
IRSD-Net: An Adaptive Infrared Ship Detection Network for Small Targets in Complex Maritime Environments


Abstract
1. Introduction
- We design IRSD-Net, an efficient architecture that balances multi-scale feature extraction and cross-layer semantic fusion, achieving high accuracy with low computational overhead.
- We develop a novel backbone named HMKCNet that leverages parallel convolutions with diverse kernel sizes for simultaneous local detail and contextual feature capture, enhanced by channel partitioning for reduced redundancy.
- The DCSFPN is introduced to precisely integrate low-level detail information with high-level semantic information, which addresses information loss and the unidirectional flow of traditional methods.
- Experiments on ISDD and IRSDSS datasets validate that IRSD-Net can achieve an of 92.5% and 92.9%, respectively, outperforming existing methods with only 6.5 GFLOPs and 2.1M parameters, thus supporting real-time deployment in constrained environments.
2. Related Work
2.1. Traditional Infrared Ship Detection Methods
2.2. Deep Learning-Based Infrared Ship Detection Methods
2.3. Small-Target Detection Methods Against Complex Backgrounds
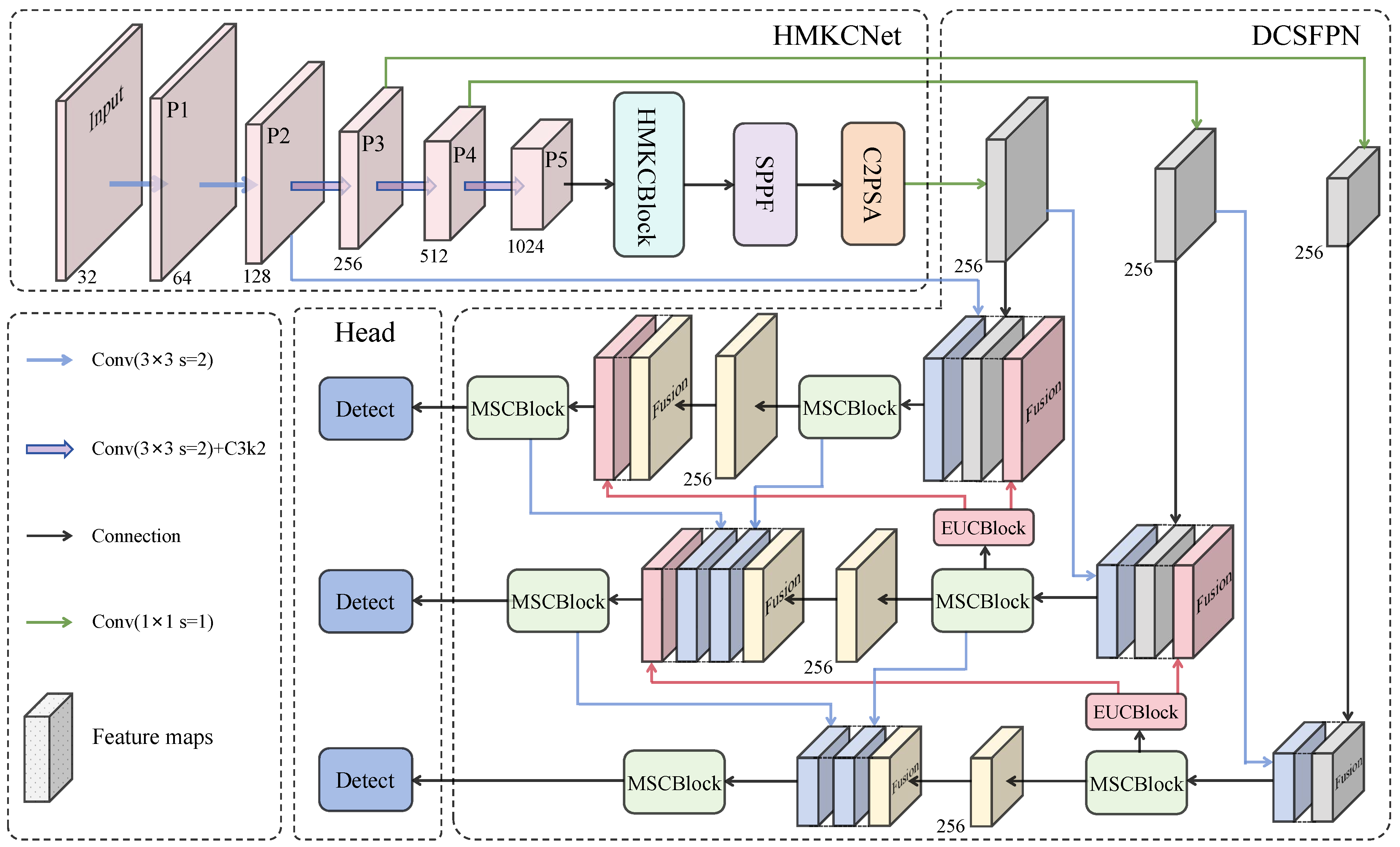
3. Method
3.1. Problem Formulation
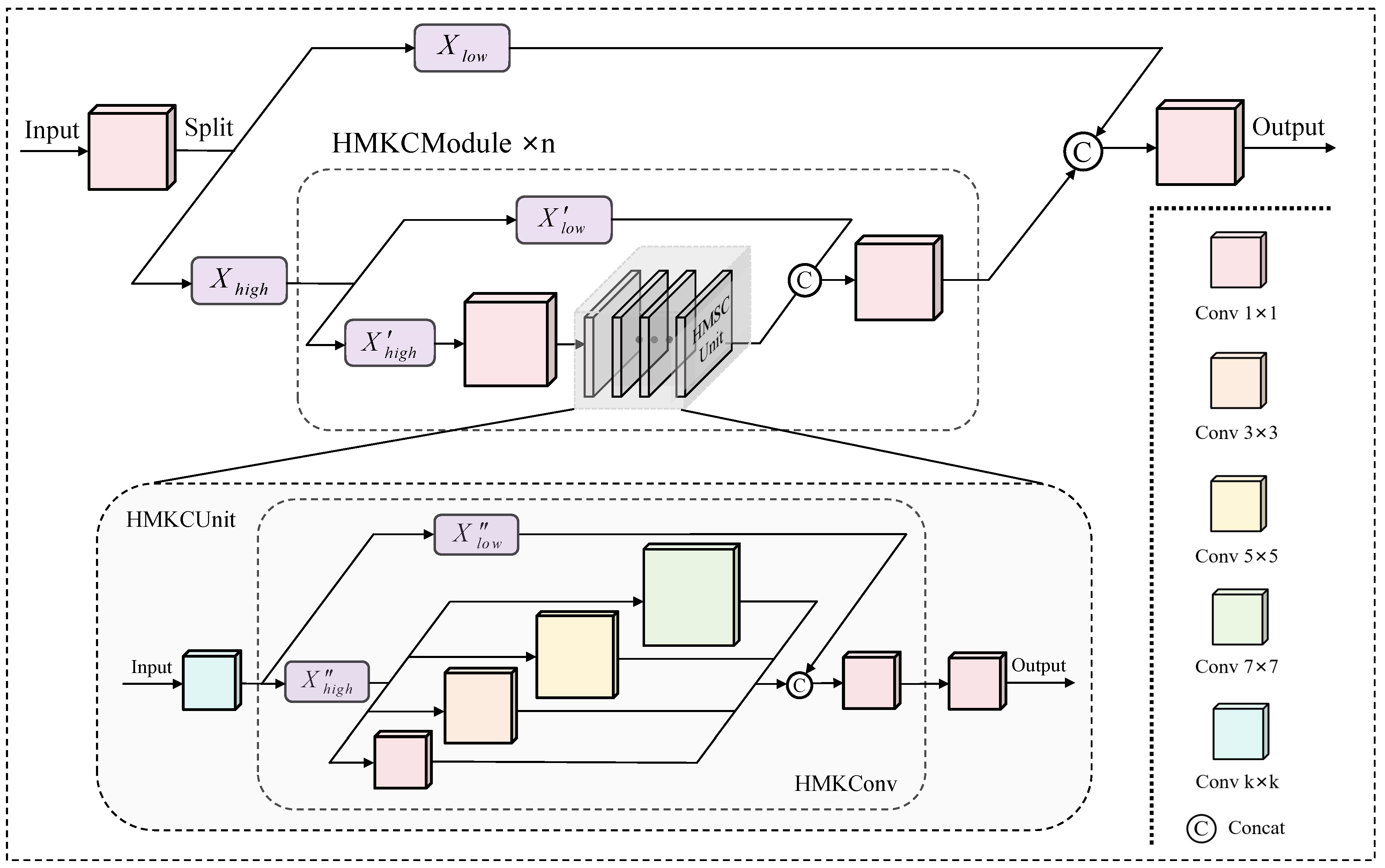
3.2. HMKCNet
