

A Lightweight Method for Road Defect Detection in UAV Remote Sensing Images with Complex Backgrounds and Cross-Scale Fusion

 , , , and
, , , and
Abstract
1. Introduction
2. Related Works
2.1. Algorithmic Solutions
2.2. Data Enhancement
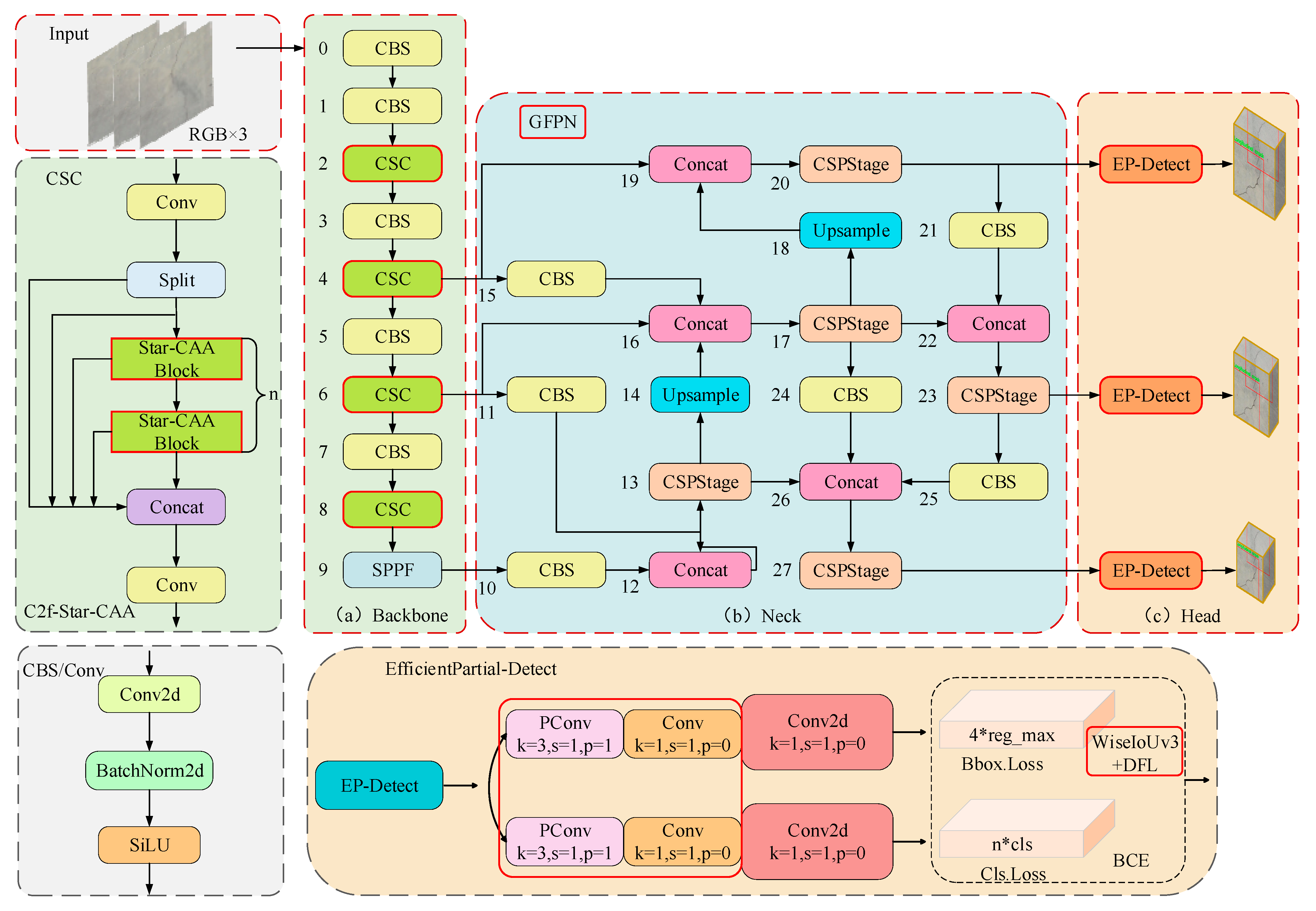
3. Materials and Methods
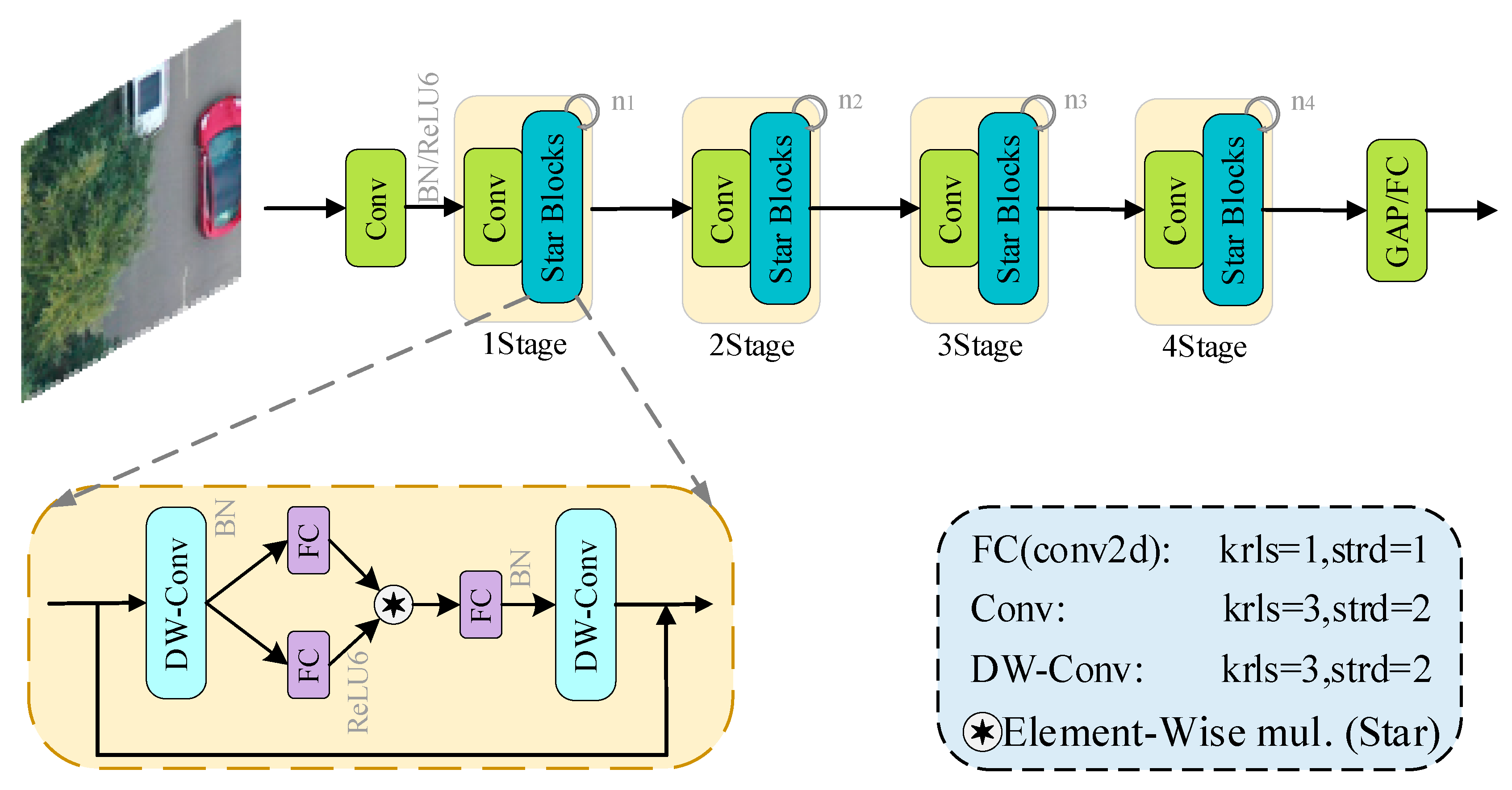
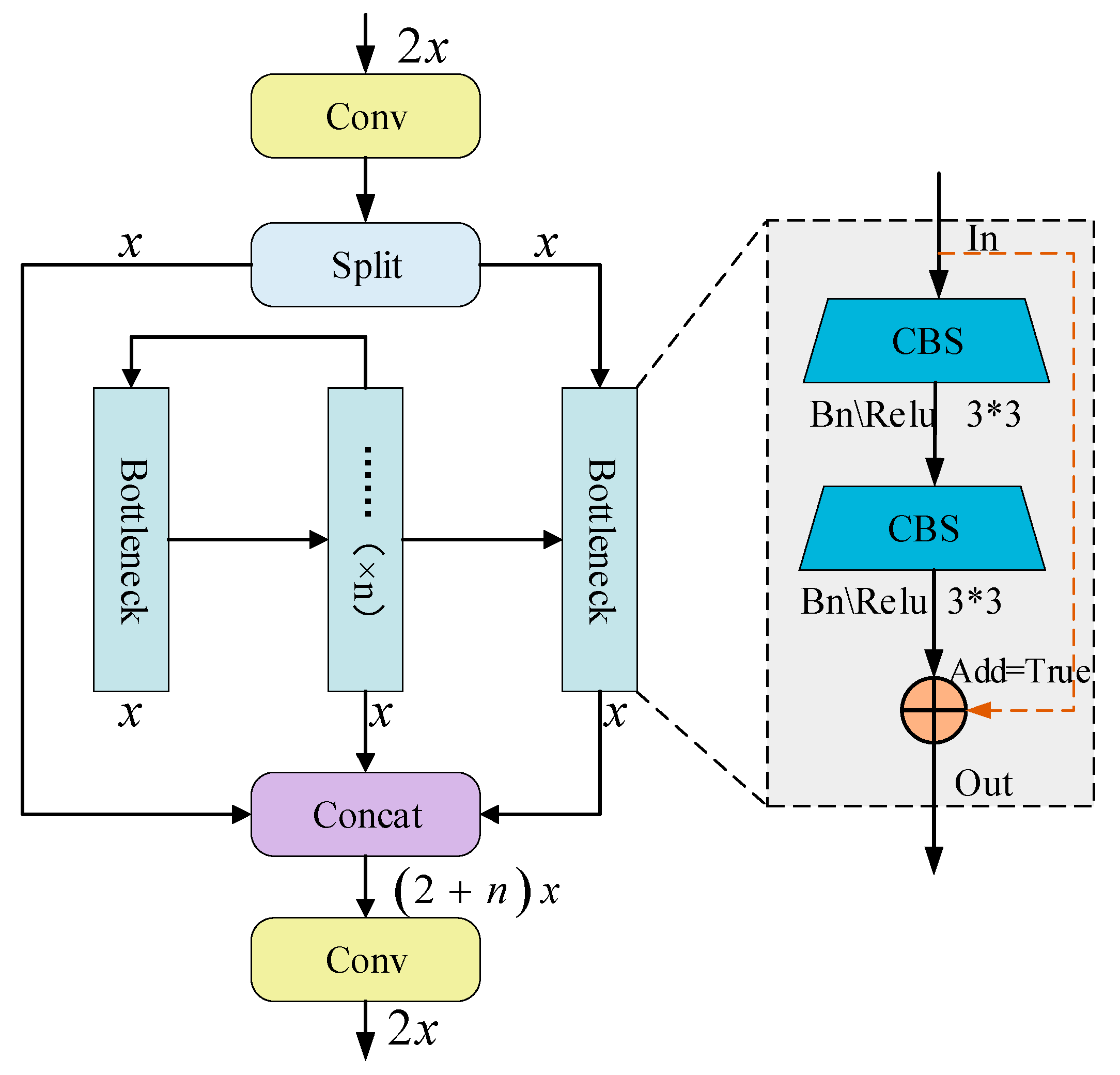
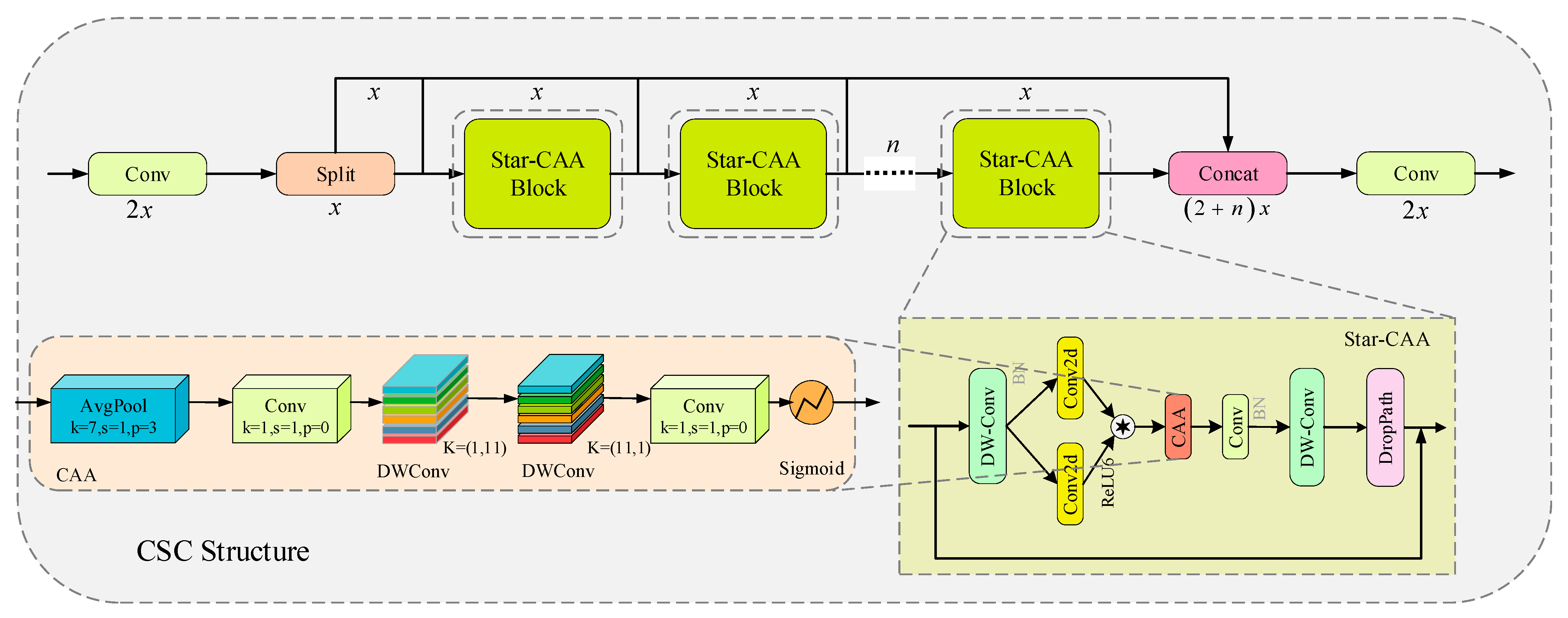
3.1. CSC Feature Extraction Structure
3.1.1. StarNetwork
