
CSDNet: Context-Aware Segmentation of Disaster Aerial Imagery Using Detection-Guided Features and Lightweight Transformers

Abstract
1. Introduction
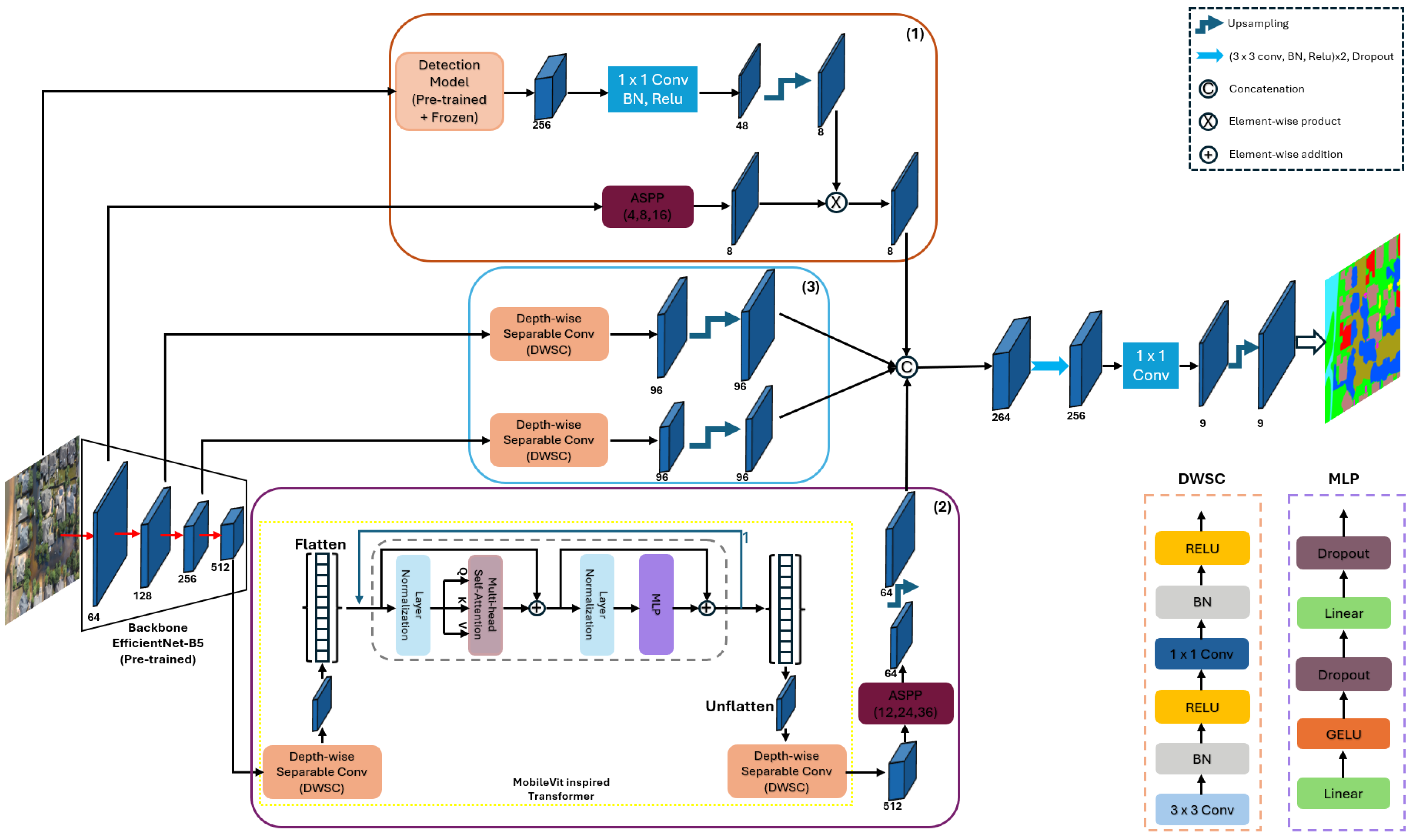
- We propose CSDNet, a novel context-aware segmentation model specifically designed for natural disaster-affected areas. CSDNet advances semantic segmentation by integrating three key innovations: (i) a lightweight transformer module to enhance global context understanding, (ii) depthwise separable convolutions (DWSC) to improve computational efficiency without compromising performance, and (iii) a detection-guided feature fusion mechanism that injects auxiliary detection cues into the segmentation pipeline. This unique combination addresses critical challenges in disaster scene analysis, including class imbalance, poor small-object segmentation, and the difficulty of distinguishing visually similar categories.
- We introduce a multi-scale feature fusion strategy that hierarchically combines low-level spatial details with mid-level semantic features within the decoder. This enhances boundary precision and improves the detection of small, underrepresented structures such as debris, vehicles, narrow roads, and damaged infrastructure, which are often missed by conventional approaches. To further strengthen class separation, especially for visually similar categories like “intact roof” and “collapsed roof,” we integrate detection-aware features from an auxiliary object detection branch. These semantic cues act as class-specific attention signals within the decoder, guiding the network toward more discriminative regions and improving segmentation robustness in complex, cluttered UAV imagery.
