1. Introduction
Hyperspectral imaging (HSI) plays a crucial role in various applications within the field of remote sensing. HSI encompasses tens to hundreds of narrow, continuous spectral bands that span from the visible spectrum to near-infrared wavelengths. Consequently, HSI provides rich information regarding ground features. It is instrumental in agricultural technology [
1], resource exploration [
2], urban planning [
3] and military applications [
4]. To fully harness the potential of HSI, researchers have developed numerous methodologies including unmixing [
5], sharpening [
6], super-resolution [
7] and classification [
8]. Among these, hyperspectral image classification (HSIC) stands out as one of the key areas of research within HSI. The HSIC process involves assigning specific labels to individual pixel units. Initially, researchers proposed a variety of classical methods primarily focused on feature extraction techniques and traditional machine learning approaches. Classical feature extraction methods encompass Principal Component Analysis (PCA) [
9] and linear discriminant analysis (LDA) [
10], among others. These techniques facilitate feature selection and dimensionality reduction on the input hyperspectral data, enabling the extraction of discriminative spectral features. Furthermore, traditional machine learning algorithms are employed for classification purposes, including Support Vector Machines (SVMs) [
11], Random Forest (RF) algorithms [
12], and K-Nearest Neighbor (KNN) algorithms [
13]. However, many conventional methods fail to effectively leverage spatial information, which can adversely affect classification accuracy.
In recent years, researchers have increasingly focused on the field of deep learning due to its ability to automatically learn abstract features from raw data. This shift has led to remarkable advancements in the domain of computer vision. Currently, deep learning exhibits exceptional performance in HSIC, with many HSIC accuracies achieved through deep learning models surpassing those of traditional methods. Chen et al. [
14] previously employed a stacking approach using varying numbers of autoencoders to extract different levels of spatial–spectral features. However, compressing input features into one-dimensional vectors results in a partial loss of spatial information. Subsequently, Convolutional Neural Networks (CNNs) have emerged as a significant advancement within deep learning. Due to their advantages such as weight sharing and local connectivity, along with their capability to extract extensive spatial and spectral features from hyperspectral images, CNNs have become prominent methodologies in this field. Hu et al. [
15] designed a Convolutional Neural Network comprising five layers specifically for processing spectral information. To enhance the extraction of spatial information from HSI images, Zhao et al. [
16] proposed utilizing 2D-CNNs for extracting spatial features and integrating them with spectral features obtained through local discriminative embedding methods, thereby improving classification accuracy. Yue et al. [
17] proposed the use of 2D-CNN to extract spatial spectral features, employing logistic regression for classification. Yang et al. [
18] implemented a dual-branch CNN architecture that utilized both 1D-CNN and 2D-CNN to separately extract spectral and spatial features, respectively. The two feature sets were then concatenated and forwarded to a fully connected layer, resulting in improved classification accuracy. However, the limitation of this approach is that 1D-CNN focuses solely on the spectral vector while 2D-CNN addresses only the spatial vector; thus, effective integration of these two types of features remains challenging. To address this issue, Chen et al. [
19] introduced a 3D-CNN model designed for the enhanced extraction of spatial–spectral features and experimentally demonstrated its superior classification accuracy compared to previous methods. Roy et al. [
20] employed a hybrid CNN structure that first utilized 3D-CNN to capture spectral–spatial features before applying 2D-CNN for further extraction of spatial characteristics. This methodology not only facilitates the learning of more advanced feature representations but also significantly reduces the computational burden on the model. Zhou et al. [
21] proposed the Spatial–Spectral Pyramid Network (SSPN) model for HSIC, which innovatively combined a 3D Convolutional Neural Network with feature pyramids while introducing multi-scale convolution kernels to extract local features across varying receptive fields. This approach achieves multilevel feature fusion and markedly enhances feature expressiveness. Deep Convolutional Neural Networks (CNNs) are capable of capturing more global feature representations by incrementally stacking multiple convolutional layers, thereby improving classification accuracy. However, this advancement introduces new challenges; specifically, an increase in network depth can exacerbate issues related to gradient vanishing or explosion, ultimately leading to diminished classification performance. Zhong et al. [
22] introduced the residual network architecture to enhance effective information transmission within neural networks. This connection method aids in preserving original feature information, partially alleviating the gradient vanishing problem, and ultimately improving classification performance. Zhu et al. [
23] proposed the Residual Spectral–Spatial Attention Network (RSSAN), which incorporates an attention mechanism to strengthen spatial–spectral features while employing Convolutional Neural Networks (CNNs) and residual blocks to jointly refine features across multiple levels. Cui et al. [
24] decomposed standard 3D convolution into depthwise convolution and pointwise convolution, achieving a lightweight design that significantly reduces parameters while maintaining high classification accuracy.
Beyond the aforementioned CNN-based approaches, a variety of networks exhibiting exceptional performance have been utilized in the context of HSIC. Mou et al. [
25] introduced an RNN framework for HSIC that employs Parametric Rectified Tanh (PRetanh) and a Gated Recurrent Unit (GRU) to analyze hyperspectral sequences, thereby facilitating efficient feature learning. Paoletti et al. [
26] enhanced the CNN architecture by incorporating a spectral space capsule network. This capsule network not only learns spectral–spatial features but also considers spatial locations and their associated spectral characteristics. In addition to these advancements, there are various network architectures based on Generative Adversarial Networks (GANs) [
27,
28], Graph Convolutional Networks (GCNs) [
29,
30], and other models that demonstrate strong classification performance.
The network architecture based on Convolutional Neural Networks (CNNs) has exhibited exceptional performance in extracting local features. However, the receptive field of CNNs is constrained by both the size of the convolutional kernel and the number of stacked layers. This limitation also restricts a CNN’s ability to capture long-range contextual information. In 2017, a team at Google introduced a novel model architecture known as Transformer. Unlike CNNs, Transformers leverage a self-attention mechanism (SA) to compute the degree of correlation between elements within the model, thereby effectively capturing long-range dependencies. The introduction of ViT [
31] signifies that Transformers have been successfully applied to computer vision tasks. Following this development, ViT and its variants have found applications in hyperspectral image classification. From the perspective of spectral sequence information, Hong et al. [
32] proposed a structure called SpectralFormer (SF), which utilizes Transformers to learn local spectral sequence information from adjacent spectral bands in hyperspectral images. They also incorporated skip connections to enhance information transitivity. He et al. [
33] introduced the Spatial–Spectral Transformer (SST), which integrates both the CNN and Transformer architectures. In this approach, CNNs are employed to capture spatial features, while densely connected Transformer designs are utilized for feature extraction as well. This dual strategy not only facilitates rich feature extraction but also helps mitigate issues related to gradient vanishing. Finally, a multilayer perceptron (MLP) was employed for classification purposes. Sun et al. [
34] proposed a novel classification method known as SSFTT, which transforms spatial and spectral features using a Gaussian distribution-weighted tokenizer and employs a Transformer to model these features, thereby enhancing the extraction of semantic information. However, SSFTT may suffer from inaccuracies in feature labeling. To address this issue, Zou et al. [
35] introduced LESSFormer, which first generates representative spatial–spectral labels through a feature labeling module before utilizing a Transformer to improve feature expression capabilities. Mei et al. [
36] contend that the features extracted via the multi-head self-attention mechanism (MHSA) tend to be overly discrete; thus, they proposed the Group-Aware Hierarchical Transformer (GAHT) model. By incorporating the Grouped Pixel Embedding (GPE) module, discriminative features are extracted from non-overlapping channels. This is then integrated with a Transformer architecture where attention is confined to local spatial–spectral contexts to mitigate issues related to feature dispersion. Yang et al. [
37] proposed a novel Transformer network, QTN, which introduces BASM to dynamically select appropriate spectral bands. Additionally, it employs quaternion attention to capture local features and global long-range dependencies. The model has demonstrated excellent classification performance across multiple datasets. Roy et al. [
38] introduced a novel classification model named MorphFormer, which integrates mathematical morphological operations to enhance the traditional attention mechanism. This model effectively extracts both morphological spatial and spectral features while improving the interaction of structural shape information among different tokens through morphological convolution. Zhao et al. [
39] proposed a Transformer architecture known as the Group Separable Convolutional Transformer (GSC-ViT). This model captures local spatial–spectral features via a group separable convolution module and subsequently extracts local–global spatial features using a group separable self-attention mechanism (GSSA). The GSC-ViT demonstrates commendable classification accuracy while maintaining a lightweight design.
However, CNNs and Transformers tend to focus on singular aspects of representation. To address this limitation, Yang et al. [
40] proposed an excellent classification model known as the Adaptive Coupling Transformer Network (ACTN). This model effectively extracts both local and global information, adaptively fusing the two to enhance the expressive power of features.
Although existing deep learning-based methods achieve commendable performance in HSIC, we have observed that certain Transformer-based approaches incorporate multiple Transformer encoders. This necessitates the repeated transmission of spatial–spectral information, which may result in the loss or degradation of some data. Some Transformer-based methods address this issue by integrating residual networks between adjacent Transformers and fusing feature information across layers. The features captured by deep networks are typically high-level and abstract, while shallow networks tend to capture low-level, more interpretable features. There exists a gap between these two distinct levels of features, and merely employing residual connections is insufficient for effective fusion. Sun et al. [
41] recognized this challenge and proposed a novel method called MASSFormer method. They utilized convolutional layers to extract shallow spectral–spatial features, subsequently applying pooling to convert these features into memory tokens that are then expanded into each Transformer encoder. This approach effectively preserves the original feature information for subsequent Transformers, thereby mitigating the impact of information degradation to some extent. However, it is important to note that the shallow features employed by each Transformer encoder in MASSFormer remain consistent across all encoders, resulting in a lack of cross-layer interaction among them. Consequently, the noise present in the shallow features may be redundantly exploited and continuously propagated throughout the training process, ultimately affecting classification performance.
Furthermore, the recently emerged Mamba has made significant progress in modeling long sequence dependencies and has demonstrated potential in HSIC tasks. Chen et al. [
42] proposed the RSMamba structure, which enhances the modeling capability for non-causal data through a multi-path activation mechanism, achieving commendable classification results across multiple datasets. However, the design of the Mamba structure primarily targets general sequence tasks and lacks adaptation for joint modeling of spatial–spectral features in hyperspectral imaging (HSI). Additionally, the Mamba network relies on a recursive state update mechanism that limits its ability to preserve local spatial details. This may result in shallow local discriminative information being weakened within deeper features, ultimately affecting the model’s classification performance.
To more effectively address the issues of information loss and underutilization resulting from the stacking of multiple Transformer encoders, this paper proposes a Dual-Branch Spatial–Spectral Transformer with Similarity Propagation (DBSSFormer-SP). The model comprises two branches that independently extract spatial and spectral features.