3.1.2. CAA Attention Mechanism
3.1.3. CSC Architecture
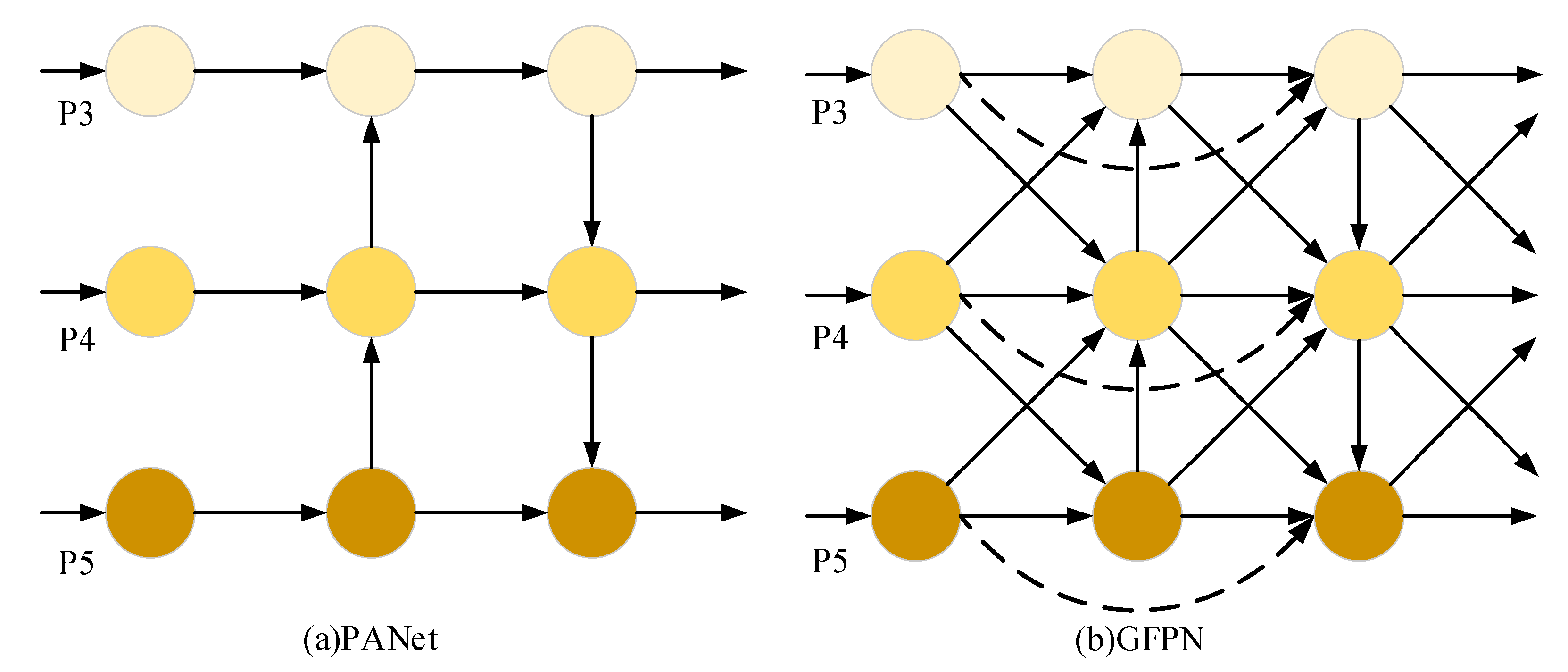
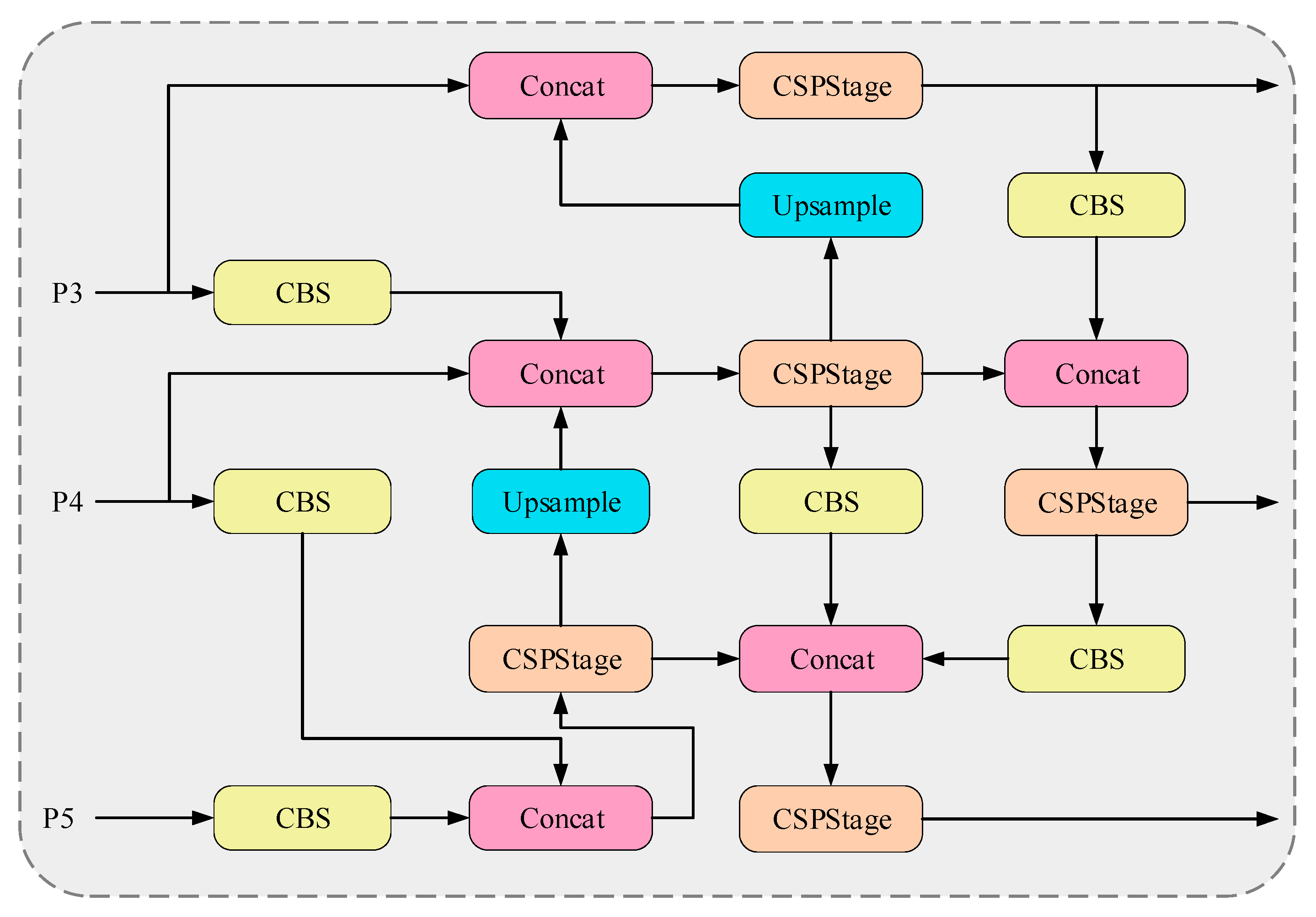
3.2. Cross-Scale Feature Fusion Strategies
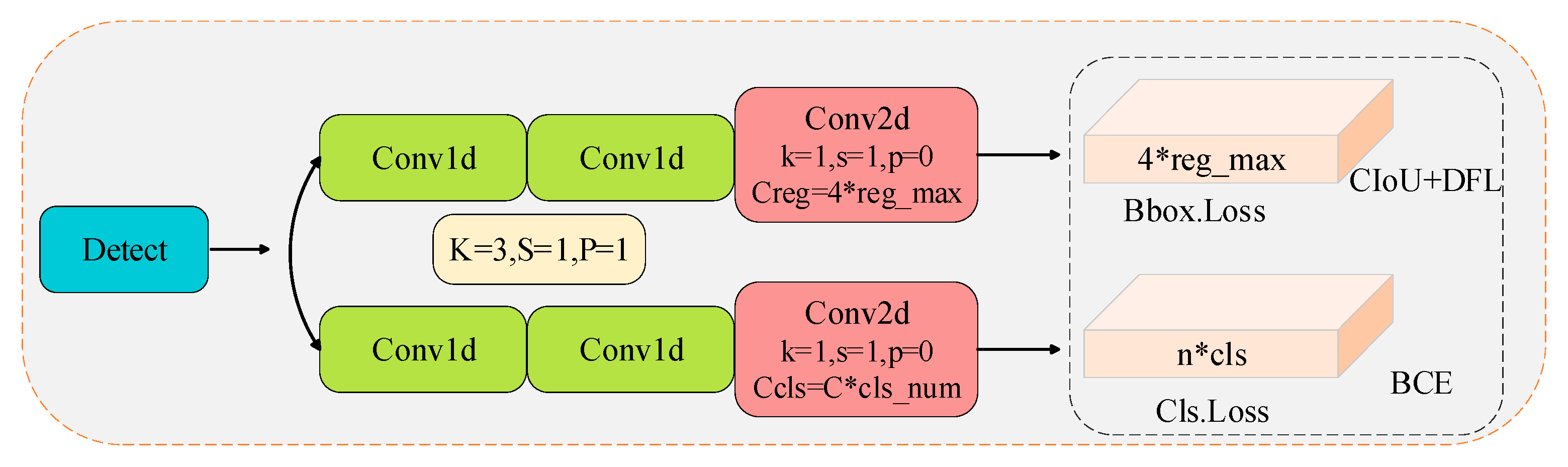
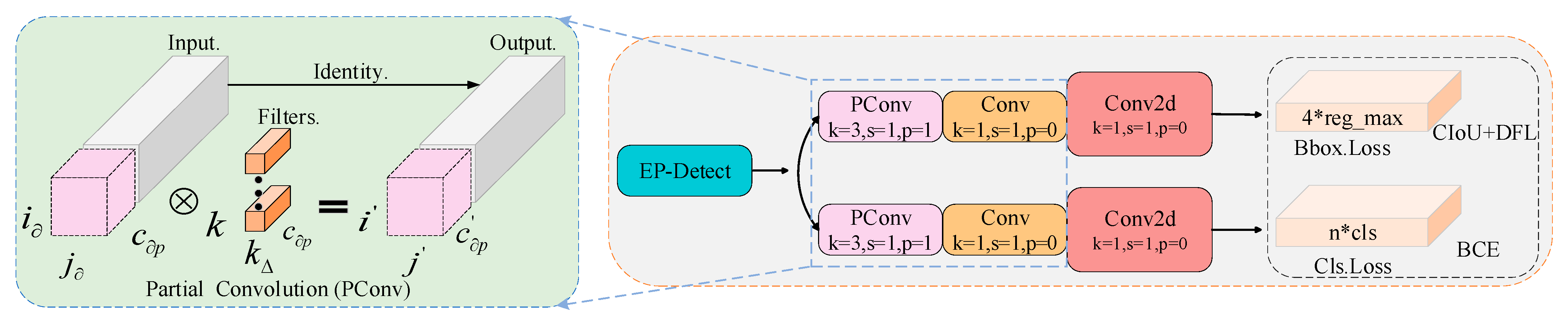
3.3. Lightweight Detection Module
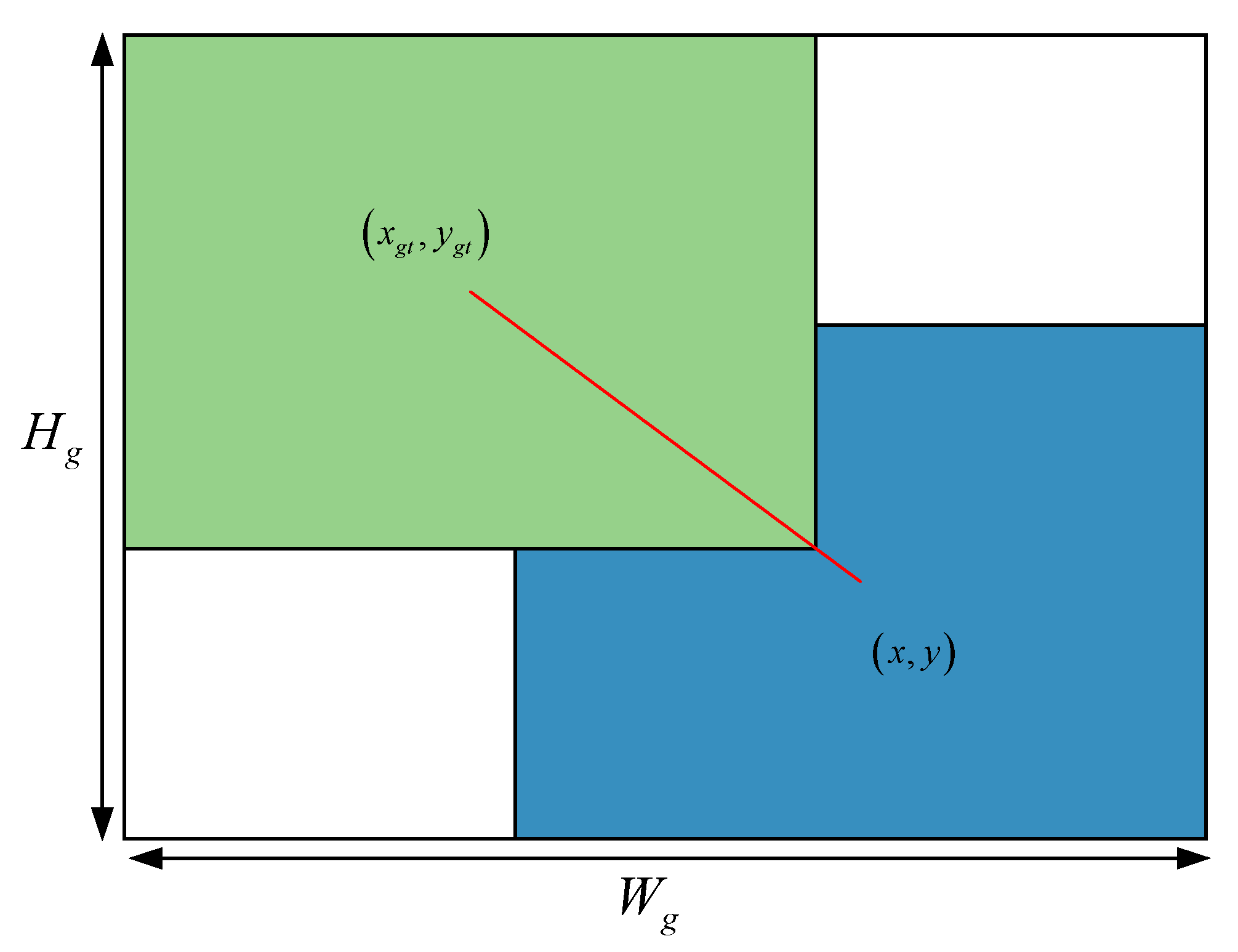
3.4. Regression Loss Function Optimization
4. Results
4.1. Introduction and Handling of Datasets
4.2. Experimental Setup
4.3. Ablation Experiments
