

Multi-Level Intertemporal Attention-Guided Network for Change Detection in Remote Sensing Images


Abstract
1. Introduction
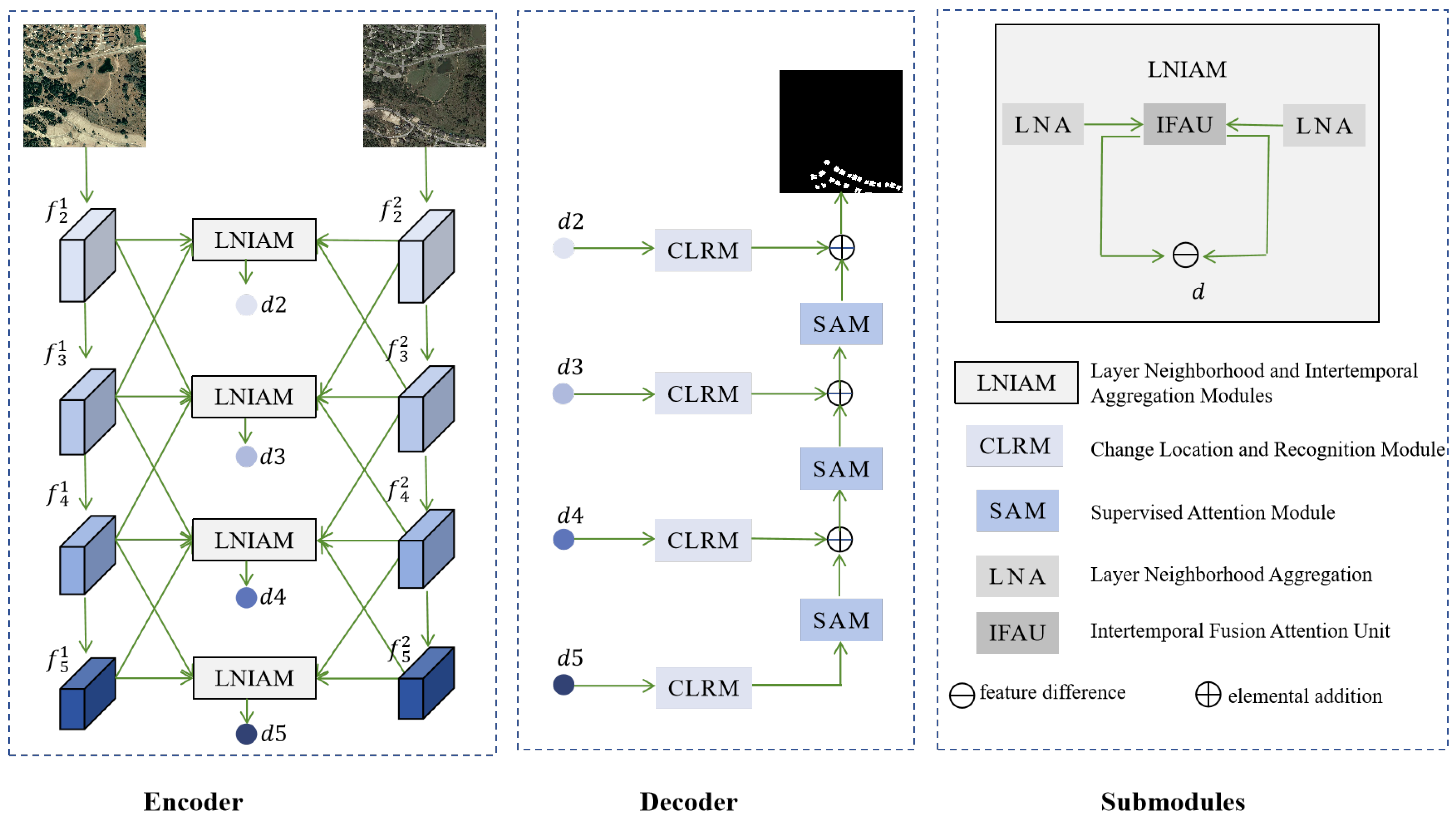
- We propose an IFAU that leverages the change information in feature maps at different time phases to guide the attention matrix. This approach effectively mines early correlation information between bi-temporal images and efficiently suppresses the influence of irrelevant changes.