Despite the increasing prevalence of Transformer-based dual-branch architectures in hyperspectral image classification [
43], these methods generally face two critical issues: on one hand, the spatial branch overlooks the degradation of feature extraction capabilities caused by stacking Transformer blocks; on the other hand, the spectral branch fails to adequately model the global correlations among various spectral bands.
In this paper, we propose DBSSFormer-SP, which introduces attention propagation to facilitate attention guidance from shallow to deep layers, effectively alleviating issues related to deep feature degradation and information ambiguity. Additionally, by employing a spectral Transformer module that models global dependencies between bands and integrating convolutional operations, our approach successfully extracts discriminative spectral features.
In detail, within the spatial branch, shallow spatial–spectral features are initially extracted through shallow convolutional layers. Subsequently, to fully leverage the spatial information present in hyperspectral images, we employ a Hybrid Pooling Spatial Channel Attention (HPSCA) module designed to enhance the discriminative capability of these features. The tokens generated from the flattened features serve as input for the Transformer encoders. We introduce a transitive similarity mechanism across adjacent Transformer encoders, which facilitates the transfer of low-level attention distributions to higher-level encoders via nonlinear transformations. This approach not only enhances information circulation but also ensures effective fusion of attention distributions across different levels. In the spectral branch, we utilize Transformers to capture dependencies among non-local bands within one-dimensional spectral sequences. Ultimately, both feature sets are integrated into a linear classifier for pixel label determination.
The three primary contributions of this paper are as follows:
- (1)
DBSSFormer-SP is proposed, in which, to enhance the expressive capability of spatial features, we design a Hybrid Pooling Spatial Channel Attention (HPSCA) module. This module captures various long-range dependencies through attention mechanisms across different dimensions and integrates spatial information into the channel attention map to acquire global information dependencies. Subsequently, the channel dimension is compressed to generate spatial attention weights, thereby augmenting the discriminative power of spatial features.
- (2)
This paper introduces a Similarity Propagation Transformer Encoder (SPTE) module. This module effectively integrates information by transferring the attention distribution across different encoder layers and employing nonlinear transformations. The transmission of information is enhanced, facilitating the interaction among various characteristic features. While it strengthens the representation of salient features, it also mitigates the issue of information attenuation commonly encountered in deep networks, thereby improving the classification performance of the model.
- (3)
To effectively capture the relationships among spectral features, we propose the Spectral Transformer (SpecFormer) module. This module replaces the multilayer perceptron found in traditional Transformers with depth-wise separable convolutions. This approach not only enhances the ability to discern relationships between different spectral bands and emphasizes key spectral features but also significantly reduces both the number of parameters and their computational complexity.
The remainder of this paper is organized as follows:
Section 2 details the implementation of the proposed method.
Section 3 provides an overview of the dataset, outlines the design of experimental parameters, and presents the experimental results.
Section 4 discusses the conclusions drawn from these experiments. Finally,
Section 5 summarizes the key findings of this study and suggests directions for future research improvements.
2. Methodology
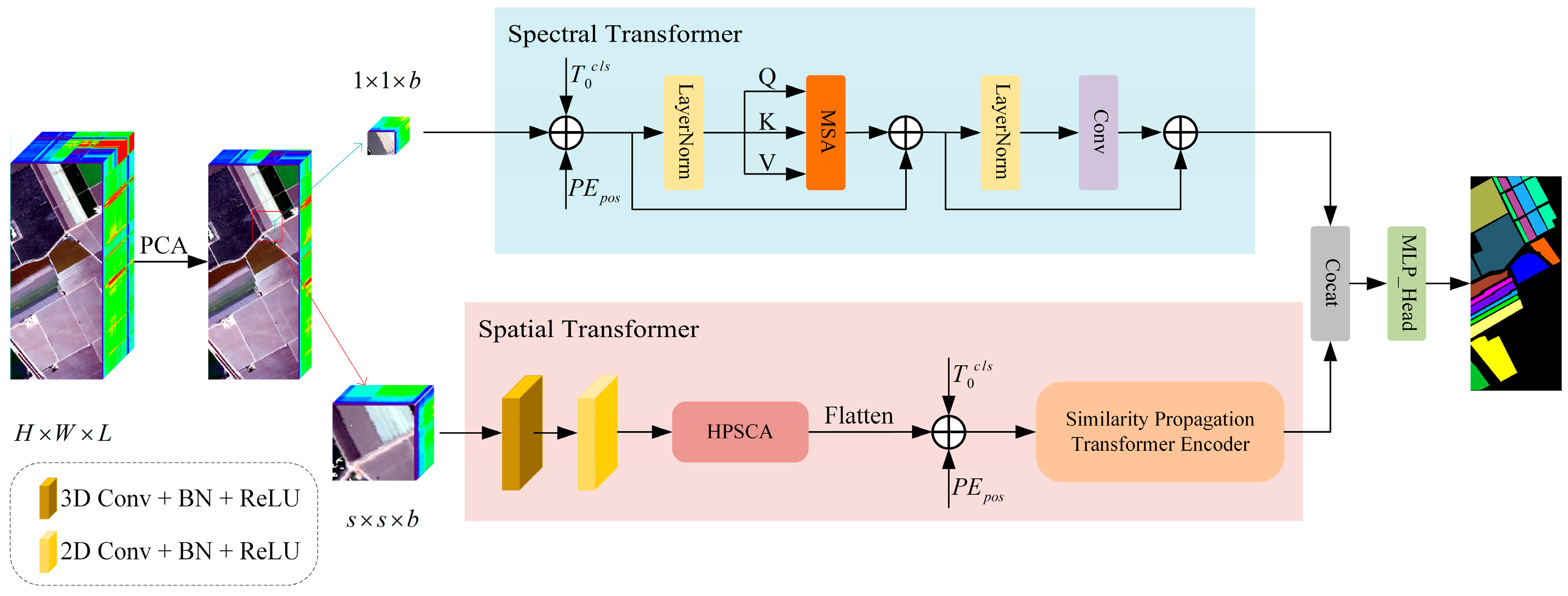
The overall structure of the proposed approach is presented in
Figure 1. It primarily consists of hyperspectral data preprocessing, a Hybrid Pooling Spatial Channel Attention (HPSCA) module, and a Similarity Propagation Transformer Encoder (SPTE) for the spatial branch. Additionally, it includes the spectral branch of the Spectral Transformer (SpecFormer) module.
2.1. Hyperspectral Data Preprocessing
Hyperspectral data typically encompass hundreds of spectral bands, which provides extensive spectral information but also introduces a significant amount of redundant data. We employed Principal Component Analysis (PCA) to reduce the dimensionality of the original hyperspectral data, thereby compressing the spectral bands. PCA identifies orthogonal principal component directions that maximize variance across all samples, effectively eliminating redundant information while preserving essential details, thus reducing computational complexity. The HSI data cube is represented as , where , , and denote the height, width, and number of spectral bands in the HSI dataset, respectively. PCA facilitates the reduction in the number of bands from to , while maintaining the overall size of the HSI space. Consequently, after applying PCA for dimensionality reduction, the transformed HSI data can be expressed as . Where signifies the number of spectral bands post-dimension reduction.
Subsequently, we extract the 3D block from , where denotes the dimensions of the spatial window. The center pixel position of each block is defined as , with constraints , . The label associated with the center pixel of each block determines its corresponding class. When extracting blocks centered on a single pixel, edge pixels become inaccessible; thus, padding is required for these pixels. Ultimately, the total number of generated 3D blocks amounts to . Concurrently, we perform PCA dimensionality reduction on the spectral information extracted from , converting it into a one-dimensional spectral sequence that serves as input for the spectral branch. Finally, both spatial and spectral features are concatenated for classification purposes.
2.2. HPSCA Module
Before the HPSCA module, we first conduct simple 3D and 2D convolution operations on the input
to initially extract spatial–spectral features. The 3D convolutional block comprises a convolutional layer with a kernel size of
, followed by a batch normalization layer and a nonlinear activation layer. The calculation process is as follows:
where
and
represent the weight parameters and bias parameters of the 3D convolution.
stands for the 3D convolution operator.
stands for batch normalization operation for 3D convolutions.
stands for nonlinear activation function.
is the output of the 3D convolution.
The adjusted data are subsequently transmitted to the following 2D convolutional layer for further processing. This process mirrors the previous procedure; the 2D convolutional block comprises a convolutional layer with a kernel size of
, followed by a batch normalization layer and a nonlinear activation layer. Ultimately, the output
from the 2D convolution is obtained. The calculation process is as follows:
Here, and represent the weight parameters and bias parameters of the 2D convolution. stands for the 2D convolution operator. denotes the rearrangement operation. stands for batch normalization operation of 2D convolution. stands for nonlinear activation function.
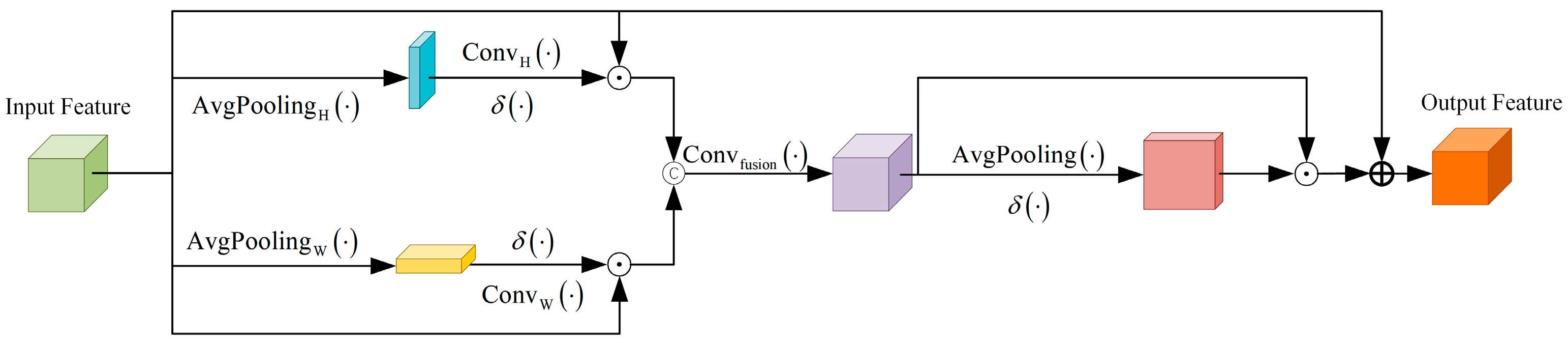
However, due to the limited receptive field of shallow CNNs, they typically capture only local spatial spectral features. Inspired by Coordinate Attention [
44], we have designed the HPSCA module to achieve a more comprehensive modeling of spatial information, thereby enhancing the expressive capability of spatial features. Traditional global pooling methods process entire spatial information and compress it into channels, resulting in a loss of spatial positional information and an inability to perceive the directional characteristics of spatial structures. In contrast, HPSCA performs pooling along two spatial dimensions: height and width. This approach does not completely compress the spatial dimensions; rather, it retains responses at each position within the retained direction. Specifically, this pooling operation preserves positional information in one direction while capturing long-range dependency information in the other direction, which is utilized to guide subsequent feature weighting. The process of HPSCA is illustrated in
Figure 2.
