


A High-Resolution Remote Sensing Road Extraction Method Based on the Coupling of Global Spatial Features and Fourier Domain Features
Abstract
1. Introduction
- (1)
- We propose a road extraction method that couples global spatial features with Fourier domain features to express road features from multiple perspectives and improve the separability of roads from other objects by integrating spatial domain features and frequency domain features.
- (2)
- We construct Fourier feature blocks to achieve the separation of high-frequency and low-frequency road information, enhance the distinction between roads and the background, and improve the feature expression of roads from a frequency domain perspective.
- (3)
- We explore the impact of the Fourier feature blocks on road extraction across different layers of the network.
2. Methodology
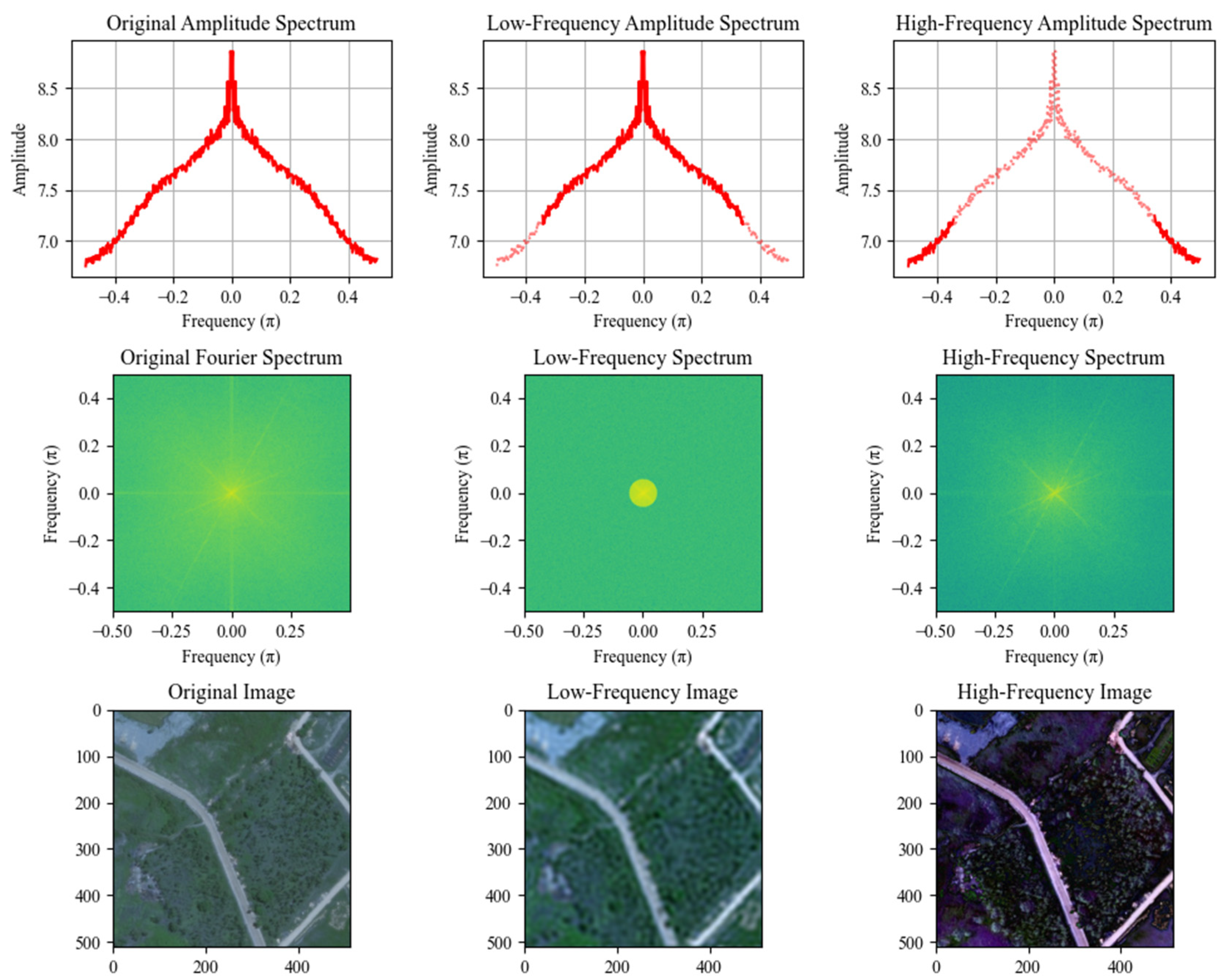
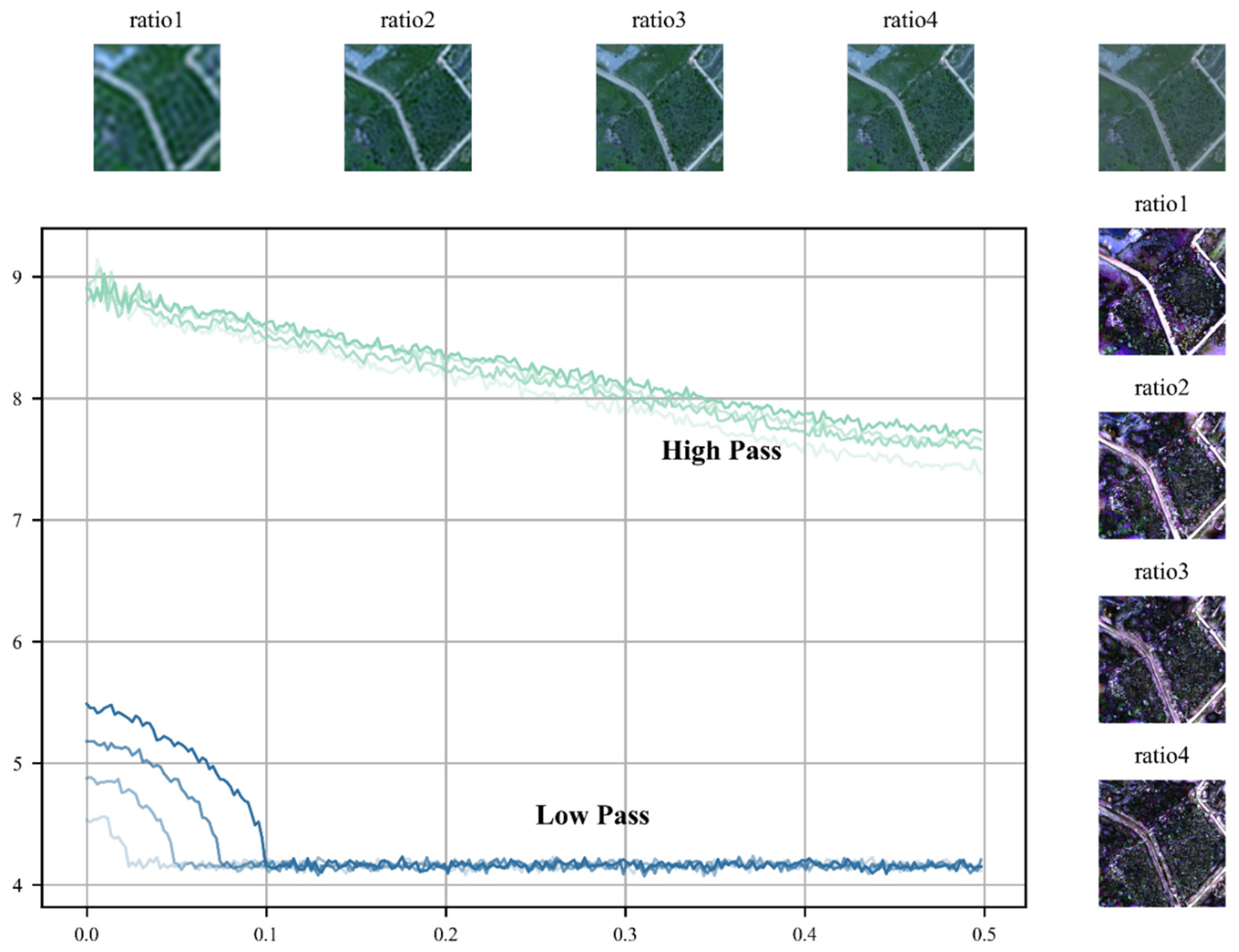
2.1. Fourier Transform
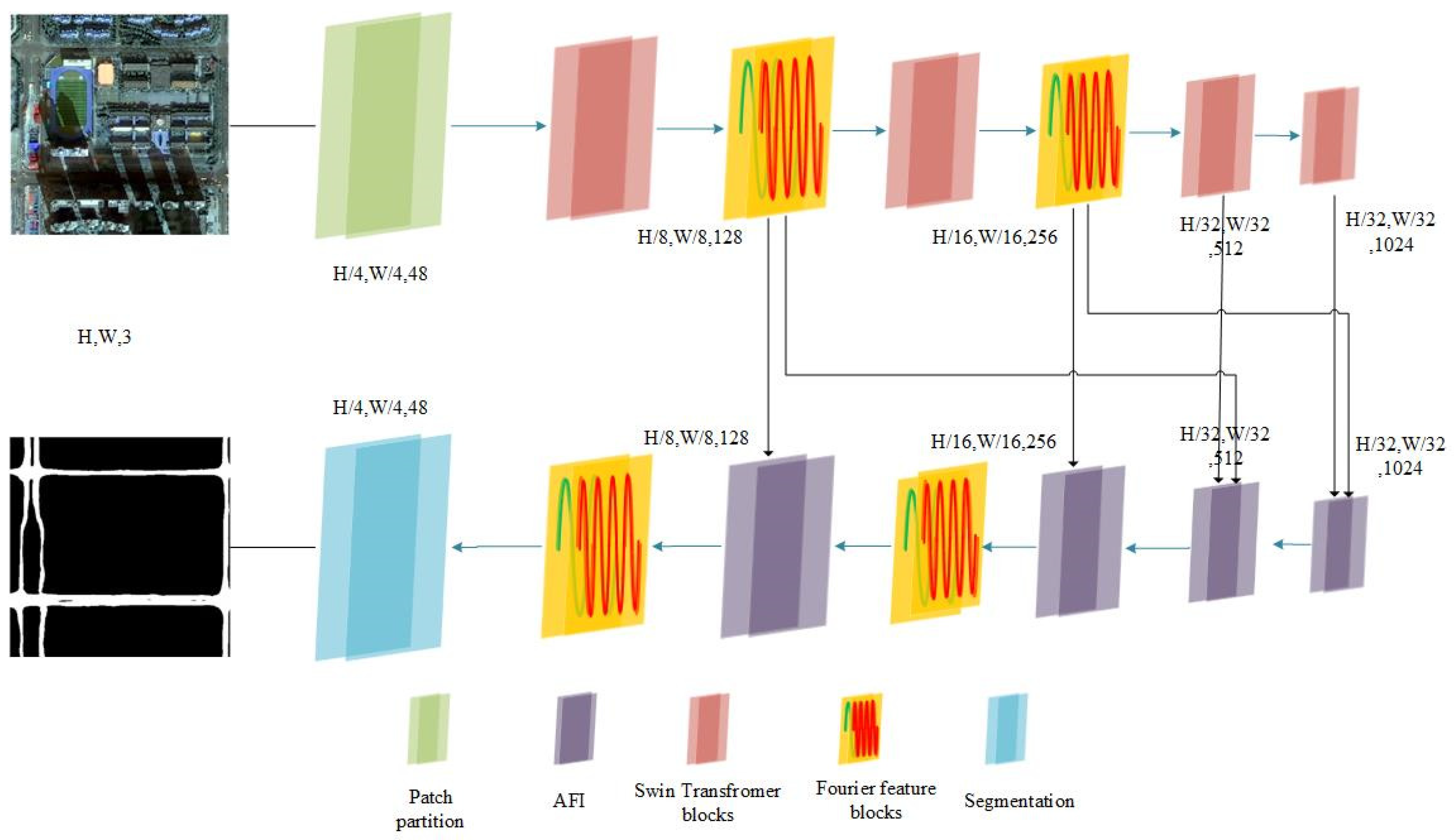
2.2. Network Architecture
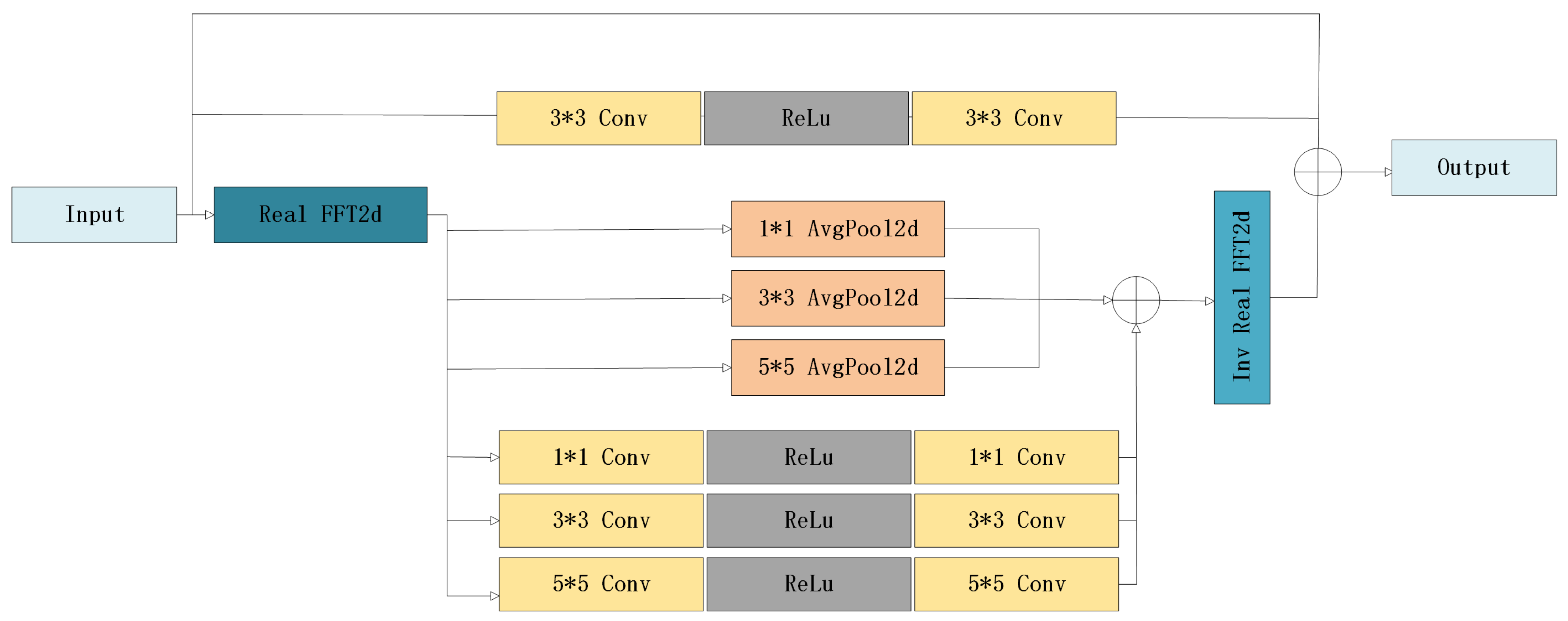
2.3. Fourier Feature Blocks
3. Experiments and Evaluation
3.1. Setting Loss Functions and Evaluation Metrics
3.2. Experimental Configuration
3.3. Experimental Dataset
3.3.1. HF Dataset
3.3.2. Massachusetts Roads Dataset
3.3.3. DeepGlobe Dataset
3.4. Comparative Test of Various Road Datasets
3.4.1. Experiment on HF Dataset
3.4.2. Experiment on Massachusetts Roads Dataset
3.4.3. Experiment on DeepGlobe Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Sussi, E.; Husni, R.; Yusuf, A.; Harto, D.B.; Suwardhi, D.; Siburian, A. Utilization of Improved Annotations from Object-Based Image Analysis as Training Data for DeepLab V3+ Model: A Focus on Road Extraction in Very High-Resolution Orthophotos. IEEE Access 2024, 12, 67910–67923. [Google Scholar] [CrossRef]
- Montenegro, A.L.; Rey-Gozalo, G.; Arenas, J.P.; Suárez, E. Streets Classification Models by Urban Features for Road Traffic Noise Estimation. Sci. Total Environ. 2024, 932, 173005. [Google Scholar] [CrossRef] [PubMed]
