Detecting Planting Holes Using Improved YOLO-PH Algorithm with UAV Images



Abstract
1. Introduction
2. Study Area and Data
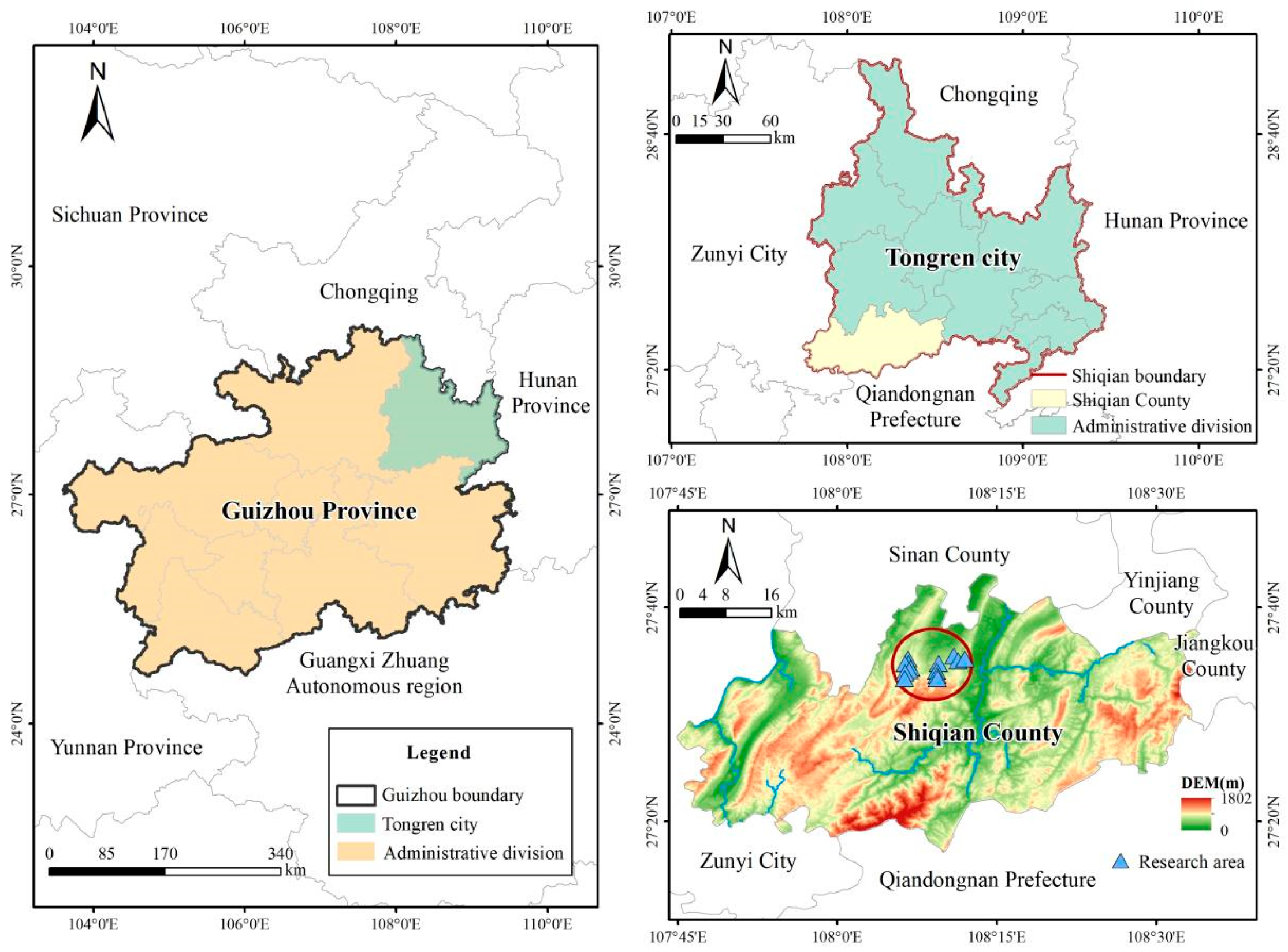
2.1. Study Area
2.2. Datasets
3. Methods
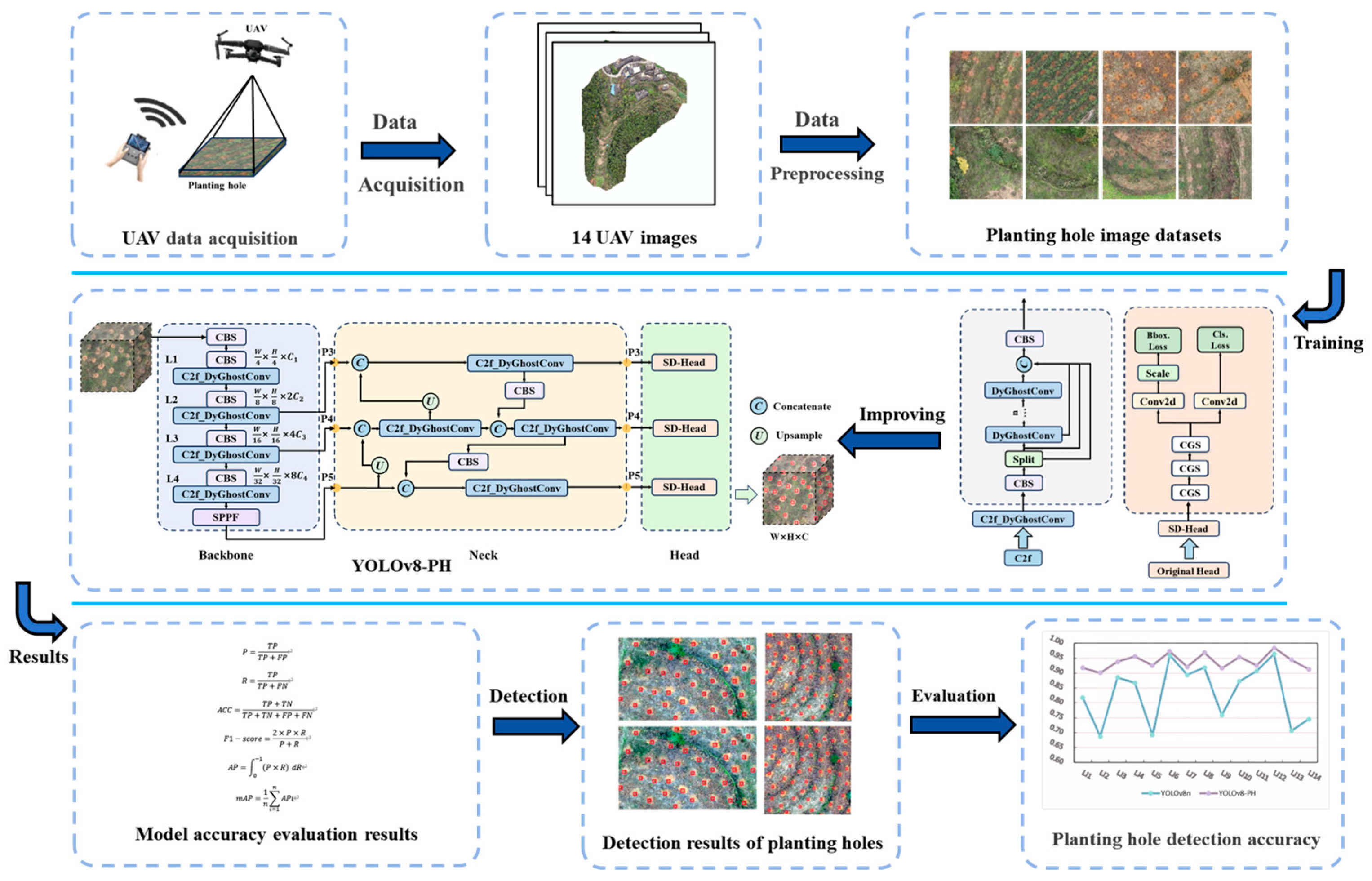
3.1. YOLOv8 Detection Algorithm
