
Terrain and Atmosphere Classification Framework on Satellite Data Through Attentional Feature Fusion Network



Abstract
1. Introduction
- Presenting a framework for terrain classification based on satellite images, featuring novel ML methods and user-accessible model updates;
- Proposing a new dual-channel CNN-based backbone architecture is introduced, incorporating contextual attention and multi-head feature fusion to enhance semantic discrimination;
- Offering a lightweight and effective attention mechanism that dynamically re-weights feature maps based on spatial and channel-wise information;
- Conducting experimental analysis on public remote sensing datasets demonstrates that the proposed methods perform well and could be used in production.
2. Methodology
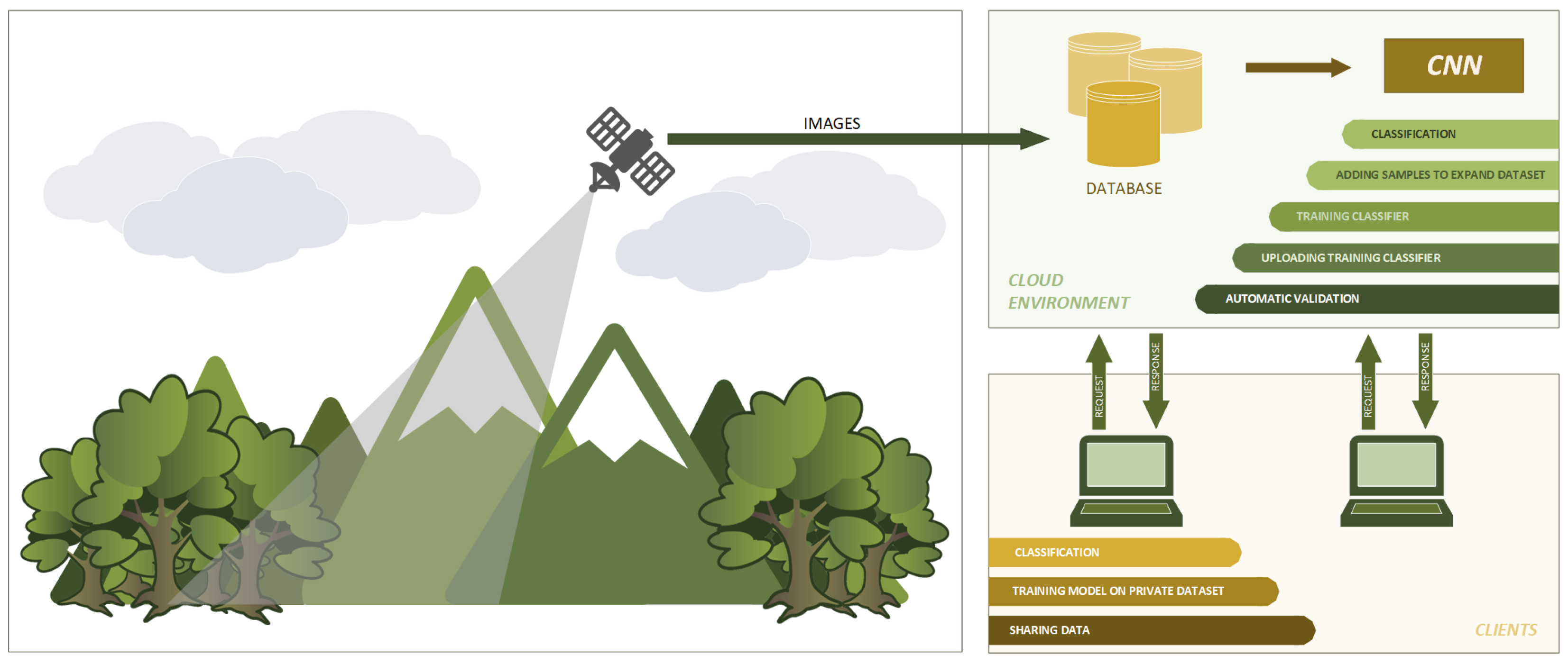
2.1. Framework Architecture for Terrain and Atmosphere Analysis Purposes
| Algorithm 1: Framework’s operation: cloud. |
 |
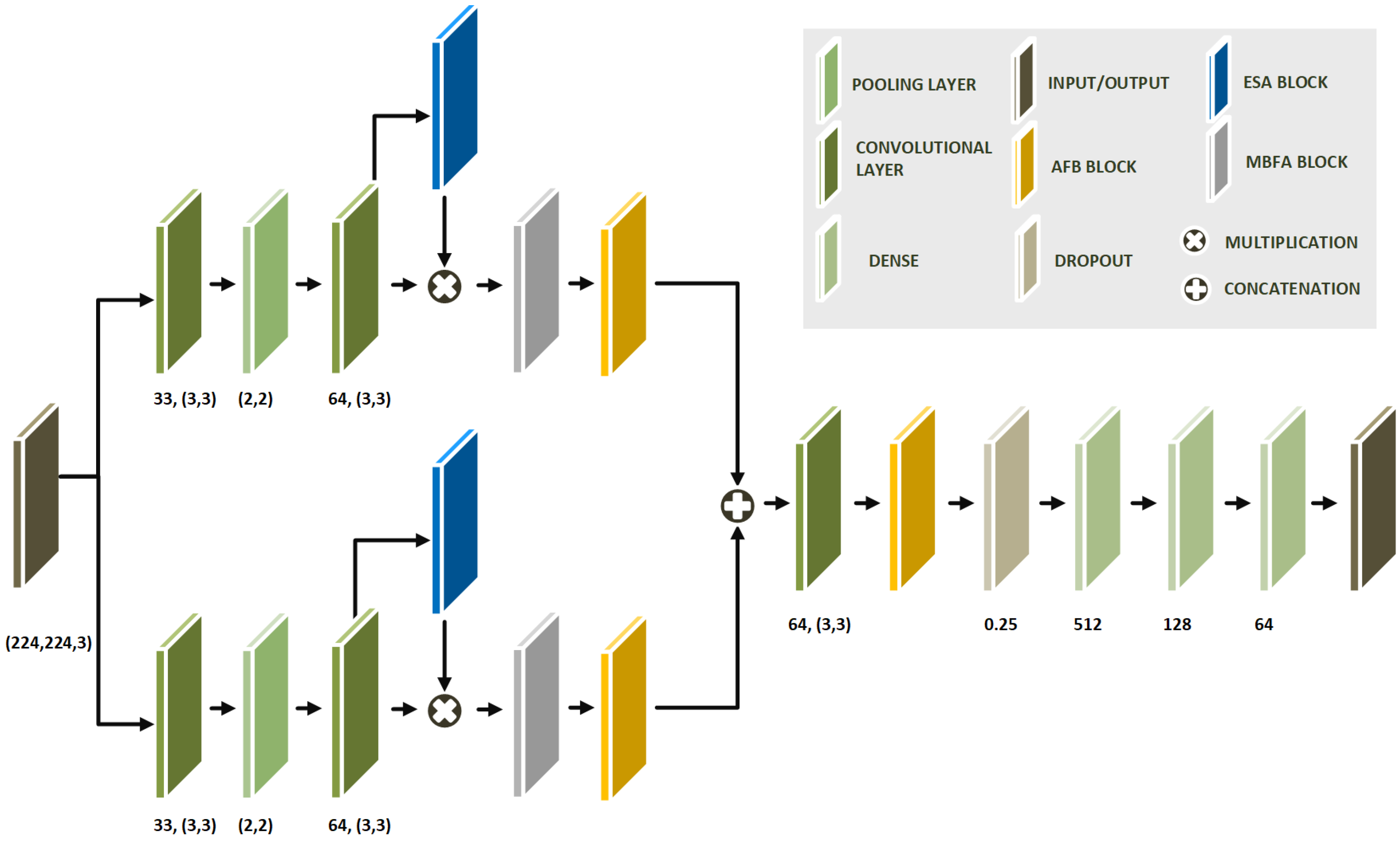
2.2. Proposed Neural Network Architecture
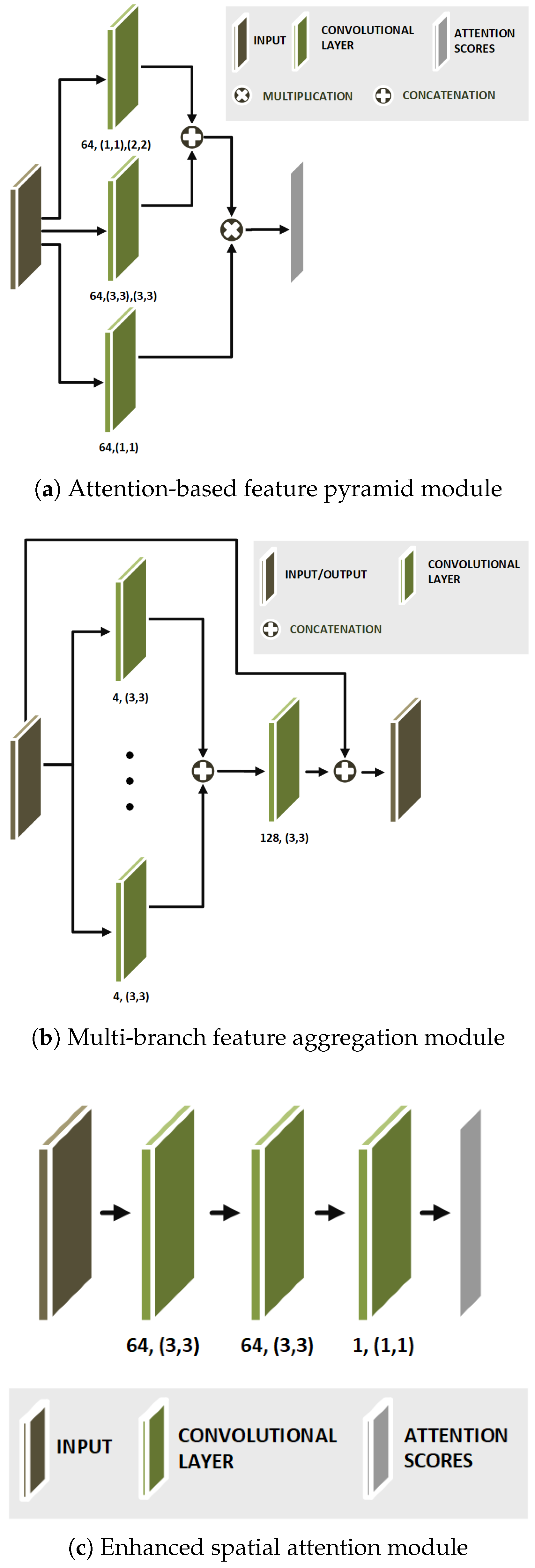
2.2.1. Enhanced Spatial Attention Module
2.2.2. Attention-Based Feature Pyramid Module
2.2.3. Multi-Branch Feature Aggregation Module