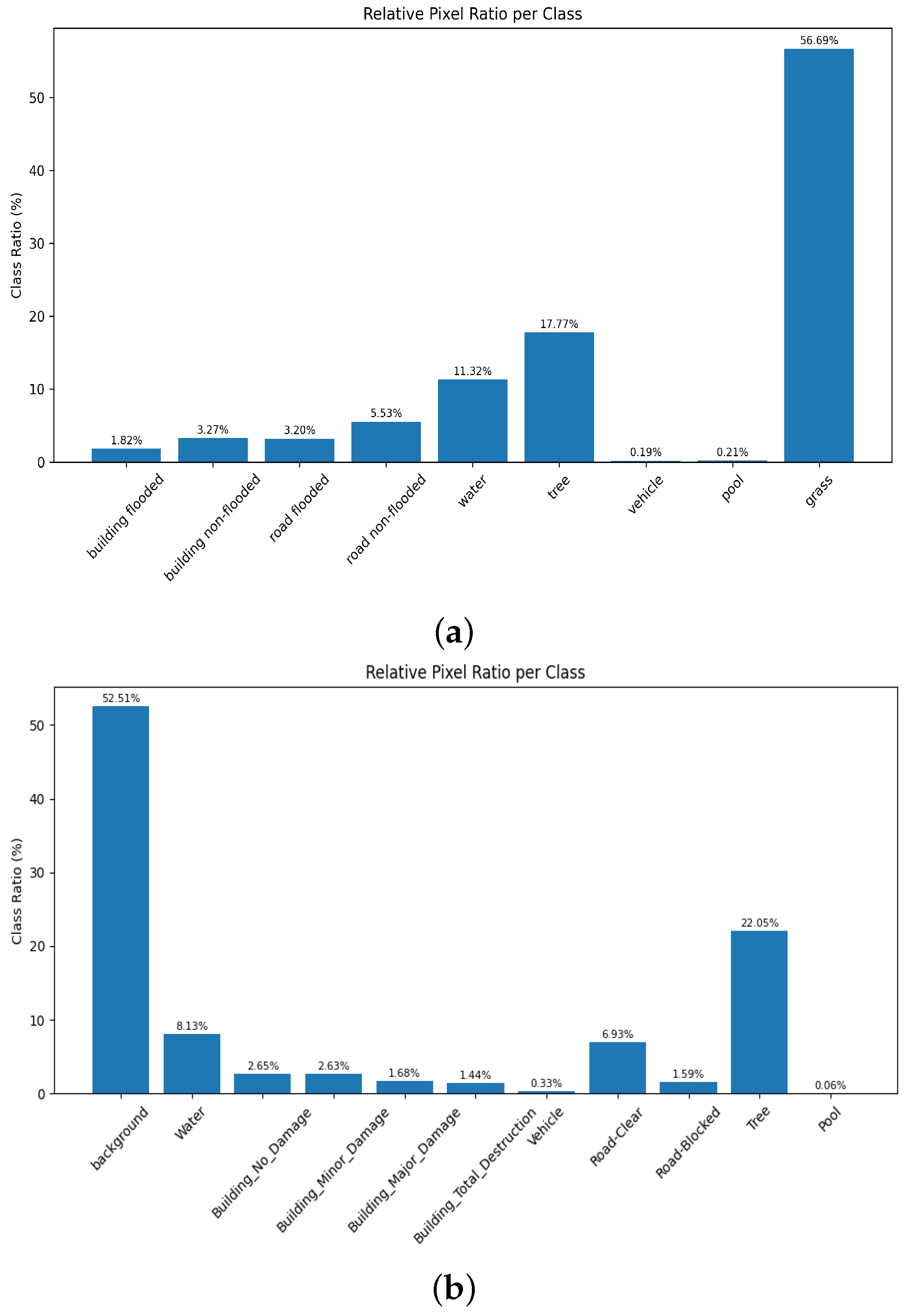
- We evaluate CSDNet on FloodNet [21] and RescueNet [7] datasets, two challenging UAV-based disaster datasets that include diverse environmental conditions, complex scene structures, and significant class imbalance (see image examples on Figure 1). Extensive experiments demonstrate that our approach consistently outperforms baseline models in accurately segmenting both large-scale disaster zones and small critical objects. The results confirm the effectiveness of our architectural enhancements in improving segmentation robustness, boundary precision, and semantic clarity, making CSDNet a reliable tool for rapid situational assessment in real-world disaster response scenarios.
