Abstract
Building change detection and building damage assessment are two essential tasks in post-disaster analysis. Building change detection focuses on identifying changed building areas between bi-temporal images, while building damage assessment involves segmenting all buildings and classifying their damage severity. These tasks play a critical role in disaster response and urban development monitoring. Although supervised learning has significantly advanced building change detection and damage assessment, its reliance on large labeled datasets remains a major limitation. In contrast, self-supervised learning enables the extraction of meaningful data representations without explicit training labels. To address this challenge, we propose a self-supervised learning approach that unifies denoising autoencoders and contrastive learning, enabling effective data representation for building change detection and damage assessment. The proposed architecture integrates a dual denoising autoencoder with a Vision Transformer backbone and contrastive learning strategy, complemented by a Feature Pyramid Network-ResNet dual decoder and an Edge Guidance Module. This design enhances multi-scale feature extraction and enables edge-aware segmentation for accurate predictions. Extensive experiments were conducted on five public datasets, including xBD, LEVIR, LEVIR+, SYSU, and WHU, to evaluate the performance and generalization capabilities of the model. The results demonstrate that the proposed Denoising AutoEncoder-enhanced Dual-Fusion Network (DAEDFN) approach achieves competitive performance compared with fully supervised methods. On the xBD dataset, the largest dataset for building damage assessment, our proposed method achieves an F1 score of 0.892 for building segmentation, outperforming state-of-the-art methods. For building damage severity classification, the model achieves an F1 score of 0.632. On the building change detection datasets, the proposed method achieves F1 scores of 0.837 (LEVIR), 0.817 (LEVIR+), 0.768 (SYSU), and 0.876 (WHU), demonstrating model generalization across diverse scenarios. Despite these promising results, challenges remain in complex urban environments, small-scale changes, and fine-grained boundary detection. These findings highlight the potential of self-supervised learning in building change detection and damage assessment tasks.
1. Introduction
Both building change detection and damage assessment using Remote Sensing (RS) images play a vital role in timely and accurate post-disaster analysis and response [1,2]. Optical RS imagery is one of the most widely used data sources for change detection. Rapid detection of building changes and assessment of damage levels is crucial for disaster response, resource allocation, and recovery planning to minimize loss of life and economic impact [3]. Figure 1 represents the hierarchical structure of building change detection and damage assessment tasks. Specifically, building change detection focuses on identifying changed building areas between bi-temporal images. On the other hand, building damage assessment can be divided into building segmentation, which identifies all buildings in the images, and damage classification, which assesses the severity of damage in segmented buildings.
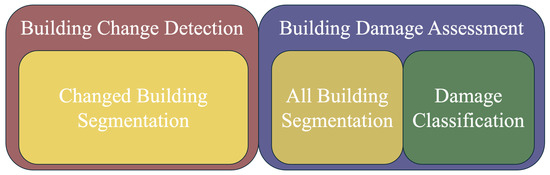
Figure 1.
Hierarchical Structure for Building Change Detection and Damage Assessment Tasks.
In recent years, deep learning has become the dominant method of Geospatial Artificial Intelligence (GeoAI) for RS of building change detection and damage assessment [4]. Among the various approaches, models based on convolutional neural networks (CNN) are popular due to their ability to capture spatial patterns [5,6]. However, CNNs have inherent limitations, such as limited receptive fields, which limit their ability to model complex and diverse multi-temporal scenes [7]. To address this, attention mechanisms have been integrated into deep learning. For example, D2ANet utilizes dual-temporal aggregation and attention modules to capture multi-level changes [8].
Moving beyond CNNs, Vision Transformer (ViT) has gained attention. ViTs are advantageous in handling complex spatial relationships and capturing long-distance dependencies in images [9]. Recent works, such as the Bitemporal Attention Module with ViT, utilize cross-attention mechanisms to achieve temporal fusion for building change detection [10]. Additionally, the ChangeMamba architecture, based on the Visual Mamba model, has shown promising results in enhancing the accuracy of building damage assessment [11]. Despite these advancements, supervised learning approaches have limitations, including reliance on large labeled datasets and overfitting to training datasets [12].
Self-supervised learning (SSL) has contributed to the field of deep learning by allowing models to learn generalized feature representations from unlabeled datasets [13]. SSL achieves this by creating pretext tasks from raw data, which use patterns within raw data to train models without labels. Once pre-trained on these pretext tasks, the model can be fine-tuned on labeled datasets for downstream tasks such as classification, segmentation, and object detection. Notable SSL frameworks in computer vision include Bootstrap your own latent (BYOL) [14], Simple framework for contrastive learning (SimCLR) [15], Momentum contrast (MoCo) [16,17], Self-distillation with no labels (DINO) [18], and Masked Autoencoder (MAE) [19].
In the context of RS building change detection, SSL frameworks like RECM combine RGB-elevation knowledge distillation and image mask prediction to improve detection performance [20]. However, RS images differ significantly from typical RGB images (e.g., ImageNet [21]). ImageNet provides clear object categories, while RS images capture the Earth’s surface, featuring objects that vary widely in scale, color, shape, and texture due to different weather conditions, human mobility, and urban changes [22]. Thus, masking large regions of RS images (the methodology of MAE) might cause semantic loss. Other SSL methods, such as the spatiotemporal contrastive representation learning model (ST-CRL), learn features of building damages using contrastive learning [3]. This method focuses on learning an embedding space where similar features are close together, and dissimilar ones are pushed apart [15]. However, RS images often contain information across coarse, middle, and fine-grained levels, which are not fully exploited solely by contrastive learning methods [22].
However, existing SSL research primarily relies on either denoising or masked prediction strategies, with limited investigation into their impact on information representation. To address this gap, we compared these two strategies by evaluating their generative ability. Based on this, we further propose a novel SSL framework, known as the Denoising AutoEncoder-enhanced Dual-Fusion Network (DAEDFN), which integrates denoising strategies instead of masked prediction. This approach helps to preserve essential semantic information while forcing the model to learn latent semantic representations. To further evaluate the effectiveness of the proposed SSL framework, we conduct experiments on five datasets for two main downstream tasks: building damage assessment and building change detection. In general, the main contributions of this work are summarized as follows:
- Investigate the performance of denoising and masking strategies for semantic information reconstruction in remote sensing images.
- Develop a dual denoising autoencoder (DAE) with a Vision Transformer backbone and contrastive learning strategy for self-supervised pretraining, enabling effective extraction of multi-scale image representations for various vision tasks.
- Design and implement two transfer learning networks, composed of task-specific decoders, incorporating an edge guidance module and edge detection loss, to effectively adapt the pretrained model for building damage assessment and change detection tasks.
2. Related Work
This section reviews the research progress in building change detection and damage assessment using optical high-resolution RS images, classified as supervised learning and SSL advancements.