2.2.4. Model Architecture
3. Experiments
3.1. Satellite Images Dataset
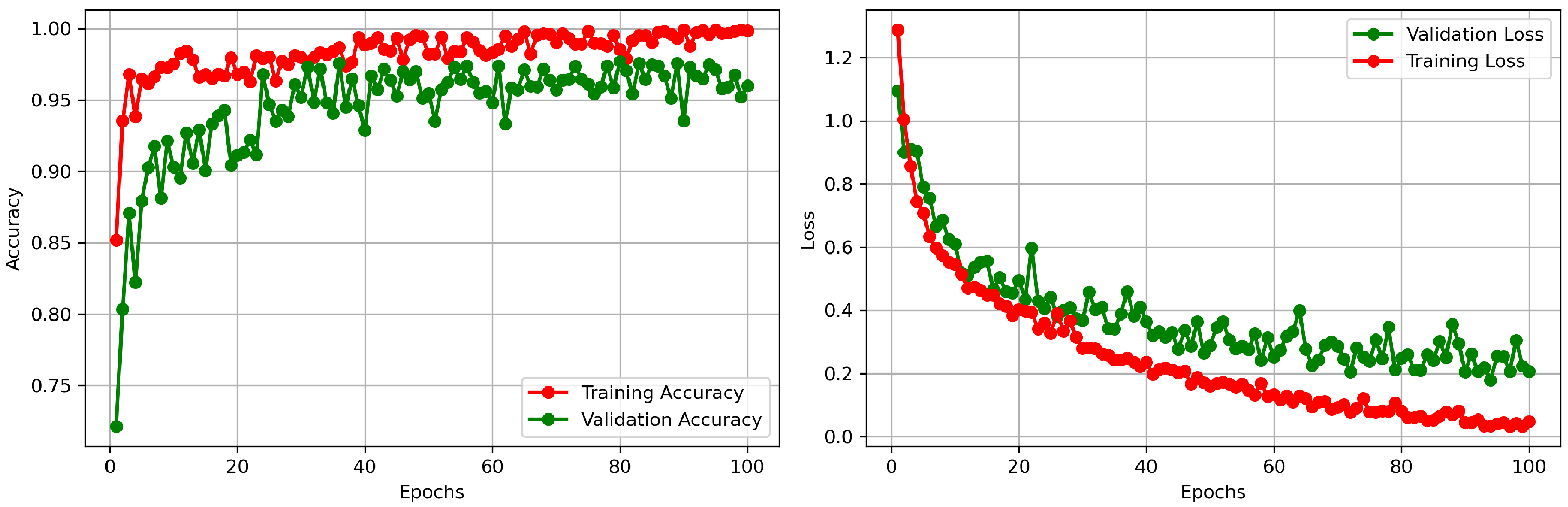
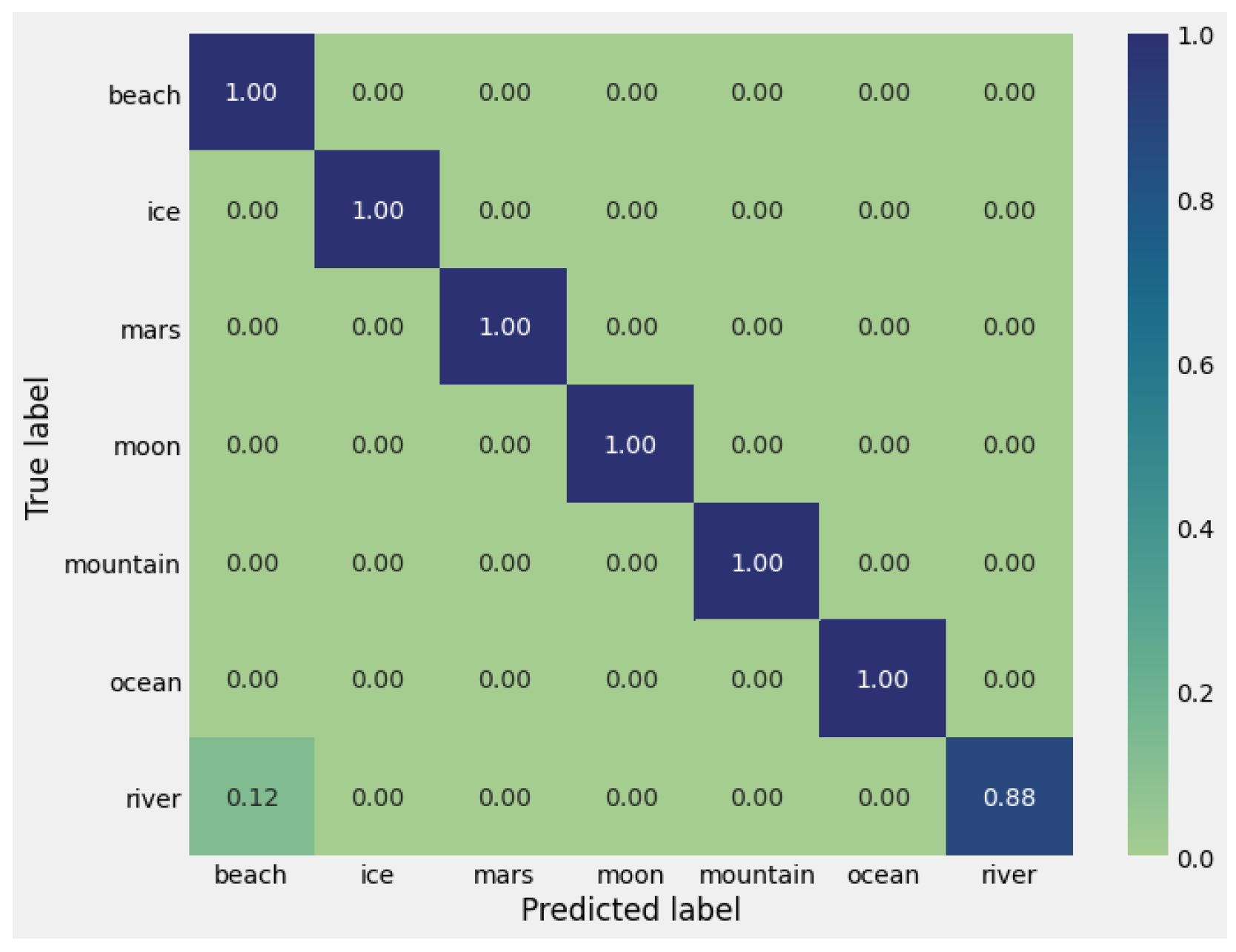
3.2. Visual Terrain Recognition
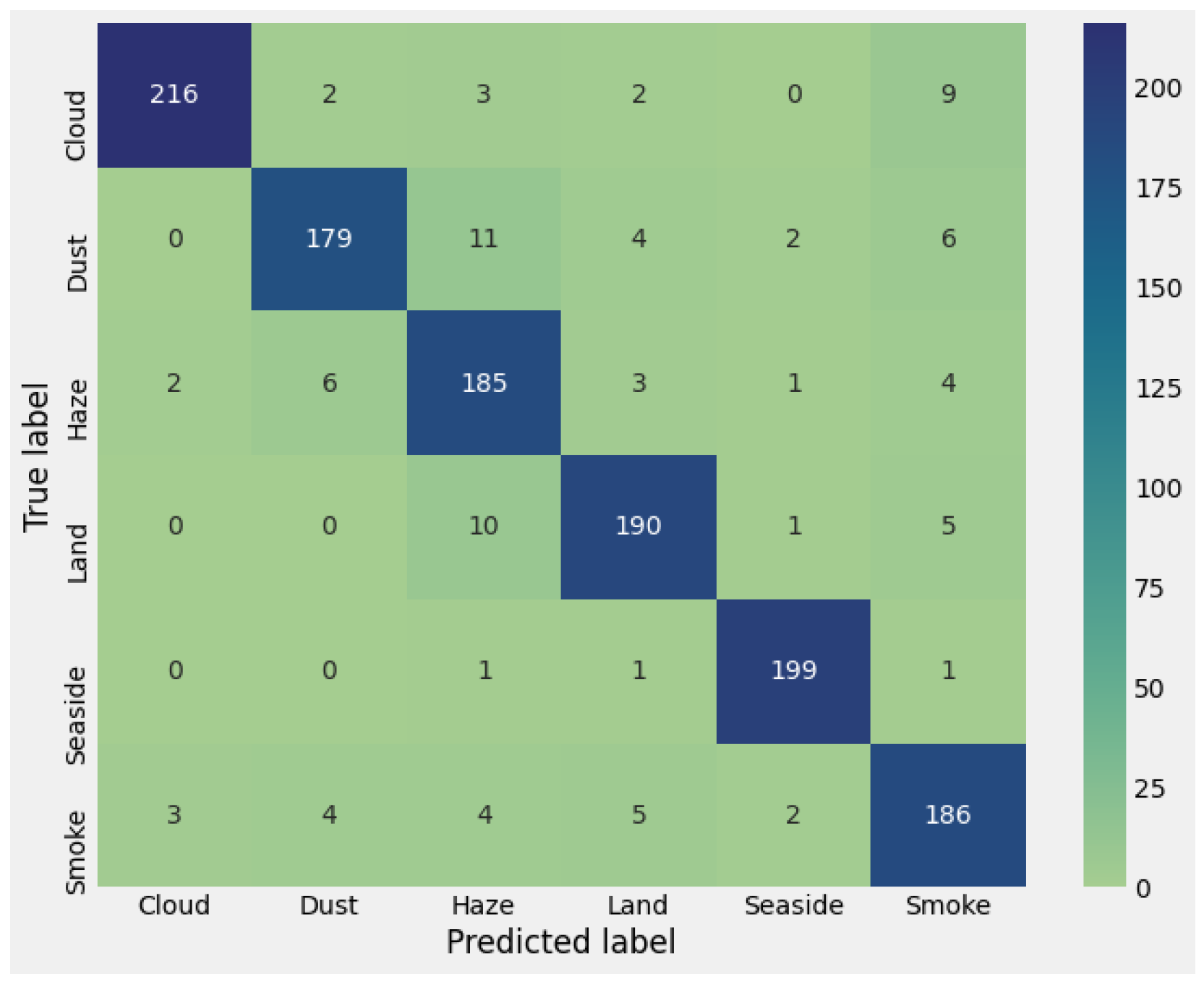
3.3. USTC SmokeRS
3.4. Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bai, J.; Zhang, M. RiseNet: Residual Attention-Gated CNNs for Efficient Feature Focus. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 567–579. [Google Scholar]
- Dai, Y.; Liu, F. HDCDF: Hierarchical Dual-Channel Dense Fusion Networks for Fine-Grained Attention. Pattern Recognit. 2025, 142, 109819. [Google Scholar]
- Wang, L.; Xu, J. TGF-Net: Transformer-Guided Fusion Network for Multi-Source Satellite Image Classification. Remote Sens. Environ. 2025, 303, 113017. [Google Scholar]
- Chen, Y.; Xia, R.; Yang, K.; Zou, K. MFFN: Image super-resolution via multi-level features fusion network. Vis. Comput. 2023, 40, 489–504. [Google Scholar] [CrossRef]
- Lee, H.; Park, M. HyFusion: Hybrid CNN-Attention Model for Robust Feature Extraction in Hyperspectral Imaging. Sensors 2025, 25, 987. [Google Scholar]
