
RPFusionNet: An Efficient Semantic Segmentation Method for Large-Scale Remote Sensing Images via Parallel Region–Patch Fusion

Abstract
1. Introduction
- A novel large-format image semantic segmentation network, termed RPFusionNet, is proposed in this paper. RPFusionNet effectively addresses the challenges of weakly textured or untextured regions in large ground objects. By analyzing patches and regions in parallel, this architecture not only enhances the ability to capture fine details but also improves the understanding of diverse scenes, thereby increasing the overall segmentation accuracy.
- An information aggregation module is designed to efficiently fuse global and local features at multiple scales. This module effectively addresses the issue of multi-scale information fusion, enhancing the model’s capability to interpret complex scenes.
- A novel stepped pooling strategy is introduced to improve the model’s ability to capture information at different scales. This strategy not only aids in better understanding the contextual relationships within the entire scene but also effectively handles the issue of weak or no texture in large objects, thus enhancing the overall segmentation performance.
- The proposed algorithm was tested on three publicly available datasets. The framework demonstrates superior performance in segmentation accuracy, surpassing the current state-of-the-art semantic segmentation methods. Furthermore, extensive ablation studies were performed on the individual components to confirm the effectiveness of each module.
2. Methodology
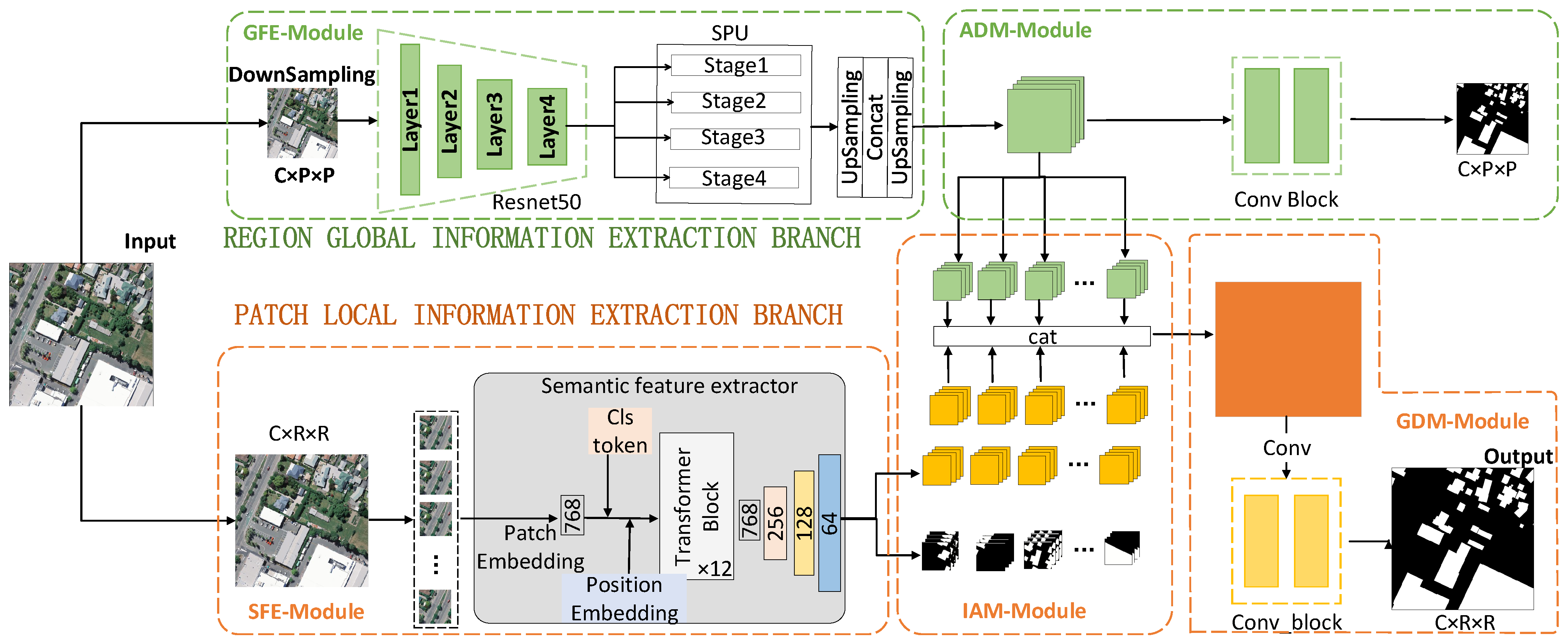
2.1. Overview
- REGION Global Information Extraction Branch: This branch consists of two main components: a multi-scale feature extraction module and an auxiliary decoding module. The multi-scale feature extraction module first downsamples the original image and applies multiple pooling operations of different sizes to enhance the model’s ability to perceive multi-scale targets. This process helps in extracting high-dimensional semantic information from the region. The auxiliary decoding module then generates a region-level semantic segmentation map enriched with contextual information through a series of convolutional operations.
