1. Introduction
With the rapid advancement of unmanned aerial vehicle (UAV) technology, the paradigms and technical pathways of modern agricultural production have been profoundly restructured [
1,
2]. Plant protection UAVs, characterized by exceptional maneuverability and a broad aerial perspective, have overcome operational bottlenecks associated with complex terrains—including plains, hills, and mountainous regions—and have significantly enhanced the flexibility and efficiency of crop protection operations. By alleviating rural labor shortages and mitigating pesticide overuse, the large-scale deployment of UAV platforms also signifies an evolution in the precision-agriculture technology framework, opening new avenues for the efficient utilization of agricultural resources and the sustainable management of ecosystems. As a result, the construction and comprehensive development of integrated rural systems have been powerfully advanced [
3,
4,
5,
6].
In UAV-driven precision-agriculture systems, the formulation of an effective path planning strategy is paramount to harmonizing the “perception–decision–action” pipeline. Fundamentally, this challenge entails not only achieving comprehensive spatial coverage but also deeply integrating the time-varying characteristics of the agricultural environment with the dynamic requirements of field tasks [
7,
8]. To date, two primary categories of planning methods have been employed. The first comprises classical approaches—such as heuristic-based A* search [
9], population-inspired genetic and particle-swarm algorithms [
10], and sampling-based rapidly exploring random trees [
11]—which generally excel in simple, well-defined scenarios but suffer from high computational complexity and limited adaptability when environmental conditions, targets, or obstacles change, necessitating full replanning. The second category encompasses machine-learning techniques, notably Deep Q-Networks (DQN) [
12] leveraging experience replay and policy gradient methods such as Proximal Policy Optimization (PPO) [
13]. In the context of agriculture—where environments are complex and constraints are numerous—traditional algorithms often struggle to accommodate all operational factors, whereas deep reinforcement-learning (DRL) algorithms, by virtue of their capacity for autonomous representation of high-dimensional state spaces and end-to-end decision optimization, are emerging as a promising avenue for overcoming the limitations of conventional path planning solutions.
In recent years, a variety of advanced path planning approaches have been developed for coverage tasks in agricultural and orchard environments. Zhang et al. proposed a method based on an improved A* algorithm for orchard-weeding robots [
14], in which a weighted heuristic cost function and an additional turning-angle penalty were introduced to optimize coverage-path planning. Wu et al. developed an enhanced genetic algorithm incorporating simulated-annealing-inspired stretch-fitness evaluation tailored for complete coverage path planning [
15], the hyperbolic-tangent activation function from neural networks, and fireworks-algorithm operators to mitigate early-stage premature convergence and bolster global search capabilities. Kong et al. presented B-APFDQN [
16], a UAV-based coverage-path planning algorithm that fuses DQN learning with an artificial potential field (APF). In this approach, APF-derived priors are used to curtail blind exploration during training, and a novel network architecture simultaneously outputs both Q-values and action-distribution probabilities, thereby accelerating convergence. Zhou et al. introduced a robot-coverage strategy grounded in DRL [
17], employing a DDQN with prioritized experience replay (PER) and incorporating a blockage-and-blind-area (BBA) mechanism to guide exploration toward unvisited regions. Lin et al. designed a collision-free coverage method for guava-picking robots by combining a recurrent neural network (RNN) with an enhanced deep deterministic policy gradient (DDPG) algorithm to predict safe trajectories in unknown states [
18]. Finally, Ahmad et al. proposed a DRL-based coverage scheme for precision crop-health monitoring in smart agriculture, in which a centralized convolutional neural network (CNN) is integrated with DDQN. A bespoke reward function was devised to incentivize visits to high-value, uninspected areas while penalizing suboptimal actions [
19].
Despite the considerable progress made in UAV path planning research, existing approaches still exhibit limited applicability in agricultural scenarios. Many current methods tend to oversimplify farmland as homogeneous areas and focus on global traversal optimization, which fails to meet the integrated demands of precision agriculture in terms of operational accuracy, resource efficiency, and ecological sustainability. On the one hand, prevailing strategies often overlook critical factors such as variations in cropping patterns, spatial heterogeneity of pest and disease distribution, and dynamic changes in UAV payloads. This omission restricts both the precision of pesticide application and the overall energy efficiency. On the other hand, the singular pursuit of globally optimal paths may result in issues such as redundant pesticide application, energy waste, and contamination of ecologically sensitive zones, thereby making it difficult to balance increased agricultural output with environmental sustainability.
To address these challenges, Mukhamediev et al. proposed a genetic algorithm-based heterogeneous UAV swarm coverage planning method [
7], which targets irregular farmland operations by jointly optimizing UAV selection, flight route design, and ground platform scheduling, significantly reducing overall system costs. Syed et al. focused on semi-structured orchard environments and developed an improved YOLOv8-CNN model integrating Ghost modules and a SE attention mechanism [
20], enabling efficient classification of real versus false obstacles and enhancing the safety and decision-making efficiency of autonomous navigation. In another study, Li et al. addressed multi-region fertilization tasks in large and complex farmland by proposing a path planning method based on an enhanced Double Deep Q-Learning algorithm [
21]. By utilizing GEE-GNDVI to extract nitrogen stress distribution and construct multi-region task maps, the approach effectively enabled intelligent optimization of fertilization paths. These studies underscore the inherent complexity and specificity of agricultural environments and offer valuable insights for improving UAV path planning strategies tailored to the needs of precision agriculture.
To address these limitations, a hierarchical coverage path planning (H-CPP) framework is proposed in this study, whereby adaptability to agricultural environments is enhanced via a two-tier optimization structure. Using satellite-derived organic-matter indices, croplands are first subdivided into graded subzones; high-risk areas are then prioritized for scheduling. Concurrently, dynamic energy consumption constraints and a hybrid-expert architecture are integrated to further improve coverage efficiency.
The principal contributions of this study are summarized as follows:
1. To address the limited policy generalization capability of the D3QN algorithm caused by insufficient representational power in complex and dynamic environments, an improved deep reinforcement learning algorithm, termed MoE-D3QN, is proposed in this study. The algorithm integrates the expert mechanism of a Mixture-of-Experts (MoE) structure with a Bi-directional Long Short-Term Memory (Bi-LSTM) module to enhance the model’s ability to capture temporal features, improve state perception accuracy, and enable efficient policy generation under complex state conditions.
2. To better simulate real-world agricultural scenarios and enhance the applicability of the proposed algorithm, a hierarchical coverage path planning (H-CPP) framework is developed in this study. This framework utilizes Sentinel-2 satellite data to extract spectral bands for the calculation of the CCC index, which is employed to detect chlorophyll content in crops. A hierarchical approach is then applied to segment multi-level task regions, while a grid-based method is used to simulate the agricultural UAV mapping environment.
3. This study designs a progressive composite reward function that synergistically combines hierarchical reward guidance—including priority coverage reward, target distance guidance reward, and energy efficiency reward—with dynamic penalty mechanisms, such as invalid exploration penalty and safety violation penalty. This approach aims to balance coverage efficiency and energy consumption while ensuring adherence to priority constraints.
2. Materials and Methods
2.1. Designed Planning Area Description
Canopy chlorophyll content serves as a pivotal indicator of crop photosynthetic physiology and is thus of paramount importance for modern agricultural monitoring. As the principal pigment driving photosynthesis, chlorophyll concentration directly governs the efficiency of material and energy exchange between the plant and its environment, while simultaneously reflecting the crop’s photosynthetic capacity, nutritional status, and growth trajectory [
22,
23]. By leveraging spectral remote-sensing techniques to obtain three-dimensional distributions of canopy chlorophyll, quantitative linkages can be established between crop phenotypic traits and underlying ecological processes. Such data furnish essential support for real-time growth diagnostics, fertility management, and yield forecasting in precision-agriculture systems, representing a critical technological enabler for scientific crop monitoring and management.