2.1. Supervised Learning
Supervised learning has been popular and dominant in building change detection, using deep learning models such as CNNs and ViTs. Table 1 summarizes methods and their backbones. Early works were primarily based on CNN architectures. For example, xBD Baseline [23] uses the U-Net backbone. Models such as AGCDetNet [24] and BDANet [25] integrate attention mechanisms to improve feature extraction and detection accuracy. To improve spatial and temporal modeling, methods like EGRCNN [26] adopt LSTMs for sequential reasoning. ViT-based methods have been a powerful alternative. Models such as DamFormer [27] and BAT [10] employ ViT backbones to integrate spatial and semantic information. U-Conformer [28] combines CNNs with ViTs to leverage local and global feature representations. Recently, the Mamba-based framework introduced a novel paradigm. ChangeMamba [11] utilizes the Visual Mamba [29] to achieve spatio-temporal fusion, demonstrating state-of-the-art performance across multiple large-scale RS datasets.

Table 1.
Summary of Supervised Learning Methods in RS building change detection.
2.2. Self-Supervised Learning
SSL methods typically fall into two categories: image reconstruction and contrastive learning.
2.2.1. Image Reconstruction
Masked image modeling (MIM) is a reconstruction-based SSL technique where parts of the image are masked, and the model learns to reconstruct the missing regions. MIM forces models to learn image representations, which might be useful for downstream tasks [19,33]. Inspired by BERT [34] in natural language understanding, MAE [19] utilizes a similar masked strategy. In MAE, random patches of the input are masked, and the model reconstructs the original images. This is called the pretraining stage. After pretraining, only the encoder weights are retained as a feature extractor for downstream tasks. Notably, MAE with a ViT-Huge model backbone achieves an accuracy of 87.8% on the ImageNet-1K classification task when 75% of patches are masked out [19].
Denoising-based methods, another form of reconstruction, focus on learning feature representations by recovering clean data from corrupted inputs [35]. This strategy also improves the feature extractor performance by extracting meaningful patterns and structures from unlabeled data.
2.2.2. Contrastive Learning
Contrastive learning (CL) enables models to distinguish between similar (positive pairs) and dissimilar (negative pairs) features [15]. This helps the model generate representative features for distinguishing different classes. A notable example is SimCLR [15], which achieves 76.5% top-1 accuracy on ImageNet classification when the pretrained model is frozen and 85.8% top-5 accuracy when fine-tuning with only 1% labels.
Self-knowledge distillation (SKD) is an extension of contrastive learning that transfers knowledge from a pre-trained teacher model to a smaller student model [18]. For example, DINO [18] learns feature representations by comparing augmented views of the same image. In DINO, the teacher and student networks share the same backbone, but the teacher network is updated via an exponential moving average (EMA) of the student network. The framework encourages the student model to generate consistent predictions across views. The features extracted by DINO reach 78.3% top-1 accuracy on ImageNet classification with a small ViT using k-NN classifiers [18].
2.2.3. SSL in RS Building Change Detection and Damage Assessment
Table 2 summarizes current SSL methods. These methods leverage reconstruction and contrastive learning strategies. ST-CRL [3] combines pre- and post-disaster building images (both RGB) and a ResNet CL framework for building damage level classification. It considers temporally adjacent images as positive pairs and geographically distant ones as negative pairs, leveraging the First Law of Geography [36]. MS-ResUNet [37] is also a self-supervised contrastive pretraining framework. In the pretraining stage, a CL pipeline is employed to extract domain-specific representations. These learned weights are transferred to a building extraction model, which incorporates multi-scale and multi-layer features. RECM [20] uses RGB and heights from Digital Surface Model data for pretraining. Specifically, the upper branch processes RGB images by masking random patches and encoding the visible regions using a ViT, while the lower branch encodes DSM data with a frozen encoder. During fine-tuning, the pretrained encoder is transferred to a change detection pipeline, where a spatial transformer backbone extracts spatial features from bi-temporal images. These features are fused using a temporal transformer head that integrates masked cross-attention guided by a learnable mask query. The final decoder upsamples the fused features to generate change maps. SSLCD [38] is also a combined idea of MAE and CL for change detection. It uses a three-branch encoder to extract features from multi-temporal images and enforces feature invariance and temporal consistency through contrastive-style losses. To extend MAE to the temporal domain, a self/cross-reconstruction (SCR) module is proposed, where missing regions in one image are reconstructed using both its own and the other temporal image.
Table 2.
Current SSL Methods in RS building change detection.(MIM: masked image modeling, SKD: self knowledge distillation, CL: Contrastive learning).
While existing SSL-based BCD methods have made considerable progress, they still face several limitations. For example, RECM integrates multi-modal data (RGB + DSM) and multiple SSL strategies, but its dependency on DSM data limits applicability in areas lacking such auxiliary information. In contrast, methods such as ST-CRL and SSLCD utilize only RGB data and adopt CL and MIM. However, none of these works explore the potential of denoising autoencoding, which can enhance feature learning by reconstructing missing image regions and reducing noise sensitivity. Moreover, no prior studies systematically compare its effectiveness against other SSL strategies for BCD tasks.
To address these limitations, we propose DAEDFN, which is a novel SSL framework based solely on bi-temporal RGB data. Our method integrates denoising reconstruction strategies with CL to jointly capture fine-grained semantic structures and temporal differences.
2.3. Architectural Advances in Building Change Detection and Damage Assessment
2.3.1. Residual Network
Residual Network (ResNet) has been widely used in building change detection due to its ability to extract deep features [39]. The residual connections could help mitigate potential vanishing gradient problems, allowing deeper networks to learn more complex representations [39]. In change detection, ResNet serves as a powerful backbone for encoding spatial and spectral differences between pre- and post-event images, improving the model’s ability to capture building changes. Many state-of-the-art change detection models leverage ResNet variants (e.g., ResNet-34, ResNet-50) for feature extraction stages [40,41].
2.3.2. Feature Pyramid Network
Feature Pyramid Network (FPN) could enhance building segmentation and change detection by capturing and fusing multi-scale features [42,43], which is crucial for detecting buildings of varying sizes and levels of damage. FPN builds a hierarchical representation by combining low- and high-resolution feature maps, improving the accuracy of segmentation-based building change detection models [44,45,46,47].
2.3.3. Vision Transformer
Vision Transformer (ViT) has recently gained attention in building change detection due to the ability to model long-distance dependencies and global context through self-attention mechanisms [9]. In building change detection, Transformer-based models, such as Swin Transformer and ViT [47,48], are increasingly integrated into detection frameworks to improve model robustness.
2.3.4. Edge Detection
Edge detection plays a critical role in accurately delineating building boundaries [49], which could serve as important prior information for change detection before and after disaster events. Traditional edge detection operators (e.g., Sobel, Canny, and Laplacian operators) help preprocess images to enhance building structure details [50]. In building change detection, edge-aware models improve the localization of buildings and filter out false positives caused by irrelevant changes [26].
3. Materials and Methods
3.1. Datasets
The experiments are conducted on five widely used benchmark datasets for building damage assessment and change detection tasks: xBD, LEVIR, LEVIR+, SYSU-CD, and WHU-CD. The xBD dataset, provided by Carnegie Mellon University and the Defense Innovation Unit, USA [23], is the largest publicly available dataset for building damage assessment. It includes 850,736 annotated buildings spanning a total area of 45,362 square kilometers. Image resolution of the dataset is 0.8 meters. Building annotations are categorized into four damage levels: no damage, minor damage, major damage, and destroyed. In this study, the xBD training set is used for self-supervised pretraining and the supervised building damage assessment task.
