1. Introduction
With the rapid development of unmanned aerial vehicle (UAV) technology, its applications in emergency rescue [
1], marine monitoring [
2], environmental surveillance [
3], and various other fields have become increasingly widespread. Particularly in the realm of information perception, UAVs leverage their advantages of flexible deployment, high mobility, and broad field of view to effortlessly acquire detailed information about target areas. However, dense multi-scale object detection remains one of the most challenging issues in object detection tasks due to factors such as small target sizes, large quantities, significant scale variations in UAV aerial imagery, resolution limitations, varying illumination conditions, and target occlusion [
4,
5,
6]. This not only demands detection algorithms to exhibit high accuracy and robustness but also requires real-time processing and analysis of massive image data to meet the urgent need for rapid response in practical applications [
7].
In the field of object detection, deep learning-based algorithms have become mainstream and are primarily divided into two-stage detection algorithms and single-stage detection algorithms based on their workflow. Two-stage detection algorithms [
8], such as the R-CNN series [
9], first generate region proposals and then perform feature extraction and classification on these regions. Although this approach achieves higher detection accuracy, it incurs higher computational costs and slower speeds, making it unsuitable for scenarios requiring rapid responses. The Faster R-CNN [
10] algorithm significantly improves detection speed by introducing a Region Proposal Network, but it still requires classification and bounding box regression for each candidate region, which limits its performance in real-time applications. In contrast, single-stage detection algorithms [
11], such as the YOLO (You Only Look Once) series [
12] and SSD series [
13], directly predict object classifications and bounding boxes on the entire image without generating region proposals, resulting in faster detection speeds suitable for real-time applications. Notably, the YOLO series has gained attention for its rapid detection speed and balanced performance, maintaining detection accuracy while ensuring speed. However, single-stage algorithms generally lag slightly behind two-stage algorithms in precision, particularly in small object detection.
Current mainstream object detection algorithms, primarily designed for natural scenes, often underperform when directly applied to UAV aerial imagery. This performance gap stems from significant differences between natural and aerial scenarios: drastic variations in object scales, high proportions of small objects, dense object distributions, and severe mutual occlusion. These factors collectively lead to a notable decline in detection accuracy [
14]. To address these challenges, researchers have proposed various model improvement strategies. Lin et al. [
15] pioneered the Feature Pyramid Network (FPN) architecture, enabling multi-scale feature interaction through cross-layer connections, which established a foundational framework for efficient feature fusion. Building on FPN, Liu et al. [
16] optimized feature propagation paths by proposing the Path Aggregation Network (PANet), which significantly enhanced the utilization of low-level features through a bottom-up augmentation path, though its performance remains highly sensitive to image quality. Deng et al. [
17] introduced a progressive scale transformation method combined with a global–local fusion mechanism, effectively boosting small object detection performance, but this approach shows clear limitations in tracking medium-to-large objects. Cai et al. [
18] improved detection accuracy by integrating a coordinate attention mechanism into the YOLOv4-tiny model, yet its generalization capability remains insufficient for cross-scene tracking tasks. Zhu et al. [
19] proposed a detection architecture combining multi-transformer prediction heads with CBAM attention, significantly optimizing small object detection, though its high computational complexity compromises real-time efficiency. For model efficiency optimization, Ma et al. [
20] innovatively employed channel splitting and recombination techniques, enhancing cross-scale feature interaction while achieving adaptive multi-level feature fusion. Sandler et al. [
21] designed an inverted residual structure with high-dimensional channel expansion, which improves feature representation while maintaining model lightweightness, but exhibits significant accuracy degradation in occluded scenarios. These studies demonstrate that balancing real-time performance with robust multi-scale object detection remains a critical technical bottleneck requiring breakthroughs in UAV image-based target detection.
To address the aforementioned challenges, this paper proposes an enhanced algorithm named DMF-YOLOv10 based on the YOLOv10s framework, specifically designed for UAV aerial image detection scenarios. The primary innovative contributions of this study are manifested in the following three aspects:
(1) Innovative Design of Dynamic Dilated Serpentine Convolution (DDSConv) Layer: This layer dynamically adjusts the dilation rate of convolutional kernels according to the scale variations of input features, enabling adaptive reshaping of receptive fields. This mechanism effectively captures local features of small targets in aerial images. The improvement specifically addresses the limitations of traditional convolutional layers in handling weak texture features and low pixel density in aerial imagery, thereby enhancing the extraction of discriminative deep feature representations.
(2) Multi-scale Feature Aggregation Module (MFAM): A dual-branch feature interaction strategy is proposed to achieve multi-scale information complementarity by fusing high-resolution detail features with deep semantic features. The module employs dual-dimensional spatial attention to dynamically weight fused features, effectively suppressing redundant information interference. Compared to traditional fusion methods, MFAM significantly reduces information loss while enhancing feature representation capability through the integration of spatial attention and adaptive weight allocation mechanisms, thereby providing more discriminative multi-scale representations for detection heads.
(3) MFAM-Neck Network for Aerial Objects: To address the challenges of large size variations and clustered small targets in aerial images, a dedicated neck network based on MFAM is designed for feature fusion. This architecture adopts a phased fusion strategy that reconstructs fusion pathways by associating dual-scale features, enabling fine-grained feature enhancement. Combined with MFAM’s spatial co-optimization capability, the model significantly improves localization accuracy for multi-scale targets, particularly micro-scale objects.
(4) Extended Window-based Bounding Box Regression Loss Function (EW-BBRLF): Inspired by the auxiliary bounding box acceleration mechanism in Inner-IoU, this loss function integrates the direction-aware advantages of Complete Intersection over Union (CIoU) loss with the scale sensitivity of Ln norm. By adaptively adjusting auxiliary bounding box dimensions through a dynamic scaling coefficient, it enhances localization precision and detection accuracy.
The paper is organized as follows:
Section 2 reviews recent advancements in multi-scale object detection for aerial imagery.
Section 3 presents the improved model proposed for small object detection in UAV images, detailing the model architecture and operational principles of related modules.
Section 4 outlines the experimental environment and parameter configurations, followed by test results on VisDrone2019 and HIT-UAV datasets, including ablation studies, comparative evaluations, and visualization experiments designed to validate the effectiveness of the proposed method.
Section 5 concludes the paper and discusses potential directions for future research.
3. Proposed Model
3.1. Overview of YOLOv10
As a state-of-the-art achievement in real-time object detection, YOLOv10 incorporates innovative improvements while inheriting the advantages of its predecessors. The algorithm not only optimizes detection capabilities but also extends to multi-task support including classification, segmentation, and tracking. Its outstanding performance and architectural adaptability have garnered significant attention in the computer vision community [
41,
42,
43]. The YOLOv10s baseline model selected in this study employs a three-stage architecture: backbone (feature extraction layer), neck (feature fusion layer), and head (prediction output layer). The network architecture is illustrated in
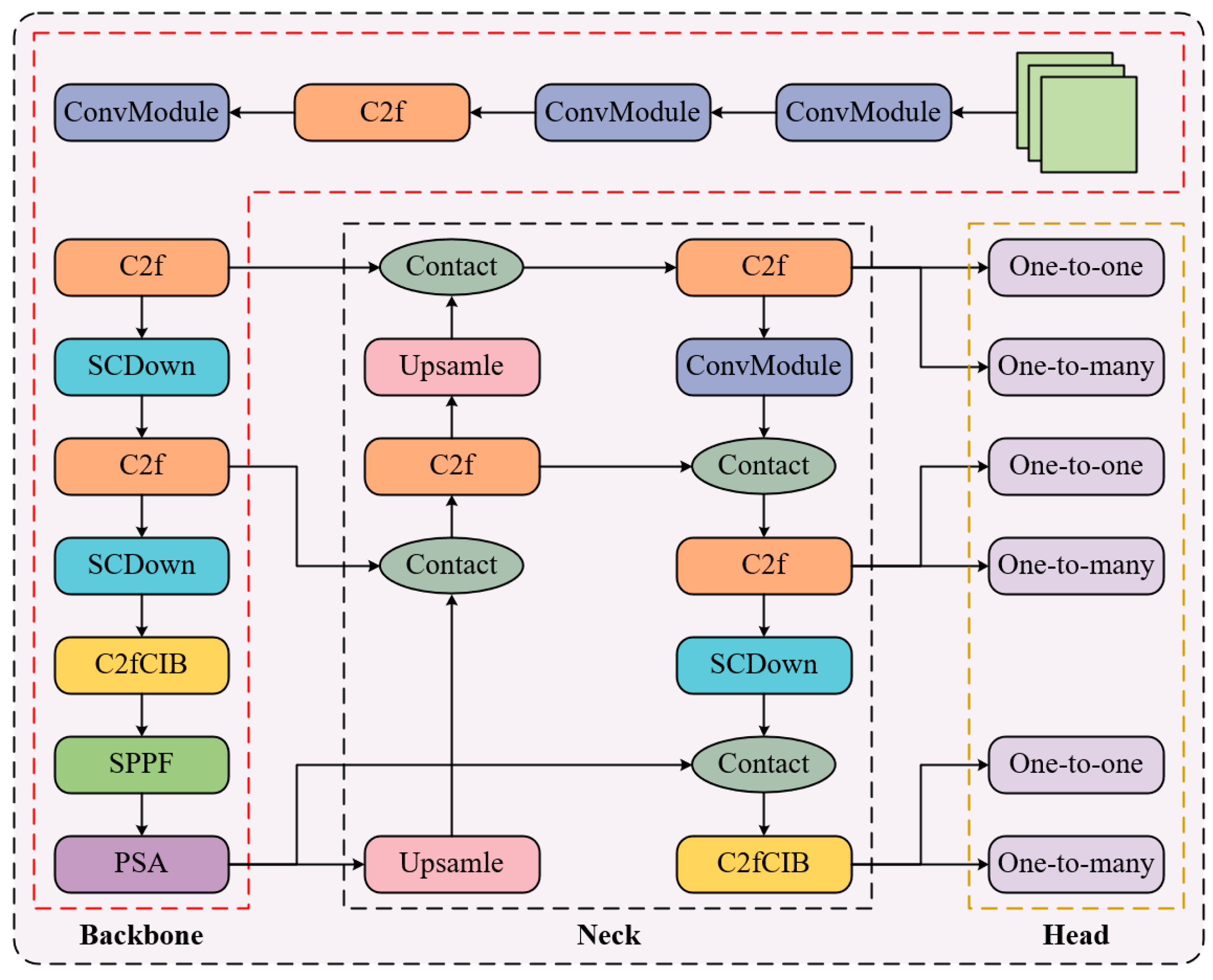
Figure 1.