The height branch assigns a weight to each row of every channel, applying this weight across the entire feature map. This process emphasizes the significance of vertical positioning within the data. Specifically, in the height branch, we first perform average pooling along the width dimension of the input data, resulting in
. This step captures long-range dependencies in the vertical direction while preserving information from each channel along the height axis. It takes into account not only the inter-channel relationships but also spatial positional information in the vertical orientation. Subsequently, vertical attention is generated for all channels through 2D convolution using a
kernel. The Sigmoid activation function is then applied to produce an output feature map that is weighted with the input features to yield a fused feature
. The formulas are as follows:
where
is pooling along the
dimension.
denotes the 2D convolution with a
kernel.
is defined as the Sigmoid activation function.
Similar to the height branch, the width branch assigns a weight to each column of every channel and applies this weight across the entire feature map. This process emphasizes the characteristics associated with horizontal positioning. The width branch employs average pooling along the height dimension to obtain
, effectively capturing feature information in the horizontal direction. Subsequently, a 2D convolution with a
kernel is utilized to generate horizontal attention across all channels, followed by the application of a Sigmoid activation function to derive the feature mapping. Ultimately, this results in
. The formulas can be written as:
where
is pooling along the
dimension.
denotes the 2D convolution with a
kernel. The remaining symbols have the same meaning as the previous ones.
The two enhanced features are concatenated along the channel dimension, followed by the application of a 2D convolution using a
convolution kernel to fuse these features. This process establishes distinct long-range dependencies from various spatial directions and integrates spatial information into channel attention mechanisms. It effectively incorporates global information to enhance the discriminative capabilities of the features, thereby improving the model’s perception and discrimination abilities in key areas. The formula for this procedure is provided below:
Here, denotes the 2D convolution with kernel 1. represents the concatenation of operations along the channel dimension.
To further emphasize prominent spatial features, we perform average pooling along the channel dimension of
, while maintaining a constant spatial dimension. The global channel information is integrated into a spatial weight template for a single channel. Subsequently, the Sigmoid activation function is employed to generate the spatial attention map, which reflects the significance of each spatial location. Finally,
is feature-weighted and added to
. This approach preserves the original basis of feature information, thereby enhancing the attention paid to salient details. The formula is provided below:
where
represents pooling along the channel dimension The rest of the symbols have similar meanings as before.
Finally, the generated feature map, , is expanded along the spatial dimension to produce the final output. The HPSCA module enhances features by incorporating various dimensions. This approach not only integrates global information but also facilitates a more refined enhancement of spatial features. Simultaneously, it effectively suppresses irrelevant noise, thereby providing more reliable input for subsequent modules.
2.3. Similarity Propagation Transformer Encoder
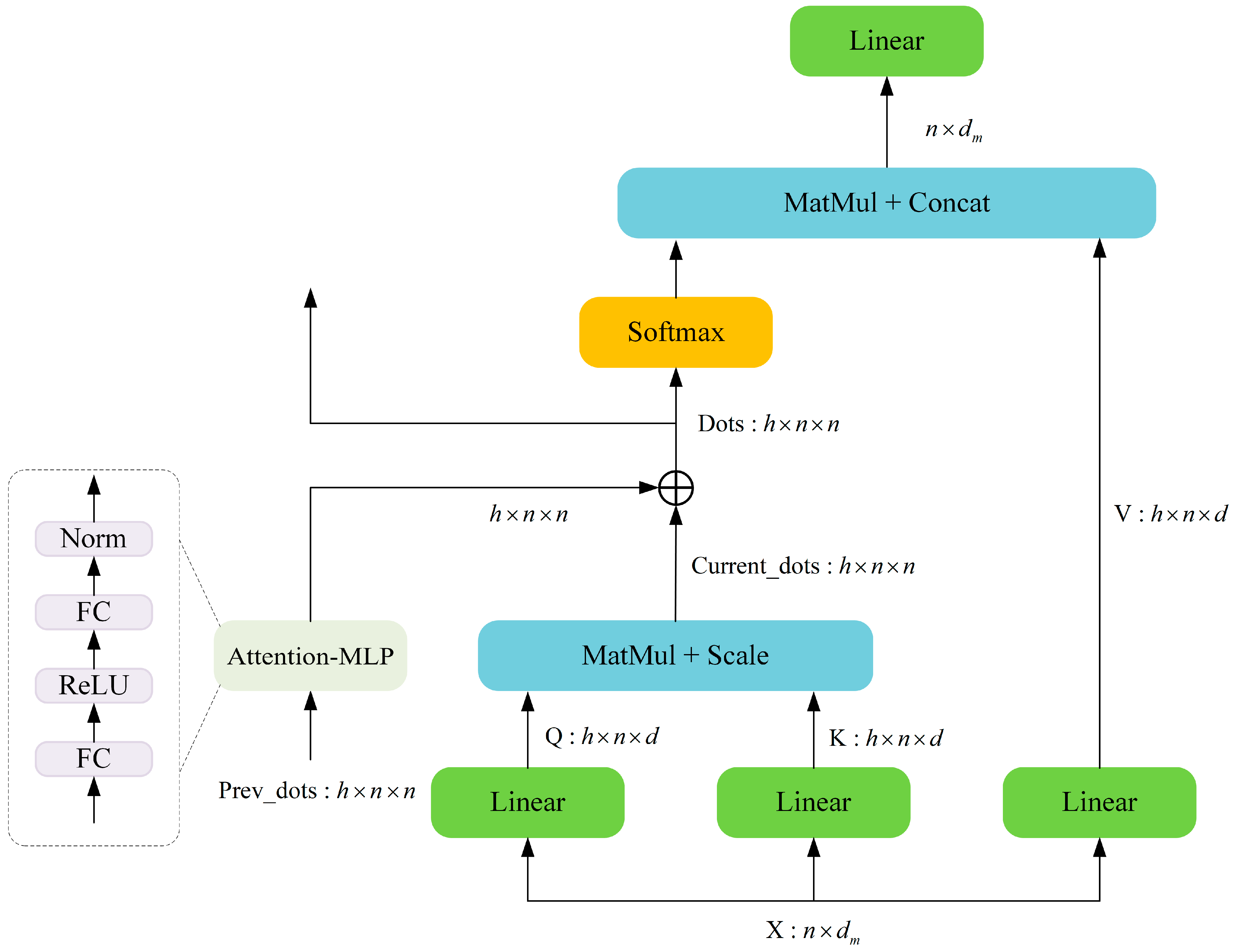
In recent years, the Transformer architecture has been extensively utilized in the field of hyperspectral image classification (HSIC) due to its exceptional capability to model long-range dependencies. Currently, there are several Transformer-based methods for HSI classification that employ multiple encoders to comprehensively extract spatial and spectral features. However, as the number of encoder layers increases, information tends to degrade during transmission. Additionally, issues related to deep attenuation may arise, which can limit the overall performance of the model. To address these challenges, we propose a Similarity Propagation Transformer Encoder comprising three key components: the Multi-head Transmission Self-attention (MHTSA) block, the Attention-MLP block, and the MLP block.
The traditional Transformer recalculates attention scores at each layer, and there exists a regularity in the semantic abstraction of attention across different layers, with higher-level attention being further refined from lower-level attention. We employ skip connections to facilitate the flow of information, allowing the attention scores from one Transformer encoder block to be transmitted to the subsequent Transformer encoder block, and thereby enhancing inter-layer information transfer.
The attention score essentially quantifies the correlation or association strength between different elements in the input sequence. Based on this principle, we add the historical attention distribution from the previous layer to the current attention scores, thereby facilitating the inheritance of cross-layer attention information. This mechanism not only alleviates information loss during inter-layer transmission but also preserves the correlations among elements from the preceding layer. As a result, it enables the model to maintain consistent focus and reinforcement on truly significant element associations across different levels.
However, the Transformer model progressively extracts features and abstracts representations from input data layer by layer. Lower layers typically focus on local information, while higher layers emphasize global or semantic information. There are significant differences between high-level semantic features and low-level semantic features; simply summing attention scores from different levels does not yield effective integration and may interfere with subsequent calculations of inter-element correlations. In light of these considerations, we have designed a nonlinear mapping module called Attention-MLP, which consists of two linear layers, a ReLU activation function and layer normalization. The Attention-MLP performs abstract modeling of the attention scores from the previous layer to accommodate deep semantic requirements. It transforms comprehensible features from lower layers into high-level abstract semantics, thereby facilitating more effective integration of low-level and high-level semantics.
