
LWSARDet: A Lightweight SAR Small Ship Target Detection Network Based on a Position–Morphology Matching Mechanism
 ,
,  , , ,
, , ,
Abstract
1. Introduction
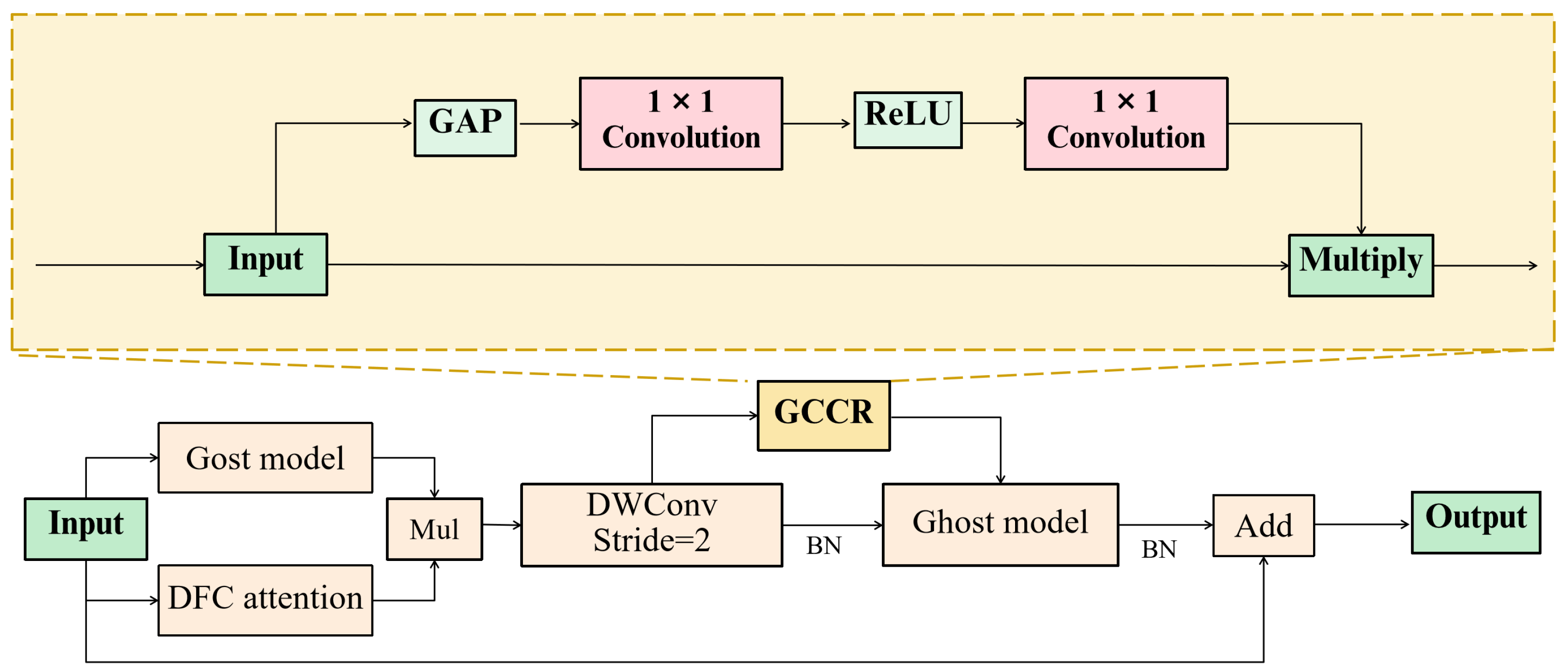
- To address the limitations of the original network in nonlinear expression capability, we construct a feature extraction module (GCCR-GhostNet) by embedding a global channel attention mechanism, which significantly reduces the network training parameter scale while enhancing multi-scale correlation and spatial semantic relationship modeling ability in feature space representation, so as to achieve the optimal balance between model ability and computational efficiency.
- Aiming at the defects of traditional detection heads in feature sparseness and computational cost when dealing with small targets, we design a lightweight detection head (LSD-Head) by utilizing simple linear transformations to replace traditional convolutions, further improving network efficiency.
- Given the challenges of low localization accuracy and shape mismatch, we propose a matching loss function (P-MIoU) by integrating center distance constraints and aspect ratio penalty mechanisms, which combines center distance constraints, aspect ratio penalties, and angular limitation mechanisms to accurately reflect positional and morphological deviations, improving the localization accuracy of small targets.
- Extensive experiments conducted on the High-Resolution SAR Image Dataset (HRSID) and the SAR Ship Detection Dataset (SSDD) demonstrate that LWSARDet achieves superior overall performance compared to existing state-of-the-art (SOTA) methods.