- Tao, Y.; Tian, L.; Wang, C.; Dai, W.; Xu, Y. A fine construction method of urban road DEM considering road morphological characteristics. Sci. Rep. 2022, 12, 14958. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, H.; Du, C.; Li, J. MSACon: Mining spatial attention-based contextual information for road extraction. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5604317. [Google Scholar] [CrossRef]
- Wang, Y.; Seo, J.; Jeon, T. NL-LinkNet: Toward lighter but more accurate road extraction with nonlocal operations. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3000105. [Google Scholar] [CrossRef]
- Lin, Y.; Saripalli, S. Road Detection and Tracking from Aerial Desert Imagery. J. Intell. Robotic Syst. 2012, 65, 345–359. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, L.; Li, L.; Chen, Y. Dictionary Learning-Based Hough Transform for Road Detection in Multispectral Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2330–2334. [Google Scholar] [CrossRef]
- Yang, J.; He, Y.; Caspersen, J. Region merging using local spectral angle thresholds: A more accurate method for hybrid segmentation of remote sensing images. Remote Sens. Environ. 2017, 190, 137–148. [Google Scholar] [CrossRef]
- Courtrai, L.; Lefèvre, S. Morphological path filtering at the region scale for efficient and robust road network extraction from satellite imagery. Pattern Recognit. Lett. 2016, 83, 195–204. [Google Scholar] [CrossRef]
- Yeom, J.; Kim, Y. A Regular Grid-Based Hough Transform for the Extraction of Urban Features Using High-Resolution Satellite Images. Remote Sens. Lett. 2015, 6, 409–417. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015; IEEE: New York, NY, USA, 2015; Volume 2015, pp. 3431–3440. [Google Scholar] [CrossRef]
- Kestur, R.; Farooq, S.; Abdal, R.; Mehraj, E.; Narasipura, O.; Mudigere, M. UFCN: A fully convolutional neural network for road extraction in RGB imagery acquired by remote sensing from an unmanned aerial vehicle. J. Appl. Remote Sens. 2018, 12, 016020. [Google Scholar] [CrossRef]