The LEVIR dataset [51] contains 637 pairs of Google Earth image patches, each with a high resolution of 0.5 m/pixel and a size of 1024 × 1024 pixels. These images were collected from 20 different regions in various cities across TX, USA, between 2002 and 2018. This dataset includes diverse building types such as villas, high-rise apartments, small garages, and large warehouses. In this study, it is used for the building change detection task.
The LEVIR+ dataset is an extension of the LEVIR-CD dataset [52]. It includes over 985 very high-resolution (0.5 m/pixel) bitemporal GE images with dimensions of 1024 × 1024 pixels. These images were captured from 20 different regions located in various cities across TX and span a time period ranging from 2002 to 2020. LEVIR+ is used for the building change detection task in this study.
The SYSU CD dataset [53] is a category-agnostic CD dataset, which introduces a comprehensive collection of 20,000 pairs of 0.5 meter/pixel resolution aerial images from Hong Kong, spanning 2007 to 2014, to advance the field of CD. This dataset is distinguished by its focus on urban and coastal changes, featuring high-rise buildings and infrastructure developments, where CD poses significant challenges due to shadow and deviation effects. In this study, the SYSU CD dataset is used in building the change detection task.
The WHU-CD dataset [54], a subset of the larger WHU Building dataset, is tailored for the building CD task. It comprises two aerial datasets from Christchurch, New Zealand, captured in April 2012 and 2016, with a spatial resolution of 0.3 meters/pixel. This dataset is particularly focused on detecting changes in large and sparse building structures. The aerial images captured in 2012 cover an area of 20.5 km2, featuring 12,796 buildings, while the image captured in 2016 shows an increase to 16,077 buildings within the same area, reflecting significant urban development over the four-year period. The dataset follows an official split into training (21,243 × 15,354) and testing (11,265 × 15,354) areas. In this study, WHU is used for the building change detection task.
In this study, the multitemporal image pairs and associated labels of all datasets are cropped to 224 × 224 pixels for input to the network. We also divide the datasets into training and test sets using an 80%/20% ratio. For few-shot experiments (e.g., 5% and 10% settings), we randomly sample the specified proportion from the training set while keeping the test sets fixed.
3.2. Problem Statement
3.2.1. SSL Pretraining
In the context of SSL using a dual DAE, the model aims to learn feature representations by reconstructing clean images from noisy inputs. The pretraining process can be formulated as follows:
where and are pre-event and post-event, is the original clean input, represents the noisy input, E is the encoding function that extracts latent representations, D is the decoding function that reconstructs the clean images, and is the reconstructed output.
The objective is to minimize the reconstruction error while ensuring the decoder D also constrains the dissimilarity between pre-event and post-event image pairs. This pretraining step allows the encoder to extract meaningful latent features, which are later frozen or fine-tuned for downstream tasks.
3.2.2. Building Change Detection Task
Binary change detection focuses on identifying where changes happen between bi-temporal images. It can be formally defined as
where , and are pre-event and post-event images, respectively; is the building change mask for the , pair.
In this task, the decoder of the pre-trained DAE is replaced with a task-specific segmentation head. The latent representation extracted from the encoder is used to predict the change mask:
where represents the segmentation head, is the predicted segmentation mask.
3.2.3. Building Damage Assessment Task
Building damage assessment extends binary change detection by identifying both the location and the severity of building damage. This can be considered a one-to-many semantic change detection task [4]. It is defined as
where is the building mask at , and is the post-disaster damage level of the building at , where is the number of damage classes.
For this task, we add two task-specific heads: a segmentation head for localization and a classification head for damage severity prediction. The formulation is as follows:
where and represent the segmentation head and classification head, is the predicted segmentation mask, and is the predicted damage severity level.
3.3. Image Reconstruction Strategy Comparison
Masked image reconstruction randomly masks patches in an image and learning to generate the original one [19], thus enabling the representation of images from unlabeled data. Meanwhile, there are works that utilize self-supervised pretraining to improve image denoising [55,56], and some studies have proposed hybrid approaches that unify masked and denoising strategies for representation learning [57]. However, to the best of our knowledge, no prior work has systematically compared these two strategies in terms of their effectiveness for RS image reconstruction. Given that RS images contain complex object environments and changes, evaluating their reconstruction performance is essential.
In this study, we compare denoising and masked reconstruction strategies using generative evaluation metrics, namely PSNR and SSIM [58]. Based on this analysis, we determine the most suitable strategy for constructing our SSL framework.
3.4. Overview of DAE-Enhanced Dual-Fusion Network
The proposed method consists of three key stages (Figure 2): Self-Supervised Pretraining, Supervised Building Damage Assessment, and Supervised Building Change Detection. This framework integrates self-supervised feature extraction with fine-tuning for both building change detection and building damage assessment tasks. Our proposed method consists of three stages: Stage A (self-supervised pretraining), Stage B1, and Stage B2 (two downstream tasks). Stage A serves as a shared pretraining phase, where a dual-encoder-decoder model learns spatial and semantic representations. After Stage A, the pretrained encoder is reused in two independent tasks (B1 and B2), each trained with task-specific supervision.
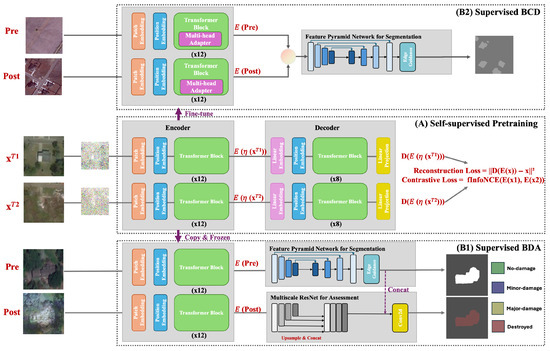
Figure 2.
Overview of our DAEDFN method. (A) Self-Supervised Pretraining: The encoder-decoder architecture learns feature representations using reconstruction loss and contrastive InfoNCE loss from distorted input pairs. (B1) Supervised Building Damage Assessment: The pretrained and frozen encoder extracts features from pre-event and post-event images, which are processed through a dual decoder for damage assessment. (B2) Supervised Building Change Detection: The pretrained encoder is fine-tuned using multi-head adapters integrated into the Transformer blocks, enhancing the segmentation results via the FPN decoder.
- Stage A: Self-Supervised Pretraining Integrating Unified Denoising and Contrastive LearningIn this stage, distorted bi-temporal input pairs are passed through a dual encoder–decoder structure. The model learns visual representations using a combination of reconstruction loss (recovering clean images) and contrastive InfoNCE loss (aligning latent embeddings). This ensures the encoder effectively captures spatial features and semantic differences across bi-temporal images.
- Stage B1: Supervised Building Damage Assessment using Multi-task LearningThe pretrained encoder is frozen and utilized for supervised building damage assessment. The encoder features are processed through a dual decoder consisting of an FPN for building segmentation and a multi-scale ResNet for predicting damage severity levels. This generates both segmentation masks for building localization and post-event damage maps for each pixel.