The study area selected for this investigation is Changchun, the capital city of Jilin Province, China, geographically bounded by latitudes 43°05′ to 45°15′N and longitudes 124°18′ to 127°05′E. Situated at the core of the Songliao Plain within the Northeast China Plain, this region is underlain by the characteristic “black soil” belt. The predominant soil types—highly fertile Chernozem and meadow soils—exhibit elevated surface organic-matter content, classifying the area as a globally scarce high-yield arable land resource [
24]. The extensive, flat terrain further provides an ideal physical foundation for the implementation of precision-agriculture technologies [
25].
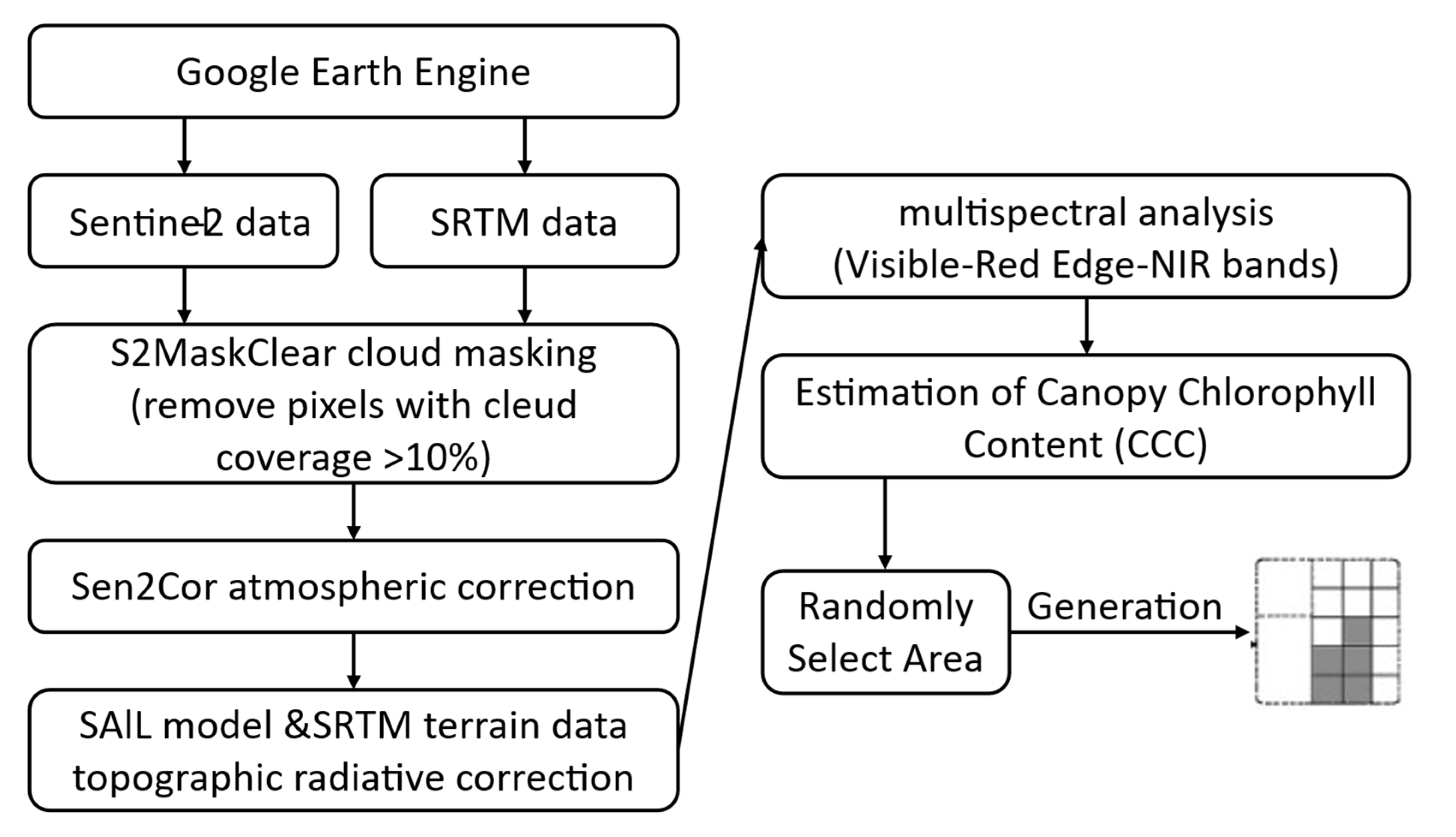
This study was implemented on the Google Earth Engine platform, employing the LEAF-Toolbox inversion routines developed by Sentinel-2 Level-2A surface reflectance data were integrated with SRTM terrain elevations to drive a PROSAIL radiative-transfer-model–based retrieval workflow [
26,
27,
28]. First, the S2MaskClear algorithm was used to exclude pixels exhibiting over 10% cloud cover, and atmospheric correction was applied via Sen2Cor. Thereafter, topographic illumination and radiometric distortions were corrected by merging the SAIL canopy model with SRTM-derived terrain information. Finally, multispectral inversion was performed using the SL2P module—synergizing visible, red-edge, and near-infrared bands—to generate a canopy chlorophyll-content (CCC) estimate for the Changchun region (125.17°E–125.82°E, 43.45°N–44.15°N), as illustrated in
Figure 1.
After obtaining the CCC index map, the area was partitioned into multi-level task regions and non-task regions, which were subsequently converted into a grid map format suitable for computational processing, as illustrated in
Figure 2. To ensure that the task regions accurately reflect the actual crop distribution, a CCC lower threshold of 100,000 was established. Areas below this threshold were classified as non-task zones and excluded from the path planning process.
Following this, a quantile-based method was employed to categorize task priorities: regions with CCC values exceeding 410,000 were assigned Priority I, representing vigorously growing crop areas; values between 230,000 and 410,000 were designated Priority II; and those between 100,000 and 230,000 were classified as Priority III, corresponding to low-density or potentially stressed crop zones.
This prioritization scheme is grounded in the principle of maximizing operational resource efficiency by focusing coverage on high-yield potential areas. Such prioritization helps consolidate the healthy growth of major production zones and prevents the spread of pests and diseases, thereby enhancing the operational value and responsiveness of the path planning.
2.2. State Space
The current temporal characteristics of the mission environment were defined as the state space. Using a grid-based discretization approach, the study area was partitioned into a series of discrete cells. Each cell was assigned a unique identifier corresponding to a specific environmental state—such as task zone, obstacle region, or energy-resupply area—to facilitate subsequent decision-making and path planning processes. The meaning of environmental unit is shown in
Table 1.
2.3. Action Space and Action Selection Strategy
The action space was defined as the set of all feasible commands available to the UAV during the path planning process. Although the UAV’s motion model theoretically supports a continuous action set capable of omnidirectional pose transformations, the accompanying increase in degrees of freedom has been shown to markedly impede training efficiency. To alleviate the computational burden associated with continuous control dimensions, an action policy comprising eight discrete commands was devised. Upon execution of any given command, the state space is immediately updated and the current state St transitions to the subsequent state St + 1. The detailed state-transition mechanism is illustrated in
Table 2.
The balance between exploration and exploitation is central to the action-selection strategy. To pursue higher rewards, the UAV must attempt various actions during exploration; however, excessive exploration can degrade algorithmic efficiency and slow convergence, whereas excessive exploitation may lead to entrapment in local optima and hinder discovery of a global optimum. To address this issue, an ε-greedy algorithm was adopted for action selection: with probability ε the action yielding the maximum estimated return is chosen, and with probability 1 − ε a random action is selected, as shown in Equation (1).
Meanwhile, to avoid the meaningless exploration and slow convergence caused by a fixed ε in the traditional ε-greedy algorithm, a dynamic ε schedule was employed. In this scheme, exploration is initially prioritized, and, as the number of training episodes increases, the exploration probability is gradually reduced while the exploitation weight is correspondingly increased, as shown in the following Equation (2). Here,
denotes the minimum exploration probability,
the maximum probability,
the rate at which exploration probability decays, and
the index of the current episode.