All tokens are connected to a learnable classification token,
. Then, position embedding is introduced to increase the information between locations. The input,
, of the Transformer is obtained:
The structure of MHTSA is shown in
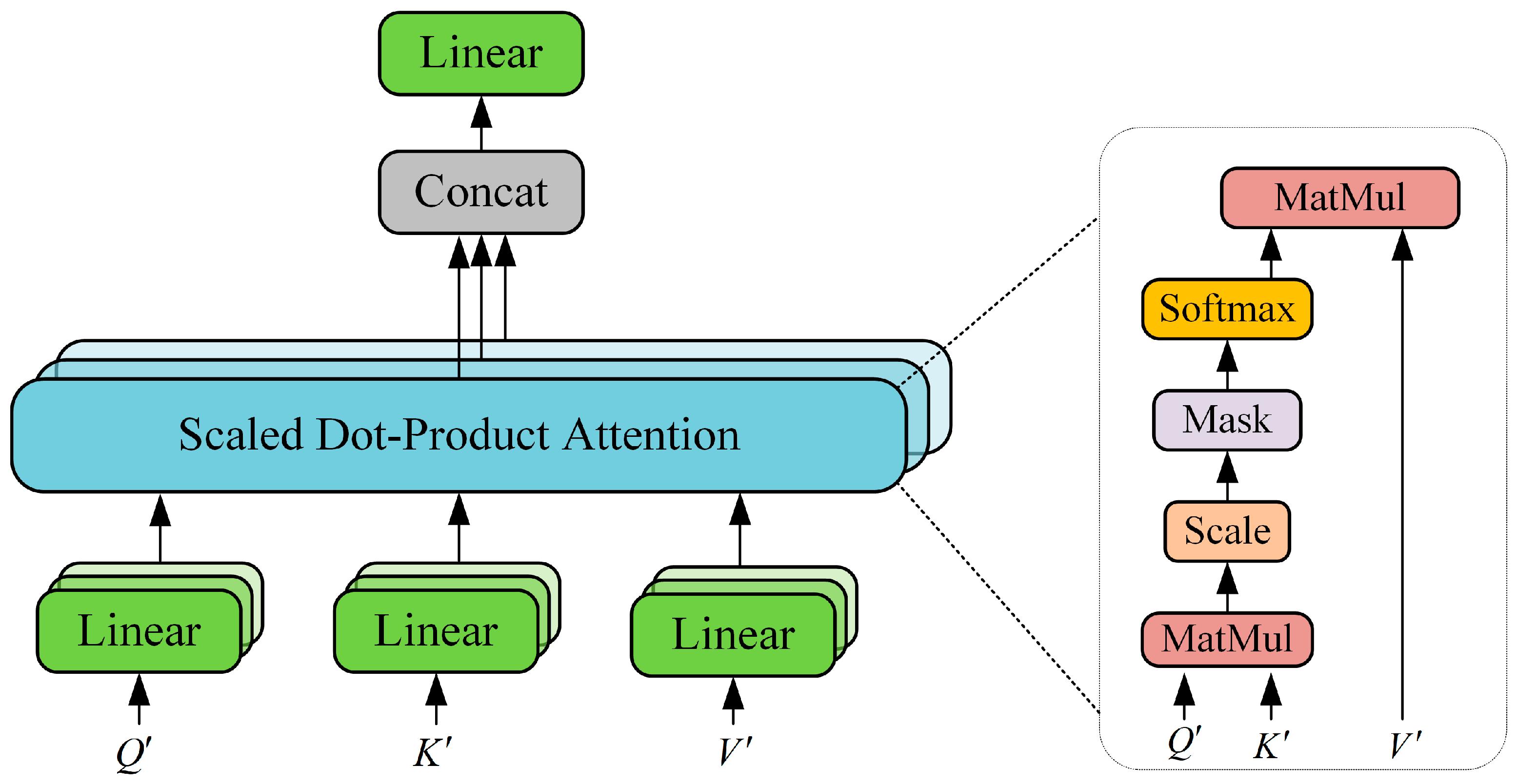
Figure 3. MHTSA usually includes three feature inputs, namely query (
), key (
), and value (
). In order to learn their different meanings, three learnable weight matrices are defined, which are
,
, and
. The feature vector tokens are linearly mapped through these three weight matrices to obtain
,
, and
, where
represents the number of feature vectors and
represents their feature dimension. In order to conveniently explain the process of attention score transmission, we make the following definition of the calculation process:
where Equations (10)–(12) reflect the process of transferring the attention scores of layer
to layer
after the nonlinear transformation. The range of
is in
, and
denotes the maximum number of encoders in SPTE.
is the raw attention score of the
layer.
performs a nonlinear transformation, where
and
are two fully connected layers designed to achieve nonlinear mapping of the attention scores from the previous layer, thereby enhancing feature representation.
is obtained by performing
on the attention scores at layer
.
represents the final attention score of the
layer. For the sake of brevity, we omit the dimension transformation operation in the data processing.
After that, the Softmax function is used to convert the obtained attention scores into attention weights, and the attention weights are multiplied with
. The calculation process of each head is shown in Equation (13). Finally, all attention heads are connected, and the process is shown in Equation (14):
where
is the number of heads.
is a weight parameter matrix, which is used to fuse the output of multiple heads to make the feature representation richer and more comprehensive.
The output generated by
is subsequently transmitted to the
block for further processing. The
block consists of two fully connected layers (
) and a Gaussian error linear unit (
). The
block is defined as:
It is noteworthy that and in Equation (15) represent two fully connected layers within the standard MLP module.
Figure 4 illustrates the detailed architecture of the SPTE when
. In summary, the calculation process of the whole module can be summarized in more general formulas:
where
stands for layer normalization, which effectively alleviates the problem of gradient disappearance or gradient explosion and improves the stability of the model.
represents the input of the
th encoder and
represents the output of the
th encoder. The input to the first encoder is
.
In summary, the SPTE module enhances feature interaction among encoders through a similarity propagation mechanism. This mechanism utilizes attention scores from the previous layer as a form of historical memory and employs nonlinear transformations for abstraction and adaptation. As a result, the attention distributions learned in shallower layers are preserved within deeper networks, alleviating the issue of information degradation commonly encountered in deep architectures. This design not only strengthens the local detail features captured by shallow layers but also integrates global contextual information extracted from deeper layers, thereby creating a hierarchical attention enhancement that improves the model’s classification performance.
2.4. SpecFormer
Hyperspectral imaging not only provides fine spatial details but also contains rich spectral feature information. Extracting spectral features from hyperspectral images enhances the ability to recognize features, thereby improving the classification accuracy of models. The structure of the Spectral Transformer is illustrated in
Figure 1. The selection of a self-attention mechanism for extracting spectral information offers several advantages.
First, Transformers possess the capability to effectively manage global dependencies within the spectral range, allowing them to capture complex nonlinear relationships between different bands more efficiently. By modeling the entire spectral sequence, Transformers can extract richer contextual information and enhance the global representational capacity of features, thus improving both the integrity and discriminative power of spectral features.
Second, Transformers can assign varying attention weights based on the significance of different features through their self-attention mechanism. Higher weights are allocated to key features that aid in distinguishing target classes, while lower attention weights are applied to noise and irrelevant information present in the spectral sequence. This mechanism enables models to autonomously amplify essential spectral features while effectively suppressing noisy bands, ultimately contributing to improved accuracy in HSI classification.
The input spectral information is
, we connect
with the learnable classification token, and perform position embedding, and finally obtain the spectral feature vector
.
In SpecFormer, we use traditional multi-head self-attention (
) (
Figure 5) to first obtain
,
, and
by linearly mapping the three learnable weight matrices
,
, and
to the input. The self-attention formula is as follows:
where
is the characteristic dimension of
.
calculates the multi-head attention values by using the same operation. Subsequently, the outputs from each attention head are merged. This process can be depicted by the following formula.
where
is the number of heads and
is a weight parameter matrix.
The MLP (multilayer perceptron) excels at capturing global feature interactions; however, it exhibits relatively weak capabilities in local feature extraction, often overlooking the local correlations present within spectral sequences. Additionally, the parameter count and computational complexity of MLPs are quite high. These factors can significantly limit the model’s performance. Therefore, we have opted to replace the MLP block with depthwise separable convolutions.
Compared to standard convolutional layers, depthwise separable convolutions require fewer parameters and exhibit lower computational complexity. However, standard convolutions possess stronger local feature extraction capabilities than their depthwise separable counterparts. To mitigate the potential accuracy loss associated with using depthwise separable convolutions, our model employs two such convolutional layers to further enhance feature representation. As illustrated in
Figure 6, the Conv block is constructed from two modules of depthwise separable convolutions.
The depthwise separable convolution consists of two components: the channel-independent depthwise convolution and the cross-channel fusion pointwise convolution. Both the parameter count and the computational complexity are significantly lower than those of MLP blocks. In depthwise separable convolution, a depthwise convolution is first performed independently on each channel, followed by a pointwise convolution that executes
convolutions to integrate information across channels. The formula governing this module is presented below:
where
is depthwise separable convolution,
represents the composite function of pointwise convolution, BatchNorm, and GELU, and
represents the composite function of depthwise convolution, BatchNorm, and GELU.
is the output of the SpecFormer module.
2.5. Classification Head
In order to achieve the final feature classification, we have incorporated an MLP head following the concatenation of spatial and spectral features, as illustrated in
Figure 1. Specifically, the MLP head constitutes the final component of the MLP architecture, which includes a LayerNorm and a fully connected layer. The LayerNorm serves to normalize the final features, thereby enhancing the stability of the model. The output dimension of the fully connected layer corresponds to the total number of target classes. Consequently, among the final output results, the class with the highest value represents the predicted classification result for that pixel.
2.6. Implementation
After data preprocessing, and are obtained. first performs a 3D convolution operation with 8 convolution kernels of size and then performs the 2D convolution operation with 64 convolution kernels of size . Next, as the input of the HPSCA module, feature fusion is carried out to obtain 64 feature mappings with a size of . Each feature map is flattened along the spatial dimension to obtain vectors. Adding learnable classification tokens and position embedding yields . After processing by the SPTE module, the first classification label is the learned spatial feature, denoted as . is used as the input of the Spectral Transformer. It obtains by linear mapping, adding learnable classification tokens, and position embedding. After processing with SpecFormer, the first classification label corresponds to the learned spectral feature, which is denoted as . Finally, the two features were concatenated into the classifier for classification.
3. Experimental Results and Analysis
In our experiments, we selected four publicly accessible HSI datasets to evaluate the performance of the proposed method. Subsequently, we will provide a detailed introduction to the information regarding these four datasets utilized in the experiment, along with a description of the configuration parameters employed. Following this, we will examine the influence of various parameters on model performance and present a quantitative analysis of classification results alongside visual outcomes and analyses. This will serve to demonstrate both the rationale behind our chosen parameters and the superiority of our model’s performance. Additionally, we conducted ablation experiments on the model to assess the specific impact of each component on classification accuracy. Finally, an analysis will be presented concerning parameter scale, number of floating-point operations, as well as training and testing times for all methods across the four datasets.
3.1. Introduction to Hyperspectral Datasets
To evaluate the classification performance of the model, we selected four HSI datasets for our experiments. These datasets include the Salinas dataset, WHU-Hi-LongKou dataset, WHU-Hi-HanChuan dataset, and the WHU-Hi-HongHu dataset.
Salinas: The dataset was obtained using an Airborne Visible Infrared Imaging Spectrometer (AVIRIS) sensor in the Salinas Valley region of California. It encompasses 224 spectral bands, ranging from 0.4 microns to 2.5 microns, with a spatial resolution of 3.7 m. Due to the water absorption characteristics present in certain bands, 20 relevant bands were excluded from the dataset, resulting in a final selection of 204 bands for analysis. The dataset comprises a coverage area of 512
217 pixels and includes 16 distinct land cover types, as illustrated in
Figure 7.
WHU-Hi-LongKou: The dataset was collected in Longkou Town, Hubei Province, China. The Headwall nano-hyperspectral imaging sensor, mounted on the DJI Matrice 600 Pro UAV platform, was utilized for data acquisition. The dataset comprises images with a resolution of 550
400 pixels. It covers a spectral range from 0.4 microns to 1 micron and includes a total of 270 bands. The spectral resolution is measured at 6 nm, while the spatial resolution is approximately 0.463 m, encompassing nine distinct land cover types. This information is illustrated in
Figure 8.