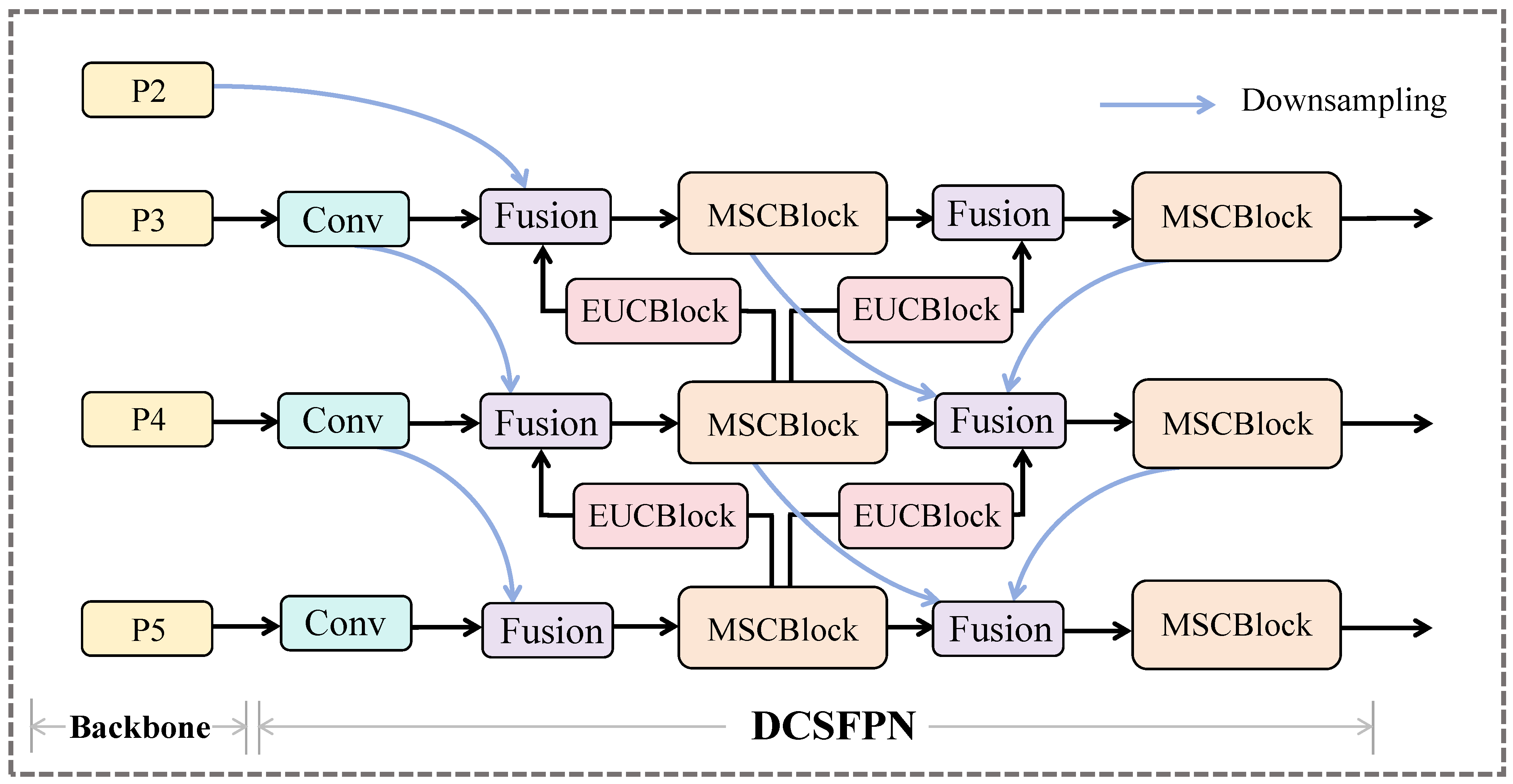
3.3. DCSFPN
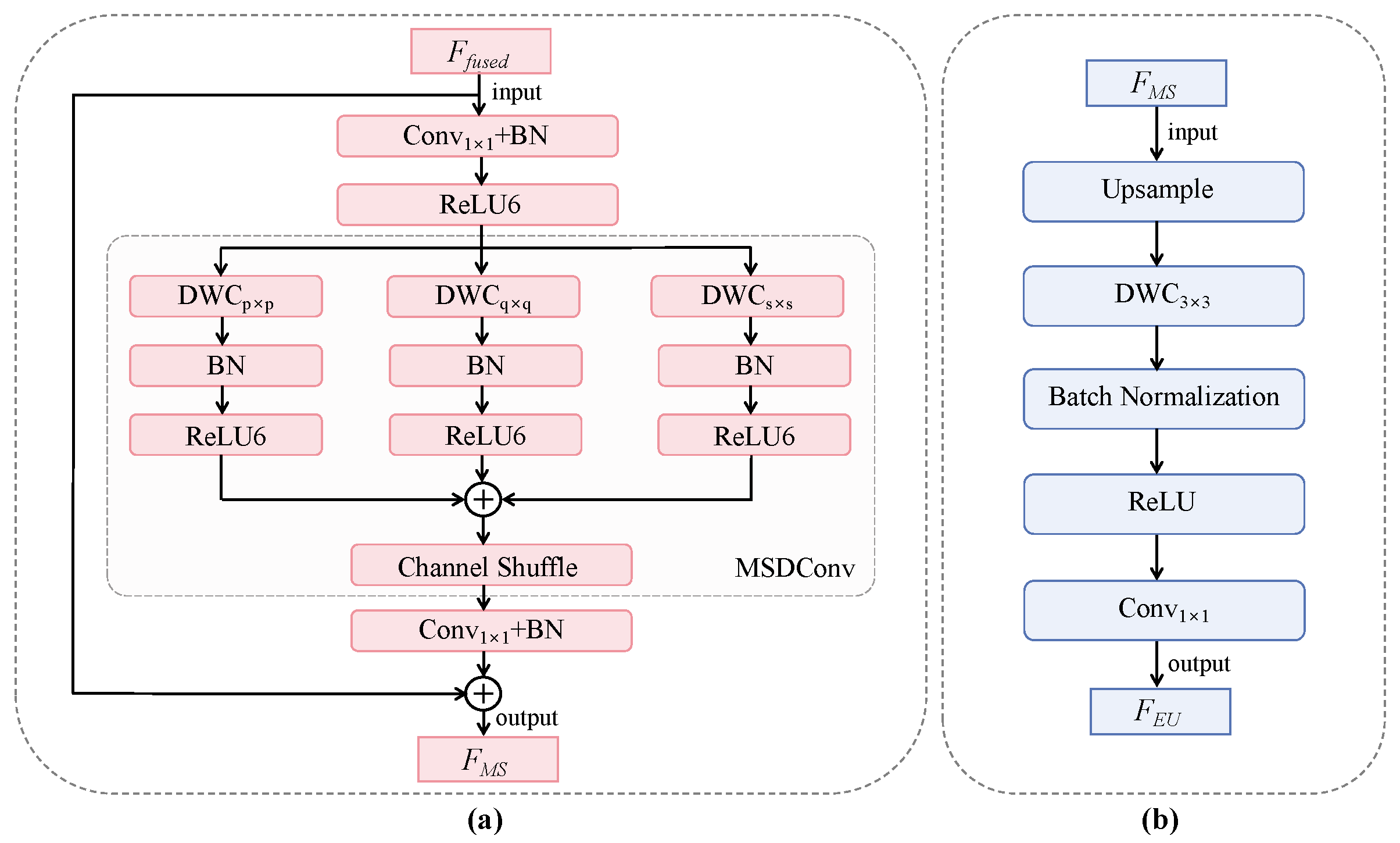
3.3.1. Design of the MSCBlock
3.3.2. Design of the EUCBlock
3.4. Wise-PIoU
4. Datasets and Experimental Setup
4.1. Datasets
- ISDD: This collection comprises 1284 shortwave infrared images of 500 × 500 pixel resolution and 3061 annotated ship instances covering multiple regions. ISDD features small target scales, with an average target area occupying only 0.18% of the image area, diverse near-shore and open-ocean scenarios, and complex weather conditions including wind waves, thin clouds, and thick clouds. These characteristics impose higher requirements on detection networks for fine-grained modeling and robustness against complex backgrounds.
- IRSDSS: This collection includes 1491 infrared images of 640 × 640 pixel resolution, encompassing 4062 annotated ship targets. Ship lengths range from 3.32 to 85.88 m, with dimensions spanning from 16.28 to 4780.24 square meters and aspect ratios varying between 0.25 and 4.20, comprehensively covering ship instances of diverse scales and morphologies. Additionally, IRSDSS encompasses rich sea–land scenarios, varied wake features, and multiple kinds of weather interference like thin clouds, thick clouds, and wind waves, significantly increasing detection challenges.
4.2. Parameters and Settings
4.3. Evaluation Metrics
5. Results
5.1. Comparative Experiments
5.2. Performance Comparison of Different Necks
5.3. Performance Comparison of Different Loss Functions
5.4. Ablation Experiments
5.4.1. Ablation Experiments on the HMKConv Kernel Configuration
5.4.2. Hyperparameter Sensitivity Analysis of Wise-PIoU
5.4.3. Ablation Experiments on the Overall Model
5.5. Visual Presentation
5.6. Generalization Analysis
5.6.1. Cross-Model Validation
5.6.2. Cross-Platform Performance Analysis
6. Discussion
7. Conclusions
- In this work, we introduce the HMKCNet into the backbone architecture to enhance feature extraction capabilities. This novel component employs parallel convolutions with varying kernels and receptive field regulation, thereby optimizing multi-scale target processing. As a result, the HMKCNet demonstrates particularly significant performance improvements when detecting small targets and processing low-contrast images.
- In terms of network architecture, we propose the DCSFPN. This innovation optimizes the fusion and transmission mechanisms of multi-scale features, thus enhancing global contextual perception capabilities. To achieve this, we incorporate two key components: the MSCBlock and EUCBlock. The components enable efficient integration and transmission of cross-scale semantic information.
