Abstract
The efficient recognition of unpaved roads from remote sensing (RS) images holds significant value for tasks such as emergency response and route planning in outdoor environments. However, unpaved roads often face challenges such as blurred boundaries, low contrast, complex shapes, and a lack of publicly available datasets. To address these issues, this paper proposes a novel architecture, Swin-FSNet, which combines frequency analysis and spatial enhancement techniques to optimize feature extraction. The architecture consists of two core modules: the Wavelet-Based Feature Decomposer (WBFD) module and the Hybrid Dynamic Snake Block (HyDS-B) module. The WBFD module enhances boundary detection by capturing directional gradient changes at the road edges and extracting high-frequency features, effectively addressing boundary blurring and low contrast. The HyDS-B module, by adaptively adjusting the receptive field, performs spatial modeling for complex-shaped roads, significantly improving adaptability to narrow road curvatures. In this study, the southern mountainous area of Shihezi, Xinjiang, was selected as the study area, and the unpaved road dataset was constructed using high-resolution UAV images. Experimental results on the SHZ unpaved road dataset and the widely used DeepGlobe dataset show that Swin-FSNet performs well in segmentation accuracy and road structure preservation, with an IoUroad of 81.76% and 71.97%, respectively. The experiments validate the excellent performance and robustness of Swin-FSNet in extracting unpaved roads from high-resolution RS images.
1. Introduction
The efficient and precise extraction of road features from RS data is a long-standing research priority in geographic information science [1]. As fundamental transportation routes in remote areas, unpaved roads are widely distributed across rural and mountainous regions with complex terrain. Accurate knowledge of the spatial distribution of these roads is vital for tasks such as emergency rescue, rural road management, wind farm inspection, and path planning in complex environments. As a key tool for updating fundamental geographic information, RS has played an increasingly important role in urban management [2], traffic navigation [3], emergency response, and spatial planning in recent years [4,5].
Although RS data sources are becoming more accessible, the spatial coverage of existing geographic information remains significantly imbalanced. Open geographic data platforms such as OpenStreetMap can provide relatively complete road network information in urban areas, but coverage remains severely lacking in rural and remote mountainous regions, especially for unpaved roads. This data deficiency not only restricts the effective management and utilization of rural road resources but also hinders the planning and optimization of transportation infrastructure, thereby affecting the development and modernization of agricultural and rural regions [6,7]. Unlike the well-structured and clearly bounded urban roads, unpaved roads in remote areas are often influenced by complex terrain, vegetation occlusion, and poor maintenance, resulting in highly unstructured characteristics. Specifically, these roads often appear narrow and winding, with blurred edges, low contrast, and complex textures, making them difficult to identify in RS images and posing significant challenges to conventional road extraction methods.
Traditional approaches in early RS road extraction research were mainly based on mathematical morphology [8], spectral information [9], and structural cues [10]. While effective on high-contrast imagery, such approaches rely heavily on hand-crafted parameters, limiting their adaptability and robustness in complex environments [11]. Recent developments in deep learning techniques have greatly enhanced the performance of road detection from RS imagery. Convolutional neural networks (CNNs), represented by U-Net [12] and SegNet [13], have achieved breakthroughs across various RS applications through end-to-end feature learning. However, the local receptive field and fixed kernel shape of standard CNNs result in a square sampling pattern that is inadequate for capturing the linear structures and complex topology of roads [14,15]. To address this limitation, various improved models have been proposed. For example, D-LinkNet [16] utilizes conditional dilated convolution [17] to expand the receptive field. MECA-Net [18] integrates multi-scale features and attention mechanisms [19,20]. Deformable convolutional networks [21,22] enhance spatial adaptability by dynamically adjusting sampling positions. While these methods achieve outstanding performance in urban scenarios, they still struggle to address the unique challenges of unpaved roads, which can be summarized as follows.
- (1)
- One critical limitation is the inadequate modeling of long-range dependencies and blurred low-contrast features. CNNs, constrained by their local receptive fields, struggle to capture long-range dependencies between elongated roads and complex backgrounds in RS imagery, resulting in discontinuous road predictions [23]. Enlarging the kernel size or adding layers can extend the receptive field, but it still fails to efficiently capture global relationships. As a result, transformer architectures with global self-attention have become a research focus for their ability to capture long-range pixel dependencies effectively [24,25]. As shown in Figure 1a, unpaved roads often share similar textures and edge characteristics with the background, appearing as low-contrast regions in RS images and thus difficult to identify accurately. As depicted in Figure 1c, grayscale gradient transitions along road boundaries serve as useful cues in such scenarios, and their pronounced and directional gradients [26] can help the model detect latent boundary structures within blurry regions, thereby enhancing unpaved road recognition under low-contrast conditions [27].
 Figure 1. Illustration of unpaved road characteristics. (a) Low-contrast unpaved roads are difficult to distinguish. (b) Low-frequency (LF) features capture the overall structure of roads. (c) High-frequency (HF) features reflect detailed road edge information. (d) Roads are occluded by trees. (e) Dynamic snake convolution (DSC) is more effective than square convolution (SC) for extracting narrow and curved roads. (f) In low-altitude UAV RS images, narrow roads occupy a higher proportion of pixels.
Figure 1. Illustration of unpaved road characteristics. (a) Low-contrast unpaved roads are difficult to distinguish. (b) Low-frequency (LF) features capture the overall structure of roads. (c) High-frequency (HF) features reflect detailed road edge information. (d) Roads are occluded by trees. (e) Dynamic snake convolution (DSC) is more effective than square convolution (SC) for extracting narrow and curved roads. (f) In low-altitude UAV RS images, narrow roads occupy a higher proportion of pixels. - (2)
- Another challenge is the mismatch between fixed sampling patterns and road geometry. Unpaved roads in remote areas often exhibit curved and branched structures that do not align well with the square-shaped receptive fields of conventional CNNs, making it difficult to extract continuous road shapes. Methods such as the stripe convolution proposed in CoANet [28] have improved contextual perception to some extent. However, the fixed linear sampling pattern still fails to fully capture the curved geometry and complex topology of unpaved roads. The recently proposed Dynamic Serpentine Convolution (DSC) [29] dynamically adjusts the sampling paths of convolutional kernels. This enables the receptive field to adapt to variations in road curvature, thereby enhancing the model’s capability to extract complex topological road structures, as illustrated in Figure 1e.
