Abstract
Mainstream deep learning segmentation models are designed for small-sized images, and when applied to high-resolution remote sensing images, the limited information contained in small-sized images greatly restricts a model’s ability to capture complex contextual information at a global scale. To mitigate this challenge, we present RPFusionNet, a novel parallel semantic segmentation framework that is specifically designed to efficiently integrate both local and global features. RPFusionNet leverages two distinct feature representations: REGION (representing large areas) and PATCH (representing smaller regions). This framework comprises two parallel branches: the REGION branch initially downsamples the entire image, then extracts features via a convolutional neural network (CNN)-based encoder, and subsequently captures multi-level information using pooled kernels of varying sizes. This design enables the model to adapt effectively to objects of different scales. In contrast, the PATCH branch utilizes a pixel-level feature extractor to enrich the high-dimensional features of the local region, thereby enhancing the representation of fine-grained details. To model the semantic correlation between the two branches, we have developed the Region–Patch scale fusion module. This module ensures that the network can comprehend a wider range of image contexts while preserving local details, thus bridging the gap between regional and local information. Extensive experiments were conducted on three public datasets: WBDS, AIDS, and Vaihingen. Compared to other state-of-the-art methods, our network achieved the highest accuracy on all three datasets, with an IoU score of 92.08% on the WBDS dataset, 89.99% on the AIDS dataset, and 88.44% on the Vaihingen dataset.
1. Introduction
Currently, deep learning-based technology has become the core method for the semantic segmentation of remote sensing images. Depending on the network architecture employed, these techniques can be divided into three categories: convolutional neural network (CNN)-based models, Transformer-based models, and hybrid models that combine the advantages of both.
Classical CNN-based semantic segmentation models include FCN [1], U-Net [2], DeepLab [3,4,5,6], PSPNet [7], DenseNet [8], etc. FCN [1] was the first network to realize image semantic segmentation, restoring feature map resolution by removing the fully connected layer and introducing a deconvolution layer. U-Net’s encoder–decoder structure and skip connections effectively utilize multi-scale features. The DeepLab series addresses spatial resolution degradation through dilated convolution and improves segmentation accuracy with technologies such as deep separable convolution and parallel dilated convolution. PSPNet [7] enhances global information extraction by fusing multi-scale features through pooling layers at different scales. DenseNet [8] alleviates the vanishing gradient problem by improving feature multiplexing through dense connections. Dual Attention Networks (DANets) [9] and parallel spatial and channel attention modules capture feature dependencies, while LANet [10] reinforces high-level feature semantic information through local attention mechanisms. UANet [11] achieves uncertainty-aware building extraction through prior information guidance and an uncertainty ranking fusion strategy, effectively improving the accuracy and robustness of building segmentation. Other models, such as SLU-CNN [12], DRDG [13], PEG-Net [14], GLF-Net [15], and SPGAN [16], also enhance performance through self-updating and cross-domain semantic separation.
In terms of Transformer-based models, Vision Transformer (ViT) [17] pioneered the division of images into fixed-size patches, encoding serialized images by position, and using the Transformer to process these serialized vectors. However, the patch division method may lead to overly coarse segmentation results or high computational costs. Swin Transformer [18] reduces computation while maintaining detail through a hierarchical design and a sliding window mechanism. To address the challenges of semantic segmentation in high-resolution remote sensing images, FAENet [19], a frequency attention-enhanced network, was proposed to integrate spectral and spatial context modeling through a frequency attention model (FreqA) based on discrete wavelet transform and dual-stage channel attention mechanisms. Although Transformer-based models excel at processing global information, their need for large amounts of training data and powerful computing resources becomes a constraint. To address this, researchers have proposed improvements such as TopFormer [20], but these can only partially reduce training complexity.
Semantic segmentation networks combining the advantages of CNNs and Transformers have gradually become a research hotspot, and TransUNet [21] adds a Transformer module after the classical U-Net [2] encoder to improve the segmentation accuracy by using global context information. RDAU-Net [22] has designed a residual dynamic truncated down-sampling (RDSC) module to minimize the impact of complex building shapes and scales on the model, and to improve building segmentation accuracy by fusing convolutional neural networks and Transformers to extract features. CMTFNet [23] fuses CNN and multi-scale Transformer to improve the segmentation quality by extracting and fusing local and multi-scale global contextual information. STransFuse [24] joins the Swin Transformer [18] branch to extract features at different scales. CMT [25] replaces the multilayer perceptron in a Transformer with a convolution, improving accuracy while maintaining speed. As a cross-modal multi-scale fusion network, CMFNet [26] uses a Transformer to capture the multi-scale feature dependencies between different modal remote sensing data.
Compared to CNN and Transformer architectures, Mamba achieves long-sequence modeling with linear computational complexity through Selective State Spaces (SSMs) [27] and hardware-aware design, overcoming the quadratic computation bottleneck of Transformers. Early explorations of visual Mamba (e.g., Vim [28]) utilized image serialization but suffered from directional sensitivity limitations. VMamba [29] proposed a cross-scan strategy with four-directional state propagation, achieving a 3× greater inference speedup over ViT on ImageNet classification. Recent advances in remote sensing include RSMamba [30], which employs a dynamic multi-path activation mechanism (the parallel integration of forward/backward/random scans), significantly enhancing adaptability to irregular geographical features. As an efficient U-shaped segmentation framework, UNetMamba [31] incorporates a Mamba segmentation decoder (MSD) with Visual State Space (VSS) blocks, replacing conventional decoding modules while maintaining competitive accuracy under significantly reduced computational costs. GLFFNet [32] innovatively constructs a dual-branch CNN-VMamba architecture: its CNN main branch preserves building edge details (<64 px) through hierarchical convolution, while the VMamba auxiliary branch incorporates a Multi-Scale Feature Refinement (MSFR) module that compensates for detail loss in high-level features via cross-layer channel–spatial attention fusion. Nevertheless, existing Mamba architectures still exhibit a critical limitation—even advanced solutions like GLFFNet—where single-scan strategies struggle to adapt to extreme scale variations in remote sensing targets, leading to insufficient cross-scale modeling capability.
In response to the challenges in the field of remote sensing image processing, some studies have proposed specialized solutions. SCBANet [33] addresses poor segmentation performance under significant interference; HSDN [34] enhances complex and distorted image segmentation capabilities through high-order feature decoupling. DSFA-SwinNet [35] uses dynamic spatial–frequency attention and multi-scale feature processing mechanisms to achieve accurate photovoltaic area detection in high-resolution remote sensing images, thereby improving the quality of semantic segmentation of remote sensing images. The WFE module [36] boosts CNN feature extraction from remote sensing images. MLDANets [37] capture long-term dependencies via multi-level deformable attention. Considering that traditional methods mainly focus on spatial domain learning, which leads to insufficient recognition ability, models such as SSCNet [38] and MACU-Net [39] improve their performance in fine-resolution remote sensing image segmentation through spectral–spatial cooperation or asymmetric convolution. PTRSegNet [40] fuses global and local information using a top-down pyramid framework to improve the segmentation accuracy of large-format high-resolution remote sensing images.