2.4. Environmental Constraints
2.4.1. Priority Constraints
In hierarchical coverage path planning tasks, priority constraints constitute the core logic of task planning and resource scheduling. A well-designed constraint directly influences operational efficiency. Task types are arranged in descending order of priority, as illustrated in Equation (3), where
represents the highest priority and
the lowest. The symbol “>” denotes a strict priority relationship, indicating that all tasks of type
must be completed before proceeding to those of type
.
At the end of each time step, the remaining number of tasks in each priority region is calculated, as defined in Equation (4).
denotes the number of remaining tasks of priority level
at time step
. This value is obtained by traversing all positions (
i,
j) in the environment and counting the locations that satisfy the corresponding conditions.
As the UAV continues to operate, the state is updated dynamically according to the state transition function defined in Equation (5). Specifically,
is used to determine the task type at the current location, identifying whether the agent is positioned at a task point of priority
. The term
serves to verify whether all higher-priority tasks have been completed.
denotes the number of uncompleted tasks of priority level k remaining at time step
.
To enhance the agent’s understanding of task constraints, a nearest-distance function is introduced to guide the UAV toward uncompleted high-priority regions. The agent is encouraged to navigate preferentially toward the nearest area with higher task priority, as defined in Equation (6). Here,
denotes the set of coordinates corresponding to the remaining unprocessed tasks of priority level k.
2.4.2. Energy Consumption Constraint
During agricultural operations, unmanned aerial vehicles (UAVs) are susceptible to disturbances from natural environmental factors and their own payload. Therefore, path planning for UAVs should not be based solely on minimizing time or distance, while neglecting energy consumption. To address this, a dynamic energy consumption constraint for UAVs is proposed in this study, as shown in Equation (7). This constraint is developed based on a mechanism-guided black-box approach, taking into account both payload variations and environmental influences.
In this context, denotes the energy consumption incurred by the UAV at time step t. Specifically, represents the baseline energy consumption during unloaded flight, while accounts for the additional energy required due to payload. The coefficient refers to the environmental coupling factor, which integrates external influences such as headwind velocity . The term denotes Gaussian white noise, capturing unmodeled disturbances including sensor inaccuracies and atmospheric turbulence.
2.5. Improved Algorithm
2.5.1. Basic Theory
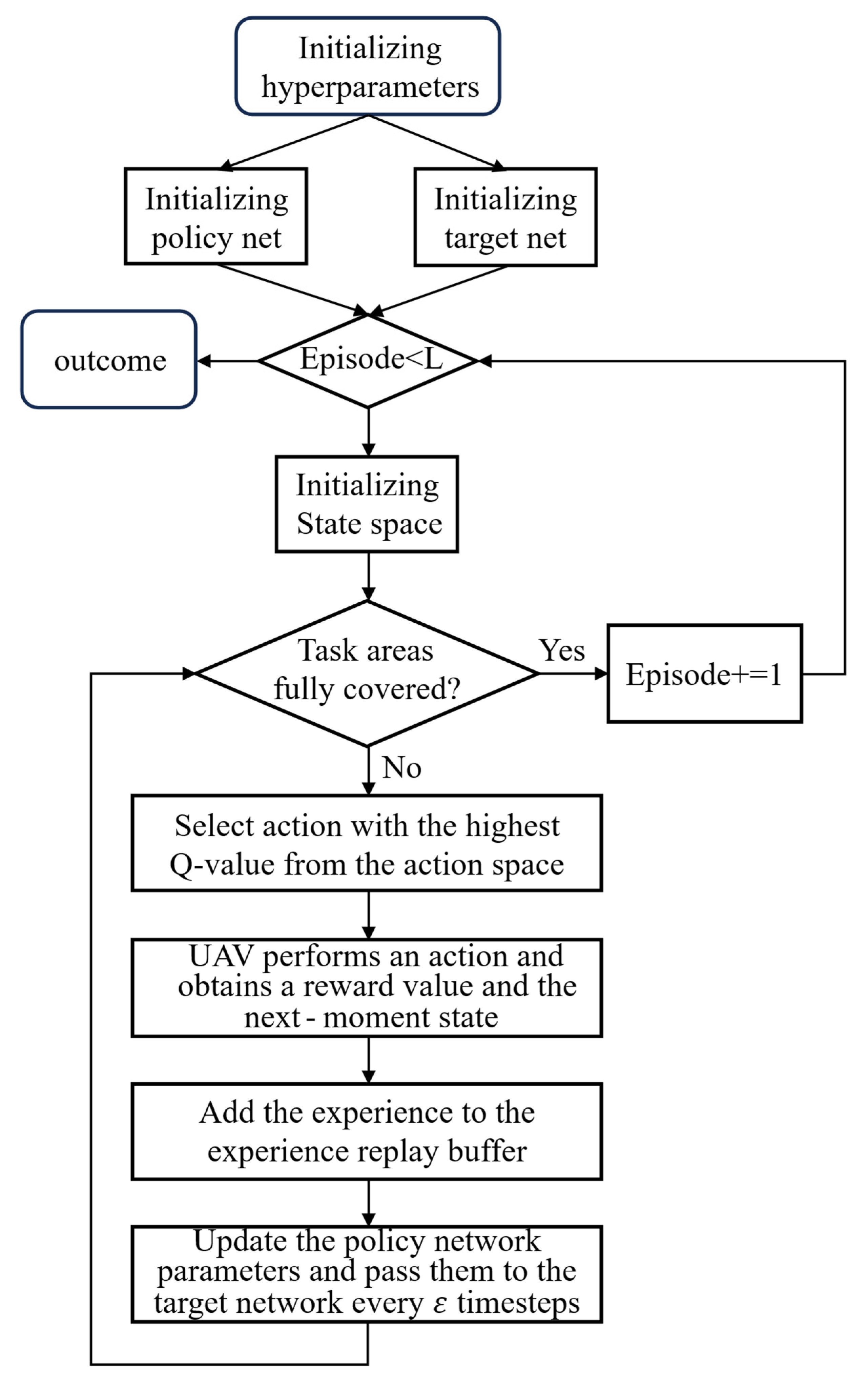
Reinforcement learning primarily functions through real-time interactions between an agent and its environment. At time step t, the agent perceives the environmental state s and selects an action accordingly. The environment then provides a reward based on the selected action, and the agent’s state is updated to the next state St + 1. Through repeated iterations of this process, the agent aims to maximize cumulative rewards.
In 2015, the Deep Q-Network algorithm was proposed [
29], which employed deep neural networks to approximate the Q-value function in high-dimensional continuous state spaces. To improve learning stability and efficiency, the algorithm introduced an experience replay mechanism and a target network. However, since a single neural network was used to estimate the Q-values, estimation bias could occur, leading to the systematic overestimation of Q-values for certain actions. As training progresses, this estimation error may accumulate and be further amplified, potentially impairing the optimization of the policy.
The Double Denoising Deep Q-Network (D3QN) algorithm adopts the dual-network mechanism of the Double Deep Q-Network [
30], employing two structurally identical but parameter-independent networks: the policy network and the target network. The policy network is used for training and action selection, while after a fixed number of training iterations, its parameters are copied to the target network. The target network then computes the Q-values to decouple action selection from value evaluation, thereby reducing overestimation bias. The target Q-value is calculated according to Equation (8),
where
denotes the target Q-value, R represents the immediate reward,
refers to the target network,
is the optimal action that maximizes the Q-value in state
, and
represents the parameters updated with delay.
In addition, to further enhance the network’s ability to distinguish between state value and action advantage, D3QN incorporates the Dueling DQN architecture [
31]. By introducing the state-value function
and the action-advantage function
, which represent the average value of state
independent of specific actions and the relative advantage of action
compared to the average of all actions in that state, respectively, the policy evaluation capability of the reinforcement learning algorithm is significantly enhanced. The calculation formula is shown in Equation (9).