- Zhou, T.; He, X. SSFCT: Spectral-Spatial Fusion with Channel-wise Transformers for Hyperspectral Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 18345–18358. [Google Scholar]
- Li, Q.; Sun, Z. STNet: Spatio-Temporal Feature Fusion for Satellite Terrain Analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 October 2025; pp. 12345–12354. [Google Scholar]
- Chen, R.; Tan, H. CTANet: Cross-Transformer Attention Network for Remote Sensing Image Segmentation. ISPRS J. Photogramm. Remote Sens. 2025, 202, 32–45. [Google Scholar]
- Zhou, Z.; Islam, M.T.; Xing, L. Multibranch CNN with MLP-Mixer-Based Feature Exploration for High-Performance Disease Diagnosis. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 7351–7362. [Google Scholar] [CrossRef] [PubMed]
- Hao, Y.; Jing, X.Y.; Chen, R.; Liu, W. Learning enhanced specific representations for multi-view feature learning. Knowl.-Based Syst. 2023, 272, 110590. [Google Scholar] [CrossRef]
- Hu, T.; Xu, C.; Zhang, S.; Tao, S.; Li, L. Cross-site scripting detection with two-channel feature fusion embedded in self-attention mechanism. Comput. Secur. 2023, 124, 102990. [Google Scholar] [CrossRef]
- Zhang, Y.; Liang, L.; Mao, J.; Wang, Y.; Jia, L. From Global to Local: A Dual-Branch Structural Feature Extraction Method for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 1778–1791. [Google Scholar] [CrossRef]