2. Related Work
2.1. SAR Small Target Detection Methods
2.2. Model Lightweight Method
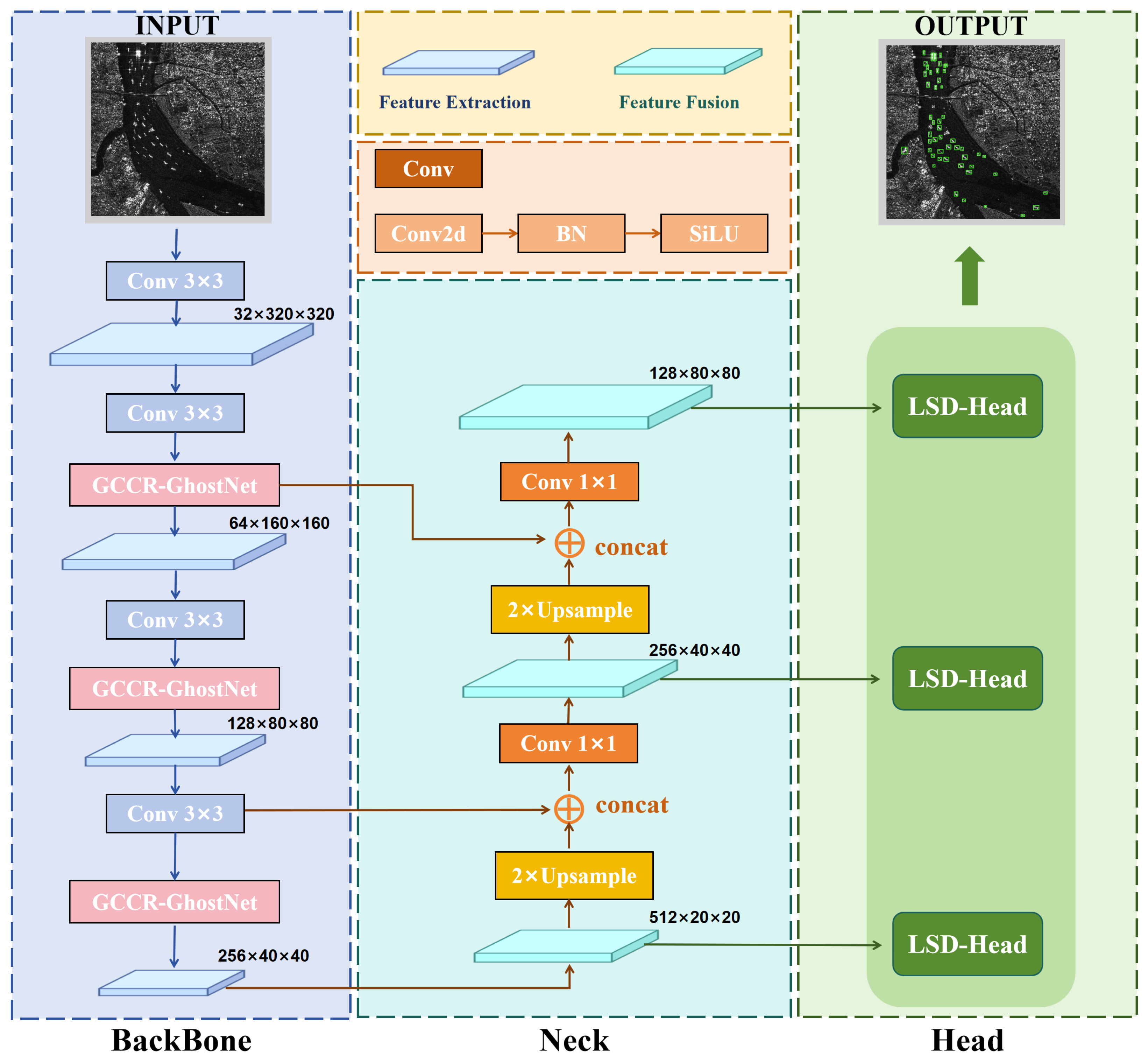
3. Proposed Methods
3.1. GhostNet with Global Channel Recalibration (GCCR-GhostNet)
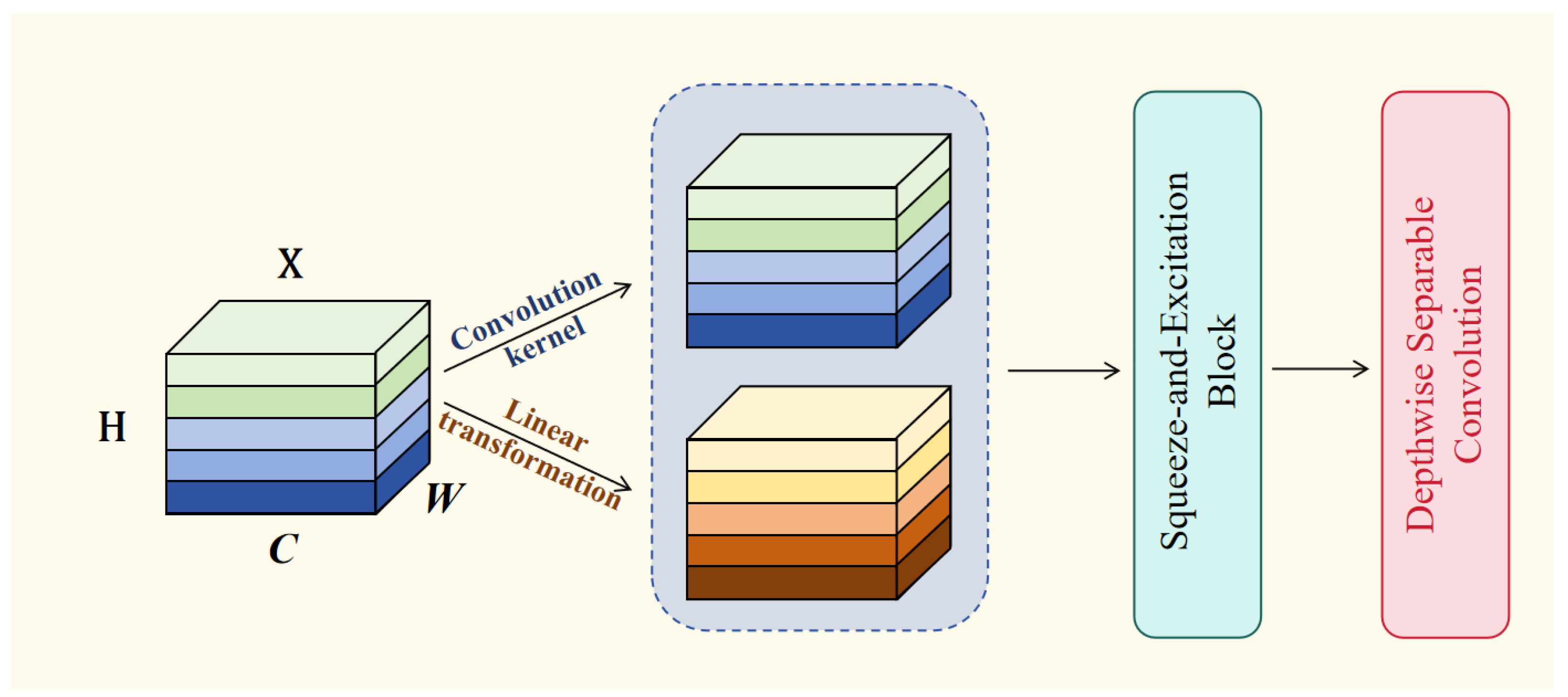
3.2. Detection Head Structure Integrating Attention Mechanism and Lightweight Convolution (LSD-Head)
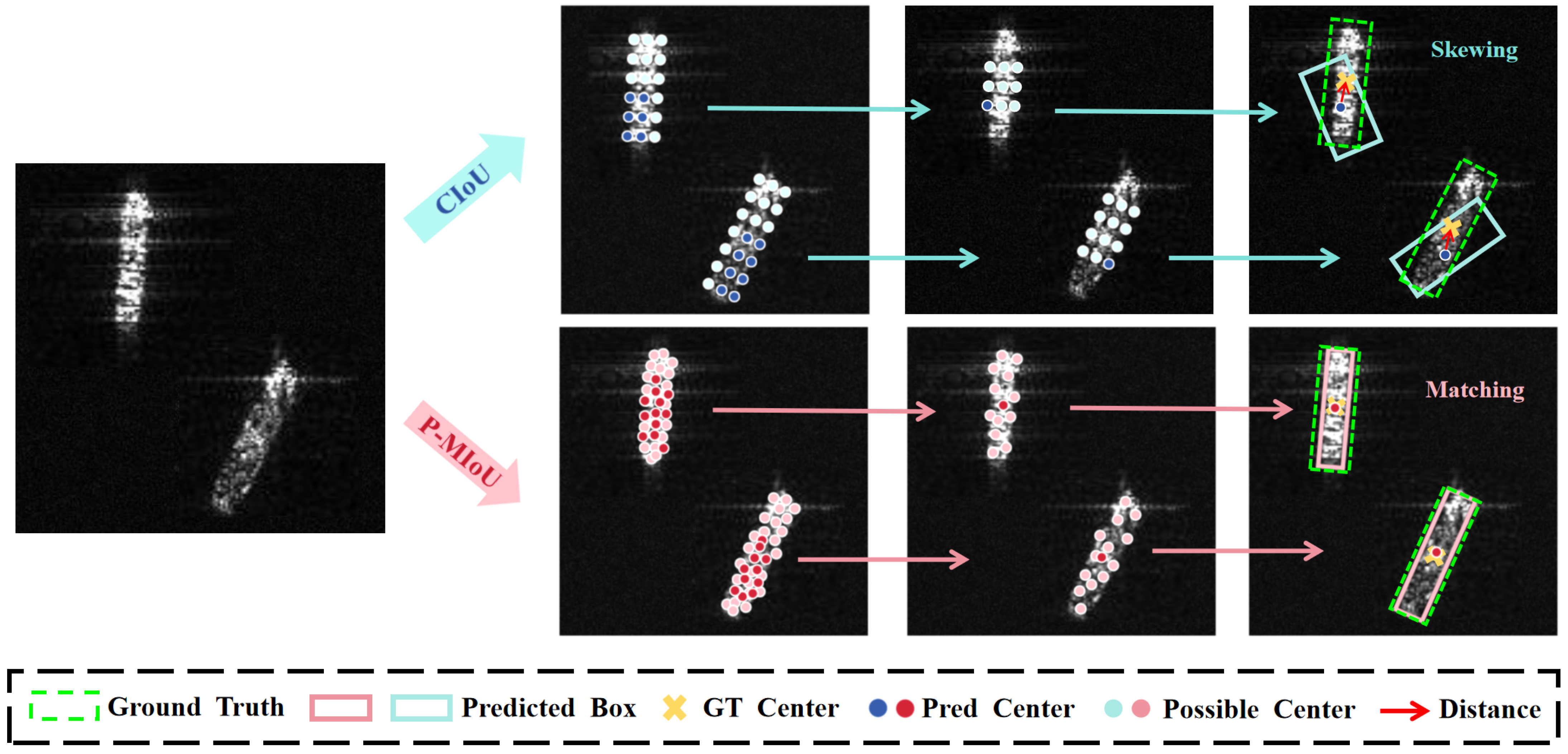
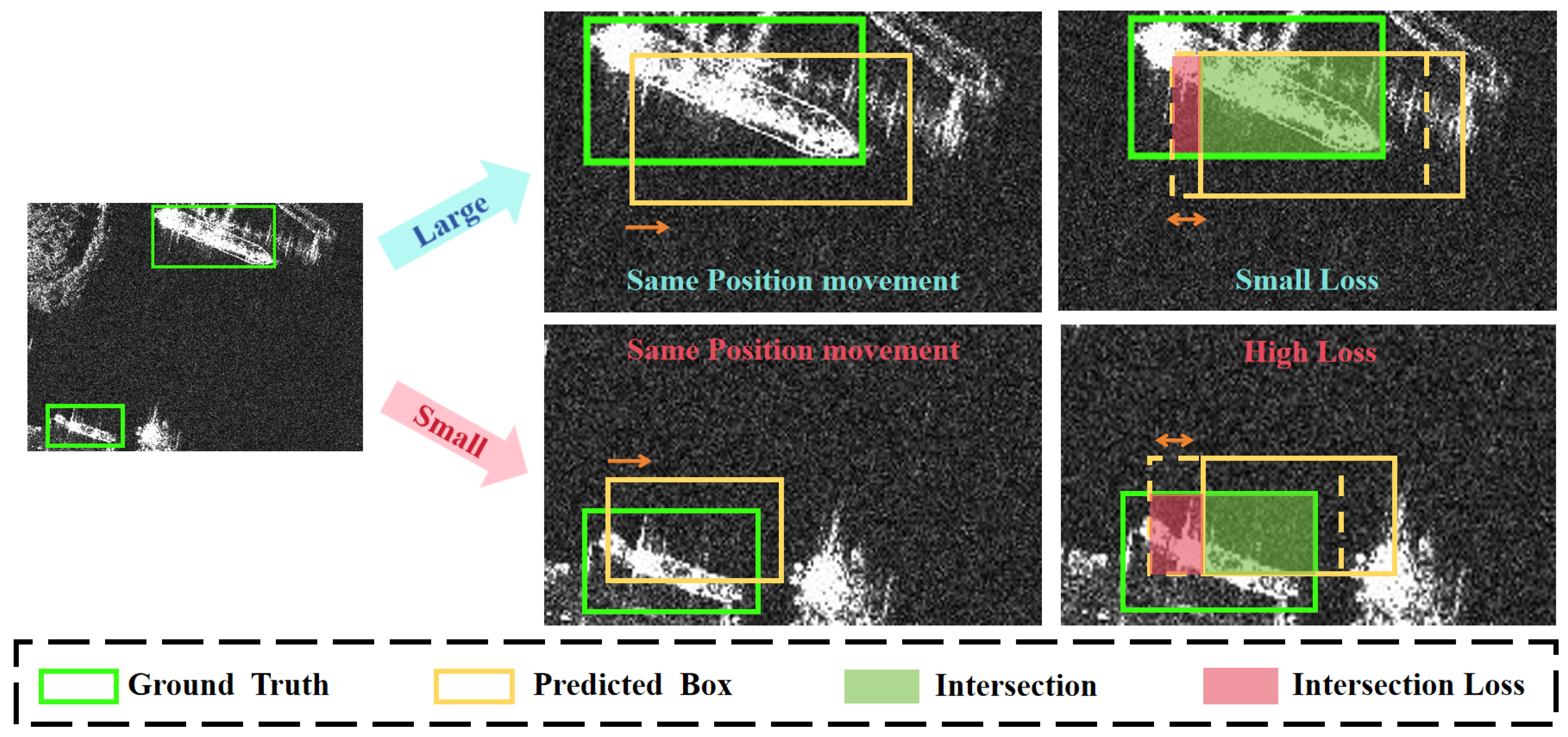
3.3. Position–Morphology Matching IoU(P-MIoU)
3.3.1. Loss Constraint Based on Center Point Position
3.3.2. Loss Constraint Based on Morphological Matching
4. Results
4.1. Dataset
4.2. Experimental Environment
4.3. Evaluation Criteria
4.4. Performance Comparison
4.4.1. Performance on HRSID Datasets
4.4.2. Performance on SSDD Datasets
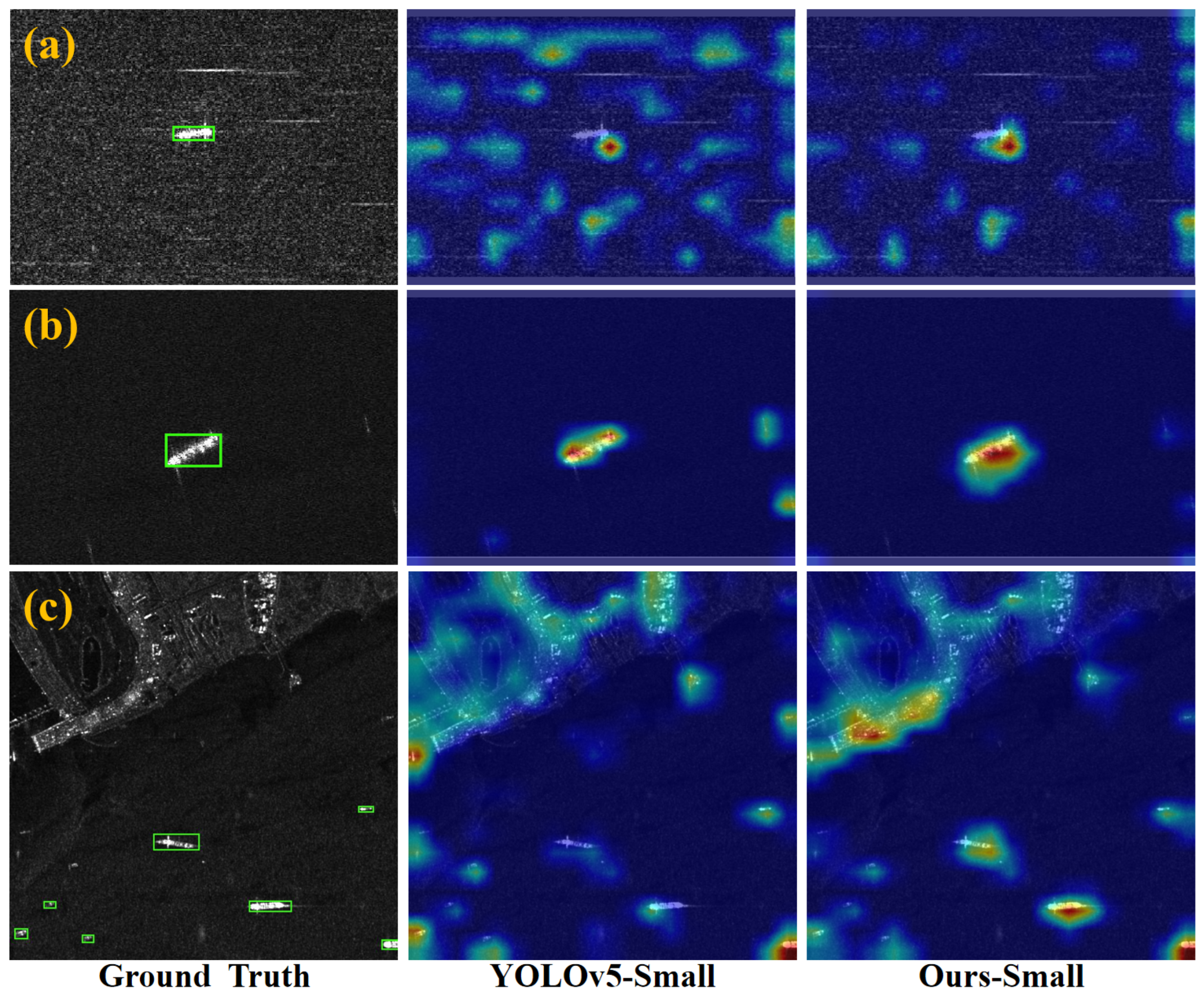
4.4.3. Attention Visualization Analysis
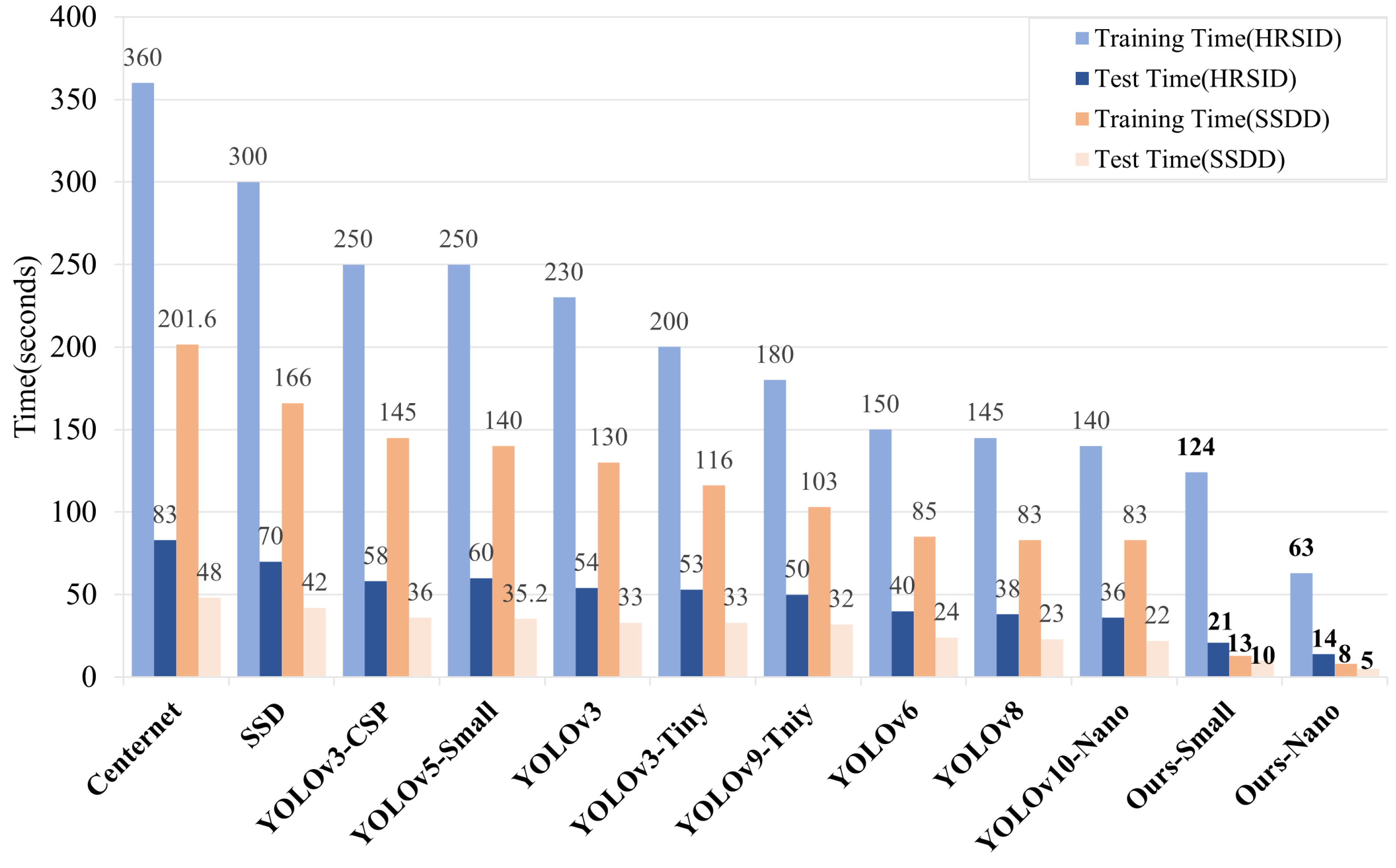
4.4.4. Computational Efficiency Analysis
4.5. Ablation Study
4.5.1. Ablation on Attention Network
4.5.2. Ablation Experiments on IoU Loss Function
4.5.3. Overall Impact of Components
Sensitivity Analysis on LWSARDet-Small
Sensitivity Analysis on LWSARDet-Nano
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, C.A.; Chen, Z.; Hao, P.; Li, K.; Wang, X. LAI Retrieval of Winter Wheat using Simulated Compact SAR Data through GA-PLS Modeling. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 3840–3843. [Google Scholar]
- Chen, Y.; Liu, X. Research on Methods of Quick Monitoring and Evaluating of Flood Disaster in Poyang Lake Area Based on RS and GIS. In Proceedings of the 2008 IEEE International Symposium on Knowledge Acquisition and Modeling Workshop, Wuhan, China, 21–22 December 2008; pp. 1105–1108. [Google Scholar]
- Gu, Y.; Tao, J.; Feng, L.; Wang, H. Using VGG16 to Military Target Classification on MSTAR Dataset. In Proceedings of the 2021 2nd China International SAR Symposium (CISS), Shanghai, China, 3–5 November 2021; pp. 1–3. [Google Scholar]
- Moroni, D.; Pieri, G.; Salvetti, O.; Tampucci, M. Proactive marine information system for environmental monitoring. In Proceedings of the OCEANS 2015-Genova, Genova, Italy, 18–21 May 2015; pp. 1–5. [Google Scholar]
- Arguedas, V.F. Texture-based vessel classifier for electro-optical satellite imagery. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3866–3870. [Google Scholar]
- Jiang, Z.; Wang, Y.; Zhou, X.; Chen, L.; Chang, Y.; Song, D.; Shi, H. Small-Scale Ship Detection for SAR Remote Sensing Images Based on Coordinate-Aware Mixed Attention and Spatial Semantic Joint Context. Smart Cities 2023, 6, 1612–1629. [Google Scholar] [CrossRef]