4.4. Comparison of Data Enhancement Results
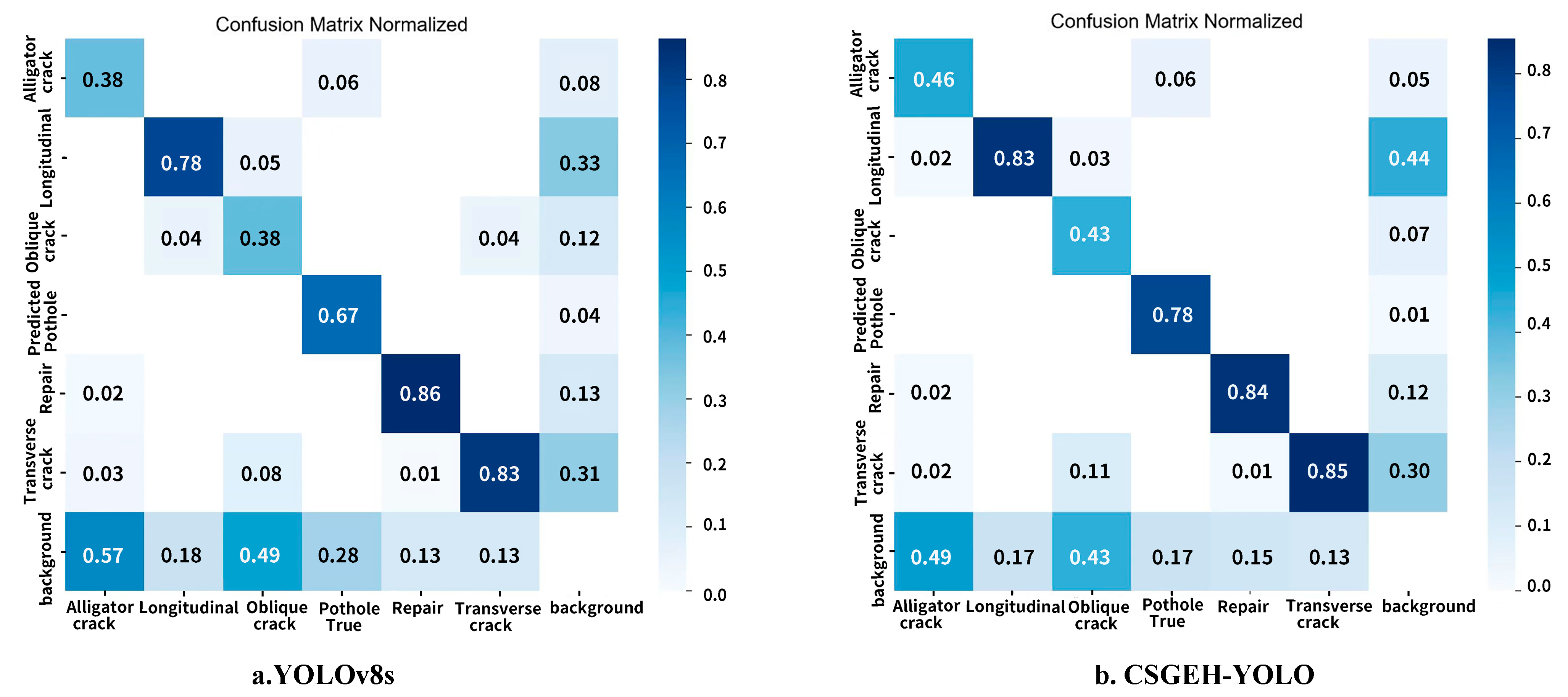
4.5. Comparison Experiments
4.6. Model Generalizability Validation
5. Discussion
5.1. Theoretical Mechanisms of Performance Enhancement
- (1)
- This paper innovatively introduces the CSC structure, which facilitates the mapping of high-dimensional nonlinear feature spaces through the integration of the star operation and the CAA attention mechanism. This integration is particularly beneficial for generating richer semantic feature representations, especially for small targets and complex scenes. The enhanced feature representations significantly improve the detection performance, enabling the improved network to exhibit superior shallow spatial information extraction capabilities for road damage features within complex backgrounds.
- (2)
- In this study, a cross-scale feature fusion strategy is devised, incorporating multilayer up-sampling, standard convolutional block down-sampling, and channel fusion operations. This strategy effectively integrates the characteristics of deep semantic information and shallow spatial information, achieving efficient cross-scale feature fusion. The proposed structure not only enhances the expressive capability of multi-scale road damage features but also extends the network’s connectivity to deep-level features.
- (3)
- In response to the computational burden imposed by the decoupling head in the baseline model, while recognizing that partial convolution (PConv) reduces feature map redundancy by convolving only a subset of channels without affecting the remaining channels, this paper ingeniously designs a lightweight detection head, EP-Detect. This improvement effectively reduces the model’s computational cost, fully leveraging the device’s computational performance to alleviate the computational burden. Simultaneously, it achieves efficient aggregation of global spatial information.