- PATCH Local Semantic Feature Extraction Branch: This branch primarily includes three modules: PATCH high-dimensional feature extraction, information aggregation, and global decoding. The PATCH high-dimensional feature extraction module divides the large-format image into several small patches to obtain patch-level high-dimensional features rich in semantic information. The information aggregation module fuses these patch-level high-dimensional semantic features with the region-level high-dimensional semantic information from the REGION branch, deriving new features that integrate both contextual and local information. Notably, the global decoding module shares the same weights as the auxiliary decoding module in the REGION branch. This parameter-sharing mechanism reduces the number of model parameters and enables more efficient feature extraction from image data.
2.2. The REGION Global Information Extraction Branch
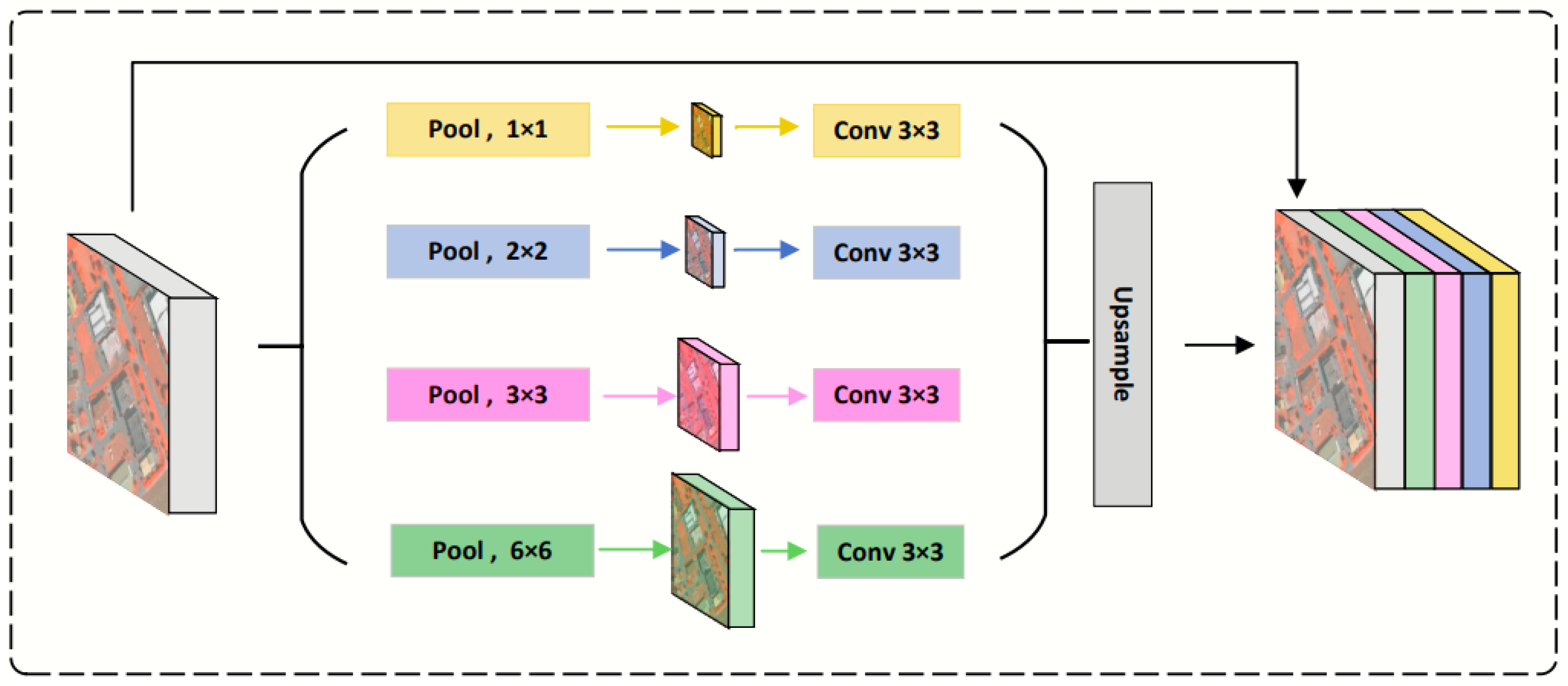
- Multi-Scale Feature Extraction Module (GFE—Global Feature Extraction Module): Before feature extraction, a given input large-format high-resolution image is first downsampled to a coarse-grained image with the size of a PATCH. ResNet50 is used as the encoder to learn the contextual information. To further supplement the boundary information in different regions, we introduce the Stepped Pooling Unit (SPU) to construct global multi-scale information on the final layer of the encoder.The stepped pooling unit(SPU) incorporates features of different sizes, as illustrated in Figure 2. First, the feature map is evenly divided into four parts along the depth dimension. Each part uses a pooling kernel of a different size, sequentially aggregating all pixel values within the pooling window and outputting feature maps of varying sizes. To extract higher-dimensional contextual features, a 1 × 1 convolutional layer is applied to restore the dimension of the contextual feature to the specified dimension. Finally, bilinear interpolation is performed on the feature map of each part to resize it to the same dimensions as the input image. These feature maps of different levels are then concatenated to obtain high-dimensional features containing global information.It is important to note that the height and size of the SPU units can be flexibly adjusted, and their settings are directly related to the input x. This unit obtains global information through multiple regional divisions and different pooling kernels. Therefore, when designing multi-level pooling kernels, it is essential to ensure an appropriate representation range to adapt to features of different scales. The calculation of the SPU units is as follows:where x represents the feature map obtained from ResNet50, and and represent the feature maps before and after pooling, respectively. denotes the feature map following the aggregation of information at different scales. refers to uniformly slicing the input feature map along the channel dimension, represents average pooling operation, represents the bilinear interpolation operation, and refers to the fusion operation that integrates multi-scale feature maps along channel dimensions. In this method, the feature dimensions processed by the encoder amount to 2048, subsequently divided by the SPU unit into four portions of feature maps, each consisting of 512 channels. After undergoing pooling through each layer, four layers of feature maps of distinct sizes are acquired, with the respective sizes of the pooling kernels being 1 × 1, 2 × 2, 3 × 3, and 6 × 6. The different pooling kernels are mainly used to capture multi-scale features, in order to accommodate objects of various scales. Ultimately, these four layers of differently sized feature maps are upsampled back to 256 × 256.
- Auxiliary Decoding Module (ADM): The ADM is a decoding component specifically designed by the REGION branch to process global information. It assists the REGION branch in inferring global information more effectively and provides accurate context features for the subsequent PATCH branch. The module consists of three lightweight convolutional blocks and employs convolutional operations to process multi-channel region-level semantic feature maps. It ultimately reduces the number of channels to one, aiming to produce a semantic segmentation result for a region of “patch” size. This global feature segmentation map facilitates the model’s understanding of the overall image structure and semantic content, thereby aiding in precise pixel-level segmentation across various object categories.