2. Related Work
2.1. Disaster Scene Segmentation from Aerial Imagery
2.2. Attention in Semantic Segmentation
2.3. Context-Aware Image Segmentation
2.4. Class Imbalance in Semantic Segmentation
2.5. Summary
3. Methodology
3.1. Targeted Classes Enhancement Module
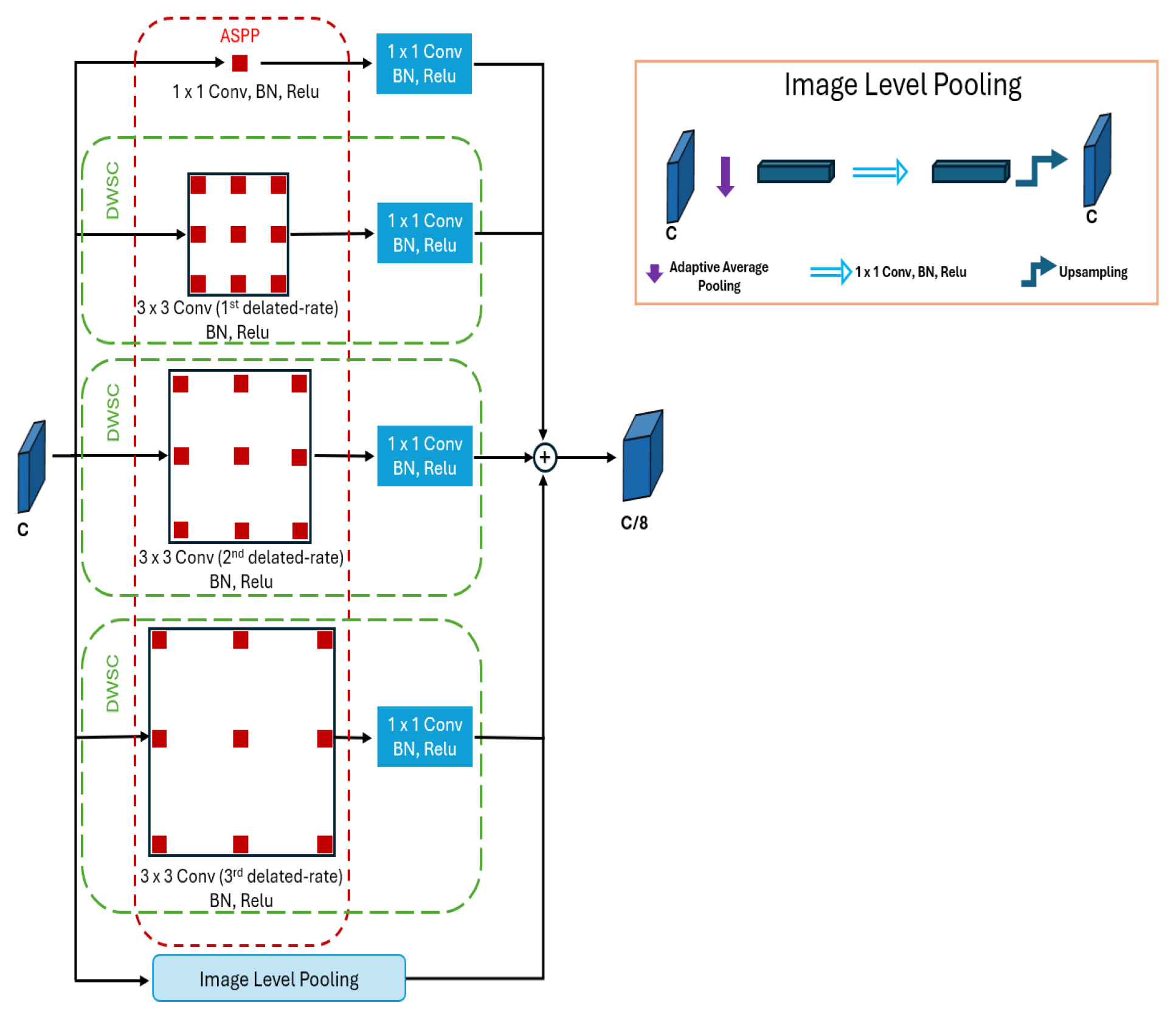
3.2. Deep Contextual Attention Module
3.3. Multi-Scale Feature Fusion Module
3.4. Model Training, Implementation, and Loss Function
3.4.1. Training Strategy and Implementation
3.4.2. Loss Function
| Algorithm 1 CSDNet training script |
Input: Set of input images and targeted classes to enhance ; Output: Trained CSDNet model Step 1: Pre-train the detection module on and freeze it; Step 2: For epoch = 1 to : Compute , using Equation (2); Compute using Equation (5); Compute using Equation (7); Compute using Equation (8); Predict ; Backpropagate using loss function ; |
4. Experiments
4.1. Datasets
4.2. Training Setup
4.3. Evaluation Metrics
4.4. Ablation Study
4.4.1. Effect of Removing the Transformer Block
4.4.2. Effect of Removing Detection Features
4.4.3. Effect of Removing Both Transformer and Detection Features
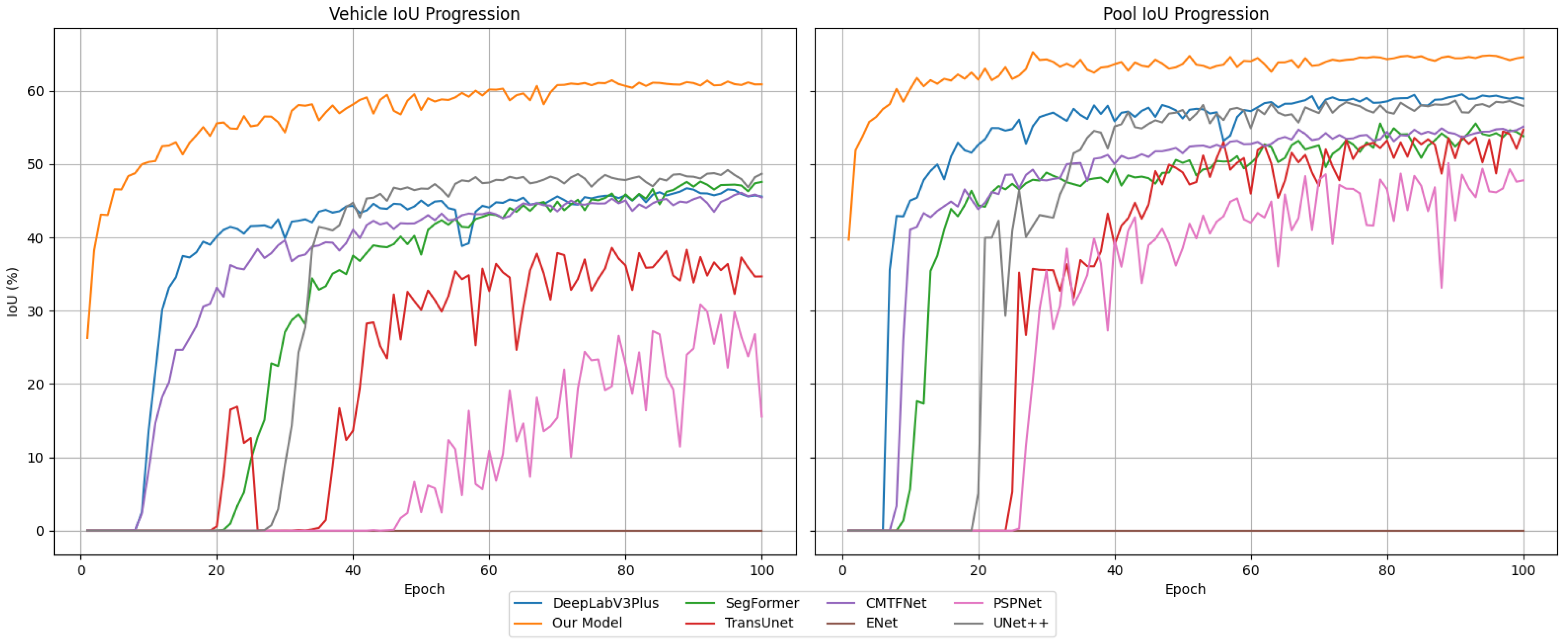
4.5. Quantitative Results and Analysis
4.6. Computational Analysis
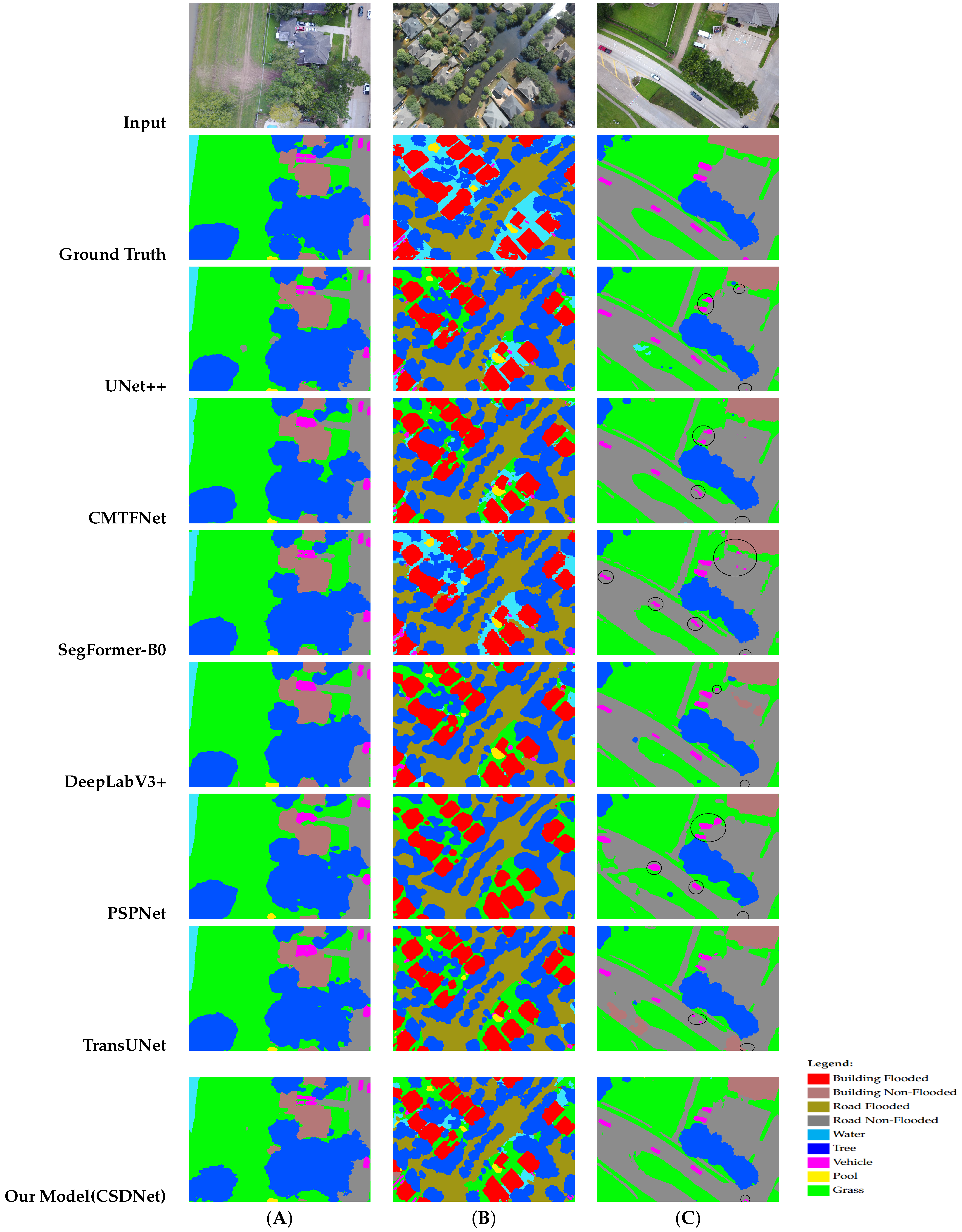
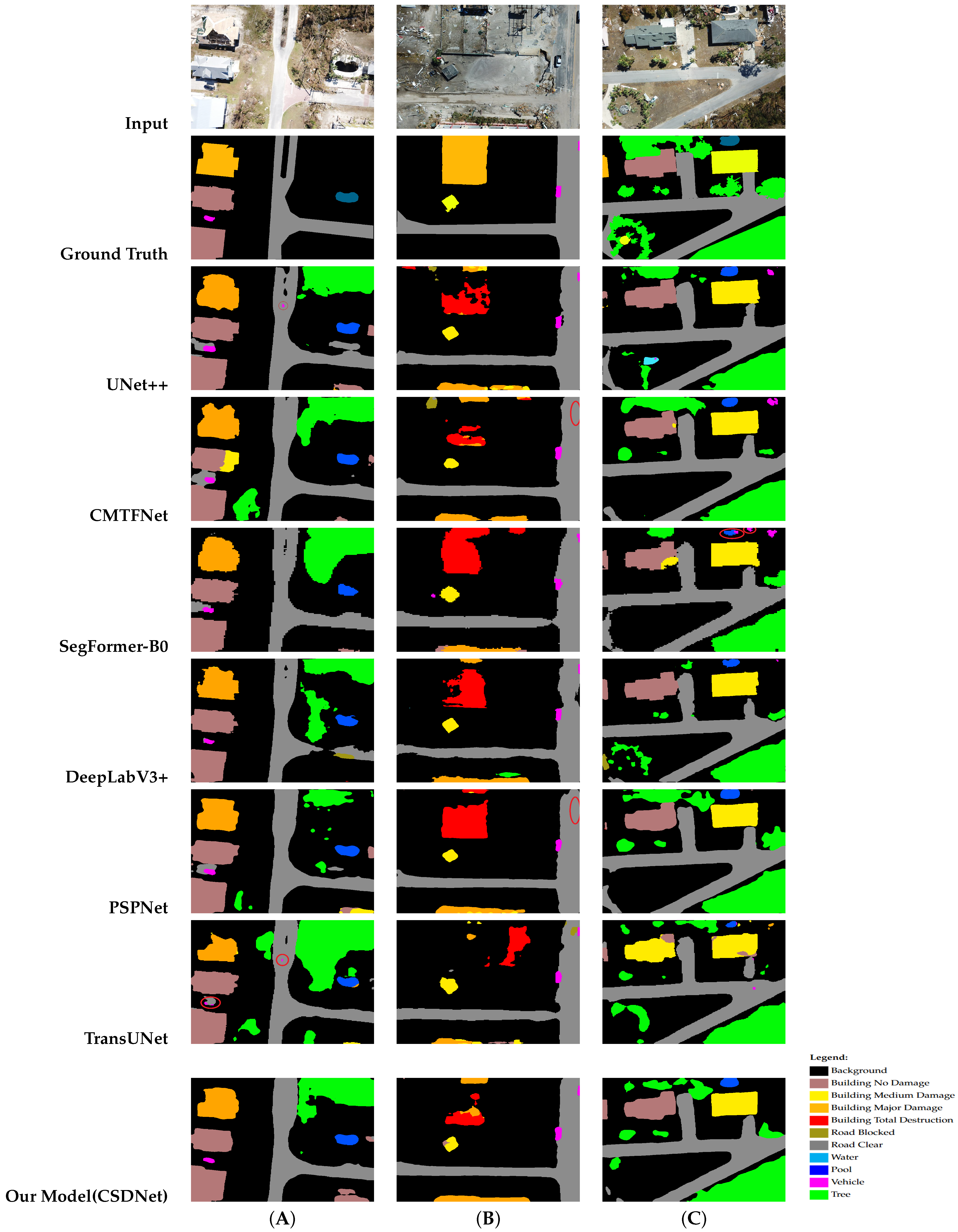
4.7. Qualitative Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krichen, M.; Abdalzaher, M.S.; Elwekeil, M.; Fouda, M.M. Managing natural disasters: An analysis of technological advancements, opportunities, and challenges. Internet Things Cyber-Phys. Syst. 2024, 4, 99–109. [Google Scholar] [CrossRef]
- Summers, J.K.; Lamper, A.; McMillion, C.; Harwell, L.C. Observed Changes in the Frequency, Intensity, and Spatial Patterns of Nine Natural Hazards in the United States from 2000 to 2019. Sustainability 2022, 14, 4158. [Google Scholar] [CrossRef]
- Bashir, M.H.; Ahmad, M.; Rizvi, D.R.; Abd El-Latif, A.A. Efficient CNN-based disaster events classification using UAV-aided images for emergency response application. Neural Comput. Appl. 2024, 36, 10599–10612. [Google Scholar] [CrossRef]
- Lapointe, J.F.; Molyneaux, H.; Allili, M.S. A literature review of AR-based remote guidance tasks with user studies. In Virtual, Augmented and Mixed Reality, Industrial and Everyday Life Applications, Proceedings of the12th International Conference, VAMR 2020, Held as Part of the 22nd HCI International Conference, HCII 2020, Copenhagen, Denmark, 19–24 July 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 111–120. [Google Scholar]