- Rowley, A.; Karakuş, O. Predicting air quality via multimodal AI and satellite imagery. Remote Sens. Environ. 2023, 293, 113609. [Google Scholar] [CrossRef]
- Thomas, M.; Tellman, E.; Osgood, D.E.; DeVries, B.; Islam, A.S.; Steckler, M.S.; Goodman, M.; Billah, M. A framework to assess remote sensing algorithms for satellite-based flood index insurance. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2589–2604. [Google Scholar] [CrossRef]
- Zhao, S.; Liu, M.; Tao, M.; Zhou, W.; Lu, X.; Xiong, Y.; Li, F.; Wang, Q. The role of satellite remote sensing in mitigating and adapting to global climate change. Sci. Total Environ. 2023, 904, 166820. [Google Scholar] [CrossRef] [PubMed]
- Muhammad, U.; Gao, L. DACN: Dual Attention Convolutional Network for Satellite Terrain Change Detection. Int. J. Appl. Earth Obs. Geoinf. 2025, 126, 103202. [Google Scholar]
- Bednarek, M.; Nowicki, M.R.; Walas, K. HAPTR2: Improved Haptic Transformer for legged robots’ terrain classification. Robot. Auton. Syst. 2022, 158, 104236. [Google Scholar] [CrossRef]
