1. Introduction
Semantic segmentation of remote sensing (RS) imagery is a foundational task in intelligent interpretation [
1,
2], enabling pixel-level precise classification of diverse ground objects [
3,
4,
5,
6,
7]. The rapid evolution of RS sensors, characterized by progressively higher spatial resolutions and imaging frequencies, has significantly expanded the applications of high-resolution imagery [
8,
9,
10]. This expansion encompasses domains such as urban monitoring, land use mapping, ecological assessment, and disaster management [
11,
12,
13,
14,
15]. Compared to conventional resolution data, modern high-precision RS imagery exhibits substantially richer textural details and structural complexity, which theoretically supports both enhanced recognition accuracy and finer segmentation boundaries. Nevertheless, this also puts higher requirements on the semantic segmentation model in terms of feature extraction, context understanding, and computational efficiency.
Convolutional neural networks (CNNs) [
16] have been widely used in various image analysis tasks since their emergence and have gradually become the dominant technical framework for semantic segmentation of remote sensing images. By leveraging the concepts of local receptive fields and parameter sharing, CNNs can efficiently extract edge, texture, and structural information from images, making them particularly well-suited for remote sensing applications characterized by strong spatial locality. U-Net, a notable architecture, employs a symmetrical encoder–decoder configuration, leveraging skip connections to seamlessly integrate multi-scale features. This architecture has demonstrated remarkable efficacy in medical image segmentation and remote sensing image segmentation tasks. The efficacy of these architectures is evident in the substantial advancements achieved in semantic segmentation, particularly in terms of accuracy and generalization capability.
Despite their pervasive utilization, CNNs are inherently limited by their local receptive fields, which are constrained by both kernel size and network depth. This fundamental characteristic impedes their ability to capture long-range dependencies and complex spatial–semantic relationships in remote sensing imagery, particularly when processing high-resolution images [
17]. These architectural constraints compromise global context integration, ultimately degrading segmentation accuracy [
18,
19,
20]. To address these limitations, researchers have proposed several enhancement strategies: Spatial Transformer Networks (STNs) [
21] incorporate learnable geometric transformation modules to adaptively adjust spatial representations, thereby improving structural awareness. Dilated Convolutions [
22] expand receptive fields through dilation rates, enabling large-scale context capture without substantial increases in parameters or computational complexity. Squeeze-and-Excitation Networks (SE-Net) [
23] establish explicit inter-channel dependencies via attention mechanisms for feature recalibration. The Convolutional Block Attention Module (CBAM) [
24] dynamically enhances features through coordinated channel and spatial attention mechanisms. Adaptive Spatial Feature Fusion (ASFF) [
25] mitigates multi-scale feature conflicts through spatial filtering, improving semantic consistency. While these approaches partially improve global context perception, they remain fundamentally rooted in local convolution operations, failing to fully address long-range dependency modeling. Moreover, most enhancements introduce additional computational overhead and parameter complexity, creating deployment challenges in resource-constrained environments [
26,
27,
28,
29]. This trade-off between accuracy and efficiency becomes particularly acute in high-resolution remote sensing image segmentation tasks.
To address the limitations of CNNs in modeling long-range dependencies, the Transformer [
30] architecture has been introduced to semantic segmentation tasks [
31,
32]. The core multi-head self-attention mechanism of Transformers offers robust global modeling capabilities, which significantly enhances the recognition of complex land structures in remote sensing images [
33,
34]. However, a Vision Transformer (ViT) faces two significant challenges in image tasks. First, the computation of global self-attention is highly expensive, making it difficult to scale to high-resolution images. Second, a ViT lacks an inherent ability to model local details, resulting in insufficient extraction of fine-grained features [
35,
36,
37]. These limitations hinder their effectiveness in remote sensing image applications. To overcome the limitations of ViTs, researchers have proposed various efficient variants to improve its adaptability in image tasks. A Swin Transformer [
38], for instance, achieves a balance between local modeling and global interaction through a sliding window mechanism. A Cross-Shape Window Transformer (CSWin) [
39] enhances spatial structure modeling with cross-window attention. Architectures such as Mobile-Former [
40] and EdgeViT [
41] have been developed to strike a balance between lightweight design and modeling capability. As Transformer technology expands into the domain of remote sensing, models such as ST-UNet [
42], MAResU-Net [
43], UNetFormer [
44], and AerialFormer [
44] have been developed. These models incorporate mechanisms such as window attention, linear attention, skip connection reconstruction, and multi-scale convolution, thereby enhancing the accuracy and expressive power of remote sensing semantic segmentation.
Transformer-based methods have exhibited remarkable efficacy in remote sensing semantic segmentation tasks. However, several challenges persist. On one hand, the increasing number of modules has led to more complex network architectures, significantly extending model inference time and making it difficult to meet the real-time and lightweight requirements of practical applications [
45]. On the other hand, current research focuses primarily on the optimization of encoder structures, often overlooking the critical role of decoders in feature reconstruction and boundary detail restoration [
46]. This oversight often leads to suboptimal recognition of fine-grained object structures in the resulting segmentation maps [
43]. Furthermore, remote sensing imagery is distinguished by substantial spatial heterogeneity and a wide spectrum of object morphologies, which impose elevated demands on the generalization capability of models [
47]. However, existing studies have paid limited attention to data augmentation strategies and task-adaptive modeling, further limiting performance in real-world scenarios [
44].