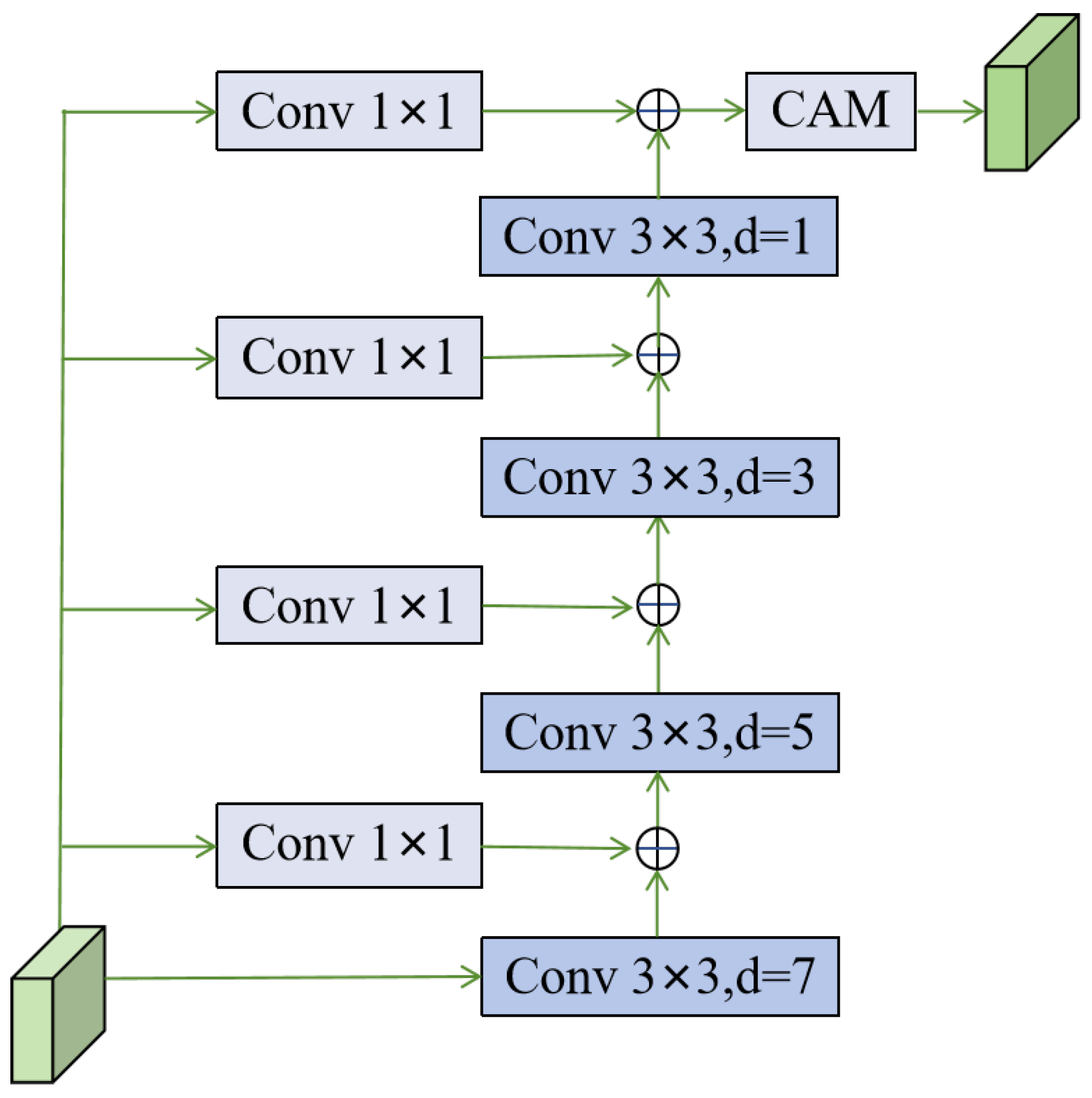
- We present a CLRM that investigates change information using dilated convolutions on multi-scale feature maps, while CAM is employed for precise localization and recognition of the change areas.