2.3. The PATCH Local Semantic Feature Extraction Branch
- PATCH Semantic Feature Extractor (SFE): The PATCH SFE adopts the TransUNet architecture, specifically designed for efficient extraction of local multi-dimensional features. The hybrid CNN–Transformer design enables TransUNet to effectively integrate hierarchical spatial information within local regions while maintaining structural adaptability to varying input sizes. This hybrid architecture leverages the complementary advantages of convolutional operations for preserving local features and self-attention mechanisms for modeling contextual relationships. To comprehensively capture features within each PATCH region, TransUNet employs a convolutional encoder to extract multi-scale representations, followed by a Transformer module that processes the reshaped feature sequence. Positional encoding is integrated into the flattened feature vectors to maintain spatial relationships across the entire feature map. Subsequently, stacked Transformer blocks process the rich embeddings, where each block incorporates multi-head self-attention and position-wise feed-forward networks to simultaneously model local details and long-range dependencies. Unlike traditional vision Transformers, the TransUNet-based SFE in this work utilizes a U-Net-style decoder with skip connections. This design progressively fuses high-resolution encoder features with semantically rich decoder representations, generating multi-dimensional features aligned with the output dimensions of the global REGION branch. The decoder further produces auxiliary segmentation maps for performance validation, ensuring feature quality prior to fusion. The computational formulation is as follows:where represents the local patch blocks cropped from the original image; and denote the multi-scale convolutional features extracted by the ResNet encoder; and refers to the high-level semantic features processed by the Transformer encoder. and represent the multi-dimensional tensor generated by decoding the local feature sequence and the predicted segmentation map. represents a dimensional transformation of feature representations from 1D sequences (e.g., flattened feature vectors) to 2D spatial forms (e.g., spatial feature maps). denotes the decoder layer, which includes upsampling, convolution, and skip-connection-based feature fusion operations to progressively restore spatial resolution.During training, our method pre-trains a model to effectively extract high-dimensional features from image patches. In subsequent experiments with large-format high-resolution images, this pre-trained feature extractor is loaded and fixed, and it does not participate in the backpropagation and gradient update processes of the network. In this stage, we retain only the high-dimensional information from the high-dimensional semantic feature branch.
- Information Aggregation Module (IAM). The Information Aggregation Module (IAM) integrates global and local features, thereby enhancing the model’s comprehension of the overall image structure while maintaining sensitivity to critical local details. Specifically, for the global contextual information derived from the downsampled and feature-extracted REGION branch, the module first employs bilinear interpolation to estimate the value of each new pixel. This is achieved by assigning different weights to the four adjacent pixels surrounding the target pixel, thus restoring the feature representation to the original region-level resolution. Subsequently, the region-level high-dimensional features, enriched with contextual information, are reorganized into multiple feature map sets based on the initial cropping sequence, each corresponding to a specific patch size. Lastly, these feature maps are concatenated to produce a more comprehensive and informative representation. A detailed calculation process is outlined below:where represents the feature map resulting from the aggregation of information across diverse scales, stands for the bilinear interpolation operation, and refers to uniformly slicing the input feature map along the channel dimension. The interpolated feature map is segmented into blocks consistent with the patch size, is the feature map after blocking, is the high-dimensional feature after the decoding of the local feature sequence, and is the new feature following the fusion of global and local information.