- We implement Wise-PIoU, combining geometric alignment penalties with dynamic focusing. This addresses the performance degradation caused by numerous low-quality examples in detection tasks. Unlike traditional IoU-based loss functions, Wise-PIoU handles bounding box misalignments more accurately, enhancing regression precision while preventing domination by extreme samples. This approach optimizes small-ship detection in dynamic scenarios and complex environments, significantly improving both precision and recall metrics.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Wang, A.; Zheng, Y.; Mazhar, S.; Chang, Y. A detection method with antiinterference for infrared maritime small target. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3999–4014. [Google Scholar] [CrossRef]
- Yang, P.; Dong, L.; Xu, H.; Dai, H.; Xu, W. Robust infrared maritime target detection via anti-jitter spatial–temporal trajectory consistency. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Dong, L.; Wang, B.; Zhao, M.; Xu, W. Robust infrared maritime target detection based on visual attention and spatiotemporal filtering. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3037–3050. [Google Scholar] [CrossRef]
- Gao, Y.; Wu, C.; Ren, M.; Feng, Y. Refined anchor-free model with feature enhancement mechanism for ship detection in infrared images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 12946–12960. [Google Scholar] [CrossRef]
- Yao, T.; Hu, J.; Zhang, B.; Gao, Y.; Li, P.; Hu, Q. Scale and appearance variation enhanced siamese network for thermal infrared target tracking. Infrared Phys. Technol. 2021, 117, 103825. [Google Scholar] [CrossRef]
- Guo, L.; Wang, Y.; Guo, M.; Zhou, X. YOLO-IRS: Infrared Ship Detection Algorithm Based on Self-Attention Mechanism and KAN in Complex Marine Background. Remote Sens. 2024, 17, 20. [Google Scholar] [CrossRef]
- Cao, Z.; Kong, X.; Zhu, Q.; Cao, S.; Peng, Z. Infrared dim target detection via mode-k1k2 extension tensor tubal rank under complex ocean environment. ISPRS J. Photogramm. Remote Sens. 2021, 181, 167–190. [Google Scholar] [CrossRef]
- Liu, Y.; Li, C.; Fu, G. PJ-YOLO: Prior-Knowledge and Joint-Feature-Extraction Based YOLO for Infrared Ship Detection. J. Mar. Sci. Eng. 2025, 13, 226. [Google Scholar] [CrossRef]
- Deshpande, S.D.; Er, M.H.; Venkateswarlu, R.; Chan, P. Max-mean and max-median filters for detection of small targets. In Proceedings of the Signal and Data Processing of Small Targets, Denver, CO, USA, 19–23 June 1999; SPIE: Washington, DC, USA, 1999; Volume 3809, pp. 74–83. [Google Scholar]
- Li, Y.; Li, Z.; Li, J.; Yang, J.; Siddique, A. Robust small infrared target detection using weighted adaptive ring top-hat transformation. Signal Process. 2024, 217, 109339. [Google Scholar] [CrossRef]
- Lin, F.; Bao, K.; Li, Y.; Zeng, D.; Ge, S. Learning contrast-enhanced shape-biased representations for infrared small target detection. IEEE Trans. Image Process. 2024, 33, 3047–3058. [Google Scholar] [CrossRef]
- Hao, C.; Li, Z.; Zhang, Y.; Chen, W.; Zou, Y. Infrared Small Target Detection Based on Adaptive Size Estimation by Multi-directional Gradient Filter. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5007915. [Google Scholar] [CrossRef]
- Yang, X.; Li, Y.; Li, D.; Wang, S.; Yang, Z. Siam-AUnet: An end-to-end infrared and visible image fusion network based on gray histogram. Infrared Phys. Technol. 2024, 141, 105488. [Google Scholar] [CrossRef]
- Wu, J.; He, Y.; Zhao, J. An infrared target images recognition and processing method based on the fuzzy comprehensive evaluation. IEEE Access 2024, 12, 12126–12137. [Google Scholar] [CrossRef]
- Gan, C.; Li, C.; Zhang, G.; Fu, G. DBNDiff: Dual-branch network-based diffusion model for infrared ship image super-resolution. Displays 2025, 88, 103005. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, B.; Fan, Y. PPGS-YOLO: A lightweight algorithms for offshore dense obstruction infrared ship detection. Infrared Phys. Technol. 2025, 145, 105736. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Chen, S.; Zhan, R.; Wang, W.; Zhang, J. Learning slimming SAR ship object detector through network pruning and knowledge distillation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1267–1282. [Google Scholar] [CrossRef]
- Zhan, W.; Zhang, C.; Guo, S.; Guo, J.; Shi, M. EGISD-YOLO: Edge guidance network for infrared ship target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 10097–10107. [Google Scholar] [CrossRef]
- Deng, H.; Zhang, Y. FMR-YOLO: Infrared ship rotating target detection based on synthetic fog and multiscale weighted feature fusion. IEEE Trans. Instrum. Meas. 2023, 73, 1–17. [Google Scholar] [CrossRef]
- Ge, Y.; Ji, H.; Liu, X. Infrared remote sensing ship image object detection model based on YOLO In multiple environments. Signal Image Video Process. 2025, 19, 1–12. [Google Scholar] [CrossRef]
- Sun, Z.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. BiFA-YOLO: A novel YOLO-based method for arbitrary-oriented ship detection in high-resolution SAR images. Remote Sens. 2021, 13, 4209. [Google Scholar] [CrossRef]
- Wang, W.; Li, Z.; Siddique, A. Infrared maritime small-target detection based on fusion gray gradient clutter suppression. Remote Sens. 2024, 16, 1255. [Google Scholar] [CrossRef]
- Guo, F.; Ma, H.; Li, L.; Lv, M.; Jia, Z. FCNet: Flexible convolution network for infrared small ship detection. Remote Sens. 2024, 16, 2218. [Google Scholar] [CrossRef]
- Zhou, A.; Xie, W.; Pei, J. Background modeling combined with multiple features in the Fourier domain for maritime infrared target detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Xie, B.; Hu, L.; Mu, W. Background suppression based on improved top-hat and saliency map filtering for infrared ship detection. In Proceedings of the 2017 International Conference on Computing Intelligence and Information System (CIIS), Nanjing, China, 21–23 April 2017; IEEE: New York, NY, USA, 2017; pp. 298–301. [Google Scholar]
- Cui, Z.; Yang, J.; Li, J.; Jiang, S. An infrared small target detection framework based on local contrast method. Measurement 2016, 91, 405–413. [Google Scholar] [CrossRef]
- Sun, H.; Jin, Q.; Xu, J.; Tang, L. Infrared small-target detection based on multi-level local contrast measure. Procedia Comput. Sci. 2023, 221, 549–556. [Google Scholar] [CrossRef]
- Wei, Y.; You, X.; Li, H. Multiscale patch-based contrast measure for small infrared target detection. Pattern Recognit. 2016, 58, 216–226. [Google Scholar] [CrossRef]
- Han, J.; Liang, K.; Zhou, B.; Zhu, X.; Zhao, J.; Zhao, L. Infrared small target detection utilizing the multiscale relative local contrast measure. IEEE Geosci. Remote Sens. Lett. 2018, 15, 612–616. [Google Scholar] [CrossRef]
- Zhou, A.; Xie, W.; Pei, J. Maritime infrared target detection using a dual-mode background model. Remote Sens. 2023, 15, 2354. [Google Scholar] [CrossRef]
- Lin, J.; Yu, Q.; Chen, G. Infrared ship target detection based on the combination of Bayesian theory and SVM. In Proceedings of the MIPPR 2019: Automatic Target Recognition and Navigation, Wuhan, China, 2–3 November 2019; SPIE: Washington, DC, USA, 2020; Volume 11429, pp. 244–251. [Google Scholar]
- Li, N.; Ding, L.; Zhao, H.; Shi, J.; Wang, D.; Gong, X. Ship Detection Based on Multiple Features in Random Forest Model for Hyperspectral Images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 891–895. [Google Scholar] [CrossRef]