- Stage B2: Supervised Building Change Detection with Transfer LearningIn this stage, the Transformer blocks in the pretrained encoder are fine-tuned, followed by multi-head adapters for extracting features from pre-event and post-event images, which are further concatenated and processed using an FPN for generating high-quality change detection masks.This unified approach effectively combines self-supervised learning for feature extraction and transfer learning for task-specific fine-tuning, enabling competitive performance across building change detection and damage assessment tasks.
3.5. Self-Supervised Pretraining Integrating Unified Denoising and Contrastive Learning
3.5.1. Network Architecture
The self-supervised pretraining framework is illustrated in Figure 2A. It follows a structure inspired by MAE [19], but instead employs a denoising strategy [59] instead of a masked image modeling strategy. The proposed pretraining framework consists of two key components: the denoising strategy and a dual DAE with a ViT backbone.
First, Gaussian noise is generated from a normal distribution and added to both the pre-event and post-event images. This distortion disrupts the semantic content of the inputs, forcing the network to learn meaningful representations by reconstructing the clean images.
The dual DAE model consists of an encoder-decoder architecture, both based on the ViT base model. The encoder comprises 12 transformer blocks, which map noisy inputs into latent representations. The decoder includes eight transformer blocks followed by a final linear projection layer, which reconstructs the original clean images. During training, the distorted bi-temporal inputs (, ) are passed through the dual DAE to recover the clean pre-event and post-event images.
3.5.2. Loss Functions
The self-supervised pretraining phase optimizes a combined loss function consisting of a Mean Squared Error (MSE) loss and a contrastive InfoNCE loss [60]:
Here, the MSE loss is calculated between the reconstructed images and the original input patches, encouraging the model to accurately reconstruct the input data. The contrastive InfoNCE loss ensures the model aligns the latent representations of pre-event and post-event images while distinguishing them from unrelated samples. It is defined as
where is the temperature parameter, and B is defined as
Here, and are the latent representations of pre-event and post-event images and , respectively. is the cosine similarity, defined as
The contrastive loss ensures that the representations of corresponding pre-event and post-event images are pulled together, while unrelated samples are pushed apart. This alignment allows the encoder to learn discriminative features that highlight subtle differences between pre- and post-disaster inputs.
3.6. Supervised Building Damage Assessment Using Multi-Task Learning
Figure 2(B1) shows the network architecture for building damage assessment task. This multi-task network consists of a frozen dual DAE encoder, a two-branch FPN-ResNet decoder, and an Edge Guidance Module (EGM). It is designed to predict building localization and damage severity simultaneously.
First, the pretrained DAE encoder is frozen for latent image representation extraction. For building segmentation, the FPN is used to capture pre-disaster building characteristics at multiple spatial resolutions. The EGM, composed by two 1 × 1 convolution layers, enhances the segmentation results by emphasizing edge information. For building damage assessment, multi-level features of post-disaster images are extracted using a ResNet-50 backbone, upsampled, and concatenated with the pre-event edge map. A final classification head outputs a multi-class damage severity map.
To supervise building segmentation, a combined Focal-Dice loss is employed:
where handles class imbalance [61], measures the overlap alignment [62].
For building edge and mask predictions, the combined loss can be extended as
where , and . After experiments, we set w to 0.5 for balancing edge and mask detections.
For damage severity classification, the loss is cross-entropy loss:
The final loss for the BDA task is
3.7. Supervised Building Change Detection with Transfer Learning
Figure 2(B2) shows the network tailored to building change detection with binary segmentation only. Similarly, pre-event and post-event images are first fed into the dual DAE encoder, where multi-head adapters are integrated into each Transformer block to fine-tune features. After feature extraction, latent features from pre-event and post-event images are compared with compute a difference map. Finally, the EGM refines the output by producing edge maps and segmentation masks for precise boundary detection.
Similar to the BDA task, a customized combined Focal-Dice loss supervises the segmentation and edge predictions:
Here, and are applied to edge maps, and and are applied to segmentation masks. After experiments, we set w to 0.5 for balancing edge and mask detections.
The ground truth edge map Edge is computed using the Sobel operator [63]:
where and are the image gradients along the horizontal and vertical directions, respectively.
3.8. Evaluation Metrics
The evaluation of our method is based on the F1 Score (F1), a metric that balances precision and recall using their harmonic mean. The F1 Score is defined as
In which,
where TP represents true positives and FN denotes false negatives.
with FP standing for false positives.
Specifically, F1 Score for building localization is known as ), and F1 Score for different damage severity classes is known as ), F1 Score for damage severity classification is known as ). In the xBD dataset, 1 to 4 are “no damage”, “minor damage”, “major damage”, and “destroyed”, respectively.
In addition to the F1 Score, we also evaluate our method using the Intersection over Union (IoU), a widely adopted metric for measuring the overlap between predicted and ground truth regions. The IoU is defined as:
where TP denotes true positives, FP false positives, and FN false negatives. A higher IoU indicates better spatial agreement between predictions and ground truth.
We chose to use the F1 score and IoU as the sole evaluation metric in this study to maintain consistency with the previous work [3] we compared against. This ensures a fair comparison of results.
3.9. Experimental Setup
The proposed architectures are implemented in PyTorch [64]. The bi-temporal image pairs and associated labels are resized to 224 × 224 pixels before input to the network. During SSL pretraining, the Adam optimizer is employed with an initial learning rate of scheduled using ReduceLROnPlateau and a weight decay of . The batch size is set to 32, and data augmentation techniques, including random flip, color jitter, random grayscale, and Gaussian blur, are applied to improve generalization. The xBD training set serves as the pretraining dataset.
For downstream tasks, all experimental settings remain the same except for the learning rate, which is adjusted to . To address class imbalance, we randomly sampled xBD training sets of size n = 200,000 and testing sets of size n = 20,000 [3]. The same data augmentation methods are applied to ensure robustness in downstream training for both building change detection and building damage assessment. For both training and inference, we used an NVIDIA TITAN RTX GPU (NVIDIA Corporation, Santa Clara, CA, USA) featuring 24 GB of memory, with CUDA 12.2.
4. Results
4.1. Remote Sensing Imagery Reconstruction Ability
Before model construction, this study first evaluates the RS image reconstruction performance of denoising and masked strategies (masking ratio = 0.50) on the xBD dataset using Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) metrics. Both metrics measure the quality of reconstructed images compared with the originals, with higher values indicating better fidelity and less distortion. Table 3 demonstrates that the denoising strategy achieves significantly better results, achieving a PSNR of 20.21 and an SSIM of 0.90, compared with 7.04 and 0.63, respectively, for the masked strategy. This trend is consistent on the LEVIR dataset; the denoising strategy achieves a PSNR of 14.70 and SSIM of 0.81, outperforming the masked strategy (PSNR = 6.73, SSIM = 0.61). The visual comparison between the denoising and masked reconstructions in Figure 3 also reveals notable differences in reconstruction quality. The DAE produces sharper and more coherent images, preserving structural details such as building edges and roof textures. In contrast, the MAE outputs appear significantly more blurred, with noticeable block artifacts and a loss of fine details. While DAE maintains natural color continuity and texture fidelity, MAE reconstructions suffer from visual discontinuities and reduced clarity.