- Global Decoding Module (GDM). The global decoding module combines the previously mentioned fusion features into a region-level feature map. Following this, a three-layer convolutional neural network is utilized to form a decoder, which generates the final large-area semantic segmentation map. The mathematical formulation of this process is given by:where represents the final semantic segmentation result for the large-format image and denotes the operation of reassembling the set of patch-size feature maps into the REGION format, adhering to the trimming order.
2.4. Loss Function
3. Datasets and Experiment Details
3.1. Datasets
- WBDS (WHU Building Dataset)The WBDS dataset is located in Christchurch, New Zealand, and includes two aerial images with a size of 32,507 × 15,345 pixels, along with their corresponding labels, captured in 2012 and 2016, respectively. Both area images and labels have been cropped to create large-format images of 2048 × 2048 pixels, yielding a total of 630 image–label pairs. These pairs are divided into a training set (378 pairs), a validation set (126 pairs), and a test set (126 pairs) according to a 6:2:2 ratio.
- AIDS (Aerial imagery Dataset)The AIDS dataset encompasses a remote sensing image with a size of 1,560,159 × 517,909, sourced from the New Zealand Land Information Service website. This dataset spans a broad geographical region characterized by a variety of features, including buildings, roads, vehicles, forests, water bodies, and arable land. Approximately 22,000 individual buildings were manually annotated by Ji et al. [41], with the original image having a spatial resolution of 0.075 meters. Both the image and vector labels were cropped to produce 12,940 large-format image–label pairs, each of size 2048 × 2048 pixels. These pairs were further divided into a training set (7764 pairs), a validation set (2588 pairs), and a test set (2588 pairs). It is noteworthy that the AIDS dataset exhibits a substantial disparity in the number of foreground and background pixels, a common issue in many high-resolution remote sensing image datasets due to the highly imbalanced sample distribution.
- VaihingenThe Vaihingen dataset was collected by the International Society for Photogrammetry and Remote Sensing (ISPRS) and is situated in a small town in southwestern Germany. The dataset features various landscapes, including villages, farmlands, and forests, with numerous freestanding and small multi-story buildings. The Vaihingen dataset consists of 38 images with a size of 6000 × 6000 pixels. Given the absence of building vector labels in the complete image coverage area, we first assembled 38 adjacent non-overlapping images from the dataset into a single large remote sensing image. Using ArcGIS software, we then manually delineated the corresponding building vector labels. Subsequently, the image and its associated building vector labels were cropped simultaneously to generate 140 image–label pairs, all of size 2048 × 2048 pixels. These pairs were allocated to a training set (84 pairs), a validation set (28 pairs), and a test set (28 pairs) in a 6:2:2 ratio.
3.2. Data Preprocessing
3.3. Training Details
3.4. Metrics
4. Experimental Results and Analysis
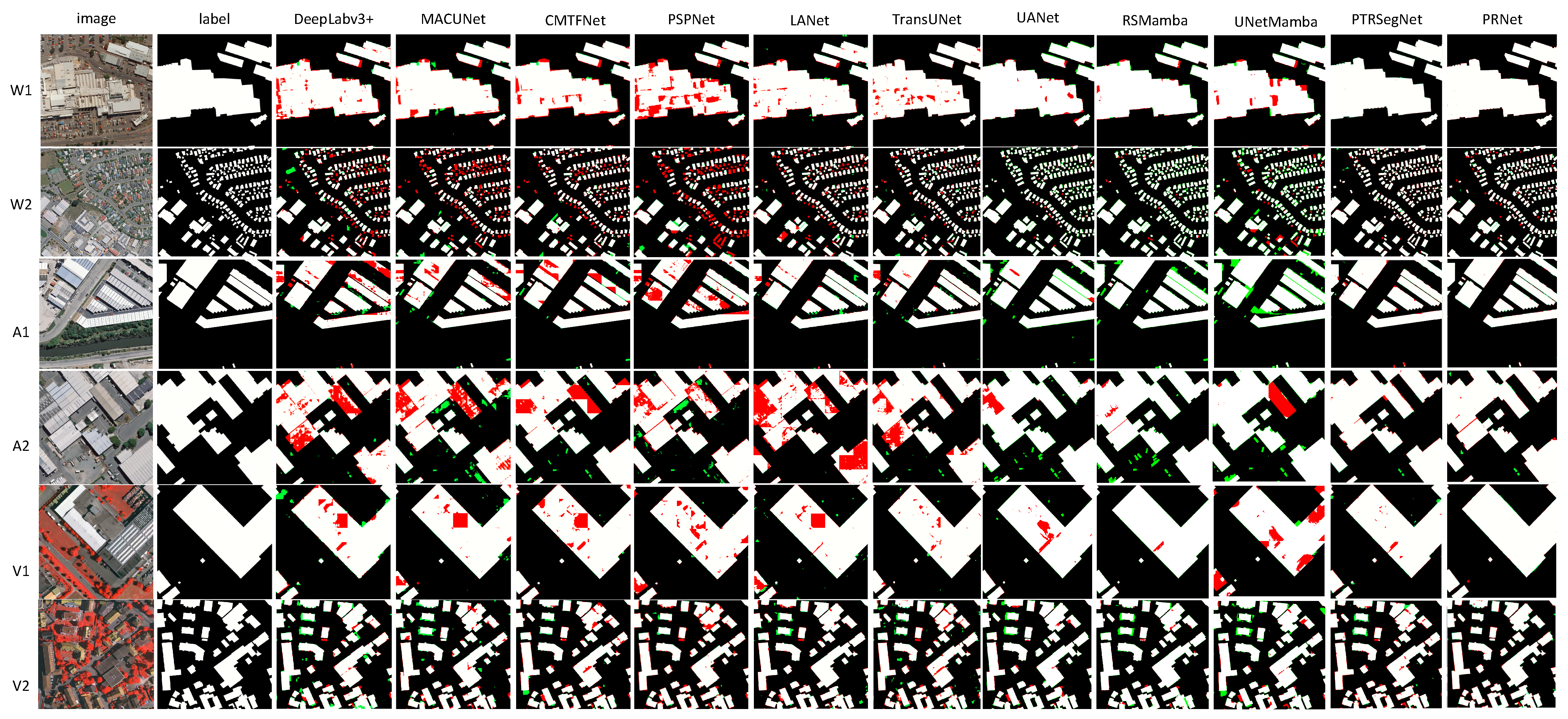
4.1. Comparisons with State-of-the-Art Methods
- -
- -
- -
- -
- PTRSegNet [40], which employs a concatenation architecture integrating REGION and PATCH.
4.2. Ablation Study