- (3)
- A third issue concerns the data imbalance and weak feature representation capability for unpaved roads. Most existing public road datasets in RS focus on urban environments and lack sufficient representation of unpaved roads in remote areas. This limitation is primarily due to the narrow physical width of such roads, typically only 2 to 10 m [30]. At the commonly used spatial resolution of 0.5 m in commercial satellite imagery, unpaved roads span only a few pixels, making them highly susceptible to mixed pixel effects [31], which makes segmentation challenging. In contrast, UAV platforms can capture centimeter-level high-resolution images. As shown in Figure 1f, this allows narrow roads to cover dozens or even hundreds of pixels, significantly enhancing the structural integrity and edge clarity of unpaved roads. As a result, the morphological features of these roads become more interpretable in UAV-based RS imagery.
To tackle the challenges discussed above, we propose Swin-FSNet, a frequency-aware and spatially enhanced framework designed to extract unpaved roads from RS imagery. Built upon the Swin Transformer [32] as the encoder backbone, the framework further incorporates WBFD to extract high-frequency edge features and low-frequency structural cues [33] while also employing HyDS-B in the decoder stage to flexibly model the complex curved structures of unpaved roads. Additionally, we construct a dedicated dataset specifically for unpaved road extraction. The key contributions of this study include the following.
- (1)
- We introduce Swin-FSNet, a novel network architecture that incorporates frequency-domain perception and spatial enhancement for unpaved road extraction. The network is built upon the Swin Transformer backbone, which provides strong capabilities for modeling long-range dependencies. To address the typical challenges in RS imagery of unpaved roads, such as low contrast, blurred boundaries, weak textures, and elongated, curved geometries, a series of targeted architectural enhancements is introduced. These modifications greatly enhance the precision of road identification and ensure smoother road topology preservation in challenging environments.
- (2)
- The WBFD module is introduced to strengthen frequency-domain representation. Positioned along the intermediate pathways linking the encoder and decoder stages, it utilizes discrete wavelet transform (DWT) [34] to separate features into low-frequency structural cues and high-frequency edge details, enhancing segmentation results in scenes with indistinct boundaries and minimal texture.
- (3)
- We develop the HyDS-B to address the geometrical complexity of unpaved roads. Based on dynamic serpentine convolution, this module adaptively adjusts the sampling paths of convolutional kernels, enabling flexible modeling of local curvature and branched topologies, and significantly improving the network’s perception of complex road morphologies.
- (4)
- We construct a high-resolution unpaved road dataset based on UAV imagery captured over the southern mountainous region of Shihezi, Xinjiang. The dataset covers various land surface types common in remote areas, including bare soil and grassland. It provides reliable data support for unpaved road extraction research and facilitates the development of more robust and accurate models for road detection under challenging environmental conditions.
2. Materials and Methods
2.1. Study Area and Data Collection
The research site is situated in the mountainous southern part of Shihezi City, in the Xinjiang Uygur Autonomous Region of China, as shown in Figure 2. The road conditions in this region are similar to those in most remote areas of northern Xinjiang and are primarily composed of unpaved roads. These roads are essential for supporting local transportation networks and meeting the everyday mobility needs of nearby residents. The geographic coordinates of the site are provided in the WGS 1984 coordinate system, using degrees, minutes, and seconds (DMS) for precision.
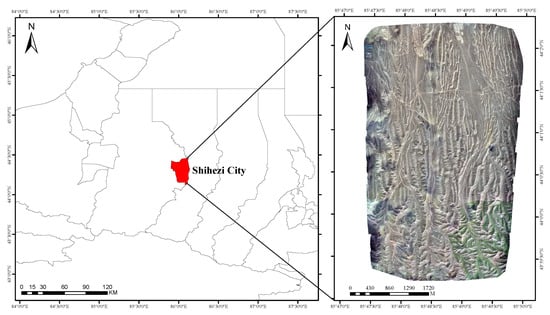
Figure 2.
Schematic diagram of the study area.
The data acquisition was conducted using the JOUAV, Chengdu, China, CW-15 UAV platform, equipped with a Sony, Tokyo, Japan, A7R4 sensor. Flight routes were planned via the JOUAV ground control station to ensure precise trajectory control during data acquisition. The relative flight altitude was set at 745 m, measured relative to the ground elevation of 630 m above sea level. The camera was consistently oriented vertically downward at a 90° angle. The flight route followed a Z-pattern, with 80% forward overlap and 75% lateral overlap, which ensured high image redundancy and data quality. In total, 732 aerial photos were taken and subsequently post-processed with Pix4D software (version 4.8.2) for orthomosaic stitching and correction. The final orthomosaic yielded a ground sampling distance (GSD) of 8.18 cm and covered an area of 18.127 km2.
2.2. Dataset Construction
2.2.1. SHZ Unpaved Road Dataset
For the efficient training of the segmentation model, this study manually labeled UAV imagery from the study area using the Labelme annotation tool, informed by field survey data. Pixels corresponding to road areas were assigned a value of 1, while non-road areas were labeled with a value of 0. To enhance computational efficiency, the annotated images were divided into uniform patches of 512 × 512 pixels. In addition, we applied various augmentation strategies, including random rotation by 90 degrees, bidirectional mirroring (horizontal and vertical flipping), and stochastic contrast modulation. As a result, the final dataset consisted of 6220 training samples, 345 validation samples, and 350 test samples.