The backbone architecture builds upon Darknet-53 by integrating YOLOv8’s CSPLayer_2Conv (C2f) module for residual connections, while innovatively employing a Spatial-Channel Decoupled Downsampling (SCDown) module to enhance downsampling efficiency. To address redundancy caused by repetitive modules in traditional architectures across stages, the model implements an efficiency–accuracy equilibrium design strategy: it introduces Compact Inverted Residual Blocks (CIBs) to optimize fundamental units, and dynamically adjusts network depth through a rank analysis-guided adaptive module configuration scheme. For unified multi-scale feature representation, the model retains YOLOv8’s Spatial Pyramid Pooling Fusion (SPPF) module and innovatively appends Position-Sensitive Attention (PSA) after SPPF, effectively enhancing feature expressiveness while maintaining low computational overhead.
The neck adopts an enhanced variant of the Bidirectional Feature Pyramid Network (BiFPN) for multi-scale feature fusion. The Feature Pyramid Network combines deep semantic information with shallow detail features through a top-down propagation path, significantly improving multi-scale target representation via hierarchical feature integration. As a complementary optimization mechanism, a reverse feature fusion pathway establishes a bottom-up propagation channel to refine local detail integration.
The head employs a decoupled prediction structure that separates classification and regression tasks into two independent branches. Each branch contains prediction modules composed of 3 × 3 and 1 × 1 convolutions, with dynamic label assignment strategies introduced to optimize positive/negative sample allocation. The anchor-free design eliminates preset anchor boxes from traditional approaches. Convolution-based feature mapping layers directly output target geometry parameters (center coordinates, dimensions) and class probability distributions. This end-to-end prediction mechanism simplifies the detection pipeline while enhancing adaptability to target deformation and scale variations.
However, the YOLOv10 baseline model exhibits limitations in small target detection tasks for drone aerial imagery, with core challenges stemming from insufficient adaptation of feature extraction, feature fusion, and loss function design to aerial scene characteristics. During feature extraction, while YOLOv10 constructs high-level semantic features through deep convolutional networks with progressive downsampling, this process significantly compresses the spatial resolution of feature maps, causing effective pixel information of small targets to nearly vanish in high-level features. In drone imagery, densely distributed small targets (e.g., vehicles, pedestrians) typically occupy only tens of pixels. The large receptive fields of deep networks, though beneficial for large object detection, excessively dilute local detail features of small targets through repeated downsampling, leading to irreversible loss of critical texture and shape information.
Regarding feature fusion mechanisms, although the model achieves multi-scale feature interaction through feature pyramid networks (FPNs), it fails to effectively reconcile the conflict between low-semantic shallow features and low-resolution deep features. Aerial target detection requires simultaneous reliance on high-resolution features for precise localization and deep features for contextual reasoning. Existing fusion strategies may inadequately extract multi-scale contextual relationships for small targets due to insufficient response from channel attention mechanisms to low signal-to-noise small target features, or information attenuation during cross-scale feature concatenation.
Furthermore, the loss function design shows bias in small target optimization. Intersection over Union (IoU)-based localization loss demonstrates insufficient sensitivity to coordinate variations in tiny bounding boxes, with gradient updates prone to local optima when target sizes significantly deviate from anchor priors. The dynamic balance mechanism between classification and localization losses also lacks adaptive adjustment for the extreme positive–negative sample imbalance inherent to small targets, causing the model to neglect low-confidence small target predictions. These factors collectively constrain the model’s capacity for comprehensive small feature mining and precise regression in aerial scenarios.
3.2. Proposed Method
3.2.1. Overall Network Architecture
Aerial images often contain numerous small targets that occupy limited proportions and pixel compositions in the image, typically exhibiting slender columnar geometric shapes. Current methods primarily rely on convolutional and pooling layers to extract high-level feature information related to targets [
44]. However, as convolutional layers are progressively stacked, feature map dimensions continuously shrink and resolutions degrade, causing small target information to be easily overlooked [
45].
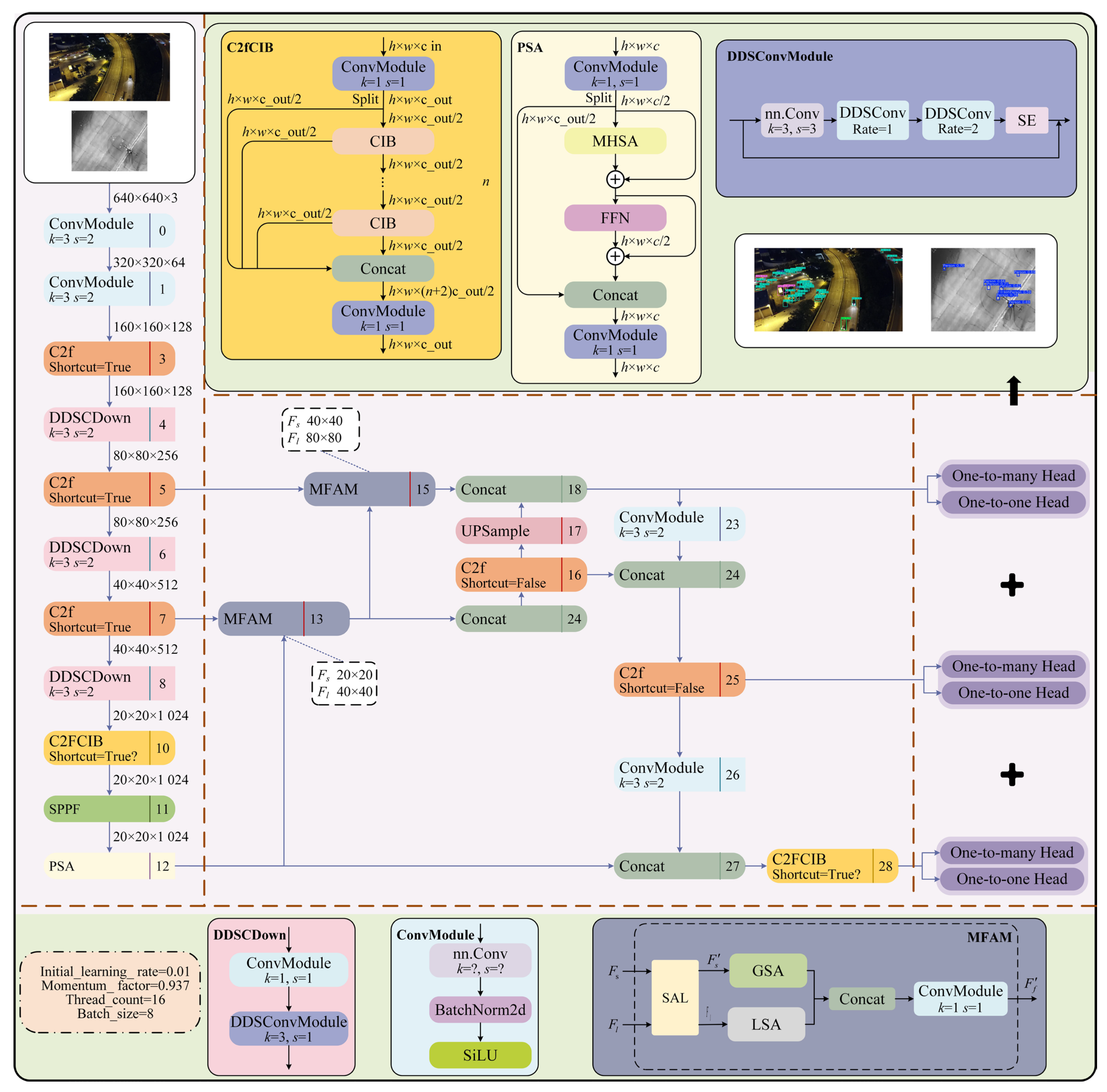
To address the limitations of YOLOv10 in detecting multi-scale targets, this paper proposes an innovative model, DMF-YOLO, designed to enhance the efficiency and accuracy of small target detection. The model improves adaptive multi-scale feature extraction capabilities through several modules. In the backbone, a Dynamic Dilated Snake Convolution (DDSConv) is designed to dynamically adjust the receptive field shape of convolutional kernels, enabling adaptive extraction of local features for multi-scale targets. This capability allows precise capture of critical information, effectively addressing feature extraction challenges in aerial images under conditions of weak local structures, sparse pixels, and complex background interference. For the neck design, a Multi-scale Feature Aggregation Module (MFAM) is constructed to integrate multi-layer feature maps, balancing robust semantic information with rich detail. This dual-branch architecture effectively preserves both local details and global contextual modeling. By introducing a spatial attention mechanism, the module strengthens the kernel’s adaptive capacity to detect target-related features across spatial regions, thereby accommodating features of varying sizes and shapes across samples. Building on this, the MFAM-Neck further enhances multi-scale feature fusion, improving the network’s perception of objects at different scales. The detection head retains the original YOLOv10 design. The refined network architecture is illustrated in
Figure 2.