- Khan, A.; Gupta, S.; Gupta, S.K. Emerging UAV technology for disaster detection, mitigation, response, and preparedness. J. Field Robot. 2022, 39, 905–955. [Google Scholar] [CrossRef]
- Ijaz, H.; Ahmad, R.; Ahmed, R.; Ahmed, W.; Kai, Y.; Jun, W. A UAV-Assisted Edge Framework for Real-Time Disaster Management. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1001013. [Google Scholar] [CrossRef]
- Rahnemoonfar, M.; Chowdhury, T.; Murphy, R. RescueNet: A high resolution UAV semantic segmentation dataset for natural disaster damage assessment. Sci. Data 2023, 10, 913. [Google Scholar] [CrossRef]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M.; de Castro Jorge, L.A.; Fatholahi, S.N.; de Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A review on deep learning in UAV remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Dimitrovski, I.; Spasev, V.; Loshkovska, S.; Kitanovski, I. U-Net ensemble for enhanced semantic segmentation in remote sensing imagery. Remote Sens. 2024, 16, 2077. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A nested U-Net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 334–349. [Google Scholar]
- Poudel, R.P.K.; Liwicki, S.; Cipolla, R. Fast-SCNN: Fast Semantic Segmentation Network. In Proceedings of the British Machine Vision Conference, Cardiff, UK, 9–12 September 2019; p. 285. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. In Proceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS 2021), Virtual, 6–14 December 2021; pp. 12077–12090. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: U-Net-like pure transformer for medical image segmentation. In Proceedings of the ECCVWorkshops, Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Gupta, A.; Watson, S.; Yin, H. Deep learning-based aerial image segmentation with open data for disaster impact assessment. Neurocomputing 2021, 439, 22–33. [Google Scholar] [CrossRef]
- Almarzouqi, H.; Saad Saoud, L. Semantic labeling of high-resolution images using EfficientUNets and transformers. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4402913. [Google Scholar] [CrossRef]
- Lee, H.; Kim, G.; Ha, S.; Kim, H. Lightweight disaster semantic segmentation for UAV on-device intelligence. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Athens, Greece, 7–12 July 2024; pp. 8821–8825. [Google Scholar]