In high-resolution remote sensing images, ground objects exhibit significant scale variations. In large building areas, image patches of size 512 × 512 pixels may contain only a part of the building. Combined with the influence of texture similarity, the segmentation performance on small patches in such scenes drops sharply. Therefore, it is necessary to simultaneously capture global scene layouts (>512 × 512 pixels) and local details (<64 × 64 pixels) to improve segmentation accuracy. In our previous research on the large-format semantic segmentation network PTRSegNet, the architecture consists of two key modules: the local semantic feature extraction module and the global feature extraction module. These modules are designed to extract local detailed features and global contextual information, respectively. Subsequently, these two types of features are fused in a sequential manner, which effectively improves the accuracy of semantic segmentation. However, through subsequent experiments and analysis, we found that this structure still has certain limitations. First, the global feature extraction module employs a single-scale feature extraction approach, which remains challenged when dealing with scenes containing objects of significantly different scales. Second, the serial fusion structure between local and global features may lead to interference from the local details during the global feature extraction process, negatively affecting the integrity of the global semantic representation.
To address the aforementioned issues, we further optimize the model architecture based on PTRSegNet and propose a new dual-branch decoupled semantic segmentation network named RPFusionNet; while inheriting the strengths of the original design, RPFusionNet enhances multi-scale modeling capabilities and effectively avoids interference from local details during global feature extraction through its dual-branch decoupled architecture. Specifically, the proposed RPFusionNet consists of two branches: the REGION branch for global information extraction and the PATCH branch for local detail feature extraction. In the REGION global information extraction branch, the entire input image is first downsampled, and a CNN-based encoder is used to extract features from the downsampled large-format remote sensing images. A multi-scale feature extraction module is designed to capture and integrate high-dimensional REGION-level information at different scales by using pooling kernels of various sizes, enabling the model to adapt to targets of different sizes. On the other hand, the PATCH branch utilizes a pixel-level feature extractor to enhance the high-dimensional features within the local region, thereby enriching the representation of fine-grained details. Subsequently, a Region–Patch scale fusion module is designed to model the semantic correlation between the two branches, allowing the network to maintain local details while having a broader view of the image. Furthermore, lightweight decoding blocks with shared parameters are designed at the end of both branches, producing a semantic segmentation map that contains only REGION information and the final semantic segmentation map to ensure the reliability of REGION-level semantic information.
The contributions of this paper can be summarized as follows.
- A novel large-format image semantic segmentation network, termed RPFusionNet, is proposed in this paper. RPFusionNet effectively addresses the challenges of weakly textured or untextured regions in large ground objects. By analyzing patches and regions in parallel, this architecture not only enhances the ability to capture fine details but also improves the understanding of diverse scenes, thereby increasing the overall segmentation accuracy.
- An information aggregation module is designed to efficiently fuse global and local features at multiple scales. This module effectively addresses the issue of multi-scale information fusion, enhancing the model’s capability to interpret complex scenes.
- A novel stepped pooling strategy is introduced to improve the model’s ability to capture information at different scales. This strategy not only aids in better understanding the contextual relationships within the entire scene but also effectively handles the issue of weak or no texture in large objects, thus enhancing the overall segmentation performance.
- The proposed algorithm was tested on three publicly available datasets. The framework demonstrates superior performance in segmentation accuracy, surpassing the current state-of-the-art semantic segmentation methods. Furthermore, extensive ablation studies were performed on the individual components to confirm the effectiveness of each module.
2. Methodology
2.1. Overview
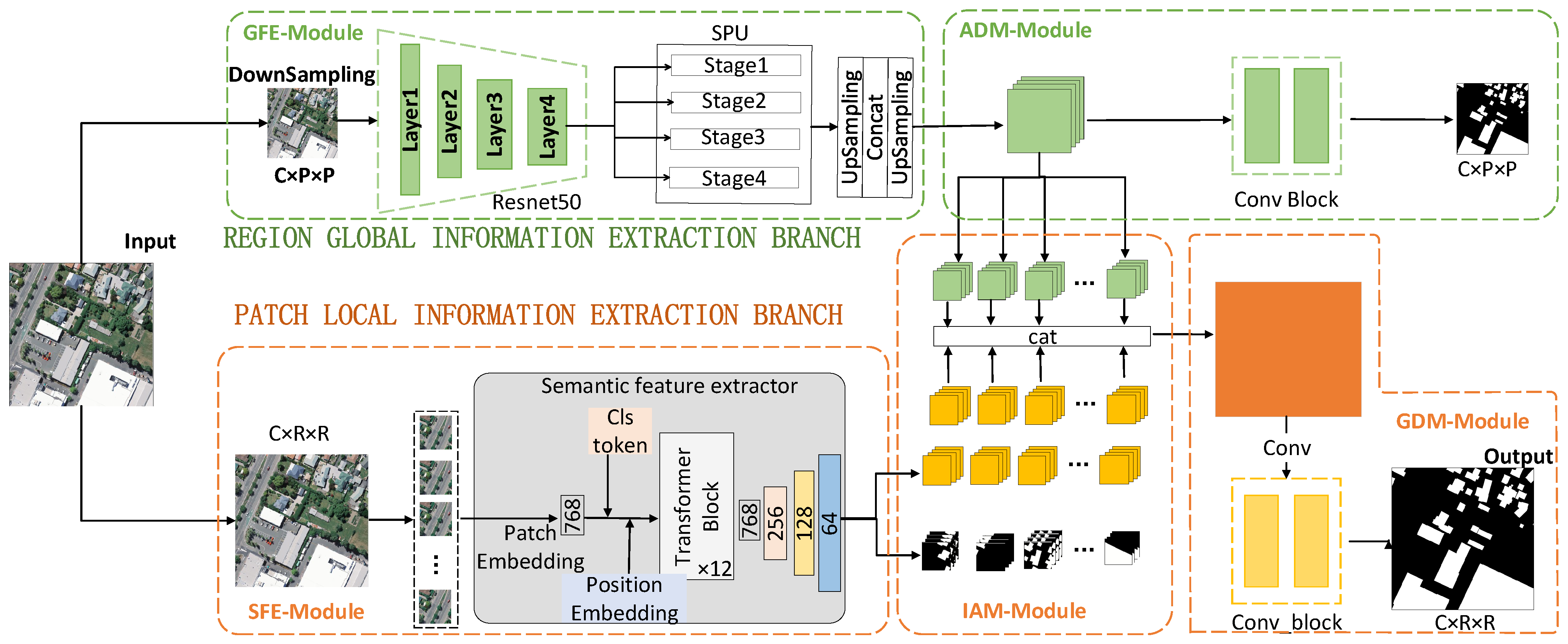
The network structure of this paper is illustrated in Figure 1. The proposed RPFusionNet is a parallel architecture comprising two branches. During the training phase, two corresponding segmentation maps are generated. The REGION branch serves as the primary component of RPFusionNet, designed to model long-range dependencies at a larger scale. Structurally, the parallel architecture allows for parameter sharing across multiple parallel network modules, thereby reducing the number of network parameters while enhancing segmentation accuracy.
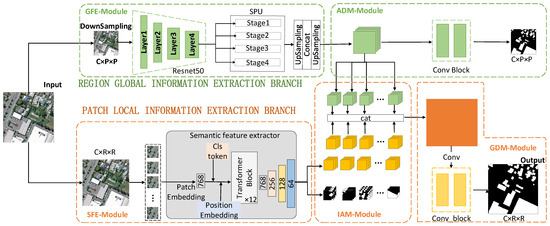
Figure 1.
Network structure of RPFusionNet.
The functions of each branch are as follows:
- REGION Global Information Extraction Branch: This branch consists of two main components: a multi-scale feature extraction module and an auxiliary decoding module. The multi-scale feature extraction module first downsamples the original image and applies multiple pooling operations of different sizes to enhance the model’s ability to perceive multi-scale targets. This process helps in extracting high-dimensional semantic information from the region. The auxiliary decoding module then generates a region-level semantic segmentation map enriched with contextual information through a series of convolutional operations.
