1. Introduction
As remote sensing technology has developed rapidly, the methods of acquiring remote sensing images have become increasingly diverse [
1]. Nowadays, remote sensing images are widely used in many fields, such as land use classification [
2,
3], urban planning [
4,
5,
6], ecological monitoring [
7], disaster assessment [
8,
9], and agricultural monitoring [
10,
11]. In this context, accurately identifying semantic categories has become a significant focus of current research.
Conventional visual images are typically characterized by high resolution and clear targets [
12,
13]. In recent years, with the rapid development of deep learning, various vision tasks based on such images have achieved remarkable results. As a result, researchers in the field of remote sensing have begun to adopt these methods to automate remote sensing tasks. However, unlike conventional images, remote sensing imagery exhibits a wider coverage and more diverse semantic categories within a fixed pixel matrix [
14,
15]. To address these challenges, Transformer-based architectures [
16] have been introduced. This model leverage self-attention mechanisms to capture long-range dependencies. Additionally, some studies explore hybrid approaches by combining CNNs with Transformers. For example, DBSANet [
8] effectively balances local feature extraction and global context analysis, achieving significant performance improvements. Similar results have been demonstrated with RingMoE [
17].
Meanwhile, frequency domain methods have also been introduced into segmentation tasks. FAENet [
18] decomposes features using the discrete wavelet transform (DWT) and constructs global relationships based on frequency components. This enhances the representation of features. In contrast, FDNet [
19] separates features into components of high and low frequencies, which strengthens the representation of features by compressing redundant information.These approaches significantly alleviate the problem of ambiguous semantic boundaries. However, despite the promising results achieved in the intelligent understanding of remote sensing imagery, there are still several challenges.
Firstly, remote sensing imagery covers large spatial areas and contains objects of various scales. These characteristics make it difficult for a single-scale receptive field to effectively recognize targets of different categories. Although existing methods have introduced Transformer mechanisms to capture global and local relationships, the perceptual scope remains fixed. This hinders the accurate interpretation of targets, especially in regions with densely distributed semantic categories.To address this issue, this study presents an attention multi-scale feature fusion module. This module introduces an attention similarity matrix and a feature confidence matrix. The attention similarity matrix captures global semantic relationships, and the feature confidence matrix identifies stable and ambiguous regions. These two components collaborate to provide global-to-local feature guidance, which effectively corrects ambiguous representations and enhances the stability and discriminative power of the features.
Secondly, existing methods primarily focus on overall semantic relationships, overlooking local regions. Therefore, they still present challenges in addressing complex issues, such as shadow interference and local pixel variations. Due to the relatively low spatial resolution of remote sensing imagery, each pixel often corresponds to a broad area, which leads to ambiguity in representing surface features. In the presence of multiple texture variations within a target, local regions are susceptible to inconsistent pixel representations, which can lead to inaccurate segmentation.To address this issue, the study designs a neighborhood feature enhancement module. This module integrates contextual correlations and spatial semantics from multiple neighborhoods to enhance the perception of local structures, effectively mitigating segmentation errors caused by pixel inconsistency.
Overall, the main contributions of this study are as follows:
An attention multi-scale feature fusion (AF) module is proposed. This module captures global information from the image and constructs a confidence map based on the differences between multi-scale feature. This improves the maintenance of information and enables effective fusion of multi-scale information.
A novel neighborhood feature enhancement (NE) module is designed. This uses semantic representations from neighboring regions to reduce the network’s sensitivity to local pixel variations. This helps the network better capture local expressions of semantic classes.
The AFNE-Net model is introduced for the semantic segmentation of remote sensing images. This model achieves state-of-the-art performance on all publicly available benchmark datasets.