2.2.2. DeepGlobe Dataset
To evaluate the performance and generalization ability of the proposed model across different scenarios, we conducted experiments not only on the SHZ unpaved road dataset but also on the DeepGlobe dataset [35]. The DeepGlobe dataset consists of 6226 high-resolution satellite images, each with a size of 1024 × 1024 pixels and a ground sampling distance (GSD) of 50 cm. The dataset encompasses various geographical environments, including urban, suburban, and rural areas, and partially features unpaved roads. It provides complex scenarios, including different types of roads, reflecting the interwoven nature of road types in real-world environments and thereby offering substantial diversity and challenges for model evaluation. The dataset is divided into three subsets: 80% for training, 10% for validation, and 10% for testing. Each image is subsequently divided into 512 × 512 patches, with non-annotated patches excluded. As a result, 16,235 training samples, 2037 validation samples, and 2054 test samples were obtained.
2.3. Overview of the Proposed Method
The overall architecture of the Swin-FSNet model is illustrated in Figure 3, which is centered on an encoder–decoder framework integrating frequency-domain features and spatial enhancement strategies. The encoder adopts the Tiny version of the Swin Transformer as the backbone, which utilizes a window-based self-attention mechanism with shifted windowing to perform multi-scale feature extraction. Specifically, the hierarchically stacked Swin Transformer Blocks (SwinT-B) alternate between intra-window interaction and inter-window fusion, progressively building long-range dependencies from local details to global semantics. The decoder introduces HyDS-B, an innovative hybrid dynamic snake block, which consists of three parallel branches: a standard convolutional layer, a horizontal dynamic serpentine convolution (H-DSC), and a vertical dynamic serpentine convolution (V-DSC). The standard convolution branch is responsible for extracting fundamental spatial features. The two orthogonal dynamic convolution branches adaptively adjust the receptive field using deformable kernels, thereby improving the model’s ability to capture and represent curved road geometries. Considering the frequency-domain characteristics of unpaved roads in RS imagery, the WBFD module is integrated into the skip connections of the network. This module utilizes DWT to separate encoder features into low- and high-frequency features. After channel scaling, these frequency features are transmitted through skip connections to their corresponding decoder layers, providing complementary frequency information for feature reconstruction.
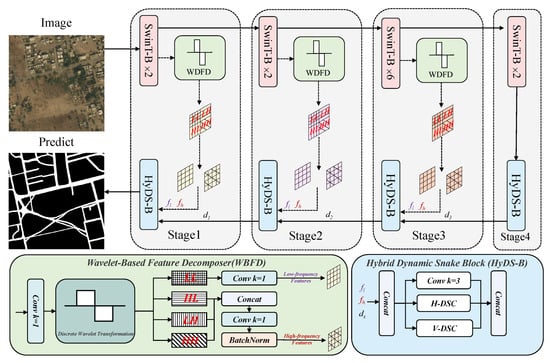
Figure 3.
Swin-FSNet overview architecture.
2.4. Swin-Transformer Backbone
Swin Transformer has demonstrated outstanding performance in computer vision tasks and has become a powerful baseline model. To address the high computational complexity introduced by the global self-attention mechanism in vision transformers [36], Swin Transformer introduces a hierarchical window partitioning strategy. This strategy computes local self-attention within non-overlapping windows and enables cross-window information exchange via shifted windowing. This significantly reduces computational complexity to a linear scale with input length, thereby improving inference efficiency for dense prediction tasks.
The architecture of the SwinT-B is illustrated in Figure 4. Each SwinT-B comprises cascaded regular-window (W-MSA) and shifted-window (SW-MSA) self-attention blocks, which operate on different attention windows, respectively. By linking positions in neighboring windows, the SW-MSA module captures global context more effectively. The cascade of these modules allows subsequent windowed attention to transcend previous window limits, building long-range dependencies across windows. Specifically, the output features of the W-MSA block and the SW-MSA block are denoted as and , respectively, and they are defined as follows.
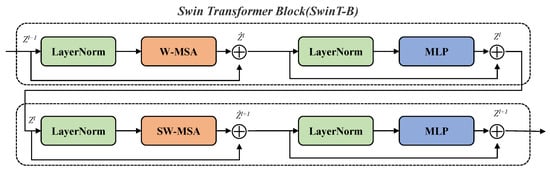
Figure 4.
Architecture of the Swin Transformer module.
2.5. Wavelet-Based Feature Decomposer
Frequency-domain analysis methods play a vital role in image processing, enabling the transformation of images from the spatial domain to the frequency domain for spectral feature analysis. In remote regions with unpaved roads, RS imagery often exhibits low contrast, diminished textures, and unclear boundaries. It is difficult to distinguish roads from the background using only spatial-domain features. Notably, road edges in images often exhibit strong directional gradient changes; for instance, longitudinal road boundaries typically result in sharp changes along the horizontal direction. These directional gradients are not easily observable in the spatial domain but can be explicitly revealed using DWT, which decomposes them into directional high-frequency sub-bands: HL corresponds to horizontal gradients, LH to vertical gradients, and HH captures diagonal variations. A directional analysis of these sub-bands enables the enhancement of edge features, which strengthens the model’s capacity to identify structural outlines, particularly in regions with low contrast.
Based on this principle, we propose the WBFD, designed to jointly model spatial and frequency domain components. In the bottom-left region of Figure 3, the input features are decomposed by DWT into one low-frequency sub-band and three direction-sensitive high-frequency sub-bands. The high-frequency sub-bands reflect directional variations in local features along horizontal, vertical, and diagonal axes. These directional responses are combined and processed through a feature transformation module comprising convolution and activation operations. Finally, the frequency-enhanced features are fused with the original spatial-domain features to improve the network’s ability to detect road boundaries under complex conditions.
The computational flow of DWT is illustrated in Figure 5. The DWT operates independently on every channel extracted from the input tensor X. First, a one-dimensional DWT is performed along the horizontal direction, producing a low-frequency feature map, , and a high-frequency feature map, . The detailed computation is as follows.
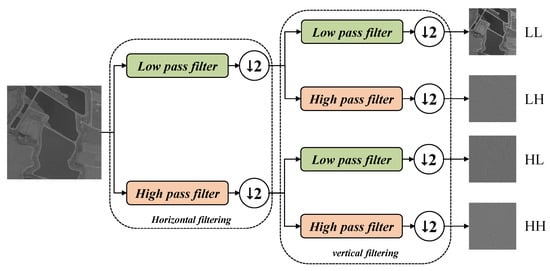
Figure 5.