Table 3.
Comparison of Reconstruction Ability between Denoising and Masked Strategies on the xBD and LEVIR Dataset.

Figure 3.
Visual Comparison of Two Reconstruction Strategies from xBD Dataset.
The large gap in performance suggests that masked image reconstruction struggles to recover fine-grained structural and semantic details in RS imagery, likely because of the complex spatial-temporal patterns and object scales in RS images [65,66]. In contrast, the denoising strategy effectively reconstructs critical semantic information, making it a more suitable choice for RS image reconstruction. Thus, this study selects the denoising strategy for self-supervised learning method development, tailored to RS data characteristics rather than directly adopting methodologies from the natural image domain.
4.2. Building Damage Assessment
In this study, we evaluated both building segmentation and damage classification tasks.
Building Segmentation: The performance of the proposed method is compared against state-of-the-art approaches for building localization (Table 4). The proposed method achieves the highest F1 score of 0.892, outperforming both BAT [10] (0.882) and ChangeMamba [11] (0.874). The results indicate a trend that SSL methods can effectively learn visual representations, achieving competitive results even compared with fully supervised approaches.
Table 4.
Comparison of methods for building severity assessment on the xBD dataset. (Boldface: best in all methods; underlined: best in SSL methods).
Damage Classification: For damage severity classification, the results are summarized in Table 4. Our proposed DAEDFN demonstrates competitive performance across multiple categories, achieving the second-highest F1 score for the “Minor Damage” category (0.555). Although the scores for “No Damage” (0.631), “Major Damage” (0.594), and “Destroyed” (0.760) are not the highest, they are still robust compared with ST-CRL [3]. While the ST-CRL method achieves a relatively higher overall F1 score of 0.652 compared with our method’s 0.632, its performance across specific damage levels reveals critical limitations for practical damage assessment tasks. Notably, while ST-CRL achieves a higher score in the “No Damage” category (0.838), it shows lower performance across other damage categories. This suggests a tendency to produce false positives and overestimate the number of non-damaged buildings, which may limit its practical applicability for real-world building damage assessment. The ability to accurately detect varying levels of damage severity, such as “Minor,” “Major,” and “Destroyed,” is more critical for assessing post-disaster impacts. Similarly, although the MAE achieves a higher F1 score in “No Damage” (0.820), its performance on the remaining damage levels—”Minor” (0.431), “Major” (0.538), and “Destroyed” (0.695)—is significantly lower compared with our proposed DAEDFN method. This results in a lower overall F1 score (0.5377), suggesting that MAE tends to oversimplify damage categories and struggles with fine-grained classification. In this way, our method demonstrates more balanced performance across these key categories, achieving 0.555, 0.594, and 0.760 for “Minor,” “Major,” and “Destroyed” classes, respectively. This highlights the robustness of our approach in identifying affected buildings with varying degrees of damage.
Figure 4 and Figure 5 include visual examples of building damage assessment maps generated by the proposed SSL architecture on the xBD test dataset. The reference and prediction columns illustrate the model’s ability to accurately identify damaged regions, including boundaries, demonstrating strong visual alignment with the ground truth. Furthermore, visual comparisons show that MAE frequently produces fragmented and inconsistent predictions, especially in complex cases involving partial structural damage. Our DAEDFN model predicts more coherent and accurate damage masks compared with the ground truth. These results highlight the effectiveness of our denoising-based representation learning in encoding fine spatial details.

Figure 4.
Samples of building damage assessment maps obtained by the proposed architecture and MAE on the xBD dataset.

Figure 5.
Samples of building damage assessment maps obtained by the proposed architecture and MAE on the xBD dataset (continued from Figure 4).
4.3. Building Change Detection
The analysis of Table 5, Table 6, Table 7 and Table 8 compares the proposed method with state-of-the-art methods for building change detection (i.e., building localization) across four datasets: LEVIR, LEVIR+, SYSU, and WHU.
Table 5.
Comparison of Methods for building change detection on LEVIR dataset. (Boldface: best in all methods; underlined: best in SSL methods)).
Table 6.
Comparison of Methods in the task of building change detection in LEVIR+ dataset. (Boldface: best in all methods; underlined: best in SSL methods)).
Table 7.
Comparison of Methods in the task of building change detection in SYSU dataset. (Boldface: best in all methods; underlined: best in SSL methods)).
Table 8.
Comparison of methods in the task of building change detection in WHU dataset. (Boldface: best in all methods; underlined: best in SSL methods).
Table 5 shows the compared results on the LEVIR dataset. Our method achieves an F1 score of 0.837, significantly outperforming the MAE baseline (0.700). Although RECM achieves the best overall performance with an F1 score of 0.927, outperforming other methods [20], it relies on multi-modal input (RGB + DSM), while our method operates solely on RGB images, making it more widely applicable in DSM-limited scenarios.
Figure 6 presents visual comparisons between our DAEDFN model and the MAE-based baseline. As highlighted by the red boxes, MAE tends to produce false positives or distorted boundaries in unchanged regions, especially when background textures are complex or illumination conditions vary. In contrast, our model produces more precise change maps that align better with the ground truth. These results illustrate the superior spatial discrimination capability and robustness of our denoising-based SSL design when transferred to change detection tasks.

Figure 6.
Samples of building change detection maps obtained by the proposed architecture and MAE on the LEVIR dataset. Red boxes mark areas where the MAE exhibits noticeable classification errors.
In Table 6, methods for building change detection on the LEVIR+ dataset are compared. Among the methods evaluated, ChangeMamba [11] achieves the highest performance overall with an F1 score of 0.884, while RECM (SSL) [20] achieves the best performance among self-supervised learning methods with an F1 of 0.902. Our DAEDFN method achieves an F1 score of 0.817 and an IoU of 0.738, outperforming MAE (F1 of 0.653 and IoU of 0.558).
Figure 7 presents the building change detection samples obtained by the proposed architecture in the LEVIR+ dataset. In terms of overall performance, the predictions demonstrate good alignment with the ground truth in many cases, particularly in areas where buildings are densely packed and clear boundaries are evident. Compared with the MAE model, which suffers from fragmented predictions, false positives, and shape distortions (highlighted with red boxes), DAEDFN proves more robust for preserving structural integrity in building footprints.

Figure 7.
Samples of building change detection maps obtained by the proposed architecture and MAE on the LEVIR+ dataset. Red boxes mark areas where the MAE exhibits noticeable classification errors.
We further evaluate our method on the SYSU dataset, which presents diverse building morphologies and complex natural environments, such as hilly terrains and shadowed areas. As shown in Table 7, ChangeMamba [11] achieves the highest score (0.831) among all methods, demonstrating its strong performance in detecting building changes. The BIT and SwinSUNet methods also achieve competitive F1 scores (0.815 and 0.816, respectively). Our proposed method has an F1 score of 0.768 and an IoU of 0.662, which outperforms the supervised FC-EF and self-supervised MAE but lags behind the supervised methods. This indicates that the self-supervised approach still struggles to learn generalized fine-grained building changes effectively.