In practical applications such as precision agriculture, environmental states are neither static nor isolated; rather, they exhibit pronounced temporal continuity and undergo constant changes. Therefore, when making decisions, agents are required not only to perceive the current state but also to incorporate trends in environmental dynamics over time, in order to form more forward-looking and informed judgments.
To address this need, researchers have increasingly incorporated recurrent neural network (RNN) architectures—particularly Long Short-Term Memory (LSTM) networks—owing to their capacity for temporal sequence modeling. Through the use of a gating mechanism comprising forget, input, and output gates, LSTM networks are capable of selectively retaining relevant information while suppressing noise, thereby enhancing the model’s ability to capture and interpret long-term dependencies.
Building upon conventional LSTM models, Bi-directional Long Short-Term Memory (Bi-LSTM) networks introduce two parallel LSTM layers that process the input sequence in both forward and backward directions. This bi-directional structure enables the simultaneous capture of past and future contextual information within a sequence. Each LSTM unit dynamically regulates information flow via its gating mechanisms, effectively modeling long-range dependencies while mitigating the vanishing gradient problem. By integrating information from both directions, Bi-LSTM networks substantially improve the model’s representational capacity for complex temporal patterns.
2.5.2. MOE-D3QN
The Mixture-of-Experts architecture has emerged as a prominent paradigm in deep learning, offering notable advantages in enhancing model capacity and computational efficiency through the dynamic routing and integration of multiple expert sub-models. This architecture adaptively allocates computational resources based on the characteristics of input data and employs a gating network to aggregate the outputs of selected experts.
In recent years, with the rapid development of large-scale models, the MoE framework has demonstrated significant potential in fields such as natural language processing. Representative implementations include Google’s GShard [
32] and the subsequent Switch Transformer [
33], both of which activate only a subset of experts during training. This selective activation mechanism substantially improves training efficiency and reduces computational cost, thereby laying a solid foundation for the practical deployment of MoE-based models.
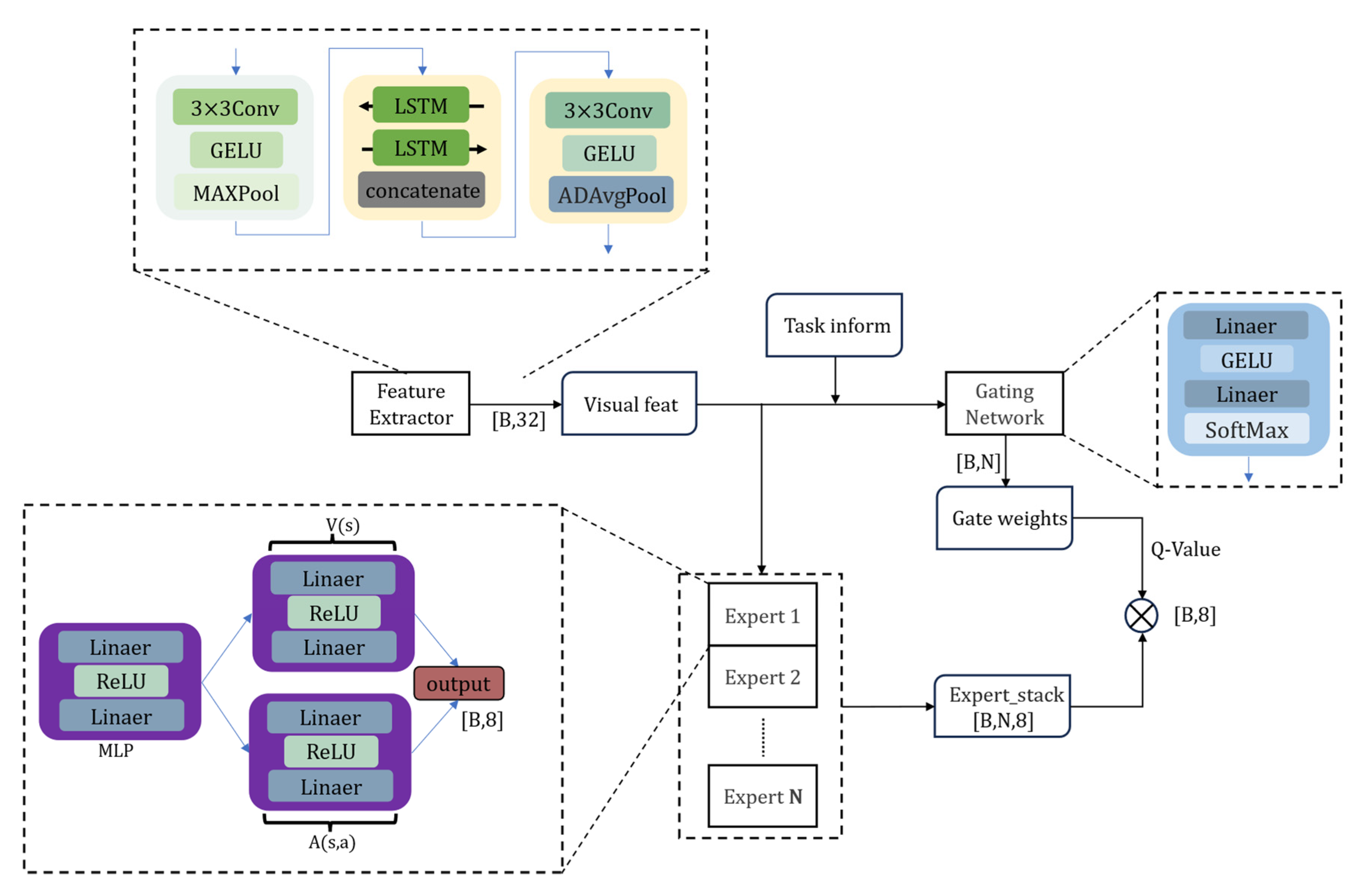
To address the dual optimization challenges inherent in the conventional D3QN algorithm—namely, the need for synchronous updates of the policy network and the target network, as well as the joint optimization of the state-value function and action-advantage function, which lead to increased parameter counts and reduced training efficiency—this study proposes an improved scheme based on the Mixture-of-Experts framework combined with a Bi-directional Long Short-Term Memory (Bi-LSTM). The enhanced MoE-D3QN model establishes a multi-expert collaboration mechanism where the gating network dynamically allocates parameters, improving model expressiveness under computational constraints. Additionally, the integration of the Bi-LSTM module strengthens temporal feature extraction by capturing long-range dependencies through bi-directional state propagation.
To address the dual challenges faced by the traditional D3QN algorithm—namely, the need for synchronized updates of the policy and target networks, and the parameter redundancy and training inefficiency arising from the joint optimization of the state-value and action-advantage functions—an improved framework, termed MoE-D3QN, is proposed in this study. By incorporating MoE architecture with a gating network, the model enables dynamic parameter allocation and adaptive feature selection. This design significantly enhances policy representation and training efficiency while maintaining constraints on computational resources.
In addition, to further improve the model’s capability for temporal feature modeling, Bi-LSTM module is integrated as an auxiliary component. Leveraging its bi-directional state propagation mechanism, the Bi-LSTM effectively captures long-term dependencies during task execution. In the context of the UAV-based precision spraying task addressed in this study, where path planning depends on the dynamic evolution of environmental states, the integration of Bi-LSTM improves the model’s ability to perceive historical changes. This, in turn, reduces redundant path coverage and resource waste, while enhancing the continuity and robustness of the learned policies.
As illustrated in
Figure 3, the model architecture comprises three core components:
(1) A CNN-LSTM cascaded feature extraction module, which adopts depthwise separable convolution and channel attention mechanisms to achieve a lightweight design, with the computation defined in Equation (10).
(2) An expert network ensemble, where each expert includes a feature transformation layer as well as independent computation units for the state-value function and the advantage function, as defined in Equation (11).