- Zhang, Y.; Xia, G.; Wang, J.; Lha, D. A Multiple Feature Fully Convolutional Network for Road Extraction From High-Resolution Remote Sensing Image Over Mountainous Areas. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1600–1604. [Google Scholar] [CrossRef]
- Yang, X.; Li, X.; Ye, Y.; Lau, R.Y.K.; Zhang, X.; Huang, X. Road Detection and Centerline Extraction via Deep Recurrent Convolutional Neural Network U-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7209–7220. [Google Scholar] [CrossRef]
- Çalışkan, E.; Sevim, Y. Forest Road Extraction from Orthophoto Images by Convolutional Neural Networks. Geocarto Int. 2022, 37, 11671–11685. [Google Scholar] [CrossRef]
- Eerapu, K.K.; Ashwath, B.; Lal, S.; Dell’Acqua, F.; Narasimha Dhan, A.V. Dense Refinement Residual Network for Road Extraction From Aerial Imagery Data. IEEE Access 2019, 7, 151764–151782. [Google Scholar] [CrossRef]
- Das, S.; Fime, A.A.; Siddique, N.; Hashem, M.M.A. Estimation of Road Boundary for Intelligent Vehicles Based on DeepLabV3+ Architecture. IEEE Access 2021, 9, 121060–121075. [Google Scholar] [CrossRef]
- Wang, R.; Cai, M.; Xia, Z. A Lightweight High-Resolution RS Image Road Extraction Method Combining Multi-Scale and Attention Mechanism. IEEE Access 2023, 11, 108956–108966. [Google Scholar] [CrossRef]
- Hou, Y.; Liu, Z.; Zhang, T.; Li, Y. C-UNet: Complement UNet for Remote Sensing Road Extraction. Sensors 2021, 21, 2153. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Chen, Z.; Fan, W.; Zhong, B.; Li, J.; Du, J.; Wang, C. Corse-to-Fine Road Extraction Based on Local Dirichlet Mixture Models and Multiscale-High-Order Deep Learning. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4283–4293. [Google Scholar] [CrossRef]
- Yang, X.; Li, X.; Ye, Y.; Zhang, X.; Zhang, H.; Huang, X.; Zhang, B. Road detection via deep residual dense U-Net. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Lin, Y.; Xu, D.; Wang, N.; Shi, Z.; Chen, Q. Road Extraction from Very-High-Resolution Remote Sensing Images via a Nested SE-Deeplab Model. Remote Sens. 2020, 12, 2985. [Google Scholar] [CrossRef]