3.2. Improved YOLO-PH Detection Algorithm
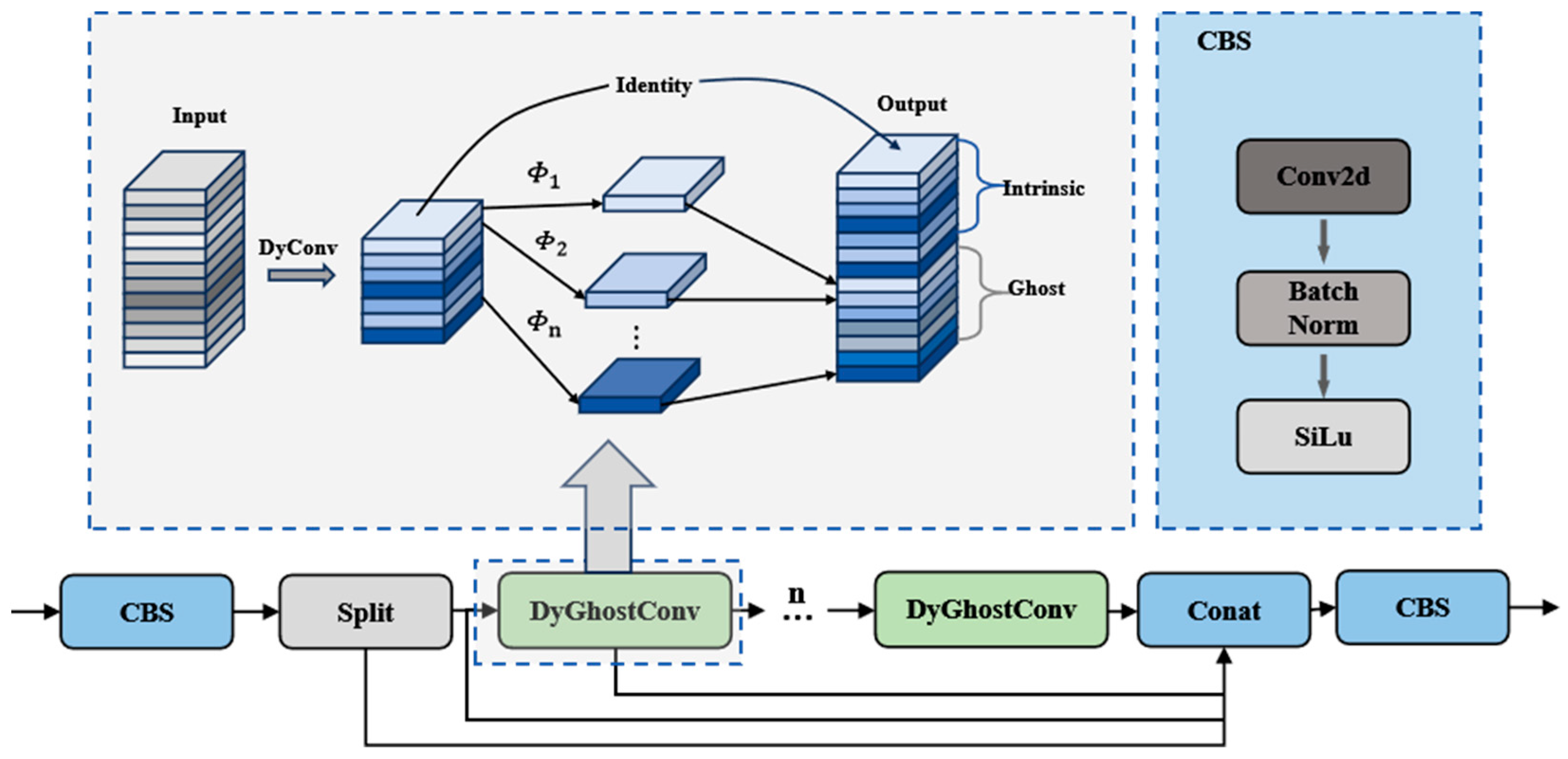
3.2.1. C2f_DyGhostConv Module
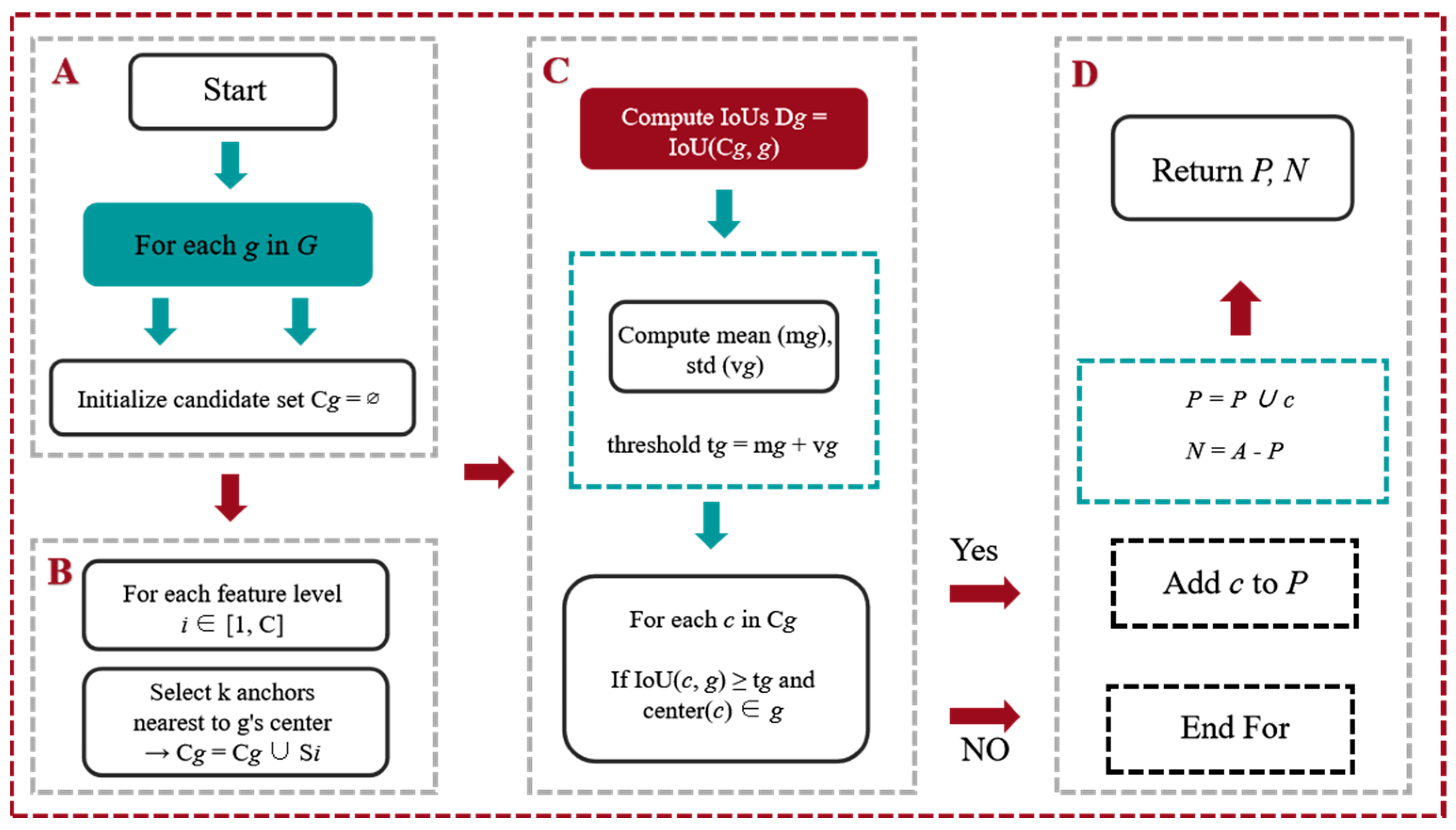
3.2.2. Adaptive Training Sample Selection
3.2.3. Siblings Detection Head
3.3. Detection Process of Planting Holes
4. Results
4.1. Experimental Environment Configuration
4.2. Model Performance Evaluation Indicators
4.3. Results of Ablation Experiments
4.4. Detection Results of Planting Holes
4.4.1. The Performance of YOLO-PH Detection Algorithm
4.4.2. Detection Results of Planting Holes
5. Discussion
6. Conclusions
- (1)
- Introducing lightweight feature modules such as the Ghost module and dynamic convolution, along with a new detection head called Siblings Detection Head, resulted in the proposed YOLO-PH model that is suitable for detecting planting holes in complex scenes.