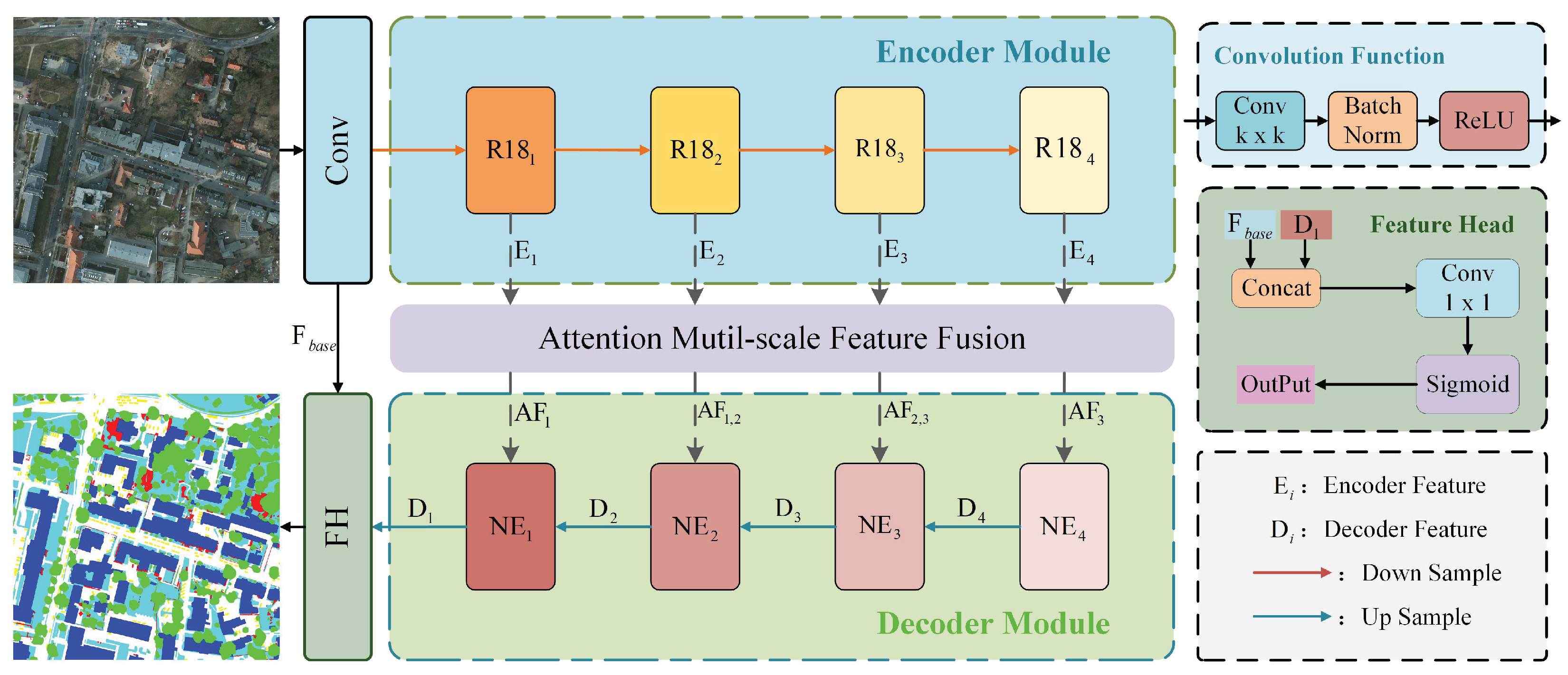
3. Methods
The study utilizes the U-Net architecture and is designed to efficiently perform semantic segmentation of remote sensing images. As illustrated in
Figure 1, the proposed AFNE-Net is composed of three primary components: an encoder module, an feature fusion module, and a decoder module. The decoder incorporates three neighborhood feature enhancement modules, which focus on feature refinement and the enhancement of spatial semantic representation. The input is a remote sensing image
. ResNet-18(R18) [
36] is used to extract feature vectors
at different resolutions. The AF module fuses features from neighboring resolutions, enhancing interactions between layers and improving semantic relevance. The fused features are finally passed to the decoder, which strengthens the feature representations based on neighborhood expression consistency. This effectively reduces mis-segmentation caused by local pixel interference. Each component will be described in detail in the following subsections.
3.1. Encoder Module
The encoder is able to project low-variance RGB information into a high-dimensional space, enabling the discriminative representation of different semantic categories in the image. This study uses the U-Net backbone to build the encoder, which consists of four feature encoding modules. Each feature encoding module performs downsampling at a rate that is twice that of the preceding layer. This process is intended to expand the receptive field of the network and establish the foundation for capturing semantic correlations between categories.
R18 is a residual-based feature encoding network, showing high efficiency and accuracy in semantic segmentation tasks. This study adopts ResNet-18 as the feature encoder, aiming to extract deep feature vectors from multi-resolution images.