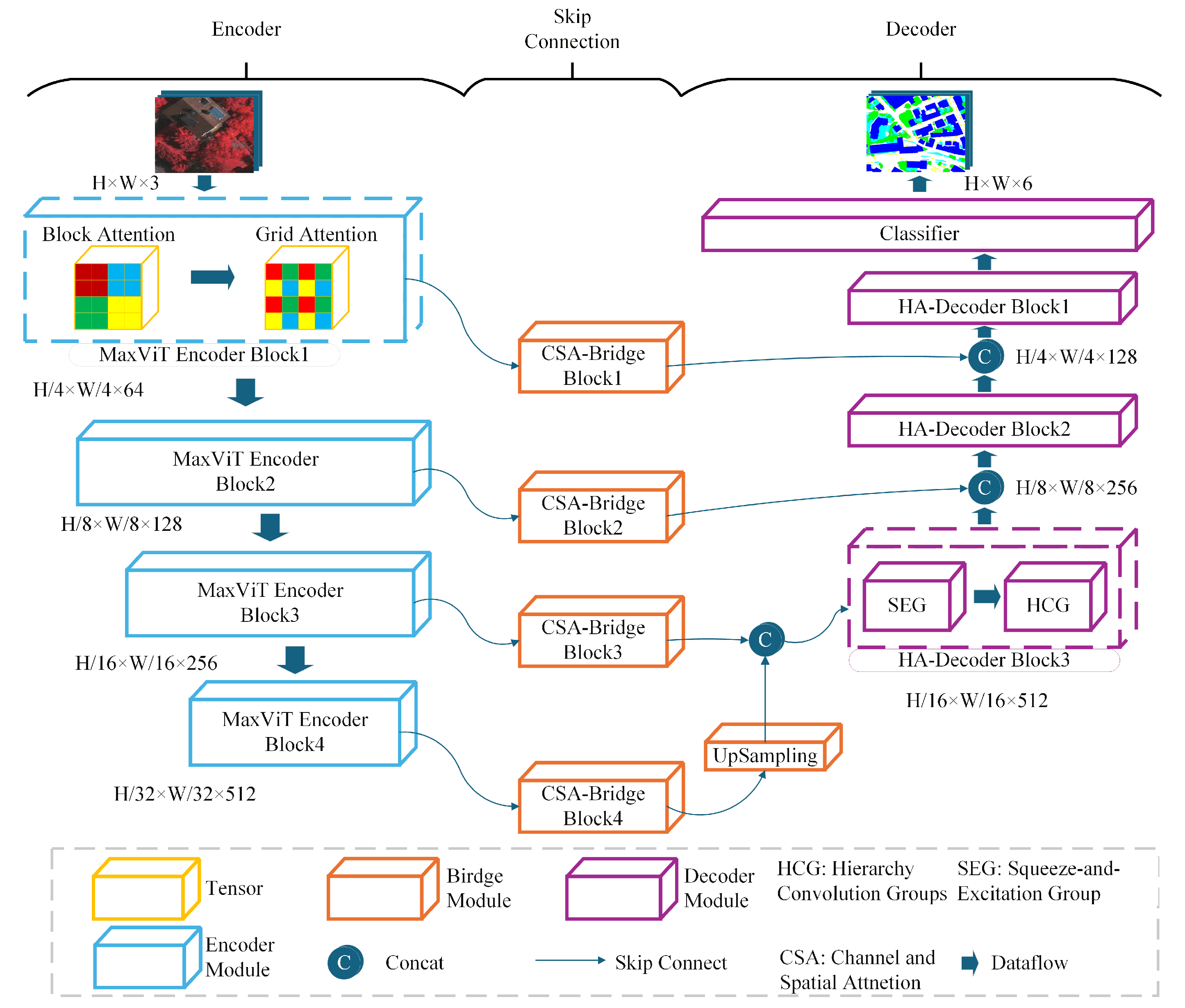
To address the aforementioned challenges, this study proposes a lightweight and efficient Dynamic Morphology-Aware Segmentation Network (DMA-Net), which is designed to achieve fine-grained segmentation of land cover objects in high-resolution remote sensing imagery while maintaining a compact architecture and high inference efficiency. The proposed model employs an encoder–decoder framework. The encoder integrates the Multi-Axis Vision Transformer (MaxViT) as the backbone, leveraging multi-axis self-attention to jointly model local details and global semantics efficiently. The decoder employs a Hierarchical Attention Decoder (HA-Decoder), which incorporates a Hierarchical Convolutional Group (HCG) to enhance the restoration of edge structures and small-scale features. Furthermore, a Channel-Spatial Attention Bridge (CSA-Bridge) is introduced to effectively mitigate the semantic gap between the encoder and decoder, thereby improving feature consistency and discriminability. The primary contributions of this study are as follows:
- 1.
We propose DMA-Net, a lightweight segmentation network that integrates MaxViT to efficiently capture both local and global features in high-resolution remote sensing imagery.
- 2.
We design a novel HA-Decoder with HCG to enhance multi-scale context fusion and fine-grained detail restoration.
- 3.
We introduce a CSA-Bridge to improve semantic consistency between encoder and decoder by enhancing inter-patch feature representation.
The remainder of this study is organized as follows:
Section 2 reviews the related work on semantic segmentation networks, with particular emphasis on MaxViT and U-Net-like architectures.
Section 3 presents the overall architecture of the proposed DMA-Net, including the design of its key components: the MaxViT encoder, the HA-Decoder, and the CSA-Bridge.
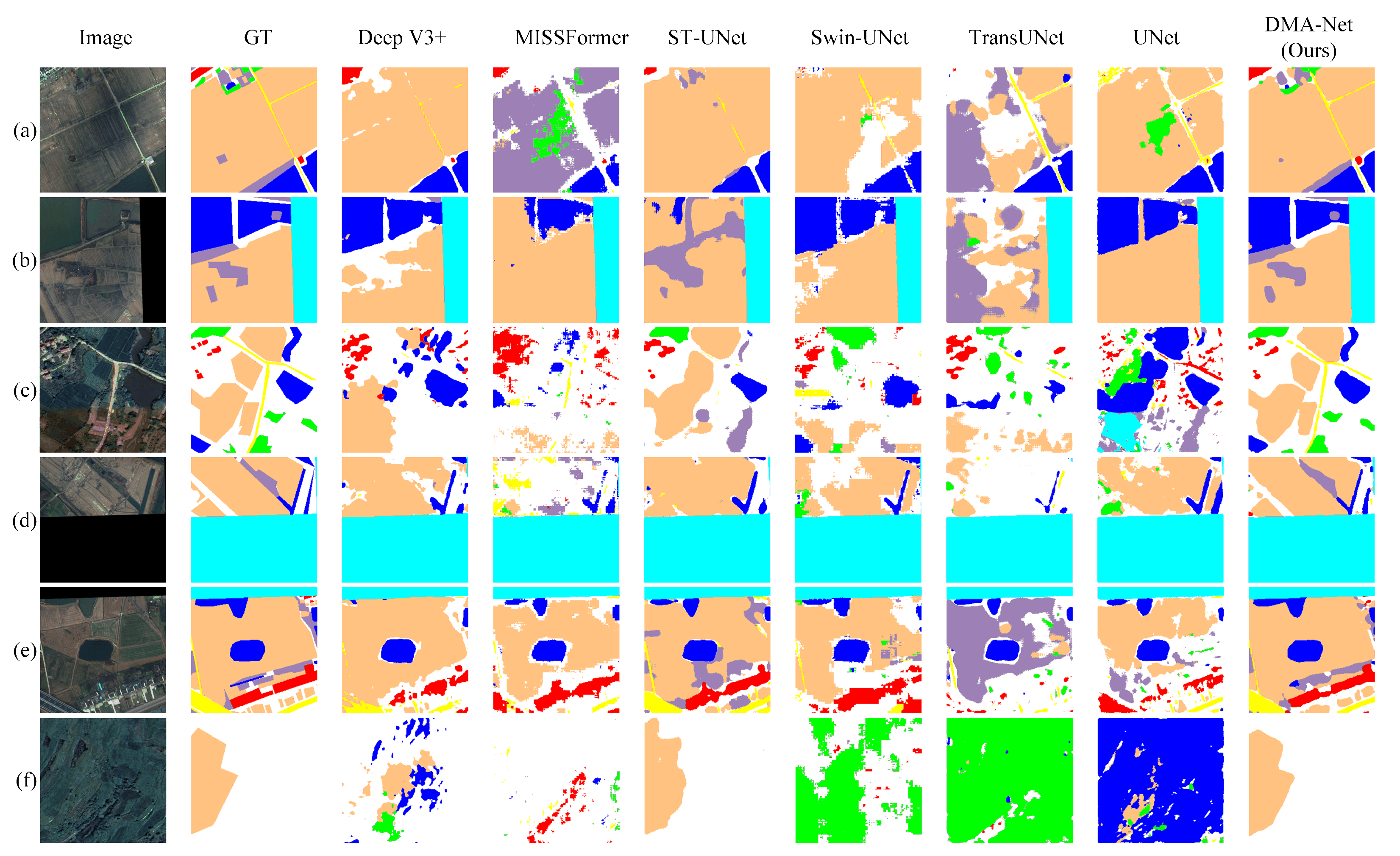
Section 4 introduces the experimental settings and datasets, presents ablation results, and compares the model’s performance on the Potsdam, Vaihingen, and LoveDA datasets.