The visual analysis of Figure 8 reveals both strengths and limitations of the proposed architecture. The proposed method is more robust to subtle changes in densely vegetated or mountainous regions, while MAE often suffers from misclassification, such as missing change regions or predicting false positives. These results demonstrate the effectiveness of our architecture in learning semantically meaningful representations under complex visual conditions, particularly when applied to challenging real-world scenarios like those in the SYSU dataset.

Figure 8.
Samples of building change detection maps obtained by the proposed architecture and MAE on the SYSU dataset. Red boxes mark areas where the MAE exhibits noticeable classification errors.
Table 8 compares the results of build change detection in the WHU dataset, highlighting the performance of the fully supervised and SSL-based approaches. ChangeMamba [11] still achieves the highest F1 score (0.942) among all methods, showcasing its strong capability in detecting building changes. This indicates its effectiveness in fully supervised scenarios. RECM(SSL) is not listed here because the method did not show its performance in the WHU dataset. Ours (SSL) achieves an F1 score of 0.876, which is almost equal to most fully supervised models (FC-EF [69], ChangeFormer [67]).
This result highlights the gap between SSL and fully supervised methods in this dataset, suggesting that SSL methods still struggle to reach the performance of models trained with labeled data. Fully supervised methods benefit from extensive labeled data, enabling precise learning of complex building changes, whereas SSL methods rely on unsupervised pretraining, limiting their ability to capture fine-grained differences.
Figure 9 shows building change detection results for the WHU dataset generated by the proposed model. The proposed model captures most of the building changes effectively, with general alignment between the predicted masks and the reference masks, better than MAE. However, our predictions occasionally misidentify changes in regions without actual buildings (e.g., empty fields or non-relevant ground textures). This is particularly visible in rows with large ground patches where predicted masks show artifacts. Furthermore, building edges are sometimes less sharp and deviate slightly from the reference mask, leading to partial misalignments or overly smoothed boundaries.

Figure 9.
Samples of building change detection maps obtained by the proposed architecture and MAE on the WHU dataset. Red boxes mark areas where the MAE exhibits noticeable classification errors.
4.4. Ablation Study
Based on the results presented in Table 9, we can analyze the effectiveness of different modules in our model for the building damage assessment task. First, the results highlight the effectiveness of SSL over supervised learning. Specifically, using SSL with ViT Base and FPN modules yields an F1 localization score of 0.861, significantly higher than the 0.520 achieved with the supervised ViT Base model. The addition of the EGM further boosts the localization score to 0.895, achieving state-of-the-art performance. For the damage severity classification task, the supervised ViT base model combined with ResNet provides a moderate level of classification accuracy. After using our SSL with ViT Base and building the localization branch, the F1 classification score increased to 0.585, indicating that the SSL framework provides valuable visual representations. The addition of the customized loss EDL led to a slight improvement from 0.585 to 0.632. The use of EDL helps refine edge detection, which contributes to better classification outcomes.
Table 9.
Effectiveness of proposed modules on building damage assessment task. A checkmark indicates the presence of the corresponding module in the model configuration.
Furthermore, Table 10 compares the model efficiency of different methods for both Building Change Detection and Building Damage Assessment tasks in terms of trainable parameters and GFLOPs. ChangeMamba [11], the current state-of-the-art supervised learning method, demonstrates competitive performance with relatively low parameter counts (89.99M for change detection and 87.76M for damage assessment). In contrast, both SSL methods, including MAE and our DAEDFN, have significantly higher parameter counts. Notably, in the Building Damage Assessment task, our DAEDFN achieves significantly lower GFLOPs (171.13 vs. 195.43) compared with ChangeMamba. This efficiency benefits from freezing the DAE encoder during the downstream task, which reduces the number of active computations without sacrificing model effectiveness.
Table 10.
Efficiency of Methods.
4.5. Effect of Limited Training Data
To evaluate the robustness of our model under low-data regimes, we conducted additional experiments using 5%, 10%, 25%, 50%, and 100% of the original training dataset. Table 11 presents the model performance across five datasets under varying training set ratios. When using only 10% of the training data, the model retains a substantial proportion of its full-capacity performance, achieving 78.80% on xBD, 62.97% on LEVIR, 71.23% on LEVIR+, 78.39% on SYSU, and 71.15% on WHU, relative to their respective F1 scores using full training data. This suggests that the model generalizes relatively well on these datasets with limited supervision, highlighting its efficiency and robustness in data-scarce scenarios.
Table 11.
DAEDFN Model Performance under different training set ratios.
5. Discussion
5.1. Evaluating Denoising and Masked Strategies in SSL for Change Detection
Despite the increasing popularity of masked modeling strategies such as MAE, we observe that directly reconstructing masked regions in change detection tasks tends to lose fine-grained boundary and texture details (see Figure 4, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9). To address this, we explicitly compare masked denoising with conventional denoising autoencoding in Table 3 and Figure 3. Results indicate that denoising better preserves pixel-level spatial information, enabling more precise change localization, which is particularly beneficial for remote sensing images containing multi-scale objects and complex environments [71]. This finding highlights that, for pixel-sensitive tasks like building change detection, denoising serves as a more effective pretext task than masking. While our SSL method does not surpass supervised approaches such as ChangeMamba or RECM in all metrics, it significantly outperforms MAE and demonstrates cross-dataset generalizability. We hope this work opens new perspectives on designing more spatially aligned SSL pretraining strategies for change detection.
On the other hand, the CL mechanism in our framework enforces semantic consistency, which could bring similar semantic representations closer while pushing dissimilar ones apart [72]. This improves the model’s ability to differentiate between unchanged and changed buildings. The integration of DAE and contrastive learning provides complementary benefits—DAE ensures pixel-level feature representations, while contrastive learning exploits an embedding space where building changes are more distinguishable—extracting relational pixel-level feature representation [73]. For example, the Code-Aligned Autoencoders for Unsupervised Change Detection [73] is a model to align the latent spaces of two autoencoders in a contrastive learning manner, and this synergy enhances the model’s performance in change detection and the model’s generalization in multispectral and multipolarization images.
5.2. Limitations
The experiments presented in Table 4 and Table 9 show significant improvements in building localization and damage severity classification performance using SSL. The marginal improvement observed with the addition of EGM and EDL (in Table 9) suggests that building boundary information does contribute positively to building-related tasks.
However, as seen in Table 4, supervised methods (e.g., ChangeMamba [11]) generally achieve higher and more stable scores in damage severity classification. A closer look at Figure 10 reveals some misclassifications, where the model predicts mixed “Minor” and “Major” damage categories instead of the ground truth “Destroyed” class. This indicates a misalignment between the pretrained visual representations and the semantic damage information.

Figure 10.
Bad cases of building damage assessment maps obtained by the proposed architecture on the xBD dataset.
Similar observations have been seen by RECM [20], where SSL performs well for binary change detection tasks (e.g., LEVIR-CD [51]) but struggles with more complex semantic segmentation datasets like xBD and Landcover [74]. To address this, hard negative sampling [75] could be explored as a future direction. Hard negative sampling encourages the model to focus on the most challenging negative samples within a batch, enhancing its ability to learn discriminative features. Furthermore, unsupervised single-temporal change adaptation [76] is also a domain-adaptive transfer learning method to improve model effectiveness and computational efficiency.