- El-Darymli, K.; Gill, E.W.; Mcguire, P.; Power, D.; Moloney, C. Automatic target recognition in synthetic aperture radar imagery: A state-of-the-art review. IEEE Access 2016, 4, 6014–6058. [Google Scholar] [CrossRef]
- Qian, G.; Haipeng, W.; Feng, X. Research progress on aircraft detection and recognition in SAR imagery. J. Radars 2020, 9, 497–513. [Google Scholar]
- Gong, S.; Xu, S.; Zhou, L.; Zhu, J.; Zhong, S. Deformable atrous convolution nearshore SAR small ship detection incorporating mixed attention. J. Image Graph. 2022, 27, 3663–3676. [Google Scholar] [CrossRef]
- Ruan, C.; Guo, H.; An, J. SAR Inshore Ship Detection Algorithm in Complex Background. J. Image Graph. 2021, 26, 1058–1066. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Qian, Y.; He, X. Design and Implementation of Lightweight Neural Network Inference Accelerator Based on FPGA. In Proceedings of the 2024 International Conference on Control, Electronic Engineering and Machine Learning (CEEML), Kuala Lumpur, Malaysia, 22–24 November 2024; pp. 98–104. [Google Scholar]
- Wang, P.; Wang, W.; Wang, H. Infrared unmanned aerial vehicle targets detection based on multi-scale filtering and feature fusion. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 1746–1750. [Google Scholar]
- Liu, D.; Liang, J.; Geng, T.; Loui, A.; Zhou, T. Tripartite Feature Enhanced Pyramid Network for Dense Prediction. IEEE Trans. Image Process. 2023, 32, 2678–2692. [Google Scholar] [CrossRef] [PubMed]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered Object Detection in Aerial Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8231–8240. [Google Scholar]
- Li, R. Improved YOLOv7 Aerial Small Target Detection Algorithm Based on Hole Convolutional ASPP. In Proceedings of the 2023 3rd International Conference on Electronic Information Engineering and Computer Communication (EIECC), Wuhan, China, 22–24 December 2023; pp. 663–666. [Google Scholar]
- He, Y.; Zhang, X.; Zheng, S.; Peng, L.; Chen, Y. Object Detector with Multi-head Self-attention and Multi-scale Fusion. In Proceedings of the 2022 International Conference on Algorithms, Data Mining, and Information Technology (ADMIT), Xi’an, China, 23–25 September 2022; pp. 147–154. [Google Scholar]
- Chung, W.Y.; Lee, I.H.; Park, C.G. Lightweight Infrared Small Target Detection Network Using Full-Scale Skip Connection U-Net. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Ou, J.; Li, X.; Sun, Y.; Shi, Y. A Configurable Hardware Accelerator Based on Hybrid Dataflow for Depthwise Separable Convolution. In Proceedings of the 2022 4th International Conference on Advances in Computer Technology, Information Science and Communications (CTISC), Suzhou, China, 22–24 April 2022; pp. 1–5. [Google Scholar]