- The proposed algorithm demonstrates robust performance in complex scenes, as evidenced by the experimental results obtained on the challenging GVLM dataset.
2. Related Work
2.1. Attention Mechanism
2.2. Deep Learning-Based Change Detection Methods
3. Method
3.1. Network Architecture
3.1.1. Encoder
3.1.2. Decoder
3.2. Layer Neighborhood and Intertemporal Aggregation Modules
3.3. Change Location and Recognition Module
3.4. Loss Function
3.5. Optimizing Strategy
| Algorithm 1 MIANet |
| Input: 256 × 256 pixel size training set, verification set, and test set Steps:
After reaching a fixed number of epochs, the best model is obtained. Output:
|
4. Experiment
4.1. Datasets
4.1.1. LEVIR-CD [41]
4.1.2. GVLM [42]
4.2. Evaluation Metrics
4.3. Parameter Experiments
4.4. Ablation Experiments
4.5. Visualization of Differential Features
4.6. Comparison Experiments
- BIT [33]: The contextual information modeling across different time phases is achieved through the use of a bi-temporal image converter. This model, characterized by its reduced computational complexity and parameter count, attains better results in terms of both efficiency and accuracy.
- USSFC-Net [43]: By employing a multi-scale coupled convolution design, the extraction of multi-scale change features is accomplished, facilitating the integration of spectral and spatial information while minimizing parameters and computational load.
- SNUNet [44]: The integration of a Siamese network and NestedUNet addresses challenges related to small targets and misjudgment of edge pixels. By leveraging densely connected network transmission, the algorithm mitigates the loss of deep positional information. Furthermore, the utilization of the Ensemble Channel Attention Module (ECAM) enables the mining of diverse information across various levels to extract more representative features.
- DMINet [45]: An intertemporal joint attention block is proposed, which merges self-attention and cross-attention mechanisms. This attention block is informed by the change features observed in images captured at different moments, enabling it to suppress the interference of irrelevant changes effectively.
- C2FNet [46]: The collaborative action of multiple attention modules enables multi-scale feature fusion, facilitating feature extraction from coarse to fine levels.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CD | Change Detection |
| RSIs | Remote Sensing Images |
| MIANet | Multi-level Intertemporal Attention-guided Network |
| IFAU | Intertemporal Fusion Attention Unit |
| CLRM | Change Location and Recognition Module |
| LNA | Layer Neighborhood Aggregation |
| CAM | Coordinate Attention Mechanism |
| SAM | Supervised Attention Module |
| SENets | Squeeze-and-Excitation Networks |
| STN | Spatial Transformer Network |
| CBAM | Convolutional Block Attention Module |
| LNIAMs | Layer Neighborhood and Intertemporal Aggregation Modules |
| AFM | Attention Feature Map |
References
- Lynch, P.; Blesius, L.; Hines, E. Classification of urban area using multispectral indices for urban planning. Remote Sens. 2020, 12, 2503. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Yang, C.; Zhao, S. Urban vertical profiles of three most urbanized Chinese cities and the spatial coupling with horizontal urban expansion. Land Use Policy 2022, 113, 105919. [Google Scholar] [CrossRef]
- Aamir, M.; Ali, T.; Irfan, M.; Shaf, A.; Azam, M.Z.; Glowacz, A.; Brumercik, F.; Glowacz, W.; Alqhtani, S.; Rahman, S. Natural disasters intensity analysis and classification based on multispectral images using multi-layered deep convolutional neural network. Sensors 2021, 21, 2648. [Google Scholar] [CrossRef]
