


SMA-YOLO: An Improved YOLOv8 Algorithm Based on Parameter-Free Attention Mechanism and Multi-Scale Feature Fusion for Small Object Detection in UAV Images


Abstract

1. Introduction
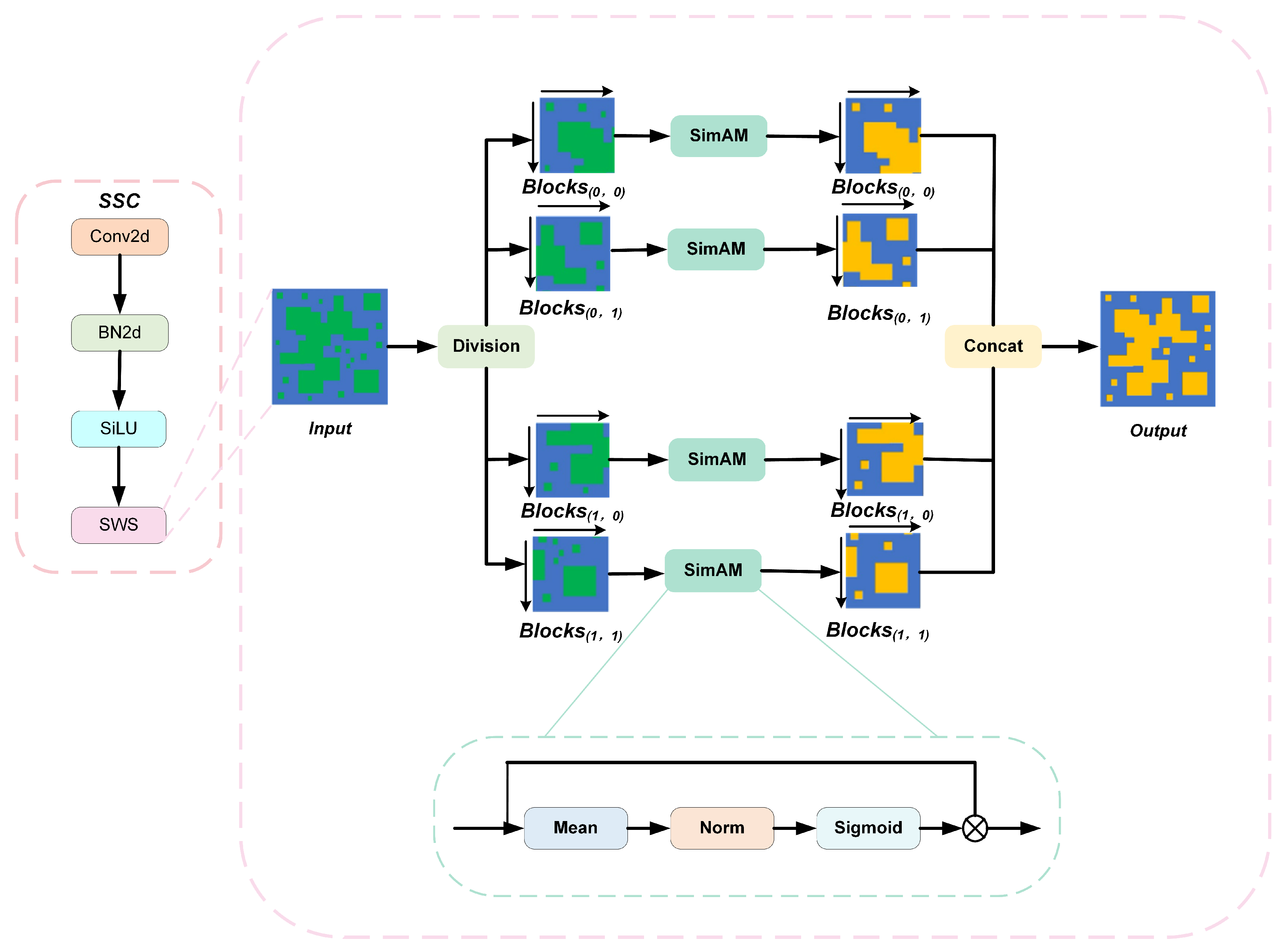
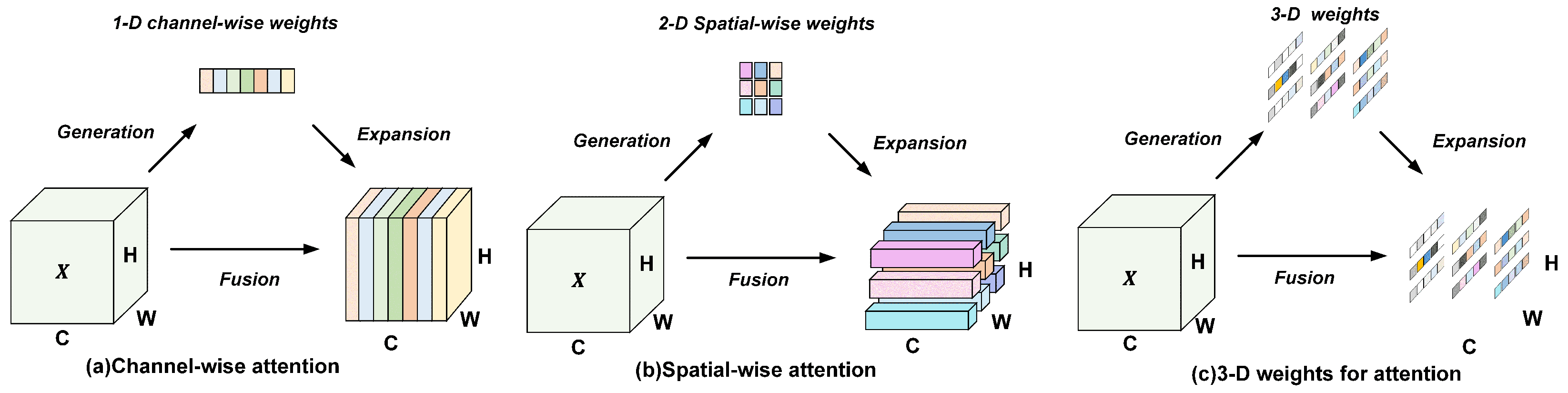
- We propose a parameter-free simple slicing convolution (SSC) to take the place of standard convolutions in the backbone network. By strategically partitioning feature maps and incorporating SimAM [18] attention, this module effectively preserves and enhances the discriminative features of small objects.