- Comparisons of Model Performance Under Different SFEsWithin the RPFusionNet framework, we evaluated the performance of U-Net, ViT, and TransUNet as Semantic Feature Extractors (SFEs) for large-format image semantic segmentation. The experimental results demonstrate that all SFEs exhibit significant performance improvements after integration into the RPFusionNet framework (as shown in the “IoU improvement” column of Table 2), validating the effectiveness of the dual-branch collaborative design. Notably, TransUNet achieves the best performance under both strategies, with an average IoU outperforming U-Net and ViT by 2.3% and 4.1%, respectively. This superiority stems from TransUNet’s hybrid architecture, which leverages the complementarity between CNNs and Transformers through a multi-scale feature fusion mechanism, making it highly suitable for the complex characteristics of remote sensing images. Specifically, the Transformer encoder in TransUNet dynamically aggregates cross-regional information via self-attention mechanisms, addressing the locality limitations of U-Net convolutions. Additionally, TransUNet employs a ResNet backbone to extract hierarchical multi-scale features (ranging from shallow local details to deep semantic features), while the Transformer encoder further refines these features using multi-head attention mechanisms. This two-level design aligns well with the hierarchical structure of remote sensing images (e.g., the coexistence of small buildings and large land cover regions), enabling the simultaneous optimization of segmentation accuracy for both small targets (e.g., vegetation types) and large targets (e.g., urban expansion). By contrast, U-Net’s pure convolutional architecture lacks global modeling capabilities, leading to incomplete boundary predictions for large-scale objects, while ViT directly models image patches, ignoring local details (e.g., building edges) and exhibiting insufficient noise robustness for remote sensing images.
- Comparisons of Model Performance Under Different Pooling UnitsIn this paper, we employed a stepped pooling unit to extract feature representations at different scales, enabling the model to handle large buildings and thereby improving semantic segmentation performance. Four different pooling kernels (1 × 1, 2 × 2, 3 × 3, and 6 × 6) were used, and these features were fused to enhance contextual information. To verify the effectiveness of the stepped pooling unit, we compared the results of single-scale pooling (SSPU) and multi-scale pooling (MSPU) under different SFEs, including U-Net, ViT, and TransUNet. Single-scale pooling (SSPU) refers to a single-scale pooling unit that retains only the 1 × 1 scale features. The comparisons of model performance under different pooling units are presented in Table 3.Table 3 shows that the multi-scale pooling unit (MSPU) achieves a 2.05% IoU improvement over the single-scale pooling unit (SSPU) on both WBDS and AIDS datasets. Specifically, the TransUNet + MSPU combination achieves an optimal mIoU of 92.08%, outperforming the SSPU-based solution by 2.4%. This performance gain is attributed to the synergistic effect of multi-size pooling kernels, particularly the 6 × 6 large-scale pooling kernel, which enhances segmentation accuracy for large buildings exceeding 512 × 512 pixels by integrating local detail features. Empirical evidence confirms that the multi-scale feature fusion mechanism effectively mitigates the scale sensitivity inherent in single receptive field designs, significantly improving the boundary completeness of large structures such as industrial plants.