- (2)
- The experimental results demonstrate that the YOLO-PH model achieves a mAP50 of 96%, mAP50:95 of 51.6%, FLOPs of 4.2 G, and detection speed of 220.7 FPS. Compared to the baseline model, there is an improvement in mAP50 by 1.3% and mAP50:95 by 1.1%. Additionally, the detection speed has increased by 13.8%, while FLOPs have been reduced by 48.8%.
- (3)
- Further evaluation of the model’s detection performance in complex scenes demonstrated its exceptional accuracy and robustness in detecting planting holes. The model exhibits remarkable precision and rapid detection capabilities, and is well-suited for deployment on resource-constrained devices.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Paudel, D.; Boogaard, H.; de Wit, A.; Janssen, S.; Osinga, S.; Pylianidis, C.; Athanasiadis, I.N. Machine Learning for Large-Scale Crop Yield Forecasting. Agric. Syst. 2021, 187, 103016. [Google Scholar] [CrossRef]
- Mulla, D.J. Twenty Five Years of Remote Sensing in Precision Agriculture: Key Advances and Remaining Knowledge Gaps. Biosyst. Eng. 2013, 114, 358–371. [Google Scholar] [CrossRef]
- Sishodia, R.P.; Ray, R.L.; Singh, S.K. Applications of Remote Sensing in Precision Agriculture: A Review. Remote Sens. 2020, 12, 3136. [Google Scholar] [CrossRef]
- Faiçal, B.S.; Freitas, H.; Gomes, P.H.; Mano, L.Y.; Pessin, G.; de Carvalho, A.C.P.L.F.; Krishnamachari, B.; Ueyama, J. An Adaptive Approach for UAV-Based Pesticide Spraying in Dynamic Environments. Comput. Electron. Agric. 2017, 138, 210–223. [Google Scholar] [CrossRef]
- Hopkins, M. The Role of Drone Technology in Sustainable Agriculture—Global Ag Tech Initiative. Available online: https://www.precisionag.com/in-fieldtechnologies/drones-uavs/the-role-of-drone-technology-in-sustainable-agriculture/ (accessed on 11 March 2021).
- Wu, J.; Yang, G.; Yang, H.; Zhu, Y.; Li, Z.; Lei, L.; Zhao, C. Extracting Apple Tree Crown Information from Remote Imagery Using Deep Learning. Comput. Electron. Agric. 2020, 174, 105504. [Google Scholar] [CrossRef]
- Liu, S.; Yin, D.; Feng, H.; Li, Z.; Xu, X.; Shi, L.; Jin, X. Estimating Maize Seedling Number with UAV RGB Images and Advanced Image Processing Methods. Precis. Agric. 2022, 23, 1604–1632. [Google Scholar] [CrossRef]
- Luo, X.; Wu, Y.; Zhao, L. YOLOD: A Target Detection Method for UAV Aerial Imagery. Remote Sens. 2022, 14, 3240. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep Learning in Agriculture: A Survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Osco, L.P.; Marcato Junior, J.; Marques Ramos, A.P.; de Castro Jorge, L.A.; Fatholahi, S.N.; de Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A Review on Deep Learning in UAV Remote Sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, H.; Meng, Z.; Chen, J. Deep Learning-Based Automatic Recognition Network of Agricultural Machinery Images. Comput. Electron. Agric. 2019, 166, 104978. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Jiang, B.; Wang, P.; Zhuang, S.; Li, M.; Li, Z.; Gong, Z. Detection of Maize Drought Based on Texture and Morphological Features. Comput. Electron. Agric. 2018, 151, 50–60. [Google Scholar] [CrossRef]
- Han, L.; Yang, G.; Dai, H.; Xu, B.; Yang, H.; Feng, H.; Li, Z.; Yang, X. Modeling Maize Above-Ground Biomass Based on Machine Learning Approaches Using UAV Remote-Sensing Data. Plant Methods 2019, 15, 10. [Google Scholar] [CrossRef]