- Shaban, A.; Meng, X.; Lee, J.; Boots, B.; Fox, D. Semantic terrain classification for off-road autonomous driving. In Proceedings of the Conference on Robot Learning, PMLR, Auckland, New Zealand, 4–18 December 2022; pp. 619–629. [Google Scholar]
- Sarinova, A.; Rzayeva, L.; Tendikov, N.; Shayea, I. Simple Implementation of Terrain Classification Models via Fully Convolutional Neural Networks. In Proceedings of the 2023 10th International Conference on Wireless Networks and Mobile Communications (WINCOM), Istanbul, Turkey, 26–28 October 2023; pp. 1–6. [Google Scholar]
- Wang, W.; Zhang, B.; Wu, K.; Chepinskiy, S.A.; Zhilenkov, A.A.; Chernyi, S.; Krasnov, A.Y. A visual terrain classification method for mobile robots’ navigation based on convolutional neural network and support vector machine. Trans. Inst. Meas. Control. 2022, 44, 744–753. [Google Scholar] [CrossRef]
- Tamilarasan, K.; Anbazhagan, S.; Ranjithkumar, S. Rock type discrimination using Landsat-8 OLI satellite data in mafic-ultramafic terrain. Geol. Geophys. Environ. 2023, 49, 281–298. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Hong, D.; Cai, W.; Yu, C.; Yang, N.; Cai, W. Multi-feature fusion: Graph neural network and CNN combining for hyperspectral image classification. Neurocomputing 2022, 501, 246–257. [Google Scholar] [CrossRef]