- Ablation Study of Four Different Module Combinations Under Different SFEsTo verify the effectiveness of each module in the RPFusionNet framework, an ablation study was conducted using four different module combinations. The experiments were performed on two datasets—WBDS and AIDS—and employed three SFEs: U-Net, ViT, and TransUNet. The four combinations are as follows:
- (a)
- Baseline: The baseline model only includes the semantic feature extraction module and does not use the large-format image processing framework.
- (b)
- Baseline + GDM: In the REGION branch, only a single-scale pooling kernel is used for global feature mapping, and the region-level segmentation map is obtained through the global decoding module (GDM) of the PATCH branch.
- (c)
- Baseline + GDM + GFE: On the basis of (b), the Global Feature Extraction Module (GFE) is added, specifically the GFE (MSPU) module in the REGION branch, to capture multi-scale global information.
- (d)
- Baseline + GDM + GFE + ADM: On the basis of (c), the Auxiliary Decoding Module (ADM) is added to form a complete RPFusionNet.
4.3. Comparisons of Computational Efficiency
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Firdaus-Nawi, M.; Noraini, O.; Sabri, M.; Siti-Zahrah, A.; Zamri-Saad, M.; Latifah, H. Deeplabv3+ Encoder–Decoder with Atrous Separable Convolution for Semantic Image Segmentation. Pertanika J. Trop. Agric. Sci. 2021, 44, 137–143. [Google Scholar]
- Guo, S.; Zhu, C. Cascaded ASPP and Attention Mechanism-Based Deeplabv3+ Semantic Segmentation Model. In Proceedings of the IEEE 8th International Conference on Cloud Computing and Intelligent Systems (CCIS), Guangzhou, China, 9–11 December 2022; pp. 315–318. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yan, Z.; Wang, K.; Li, X.; Zhang, Z.; Li, J.; Yang, J. DesNet: Decomposed Scale-Consistent Network for Unsupervised Depth Completion. arXiv 2022, arXiv:2211.10994. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 426–435. [Google Scholar] [CrossRef]
- Li, J.; He, W.; Cao, W.; Zhang, L.; Zhang, H. UANet: An Uncertainty-Aware Network for Building Extraction From Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5608513. [Google Scholar] [CrossRef]
- Zheng, C.; Hu, C.; Chen, Y.; Li, J. A Self-Learning-Update CNN Model for Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6004105. [Google Scholar] [CrossRef]
- Zhao, Y.; Guo, P.; Sun, Z.; Chen, X.; Gao, H. ResiDualGAN: Resize-Residual DualGAN for Cross-Domain Remote Sensing Images Semantic Segmentation. Remote Sens. 2023, 15, 1428. [Google Scholar] [CrossRef]
- Pan, S.; Tao, Y.; Nie, C.; Chong, Y. PEGNet: Progressive Edge Guidance Network for Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 637–641. [Google Scholar] [CrossRef]
- Tragakis, A.; Liu, Q.; Kaul, C.; Roy, S.K.; Dai, H.; Deligianni, F.; Murray-Smith, R.; Faccio, D. GLFNet: Global-Local (Frequency) Filter Networks for Efficient Medical Image Segmentation. In Proceedings of the IEEE International Symposium on Biomedical Imaging (ISBI), Athens, Greece, 27–30 May 2024; pp. 1–5. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 994–1003. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhong, J.; Zeng, T.; Xu, Z.; Wu, C.; Qian, S.; Xu, N.; Chen, Z.; Lyu, X.; Li, X. A Frequency Attention-Enhanced Network for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2025, 17, 402. [Google Scholar] [CrossRef]
- Zhang, W.; Huang, Z.; Luo, G.; Chen, T.; Wang, X.; Liu, W.; Yu, G.; Shen, C. TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12083–12093. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Wang, Y.; Wang, D.; Xu, T.; Shi, Y.; Liang, W.; Wang, Y.; Petropoulos, G.P.; Bao, B. RDAU-Net: A U-Shaped Semantic Segmentation Network for Buildings Near Rivers and Lakes Based on a Fusion Approach. Remote Sens. 2025, 17, 2. [Google Scholar] [CrossRef]