- (4)
- This paper optimizes the bounding box regression loss function by introducing the dynamic non-monotonic focusing WIoUv3 weighting function. This enhancement effectively focuses the model’s attention on challenging and interfering road damages within complex backgrounds, prompting the model to comprehensively learn the characteristics of road damage. Consequently, it significantly improves the detection accuracy index while accelerating model convergence and maintaining the model’s parameter count and computational volume.
5.2. Limitations and Future Directions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, M.; Dong, Q.; Ni, F.; Wang, L. LCA and LCCA based multi-objective optimization of pavement maintenance. J. Clean. Prod. 2021, 283, 124583. [Google Scholar] [CrossRef]
- Qiu, Q.; Lau, D. Real-time detection of cracks in tiled sidewalks using YOLO-based method applied to unmanned aerial vehicle (UAV) images. Autom. Constr. 2023, 147, 104745. [Google Scholar] [CrossRef]
- Silva, L.A.; Leithardt, V.R.Q.; Batista, V.F.L.; Villarrubia González, G.; De Paz Santana, J.F. Automated Road Damage Detection Using UAV Images and Deep Learning Techniques. IEEE Access 2023, 11, 62918–62931. [Google Scholar] [CrossRef]
- Devi, M.P.A.; Latha, T.; Sulochana, C.H. Iterative thresholding based image segmentation using 2D improved Otsu algorithm. In Proceedings of the Global Conference on Communication Technologies (GCCT), Thuckalay, India, 23–24 April 2015. [Google Scholar]
- Hu, W.; Wang, W.; Ai, C.; Wang, J.; Wang, W.; Meng, X.; Liu, J.; Tao, H.; Qiu, S. Machine vision-based surface crack analysis for transportation infrastructure. Autom. Constr. 2021, 132, 103973. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 379–387. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C. SSD: Single Shot Multibox Detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Jiang, T.-Y.; Liu, Z.-Y.; Zhang, G.-Z. YOLOv5s-road: Road surface defect detection under engineering environments based on CNN-transformer and adaptively spatial feature fusion. Measurement 2025, 242, 115990. [Google Scholar] [CrossRef]
- Wu, C.; Ye, M.; Zhang, J.; Ma, Y. YOLO-LWNet: A Lightweight Road Damage Object Detection Network for Mobile Terminal Devices. Sensors 2023, 23, 3268. [Google Scholar] [CrossRef]
- Liu, T.; Gu, M.; Sun, S. RIEC-YOLO: An improved road defect detection model based on YOLOv8. Signal Image Video Process. 2025, 19, 285. [Google Scholar] [CrossRef]
- Wang, X.; Gao, H.; Jia, Z.; Zhao, J. A road defect detection algorithm incorporating partially transformer and multiple aggregate trail attention mechanisms. Meas. Sci. Technol. 2024, 36, 026003. [Google Scholar] [CrossRef]
- Ruggieri, S.; Cardellicchio, A.; Nettis, A.; Renò, V.; Uva, G. Using Attention for Improving Defect Detection in Existing RC Bridges. IEEE Access 2025, 13, 18994–19015. [Google Scholar] [CrossRef]
- Yaseen, M. What is YOLOv8: An in-depth exploration of the internal features of the next-generation object detector. arXiv 2024, arXiv:2408.15857. [Google Scholar]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the Stars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 5694–5703. [Google Scholar]
- Cai, X.; Lai, Q.; Wang, Y.; Sun, Z.; Yao, Y. Poly kernel inception network for remote sensing detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 27706–27716. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Jiang, Y.; Tan, Z.; Wang, J.; Sun, X. GiraffeDet: A heavy-neck paradigm for object detection. arXiv 2022, arXiv:2202.04256. [Google Scholar]
- Shi, T.; Gong, J.; Hu, J.; Zhi, X.; Zhu, G.; Yuan, B.; Sun, Y.; Zhang, W. Adaptive feature fusion with attention-guided small target detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Chen, J.; He, H.; Zhuo, W.; Wen, S. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031.
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Zhu, J.; Zhong, J.; Ma, T.; Huang, X.; Zhang, W.; Zhou, Y. Pavement distress detection using convolutional neural networks with images captured via UAV. Autom. Constr. 2022, 133, 103991. [Google Scholar] [CrossRef]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS) IEEE, Coimbatore, India, 6–7 March 2020; pp. 687–694. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Hogan, A.; Diaconu, L.; Poznanski, J.; Yu, L.; Rai, P.; Ferriday, R. ultralytics/yolov5: V3.0. Zenodo 2020. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; LIao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Mark Liao, H.-Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the Computer Vision—ECCV 2024, Milan, Italy, 29 September–4 October 2024; pp. 1–21.
