
Semantic Segmentation of Rice Fields in Sub-Meter Satellite Imagery Using an HRNet-CA-Enhanced DeepLabV3+ Framework

 , ,
, ,
Abstract
1. Introduction
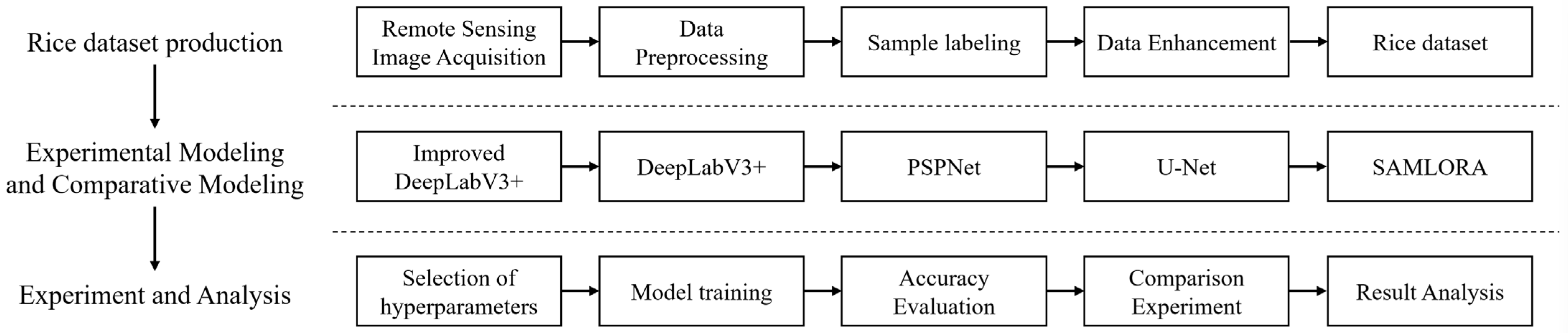
2. Materials and Methods
2.1. Study Area
2.2. Data Sources and Preprocessing
2.3. Sample Labeling and Dataset Partitioning
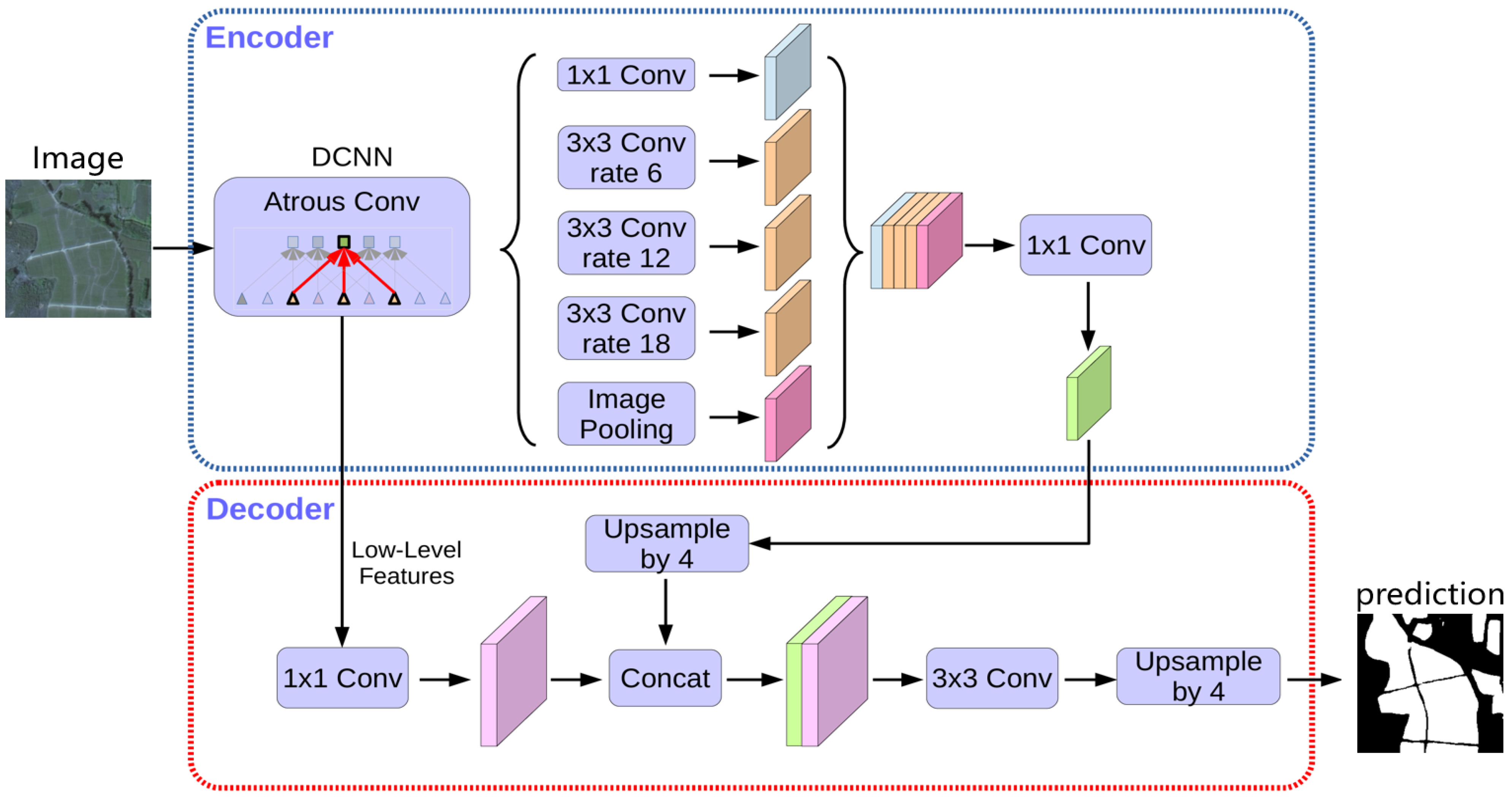
2.4. Improved DeepLabV3+ Network
2.4.1. DeepLabV3+ Infrastructure
2.4.2. High-Resolution Network (HRNet)
2.4.3. Coordinate Attention (CA) Mechanism
2.5. Segmentation Loss Function
2.6. Evaluation Metrics and Interpretatio
3. Experiments and Results
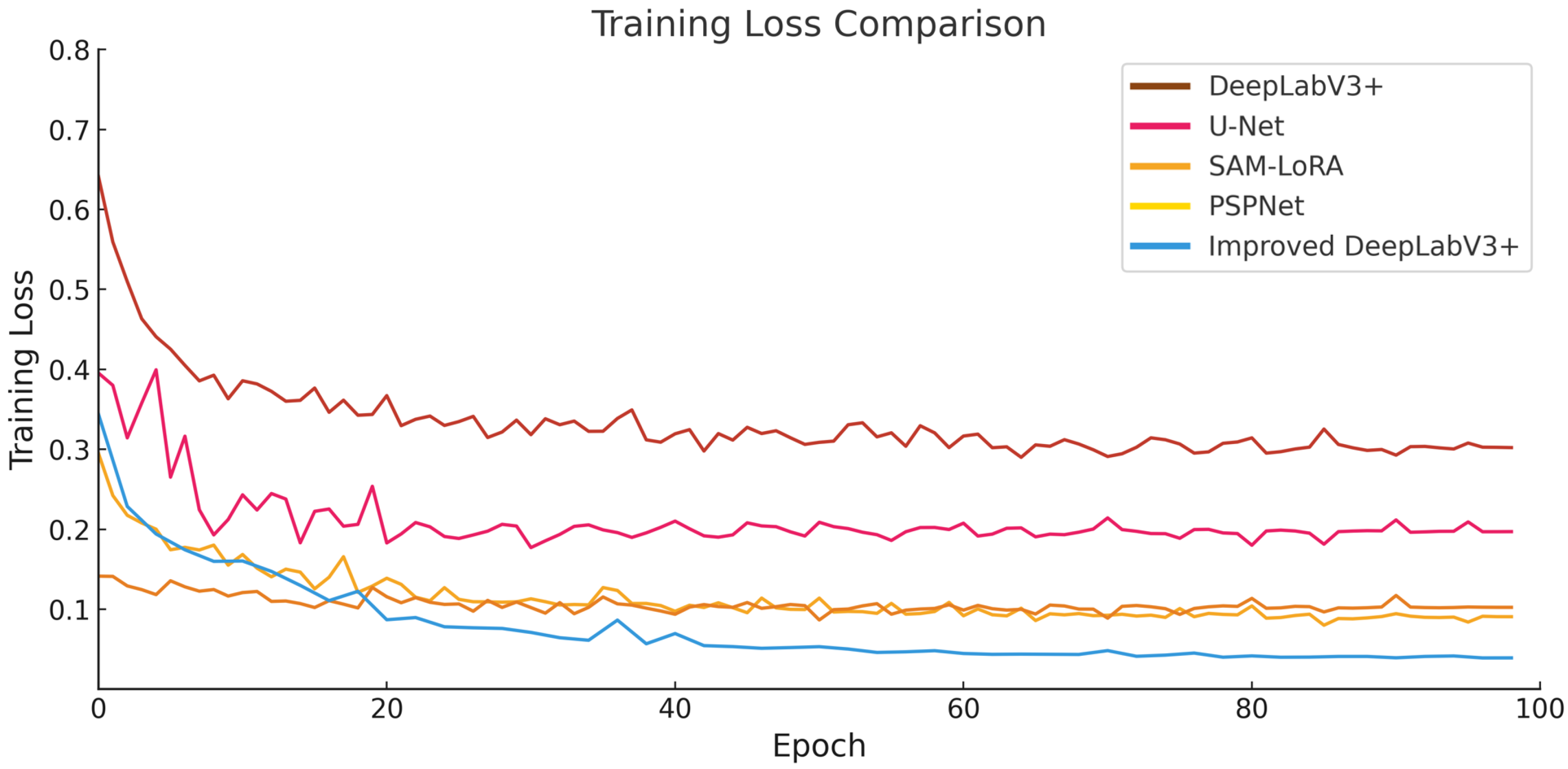
3.1. Training Settings
3.2. Comparative Experiments
3.3. Ablation Studies
3.4. Case Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| HRNet | High-Resolution Network |
| CA | Coordinate Attention |
References
- Ramos-Fernández, L.; Gonzales-Quiquia, M.; Huanuqueño-Murillo, J.; Tito-Quispe, D.; Heros-Aguilar, E.; Flores del Pino, L.; Torres-Rua, A. Water Stress Index and Stomatal Conductance under Different Irrigation Regimes with Thermal Sensors in Rice Fields on the Northern Coast of Peru. Remote Sens. 2024, 16, 796. [Google Scholar] [CrossRef]
- Xu, T.; Wang, F.; Shi, Z.; Miao, Y. Multi-scale monitoring of rice aboveground biomass by combining spectral and textural information from UAV hyperspectral images. Int. J. Appl. Earth Obs. Geoinf. 2024, 127, 103655. [Google Scholar] [CrossRef]
- Jiang, P.; Zhou, X.; Zhang, L.; Liu, M.; Xiong, H.; Guo, X.; Zhu, Y.; Luo, J.; Chen, L.; Liu, J.; et al. Improving Rice Yield by Promoting Pre-anathesis Growth in Subtropical Environments. Agronomy 2023, 13, 820. [Google Scholar] [CrossRef]
- Mallareddy, M.; Thirumalaikumar, R.; Balasubramanian, P.; Naseeruddin, R.; Nithya, N.; Mariadoss, A.; Eazhilkrishna, N.; Choudhary, A.K.; Deiveegan, M.; Subramanian, E.; et al. Maximizing Water Use Efficiency in Rice Farming: A Comprehensive Review of Innovative Irrigation Management Technologies. Water 2023, 15, 1802. [Google Scholar] [CrossRef]