- Li, Z.; Liu, Z.; Yang, Z.; Peng, Z.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Rahnemoonfar, M.; Chowdhury, T.; Sarkar, A.; Varshney, D.; Yari, M.; Murphy, R.R. FloodNet: A high resolution aerial imagery dataset for post flood scene understanding. IEEE Access 2021, 9, 89644–89654. [Google Scholar] [CrossRef]
- Guo, D.; Weeks, A.; Klee, H. Robust approach for suburban road segmentation in high-resolution aerial images. Int. J. Remote Sens. 2007, 28, 307–318. [Google Scholar] [CrossRef]
- Sang, S.; Zhou, Y.; Islam, M.T.; Xing, L. Small-object sensitive segmentation using across feature map attention. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6289–6306. [Google Scholar] [CrossRef]
- Doshi, J. Residual inception skip network for binary segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 206–2063. [Google Scholar]
- Rahnemoonfar, M.; Murphy, R.; Vicens Miquel, M.; Dobbs, D.; Adams, A. Flooded area detection from UAV images based on densely connected recurrent neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1788–1791. [Google Scholar]
- Rudner, T.G.J.; Rußwurm, M.; Fil, J.; Pelich, R.; Bischke, B.; Kopačková, V.; Biliński, P. Multi3Net: Segmenting flooded buildings via fusion of multiresolution, multisensor, and multitemporal satellite imagery. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 702–709. [Google Scholar]
- Shen, Y.; Zhu, S.; Yang, T.; Chen, C.; Pan, D.; Chen, J. BDANet: Multiscale Convolutional Neural Network With Cross-Directional Attention for Building Damage Assessment From Satellite Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5402114. [Google Scholar] [CrossRef]
- Gupta, R.; Hosfelt, R.; Sajeev, S.; Patel, N.; Goodman, B.; Doshi, J.; Heim, E.; Choset, H.; Gaston, M. Creating xBD: A dataset for assessing building damage from satellite imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 10–17. [Google Scholar]
- Zhang, Y.; Gao, X.; Duan, Q.; Yuan, L.; Gao, X. DHT: Deformable hybrid transformer for aerial image segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6518805. [Google Scholar] [CrossRef]
- Khan, B.A.; Jung, J.-W. Semantic segmentation of aerial imagery using U-Net with self-attention and separable convolutions. Appl. Sci. 2024, 14, 3712. [Google Scholar] [CrossRef]
- Soleimani, R.; Soleimani-Babakamali, M.H.; Meng, S.; Avci, O.; Taciroglu, E. Computer vision tools for early post-disaster assessment: Enhancing generalizability. Eng. Appl. Artif. Intell. 2024, 136 Pt A, 108855. [Google Scholar] [CrossRef]