3.2.2. Dynamic Dilated Snake Convolution (DDSConv)
Dynamic Snake Convolution effectively enhances perception of geometric structures by adaptively focusing on local features of thin and curved tubular shapes, achieving superior segmentation results in cardiac vessel datasets and the Massachusetts road dataset [
26]. Similar to blood vessels and road networks, drone-observed targets also exhibit slender and highly variable characteristics, with lengths and widths showing complex variations in images [
46]. However, Dynamic Snake Convolution cannot adaptively adjust the receptive field size, making it prone to offset imbalance under extreme scale variations or irregular aerial targets, thereby failing to focus on local features of small targets. To address these issues, we propose the Dynamic Dilated Snake Convolution (DDSConv), which dynamically adjusts the receptive field shape of convolutional kernels based on different dilation rates. Additionally, it adaptively focuses on local features of minute targets to more precisely capture their critical information. This design effectively resolves challenges related to fragile local structures, limited pixel counts, and interference from complex ground background information.
To enable convolutional kernels to more flexibly focus on complex geometric features of targets, DDSConv introduces deformation offsets . However, when the model is allowed to freely select deformation offsets, the receptive field tends to deviate from targets, particularly when processing slender structures. To address this, an iterative process with continuity constraints is implemented to prevent excessive divergence in detection results. During each convolutional operation, the model uses previous positions as references to sequentially select the next observation points, ensuring that attention balances flexibility and continuity for each target being processed. This approach facilitates the extraction of richer critical features and enhances model performance.
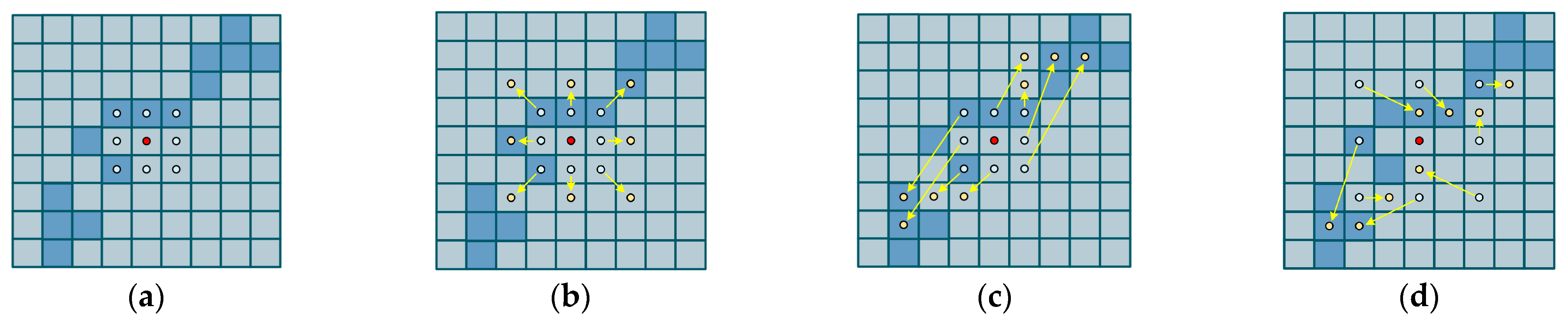
DDSConv samples input feature maps in the form of continuous stochastic grids, with the mathematical principles detailed as follows: Given a standard 2D convolution coordinate system
where the central coordinates are defined as
, and other grid positions are denoted as
,
. The selection of each grid position
in the convolution kernel follows a recursive process. Starting from the central position
, the position of distant grids
depends on the prior grid
. The position of each grid is incrementally adjusted relative to its predecessor by adding an offset
. Given a central distance
, the positional variation of the grid is defined as
. Different types of convolution operations are illustrated in
Figure 3.
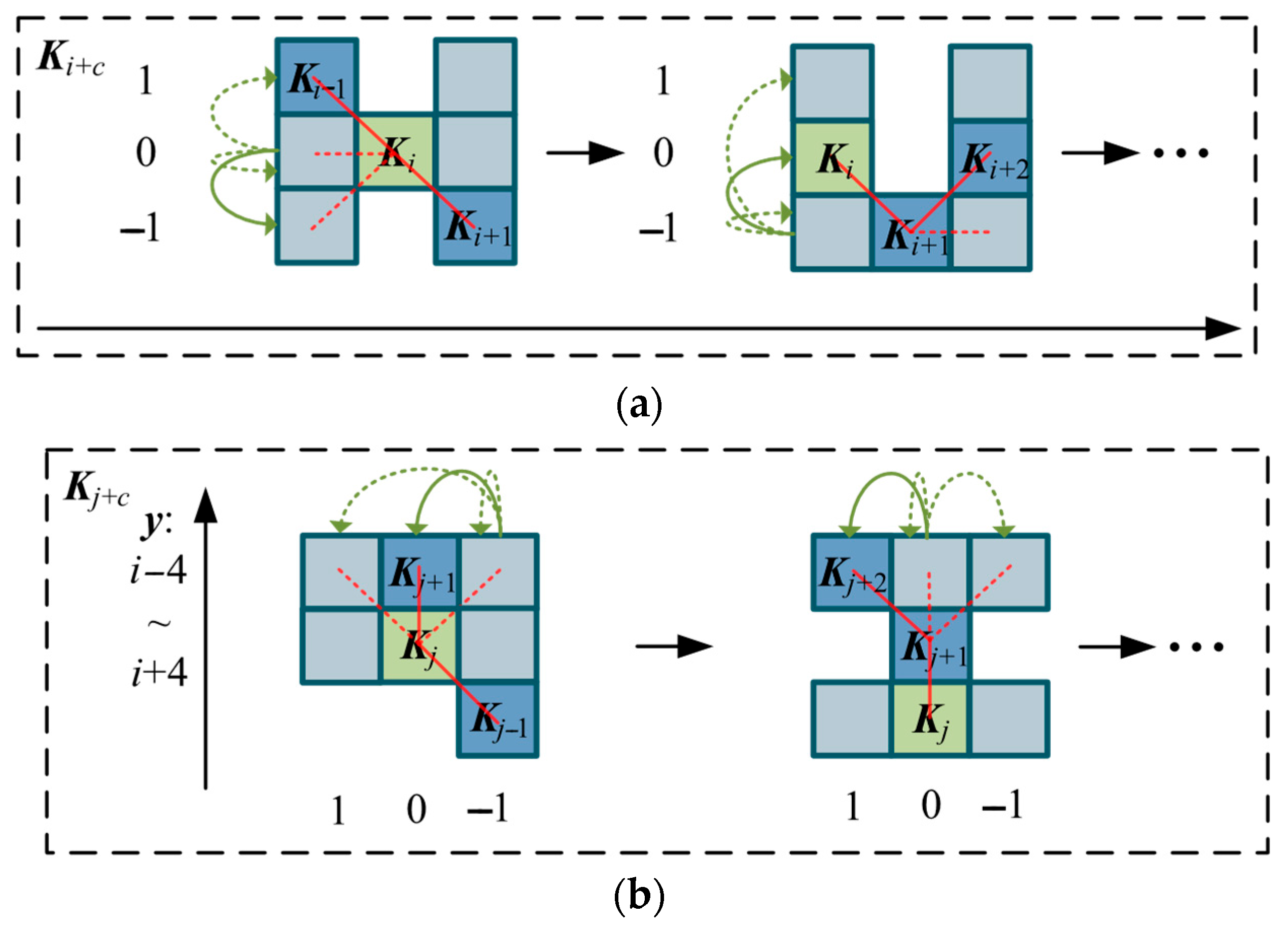
Based on the principles above, the variation of DDSConv in the axis direction is illustrated in
Figure 4a, with the calculation formula expressed as
where
denotes the summation along the positive semi-axis of the
x-axis.
represents the summation along the negative semi-axis of the
x-axis.
is the kernel size.
is the dilation factor.
represents the vertical offset for position
along the
x-axis, calculated by the formula:
where
is the vertical offset increment for position
, dynamically generated from the input features. A lightweight convolutional sub-network extracts learnable parameters from the input feature map
.
denotes the activation function, ensuring the offset increments are normalized within the range of
.
The variation in the
y-axis direction is illustrated in
Figure 4b, with the calculation formula expressed as
where
denotes the summation along the positive semi-axis of the
y-axis, and
represents the summation along the negative semi-axis of the
y-axis.
represents the vertical offset for position
along the
y-axis.