- Zan, X.; Zhang, X.; Xing, Z.; Liu, W.; Zhang, X.; Su, W.; Liu, Z.; Zhao, Y.; Li, S. Automatic Detection of Maize Tassels from UAV Images by Combining Random Forest Classifier and VGG16. Remote Sens. 2020, 12, 3049. [Google Scholar] [CrossRef]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A Review of Object Detection Based on Deep Learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Mittal, P.; Singh, R.; Sharma, A. Deep Learning-Based Object Detection in Low-Altitude UAV Datasets: A Survey. Image Vis. Comput. 2020, 104, 104046. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2020; Volume 12346 LNCS. [Google Scholar]
- Soviany, P.; Ionescu, R.T. Optimizing the Trade-off between Single-Stage and Two-Stage Deep Object Detectors Using Image Difficulty Prediction. In Proceedings of the 2018 20th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing, SYNASC 2018, Timisoara, Romania, 20–23 September 2018. [Google Scholar]
- Luo, X.; Tian, X.; Zhang, H.; Hou, W.; Leng, G.; Xu, W.; Jia, H.; He, X.; Wang, M.; Zhang, J. Fast Automatic Vehicle Detection in UAV Images Using Convolutional Neural Networks. Remote Sens. 2020, 12, 1994. [Google Scholar] [CrossRef]
- Bao, W.; Du, X.; Wang, N.; Yuan, M.; Yang, X. A Defect Detection Method Based on BC-YOLO for Transmission Line Components in UAV Remote Sensing Images. Remote Sens. 2022, 14, 5176. [Google Scholar] [CrossRef]
- Qin, Z.; Wang, W.; Dammer, K.H.; Guo, L.; Cao, Z. Ag-YOLO: A Real-Time Low-Cost Detector for Precise Spraying With Case Study of Palms. Front. Plant Sci. 2021, 12, 753603. [Google Scholar] [CrossRef]
- Boudjit, K.; Ramzan, N. Human Detection Based on Deep Learning YOLO-v2 for Real-Time UAV Applications. J. Exp. Theor. Artif. Intell. 2022, 34, 527–544. [Google Scholar] [CrossRef]
- Chen, G.; Cheng, R.; Lin, X.; Jiao, W.; Bai, D.; Lin, H. LMDFS: A Lightweight Model for Detecting Forest Fire Smoke in UAV Images Based on YOLOv7. Remote Sens. 2023, 15, 3790. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Zhou, Y. A YOLO-NL Object Detector for Real-Time Detection. Expert Syst. Appl. 2024, 238, 122256. [Google Scholar] [CrossRef]
- Vasanthi, P.; Mohan, L. Multi-Head-Self-Attention Based YOLOv5X-Transformer for Multi-Scale Object Detection. Multimed. Tools Appl. 2024, 83, 36491–36517. [Google Scholar] [CrossRef]
- Jianqiang, L.; Haoxuan, L.; Chaoran, Y.; Xiao, L.; Jiewei, H.; Haiwei, W.; Liang, W.; Caijuan, Y. Tea Bud DG: A Lightweight Tea Bud Detection Model Based on Dynamic Detection Head and Adaptive Loss Function. Comput. Electron. Agric. 2024, 227, 109522. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic Head: Unifying Object Detection Heads with Attentions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zhang, C.; Gao, Q.; Shi, R.; Yue, M. LDHD-Net: A Lightweight Network With Double Branch Head for Feature Enhancement of UAV Targets in Complex Scenes. Int. J. Intell. Syst. 2024, 2024, 7259029. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobile-Former: Bridging MobileNet and Transformer. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. TOOD: Task-Aligned One-Stage Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. Int. J. Comput. Vis. 2020, 128, 742–755. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Types of Scenes | The Number of Regions |