- Ye, J.; Yuan, Z.; Qian, C.; Li, X. Caa-yolo: Combined-attention-augmented yolo for infrared ocean ships detection. Sensors 2022, 22, 3782. [Google Scholar] [CrossRef]
- Li, L.; Jiang, L.; Zhang, J.; Wang, S.; Chen, F. A complete YOLO-based ship detection method for thermal infrared remote sensing images under complex backgrounds. Remote Sens. 2022, 14, 1534. [Google Scholar] [CrossRef]
- Wu, T.; Li, B.; Luo, Y.; Wang, Y.; Xiao, C.; Liu, T.; Yang, J.; An, W.; Guo, Y. MTU-Net: Multilevel TransUNet for space-based infrared tiny ship detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Wu, H.; Huang, X.; He, C.; Xiao, H.; Luo, S. Infrared small target detection with Swin Transformer-based multi-scale atrous spatial pyramid pooling network. IEEE Trans. Instrum. Meas. 2024, 74, 5003914. [Google Scholar]
- Chen, F.; Gao, C.; Liu, F.; Zhao, Y.; Zhou, Y.; Meng, D.; Zuo, W. Local patch network with global attention for infrared small target detection. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 3979–3991. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, F.; Hu, P. Small-object detection in UAV-captured images via multi-branch parallel feature pyramid networks. IEEE Access 2020, 8, 145740–145750. [Google Scholar] [CrossRef]
- Yue, T.; Lu, X.; Cai, J.; Chen, Y.; Chu, S. YOLO-MST: Multiscale deep learning method for infrared small target detection based on super-resolution and YOLO. Opt. Laser Technol. 2025, 187, 112835. [Google Scholar] [CrossRef]
- Zhang, T.; Li, L.; Cao, S.; Pu, T.; Peng, Z. Attention-guided pyramid context networks for detecting infrared small target under complex background. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 4250–4261. [Google Scholar] [CrossRef]
- Xin, J.; Luo, M.; Cao, X.; Liu, T.; Yuan, J.; Liu, R.; Xin, Y. Infrared superpixel patch-image model for small target detection under complex background. Infrared Phys. Technol. 2024, 142, 105490. [Google Scholar] [CrossRef]
- Bao, C.; Cao, J.; Ning, Y.; Zhao, T.; Li, Z.; Wang, Z.; Zhang, L.; Hao, Q. Improved dense nested attention network based on transformer for infrared small target detection. arXiv 2023, arXiv:2311.08747. [Google Scholar]
- Rahman, M.M.; Munir, M.; Marculescu, R. Emcad: Efficient multi-scale convolutional attention decoding for medical image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 11769–11779. [Google Scholar]
- Raza, A.; Liu, J.; Liu, Y.; Liu, J.; Li, Z.; Chen, X.; Huo, H.; Fang, T. IR-MSDNet: Infrared and visible image fusion based on infrared features and multiscale dense network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3426–3437. [Google Scholar] [CrossRef]
- Chen, X.; Qiu, C.; Zhang, Z. A multiscale method for infrared ship detection based on morphological reconstruction and two-branch compensation strategy. Sensors 2023, 23, 7309. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Wang, S.; Wang, Y.; Chang, Y.; Zhao, R.; She, Y. EBSE-YOLO: High precision recognition algorithm for small target foreign object detection. IEEE Access 2023, 11, 57951–57964. [Google Scholar] [CrossRef]
- Hou, Q.; Wang, Z.; Tan, F.; Zhao, Y.; Zheng, H.; Zhang, W. RISTDnet: Robust infrared small target detection network. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, R.; Yang, Y.; Bai, H.; Zhang, J.; Guo, J. ISNet: Shape matters for infrared small target detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 877–886. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 11–13 April 2011; JMLR Workshop and Conference Proceedings. pp. 315–323. [Google Scholar]
- Zhang, Y.; Jiu, B.; Wang, P.; Liu, H.; Liang, S. An end-to-end anti-jamming target detection method based on CNN. IEEE Sen. J. 2021, 21, 21817–21828. [Google Scholar] [CrossRef]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? Adv. Neural Inf. Process. Syst. 2018, 31, 2488–2498. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Convolutional deep belief networks on cifar-10. Unpubl. Manuscr. 2010, 40, 1–9. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Zhao, L.; Fu, L.; Jia, X.; Cui, B.; Zhu, X.; Jin, J. YOLO-BOS: An Emerging Approach for Vehicle Detection with a Novel BRSA Mechanism. Sensors 2024, 24, 8126. [Google Scholar] [CrossRef]
- Liu, C.; Wang, K.; Li, Q.; Zhao, F.; Zhao, K.; Ma, H. Powerful-IoU: More straightforward and faster bounding box regression loss with a nonmonotonic focusing mechanism. Neural Net. 2024, 170, 276–284. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Han, Y.; Liao, J.; Lu, T.; Pu, T.; Peng, Z. KCPNet: Knowledge-driven context perception networks for ship detection in infrared imagery. IEEE Trans. Geosci. Remote Sens. 2022, 61, 1–19. [Google Scholar] [CrossRef]
- Hu, C.; Dong, X.; Huang, Y.; Wang, L.; Xu, L.; Pu, T.; Peng, Z. SMPISD-MTPNet: Scene Semantic Prior-Assisted Infrared Ship Detection Using Multi-Task Perception Networks. IEEE Trans. Geosci. Remote Sens. 2024, 63, 5000814. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Fei, X.; Guo, M.; Li, Y.; Yu, R.; Sun, L. ACDF-YOLO: Attentive and Cross-Differential Fusion Network for Multimodal Remote Sensing Object Detection. Remote Sens. 2024, 16, 3532. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Zhu, R.; Jin, H.; Han, Y.; He, Q.; Mu, H. Aircraft Target Detection in Remote Sensing Images Based on Improved YOLOv7-Tiny Network. IEEE Access 2025, 13, 48904–48922. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar] [CrossRef]
- Li, S.; Li, Y.; Li, Y.; Li, M.; Xu, X. Yolo-firi: Improved yolov5 for infrared image object detection. IEEE Access 2021, 9, 141861–141875. [Google Scholar] [CrossRef]
- Feng, Y.; Huang, J.; Du, S.; Ying, S.; Yong, J.H.; Li, Y.; Ding, G.; Ji, R.; Gao, Y. Hyper-yolo: When visual object detection meets hypergraph computation. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 47, 2388–2401. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense nested attention network for infrared small target detection. IEEE Trans. Image Process. 2022, 32, 1745–1758. [Google Scholar] [CrossRef] [PubMed]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional local contrast networks for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Jiang, Y.; Tan, Z.; Wang, J.; Sun, X.; Lin, M.; Li, H. GiraffeDet: A heavy-neck paradigm for object detection. arXiv 2022, arXiv:2202.04256. [Google Scholar]
- Yang, Z.; Guan, Q.; Yu, Z.; Xu, X.; Long, H.; Lian, S.; Hu, H.; Tang, Y. MHAF-YOLO: Multi-Branch Heterogeneous Auxiliary Fusion YOLO for accurate object detection. arXiv 2025, arXiv:2502.04656. [Google Scholar]
- Chen, Y.; Zhang, C.; Chen, B.; Huang, Y.; Sun, Y.; Wang, C.; Fu, X.; Dai, Y.; Qin, F.; Peng, Y.; et al. Accurate leukocyte detection based on deformable-DETR and multi-level feature fusion for aiding diagnosis of blood diseases. Comput. Biol. Med. 2024, 170, 107917. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Ma, S.; Xu, Y. Mpdiou: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, C.; Zhang, S. Inner-iou: More effective intersection over union loss with auxiliary bounding box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Nghiem, V.Q.; Nguyen, H.H.; Hoang, M.S. LEAF-YOLO: An Edge-Real-Time and Lightweight YOLO for Small Object Detection. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4868866 (accessed on 10 May 2025).