- Sundaresan, A.A.; Solomon, A.A. Post-disaster flooded region segmentation using DeepLabv3+ and unmanned aerial system imagery. Nat. Hazards Res. 2025, 5, 363–371. [Google Scholar] [CrossRef]
- Zhao, Q.; Liu, J.; Li, Y.; Zhang, H. Semantic segmentation with attention mechanism for remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5403913. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Chen, Y.; Dong, Q.; Wang, X.; Zhang, Q.; Kang, M.; Jiang, W.; Wang, M.; Xu, L.; Zhang, C. Hybrid Attention Fusion Embedded in Transformer for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4421–4435. [Google Scholar] [CrossRef]
- Liu, R.Z.J.; Pan, H.; Tang, D.; Zhou, R. An Improved Instance Segmentation Method for Fast Assessment of Damaged Buildings Based on Post-Earthquake UAV Images. Sensors 2024, 24, 4371. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Liang, J.; Hauptmann, A. MSNet: A Multilevel Instance Segmentation Network for Natural Disaster Damage Assessment in Aerial Videos. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Vitrual, 5–9 January 2021; pp. 2022–2031. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Xu, Y.; Liu, H.; Yang, R.; Chen, Z. Remote Sensing Image Semantic Segmentation Sample Generation Using a Decoupled Latent Diffusion Framework. Remote Sens. 2025, 17, 2143. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, Q.; Zhang, G. LSRFormer: Efficient Transformer Supply Convolutional Neural Networks With Global Information for Aerial Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5610713. [Google Scholar] [CrossRef]
- Maki, M.B.A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar]
- Hebbache, L.; Amirkhani, D.; Allili, M.S.; Hammouche, N.; Lapointe, J.F. Leveraging saliency in single-stage multi-label concrete defect detection using unmanned aerial vehicle imagery. Remote Sens. 2023, 15, 1218. [Google Scholar] [CrossRef]
- Azad, R.; Heidary, M.; Yilmaz, K.; Hüttemann, M.; Karimijafarbigloo, S.; Wu, Y.; Schmeink, A.; Merhof, D. Loss Functions in the Era of Semantic Segmentation: A Survey and Outlook. arXiv 2023, arXiv:2312.05391. [Google Scholar] [CrossRef]
- Chu, S.; Kim, D.; Han, B. Learning debiased and disentangled representations for semantic segmentation. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; pp. 8355–8366. [Google Scholar]