- PATCH Local Semantic Feature Extraction Branch: This branch primarily includes three modules: PATCH high-dimensional feature extraction, information aggregation, and global decoding. The PATCH high-dimensional feature extraction module divides the large-format image into several small patches to obtain patch-level high-dimensional features rich in semantic information. The information aggregation module fuses these patch-level high-dimensional semantic features with the region-level high-dimensional semantic information from the REGION branch, deriving new features that integrate both contextual and local information. Notably, the global decoding module shares the same weights as the auxiliary decoding module in the REGION branch. This parameter-sharing mechanism reduces the number of model parameters and enables more efficient feature extraction from image data.
After introducing the overall architecture, we now proceed to provide a detailed description of each branch. We first describe the REGION global information extraction branch, which plays a central role in capturing global contextual information. Next, we introduce the PATCH local semantic feature extraction branch. Finally, we present a brief description of the loss function used in this paper.
2.2. The REGION Global Information Extraction Branch
As part of the network structure, global features play a crucial role in analyzing and utilizing the overall information of the data. In this paper, RPFusionNet employs a multi-scale analysis module to adapt to segmentation targets of different scales, supplementing subtle features and restoring details as much as possible when designing the REGION global information extraction branch. This branch consists of two main components: a multi-scale feature extraction module and an auxiliary decoding module.
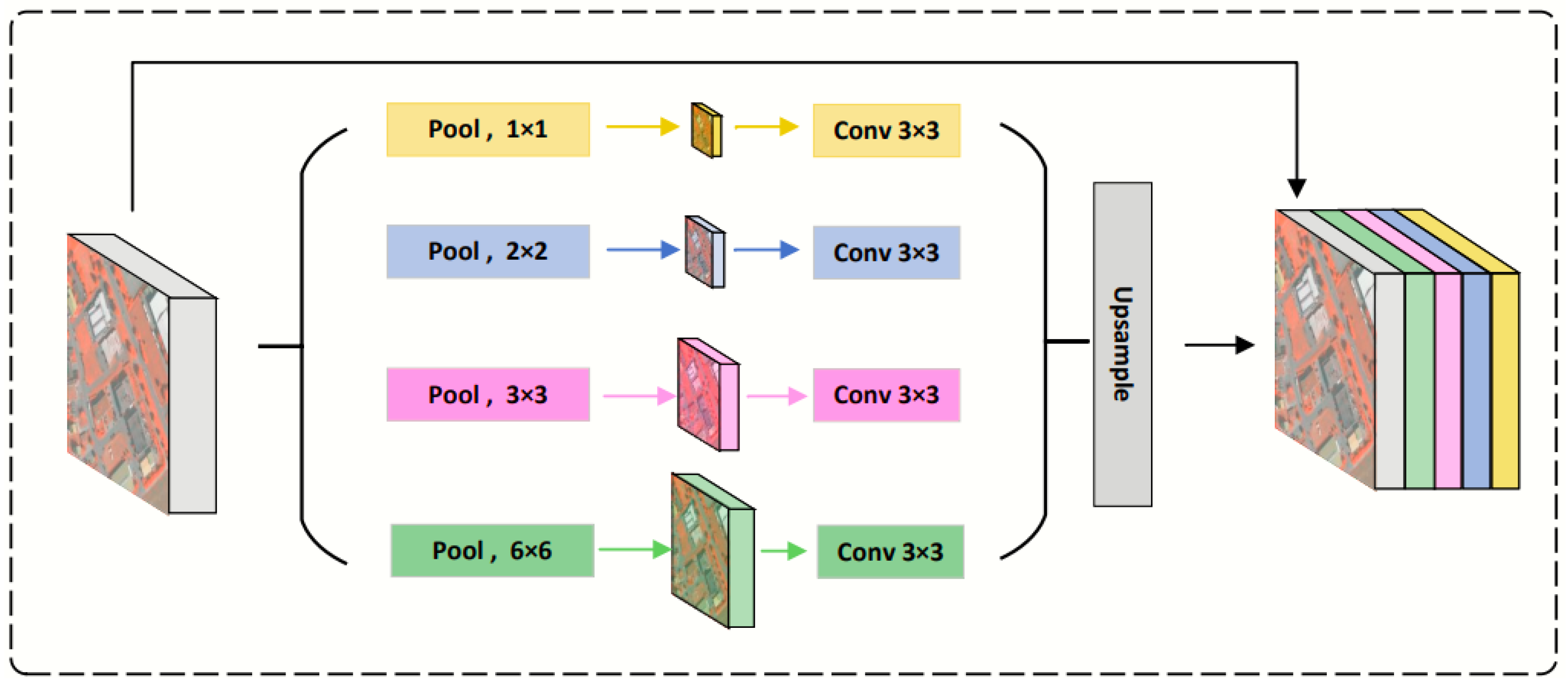
- Multi-Scale Feature Extraction Module (GFE—Global Feature Extraction Module): Before feature extraction, a given input large-format high-resolution image is first downsampled to a coarse-grained image with the size of a PATCH. ResNet50 is used as the encoder to learn the contextual information. To further supplement the boundary information in different regions, we introduce the Stepped Pooling Unit (SPU) to construct global multi-scale information on the final layer of the encoder.The stepped pooling unit(SPU) incorporates features of different sizes, as illustrated in Figure 2. First, the feature map is evenly divided into four parts along the depth dimension. Each part uses a pooling kernel of a different size, sequentially aggregating all pixel values within the pooling window and outputting feature maps of varying sizes. To extract higher-dimensional contextual features, a 1 × 1 convolutional layer is applied to restore the dimension of the contextual feature to the specified dimension. Finally, bilinear interpolation is performed on the feature map of each part to resize it to the same dimensions as the input image. These feature maps of different levels are then concatenated to obtain high-dimensional features containing global information.
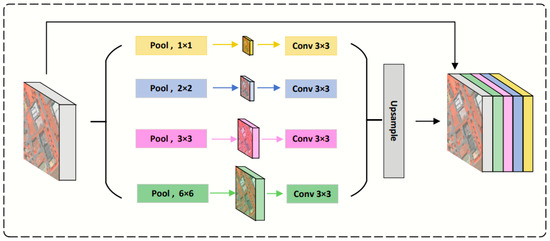 Figure 2. Schematic diagram of a stepped pooling unit.It is important to note that the height and size of the SPU units can be flexibly adjusted, and their settings are directly related to the input x. This unit obtains global information through multiple regional divisions and different pooling kernels. Therefore, when designing multi-level pooling kernels, it is essential to ensure an appropriate representation range to adapt to features of different scales. The calculation of the SPU units is as follows:where x represents the feature map obtained from ResNet50, and and represent the feature maps before and after pooling, respectively. denotes the feature map following the aggregation of information at different scales. refers to uniformly slicing the input feature map along the channel dimension, represents average pooling operation, represents the bilinear interpolation operation, and refers to the fusion operation that integrates multi-scale feature maps along channel dimensions. In this method, the feature dimensions processed by the encoder amount to 2048, subsequently divided by the SPU unit into four portions of feature maps, each consisting of 512 channels. After undergoing pooling through each layer, four layers of feature maps of distinct sizes are acquired, with the respective sizes of the pooling kernels being 1 × 1, 2 × 2, 3 × 3, and 6 × 6. The different pooling kernels are mainly used to capture multi-scale features, in order to accommodate objects of various scales. Ultimately, these four layers of differently sized feature maps are upsampled back to 256 × 256.