Section 5 concludes the study and discusses potential directions for future research. The source code will be available at
https://github.com/HIGISX/DMA-Net (accessed on 4 June 2025).
3. Method
To achieve efficient and accurate segmentation of complex land cover structures in remote sensing images [
71,
72], this study proposes DMA-Net, a novel semantic segmentation network built upon an encoder–decoder architecture. The network incorporates a multi-axis attention mechanism to enhance local and global feature modeling, and integrates a fine-grained Hierarchical Attention Decoder (HA-Decoder) and a Channel-Spatial Attention Bridge (CSA-Bridge) to recover small object details and boundary structures. These components are jointly optimized to ensure high segmentation accuracy while maintaining low computational complexity and strong deployability. This section offers a thorough overview of the DMA-Net architecture, introducing its fundamental modules: the encoder, decoder, and skip connection.
3.1. Network Structure
As illustrated in
Figure 1, DMA-Net consists of three main components: the encoder based on MaxViT, the HA-Decoder, and the CSA-Bridge for skip connections.
Given an input image
, the encoder extracts multi-scale feature maps from different stages:
Here,
represents the feature maps at each encoding stage, with progressively reduced spatial resolution and increased channel depth. These multi-scale features are refined through the CSA-Bridge:
Finally, the decoder aggregates and upsamples these refined features to generate the segmentation output:
where
C is the number of semantic classes.
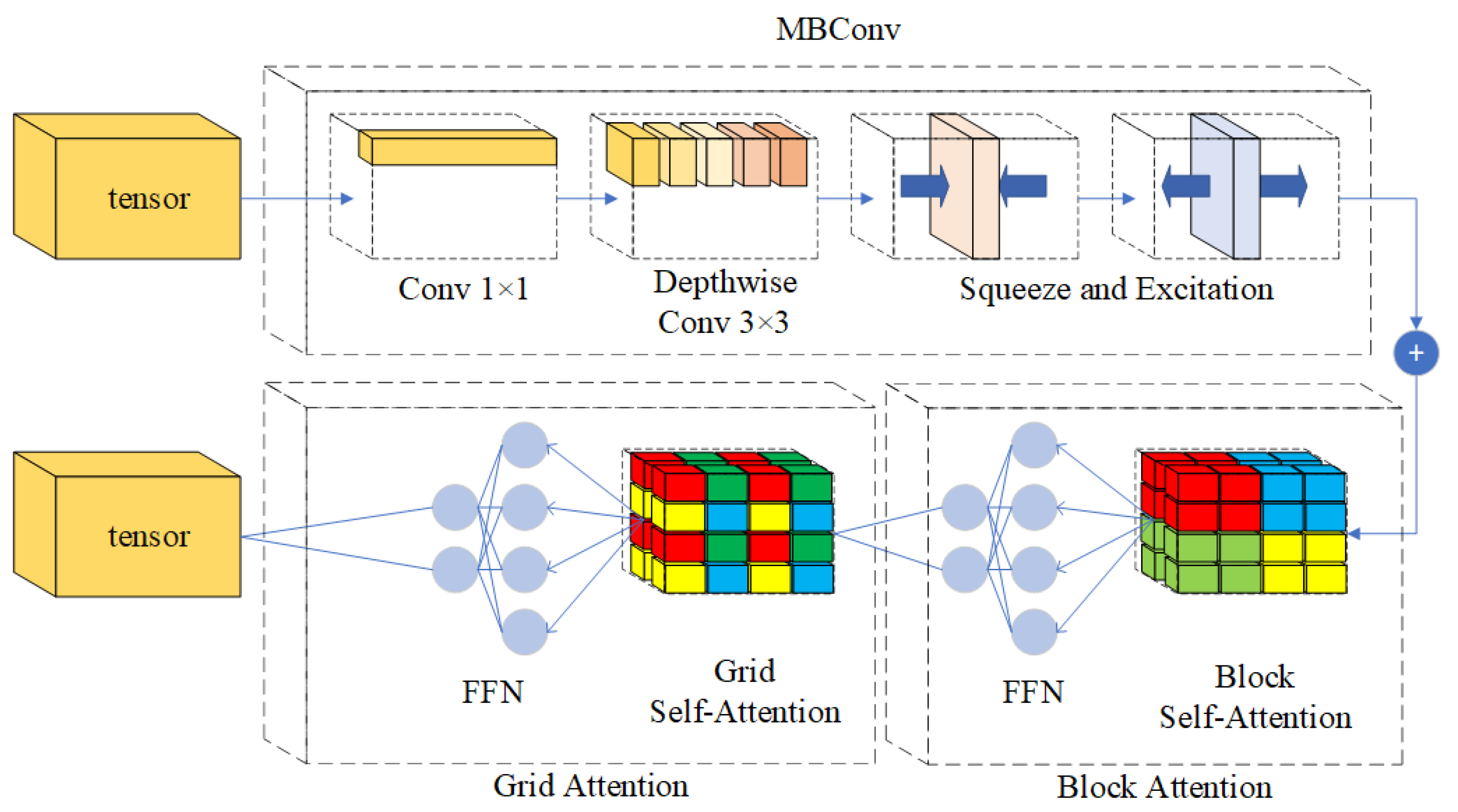
3.2. MaxViT Encoder Block
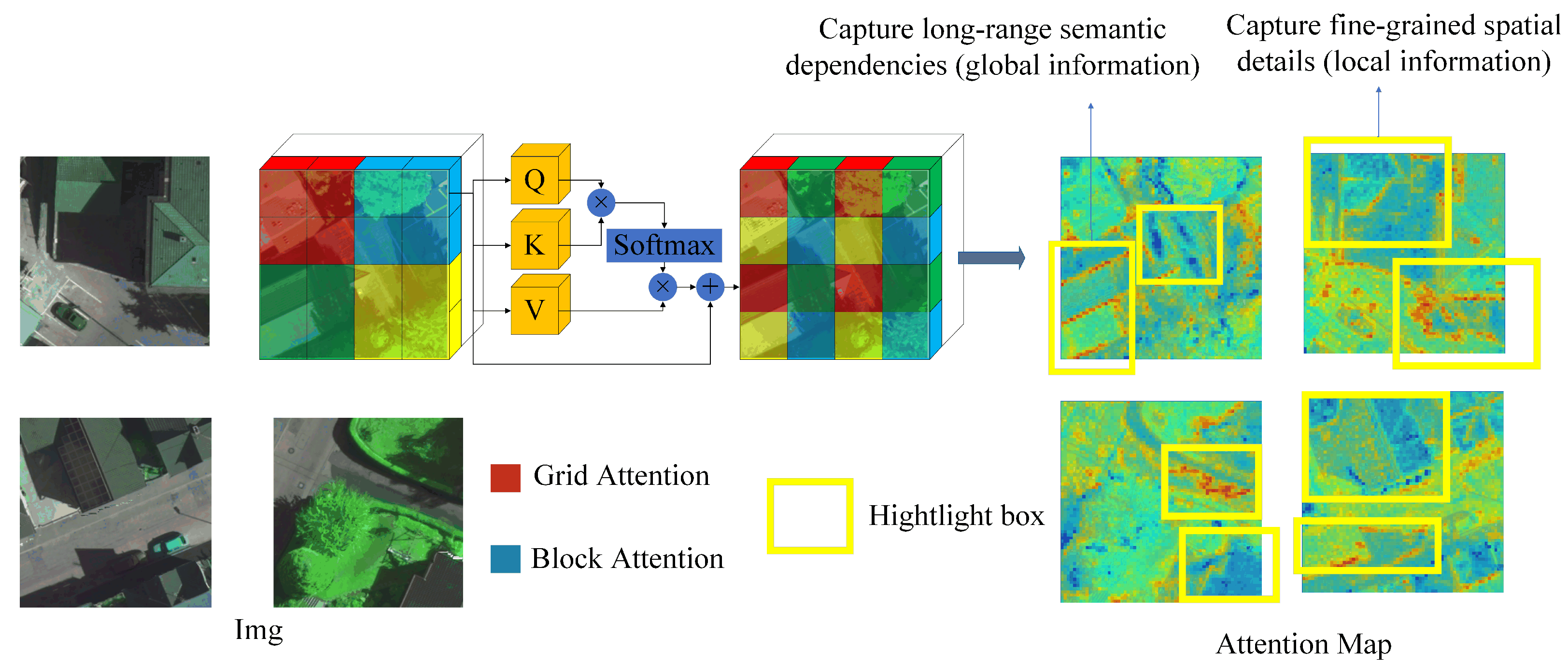
To effectively extract hierarchical and multi-scale representations from high-resolution remote sensing imagery, DMA-Net adopts MaxViT as the backbone of its encoder. In
Figure 2, MaxViT introduces a hybrid structure that combines convolutional modules with a multi-axis attention mechanism. Different colors represent the patches covered by the self-attention operation in MaxViT. The alternating use of Grid Attention and Block Attention enables the network to model both fine-grained spatial details and long-range semantic dependencies efficiently. As shown in
Figure 3, each encoder stage contains a Mobile Inverted Bottleneck Convolution (MBConv) module followed by a MaxViT encoder block composed of Block Attention and Grid Attention.