- Kurihara, J.; Nagata, T.; Tomiyama, H. Rice Yield Prediction in Different Growth Environments Using Unmanned Aerial Vehicle-Based Hyperspectral Imaging. Remote Sens. 2023, 15, 2004. [Google Scholar] [CrossRef]
- Luo, S.; Jiang, X.; Jiao, W.; Yang, K.; Li, Y.; Fang, S. Remotely Sensed Prediction of Rice Yield at Different Growth Durations Using UAV Multispectral Imagery. Agriculture 2022, 12, 1447. [Google Scholar] [CrossRef]
- Franch, B.; Bautista, A.S.; Fita, D.; Rubio, C.; Tarrazó-Serrano, D.; Sánchez, A.; Skakun, S.; Vermote, E.; Becker-Reshef, I.; Uris, A. Within-Field Rice Yield Estimation Based on Sentinel-2 Satellite Data. Remote Sens. 2021, 13, 4095. [Google Scholar] [CrossRef]
- Zhou, X.; Zheng, H.B.; Xu, X.Q.; He, J.Y.; Ge, X.K.; Yao, X.; Cheng, T.; Zhu, Y.; Cao, W.X.; Tian, Y.C. Predicting grain yield in rice using multi-temporal vegetation indices from UAV-based multispectral and digital imagery. Isprs J. Photogramm. Remote Sens. 2017, 130, 246–255. [Google Scholar] [CrossRef]
- Seelwal, P.; Dhiman, P.; Gulzar, Y.; Kaur, A.; Wadhwa, S.; Onn, C. A systematic review of deep learning applications for rice disease diagnosis: Current trends and future directions. Front. Comput. Sci. 2024, 6, 1452961. [Google Scholar] [CrossRef]
- Malik, I.; Ahmed, M.; Gulzar, Y.; Baba, S.H.; Mir, M.S.; Soomro, A.B.; Sultan, A.; Elwasila, O. Estimation of the Extent of the Vulnerability of Agriculture to Climate Change Using Analytical and Deep-Learning Methods: A Case Study in Jammu, Kashmir, and Ladakh. Sustainability 2023, 15, 11465. [Google Scholar] [CrossRef]
- Gulzar, Y. Enhancing soybean classification with modified inception model: A transfer learning approach. Emir. J. Food Agric. 2024, 36, 1–9. [Google Scholar] [CrossRef]
- Alkanan, M.; Gulzar, Y. Enhanced corn seed disease classification: Leveraging MobileNetV2 with feature augmentation and transfer learning. Front. Appl. Math. Stat. 2024, 9, 1320177. [Google Scholar] [CrossRef]
- Gulzar, Y.; Unal, Z. Optimizing Pear Leaf Disease Detection Through PL-DenseNet. Appl. Fruit Sci. 2025, 67, 40. [Google Scholar] [CrossRef]