- Romero, A.; Gatta, C.; Camps-Valls, G. Unsupervised deep feature extraction of hyperspectral images. In Proceedings of the 2014 6th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Lausanne, Switzerland, 24–27 June 2014; pp. 1–4. [Google Scholar]
- Li, G.; Liu, Z.; Zhang, X.; Lin, W. Lightweight Salient Object Detection in Optical Remote-Sensing Images via Semantic Matching and Edge Alignment. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Peng, W.; Zhang, L.; Zhao, L.; Li, X. Lite-ODNet: A Lightweight Object Detection Network. In Proceedings of the 2024 3rd International Conference on Artificial Intelligence, Human-Computer Interaction and Robotics (AIHCIR), Hong Kong, China, 15–17 November 2024; pp. 229–236. [Google Scholar]
- Li, L.; Du, L.; Wang, Z. Target Detection Based on Dual-Domain Sparse Reconstruction Saliency in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4230–4243. [Google Scholar] [CrossRef]
- Gan, R.; Wang, J. Distribution-based CFAR detectors in SAR images. J. Syst. Eng. Electron. 2006, 17, 717–721. [Google Scholar] [CrossRef]
- Li, J.x.; Chen, H. SAR image preprocessing based on the CFAR and ROA algorithm. In Proceedings of the IET International Radar Conference 2013, Xi’an, China, 14–16 April 2013; pp. 1–4. [Google Scholar]
- Gao, G.; Liu, L.; Zhao, L.; Shi, G.; Kuang, G. An Adaptive and Fast CFAR Algorithm Based on Automatic Censoring for Target Detection in High-Resolution SAR Images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1685–1697. [Google Scholar] [CrossRef]
- Tian, S.; Wang, C.; Zhang, H. A segmentation based global iterative censoring scheme for ship detection in synthetic aperture radar image.doc. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 6513–6516. [Google Scholar]
- Nercessian, S.; Panetta, K.; Agaian, S. Improving edge-based feature extraction using feature fusion. In Proceedings of the 2008 IEEE International Conference on Systems, Man and Cybernetics, Singapore, 12–15 October 2008; pp. 679–684. [Google Scholar]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed]
- Xue, Z.; Chen, W.; Li, J. Enhancement and Fusion of Multi-Scale Feature Maps for Small Object Detection. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 7212–7217. [Google Scholar]
- Yang, Z.; Liu, Y.; Gao, Z.; Wen, G.; Emma Zhang, W.; Xiao, Y. Deep Convolutional Feature Enhancement for Remote Sensing Object Detection. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Dai, Y.; Liu, W.; Wang, H.; Xie, W.; Long, K. YOLO-Former: Marrying YOLO and Transformer for Foreign Object Detection. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Chen, P.; Yang, J.; An, W.; Zheng, G.; Luo, D.; Lu, A.; Wang, Z. TKP-Net: A Three Keypoint Detection Network for Ships Using SAR Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 364–376. [Google Scholar] [CrossRef]