WHU-Hi-HanChuan: The dataset was collected in Hanchuan City, Hubei Province. The image data for this dataset were acquired using the Headwall nano-hyperspectral imaging sensor mounted on the Leica Aibot X6 UAV V1 platform. Each image has a resolution of 1217
303 pixels and encompasses spectral bands ranging from 0.4 microns to 1 micron, totaling 274 bands. The sensor features a spectral resolution of 6 nm and a spatial resolution of 0.109 m, while this dataset includes 16 distinct land cover types, as illustrated in
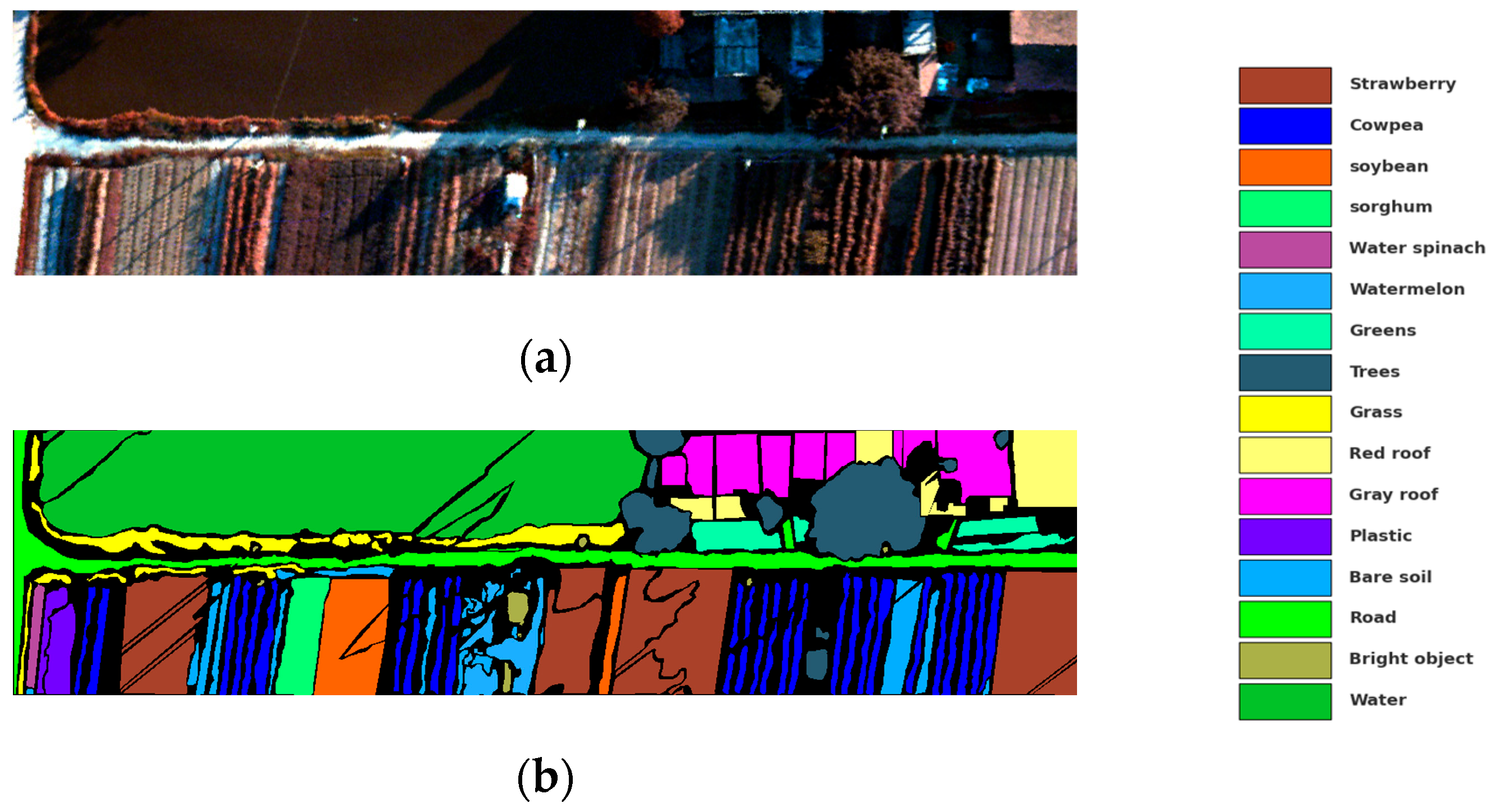
Figure 9.
WHU-Hi-HongHu: The dataset was collected in Honghu City, Hubei Province, China, utilizing a Headwall nano-hyperspectral imaging sensor mounted on a DJI Matrice 600 Pro UAV platform. The dimensions of the images in this dataset are 940
475 pixels, with a spectral range extending from 0.4 microns to 1 micron, encompassing a total of 270 bands. Featuring a spectral resolution of 6 nm and a spatial resolution of 0.043 m, the dataset covers 22 distinct land cover types. This is illustrated in
Figure 10.
3.2. Experimental Configuration
The classification performance of the proposed model was assessed using three quantitative metrics: overall accuracy (OA), average accuracy (AA), and kappa coefficient (). Specifically, OA is defined as the ratio of the number of samples accurately classified to the total number of samples in the test set. AA represents the mean classification accuracy across all classes, while is closely associated with the confusion matrix and serves to measure the agreement between the classification results and true labels. Higher values for these evaluation metrics indicate superior performance.
The experimental environment is based on the Ubuntu operating system, utilizing the GeForce RTX 2080Ti GPU manufactured by NVIDIA Corporation in the United States. The programming language framework employed is Python 3.9, with PyCharm 2021.1.3 serving as the integrated development environment (IDE). We have configured the batch size to 64, selected Adaptive Moment Estimation (Adam) as the optimizer, set the learning rate at 0.001, and established a total of 100 epochs for training. For our dataset, we allocate 25 samples from each category to form the training set and another 25 samples for the validation set, while reserving the remaining samples for testing purposes. More detailed information can be founded at
https://github.com/hfwiu/DBSSFormer-SP (accessed on 19 June 2025).
3.3. Classification Maps and Experimental Results
To assess the effectiveness of the proposed method, we conducted comparative trials involving our model and several representative classification methods: RSSAN [
23], SPRN [
45], SF [
32], SSFTT [
34], GAHT [
36], MorphFormer [
38], GSCViT [
39], and MASSFormer [
41]. To ensure fairness in the experimental outcomes, all methods were evaluated under identical settings across four datasets. In order to mitigate the influence of randomness on the results and enhance both reliability and stability in our evaluation process, we computed five sets of experimental averages for comparison purposes. These averages pertain to overall accuracy (OA), average accuracy (AA), and Cohen’s kappa (
) across the four datasets; the noteworthy results are emphasized in bold.
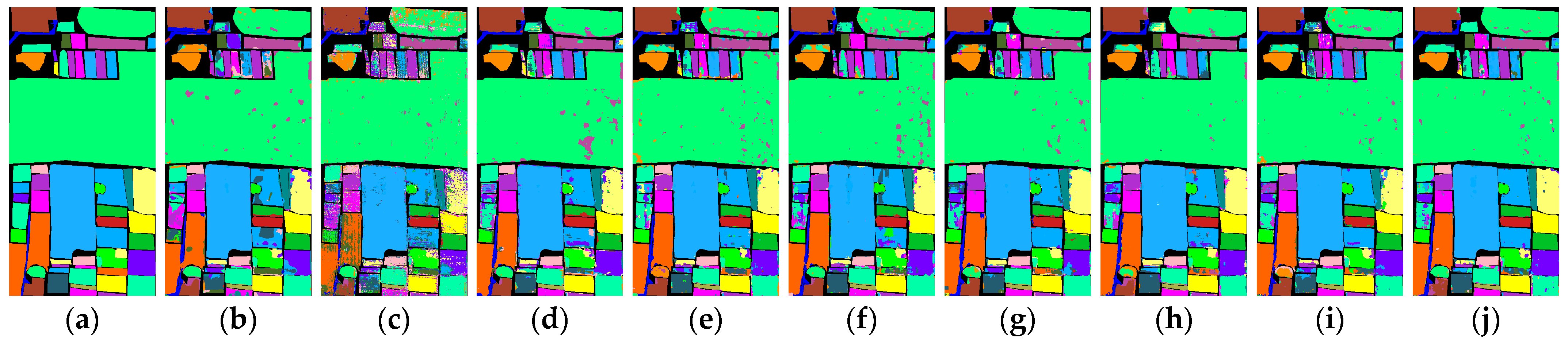
3.3.1. Classification Maps and Experimental Results for the Salinas Dataset
Table 1 presents the evaluation metrics of various methods applied to the Salinas dataset, while
Figure 11 illustrates the corresponding classification maps. It is evident that our proposed method achieves remarkable classification accuracy, attaining nearly half of the highest accuracy in each category. The three evaluation metrics for our method are 97.26%, 98.88%, and 96.95%, respectively. In comparison to the second-best method, GAHT, our approach demonstrates improvements of 0.44%, 0.46%, and 0.49%. Among the other comparative methods, only RSSAN did not surpass an overall accuracy (OA) of 90%. The OAs for SPRN, SF, SSFTT, MorphFormer, GSCViT, and MASSFormer were recorded at 95.98%, 95.20%, 96.02%, 96.55%, 95.55%, and 95.90%, respectively. In the Salinas dataset, class 8, referred to as “untrained grapes”, and class 15, known as “untrained vineyards”, are both situated in the upper left region of the image and exhibit similar spectral characteristics. This overlap complicates the differentiation between these two classes. Both SF and GSCViT demonstrate significant areas of classification errors within the gray zone corresponding to Grapes_untrained. In contrast, the classification maps produced by our method show improved performance in this area, featuring relatively distinct boundaries.
3.3.2. Classification Maps and Experimental Results for the LongKou Dataset
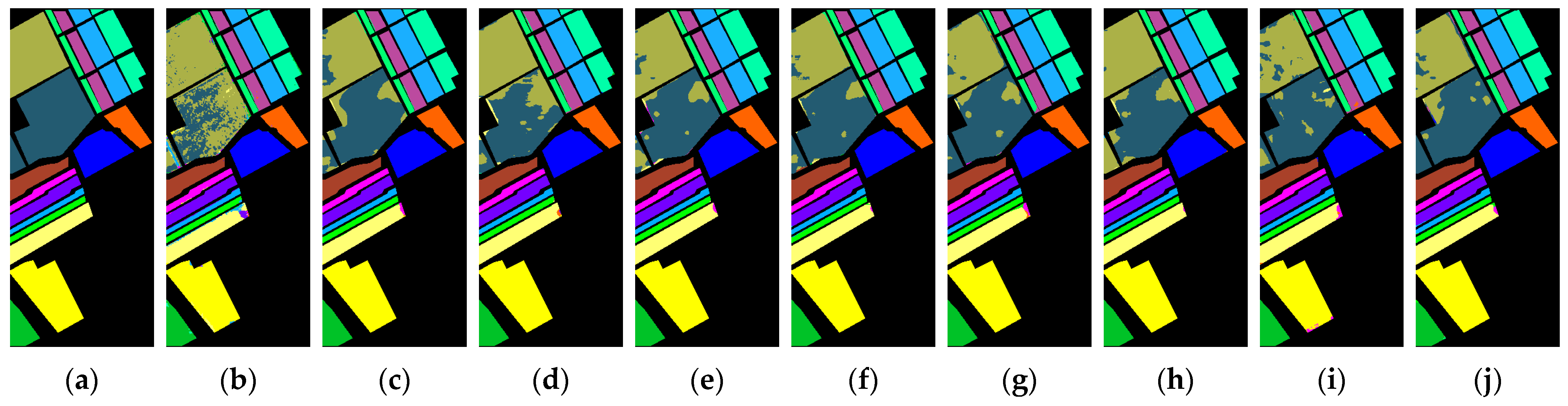
Table 2 presents the classification performance indicators of various methods applied to the LongKou dataset, while
Figure 12 illustrates the corresponding visual classification maps. Our proposed method demonstrates exceptional classification performance on this dataset, achieving OA, AA, and
of 98.72%, 98.60%, and 98.32%, respectively. In comparison to the second-best method, MASSFormer, our approach shows improvements of 0.78%, 1.27%, and 1.01% across these three evaluation metrics.