Figure 2. Schematic diagram of a stepped pooling unit.It is important to note that the height and size of the SPU units can be flexibly adjusted, and their settings are directly related to the input x. This unit obtains global information through multiple regional divisions and different pooling kernels. Therefore, when designing multi-level pooling kernels, it is essential to ensure an appropriate representation range to adapt to features of different scales. The calculation of the SPU units is as follows:where x represents the feature map obtained from ResNet50, and and represent the feature maps before and after pooling, respectively. denotes the feature map following the aggregation of information at different scales. refers to uniformly slicing the input feature map along the channel dimension, represents average pooling operation, represents the bilinear interpolation operation, and refers to the fusion operation that integrates multi-scale feature maps along channel dimensions. In this method, the feature dimensions processed by the encoder amount to 2048, subsequently divided by the SPU unit into four portions of feature maps, each consisting of 512 channels. After undergoing pooling through each layer, four layers of feature maps of distinct sizes are acquired, with the respective sizes of the pooling kernels being 1 × 1, 2 × 2, 3 × 3, and 6 × 6. The different pooling kernels are mainly used to capture multi-scale features, in order to accommodate objects of various scales. Ultimately, these four layers of differently sized feature maps are upsampled back to 256 × 256. - Auxiliary Decoding Module (ADM): The ADM is a decoding component specifically designed by the REGION branch to process global information. It assists the REGION branch in inferring global information more effectively and provides accurate context features for the subsequent PATCH branch. The module consists of three lightweight convolutional blocks and employs convolutional operations to process multi-channel region-level semantic feature maps. It ultimately reduces the number of channels to one, aiming to produce a semantic segmentation result for a region of “patch” size. This global feature segmentation map facilitates the model’s understanding of the overall image structure and semantic content, thereby aiding in precise pixel-level segmentation across various object categories.
2.3. The PATCH Local Semantic Feature Extraction Branch
The PATCH local semantic feature extraction branch primarily focuses on extracting pixel-level semantic features from large-format input images and fusing the high-dimensional information provided by the REGION branch to generate a segmentation prediction map that matches the original image size. To effectively capture local detail features, the large-format images are divided into smaller, adjacent patch-level images using an n × n grid. A pre-trained semantic feature extractor is then employed to individually extract high-dimensional local feature maps from each of these small image patches. Furthermore, the PATCH local semantic feature extraction branch, as described in this section, integrates both an information aggregation module and a global decoding module, which are elaborated upon below:
- PATCH Semantic Feature Extractor (SFE): The PATCH SFE adopts the TransUNet architecture, specifically designed for efficient extraction of local multi-dimensional features. The hybrid CNN–Transformer design enables TransUNet to effectively integrate hierarchical spatial information within local regions while maintaining structural adaptability to varying input sizes. This hybrid architecture leverages the complementary advantages of convolutional operations for preserving local features and self-attention mechanisms for modeling contextual relationships. To comprehensively capture features within each PATCH region, TransUNet employs a convolutional encoder to extract multi-scale representations, followed by a Transformer module that processes the reshaped feature sequence. Positional encoding is integrated into the flattened feature vectors to maintain spatial relationships across the entire feature map. Subsequently, stacked Transformer blocks process the rich embeddings, where each block incorporates multi-head self-attention and position-wise feed-forward networks to simultaneously model local details and long-range dependencies. Unlike traditional vision Transformers, the TransUNet-based SFE in this work utilizes a U-Net-style decoder with skip connections. This design progressively fuses high-resolution encoder features with semantically rich decoder representations, generating multi-dimensional features aligned with the output dimensions of the global REGION branch. The decoder further produces auxiliary segmentation maps for performance validation, ensuring feature quality prior to fusion. The computational formulation is as follows:where represents the local patch blocks cropped from the original image; and denote the multi-scale convolutional features extracted by the ResNet encoder; and refers to the high-level semantic features processed by the Transformer encoder. and represent the multi-dimensional tensor generated by decoding the local feature sequence and the predicted segmentation map. represents a dimensional transformation of feature representations from 1D sequences (e.g., flattened feature vectors) to 2D spatial forms (e.g., spatial feature maps). denotes the decoder layer, which includes upsampling, convolution, and skip-connection-based feature fusion operations to progressively restore spatial resolution.During training, our method pre-trains a model to effectively extract high-dimensional features from image patches. In subsequent experiments with large-format high-resolution images, this pre-trained feature extractor is loaded and fixed, and it does not participate in the backpropagation and gradient update processes of the network. In this stage, we retain only the high-dimensional information from the high-dimensional semantic feature branch.
- Information Aggregation Module (IAM). The Information Aggregation Module (IAM) integrates global and local features, thereby enhancing the model’s comprehension of the overall image structure while maintaining sensitivity to critical local details. Specifically, for the global contextual information derived from the downsampled and feature-extracted REGION branch, the module first employs bilinear interpolation to estimate the value of each new pixel. This is achieved by assigning different weights to the four adjacent pixels surrounding the target pixel, thus restoring the feature representation to the original region-level resolution. Subsequently, the region-level high-dimensional features, enriched with contextual information, are reorganized into multiple feature map sets based on the initial cropping sequence, each corresponding to a specific patch size. Lastly, these feature maps are concatenated to produce a more comprehensive and informative representation. A detailed calculation process is outlined below:where represents the feature map resulting from the aggregation of information across diverse scales, stands for the bilinear interpolation operation, and refers to uniformly slicing the input feature map along the channel dimension. The interpolated feature map is segmented into blocks consistent with the patch size, is the feature map after blocking, is the high-dimensional feature after the decoding of the local feature sequence, and is the new feature following the fusion of global and local information.
- Global Decoding Module (GDM). The global decoding module combines the previously mentioned fusion features into a region-level feature map. Following this, a three-layer convolutional neural network is utilized to form a decoder, which generates the final large-area semantic segmentation map. The mathematical formulation of this process is given by:where represents the final semantic segmentation result for the large-format image and denotes the operation of reassembling the set of patch-size feature maps into the REGION format, adhering to the trimming order.
2.4. Loss Function
The loss function in this paper comprises two components: one originating from the REGION branch and the other from the PATCH branch. For each component, binary cross-entropy is used as the loss function. The equation for calculating the mixed loss function is as follows:
Here, denotes a weight coefficient, and and are the loss values of the REGION branch and the PATCH branch, respectively. , serving as an auxiliary optimization objective, ensures that the model can accurately capture the overall semantic structure of the image. and correspond to the global labels of sample i for the PATCH size and REGION size, respectively. and denote the probabilities that the i-th sample will be classified positively in the respective branches. Since the information extracted from the PATCH branch has been modeled by the feature fusion module, the predicted binary map generated by this branch is directly used as the segmentation result during the testing phase.
3. Datasets and Experiment Details
3.1. Datasets
The initial format of the experimental dataset in this study comprises a large image of the entire area and a building label provided in Shapefile format. Due to the constraints imposed by GPU memory, the proposed algorithm cannot process the large image directly. Therefore, the large image of the entire area is cropped to produce relatively large-format images of size 2048 × 2048, which have eight times the area of the standard 256 × 256 images. These images are divided into training, validation, and test sets in a 6:2:2 ratio. To facilitate the training of the global information extraction module, this study employs a strategy of downscaling the large-format 2048 × 2048 images to generate lower-resolution 256 × 256 images. The efficacy of the proposed method is validated through comparative experiments using the large-format dataset, while a trimmed dataset of 256 × 256 images is prepared for pre-training the SFE module. The detailed parameters of the three experimental datasets are as follows.