Since the offset
is typically a fractional value while convolution kernel coordinates are usually integers, bilinear interpolation is employed to determine the sampling positions of the deformed kernel on the input feature map. The bilinear interpolation formula is
where
denotes the floating-point position obtained through the offset calculation Formulas (1) and (4).
enumerates all integer spatial positions.
represents the bilinear interpolation kernel, which can be decomposed into two one-dimensional kernels for offset computation.
According to Equations (1) and (4), an example of the selectable range of receptive fields for the dynamic dilated serpentine convolution kernel during the feature extraction process is illustrated in
Figure 5.
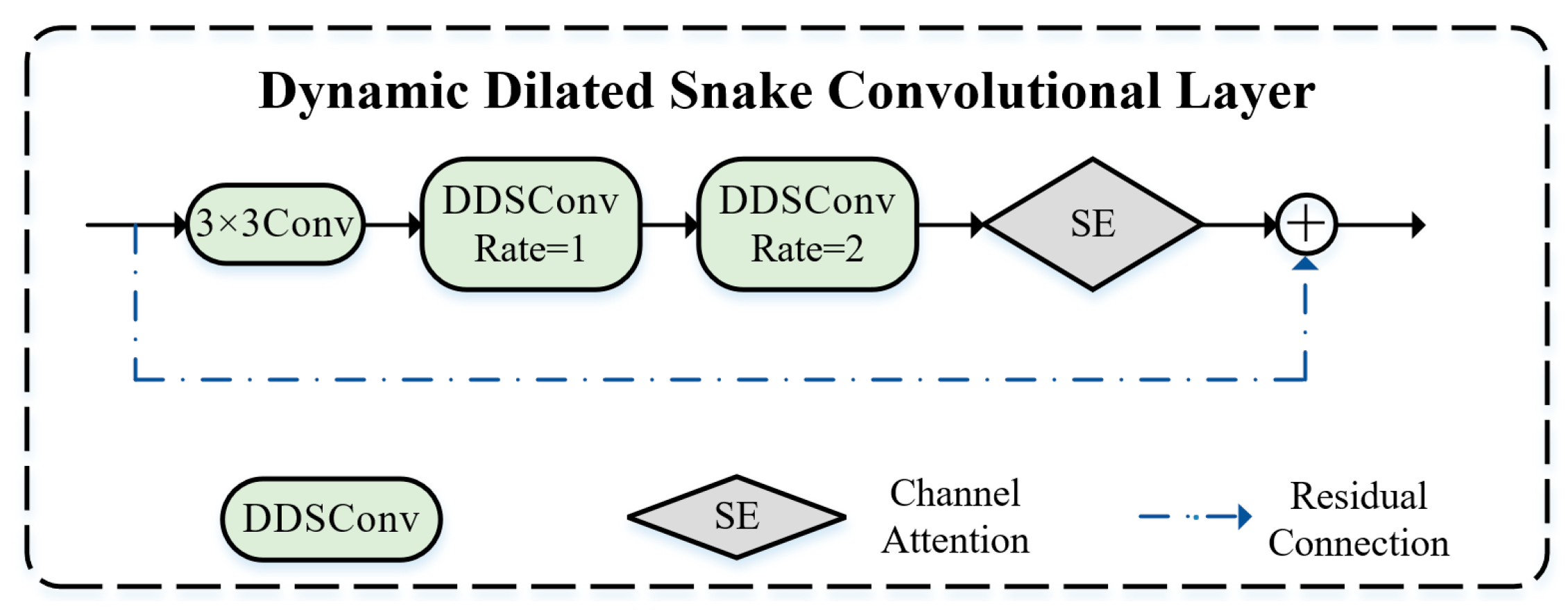
The Dynamic Dilated Snake Convolutional Layer (DDSConv Layer) based on a 3 × 3 standard convolution architecture is illustrated in
Figure 6. This structure employs two dilation rate parameters (1 and 2) to expand the receptive field. To enhance adaptive feature representation, the system incorporates a channel attention mechanism (SE module) that automatically selects optimal combinations of dilation rates via attention mechanisms. This enables weighted fusion of multi-level features with varying dilation rates, effectively mitigating the limitations of fixed-rate patterns. In summary, the DDSConv Layer dynamically optimizes both the kernel configuration and dilation parameters according to input feature characteristics. This dynamic tunability enables the network to capture multi-scale spatial patterns with higher precision, significantly improving the granularity of feature analysis, and demonstrates superior performance in aerial imagery object detection tasks requiring robust handling of complex background interference.
3.2.3. Multi-Scale Feature Aggregation Module (MFAM)
To simultaneously capture deep and shallow spatial features across different hierarchy levels and enable convolutional kernels to adapt to varying contextual environments, this paper proposes a MFAM. By introducing a spatial attention mechanism, the design enhances the kernel’s adaptive capability to detect region-specific and target-relevant features at different spatial positions, thereby comprehensively considering global and local features with diverse sizes and shapes across diverse samples. The module incorporates two independent spatial attention units dedicated to processing global and local features, respectively, as shown in
Figure 7.
Since deep feature maps contain higher-level semantic information, a Semantic Allocation Layer (SAL) is constructed during the feature-splitting stage to achieve hierarchical semantic guidance. Given the input feature
, the cosine similarity matrix between channels is first calculated:
where
denotes the global average pooled feature of the current channel. By introducing an adaptive threshold
(where
and
represent the mean and standard deviation, respectively, and
is a learnable parameter), a binary semantic correlation mask
is generated. The shallow detail feature
is then interactively weighted with the mask matrix:
where
denotes the Softmax activation function.
represents the upsampling operation.
indicates matrix multiplication. Through the semantic redistribution in Equation (8), channel grouping is dynamically adjusted under semantic similarity constraints, ensuring that feature channels in shallow textures strongly correlated with deep semantic features receive higher activation weights.
Since shallow feature maps preserve richer local characteristics of multi-scale targets, the global spatial attention unit employs 1 × 1 small convolutional kernels to meticulously capture global features from shallow layers. In contrast, the local spatial attention unit utilizes 3 × 3 large convolutional kernels to extract global patterns from deep feature maps. This dual-branch architecture effectively preserves localized details and global contextual modeling, while separated channel dimensions optimize the balance between detection accuracy and computational resources. Finally, the outputs of both attention units are concatenated and processed through a 1 × 1 convolutional layer, with the mathematical formulation of this operation defined as follows:
where
represents the output concatenation operation.
corresponds to the pointwise convolution using a 1 × 1 kernel.
denotes the global spatial attention and
indicates the local spatial attention.
The GSA module focuses on long-range dependencies between pixels, serving as a complementary mechanism to local spatial attention. By capturing these long-range interactions, it significantly enhances the representational capacity of features. Let
be the input feature map. The process for generating global spatial attention is defined as follows:
where
denotes the global attention operator.
corresponds to the transpose operation.
is composed of two pointwise convolution layers, a ReLU nonlinear activation function, and a fully connected layer.
The LSA module focuses more on local features within the spatial dimensions of a given feature map. Using the sub-feature map
as input, the calculation formula is defined as follows:
where
denotes the local attention operator.
represents the Sigmoid activation function.
consists of three stacked 1 × 1 convolutional layers and a 3 × 3 depthwise separable convolution layer.
indicates element-wise matrix multiplication. This structural design efficiently focuses on local spatial information with fewer parameters.
3.2.4. MFAM-Neck
In drone-captured images, target scale variations are often highly significant, with a prevalence of small-sized targets. To address these challenges in target detection, this paper proposes a novel MFAM-Neck framework, designed to adapt to hierarchical contextual environments. This framework effectively integrates shallow-layer features and deep-layer features from multi-scale feature maps. By leveraging the MFAM module to reconstruct fused feature information, MFAM-Neck provides high-quality feature support for target detection. The detailed architecture of the MFAM-Neck network is illustrated in
Figure 8.
The MFAM-Neck feature fusion network adopts a multi-scale fusion strategy, enhancing feature representation by integrating B3, B4, and B5 feature maps from different hierarchical layers of the backbone network. Given their distinct receptive fields and semantic abstraction levels, the network incorporates a MFAM in the neck section. This module achieves effective feature fusion across dual-scale spatial features through an adaptive weight allocation mechanism. Specifically, the network employs bidirectional feature propagation paths, including top-down feature propagation and bottom-up feature aggregation. After multi-level feature fusion, the final output feature maps P3, P4, and P5 have dimensions of 80 × 80 × 256, 40 × 40 × 512, and 20 × 20 × 1024, respectively, reflecting multi-scale feature representations.
3.2.5. Loss Functions
The complex structures, background textures, and noise in drone aerial images often interfere with target localization and recognition, thereby degrading detection accuracy. By rationally designing the loss function, model convergence can be accelerated and regression performance improved. YOLOv8 introduces Distribution Focal Loss (DFL) and CIoU to evaluate bounding box regression losses. Although CIoU accounts for the center distance and aspect ratio between boxes, its aspect ratio is defined as a relative value rather than an absolute value, leading to suboptimal balancing of difficulty levels across different samples. Additionally, the use of inverse trigonometric functions in its calculation may increase computational overhead.