- Guan, H.; Yu, Y.; Li, D.; Wang, H. RoadCapsFPN: Capsule Feature Pyramid Network for road extraction from VHR optical remote sensing imagery. IEEE Trans. Intell. Transp. Syst. 2022, 23, 11041–11051. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, Z.; Zhong, R.; Zhang, L.; Ma, H.; Liu, L. A dense feature pyramid network-based deep learning model for road marking instance segmentation using MLS point clouds. IEEE Trans. Geosci. Remote Sens. 2021, 59, 784–800. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef]
- Islam, K. Recent advances in Vision Transformer: A survey and outlook of recent work. arXiv 2022, arXiv:2203.01536. [Google Scholar] [CrossRef]
- Zhu, X.; Huang, X.; Cao, W.; Yang, X.; Zhou, Y.; Wang, S. Road extraction from remote sensing imagery with spatial attention based on Swin Transformer. Remote Sens. 2024, 16, 1183. [Google Scholar] [CrossRef]
- Han, Y.; Liu, Q.; Liu, H.; Hu, X.; Wang, B. PT-RE: Prompt-based multi-modal transformer for road network extraction from remote sensing images. IEEE Sens. J. 2024. [Google Scholar] [CrossRef]
- Liu, W.; Gao, S.; Zhang, C.; Yang, B. RoadCT: A hybrid CNN-transformer network for road extraction from satellite imagery. IEEE Geosci. Remote Sens. Lett. 2024, 21, 2501805. [Google Scholar] [CrossRef]
- Wang, X.; Cai, Y.; He, K.; Wang, S.; Liu, Y.; Dong, Y. Global–local information fusion network for road extraction: Bridging the gap in accurate road segmentation in China. Remote Sens. 2023, 15, 4686. [Google Scholar] [CrossRef]
- Kumar, K.M.; Velayudham, A. CCT-DOSA: A Hybrid Architecture for Road Network Extraction From Satellite Images in the Era of IoT. Evol. Syst. 2024, 15, 1939–1955. [Google Scholar] [CrossRef]
- Kumar, K.M. RoadTransNet: Advancing remote sensing road extraction through multi-scale features and contextual information. Signal Image Video Process. 2024, 18, 2403–2412. [Google Scholar] [CrossRef]
- Wei, D.; Li, P.; Xie, H.; Xu, Y. DRCNet: Road Extraction From Remote Sensing Images Using DenseNet With Recurrent Criss-Cross Attention and Convolutional Block Attention Module. IEEE Access 2023, 11, 126879–126891. [Google Scholar] [CrossRef]