- Jun, L.; Shao-qing, L.; Yan-rong, L.; Rong-rong, Q.; Tao-ran, Z.; Qiang, Y.; Ling-tong, D. Evaluation and Modifying of Multispectral Drought Severity Index. Spectrosc. Spectr. Anal. 2020, 40, 3522–3529. [Google Scholar]
- Peng, B.; Meng, Z.; Huang, Q.; Wang, C. Patch similarity convolutional neural network for urban flood extent mapping using bi-temporal satellite multispectral imagery. Remote Sens. 2019, 11, 2492. [Google Scholar] [CrossRef]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Di Francesco, S.; Casadei, S.; Di Mella, I.; Giannone, F. The role of small reservoirs in a water scarcity scenario: A computational approach. Water Resour. Manag. 2022, 36, 875–889. [Google Scholar] [CrossRef]
- Li, J.; Peng, B.; Wei, Y.; Ye, H. Accurate extraction of surface water in complex environment based on Google Earth Engine and Sentinel-2. PLoS ONE 2021, 16, e0253209. [Google Scholar] [CrossRef]
- Tewkesbury, A.P.; Comber, A.J.; Tate, N.J.; Lamb, A.; Fisher, P.F. A critical synthesis of remotely sensed optical image change detection techniques. Remote Sens. Environ. 2015, 160, 1–14. [Google Scholar] [CrossRef]
- Asokan, A.; Anitha, J. Change detection techniques for remote sensing applications: A survey. Earth Sci. Informatics 2019, 12, 143–160. [Google Scholar] [CrossRef]
- Afaq, Y.; Manocha, A. Analysis on change detection techniques for remote sensing applications: A review. Ecol. Informatics 2021, 63, 101310. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change detection based on artificial intelligence: State-of-the-art and challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Caye Daudt, R.; Le Saux, B.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar] [CrossRef]
- Rahman, F.; Vasu, B.; Van Cor, J.; Kerekes, J.; Savakis, A. Siamese network with multi-level features for patch-based change detection in satellite imagery. In Proceedings of the 2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Anaheim, CA, USA, 26–28 November 2018; IEEE: Piscataway Township, NJ, USA, 2018; pp. 958–962. [Google Scholar]
- Liu, M.; Shi, Q.; Marinoni, A.; He, D.; Liu, X.; Zhang, L. Super-resolution-based change detection network with stacked attention module for images with different resolutions. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4403718. [Google Scholar] [CrossRef]
- Zhang, X.; Cheng, S.; Wang, L.; Li, H. Asymmetric cross-attention hierarchical network based on CNN and transformer for bitemporal remote sensing images change detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2000415. [Google Scholar] [CrossRef]
- Lv, Z.; Zhong, P.; Wang, W.; You, Z.; Falco, N. Multiscale Attention Network Guided With Change Gradient Image for Land Cover Change Detection Using Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 2501805. [Google Scholar] [CrossRef]
- Li, Z.; Tang, C.; Liu, X.; Zhang, W.; Dou, J.; Wang, L.; Zomaya, A.Y. Lightweight remote sensing change detection with progressive feature aggregation and supervised attention. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5602812. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Tsotsos, J.K.; Culhane, S.M.; Wai, W.Y.K.; Lai, Y.; Davis, N.; Nuflo, F. Modeling visual attention via selective tuning. Artif. Intell. 1995, 78, 507–545. [Google Scholar] [CrossRef]
- Yu, C.; Han, R.; Song, M.; Liu, C.; Chang, C.I. Feedback attention-based dense CNN for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5501916. [Google Scholar] [CrossRef]