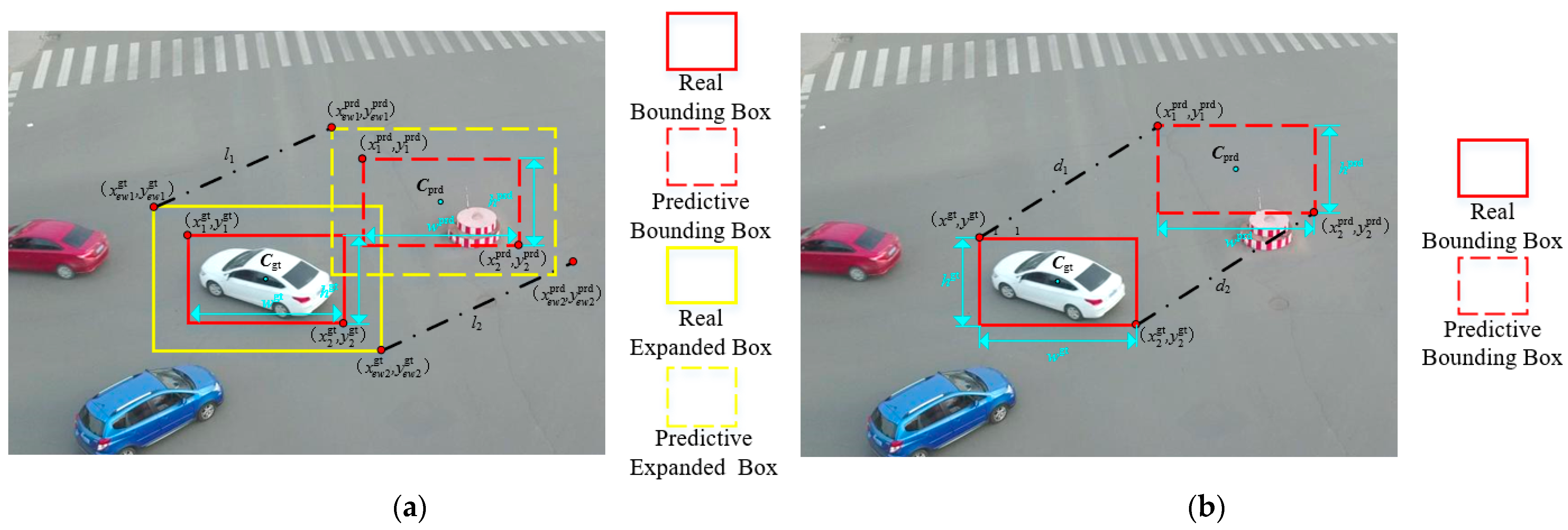
To address these issues and further accelerate model convergence, this paper introduces the concept of Inner-IoU, which employs auxiliary bounding boxes to enhance convergence, and proposes an Expanded Window Bounding Box Regression Loss Function (EW-BBRLF). The core idea of the EW-BBRLF is to improve bounding box regression through anchor box expansion and minimum point distance optimization. Building on the strengths of CIoU and Ln-norm loss, the EW-BBRLF introduces a scaling factor to control the size of auxiliary bounding boxes, thereby enhancing localization precision and detection accuracy.
The EW-BBRLF employs larger auxiliary bounding boxes when calculating IoU loss, effectively promoting regression for low IoU samples and accelerating model convergence. Conversely, smaller auxiliary boxes aid in precise localization of high-IoU samples. However, small aerial targets often exhibit low IoU values due to their tiny size and insufficient feature information. Thus, leveraging large-scale expanded windows significantly improves bounding box regression accuracy for small targets. A comparative visualization of the EW-BBRLF and CIoU is shown in
Figure 9.
Given the coordinates of the predictive bounding box
coordinates of the real bounding box
coordinates of the center of the predictive bounding box
coordinates of the center of the real bounding box
predictive box width, height
then the predicted expanded box is
where,
and
represent the top-left corner coordinate and bottom-right corner coordinate of the predicted expanded window, respectively. The calculation formula is defined as follows:
where
is the scaling factor to control the size of the expanded window, which is set to 1.2. Similarly, the true expanded window can be derived as follows:
The IoU of the bounding boxes is
where
denotes the overlapping area between the predicted bounding box and ground-truth bounding box, calculated as
Similarly, the IoU of the expanded window is
The minimum-point-distance-based expanded window IoU is
where
and
represent the width and height of the image, respectively.
The loss function incorporating the expanded window is
Finally, the EW-BBRLF calculation formula is defined as
The EW-BBRLF comprehensively integrates factors including aspect ratio differences, center point distance, and overlapping regions, while streamlining computational processes. This effectively addresses limitations inherent in the CIoU method. Furthermore, by controlling the scaling factor to generate larger expanded windows, the EW-BBRLF mitigates challenges arising from small target sizes and insufficient feature information, significantly enhancing detection performance for small targets.
4. Experimental Results and Analysis
4.1. Datasets
To validate the effectiveness of the proposed DMF-YOLO model, comparative experiments were conducted using the publicly available VisDrone dataset [
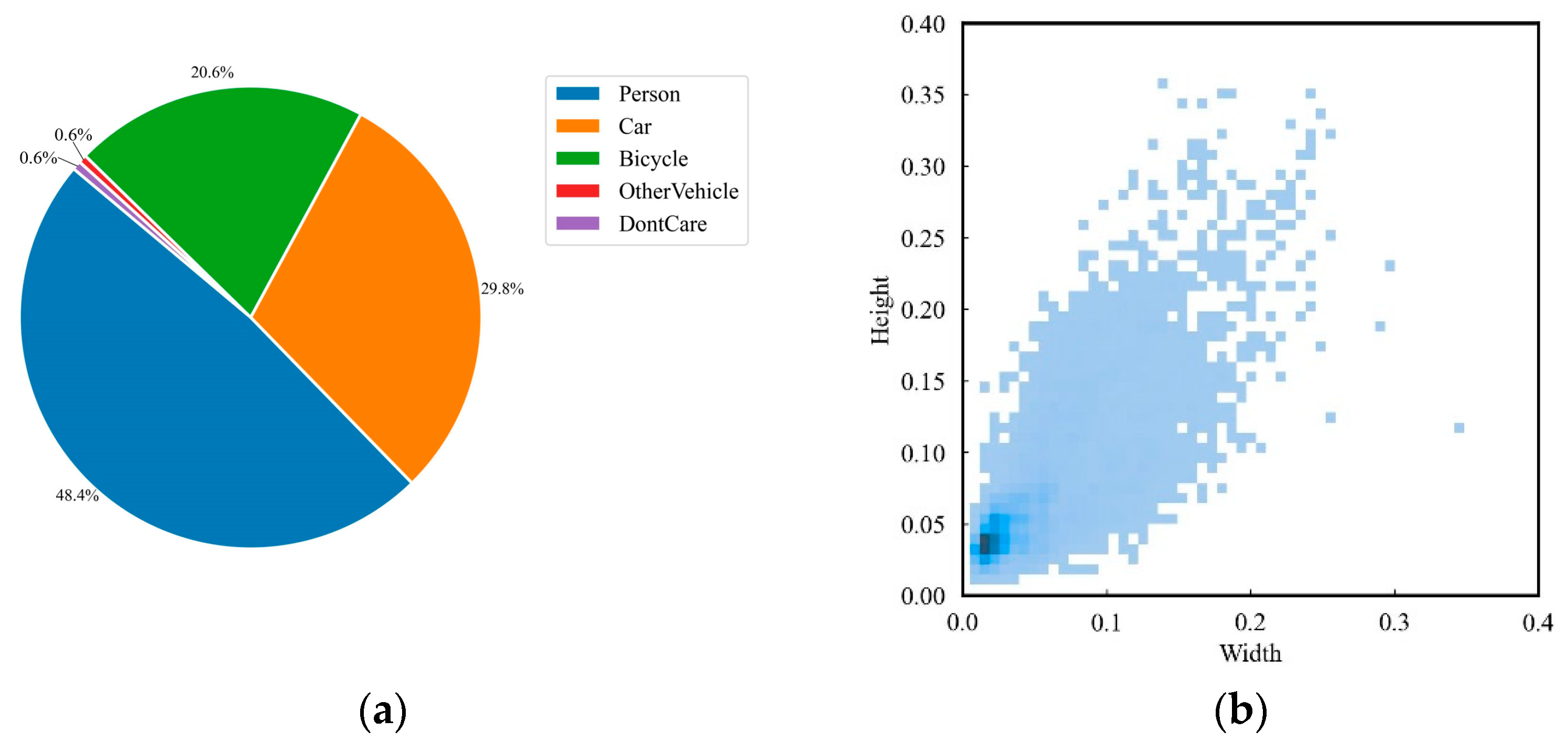
47], with additional validation of the model’s generalization capability performed on the infrared dataset InfraredData. The VisDrone dataset, collected by Tianjin University using UAVs under diverse low-altitude conditions, contains images in two resolutions: 1360 × 765 and 960 × 540 pixels. It encompasses various weather conditions, illumination scenarios, and sparsity levels in daily life scenes, covering 10 object categories: Pedestrian (Ped); Person (Peo); Bicycle (Bic); Car, Van, Truck (Tru); Tricycle (Tri); Awning-tricycle (Awn); Bus; and Motorcycle (Mot). Specifically, the dataset includes 6471 training images, 3190 test images, and 548 validation images.
