1. Introduction
In recent years, aerial vehicles have been widely used in agriculture, logistics, military operations, disaster rescue, and environmental monitoring [
1,
2,
3,
4,
5]. The Global Navigation Satellite System (GNSS) serves as the primary approach for aerial vehicle geolocalization. However, aerial vehicles struggle to achieve autonomous geolocalization in GNSS-denied environments. Advances in computer vision have established vision-based perception as the preferred solution for this challenge. This approach follows a progressive three-tiered architecture: cross-domain image retrieval, heterogeneous image matching, and geographic location estimation. Related works in this domain are outlined below.
Cross-domain image retrieval can be defined as the process of utilizing aerial images to identify the most similar ones in a database of satellite remote sensing images, thereby establishing indexing relationships. Traditional methods have relied on hand-crafted features to capture the semantic content of images [
6,
7]. Compared to traditional systems, recent advancements in deep neural networks have significantly enhanced the performance of content-based retrieval. Unar et al. [
8] utilized VGG16 and ResNet50 for feature extraction, improving the semantic information of the feature learner by employing multi-kernel feature learning to identify the most critical image-representation features. Meanwhile, Yamani et al. [
9] combined Transformer encoders with CNN-based feature extractors to derive advanced semantic interpretations. Meng et al. [
10] utilize DINOV2 [
11] to extract features from aerial, satellite, and image sources, and VLAD [
12] vectors are employed to combine sequential images with particle filters for the purpose of image retrieval.
Heterogeneous image matching establishes pixel-level feature correspondences between aerial and satellite remote sensing imagery. Traditional approaches relied on hand-crafted feature detection algorithms, such as Scale-Invariant Feature Transform (SIFT) [
13], Speeded-Up Robust Features (SURF) [
14], and Oriented FAST and Rotated BRIEF (ORB) [
15]. Saleem et al. [
16] proposed an improved SIFT algorithm based on normalized gradient enhancement. The RIFT algorithm, introduced by Li et al. [
17], significantly enhanced feature point robustness and achieved rotation invariance. However, traditional algorithms exhibit limitations due to sensor discrepancies, inconsistent resolutions, and viewpoint variations inherent in cross-source imagery. In recent years, deep learning has revolutionized traditional feature extraction and matching techniques, gradually evolving from sparse feature extraction and matching to end-to-end dense matching. Han et al. [
18] utilizes a convolutional neural network (CNN) to extract features from image patches. DeTone et al. [
19] pioneered self-supervised joint feature detection and description with SuperPoint. Subsequently, Sarlin et al. [
20] introduced SuperGlue, which incorporates a graph attention network (GAT) to model feature matching as a structural optimization problem between two views. SuperPoint combined with SuperGlue has become a paradigm for feature point extraction and matching. Lindenberger et al. [
21] designed an adaptive pruning mechanism for LightGlue to address real-time bottlenecks, improving inference speed by 2-3 times while maintaining accuracy. Furthermore, Sun et al. [
22] proposed LoFTR, which completely overturned the “detect-match” divide-and-conquer paradigm.
Geographic location estimation refers to calculating the position of the aerial vehicle using image-matching results to obtain longitude and latitude coordinates. Wang et al. [
23] computed homography transformations based on the matching results of aerial and satellite imagery, subsequently employing the projection coordinates of the aerial image’s center pixel onto the satellite image as the aerial vehicle geolocalization. This methodology yields accurate positioning results exclusively when the onboard camera is oriented in a nadir-view configuration. Yao et al. [
24] leveraged ground elevation data, in conjunction with feature matching results, to formulate a 3D-2D Perspective-n-Point (PnP) problem, employing algorithms such as EPnP [
25] to determine the aerial vehicle’s geographic location. Following the establishment of a matching relationship between aerial image pixel coordinates and real-world geographic coordinates [
26,
27,
28], a planar scene constraint is assumed, wherein all geographic points lie on a horizontal plane, thereby enabling the formulation and solution of a PnP problem. Li et al. [
29] derived a homography transformation between aerial image pixel coordinates and road network geographic coordinates, predicated on the assumption of a horizontal plane. By computing the homography matrix H and subsequently decomposing it, the geographic location of the aerial vehicle can be determined.