- Shi, C.; Liao, D.; Zhang, T.; Wang, L. Hyperspectral image classification based on 3D coordination attention mechanism network. Remote Sens. 2022, 14, 608. [Google Scholar] [CrossRef]
- Peng, C.; Tian, T.; Chen, C.; Guo, X.; Ma, J. Bilateral attention decoder: A lightweight decoder for real-time semantic segmentation. Neural Networks 2021, 137, 188–199. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; Gousseau, Y. Urban Change Detection for Multispectral Earth Observation Using Convolutional Neural Networks. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2115–2118. [Google Scholar] [CrossRef]
- Song, K.; Jiang, J. AGCDetNet:An Attention-Guided Network for Building Change Detection in High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4816–4831. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, F.; Zhao, J.; Yao, R.; Chen, S.; Ma, H. Spatial-Temporal Based Multihead Self-Attention for Remote Sensing Image Change Detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6615–6626. [Google Scholar] [CrossRef]
- Li, Z.; Ouyang, B.; Qiu, S.; Xu, X.; Cui, X.; Hua, X. Change Detection in Remote-Sensing Images Using Pyramid Pooling Dynamic Sparse Attention Network With Difference Enhancement. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 7052–7067. [Google Scholar] [CrossRef]
- Noman, M.; Fiaz, M.; Cholakkal, H.; Narayan, S.; Muhammad Anwer, R.; Khan, S.; Shahbaz Khan, F. Remote Sensing Change Detection With Transformers Trained From Scratch. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4704214. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607514. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. A transformer-based siamese network for change detection. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; IEEE: Piscataway Township, NJ, USA, 2022; pp. 207–210. [Google Scholar]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SwinSUNet: Pure transformer network for remote sensing image change detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5224713. [Google Scholar] [CrossRef]
- Yan, T.; Wan, Z.; Zhang, P. Fully transformer network for change detection of remote sensing images. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022; pp. 1691–1708. [Google Scholar]
- Li, Z.; Cao, S.; Deng, J.; Wu, F.; Wang, R.; Luo, J.; Peng, Z. STADE-CDNet: Spatial–Temporal Attention With Difference Enhancement-Based Network for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611617. [Google Scholar] [CrossRef]
- Chen, Y.; Feng, S.; Zhao, C.; Su, N.; Li, W.; Tao, R.; Ren, J. High-Resolution Remote Sensing Image Change Detection Based on Fourier Feature Interaction and Multiscale Perception. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5539115. [Google Scholar] [CrossRef]
- Chen, H.; Song, J.; Han, C.; Xia, J.; Yokoya, N. ChangeMamba: Remote Sensing Change Detection With Spatiotemporal State Space Model. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4409720. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, W.; Pun, M.O.; Shi, W. Cross-domain landslide mapping from large-scale remote sensing images using prototype-guided domain-aware progressive representation learning. ISPRS J. Photogramm. Remote Sens. 2023, 197, 1–17. [Google Scholar] [CrossRef]
- Lei, T.; Geng, X.; Ning, H.; Lv, Z.; Gong, M.; Jin, Y.; Nandi, A.K. Ultralightweight spatial–spectral feature cooperation network for change detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4402114. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A densely connected Siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8007805. [Google Scholar] [CrossRef]