- Akhtarmanesh, A.; Abbasi-Moghadam, D.; Sharifi, A.; Yadkouri, M.H.; Tariq, A.; Lu, L. Road Extraction from Satellite Images Using Attention-Assisted UNet. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 1126–1136. [Google Scholar] [CrossRef]
- Jamali, A.; Roy, S.K.; Li, J.; Ghamisi, P. Neighborhood Attention Makes the Encoder of ResUNet Stronger for Accurate Road Extraction. IEEE Geosci. Remote Sens. Lett. 2024, 21, 6003005. [Google Scholar] [CrossRef]
- Sundarapandi, A.M.S.; Alotaibi, Y.; Thanarajan, T.; Rajendran, S. Archimedes Optimisation Algorithm Quantum Dilated Convolutional Neural Network for Road Extraction in Remote Sensing Images. Heliyon 2024, 10, e26589. [Google Scholar] [CrossRef]
- Toni, Y.; Meena, U.; Mishra, V.K.; Garg, R.D.; Sharma, K.P. AM-UNet: Road Network Extraction from High-Resolution Aerial Imagery Using Attention-Based Convolutional Neural Network. J. Indian Soc. Remote Sens. 2024. [Google Scholar] [CrossRef]
- Mehmood, M.; Shahzad, A.; Zafar, B.; Shabbir, A.; Ali, N. Remote sensing image classification: A comprehensive review and applications. Math. Probl. Eng. 2022, 2022, 5880959. [Google Scholar] [CrossRef]
- Wang, D.; Gao, L.; Qu, Y.; Sun, X.; Liao, W. Frequency-to-Spectrum Mapping GAN for Semisupervised Hyperspectral Anomaly Detection. CAAI Trans. Intell. Technol. 2023, 8, 1258–1273. [Google Scholar] [CrossRef]
- Gao, L.; Wang, D.; Zhuang, L.; Sun, X.; Huang, M.; Plaza, A. BS3LNet: A New Blind-Spot Self-Supervised Learning Network for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5504218. [Google Scholar] [CrossRef]
- Wang, J.; Guo, S.; Hua, Z.; Huang, R.; Hu, J.; Gong, M. CL-CaGAN: Capsule Differential Adversarial Continual Learning for Cross-Domain Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5517315. [Google Scholar] [CrossRef]