- Zhang, Y.; Duan, P.; Liang, L.; Kang, X.; Li, J.; Plaza, A. PFS3F: Probabilistic Fusion of Superpixel-wise and Semantic-aware Structural Features for Hyperspectral Image Classification. IEEE Trans. Circuits Syst. Video Technol. 2025, 1. [Google Scholar] [CrossRef]
- Wang, J.; Huang, Q.; Tang, F.; Meng, J.; Su, J.; Song, S. Stepwise feature fusion: Local guides global. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Online, 16 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 110–120. [Google Scholar]
- Zeng, N.; Wu, P.; Wang, Z.; Li, H.; Liu, W.; Liu, X. A small-sized object detection oriented multi-scale feature fusion approach with application to defect detection. IEEE Trans. Instrum. Meas. 2022, 71, 3507014. [Google Scholar] [CrossRef]
- Huang, L.; Chen, C.; Yun, J.; Sun, Y.; Tian, J.; Hao, Z.; Yu, H.; Ma, H. Multi-scale feature fusion convolutional neural network for indoor small target detection. Front. Neurorobotics 2022, 16, 881021. [Google Scholar] [CrossRef] [PubMed]
- Zhou, K.; Zhang, M.; Wang, H.; Tan, J. Ship detection in SAR images based on multi-scale feature extraction and adaptive feature fusion. Remote Sens. 2022, 14, 755. [Google Scholar] [CrossRef]