The internal transformation at each encoder stage is formulated as follows:
Here, denotes the input feature maps for stage i; and are learnable projection parameters; is the activation function; reflects spatial transformation within attention; is the intermediate transformation or decoding function; and ⊙ denotes element-wise multiplication.
To better adapt MaxViT to remote sensing image segmentation, DMA-Net modifies the default MaxViT encoder design to preserve high spatial resolution in early layers. We have combined the deep supervision training framework with MaxViT, which involves the feature maps output by MaxViT at different stages in the loss calculation. This allows the loss to supervise the learning of both high-level abstract semantic information and low-level detailed texture information in MaxViT, thereby improving its ability to retain edge contours and shape details of small-scale targets. Moreover, features from all four encoding stages are retained and forwarded to the following components, enabling rich multi-level semantic representation and ensuring that both shallow textures and deep semantics are fully leveraged during decoding.
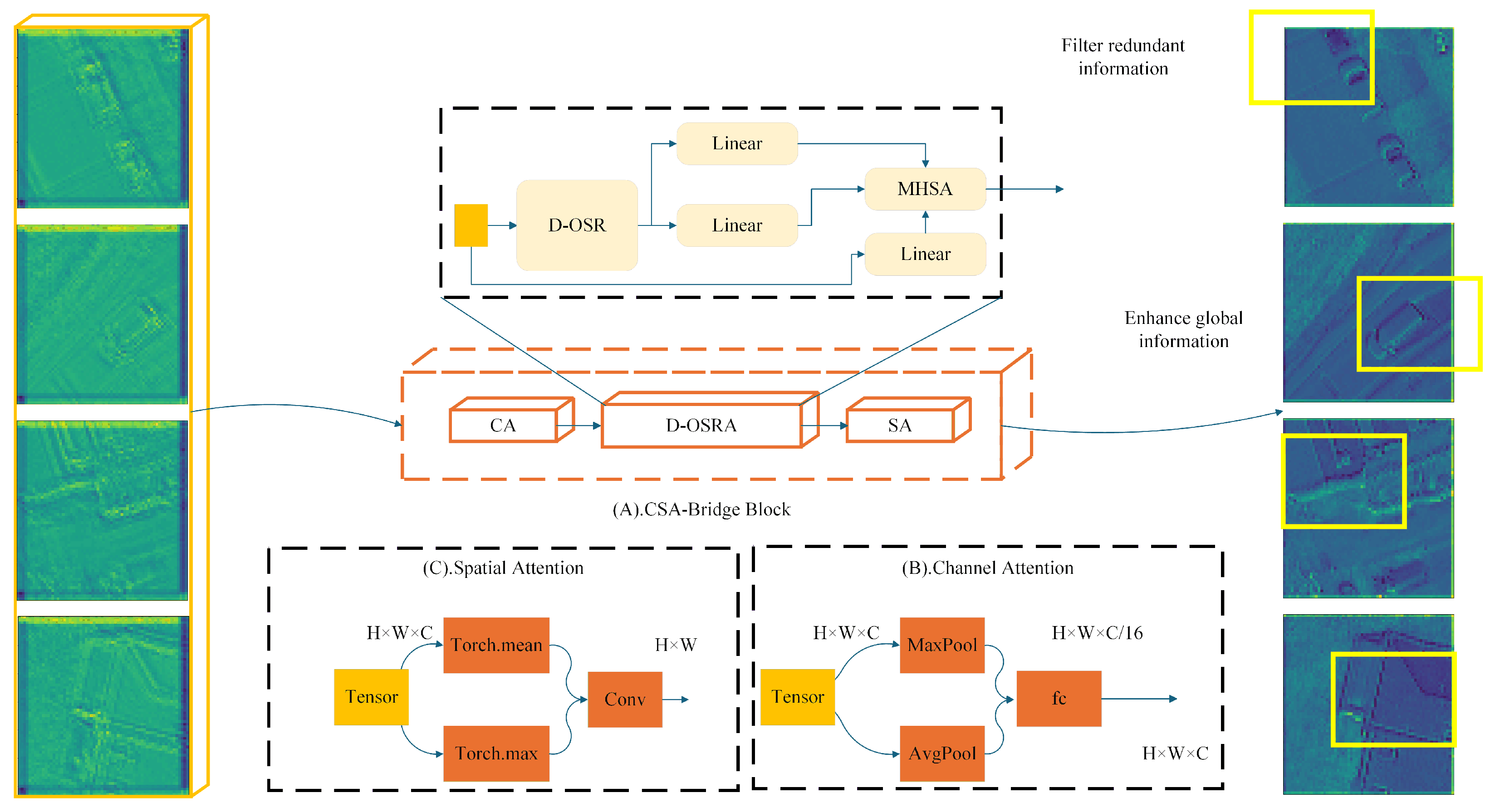
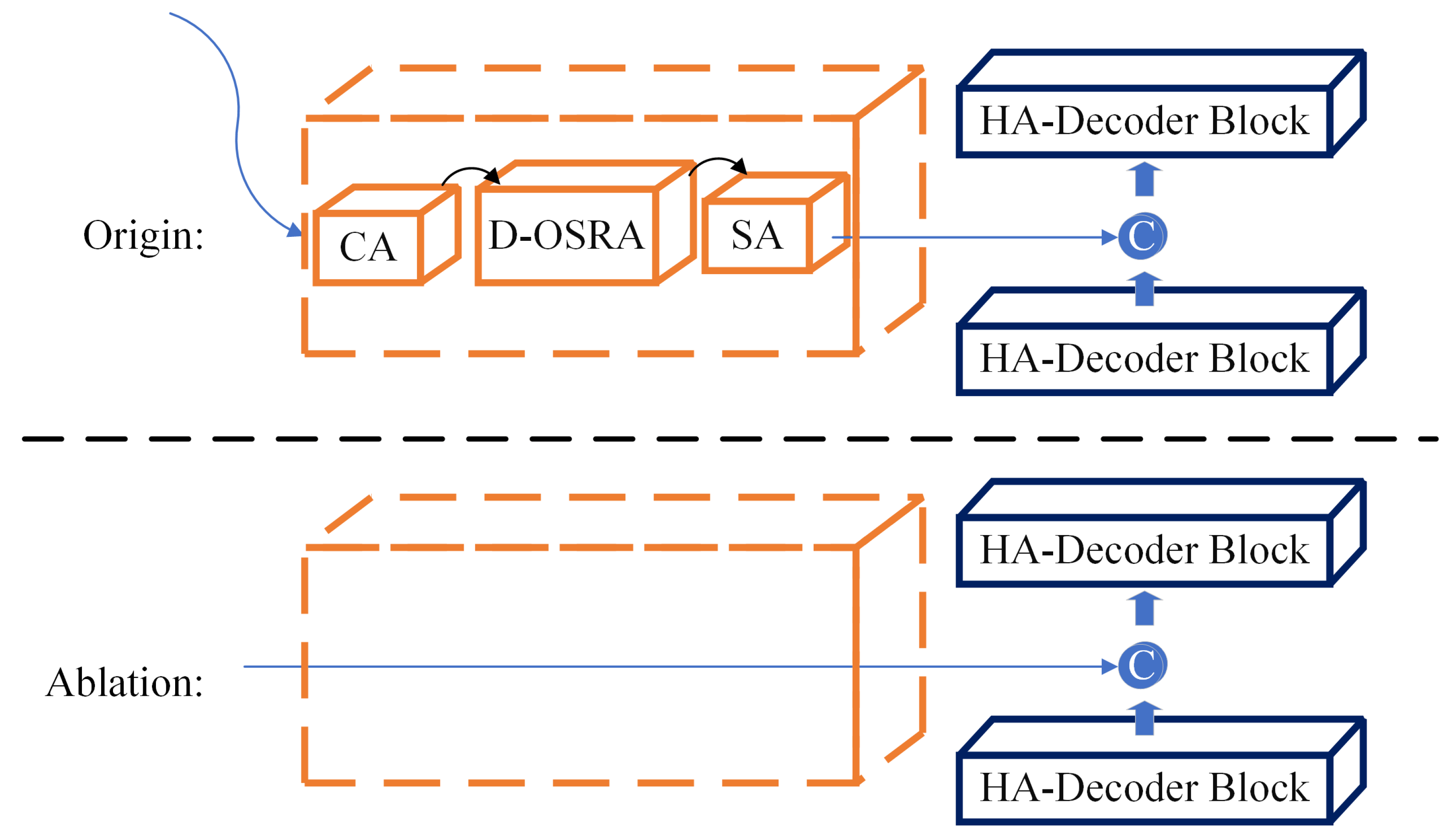
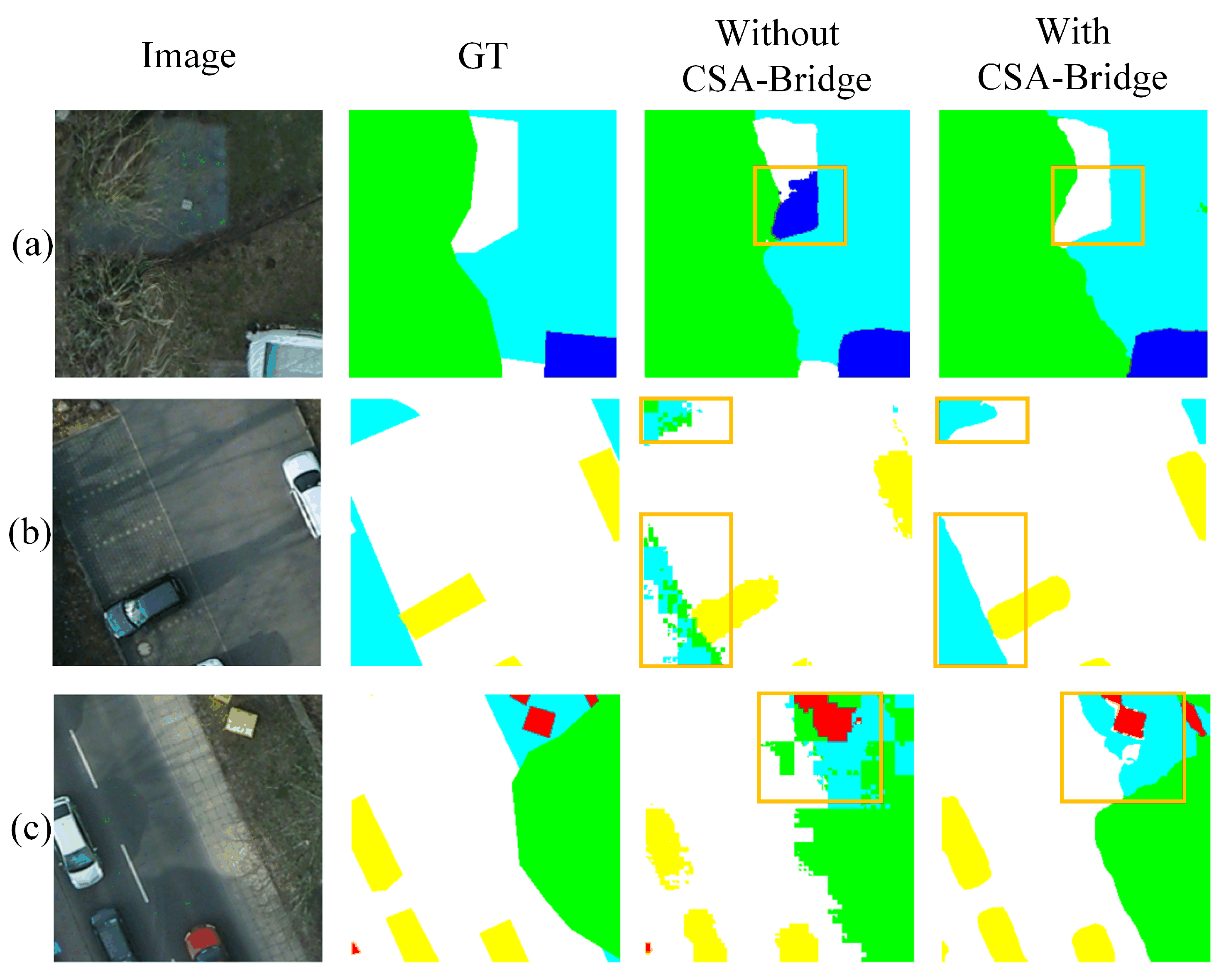
3.3. CSA-Bridge
While the encoder effectively captures hierarchical features at multiple scales, directly transmitting these raw feature maps to the decoder may introduce redundant or noisy information that compromises segmentation precision. To bridge the encoder and decoder more effectively, DMA-Net incorporates a Channel-Spatial Attention Bridge (CSA-Bridge) module, which selectively enhances and refines the skip connection features before fusion. The structure and mechanism of CSA-Bridge are detailed as follows.