- WBDS (WHU Building Dataset)The WBDS dataset is located in Christchurch, New Zealand, and includes two aerial images with a size of 32,507 × 15,345 pixels, along with their corresponding labels, captured in 2012 and 2016, respectively. Both area images and labels have been cropped to create large-format images of 2048 × 2048 pixels, yielding a total of 630 image–label pairs. These pairs are divided into a training set (378 pairs), a validation set (126 pairs), and a test set (126 pairs) according to a 6:2:2 ratio.
- AIDS (Aerial imagery Dataset)The AIDS dataset encompasses a remote sensing image with a size of 1,560,159 × 517,909, sourced from the New Zealand Land Information Service website. This dataset spans a broad geographical region characterized by a variety of features, including buildings, roads, vehicles, forests, water bodies, and arable land. Approximately 22,000 individual buildings were manually annotated by Ji et al. [41], with the original image having a spatial resolution of 0.075 meters. Both the image and vector labels were cropped to produce 12,940 large-format image–label pairs, each of size 2048 × 2048 pixels. These pairs were further divided into a training set (7764 pairs), a validation set (2588 pairs), and a test set (2588 pairs). It is noteworthy that the AIDS dataset exhibits a substantial disparity in the number of foreground and background pixels, a common issue in many high-resolution remote sensing image datasets due to the highly imbalanced sample distribution.
- VaihingenThe Vaihingen dataset was collected by the International Society for Photogrammetry and Remote Sensing (ISPRS) and is situated in a small town in southwestern Germany. The dataset features various landscapes, including villages, farmlands, and forests, with numerous freestanding and small multi-story buildings. The Vaihingen dataset consists of 38 images with a size of 6000 × 6000 pixels. Given the absence of building vector labels in the complete image coverage area, we first assembled 38 adjacent non-overlapping images from the dataset into a single large remote sensing image. Using ArcGIS software, we then manually delineated the corresponding building vector labels. Subsequently, the image and its associated building vector labels were cropped simultaneously to generate 140 image–label pairs, all of size 2048 × 2048 pixels. These pairs were allocated to a training set (84 pairs), a validation set (28 pairs), and a test set (28 pairs) in a 6:2:2 ratio.
3.2. Data Preprocessing
To mitigate overfitting and enhance the robustness of the network, we augmented the sample data through random rotation, mirroring, and adjustments to the color, saturation, and contrast of the images. For the WBDS dataset, which has a limited number of samples, the size of the cropped images is randomly set within the range of 1024 to 3072 pixels on the original image. These cropped images were then resized to 2048 pixels to reduce the model’s sensitivity to the location and scale of buildings.
3.3. Training Details
The experiments in this study were conducted using the PyTorch 1.7.1 deep learning framework with CUDA 11.0, running on a hardware environment equipped with an NVIDIA V100 GPU featuring 32 GB of video memory. The AdamW optimizer was employed with a base learning rate of 0.0001 and a weight decay parameter set to . To ensure experimental fairness, the batch size for the PATCH feature extractor used in the RPFusionNet method was set to 64, and the model underwent 200 training epochs to obtain a pre-trained model capable of fully extracting 64-dimensional local feature information. For the PATCH branch of the RPFusionNet network, the parameters of the SFE module are derived from a pre-trained semantic segmentation model. In the pre-training phase of this model, training samples were obtained by cropping the original 2048 × 2048 high-resolution images into non-overlapping 256 × 256 image patches. Throughout the entire training process of the RPFusionNet network, the parameters of this module remain fixed in order to preserve the learned semantic features of the image patches. The batch size was set to 64, and the model was trained for 200 epochs. In the Region branch, following the pyramid pooling approach, the pooling kernel sizes for the four layers of the SPU unit were set to 1, 2, 3, and 6, respectively. During training, the loss was computed by combining the original image labels with the global labels of the downsampled PATCH size, and the model parameters were updated through backpropagation until convergence. The loss calculation was weighted with a parameter set at 1.
3.4. Metrics
Four metrics were utilized to assess the performance of our experimental results: Intersection over Union (IoU), precision, recall, and F1 score. The calculations for these metrics are as follows:
where TP denotes true positive, representing the number of pixels correctly identified as buildings; FP signifies false positive, indicating the number of background pixels incorrectly classified as buildings; FN stands for false negative, denoting the number of pixels that belong to buildings but are misclassified as background; and TN represents true negative, indicating the number of background pixels correctly identified as background.
4. Experimental Results and Analysis
To validate the effectiveness of the proposed RPFusionNet architecture, a series of comprehensive experiments were conducted. First, comparative experiments were performed on three datasets—WBDS, AIDS, and Vaihingen—to evaluate the performance of RPFusionNet against other state-of-the-art semantic segmentation networks. Second, an ablation study was carried out to assess the impact of each module within RPFusionNet, ensuring that every component contributes effectively to the overall performance. Finally, the computational efficiency of different models was compared to understand how RPFusionNet performs in terms of resource utilization.
4.1. Comparisons with State-of-the-Art Methods
To verify the effectiveness of the proposed RPFusionNet, comparative experiments were conducted on three datasets: WBDS, AIDS, and Vaihingen. The methods included in the comparison are as follows:
- -
- DeepLabv3+ [5], PSPNet [7], UANet [11], and MACU-Net [39], which utilize multi-scale feature extraction;
- -
- LANet [10], TransUNet [21], and CMTFNet [23], which incorporate both CNN and Transformer architectures;
- -
- RSMamba [30], and UNetMamba [31], which achieve linear-complexity global modeling.
- -
- PTRSegNet [40], which employs a concatenation architecture integrating REGION and PATCH.
The results of these comparisons are presented in Table 1.

Table 1.
Comparisons of RPFusionNet with other semantic segmentation methods on the WBDS, AIDS, and Vaihingen datasets.
Table 1 demonstrates that classical semantic segmentation networks, such as DeepLabv3+, MACU-Net, CMTFNet, PSPNet, LANet, TransUNet, UANet, RSMamba, and UNetMamba, are primarily designed for processing small-sized images. These models are constrained by their limited image size and receptive field, which leads to lower segmentation accuracy. Among these, earlier CNN-based network structures like DeepLabv3+ performed the worst, primarily due to the absence of an attention mechanism.
In contrast, TransUNet and LANet exhibit relatively stable performance across the three datasets due to the integration of CNN and attention mechanisms. UANet achieves strong F1 scores across all datasets, particularly excelling in recall (e.g., 98.57% on WBDS), indicating its effectiveness in capturing positive instances. RSMamba, leveraging state space modeling, exhibits robust recall values (e.g., 98.96% on WBDS), though its precision remains relatively moderate. UNetMamba, built upon vision Mamba architecture, delivers high IoU and balanced precision-recall trade-offs, especially on the WBDS dataset, where it outperforms most models. While these models perform well, they still fall short of the superior accuracy achieved by RPFusionNet, highlighting the latter’s effectiveness in handling high-resolution remote sensing images. However, their accuracy is notably lower compared to PTRSegNet and RPFusionNet. Both PTRSegNet and RPFusionNet are specifically designed for large-format images, with RPFusionNet achieving higher accuracy. Specifically, in terms of IoU metrics, RPFusionNet’s large-format image segmentation accuracy has improved from 91.46%, 88.69%, and 86.56% (for PTRSegNet) to 92.08%, 89.99%, and 88.44% on the WBDS, AIDS, and Vaihingen datasets, respectively, representing a significant enhancement.