The overall accuracies for SPRN, RSSAN, SF, SSFTT, GAHT, MorphFormer, and GSCViT are recorded at 95.09%, 94.82%, 97.23%, 97.55%, 95.86%, 96.51%, and 97.10%, respectively; our proposed model surpasses these methods by margins of 3.63%, 3.90%, 1.49%, 1.17%, 2.89%, 2.21%, and 1.62%. Furthermore, in terms of category accuracy, our method consistently achieves over a remarkable threshold of more than 96% across all categories.
In the classification maps of the LongKou dataset, all comparison methods exhibit varying degrees of classification errors at the boundary between class 1 and class 2. Notably, even the second-best performing method, MASSFormer, encounters this issue. In contrast, our method demonstrates a remarkably clear delineation at the boundaries of these two categories. Furthermore, in classes 8 (“Roads and houses”) and 9 (“mixed weed”), our method’s classification maps are distinguished by their well-defined boundaries. These two classes are spatially adjacent with interconnected boundaries, making them particularly susceptible to classification errors.
3.3.3. Classification Maps and Experimental Results for the HanChuan Dataset
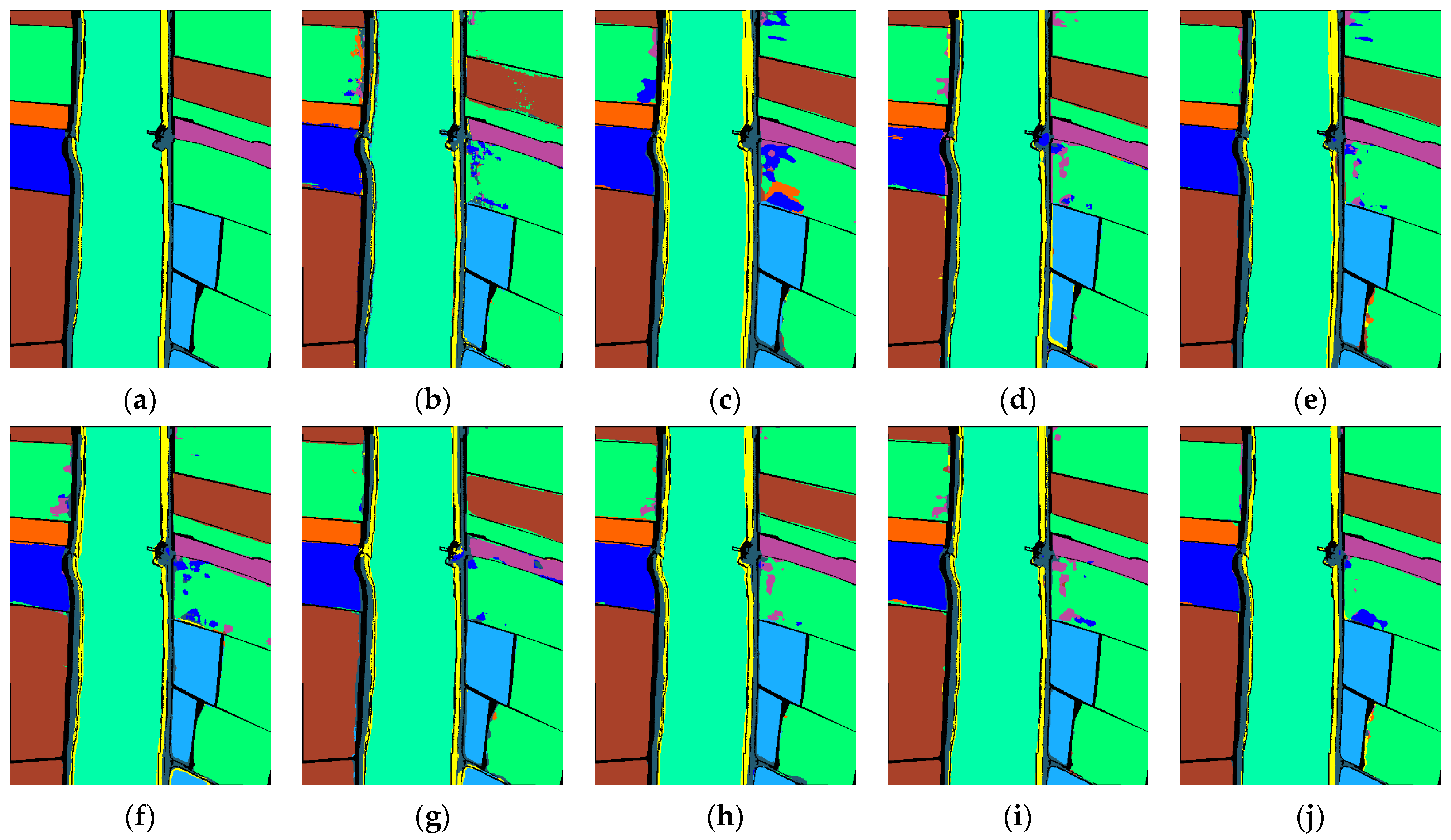
Table 3 presents the classification performance metrics obtained by various methods on the HanChuan dataset, while
Figure 13 illustrates the visual classification results. The HanChuan dataset utilized in this study contains numerous shadowed areas within the images, which pose significant challenges to the classification task. The overall accuracy (OA) of two CNN-based methods, namely RSSAN and SPRN, falls below 90%. Despite CNNs possessing robust local feature extraction capabilities, they struggle to effectively capture global features. This limitation adversely impacts their performance in classification tasks, resulting in a significantly inferior classification effect compared to the Transformer-based methods. Among the Transformer-based comparison methods, MASSFormer demonstrates superior classification performance, with the OA, average accuracy (AA), and kappa coefficient (
) reaching 91.86%, 91.14%, and 90.51%, respectively. Our proposed method achieves even better classification outcomes with OA, AA, and
recorded at 93.20%, 92.03%, and 92.06%, respectively—an improvement of 1.34% over MASSFormer. In examining the classification maps for the HanChuan dataset, it is evident that category eight (“Tree”) poses considerable identification challenges; nearly all comparative methods exhibit errors in classifying this category. Notably, similar to findings from the LongKou dataset analysis, our classification map maintains clarity at class boundaries across different categories. Conversely, confusion errors are observed in both light blue and dark blue regions of the image’s lower right section as identified by MASSFormer et al., specifically between class two (“Cowpea”) and class thirteen (“Bare soil”).
3.3.4. Classification Maps and Experimental Results for the HongHu Dataset
It can be observed from
Table 4 and
Figure 14 that, in the HongHu dataset, our method achieved superior classification results, with OA, AA, and
recorded at 93.94%, 94.40%, and 92.39%, respectively. The HongHu dataset presents significant challenges due to the diversity of crops, including various varieties of the same crop cultivated within the same region. In comparison to MorphFormer, which attained the highest classification accuracy among all evaluated methods, our approach improved upon three key metrics by margins of 0.76%, 1.48%, and 0.95%. Notably, our method surpassed a classification accuracy of over 90% across 17 out of the total 22 categories assessed. Conversely, two CNN-based methods demonstrated lower performance levels; specifically, SPRN achieved an OA of only 86.83%, while RSSAN recorded an OA of merely 81.86%. Among the Transformer-based methodologies, SF, SSFTT, GAHT, GSCViT, and MASSFormer yielded OAs of 90.68%, 92.04%, 91.93%, 93.18%, and approximately 93%, respectively. The OA of our model is 3.26%, 1.9%, 2.01%, 0.76%, 0.88%, and 0.92% higher than those of these methods, respectively.
In the classification maps of the HongHu dataset, SSFTT, GAHT, MorphFormer, GSCViT, and MASSFormer exhibit significant areas of classification errors in the green region at the top of the image. In contrast, our method demonstrates a relatively clean representation in this area of the classification map. This further substantiates that our approach achieves exceptional classification performance.