- Gulzar, Y.; Nal, Z. Time-Sensitive Bruise Detection in Plums Using PlmNet with Transfer Learning. Procedia Comput. Sci. 2025, 257, 127–132. [Google Scholar] [CrossRef]
- Tang, Y.; Sun, X.; Chen, Q.; Tang, J.; Chen, W.; Huang, X. Rice Identification Based on Remote Sensing Big Data Cloud Computing. Spacecr. Recovery Remote Sens. 2022, 43, 113–123. [Google Scholar]
- Wagner, W.; Lindorfer, R.; Melzer, T.; Hahn, S.; Bauer-Marschallinger, B.; Morrison, K.; Calvet, J.C.; Hobbs, S.; Quast, R.; Greimeister-Pfeil, I.; et al. Widespread occurrence of anomalous C-band backscatter signals in arid environments caused by subsurface scattering. Remote Sens. Environ. 2022, 276, 113025. [Google Scholar] [CrossRef]
- Saravia, D.; Salazar, W.; Valqui-Valqui, L.; Quille-Mamani, J.; Porras-Jorge, R.; Corredor, F.-A.; Barboza, E.; Vásquez, H.V.; Casas Diaz, A.V.; Arbizu, C.I. Yield Predictions of Four Hybrids of Maize (Zea mays) Using Multispectral Images Obtained from UAV in the Coast of Peru. Agronomy 2022, 12, 2630. [Google Scholar] [CrossRef]
- Su, X.; Wang, J.; Ding, L.; Lu, J.; Zhang, J.; Yao, X.; Cheng, T.; Zhu, Y.; Cao, W.; Tian, Y. Grain yield prediction using multi-temporal UAV-based multispectral vegetation indices and endmember abundance in rice. Field Crops Res. 2023, 299, 108992. [Google Scholar] [CrossRef]
- Quille-Mamani, J.A.; Ruiz, L.A.; Ramos-Fernández, L. Rice Crop Yield Prediction from Sentinel-2 Imagery Using Phenological Metric. Environ. Sci. Proc. 2023, 28, 16. [Google Scholar]
- Pi, F.; Chen, Y.; Huang, G.; Lei, S.; Hong, D.; Ding, N.; Shi, Y. Tracking and analyzing the spatio-temporal changes of rice planting structure in Poyang Lake using multi-model fusion method with sentinel-2 multi temporal data. PLoS ONE 2025, 20, e0320781. [Google Scholar] [CrossRef]
- Lin, Z.; Zhong, R.; Xiong, X.; Guo, C.; Xu, J.; Zhu, Y.; Xu, J.; Ying, Y.; Ting, K.C.; Huang, J.; et al. Large-Scale Rice Mapping Using Multi-Task Spatiotemporal Deep Learning and Sentinel-1 SAR Time Series. Remote Sens. 2022, 14, 699. [Google Scholar] [CrossRef]