- Alqahtani, D.K.; Cheema, M.A.; Toosi, A.N. Benchmarking deep learning models for object detection on edge computing devices. In Proceedings of the International Conference on Service-Oriented Computing, Tunis, Tunisia, 3–6 December 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 142–150. [Google Scholar]
- Mittal, P. A comprehensive survey of deep learning-based lightweight object detection models for edge devices. Artif. Intell. Rev. 2024, 57, 242. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Model | Precision (%) | Recall (%) | (%) | (%) | APS@50 (%) | APM@50 (%) | GFLOPs | Parameters (M) |
|---|---|---|---|---|---|---|---|---|---|
| ISDD | SSD [20] | 89.3 | 80.4 | 88.4 | 41.5 | 81.1 | 88.5 | 87.5 | 24.4 |
| Faster R-CNN [18] | 86.7 | 83.8 | 91.8 | 39.7 | 84.9 | 90.0 | 134 | 41.3 | |
| YOLOv3 [67] | 90.7 | 83.6 | 89.6 | 45.1 | 86.3 | 89.4 | 282.2 | 103.7 | |
| YOLOv5n [68] | 92.1 | 85.2 | 91.5 | 45.6 | 89.8 | 94.6 | 7.1 | 2.5 | |
| YOLOv6n [69] | 89.7 | 83.9 | 89.3 | 44.9 | 88.2 | 95.1 | 11.8 | 4.2 | |
| YOLOv7-tiny [70] | 91.8 | 81.1 | 90.0 | 42.3 | 87.9 | 93.1 | 13.2 | 6.0 | |
| YOLOv8n [71] | 92.1 | 84.8 | 91.9 | 45.2 | 90.5 | 94.7 | 8.1 | 3.0 | |
| RT-DETR-l [72] | 84.3 | 76.1 | 84.3 | 39.2 | 87.7 | 91.2 | 100.6 | 28.4 | |
| YOLOv11n [73] | 90.0 | 85.0 | 90.8 | 44.6 | 86.3 | 92.4 | 6.3 | 2.6 | |
| YOLO-FIRI [74] | 89.9 | 82.9 | 88.7 | 43.4 | 85.3 | 93.2 | 6.8 | 4.7 | |
| Hyper-YOLO [75] | 91.8 | 85.3 | 90.9 | 44.7 | 90.0 | 94.8 | 12.5 | 5.3 | |
| DNA-Net [76] | 90.6 | 84.6 | 91.7 | 42.5 | 90.1 | 92.7 | 44.0 | 10.5 | |
| ALCNet [77] | 90.3 | 81.7 | 89.1 | 40.9 | 89.7 | 94.9 | 68 | 14.7 | |
| IRSD-Net | 92.2 | 85.6 | 92.5 | 45.7 | 91.2 | 96.8 | 6.5 | 2.1 | |
| IRSDSS | SSD [20] | 84.9 | 85.5 | 88.3 | 40.6 | 90.7 | 92.6 | 87.5 | 24.4 |
| Faster R-CNN [18] | 88.9 | 87.3 | 91.8 | 39.7 | 89.1 | 93.2 | 134 | 41.3 | |
| YOLOv3 [67] | 92.0 | 88.1 | 92.2 | 43.5 | 91.0 | 92.0 | 282.2 | 103.7 | |
| YOLOv5n [68] | 91.9 | 89.2 | 92.8 | 42.8 | 92.8 | 95.9 | 7.1 | 2.5 | |
| YOLOv6n [69] | 91.7 | 86.9 | 91.8 | 43.3 | 91.9 | 96.4 | 11.8 | 4.2 | |
| YOLOv7-tiny [70] | 87.2 | 84.7 | 90.5 | 41.3 | 91.4 | 94.7 | 13.2 | 6.0 | |
| YOLOv8n [71] | 91.5 | 89.1 | 92.8 | 42.7 | 93.2 | 95.1 | 8.1 | 3.0 | |
| RT-DETR-l [72] | 83.8 | 83.5 | 86.3 | 38.0 | 92.7 | 94.8 | 100.6 | 28.4 | |
| YOLOv11n [73] | 91.3 | 87.9 | 91.8 | 42.6 | 92.9 | 94.5 | 6.3 | 2.6 | |
| YOLO-FIRI [74] | 90.8 | 88.0 | 91.9 | 41.1 | 93.8 | 95.7 | 6.8 | 4.7 | |
| Hyper-YOLO [75] | 91.9 | 86.7 | 92.1 | 40.9 | 94.2 | 96.1 | 12.5 | 5.3 | |
| DNA-Net [76] | 89.6 | 88.1 | 92.0 | 40.4 | 92.7 | 95.9 | 44.0 | 10.5 | |
| ALCNet [77] | 91.2 | 87.1 | 90.7 | 42.9 | 93.4 | 95.8 | 13.2 | 6.0 | |
| IRSD-Net | 92.1 | 88.7 | 92.9 | 43.7 | 94.9 | 97.8 | 6.5 | 2.1 |
| Dataset | Model | Precision (%) | Recall (%) | (%) | (%) | APS@50 (%) | APM@50 (%) | GFLOPs | Parameters (M) |
|---|---|---|---|---|---|---|---|---|---|
| ISDD | YOLOv11-Neck [73] | 91.3 | 85.3 | 91.2 | 45.6 | 90.4 | 94.2 | 6.3 | 2.5 |
| BIFPN [53] | 90.6 | 85.8 | 91.4 | 45.1 | 90.9 | 94.5 | 6.2 | 1.9 | |
| GFPN [78] | 90.3 | 86.3 | 91.4 | 45.3 | 89.3 | 95.7 | 8.5 | 3.2 | |
| MAFPN [79] | 91.3 | 86.8 | 91.8 | 45.1 | 90.6 | 96.0 | 7.0 | 2.6 | |
| HS-FPN [80] | 91.9 | 85.5 | 91.6 | 45.6 | 90.2 | 95.9 | 5.5 | 1.8 | |
| DCSFPN | 92.2 | 85.6 | 92.5 | 45.7 | 91.2 | 96.8 | 6.5 | 2.1 | |
| IRSDSS | YOLOv11-Neck [73] | 91.7 | 88.6 | 92.6 | 43.7 | 94.5 | 96.3 | 6.3 | 2.5 |
| BIFPN [53] | 91.5 | 88.2 | 92.4 | 43.6 | 93.6 | 96.6 | 6.2 | 1.9 | |
| GFPN [78] | 91.6 | 89.0 | 92.8 | 43.3 | 93.9 | 95.8 | 8.5 | 3.2 | |
| MAFPN [79] | 92.0 | 88.6 | 92.3 | 43.6 | 94.3 | 97.2 | 7.0 | 2.6 | |
| HS-FPN [80] | 91.4 | 88.4 | 92.3 | 43.5 | 92.8 | 97.7 | 5.5 | 1.8 | |