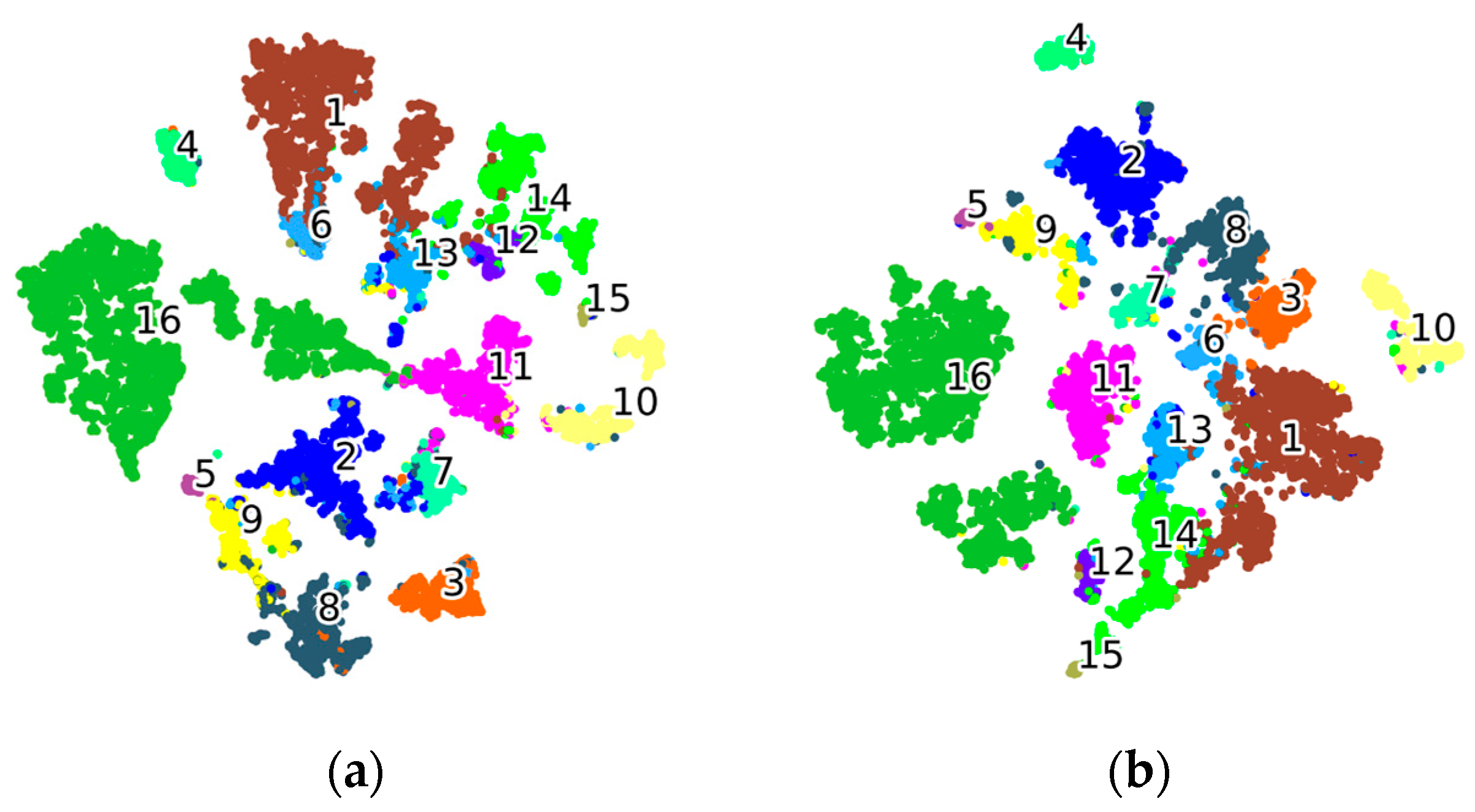
3.4. T-SNE Visualization
In order to better assess the effectiveness of the model, we generated t-distributed stochastic neighbor embedding (T-SNE) visualizations of the patterned features obtained by DBSSFormer-SP on the HanChuan dataset. In this dataset, MASSFormer achieved the second-best classification performance. Therefore, we compared the visualization results of DBSSFormer-SP with those of MASSFormer.
As illustrated in
Figure 15, it is evident that our method effectively clusters samples of different categories within their respective subspaces in the T-SNE visualization. The boundaries are more distinct, and the overlapping regions have been significantly reduced. The intra-class compactness of DBSSFormer-SP surpasses that of MASSFormer, with most categories exhibiting a relatively compact cluster distribution and fewer outliers. This indicates that our model demonstrates greater consistency in feature extraction for similar samples. In contrast, the second and seventh classes of MASSFormer show noticeable confusion states. Our proposed method exhibits fewer inter-class errors. The comparison with MASSFormer highlights that our approach possesses superior feature discrimination and expressive capabilities.
3.5. Parametric Analysis
- (1)
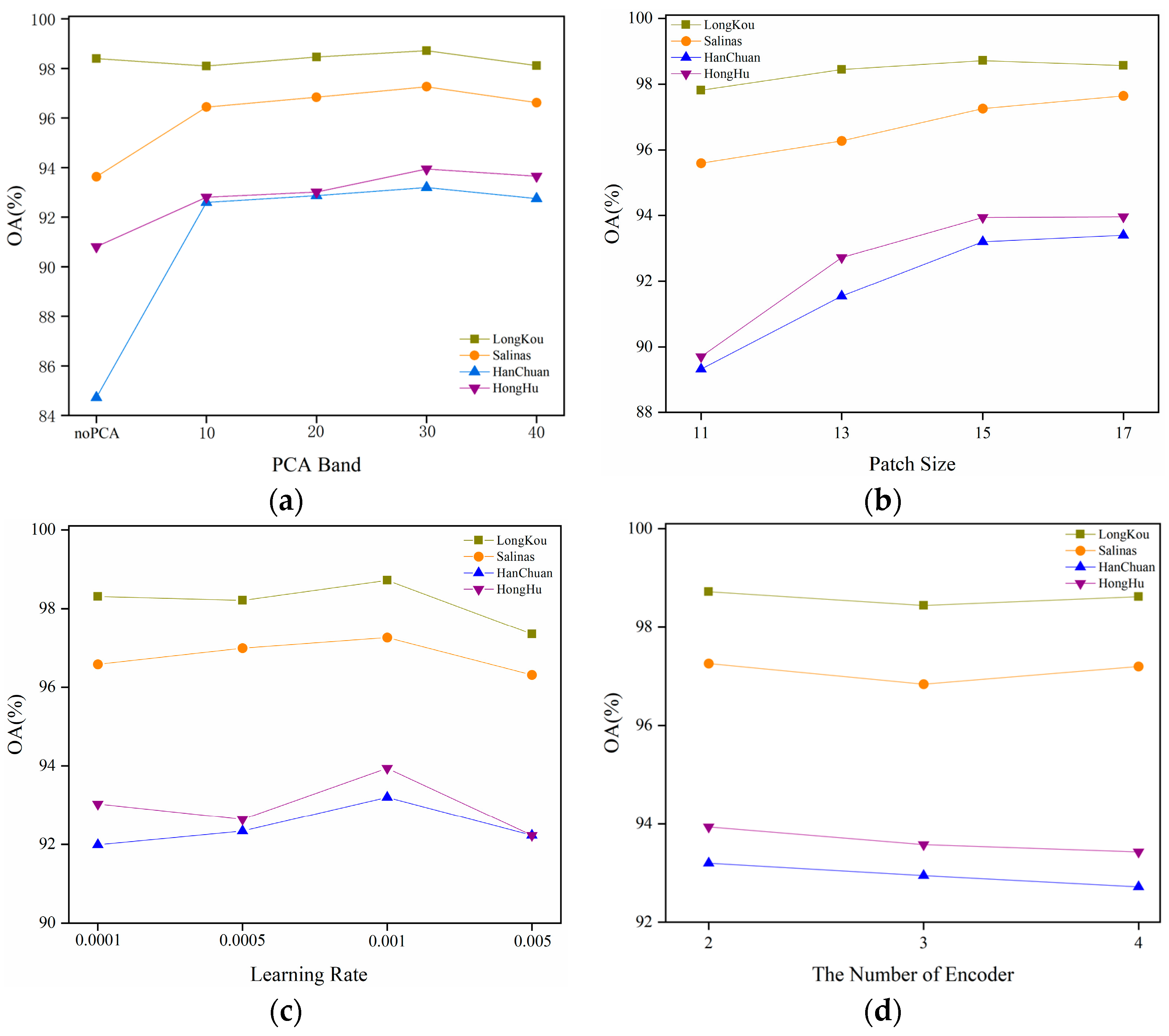
PCA band: The impact of the number of PCA bands on the experimental results cannot be overlooked. If dimensionality reduction is performed using PCA based on the information ratio, it may still retain a significant number of spectral bands. For large datasets such as LongKou, HanChuan, and HongHu, retaining a substantial number of spectral bands can consume considerable memory space and lead to increased training and testing times for a model. Therefore, we propose a set of fixed values for experimentation in order to select optimal parameters. Furthermore, we also took into account the experimental results obtained without performing PCA. The results are illustrated in
Figure 16a. It is evident that the classification performance of the model is significantly poor without applying PCA for dimensionality reduction. This is particularly pronounced in the HanChuan dataset, where the overall accuracy falls below 90%. Following the dimensionality reduction through PCA, as the number of bands increases, the OA for the LongKou dataset, Salinas dataset, HanChuan dataset, and HongHu dataset initially rise before subsequently declining. The maximum OA for all four datasets occurs when the number of bands is set to 30: 98.72% for LongKou, 97.26% for Salinas, 93.2% for HanChuan, and 93.94% for HongHu. Consequently, we have determined to set the number of PCA bands to 30 in our analyses.
- (2)
Patch size: The size of the patch window significantly influences the spatial perception capabilities of the model. While smaller patch sizes can effectively reduce computational complexity, they may fail to capture essential information fully. Conversely, larger patch sizes facilitate the acquisition of richer contextual information, thereby enhancing performance. However, excessively large window sizes may introduce redundant data, which can diminish the model’s discriminative power. To assess the impact of various patch sizes on classification performance, multiple sets of patch dimensions were established for experiments across four datasets while keeping other experimental parameters constant.
Figure 16b illustrates the variation in overall accuracy (OA), corresponding to the different patch sizes across these datasets. As the window size increases, OA for the Salinas dataset consistently rises; at a window size of 17, OA reaches 97.65%, marking optimal classification performance. For both the HanChuan and HongHu datasets, OA initially increases with increasing window size before stabilizing. At a window size of 15, OAs are recorded at 93.2% and 93.94%, respectively. In contrast, for the LongKou dataset, OA first ascends and then descends as window size grows; it achieves its peak value of 98.72% when set to a window size of 15. When employing a patch size of 17, numerous parameters are introduced that escalate computational costs significantly. Therefore, we have opted to maintain a patch size of 15 to ensure adequate classification accuracy while preserving low model complexity.
- (3)
Learning rate: The learning rate is a crucial hyperparameter in model training. Establishing an appropriate learning rate can significantly accelerate the convergence process, facilitate faster attainment of the global optimal solution, and enhance overall model performance. We select the optimal learning rate from a range of candidate values.
Figure 16c illustrates the impact of various learning rates on overall accuracy (OA). It is evident that as the learning rate increases, so does the OA across all four datasets. The OA reaches its peak when the learning rate is set to 0.001. Beyond this point, although the learning rate continues to rise, there is a noticeable decline in OA for all four datasets to varying degrees. Consequently, we have determined that a learning rate of 0.001 will be employed for our model.
- (4)
Number of encoders: The number of distinct Transformer encoders can significantly influence classification performance. We aim to utilize varying numbers of encoder blocks in SPTE and examine how the model’s classification performance evolves as the number of encoders increases. As illustrated in
Figure 16d, it is evident that, when the number of encoders is set to 2, optimal classification accuracy is achieved across all four datasets. As the number of encoders rises, the overall accuracy (OA) on these datasets exhibits minor fluctuations within a small amplitude.
Figure 16.
Impact of different parameters on OA. (a) PCA band. (b) Patch size. (c) Learning rate. (d) The number of encoders.
Figure 16.
Impact of different parameters on OA. (a) PCA band. (b) Patch size. (c) Learning rate. (d) The number of encoders.