- Wang, D.; Zhuang, L.; Gao, L.; Sun, X.; Huang, M.; Plaza, A. BockNet: Blind-Block Reconstruction Network with a Guard Window for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5531916. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, Y.; Chen, J. Multi-Scale Fast Fourier Transform Based Attention Network for Remote-Sensing Image Super-Resolution. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2023, 16, 2728–2740. [Google Scholar] [CrossRef]
- Song, B.; Min, S.; Yang, H.; Wu, Y.; Wang, B. A Fourier Frequency Domain Convolutional Neural Network for Remote Sensing Crop Classification Considering Global Consistency and Edge Specificity. Remote Sens. 2023, 15, 4788. [Google Scholar] [CrossRef]
- Yu, L.; Xie, J.; Zheng, X. The Relationship Between Graph Fourier Transform (GFT) and Discrete Cosine Transform (DCT) for 1D Signal and 2D Image. SIViP 2023, 17, 445–451. [Google Scholar] [CrossRef]
- Wang, S.; Cheng, H.; Ying, L.; Xiao, T.; Ke, Z.; Zheng, H.; Liang, D. DeepcomplexMRI: Exploiting deep residual network for fast parallel MR imaging with complex convolution. Magn. Reson. Imag. 2020, 68, 136–147. [Google Scholar] [CrossRef]
- Xi, J.; Ersoy, O.K.; Cong, M.; Zhao, C.; Qu, W.; Wu, T. Wide and Deep Fourier Neural Network for Hyperspectral Remote Sensing Image Classification. Remote Sens. 2022, 14, 2931. [Google Scholar] [CrossRef]
- Yao, Z.; Fan, G.; Fan, J.; Gan, M.; Chen, C.L.P. Spatial–Frequency Dual-Domain Feature Fusion Network for Low-Light Remote Sensing Image Enhancement. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4706516. [Google Scholar] [CrossRef]
- Yu, B.; Yang, A.; Chen, F.; Wang, N.; Wang, L. SNNFD, spiking neural segmentation network in frequency domain using high spatial resolution images for building extraction. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102930. [Google Scholar] [CrossRef]
- Ricaud, B.; Borgnat, P.; Tremblay, N.; Gonçalves, P.; Vandergheynst, P. Fourier could be a data scientist: From graph Fourier transform to signal processing on graphs. C. R. Phys. 2019, 20, 474–488. [Google Scholar] [CrossRef]
- Hu, Y.; Lu, L.; Li, C. Memory-accelerated parallel method for multidimensional fast fourier implementation on GPU. J. Supercomput. 2022, 78, 18189–18208. [Google Scholar] [CrossRef]