Schematic diagram of discrete wavelet feature decomposition. The symbol indicates that the feature map is downsampled by half after high-pass or low-pass filtering. In the proposed WBFD module, the Haar wavelet transform is applied along horizontal and vertical directions, yielding four sub-bands: LL (low-frequency), LH (horizontal high-frequency), HL (vertical high-frequency), and HH (diagonal high-frequency).
Here, refers to the input feature map of size . is obtained by applying a low-pass filter along each row, capturing horizontal approximation components. is the output of high-pass filtering along each row, reflecting horizontal detail features. and denote the low-pass and high-pass filters, respectively. k is the index after downsampling along the horizontal axis; as a result, the width is reduced from W to after one-level horizontal wavelet transform.
After and were obtained, a one-dimensional discrete wavelet transform is applied along the vertical direction to further decompose the input into four sub-bands.
After vertical decomposition, four sub-bands are obtained: , , , and . Each sub-band has a spatial size of . This decomposition enables the independent extraction of features at different frequencies, facilitating subsequent feature analysis.
2.6. Hybrid Dynamic Snake Block
Deformable convolution has demonstrated great potential in image segmentation tasks due to its flexibility in feature modeling. However, the unrestricted geometric flexibility it offers may lead to uncontrolled receptive field deformation. To address this issue and guide the model to focus on the continuous, curved, and elongated structures of unpaved roads, we design a HyDS-B, inspired by the work in [29]. HyDS-B integrates standard convolution with the DSC in two orthogonal directions to adaptively focus on local geometric structures. The standard convolution path extracts detailed local information, benefiting from a relatively small receptive field. The orthogonal DSC branches focus on curved and elongated structures, enhancing the model’s ability to perceive complex geometries. The visualized sampling pattern of DSC is illustrated in Figure 6.
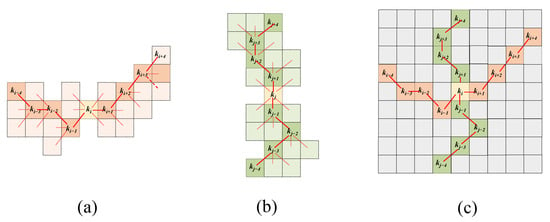
Figure 6.
Illustration of the DSC operation. (a) Sampling point computation of H-DSC; (b) Sampling point computation of V-DSC; (c) Receptive field visualization of DSC. Confirmed sampling points are depicted using solid lines, with dashed lines used to show tentative or optional sampling areas, reflecting the constraints within the sampling approach.
Taking H-DSC as an example, a standard convolutional kernel can be unfolded into a set of 9 sampling points. Each point in the sampling sequence is denoted by coordinates , where marks the initial anchor position, and the index set indicates the lateral offset from this anchor. Within the DSC framework, a series of sampling positions is progressively constructed by iteratively shifting from the current location. Each new coordinate is derived by adding a relative step (with ) to the preceding point, such that . Therefore, a cumulative summation of offsets is required to ensure that the kernel’s spatial layout follows a continuous linear structure. This sampling configuration enables the kernel to follow a serpentine trajectory, effectively fitting curved road shapes. The coordinates of H-DSC sampling points can be calculated using the following formulation.
Here, represent the horizontal and vertical coordinates of the current sampling point, c is the horizontal offset distance, denotes the vertical offset accumulated during horizontal sampling, and denotes the cumulative vertical offset between the current and target points in the sampling sequence.
The sampling point coordinates for V-DSC are calculated as follows.
Here, and represent the horizontal and vertical coordinates of the current sampling point, respectively. c is the vertical offset distance, and indicates the incremental horizontal displacement during vertical sampling. denotes the cumulative horizontal offset from the current point to the target point along the sampling path.
By incorporating cumulative offsetting, this design ensures a continuous sampling trajectory during convolution, thereby enabling the extracted features to better conform to the elongated and curved patterns of roads.
2.7. Loss Function
This work treats road extraction as a standard pixel-level binary classification task. To assess pixel-wise classification performance, we adopt the binary cross-entropy (BCE) loss. It is defined as follows.
Here, denotes the predicted probability that the i-th pixel belongs to the road class, and is the corresponding ground truth label. N is the total number of pixels in the image. The BCE loss effectively evaluates the model’s pixel-wise discriminative capability and is suitable for measuring local prediction errors.
Road regions typically occupy a relatively small area in RS imagery, which leads to a foreground-background class imbalance during model training. This imbalance negatively affects the optimization of BCE loss and causes the model to underperform in foreground object recognition. To mitigate this issue, dice loss is additionally introduced, which evaluates the overlap between predictions and ground truth from a global perspective. It is defined as follows.
Here, is introduced as a stabilizing constant to ensure numerical safety, typically set to . Dice loss exhibits stronger discriminative power for sparse targets, which helps improve the model’s sensitivity and accuracy in detecting fine structures.
Considering both pixel-level classification accuracy and global structural consistency, we formulate the final loss as a weighted sum of BCE loss and dice loss.
Here, the weights and are introduced to modulate the balance between the two loss components, aiming for a trade-off between precision in local details and the comprehensive detection of sparse road structures.
3. Results
3.1. Experimental Settings and Evaluation Metrics
All experiments were carried out in an Ubuntu 18.04 environment. The implementation was based on PyTorch version 1.7.1. All models were trained and deployed on a single NVIDIA GeForce RTX 3090 GPU with 24 GB of memory. During training, the batch size was set to 8. The optimization was performed using the Adam algorithm [37]. The learning rate was initialized at 0.0001, followed by a cosine annealing schedule to facilitate better convergence and training dynamics. All models were trained for 150 epochs. For model training, input samples were randomly cropped to a fixed size of 448 × 448 pixels.
Given that road detection involves distinguishing road pixels from the background, we employed several widely used semantic segmentation metrics, including IoUroad, mIoU, precision, recall, and F1-score, to objectively measure model accuracy. These metrics are formally defined as follows.
where TP, TN, FP, and FN denote correct positives, correct negatives, false positives, and false negatives, respectively.