3.2. Attention Feature Fusion Module
Remote sensing images cover large areas and contain various object types with inconsistent sizes. To effectively represent target features at different scales, it is essential to enhance the feature representation capability of the network from a multi-scale perspective. This helps deal with challenges like feature blurring and semantic ambiguity caused by scale variations. The proposed module introduces diverse weighting matrices to increase the saliency of feature vectors. Additionally, a residual structure is incorporated to preserve fine-grained details. These improvements collectively enhance the precision of the model in segmentation tasks.
As shown in
Figure 2, the multi-scale feature fusion module proposed in this paper consists of three AF modules, which are designed to replace traditional feature fusion and transmission mechanisms. Feature maps
from different levels are input to the corresponding AF module. In order to achieve multi-scale feature fusion, the low-resolution features are first upsampled to match the spatial dimensions of the high-resolution features. Subsequently, these elements are amalgamated as inputs to the fusion process. Finally, the fused feature maps are transmitted to the NE module.
As shown on the right side of
Figure 2, a detailed view of the AF module is presented. The low-resolution map
and the high-resolution feature map
capture different scale representations of the image. Multi-resolution features help build semantic connections and improve the accuracy of feature descriptions. Firstly, a convolution operation is applied to project the input features into a unified feature space, as shown in the following equation:
where
denotes the upsampling operation used to match the spatial dimensions.
represents a convolution operation with a
kernel.
and
are the feature maps after matching the channel dimensions.
Then, a feature similarity matrix is computed to enhance the global perception of the features. Meanwhile, the differences among multi-level features are used to estimate the confidence, reducing the weights of features with large representation differences. The following is a detailed description of the process:
where
is the vector normalization function,
is the attention score matrix,
is the confidence matrix,
denotes matrix multiplication, and
denotes the dot product.
Subsequently, the low-resolution feature is multiplied by the attention score matrix to obtain the feature association vector. Meanwhile, the high-resolution feature is point-wise multiplied by the confidence matrix, weighting the features based on the similarity across multiple scales. This promotes consistent expression across layers and reduces feature diversity. Next, the two types of features are concatenated and fused through a convolution operation. A residual connection is introduced to combine the fused result with the high-resolution feature map, preserving fine-grained details and further enhancing multi-scale feature fusion. More information is provided below:
where
is the feature concatenation function, and
denotes the Hadamard product.
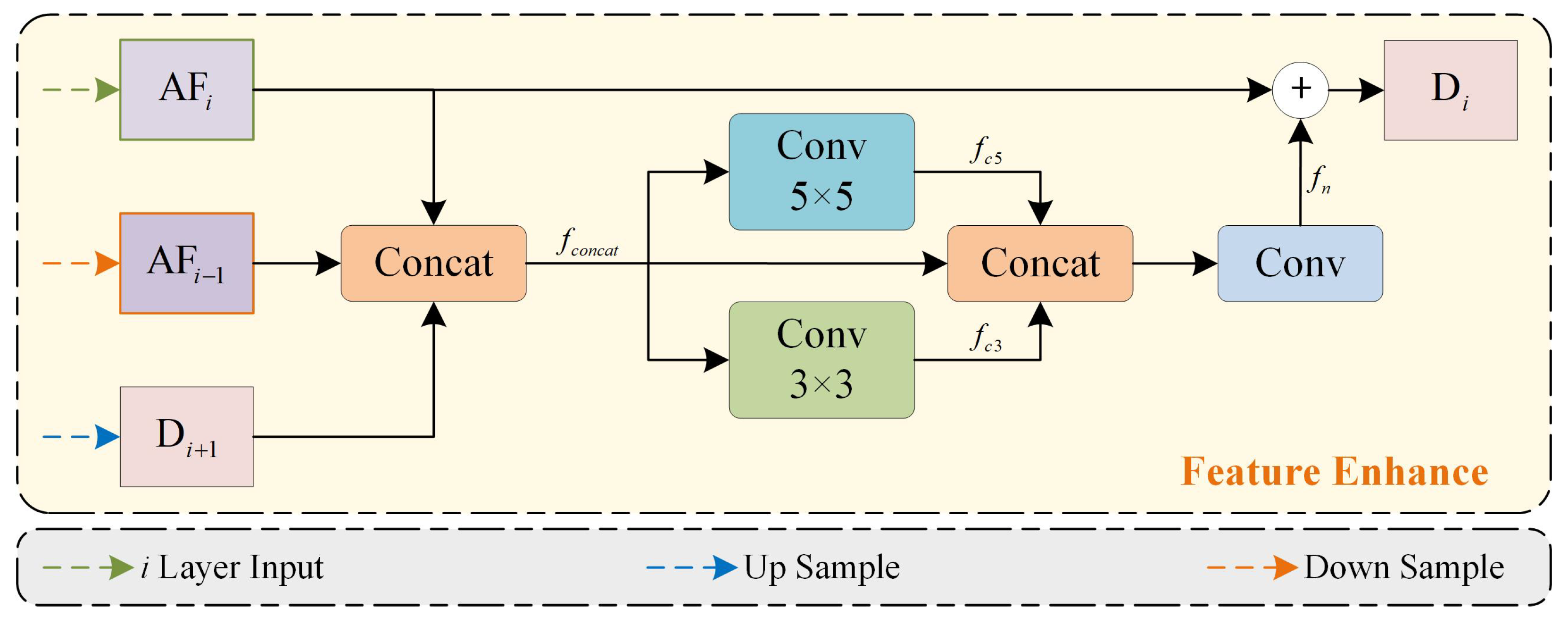
3.3. Feature Enhance Decoder
Due to the wide coverage of images, factors such as surface aging, lighting variations, and shadows can cause significant local differences in the same object at the different images. Convolution operations have been demonstrated to be effective in capturing the spatial relationships between neighbors. This capability contributes to enhancing the modeling of neighborhood consistency. In this study, a feature enhancement method is proposed. This method is based on the principle of neighborhood consistency, which helps mitigate the impact of local disturbances on results.
As shown in
Figure 3, this module uses neighborhood consistency based on multi-scale features to smooth local differences and avoid interference from local noise. Additionally, residual operations maintain strong high-resolution representations, which ensure clear segmentation boundaries.
Firstly, the low-resolution decoding feature
is concatenated with the adjacent multi-scale features
and
. This is expressed as follows:
Then,
is passed through different kernel sizes for feature smoothing. This considers neighborhood feature representations under different receptive fields and helps mitigate feature ambiguity caused by noise interference. This process can be expressed as follows:
where
denotes a convolution operation with a
kernel, and
represents a convolution operation with a
kernel.
Next, adjacent expressions are used as guidance. Multi-neighborhood features are then integrated to correct local errors. Finally, residual operations are applied to ensure accurate segmentation boundaries. The specific operations are as follows:
3.4. Loss Function
This study uses cross-entropy [
37] and Dice loss [
38] to measure the difference between the predictions of the model and the ground truth. In this paper, the weights
and
are both set to 1. This can be expressed as follows:
The goal of cross-entropy loss is to minimize the negative log difference between the true labels and the predicted probabilities of the model. Cross-entropy loss for multi-class classification is defined as follows:
where
C represents the number of classes in the dataset.
is the predicted probability for the
i-th class at a given pixel.
is the corresponding ground truth.
The purpose of Dice loss is to make the predicted semantic area closely match the ground truth (GT). This helps effectively address the class imbalance issue in the scene. Dice loss is defined as follows:
where
represents the total area of the predicted semantic class, and
is the corresponding ground truth.