CSA-Bridge operates on each stage of encoder output and refines feature quality through a sequential attention mechanism. It first applies channel attention to model inter-channel dependencies and emphasize semantically informative feature channels. Then, a Dynamic Overlapping Spatial Reduction Attention (D-OSRA) module compresses spatial redundancy using dynamically adaptive convolutional kernels, effectively retaining structural information. Finally, a spatial attention module enhances salient regions, particularly edges and small objects, ensuring spatial focus in feature refinement. The overall architecture of CSA-Bridge is illustrated in
Figure 4.
Given an encoder output feature map
from stage
i, the refined feature produced by CSA-Bridge is computed as follows:
where
is the output of the D-OSRA module,
and
represent the transformation matrices of the CA and SA modules, respectively, and ⊙ denotes element-wise multiplication. The kernel size used in D-OSRA is dynamically determined as
where
L is the side length of the input feature map, enabling adaptive receptive field adjustment based on the spatial scale of the input. By jointly leveraging attention mechanisms in both channel and spatial dimensions, combined with a dynamic receptive field spatial reduction strategy, the CSA-Bridge effectively suppresses redundant information while enhancing discriminative features. This provides the decoder with more representative multi-scale contextual support, thereby improving overall segmentation performance.
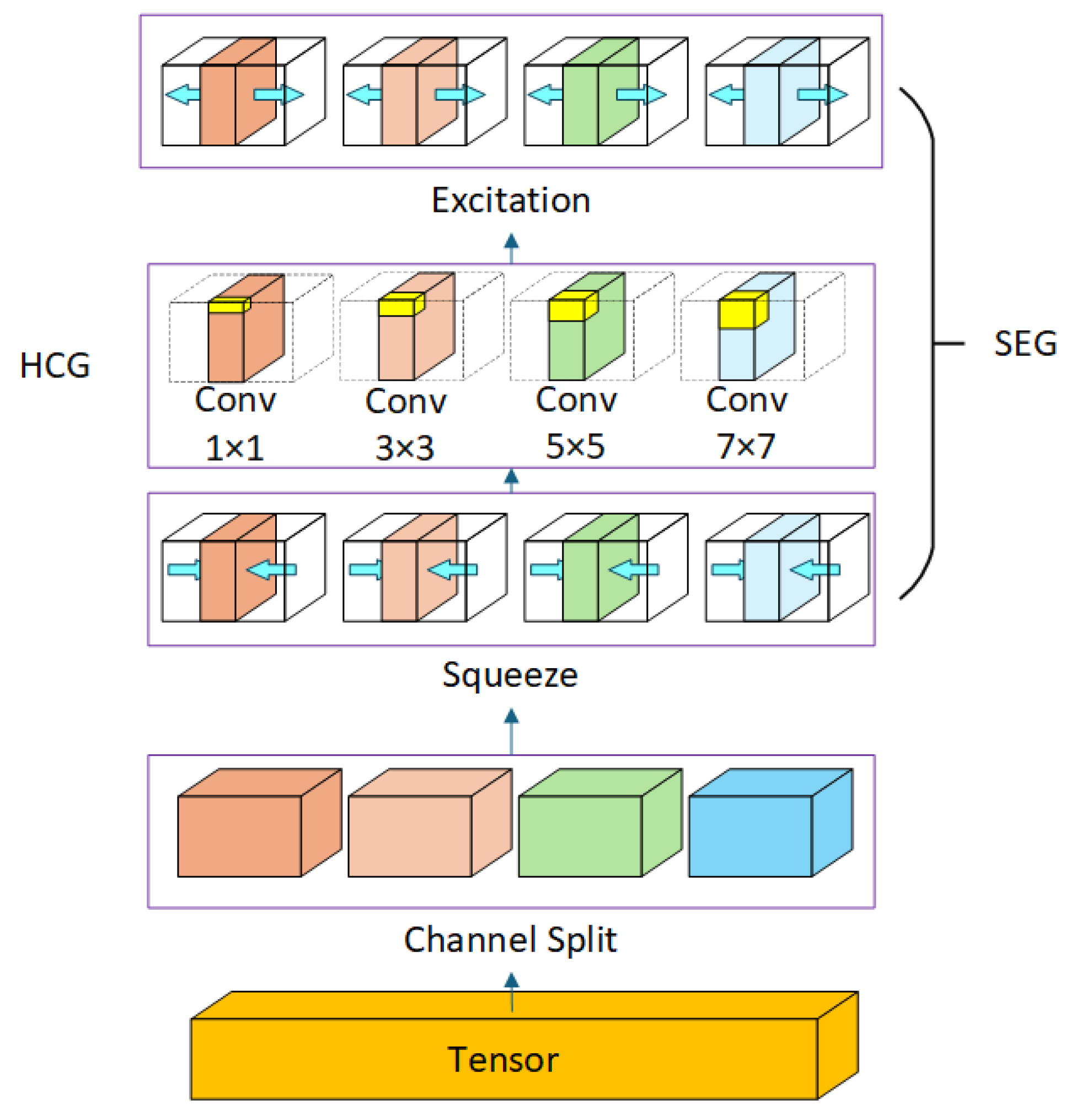
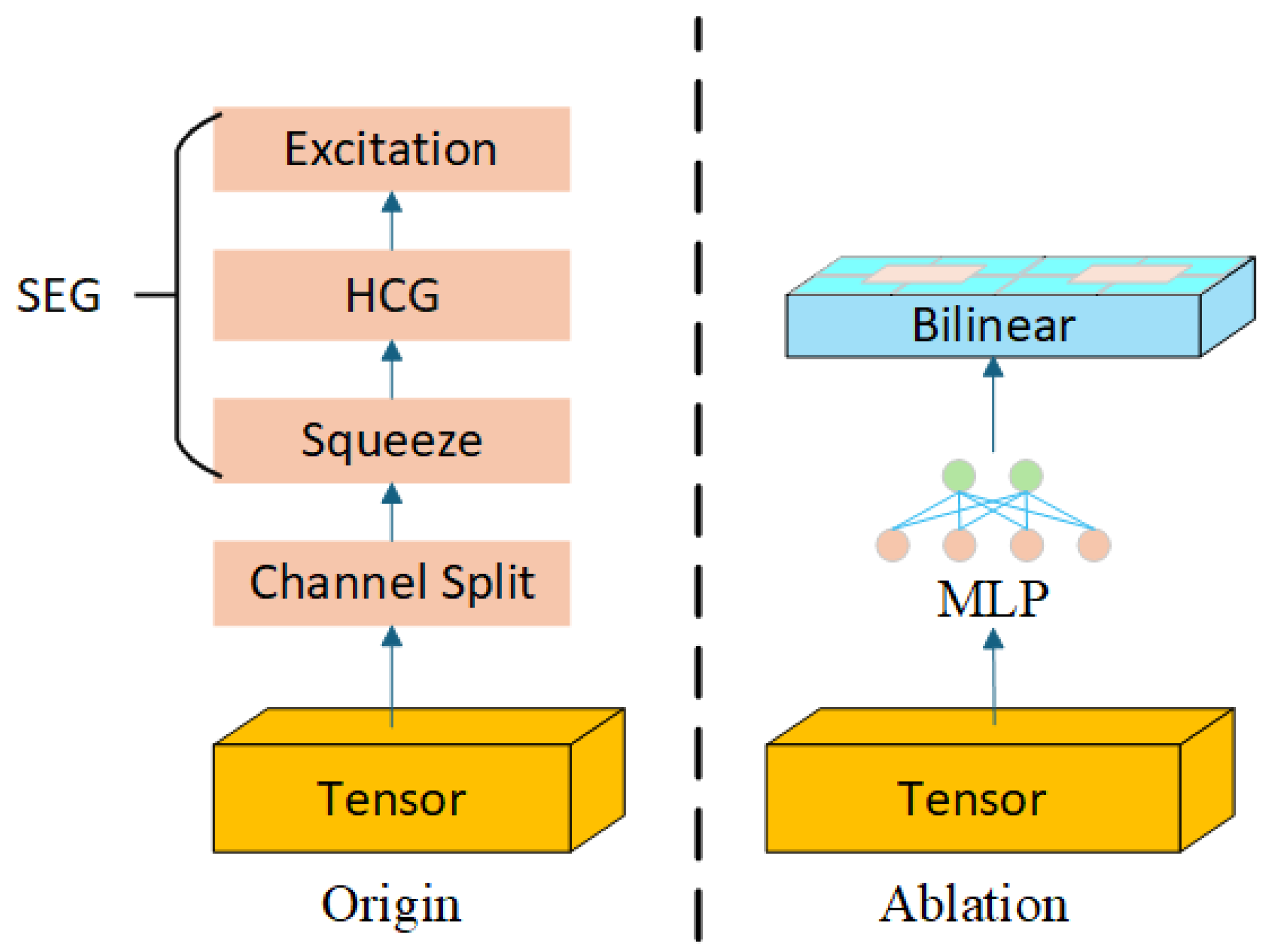
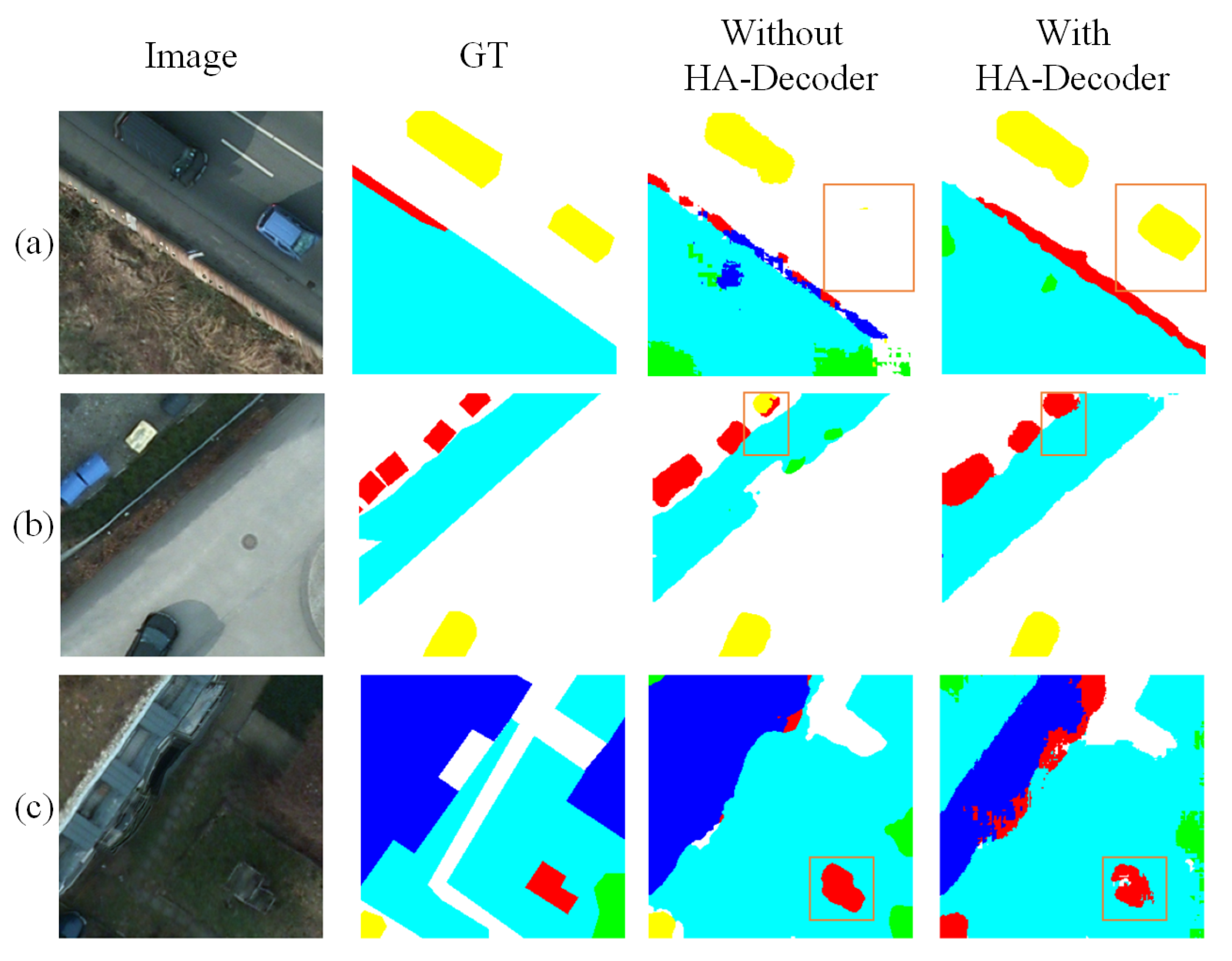
3.4. HA-Decoder