- Wu, H.; Huang, P.; Zhang, M.; Tang, W.; Yu, X. CMTFNet: CNN and Multiscale Transformer Fusion Network for Remote-Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2004612. [Google Scholar] [CrossRef]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing Swin Transformer and Convolutional Neural Network for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. CMT: Convolutional Neural Networks Meet Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12175–12185. [Google Scholar]
- Fan, C.-M.; Liu, T.-J.; Liu, K.-H. Compound Multi-Branch Feature Fusion for Image Deraindrop. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 3399–3403. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model. In Proceedings of the 41st International Conference on Machine Learning (ICML 2024), Vienna, Austria, 21–27 July 2024; Volume 235, pp. 62429–62442. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Liu, Y. VMamba: Visual State Space Model. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2024), Vancouver, BC, Canada, 16 December 2024; Curran Associates, Inc.: Granada, Spain, 2024; Volume 37, pp. 103031–103063. [Google Scholar]
- Chen, K.; Chen, B.; Liu, C.; Li, W.; Zou, Z.; Shi, Z. RSMamba: Remote Sensing Image Classification with State Space Model. IEEE Geosci. Remote Sens. Lett. 2024, 21, 8002605. [Google Scholar] [CrossRef]
- Zhu, E.; Chen, Z.; Wang, D.; Shi, H.; Liu, X.; Wang, L. UNetMamba: An Efficient UNet-Like Mamba for Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2025, 22, 6001205. [Google Scholar] [CrossRef]
- Zhu, S.; Zhao, L.; Xiao, Q.; Ding, J.; Li, X. GLFFNet: Global–Local Feature Fusion Network for High-Resolution Remote Sensing Image Semantic Segmentation. Remote Sens. 2025, 17, 1019. [Google Scholar] [CrossRef]
- Nie, J.; Wang, Z.; Liang, X.; Yang, C.; Zheng, C.; Wei, Z. Semantic Category Balance-Aware Involved Anti-Interference Network for Remote Sensing Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4409712. [Google Scholar] [CrossRef]
- Hu, B.; Wang, X.; Feng, Z.; Song, J.; Zhao, J.; Song, M.; Wang, X. HSDN: A High-Order Structural Semantic Disentangled Neural Network. IEEE Trans. Knowl. Data Eng. 2023, 35, 8742–8756. [Google Scholar] [CrossRef]
- Lin, S.; Yang, Y.; Liu, X.; Tian, L. DSFA-SwinNet: A Multi-Scale Attention Fusion Network for Photovoltaic Areas Detection. Remote Sens. 2025, 17, 332. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Z.; Yang, J.; Zhang, H. Wavelet Transform Feature Enhancement for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2023, 15, 5644. [Google Scholar] [CrossRef]
- Song, X.; Li, W.; Zhou, D.; Dai, Y.; Fang, J.; Li, H.; Zhang, L. MLDA-Net: Multi-Level Dual Attention-Based Network for Self-Supervised Monocular Depth Estimation. IEEE Trans. Image Process. 2021, 30, 4691–4705. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Yong, X.; Chen, D.; Xia, R.; Ye, B.; Gao, H.; Chen, Z.; Lyu, X. SSCNet: A Spectrum-Space Collaborative Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2023, 15, 5610. [Google Scholar] [CrossRef]
- Li, R.; Duan, C.; Zheng, S.; Zhang, C.; Atkinson, P.M. MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8007205. [Google Scholar] [CrossRef]
- Pang, S.; Shi, Y.; Hu, H.; Ye, L.; Chen, J. PTRSegNet: A Patch-to-Region Bottom–Up Pyramid Framework for the Semantic Segmentation of Large-Format Remote Sensing Images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2024, 17, 3664–3673. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Dataset. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Model | WBDS | AIDS | Vaihingen | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | Precision | Recall | F1 | IoU | Precision | Recall | F1 | IoU | Precision | Recall | F1 | |