Contemporary research predominantly focuses on cross-domain image retrieval and heterogeneous image matching, with relatively limited attention devoted to geographic location estimation. Current estimation methods primarily depend on either a priori geographic elevation data or planar terrain assumptions. The former approach is constrained by insufficient data accuracy and regional data gaps, while the latter introduces errors by disregarding actual topographic undulations and elevation variations. To address these limitations, this paper presents an innovative visual geolocalization method for aerial vehicles that integrates satellite remote sensing imagery with relative depth information. This approach significantly enhances geolocalization accuracy and stability in complex terrain environments. The principal contributions of this work are detailed below:
We have conducted an error analysis of the planar assumption-based method for aerial vehicle geolocalization.
We propose a novel method for aerial vehicle geolocalization that leverages relative depth consistency from satellite remote sensing imagery.
2. Materials and Methods
2.1. Problem Definition
Map projection transforms geodetic coordinates into planimetric map coordinates. The Pseudo-Mercator Projection (EPSG:3857), widely adopted by web mapping services like Google Maps, establishes its coordinate origin at the equator–prime meridian intersection. This system extends eastward along the positive X-axis and northward along the positive Y-axis. The X-axis and Y-axis take values in the range [−20,037,508.3427892, 20,037,508.3427892] in m units. Under the Pseudo-Mercator Projection, the geodetic coordinates of a terrestrial point are defined as
, with longitude
constrained to
and latitude
bound with
. The corresponding Mercator plane coordinates are derived through
where
represents the radius of the Earth, which is 6378137 m, and
and
are the radians of the
and
. This study establishes a global coordinate system with the following definitions:
X/Y-axis Definition: The X-Y plane originates at the intersection of the Earth’s equator (0° latitude) and prime meridian (0° longitude), with axis orientations aligned with the Pseudo-Mercator coordinate system-X-axis positive eastward and Y-axis positive northward.
Z-axis Definition: A local vertical axis originates from the aerial vehicle’s takeoff position, orthogonal to the X-Y plane, with a positive direction aligned with the upward vector in the East–North–Up (ENU) geodetic frame.
This study addresses the following problem: In the world coordinate system, given a satellite remote sensing reference image and the Mercator coordinates of each of its pixels, the aim is to geolocate the aerial vehicle based on aerial images.
