improvement primarily stems from the CLF mechanism’s successful dynamic integration of shallow spatial details with deep semantic information, effectively mitigating detail loss during the encoder’s downsampling process. The MSMA module, incorporating a multimodal attention submodule, achieves a significant mIoU boost. This clearly demonstrates its crucial role in establishing global dependencies between RGB and DSM features at high-level semantic scales, effectively resolving category confusion issues. The multi-scale convolution submodule expands the receptive field through multi-branch depth-separated convolutions, significantly enhancing the model’s feature extraction capability for objects with pronounced scale variations. This particularly improves recognition of small-to-medium-scale targets. The complete MSMA module elevates mIoU to 87.1%, demonstrating synergistic effects between multimodal attention and multi-scale convolutions.
As depicted in Figure 10, the visual results of the ablation studies clearly demonstrate that removing any proposed module leads to noticeable performance degradation. Specifically, in the first row, compared with the complete CLMF module, the method lacking the CLF has deviations in classifying cars and cannot accurately identify cars in hidden positions. This is because the absence of cross-layer fusion leads to the neglect of local features and the loss of detailed information. In the second row, if the MSMA multi-scale attention module is missing, the segmentation effect of buildings will be poor, and the segmentation boundaries will be relatively blurred. Due to the lack of complementarity between different modalities, the segmentation accuracy of some low vegetation and trees decreases. The results in the third row are similar; the absence of the MSMA module will lead to incorrect segmentation of buildings, which also verifies the data of the above ablation experiments.
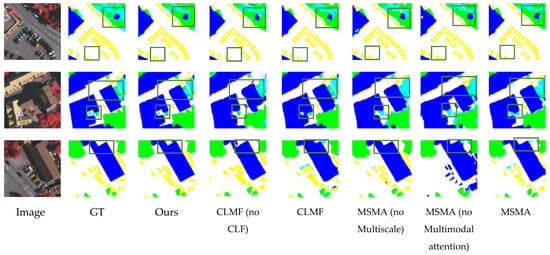
Figure 10.
Visualization results of ablation experiments.
- (2)
- Number of Multi-scale Multi-attention Layers
The depth of the MSMA module represents a crucial design choice, directly affecting both the model’s ability to capture multi-scale multimodal dependencies and its computational requirements. Too few layers hinder effective modeling of long-range dependencies across scales and modalities, limiting segmentation accuracy. Too many layers, on the other hand, introduce redundant computations, increase the model’s parameter size and inference time, and reduce its practical application value. Table 4 presents the comparison results for different MSMA layer settings (1, 2, 3, and 4 layers). In the experiments, other modules (such as the CLMF module and decoder structure) and hyperparameters (12 attention heads, 512 channels) remain unchanged, with only the number of MSMA layers being adjusted.
Table 4.
Ablation experiments on the number of MSMA layers on the Potsdam dataset.
The experimental results indicate a clear correlation between MSMA depth and model performance. As the number of layers increases from 1 to 3, all evaluation metrics (mIoU, mF1, OA) on the Potsdam dataset show consistent improvement, with mIoU rising from 85.21% to 88.74%. This suggests that augmenting the layer count enhances the model’s capability to capture multi-scale features and multi-modal dependencies. Nevertheless, when the layer number is increased to 4, performance improvements tend to plateau or even decline marginally, whereas complexity metrics rise substantially: the parameter count increases from 53.28 M to 61.57 M, and FLOPs grow from 51.83 G to 63.41 G. Therefore, a 3-layer configuration achieves the optimal balance between accuracy and efficiency, maximizing the multi-scale attention mechanism’s ability to explore intra-modal and inter-modal correlations while avoiding the significant computational overhead of excessive layer stacking.
4.6. Complexity Analysis
We evaluate the computational complexity of the proposed MMA-Net through the following metrics: Floating-Point Operations (FLOPs), model parameter count, memory consumption, and frames per second (FPS). Table 5 provides the complexity analysis results for all comparative methods included in this study. As shown in Table 5, MMA-Net (as a multimodal model)naturally exhibits higher FLOPs and parameter counts compared to single-modal methods like HRCNet, MANet, and SSNet, due to its dual-branch architecture processing both RGB and DSM data along with dedicated fusion modules. However, this increase is offset by a significant improvement in segmentation performance: on the Potsdam dataset, the mIoU rises from the previous highest of 87.31% to 88.74%.