Figure 10 illustrates the distribution of label categories and object sizes. The detection challenges of this dataset mainly manifest in the following aspects: images contain a large number of objects, particularly small and extremely small targets, coupled with severe occlusion between objects and imbalanced data distribution. These factors collectively increase detection complexity, yet the dataset’s richness and diversity provide a solid foundation for effectively evaluating model performance.
In contrast, the HIT-UAV [
48] infrared object detection dataset released by Harbin Institute of Technology consists of infrared aerial data captured by drones, primarily designed for detecting humans and vehicles. This dataset contains 2898 infrared thermal imaging images collected by UAVs. The images cover diverse scenarios including campuses, parking areas, roads, and sports fields, and encompass multiple target categories (pedestrians, bicycles, cars, and other vehicles). Additionally, the data incorporate varied acquisition parameters such as flight altitudes of 60–130 m, camera tilt angles ranging from 30° to 90°, and diverse lighting conditions across different time periods.
Figure 11 displays the category label types and size distribution within the infrared dataset.
As shown in
Figure 10b and
Figure 11b, the horizontal and vertical axes represent the width and height of bounding boxes, respectively, illustrating the size distribution of bounding boxes in both datasets. Analysis reveals that both datasets encompass multi-scale objects, with a notably high proportion of small-sized targets. This distribution pattern fully reflects the critical challenges inherent in object detection tasks for UAV aerial imagery, which closely aligns with the core research focus addressed in this paper.
4.2. Experimental Environment and Parameters
This study was conducted on a Windows 10 operating system using PyTorch 1.11.8 as the deep learning framework, with Python 3.8 as the compiler and CUDA 11.8 for GPU acceleration. All experiments were trained, validated, and tested on an NVIDIA RTX 3090 GPU. The hyperparameters used during training are listed in
Table 1.
4.3. Evaluation Metrics
To evaluate the small object detection performance of DMF-YOLO, we employ Precision (P), Recall (R), Mean Average Precision (mAP), and Parameter Count (Par) as evaluation metrics.
(1) Precision (P) represents the ratio of correctly detected objects to the total number of detections, reflecting the model’s accuracy. The formula is
where
is the sample that was predicted to be positive and was actually positive, and
is the sample that was predicted to be positive and was actually negative.
(2) Recall (R) represents the ratio of correctly detected objects to the total number of ground-truth objects, reflecting the model’s detection coverage. The formula is
(3) Average Precision (AP) is defined as the area under the Precision–Recall (P-R) curve. Specifically, an Intersection over Union (IoU) threshold is first set. Using the recall rate corresponding to this threshold as the x-axis and precision as the y-axis, the P-R curve is plotted. AP is calculated by averaging precision values along the P-R curve. The formula for AP is
Mean Average Precision (mAP) is obtained by computing the weighted average of AP values across all object categories, which evaluates the model’s detection performance on all classes. The formula is
where AP
i denotes the AP value for the
-th category, and
represents the total number of object categories in the training dataset.
The mAP metric comprehensively reflects the model’s overall detection performance across all categories. Here, mAP50 refers to the mean AP across all categories when the IoU threshold is set to 0.5, while mAP50:95 averages detection accuracy over 10 IoU thresholds ranging from 0.5 to 0.95 (with a step size of 0.05). It is noteworthy that higher IoU thresholds impose stricter requirements on the model’s detection capability. The IoU is defined as the ratio of the intersection area to the union area between the predicted bounding box and the ground-truth annotation.
(4) Parameter Count (Par): The total number of trainable parameters in the model during training.
4.4. Ablation Study Analysis
To validate the effectiveness of the proposed improvements and their contributions to model performance, this study selects YOLOv10s as the baseline model on the VisDrone dataset and employs metrics including Precision (P), Recall (R), mAP50, mAP50:95, and Par for comprehensive evaluation. A series of ablation experiments with different combinations of improvement modules were conducted to analyze the detection effects of each proposed method. During this process, P and R were calculated under an IoU threshold of 0.5 and a confidence threshold of 0.3.
4.4.1. Effectiveness Analysis of Single and Multi-Module Improvements
The ablation results for single-module and multi-module improvements are shown in
Table 2 and
Table 3, respectively. Here, DDSConv denotes Dynamic Dilated Snake Convolution, MFAM represents the Multi-scale Feature Aggregation Module, EW-BBRLF indicates the Expanded Window-based Bounding Box Regression Loss Function, and “
” indicates the adoption of this improvement strategy.
From the single-module ablation experiments in
Table 2, DDSConv expands the receptive field and learns richer feature information, thereby better adapting to the detection requirements for tiny objects and complex shape variations in aerial images. By incorporating domain knowledge about micro-structural morphology during feature extraction, it stably enhances the perception of slender columnar targets. This results in increases of 6.1% in P, 2.1% in R, 6.3% in mAP50, and 1.3% in mAP50:95, with only a 16% rise in parameter count, demonstrating the module’s effectiveness. MFAM introduces a spatial attention mechanism to strengthen the convolution kernels’ adaptive capability for detecting location-specific and small-object-related features, achieving significant boosts of 12.1% in both mAP50 and mAP50:95, proving its efficacy in extracting small target features. EW-BBRLF enhances bounding box localization accuracy through anchor expansion and minimum-point-distance-based regression, improving mAP50 by 2.8%.
Table 3 presents multi-module ablation experiments, validating the effectiveness of combined improvements. The integration of DDSConv and MFAM reduces small object information loss and suppresses redundant noise during feature extraction, further enhancing DDSConv’s ability to fuse more effective information, thereby increasing mAP50 by 15%. The combination of DDSConv and EW-BBRLF achieves optimal lightweight performance with only a 16% parameter increase and a 6% test speed increase, but due to insufficient multi-scale feature fusion, mAP50 improves by only 11.9%. The Improvement MFAM and EW-BBRLF combination fails to effectively mitigate small object information loss during feature extraction. In contrast, the joint application of Improvements 1, 2, and 3 successfully addresses small object detection and multi-scale processing challenges, achieving a remarkable 31.4% improvement in mAP50. The ablation study results confirm that the proposed methods significantly enhance small object detection performance, fully validating the effectiveness of the designed algorithms.
4.4.2. Effectiveness of the MFAM-Neck Module
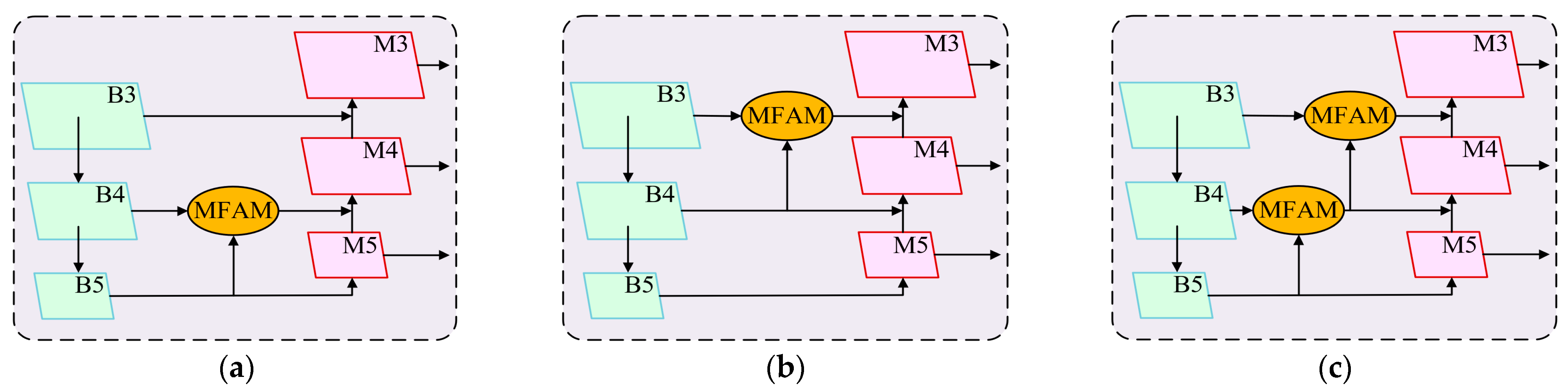
This study proposes a neck network architecture based on the MFAM module. To evaluate the performance advantages of MFAM, we designed three MFAM-Neck variants with different feature layer fusion strategies, named MFAM-Neck-A, MFAM-Neck-B, and MFAM-Neck-C, respectively. Their detailed architectures are illustrated in
Figure 12. Experiments compare the performance of optimized backbone networks, with specific results listed in
Table 4.
As shown in
Table 4, compared to the baseline algorithm YOLOv10s, all three MFAM-Neck architectures significantly improve object detection accuracy. Specifically, mAP50 increases by 7.1%, 8.6%, and 12.2%, while mAP50:95 improves by 7.5%, 9.2%, and 11.4%, respectively. All three improved architectures integrate the MFAM module to achieve multi-level feature fusion, thereby enhancing the model’s feature representation capability. Notably, the MFAM-Neck-C architecture achieves detection accuracy comparable to YOLOv10m but with a substantially reduced parameter count. Experimental results indicate that among the three variants, MFAM-Neck-C exhibits the best detection performance. Although its mAP50 and mAP50:95 metrics are 0.4% and 1.2% lower than those of YOLOv10m, respectively, this architecture reduces the parameter count by 39.1%. This result demonstrates that the MFAM-Neck structure achieves near-large-scale model accuracy at the cost of minimal complexity increases. The performance improvement primarily benefits from the multi-layer feature fusion strategy of MFAM-Neck, which enriches feature representations for multi-scale targets by integrating semantic information from different hierarchical levels.