These results highlight the importance of the receptive field in improving segmentation accuracy for large-format and high-resolution images. Classical networks, which are designed for small-sized images, are inherently limited in their segmentation accuracy. However, well-designed frameworks for large-format image processing, such as PTRSegNet and RPFusionNet, have significantly enhanced segmentation accuracy by effectively extracting global information on a larger scale. The superior performance of RPFusionNet in this study can be attributed to its more effective global–local feature fusion method, particularly the designed stepped pooling strategy. This strategy enables information extraction and fusion at multiple scales, thereby further enhancing segmentation accuracy.
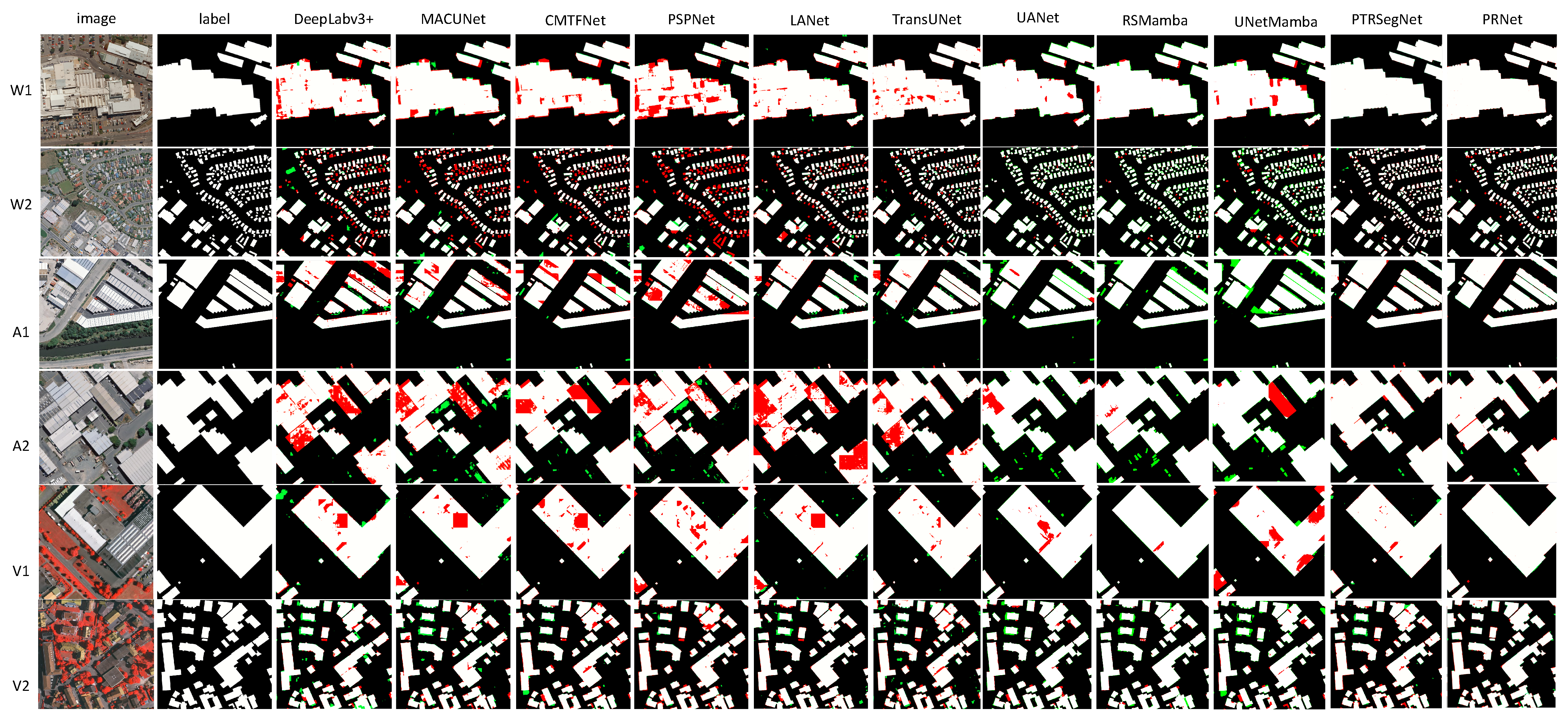
To further demonstrate the effectiveness of the proposed method, we selected several images to visualize the segmentation results, as shown in Figure 3. Rows 1–2 (W1, W2) are from the WBDS dataset, rows 3–4 (A1, A2) are from the AIDS dataset, and rows 5–6 (V1, V2) are from the Vaihingen dataset. Each image presents the prediction results of the model after semantic segmentation, showcasing the model’s ability to recognize and segment target objects.

Figure 3.
The visualization results of different segmentation models on various datasets are presented, where white, black, green, and red represent true positives, true negatives, false positives, and false negatives, respectively. The datasets used are denoted as W for WBDS, A for AIDS, and V for Vaihingen.
As illustrated in Figure 3, RPFusionNet demonstrates superior performance across diverse scenarios. In dense small-target regions (e.g., W2), RPFusionNet exhibits enhanced structural coherence preservation in building clusters, with significantly reduced missed detection areas in red boxes (e.g., 3.86% false detection rate, a 0.2% improvement over PTRSegNet). This is attributed to the 1 × 1 pooling kernel in the REGION branch, which preserves pixel-level edge localization, and the 6 × 6 pooling kernel, which suppresses false detections caused by shadow gaps between adjacent buildings (e.g., clearer separation in W2). In contrast, PTRSegNet’s single-scale pyramid pooling leads to over-smoothing, resulting in higher missed detection rates (0.44% higher than RPFusionNet). For large-scale isolated targets (e.g., A1), RPFusionNet achieves notable improvements in boundary accuracy and weak-texture rooftop segmentation. This stems from the local attention mechanism in the PATCH branch, which enhances surface pattern recognition in low-texture regions, and the 3 × 3 pooling kernel in the REGION branch, which optimizes geometric constraints and mitigates the “edge blurring” issue in DeepLabv3+, reducing missed detection rates by 5.7%. In small-target scenarios (e.g., V2), although the missed detection rate is slightly lower than PTRSegNet, RPFusionNet achieves a significant boundary IoU improvement, reaching an optimal value of 88.44%. This is enabled by the 2 × 2/3 × 3 kernels in the SPU module, which capture neighborhood contextual information and suppress vegetation-related false detections (false detection rate: 4.6%), and the shared-parameter decoder, which balances global consistency and avoids overfitting caused by redundant high-resolution streams in PTRSegNet.
4.2. Ablation Study
In this paper, we conducted an ablation study using the WBDS and AIDS datasets to evaluate the role of each module. First, we assessed the performance of different SFEs within the RPFusionNet framework. Next, we compared single-scale and multi-scale pooling units to demonstrate the effectiveness of stepped pooling units in multi-scale information fusion. Finally, we used various combinations to verify the effectiveness of each module in detail. It is important to note that, to ensure the fairness of the experimental comparison, all experiments were conducted using the same training parameters.
- Comparisons of Model Performance Under Different SFEsWithin the RPFusionNet framework, we evaluated the performance of U-Net, ViT, and TransUNet as Semantic Feature Extractors (SFEs) for large-format image semantic segmentation. The experimental results demonstrate that all SFEs exhibit significant performance improvements after integration into the RPFusionNet framework (as shown in the “IoU improvement” column of Table 2), validating the effectiveness of the dual-branch collaborative design. Notably, TransUNet achieves the best performance under both strategies, with an average IoU outperforming U-Net and ViT by 2.3% and 4.1%, respectively. This superiority stems from TransUNet’s hybrid architecture, which leverages the complementarity between CNNs and Transformers through a multi-scale feature fusion mechanism, making it highly suitable for the complex characteristics of remote sensing images. Specifically, the Transformer encoder in TransUNet dynamically aggregates cross-regional information via self-attention mechanisms, addressing the locality limitations of U-Net convolutions. Additionally, TransUNet employs a ResNet backbone to extract hierarchical multi-scale features (ranging from shallow local details to deep semantic features), while the Transformer encoder further refines these features using multi-head attention mechanisms. This two-level design aligns well with the hierarchical structure of remote sensing images (e.g., the coexistence of small buildings and large land cover regions), enabling the simultaneous optimization of segmentation accuracy for both small targets (e.g., vegetation types) and large targets (e.g., urban expansion). By contrast, U-Net’s pure convolutional architecture lacks global modeling capabilities, leading to incomplete boundary predictions for large-scale objects, while ViT directly models image patches, ignoring local details (e.g., building edges) and exhibiting insufficient noise robustness for remote sensing images.