| DCSFPN | 92.1 | 88.7 | 92.9 | 43.7 | 94.9 | 97.8 | 6.5 | 2.1 |
| Dataset | Loss Function | Precision (%) | Recall (%) | (%) | (%) | APS@50 (%) | APM@50 (%) | GFLOPs | Parameters (M) |
|---|---|---|---|---|---|---|---|---|---|
| ISDD | CIoU [81] | 91.2 | 85.5 | 91.1 | 45.1 | 90.0 | 95.1 | 6.5 | 2.1 |
| PIOU v2 [63] | 91.3 | 84.6 | 91.1 | 44.8 | 90.1 | 95.7 | 6.5 | 2.1 | |
| Wise-IoU [64] | 91.1 | 84.7 | 90.7 | 44.6 | 89.5 | 96.3 | 6.5 | 2.1 | |
| MPDIoU [82] | 88.2 | 85.9 | 90.6 | 44.9 | 90.0 | 95.7 | 6.5 | 2.1 | |
| Inner-CIoU [83] | 90.6 | 84.2 | 90.4 | 44.8 | 89.2 | 93.5 | 6.5 | 2.1 | |
| Wise-PIoU | 92.2 | 85.6 | 92.5 | 45.7 | 91.2 | 96.8 | 6.5 | 2.1 | |
| IRSDSS | CIoU [81] | 91.5 | 87.2 | 92.8 | 42.3 | 93.2 | 95.8 | 6.5 | 2.1 |
| PIOU v2 [63] | 91.3 | 87.7 | 91.9 | 43.5 | 94.4 | 95.9 | 6.5 | 2.1 | |
| Wise-IoU [64] | 91.0 | 87.8 | 92.0 | 43.6 | 94.1 | 96.2 | 6.5 | 2.1 | |
| MPDIoU [82] | 92.0 | 87.3 | 91.5 | 43.0 | 93.7 | 97.9 | 6.5 | 2.1 | |
| Inner-CIoU [83] | 91.9 | 88.1 | 92.3 | 43.1 | 92.9 | 96.6 | 6.5 | 2.1 | |
| Wise-PIoU | 92.1 | 88.7 | 92.9 | 43.7 | 94.9 | 97.8 | 6.5 | 2.1 |
| Dataset | Kernel Configuration | (%) | APS@50 (%) | APM@50 (%) | GFLOPs | Parameters (M) |
|---|---|---|---|---|---|---|
| ISDD | 3 × 3 | 91.5 | 91.1 | 91.6 | 2.10 | 6.7 |
| [1, 3] | 90.6 | 91.1 | 95.3 | 2.09 | 6.7 | |
| [3, 5] | 91.3 | 91.0 | 94.7 | 2.07 | 6.7 | |
| [5, 7] | 89.5 | 88.3 | 96.2 | 2.09 | 6.6 | |
| [1, 3, 5] | 90.2 | 90.8 | 92.1 | 2.07 | 6.6 | |
| [3, 5, 7] | 90.7 | 89.6 | 95.9 | 2.09 | 6.5 | |
| [1, 3, 5, 9] | 92.1 | 91.0 | 96.5 | 2.10 | 6.7 | |
| [3, 5, 7, 9] | 91.5 | 90.2 | 97.8 | 2.12 | 6.8 | |
| [1, 3, 5, 7] (ours) | 92.5 | 91.2 | 96.8 | 2.07 | 6.5 | |
| IRSDSS | 3 × 3 | 89.4 | 90.8 | 89.1 | 2.10 | 6.7 |
| [1, 3] | 89.0 | 92.0 | 91.5 | 2.09 | 6.7 | |
| [3, 5] | 90.7 | 91.4 | 92.3 | 2.07 | 6.7 | |
| [5, 7] | 90.5 | 91.6 | 96.6 | 2.09 | 6.6 | |
| [1, 3, 5] | 91.7 | 92.2 | 94.7 | 2.07 | 6.6 | |
| [3, 5, 7] | 91.2 | 88.7 | 95.2 | 2.09 | 6.5 | |
| [1, 3, 5, 9] | 91.5 | 91.8 | 96.9 | 2.10 | 6.7 | |
| [3, 5, 7, 9] | 91.3 | 90.1 | 97.2 | 2.12 | 6.7 | |
| [1, 3, 5, 7] (ours) | 92.9 | 92.1 | 97.8 | 2.07 | 6.5 |
| Dataset | Precision (%) | Recall (%) | (%) | (%) | |||
|---|---|---|---|---|---|---|---|
| ISDD | 1.1 | 1.5 | 2.5 | 91.6 | 85.4 | 92.0 | 45.5 |
| 1.1 | 1.7 | 2.7 | 91.5 | 85.3 | 92.3 | 44.7 | |
| 1.3 | 1.5 | 2.7 | 91.7 | 84.3 | 89.9 | 45.1 | |
| 1.3 | 1.7 | 2.5 | 92.0 | 85.1 | 92.1 | 44.8 | |
| 1.3 | 1.7 | 3.0 | 91.7 | 85.2 | 92.0 | 45.2 | |
| 1.3 | 1.9 | 3.0 | 90.8 | 84.7 | 91.4 | 45.0 | |
| 1.5 | 1.7 | 2.7 | 91.9 | 85.3 | 92.0 | 45.2 | |
| 1.3 | 1.9 | 3.0 | 90.2 | 84.2 | 91.7 | 44.3 | |
| 1.3 (ours) | 1.7 (ours) | 2.7 (ours) | 92.2 | 85.6 | 92.5 | 45.7 | |
| IRSDSS | 1.1 | 1.5 | 2.5 | 90.5 | 88.6 | 92.1 | 42.1 |
| 1.1 | 1.7 | 2.7 | 91.7 | 88.2 | 91.8 | 43.6 | |
| 1.3 | 1.5 | 2.7 | 90.8 | 89.2 | 92.2 | 42.0 | |
| 1.3 | 1.7 | 2.5 | 91.4 | 87.3 | 92.5 | 43.5 | |
| 1.3 | 1.7 | 3.0 | 91.6 | 88.4 | 92.0 | 42.6 | |
| 1.3 | 1.9 | 3.0 | 91.9 | 87.9 | 91.4 | 42.9 | |
| 1.5 | 1.7 | 2.7 | 91.4 | 88.5 | 92.7 | 41.8 | |
| 1.3 | 1.9 | 3.0 | 91.1 | 87.4 | 91.2 | 41.4 | |
| 1.3 (ours) | 1.7 (ours) | 2.7 (ours) | 92.1 | 88.7 | 92.9 | 43.7 |
| Original | HMKCNet | DCSFPN | Wise-PIoU | Precision (%) | Recall (%) | (%) | (%) | APS@50 (%) | APM@50 (%) | GFLOPs | Parameters (M) | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 90.0 | 85.0 | 90.8 | 44.6 | 86.3 | 92.4 | 6.3 | 2.6 | 909.1 | |||
| ✓ | ✓ | 91.6 | 85.9 | 92.3 | 45.1 | 88.5 | 93.9 | 6.3 | 2.5 | 833.3 | ||
| ✓ | ✓ | 92.1 | 85.2 | 91.3 | 45.0 | 90.1 | 93.1 | 6.5 | 2.1 | 769.2 | ||
| ✓ | ✓ | 90.4 | 86.1 | 91.2 | 45.5 | 89.4 | 95.3 | 6.3 | 2.6 | 833.3 | ||