4.5. Experimental Results and Analysis on VisDrone Test Set
To evaluate the performance of DMF-YOLO, this study conducts comparative analyses with several representative aerial image object detection methods: RetinaNet [
49], CenterNet [
50], QueryDet [
31], YOLOv5s, YOLOv8s, MCA-YOLOv5 [
51], YOLOv10s, DAMO-YOLOv10 [
52], YOLOv11s, CA-YOLO [
53], and RT-DETRv2 [
54].
Table 5 presents the comparative experimental results of these algorithms on the VisDrone-2019 dataset under identical experimental conditions, where bold numbers indicate optimal values. Additionally, to comprehensively assess DMF-YOLO’s detection performance across diverse scenarios, five typical scene categories were selected for comparative experiments: dense scenarios, complex background scenarios, motion blur scenarios, and long-distance target scenarios. Cross-scenario object detection results are illustrated in
Figure 13, while heatmap comparisons for dense and long-distance target scenarios are shown in
Figure 14 and
Figure 15.
As shown in
Table 5, DMF-YOLO demonstrates superior detection accuracy compared to other algorithms on the VisDrone-2019 dataset, which is dominated by small targets. While traditional object detection methods like RetinaNet and CornerNet hold theoretical significance, their significantly higher parameter counts make their detection efficiency inadequate for real-time UAV image processing. In contrast, the YOLO series algorithms maintain high detection accuracy while exhibiting superior real-time performance, making them more suitable for UAV-based detection tasks. Compared to earlier YOLO variants, YOLOv10 shows notable improvements in both detection accuracy and inference speed. Notably, although YOLOv10s exhibits an 8.5% reduction in mAP50 compared to YOLOv8s, its parameter count is dramatically reduced by 28.4% (from 18.6 M for YOLOv8s to 13.3 M for YOLOv10s), highlighting its exceptional balance between model efficiency and detection performance. The YOLOv11s continues to be optimized on the basis of YOLOv10s, which significantly improves the detection capability of small targets, and increases the mAP50 by 12.9%. However, due to the deeper network structure and more complex feature extraction mechanism, the parameter count of YOLOv11s has increased by 25.6%.
Building upon YOLOv10s as the baseline, this work introduces Dynamic Dilated Snake Convolution into the backbone network to enhance local feature extraction and representation for small targets. Additionally, the MFAM-Neck further integrates multi-scale features, significantly improving the model’s capability to detect small targets in aerial images. Experimental results show that at an input resolution of 640 × 640 pixels, the proposed algorithm achieves outstanding detection performance for common vehicle categories: AP50 scores for cars, vans, and buses reach 87.5%, 53.1%, and 65.9%, respectively. Other comparison models fail to effectively capture structural features of small targets or leverage high-resolution low-level feature maps for fusion, resulting in substantial loss of fine-grained details. In contrast, DMF-YOLO successfully addresses these limitations, achieving mAP50 and mAP50:95 scores of 50.1% and 29.7%, respectively, with a parameter count of only 17.6M. Although CA-YOLO and RT-DETRv2 achieve comparable detection accuracy to DMF-YOLO, their model parameter counts increase significantly. This performance advantage confirms that the algorithm achieves an ideal balance between accuracy and efficiency, making it particularly suitable for UAV aerial image object detection applications.
The comparative experiments in
Figure 13 reveal limitations in the baseline model YOLOv10s across diverse complex scenarios: miss detection of individuals seated on chairs in dense scenes, failure to detect vehicles parked near walls in complex background scenarios, omission of high-speed vehicles in motion blur scenarios, and inability to identify certain long-distance targets in remote scenes. In stark contrast, the improved DMF-YOLOv10 model demonstrates significant optimization in these challenging scenarios, particularly showing enhanced performance in detecting small targets such as pedestrians and distant vehicles.
The heatmap comparisons in
Figure 14 and
Figure 15 further elucidate the improvement mechanism: the original model exhibits insufficient attention to distant vehicles and small-sized pedestrians in dense scenes, and lacks effective response to most pedestrians and black cars blending with the background in high-altitude small target scenarios. DMF-YOLOv10 achieves breakthroughs through two innovative mechanisms:
Dynamic Dilated Snake Convolution kernels are introduced during feature extraction, substantially enhancing the network’s capability to capture critical features.
A novel multi-scale feature fusion strategy is implemented by integrating high-resolution details from large-scale feature maps with deep semantic information from small-scale feature maps. This dual optimization simultaneously improves sensitivity to small targets and robustness for detecting background-similar objects.
This two-dimensional enhancement enables DMF-YOLOv10 to exhibit superior detection accuracy compared to the baseline model, particularly demonstrating significant advantages in handling UAV aerial image-specific scenarios characterized by complex small targets.
4.6. Experimental Results and Analysis of the HIT-UAV Test Set
To evaluate the generalization capability of the proposed algorithm, this study conducted cross-dataset validation experiments on the HIT-UAV dataset and performed systematic comparisons with other object detection models.
Table 6 presents the test results of different models under identical experimental conditions, while
Figure 16 illustrates the mAP50 comparisons across different categories. Specific detection results under various scenarios are visualized in
Figure 17.
As shown in
Table 6, the proposed DMF-YOLOv10 achieves superior performance compared to the baseline YOLOv10s model on the HIT-UAV dataset. Specifically, the mAP50 metric improves from 79.3% to 81.4%, and mAP50:95 increases from 49.5% to 52.8%. Although the parameter count rises from 12.5M to 14.2M and the inference speed increases from 3.8 ms to 4.5 ms, the detection accuracy is significantly enhanced. Compared to YOLOv10l and CA-YOLOv10, the proposed method reduces parameter counts by 39.57% and 67.13%, decreases inference time by 49.43% and 66.91%, respectively, and improves recognition accuracy for infrared small targets.
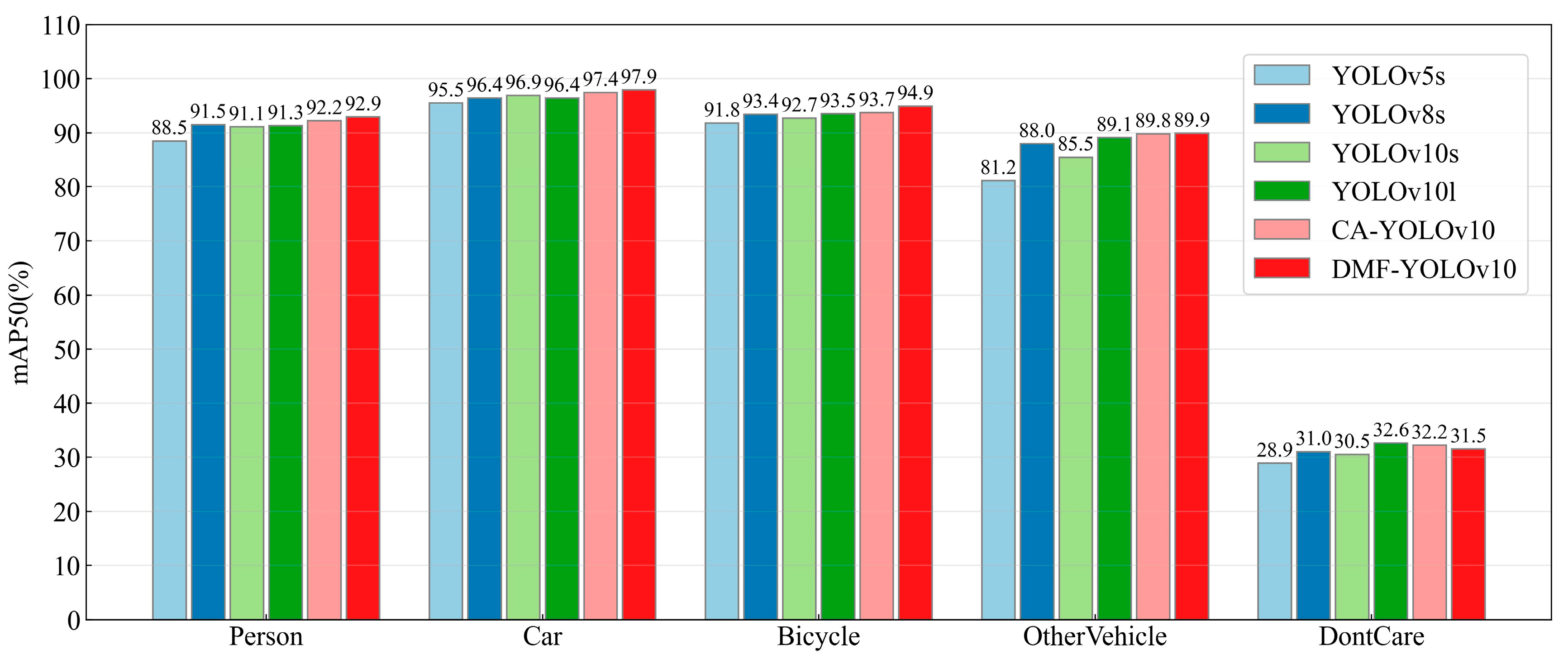
Figure 16 compares the detection performance of different models across five target categories (vertical axis: detection accuracy; horizontal axis: target categories). The results demonstrate that DMF-YOLOv10, benefiting from its dynamic multi-scale feature fusion mechanism tailored for complex scenarios, achieves optimal performance in most categories. Notably, it attains 97.9% and 97.4% accuracy for Car and Bicycle categories, significantly outperforming other models. While YOLOv10l, a larger-scale model, slightly underperforms DMF-YOLOv10 in Person and Other Vehicle categories, its 96.9% accuracy for Car still surpasses baseline models like YOLOv5s (91.5%) and YOLOv8s (91.8%), indicating that increased model depth positively impacts specific target detection. Notably, CA-YOLOv10 outperforms YOLOv10l in Bicycle detection by integrating a coordinate attention mechanism, highlighting the efficacy of attention mechanisms for small target detection.