Table 5.
Comparative analysis of model complexity based on the Potsdam dataset. √ indicates a multimodal method, × indicates a unimodal method.
Notably, compared to FTransUNet, our ResNet50-based model reduces the parameter size by 57.5% (68.45 M vs. 160.88 M) and nearly doubles the inference speed (19.63 FPS vs. 10.25 FPS), while achieving a 2.6% higher mIoU. This can be ascribed to the MSMA, which adopts depth-wise separable convolutions and a parallel branch architecture to mitigate complexity while boosting the capability of feature modeling. In comparison to LMFNet, which has a similar complexity level, Ours (ResNet50) achieves a 2.65% higher mIoU with 6.8% less memory usage, validating the efficiency of the collaborative design between CLMF and MSMA. Overall, MMA-Net (ResNet50) achieves an optimal balance between performance and complexity on the Potsdam dataset. With moderate computational costs (56.82 G FLOPs, 68.45 M parameters), it attains the highest mIoU (88.74%), exhibiting particularly strong performance on small objects (e.g., cars) and ambiguous boundary regions (e.g., between low vegetation and trees). This underscores the model’s practical value in semantic segmentation tasks for HRRSI.
The computational characteristics of MMA-Net on the Potsdam dataset are based on results from NVIDIA RTX 3090 servers. For deployment on resource-constrained edge devices (e.g., drones) or real-time systems, the model can be further optimized using lightweight backbone networks (e.g., MobileNet) or inference acceleration frameworks like TensorRT. Another practical consideration involves reliance on DSM data. When high-quality DSMs are unavailable, approximations can be generated from stereo imagery, or robustness can be enhanced through modal loss strategies during training.
5. Discussion
The excellent performance of MMA-Net on the ISPRS Potsdam and Vaihingen datasets stems primarily from the collaborative design of the CLMF and the MSMA module. In the CLF stage, this module dynamically associates shallow spatial details with deep semantic information by concatenating adjacent hierarchical RGB features and weighting them via channel attention, effectively avoiding the loss of shallow features during encoder downsampling. In the multimodal fusion stage, the parallel convolutional filtering branch efficiently suppresses noise and redundancy in DSM data. The MSMA module enhances the model’s ability to model multi-scale ground objects and capture multi-modal dependencies. SA and CA enable the model to not only explore intra-modal local context but also capture inter-modal complementary relationships. Additionally, the multi-scale depthwise separable convolutions employed in the MSMA module expand the receptive field to cover ground objects of different sizes, effectively resolving the limitation of “fixed receptive field” in traditional convolutions.
Despite its competitive performance, MMA-Net still has limitations. It struggles to accurately segment extremely small targets (e.g., individual street lamps) and extremely large targets (e.g., continuous urban blocks). This is because the receptive field of the multi-scale convolutions in the MSMA module relies on a fixed dilation rate and cannot be dynamically adjusted according to the scale characteristics of the input content. Moreover, in areas with complex terrain or severe noise, the model fails to eliminate high-frequency interference, which leads to distortion of elevation features and subsequently degrades the multimodal fusion effect.
6. Conclusions
This study centers on the semantic segmentation task for HRRSI.To address the issues of blurred boundary segmentation and insufficient multi-scale feature perception in existing multimodal semantic segmentation methods, we propose the MMA-Net architecture. This network aims to improve semantic segmentation accuracy by effectively fusing RGB and DSM multi-modal data. The introduced CLMF strategy reduces intra-class variations to a minimum while maximizing inter-class discrepancies, facilitating better segmentation of ground objects with similar spectra while effectively preventing the loss of local details. The introduced multi-scale multi-attention module, which incorporates both SA and CA mechanisms, not only enhances interactions between modalities while preserving intra-modal information but also combines multi-scale depth-wise separable convolutions to effectively model features of ground objects at different scales, improving adaptability to complex scenes. Experimental validation on the ISPRS Potsdam and Vaihingen datasets demonstrates that MMA-Net outperforms mainstream methods on key metrics including OA, mIoU, and mF1, fully validating the rationality and effectiveness of the proposed modules and overall network design.