- Dong, Y.; Liu, Q.; Du, B.; Zhang, L. Weighted feature fusion of convolutional neural network and graph attention network for hyperspectral image classification. IEEE Trans. Image Process. 2022, 31, 1559–1572. [Google Scholar] [CrossRef] [PubMed]
- Liang, L.; Zhang, Y.; Zhang, S.; Li, J.; Plaza, A.; Kang, X. Fast Hyperspectral Image Classification Combining Transformers and SimAM-Based CNNs. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5522219. [Google Scholar] [CrossRef]
- Ba, R.; Chen, C.; Yuan, J.; Song, W.; Lo, S. SmokeNet: Satellite smoke scene detection using convolutional neural network with spatial and channel-wise attention. Remote Sens. 2019, 11, 1702. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite Images | Visual Terrain Recognition | USTC SmokeRS | |
|---|---|---|---|
| Description | Small-scale dataset focused on satellite-based land cover | Large-scale dataset for terrain classification with diverse surface textures | Medium-scale dataset for smoke and atmospheric condition recognition |
| Image Size | Varying | ||
| N. o. Classes | 7 | 23 | 6 |
| Train/Test Split | 673/46 | 303,901/37,993 | 4980/1245 |
| Accuracy [%] | 97.8 | 100.0 | 92.4 |
| Satellite Images | Visual Terrain Recognition | USTC SmokeRS | |
|---|---|---|---|
| No module | 0.9130 | 0.8691 | 0.8790 |
| ESA | 0.9348 | 0.9030 | 0.8742 |
| ESA+MBFA | 0.9565 | 0.9140 | 0.9046 |
| ESA+MBFA+AFB | 0.9783 | 1.000 | 0.9240 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaszcz, A.; Połap, D. Terrain and Atmosphere Classification Framework on Satellite Data Through Attentional Feature Fusion Network. Remote Sens. 2025, 17, 2477. https://doi.org/10.3390/rs17142477
Jaszcz A, Połap D. Terrain and Atmosphere Classification Framework on Satellite Data Through Attentional Feature Fusion Network. Remote Sensing. 2025; 17(14):2477. https://doi.org/10.3390/rs17142477
Chicago/Turabian StyleJaszcz, Antoni, and Dawid Połap. 2025. "Terrain and Atmosphere Classification Framework on Satellite Data Through Attentional Feature Fusion Network" Remote Sensing 17, no. 14: 2477. https://doi.org/10.3390/rs17142477
APA StyleJaszcz, A., & Połap, D. (2025). Terrain and Atmosphere Classification Framework on Satellite Data Through Attentional Feature Fusion Network. Remote Sensing, 17(14), 2477. https://doi.org/10.3390/rs17142477