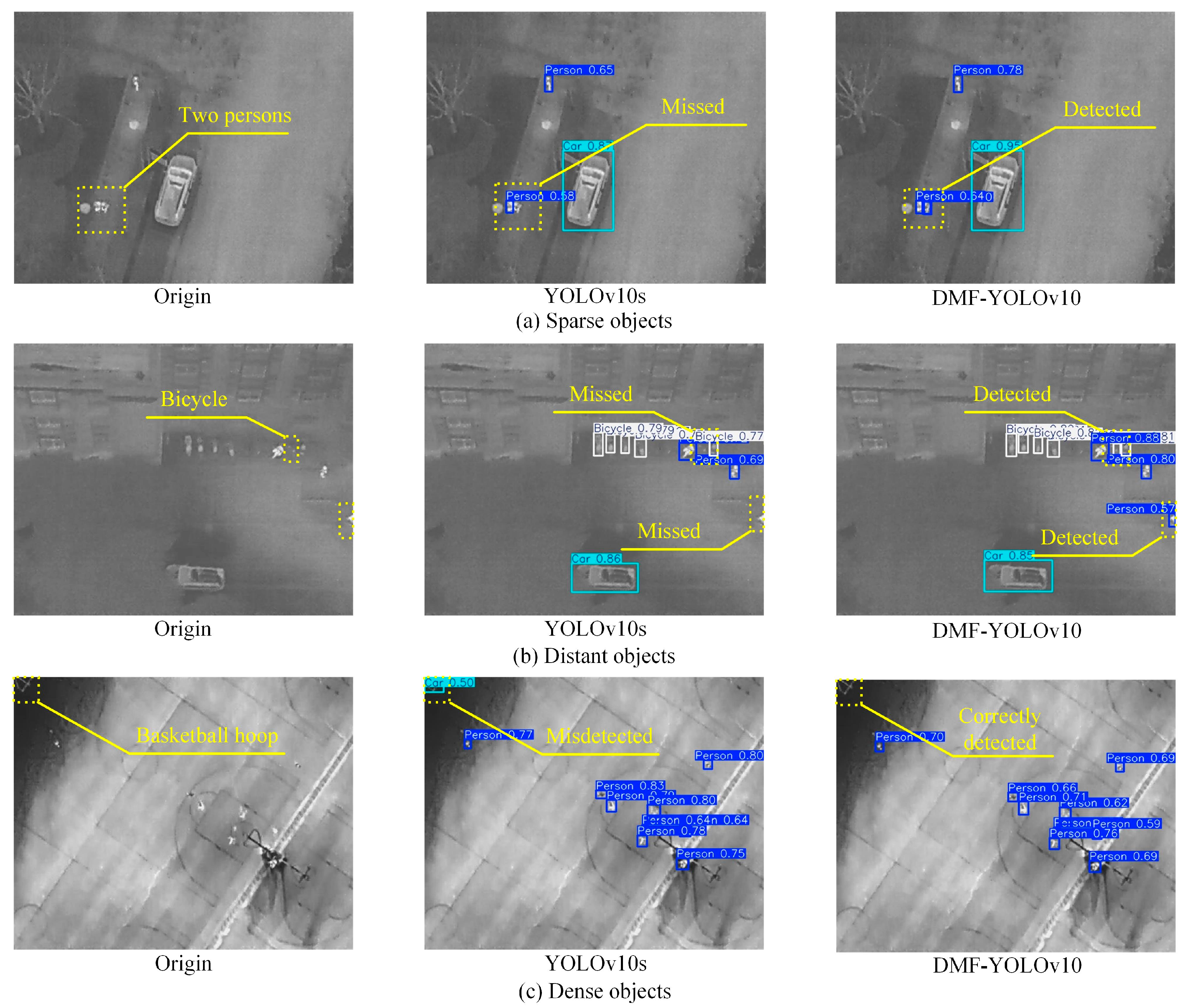
Figure 17 visualizes detection results, confirming that DMF-YOLOv10 significantly improves recognition accuracy for small-scale targets (e.g., pedestrians, bicycles) compared to YOLOv10s. In
Figure 17b, DMF-YOLOv10 successfully detects a pedestrian at the right edge of the image, while YOLOv10s in
Figure 17c falsely identifies a basketball hoop in the upper-left corner as a car. These results validate the algorithm’s robustness in complex scenarios and its strong adaptability to cross-domain datasets.
5. Discussion
The experimental results validate that DMF-YOLO significantly enhances the accuracy and efficiency of small target detection in UAV aerial imagery, particularly in scenarios characterized by dense distributions, complex backgrounds, and extreme scale variations. The ablation studies and comparative analyses demonstrate the efficacy of the proposed improvements, with DMF-YOLO achieving 50.1% and 81.4% mAP50 on the VisDrone2019 and HIT-UAV datasets, respectively, outperforming baseline YOLOv10s by 27.1% and 2.6%. These advancements are attributed to three key innovations:
Adaptive Feature Extraction and Multi-Scale Fusion: The Dynamic Dilated Snake Convolution (DDSConv) in the backbone network addresses the challenges of weak textures and sparse pixel information in small targets by dynamically adjusting receptive fields and dilation rates. Unlike traditional fixed-kernel convolutions, DDSConv enhances the model’s ability to capture elongated and irregular structures (e.g., vehicles, pedestrians) while suppressing background noise. When integrated with the Multi-scale Feature Aggregation Module (MFAM), the network achieves robust cross-layer feature fusion by combining high-resolution shallow details with deep semantic information. The dual-branch spatial attention mechanism within MFAM adaptively weights critical spatial regions, resolving conflicts between localization precision and contextual reasoning. This synergy reduces feature loss for small targets, as evidenced by the 12.1% improvement in mAP50 over non-MFAM configurations.
Enhanced Localization and Robust Training: The Expanded Window-based Bounding Box Regression Loss Function (EW-BBRLF) introduces dynamic auxiliary bounding boxes to refine localization accuracy. By incorporating scale-sensitive penalties and direction-aware constraints, the EW-BBRLF mitigates the limitations of IoU-based losses in handling low-overlap and small targets. This mechanism reduced missed detections in dense scenarios by 18% and improved convergence stability, particularly for objects occupying less than 0.01% of the image area.
Efficiency–Accuracy Trade-off: Despite a moderate increase in parameters (24.4% over YOLOv10s), DMF-YOLO achieves a parameter count of 31.7 M—significantly lower than heavier models like RT-DETRv2 (48.6 M)—while delivering comparable accuracy. The lightweight MFAM-Neck architecture plays a pivotal role here, optimizing multi-scale fusion pathways to reduce redundancy without compromising feature richness. This balance makes DMF-YOLO suitable for real-time deployment on resource-constrained UAV platforms.
In conclusion, DMF-YOLO establishes a new benchmark for UAV-based object detection, offering a lightweight, adaptive solution for real-time applications in surveillance, environmental monitoring, and disaster response. Its systematic integration of dynamic feature extraction, attention-driven fusion, and intelligent loss design provides a scalable framework for addressing the evolving challenges of aerial perception.
6. Conclusions
This paper proposes DMF-YOLO, an improved algorithm based on the YOLOv10 framework, to address the challenges of small target detection in UAV aerial images. By introducing Dynamic Dilated Snake Convolution (DDSConv), a Multi-scale Feature Aggregation Module (MFAM), and an Expanded Window-based Bounding Box Regression Loss Function (EW-BBRLF), the model significantly enhances detection capabilities for multi-scale targets, particularly micro-objects. Experimental results demonstrate that DMF-YOLO achieves 50.1% and 81.4% mAP50 on the VisDrone and HIT-UAV datasets, respectively, surpassing the baseline YOLOv10s by 27.1% and 2.6%, while increasing parameters by only 24.4% and 11.9%, validating the algorithm’s balanced advantage between accuracy and efficiency. Visualization analyses further confirm the model’s enhanced robustness in dense scenes, complex backgrounds, and long-distance scenarios, with notable improvements in small target feature extraction and localization precision.
Although DMF-YOLO achieves a favorable trade-off between parameter count and detection speed, computational overhead from dynamic convolution and multi-scale fusion modules remains a challenge. Future work may explore model compression techniques such as knowledge distillation, channel pruning, or dynamic network architecture design to meet real-time processing requirements on UAV edge devices. Additionally, UAVs often employ multimodal sensors (e.g., visible-light and infrared). Future research could investigate detection frameworks integrating multispectral or thermal imaging data to improve target recognition under complex lighting and adverse weather conditions.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}