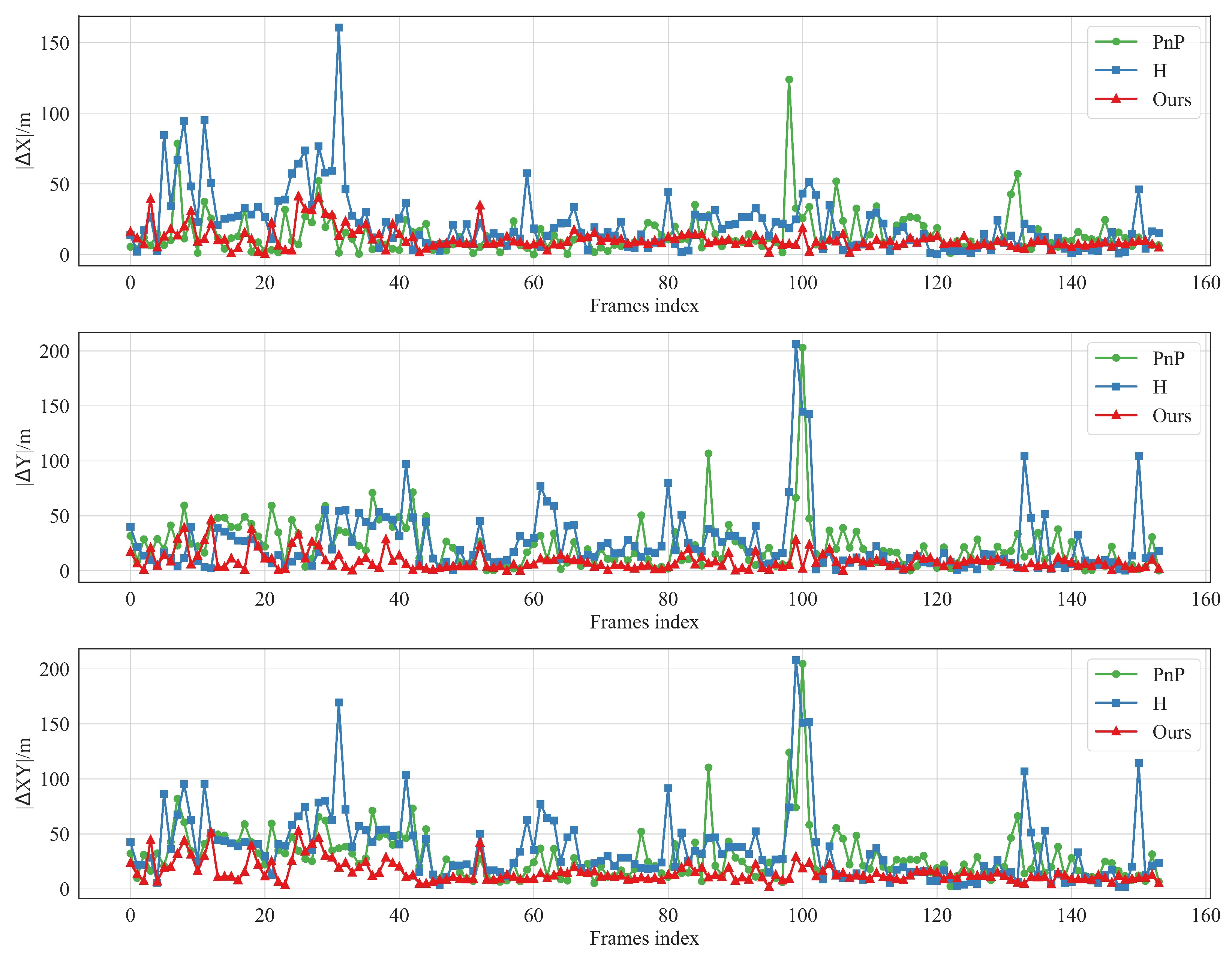
2.2. Error Analysis in Aerial Vehicle Geolocalization Under Planar Assumption
Image-matching geolocalization establishes pixel-to-geographic coordinate mappings using satellite imagery. When elevation data are unavailable, geographic positions are calculated under a planar terrain assumption. However, actual terrain variations and building heights introduce localization errors. This section analyzes errors attributable to the planar assumption.
Let denote the world coordinates of a geographical point, and represent its corresponding pixel coordinates in an aerial image. The elevation within the image coverage area follows a Gaussian distribution . Under the plane hypothesis, spatial points are approximated as . Define the true pose of the aerial vehicle as and , and the estimated pose as and . The PnP problem is established based on the projection relationship between pixel points and geographical points for pose solution.
Actual Reprojection Error:
Assuming a planar configuration, the reprojection error can be defined as follows:
Among them,
is the internal parameter matrix of the camera;
is the depth value of
in the camera coordinate system under the true pose; and
is the depth value of
in the estimated pose under the planar assumption. When the re-projection errors
E and
converge to zero through optimization, the normalized camera coordinate direction vectors projected to the same point by the real model and the planar hypothetical model must be equal. The difference between the depth scale
and
is compensated by the pose error, and we can approximately obtain
where
,
and
, respectively. Assume that
and
.
and
are the pose errors caused by the planar assumption, where
and
. By substituting
and
into Equation (
4), one obtains
By conducting a first-order Taylor expansion on the term associated with rotational disturbances, we can obtain
Assume that
; then, we can obtain
The mathematical expectation of
is as follows:
Assume that
and
. We can then obtain
It can be inferred that the expected value of the translation vector error comprises two components: the first component is the compensation error attributable to elevation data, while the second component arises from coupling errors associated with rotational disturbances and the arrangement of two-dimensional geographic coordinates. The equation suggests that an increase in the mean elevation of geographic points correlates with a corresponding increase in the translation vector error as determined by the PnP method under the assumption of a planar configuration.