- Bascon, M.V.; Nakata, T.; Shibata, S.; Takata, I.; Kobayashi, N.; Kato, Y.; Inoue, S.; Doi, K.; Murase, J.; Nishiuchi, S. Estimating Yield-Related Traits Using UAV-Derived Multispectral Images to Improve Rice Grain Yield Prediction. Agriculture 2022, 12, 1141. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, Y.-y.; Qin, Z.-y.; Zhang, M.-y.; Zhang, J. Remote sensing extraction method of terraced fields based on improved DeepLab v3+. Smart Agric. 2024, 6, 46–57. [Google Scholar] [CrossRef]
- Chang, Z.; Li, H.; Chen, D.H.; Liu, Y.F.; Zou, C.; Chen, J.; Han, W.J.; Liu, S.S.; Zhang, N.M. Crop Type Identification Using High-Resolution Remote Sensing Images Based on an Improved DeepLabV3+Network. Remote Sens. 2023, 15, 5088. [Google Scholar] [CrossRef]
- Sun, L.; Yang, T.; Lou, Y.; Shi, Q.; Zhang, L. Paddy Rice Mapping Based on Phenology Matching and Cultivation Pattern Analysis Combining Multi-Source Data in Guangdong, China. J. Remote Sens. 2024, 4, 0152. [Google Scholar] [CrossRef]
- Wang, Y.; Tao, F.; Chen, Y.; Yin, L. Mapping irrigation regimes in Chinese paddy lands through multi-source data assimilation. Agric. Water Manag. 2024, 304, 109083. [Google Scholar] [CrossRef]
- Meng, L.; Li, Y.; Shen, R.; Zheng, Y.; Pan, B.; Yuan, W.; Li, J.; Zhuo, L. Large-scale and high-resolution paddy rice intensity mapping using downscaling and phenology-based algorithms on Google Earth Engine. Int. J. Appl. Earth Obs. Geoinf. 2024, 128, 103725. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, B.; Tao, J.; Tian, S.; Sheng, Q.; Li, J.; Wang, S.; Liu, X.; He, H. Canopy structure dynamics constraints and time sequence alignment for improving retrieval of rice leaf area index from multi-temporal Sentinel-1 imagery. Comput. Electron. Agric. 2024, 227, 109658. [Google Scholar] [CrossRef]
- Tian, S.; Sheng, Q.; Cui, H.; Zhang, G.; Li, J.; Wang, B.; Xie, Z. Rice recognition from Sentinel-1 SLC SAR data based on progressive feature screening and fusion. Int. J. Appl. Earth Obs. Geoinf. 2024, 134, 104196. [Google Scholar] [CrossRef]