To restore spatial resolution and accurately reconstruct fine structures such as object boundaries and small targets, DMA-Net employs a lightweight, yet expressive decoding module named the Hierarchical Attention Decoder (HA-Decoder). Unlike conventional decoders that stack basic upsampling layers, the HA-Decoder introduces a structured decoding unit that integrates multi-scale convolution and nested attention operations in a hierarchical fashion. The internal structure of the decoder is illustrated in
Figure 5.
Each decoding stage in the HA-Decoder is aligned with its corresponding encoder stage and receives refined skip features
from the CSA-Bridge. The core component of the HA-Decoder is the Hierarchical Convolutional Group (HCG) module, which performs multi-scale feature enhancement in two steps: channel grouping and nested attention-based modulation. Given an input feature map
, we first partition it into
G channel groups
, where in each sub-feature map,
. These sub-groups are processed in parallel using convolutional kernels of different receptive fields:
The multi-scale convolved features are then concatenated and passed through a nested Squeeze-and-Excitation Group (SEG) attention block to recalibrate channel-wise responses. This block includes a squeeze transformation
, an excitation transformation
, and a residual enhancement layer:
where
and
b are learnable projection parameters. The output
serves as the decoded feature map at stage
i, which is upsampled and propagated to the next decoding level. This hierarchical decoding structure enables the HA-Decoder to progressively recover spatial resolution while preserving small-object details and boundary integrity, significantly enhancing final segmentation accuracy.