- Feng, Y.; Jiang, J.; Xu, H.; Zheng, J. Change detection on remote sensing images using dual-branch multilevel intertemporal network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4401015. [Google Scholar] [CrossRef]
- Han, C.; Wu, C.; Hu, M.; Li, J.; Chen, H. C2F-SemiCD: A Coarse-to-Fine Semi-Supervised Change Detection Method Based on Consistency Regularization in High-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4702621. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Kappa | IoU | F1 | Recall | Precision | |
|---|---|---|---|---|---|---|
| LEVIR | 90.59 | 83.59 | 91.06 | 89.37 | 92.82 | |
| 90.67 | 83.72 | 91.14 | 89.99 | 92.33 | ||
| 90.46 | 83.39 | 90.94 | 89.74 | 92.17 | ||
| 90.34 | 83.19 | 90.82 | 88.26 | 93.53 | ||
| GVLM | 86.86 | 78.01 | 87.65 | 85.02 | 90.45 | |
| 87.63 | 79.20 | 88.39 | 87.60 | 89.20 | ||
| 86.97 | 78.19 | 87.76 | 86.30 | 89.27 | ||
| 86.73 | 77.84 | 87.54 | 86.82 | 88.27 |
| Dataset | Network Architecture | Kappa | IoU | F1 | Recall | Precision |
|---|---|---|---|---|---|---|
| LEVIR | base | 90.39 | 83.27 | 90.87 | 89.17 | 92.64 |
| base only with | 89.79 | 82.33 | 90.31 | 89.45 | 91.18 | |
| base+IFAU | 90.61 | 83.62 | 91.08 | 89.76 | 92.44 | |
| base+IFAU+CAM | 89.86 | 82.44 | 90.37 | 88.97 | 91.82 | |
| base+IFAU+CLRM | 90.67 | 83.72 | 91.14 | 89.99 | 92.33 | |
| GVLM | base | 87.38 | 78.83 | 88.16 | 88.35 | 87.97 |
| base only with | 87.35 | 78.80 | 88.14 | 88.56 | 87.73 | |
| base+IFAU | 87.61 | 79.15 | 88.36 | 86.87 | 89.90 | |
| base+IFAU+CAM | 87.23 | 78.60 | 88.02 | 87.93 | 88.11 | |
| base+IFAU+CLRM | 87.63 | 79.20 | 88.39 | 87.60 | 89.20 |
| Dataset | BIT | DMINet | SNUNet | USSFC-Net | C2FNet | Ours | |
|---|---|---|---|---|---|---|---|
| LEVIR-CD | Kappa | 81.89 | 80.16 | 79.65 | 89.35 | 90.59 | 90.67 |
| IoU | 84.41 | 83.17 | 83.08 | 81.88 | 83.59 | 83.72 | |
| F1 | 90.94 | 90.08 | 89.82 | 90.04 | 91.06 | 91.14 | |
| Recall | 91.02 | 87.24 | 86.56 | 91.47 | 89.06 | 89.99 | |
| Precision | 90.87 | 93.45 | 93.73 | 88.65 | 93.15 | 92.33 | |
| GVLM | Kappa | 63.36 | 72.62 | 71.78 | 85.62 | 86.54 | 87.63 |
| IoU | 72.04 | 77.77 | 77.27 | 76.55 | 77.59 | 79.20 | |
| F1 | 81.66 | 86.28 | 85.87 | 86.72 | 87.38 | 88.39 | |
| Recall | 86.26 | 92.20 | 82.17 | 88.24 | 88.18 | 87.60 | |
| Precision | 78.27 | 82.06 | 90.81 | 85.22 | 86.60 | 89.20 | |
| FLOPs (G) | 8.75 | 14.55 | 54.83 | 4.09 | 60.65 | 3.17 | |
| Params (M) | 3.04 | 6.24 | 3.04 | 1.52 | 16.17 | 3.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Zhang, Q.; Zhang, Y.; Niu, X.; Zhang, W.; Xie, F. Multi-Level Intertemporal Attention-Guided Network for Change Detection in Remote Sensing Images. Remote Sens. 2025, 17, 2233. https://doi.org/10.3390/rs17132233
Liu S, Zhang Q, Zhang Y, Niu X, Zhang W, Xie F. Multi-Level Intertemporal Attention-Guided Network for Change Detection in Remote Sensing Images. Remote Sensing. 2025; 17(13):2233. https://doi.org/10.3390/rs17132233
Chicago/Turabian StyleLiu, Shuo, Qinyu Zhang, Yuhang Zhang, Xiaochen Niu, Wuxia Zhang, and Fei Xie. 2025. "Multi-Level Intertemporal Attention-Guided Network for Change Detection in Remote Sensing Images" Remote Sensing 17, no. 13: 2233. https://doi.org/10.3390/rs17132233
APA StyleLiu, S., Zhang, Q., Zhang, Y., Niu, X., Zhang, W., & Xie, F. (2025). Multi-Level Intertemporal Attention-Guided Network for Change Detection in Remote Sensing Images. Remote Sensing, 17(13), 2233. https://doi.org/10.3390/rs17132233