Params and FLOPs represent the number of model parameters and the computational complexity of the model, respectively.
3.2. Comparative Experimental Results on SHZ Unpaved Road Dataset
In order to fully assess the effectiveness of the Swin-FSNet model for unpaved road segmentation, a series of comparative experiments were conducted on the self-constructed SHZ unpaved road dataset using several representative semantic segmentation models. These models cover a variety of architectural designs and technical paradigms. Specifically, they include the following: classical encoder–decoder architectures such as UNet [12], LinkNet [38], and D-LinkNet [16] deep-feature models based on atrous convolution and multi-scale context fusion, such as DeepLabV3+ [39]; global context modeling models based on the transformer architecture, such as SegFormer [40]; and the context-aware model CoANet [28], which focuses on road extraction applications based on RS images.
Six representative RS images were selected from the test set for visual analysis, as illustrated in Figure 7. In remote areas, unpaved roads often exhibit blurred boundaries, low contrast, and irregular textures, posing significant challenges to road extraction tasks. As observed in Figure 7, most existing models demonstrate noticeable performance limitations in such complex scenarios. For instance, UNet and LinkNet show poor sensitivity to elongated road structures. Although DeepLabV3+ and D-LinkNet perform relatively well in extracting main roads, they tend to miss fine structures such as intersections. SegFormer exhibits misclassification in low-contrast regions, particularly in rows 5 and 6 of Figure 7, indicating limited discriminative ability under such conditions. CoANet yields generally stable results but suffers from segmentation discontinuities in fine road bifurcations.

Figure 7.
Comparison of model extraction results on the SHZ unpaved road dataset, with the red box indicating areas with significant differences.
Compared with the aforementioned models, the proposed Swin-FSNet exhibits clear advantages in complex unpaved road scenarios. These advantages are reflected in sharper edge delineation, enhanced main-road continuity, and improved structural completeness. As highlighted by the red boxes in rows 1 and 4 of Figure 7, Swin-FSNet preserves the continuity and edge clarity of narrow and elongated roads, significantly reducing fragmentation and blurring. This benefit is attributed to the hierarchical window-based attention mechanism of the Swin Transformer architecture, which enhances global contextual modeling capacity, enabling the effective modeling of spatial dependencies in sparse and long-range road structures. Meanwhile, the WBFD module separates high-frequency edge cues from low-frequency structural content, enhancing road boundary awareness. The HyDS-B module leverages shape-aware convolution to improve segmentation in morphologically complex regions such as intersections, as shown in rows 2 and 6 of Figure 7.
The outcome of the quantitative analysis is shown in Table 1. Swin-FSNet outperforms classical semantic segmentation models. Specifically, Swin-FSNet improves IoUroad by 3.13%, F1-score by 2.47%, mIoU by 1.67%, and Recall by 1.25% compared to the second-best model, CoANet. Although slightly lower than SegFormer in terms of precision, Swin-FSNet surpasses SegFormer by 3.95% in recall, indicating that Swin-FSNet is more effective at detecting complete road regions.

Table 1.
Quantitative performance results on the SHZ unpaved road dataset.
In summary, Swin-FSNet achieves a favorable balance between accuracy and completeness in the task of unpaved road extraction, consistently outperforming existing mainstream models. It is capable of handling unpaved road segmentation under complex real-world conditions.
3.3. Comparison Experiments on DeepGlobe Dataset
To further examine the effectiveness of Swin-FSNet, we conducted comparative experiments on the DeepGlobe dataset. This dataset contains a variety of road scenarios that cover different environmental features and road types. Notably, unpaved roads are often intertwined with other roads, which makes the task more challenging in complex scenarios. This also verifies the generality and robustness of our method across diverse environments. Figure 8 shows six representative test images and their segmentation results, including typical cases of unpaved roads, urban neighborhoods, winding roads, and mixed environments, further demonstrating the model’s ability to handle complex scenes.

Figure 8.
Comparison of model extraction results on the DeepGlobe road dataset, with the red box indicating areas with significant differences.
Swin-FSNet demonstrates a superior extraction capability across multiple key regions, as illustrated in Figure 8. Other models tend to suffer from disconnection, misclassification, and geometric distortion in complex road structures such as intersections and bends. For instance, in the curved branch structure highlighted in the red box of row 1, other methods struggle to reconstruct the narrow, curved path, whereas Swin-FSNet successfully captures the connection between minor and main roads. In row 2, which shows an urban block scene with unpaved roads, Swin-FSNet effectively identifies the road network, greatly reducing breakage and maintaining global topological coherence. In row 3, despite the presence of tree occlusions, and in row 5 under low-contrast conditions, Swin-FSNet achieves clear road–background separation with smooth edges, demonstrating strong boundary discrimination. In rows 4 and 6, which feature curved road segments, Swin-FSNet accurately restores road curvature and topology, showing strong stability and shape preservation. Notably, in the top-right red box of row 6, the ground truth omits an existing road segment, yet Swin-FSNet successfully extracts it. This indicates that the model not only fits the annotated data well but also learns and generalizes the intrinsic structural features of roads, demonstrating strong semantic understanding.
The quantitative analysis results are shown in Table 2. Compared with classical semantic segmentation models and recent advanced architectures such as CasMT [41], LCMorph [42], DDCT [43], and GAMS-Net [44], Swin-FSNet outperforms all compared methods in every major evaluation metric, achieving an IoUroad of 71.97%, mIoU of 85.25%, F1-score of 82.87%, and precision and recall of 82.68% and 82.11%, respectively.
Table 2.
Quantitative performance results on the DeepGlobe dataset.
Although Swin-FSNet performs slightly worse than GAMSNet in terms of precision, it excels in other metrics, such as recall and IOU. This slight difference in precision can be attributed to Swin-FSNet’s greater focus on capturing fine structural details, particularly when dealing with complex and irregular road structures. While this strategy significantly enhances performance in recall and IOU, it occasionally results in a small number of false positives, slightly affecting precision.