Author Contributions
For Conceptualization, X.H.; Methodology, X.H.; Validation, X.Z.; Formal analysis, D.Y.; Data curation, X.H. and Z.Z.; Writing—original draft, X.H.; Writing—review & editing, S.X. and L.W.; Visualization, X.H. and F.Z.; Funding acquisition, X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The datasets can be downloaded from the following link: https://github.com/open-mmlab/mmsegmentation/blob/main/docs/en/user_guides/2_dataset_prepare.md#prepare-datasets (accessed on 1 December 2022).
Conflicts of Interest
Author Fengguang Zhou was employed by the company China Aerospace Science and Industry Corporation. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DL | Deep learning |
| HRRSI | high-resolution remote sensing imagery |
| RGB | Red-green-blue |
| FCN | Fully convolutional network |
| nDSM | Normalized digital surface model |
| MMA-Net | Multi-scale Multimodal Fusion Network |
| CLMF | Cross-layer Multimodal Fusion |
| CLF | Cross-layer fusion |
| MMF | Multi-modal fusion |
| MSMA | Multi-Scale Multi-Attention |
| ReLu | Rectified linear unit |
| GAP | Global Average Pooling |
| CA | Cross Attention |
| SA | Self-Attention |
References
- Ye, C.; Li, Y.; Cui, P.; Liang, L.; Pirasteh, S.; Marcato, J.; Goncalves, W.N.; Li, J. Landslide Detection of Hyperspectral Remote Sensing Data Based on Deep Learning with Constrains. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 99, 5047–5060. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, W.; Pun, M.-O.; Shi, W. Cross-domain landslide mapping from large-scale remote sensing images using prototype-guided domain-aware progressive representation learning. ISPRS J. Photogramm. Remote Sens. 2023, 197, 1–17. [Google Scholar] [CrossRef]
- Xu, Z.; Shen, Z.; Li, Y.; Xia, L.; Wang, H.; Li, S.; Jiao, S.; Lei, Y. Road extraction in mountainous regions from high-resolution images based on DSDNet and terrain optimization. Remote Sens. 2020, 13, 90. [Google Scholar] [CrossRef]
- Meng, Y.; Chen, S.; Liu, Y.; Li, L.; Zhang, Z.; Ke, T.; Hu, X. Unsupervised building extraction from multimodal aerial data based on accurate vegetation removal and image feature consistency constraint. Remote Sens. 2022, 14, 1912. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Wang, L.; Zhang, C. Land cover classification from remote sensing images based on multi-scale fully convolutional network. Geo-Spatial Inf. Sci. 2022, 25, 278–294. [Google Scholar] [CrossRef]
- Liu, H.; Li, W.; Xia, X.-G.; Zhang, M.; Gao, C.-Z.; Tao, R. Central attention network for hyperspectral imagery classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 8989–9003. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Li, W.; Zhang, Y.; Tao, R.; Du, Q. Hyperspectral and LiDAR data classification based on structural optimization transmission. IEEE Trans. Cybern. 2023, 53, 3153–3164. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef]
- Yao, H.; Qin, R.; Chen, X. Unmanned aerial vehicle for remote sensing applications—A review. Remote Sens. 2019, 11, 1443. [Google Scholar] [CrossRef]
- Yan, L.; Fan, B.; Liu, H.; Huo, C.; Xiang, S.; Pan, C. Triplet adversarial domain adaptation for pixel-level classification of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3558–3573. [Google Scholar] [CrossRef]
- Yang, X.; Li, S.; Chen, Z.; Chanussot, J.; Jia, X.; Zhang, B.; Li, B.; Chen, P. An attention-fused network for semantic segmentation of very-high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 177, 238–262. [Google Scholar] [CrossRef]
- Zhou, W.; Jin, J.; Lei, J.; Yu, L. CIMFNet: Cross-layer interaction and multiscale fusion network for semantic segmentation of high-resolution remote sensing images. IEEE J. Sel. Top. Signal Process. 2022, 16, 666–676. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain long-range learning for general image fusion via Swin transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, X.; Pun, M.O.; Liu, M. A multilevel multimodal fusion transformer for remote sensing semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5403215. [Google Scholar] [CrossRef]
- Chen, X.; Lin, K.-Y.; Wang, J.; Wu, W.; Qian, C.; Li, H.; Zeng, G. Bi-directional cross-modality feature propagation with separation-and-aggregation gate for RGB-D semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 561–577. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional net-works for biomedical image segmentation. In Bildverarbeitung für die Medizin 2017; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar] [CrossRef]