2.3. Geographic Location Estimate Method for the Aerial Vehicle with Consistent Relative Depth
The coordinates of a geographical point in the world coordinate system are . Here, X and Y are known Mercator coordinates, while the height information for Z is unknown. Satellite remote sensing images use orthographic projection, where each pixel in the image corresponds one-to-one with a geographic point. By performing depth estimation on the satellite images, we obtain relative depth information for each pixel, with output values ranging from 0 to 255. The relative depth value is inversely proportional to the distance from the geographic point to the shooting point; a smaller value indicates a greater distance, while a larger value indicates a closer distance. Additionally, the depth value is positively correlated with the relative height of the geographic point; a larger value corresponds to a higher elevation, while a smaller value corresponds to a lower elevation.
Within the ideal geometric model of satellite orthoimages, assuming the camera height is H, the absolute depth of a geographical point in the same image can be calculated using the formula:
where
D represents the absolute depth,
d represents the relative depth, and
c represents the scale factor which has a unit of m. Assuming the elevation value of the camera is
H, and the elevation value of a certain geographical point is
, we can obtain
Thus, when the relative depth is the same, the actual terrain elevation data should also be consistent. Select the geographical coordinate
, ensuring that it maintains the same relative depth
d. Find the coordinate system such that
in this coordinate system is
and name this coordinate system the reference coordinate system. We can easily determine that
,
.
and
represent the rotation matrix and translation vector from the world coordinate system to the reference coordinate system, respectively, and the following can be obtained:
In the case of
, assume that the homogeneous coordinate of
pixel corresponding to the aerial image is
. Then, the coordinates
and
in the reference coordinate system satisfy the projection relationship as follows:
where
s is the scale factor,
and