Furthermore, Table 4 shows that ST-CRL performs well in detecting No Damage cases, achieving an accuracy of 0.858. However, our proposed DAEDFN model demonstrates superior performance in detecting damaged buildings, particularly in the Minor (0.555), Major (0.594), and Destroyed (0.760) categories. In the context of damage assessment, accurately identifying damaged buildings is more critical than overestimating undamaged structures. Our model prioritizes detecting affected buildings, which is essential for post-disaster response and resource allocation.
Across the four building change detection datasets (LEVIR, LEVIR+, SYSU-CD, and WHU), the proposed SSL method achieves competitive results but does not outperform fully supervised methods such as ChangeMamba [11] and TransUNetCD [68]. The method shows a relative weakness in regions with dense vegetation, shadows, or small-scale structures, where fine-grained changes and building boundaries remain challenging to detect. These limitations reveal the need for further research in complex environments and precise boundary delineation.
In this study, we mainly conduct evaluations on high-quality, fully labeled public datasets, which provide a standardized setting for benchmarking and comparative analysis. However, these datasets may not fully capture the complexities and uncertainties encountered in real-world applications, such as image noise or distribution shifts across geographic regions and different sensor types. As a result, further investigation is needed to assess the model’s robustness under more practical satellite images, including Landsat-8, Sentinel-2, etc.
6. Conclusions
In this study, we proposed a self-supervised pretraining framework that unifies DAE with contrastive learning for building change detection and damage assessment in optical remote sensing image pairs. Our experiments on the xBD dataset demonstrate that the proposed method achieves an F1 score of 0.892 in building localization and an F1 score of 0.632 in building damage severity assessment. Additionally, the model demonstrates competitive performance across four building change detection datasets. Notably, incorporating edge guidance and edge detection loss contributes positively to model accuracy, particularly for building boundary refinement. While the proposed SSL approach achieves promising results, challenges remain in handling complex damage assessment tasks and fine-grained building change detection. We anticipate that visual representation learning, combined with feature discrimination strategies, could play a more significant role in GeoAI for remote sensing tasks.
Author Contributions
Conceptualization, S.Y. and Q.H.; methodology, S.Y. and B.P.; software, S.Y.; validation, S.Y., B.P., T.S., M.W., and Q.H.; formal analysis, S.Y. and Q.H.; investigation, S.Y. and B.P.; resources, S.Y.; data curation, S.Y.; writing—original draft preparation, S.Y. and Q.H.; writing—review and editing, S.Y., M.W., and Q.H.; visualization, S.Y.; supervision, Q.H.; project administration, Q.H.; funding acquisition, Q.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the United States Department of Agriculture (USDA) National Institute of Food and Agriculture, Agriculture and Food Research Initiative Foundational Program (Award No. 2022-67021-36468). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the funders.
Informed Consent Statement
Not applicable.
Data Availability Statement
Datasets used in this study are public available data.
Conflicts of Interest
Author Bo Peng was employed by the company PAII. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Chen, J.; Hou, D.; He, C.; Liu, Y.; Guo, Y.; Yang, B. Change Detection with Cross-Domain Remote Sensing Images: A Systematic Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 11563–11582. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, L.; Du, B.; Chen, H.; Wang, J.; Zhong, H. UNet-Like Remote Sensing Change Detection: A review of current models and research directions. IEEE Geosci. Remote Sens. Mag. 2024, 12, 305–334. [Google Scholar] [CrossRef]
- Peng, B.; Huang, Q.; Rao, J. Spatiotemporal contrastive representation learning for building damage classification. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 8562–8565. [Google Scholar]
- Toker, A.; Kondmann, L.; Weber, M.; Eisenberger, M.; Camero, A.; Hu, J.; Hoderlein, A.P.; Şenaras, Ç.; Davis, T.; Cremers, D.; et al. Dynamicearthnet: Daily multi-spectral satellite dataset for semantic change segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21158–21167. [Google Scholar]
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A.; Zhang, L. Building damage assessment for rapid disaster response with a deep object-based semantic change detection framework: From natural disasters to man-made disasters. Remote Sens. Environ. 2021, 265, 112636. [Google Scholar] [CrossRef]
- Li, Y.C.; Lei, S.; Liu, N.; Li, H.C.; Du, Q. IDA-SiamNet: Interactive-and Dynamic-Aware Siamese Network for Building Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5628213. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607514. [Google Scholar] [CrossRef]
- Mei, J.; Zheng, Y.B.; Cheng, M.M. D2ANet: Difference-aware attention network for multi-level change detection from satellite imagery. Comput. Vis. Media 2023, 9, 563–579. [Google Scholar] [CrossRef]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Lu, W.; Wei, L.; Nguyen, M. Bi-temporal attention transformer for building change detection and building damage assessment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4917–4935. [Google Scholar] [CrossRef]
- Chen, H.; Song, J.; Han, C.; Xia, J.; Yokoya, N. Changemamba: Remote sensing change detection with spatio-temporal state space model. arXiv 2024, arXiv:2404.03425. [Google Scholar]
- Wang, Y.; Albrecht, C.M.; Braham, N.A.A.; Mou, L.; Zhu, X.X. Self-supervised learning in remote sensing: A review. IEEE Geosci. Remote Sens. Mag. 2022, 10, 213–247. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; PMLR. pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, X.; Xie, S.; He, K. An empirical study of training self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 9640–9649. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 9650–9660. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Zhang, Y.; Zhao, Y.; Dong, Y.; Du, B. Self-supervised pretraining via multimodality images with transformer for change detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5402711. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Han, W.; Chen, J.; Wang, L.; Feng, R.; Li, F.; Wu, L.; Tian, T.; Yan, J. Methods for small, weak object detection in optical high-resolution remote sensing images: A survey of advances and challenges. IEEE Geosci. Remote Sens. Mag. 2021, 9, 8–34. [Google Scholar] [CrossRef]
- Gupta, R.; Goodman, B.; Patel, N.; Hosfelt, R.; Sajeev, S.; Heim, E.; Doshi, J.; Lucas, K.; Choset, H.; Gaston, M. Creating xBD: A dataset for assessing building damage from satellite imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 10–17. [Google Scholar]
- Song, K.; Jiang, J. AGCDetNet: An attention-guided network for building change detection in high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4816–4831. [Google Scholar] [CrossRef]
- Shen, Y.; Zhu, S.; Yang, T.; Chen, C.; Pan, D.; Chen, J.; Xiao, L.; Du, Q. Bdanet: Multiscale convolutional neural network with cross-directional attention for building damage assessment from satellite images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5402114. [Google Scholar] [CrossRef]
- Bai, B.; Fu, W.; Lu, T.; Li, S. Edge-guided recurrent convolutional neural network for multitemporal remote sensing image building change detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5610613. [Google Scholar] [CrossRef]