- Yang, C.; Li, B.; Wang, Y. A Fully Quantitative Scheme with Fine-grained Tuning Method for Lightweight CNN Acceleration. In Proceedings of the 2019 26th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Genoa, Italy, 27–29 November 2019; pp. 125–126. [Google Scholar]
- Zheng, X.; Feng, Y.; Shi, H.; Zhang, B.; Chen, L. Lightweight convolutional neural network for false alarm elimination in SAR ship detection. In Proceedings of the IET International Radar Conference (IET IRC 2020), Online, 4–6 November 2020; Volume 2020, pp. 287–291. [Google Scholar] [CrossRef]
- Zhou, L.; Wei, S.; Cui, Z.; Fang, J.; Yang, X.; Ding, W. Lira-YOLO: A lightweight model for ship detection in radar images. J. Syst. Eng. Electron. 2020, 31, 950–956. [Google Scholar] [CrossRef]
- Lan, R.; Sun, L.; Liu, Z.; Lu, H.; Pang, C.; Luo, X. MADNet: A Fast and Lightweight Network for Single-Image Super Resolution. IEEE Trans. Cybern. 2021, 51, 1443–1453. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Zhang, S.; Duan, S.; Yang, W. An Effective and Lightweight Hybrid Network for Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–11. [Google Scholar] [CrossRef]
- Deng, L.; Bi, L.; Li, H.; Chen, H.; Duan, X.; Lou, H.; Zhang, H.; Bi, J.; Liu, H. Lightweight aerial image object detection algorithm based on improved YOLOv5s. Sci. Rep. 2023, 13, 7817. [Google Scholar] [CrossRef] [PubMed]
- Ma, T.; Yang, Z.; Liu, B.; Sun, S. A Lightweight Infrared Small Target Detection Network Based on Target Multiscale Context. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for Small Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Kou, R.; Wang, C.; Yu, Y.; Peng, Z.; Yang, M.; Huang, F.; Fu, Q. LW-IRSTNet: Lightweight Infrared Small Target Segmentation Network and Application Deployment. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Ye, T.; Qin, W.; Zhao, Z.; Gao, X.; Deng, X.; Ouyang, Y. Real-time object detection network in UAV-vision based on CNN and transformer. IEEE Trans. Instrum. Meas. 2023, 72, 1–13. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Misbah, M.; Khan, M.U.; Kaleem, Z.; Muqaibel, A.; Alam, M.Z.; Liu, R.; Yuen, C. MSF-GhostNet: Computationally Efficient YOLO for Detecting Drones in Low-Light Conditions. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 3840–3851. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Cao, C.; Chen, S.; Zhang, W.; Tian, W.; Miao, H. A Real-Time SAR Ship Detection Method Based on Improved Yolov5. In Proceedings of the 2023 Cross Strait Radio Science and Wireless Technology Conference (CSRSWTC), Guilin, China, 10–13 November 2023; pp. 1–3. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A High-Resolution SAR Images Dataset for Ship Detection and Instance Segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Yue, T.; Zhang, Y.; Liu, P.; Xu, Y.; Yu, C. A Generating-Anchor Network for Small Ship Detection in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7665–7676. [Google Scholar] [CrossRef]
- Guan, T.; Chang, S.; Wang, C.; Jia, X. SAR Small Ship Detection Based on Enhanced YOLO Network. Remote Sens. 2025, 17, 839. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Deng, L.; Li, H.; Liu, H.; Gu, J. A lightweight YOLOv3 algorithm used for safety helmet detection. Sci. Rep. 2022, 12, 10981. [Google Scholar] [CrossRef] [PubMed]
- Rani, E. LittleYOLO-SPP: A delicate real-time vehicle detection algorithm. Optik 2021, 225, 165818. [Google Scholar]
- Zheng, Y.; Zhang, Y.; Qian, L.; Zhang, X.; Diao, S.; Liu, X.; Cao, J.; Huang, H. A lightweight ship target detection model based on improved YOLOv5s algorithm. PLoS ONE 2023, 18, 1–23. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar]
- Jha, A.; Tiwari, S.K. Glioma Detection Using YOLO V9: A Deep Learning Framework. In Proceedings of the 2025 3rd International Conference on Smart Systems for Applications in Electrical Sciences (ICSSES), Tumakuru, India, 7–8 March 2025; pp. 1–6. [Google Scholar]
- Tasin, M.A.U.; Faiyaz, G.M.F.; Uddin, M.N. Deep Learning for Brain Tumor Detection Leveraging YOLOv10 for Precise Localization. In Proceedings of the 2024 IEEE 3rd International Conference on Robotics, Automation, Artificial-Intelligence and Internet-of-Things (RAAICON), Dhaka, Bangladesh, 29–30 November 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 207–212. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv 2024, arXiv:2502.12524. [Google Scholar]
- Han, G.; Huang, S.; Zhao, F.; Tang, J. SIAM: A parameter-free, Spatial Intersection Attention Module. Pattern Recognit. 2024, 153, 110509. [Google Scholar] [CrossRef]
- Jiang, Y.; Jiang, Z.; Han, L.; Huang, Z.; Zheng, N. MCA: Moment channel attention networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 2579–2588. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized self-attention: Towards high-quality pixel-wise regression. arXiv 2021, arXiv:2107.00782. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar] [CrossRef]
- Xin, Z.; Lu, T.; Li, X. Detection of Train Bottom Parts Based on XIoU. In Proceedings of the 2019 International Conference on Robotics Systems and Vehicle Technology, New York, NY, USA, 27 June–1 July 2019; pp. 91–96. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | GFLOPs/G ↓ | mAP/% ↑ | mAP50-90/% ↑ | Recall/% ↑ | Precision/% ↑ | Params/M ↓ |