- Singh, A.; Chougule, A.; Narang, P.; Chamola, V.; Yu, F.R. Low-Light Image Enhancement for UAVs with Multi-Feature Fusion Deep Neural Networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3513305. [Google Scholar] [CrossRef]
- Chen, H.; Yokoya, N.; Chini, M. Fourier domain structural relationship analysis for unsupervised multimodal change detection. ISPRS J. Photogramm. Remote Sens. 2023, 198, 99–114. [Google Scholar] [CrossRef]
- Zhu, P.; Zhang, X.; Han, X.; Cheng, X.; Gu, J.; Chen, P.; Jiao, L. Cross-Domain Classification Based on Frequency Component Adaptation for Remote Sensing Images. Remote Sens. 2024, 16, 2134. [Google Scholar] [CrossRef]
- Wang, W.; Wang, J.; Chen, C.; Jiao, J.; Cai, Y.; Song, S.; Li, J. Fremae: Fourier transform meets masked autoencoders for medical image segmentation. arXiv 2023, arXiv:2304.10864. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; IEEE: New York, NY, USA, 2018; pp. 172–17209. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High-Resolution Satellite Imagery Road Extraction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; IEEE: New York, NY, USA, 2018; pp. 192–1924. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A Novel Transformer-Based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506105. [Google Scholar] [CrossRef]
- Zhou, G.; Chen, W.; Gui, Q.; Li, X.; Wang, L. Split Depth-Wise Separable Graph-Convolution Network for Road Extraction in Complex Environments from High-Resolution Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614115. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | IOU | Recall | F1 | Precision | OA |
|---|---|---|---|---|---|
| U-Net | 63.97% | 70.48% | 75.59% | 84.30% | 96.83% |
| D-Linknet | 66.56% | 73.33% | 77.83% | 84.94% | 97.11% |
| DeepLab-v3 | 67.85% | 74.02% | 78.56% | 85.17% | 97.35% |
| DCSwin | 70.21% | 75.49% | 80.27% | 87.87% | 97.63% |
| SGCN | 69.78% | 74.56% | 80.13% | 84.94% | 97.54% |
| ours | 72.54% | 76.99% | 82.22% | 89.59% | 98.03% |
| Model | IOU | Recall | F1 | Precision | OA |
|---|---|---|---|---|---|