are the rotation matrix and translation vector from the reference coordinate system to the aerial vehicle coordinate system, respectively. Let
, where
represents the
column
i vector. We can then obtain
Expanding Equation (
15) yields
We can then determine that
and
satisfy the homography transformation.
is the homologous transformation matrix from
to
. Let
and
, where
represents the matrix
column
i vector. Then, conduct Singular Value Decomposition (SVD) on matrices
and
:
where
. According to the conclusion of [
29], let
and
. Then, we can obtain
where
and
are the first two columns of
.
The coordinates of the aircraft in the world coordinate system are
where
Substituting it into Equation (
20) gives
Writing
, we can obtain
represents the coordinates of the aerial vehicle in the world coordinate system. The theoretical analysis indicates that when selecting geographical points with identical relative depth, the position of the aerial vehicle in the pseudo-Mercator coordinate system, namely
, can be accurately determined. Subsequently, by applying Equation (
24), the conversion from
to longitude
and latitude
coordinates can be achieved, thereby identifying the geographic location of the aerial vehicle.
2.4. Satellite Remote Sensing Image with Relative Depth-Assisted Aerial Vehicle Geolocalization Method
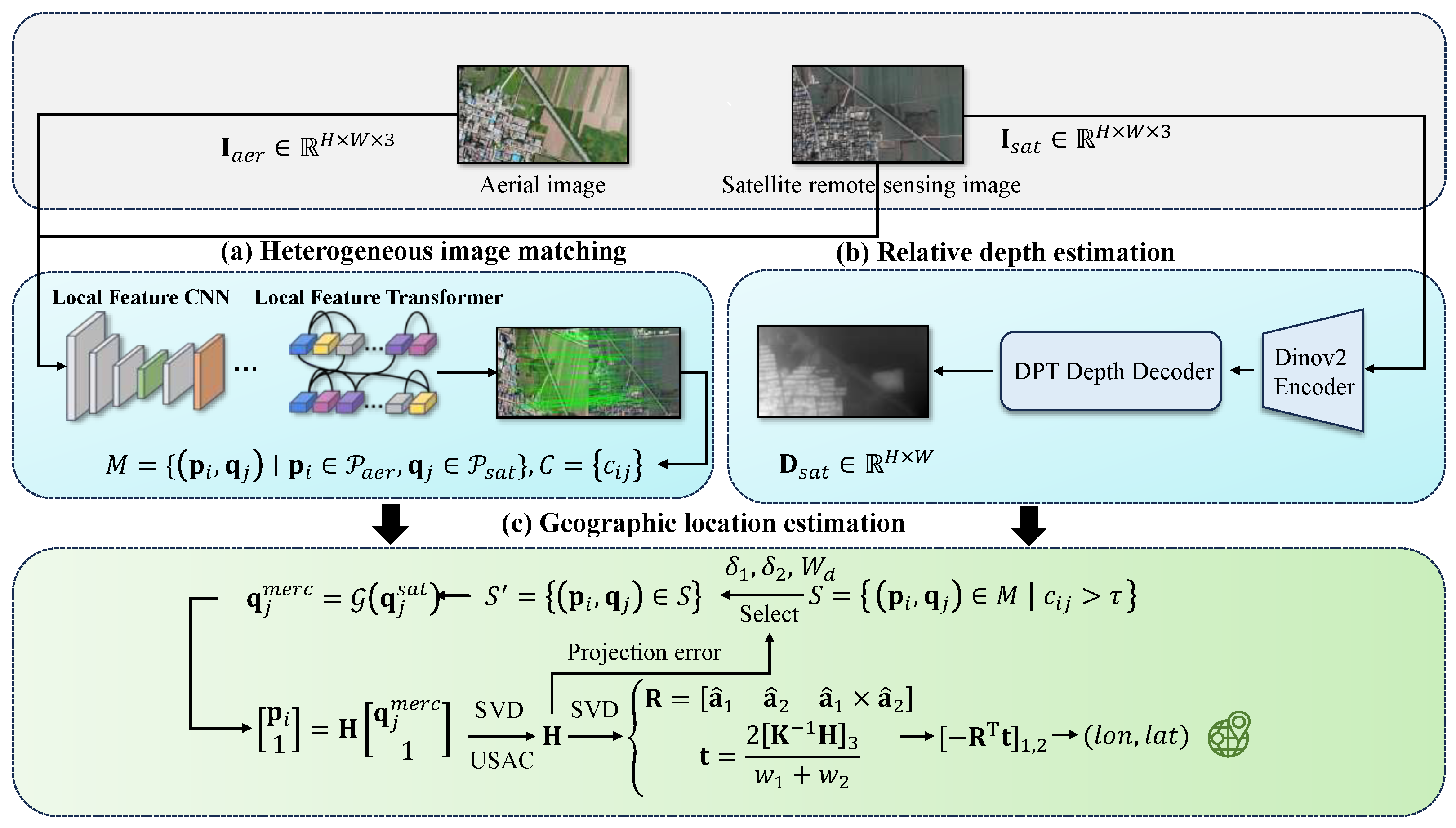
The methodology presented in this study consists of three core components: (a) a heterogeneous image-matching module, (b) a relative depth estimation module, and (c) a geographic location estimation module. As shown in
Figure 1, the approach takes aerial images and their corresponding satellite remote sensing images as input. These aerial and satellite images are first processed by the heterogeneous image-matching module to extract matched feature pairs and their associated confidence levels. The satellite remote sensing image is then channeled into the relative depth estimation module to generate its corresponding relative depth map. Finally, the matched feature pairs, their confidence levels, and the satellite-derived relative depth map are input to the geographic location estimation module. This module integrates these inputs to accurately estimate the geographic location of the aerial vehicle.