Table 2. Performance comparison of different models on WBDS and AIDS datasets.
- Comparisons of Model Performance Under Different Pooling UnitsIn this paper, we employed a stepped pooling unit to extract feature representations at different scales, enabling the model to handle large buildings and thereby improving semantic segmentation performance. Four different pooling kernels (1 × 1, 2 × 2, 3 × 3, and 6 × 6) were used, and these features were fused to enhance contextual information. To verify the effectiveness of the stepped pooling unit, we compared the results of single-scale pooling (SSPU) and multi-scale pooling (MSPU) under different SFEs, including U-Net, ViT, and TransUNet. Single-scale pooling (SSPU) refers to a single-scale pooling unit that retains only the 1 × 1 scale features. The comparisons of model performance under different pooling units are presented in Table 3.
Table 3. Comparisons of model performance under different pooling units.Table 3 shows that the multi-scale pooling unit (MSPU) achieves a 2.05% IoU improvement over the single-scale pooling unit (SSPU) on both WBDS and AIDS datasets. Specifically, the TransUNet + MSPU combination achieves an optimal mIoU of 92.08%, outperforming the SSPU-based solution by 2.4%. This performance gain is attributed to the synergistic effect of multi-size pooling kernels, particularly the 6 × 6 large-scale pooling kernel, which enhances segmentation accuracy for large buildings exceeding 512 × 512 pixels by integrating local detail features. Empirical evidence confirms that the multi-scale feature fusion mechanism effectively mitigates the scale sensitivity inherent in single receptive field designs, significantly improving the boundary completeness of large structures such as industrial plants.
- Ablation Study of Four Different Module Combinations Under Different SFEsTo verify the effectiveness of each module in the RPFusionNet framework, an ablation study was conducted using four different module combinations. The experiments were performed on two datasets—WBDS and AIDS—and employed three SFEs: U-Net, ViT, and TransUNet. The four combinations are as follows:
- (a)
- Baseline: The baseline model only includes the semantic feature extraction module and does not use the large-format image processing framework.
- (b)
- Baseline + GDM: In the REGION branch, only a single-scale pooling kernel is used for global feature mapping, and the region-level segmentation map is obtained through the global decoding module (GDM) of the PATCH branch.
- (c)
- Baseline + GDM + GFE: On the basis of (b), the Global Feature Extraction Module (GFE) is added, specifically the GFE (MSPU) module in the REGION branch, to capture multi-scale global information.
- (d)
- Baseline + GDM + GFE + ADM: On the basis of (c), the Auxiliary Decoding Module (ADM) is added to form a complete RPFusionNet.
As shown in Table 4, the systematic ablation experiments on the WBDS and AIDS datasets confirm the progressive performance gains achieved by the RPFusionNet module combinations. When using only the baseline model, TransUNet as the SFE achieves an 87.8% IoU on the WBDS dataset, revealing the modeling limitations of single-architecture approaches for large-scale remote sensing images. Introducing the GDM module results in a slight dip (87.78%), but its cross-branch feature alignment mechanism lays the foundation for subsequent modules. Adding the GFE multi-scale feature extraction module leads to a significant 2.78% IoU increase (reaching 90.56%), while finally integrating the ADM multi-level supervision mechanism achieves a peak performance of 92.08% (cumulative gain: 4.19%), with this module accelerating convergence through optimized gradient propagation. Notably, this progressive improvement exhibits cross-architecture universality: the U-Net-based complete RPFusionNet achieves a 6.89% improvement over the baseline (85.17%→92.06%), while the ViT-based complete RPFusionNet yields a 5.65% gain. The nonlinear optimization system formed by the synergy of these three modules demonstrates indispensability, as removing any component causes performance collapse (e.g., a 1.52% abrupt drop when ADM is removed from the TransUNet-based SFE). This demonstrates that the GDM helps to fix spatial structure inconsistencies, the GFE improves the model’s ability to handle objects at different scales, and the ADM speeds up the training process—all of which are essential and interconnected parts of the overall framework.
Table 4.
Ablation study of four different module combinations on the WBDS dataset.
4.3. Comparisons of Computational Efficiency
To further explore the performance of RPFusionNet in terms of training parameters and floating-point operations (FLOPs), we compared the training parameters and FLOPs of the proposed method with state-of-the-art models, and the results are shown in Table 5. It should be noted that, due to limited GPU resources, some of the models being compared are unable to directly compute the number of parameters (Params) and floating-point operations (FLOPs) for large-format images. To address this limitation, we uniformly evaluated these metrics using images of a 256 × 256 resolution.
Table 5.
Comparison of different models in terms of inference time, training parameters, and FLOPs.
As shown in Table 5, RPFFusionNet achieved competitive computing efficiency with a FLOP of 6.97 G, ranking second among all compared models (only behind UNetMamba’s 3.85 G). This efficiency is attributed to the shared parameters in the dual-branch decoder and the fixed parameter design in the Semantic Feature Extractor (SFE) module. Since fixed parameters are not included in the count, RPFusionNet contains only 46.83 M trainable parameters—comparable to several state-of-the-art networks and notably fewer than the parameter count of TransUNet.
5. Conclusions
To effectively mitigate the semantic segmentation of large-scale objects with weak or no texture, a novel semantic segmentation network (RPFusionNet) based on PATCH-to-REGION parallel analysis has been developed. In this framework, a semantic feature extractor is first employed to extract local information with rich details. Subsequently, a global feature extraction module is designed to capture global information, utilizing a stepped pooling strategy to extract information at multiple scales. The Information Aggregation Module then effectively combines global and local features at multiple scales, facilitating the deep integration of multi-scale features. Finally, the global decoding module generates the semantic segmentation results for large-format images.
To validate the effectiveness of the proposed algorithm, we conducted extensive experiments using three public datasets. Ablation studies, including comparisons of model performance under different pooling units, comparisons of model performance under different SFEs, and an ablation study of four different module combinations under different SFEs, were conducted to evaluate the performance of each module. Additionally, comparisons with state-of-the-art models, such as PSPNet, DeepLabv3+, MACU-Net, LANet, TransUNet, CMTFNet, UANet, RSMamba, UNetMamba, and PTRSegNet, were performed to highlight the advantages of our method in large-format image segmentation. In our future research, we will focus on optimizing the algorithm and model architecture to further reduce memory usage during training, enhance the image size and segmentation accuracy for single-processing tasks, and ensure efficient inference.