6. Conclusions
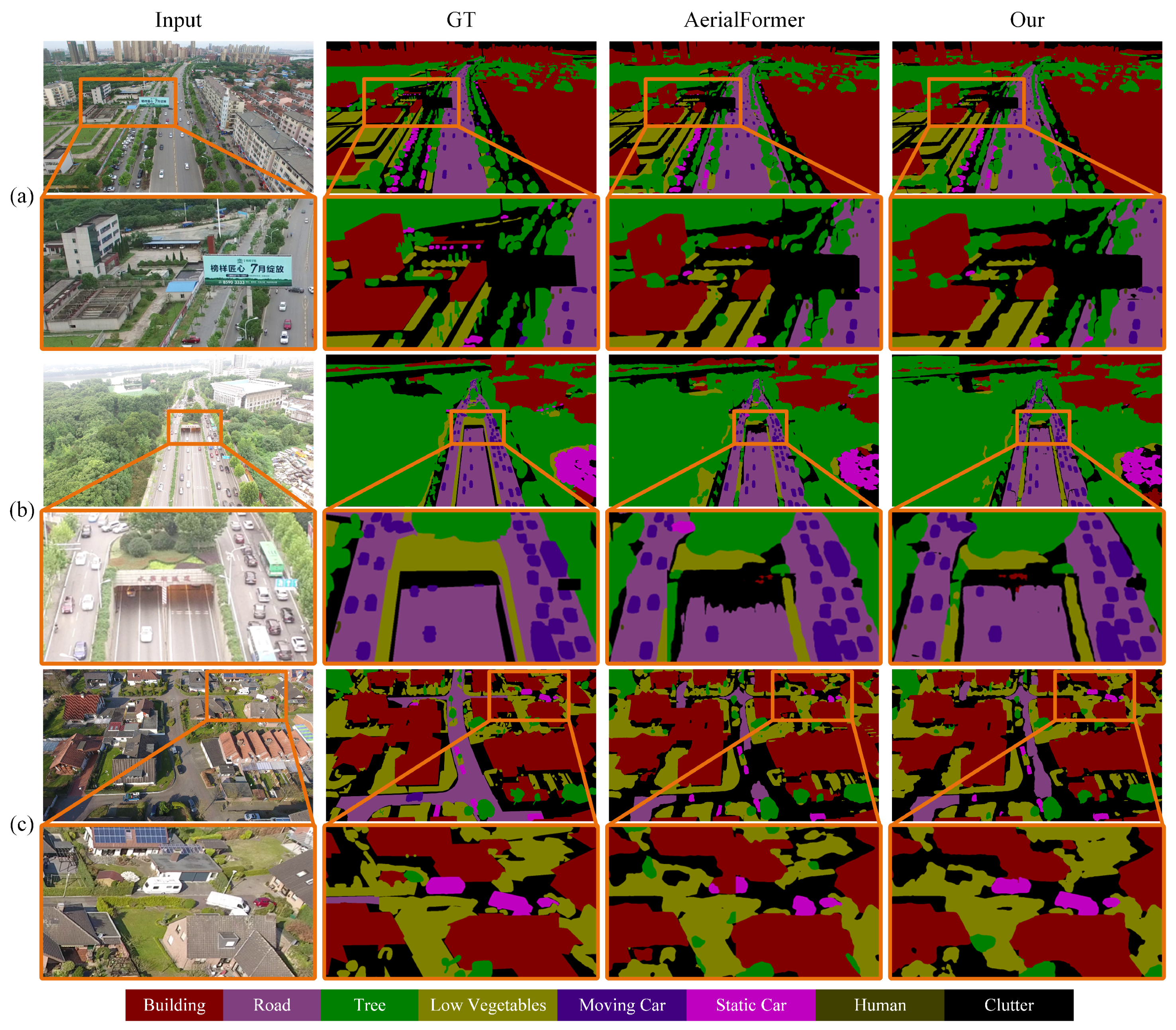
This paper proposes AFNE-Net, a novel neural network model for understanding remote sensing images. To address the challenges posed by variations in object scale and insufficient attention to local regions, the AF module is designed. This module uses a multi-resolution feature fusion strategy to create multi-scale feature representations. It also incorporates an attention mechanism to fuse global and local features, enhancing local perception. Additionally, the NE module is introduced to address local texture inconsistency caused by lighting variations, shadow interference, and internal texture differences. This module employs the principle of neighborhood consistency. By leveraging spatial similarity among pixels, the module effectively mitigates mis-segmentation caused by local texture inconsistencies, enhancing the understanding and robustness of the model in large-scale remote sensing scenes.
A comprehensive evaluation of AFNE-Net was conducted using three datasets: Potsdam, UAVID and LoveDA. The experimental results demonstrate that the proposed method achieves high accuracy and stability in addressing multi-class semantic regions and local mis-segmentation issues. This highlights the potential and practical value of the method in remote sensing image segmentation tasks.
In future work, we will explore lightweight improvements and introduce new strategies to expand the model’s applicability to shadow-heavy problems. These improvements will enable the model to adapt more effectively to large-scale, multi-source, heterogeneous remote sensing scenarios, expanding its range of practical applications.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}