- Xing, H.; Wei, W.; Zhang, L.; Zhang, Y. Multi-scale feature extraction and fusion with attention interaction for RGB-T tracking. Pattern Recognit. 2025, 157, 110917. [Google Scholar] [CrossRef]
- Hou, J.; Guo, Z.; Wu, Y.; Diao, W.; Xu, T. BSNet: Dynamic hybrid gradient convolution based boundary-sensitive network for remote sensing image segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5624022. [Google Scholar] [CrossRef]
- Niu, R.; Sun, X.; Tian, Y.; Diao, W.; Chen, K.; Fu, K. Hybrid multiple attention network for semantic segmentation in aerial images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5603018. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, X.; Pun, M.-O. A crossmodal multiscale fusion network for semantic segmentation of remote sensing data. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2022, 15, 3463–3474. [Google Scholar] [CrossRef]
- Hosseinpour, H.; Samadzadegan, F.; Javan, F.D. CMGFNet: A deep cross-modal gated fusion network for building extraction from very high-resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2022, 184, 96–115. [Google Scholar] [CrossRef]
- Mohammadi, H.; Samadzadegan, F. An object based framework for building change analysis using 2D and 3D information of high resolution satellite images. Adv. Space Res. 2020, 66, 1386–1404. [Google Scholar] [CrossRef]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. Fusenet: Incorporating depth into semantic segmentation via fusion-based cnn architecture. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 213–228. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- Liu, K.; Li, M.; Zuo, E.; Chen, C.; Chen, C.; Wang, B.; Wang, Y.; Lv, X. ASFFuse:Infrared and visible image fusion model based on adaptive selection feature maps. Pattern Recognit. 2024, 149, 110226. [Google Scholar] [CrossRef]
- Xing, M.; Liu, G.; Tang, H.; Qian, Y.; Zhang, J. CFNet: An infrared and visible image compression fusion network. Pattern Recognit 2024, 156, 110774. [Google Scholar] [CrossRef]
- Prakash, A.; Chitta, K.; Geiger, A. Multi-Modal Fusion Transformer for End-to-End Autonomous Driving. arXiv 2021, arXiv:2104.09224. [Google Scholar] [CrossRef]
- Wang, T.; Chen, G.; Zhang, X.; Liu, C.; Wang, J.; Tan, X.; Zhou, W.; He, C. LMFNet: Lightweight Multimodal Fusion Network for high-resolution remote sensing image segmentation. Pattern Recognit. 2025, 164, 111579. [Google Scholar] [CrossRef]
- Yan, L.; Huang, J.; Xie, H.; Wei, P.; Gao, Z. Efficient depth fusion transformer for aerial image semantic segmentation. Remote Sens. 2022, 14, 1294–1304. [Google Scholar] [CrossRef]
- He, S.; Yang, H.; Zhang, X.; Li, X. MFTransNet: A multi-modal fusion with CNN-transformer network for semantic segmentation of HSR remote sensing images. Mathematics 2023, 11, 722–735. [Google Scholar] [CrossRef]
- Feng, H.; Hu, Q.; Zhao, P.; Wang, S.; Ai, M.; Zheng, D.; Liu, T. FTransDeepLab: Multimodal Fusion Transformer-Based DeepLabv3+ for Remote Sensing Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2025, 63, 4406618. [Google Scholar] [CrossRef]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-resolution context extraction network for semantic segmentation of remote sensing images. Remote Sens. 2020, 13, 71. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention network for semantic segmentation of fine-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607713. [Google Scholar] [CrossRef]
- Yao, M.; Zhang, Y.; Liu, G.; Pang, D. SSNet: A novel transformer and CNN hybrid network for remote sensing semantic segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3023–3037. [Google Scholar] [CrossRef]
- Zhu, L.; Kang, Z.; Zhou, M.; Yang, X.; Wang, Z.; Cao, Z.; Ye, C. CMANet: Cross-Modality Attention Network for Indoor-Scene Semantic Segmentation. Sensors 2022, 22, 8520. [Google Scholar] [CrossRef] [PubMed]
- Pan, C.; Fan, X.; Tjahjadi, T.; Guan, H.; Fu, L.; Ye, Q.; Wang, R. Vision foundation model guided multi-modal fusion network for remote sensing semantic segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 9409–9431. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).