|---|---|---|---|---|---|---|
| CenterNet [60] | 70.2 | 62.5 | 30.2 | 42.0 | 97.9 | 3.27 |
| SSD [61] | 360.7 | 50.0 | 22.4 | 22.7 | 89.3 | 50.21 |
| YOLOv3 [35] | 154.5 | 94.1 | 67.6 | 78.0 | 91.8 | 61.50 |
| YOLOv3-CSP [62] | 155.4 | 93.7 | 67.1 | 88.6 | 92.1 | 62.55 |
| YOLOv3-Tiny [63] | 12.9 | 83.7 | 56.2 | 76.5 | 90.1 | 8.67 |
| YOLOv5-Small [64] | 15.8 | 91.1 | 67.8 | 83.5 | 90.2 | 7.01 |
| YOLOv6 [65] | 11.8 | 88.9 | 63.3 | 81.1 | 89.7 | 4.23 |
| YOLOv8 [66] | 8.1 | 90.9 | 65.3 | 84.1 | 90.4 | 3.01 |
| YOLOv9-Tiny [67] | 7.6 | 91.6 | 65.8 | 83.5 | 91.3 | 1.97 |
| YOLOv10-Nano [68] | 8.2 | 90.2 | 65.1 | 79.3 | 91.6 | 2.69 |
| YOLOv12-Nano [69] | 5.8 | 88.6 | 62.4 | 85.1 | 89.0 | 2.50 |
| Yue et al. [58] | 105.6 | 91.3 | 66.5 | 87.2 | 91.7 | 43.42 |
| Guan et al. [59] | 19.2 | 91.0 | 66.3 | 83.7 | 90.4 | 8.50 |
| LWSARDet-Small | 12.8 | 94.2 | 66.9 | 89.3 | 92.5 | 6.45 |
| LWSARDet-Nano | 3.4 | 94.1 | 67.0 | 87.9 | 92.0 | 1.63 |
| Methods | GFLOPs/G ↓ | mAP/% ↑ | mAP50-90/% ↑ | Recall/% ↑ | Precision/% ↑ | Params/M ↓ |
|---|---|---|---|---|---|---|
| CenterNet [60] | 70.2 | 73.5 | 40.7 | 57.7 | 83.5 | 3.27 |
| SSD [61] | 360.7 | 51.3 | 22.9 | 53.4 | 83.1 | 50.21 |
| YOLOv3 [35] | 154.5 | 90.5 | 68.9 | 81.0 | 83.5 | 61.50 |
| YOLOv3-CSP [62] | 155.4 | 90.7 | 69.5 | 86.6 | 79.9 | 62.55 |
| YOLOv3-Tiny [63] | 12.9 | 90.3 | 68.0 | 85.3 | 81.4 | 8.67 |
| YOLOv5-Small [64] | 15.8 | 89.1 | 67.3 | 85.1 | 81.8 | 7.01 |
| YOLOv6 [65] | 11.8 | 89.1 | 65.7 | 85.2 | 82.1 | 4.23 |
| YOLOv8 [66] | 8.1 | 88.7 | 65.5 | 86.5 | 80.1 | 3.01 |
| YOLOv9-Tiny [67] | 7.6 | 89.2 | 66.6 | 84.1 | 81.4 | 1.97 |
| YOLOv10-Nano [68] | 8.2 | 86.1 | 62.5 | 80.6 | 81.1 | 2.69 |
| YOLOv12-Nano [69] | 5.8 | 86.5 | 62.4 | 85.1 | 81.2 | 2.50 |
| Yue et al. [58] | 105.6 | 91.8 | 64.5 | 88.1 | 81.7 | 43.42 |
| Guan et al. [59] | 19.2 | 90.0 | 66.3 | 81.3 | 77.4 | 8.50 |
| LWSARDet-Small | 12.8 | 92.1 | 70.4 | 90.5 | 81.2 | 6.45 |
| LWSARDet-Nano | 3.4 | 90.4 | 67.7 | 89.7 | 78.2 | 1.63 |
| Metric | - | Siam2 [70] | MCA [71] | CA [72] | PSA [73] | LSD-Head |
|---|---|---|---|---|---|---|
| GFLOPs/G ↓ | 12.8 | 12.8 | 12.8 | 12.8 | 13.8 | 12.8 |
| mAP/% ↑ | 92.8 | 92.9 | 93.2 | 93.4 | 92.8 | 94.2 |
| mAP50-90/% ↑ | 63.7 | 64.7 | 64.3 | 64.4 | 64.5 | 66.9 |
| Recall/% ↑ | 84.9 | 85.7 | 86.1 | 86.1 | 84.7 | 89.2 |
| Precision/% ↑ | 91.2 | 92.0 | 92.3 | 93.4 | 94.5 | 92.4 |
| Params/M ↓ | 6.45 | 6.45 | 6.45 | 6.49 | 7.14 | 6.45 |
| Metric | - | EIoU [74] | SIoU [75] | XIoU [76] | P-MIoU |
|---|---|---|---|---|---|