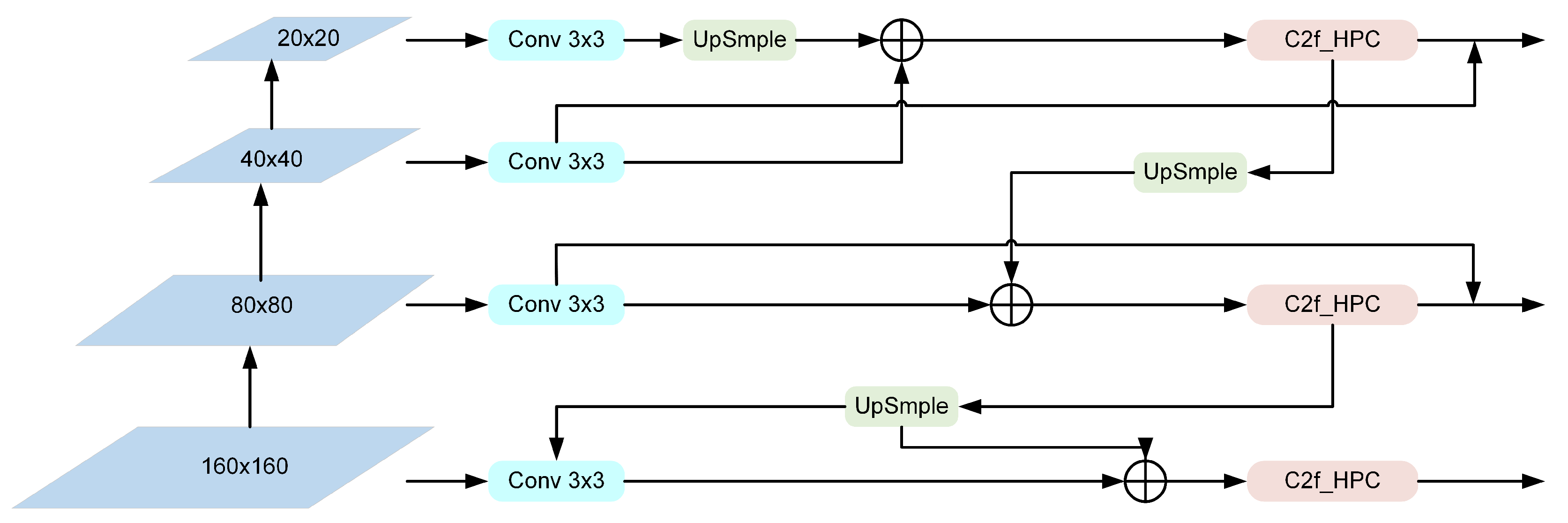
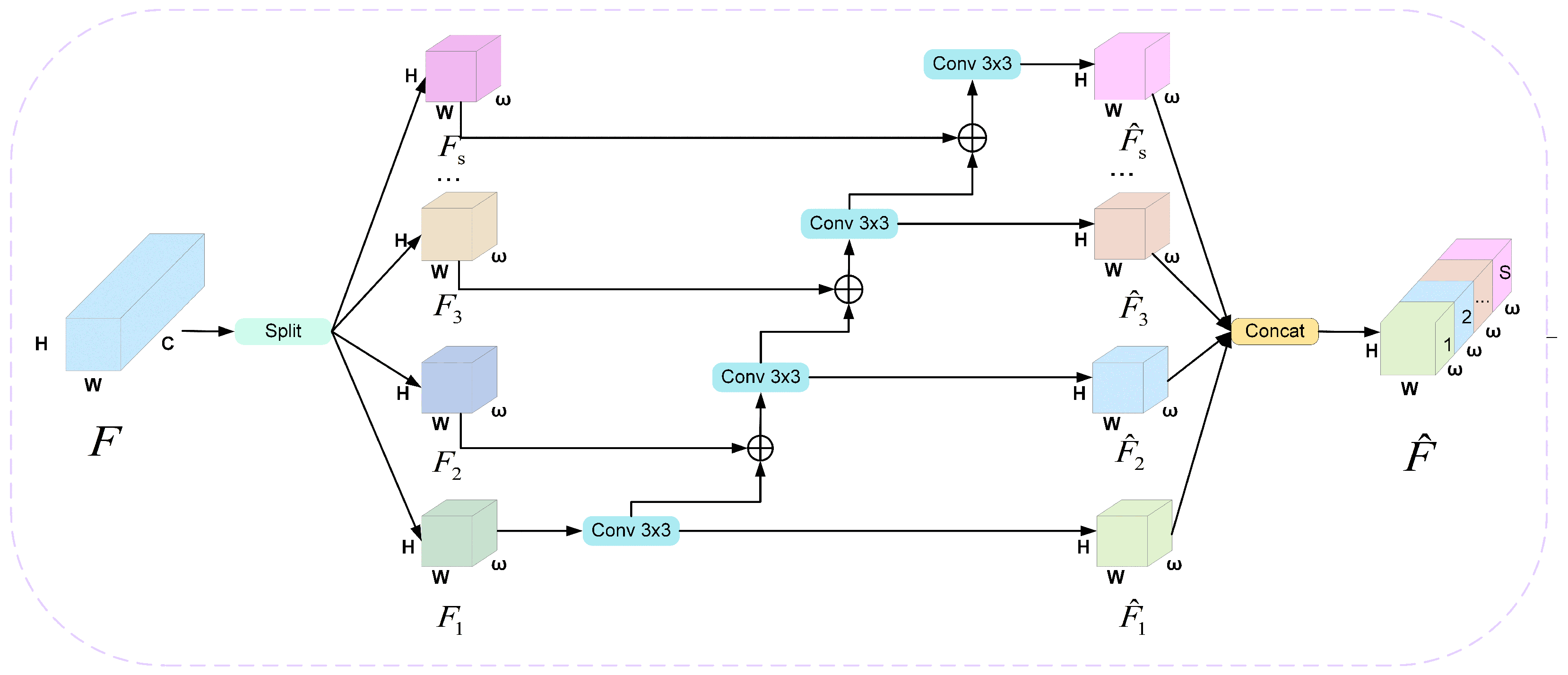
- A multi-cross-scale feature pyramid network (M-FPN) is designed to optimize feature fusion in the neck network. Through its unique multi-level and cross-scale connections combined with the C2f-HPC