| ✓ | ✓ | ✓ | 91.2 | 85.5 | 91.1 | 45.1 | 90.0 | 95.1 | 6.5 | 2.1 | 625.0 | |
| ✓ | ✓ | ✓ | 91.3 | 85.3 | 91.2 | 45.6 | 90.9 | 94.2 | 6.3 | 2.5 | 909.1 | |
| ✓ | ✓ | ✓ | 91.5 | 85.2 | 91.7 | 45.3 | 90.5 | 95.6 | 6.5 | 2.1 | 714.3 | |
| ✓ | ✓ | ✓ | ✓ | 92.2 | 85.6 | 92.5 | 45.7 | 91.2 | 96.8 | 6.5 | 2.1 | 714.3 |
| Original | HMKCNet | DCSFPN | Wise-PIoU | Precision (%) | Recall (%) | (%) | (%) | APS@50 (%) | APM@50 (%) | GFLOPs | Parameters (M) | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 91.3 | 87.9 | 91.8 | 42.6 | 91.3 | 94.5 | 6.3 | 2.6 | 1111.1 | |||
| ✓ | ✓ | 91.4 | 88.5 | 92.4 | 42.7 | 91.4 | 95.4 | 6.3 | 2.6 | 833.3 | ||
| ✓ | ✓ | 91.9 | 87.4 | 92.3 | 43.2 | 91.9 | 94.7 | 6.5 | 2.1 | 666.7 | ||
| ✓ | ✓ | 91.2 | 89.1 | 92.1 | 43.5 | 91.2 | 95.9 | 6.3 | 2.6 | 909.1 | ||
| ✓ | ✓ | ✓ | 91.5 | 87.2 | 92.8 | 42.3 | 91.5 | 95.8 | 6.5 | 2.1 | 625.0 | |
| ✓ | ✓ | ✓ | 91.7 | 88.6 | 92.6 | 43.7 | 91.7 | 96.3 | 6.3 | 2.5 | 909.1 | |
| ✓ | ✓ | ✓ | 92.0 | 88.3 | 92.4 | 42.9 | 92.0 | 96.7 | 6.5 | 2.1 | 769.2 | |
| ✓ | ✓ | ✓ | ✓ | 92.1 | 88.7 | 92.9 | 43.7 | 92.1 | 97.8 | 6.5 | 2.1 | 769.2 |
| Dataset | Model Configuration | Precision (%) | Recall (%) | (%) | (%) | APS@50 (%) | APM@50 (%) | GFLOPs | Parameters (M) |
|---|---|---|---|---|---|---|---|---|---|
| ISDD | Baseline | 91.5 | 87.4 | 91.8 | 45.4 | 90.2 | 91.8 | 22.0 | 7.9 |
| + HMKCNet | 92.1 | 88.2 | 92.3 | 45.3 | 90.9 | 92.8 | 22.0 | 7.9 | |
| + HMKCNet + DCSFPN | 92.7 | 88.1 | 92.7 | 45.8 | 91.4 | 93.9 | 22.3 | 7.5 | |
| + HMKCNet + DCSFPN + Wise-PIoU | 93.3 | 88.4 | 93.1 | 46.1 | 92.3 | 93.6 | 22.3 | 7.5 | |
| IRSDSS | Baseline | 91.8 | 88.3 | 92.9 | 44.8 | 92.3 | 95.6 | 22.0 | 7.9 |
| + HMKCNet | 92.0 | 88.9 | 93.2 | 45.7 | 92.5 | 97.3 | 22.0 | 7.9 | |
| + HMKCNet + DCSFPN | 92.6 | 89.2 | 93.4 | 44.9 | 92.7 | 97.6 | 22.3 | 7.5 | |
| + HMKCNet + DCSFPN + Wise-PIoU | 92.9 | 89.6 | 93.7 | 45.9 | 92.9 | 97.9 | 22.3 | 7.5 |
| Dataset | Platform | Model | FPS | Latency (ms) | (%) | GFLOPs | Parameters (M) | Memory (MB) |
|---|---|---|---|---|---|---|---|---|
| ISDD | RTX4090 | YOLOv11n | 909.1 | 1.1 | 90.8 | 6.3 | 2.6 | 73.7 |
| IRSD-Net | 714.3 | 1.4 | 92.5 (+1.7) | 6.5 | 2.1 | 78.0 | ||
| RTX3060 | YOLOv11n | 260.5 | 3.8 | 90.5 | 6.3 | 2.6 | 50.2 | |
| IRSD-Net | 242.5 | 4.1 | 91.6 (+1.1) | 6.5 | 2.1 | 53.2 | ||
| CPU | YOLOv11n | 13.07 | 76.5 | 90.5 | 6.3 | 2.6 | 378 | |
| IRSD-Net | 6.09 | 164.3 | 92.1 (+1.6) | 6.5 | 2.1 | 374 | ||
| IRSDSS | RTX4090 | YOLOv11n | 1111.1 | 0.9 | 91.8 | 6.3 | 2.6 | 73.7 |
| IRSD-Net | 769.2 | 1.3 | 92.9 (+1.1) | 6.5 | 2.1 | 78.0 | ||
| RTX3060 | YOLOv11n | 270.3 | 3.7 | 91.7 | 6.3 | 2.6 | 50.2 | |
| IRSD-Net | 238.2 | 4.2 | 92.8 (+1.1) | 6.5 | 2.1 | 53.2 | ||
| CPU | YOLOv11n | 12.85 | 77.8 | 91.4 | 6.3 | 2.6 | 378 | |
| IRSD-Net | 5.93 | 168.6 | 91.5 (0.1) | 6.5 | 2.1 | 374 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Lian, J. IRSD-Net: An Adaptive Infrared Ship Detection Network for Small Targets in Complex Maritime Environments. Remote Sens. 2025, 17, 2643. https://doi.org/10.3390/rs17152643
Sun Y, Lian J. IRSD-Net: An Adaptive Infrared Ship Detection Network for Small Targets in Complex Maritime Environments. Remote Sensing. 2025; 17(15):2643. https://doi.org/10.3390/rs17152643
Chicago/Turabian StyleSun, Yitong, and Jie Lian. 2025. "IRSD-Net: An Adaptive Infrared Ship Detection Network for Small Targets in Complex Maritime Environments" Remote Sensing 17, no. 15: 2643. https://doi.org/10.3390/rs17152643
APA StyleSun, Y., & Lian, J. (2025). IRSD-Net: An Adaptive Infrared Ship Detection Network for Small Targets in Complex Maritime Environments. Remote Sensing, 17(15), 2643. https://doi.org/10.3390/rs17152643