(3) A dynamic gating network, which achieves sparse expert weight distribution through low-rank matrix decomposition and temperature coefficient adjustment. Specifically, the input observation data are first transformed into a high-dimensional representation via the feature extraction module. Based on the complexity of the current state, the gating network generates activation weights for the experts. Each expert network processes the feature vector in parallel, and the outputs are then fused through a weighted aggregation to produce the final action-value function prediction, as defined in Equation (12).
represents the temperature coefficient, which is used to control the smoothness of the Softmax distribution output by the gating network. A linear annealing strategy is adopted to dynamically adjust the temperature coefficient during training, as shown in Equation (13). At the early stages of training, a higher temperature value is assigned to encourage the participation of multiple experts, thereby enhancing the model’s responsiveness to complex environmental states encountered in coverage path planning tasks. As training progresses,
is gradually annealed to a lower value, increasing the determinism of expert selection and thereby improving policy stability and convergence speed.
However, if the temperature coefficient decreases excessively, the Softmax output tends to approximate a one-hot distribution, activating only a single expert. This over-sparsity may hinder the model’s generalization ability and lead to inefficient path selection in local regions, ultimately resulting in convergence to suboptimal solutions. To mitigate this issue, a lower bound is imposed on the temperature coefficient, ensuring a balance between determinism and diversity in expert selection. This constraint helps maintain a dynamic equilibrium between exploration and exploitation throughout the training process.
The process of the MOE-D3QN algorithm is shown in
Figure 4.
2.5.3. Reward
To address the challenge faced by traditional path planning algorithms in agricultural environments—namely, the difficulty in simultaneously optimizing task priority, energy efficiency, and safety constraints—this study proposes a reward function designed to guide the UAV. The function encourages the UAV to approach the target coverage area promptly and prioritizes the coverage of high-priority regions in descending order, as defined in Equation (14).
The term
represents the reward assigned to non-task areas, as defined in Equation (15). The variable
denotes the environmental state at the UAV’s current location on the map, where 0 indicates a covered task area and 1 denotes a non-task area. A penalty is applied when the UAV enters an already covered area, while a base penalty is also imposed when the UAV moves into a non-task area. Additionally, a distance-based reward is provided to encourage the UAV to navigate toward task regions, thereby guiding it effectively toward completing mission objectives.
The term
, defined as in Equation (16), denotes the coverage reward. A positive reward is assigned whenever the UAV moves into a region that corresponds to the current priority level. In contrast, if the UAV enters a region that does not match the required priority—such as covering a lower-priority area prematurely—a penalty is applied. This reward mechanism is designed to guide the UAV toward prioritizing the coverage of higher-priority areas.
The term
, as defined in Equation (17), represents the task completion reward. After each step, a check is performed: if all priority levels in the task sequence have been fully covered, the task is considered complete, and a substantial positive reward is granted. If the sequence is not yet empty, no completion reward is given, and the UAV proceeds to execute the remaining tasks.
To prevent ineffective exploration, improve training efficiency, avoid local optima or infinite loops, and enhance the safety of the path planning process, this study introduces a task termination constraint, as defined in Equation (18). Let
denote the number of steps taken in the current episode,
represent the maximum allowable steps,
denote the number of consecutive steps without a reward, and
indicate the maximum allowed consecutive non-rewarded steps. The episode is terminated under any of the following conditions: (1) the total steps taken exceed the maximum allowable steps; (2) the consecutive non-rewarded steps exceed the predefined limit; or (3) the UAV enters an obstacle region.
2.5.4. Sensitivity Analysis of Reward Function Parameters
To further evaluate the influence of key parameters in the reward function and gating mechanism on path planning performance, a sensitivity analysis was conducted from the perspectives of coverage efficiency, redundancy rate, and task completion rate. For each parameter, a univariate perturbation approach was employed: the target parameter was individually adjusted while keeping all other parameters fixed. Specifically, the parameter was varied by ±30% around its baseline value, and the resulting impact on path quality was systematically observed and analyzed.
As shown in
Table 3, under the default configuration (Our), the algorithm achieved superior coverage performance with a low redundancy rate of only 3.23% and a coverage efficiency of 0.8378. In comparative experiments 1a, b, when the non-task area penalty_
was increased, a reduction in redundant paths was observed. However, due to the absence of guidance from target-directed rewards, the agent struggled to understand the priority coverage relationships. This resulted in an increased number of steps taken in non-task areas and a consequent decline in overall efficiency. Furthermore, as the penalty was reduced, the base movement cost decreased, which inadvertently caused the agent to receive positive rewards for covering non-task regions, leading to significant ineffective coverage in these areas.
In experiments 2a,b, adjustments were made to the priority area reward Increasing this parameter did not yield substantial improvements, indicating that priority relationships were already reasonably well handled. Conversely, decreasing the reward, as demonstrated in 2b, noticeably degraded the prioritization of coverage paths, resulting in increased redundancy and reduced efficiency. Additionally, experiments 3a,b tested the impact of the full coverage task reward. It was found that setting this reward too low or too high disrupted the original planning rhythm, slightly decreasing path efficiency, although the overall effect remained limited.
3. Results and Discussion
3.1. Experimental Setup
All simulation experiments in this study were conducted on a high-performance desktop workstation configured with dual NVIDIA GeForce RTX 3090 GPUs (24 GB VRAM each) operating in parallel under the Ubuntu OS. The algorithms were developed and implemented using the Python 3.11.5 programming environment. The experimental parameters are configured as shown in
Table 4.
3.2. Experimental Results
To systematically validate the performance advantages of the proposed algorithm in multi-level agricultural task scenarios, representative traditional path planning algorithms, namely A-Star and the genetic algorithm (GA), as well as mainstream deep reinforcement learning models including DQN, DDQN, D3QN, and Dueling DQN, were selected as baseline references for comparative experiments. Considering the spatial complexity characteristics of agricultural operational environments, this study constructed representative two-level and three-level hierarchical task regions based on satellite remote sensing imagery data. After 60,000 training iterations, the algorithms’ performances were quantitatively evaluated in terms of coverage repetition rate, coverage rate, and coverage efficiency.