- Gao, Y.; Pan, Y.; Zhu, X.; Li, L.; Ren, S.; Zhao, C.; Zheng, X. FARM: A fully automated rice mapping framework combining Sentinel-1 SAR and Sentinel-2 multi-temporal imagery. Comput. Electron. Agric. 2023, 213, 108262. [Google Scholar] [CrossRef]
- Xia, L.; Zhang, R.; Chen, L.; Li, L.; Yi, T.; Chen, M. Monitoring the leaf damage by the rice leafroller with deep learning and ultra-light UAV. Pest Manag. Sci. 2024, 80, 6620–6633. [Google Scholar] [CrossRef] [PubMed]
- Gao, R.; Chang, P.; Chang, D.; Tian, X.; Li, Y.; Ruan, Z.; Su, Z. RTAL: An edge computing method for real-time rice lodging assessment. Comput. Electron. Agric. 2023, 215, 108386. [Google Scholar] [CrossRef]
- Jiang, M.; Xin, L.; Li, X.; Tan, M.; Wang, R. Decreasing Rice Cropping Intensity in Southern China from 1990 to 2015. Remote Sens. 2018, 11, 35. [Google Scholar] [CrossRef]
- Gao, S.; Zhou, G.; Rees, R.M.; Cao, W. Green manuring inhibits nitrification in a typical paddy soil by changing the contributions of ammonia-oxidizing archaea and bacteria. Appl. Soil Ecol. 2020, 156, 103698. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Liu, J.; Li, D.; Xu, X. Enhancing bridge damage detection with Mamba-Enhanced HRNet for semantic segmentation. PLoS ONE 2024, 19, e0312136. [Google Scholar] [CrossRef]
- Yang, X.; Fan, X.; Peng, M.; Guan, Q.; Tang, L. Semantic segmentation for remote sensing images based on an AD-HRNet model. Int. J. Digit. Earth 2022, 15, 2376–2399. [Google Scholar] [CrossRef]
- Seong, S.; Choi, J. Semantic Segmentation of Urban Buildings Using a High-Resolution Network (HRNet) with Channel and Spatial Attention Gates. Remote Sens. 2021, 13, 3087. [Google Scholar] [CrossRef]
- Li, R.; Yan, A.; Yang, S.; He, D.; Zeng, X.; Liu, H. Human Pose Estimation Based on Efficient and Lightweight High-Resolution Network (EL-HRNet). Sensors 2024, 24, 396. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Area/km2 | Collection Time | Sensor | Cloudiness/% | Satellite |
|---|---|---|---|---|---|
| Tianya District 1 m resolution image | 24.47 | 19 January 2024 | 1mCCD2 | 0.0 | GF-2 |