Overall, Swin-FSNet demonstrated stable structural extraction performance on the SHZ unpaved road dataset and achieved leading results on the DeepGlobe dataset, particularly in handling the complex scenarios where unpaved roads are interwoven with other types of roads, thereby demonstrating its robustness in diverse RS image segmentation tasks.
3.4. Ablation Study
3.4.1. Impact of Individual Modules in Swin-FSNet
Swin-FSNet integrates the WBFD module to capture frequency-domain edge features of roads, and the HyDS-B module to enhance spatial structure modeling. To assess the contribution and synergy of these modules, ablation experiments were performed using the Swin Transformer–Tiny backbone on the publicly available DeepGlobe dataset and the SHZ unpaved road dataset. Detailed outcomes are presented in Table 3.
Table 3.
Ablation Study Results: Performance Evaluation of Different Modules and Datasets.
As shown in the results, the baseline model achieves IoUroad scores of 79.76% and 69.16% on the two datasets, respectively. When the WBFD module is added, IoUroad improves to 80.53% and 70.85%, suggesting that frequency-domain features help capture edge structures more effectively. When the HyDS-B module is added independently, the IoUroad further improves to 81.16% and 71.13%, demonstrating its positive contribution to spatial structural modeling. Combining both WBFD and HyDS-B results in the highest performance, reaching IoUroad values of 81.76% and 71.97%. This confirms the complementary and synergistic effectiveness of the two modules in boundary perception and spatial modeling.
3.4.2. Visualization of Road Probability Heatmaps
To gain deeper insights into the attention distribution of the proposed Swin-FSNet during road extraction, the Grad-CAM technique [45] is utilized to produce visual heatmaps using the publicly available DeepGlobe dataset and the SHZ unpaved road dataset. Visualization outcomes are presented in Figure 9. Darker regions in the heatmaps correspond to higher prediction confidence. This intuitively reveals how the model allocates its attention across the scene.

Figure 9.
Comparison of activation heatmaps from the final deconvolution block, with the red box indicating areas with significant differences. (a) Original RS image; (b) activation map before introducing the WBFD module; (c) activation map after introducing the WBFD module; (d) activation map after further introducing the HyDS-B module; (e) corresponding ground truth labels.
A visual analysis shows that the deployment of the WBFD improves the model’s attention to road-related features, especially in complex or low-contrast areas. Notably, in cases with blurry road-background boundaries, low contrast, or occlusions from trees or buildings, the model demonstrates enhanced edge perception capability. When the HyDS-B module is added, the model responds more strongly to narrow and curved road regions. This enables the model to maintain higher structural continuity. Effectively improving its capability to model road continuity in morphologically complex conditions. These improvements stem from the frequency-aware enhancement achieved via the WBFD module, and the HyDS-B module’s advantage in modeling morphological structures spatially.
3.4.3. Impact of Different Frequency Components
In this section, we delve deeper into the design of the WBFD module, and we validate it through experiments on the SHZ unpaved road dataset, demonstrating the design’s reasonableness and effectiveness. As illustrated in Figure 5, when DWT is applied to RS images, the image is split into four frequency components: LL, LH, HL, and HH. The main body of the road appears clearly in the LL component as a continuous and smooth low-frequency structure, while road edges and contours are prominently represented as high-frequency features in the LH, HL, and HH components.
Although previous research commonly treated the diagonal sub-band (HH) as the key source of high-frequency information in wavelet-based feature extraction, and developed edge-aware modules accordingly. However, textures in actual road images often present significant directional features. In response, this study revisits the role of individual high-frequency components. We propose a feature fusion strategy that simultaneously incorporates the LH, HL, and HH components to comprehensively capture road boundary features. Four different feature combination schemes were designed, and corresponding quantitative experiments were conducted. The results are reported in Table 4.
Table 4.
Quantitative results of different frequency components on the SHZ unpaved road dataset.
The experimental results indicate that the model achieves the highest IoUroad score of 81.76% when all frequency-domain components (LL, LH, HL, and HH) are fused. Removing HH and retaining only LH and HL reduces the IoUroad to 79.90%, yet it remains above the 79.55% achieved using HH alone. This indicates that LH and HL are more effective in encoding directional edge features of roads. Using only the LL component still yields an IoUroad of 80.45%, confirming the importance of low-frequency components in representing road layout. In summary, the WBFD module exhibits superior performance when integrating all frequency components, and its frequency-domain fusion strategy effectively enhances the accuracy and structural completeness in unpaved road segmentation.
4. Discussion
The ablation study results demonstrate that Swin-FSNet achieves significant improvements in IoUroad performance after the incorporation of the WBFD and HyDS-B modules. Specifically, the IoU reached 81.76% on the SHZ unpaved road dataset and 71.97% on the DeepGlobe dataset, both of which represent significant gains over the baseline model. To explore the underlying causes of this improvement, the functional mechanisms of the WBFD and HyDS-B modules are analyzed from the perspectives of frequency-domain modeling and structural perception, respectively.
First, a comparative analysis of the experimental results before and after the incorporation of the WBFD module reveals that the inclusion of frequency-domain information enhances the model’s edge sensitivity. Additionally, related studies by Huajun et al. [46] demonstrated that applying Fourier transforms to extract global frequency-domain features can improve road segmentation performance, while Yunsong et al. [47] leveraged wavelet transforms to capture multi-scale frequency information, thereby enhancing building boundary recognition. These findings collectively highlight the importance of frequency-domain features in reinforcing edge perception, particularly in RS scenarios characterized by complex textures and indistinct boundaries. The proposed WBFD module utilizes a discrete wavelet decomposition approach to partition RS images into a low-frequency sub-band (LL) and three high-frequency sub-bands sensitive to different directions (LH, HL, and HH). These components are respectively employed to extract global structural information and fine-grained edge details. The low-frequency band retains the primary morphology of roads, while the high-frequency bands strengthen the model’s responsiveness to textures and edges, leading to improved discrimination in scenes with ambiguous boundaries and complex backgrounds.