- Chen, H.; Nemni, E.; Vallecorsa, S.; Li, X.; Wu, C.; Bromley, L. Dual-tasks siamese transformer framework for building damage assessment. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 1600–1603. [Google Scholar]
- Cui, Y.; Chen, H.; Dong, S.; Wang, G.; Zhuang, Y. U-Shaped CNN-ViT Siamese Network With Learnable Mask Guidance for Remote Sensing Building Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 11402–11418. [Google Scholar] [CrossRef]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv 2024, arXiv:2401.09417. [Google Scholar]
- Wang, C.; Zhao, D.; Qi, X.; Liu, Z.; Shi, Z. A hierarchical decoder architecture for multilevel fine-grained disaster detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5607114. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Zhao, J.; Ma, A.; Zhang, L. Unifying remote sensing change detection via deep probabilistic change models: From principles, models to applications. ISPRS J. Photogramm. Remote Sens. 2024, 215, 239–255. [Google Scholar] [CrossRef]
- Zhao, Z.; Wang, F.; Chen, S.; Wang, H.; Cheng, G. Deep object segmentation and classification networks for building damage detection using the xBD dataset. Int. J. Digit. Earth 2024, 17, 2302577. [Google Scholar] [CrossRef]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Tobler, W. On the first law of geography: A reply. Ann. Assoc. Am. Geogr. 2004, 94, 304–310. [Google Scholar] [CrossRef]
- Feng, W.; Guan, F.; Tu, J.; Sun, C.; Xu, W. Detection of changes in buildings in remote sensing images via self-supervised contrastive pre-training and historical geographic information system vector maps. Remote Sens. 2023, 15, 5670. [Google Scholar] [CrossRef]
- Wan, L.; Xiang, Y.; Kang, W.; Ma, L. A Self-Supervised Learning Pretraining Framework for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5630116. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, J.; Pan, B.; Zhang, Y.; Liu, Z.; Zheng, X. Building change detection in remote sensing images based on dual multi-scale attention. Remote Sens. 2022, 14, 5405. [Google Scholar] [CrossRef]
- Alsabhan, W.; Alotaiby, T. Automatic building extraction on satellite images using Unet and ResNet50. Comput. Intell. Neurosci. 2022, 2022, 5008854. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Yang, M.; Jiao, L.; Liu, F.; Hou, B.; Yang, S.; Jian, M. DPFL-Nets: Deep pyramid feature learning networks for multiscale change detection. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6402–6416. [Google Scholar] [CrossRef]
- Gao, S.; Li, W.; Sun, K.; Wei, J.; Chen, Y.; Wang, X. Built-up area change detection using multi-task network with object-level refinement. Remote Sens. 2022, 14, 957. [Google Scholar] [CrossRef]
- He, H.; Chen, Y.; Li, M.; Chen, Q. ForkNet: Strong semantic feature representation and subregion supervision for accurate remote sensing change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2142–2153. [Google Scholar] [CrossRef]
- Chen, P.; Zhang, B.; Hong, D.; Chen, Z.; Yang, X.; Li, B. FCCDN: Feature constraint network for VHR image change detection. ISPRS J. Photogramm. Remote Sens. 2022, 187, 101–119. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Jiao, L.; Li, L.; Liu, F.; Yang, S.; Hou, B. MutSimNet: Mutually reinforcing similarity learning for RS image change detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4403613. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SwinSUNet: Pure transformer network for remote sensing image change detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5224713. [Google Scholar] [CrossRef]
- Wen, X.; Li, X.; Han, W.; Li, E.; Liu, W.; Zhang, L.; Zhu, Y.; Wang, S.; Hao, S. A Building Shape Vectorization Hierarchy From VHR Remote Sensing Imagery Combined DCNNs-Based Edge Detection and PCA-Based Corner Extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 750–761. [Google Scholar] [CrossRef]
- Dharampal, V.M. Methods of image edge detection: A review. J. Electr. Electron. Syst 2015, 4, 2332-0796. [Google Scholar]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Shen, L.; Lu, Y.; Chen, H.; Wei, H.; Xie, D.; Yue, J.; Chen, R.; Lv, S.; Jiang, B. S2Looking: A satellite side-looking dataset for building change detection. Remote Sens. 2021, 13, 5094. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5604816. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Batson, J.; Royer, L. Noise2self: Blind denoising by self-supervision. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR. pp. 524–533. [Google Scholar]
- Xie, Y.; Wang, Z.; Ji, S. Noise2same: Optimizing a self-supervised bound for image denoising. Adv. Neural Inf. Process. Syst. 2020, 33, 20320–20330. [Google Scholar]
- Wu, Q.; Ye, H.; Gu, Y.; Zhang, H.; Wang, L.; He, D. Denoising masked autoencoders help robust classification. arXiv 2022, arXiv:2210.06983. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 IEEE 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Proceedings of the Deep Learning in Medical Image Analysis 2017, Québec City, QC, Canada, 14 September 2017; Proceedings 3. Springer: Berlin/Heidelberg, Germany, 2017; pp. 240–248. [Google Scholar]
- Kanopoulos, N.; Vasanthavada, N.; Baker, R.L. Design of an image edge detection filter using the Sobel operator. IEEE J. Solid-State Circuits 1988, 23, 358–367. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS Workshop, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Goetz, A.F.; Vane, G.; Solomon, J.E.; Rock, B.N. Imaging spectrometry for earth remote sensing. Science 1985, 228, 1147–1153. [Google Scholar] [CrossRef] [PubMed]
- Woodcock, C.E.; Strahler, A.H. The factor of scale in remote sensing. Remote Sens. Environ. 1987, 21, 311–332. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. A transformer-based siamese network for change detection. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 207–210. [Google Scholar]
- Li, Q.; Zhong, R.; Du, X.; Du, Y. TransUNetCD: A hybrid transformer network for change detection in optical remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5622519. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Chen, H.; Wu, C.; Du, B.; Zhang, L.; Wang, L. Change detection in multisource VHR images via deep siamese convolutional multiple-layers recurrent neural network. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2848–2864. [Google Scholar] [CrossRef]
- Liang, P.; Shi, W.; Zhang, X. Remote sensing image classification based on stacked denoising autoencoder. Remote Sens. 2017, 10, 16. [Google Scholar] [CrossRef]
- Mall, U.; Hariharan, B.; Bala, K. Change-aware sampling and contrastive learning for satellite images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5261–5270. [Google Scholar]
- Luppino, L.T.; Hansen, M.A.; Kampffmeyer, M.; Bianchi, F.M.; Moser, G.; Jenssen, R.; Anfinsen, S.N. Code-aligned autoencoders for unsupervised change detection in multimodal remote sensing images. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 60–72. [Google Scholar] [CrossRef] [PubMed]
- Boguszewski, A.; Batorski, D.; Ziemba-Jankowska, N.; Dziedzic, T.; Zambrzycka, A. LandCover.ai: Dataset for automatic mapping of buildings, woodlands, water and roads from aerial imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1102–1110. [Google Scholar]
- Robinson, J.; Chuang, C.Y.; Sra, S.; Jegelka, S. Contrastive learning with hard negative samples. arXiv 2020, arXiv:2010.04592. [Google Scholar]
- Zheng, Z.; Zhong, Y.; Zhang, L.; Burke, M.; Lobell, D.B.; Ermon, S. Towards transferable building damage assessment via unsupervised single-temporal change adaptation. Remote Sens. Environ. 2024, 315, 114416. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).