| U-Net | 44.93% | 55.77% | 58.29% | 65.76% | 97.01% |
| D-Linknet | 45.14% | 61.42% | 58.80% | 60.13% | 96.80% |
| DeepLabv3 | 48.34% | 63.94% | 61.71% | 63.56% | 97.08% |
| DCSwin | 52.54% | 63.55% | 64.58% | 69.71% | 97.53% |
| SGCN | 53.46% | 61.80% | 66.19% | 73.77% | 97.68% |
| ours | 55.35% | 66.63% | 68.04% | 71.83% | 97.74% |
| Model | IOU | Recall | F1 | Precision | OA |
|---|---|---|---|---|---|
| U-Net | 60.79% | 73.05% | 75.96% | 79.54% | 97.83% |
| D-Linknet | 64.36% | 73.42% | 77.65% | 85.47% | 97.88% |
| DeepLab-v3 | 65.51% | 75.23% | 79.30% | 85.36% | 97.96% |
| DCSwin | 67.83% | 75.85% | 80.43% | 88.17% | 98.35% |
| SGCN | 66.01% | 74.89% | 79.82% | 84.75% | 98.10% |
| ours | 71.87% | 77.49% | 82.67% | 89.95% | 98.58% |
| Model | IOU | Recall | F1 | Precision | OA |
|---|---|---|---|---|---|
| No Fourier | 70.29% | 75.96% | 79.85% | 87.52% | 97.46% |
| Full Fourier | 72.05% | 76.11% | 81.55% | 86.71% | 97.91% |
| Ours | 72.54% | 76.99% | 82.22% | 89.59% | 98.03% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Zhou, C.; Xing, X.; Wu, Y.; Wu, Y. A High-Resolution Remote Sensing Road Extraction Method Based on the Coupling of Global Spatial Features and Fourier Domain Features. Remote Sens. 2024, 16, 3896. https://doi.org/10.3390/rs16203896
Yang H, Zhou C, Xing X, Wu Y, Wu Y. A High-Resolution Remote Sensing Road Extraction Method Based on the Coupling of Global Spatial Features and Fourier Domain Features. Remote Sensing. 2024; 16(20):3896. https://doi.org/10.3390/rs16203896
Chicago/Turabian StyleYang, Hui, Caili Zhou, Xiaoyu Xing, Yongchuang Wu, and Yanlan Wu. 2024. "A High-Resolution Remote Sensing Road Extraction Method Based on the Coupling of Global Spatial Features and Fourier Domain Features" Remote Sensing 16, no. 20: 3896. https://doi.org/10.3390/rs16203896
APA StyleYang, H., Zhou, C., Xing, X., Wu, Y., & Wu, Y. (2024). A High-Resolution Remote Sensing Road Extraction Method Based on the Coupling of Global Spatial Features and Fourier Domain Features. Remote Sensing, 16(20), 3896. https://doi.org/10.3390/rs16203896