- Chen, P.; Liu, Y.; Ren, Y.; Zhang, B.; Zhao, Y. A Deep Learning-Based Solution to the Class Imbalance Problem in High-Resolution Land Cover Classification. Remote Sens. 2025, 17, 1845. [Google Scholar] [CrossRef]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7151–7160. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, general-purpose, and mobile-friendly vision transformer. In Proceedings of the International Conference on Learning Representations, Vitrual, 22–29 April 2022. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Chen, X.; Mei, J.; Li, X.; Lu, Y.; Yu, Q.; Wei, Q.; Luo, X.; Xie, Y.; Adeli, E.; Wang, Y.; et al. TransUNet: Rethinking the U-Net architecture design for medical image segmentation through the lens of transformers. Med. Image Anal. 2024, 97, 103280. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Huang, P.; Zhang, M.; Tang, W.; Yu, X. CMTFNet: CNN and multiscale transformer fusion network for remote-sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2004612. [Google Scholar] [CrossRef]
- Bouafia, Y.; Allili, M.S.; Hebbache, L.; Guezouli, L. SES-ReNet: Lightweight deep learning model for human detection in hazy weather conditions. Signal Process. Image Commun. 2025, 130, 117223. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Full Model | w/o Transformer | w/o RetinaNet | w/o Transformer w/o RetinaNet | DeepLabV3+ |
|---|---|---|---|---|---|
| Vehicle | 58.62 | 34.62 | 47.91 | 31.32 | 44.25 |
| Pool | 66.12 | 48.12 | 60.22 | 47.67 | 51.80 |
| Road Flooded | 56.81 | 53.21 | 45.61 | 43.28 | 52.91 |
| Building Flooded | 75.77 | 73.14 | 65.87 | 48.42 | 47.24 |
| mIoU | 73.03 | 65.74 | 68.36 | 63.52 | 67.24 |
| Model | BF | BNF | RF | RNF | Water | Tree | Vehicle | Pool | Grass | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|
| SegFormer (B0) [15] | 48.42 | 78.90 | 53.88 | 82.95 | 76.46 | 82.05 | 45.38 | 46.95 | 89.39 | 67.15 |
| PSPNet [40] | 44.18 | 74.53 | 49.60 | 80.14 | 75.05 | 78.55 | 28.40 | 39.89 | 87.54 | 61.99 |
| ENet [51] | 45.39 | 71.30 | 46.24 | 77.68 | 75.18 | 77.81 | 0.00 | 0.00 | 86.64 | 53.36 |
| DeepLabV3+ [11] | 47.24 | 78.66 | 52.91 | 82.81 | 76.39 | 81.97 | 44.25 | 51.80 | 89.14 | 67.24 |
| UNet++ [10] | 57.31 | 76.18 | 45.73 | 80.13 | 65.58 | 79.28 | 26.45 | 47.37 | 86.59 | 62.74 |
| TransUNet [52] | 46.96 | 72.52 | 48.86 | 79.49 | 71.77 | 78.50 | 35.84 | 43.90 | 86.81 | 62.74 |
| CMTFNet [53] | 48.04 | 78.64 | 50.44 | 82.15 | 75.21 | 81.10 | 41.91 | 45.46 | 88.85 | 65.76 |