Second, the integration of the HyDS-B module also significantly enhances the extraction of unpaved roads. Experimental analyses show that the two orthogonal dynamic deformable convolution structures within this module effectively capture the intricate geometry of road features. Ziye et al. [48] emphasized that employing heterogeneous convolutional kernels, which are specifically designed to align with the geometric characteristics of road structures, can significantly enhance the model’s capability to capture complex spatial patterns. In a similar vein, the HyDS-B module introduces a dynamic sampling mechanism that flexibly adjusts the receptive field positions of the convolution kernels. This enables the kernels to adapt to variations in unpaved road curvature and topological expansion, overcoming the limitations of traditional static convolutions in deformation modeling. Consequently, the model’s ability to adapt to irregular road geometries is enhanced, resulting in more coherent and accurate road extraction outputs.
Furthermore, visualized heatmaps reveal that, after incorporating the aforementioned modules, the model exhibits more focused activation in regions with low contrast, narrow or curved roads, and partially occluded areas. The resulting contours are sharper, and the extracted road segments display improved structural integrity and continuity. These observations further verify the effectiveness of the WBFD and HyDS-B modules in enhancing the model’s capability to represent the morphology of unpaved roads.
The masks obtained from RS image segmentation, due to the lack of geometric information and spatial structure of roads, cannot reflect the connectivity between different road segments. Therefore, post-processing steps are necessary to convert these masks into a vectorized road network that preserves the shape and spatial information of the roads. During the post-processing stage, spatial constraints are introduced to account for the structural connectivity of roads. Using spatial constraint information, we assess the actual connectivity between adjacent road segments and generate a vectorized road skeleton. Subsequently, based on the metadata from the original imagery, we assign geographic coordinates to the vector skeleton, ultimately creating a vectorized road network that can be directly integrated into geographic information systems (GISs) for efficient spatial analysis. Future research will focus on further optimizing the loss function design, particularly by considering the semantic–physical consistency between RS imagery and natural scenes, to enhance the model’s robustness and generalizability.
5. Conclusions
In this paper, an unpaved road extraction network, Swin-FSNet, has been proposed. This network integrates frequency-domain perception and spatial enhancement techniques, aiming to solve the problems of ambiguous boundaries, low contrast, and complex texture of unpaved roads in RS images. The model effectively captures frequency-aware edge features by introducing the WBFD module and enhances feature representation in both the frequency and spatial domains by combining the HyDS-B module for adaptive spatial shape learning. The experimental results show that Swin-FSNet outperforms other state-of-the-art methods on the SHZ Unpaved Road Dataset and DeepGlobe Dataset, especially in maintaining road continuity and structural integrity. The method demonstrates great potential for the extraction of unpaved roads in complex environments and provides a solid technical foundation for applications in emergency response, rural road management, and path planning.
Despite its excellent performance, robustness, and reliability, Swin-FSNet still faces some limitations. For example, the accuracy of road boundary detection may degrade in scenes with dense vegetation or severe occlusion, and the use of some high-frequency sub-bands may introduce redundancy or noise. To address these challenges, future research will focus on utilizing multi-source RS data to enhance the model’s adaptability and robustness in complex environments. Additionally, we plan to explore the use of UAV RS imagery to investigate how the model can recover global road connectivity in occluded scenarios and further optimize the frequency domain fusion strategy to improve the representation of road details and boundary integrity.
Author Contributions
Conceptualization, J.G.; data curation, J.G., J.L. and W.L.; formal analysis, X.Y.; funding acquisition, Q.Z.; methodology, J.G., Q.Z., X.Y. and W.T.; resources, W.T.; software, J.G.; supervision, Q.Z., J.L., W.L. and W.T.; visualization, J.G.; writing–original draft, J.G.; writing—review and editing, J.G. and X.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The UAV remote sensing imagery utilized in this study is subject to licensing restrictions, and the authors are not authorized to publicly share the full dataset. Certain portions of the data may be available from the corresponding author upon reasonable request. Public access to the complete dataset is restricted due to the requirement for formal approval from the local road authority in the country/region where the study was conducted.
Conflicts of Interest
The research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road Extraction Methods in High-Resolution Remote Sensing Images: A Comprehensive Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. Engl. Ed. 2016, 3, 271–282. [Google Scholar] [CrossRef]
- Hou, X.; Chen, P. Analysis of Road Safety Perception and Influencing Factors in a Complex Urban Environment—Taking Chaoyang District, Beijing, as an Example. ISPRS Int. J.-Geo-Inf. 2024, 13, 272. [Google Scholar] [CrossRef]
- Das, S.; Mirnalinee, T.T.; Varghese, K. Use of Salient Features for the Design of a Multistage Framework to Extract Roads From High-Resolution Multispectral Satellite Images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3906–3931. [Google Scholar] [CrossRef]
- Qin, Y.; Zhang, X. The Road to Specialization in Agricultural Production: Evidence from Rural China. World Dev. 2016, 77, 1–16. [Google Scholar] [CrossRef]
- Shamdasani, Y. Rural road infrastructure & agricultural production: Evidence from India. J. Dev. Econ. 2021, 152, 102686. [Google Scholar] [CrossRef]
- Valero, S.; Chanussot, J.; Benediktsson, J.; Talbot, H.; Waske, B. Advanced directional mathematical morphology for the detection of the road network in very high resolution remote sensing images. Pattern Recognit. Lett. 2010, 31, 1120–1127. [Google Scholar] [CrossRef]