3.5. Data Augmentation Strategies
Remote sensing imagery is often subject to various forms of environmental interference, including shadow occlusions, acquisition distortions, and intra-class appearance variability [
73,
74]. These factors can have a substantial impact on the efficacy of semantic segmentation models. As demonstrated in
Figure 6, such interference may result in the obscuring of object boundaries, the alteration of geometric consistency, or the augmentation of intra-class ambiguity. Consequently, this may impede the model’s capacity to accurately discern spatial and semantic features. While architectural design plays a central role in enhancing model robustness, it is equally important to address these challenges from the perspective of data distribution. To this end, this study adopts a comprehensive data augmentation strategy aimed at improving the diversity and realism of training samples, thereby mitigating the impact of interference during training.
The augmentation operations are implemented through the utilization of the Albumentations library, which furnishes a malleable and efficient framework for image transformation. As illustrated in
Figure 7, the proposed strategy is categorized into three distinct functions: planar information augmentation, spatial distortion augmentation, and environmental information augmentation. Planar information augmentation includes basic geometric operations such as random cropping, horizontal and vertical flipping, and random angle rotation, which increase positional and directional variation across samples. Spatial distortion augmentation simulates image deformations caused by terrain variation or sensor instability using elastic transform, grid distortion, and optical distortion techniques, thereby enriching the spatial diversity of training data. Environmental information augmentation is designed to enhance model adaptability to illumination inconsistencies and visual interference, such as shadowing or haze. Techniques such as Contrast Limited Adaptive Histogram Equalization (CLAHE), Random Brightness/Contrast adjustment, and Random Gamma correction are employed to improve the model’s ability to capture consistent semantic cues under varying environmental conditions.
By jointly applying augmentations from geometric, spatial, and environmental dimensions, the resulting training samples better reflect the variability present in real-world remote sensing scenarios. This strategy complements the structural robustness of DMA-Net and plays a crucial role in improving segmentation accuracy under complex imaging conditions.
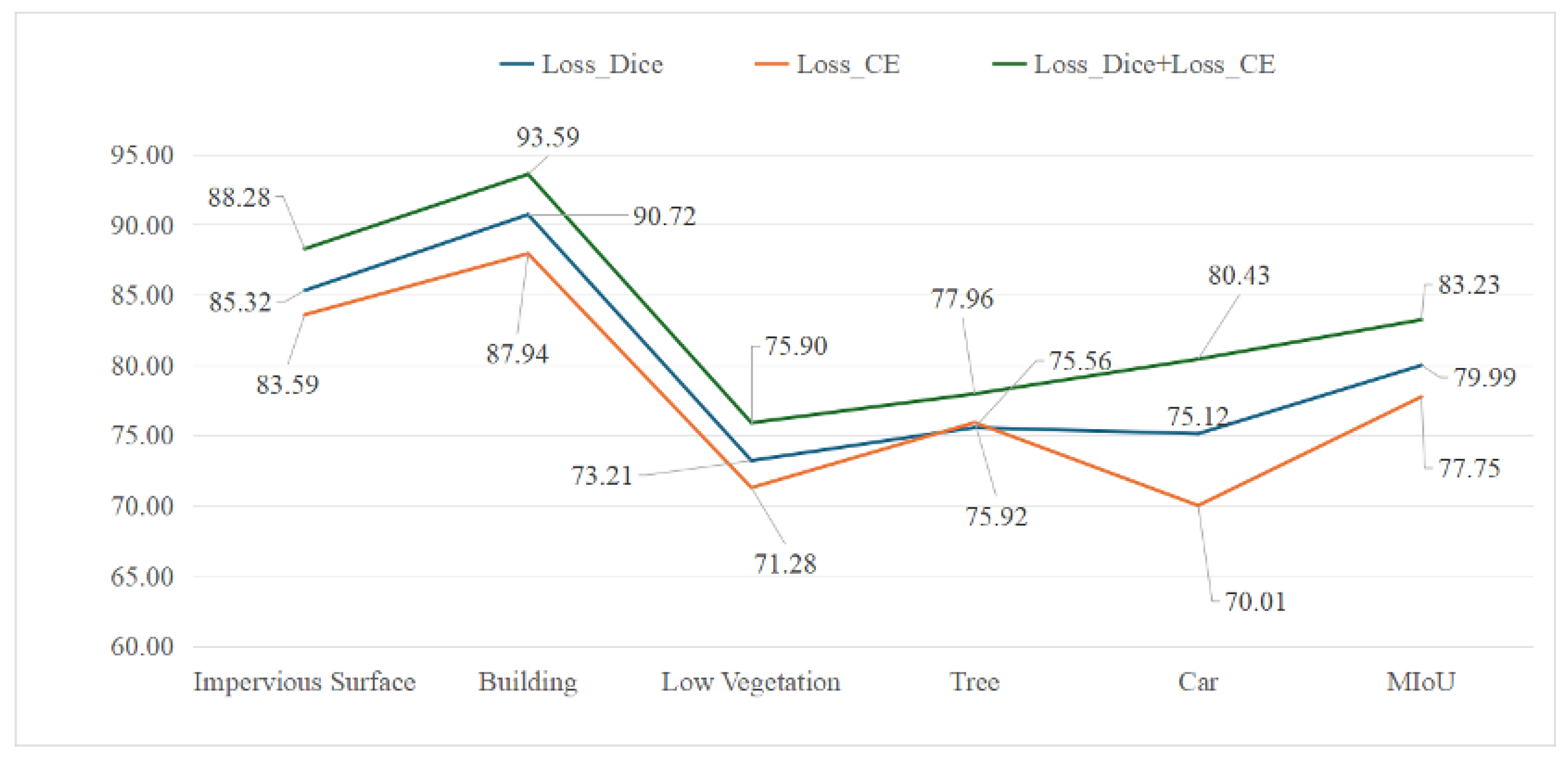
5. Conclusions
In this study, we propose a novel and efficient semantic segmentation network, DMA-Net, and validate its effectiveness in the field of remote sensing image segmentation. DMA-Net employs MaxViT as the backbone encoder, which leverages its dual-axis attention mechanisms—Grid Attention and Block Attention mechanisms—to efficiently capture both local and global information. To enhance the skip connection design, we introduce a CSA-Bridge module, which combines D-OSRA with CA and SA to supplement missing details between encoder stages and enhance fine-grained feature representations. In the decoding stage, we propose a HA-Decoder which integrates ConvG and SE-Net to comprehensively recover the missing details and improve the semantic integrity of the segmentation output.
While DMA-Net achieves promising results, it still exhibits several limitations. Notably, some output maps show jagged boundaries that fail to align precisely with the ground truth images. In scenarios involving multiple adjacent objects, the model occasionally struggles to delineate clear boundaries. Furthermore, DMA-Net only meets the minimum threshold for visual smoothness, and noticeable stuttering often occurs during practical operation. We also observe that DMA-Net has limited capability in handling class-imbalanced datasets, leading to inefficient capture of small-sample object information. Future work will focus on further improving the model’s processing speed and edge refinement capabilities, while continuing to explore lightweight and high-performance designs suitable for complex remote sensing environments. Additionally, methods such as imbalanced learning and ensemble learning will be adopted to enhance DMA-Net’s ability to capture small-sample object information.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}