|---|---|
| Simple Scenes | Region 1, Region 3, Region 4, Region 6, Region 7, Region 8, Region 10, Region 11, Region 12 |
| Complex Scenes | Region 2, Region 5, Region 9, Region 13, Region 14 |
| Datasets | Number of Images | Planting Holes |
|---|---|---|
| Training set | 779 | 5449 |
| Test set | 223 | 1552 |
| Validation set | 111 | 816 |
| Total | 1113 | 7817 |
| Experimental Environment | Specific Parameters |
|---|---|
| CPU | 12 vCPU Intel(R) Xeon(R) Platinum 8352 V CPU @ 2.10 GHz |
| GPU | NVIDIA GeForce RTX 4090 24 GB |
| PyTorch | 2.0.0 |
| CUDA | 11.8 |
| Model | A | B | C | mAP50 /% | mAP75 /% | mAP50:95 /% | Parameter /M | FLOPs /G | Detection Speed /FPS |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv8n | 94.7 | 48.0 | 50.5 | 3.01 | 8.2 | 193.9 | |||
| YOLOv8n-A | √ | 94.9 | 48.2 | 50.3 | 2.18 | 5.8 | 208.6 | ||
| YOLOv8n-B | √ | 94.8 | 49.1 | 50.8 | 2.36 | 6.6 | 204.5 | ||
| YOLOv8n-C | √ | 94.9 | 50.0 | 50.6 | 3.01 | 8.2 | 193.9 | ||
| YOLOv8n-AB | √ | √ | 95.8 | 48.7 | 51.1 | 1.54 | 4.2 | 220.7 | |
| YOLOv8n-AC | √ | √ | 95.5 | 48.8 | 51.4 | 2.18 | 5.8 | 208.6 | |
| YOLOv8n-BC | √ | √ | 95.3 | 49.7 | 51.8 | 2.36 | 6.6 | 204.5 | |
| YOLO-PH | √ | √ | √ | 96.0 | 50.1 | 51.6 | 1.54 | 4.2 | 220.7 |
| Mode | mAP50 /% | mAP75 /% | mAP50:95 /% | Parameter /M | FLOPs /G | Detection Speed /FPS |
|---|---|---|---|---|---|---|
| YOLO-PH | 96.0 | 50.1 | 51.6 | 1.54 | 4.2 | 220.7 |
| YOLOv8n | 94.7 | 48.0 | 50.5 | 3.01 | 8.2 | 193.9 |
| YOLOv11n | 95.1 | 47.9 | 50.1 | 2.40 | 6.1 | 201.6 |
| YOLOv7-tiny | 94.5 | 47.1 | 49.8 | 5.98 | 13.2 | 196.7 |
| YOLOv5n | 94.8 | 49.2 | 51.0 | 1.70 | 4.2 | 214.9 |
| RetinaNet-R18 | 94.8 | 47.5 | 48.5 | 20.03 | 96 | 93.3 |
| Faster R-CNN-R18 | 95.2 | 48.2 | 52.6 | 28.7 | 101 | 82.7 |
| Model | Actual | Detection | Missed Detections | False Positive | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|
| YOLO-PH | 7817 | 7559 | 511 | 253 | 0.91 | 0.97 | 0.93 | 0.95 |
| YOLOv8n | 7817 | 6470 | 1496 | 149 | 0.79 | 0.98 | 0.81 | 0.88 |
| YOLOv5n | 7817 | 7480 | 923 | 586 | 0.82 | 0.92 | 0.88 | 0.90 |
| YOLOv11n | 7817 | 7159 | 939 | 281 | 0.85 | 0.96 | 0.88 | 0.92 |
| YOLOv7-tiny | 7817 | 6750 | 1453 | 386 | 0.78 | 0.94 | 0.81 | 0.87 |
| RetinaNet-R18 | 7817 | 6932 | 1306 | 421 | 0.79 | 0.94 | 0.83 | 0.88 |
| Faster R-CNN-R18 | 7817 | 7005 | 1204 | 392 | 0.81 | 0.94 | 0.85 | 0.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Long, K.; Li, S.; Long, J.; Lin, H.; Yin, Y. Detecting Planting Holes Using Improved YOLO-PH Algorithm with UAV Images. Remote Sens. 2025, 17, 2614. https://doi.org/10.3390/rs17152614
Long K, Li S, Long J, Lin H, Yin Y. Detecting Planting Holes Using Improved YOLO-PH Algorithm with UAV Images. Remote Sensing. 2025; 17(15):2614. https://doi.org/10.3390/rs17152614
Chicago/Turabian StyleLong, Kaiyuan, Shibo Li, Jiangping Long, Hui Lin, and Yang Yin. 2025. "Detecting Planting Holes Using Improved YOLO-PH Algorithm with UAV Images" Remote Sensing 17, no. 15: 2614. https://doi.org/10.3390/rs17152614
APA StyleLong, K., Li, S., Long, J., Lin, H., & Yin, Y. (2025). Detecting Planting Holes Using Improved YOLO-PH Algorithm with UAV Images. Remote Sensing, 17(15), 2614. https://doi.org/10.3390/rs17152614