2.4.1. Heterogeneous Image Matching
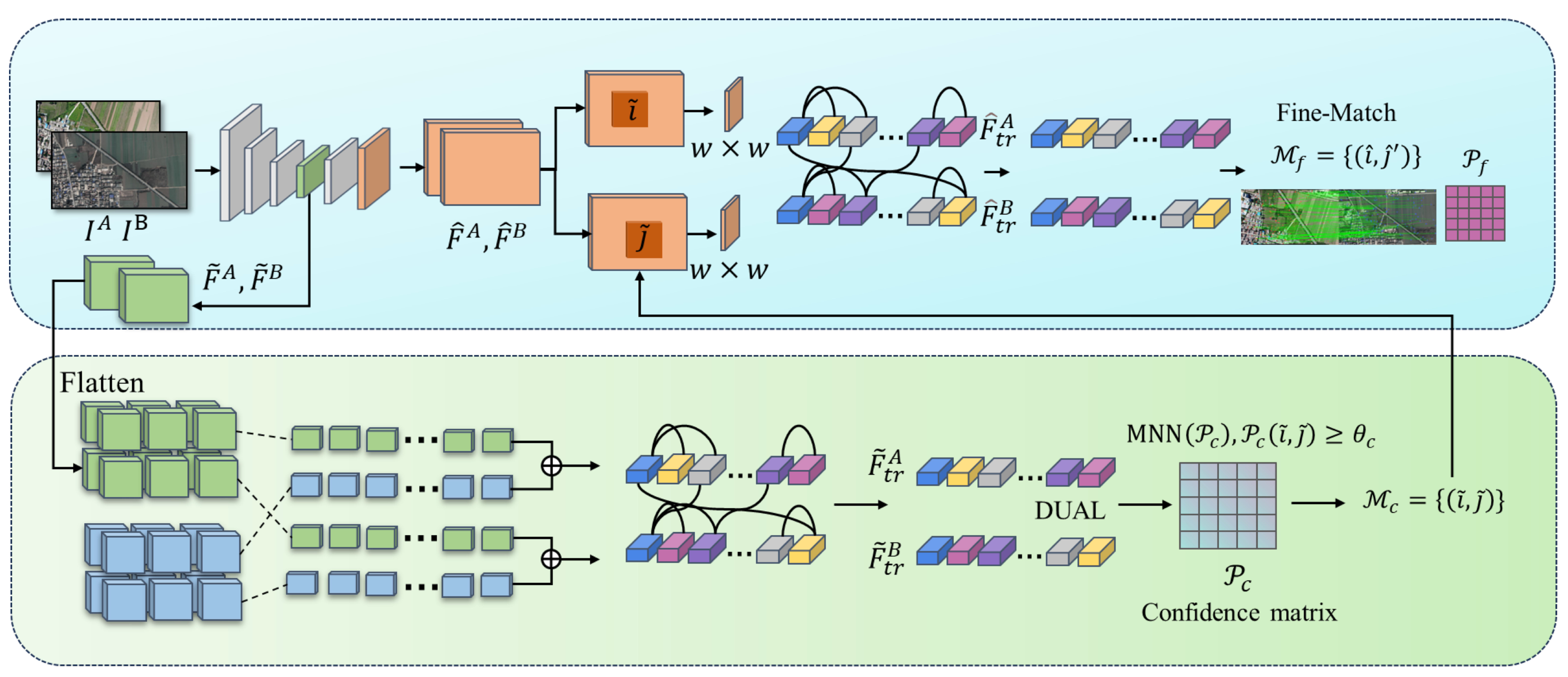
Heterogeneous image matching is facilitated by the use of LoFTR [
22]. This method adeptly addresses cross-modal discrepancies through its end-to-end architecture, which operates without the need for detectors. It employs global modeling via Transformers and integrates fine-to-coarse granularity fusion. Notably, LoFTR is capable of producing dense and highly accurate matching point pairs even in scenes characterized by low texture and non-linear variations. The framework of this approach is illustrated in
Figure 2.
The aerial image and the satellite remote sensing image are inputted into using the CNN feature extraction network to extract rough feature maps and of 1/8 size of the original image for quick screening of candidate matching regions. Fine feature maps and of 1/2 size retaining more details are used for precise localization.
Then,
and
are expanded, and positional encoding is added to the LoFTR module for processing to extract positional and context-dependent local features to obtain
and
.
and
are input into the differentiable matching layer to compute the score matrix
between the features:
When the dual-softmax micromatchable layer is then used, the matching confidence matrix
is obtained:
The matches are then selected based on confidence thresholds and mutual proximity criteria:
The coarse matching prediction is obtained. For each coarse matching result , the position is centered in the fine feature maps , . Then, the center vectors of are correlated with all the vectors of , respectively, to generate the heatmap, which represents the probability of matching each pixel in the neighborhood of with . Finally, the expectation value on the probability distribution is calculated to bring the coarse matching result up to the sub-pixel matching level to obtain the final matching result .