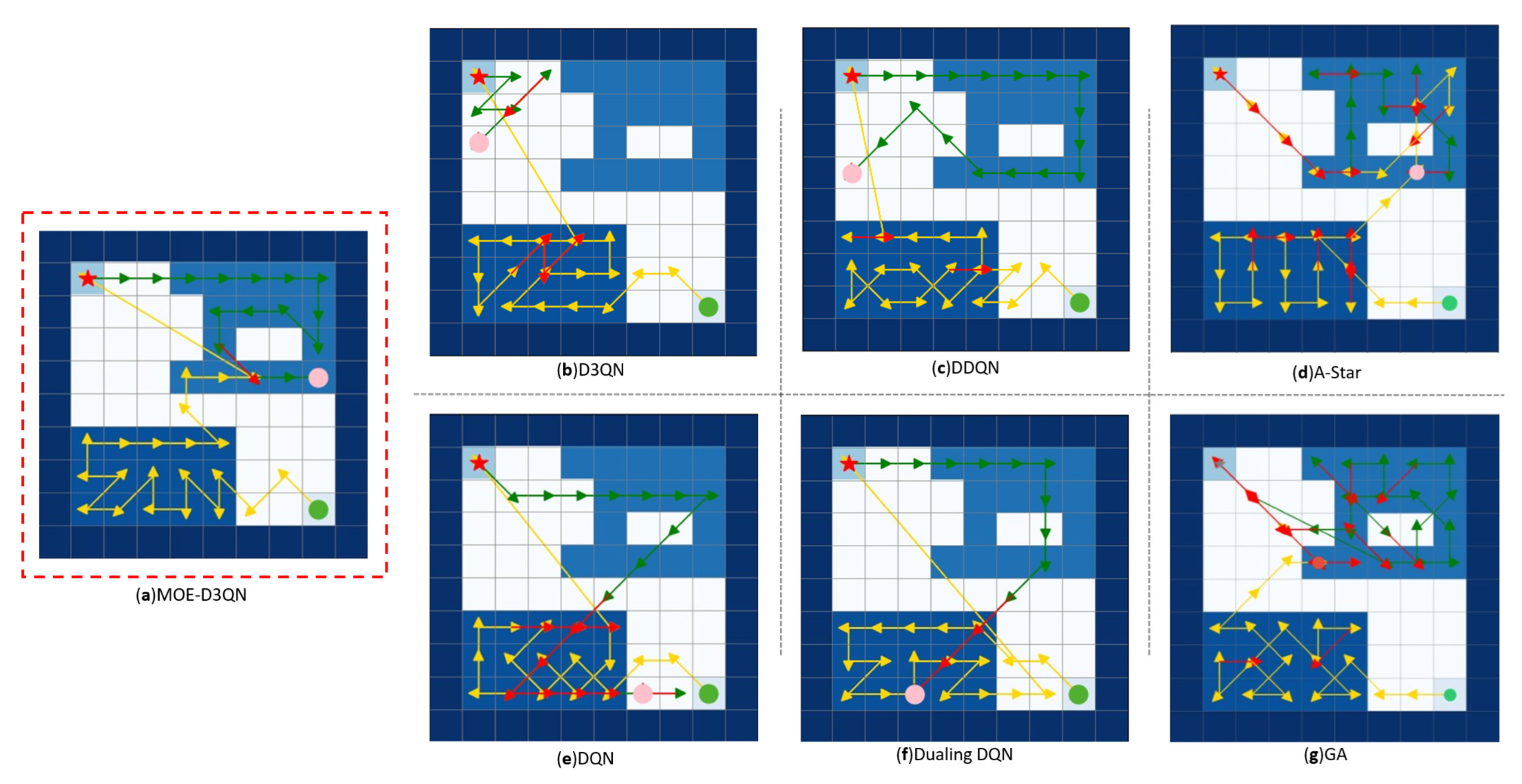
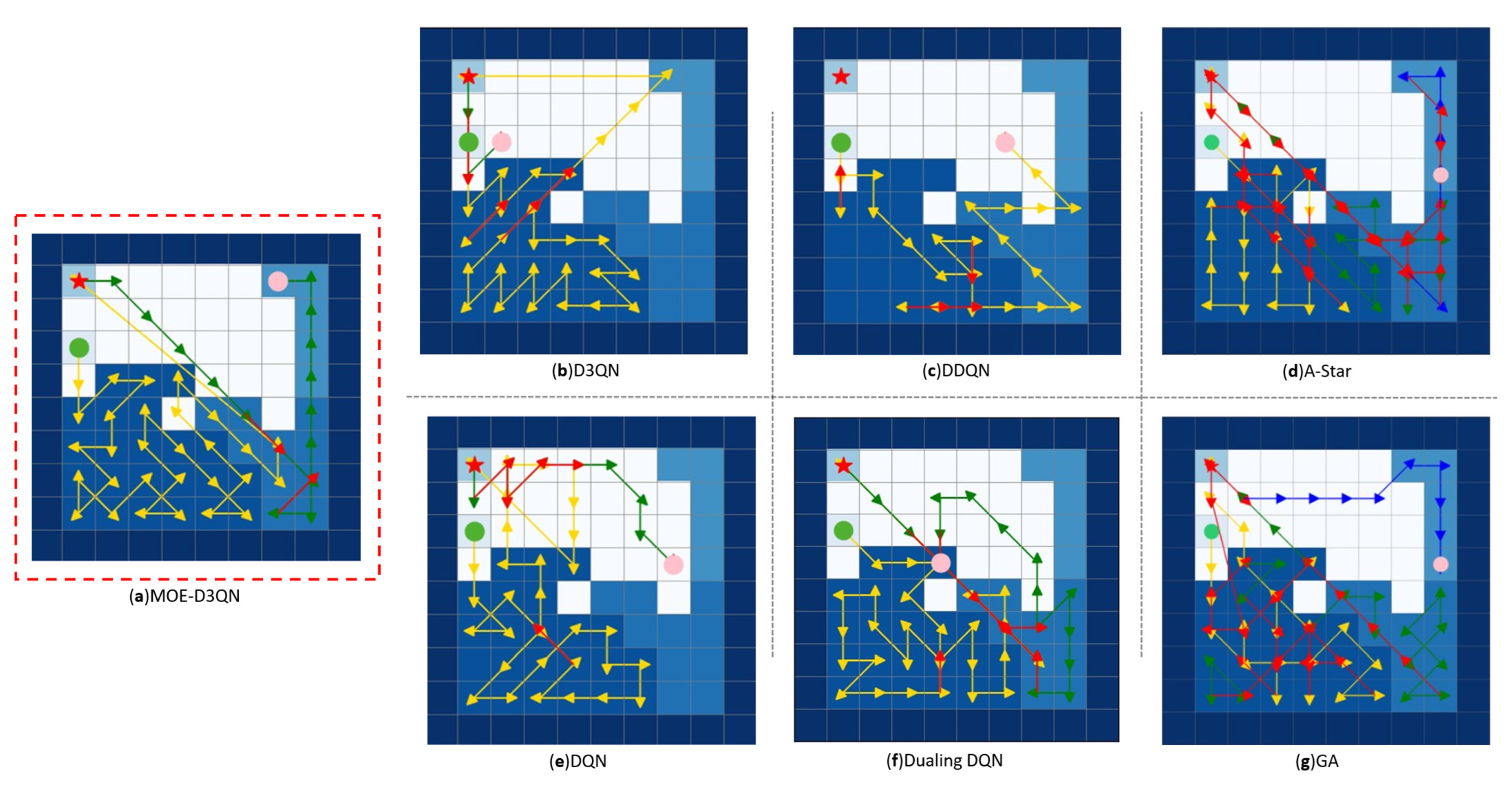
In this study, dark blue was assigned to obstacle areas, while task region priorities were represented using progressively lighter shades of blue. White areas indicated non-task regions. Charging stations were marked with red stars, UAV starting points with green circles, and UAV task termination points with pink circles. Yellow lines depicted the initial outbound paths, green lines represented routes taken after returning to charging stations for battery replenishment, and red lines indicated repeated paths.
As shown in
Figure 5 and
Figure 6, the MOE-D3QN algorithm demonstrated superior coverage efficiency in both two-level and three-level hierarchical task maps, successfully completing the coverage tasks without any confusion in task hierarchy. However, from a global perspective, some route redundancies were observed, with partial path repetitions occurring. Among the comparison algorithms, only the traditional A-Star and genetic algorithms (GA) completed the coverage tasks. The A-Star algorithm, relying on heuristic functions to prioritize exploration in the “optimal” direction, encountered challenges in coverage tasks where the globally optimal path may require temporary deviations from the target direction to satisfy energy consumption and priority constraints. This caused repeated attempts along the same paths. The GA algorithm, when faced with complex constraints, tended to have its population dominated by a few individuals meeting basic constraints but exhibiting similar structures. Subsequent crossover and mutation operations could only slightly adjust path sequences, preventing escape from local optima and resulting in numerous redundant paths differing only in minor details. Furthermore, algorithms such as DDQN and Dueling DQN exhibited limitations due to inherent algorithmic shortcomings, which led to difficulties in convergence during training and entrapment in local optima.
To further evaluate the performance of the algorithms, quantitative analyses were conducted by calculating the coverage repetition rate, coverage rate, and coverage efficiency. A detailed comparison of the results is presented in
Table 5.
(a) Path length: UAV’s movement steps.
(b) Coverage efficiency: ratio of effectively covered area to total target region area, as shown in Equation (19).