Author Contributions
Conceptualization, S.P. and K.X.; methodology, W.Z.; software, Z.Z.; validation, W.Z., Y.S. and Y.W.; formal analysis, Y.S.; investigation, K.X.; resources, Z.Z.; data curation, Y.S.; writing—original draft preparation, S.P.; writing—review and editing, W.Z.; visualization, Y.S.; supervision, Z.Z.; project administration, K.X.; funding acquisition, K.X. and Z.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Natural Science Foundation of China (Grants: 62377023 and 62173158), in part by the Key Project of Hubei Provincial Natural Science Foundation Innovation and Development Joint Found (Grant: 2025AFD195), in part by the Fundamental Research Funds for the Central Universities (Grant: CCNU25ZZ104 and CCNU25ai013), in part by the Open Fund of Hubei Key Laboratory of Digital Education under Grant F2024E05 and F2024G01, and in part by the MOE Industry-University Cooperation Collaborative Education Program under Grant 230806008021539.
Data Availability Statement
The AIDS and Vaihingen datasets utilized in this study are publicly accessible at https://gpcv.whu.edu.cn/data/building_dataset.html (accessed on 21 June 2025) and https://github.com/ai4os-hub/semseg-vaihingen (accessed on 21 June 2025) respectively. The WBDS is available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Firdaus-Nawi, M.; Noraini, O.; Sabri, M.; Siti-Zahrah, A.; Zamri-Saad, M.; Latifah, H. Deeplabv3+ Encoder–Decoder with Atrous Separable Convolution for Semantic Image Segmentation. Pertanika J. Trop. Agric. Sci. 2021, 44, 137–143. [Google Scholar]
- Guo, S.; Zhu, C. Cascaded ASPP and Attention Mechanism-Based Deeplabv3+ Semantic Segmentation Model. In Proceedings of the IEEE 8th International Conference on Cloud Computing and Intelligent Systems (CCIS), Guangzhou, China, 9–11 December 2022; pp. 315–318. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yan, Z.; Wang, K.; Li, X.; Zhang, Z.; Li, J.; Yang, J. DesNet: Decomposed Scale-Consistent Network for Unsupervised Depth Completion. arXiv 2022, arXiv:2211.10994. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 426–435. [Google Scholar] [CrossRef]
- Li, J.; He, W.; Cao, W.; Zhang, L.; Zhang, H. UANet: An Uncertainty-Aware Network for Building Extraction From Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5608513. [Google Scholar] [CrossRef]
- Zheng, C.; Hu, C.; Chen, Y.; Li, J. A Self-Learning-Update CNN Model for Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6004105. [Google Scholar] [CrossRef]
- Zhao, Y.; Guo, P.; Sun, Z.; Chen, X.; Gao, H. ResiDualGAN: Resize-Residual DualGAN for Cross-Domain Remote Sensing Images Semantic Segmentation. Remote Sens. 2023, 15, 1428. [Google Scholar] [CrossRef]
- Pan, S.; Tao, Y.; Nie, C.; Chong, Y. PEGNet: Progressive Edge Guidance Network for Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 637–641. [Google Scholar] [CrossRef]
- Tragakis, A.; Liu, Q.; Kaul, C.; Roy, S.K.; Dai, H.; Deligianni, F.; Murray-Smith, R.; Faccio, D. GLFNet: Global-Local (Frequency) Filter Networks for Efficient Medical Image Segmentation. In Proceedings of the IEEE International Symposium on Biomedical Imaging (ISBI), Athens, Greece, 27–30 May 2024; pp. 1–5. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 994–1003. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhong, J.; Zeng, T.; Xu, Z.; Wu, C.; Qian, S.; Xu, N.; Chen, Z.; Lyu, X.; Li, X. A Frequency Attention-Enhanced Network for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2025, 17, 402. [Google Scholar] [CrossRef]
- Zhang, W.; Huang, Z.; Luo, G.; Chen, T.; Wang, X.; Liu, W.; Yu, G.; Shen, C. TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12083–12093. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Wang, Y.; Wang, D.; Xu, T.; Shi, Y.; Liang, W.; Wang, Y.; Petropoulos, G.P.; Bao, B. RDAU-Net: A U-Shaped Semantic Segmentation Network for Buildings Near Rivers and Lakes Based on a Fusion Approach. Remote Sens. 2025, 17, 2. [Google Scholar] [CrossRef]
- Wu, H.; Huang, P.; Zhang, M.; Tang, W.; Yu, X. CMTFNet: CNN and Multiscale Transformer Fusion Network for Remote-Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2004612. [Google Scholar] [CrossRef]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing Swin Transformer and Convolutional Neural Network for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. CMT: Convolutional Neural Networks Meet Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12175–12185. [Google Scholar]
- Fan, C.-M.; Liu, T.-J.; Liu, K.-H. Compound Multi-Branch Feature Fusion for Image Deraindrop. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 3399–3403. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model. In Proceedings of the 41st International Conference on Machine Learning (ICML 2024), Vienna, Austria, 21–27 July 2024; Volume 235, pp. 62429–62442. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Liu, Y. VMamba: Visual State Space Model. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2024), Vancouver, BC, Canada, 16 December 2024; Curran Associates, Inc.: Granada, Spain, 2024; Volume 37, pp. 103031–103063. [Google Scholar]
- Chen, K.; Chen, B.; Liu, C.; Li, W.; Zou, Z.; Shi, Z. RSMamba: Remote Sensing Image Classification with State Space Model. IEEE Geosci. Remote Sens. Lett. 2024, 21, 8002605. [Google Scholar] [CrossRef]
- Zhu, E.; Chen, Z.; Wang, D.; Shi, H.; Liu, X.; Wang, L. UNetMamba: An Efficient UNet-Like Mamba for Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2025, 22, 6001205. [Google Scholar] [CrossRef]
- Zhu, S.; Zhao, L.; Xiao, Q.; Ding, J.; Li, X. GLFFNet: Global–Local Feature Fusion Network for High-Resolution Remote Sensing Image Semantic Segmentation. Remote Sens. 2025, 17, 1019. [Google Scholar] [CrossRef]
- Nie, J.; Wang, Z.; Liang, X.; Yang, C.; Zheng, C.; Wei, Z. Semantic Category Balance-Aware Involved Anti-Interference Network for Remote Sensing Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4409712. [Google Scholar] [CrossRef]
- Hu, B.; Wang, X.; Feng, Z.; Song, J.; Zhao, J.; Song, M.; Wang, X. HSDN: A High-Order Structural Semantic Disentangled Neural Network. IEEE Trans. Knowl. Data Eng. 2023, 35, 8742–8756. [Google Scholar] [CrossRef]
- Lin, S.; Yang, Y.; Liu, X.; Tian, L. DSFA-SwinNet: A Multi-Scale Attention Fusion Network for Photovoltaic Areas Detection. Remote Sens. 2025, 17, 332. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Z.; Yang, J.; Zhang, H. Wavelet Transform Feature Enhancement for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2023, 15, 5644. [Google Scholar] [CrossRef]
- Song, X.; Li, W.; Zhou, D.; Dai, Y.; Fang, J.; Li, H.; Zhang, L. MLDA-Net: Multi-Level Dual Attention-Based Network for Self-Supervised Monocular Depth Estimation. IEEE Trans. Image Process. 2021, 30, 4691–4705. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Yong, X.; Chen, D.; Xia, R.; Ye, B.; Gao, H.; Chen, Z.; Lyu, X. SSCNet: A Spectrum-Space Collaborative Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2023, 15, 5610. [Google Scholar] [CrossRef]
- Li, R.; Duan, C.; Zheng, S.; Zhang, C.; Atkinson, P.M. MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8007205. [Google Scholar] [CrossRef]
- Pang, S.; Shi, Y.; Hu, H.; Ye, L.; Chen, J. PTRSegNet: A Patch-to-Region Bottom–Up Pyramid Framework for the Semantic Segmentation of Large-Format Remote Sensing Images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2024, 17, 3664–3673. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Dataset. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).