module, our approach achieves fine-grained multi-scale feature integration, significantly reducing information loss for small objects in complex scenarios.
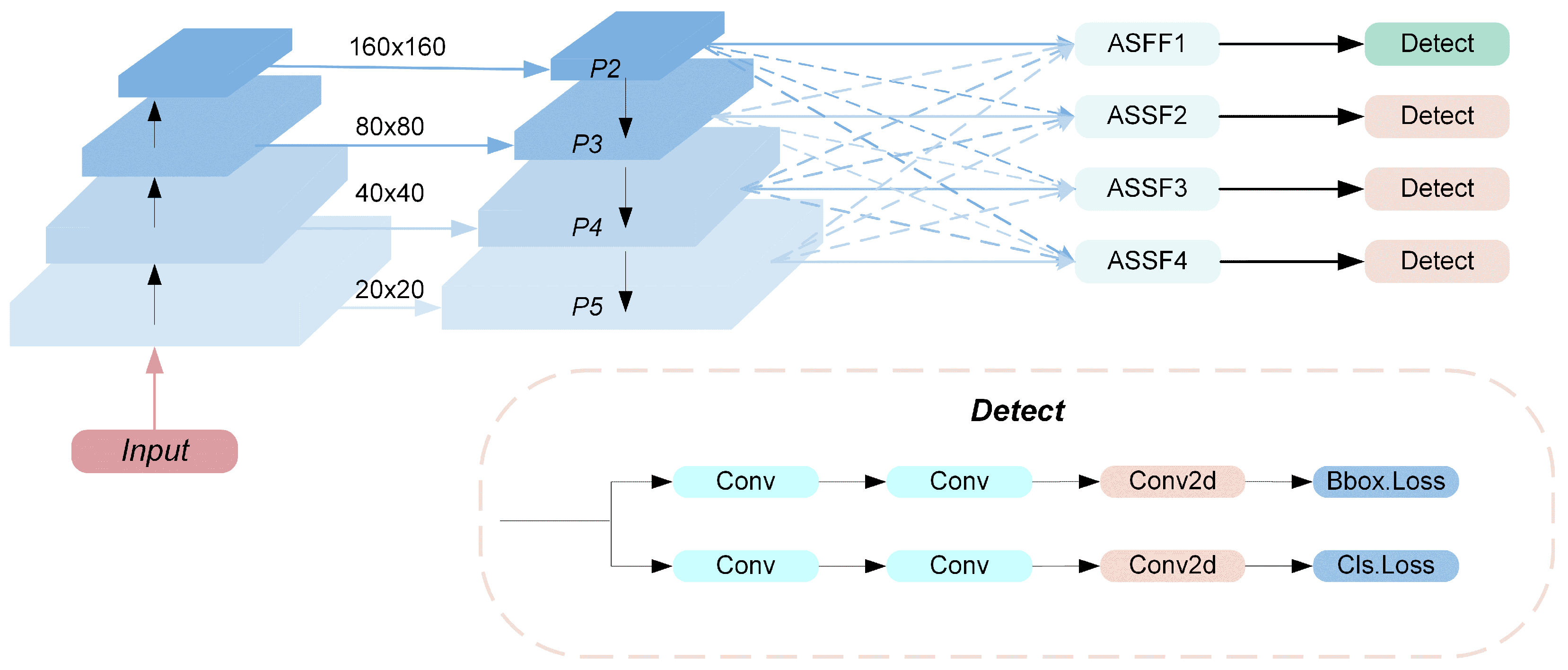
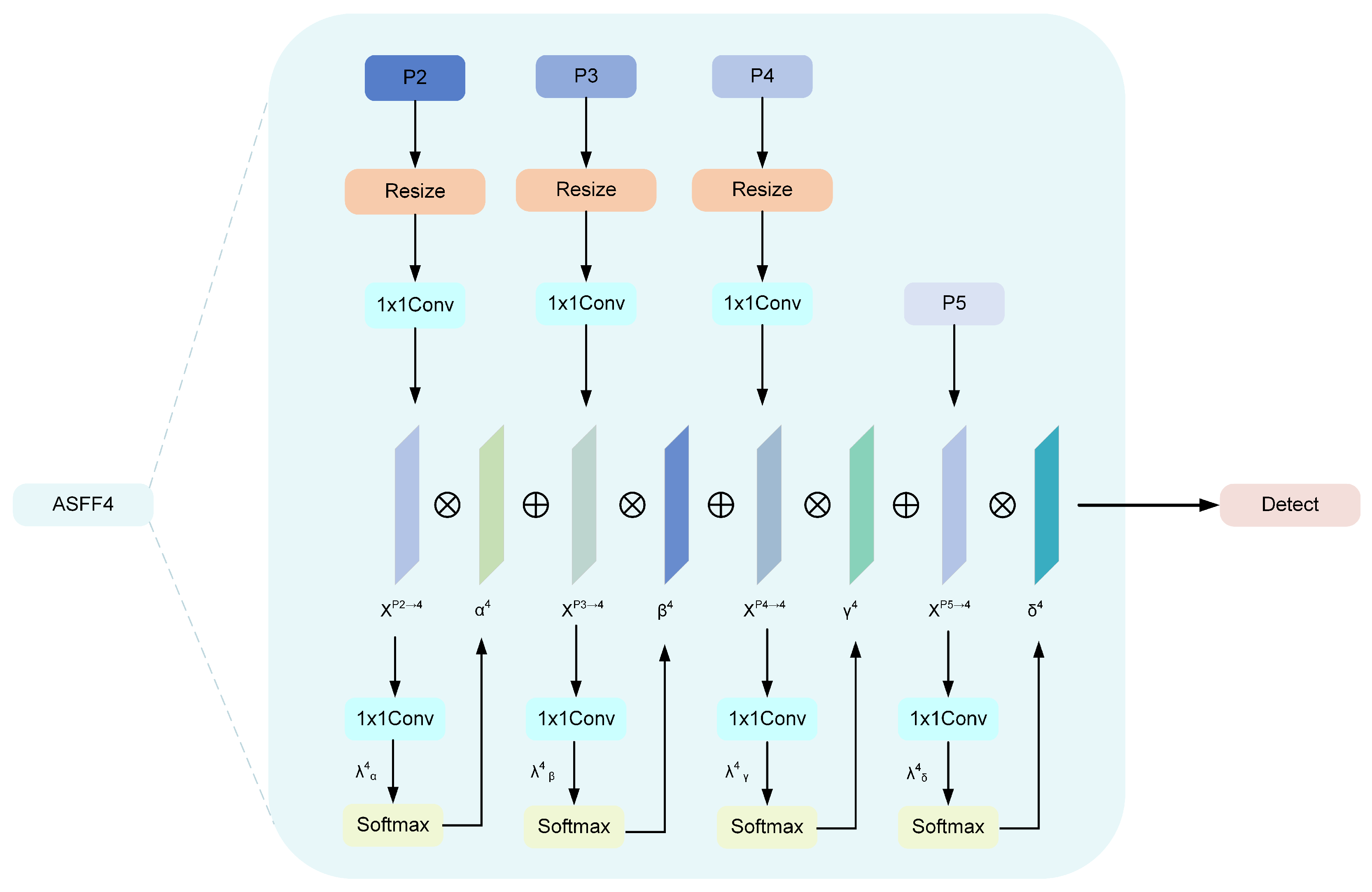
- We develop an adaptive spatial feature fusion detection head (ASFFDHead) featuring an additional P2 detection head for small objects specifically. By implementing the ASFF [19] mechanism to resolve feature conflicts during multi-scale fusion, the proposed structure substantially improves detection accuracy for small objects.