(c) Redundancy rate: ratio of repeatedly visited areas to total covered regions in the planned path, as formalized in Equation (20)
3.3. Experimental Analysis
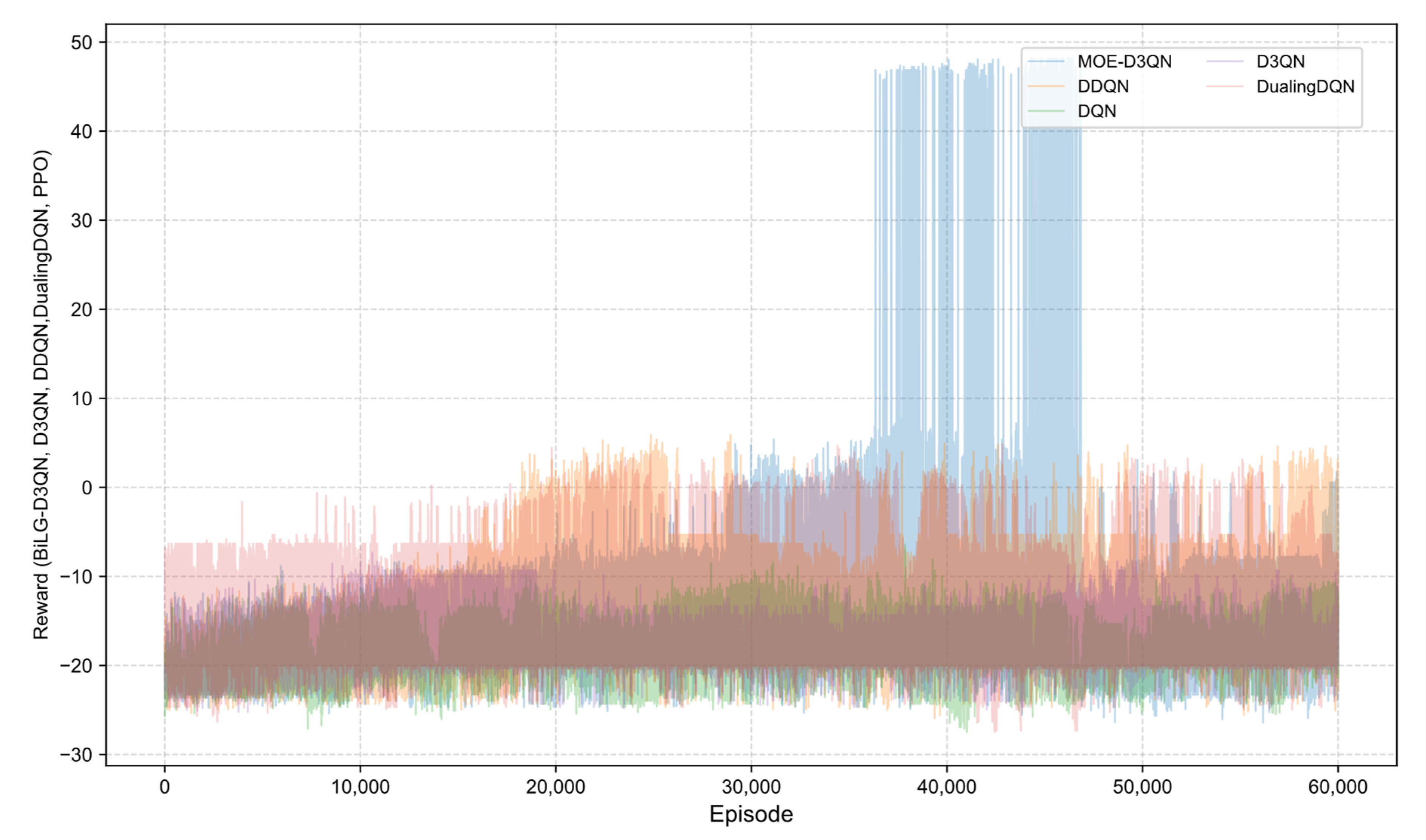
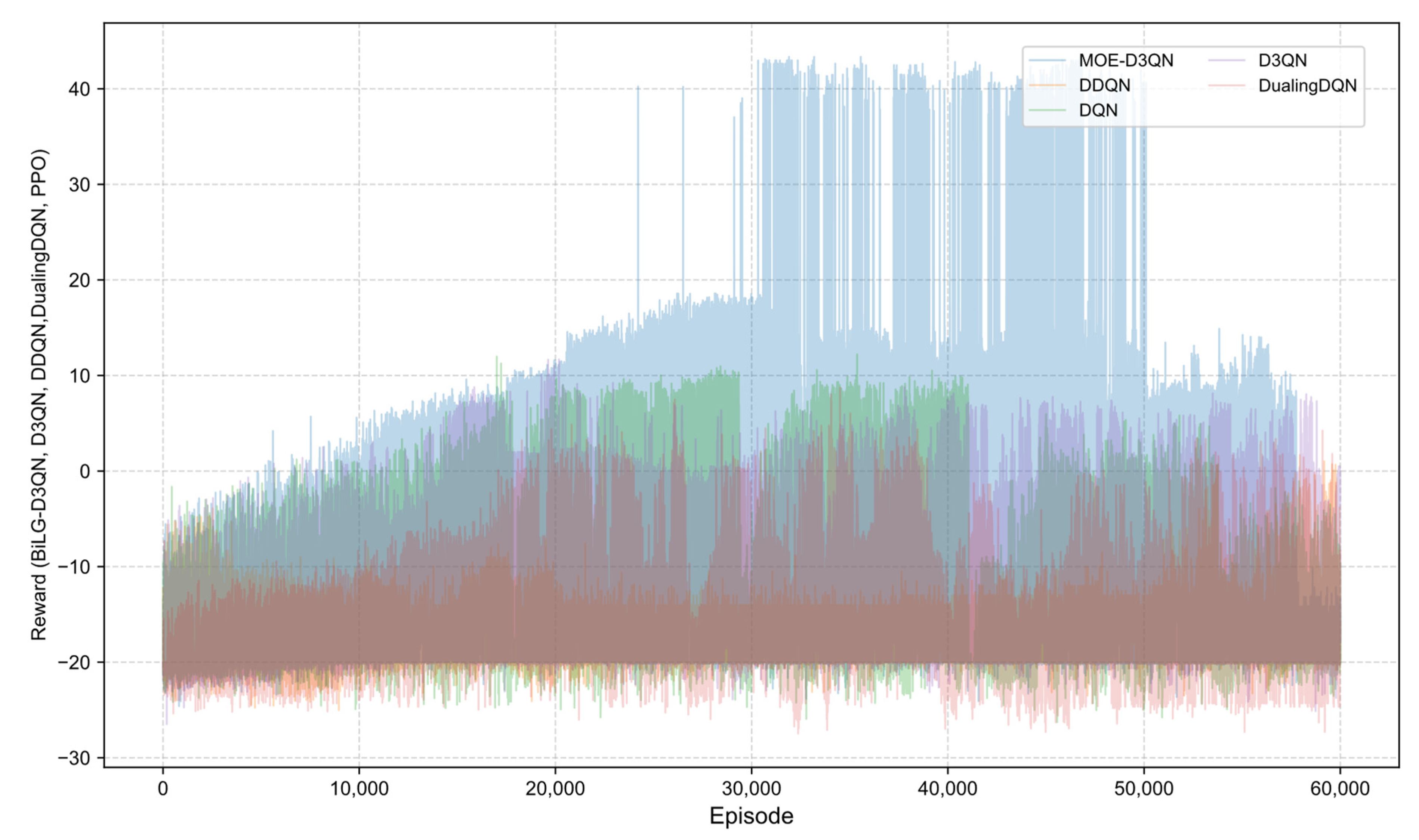
The reward curves presented in
Figure 7 and
Figure 8 illustrate the training process, where the MOE-D3QN algorithm initially exhibited a gradual upward trend. Due to the exploration-promoting action selection strategy employed in this study, the overall reward curve demonstrated a spiraling increase. During the early to mid-training phases, the model progressively learned to understand environmental constraints and developed effective action strategies. By the mid-training stage, the model had achieved a satisfactory comprehension of the task requirements, successfully completing the planning task and obtaining the final reward. However, in the later stages, due to the chosen training strategy, the model showed signs of overfitting, resulting in fluctuations in the reward values.