- Yang, X.; Wen, G. Road extraction from high-resolution remote sensing images using wavelet transform and hough transform. In Proceedings of the 2012 5th International Congress on Image and Signal Processing, Agadir, Morocco, 16–18 October 2012; pp. 1095–1099. [Google Scholar] [CrossRef]
- Zhou, L.; Ye, Y.; Tang, T.; Nan, K.; Qin, Y. Robust Matching for SAR and Optical Images Using Multiscale Convolutional Gradient Features. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4017605. [Google Scholar] [CrossRef]
- Chen, Z.; Deng, L.; Luo, Y.; Li, D.; Marcato, J., Jr.; Nunes Gonçalves, W.; Awal Md Nurunnabi, A.; Li, J.; Wang, C.; Li, D. Road extraction in remote sensing data: A survey. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102833. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Hong, D.; Chanussot, J. Convolutional Neural Networks for Multimodal Remote Sensing Data Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5517010. [Google Scholar] [CrossRef]
- Li, C.; Zhang, B.; Hong, D.; Jia, X.; Plaza, A.; Chanussot, J. Learning Disentangled Priors for Hyperspectral Anomaly Detection: A Coupling Model-Driven and Data-Driven Paradigm. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 6883–6896. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 192–1924. [Google Scholar] [CrossRef]
- Ge, Z.; Zhao, Y.; Wang, J.; Wang, D.; Si, Q. Deep Feature-Review Transmit Network of Contour-Enhanced Road Extraction From Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3001805. [Google Scholar] [CrossRef]
- Jie, Y.; He, H.; Xing, K.; Yue, A.; Tan, W.; Yue, C.; Jiang, C.; Chen, X. MECA-Net: A MultiScale Feature Encoding and Long-Range Context-Aware Network for Road Extraction from Remote Sensing Images. Remote Sens. 2022, 14, 5342. [Google Scholar] [CrossRef]
- Chen, S.B.; Ji, Y.X.; Tang, J.; Luo, B.; Wang, W.Q.; Lv, K. DBRANet: Road Extraction by Dual-Branch Encoder and Regional Attention Decoder. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3002905. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Jin, J.; Qian, M.; Zhang, Y. SUACDNet: Attentional change detection network based on siamese U-shaped structure. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102597. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Zuo, R.; Zhang, G.; Zhang, R.; Jia, X. A Deformable Attention Network for High-Resolution Remote Sensing Images Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4406314. [Google Scholar] [CrossRef]
- Dai, L.; Zhang, G.; Zhang, R. RADANet: Road Augmented Deformable Attention Network for Road Extraction From Complex High-Resolution Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5602213. [Google Scholar] [CrossRef]
- Yang, Z.; Zhou, D.; Yang, Y.; Zhang, J.; Chen, Z. TransRoadNet: A Novel Road Extraction Method for Remote Sensing Images via Combining High-Level Semantic Feature and Context. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6509505. [Google Scholar] [CrossRef]
- Liu, X.; Wang, Z.; Wan, J.; Zhang, J.; Xi, Y.; Liu, R.; Miao, Q. RoadFormer: Road Extraction Using a Swin Transformer Combined with a Spatial and Channel Separable Convolution. Remote Sens. 2023, 15, 1049. [Google Scholar] [CrossRef]
- Xie, C.; Xia, C.; Yu, T.; Li, J. Frequency Representation Integration for Camouflaged Object Detection. In Proceedings of the 31st ACM International Conference on Multimedia, MM ’23, Ottawa, ON, Canada, 29 October–3 November 2023; ACM: New York, NY, USA; pp. 1789–1797. [Google Scholar] [CrossRef]
- Awad, B.; Erer, I. High-Frequency Attention U-Net for Road Segmentation in High-Resolution Remote Sensing Imagery. In Proceedings of the IGARSS 2024–2024 IEEE International Geoscience and Remote Sensing Symposium, Athens, Greece, 7–12 July 2024; pp. 9609–9613. [Google Scholar] [CrossRef]
- Mei, J.; Li, R.J.; Gao, W.; Cheng, M.M. CoANet: Connectivity Attention Network for Road Extraction From Satellite Imagery. IEEE Trans. Image Process. 2021, 30, 8540–8552. [Google Scholar] [CrossRef] [PubMed]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic Snake Convolution based on Topological Geometric Constraints for Tubular Structure Segmentation. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 6047–6056. [Google Scholar] [CrossRef]
- Wang, N.; Wang, X.; Pan, Y.; Yao, W.; Zhong, Y. WHU-RuR+: A benchmark dataset for global high-resolution rural road extraction. Int. J. Appl. Earth Obs. Geoinf. 2025, 139, 104518. [Google Scholar] [CrossRef]
- Keshava, N.; Mustard, J. Spectral unmixing. IEEE Signal Process. Mag. 2002, 19, 44–57. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Yang, J.; Liu, T.; Zhang, L.; Zhang, Y. Effective Road Segmentation With Selective State-Space Model and Frequency Feature Compensation. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5603813. [Google Scholar] [CrossRef]
- Wu, P.C.; Chen, L.G. An efficient architecture for two-dimensional discrete wavelet transform. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 536–545. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–17209. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Lu, X.; Zhong, Y.; Zheng, Z.; Chen, D.; Su, Y.; Ma, A.; Zhang, L. Cascaded Multi-Task Road Extraction Network for Road Surface, Centerline, and Edge Extraction. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5621414. [Google Scholar] [CrossRef]
- Li, X.; Yang, S.; Meng, F.; Li, W.; Yang, Z.; Wei, R. LCMorph: Exploiting Frequency Cues and Morphological Perception for Low-Contrast Road Extraction in Remote Sensing Images. Remote Sens. 2025, 17, 257. [Google Scholar] [CrossRef]
- Gao, L.; Zhou, Y.; Tian, J.; Cai, W. DDCTNet: A Deformable and Dynamic Cross-Transformer Network for Road Extraction From High-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4407819. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Zhang, L. GAMSNet: Globally aware road detection network with multi-scale residual learning. ISPRS J. Photogramm. Remote Sens. 2021, 175, 340–352. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, X.; Wang, C.; Chen, S.; Kong, H. Fourier-Deformable Convolution Network for Road Segmentation From Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4415117. [Google Scholar] [CrossRef]
- Yang, Y.; Yuan, G.; Li, J. SFFNet: A Wavelet-Based Spatial and Frequency Domain Fusion Network for Remote Sensing Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 3000617. [Google Scholar] [CrossRef]
- Wang, Z.; Luo, Z.; Zhu, Q.; Peng, S.; Ran, L.; Zhang, Y.; Wang, L.; Chen, Y.; Hu, Z.; Luo, J. A Road-Detail Preserving Framework for Urban Road Extraction From VHR Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5400913. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).