2. Materials
2.1. YOLOv8
2.2. UAV Images Small Object Detection
3. Methods
3.1. Simple Slicing Convolution
3.2. Multi-Cross-Scale Feature Pyramid Network
C2f-Hierarchical-Phantom Convolution
3.3. Adaptively Spatial Feature Fusion Detect Head
4. Results
4.1. Experimental Basic Configuration
4.2. Dataset
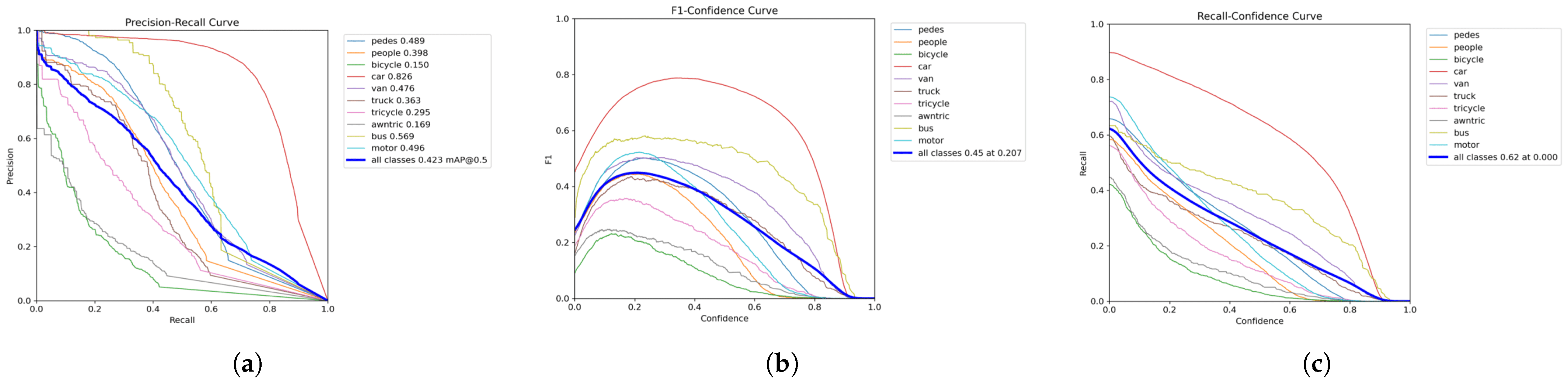
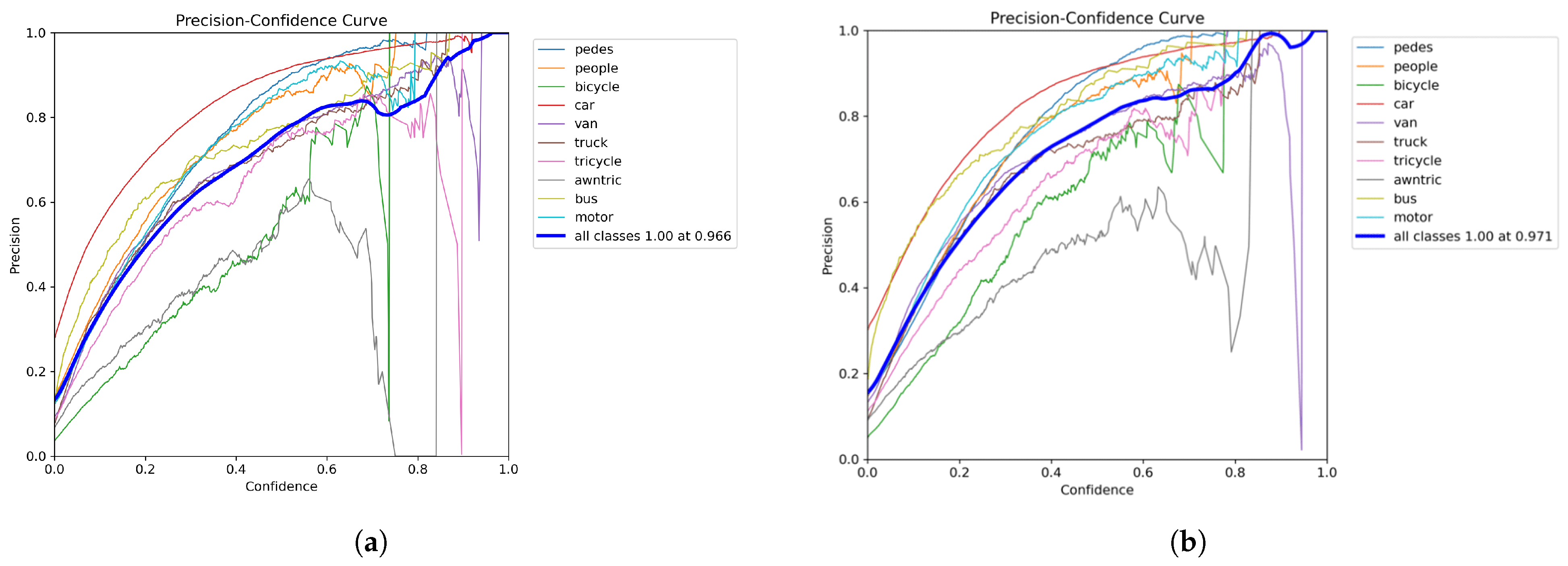
4.3. Metrics
4.4. Comparison Experiments
4.5. Ablation Experiments
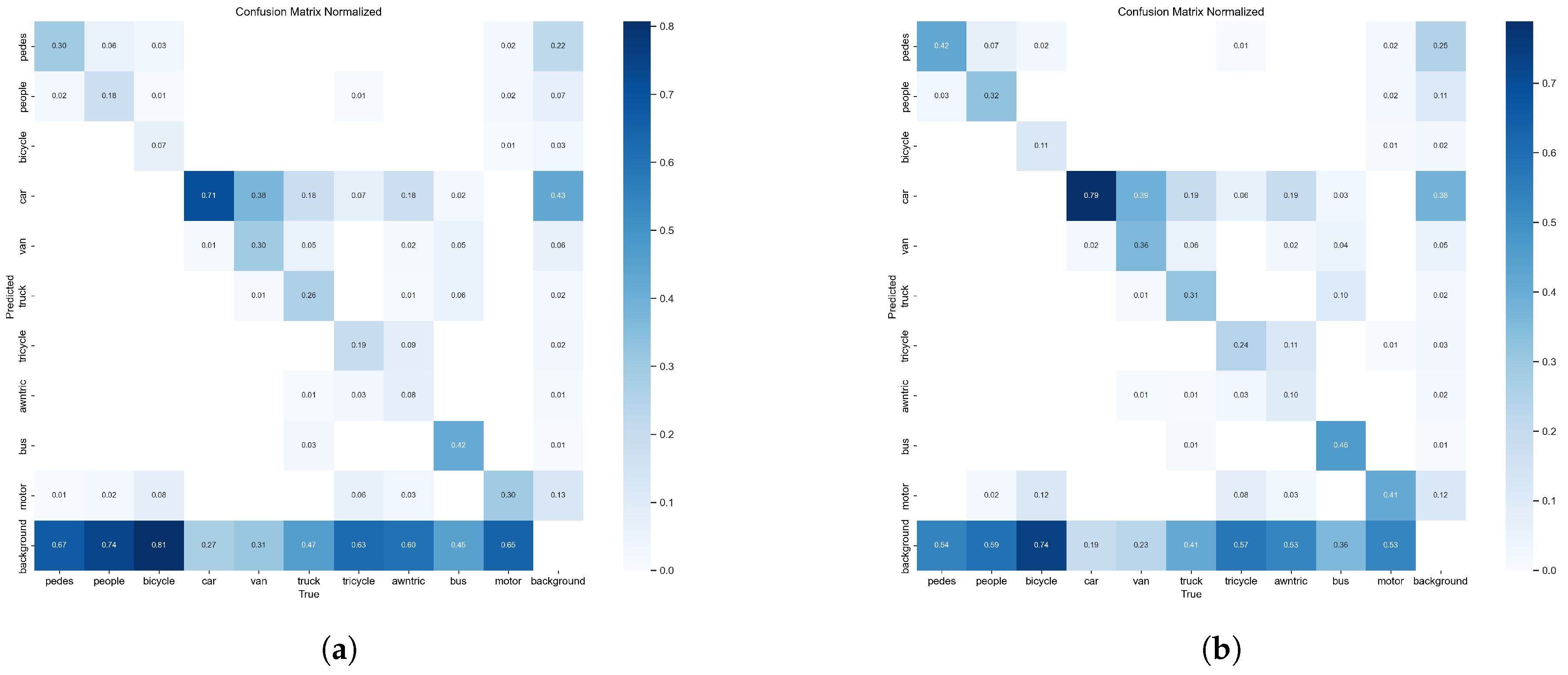
4.6. Visualization
4.7. Generalization Experiments
5. Dicussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ahirwar, S.; Swarnkar, R.; Bhukya, S.; Namwade, G. Application of drone in agriculture. Int. J. Curr. Microbiol. Appl. Sci. 2019, 8, 2500–2505. [Google Scholar] [CrossRef]
- Cvitanić, D. Drone applications in transportation. In Proceedings of the 2020 5th International Conference on Smart and Sustainable Technologies (SpliTech), Split, Croatia, 23–26 September 2020; pp. 1–4. [Google Scholar]
- Shahmoradi, J.; Talebi, E.; Roghanchi, P.; Hassanalian, M. A comprehensive review of applications of drone technology in the mining industry. Drones 2020, 4, 34. [Google Scholar] [CrossRef]
- Fan, B.; Li, Y.; Zhang, R.; Fu, Q. Review on the technological development and application of UAV systems. Chin. J. Electron. 2020, 29, 199–207. [Google Scholar] [CrossRef]
- Yao, H.; Qin, R.; Chen, X. Unmanned aerial vehicle for remote sensing applications—A review. Remote Sens. 2019, 11, 1443. [Google Scholar] [CrossRef]
- Bouguettaya, A.; Zarzour, H.; Kechida, A.; Taberkit, A.M. Vehicle detection from UAV imagery with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6047–6067. [Google Scholar] [CrossRef]
- Al-lQubaydhi, N.; Alenezi, A.; Alanazi, T.; Senyor, A.; Alanezi, N.; Alotaibi, B.; Alotaibi, M.; Razaque, A.; Hariri, S. Deep learning for unmanned aerial vehicles detection: A review. Comput. Sci. Rev. 2024, 51, 100614. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ross, T.Y.; Dollár, G. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Varghese, R.; Sambath, M. Yolov8: A novel object detection algorithm with enhanced performance and robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Liu, Y.; Sun, P.; Wergeles, N.; Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Tang, G.; Ni, J.; Zhao, Y.; Gu, Y.; Cao, W. A survey of object detection for UAVs based on deep learning. Remote Sens. 2023, 16, 149. [Google Scholar] [CrossRef]