3.6. Ablation Experiments
3.6.1. Ablation Experiment of Similarity Propagation
To validate the effectiveness of the proposed similarity propagation mechanism in alleviating information degradation and deep attenuation in deep networks, we designed ablation experiments under different encoder depths. Specifically, we constructed network architectures with varying numbers of Transformer encoder layers (two, three, and four layers) across four hyperspectral datasets. We compared the impact on model classification performance based on whether or not the similarity propagation mechanism was incorporated (denoted as SP for models that include this mechanism and Non-SP for those that do not).
All experiments were conducted under the same conditions, repeated five times to obtain average values. The experimental results are presented in
Table 5. As the depth of the network increases, both models exhibit a certain degree of performance degradation, which aligns with the common phenomenon of feature deterioration observed in deep models. However, compared to models that do not employ a similarity propagation mechanism, those incorporating SP demonstrate superior classification accuracy across all datasets, particularly evident in deeper architectures. In the challenging HanChuan dataset, when the number of encoders increased from 2 to 4, the overall accuracy (OA) for SP decreased by 0.48%, while Non-SP’s OA declined by 0.84%. In the LongKou dataset, SP’s OA reduced by 0.1%, whereas Non-SP’s OA experienced a decrease of 1.05%. This indicates that the introduction of a similarity propagation mechanism effectively alleviates the issues of information degradation and attenuation in deep networks, thereby enhancing the classification performance and robustness of the model.
3.6.2. Ablation Experiment of Different Modules
The DBSSFormer-SP consists of three key components: HPSCA, SPTE, and SpecFormer. To evaluate the impact of each component on classification performance, ablation experiments were conducted across four datasets. This approach aimed to assess how each component influences the overall classification effectiveness. To ensure the stability and reliability of the experimental results, we conducted five independent experiments for all model configurations and calculated the average values to eliminate biases introduced by random factors.
Table 6 presents the overall accuracy (OA), average accuracy (AA), and kappa (
) values for each module within the four datasets.
TE refers to the approach of discarding the similarity propagation mechanism and employing two stacked encoders. It is evident that merely stacking two encoder modules results in a decline in classification accuracy across all four datasets. Notably, in the HongHu dataset, OA, AA, and decrease by 1.68%, 1.61%, and 2.07%, respectively. The introduction of the similarity propagation mechanism enhances feature interaction between different layers, which plays a crucial role in improving the model’s classification accuracy. The absence of the HPSCA module leads to varying degrees of reduction in classification accuracy across the four datasets, with OA decreasing by 0.56%, 0.95%, 0.95%, and 0.77%, respectively. This outcome demonstrates that the HPSCA module can effectively enhance model performance by strengthening spatial feature representation. Spectral features encompass a substantial amount of discriminative information; thus, omitting the SpecFormer module significantly impairs classification accuracy as well. Specifically, on the HanChuan dataset, OA, AA, and are reduced by 1.88%, 1.00%, and 2.17%, respectively. This evidence underscores the idea that spectral features are pivotal for enhancing classification accuracy while highlighting the necessity of integrating both types of features.
Despite the relatively limited improvement in model accuracy observed in certain scenarios, the validity of this ablation study can be substantiated through stable and repeated experiments conducted across multiple datasets.
3.7. Efficiency Evaluation
To evaluate the computational efficiency of DBSSFormer-SP, we compare the model parameters, FLOPs, training time, and testing time with the comparison methods in four datasets, and the results are shown in
Table 7.
The comparison methods based on Convolutional Neural Networks (CNNs), such as RSSAN, exhibit relatively simple structures. Consequently, both the number of parameters and floating-point operations (FLOPs) are comparatively low among all evaluated methods, resulting in shorter training and testing times. Notably, SSFTT demonstrates the shortest processing time among Transformer-based approaches, primarily due to its innovative transformation of features into semantic tokens via a Gaussian-weighted feature tokenizer. In contrast, GAHT has the highest number of parameters and FLOPs. This can be attributed to the presence of multiple Transformer blocks within GAHT, an initial embedding dimension set at 256, and fully connected layers incorporated in each block’s multilayer perceptron (MLP) module. These factors contribute significantly to both parameter count and computational complexity. It is noteworthy that the parameters and FLOPs of DBSSFormer-SP are lower than those of MASSFormer. Additionally, the FLOPs of DBSSFormer-SP are comparable to those of GSCViT, while its parameters are also lower than those of GSCViT. However, the time expenditure for DBSSFormer-SP exceeds that of MASSFormer and GSCViT. This can be attributed to the similarity propagation mechanism, where we apply a nonlinear transformation to the attention scores before passing them into Attention-MLP, which incurs significant computational overheads.
In summary, although our proposed method does not achieve the shortest runtime among all approaches evaluated, it consistently attains the highest classification accuracy across all datasets.
4. Discussion
DBSSFormer-SP demonstrates the highest classification accuracy, and the classification map produced by DBSSFormer-SP exhibits reduced noise levels, resulting in a cleaner overall image with clearer boundaries that closely resemble the ground truth map. In contrast, methods such as RSSAN across all datasets yield classified images that are notably fuzzy, with noise being particularly pronounced. On one hand, RSSAN does not preprocess the data and utilizes the original hyperspectral imaging (HSI) dataset as input for its model. The original HSI images contain substantial redundant information, which adversely affects classification accuracy. On the other hand, CNN-based approaches struggle to capture global features effectively; consequently, RSSAN’s classification performance is suboptimal in complex scenes. The OA on the HanChuan and HongHu datasets are only 75.42% and 81.86%, respectively. Although SPRN has achieved commendable classification results in the Salinas dataset through enhancements such as an improved residual block and spatial attention module, its performance remains insufficient in more intricate scenarios.
In the Transformer-based approach, while the classification accuracy surpasses that of CNN-based methods, there remains considerable noise in the classification map, and the edges are not distinctly defined. The spectral feature (SF) method solely focuses on spectral characteristics, neglecting the significance of spatial features, which results in suboptimal classification performance in complex scenes. The GSCViT model employs a grouped separable approach to extract local spatial spectral features and global spatial characteristics. However, it does not fully leverage the available spectral information. While GSCViT demonstrates high classification accuracy on simpler datasets, such as the SA and LK datasets, its overall accuracy (OA) on the HC dataset is only 90.37%. MorphFormer integrates morphological techniques into Vision Transformers (ViTs), yielding commendable classification results across both HanChuan and HongHu datasets. SSFTT and MASSFormer represent lightweight classification models that amalgamate CNNs with Transformers. SSFTT first extracts features through a shallow CNN before employing tokenization followed by a Transformer to derive semantic tokens. Conversely, MASSFormer utilizes a shallow CNN to extract local features which are then embedded within a Transformer framework. Both models have demonstrated high levels of classification accuracy across various datasets; however, it is noteworthy that MASSFormer’s encoder incorporates identical shallow features throughout its architecture—this may adversely affect its overall classification performance.
The methods discussed above represent lightweight models that demonstrate commendable classification performance within the HSIC domain. The GAHT model incorporates a stacked Transformer module and possesses the highest number of parameters among them. Consequently, we will compare GAHT with DBSSFormer-SP in our discussion. These two approaches differ significantly in their focus on attention mechanisms. GAHT employs Grouped Pixel Embedding (GPE) to extract global–local spectral–spatial features while constraining multi-head self-attention (MHSA) within a local context, effectively alleviating the common issue of attention dispersion found in Transformers. However, the GAHT method still faces certain limitations regarding modeling long-term dependencies and aggregating global features. In contrast, our proposed DBSSFormer enhances discriminative capabilities for complex scenes through an attention propagation mechanism that facilitates the flow of attention weights between different layers. Nevertheless, it is important to note that this similarity propagation mechanism relies heavily on the quality of attention from preceding layers and may be susceptible to erroneous guidance.
From the experiments conducted, it is evident that our proposed method achieves higher classification accuracy while utilizing fewer training samples. By incorporating the HPSCA module and SPTE module, DBSSFormer-SP effectively extracts more refined spatial features. Furthermore, we employ the SpecFormer module to comprehensively capture contextual information from the spectrum. The spatial features and spectral features are combined through concatenation. This approach preserves the complete representation of both types of features, providing the model with a richer information input during the final classification stage, thereby enhancing its accuracy in complex classification tasks.
Through the classification results obtained from DBSSFormer-SP across four datasets, as well as the ablation experiments conducted, it is evident that the similarity propagation mechanism positively contributes to enhancing model classification performance in all four datasets. This indicates that the effectiveness of the similarity propagation mechanism is not confined to a specific dataset, thereby demonstrating its reliability. Furthermore, we have also compiled statistics on the precision for each category. The results show that our method achieves a high level of classification accuracy regardless of whether the categories are easily distinguishable or more challenging to differentiate.
In particular, “Grapes_untrained” and “Vinyard_untrained” categories from the Salinas dataset—characterized by their spatial proximity and similar spectral characteristics—present significant classification challenges. Nevertheless, our method achieves superior classification accuracies for these categories at 90.24% and 96.57%, respectively. Additionally, shadow occlusion presents difficulties in classifying data within the HanChuan dataset; however, our approach demonstrates robust performance across this dataset as well, consistently outperforming other methods in terms of OA, AA, and . These findings underscore the effectiveness of our proposed method in achieving more precise feature classifications.
5. Conclusions
In this paper, we propose a Dual-Branch Spatial–Spectral Transformer with Similarity Propagation for HSIC, referred to as DBSSFormer-SP. This method extracts spatial and spectral features through two distinct branches. Firstly, we introduce the HPSCA module, which aims to perform feature mapping across various spatial directions, establish long-range dependencies, and model global spatial information. This approach enhances the attention given to significant features. Secondly, to better mitigate degradation issues during information transmission and strengthen inter-layer information interaction, we present the SPTE module. This module effectively fuses low-level features with high-level ones through nonlinear transformation, ensuring efficient information transfer and improving the classification performance of the model. Finally, we designed the SpecFormer module to facilitate long-range modeling of spectral sequences while enhancing correlations between local continuous bands using depth-separable convolution. This design significantly improves classification accuracy.
Thanks to the synergistic effects of the aforementioned modules, this method significantly enhances the modeling capability for spatial–spectral joint features. Consequently, the classification approach proposed in this paper, which is based on a similarity transfer mechanism and employs a dual-branch structure for modeling spatial–spectral characteristics, can more accurately identify crop types and distinguish between similar lineage crops. It maintains a high level of classification performance even in complex agricultural scenarios, providing reliable technical support for scientific farmland management and demonstrating considerable application value in precision agriculture detection.
The method we proposed still requires refinement. In the HPSCA module, we only partitioned in the horizontal and vertical directions without considering multi-directional attention, which resulted in insufficiently fine modeling of spatial structures. Additionally, the presence of nonlinear transformations during similarity propagation has led to prolonged training and testing times, failing to demonstrate the model’s lightweight characteristics. Therefore, in our future research, we will continuously refine the model to enhance its classification performance while maintaining its lightweight nature.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}