In contrast, the DQN algorithm suffered from policy update bias accumulation caused by Q-value overestimation, leading to premature convergence in complex state spaces. Although DDQN mitigated some of these biases by decoupling action selection from value evaluation, its fixed-interval parameter update mechanism limited its adaptability to dynamic environmental changes. The dueling network architecture of Dueling DQN, while advantageous in some contexts, was prone to advantage function estimation errors in sparse reward scenarios, which increased the likelihood of becoming trapped in local optima.
4. Discussion
In terms of experimental metrics, MOE-D3QN demonstrated significantly higher coverage efficiency and lower redundancy rates compared to traditional algorithms and mainstream reinforcement learning methods. This not only reflects the optimization advantages of the path planning strategy but also holds profound practical significance for agricultural applications. Firstly, the high coverage efficiency ensures comprehensive and omission-free treatment of target areas for operations such as pesticide spraying and fertilization, effectively minimizing blind spots and coverage gaps. This is particularly crucial under conditions of high pest incidence or uneven crop growth, where the risk of “over-treatment and under-protection” or “localized loss of control” can be largely avoided. Secondly, the enhanced coverage efficiency markedly improves operational productivity. For plant protection UAVs, this translates into the ability to complete larger-area tasks within a single flight, thereby reducing the need for multiple flights and lowering the frequency and cost associated with battery recharging or replacement. Consequently, labor input and time consumption are further reduced.
Simultaneously, the low redundancy rate indicates a reduced frequency of path overlap during mission execution, facilitating precise control of agricultural inputs such as pesticides, fertilizers, and irrigation water. Traditional path planning methods often suffer from significant path overlap issues, leading to excessive pesticide or fertilizer concentrations in certain areas, which not only increase production costs but may also cause crop phytotoxicity and soil accumulation pollution, posing ecological risks. Conversely, the low-redundancy path planning approach ensures that each target area is uniformly and efficiently covered, promoting relative controllability of agricultural resources. This approach balances both the “precision” and “uniformity” of operational outcomes, safeguarding crop health while minimizing environmental burden—an essential factor for advancing green agriculture and resource-efficient development.
From a technical implementation perspective, this study utilized Sentinel-2 Level-2A satellite remote sensing imagery to perform spectral inversion of vegetation status in the study area, extracting the Canopy Chlorophyll Content index. Subsequently, multi-level thresholds were established using quantile methods to rasterize the imagery into a digital task map, where different grid values represented varying operational priorities (e.g., high, medium, and low risk zones). These were uniformly fed into the state space of the deep reinforcement learning model. This processing approach effectively transforms remote sensing perception data into structured inputs recognizable by the reinforcement learning agent, thereby simplifying the linkage between remote sensing information and path decision making.
Regarding the specific implementation, the rasterization method employed offers strong generalizability and operability, capable of accommodating task partitioning requirements across diverse crop scenarios. Although the current experiments were conducted in flat farmland areas, the CCC index used is derived from red-edge and near-infrared bands, possessing a degree of crop non-specificity. Theoretically, it is applicable to physiological status estimation for various crops such as rice, wheat, and soybean, thus exhibiting cross-crop adaptability potential. Moreover, the MOE-D3QN model employs a Mixture-of-Experts architecture, composed of multiple policy subnetworks dynamically fused through a gating mechanism based on input states. This architecture offers advantages in modeling heterogeneous input states and is expected to enhance the model’s responsiveness to environmental heterogeneity and task complexity.
Despite the current experiments focusing primarily on relatively flat terrain, the model’s structural design does not rely on specific landform types or single-crop characteristics, indicating certain scalability. Preliminary assessments suggest that, with appropriate adjustments to state inputs and task configurations, the model may possess adaptability for more complex terrains and multi-crop structured scenarios.
5. Conclusions
This study proposes an improved deep reinforcement learning algorithm, MoE-D3QN, which integrates D3QN, a Mixture-of-Experts mechanism, and a Bi-directional Long Short-Term Memory, aiming to enhance path planning efficiency for agricultural unmanned aerial vehicles operating in dynamic and complex environments. The algorithm leverages the Bi-LSTM module’s capability to capture temporal features, thereby strengthening contextual awareness within task sequences. Moreover, through the dynamic selection capability of expert networks and gating mechanisms in the MoE architecture, it enables adaptive decision making in response to variable states within complex environments. In addition, a hierarchical coverage path planning framework is developed, utilizing Sentinel-2 remote sensing data to invert canopy chlorophyll content and construct multi-level task maps via thresholding and rasterization techniques. A dynamic energy consumption modeling mechanism is introduced to quantify the coupling effects of payload and environmental factors. Furthermore, a progressive composite reward function is designed to achieve synergistic optimization of energy efficiency and task priority.
Simulation experiments demonstrate that MOE-D3QN achieves superior performance compared to six other algorithms in hierarchical coverage path planning tasks with load-related energy considerations. In the secondary task scenario, the MOE-D3QN algorithm achieved a coverage efficiency of 0.8378, representing improvements of 45.26% over D3QN, 63.38% over DQN, 19.19% over DDQN, 27.66% over Dueling DQN, and 37.84% over A-Star and GA. The redundancy rate was only 3.23%, far lower than D3QN at 26.67%, DQN at 45.00%, DDQN at 7.69%, Dueling DQN at 14.29%, A-Star at 41.94%, and GA at 38.71%.In the tertiary task scenario, the MOE-D3QN algorithm achieved a coverage efficiency of 0.8261, with improvements of 10.15% over D3QN, 50.2% over DQN, 17.4% over DDQN, 25.17% over Dueling DQN, 71.45% over A-Star, and 52.13% over GA. The redundancy rate was 5.26%, significantly better than D3QN at 20.83%, DQN at 22.73%, DDQN at 21.05%, Dueling DQN at 24.24%, A-Star at 92.11%, and GA at 57.89%.
These results validate the algorithm’s capability to comprehend task constraints and handle temporal information, providing a low-redundancy and highly adaptive path planning solution for precision agricultural UAV operations. The proposed approach not only enhances spraying accuracy and resource utilization but also reduces pesticide overuse and environmental pollution risks, contributing to the advancement of intelligent and sustainable agriculture.
In future research, efforts will be directed towards further expanding the practical applicability of the proposed algorithm to better support UAV systems in precision agriculture, thereby promoting agricultural intelligence and sustainable development. Specifically, the following aspects will be addressed:
1. This study will focus on the collaborative mechanisms of UAV path planning among various types of agricultural intelligent devices. Emphasis will be placed on the information interaction and operational coordination between UAVs and field sensing equipment—such as soil moisture sensors and microclimate stations—as well as variable-rate pesticide application systems. By constructing a unified crop state perception and task collaboration framework, the coupling among multi-device platforms will be enhanced, facilitating the evolution of UAV operation systems from independent execution towards intelligent collaborative operation. This will provide crucial support for the integration and intelligent application of multiple agricultural devices in precision farming.
2. To meet the demands for efficient operations across large areas and multi-crop distributions, future work will consider coordinated path planning for multi-UAV systems. By integrating plot characteristics, crop requirements, and operational time window constraints, dynamic scheduling of multiple UAVs will be realized. This approach will offer algorithmic support for UAV swarm formation and zonal operations, thus advancing the large-scale deployment of UAVs in precision agriculture.
3. To further enhance the algorithm’s generalizability across diverse scenarios, subsequent research plans include incorporating real orchard point cloud data or digital elevation models (DEM) to embed terrain factors such as slope and undulation into the state space construction. This will enable three-dimensional path planning environments that more closely align with practical operational needs. Experimental evaluations will be conducted in irregular terrains such as hilly areas and orchards, providing more comprehensive empirical support for the model’s applicability in varied agricultural settings.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}