- Zhang, X.; Izquierdo, E.; Chandramouli, K. Dense and small object detection in uav vision based on cascade network. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Yi, H.; Liu, B.; Zhao, B.; Liu, E. Small object detection algorithm based on improved YOLOv8 for remote sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 1734–1747. [Google Scholar] [CrossRef]
- Zand, M.; Etemad, A.; Greenspan, M. Oriented bounding boxes for small and freely rotated objects. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference On Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Xu, C.; Wang, J.; Yang, W.; Yu, L. Dot distance for tiny object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1192–1201. [Google Scholar]
- Zhan, W.; Sun, C.; Wang, M.; She, J.; Zhang, Y.; Zhang, Z.; Sun, Y. An improved Yolov5 real-time detection method for small objects captured by UAV. Soft Comput. 2022, 26, 361–373. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Sun, T.; Chen, H.; Liu, H.; Deng, L.; Liu, L.; Li, S. DS-YOLOv7: Dense Small Object Detection Algorithm for UAV. IEEE Access 2024, 12, 75865–75872. [Google Scholar] [CrossRef]
- Feng, F.; Hu, Y.; Li, W.; Yang, F. Improved YOLOv8 algorithms for small object detection in aerial imagery. J. King Saud Univ. Comput. Inf. Sci. 2024, 36, 102113. [Google Scholar] [CrossRef]
- Webb, B.S.; Dhruv, N.T.; Solomon, S.G.; Tailby, C.; Lennie, P. Early and late mechanisms of surround suppression in striate cortex of macaque. J. Neurosci. 2005, 25, 11666–11675. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Yu, Y.; Zhang, Y.; Cheng, Z.; Song, Z.; Tang, C. Multi-scale spatial pyramid attention mechanism for image recognition: An effective approach. Eng. Appl. Artif. Intell. 2024, 133, 108261. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Aharon, S.; Dupont, L.; Masad, O.; Yurkova, K.; Fridman, F.; Lkdci; Khvedchenya, E.; Rubin, R.; Bagrov, N.; Tymchenko, B.; et al. Super-Gradients. 2021. Available online: https://zenodo.org/records/7789328 (accessed on 1 July 2025).