| mAP/% ↑ | 92.8 | 92.6 | 92.8 | 93.1 | 94.2 |
| mAP50-90/% ↑ | 63.7 | 63.1 | 63.5 | 64.6 | 66.9 |
| Recall/% ↑ | 84.9 | 85.5 | 86.3 | 86.8 | 89.2 |
| Precision/% ↑ | 91.2 | 93.7 | 91.8 | 90.9 | 92.4 |
| Baseline | GCCR -GhostNet | LSD -Head | P-MIoU | GFLOPs/G ↓ | mAP/% ↑ | mAP50-90/% ↑ | Recall/% ↑ | Precision/% ↑ | Params/M ↓ |
|---|---|---|---|---|---|---|---|---|---|
| ✓ | – | – | – | 15.8 | 91.1 | 67.8 | 83.5 | 90.2 | 7.01 |
| ✓ | ✓ | – | – | 12.8 | 92.9 | 63.7 | 84.9 | 91.2 | 6.45 |
| ✓ | ✓ | ✓ | – | 12.8 | 93.2 | 63.7 | 85.6 | 92.2 | 6.45 |
| ✓ | ✓ | ✓ | ✓ | 12.8 | 94.2 | 66.9 | 89.3 | 92.5 | 6.45 |
| Methods | GFLOPs/G ↓ | mAP/% ↑ | mAP50-90/% ↑ | Params/M ↓ |
|---|---|---|---|---|
| GhostNetV2 | 12.8 | 93.7 | 65.0 | 6.45 |
| GCCR-GhostNet | 12.8 | 94.2 | 66.9 | 6.45 |
| Baseline | GCCR -GhostNet | LSD -Head | P-MIoU | GFLOPs/G ↓ | mAP/% ↑ | mAP50-90/% ↑ | Recall/% ↑ | Precision/% ↑ | Params/M ↓ |
|---|---|---|---|---|---|---|---|---|---|
| ✓ | – | – | – | 15.8 | 89.1 | 67.3 | 85.1 | 81.8 | 7.01 |
| ✓ | ✓ | – | – | 3.4 | 92.3 | 69.1 | 86.2 | 87.0 | 1.63 |
| ✓ | ✓ | – | ✓ | 3.4 | 88.3 | 63.3 | 89.9 | 73.6 | 1.63 |
| ✓ | ✓ | ✓ | ✓ | 3.4 | 90.4 | 67.7 | 89.7 | 78.2 | 1.63 |
| Methods | Dataset | GFLOPs/G ↓ | mAP/% ↑ | mAP50-90/% ↑ | Recall/% ↑ | Precision/% ↑ | Params/M ↓ |
|---|---|---|---|---|---|---|---|
| LWSARDet-Small | HRSID | 12.8 | 94.2 | 66.9 | 89.3 | 92.5 | 6.45 |
| LWSARDet-Small | SSDD | 12.8 | 92.1 | 70.4 | 90.5 | 81.2 | 6.45 |
| LWSARDet-Nano | HRSID | 3.4 | 94.1 | 67.0 | 87.9 | 92.0 | 1.63 |
| LWSARDet-Nano | SSDD | 3.4 | 90.4 | 67.7 | 89.7 | 78.2 | 1.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Du, Y.; Wang, Q.; Li, C.; Miao, Y.; Wang, T.; Song, X. LWSARDet: A Lightweight SAR Small Ship Target Detection Network Based on a Position–Morphology Matching Mechanism. Remote Sens. 2025, 17, 2514. https://doi.org/10.3390/rs17142514
Zhao Y, Du Y, Wang Q, Li C, Miao Y, Wang T, Song X. LWSARDet: A Lightweight SAR Small Ship Target Detection Network Based on a Position–Morphology Matching Mechanism. Remote Sensing. 2025; 17(14):2514. https://doi.org/10.3390/rs17142514
Chicago/Turabian StyleZhao, Yuliang, Yang Du, Qiutong Wang, Changhe Li, Yan Miao, Tengfei Wang, and Xiangyu Song. 2025. "LWSARDet: A Lightweight SAR Small Ship Target Detection Network Based on a Position–Morphology Matching Mechanism" Remote Sensing 17, no. 14: 2514. https://doi.org/10.3390/rs17142514
APA StyleZhao, Y., Du, Y., Wang, Q., Li, C., Miao, Y., Wang, T., & Song, X. (2025). LWSARDet: A Lightweight SAR Small Ship Target Detection Network Based on a Position–Morphology Matching Mechanism. Remote Sensing, 17(14), 2514. https://doi.org/10.3390/rs17142514