| DeepLabv3+ | 85.12 | 95.99 | 88.25 | 91.96 | 82.98 | 96.73 | 85.37 | 90.70 | 84.41 | 93.64 | 89.54 | 91.54 |
| MACU-Net | 85.13 | 93.11 | 90.86 | 91.97 | 87.44 | 95.55 | 91.16 | 93.37 | 85.60 | 95.07 | 89.59 | 92.25 |
| CMTFNet | 86.21 | 90.12 | 95.21 | 92.59 | 88.05 | 94.26 | 93.03 | 93.64 | 85.14 | 95.98 | 88.29 | 91.98 |
| PSPNet | 86.94 | 96.79 | 89.52 | 93.01 | 84.88 | 95.26 | 88.63 | 91.82 | 83.32 | 90.89 | 90.91 | 90.90 |
| LANet | 87.62 | 95.32 | 91.56 | 93.40 | 87.21 | 94.31 | 92.05 | 93.17 | 85.42 | 93.89 | 90.46 | 92.14 |
| TransUNet | 87.89 | 94.05 | 93.07 | 93.56 | 87.11 | 96.20 | 90.22 | 93.11 | 85.35 | 93.15 | 91.07 | 92.10 |
| UANet | 87.99 | 89.13 | 98.57 | 93.61 | 87.70 | 89.21 | 98.11 | 93.45 | 86.01 | 88.90 | 96.36 | 92.48 |
| RSMamba | 88.13 | 88.96 | 98.96 | 93.69 | 87.57 | 88.71 | 98.56 | 93.38 | 86.38 | 88.72 | 97.04 | 92.69 |
| UNetMamba | 88.73 | 91.05 | 97.20 | 94.03 | 87.43 | 88.65 | 98.46 | 93.29 | 85.22 | 86.99 | 97.67 | 92.02 |
| PTRSegNet | 91.46 | 95.94 | 95.18 | 95.54 | 88.69 | 96.70 | 91.45 | 94.00 | 86.55 | 94.01 | 91.60 | 92.79 |
| RPFusionNet | 92.08 | 96.14 | 95.62 | 95.88 | 89.99 | 95.14 | 94.33 | 94.73 | 88.44 | 95.40 | 92.39 | 93.87 |
| Datasets | SFE | Direct Stitching (IoU) | RPFusionNet (IoU) | Improved IoU |
|---|---|---|---|---|
| WBDS | U-Net | 85.17 | 92.06 | 6.89 |
| ViT | 83.78 | 89.43 | 5.65 | |
| TransUNet | 87.89 | 92.08 | 4.19 | |
| AIDS | U-Net | 85.39 | 89.66 | 4.27 |
| ViT | 84.32 | 89.99 | 5.67 | |
| TransUNet | 86.50 | 88.63 | 2.13 |
| SFE | Pooling Units | WBDS (IoU) | AIDS (IoU) |
|---|---|---|---|
| U-Net | SSPU | 88.85 | 87.47 |
| MSPU | 92.06 | 89.66 | |
| ViT | SSPU | 86.78 | 89.14 |
| MSPU | 89.43 | 89.99 | |
| TransUNet | SSPU | 89.68 | 87.62 |
| MSPU | 92.08 | 88.63 |
| SFE | Baseline | GDM | GFE | ADM | WBDS (IoU) | AIDS (IoU) |
|---|---|---|---|---|---|---|
| U-Net | ✓ | 85.17 | 83.53 | |||
| ✓ | ✓ | 88.22 | 86.99 | |||
| ✓ | ✓ | ✓ | 90.58 | 88.35 | ||
| ✓ | ✓ | ✓ | ✓ | 92.06 | 89.66 | |
| ViT | ✓ | 83.78 | 84.29 | |||
| ✓ | ✓ | 85.46 | 86.73 | |||
| ✓ | ✓ | ✓ | 88.95 | 89.45 | ||
| ✓ | ✓ | ✓ | ✓ | 89.43 | 89.99 | |
| TransUNet | ✓ | 87.89 | 86.50 | |||
| ✓ | ✓ | 87.78 | 86.73 | |||
| ✓ | ✓ | ✓ | 90.56 | 88.02 | ||
| ✓ | ✓ | ✓ | ✓ | 92.08 | 88.63 |
| Model | Training Params () | FLOPs () |
|---|---|---|
| DeepLabv3+ | 40.35 | 17.36 |
| MACU-Net | 5.15 | 8.40 |
| CMTFNet | 30.10 | 8.56 |
| PSPNet | 46.58 | 44.44 |
| LANet | 23.79 | 8.31 |
| TransUNet | 93.23 | 32.23 |
| UANet | 26.73 | 7.45 |
| RSMamba | 38.75 | 8.86 |
| UNetMamba | 13.36 | 3.85 |
| RPFusionNet | 46.83 | 6.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, S.; Zeng, W.; Shi, Y.; Zuo, Z.; Xiao, K.; Wu, Y. RPFusionNet: An Efficient Semantic Segmentation Method for Large-Scale Remote Sensing Images via Parallel Region–Patch Fusion. Remote Sens. 2025, 17, 2158. https://doi.org/10.3390/rs17132158
Pang S, Zeng W, Shi Y, Zuo Z, Xiao K, Wu Y. RPFusionNet: An Efficient Semantic Segmentation Method for Large-Scale Remote Sensing Images via Parallel Region–Patch Fusion. Remote Sensing. 2025; 17(13):2158. https://doi.org/10.3390/rs17132158
Chicago/Turabian StylePang, Shiyan, Weimin Zeng, Yepeng Shi, Zhiqi Zuo, Kejiang Xiao, and Yujun Wu. 2025. "RPFusionNet: An Efficient Semantic Segmentation Method for Large-Scale Remote Sensing Images via Parallel Region–Patch Fusion" Remote Sensing 17, no. 13: 2158. https://doi.org/10.3390/rs17132158
APA StylePang, S., Zeng, W., Shi, Y., Zuo, Z., Xiao, K., & Wu, Y. (2025). RPFusionNet: An Efficient Semantic Segmentation Method for Large-Scale Remote Sensing Images via Parallel Region–Patch Fusion. Remote Sensing, 17(13), 2158. https://doi.org/10.3390/rs17132158