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Lei, M.; Li, S.; Wu, Y.; Hu, H.; Zhou, Y.; Zheng, X.; Ding, G.; Du, S.; Wu, Z.; Gao, Y. YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception. arXiv 2025, arXiv:2506.17733. [Google Scholar] [CrossRef]
- Lyu, R. Nanodet-Plus: Super Fast and High Accuracy Lightweight Anchor-Free Object Detection Model. 2021. Available online: https://github.com/RangiLyu/nanodet (accessed on 1 July 2025).
- Peng, H.; Xie, H.; Liu, H.; Guan, X. LGFF-YOLO: Small object detection method of UAV images based on efficient local–global feature fusion. J. Real-Time Image Process. 2024, 21, 167. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W. RFAG-YOLO: A Receptive Field Attention-Guided YOLO Network for Small-Object Detection in UAV Images. Sensors 2025, 25, 2193. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Qu, H. Dassf: Dynamic-attention scale-sequence fusion for aerial object detection. In Proceedings of the International Conference on Computational Visual Media, Hong Kong, China, 19–21 April 2025; Springer: Berlin/Heidelberg, Germany, 2025; pp. 212–227. [Google Scholar]
- Yue, M.; Zhang, L.; Zhang, Y.; Zhang, H. An Improved YOLOv8 Detector for Multi-scale Target Detection in Remote Sensing Images. IEEE Access 2024, 12, 114123–114136. [Google Scholar] [CrossRef]
- Lu, Y.; Sun, M. SSE-YOLO: Efficient UAV Target Detection With Less Parameters and High Accuracy. Preprints 2024, 2024011108. [Google Scholar] [CrossRef]
- Zhang, G.; Peng, Y.; Li, J. YOLO-MARS: An Enhanced YOLOv8n for Small Object Detection in UAV Aerial Imagery. Sensors 2025, 25, 2534. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Value |
|---|---|
| Image size | 640 × 640 |
| Epochs | 200 |
| Patience | 150 |
| Batch size | 8 |
| Optimizer | SGD |
| Momentum | 0.937 |
| Data enhancement | Mosaic |
| Workers | 4 |
| Learning rate | 0.01 |
| Weight decay | 0.0005 |
| Models | Pedes | People | Bicycle | Car | Van | Truck | Tricycle | Awntric | Bus | Motor | All |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv8n | 36.2 | 29.2 | 8.7 | 76.3 | 40.3 | 32.7 | 25.3 | 13.3 | 47.9 | 38.8 | 34.9 |
| Ours | 48.9 | 38.9 | 15.0 | 82.6 | 47.6 | 36.3 | 29.5 | 16.9 | 56.9 | 49.6 | 42.3 |
| Increase(%) | 12.7 | 9.7 | 6.3 | 6.3 | 7.3 | 3.6 | 4.2 | 3.6 | 9.0 | 10.8 | 7.4 |
| Models | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Parameters (M) | GFLOPs |
|---|---|---|---|---|
| YOLOv5 | 30.6 | 15.6 | 7.2 | 17.1 |
| YOLOv7 [40] | 32.7 | 17.9 | 37.3 | 105.3 |
| YOLOv8n | 34.9 | 20.3 | 3.0 | 8.2 |
| YOLO-NAS [41] | 36.3 | 20.9 | 4.2 | 10.6 |
| YOLOv10s [42] | 37.8 | 22.4 | 7.2 | 20.9 |
| YOLOv11s [43] | 38.1 | 22.4 | 9.4 | 21.6 |
| YOLOv12s [44] | 38.8 | 23.0 | 9.3 | 21.4 |
| YOLOv13s [45] | 39.1 | 23.4 | 9.0 | 20.8 |
| SMA-YOLO | 42.3 | 25.3 | 2.6 | 20.9 |
| Models | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Parameters (M) | GFLOPs |
|---|---|---|---|---|
| SSD | 25.3 | 14.6 | 58.0 | 99.2 |
| NanoDet [46] | 26.5 | 15.4 | 1.8 | 1.5 |
| Faster RCNN | 29.0 | 17.8 | 165.6 | 118.6 |
| YOLOv8n | 34.9 | 20.3 | 3.0 | 8.2 |
| LGFF-YOLO [47] | 38.3 | 22.8 | 4.2 | 12.4 |
| RFAG-YOLO [48] | 38.9 | 23.1 | 5.9 | 15.7 |