2.4.2. Relative Depth Estimation
The relative depth estimation module uses the Depth Anything V2 model [
30], which, in contrast to its predecessor V1 [
31], uses fully synthetic images in place of all labeled real images and incorporates semantic information to train the teacher model. Reliable teacher models are trained based on high-quality synthetic images DINOv2-G. Pseudo-depth is generated using the teacher model on large-scale unlabeled real images. Student models, on the other hand, are trained based on pseudo-labeled real images for robust generalization. The training used five exact synthetic datasets (595,000 images) and eight large-scale pseudo-labeled real datasets (62 million images). Using the pseudo-labeling generated by the above exploits, ref. [
30] trained four student models of different sizes (Small/Base/Large/Giant). Student models acquired the ability to make accurate depth predictions on real images by mimicking the teacher model’s behavior. The geometric constraints of nadir-view orthographic projection in satellite imagery position the imaging plane approximately perpendicular to the ground surface; consequently, relative depth differences between pixels directly correspond to changes in surface elevation. We therefore employ the Large variant to estimate satellite image depth, generating a 0–255 grayscale map representing relative depth. Lower values indicate smaller elevation values, while higher values signify greater elevation. Relative depth estimation is illustrated in
Figure 3.
2.4.3. Geographic Location Estimation
Denote the feature point matching set of the aerial image and the satellite remote sensing image as , where and denote the feature point sets of the aerial image and the satellite remote sensing image, respectively. The feature point coordinates and are pixel coordinates. Meanwhile, let be the matching confidence level of and . Let the relative depth estimation result of the satellite remote sensing image be denoted as , a grayscale image composed of 0-255.
First, screen through the confidence threshold
and take 0.3. The filtered matching set is
The relative depth values of aerial image feature points are determined by , where . Feature points with the same depth value are selected using the depth consistency constraint. Since depth estimation has errors, the windowing mechanism is chosen. A dynamic depth window is constructed, where is the standard deviation of the depth values of the feature points of the aerial image. The sliding window mechanism is then used to traverse and select the subset .
Next, a triple constraint is imposed on the candidate subset. The first is the subset size constraint; to ensure that a single-response matrix computation can be performed, the number of matches in the subset needs to be larger than 4. The second is the confidence constraint; to ensure the matching quality of the subset, the average confidence of the matched pairs needs to be larger than the threshold value of
.
does not use a fixed value and represents the average confidence level of the matching pairs. The third is the spatial distribution constraint; to ensure that the distribution of the feature points in the subset is uniform, we use the convex hull area of the feature points of aerial images in the selected subset to carve out the area of convex bags. The greater the convex hull area is over the area of the image, the more uniform its distribution is. The larger the area is, the more uniform its distribution is. The projected coordinates of the candidate subset
on the aerial image are
, and its convex hull area is computed by Graham’s scanning algorithm:
The ratio of convex hull area to image area needs to be satisfied:
The parameter
is adaptively determined through a dynamic selection strategy based on the depth window
. An increased
value signifies substantial relative depth variations within the region, thereby necessitating a higher
threshold to enforce enhanced spatial homogeneity of feature correspondences. Conversely, a diminished
indicates limited depth disparity, permitting relaxation of the threshold. This adaptive mechanism is formally expressed as
where
,
, and
.
At this point, the candidate subset
are points approximately in the same plane. The candidate subset
satisfying the above three constraints is subjected to the computation of the homography matrix. Let the mapping relation from the pixel coordinates to the Mercator coordinates of the satellite map be
where
is the known geographical alignment function and
. The geographical alignment function is
where
are the Mercator coordinates and
are the Mercator coordinates corresponding to the pixels in the upper left corner of the satellite remote sensing image. The spatial resolution of the
d satellite remote sensing image represents the actual distance corresponding to a single pixel.
For
, establish the projection relationship from the pixel coordinates of the aerial image to the Mercator coordinates:
where
is the homogeneous coordinate of the feature points in the aerial image and
is the Mercator homogeneous coordinate.
is the homography matrix. Expanding Equation (
34), we can obtain
For
that meets the conditions, solve the homography matrix
and calculate the projection error of the inner points. Select the one with the most minor error,
. Then, based on the derivation in
Section 2.3, decompose
to obtain
and
:
The geographic location of the aerial vehicle in the Mercator coordinate system
is
. The geographic location of the aerial vehicle can be obtained by bringing
into Equation (
24).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}