| Our Model (CSDNet) | 75.77 | 84.99 | 56.81 | 81.94 | 62.26 | 84.53 | 58.62 | 66.12 | 86.26 | 73.03 |
| Model | BG | Water | BND | BMND | BMJD | BTD | Vehicle | CR | BR | Tree | Pool | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SegFormer(B0) [15] | 82.76 | 83.86 | 62.95 | 53.33 | 51.48 | 53.41 | 50.65 | 74.50 | 41.22 | 81.12 | 63.02 | 61.55 |
| PSPNet [40] | 84.07 | 84.01 | 67.80 | 60.59 | 59.50 | 61.04 | 57.65 | 75.77 | 46.53 | 81.64 | 71.55 | 68.19 |
| ENet [51] | 76.35 | 74.84 | 45.12 | 36.02 | 31.10 | 41.67 | 0.00 | 52.43 | 16.98 | 74.12 | 0.00 | 40.78 |
| DeepLabV3+ [11] | 82.91 | 81.45 | 65.27 | 53.19 | 50.76 | 52.79 | 59.86 | 72.29 | 41.29 | 81.57 | 62.72 | 64.01 |
| UNet++ [10] | 83.38 | 82.19 | 67.01 | 56.13 | 53.53 | 60.53 | 57.94 | 74.85 | 40.87 | 81.01 | 60.05 | 63.41 |
| TransUNet [52] | 78.81 | 77.93 | 47.68 | 38.11 | 30.12 | 40.59 | 41.40 | 67.22 | 19.02 | 76.71 | 31.91 | 49.95 |
| CMTFNet [53] | 83.84 | 82.70 | 66.00 | 56.69 | 55.74 | 60.40 | 54.49 | 74.29 | 40.50 | 81.96 | 56.70 | 64.84 |
| Our Model (CSDNet) | 84.60 | 84.71 | 67.98 | 59.17 | 58.61 | 62.04 | 60.35 | 76.77 | 48.73 | 82.57 | 74.07 | 69.05 |
| Model | Params (M) | Inference Time (ms) | mIoU (%) |
|---|---|---|---|
| DeepLabV3+ | 39.64 | 9.14 | 67.24 |
| SegFormer-B0 | 3.72 | 10.57 | 67.15 |
| UNet++ | 48.99 | 12.46 | 62.74 |
| CMTFNet | 30.07 | 19.69 | 65.76 |
| ENet | 0.35 | 16.32 | 53.36 |
| TransUnet | 107.68 | 36.47 | 62.74 |
| PSPNet | 53.58 | 12.25 | 61.99 |
| Our Model (CSDNet) | 33.52 | 22.84 | 73.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zetout, A.; Allili, M.S. CSDNet: Context-Aware Segmentation of Disaster Aerial Imagery Using Detection-Guided Features and Lightweight Transformers. Remote Sens. 2025, 17, 2337. https://doi.org/10.3390/rs17142337
Zetout A, Allili MS. CSDNet: Context-Aware Segmentation of Disaster Aerial Imagery Using Detection-Guided Features and Lightweight Transformers. Remote Sensing. 2025; 17(14):2337. https://doi.org/10.3390/rs17142337
Chicago/Turabian StyleZetout, Ahcene, and Mohand Saïd Allili. 2025. "CSDNet: Context-Aware Segmentation of Disaster Aerial Imagery Using Detection-Guided Features and Lightweight Transformers" Remote Sensing 17, no. 14: 2337. https://doi.org/10.3390/rs17142337
APA StyleZetout, A., & Allili, M. S. (2025). CSDNet: Context-Aware Segmentation of Disaster Aerial Imagery Using Detection-Guided Features and Lightweight Transformers. Remote Sensing, 17(14), 2337. https://doi.org/10.3390/rs17142337