| DASSF [49] | 39.6 | 23.5 | 8.5 | 23.9 |
| YOLO-GE [50] | 40.7 | 23.7 | 3.5 | 15.9 |
| SSE-YOLO [51] | 40.8 | 23.6 | 3.6 | 10.9 |
| YOLO-MARS [52] | 40.9 | 23.4 | 2.9 | 13.7 |
| SMA-YOLO | 42.3 | 25.3 | 2.6 | 20.9 |
| Models | P(%) | R(%) | mAP@0.5 (%) | Parameters (M) | Learnable Parameters | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv8n | 45.8 | 34.3 | 34.9 | 3.0 | – | 8.2 | 189 |
| +SE | 45.9 | 34.6 | 35.1 | 4.1 | 2FC | 10.7 | 172 |
| +CBAM | 46.6 | 35.2 | 35.9 | 4.5 | FC + Conv | 12.9 | 164 |
| +SimAM | 46.9 | 35.6 | 36.3 | 3.0 | 0 | 8.3 | 197 |
| Models | SSC | M-FPN | ASFFDH | P (%) | R (%) | mAP@0.5 (%) | F1 (%) | Params (M) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv8n | 45.8 | 34.3 | 34.9 | 38 | 3.0 | 8.2 | 189 | |||
| 1 | ✓ | 46.9 | 35.6 | 36.3 | 38 | 3.0 | 8.3 | 197 | ||
| 2 | ✓ | 48.2 | 36.6 | 38.0 | 41 | 2.2 | 14.9 | 150 | ||
| 3 | ✓ | 48.8 | 36.9 | 38.3 | 41 | 4.3 | 17.6 | 137 | ||
| 4 | ✓ | ✓ | 50.4 | 39.2 | 41.5 | 42 | 4.3 | 17.6 | 142 | |
| 5 | ✓ | ✓ | 50.1 | 38.9 | 41.1 | 42 | 2.0 | 14.9 | 156 | |
| 6 | ✓ | ✓ | 51.7 | 40.1 | 42.1 | 44 | 2.6 | 20.9 | 102 | |
| SMA-YOLO | ✓ | ✓ | ✓ | 53.0 | 40.9 | 42.3 | 45 | 2.6 | 20.9 | 106 |
| Datasets | Models | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Parameters (M) | GFLOPs |
|---|---|---|---|---|---|
| UAVDT | SSD | 23.9 | 15.5 | 58.0 | 99.2 |
| NanoDet | 25.2 | 18.7 | 1.8 | 1.5 | |
| Faster RCNN | 27.5 | 21.3 | 165.6 | 118.6 | |
| YOLOv5 | 28.3 | 21.5 | 7.2 | 17.1 | |
| YOLOv7 | 29.8 | 21.9 | 37.3 | 105.3 | |
| YOLOv8n | 32.3 | 22.7 | 3.0 | 8.2 | |
| YOLOv10s | 33.4 | 23.1 | 7.2 | 20.9 | |
| YOLOv13s | 34.8 | 23.5 | 9.0 | 20.8 | |
| SMA-YOLO | 36.6 | 24.1 | 2.6 | 20.9 | |
| RSOD | SSD | 91.5 | 68.4 | 58.0 | 99.2 |
| NanoDet | 92.4 | 68.7 | 1.8 | 1.5 | |
| Faster RCNN | 93.7 | 69.5 | 165.6 | 118.6 | |
| YOLOv5 | 94.8 | 69.2 | 7.2 | 17.1 | |
| YOLOv7 | 93.9 | 68.9 | 37.3 | 105.3 | |
| YOLOv8n | 94.6 | 69.1 | 3.0 | 8.2 | |
| YOLOv10s | 94.7 | 69.2 | 7.2 | 20.9 | |
| YOLOv13s | 95.1 | 69.6 | 9.0 | 20.8 | |
| SMA-YOLO | 97.8 | 70.2 | 2.6 | 20.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, S.; Dang, C.; Chen, W.; Liu, Y. SMA-YOLO: An Improved YOLOv8 Algorithm Based on Parameter-Free Attention Mechanism and Multi-Scale Feature Fusion for Small Object Detection in UAV Images. Remote Sens. 2025, 17, 2421. https://doi.org/10.3390/rs17142421
Qu S, Dang C, Chen W, Liu Y. SMA-YOLO: An Improved YOLOv8 Algorithm Based on Parameter-Free Attention Mechanism and Multi-Scale Feature Fusion for Small Object Detection in UAV Images. Remote Sensing. 2025; 17(14):2421. https://doi.org/10.3390/rs17142421
Chicago/Turabian StyleQu, Shenming, Chaoxu Dang, Wangyou Chen, and Yanhong Liu. 2025. "SMA-YOLO: An Improved YOLOv8 Algorithm Based on Parameter-Free Attention Mechanism and Multi-Scale Feature Fusion for Small Object Detection in UAV Images" Remote Sensing 17, no. 14: 2421. https://doi.org/10.3390/rs17142421
APA StyleQu, S., Dang, C., Chen, W., & Liu, Y. (2025). SMA-YOLO: An Improved YOLOv8 Algorithm Based on Parameter-Free Attention Mechanism and Multi-Scale Feature Fusion for Small Object Detection in UAV Images. Remote Sensing, 17(14), 2421. https://doi.org/10.3390/rs17142421