- Wang, A.; Chen, H.; Liu, L.; Chen, H.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Sekimoto, Y. RDD2022: A multi-national image dataset for automatic road damage detection. Geosci. Data J. 2024, 11, 846–862. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, J.; Fichera, S.; Paoletti, P.; Layzell, L.; Mehta, D.; Luo, S. Road Surface Defect Detection—From Image-Based to Non-Image-Based: A Survey. IEEE Trans. Intell. Transp. Syst. 2024, 25, 10581–10603. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resolution (pixels2) | Photogrammetric Area (m2) | Flight Altitude (m) | Flight Speed (m/s) | Frontal Overlap | Sensor Size (mm2) | Focal Length (mm) | Shutter Speed (s) |
|---|---|---|---|---|---|---|---|
| 7952 × 5304 | 26 × 20.57 | 30 | 5.1425 | 75% | 35.9 × 24 | 35 | 1/1200 |
| Algorithm | CSC | GFPN | EH | WiseIoUv3 | Params/M | FLOPs/109 | mAP@0.5/% |
|---|---|---|---|---|---|---|---|
| Baseline | 11.4 | 28.8 | 59.5 | ||||
| +A | √ | 12.6 | 30.9 | 61.2 (+1.7) | |||
| +A+B | √ | √ | 12.5 | 29.6 | 61.6 (+2.1) | ||
| +A+B+C | √ | √ | √ | 11.0 | 22.6 | 62.1 (+2.6) | |
| +A+B+C+D | √ | √ | √ | √ | 11.0 | 22.6 | 62.6 (+3.1) |
| Model | All | Alligator crk | Longitudinal crk | Oblique crk | Pothole | Repair | Transverse crk |
|---|---|---|---|---|---|---|---|
| Baseline | 36.2 | 16.5 | 38 | 14.1 | 39.1 | 64.3 | 42.9 |
| Ours | 37.4 | 18.2 | 38.2 | 15.1 | 44.2 | 66.7 | 44.3 |
| Algorithm | Params/M | FLOPs/109 | mAP@0.5/% | mAP@0.5:0.95/% |
|---|---|---|---|---|
| YOLOv8s | 11.4 | 28.8 | 63 | 38.2 |
| +CSC | 12.6 | 30.9 | 63.6 | 38.2 |
| +GFPN | 12.1 | 29.3 | 64 | 40 |
| +EH | 9.6 | 21.5 | 64.7 | 40.1 |
| +WiseIoUv3 | 11.4 | 28.8 | 63.7 | 39.4 |
| CSGEH-YOLO | 11.0 | 22.6 | 65.5 | 40.3 |
| Dataset | Modeling Approach | mAP@0.5/% | Params/M | FLOPs/G | mAP@0.5:0.95/% |
|---|---|---|---|---|---|
| UAPD | YOLOv8s | 59.5 | 11.4 | 28.8 | 36.2 |
| CSGEH-YOLO | 62.6 | 11.0 | 22.6 | 37.4 | |
| UAPD-AUG | YOLOv8s | 63 (+3.5) | 11.4 | 28.8 | 38.2 (+2.0) |
| CSGEH-YOLO | 65.5 (+2.9) | 11.0 | 22.6 | 40.3 (+2.9) |
| Algorithms | Precision\% | Recall\% | mAP@0.5\% | mAP@0.5:0.95\% | Params\M | FLOPs\G |
|---|---|---|---|---|---|---|
| YOLOv3-tiny | 60.2 | 53.8 | 57.4 | 32.1 | 9.5 | 14.3 |
| YOLOv5s | 60.4 | 55 | 59.1 | 35 | 9.1 | 23.8 |
| YOLOv6s | 51.4 | 53 | 52.6 | 30.9 | 16.2 | 44.2 |
| YOLOv7-tiny | 55.4 | 53.3 | 54.5 | 31.5 | 6.2 | 13.7 |
| RT-DETR-l | 52.9 | 57.4 | 52.9 | 30.6 | 28.4 | 100.3 |
| YOLOv8n | 58.6 | 60 | 57.4 | 34.6 | 3.2 | 8.7 |
| YOLOv9s | 62.8 | 58.3 | 60.7 | 36.6 | 7.1 | 26.4 |
| YOLOv10s | 60.9 | 54.4 | 56.6 | 33.6 | 7.2 | 21.6 |
| YOLO11n | 55.6 | 53.9 | 56.3 | 33.8 | 2.5 | 6.3 |
| YOLO11s | 64.8 | 55 | 59.2 | 35.1 | 9.4 | 21.5 |
| CSGEH-YOLO | 64.1 | 61.9 | 62.6 | 37.4 | 11 | 22.6 |
| Categories | YOLOv8s | CSGEH-YOLO | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | mAP50 (%) | Precision (%) | Recall (%) | mAP50 (%) | |
| D00 | 67 | 69.7 | 65.7 | 70.2 (+3.2) | 71 (+1.3) | 70.7 (+5.0) |
| D10 | 73.2 | 78.3 | 80.5 | 74.1 (+0.9) | 79.1 (+0.8) | 81(+0.5) |
| D20 | 50.8 | 44 | 44.7 | 51.7 (+0.9) | 44(+0.0) | 46.4 (+1.7) |
| D40 | 86 | 61.6 | 67.8 | 90.8 (+4.8) | 70 (+8.4) | 71.2 (+3.4) |
| Repair | 75.3 | 82.6 | 84.7 | 71.1 | 76.7 | 82.2 |
| all | 70.5 | 67.2 | 68.7 | 71.6 (+1.1) | 68.2 (+1.0) | 70.3 (+1.6) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Li, X.; Wang, L.; Zhang, D.; Lu, P.; Wang, L.; Cheng, C. A Lightweight Method for Road Defect Detection in UAV Remote Sensing Images with Complex Backgrounds and Cross-Scale Fusion. Remote Sens. 2025, 17, 2248. https://doi.org/10.3390/rs17132248
Zhang W, Li X, Wang L, Zhang D, Lu P, Wang L, Cheng C. A Lightweight Method for Road Defect Detection in UAV Remote Sensing Images with Complex Backgrounds and Cross-Scale Fusion. Remote Sensing. 2025; 17(13):2248. https://doi.org/10.3390/rs17132248
Chicago/Turabian StyleZhang, Wenya, Xiang Li, Lina Wang, Danfei Zhang, Pengfei Lu, Lei Wang, and Chuanxiang Cheng. 2025. "A Lightweight Method for Road Defect Detection in UAV Remote Sensing Images with Complex Backgrounds and Cross-Scale Fusion" Remote Sensing 17, no. 13: 2248. https://doi.org/10.3390/rs17132248
APA StyleZhang, W., Li, X., Wang, L., Zhang, D., Lu, P., Wang, L., & Cheng, C. (2025). A Lightweight Method for Road Defect Detection in UAV Remote Sensing Images with Complex Backgrounds and Cross-Scale Fusion. Remote Sensing, 17(13), 2248. https://doi.org/10.3390/rs17132248