| Hainan Province 0.75 m resolution image | 26.79 | 8 January 2024 | PMS2 | 0.0 | JL1GF02B |
| Yazhou District 1 m resolution image | 302.34 | 19 January 2024 | 1mCCD1 | 0.0 | GF-2 |
| Yazhou District 0.75 m resolution image | 119.20 | 9 December 2023 | PMS | 2.0 | JL1GF03D24 |
| Tianya District 0.75 m resolution image | 162.54 | 17 November 2023 | PMS | 1.0 | JL1GF03D34 |
| Yazhou District 0.75 m resolution image | 76.79 | 7 January 2024 | PMS | 1.0 | JL1GF03D12 |
| Yazhou District 0.75 m resolution image | 52.44 | 17 November 2023 | PMS | 4.0 | JL1GF03D05 |
| Yazhou District 0.75 m resolution image | 204.15 | 17 November 2023 | PMS | 2.0 | JL1GF03D05 |
| 0.75 m resolution image | 111.53 | 30 January 2021 | PMS04 | 0.0 | JL1KF01A |
| 0.75 m resolution image | 82.48 | 30 January 2021 | PMS05 | 0.0 | JL1KF01A |
| Yazhou District 0.75 m Resolution Image | 197.97 | 30 January 2021 | PMS05 | 0.0 | JL1KF01A |
| Yazhou District 0.75 m resolution image | 56.85 | 28 November 2023 | PMS2 | 1.0 | JL1GF02B |
| 0.75 m resolution image | 280.51 | 28 November 2023 | PMS1 | 0.0 | JL1GF02B |
| 0.75 m resolution image | 72.15 | 28 November 2023 | PMS | 20.0 | DP04 |
| Yazhou District 0.75 m resolution image | 260.34 | 13 December 2022 | PMS2 | 0.0 | JL1GF02B |
| Tianya District 0.75 m resolution image | 53.69 | 13 December 2022 | PMS1 | 0.0 | JL1GF02B |
| Yazhou District 0.75 m resolution image | 87.53 | 13 December 2022 | PMS2 | 0.0 | JL1GF02B |
| Class | Original Images | Augmented Images | Total Images | Proportion/% |
|---|---|---|---|---|
| Rice | 3765 | 7530 | 11,295 | 48.5 |
| Non-rice | 4000 | 8000 | 12,000 | 51.5 |
| Total | 7765 | 15,530 | 23,295 | 100 |
| Parameters | Setting |
|---|---|
| Image Size | 512 × 512 |
| Batch Size | 8 |
| Max Epoch | 100 |
| Optimizer | Adam |
| Learning Rate | 0.0001 |
| loss function | Cross-Entropy Loss |
| Network Models | Recall/% | Precision/% | F1 Score/% | MIOU/% |
|---|---|---|---|---|
| U-Net | 87.02 | 86.77 | 86.89 | 85.90 |
| PSPNet | 89.24 | 90.26 | 89.75 | 88.75 |
| SAMLoRA | 88.61 | 88.80 | 88.71 | 87.68 |
| DeepLabV3+ | 82.43 | 87.73 | 84.99 | 84.20 |
| Improved DeepLabV3+ | 96.89 | 95.01 | 95.93 | 92.28 |
| Variant | Recall/% | Precision/% | F1 Score/% | MIOU/% |
|---|---|---|---|---|
| Baseline (DeepLabV3+) | 82.43 | 87.73 | 84.99 | 84.20 |
| + HRNet | 96.47 | 94.55 | 95.51 | 91.50 |
| + CA | 96.30 | 92.20 | 94.14 | 89.07 |
| + HRNet + CA | 96.89 | 95.01 | 95.93 | 92.28 |
| Variant | Params/M | FLOPs/G | Avg Epoch Time/s |
|---|---|---|---|
| Baseline (DeepLabV3+) | 42.0 | 178.7 | 32.5 |
| + HRNet | 66.5 | 210 | 45.8 |
| + CA | 42.6 | 181.6 | 33.7 |
| + HRNet + CA | 67.1 | 213 | 46.2 |
| Network Models | MIOU/% | Recall/% | Extracted Area/Acre | Error Rate/% |
|---|---|---|---|---|
| U-Net | 85.90 | 87.02 | 8524.07 | 4.12 |
| PSPNet | 88.75 | 89.24 | 8677.74 | 2.40 |
| SAMLoRA | 87.68 | 88.61 | 8638.89 | 2.83 |
| DeepLabV3+ | 84.20 | 82.43 | 8565.01 | 3.66 |
| Improved DeepLabV3+ | 92.28 | 96.89 | 8912.52 | 0.25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, Y.; Pan, P.; Zhao, H.; Li, J.; Yu, G.; Zhou, G.; Zhang, J. Semantic Segmentation of Rice Fields in Sub-Meter Satellite Imagery Using an HRNet-CA-Enhanced DeepLabV3+ Framework. Remote Sens. 2025, 17, 2404. https://doi.org/10.3390/rs17142404
Shao Y, Pan P, Zhao H, Li J, Yu G, Zhou G, Zhang J. Semantic Segmentation of Rice Fields in Sub-Meter Satellite Imagery Using an HRNet-CA-Enhanced DeepLabV3+ Framework. Remote Sensing. 2025; 17(14):2404. https://doi.org/10.3390/rs17142404
Chicago/Turabian StyleShao, Yifan, Pan Pan, Hongxin Zhao, Jiale Li, Guoping Yu, Guomin Zhou, and Jianhua Zhang. 2025. "Semantic Segmentation of Rice Fields in Sub-Meter Satellite Imagery Using an HRNet-CA-Enhanced DeepLabV3+ Framework" Remote Sensing 17, no. 14: 2404. https://doi.org/10.3390/rs17142404
APA StyleShao, Y., Pan, P., Zhao, H., Li, J., Yu, G., Zhou, G., & Zhang, J. (2025). Semantic Segmentation of Rice Fields in Sub-Meter Satellite Imagery Using an HRNet-CA-Enhanced DeepLabV3+ Framework. Remote Sensing, 17(14), 2404. https://doi.org/10.3390/rs17142404